diff --git a/Annotation_and_fine-tuning/inference.ipynb b/Annotation_and_fine-tuning/inference.ipynb
deleted file mode 100644
index 33cba22..0000000
--- a/Annotation_and_fine-tuning/inference.ipynb
+++ /dev/null
@@ -1,5233 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "code",
- "execution_count": 3,
- "id": "714cbbcd",
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Annotated videos will be saved to: /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/videos_annotated/\n",
- "Loading model from: ./runs/detect/yolov8n_car_parts_finetune/weights/best.pt\n",
- "Found 4 video(s) to process.\n",
- "\n",
- "Processing video: 20250624_185423.mp4\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Annotating 20250624_185423.mp4: 0%| | 0/266 [00:00 0.8\n",
- " confidence_mask = detections.confidence > 0.8\n",
- " # Apply the mask to filter the detections\n",
- " filtered_detections = detections[confidence_mask]\n",
- " \n",
- " # Create labels with class name AND confidence score for the filtered detections\n",
- " labels = [\n",
- " f\"{CLASSES[class_id]} {confidence:.2f}\"\n",
- " for class_id, confidence\n",
- " in zip(filtered_detections.class_id, filtered_detections.confidence)\n",
- " ]\n",
- " \n",
- " # Annotate the frame with bounding boxes and the new labels using the filtered detections\n",
- " annotated_frame = box_annotator.annotate(\n",
- " scene=frame.copy(), \n",
- " detections=filtered_detections\n",
- " )\n",
- " annotated_frame = label_annotator.annotate(\n",
- " scene=annotated_frame, \n",
- " detections=filtered_detections, \n",
- " labels=labels\n",
- " )\n",
- " \n",
- " # Write the annotated frame to the output video file\n",
- " sink.write_frame(annotated_frame)\n",
- " pbar.update(1)\n",
- "\n",
- " except Exception as e:\n",
- " print(f\"An error occurred while processing {video_filename}: {e}\")\n",
- "\n",
- "print(\"\\n--- All videos have been processed successfully! ---\")\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "c02ffab9",
- "metadata": {},
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "venv",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.12.3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 5
-}
diff --git a/Annotation_and_fine-tuning/main.ipynb b/Annotation_and_fine-tuning/main.ipynb
deleted file mode 100644
index 7d5f5d7..0000000
--- a/Annotation_and_fine-tuning/main.ipynb
+++ /dev/null
@@ -1,4225 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "id": "32527096",
- "metadata": {},
- "source": [
- "## File Renaming"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 22,
- "id": "85ad669a",
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Starting file renaming process in root directory: /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/Dataset/\n",
- "Found 7195 files to rename.\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Renaming files: 100%|██████████| 7195/7195 [00:18<00:00, 389.66it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- "--- File renaming process finished successfully! ---\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- }
- ],
- "source": [
- "import os\n",
- "from tqdm import tqdm\n",
- "\n",
- "# --- 1. CONFIGURATION ---\n",
- "\n",
- "# Path to your source dataset that has subfolders like 'Loudspeaker', 'Window', etc.\n",
- "# This is the directory where the folders you want to process are located.\n",
- "ROOT_DIRECTORY = \"/mnt/c/Users/mohsinali.mirza/Downloads/Grounding/Dataset/\"\n",
- "\n",
- "# --- 2. SCRIPT LOGIC ---\n",
- "\n",
- "print(f\"Starting file renaming process in root directory: {ROOT_DIRECTORY}\")\n",
- "\n",
- "# A list to keep track of all files to be renamed for the progress bar\n",
- "files_to_rename = []\n",
- "\n",
- "# First, walk the directory to find all files that need renaming\n",
- "for dirpath, _, filenames in os.walk(ROOT_DIRECTORY):\n",
- " for filename in filenames:\n",
- " # Check if the file is an image and follows the 'frame_...' pattern\n",
- " if filename.lower().startswith('frame_') and filename.lower().endswith(('.jpg', '.jpeg', '.png')):\n",
- " full_path = os.path.join(dirpath, filename)\n",
- " files_to_rename.append(full_path)\n",
- "\n",
- "if not files_to_rename:\n",
- " print(\"No files matching the 'frame_...' pattern were found. Exiting.\")\n",
- " exit()\n",
- " \n",
- "print(f\"Found {len(files_to_rename)} files to rename.\")\n",
- "\n",
- "# Now, iterate through the found files and rename them\n",
- "for old_path in tqdm(files_to_rename, desc=\"Renaming files\"):\n",
- " try:\n",
- " # Get the directory path and the original filename\n",
- " dirpath, old_filename = os.path.split(old_path)\n",
- " \n",
- " # Get the name of the parent folder\n",
- " folder_name = os.path.basename(dirpath)\n",
- " \n",
- " # Create the new filename\n",
- " new_filename = f\"{folder_name}_{old_filename}\"\n",
- " \n",
- " # Create the full new path\n",
- " new_path = os.path.join(dirpath, new_filename)\n",
- " \n",
- " # Rename the file\n",
- " os.rename(old_path, new_path)\n",
- "\n",
- " except Exception as e:\n",
- " print(f\"\\nError renaming {old_path}. Reason: {e}\")\n",
- "\n",
- "print(\"\\n--- File renaming process finished successfully! ---\")"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "c293c54d",
- "metadata": {},
- "source": [
- "## Vision Transformer For Annotation"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 1,
- "id": "aabd114d",
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Using Device: cuda\n",
- "Using Model: google/owlvit-base-patch32\n",
- "\n",
- "--- Class to ID Mapping ---\n",
- "{'the main object in the photo': 0}\n",
- "---------------------------\n",
- "\n",
- "Loading Owl-ViT model and processor...\n",
- "Model loaded successfully.\n",
- "Output directories created at: /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/Dataset_for_YOLOv8/\n",
- "Scanning for all images...\n",
- "Found 168 total images to process.\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Annotating with Owl-ViT: 0%| | 0/168 [00:00 max_size:\n",
- " if h > w:\n",
- " new_h = max_size\n",
- " new_w = int(w * (max_size / h))\n",
- " else:\n",
- " new_w = max_size\n",
- " new_h = int(h * (max_size / w))\n",
- " return cv2.resize(image, (new_w, new_h))\n",
- " return image\n",
- "\n",
- "# --- 6. MAIN ANNOTATION LOOP ---\n",
- "for source_image_path in tqdm(all_image_paths, desc=\"Annotating with Owl-ViT\"):\n",
- " try:\n",
- " image_filename = os.path.basename(source_image_path)\n",
- " dest_image_path = os.path.join(output_images_path, image_filename)\n",
- " label_filename = os.path.splitext(image_filename)[0] + \".txt\"\n",
- " dest_label_path = os.path.join(output_labels_path, label_filename)\n",
- "\n",
- " original_image = cv2.imread(source_image_path)\n",
- " if original_image is None:\n",
- " print(f\"\\nWarning: Could not read image {source_image_path}. Skipping.\")\n",
- " continue\n",
- " \n",
- " original_h, original_w, _ = original_image.shape\n",
- "\n",
- " resized_image = resize_image(original_image, MAX_IMAGE_SIZE)\n",
- " \n",
- " # Owl-ViT expects a list of text queries\n",
- " text_queries = [CLASSES]\n",
- " \n",
- " # Run inference\n",
- " inputs = processor(text=text_queries, images=resized_image, return_tensors=\"pt\").to(DEVICE)\n",
- " with torch.no_grad():\n",
- " outputs = model(**inputs)\n",
- "\n",
- " # Process results\n",
- " resized_h, resized_w, _ = resized_image.shape\n",
- " target_sizes = torch.tensor([[resized_h, resized_w]]).to(DEVICE)\n",
- " \n",
- " # Note: Owl-ViT uses 'post_process_object_detection'\n",
- " results = processor.post_process_object_detection(outputs=outputs, target_sizes=target_sizes, threshold=CONFIDENCE_THRESHOLD)\n",
- "\n",
- " # The results are per-image, so we take the first one (index 0)\n",
- " result = results[0]\n",
- " boxes = result[\"boxes\"]\n",
- " scores = result[\"scores\"]\n",
- " labels = result[\"labels\"]\n",
- "\n",
- " if len(scores) > 0:\n",
- " shutil.copy(source_image_path, dest_image_path)\n",
- "\n",
- " # --- Find and process only the single best detection ---\n",
- " # Find the index of the detection with the highest confidence score\n",
- " best_detection_index = torch.argmax(scores)\n",
- "\n",
- " # Get the single best box\n",
- " best_box = boxes[best_detection_index]\n",
- " \n",
- " # Since we use a generic prompt, the label_id will always be 0.\n",
- " # We will use this as a placeholder. Your label corrector script will fix it.\n",
- " placeholder_label_id = 0\n",
- " \n",
- " # Box is already in xyxy format\n",
- " x1, y1, x2, y2 = best_box.tolist()\n",
- "\n",
- " # Scale the bounding box from the resized image back to the original image's dimensions\n",
- " x1_orig = x1 * (original_w / resized_w)\n",
- " y1_orig = y1 * (original_h / resized_h)\n",
- " x2_orig = x2 * (original_w / resized_w)\n",
- " y2_orig = y2 * (original_h / resized_h)\n",
- "\n",
- " # Convert to YOLO format and normalize\n",
- " box_yolo_x = ((x1_orig + x2_orig) / 2) / original_w\n",
- " box_yolo_y = ((y1_orig + y2_orig) / 2) / original_h\n",
- " box_yolo_w = (x2_orig - x1_orig) / original_w\n",
- " box_yolo_h = (y2_orig - y1_orig) / original_h\n",
- "\n",
- " yolo_formatted_annotation = (\n",
- " f\"{int(placeholder_label_id)} {box_yolo_x:.6f} {box_yolo_y:.6f} {box_yolo_w:.6f} {box_yolo_h:.6f}\"\n",
- " )\n",
- "\n",
- " with open(dest_label_path, \"w\") as f:\n",
- " f.write(yolo_formatted_annotation + \"\\n\")\n",
- "\n",
- " except Exception as e:\n",
- " import traceback\n",
- " print(f\"\\n---!!! UNEXPECTED ERROR processing {source_image_path} !!!---\")\n",
- " traceback.print_exc()\n",
- " print(f\"Error Type: {type(e).__name__}, Message: {e}\")\n",
- " print(\"-----------------------------------------------------------------\")\n",
- " finally:\n",
- " # --- MEMORY CLEANUP ---\n",
- " if 'inputs' in locals(): del inputs\n",
- " if 'outputs' in locals(): del outputs\n",
- " if torch.cuda.is_available():\n",
- " torch.cuda.empty_cache()\n",
- " gc.collect()\n",
- "\n",
- "print(\"\\n--- Owl-ViT Annotation process finished! ---\")\n",
- "print(f\"Your YOLOv8-ready dataset is located at: {OUTPUT_DATA_PATH}\")\n"
- ]
- },
- {
- "cell_type": "markdown",
- "id": "1f1deaaf",
- "metadata": {},
- "source": [
- "## Visualization of Bounding Boxes"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 6,
- "id": "56f0d6e5",
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "--- Starting Dynamic YOLOv8 Label Correction Script ---\n",
- "Master Class-to-ID mapping has been created:\n",
- "{'unit': 0, 'speaker': 1, 'motor': 2, 'assembly': 3}\n",
- "\n",
- "Found 168 label files to process.\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Correcting Labels: 100%|██████████| 168/168 [00:00<00:00, 391.26it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- "--- Label correction process finished! ---\n",
- "Total files checked: 168\n",
- "Total files corrected: 42\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- }
- ],
- "source": [
- "import os\n",
- "from tqdm import tqdm\n",
- "\n",
- "# --- 1. CONFIGURATION ---\n",
- "\n",
- "# Path to the YOLOv8 dataset directory that contains the label files.\n",
- "LABELS_DIRECTORY = \"/mnt/c/Users/mohsinali.mirza/Downloads/Grounding/Dataset_for_YOLOv8/labels/\"\n",
- "\n",
- "# Your master class list. This is the ground truth for mapping names to IDs.\n",
- "# Ensure this list is in the final order you want for YOLOv8 training.\n",
- "# Note: The user's prompt provided a different list, so I've used that one. \n",
- "# Please verify this is correct.\n",
- "CLASSES = [\"unit\", \"speaker\", \"motor\", \"assembly\"]\n",
- "\n",
- "\n",
- "# --- 2. SCRIPT LOGIC ---\n",
- "\n",
- "print(\"--- Starting Dynamic YOLOv8 Label Correction Script ---\")\n",
- "\n",
- "# Create the master mapping from class name to the correct ID\n",
- "class_name_to_id = {name: i for i, name in enumerate(CLASSES)}\n",
- "print(\"Master Class-to-ID mapping has been created:\")\n",
- "print(class_name_to_id)\n",
- "\n",
- "# Get all the label files from the directory\n",
- "try:\n",
- " label_files = [f for f in os.listdir(LABELS_DIRECTORY) if f.endswith('.txt')]\n",
- " if not label_files:\n",
- " print(f\"Error: No .txt files found in {LABELS_DIRECTORY}. Exiting.\")\n",
- " exit()\n",
- "except FileNotFoundError:\n",
- " print(f\"Error: The directory was not found: {LABELS_DIRECTORY}. Please check the path.\")\n",
- " exit()\n",
- "\n",
- "print(f\"\\nFound {len(label_files)} label files to process.\")\n",
- "\n",
- "# Initialize a counter for corrected files\n",
- "corrected_files_count = 0\n",
- "\n",
- "# --- 3. CORRECTION LOOP ---\n",
- "for filename in tqdm(label_files, desc=\"Correcting Labels\"):\n",
- " try:\n",
- " # --- DYNAMIC CLASS NAME EXTRACTION ---\n",
- " # Parse the filename to get the class name part before \"_frame_\"\n",
- " # Example: \"Control Unit_frame_1496.txt\" -> \"Control Unit\"\n",
- " \n",
- " # We split by '_frame_' and take the first part.\n",
- " # This handles class names with spaces correctly.\n",
- " parts = filename.split('_frame_')\n",
- " if len(parts) < 2:\n",
- " print(f\"\\nWarning: Filename '{filename}' does not match 'classname_frame_xxx' format. Skipping.\")\n",
- " continue\n",
- " \n",
- " correct_class_name = parts[0]\n",
- "\n",
- " # Check if the extracted class name exists in our master list\n",
- " if correct_class_name not in class_name_to_id:\n",
- " print(f\"\\nWarning: Extracted class '{correct_class_name}' from filename '{filename}' is not in the master CLASSES list. Skipping.\")\n",
- " continue\n",
- "\n",
- " # Get the correct class ID from our master mapping\n",
- " correct_class_id = class_name_to_id[correct_class_name]\n",
- " \n",
- " label_path = os.path.join(LABELS_DIRECTORY, filename)\n",
- " \n",
- " with open(label_path, 'r') as f:\n",
- " lines = f.readlines()\n",
- " \n",
- " corrected_lines = []\n",
- " was_corrected = False\n",
- "\n",
- " for line in lines:\n",
- " line_parts = line.strip().split()\n",
- " \n",
- " if len(line_parts) == 5:\n",
- " current_class_id = int(line_parts[0])\n",
- " \n",
- " # If the ID is already correct, no change is needed.\n",
- " # If it's incorrect, we set was_corrected to True.\n",
- " if current_class_id != correct_class_id:\n",
- " was_corrected = True\n",
- " \n",
- " # Rebuild the line with the *correct* class ID, keeping coordinates.\n",
- " corrected_line = f\"{correct_class_id} {line_parts[1]} {line_parts[2]} {line_parts[3]} {line_parts[4]}\"\n",
- " corrected_lines.append(corrected_line)\n",
- " else:\n",
- " corrected_lines.append(line.strip()) # Keep malformed lines\n",
- " \n",
- " # Only rewrite the file if a correction was actually made\n",
- " if was_corrected:\n",
- " corrected_files_count += 1\n",
- " with open(label_path, 'w') as f:\n",
- " f.write(\"\\n\".join(corrected_lines))\n",
- " if corrected_lines:\n",
- " f.write(\"\\n\")\n",
- "\n",
- " except Exception as e:\n",
- " print(f\"\\nError processing file {filename}. Reason: {e}\")\n",
- "\n",
- "print(\"\\n--- Label correction process finished! ---\")\n",
- "print(f\"Total files checked: {len(label_files)}\")\n",
- "print(f\"Total files corrected: {corrected_files_count}\")\n",
- "\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": 7,
- "id": "5174398d",
- "metadata": {},
- "outputs": [
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Visualized images will be saved to: /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/annotated_images/\n",
- "Found 168 images to visualize.\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "Visualizing Annotations: 0%| | 0/168 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- "UserWarning: Deterministic behavior was enabled with either `torch.use_deterministic_algorithms(True)` or `at::Context::setDeterministicAlgorithms(true)`, but this operation is not deterministic because it uses CuBLAS and you have CUDA >= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- "UserWarning: Deterministic behavior was enabled with either `torch.use_deterministic_algorithms(True)` or `at::Context::setDeterministicAlgorithms(true)`, but this operation is not deterministic because it uses CuBLAS and you have CUDA >= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- "UserWarning: Deterministic behavior was enabled with either `torch.use_deterministic_algorithms(True)` or `at::Context::setDeterministicAlgorithms(true)`, but this operation is not deterministic because it uses CuBLAS and you have CUDA >= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\u001b[34m\u001b[1mAMP: \u001b[0mchecks passed ✅\n",
