validation_score #59
-
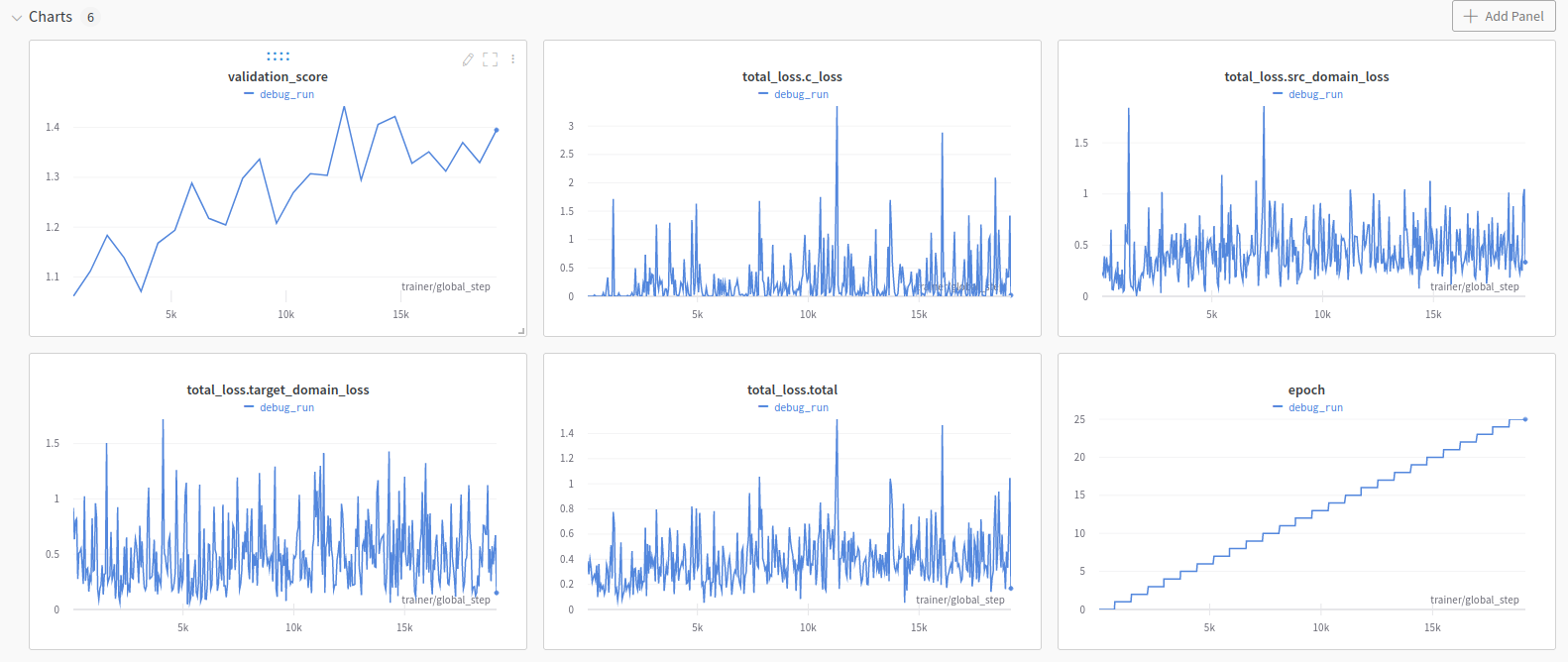
How to analyze the validation_score?I ran the DANN (MNIST & MNISTM) example for 25 epochs and logged the total_loss curves along with the validation_score from As training progresses the validation score appears to increase up from 1. What validation_score would indicate that the model is achieving a perfect score on the validation data? Sometimes one would have a validation score in the range 0-1 (where 0 = no correct predictions & 1 = all correct predictions)
|
Beta Was this translation helpful? Give feedback.
Replies: 1 comment 2 replies
-
|
The IMValidator isn't normalized, and the value of a "good" score depends on the number of classes in your dataset. Also depending on the dataset, it might have poor correlation with accuracy. You could try another validator, but most of them aren't normalized so they won't have an understandable range like [0, 1]. In my opinion the biggest challenge in the field right now is creating a validator that is well correlated with accuracy, across algorithms and datasets. Once that is found, then creating a normalizer for it wouldn't be too difficult. Unfortunately most validators are poorly correlated with accuracy. Despite there being hundreds of papers on unsupervised domain adaptation, this fatal flaw has gone largely unaddressed. |
Beta Was this translation helpful? Give feedback.
-
|
That makes sense to me. So to judge the performance of the classifier the higher the validation score the better? I wonder how one would approach a comparison two models, where; Model A has been trained on the source data only and is tested on a hold-back target set (assumed poorer performance) Model A wouldn't need to use IMValidator and would have a standard classifier validation score between 0-1 just like the standard MNIST classification models. |
Beta Was this translation helpful? Give feedback.
-
Yes, all the validators in this library output scores such that higher should be better, though to be clear, due to poor correlation with accuracy, higher might not actually be better.
You'd need to score Model A and Model B using the same validator somehow. |
Beta Was this translation helpful? Give feedback.
The IMValidator isn't normalized, and the value of a "good" score depends on the number of classes in your dataset. Also depending on the dataset, it might have poor correlation with accuracy. You could try another validator, but most of them aren't normalized so they won't have an understandable range like [0, 1]. In my opinion the biggest challenge in the field right now is creating a validator that is well correlated with accuracy, across algorithms and datasets. Once that is found, then creating a normalizer for it wouldn't be too difficult. Unfortunately most validators are poorly correlated with accuracy. Despite there being hundreds of papers on unsupervised domain adaptation, this…