- Apache Spark is an open-source framework & compute engine that is known for its speed, easy-to-use nature in the field of big data processing and analysis.
- It also has built-in modules for graph processing, machine learning, streaming, SQL etc.
- The spark execution engine supports in-memory computation and cyclic data flow.
- It can select the distributed data, create a map and then reduce the values to give proper data.
| Remarks | |
|---|---|
| Zomato - HLD Design | Generate recommendations based on continuous streams of user activity, order activity, pricing and promo changes etc. |
| Uber Driver Allocation | Select driver based on continuous streams of driver locations, user location etc. |
| Feature | Remarks |
|---|---|
| Resilient Distributed Dataset (RDD) | RDD is a collection of elements partitioned across the nodes of the cluster that can be operated on in parallel. |
| Directed acyclic graph (DAG) | Read more |
| Accumulator | A simpler value of Accumulable where the result type being accumulated is the same as the types of elements being merged, i.e. variables that are only "added" to through an associative operation and can therefore be efficiently supported in parallel. They can be used to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric value types, and programmers can add support for new types. |
| Spark UI | Apache Spark provides a suite of web user interfaces (UIs) that you can use to monitor the status and resource consumption of your Spark cluster. |
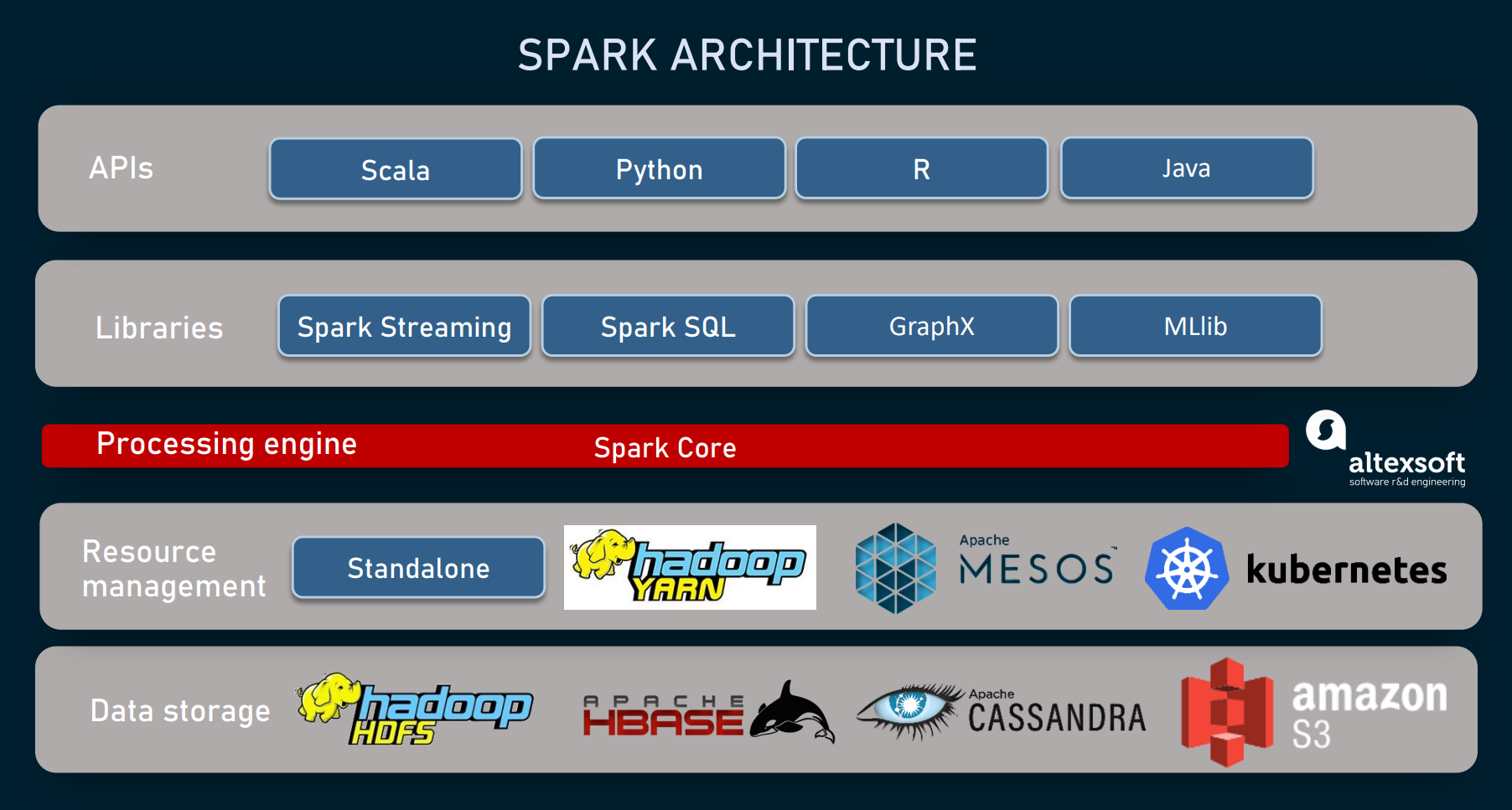
| Spark Core | |
| MLlib/GraphX | |
| Spark Streaming | Read more |
| Spark SQL | Read more |
| Associative Property | Associative property is defined as, when more than two numbers are added or multiplied, the result remains the same, irrespective of how they are grouped. |
| Cluster Manager |
|---|
| Standalone cluster manager (spark's own cluster manager) |
| Hadoop Yarn |
| Apache Mesos |
| Kubernates |