- "\u001b[34m\u001b[1mtrain: \u001b[0mFast image access ✅ (ping: 1.3±0.3 ms, read: 25.5±2.8 MB/s, size: 58.2 KB)\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\u001b[34m\u001b[1mtrain: \u001b[0mScanning /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/Dataset_for_YOLOv8/labels... 168 images, 0 backgrounds, 0 corrupt: 100%|██████████| 168/168 [00:00<00:00, 856.66it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\u001b[34m\u001b[1mtrain: \u001b[0mNew cache created: /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/Dataset_for_YOLOv8/labels.cache\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\u001b[34m\u001b[1mval: \u001b[0mFast image access ✅ (ping: 1.8±0.2 ms, read: 15.3±2.7 MB/s, size: 59.1 KB)\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\u001b[34m\u001b[1mval: \u001b[0mScanning /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/Dataset_for_YOLOv8/labels.cache... 168 images, 0 backgrounds, 0 corrupt: 100%|██████████| 168/168 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 1/100 1.59G 0.648 3.168 1.121 19 640: 100%|██████████| 21/21 [00:03<00:00, 5.49it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 6.69it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.00362 1 0.808 0.76\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 2/100 1.69G 0.6027 1.814 1.052 13 640: 100%|██████████| 21/21 [00:02<00:00, 9.51it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 5.62it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.994 0.749 0.787 0.713\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 3/100 1.69G 0.6503 1.461 1.07 15 640: 100%|██████████| 21/21 [00:02<00:00, 8.65it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.80it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.957 0.759 0.944 0.858\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 4/100 1.7G 0.6125 1.329 1.056 21 640: 100%|██████████| 21/21 [00:02<00:00, 9.27it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.17it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.996 0.993 0.995 0.913\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 5/100 1.7G 0.5918 1.275 1.016 19 640: 100%|██████████| 21/21 [00:02<00:00, 9.98it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.25it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.898 0.915 0.989 0.905\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 6/100 1.7G 0.6271 1.24 1.033 18 640: 100%|██████████| 21/21 [00:02<00:00, 10.09it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 6.96it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.845 0.987 0.993 0.873\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 7/100 1.71G 0.6546 1.203 1.068 19 640: 100%|██████████| 21/21 [00:02<00:00, 10.32it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.60it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.908\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 8/100 1.71G 0.5841 1.055 1.008 15 640: 100%|██████████| 21/21 [00:02<00:00, 10.30it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.60it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.982 0.983 0.995 0.922\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 9/100 1.73G 0.5706 0.9735 0.9834 19 640: 100%|██████████| 21/21 [00:02<00:00, 9.67it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.11it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.995 1 0.995 0.936\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 10/100 1.73G 0.5538 0.9334 0.9907 21 640: 100%|██████████| 21/21 [00:02<00:00, 8.66it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 6.79it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.804 0.905 0.871 0.783\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 11/100 1.75G 0.5254 0.8967 0.9646 22 640: 100%|██████████| 21/21 [00:02<00:00, 8.64it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.89it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.943\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 12/100 1.75G 0.5445 0.8611 0.9933 12 640: 100%|██████████| 21/21 [00:02<00:00, 9.64it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.77it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.922 0.979 0.995 0.953\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 13/100 1.76G 0.5362 0.8376 0.9626 15 640: 100%|██████████| 21/21 [00:02<00:00, 10.12it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.22it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.995 1 0.995 0.944\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 14/100 1.76G 0.4911 0.8639 0.9672 13 640: 100%|██████████| 21/21 [00:02<00:00, 10.33it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.08it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.921\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 15/100 1.78G 0.4859 0.761 0.9447 20 640: 100%|██████████| 21/21 [00:02<00:00, 9.50it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.75it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.99 1 0.995 0.954\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 16/100 1.78G 0.5276 0.7808 0.969 18 640: 100%|██████████| 21/21 [00:02<00:00, 8.61it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.15it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.948\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 17/100 1.8G 0.5388 0.7503 0.975 19 640: 100%|██████████| 21/21 [00:02<00:00, 9.16it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.88it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.972\n",
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 18/100 1.8G 0.4674 0.709 0.9382 16 640: 100%|██████████| 21/21 [00:02<00:00, 9.82it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.42it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.966\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 19/100 1.8G 0.4586 0.6896 0.9384 25 640: 100%|██████████| 21/21 [00:02<00:00, 9.55it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.35it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.954\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 20/100 1.8G 0.5281 0.7868 0.9855 16 640: 100%|██████████| 21/21 [00:02<00:00, 8.83it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.64it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.972\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 21/100 1.8G 0.4371 0.6951 0.9289 16 640: 100%|██████████| 21/21 [00:02<00:00, 8.69it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.78it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.941\n",
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 22/100 1.8G 0.4961 0.6907 0.943 14 640: 100%|██████████| 21/21 [00:02<00:00, 8.95it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.10it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.952\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 23/100 1.8G 0.4592 0.6733 0.941 19 640: 100%|██████████| 21/21 [00:02<00:00, 10.16it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.52it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.976\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 24/100 1.8G 0.4453 0.6285 0.9465 26 640: 100%|██████████| 21/21 [00:02<00:00, 10.29it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.08it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.973\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 25/100 1.8G 0.4597 0.5922 0.9261 17 640: 100%|██████████| 21/21 [00:02<00:00, 10.18it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.85it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.976\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 26/100 1.8G 0.4277 0.5668 0.9165 18 640: 100%|██████████| 21/21 [00:02<00:00, 9.63it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.21it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.964\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 27/100 1.8G 0.4539 0.5764 0.9324 23 640: 100%|██████████| 21/21 [00:02<00:00, 8.59it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.18it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.979\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 28/100 1.8G 0.4392 0.5688 0.9328 28 640: 100%|██████████| 21/21 [00:02<00:00, 9.50it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.47it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.983\n",
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 29/100 1.8G 0.4253 0.5448 0.9175 15 640: 100%|██████████| 21/21 [00:02<00:00, 10.32it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.86it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.966\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 30/100 1.8G 0.4244 0.5448 0.9419 14 640: 100%|██████████| 21/21 [00:02<00:00, 10.17it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.27it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.982\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 31/100 1.8G 0.4522 0.5673 0.9462 16 640: 100%|██████████| 21/21 [00:01<00:00, 10.67it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.49it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.973\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 32/100 1.8G 0.4213 0.5025 0.9235 20 640: 100%|██████████| 21/21 [00:01<00:00, 11.86it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.24it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.979\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 33/100 1.8G 0.447 0.5152 0.9386 21 640: 100%|██████████| 21/21 [00:02<00:00, 9.55it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.47it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.978\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 34/100 1.8G 0.4215 0.5107 0.9229 18 640: 100%|██████████| 21/21 [00:02<00:00, 10.27it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.70it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.977\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 35/100 1.8G 0.4137 0.5051 0.926 13 640: 100%|██████████| 21/21 [00:02<00:00, 8.61it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.38it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.974\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 36/100 1.8G 0.4035 0.4766 0.9309 15 640: 100%|██████████| 21/21 [00:02<00:00, 8.67it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.40it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.976\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 37/100 1.8G 0.3996 0.46 0.914 17 640: 100%|██████████| 21/21 [00:02<00:00, 10.00it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.34it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.97\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 38/100 1.8G 0.4206 0.4645 0.9271 19 640: 100%|██████████| 21/21 [00:02<00:00, 10.03it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.31it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.978\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 39/100 1.8G 0.3695 0.4334 0.9002 22 640: 100%|██████████| 21/21 [00:02<00:00, 9.29it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.91it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.982\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 40/100 1.8G 0.4039 0.4709 0.917 12 640: 100%|██████████| 21/21 [00:02<00:00, 10.09it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.82it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.98\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 41/100 1.8G 0.4228 0.4633 0.9227 18 640: 100%|██████████| 21/21 [00:02<00:00, 9.93it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.81it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.967\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 42/100 1.8G 0.377 0.4384 0.8801 16 640: 100%|██████████| 21/21 [00:02<00:00, 9.89it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.24it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.983\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 43/100 1.8G 0.4142 0.4607 0.9169 21 640: 100%|██████████| 21/21 [00:02<00:00, 9.01it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.03it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.941\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 44/100 1.8G 0.377 0.4464 0.9108 14 640: 100%|██████████| 21/21 [00:01<00:00, 10.59it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.27it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.978\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 45/100 1.8G 0.3744 0.4267 0.8949 18 640: 100%|██████████| 21/21 [00:02<00:00, 10.44it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 6.95it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.98\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 46/100 1.8G 0.3706 0.4194 0.9055 13 640: 100%|██████████| 21/21 [00:02<00:00, 9.49it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.46it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.981\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 47/100 1.8G 0.3805 0.4143 0.9053 20 640: 100%|██████████| 21/21 [00:02<00:00, 8.22it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.61it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.973\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 48/100 1.8G 0.3717 0.4106 0.91 22 640: 100%|██████████| 21/21 [00:02<00:00, 10.24it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.87it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.968\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 49/100 1.8G 0.3932 0.4035 0.9158 19 640: 100%|██████████| 21/21 [00:01<00:00, 10.83it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.27it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.999 1 0.995 0.978\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 50/100 1.8G 0.3755 0.3939 0.8921 18 640: 100%|██████████| 21/21 [00:02<00:00, 9.79it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.41it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.979\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 51/100 1.8G 0.3819 0.3941 0.9073 28 640: 100%|██████████| 21/21 [00:02<00:00, 8.75it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.60it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.978\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 52/100 1.8G 0.3677 0.4011 0.9088 22 640: 100%|██████████| 21/21 [00:01<00:00, 10.50it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.36it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.982\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 53/100 1.8G 0.3536 0.3873 0.895 12 640: 100%|██████████| 21/21 [00:02<00:00, 9.61it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.43it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.999 1 0.995 0.98\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 54/100 1.8G 0.3752 0.384 0.917 16 640: 100%|██████████| 21/21 [00:02<00:00, 9.63it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.20it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.985\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 55/100 1.8G 0.3477 0.3619 0.9016 23 640: 100%|██████████| 21/21 [00:02<00:00, 9.90it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.44it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.985\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 56/100 1.8G 0.3448 0.3596 0.8913 23 640: 100%|██████████| 21/21 [00:02<00:00, 9.40it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.39it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.988\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 57/100 1.8G 0.356 0.3873 0.8825 20 640: 100%|██████████| 21/21 [00:02<00:00, 9.74it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.55it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.997 1 0.995 0.992\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 58/100 1.8G 0.3396 0.3577 0.9078 16 640: 100%|██████████| 21/21 [00:02<00:00, 9.41it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.19it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.987\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 59/100 1.8G 0.3274 0.3421 0.8729 16 640: 100%|██████████| 21/21 [00:02<00:00, 9.65it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.39it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.984\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 60/100 1.8G 0.3267 0.3419 0.8776 16 640: 100%|██████████| 21/21 [00:02<00:00, 9.65it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.74it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.987\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 61/100 1.8G 0.3261 0.3347 0.8908 20 640: 100%|██████████| 21/21 [00:02<00:00, 9.36it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.72it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.999 1 0.995 0.99\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 62/100 1.8G 0.3445 0.3496 0.8906 22 640: 100%|██████████| 21/21 [00:02<00:00, 9.40it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.24it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.984\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 63/100 1.8G 0.3385 0.345 0.8884 22 640: 100%|██████████| 21/21 [00:02<00:00, 8.91it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.56it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 64/100 1.8G 0.3582 0.3469 0.8932 16 640: 100%|██████████| 21/21 [00:02<00:00, 10.40it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.27it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.993\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 65/100 1.8G 0.3228 0.3296 0.8825 15 640: 100%|██████████| 21/21 [00:02<00:00, 9.61it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.44it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.999 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 66/100 1.8G 0.3266 0.3334 0.8684 23 640: 100%|██████████| 21/21 [00:01<00:00, 10.93it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.62it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.99\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 67/100 1.8G 0.3321 0.3249 0.8816 21 640: 100%|██████████| 21/21 [00:01<00:00, 11.48it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:00<00:00, 11.23it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.987\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 68/100 1.8G 0.3352 0.3497 0.8954 23 640: 100%|██████████| 21/21 [00:02<00:00, 10.25it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.43it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.999 1 0.995 0.987\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 69/100 1.8G 0.3245 0.3104 0.8817 20 640: 100%|██████████| 21/21 [00:02<00:00, 9.83it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.94it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.999 1 0.995 0.989\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 70/100 1.8G 0.3165 0.3144 0.8877 17 640: 100%|██████████| 21/21 [00:02<00:00, 8.40it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.82it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.999 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 71/100 1.8G 0.3226 0.3188 0.8911 19 640: 100%|██████████| 21/21 [00:02<00:00, 9.01it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.58it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.989\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 72/100 1.8G 0.3254 0.3117 0.8899 16 640: 100%|██████████| 21/21 [00:02<00:00, 10.48it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.61it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.989\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 73/100 1.8G 0.3068 0.3096 0.8777 16 640: 100%|██████████| 21/21 [00:02<00:00, 9.20it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.74it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 74/100 1.8G 0.304 0.3202 0.8864 15 640: 100%|██████████| 21/21 [00:02<00:00, 8.55it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.05it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 75/100 1.8G 0.3009 0.2982 0.8767 11 640: 100%|██████████| 21/21 [00:02<00:00, 9.05it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.47it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.989\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 76/100 1.8G 0.2908 0.291 0.8573 19 640: 100%|██████████| 21/21 [00:02<00:00, 9.36it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.98it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 77/100 1.8G 0.3373 0.321 0.8984 16 640: 100%|██████████| 21/21 [00:02<00:00, 10.20it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 6.70it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.999 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 78/100 1.8G 0.3109 0.2995 0.8818 21 640: 100%|██████████| 21/21 [00:02<00:00, 9.70it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.46it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.99\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 79/100 1.8G 0.3021 0.2892 0.8795 24 640: 100%|██████████| 21/21 [00:02<00:00, 9.78it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.68it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.99\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 80/100 1.8G 0.3008 0.2984 0.8642 17 640: 100%|██████████| 21/21 [00:01<00:00, 11.41it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.96it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.988\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 81/100 1.8G 0.2871 0.2756 0.8619 20 640: 100%|██████████| 21/21 [00:02<00:00, 10.08it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.80it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.989\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 82/100 1.8G 0.2924 0.2877 0.8739 16 640: 100%|██████████| 21/21 [00:01<00:00, 11.43it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.86it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.989\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 83/100 1.8G 0.29 0.2801 0.8761 20 640: 100%|██████████| 21/21 [00:01<00:00, 11.66it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.29it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.99\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 84/100 1.8G 0.2914 0.2745 0.8737 18 640: 100%|██████████| 21/21 [00:02<00:00, 9.96it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.28it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.993\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 85/100 1.8G 0.289 0.2627 0.8733 16 640: 100%|██████████| 21/21 [00:02<00:00, 10.09it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.99it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.994\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 86/100 1.8G 0.2722 0.2733 0.879 13 640: 100%|██████████| 21/21 [00:02<00:00, 10.11it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.56it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.99\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 87/100 1.8G 0.2829 0.2838 0.8741 12 640: 100%|██████████| 21/21 [00:02<00:00, 10.10it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.30it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.99\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 88/100 1.8G 0.2888 0.2796 0.8791 14 640: 100%|██████████| 21/21 [00:02<00:00, 10.10it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.02it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 89/100 1.8G 0.2877 0.2732 0.8758 21 640: 100%|██████████| 21/21 [00:01<00:00, 10.55it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.85it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.988\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 90/100 1.8G 0.2701 0.2776 0.8563 17 640: 100%|██████████| 21/21 [00:02<00:00, 10.26it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.92it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.99\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "Closing dataloader mosaic\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n",
- "huggingface/tokenizers: The current process just got forked, after parallelism has already been used. Disabling parallelism to avoid deadlocks...\n",
- "To disable this warning, you can either:\n",
- "\t- Avoid using `tokenizers` before the fork if possible\n",
- "\t- Explicitly set the environment variable TOKENIZERS_PARALLELISM=(true | false)\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 91/100 1.8G 0.1962 0.2624 0.8172 8 640: 100%|██████████| 21/21 [00:02<00:00, 8.70it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.81it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.993\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 92/100 1.8G 0.1895 0.2603 0.8005 8 640: 100%|██████████| 21/21 [00:02<00:00, 9.96it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.87it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.992\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 93/100 1.8G 0.1873 0.2582 0.8103 8 640: 100%|██████████| 21/21 [00:01<00:00, 10.75it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.63it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 94/100 1.8G 0.1913 0.2502 0.7867 8 640: 100%|██████████| 21/21 [00:02<00:00, 9.93it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.06it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.992\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 95/100 1.8G 0.1895 0.249 0.7942 8 640: 100%|██████████| 21/21 [00:02<00:00, 10.27it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.45it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.992\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 96/100 1.8G 0.192 0.2474 0.7928 8 640: 100%|██████████| 21/21 [00:02<00:00, 10.04it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 10.63it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.991\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 97/100 1.8G 0.1749 0.2389 0.7923 8 640: 100%|██████████| 21/21 [00:02<00:00, 9.44it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 9.46it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.994\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 98/100 1.8G 0.1795 0.2473 0.7998 8 640: 100%|██████████| 21/21 [00:02<00:00, 9.69it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 7.51it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.994\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 99/100 1.8G 0.1911 0.2461 0.8137 8 640: 100%|██████████| 21/21 [00:02<00:00, 9.87it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.51it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.994\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- " Epoch GPU_mem box_loss cls_loss dfl_loss Instances Size\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- " 0%| | 0/21 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " 100/100 1.8G 0.1805 0.2462 0.7937 8 640: 100%|██████████| 21/21 [00:02<00:00, 9.23it/s]\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 0%| | 0/11 [00:00= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 8.25it/s]"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.994\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- "\n",
- "100 epochs completed in 0.105 hours.\n",
- "Optimizer stripped from runs/detect/yolov8n_car_parts_finetune/weights/last.pt, 6.2MB\n",
- "Optimizer stripped from runs/detect/yolov8n_car_parts_finetune/weights/best.pt, 6.2MB\n",
- "\n",
- "Validating runs/detect/yolov8n_car_parts_finetune/weights/best.pt...\n",
- "Ultralytics 8.3.159 🚀 Python-3.12.3 torch-2.7.1+cu126 CUDA:0 (NVIDIA GeForce RTX 3070 Ti, 8192MiB)\n",
- "Model summary (fused): 72 layers, 3,006,428 parameters, 0 gradients, 8.1 GFLOPs\n"
- ]
- },
- {
- "name": "stderr",
- "output_type": "stream",
- "text": [
- "UserWarning: Deterministic behavior was enabled with either `torch.use_deterministic_algorithms(True)` or `at::Context::setDeterministicAlgorithms(true)`, but this operation is not deterministic because it uses CuBLAS and you have CUDA >= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- "UserWarning: Deterministic behavior was enabled with either `torch.use_deterministic_algorithms(True)` or `at::Context::setDeterministicAlgorithms(true)`, but this operation is not deterministic because it uses CuBLAS and you have CUDA >= 10.2. To enable deterministic behavior in this case, you must set an environment variable before running your PyTorch application: CUBLAS_WORKSPACE_CONFIG=:4096:8 or CUBLAS_WORKSPACE_CONFIG=:16:8. For more information, go to https://docs.nvidia.com/cuda/cublas/index.html#results-reproducibility (Triggered internally at /pytorch/aten/src/ATen/Context.cpp:233.)\n",
- " Class Images Instances Box(P R mAP50 mAP50-95): 100%|██████████| 11/11 [00:01<00:00, 5.72it/s]\n"
- ]
- },
- {
- "name": "stdout",
- "output_type": "stream",
- "text": [
- " all 168 168 0.998 1 0.995 0.994\n",
- " control unit 42 42 0.998 1 0.995 0.995\n",
- " loud speaker 42 42 0.998 1 0.995 0.995\n",
- " Motor 42 42 0.999 1 0.995 0.991\n",
- "window regulator assembly 42 42 0.998 1 0.995 0.995\n",
- "Speed: 0.2ms preprocess, 1.6ms inference, 0.0ms loss, 3.6ms postprocess per image\n",
- "Results saved to \u001b[1mruns/detect/yolov8n_car_parts_finetune\u001b[0m\n",
- "\n",
- "--- Training finished! ---\n",
- "Your trained model and results are saved in the 'runs/detect/' directory.\n"
- ]
- }
- ],
- "source": [
- "from ultralytics import YOLO\n",
- "\n",
- "# --- 1. Load a Pre-trained Model ---\n",
- "# 'yolov8n.pt' is the smallest and fastest model, ideal for starting.\n",
- "# You can also use 'yolov8s.pt', 'yolov8m.pt', etc., for better accuracy at the cost of speed and memory.\n",
- "model = YOLO('yolov8n.pt')\n",
- "\n",
- "# --- 2. Define the path to your dataset YAML file ---\n",
- "dataset_yaml_path = '/mnt/c/Users/mohsinali.mirza/Downloads/Grounding/car_parts.yaml'\n",
- "\n",
- "# --- 3. Start Fine-Tuning ---\n",
- "# The training results, including model weights, will be saved in a 'runs/detect/train' directory.\n",
- "results = model.train(\n",
- " data=dataset_yaml_path,\n",
- " epochs=100, # Number of training epochs. Start with 100 and see the results.\n",
- " imgsz=640, # Image size for training. 640 is a common choice.\n",
- " batch=8, # Batch size. Lower this if you run into CUDA memory issues (e.g., to 4 or 2).\n",
- " name='yolov8n_car_parts_finetune' # A name for your training run\n",
- ")\n",
- "\n",
- "print(\"\\n--- Training finished! ---\")\n",
- "print(\"Your trained model and results are saved in the 'runs/detect/' directory.\")"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "id": "ca35af88",
- "metadata": {},
- "outputs": [],
- "source": []
- }
- ],
- "metadata": {
- "kernelspec": {
- "display_name": "venv",
- "language": "python",
- "name": "python3"
- },
- "language_info": {
- "codemirror_mode": {
- "name": "ipython",
- "version": 3
- },
- "file_extension": ".py",
- "mimetype": "text/x-python",
- "name": "python",
- "nbconvert_exporter": "python",
- "pygments_lexer": "ipython3",
- "version": "3.12.3"
- }
- },
- "nbformat": 4,
- "nbformat_minor": 5
-}
diff --git a/Annotation_and_fine-tuning/requirements.txt b/Annotation_and_fine-tuning/requirements.txt
deleted file mode 100644
index 69c56dd..0000000
--- a/Annotation_and_fine-tuning/requirements.txt
+++ /dev/null
@@ -1,90 +0,0 @@
-asttokens==3.0.0
-certifi==2025.6.15
-charset-normalizer==3.4.2
-comm==0.2.2
-contourpy==1.3.2
-cycler==0.12.1
-debugpy==1.8.14
-decorator==5.2.1
-defusedxml==0.7.1
-executing==2.2.0
-filelock==3.18.0
-fonttools==4.58.4
-fsspec==2025.5.1
-hf-xet==1.1.5
-huggingface-hub==0.33.1
-idna==3.10
-ipykernel==6.29.5
-ipython==9.3.0
-ipython_pygments_lexers==1.1.1
-ipywidgets==8.1.7
-jedi==0.19.2
-Jinja2==3.1.6
-jupyter_client==8.6.3
-jupyter_core==5.8.1
-jupyterlab_widgets==3.0.15
-kiwisolver==1.4.8
-MarkupSafe==3.0.2
-matplotlib==3.10.3
-matplotlib-inline==0.1.7
-mpmath==1.3.0
-nest-asyncio==1.6.0
-networkx==3.5
-numpy==2.3.1
-nvidia-cublas-cu12==12.6.4.1
-nvidia-cuda-cupti-cu12==12.6.80
-nvidia-cuda-nvrtc-cu12==12.6.77
-nvidia-cuda-runtime-cu12==12.6.77
-nvidia-cudnn-cu12==9.5.1.17
-nvidia-cufft-cu12==11.3.0.4
-nvidia-cufile-cu12==1.11.1.6
-nvidia-curand-cu12==10.3.7.77
-nvidia-cusolver-cu12==11.7.1.2
-nvidia-cusparse-cu12==12.5.4.2
-nvidia-cusparselt-cu12==0.6.3
-nvidia-nccl-cu12==2.26.2
-nvidia-nvjitlink-cu12==12.6.85
-nvidia-nvtx-cu12==12.6.77
-opencv-python==4.11.0.86
-packaging==25.0
-pandas==2.3.0
-parso==0.8.4
-pexpect==4.9.0
-pillow==11.2.1
-platformdirs==4.3.8
-prompt_toolkit==3.0.51
-psutil==7.0.0
-ptyprocess==0.7.0
-pure_eval==0.2.3
-py-cpuinfo==9.0.0
-Pygments==2.19.2
-pyparsing==3.2.3
-python-dateutil==2.9.0.post0
-pytz==2025.2
-PyYAML==6.0.2
-pyzmq==27.0.0
-regex==2024.11.6
-requests==2.32.4
-safetensors==0.5.3
-scipy==1.16.0
-setuptools==80.9.0
-six==1.17.0
-stack-data==0.6.3
-supervision==0.25.1
-sympy==1.14.0
-tokenizers==0.21.2
-torch==2.7.1
-torchaudio==2.7.1
-torchvision==0.22.1
-tornado==6.5.1
-tqdm==4.67.1
-traitlets==5.14.3
-transformers==4.53.0
-triton==3.3.1
-typing_extensions==4.14.0
-tzdata==2025.2
-ultralytics==8.3.159
-ultralytics-thop==2.0.14
-urllib3==2.5.0
-wcwidth==0.2.13
-widgetsnbextension==4.0.14
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/F1_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/F1_curve.png
deleted file mode 100644
index 722f18e..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/F1_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/PR_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/PR_curve.png
deleted file mode 100644
index 228e35a..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/PR_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/P_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/P_curve.png
deleted file mode 100644
index 56d6dae..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/P_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/R_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/R_curve.png
deleted file mode 100644
index fd45404..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/R_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/args.yaml b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/args.yaml
deleted file mode 100644
index 4dc0d9b..0000000
--- a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/args.yaml
+++ /dev/null
@@ -1,105 +0,0 @@
-task: detect
-mode: train
-model: yolov8n.pt
-data: /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/car_parts.yaml
-epochs: 100
-time: null
-patience: 100
-batch: 8
-imgsz: 640
-save: true
-save_period: -1
-cache: false
-device: null
-workers: 8
-project: null
-name: yolov8n_car_parts_aggressive_aug
-exist_ok: false
-pretrained: true
-optimizer: auto
-verbose: true
-seed: 0
-deterministic: true
-single_cls: false
-rect: false
-cos_lr: false
-close_mosaic: 10
-resume: false
-amp: true
-fraction: 1.0
-profile: false
-freeze: null
-multi_scale: false
-overlap_mask: true
-mask_ratio: 4
-dropout: 0.0
-val: true
-split: val
-save_json: false
-conf: null
-iou: 0.7
-max_det: 300
-half: false
-dnn: false
-plots: true
-source: null
-vid_stride: 1
-stream_buffer: false
-visualize: false
-augment: false
-agnostic_nms: false
-classes: null
-retina_masks: false
-embed: null
-show: false
-save_frames: false
-save_txt: false
-save_conf: false
-save_crop: false
-show_labels: true
-show_conf: true
-show_boxes: true
-line_width: null
-format: torchscript
-keras: false
-optimize: false
-int8: false
-dynamic: false
-simplify: true
-opset: null
-workspace: null
-nms: false
-lr0: 0.01
-lrf: 0.01
-momentum: 0.937
-weight_decay: 0.0005
-warmup_epochs: 3.0
-warmup_momentum: 0.8
-warmup_bias_lr: 0.1
-box: 7.5
-cls: 0.5
-dfl: 1.5
-pose: 12.0
-kobj: 1.0
-nbs: 64
-hsv_h: 0.015
-hsv_s: 0.7
-hsv_v: 0.4
-degrees: 25.0
-translate: 0.15
-scale: 0.6
-shear: 5.0
-perspective: 0.0005
-flipud: 0.5
-fliplr: 0.5
-bgr: 0.0
-mosaic: 1.0
-mixup: 0.5
-cutmix: 0.0
-copy_paste: 0.3
-copy_paste_mode: flip
-auto_augment: randaugment
-erasing: 0.4
-cfg: null
-tracker: botsort.yaml
-save_dir: runs/detect/yolov8n_car_parts_aggressive_aug
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/confusion_matrix.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/confusion_matrix.png
deleted file mode 100644
index 97e59a6..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/confusion_matrix.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/confusion_matrix_normalized.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/confusion_matrix_normalized.png
deleted file mode 100644
index 3eb1108..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/confusion_matrix_normalized.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/labels.jpg
deleted file mode 100644
index 383e9ba..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/results.csv b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/results.csv
deleted file mode 100644
index 3012cc6..0000000
--- a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/results.csv
+++ /dev/null
@@ -1,101 +0,0 @@
-epoch,time,train/box_loss,train/cls_loss,train/dfl_loss,metrics/precision(B),metrics/recall(B),metrics/mAP50(B),metrics/mAP50-95(B),val/box_loss,val/cls_loss,val/dfl_loss,lr/pg0,lr/pg1,lr/pg2
-1,107.665,1.20679,1.49314,1.38835,0.98025,0.98675,0.99426,0.72971,0.95427,0.79722,1.08283,0.000415971,0.000415971,0.000415971
-2,212.274,1.0778,0.90711,1.28548,0.99566,0.99774,0.99461,0.74562,0.95165,0.49985,1.08199,0.000824395,0.000824395,0.000824395
-3,314.118,1.02928,0.76606,1.25607,0.9982,0.99936,0.99477,0.71931,1.0596,0.55811,1.12405,0.00122457,0.00122457,0.00122457
-4,416.83,0.99985,0.69122,1.23959,0.9991,0.99938,0.99459,0.74283,1.0355,0.44094,1.09079,0.00121287,0.00121287,0.00121287
-5,515.655,0.97708,0.65669,1.22357,0.99814,0.99938,0.99487,0.77712,0.86758,0.41337,1.04557,0.0012005,0.0012005,0.0012005
-6,617.973,0.94919,0.61559,1.20881,0.99784,0.99938,0.99465,0.84432,0.62878,0.34875,0.93352,0.00118812,0.00118812,0.00118812
-7,716.391,0.90629,0.57843,1.17889,0.99757,0.99881,0.99457,0.85684,0.61074,0.36726,0.94043,0.00117575,0.00117575,0.00117575
-8,812.07,0.88872,0.56947,1.17108,0.99854,0.99938,0.99475,0.81298,0.7893,0.35132,0.98761,0.00116337,0.00116337,0.00116337
-9,911.743,0.87227,0.55105,1.16349,0.99924,0.99938,0.9947,0.81097,0.78029,0.35462,0.9947,0.001151,0.001151,0.001151
-10,1008.72,0.86109,0.53339,1.15553,0.99907,0.99938,0.99461,0.82135,0.77954,0.33846,0.96646,0.00113863,0.00113863,0.00113863
-11,1112.96,0.84367,0.5214,1.14614,0.99919,0.99938,0.99442,0.78169,0.90929,0.37584,1.03156,0.00112625,0.00112625,0.00112625
-12,1209.95,0.83638,0.51721,1.14393,0.99901,0.99938,0.99473,0.82641,0.75183,0.33962,0.97174,0.00111388,0.00111388,0.00111388
-13,1308.6,0.82989,0.5143,1.14264,0.9991,0.99919,0.99464,0.84193,0.6907,0.32187,0.93372,0.0011015,0.0011015,0.0011015
-14,1404.24,0.81499,0.49892,1.13344,0.99892,0.99938,0.99487,0.84613,0.67875,0.31027,0.93285,0.00108913,0.00108913,0.00108913
-15,1505.32,0.80445,0.48726,1.12259,0.99907,0.99938,0.99453,0.84869,0.65623,0.30338,0.92587,0.00107675,0.00107675,0.00107675
-16,1602.7,0.80527,0.48846,1.1273,0.99908,0.99938,0.99462,0.85383,0.64788,0.33348,0.91503,0.00106437,0.00106437,0.00106437
-17,1702.57,0.7878,0.47662,1.12232,0.99882,0.99938,0.99478,0.86226,0.62185,0.28894,0.9086,0.001052,0.001052,0.001052
-18,1799.71,0.78003,0.46527,1.11487,0.99958,0.99969,0.99489,0.86251,0.63687,0.2829,0.91222,0.00103962,0.00103962,0.00103962
-19,1900.92,0.76893,0.45897,1.1067,0.99908,0.99938,0.99455,0.8593,0.62654,0.29058,0.91357,0.00102725,0.00102725,0.00102725
-20,1999.83,0.77171,0.46226,1.1101,0.99909,0.99932,0.99452,0.87161,0.59252,0.28145,0.90125,0.00101488,0.00101488,0.00101488
-21,2099.08,0.76974,0.45762,1.10281,0.99863,0.99929,0.99477,0.86714,0.59834,0.28364,0.89907,0.0010025,0.0010025,0.0010025
-22,2197.73,0.74842,0.44719,1.09734,0.99924,0.99938,0.99477,0.88039,0.54648,0.26553,0.89141,0.000990125,0.000990125,0.000990125
-23,2295.63,0.76074,0.44794,1.1025,0.99918,0.99938,0.99463,0.85826,0.65685,0.28441,0.91387,0.00097775,0.00097775,0.00097775
-24,2388.16,0.74983,0.44275,1.098,0.99956,0.99969,0.99489,0.89103,0.51947,0.26201,0.87344,0.000965375,0.000965375,0.000965375
-25,2484.86,0.74487,0.44608,1.09456,0.99923,0.99938,0.99468,0.87306,0.57669,0.25849,0.89393,0.000953,0.000953,0.000953
-26,2581.75,0.73718,0.43703,1.08969,0.99923,0.99938,0.99476,0.88891,0.53739,0.25798,0.88422,0.000940625,0.000940625,0.000940625
-27,2680.09,0.73194,0.42981,1.08441,0.99924,0.99938,0.99451,0.86916,0.61322,0.26984,0.89598,0.00092825,0.00092825,0.00092825
-28,2777.22,0.73027,0.42713,1.07732,0.99919,0.99938,0.99471,0.86503,0.61223,0.26666,0.89347,0.000915875,0.000915875,0.000915875
-29,2872.07,0.71365,0.41519,1.07475,0.99918,0.99938,0.99465,0.89519,0.5119,0.2398,0.86806,0.0009035,0.0009035,0.0009035
-30,2969.86,0.71971,0.41858,1.07774,0.9992,0.99938,0.99463,0.88401,0.56823,0.25281,0.88508,0.000891125,0.000891125,0.000891125
-31,3070.57,0.71538,0.41933,1.0787,0.99924,0.99938,0.99489,0.88309,0.57678,0.25361,0.89381,0.00087875,0.00087875,0.00087875
-32,3170.44,0.71729,0.41791,1.07771,0.99925,0.99938,0.99471,0.87533,0.58978,0.25821,0.89023,0.000866375,0.000866375,0.000866375
-33,3271.82,0.70724,0.40713,1.07222,0.99925,0.99938,0.99489,0.87807,0.5839,0.25719,0.89023,0.000854,0.000854,0.000854
-34,3369.17,0.70173,0.40477,1.06753,0.99957,0.99969,0.99495,0.90132,0.50335,0.23663,0.8702,0.000841625,0.000841625,0.000841625
-35,3463.73,0.70398,0.40595,1.07017,0.99923,0.99938,0.99455,0.87857,0.58285,0.2498,0.89078,0.00082925,0.00082925,0.00082925
-36,3563.74,0.69215,0.39883,1.06238,0.99952,0.99969,0.99489,0.90391,0.51048,0.2376,0.87078,0.000816875,0.000816875,0.000816875
-37,3660.4,0.69427,0.40034,1.06344,0.99954,0.99969,0.99481,0.88015,0.57972,0.24943,0.88568,0.0008045,0.0008045,0.0008045
-38,3759.98,0.69011,0.39726,1.06091,0.99921,0.99938,0.99445,0.89123,0.54013,0.24348,0.88259,0.000792125,0.000792125,0.000792125
-39,3858.67,0.68511,0.39554,1.0591,0.99954,0.99969,0.99484,0.88803,0.54988,0.24553,0.87257,0.00077975,0.00077975,0.00077975
-40,3955.97,0.68282,0.39359,1.05676,0.99926,0.99938,0.99485,0.88598,0.55281,0.24448,0.88292,0.000767375,0.000767375,0.000767375
-41,4053.45,0.67863,0.39001,1.05855,0.99919,0.99938,0.99475,0.8911,0.53485,0.23472,0.87629,0.000755,0.000755,0.000755
-42,4152.96,0.66772,0.37824,1.04427,0.99916,0.99938,0.99494,0.8886,0.54429,0.23822,0.87412,0.000742625,0.000742625,0.000742625
-43,4249.05,0.67394,0.38958,1.05202,0.99911,0.99938,0.99466,0.86946,0.60597,0.24825,0.89343,0.00073025,0.00073025,0.00073025
-44,4344.92,0.67134,0.38854,1.05025,0.9992,0.99938,0.99491,0.87272,0.59786,0.24884,0.88956,0.000717875,0.000717875,0.000717875
-45,4442.25,0.67074,0.38265,1.0514,0.99919,0.99938,0.99478,0.87782,0.57708,0.23825,0.88684,0.0007055,0.0007055,0.0007055
-46,4542.86,0.65816,0.37811,1.04404,0.9992,0.99938,0.99485,0.89678,0.51706,0.23379,0.86219,0.000693125,0.000693125,0.000693125
-47,4641.26,0.66155,0.38115,1.04364,0.99925,0.99938,0.99451,0.87571,0.59949,0.24747,0.89237,0.00068075,0.00068075,0.00068075
-48,4740.39,0.66498,0.38062,1.0529,0.99922,0.99938,0.99482,0.89875,0.51524,0.23104,0.86866,0.000668375,0.000668375,0.000668375
-49,4835.09,0.65346,0.37645,1.04756,0.99919,0.99938,0.99471,0.89407,0.53595,0.23234,0.86912,0.000656,0.000656,0.000656
-50,4930.32,0.652,0.37492,1.04455,0.99919,0.99938,0.99483,0.86569,0.64296,0.24645,0.89825,0.000643625,0.000643625,0.000643625
-51,5028.43,0.64515,0.36456,1.03528,0.99922,0.99938,0.99441,0.89066,0.53419,0.22698,0.87091,0.00063125,0.00063125,0.00063125
-52,5123.54,0.63893,0.36139,1.03404,0.99922,0.99938,0.99454,0.89828,0.51992,0.22158,0.86599,0.000618875,0.000618875,0.000618875
-53,5219.35,0.64453,0.36132,1.03669,0.99922,0.99938,0.99483,0.88769,0.55064,0.22546,0.86971,0.0006065,0.0006065,0.0006065
-54,5315.82,0.63264,0.35659,1.03466,0.99918,0.99938,0.99466,0.8874,0.5665,0.22535,0.87198,0.000594125,0.000594125,0.000594125
-55,5413.1,0.64146,0.36395,1.03511,0.99912,0.99938,0.9948,0.90563,0.50583,0.21785,0.85783,0.00058175,0.00058175,0.00058175
-56,5512.14,0.6346,0.36024,1.03027,0.99941,0.99969,0.99495,0.8956,0.54407,0.22317,0.867,0.000569375,0.000569375,0.000569375
-57,5608.91,0.62687,0.35495,1.02971,0.99921,0.99938,0.99466,0.90108,0.51273,0.21582,0.86359,0.000557,0.000557,0.000557
-58,5708.04,0.62933,0.35103,1.02814,0.99907,0.99938,0.99468,0.89544,0.52007,0.22005,0.86602,0.000544625,0.000544625,0.000544625
-59,5807.09,0.63033,0.35492,1.03162,0.99918,0.99938,0.99491,0.87817,0.58994,0.22866,0.88158,0.00053225,0.00053225,0.00053225
-60,5905.97,0.62568,0.34762,1.02563,0.99909,0.99938,0.99471,0.88738,0.54866,0.22057,0.87016,0.000519875,0.000519875,0.000519875
-61,6001.33,0.63322,0.36007,1.03499,0.99902,0.99938,0.99441,0.90615,0.47893,0.20923,0.85278,0.0005075,0.0005075,0.0005075
-62,6096.57,0.62318,0.34799,1.02575,0.99917,0.99938,0.99471,0.89697,0.50907,0.21597,0.8637,0.000495125,0.000495125,0.000495125
-63,6196.68,0.61992,0.34673,1.02012,0.9991,0.99938,0.99467,0.8975,0.51208,0.21305,0.86518,0.00048275,0.00048275,0.00048275
-64,6295.92,0.61761,0.35052,1.01748,0.99911,0.99938,0.99467,0.89576,0.51699,0.21254,0.86256,0.000470375,0.000470375,0.000470375
-65,6394.93,0.61291,0.34535,1.02286,0.99911,0.99938,0.99475,0.90338,0.50358,0.20888,0.857,0.000458,0.000458,0.000458
-66,6494.36,0.60978,0.34309,1.02056,0.99912,0.99938,0.99443,0.8972,0.51036,0.2126,0.8627,0.000445625,0.000445625,0.000445625
-67,6592.94,0.60324,0.3408,1.01697,0.9992,0.99938,0.99483,0.90029,0.51215,0.21159,0.86441,0.00043325,0.00043325,0.00043325
-68,6690.32,0.60952,0.34105,1.02119,0.99905,0.99938,0.99493,0.90225,0.49707,0.20372,0.86038,0.000420875,0.000420875,0.000420875
-69,6787.75,0.60352,0.33723,1.02056,0.99919,0.99938,0.99488,0.91194,0.46677,0.20113,0.8511,0.0004085,0.0004085,0.0004085
-70,6887.49,0.60112,0.334,1.01461,0.99922,0.99938,0.9947,0.90956,0.49142,0.20135,0.85229,0.000396125,0.000396125,0.000396125
-71,6983.47,0.59698,0.33217,1.01263,0.9992,0.99938,0.99475,0.9071,0.49246,0.20378,0.85436,0.00038375,0.00038375,0.00038375
-72,7084.01,0.59089,0.32525,1.0099,0.99948,0.99969,0.99488,0.91499,0.47166,0.1971,0.84817,0.000371375,0.000371375,0.000371375
-73,7181.32,0.59568,0.33501,1.01714,0.99947,0.99969,0.99483,0.91506,0.46088,0.19822,0.84765,0.000359,0.000359,0.000359
-74,7277.51,0.58816,0.32332,1.00866,0.99908,0.99938,0.99473,0.90087,0.51152,0.20701,0.85865,0.000346625,0.000346625,0.000346625
-75,7376.02,0.58946,0.33013,1.01269,0.99923,0.99938,0.99495,0.91447,0.46086,0.19476,0.8508,0.00033425,0.00033425,0.00033425
-76,7476.23,0.58269,0.32804,1.00501,0.99916,0.99938,0.99492,0.90185,0.50089,0.20426,0.85767,0.000321875,0.000321875,0.000321875
-77,7571.02,0.57974,0.32159,1.00223,0.99917,0.99938,0.99486,0.90876,0.49603,0.20119,0.85289,0.0003095,0.0003095,0.0003095
-78,7668.92,0.58149,0.32313,1.00281,0.99914,0.99938,0.99481,0.91305,0.46935,0.19727,0.84913,0.000297125,0.000297125,0.000297125
-79,7764.65,0.58331,0.31913,0.99942,0.99915,0.99938,0.99485,0.91522,0.45192,0.19585,0.84426,0.00028475,0.00028475,0.00028475
-80,7860.51,0.58127,0.32444,1.00545,0.99946,0.99969,0.99489,0.91272,0.4792,0.20037,0.84885,0.000272375,0.000272375,0.000272375
-81,7955.15,0.5723,0.31949,1.00348,0.99956,0.99969,0.99471,0.92184,0.4424,0.19105,0.84103,0.00026,0.00026,0.00026
-82,8050.96,0.5736,0.31785,1.00316,0.99918,0.99938,0.9946,0.9091,0.47622,0.20067,0.85095,0.000247625,0.000247625,0.000247625
-83,8149.41,0.56511,0.31216,0.99655,0.99907,0.99938,0.99456,0.91885,0.43823,0.19501,0.84001,0.00023525,0.00023525,0.00023525
-84,8248.31,0.57088,0.31526,0.99687,0.9992,0.99938,0.99443,0.91021,0.47212,0.19679,0.84635,0.000222875,0.000222875,0.000222875
-85,8347.48,0.56493,0.30997,0.99795,0.9992,0.99938,0.99451,0.90339,0.49447,0.20152,0.85296,0.0002105,0.0002105,0.0002105
-86,8442.51,0.56601,0.31283,0.99594,0.9992,0.99938,0.99459,0.91615,0.45312,0.19181,0.84235,0.000198125,0.000198125,0.000198125
-87,8540.86,0.56761,0.3107,0.99677,0.9992,0.99938,0.99458,0.91099,0.47436,0.19643,0.84735,0.00018575,0.00018575,0.00018575
-88,8636.07,0.55965,0.30554,0.99121,0.99922,0.99938,0.99448,0.91404,0.47234,0.19421,0.8461,0.000173375,0.000173375,0.000173375
-89,8738.81,0.55214,0.30418,0.9889,0.99917,0.99938,0.99447,0.90231,0.51165,0.20084,0.85878,0.000161,0.000161,0.000161
-90,8834.65,0.55281,0.30171,0.98942,0.99915,0.99938,0.99447,0.90962,0.48521,0.19521,0.84887,0.000148625,0.000148625,0.000148625
-91,8930.36,0.38623,0.189,0.87754,0.99914,0.99938,0.99446,0.91037,0.48288,0.19973,0.84519,0.00013625,0.00013625,0.00013625
-92,9030.92,0.37337,0.17885,0.87604,0.99917,0.99938,0.99455,0.91548,0.45898,0.19233,0.84163,0.000123875,0.000123875,0.000123875
-93,9129.86,0.36988,0.17506,0.86988,0.99922,0.99938,0.99477,0.92443,0.43526,0.18667,0.83458,0.0001115,0.0001115,0.0001115
-94,9228.55,0.3616,0.17275,0.86988,0.99952,0.99969,0.99492,0.92638,0.4306,0.18467,0.83361,9.9125e-05,9.9125e-05,9.9125e-05
-95,9328.32,0.3561,0.16959,0.86724,0.99955,0.99969,0.9949,0.92547,0.43154,0.18213,0.83431,8.675e-05,8.675e-05,8.675e-05
-96,9423.51,0.35854,0.16927,0.86362,0.99956,0.99969,0.99485,0.92497,0.44053,0.1831,0.8365,7.4375e-05,7.4375e-05,7.4375e-05
-97,9519.15,0.3523,0.16731,0.86289,0.99956,0.99969,0.99483,0.92189,0.4476,0.18538,0.83867,6.2e-05,6.2e-05,6.2e-05
-98,9613.88,0.348,0.16561,0.86186,0.99957,0.99969,0.99483,0.92324,0.44566,0.18559,0.83603,4.9625e-05,4.9625e-05,4.9625e-05
-99,9712.89,0.3414,0.16307,0.85745,0.99956,0.99969,0.99484,0.92351,0.44139,0.18431,0.8348,3.725e-05,3.725e-05,3.725e-05
-100,9809.18,0.34401,0.16247,0.85795,0.99956,0.99969,0.99483,0.92067,0.44634,0.1845,0.83595,2.4875e-05,2.4875e-05,2.4875e-05
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/results.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/results.png
deleted file mode 100644
index 5311c7b..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/results.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch0.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch0.jpg
deleted file mode 100644
index 4a4e680..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch0.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch1.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch1.jpg
deleted file mode 100644
index 6c171f4..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch1.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch2.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch2.jpg
deleted file mode 100644
index b03ccf8..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch2.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch53910.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch53910.jpg
deleted file mode 100644
index b790371..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch53910.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch53911.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch53911.jpg
deleted file mode 100644
index bcc2937..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch53911.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch53912.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch53912.jpg
deleted file mode 100644
index 278023b..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/train_batch53912.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch0_labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch0_labels.jpg
deleted file mode 100644
index 35705f2..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch0_labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch0_pred.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch0_pred.jpg
deleted file mode 100644
index 9e03853..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch0_pred.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch1_labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch1_labels.jpg
deleted file mode 100644
index cf62e04..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch1_labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch1_pred.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch1_pred.jpg
deleted file mode 100644
index 9db558a..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch1_pred.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch2_labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch2_labels.jpg
deleted file mode 100644
index 78d5a01..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch2_labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch2_pred.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch2_pred.jpg
deleted file mode 100644
index d1b2849..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/val_batch2_pred.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/weights/best.pt b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/weights/best.pt
deleted file mode 100644
index a5ce3f2..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/weights/best.pt and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/weights/last.pt b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/weights/last.pt
deleted file mode 100644
index e125372..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug/weights/last.pt and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/F1_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/F1_curve.png
deleted file mode 100644
index b4a5878..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/F1_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/PR_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/PR_curve.png
deleted file mode 100644
index cd42f18..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/PR_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/P_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/P_curve.png
deleted file mode 100644
index 85219fc..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/P_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/R_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/R_curve.png
deleted file mode 100644
index a70d0ee..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/R_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/args.yaml b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/args.yaml
deleted file mode 100644
index 36cb48a..0000000
--- a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/args.yaml
+++ /dev/null
@@ -1,105 +0,0 @@
-task: detect
-mode: train
-model: yolov8n.pt
-data: /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/car_parts.yaml
-epochs: 100
-time: null
-patience: 100
-batch: 8
-imgsz: 640
-save: true
-save_period: -1
-cache: false
-device: null
-workers: 8
-project: null
-name: yolov8n_car_parts_aggressive_aug2
-exist_ok: false
-pretrained: true
-optimizer: auto
-verbose: true
-seed: 0
-deterministic: true
-single_cls: false
-rect: false
-cos_lr: false
-close_mosaic: 10
-resume: false
-amp: true
-fraction: 1.0
-profile: false
-freeze: null
-multi_scale: false
-overlap_mask: true
-mask_ratio: 4
-dropout: 0.0
-val: true
-split: val
-save_json: false
-conf: null
-iou: 0.7
-max_det: 300
-half: false
-dnn: false
-plots: true
-source: null
-vid_stride: 1
-stream_buffer: false
-visualize: false
-augment: false
-agnostic_nms: false
-classes: null
-retina_masks: false
-embed: null
-show: false
-save_frames: false
-save_txt: false
-save_conf: false
-save_crop: false
-show_labels: true
-show_conf: true
-show_boxes: true
-line_width: null
-format: torchscript
-keras: false
-optimize: false
-int8: false
-dynamic: false
-simplify: true
-opset: null
-workspace: null
-nms: false
-lr0: 0.01
-lrf: 0.01
-momentum: 0.937
-weight_decay: 0.0005
-warmup_epochs: 3.0
-warmup_momentum: 0.8
-warmup_bias_lr: 0.1
-box: 7.5
-cls: 0.5
-dfl: 1.5
-pose: 12.0
-kobj: 1.0
-nbs: 64
-hsv_h: 0.015
-hsv_s: 0.7
-hsv_v: 0.4
-degrees: 25.0
-translate: 0.15
-scale: 0.6
-shear: 5.0
-perspective: 0.0005
-flipud: 0.5
-fliplr: 0.5
-bgr: 0.0
-mosaic: 1.0
-mixup: 0.5
-cutmix: 0.0
-copy_paste: 0.3
-copy_paste_mode: flip
-auto_augment: randaugment
-erasing: 0.4
-cfg: null
-tracker: botsort.yaml
-save_dir: runs/detect/yolov8n_car_parts_aggressive_aug2
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/confusion_matrix.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/confusion_matrix.png
deleted file mode 100644
index fa72ff8..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/confusion_matrix.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/confusion_matrix_normalized.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/confusion_matrix_normalized.png
deleted file mode 100644
index 571a624..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/confusion_matrix_normalized.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/labels.jpg
deleted file mode 100644
index 2cb2360..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/results.csv b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/results.csv
deleted file mode 100644
index bc5413b..0000000
--- a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/results.csv
+++ /dev/null
@@ -1,101 +0,0 @@
-epoch,time,train/box_loss,train/cls_loss,train/dfl_loss,metrics/precision(B),metrics/recall(B),metrics/mAP50(B),metrics/mAP50-95(B),val/box_loss,val/cls_loss,val/dfl_loss,lr/pg0,lr/pg1,lr/pg2
-1,270.978,1.39382,2.17176,1.5317,0.89129,0.89701,0.93905,0.50627,1.5938,1.32625,1.6481,0.00333119,0.00333119,0.00333119
-2,539.389,1.20768,1.23155,1.35924,0.91306,0.94292,0.9674,0.671,0.90888,0.66262,1.144,0.00659854,0.00659854,0.00659854
-3,793.391,1.20265,1.09277,1.35523,0.95686,0.93737,0.97626,0.58942,1.13645,0.6638,1.25669,0.0097999,0.0097999,0.0097999
-4,1055.62,1.19328,0.98656,1.35498,0.93481,0.95876,0.97168,0.62795,1.04779,0.57202,1.22167,0.009703,0.009703,0.009703
-5,1307.05,1.14491,0.87997,1.31939,0.92225,0.95525,0.9759,0.67518,0.91324,0.54133,1.14783,0.009604,0.009604,0.009604
-6,1554.72,1.10323,0.80979,1.29313,0.96272,0.93981,0.97706,0.68195,0.88251,0.54155,1.10099,0.009505,0.009505,0.009505
-7,1798.91,1.07936,0.7722,1.28339,0.94637,0.97653,0.98709,0.68119,0.97815,0.4999,1.1531,0.009406,0.009406,0.009406
-8,2042.76,1.05685,0.7389,1.26162,0.96189,0.96017,0.98285,0.71853,0.72808,0.44393,1.01539,0.009307,0.009307,0.009307
-9,2289.54,1.0371,0.71517,1.25391,0.95643,0.96322,0.98327,0.74631,0.68259,0.41226,0.99072,0.009208,0.009208,0.009208
-10,2545.88,1.02665,0.6931,1.23927,0.94328,0.96748,0.98255,0.74815,0.67936,0.41344,0.99349,0.009109,0.009109,0.009109
-11,2793.58,1.01164,0.67994,1.23536,0.95702,0.96679,0.98086,0.72234,0.74136,0.40458,1.00603,0.00901,0.00901,0.00901
-12,3040.77,0.99932,0.66853,1.22403,0.96103,0.9722,0.98794,0.72702,0.80205,0.39737,1.03985,0.008911,0.008911,0.008911
-13,3286.22,0.98812,0.65379,1.21754,0.9609,0.97294,0.98652,0.72305,0.8228,0.40017,1.04452,0.008812,0.008812,0.008812
-14,3534.04,0.97785,0.64272,1.21459,0.95061,0.98106,0.9881,0.75344,0.68981,0.37576,0.97954,0.008713,0.008713,0.008713
-15,3784.01,0.9717,0.63591,1.20794,0.96561,0.97027,0.98571,0.768,0.61668,0.3644,0.95037,0.008614,0.008614,0.008614
-16,4036.65,0.96022,0.62253,1.20075,0.96115,0.96793,0.98813,0.76173,0.6814,0.36463,0.97633,0.008515,0.008515,0.008515
-17,4285.31,0.9572,0.619,1.19945,0.96804,0.96333,0.98689,0.74439,0.72254,0.37386,0.9859,0.008416,0.008416,0.008416
-18,4532.49,0.94777,0.60979,1.19614,0.96806,0.96611,0.98666,0.75707,0.66835,0.34925,0.95824,0.008317,0.008317,0.008317
-19,4779.83,0.94326,0.60643,1.18937,0.96793,0.96804,0.98853,0.75314,0.73809,0.35797,0.99378,0.008218,0.008218,0.008218
-20,5025.4,0.92859,0.5958,1.18325,0.96577,0.96991,0.9886,0.77042,0.61855,0.34355,0.94641,0.008119,0.008119,0.008119
-21,5267.09,0.92907,0.59623,1.18528,0.96669,0.9662,0.98874,0.75632,0.70667,0.351,0.98597,0.00802,0.00802,0.00802
-22,5518.15,0.9232,0.58698,1.17818,0.95428,0.97309,0.98646,0.77452,0.64696,0.34184,0.95521,0.007921,0.007921,0.007921
-23,5761.85,0.92253,0.58752,1.17789,0.96453,0.97045,0.98638,0.76677,0.6528,0.33959,0.95394,0.007822,0.007822,0.007822
-24,6006.11,0.91272,0.57837,1.16985,0.95445,0.97861,0.98756,0.77585,0.61192,0.33169,0.93658,0.007723,0.007723,0.007723
-25,6256.21,0.91313,0.5771,1.1667,0.95424,0.97902,0.98765,0.76498,0.6642,0.33629,0.95474,0.007624,0.007624,0.007624
-26,6498.99,0.90368,0.57032,1.16534,0.94644,0.98289,0.98701,0.77101,0.63061,0.32883,0.93895,0.007525,0.007525,0.007525
-27,6742.88,0.89777,0.56671,1.1624,0.96137,0.97333,0.98619,0.77245,0.60985,0.32463,0.93384,0.007426,0.007426,0.007426
-28,6989.65,0.89454,0.56062,1.15699,0.96338,0.97396,0.98793,0.78062,0.61113,0.31757,0.93265,0.007327,0.007327,0.007327
-29,7243.69,0.89028,0.55405,1.15549,0.9607,0.97232,0.98538,0.78344,0.59782,0.30955,0.92146,0.007228,0.007228,0.007228
-30,7489.86,0.8887,0.55082,1.15162,0.96078,0.97388,0.98748,0.7777,0.62528,0.31526,0.92897,0.007129,0.007129,0.007129
-31,7734.63,0.88065,0.55125,1.15081,0.96709,0.97097,0.98809,0.78291,0.62395,0.31746,0.93239,0.00703,0.00703,0.00703
-32,7986.56,0.88599,0.54818,1.14811,0.96836,0.9643,0.98775,0.78048,0.61005,0.31152,0.92735,0.006931,0.006931,0.006931
-33,8233.62,0.87549,0.54526,1.14848,0.95824,0.97547,0.98779,0.7872,0.58078,0.30506,0.91396,0.006832,0.006832,0.006832
-34,8480.21,0.8732,0.54035,1.14577,0.96473,0.97236,0.98757,0.78862,0.57364,0.30274,0.90958,0.006733,0.006733,0.006733
-35,8723.33,0.86782,0.54144,1.14728,0.96708,0.97272,0.98919,0.79498,0.5587,0.30086,0.90613,0.006634,0.006634,0.006634
-36,8969.35,0.86671,0.53593,1.14268,0.96844,0.97254,0.98856,0.793,0.5837,0.30171,0.91338,0.006535,0.006535,0.006535
-37,9213.81,0.86383,0.53604,1.14055,0.96563,0.97291,0.98865,0.7966,0.56645,0.29785,0.90834,0.006436,0.006436,0.006436
-38,9460.74,0.86164,0.5339,1.13809,0.96831,0.97125,0.98946,0.79175,0.57572,0.29952,0.91254,0.006337,0.006337,0.006337
-39,9703.49,0.86029,0.53463,1.14319,0.96592,0.97109,0.98862,0.79513,0.56935,0.29732,0.90878,0.006238,0.006238,0.006238
-40,9945.57,0.85568,0.52551,1.13475,0.97093,0.96312,0.98863,0.79807,0.54409,0.29047,0.90138,0.006139,0.006139,0.006139
-41,10196.6,0.85023,0.5252,1.13817,0.96072,0.9766,0.98869,0.79942,0.55715,0.29223,0.90311,0.00604,0.00604,0.00604
-42,10439.7,0.85056,0.52012,1.12803,0.96394,0.97156,0.98853,0.79465,0.56463,0.29272,0.90767,0.005941,0.005941,0.005941
-43,10683.4,0.84773,0.52161,1.12764,0.95974,0.97833,0.98924,0.80189,0.55063,0.29056,0.90149,0.005842,0.005842,0.005842
-44,10924.5,0.84625,0.51865,1.12602,0.96919,0.9695,0.98918,0.79801,0.56079,0.2911,0.90434,0.005743,0.005743,0.005743
-45,11168.4,0.83959,0.50918,1.12101,0.96029,0.97777,0.98865,0.80006,0.54347,0.28698,0.89866,0.005644,0.005644,0.005644
-46,11411.3,0.83701,0.51258,1.12505,0.96725,0.97384,0.98898,0.79852,0.55196,0.28347,0.89972,0.005545,0.005545,0.005545
-47,11658,0.83797,0.51164,1.1248,0.97108,0.96951,0.98914,0.80553,0.5343,0.28111,0.89315,0.005446,0.005446,0.005446
-48,11900.5,0.83442,0.50843,1.11829,0.97345,0.96667,0.98934,0.80636,0.53395,0.28136,0.89051,0.005347,0.005347,0.005347
-49,12146.5,0.83559,0.50882,1.1213,0.97278,0.96809,0.98912,0.80121,0.55473,0.28269,0.89761,0.005248,0.005248,0.005248
-50,12391.7,0.83288,0.50646,1.12048,0.97016,0.96967,0.98906,0.80348,0.54143,0.2827,0.89442,0.005149,0.005149,0.005149
-51,12638,0.82826,0.50172,1.11509,0.97078,0.96865,0.98866,0.80403,0.54901,0.28252,0.89654,0.00505,0.00505,0.00505
-52,12879.9,0.82539,0.50203,1.11399,0.96723,0.97408,0.98838,0.80347,0.5505,0.28237,0.89412,0.004951,0.004951,0.004951
-53,13121,0.81884,0.50071,1.11293,0.967,0.97327,0.98841,0.80767,0.53715,0.27879,0.88773,0.004852,0.004852,0.004852
-54,13363.8,0.82181,0.49883,1.10887,0.96787,0.972,0.98921,0.8093,0.52979,0.27683,0.88377,0.004753,0.004753,0.004753
-55,13606.9,0.81744,0.49286,1.10826,0.9704,0.9698,0.98927,0.81219,0.524,0.27511,0.88225,0.004654,0.004654,0.004654
-56,13860.3,0.81735,0.49465,1.10565,0.96753,0.97327,0.98956,0.81078,0.52677,0.27422,0.88296,0.004555,0.004555,0.004555
-57,14106.2,0.81154,0.49273,1.10997,0.96616,0.97405,0.98957,0.81015,0.52414,0.27484,0.88326,0.004456,0.004456,0.004456
-58,14363.3,0.81476,0.48979,1.10956,0.96783,0.9731,0.98951,0.81131,0.5221,0.27436,0.88288,0.004357,0.004357,0.004357
-59,14603.7,0.813,0.48952,1.10389,0.96776,0.97343,0.98975,0.81082,0.5264,0.27482,0.88439,0.004258,0.004258,0.004258
-60,14847.4,0.80559,0.48174,1.09924,0.9693,0.97227,0.98956,0.81029,0.52849,0.27533,0.88511,0.004159,0.004159,0.004159
-61,15094,0.80661,0.48245,1.10262,0.96925,0.97255,0.98975,0.80979,0.53046,0.27538,0.88624,0.00406,0.00406,0.00406
-62,15337.9,0.80194,0.47799,1.10276,0.96865,0.97268,0.98986,0.80936,0.5291,0.27312,0.88516,0.003961,0.003961,0.003961
-63,15582.1,0.80146,0.48215,1.09779,0.9684,0.97259,0.98997,0.8096,0.52891,0.27155,0.8845,0.003862,0.003862,0.003862
-64,15825.3,0.79603,0.48135,1.09919,0.96835,0.97319,0.98998,0.81004,0.52854,0.27015,0.88372,0.003763,0.003763,0.003763
-65,16068.9,0.80119,0.4765,1.09878,0.96995,0.97192,0.99002,0.81204,0.52419,0.26855,0.88229,0.003664,0.003664,0.003664
-66,16308.2,0.79349,0.47709,1.0963,0.96944,0.9717,0.99015,0.81203,0.52352,0.26809,0.88131,0.003565,0.003565,0.003565
-67,16555.3,0.79105,0.47537,1.09194,0.96863,0.97218,0.98994,0.81259,0.52104,0.26783,0.88011,0.003466,0.003466,0.003466
-68,16800.6,0.79059,0.47298,1.093,0.96773,0.97299,0.98991,0.81231,0.5208,0.26776,0.87989,0.003367,0.003367,0.003367
-69,17050.7,0.78507,0.46371,1.08699,0.96748,0.97352,0.98987,0.81258,0.51913,0.26738,0.87896,0.003268,0.003268,0.003268
-70,17300.2,0.78573,0.47182,1.09398,0.9682,0.97287,0.98985,0.81408,0.51576,0.26665,0.8778,0.003169,0.003169,0.003169
-71,17545.1,0.77988,0.46543,1.08858,0.96857,0.97249,0.9899,0.81479,0.51521,0.26612,0.87753,0.00307,0.00307,0.00307
-72,17791.9,0.77932,0.46242,1.08675,0.96734,0.97361,0.98973,0.81467,0.51457,0.26585,0.87735,0.002971,0.002971,0.002971
-73,18038.1,0.77979,0.4627,1.08482,0.9685,0.97189,0.98971,0.81491,0.51398,0.26532,0.87723,0.002872,0.002872,0.002872
-74,18282.5,0.77302,0.45982,1.08421,0.96911,0.97152,0.98975,0.81441,0.51563,0.26592,0.87756,0.002773,0.002773,0.002773
-75,18528.8,0.76872,0.45844,1.08611,0.97003,0.97109,0.98986,0.81485,0.51552,0.26556,0.87767,0.002674,0.002674,0.002674
-76,18775.3,0.7728,0.45658,1.08373,0.97003,0.97098,0.9899,0.8152,0.5148,0.26523,0.87763,0.002575,0.002575,0.002575
-77,19023.5,0.76923,0.45208,1.08148,0.97,0.97113,0.98991,0.81611,0.51365,0.26454,0.87739,0.002476,0.002476,0.002476
-78,19270.6,0.76499,0.45105,1.07978,0.97008,0.97124,0.98992,0.81615,0.51255,0.26398,0.87704,0.002377,0.002377,0.002377
-79,19513.5,0.76609,0.45576,1.07882,0.96971,0.97114,0.98973,0.81663,0.5119,0.2638,0.87668,0.002278,0.002278,0.002278
-80,19756.7,0.76648,0.45011,1.07514,0.96989,0.97115,0.98973,0.8173,0.51031,0.26322,0.87619,0.002179,0.002179,0.002179
-81,20002.3,0.7543,0.44684,1.07609,0.97046,0.97062,0.98971,0.81742,0.51044,0.26313,0.87632,0.00208,0.00208,0.00208
-82,20250.6,0.7557,0.44569,1.07429,0.97069,0.97093,0.98987,0.81745,0.51025,0.26283,0.87624,0.001981,0.001981,0.001981
-83,20494.1,0.75892,0.44494,1.0758,0.97029,0.97109,0.98987,0.81772,0.51038,0.26253,0.87624,0.001882,0.001882,0.001882
-84,20739.8,0.75312,0.443,1.07268,0.97054,0.97099,0.9899,0.8181,0.51016,0.26235,0.87624,0.001783,0.001783,0.001783
-85,20986.1,0.75076,0.43913,1.0696,0.97036,0.97149,0.9901,0.81825,0.50974,0.26226,0.87621,0.001684,0.001684,0.001684
-86,21225.7,0.74816,0.44036,1.0682,0.97037,0.97134,0.99001,0.81878,0.50893,0.26195,0.87592,0.001585,0.001585,0.001585
-87,21469.8,0.74159,0.43653,1.06843,0.97053,0.97134,0.99015,0.81898,0.50814,0.26163,0.87567,0.001486,0.001486,0.001486
-88,21714.8,0.74383,0.43615,1.06889,0.97047,0.97162,0.99032,0.81923,0.50789,0.26137,0.87562,0.001387,0.001387,0.001387
-89,21956.9,0.73679,0.43222,1.06503,0.97039,0.97146,0.99032,0.81942,0.50694,0.26106,0.87533,0.001288,0.001288,0.001288
-90,22199.7,0.73165,0.4283,1.06042,0.97025,0.97177,0.99036,0.81963,0.50603,0.26072,0.875,0.001189,0.001189,0.001189
-91,22439.8,0.5709,0.29685,0.9692,0.97048,0.97136,0.99036,0.81995,0.50503,0.26042,0.87466,0.00109,0.00109,0.00109
-92,22677.6,0.55722,0.28878,0.95604,0.97095,0.97068,0.99038,0.8201,0.50378,0.25997,0.87406,0.000991,0.000991,0.000991
-93,22914.3,0.55089,0.28434,0.95353,0.97077,0.97082,0.9904,0.82073,0.50256,0.25957,0.87342,0.000892,0.000892,0.000892
-94,23156.5,0.5447,0.27872,0.95163,0.97126,0.9702,0.99042,0.82107,0.50108,0.25908,0.87274,0.000793,0.000793,0.000793
-95,23396.6,0.54092,0.27484,0.94694,0.97124,0.97035,0.99043,0.82152,0.49963,0.25845,0.87205,0.000694,0.000694,0.000694
-96,23635,0.53524,0.27232,0.94397,0.97143,0.97034,0.9905,0.82184,0.49876,0.25797,0.87156,0.000595,0.000595,0.000595
-97,23874.7,0.53189,0.26654,0.94241,0.97171,0.97046,0.99059,0.82243,0.49738,0.25748,0.87086,0.000496,0.000496,0.000496
-98,24124.7,0.52769,0.26156,0.93888,0.9721,0.97021,0.99065,0.823,0.49625,0.25698,0.87026,0.000397,0.000397,0.000397
-99,24365.5,0.52674,0.26053,0.93895,0.97243,0.97026,0.99069,0.82338,0.49488,0.2565,0.86954,0.000298,0.000298,0.000298
-100,24607.8,0.52298,0.25673,0.93503,0.97391,0.96929,0.99072,0.82377,0.49361,0.25586,0.86891,0.000199,0.000199,0.000199
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/results.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/results.png
deleted file mode 100644
index 66406cd..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/results.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch0.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch0.jpg
deleted file mode 100644
index a33b8eb..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch0.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch1.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch1.jpg
deleted file mode 100644
index d2318a4..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch1.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch139770.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch139770.jpg
deleted file mode 100644
index 211c1a5..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch139770.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch139771.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch139771.jpg
deleted file mode 100644
index e9f1569..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch139771.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch139772.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch139772.jpg
deleted file mode 100644
index d2b966f..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch139772.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch2.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch2.jpg
deleted file mode 100644
index 26421ae..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/train_batch2.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch0_labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch0_labels.jpg
deleted file mode 100644
index 2b89988..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch0_labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch0_pred.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch0_pred.jpg
deleted file mode 100644
index 1d76017..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch0_pred.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch1_labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch1_labels.jpg
deleted file mode 100644
index 495a4fb..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch1_labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch1_pred.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch1_pred.jpg
deleted file mode 100644
index 926ce94..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch1_pred.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch2_labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch2_labels.jpg
deleted file mode 100644
index 7670964..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch2_labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch2_pred.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch2_pred.jpg
deleted file mode 100644
index 183597a..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/val_batch2_pred.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/weights/best.pt b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/weights/best.pt
deleted file mode 100644
index ccd14e8..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/weights/best.pt and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/weights/last.pt b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/weights/last.pt
deleted file mode 100644
index a8af123..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug2_5_objects/weights/last.pt and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/F1_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/F1_curve.png
deleted file mode 100644
index 1353f89..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/F1_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/PR_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/PR_curve.png
deleted file mode 100644
index 1bd9bc4..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/PR_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/P_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/P_curve.png
deleted file mode 100644
index e859de1..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/P_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/R_curve.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/R_curve.png
deleted file mode 100644
index eb65ce0..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/R_curve.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/args.yaml b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/args.yaml
deleted file mode 100644
index 4dc0d9b..0000000
--- a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/args.yaml
+++ /dev/null
@@ -1,105 +0,0 @@
-task: detect
-mode: train
-model: yolov8n.pt
-data: /mnt/c/Users/mohsinali.mirza/Downloads/Grounding/car_parts.yaml
-epochs: 100
-time: null
-patience: 100
-batch: 8
-imgsz: 640
-save: true
-save_period: -1
-cache: false
-device: null
-workers: 8
-project: null
-name: yolov8n_car_parts_aggressive_aug
-exist_ok: false
-pretrained: true
-optimizer: auto
-verbose: true
-seed: 0
-deterministic: true
-single_cls: false
-rect: false
-cos_lr: false
-close_mosaic: 10
-resume: false
-amp: true
-fraction: 1.0
-profile: false
-freeze: null
-multi_scale: false
-overlap_mask: true
-mask_ratio: 4
-dropout: 0.0
-val: true
-split: val
-save_json: false
-conf: null
-iou: 0.7
-max_det: 300
-half: false
-dnn: false
-plots: true
-source: null
-vid_stride: 1
-stream_buffer: false
-visualize: false
-augment: false
-agnostic_nms: false
-classes: null
-retina_masks: false
-embed: null
-show: false
-save_frames: false
-save_txt: false
-save_conf: false
-save_crop: false
-show_labels: true
-show_conf: true
-show_boxes: true
-line_width: null
-format: torchscript
-keras: false
-optimize: false
-int8: false
-dynamic: false
-simplify: true
-opset: null
-workspace: null
-nms: false
-lr0: 0.01
-lrf: 0.01
-momentum: 0.937
-weight_decay: 0.0005
-warmup_epochs: 3.0
-warmup_momentum: 0.8
-warmup_bias_lr: 0.1
-box: 7.5
-cls: 0.5
-dfl: 1.5
-pose: 12.0
-kobj: 1.0
-nbs: 64
-hsv_h: 0.015
-hsv_s: 0.7
-hsv_v: 0.4
-degrees: 25.0
-translate: 0.15
-scale: 0.6
-shear: 5.0
-perspective: 0.0005
-flipud: 0.5
-fliplr: 0.5
-bgr: 0.0
-mosaic: 1.0
-mixup: 0.5
-cutmix: 0.0
-copy_paste: 0.3
-copy_paste_mode: flip
-auto_augment: randaugment
-erasing: 0.4
-cfg: null
-tracker: botsort.yaml
-save_dir: runs/detect/yolov8n_car_parts_aggressive_aug
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/confusion_matrix.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/confusion_matrix.png
deleted file mode 100644
index 8c750f7..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/confusion_matrix.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/confusion_matrix_normalized.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/confusion_matrix_normalized.png
deleted file mode 100644
index ae00aa3..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/confusion_matrix_normalized.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/labels.jpg
deleted file mode 100644
index ae7bdd3..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/results.csv b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/results.csv
deleted file mode 100644
index 1464e5a..0000000
--- a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/results.csv
+++ /dev/null
@@ -1,101 +0,0 @@
-epoch,time,train/box_loss,train/cls_loss,train/dfl_loss,metrics/precision(B),metrics/recall(B),metrics/mAP50(B),metrics/mAP50-95(B),val/box_loss,val/cls_loss,val/dfl_loss,lr/pg0,lr/pg1,lr/pg2
-1,208.513,1.29221,1.94415,1.53706,0.98915,0.9941,0.99371,0.51281,1.76736,1.14429,1.84864,0.00333053,0.00333053,0.00333053
-2,403.893,1.0983,1.13292,1.3682,0.96964,0.98612,0.99212,0.7464,0.89832,0.67095,1.15697,0.00659789,0.00659789,0.00659789
-3,597.825,1.10362,0.99678,1.37541,0.99537,0.99493,0.99489,0.6201,1.41337,0.66288,1.60146,0.00979925,0.00979925,0.00979925
-4,789.373,1.09737,0.89865,1.37219,0.998,0.99614,0.995,0.75272,0.97206,0.50558,1.20006,0.009703,0.009703,0.009703
-5,978.613,1.04958,0.79675,1.34255,0.99628,0.99854,0.99498,0.81977,0.71314,0.40128,1.05605,0.009604,0.009604,0.009604
-6,1172.73,1.00566,0.73297,1.31489,0.99906,0.99949,0.995,0.82231,0.70894,0.37876,1.02724,0.009505,0.009505,0.009505
-7,1363.58,0.98361,0.69666,1.30225,0.9983,0.99668,0.99494,0.73526,1.0225,0.54788,1.25711,0.009406,0.009406,0.009406
-8,1556,0.95649,0.66124,1.27885,0.99888,0.99976,0.995,0.85681,0.59751,0.31934,0.97523,0.009307,0.009307,0.009307
-9,1748.04,0.93277,0.63792,1.26729,0.99929,0.99903,0.995,0.84005,0.65561,0.32519,1.00505,0.009208,0.009208,0.009208
-10,1940.31,0.91571,0.61527,1.25502,0.99833,0.99937,0.99499,0.84156,0.66773,0.33723,1.01655,0.009109,0.009109,0.009109
-11,2127.51,0.90058,0.59697,1.2476,0.99741,0.99962,0.99494,0.8627,0.57754,0.31936,0.95898,0.00901,0.00901,0.00901
-12,2317.95,0.88847,0.58869,1.23855,0.99981,0.99969,0.995,0.8716,0.56732,0.29163,0.96114,0.008911,0.008911,0.008911
-13,2508.26,0.87756,0.5755,1.23235,0.99989,0.99986,0.995,0.89575,0.46672,0.27868,0.90184,0.008812,0.008812,0.008812
-14,2697.95,0.86574,0.56178,1.22441,0.99982,0.9999,0.995,0.8827,0.53718,0.28121,0.92833,0.008713,0.008713,0.008713
-15,2889.56,0.85374,0.55347,1.21594,0.99944,0.99959,0.995,0.87814,0.55232,0.2723,0.92569,0.008614,0.008614,0.008614
-16,3081.99,0.84414,0.54291,1.20781,0.99892,0.99991,0.995,0.88673,0.51185,0.26635,0.91359,0.008515,0.008515,0.008515
-17,3269.6,0.83673,0.53515,1.20382,0.99985,0.99972,0.995,0.89756,0.50562,0.26179,0.904,0.008416,0.008416,0.008416
-18,3462,0.8286,0.52744,1.19325,0.99974,0.99969,0.995,0.88589,0.53576,0.2681,0.93849,0.008317,0.008317,0.008317
-19,3655.47,0.82292,0.52099,1.1895,0.99988,0.9998,0.995,0.90866,0.42846,0.25373,0.88494,0.008218,0.008218,0.008218
-20,3850.55,0.81223,0.51527,1.18546,0.99995,1,0.995,0.90419,0.44478,0.24332,0.88418,0.008119,0.008119,0.008119
-21,4041.04,0.80963,0.50587,1.18563,0.99991,0.99983,0.995,0.91173,0.44692,0.24265,0.8785,0.00802,0.00802,0.00802
-22,4230.91,0.79884,0.50026,1.17687,0.99985,0.99987,0.995,0.90195,0.46855,0.23958,0.89048,0.007921,0.007921,0.007921
-23,4422.69,0.79243,0.49342,1.1759,0.99965,0.99988,0.995,0.90508,0.46882,0.23727,0.88959,0.007822,0.007822,0.007822
-24,4604.76,0.78695,0.48752,1.16925,0.99989,0.99992,0.995,0.90626,0.46742,0.24825,0.88722,0.007723,0.007723,0.007723
-25,4792.19,0.79042,0.49201,1.1749,0.99987,0.99997,0.995,0.90693,0.46812,0.24186,0.88731,0.007624,0.007624,0.007624
-26,4979.89,0.78079,0.48755,1.16459,0.99991,0.99992,0.995,0.90886,0.46145,0.23122,0.88748,0.007525,0.007525,0.007525
-27,5169.6,0.77448,0.47626,1.16334,0.99982,1,0.995,0.9071,0.45651,0.22298,0.88151,0.007426,0.007426,0.007426
-28,5358.26,0.77656,0.48066,1.16467,0.99995,0.99997,0.995,0.90738,0.47778,0.23274,0.88622,0.007327,0.007327,0.007327
-29,5546.78,0.76612,0.47078,1.15759,0.99989,1,0.995,0.9057,0.46641,0.2265,0.8843,0.007228,0.007228,0.007228
-30,5731.15,0.76487,0.47068,1.1539,0.99995,0.99993,0.995,0.91341,0.4523,0.21929,0.87667,0.007129,0.007129,0.007129
-31,5916.98,0.75497,0.46468,1.15258,0.99993,0.99997,0.995,0.90109,0.48044,0.22227,0.88575,0.00703,0.00703,0.00703
-32,6105.51,0.75345,0.46433,1.14705,0.99985,0.99992,0.995,0.90414,0.47392,0.22404,0.88025,0.006931,0.006931,0.006931
-33,6294.17,0.74864,0.45731,1.15041,0.99994,0.99998,0.995,0.90247,0.48784,0.21822,0.88329,0.006832,0.006832,0.006832
-34,6482.47,0.74464,0.45566,1.14578,0.99993,0.99999,0.995,0.90266,0.48901,0.22466,0.88385,0.006733,0.006733,0.006733
-35,6670.37,0.74238,0.4524,1.14383,0.99993,0.99996,0.995,0.90466,0.48168,0.22021,0.89244,0.006634,0.006634,0.006634
-36,6862.92,0.73777,0.44276,1.1389,0.99959,0.99994,0.995,0.90352,0.49008,0.21904,0.88969,0.006535,0.006535,0.006535
-37,7050.67,0.73872,0.45002,1.14349,0.99995,0.99998,0.995,0.90052,0.48514,0.21886,0.88124,0.006436,0.006436,0.006436
-38,7241.03,0.72637,0.43964,1.1335,0.99985,0.99992,0.995,0.92322,0.41705,0.20546,0.86093,0.006337,0.006337,0.006337
-39,7431.61,0.72353,0.43928,1.13351,0.99995,0.99997,0.995,0.91044,0.46072,0.2112,0.87415,0.006238,0.006238,0.006238
-40,7625.24,0.72267,0.43622,1.12704,0.99991,0.99999,0.995,0.91318,0.43764,0.20664,0.86531,0.006139,0.006139,0.006139
-41,7815.46,0.72174,0.43767,1.12891,0.99993,0.99988,0.995,0.90454,0.47644,0.21035,0.88448,0.00604,0.00604,0.00604
-42,8009.63,0.71958,0.43279,1.1269,0.99995,0.99999,0.995,0.91422,0.44819,0.20533,0.86335,0.005941,0.005941,0.005941
-43,8205.14,0.71606,0.42988,1.12453,0.99996,0.99997,0.995,0.90616,0.48091,0.21442,0.88442,0.005842,0.005842,0.005842
-44,8391.67,0.70996,0.42559,1.12564,0.99995,0.99999,0.995,0.90754,0.4705,0.20377,0.87726,0.005743,0.005743,0.005743
-45,8581.6,0.70734,0.42411,1.12424,0.99997,0.99995,0.995,0.92294,0.42328,0.19763,0.85559,0.005644,0.005644,0.005644
-46,8772.17,0.70702,0.42174,1.12002,0.99995,0.99999,0.995,0.92037,0.41994,0.19279,0.85394,0.005545,0.005545,0.005545
-47,8961.55,0.70501,0.42019,1.12379,0.99996,0.99995,0.995,0.92269,0.41416,0.19596,0.85672,0.005446,0.005446,0.005446
-48,9148.49,0.69692,0.42124,1.12097,0.99989,0.99996,0.995,0.92271,0.41501,0.19303,0.85313,0.005347,0.005347,0.005347
-49,9332.18,0.69569,0.41643,1.11449,0.99995,0.99995,0.995,0.92027,0.4322,0.19486,0.86006,0.005248,0.005248,0.005248
-50,9519.32,0.68832,0.41189,1.11063,0.99994,0.99997,0.995,0.92715,0.40788,0.1907,0.85026,0.005149,0.005149,0.005149
-51,9711.72,0.68547,0.40805,1.11116,0.99997,0.99991,0.995,0.92672,0.41699,0.19275,0.85507,0.00505,0.00505,0.00505
-52,9902.76,0.68334,0.40709,1.10753,0.99994,0.99996,0.995,0.92722,0.41371,0.19452,0.85451,0.004951,0.004951,0.004951
-53,10088,0.68119,0.40547,1.09967,0.99995,1,0.995,0.92003,0.43415,0.1907,0.85752,0.004852,0.004852,0.004852
-54,10276.2,0.68127,0.40573,1.10328,0.99995,0.99999,0.995,0.91769,0.44132,0.19092,0.86539,0.004753,0.004753,0.004753
-55,10465,0.67496,0.39845,1.09513,0.99994,0.99997,0.995,0.92516,0.41559,0.18824,0.8497,0.004654,0.004654,0.004654
-56,10650.9,0.67778,0.40135,1.09797,0.99996,0.99998,0.995,0.92302,0.41535,0.18667,0.84931,0.004555,0.004555,0.004555
-57,10841.8,0.67226,0.39995,1.10069,0.99996,0.99995,0.995,0.92547,0.41355,0.18635,0.85172,0.004456,0.004456,0.004456
-58,11028.9,0.66813,0.39364,1.09361,0.99996,0.99996,0.995,0.93141,0.39678,0.18536,0.84673,0.004357,0.004357,0.004357
-59,11217.1,0.66564,0.3914,1.09422,0.99995,0.99996,0.995,0.92936,0.4037,0.18131,0.84714,0.004258,0.004258,0.004258
-60,11404.5,0.6689,0.39545,1.09467,0.99995,0.99995,0.995,0.9326,0.40481,0.1804,0.84643,0.004159,0.004159,0.004159
-61,11595.3,0.66243,0.38682,1.09223,0.99997,0.99995,0.995,0.93667,0.38814,0.1758,0.84099,0.00406,0.00406,0.00406
-62,11783.9,0.66042,0.38699,1.0945,0.99995,0.99996,0.995,0.93067,0.40308,0.17896,0.8452,0.003961,0.003961,0.003961
-63,11969,0.65596,0.38428,1.09004,0.99995,0.99995,0.995,0.92861,0.40725,0.18266,0.84567,0.003862,0.003862,0.003862
-64,12154.8,0.6554,0.38273,1.0884,0.99995,0.99995,0.995,0.93303,0.39232,0.17699,0.83984,0.003763,0.003763,0.003763
-65,12345.9,0.65171,0.38153,1.08157,0.99996,0.99995,0.995,0.93218,0.39689,0.17854,0.84086,0.003664,0.003664,0.003664
-66,12533.3,0.65614,0.38518,1.08815,0.99996,0.99997,0.995,0.93591,0.385,0.17554,0.83733,0.003565,0.003565,0.003565
-67,12728.8,0.64659,0.38005,1.08367,0.99996,0.99997,0.995,0.93518,0.39218,0.17647,0.84085,0.003466,0.003466,0.003466
-68,12916.3,0.6481,0.37726,1.08441,0.99997,0.99996,0.995,0.9342,0.39306,0.17524,0.84077,0.003367,0.003367,0.003367
-69,13104.4,0.64758,0.37845,1.08173,0.99996,0.99997,0.995,0.93543,0.38577,0.17464,0.83843,0.003268,0.003268,0.003268
-70,13295.6,0.64192,0.37416,1.07838,0.99995,0.99996,0.995,0.93403,0.38866,0.17431,0.839,0.003169,0.003169,0.003169
-71,13484.2,0.63914,0.3731,1.07585,0.99996,0.99997,0.995,0.92974,0.39818,0.17548,0.84179,0.00307,0.00307,0.00307
-72,13676.8,0.64035,0.37106,1.08045,0.99996,0.99997,0.995,0.9337,0.38996,0.17384,0.83922,0.002971,0.002971,0.002971
-73,13864.7,0.63145,0.36694,1.07314,0.99996,0.99997,0.995,0.93305,0.39379,0.17302,0.83998,0.002872,0.002872,0.002872
-74,14054.6,0.62885,0.36705,1.06921,0.99996,0.99997,0.995,0.93339,0.39349,0.17271,0.83918,0.002773,0.002773,0.002773
-75,14239.3,0.6302,0.36882,1.07603,0.99996,0.99996,0.995,0.93559,0.39051,0.17195,0.8386,0.002674,0.002674,0.002674
-76,14430.7,0.62565,0.36287,1.07175,0.99996,0.99996,0.995,0.93459,0.39281,0.17134,0.83988,0.002575,0.002575,0.002575
-77,14613.9,0.62268,0.36147,1.06683,0.99995,0.99997,0.995,0.93345,0.39565,0.17232,0.84075,0.002476,0.002476,0.002476
-78,14799.5,0.62114,0.36069,1.06928,0.99995,0.99997,0.995,0.93225,0.39905,0.17267,0.8428,0.002377,0.002377,0.002377
-79,14983.9,0.61843,0.35681,1.06624,0.99995,0.99997,0.995,0.93526,0.39165,0.17058,0.8395,0.002278,0.002278,0.002278
-80,15175.6,0.61076,0.35456,1.06178,0.99996,0.99996,0.995,0.93704,0.38722,0.16908,0.83728,0.002179,0.002179,0.002179
-81,15368.9,0.61508,0.35381,1.06526,0.99996,0.99996,0.995,0.93588,0.38885,0.16912,0.83796,0.00208,0.00208,0.00208
-82,15562.2,0.61471,0.35419,1.06796,0.99997,0.99996,0.995,0.93559,0.38825,0.16883,0.83736,0.001981,0.001981,0.001981
-83,15749.4,0.60851,0.35157,1.05671,0.99997,0.99996,0.995,0.93544,0.38843,0.16834,0.83675,0.001882,0.001882,0.001882
-84,15937.9,0.60932,0.35425,1.06026,0.99997,0.99996,0.995,0.93639,0.38465,0.1672,0.83506,0.001783,0.001783,0.001783
-85,16127.4,0.60263,0.34755,1.05677,0.99997,0.99996,0.995,0.9377,0.38135,0.16586,0.83334,0.001684,0.001684,0.001684
-86,16312.9,0.60113,0.34513,1.05598,0.99996,0.99996,0.995,0.93933,0.37802,0.16495,0.83207,0.001585,0.001585,0.001585
-87,16502.8,0.60211,0.34607,1.05833,0.99996,0.99997,0.995,0.9399,0.37579,0.16427,0.83142,0.001486,0.001486,0.001486
-88,16693.6,0.59282,0.34044,1.05325,0.99996,0.99997,0.995,0.9404,0.37495,0.16367,0.83097,0.001387,0.001387,0.001387
-89,16890.8,0.59578,0.34285,1.05271,0.99997,0.99996,0.995,0.94137,0.37461,0.16345,0.83064,0.001288,0.001288,0.001288
-90,17074.1,0.58795,0.33946,1.04741,0.99996,0.99997,0.995,0.94154,0.37564,0.16384,0.83074,0.001189,0.001189,0.001189
-91,17264.6,0.37242,0.18733,0.92142,0.99996,0.99996,0.995,0.94158,0.37577,0.16369,0.8308,0.00109,0.00109,0.00109
-92,17454.8,0.35505,0.17689,0.91172,0.99996,0.99996,0.995,0.94265,0.373,0.16272,0.82963,0.000991,0.000991,0.000991
-93,17645.6,0.34895,0.1737,0.90783,0.99996,0.99996,0.995,0.94506,0.36674,0.16132,0.82731,0.000892,0.000892,0.000892
-94,17839,0.34234,0.17167,0.9038,0.99996,0.99995,0.995,0.94801,0.36043,0.15978,0.82495,0.000793,0.000793,0.000793
-95,18028.1,0.33732,0.16788,0.89763,0.99996,0.99995,0.995,0.95035,0.35537,0.15857,0.82291,0.000694,0.000694,0.000694
-96,18215.7,0.33433,0.16529,0.89996,0.99997,0.99995,0.995,0.952,0.35139,0.15781,0.82138,0.000595,0.000595,0.000595
-97,18405.1,0.32894,0.1624,0.89341,0.99997,0.99995,0.995,0.954,0.34687,0.15676,0.81975,0.000496,0.000496,0.000496
-98,18595,0.32409,0.15968,0.89212,0.99997,0.99995,0.995,0.9556,0.34266,0.15575,0.81827,0.000397,0.000397,0.000397
-99,18780.4,0.31802,0.15797,0.88892,0.99997,0.99995,0.995,0.95676,0.33944,0.155,0.81719,0.000298,0.000298,0.000298
-100,18972.9,0.315,0.1563,0.88609,0.99997,0.99994,0.995,0.95746,0.33665,0.15468,0.81631,0.000199,0.000199,0.000199
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/results.png b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/results.png
deleted file mode 100644
index b9903fc..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/results.png and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch0.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch0.jpg
deleted file mode 100644
index bd7729b..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch0.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch1.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch1.jpg
deleted file mode 100644
index c495b17..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch1.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch107100.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch107100.jpg
deleted file mode 100644
index 8066c27..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch107100.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch107101.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch107101.jpg
deleted file mode 100644
index a430942..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch107101.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch107102.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch107102.jpg
deleted file mode 100644
index b256388..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch107102.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch2.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch2.jpg
deleted file mode 100644
index e621ce2..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/train_batch2.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch0_labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch0_labels.jpg
deleted file mode 100644
index 246fc05..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch0_labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch0_pred.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch0_pred.jpg
deleted file mode 100644
index 8b08dc4..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch0_pred.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch1_labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch1_labels.jpg
deleted file mode 100644
index 620a99c..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch1_labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch1_pred.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch1_pred.jpg
deleted file mode 100644
index f2695ef..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch1_pred.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch2_labels.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch2_labels.jpg
deleted file mode 100644
index 8462cea..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch2_labels.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch2_pred.jpg b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch2_pred.jpg
deleted file mode 100644
index ce7a817..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/val_batch2_pred.jpg and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/weights/best.pt b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/weights/best.pt
deleted file mode 100644
index a8802c6..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/weights/best.pt and /dev/null differ
diff --git a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/weights/last.pt b/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/weights/last.pt
deleted file mode 100644
index 27a6013..0000000
Binary files a/Annotation_and_fine-tuning/runs/detect/yolov8n_car_parts_aggressive_aug_3_objects/weights/last.pt and /dev/null differ
diff --git a/Annotation_and_fine-tuning/yolov8n.pt b/Annotation_and_fine-tuning/yolov8n.pt
deleted file mode 100644
index 0db4ca4..0000000
Binary files a/Annotation_and_fine-tuning/yolov8n.pt and /dev/null differ
diff --git a/Asjad/ignore.html b/Asjad/ignore.html
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/Asjad/ignore.html
@@ -0,0 +1 @@
+
diff --git a/Asjad/perception/launch/demo_webcam_pose.launch.py b/Asjad/perception/launch/demo_webcam_pose.launch.py
new file mode 100644
index 0000000..afaf247
--- /dev/null
+++ b/Asjad/perception/launch/demo_webcam_pose.launch.py
@@ -0,0 +1,68 @@
+from launch import LaunchDescription
+from launch.actions import DeclareLaunchArgument
+from launch.substitutions import LaunchConfiguration
+from launch_ros.actions import Node
+
+def generate_launch_description():
+ return LaunchDescription([
+ DeclareLaunchArgument(
+ 'model_path',
+ default_value='models/tools.pt',
+ description='Path to the YOLO model file'
+ ),
+
+ DeclareLaunchArgument(
+ 'device_id',
+ default_value='0',
+ description='Camera Device ID (0 for webcam, 1 for external, etc.)'
+ ),
+
+ # 1. Webcam Publisher
+ Node(
+ package='perception',
+ executable='opencv_camera_node',
+ name='webcam_publisher',
+ output='screen',
+ parameters=[{
+ 'topic_name': '/camera/color/image_raw',
+ 'device_id': LaunchConfiguration('device_id')
+ }]
+ ),
+
+ # 2. Mock Depth Publisher
+ Node(
+ package='perception',
+ executable='mock_depth_node',
+ name='mock_depth_publisher',
+ output='screen'
+ ),
+
+ # 3. YOLO Node
+ Node(
+ package='perception',
+ executable='yolo_node',
+ name='yolo_detector',
+ output='screen',
+ parameters=[{
+ 'model_path': LaunchConfiguration('model_path'),
+ 'input_mode': 'robot' # Consumes standard topics
+ }],
+ remappings=[
+ ('/detections', '/tool_detector/detections')
+ ]
+ ),
+
+ # 4. Pose Node
+ Node(
+ package='perception',
+ executable='pose_node',
+ name='pose_estimator',
+ output='screen',
+ parameters=[{
+ 'input_mode': 'robot' # Consumes standard topics
+ }],
+ remappings=[
+ ('/detections', '/tool_detector/detections')
+ ]
+ )
+ ])
diff --git a/Asjad/perception/launch/tool_pipeline.launch.py b/Asjad/perception/launch/tool_pipeline.launch.py
new file mode 100644
index 0000000..82bf7bd
--- /dev/null
+++ b/Asjad/perception/launch/tool_pipeline.launch.py
@@ -0,0 +1,43 @@
+from launch import LaunchDescription
+from launch.actions import DeclareLaunchArgument
+from launch.substitutions import LaunchConfiguration
+from launch_ros.actions import Node
+
+def generate_launch_description():
+ return LaunchDescription([
+ DeclareLaunchArgument(
+ 'model_path',
+ default_value='models/tools.pt',
+ description='Path to the YOLO model file'
+ ),
+ DeclareLaunchArgument(
+ 'input_mode',
+ default_value='realsense',
+ description='Input mode: robot, realsense, or topic name'
+ ),
+ Node(
+ package='perception',
+ executable='yolo_node',
+ name='yolo_detector',
+ output='screen',
+ parameters=[{
+ 'model_path': LaunchConfiguration('model_path'),
+ 'input_mode': LaunchConfiguration('input_mode')
+ }],
+ remappings=[
+ ('/detections', '/tool_detector/detections')
+ ]
+ ),
+ Node(
+ package='perception',
+ executable='pose_node',
+ name='pose_estimator',
+ output='screen',
+ parameters=[{
+ 'input_mode': LaunchConfiguration('input_mode')
+ }],
+ remappings=[
+ ('/detections', '/tool_detector/detections')
+ ]
+ )
+ ])
diff --git a/Asjad/perception/package.xml b/Asjad/perception/package.xml
new file mode 100644
index 0000000..39c5db7
--- /dev/null
+++ b/Asjad/perception/package.xml
@@ -0,0 +1,26 @@
+
+
+
+ perception
+ 0.0.0
+ TODO: Package description
+ mohsin
+ TODO: License declaration
+
+ sensor_msgs
+ std_msgs
+ rclpy
+ image_transport
+ cv_bridge
+ python3-opencv
+ opencv4
+
+ ament_copyright
+ ament_flake8
+ ament_pep257
+ python3-pytest
+
+
+ ament_python
+
+
diff --git a/Asjad/perception/perception/__init__.py b/Asjad/perception/perception/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/Asjad/perception/perception/mock_depth_publisher.py b/Asjad/perception/perception/mock_depth_publisher.py
new file mode 100644
index 0000000..e80964e
--- /dev/null
+++ b/Asjad/perception/perception/mock_depth_publisher.py
@@ -0,0 +1,56 @@
+import rclpy
+from rclpy.node import Node
+from sensor_msgs.msg import Image, PointCloud2, PointField
+from cv_bridge import CvBridge
+import numpy as np
+import struct
+import sensor_msgs_py.point_cloud2 as pc2
+
+class MockDepthPublisher(Node):
+ def __init__(self):
+ super().__init__('mock_depth_publisher')
+ self.bridge = CvBridge()
+
+ # Subscribe to webcam image
+ self.create_subscription(Image, '/camera/color/image_raw', self.image_callback, 10)
+
+ # Publish mock pointcloud
+ self.pc_pub = self.create_publisher(PointCloud2, '/camera/depth/color/points', 10)
+
+ self.get_logger().info("Mock Depth Publisher Started. Generating planar depth at Z=1.0m")
+
+ def image_callback(self, img_msg):
+ # Create a simple planar pointcloud matching the image resolution
+ height = img_msg.height
+ width = img_msg.width
+
+ # Generate grid of X, Y coordinates
+ # Simplified intrinsic model: assume center is (w/2, h/2) and focal length ~ width
+ fx, fy = width, width
+ cx, cy = width / 2, height / 2
+
+ u, v = np.meshgrid(np.arange(width), np.arange(height))
+ z = np.ones_like(u) * 1.0 # Fixed depth of 1 meter
+
+ x = (u - cx) * z / fx
+ y = (v - cy) * z / fy
+
+ # Stack into (N, 3) array
+ points = np.stack([x.flatten(), y.flatten(), z.flatten()], axis=1)
+
+ # Create header
+ header = img_msg.header
+
+ # Create PointCloud2
+ pc_msg = pc2.create_cloud_xyz32(header, points)
+ self.pc_pub.publish(pc_msg)
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = MockDepthPublisher()
+ rclpy.spin(node)
+ node.destroy_node()
+ rclpy.shutdown()
+
+if __name__ == '__main__':
+ main()
diff --git a/Asjad/perception/perception/opencv_camera_feed.py b/Asjad/perception/perception/opencv_camera_feed.py
new file mode 100644
index 0000000..0502e9d
--- /dev/null
+++ b/Asjad/perception/perception/opencv_camera_feed.py
@@ -0,0 +1,63 @@
+import rclpy
+from rclpy.node import Node
+from sensor_msgs.msg import Image
+from cv_bridge import CvBridge
+import cv2
+import numpy as np
+
+class SimpleCameraNode(Node):
+ def __init__(self):
+ super().__init__('simple_camera_node')
+
+ # Declare parameters
+ self.declare_parameter('device_id', 0)
+ self.declare_parameter('topic_name', '/camera/color/image_raw')
+
+ device_id = self.get_parameter('device_id').get_parameter_value().integer_value
+ topic_name = self.get_parameter('topic_name').get_parameter_value().string_value
+
+ self.publisher = self.create_publisher(Image, topic_name, 10)
+ self.bridge = CvBridge()
+
+ self.get_logger().info(f"Opening camera device {device_id}...")
+ self.cap = cv2.VideoCapture(device_id)
+
+ self.use_synthetic = False
+ if not self.cap.isOpened():
+ self.get_logger().warn(f"Could not open camera device {device_id}! Switching to SYNTHETIC MODE (Test Pattern).")
+ self.use_synthetic = True
+ self.synthetic_frame = np.zeros((480, 640, 3), dtype=np.uint8)
+ # Draw a "tool" (green rectangle) to detect
+ cv2.rectangle(self.synthetic_frame, (200, 150), (440, 330), (0, 255, 0), -1)
+
+ timer_period = 0.03 # 30ms ~ 33 FPS
+ self.timer = self.create_timer(timer_period, self.timer_callback)
+
+ def timer_callback(self):
+ if self.use_synthetic:
+ frame = self.synthetic_frame.copy()
+ # Add some noise or movement?
+ pass
+ else:
+ ret, frame = self.cap.read()
+ if not ret:
+ # self.get_logger().warn('Failed to capture frame')
+ return
+
+ msg = self.bridge.cv2_to_imgmsg(frame, encoding='bgr8')
+ msg.header.stamp = self.get_clock().now().to_msg() # Important for synchronization
+ msg.header.frame_id = "camera_frame"
+ self.publisher.publish(msg)
+
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = SimpleCameraNode()
+ rclpy.spin(node)
+ node.cap.release()
+ node.destroy_node()
+ rclpy.shutdown()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/Asjad/perception/perception/pose_pca.py b/Asjad/perception/perception/pose_pca.py
new file mode 100644
index 0000000..73c9a8a
--- /dev/null
+++ b/Asjad/perception/perception/pose_pca.py
@@ -0,0 +1,216 @@
+import rclpy
+from rclpy.node import Node
+from sensor_msgs.msg import PointCloud2, PointField, Image
+from vision_msgs.msg import Detection2DArray
+from geometry_msgs.msg import PoseStamped, TransformStamped
+from std_msgs.msg import Header
+
+import message_filters
+from cv_bridge import CvBridge
+import numpy as np
+import struct
+import sensor_msgs_py.point_cloud2 as pc2
+from transforms3d.quaternions import mat2quat
+from tf2_ros import TransformBroadcaster
+
+
+class PointCloudCropperNode(Node):
+ def __init__(self):
+ super().__init__('pointcloud_cropper_node')
+
+ self.bridge = CvBridge()
+
+ # Declare input_mode parameter only
+ self.declare_parameter('input_mode', 'realsense')
+ input_mode = self.get_parameter('input_mode').get_parameter_value().string_value
+
+ # Determine topics based on mode
+ if input_mode == 'robot':
+ pc_topic = '/camera/depth/color/points'
+ img_topic = '/camera/color/image_raw'
+ elif input_mode == 'realsense':
+ pc_topic = '/camera/camera/depth/color/points'
+ img_topic = '/camera/camera/color/image_raw'
+ else:
+ self.get_logger().warn(f"Unknown input_mode '{input_mode}', defaulting to 'realsense'")
+ pc_topic = '/camera/camera/depth/color/points'
+ img_topic = '/camera/camera/color/image_raw'
+
+ self.get_logger().info(f"Using input mode: '{input_mode}' with topics: {pc_topic}, {img_topic}")
+
+ # Message filter subscribers
+ pc_sub = message_filters.Subscriber(self, PointCloud2, pc_topic)
+ img_sub = message_filters.Subscriber(self, Image, img_topic)
+ det_sub = message_filters.Subscriber(self, Detection2DArray, '/detections')
+
+ ts = message_filters.ApproximateTimeSynchronizer(
+ [pc_sub, det_sub, img_sub],
+ queue_size=10,
+ slop=0.1
+ )
+ ts.registerCallback(self.sync_callback)
+
+ self.prev_poses = {} # Store previous pose for smoothing per object index
+ self.alpha_pos = 0.2 # low-pass filter factor for position (0.2 = slow/smooth, 1.0 = no smoothing)
+ self.alpha_rot = 0.1 # low-pass filter factor for rotation
+
+ self.get_logger().info('PointCloud Cropper Node with robust PCA starting...')
+
+ def sync_callback(self, cloud_msg, detection_msg, image_msg):
+ try:
+ color_image = self.bridge.imgmsg_to_cv2(image_msg, desired_encoding='bgr8')
+ except Exception as e:
+ self.get_logger().error(f"Image conversion error: {e}")
+ return
+
+ pc_width = cloud_msg.width
+ pc_height = cloud_msg.height
+
+ # Read all points (expensive but robust)
+ cloud_points = np.array([
+ [x, y, z]
+ for x, y, z in pc2.read_points(cloud_msg, field_names=("x", "y", "z"), skip_nans=False)
+ ]).reshape((pc_height, pc_width, 3))
+
+ all_colored_points = []
+ current_frame_poses = {}
+
+ for idx, detection in enumerate(detection_msg.detections):
+ detected_class = detection.results[0].hypothesis.class_id
+
+ # 1. Extract ROI
+ cx, cy = int(detection.bbox.center.position.x), int(detection.bbox.center.position.y)
+ w, h = int(detection.bbox.size_x), int(detection.bbox.size_y)
+ xmin, xmax = max(cx - w // 2, 0), min(cx + w // 2, pc_width)
+ ymin, ymax = max(cy - h // 2, 0), min(cy + h // 2, pc_height)
+
+ cropped_points = cloud_points[ymin:ymax, xmin:xmax, :].reshape(-1, 3)
+ cropped_colors = color_image[ymin:ymax, xmin:xmax, :].reshape(-1, 3)
+
+ # Basic NaN filtering
+ valid_mask = ~np.isnan(cropped_points).any(axis=1)
+ cropped_points = cropped_points[valid_mask]
+ cropped_colors = cropped_colors[valid_mask]
+
+ # 2. Outlier Removal (Z-Score)
+ if len(cropped_points) > 10:
+ mean = np.mean(cropped_points, axis=0)
+ std = np.std(cropped_points, axis=0)
+ # Filter points > 2 std devs away
+ z_score = np.abs((cropped_points - mean) / (std + 1e-6))
+ inlier_mask = (z_score < 2.0).all(axis=1)
+ cropped_points = cropped_points[inlier_mask]
+ cropped_colors = cropped_colors[inlier_mask]
+
+ # Re-collect for visualization
+ for pt, color in zip(cropped_points, cropped_colors):
+ x, y, z = pt
+ rgb = struct.unpack('f', struct.pack('I', (int(color[2]) << 16) | (int(color[1]) << 8) | int(color[0])))[0]
+ all_colored_points.append([x, y, z, rgb])
+
+ if len(cropped_points) < 10:
+ continue
+
+ # 3. PCA & Alignment
+ centroid = np.mean(cropped_points, axis=0)
+ centered = cropped_points - centroid
+ _, _, vh = np.linalg.svd(centered, full_matrices=False)
+ R = vh.T
+
+ # 3a. Normal Alignment (Minor Axis Z should point to Camera)
+ # Camera frame: Z is forward (positive).
+ # Objects are in front, so Z > 0. Normal pointing "at" camera means Z component should be negative.
+ # However, if we view surface, normal is usually out of surface.
+ # Let's enforce Z component of Z-axis (R[2,2]) is negative (pointing back to origin).
+ if R[2, 2] > 0:
+ R[:, 2] *= -1
+ R[:, 1] *= -1 # Maintain right-hand rule by flipping Y too
+
+ # 3b. Direction Disambiguation (Major Axis X towards "heavy" side)
+ # Project points onto X axis
+ projected_x = centered @ R[:, 0]
+ # Simple heuristic: Skewness. If skew > 0, tail is right, bulk is left.
+ # We want X to point to bulk. So if skew > 0, flip X.
+ skew = np.sum(projected_x ** 3)
+ if skew > 0:
+ R[:, 0] *= -1
+ R[:, 1] *= -1 # Maintain RHR
+
+ # 4. Temporal Smoothing
+ prev = self.prev_poses.get(idx)
+
+ if prev is not None:
+ # Position Smoothing
+ centroid = self.alpha_pos * centroid + (1 - self.alpha_pos) * prev['pos']
+
+ # Rotation Smoothing (Quaternion Lerp)
+ q_curr = mat2quat(R)
+ q_prev = prev['quat']
+
+ # Ensure shortest path (dot product > 0)
+ dot = np.dot(q_curr, q_prev)
+ if dot < 0:
+ q_curr = -q_curr
+
+ q_smooth = self.alpha_rot * q_curr + (1 - self.alpha_rot) * q_prev
+ q_smooth /= np.linalg.norm(q_smooth) # Normalize
+ quat = q_smooth
+
+ # Reconstruct R from smoothed quat for other uses if needed (omitted for speed)
+ else:
+ quat = mat2quat(R)
+
+ # Store for next frame
+ current_frame_poses[idx] = {'pos': centroid, 'quat': quat}
+
+ # Publish
+ pose_msg = PoseStamped()
+ pose_msg.header.stamp = self.get_clock().now().to_msg()
+ pose_msg.header.frame_id = cloud_msg.header.frame_id
+ pose_msg.pose.position.x = float(centroid[0])
+ pose_msg.pose.position.y = float(centroid[1])
+ pose_msg.pose.position.z = float(centroid[2])
+ pose_msg.pose.orientation.x = float(quat[1]) # Transforms3d gives w,x,y,z. ROS needs x,y,z,w
+ pose_msg.pose.orientation.y = float(quat[2])
+ pose_msg.pose.orientation.z = float(quat[3])
+ pose_msg.pose.orientation.w = float(quat[0])
+
+ self.pose_pub.publish(pose_msg)
+
+ # TF
+ t = TransformStamped()
+ t.header = pose_msg.header
+ t.child_frame_id = f'object_frame_{idx}'
+ t.transform.translation.x = pose_msg.pose.position.x
+ t.transform.translation.y = pose_msg.pose.position.y
+ t.transform.translation.z = pose_msg.pose.position.z
+ t.transform.rotation = pose_msg.pose.orientation
+ self.tf_broadcaster.sendTransform(t)
+
+ self.prev_poses = current_frame_poses # Update state with only currently seen objects (avoids stale ghosts)
+
+ if all_colored_points:
+ # ... (Publish cropped cloud code matches existing structure)
+ header = Header()
+ header.stamp = self.get_clock().now().to_msg()
+ header.frame_id = cloud_msg.header.frame_id
+ fields = [
+ PointField(name='x', offset=0, datatype=PointField.FLOAT32, count=1),
+ PointField(name='y', offset=4, datatype=PointField.FLOAT32, count=1),
+ PointField(name='z', offset=8, datatype=PointField.FLOAT32, count=1),
+ PointField(name='rgb', offset=12, datatype=PointField.FLOAT32, count=1),
+ ]
+ cropped_pc = pc2.create_cloud(header, fields, all_colored_points)
+ self.pc_pub.publish(cropped_pc)
+
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = PointCloudCropperNode()
+ rclpy.spin(node)
+ node.destroy_node()
+ rclpy.shutdown()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/Asjad/perception/perception/yolo_object_detection.py b/Asjad/perception/perception/yolo_object_detection.py
new file mode 100644
index 0000000..c59fa7b
--- /dev/null
+++ b/Asjad/perception/perception/yolo_object_detection.py
@@ -0,0 +1,130 @@
+import rclpy
+from rclpy.node import Node
+from sensor_msgs.msg import Image
+from vision_msgs.msg import Detection2DArray, Detection2D, ObjectHypothesisWithPose
+from cv_bridge import CvBridge
+from ultralytics import YOLO
+from ultralytics.engine.results import Boxes
+import torch
+import cv2
+import os
+
+# Monkeypatch torch.load to disable weights_only enforcement by default
+# Required for Ultralytics 8.1.0 with PyTorch 2.6+
+if hasattr(torch, 'load'):
+ original_load = torch.load
+ def safe_load(*args, **kwargs):
+ if 'weights_only' not in kwargs:
+ kwargs['weights_only'] = False
+ return original_load(*args, **kwargs)
+ torch.load = safe_load
+
+
+class YoloDetectorNode(Node):
+ def __init__(self):
+ super().__init__('yolo_detector_node')
+ self.bridge = CvBridge()
+
+ # Declare and get parameters
+ self.declare_parameter('model_path', '')
+ self.declare_parameter('model_type', 'default') # 'default' or 'fine_tuned' (deprecated if model_path used)
+ self.declare_parameter('input_mode', 'realsense') # 'robot' or 'realsense'
+
+ model_path_param = self.get_parameter('model_path').get_parameter_value().string_value
+ model_type = self.get_parameter('model_type').get_parameter_value().string_value
+ input_mode = self.get_parameter('input_mode').get_parameter_value().string_value
+
+ # Determine model path
+ if model_path_param:
+ model_path = model_path_param
+ elif model_type == 'fine_tuned':
+ # Fallback for legacy support, but user should prefer model_path
+ model_path = os.path.join(os.getcwd(), 'ros2_ws', 'models', 'fine_tuned.pt')
+ else:
+ model_path = 'yolov8n.pt' # Ultralytics will download/find this
+
+ self.get_logger().info(f"Using model from: {model_path}")
+ self.model = YOLO(model_path)
+
+ # Determine image topic
+ if input_mode == 'robot':
+ image_topic = '/camera/color/image_raw'
+ elif input_mode == 'realsense':
+ image_topic = '/camera/camera/color/image_raw'
+ else:
+ # Check if input_mode is actually a topic name
+ if input_mode.startswith('/'):
+ image_topic = input_mode
+ else:
+ self.get_logger().warn(f"Unknown input_mode '{input_mode}', defaulting to 'realsense'")
+ image_topic = '/camera/camera/color/image_raw'
+
+ self.get_logger().info(f"Subscribing to image topic: {image_topic}")
+
+ # Create subscriptions and publishers
+ self.image_sub = self.create_subscription(Image, image_topic, self.image_callback, 10)
+ self.annotated_image_pub = self.create_publisher(Image, '/annotated_image', 10)
+ self.detection_pub = self.create_publisher(Detection2DArray, '/detections', 10)
+
+ self.conf_threshold = 0.6 # Confidence threshold for filtering
+
+ self.get_logger().info('YOLOv8 Detector Node started.')
+
+ def image_callback(self, msg):
+ try:
+ cv_image = self.bridge.imgmsg_to_cv2(msg, 'bgr8')
+ except Exception as e:
+ self.get_logger().error(f'Image conversion error: {e}')
+ return
+
+ results = self.model(cv_image)
+ detection_array_msg = Detection2DArray()
+ detection_array_msg.header = msg.header
+
+ for result in results:
+ filtered_boxes = [box for box in result.boxes if float(box.conf) >= self.conf_threshold]
+
+ if filtered_boxes:
+ box_data = torch.stack([b.data[0] for b in filtered_boxes])
+ result.boxes = Boxes(box_data, orig_shape=result.orig_shape)
+ else:
+ result.boxes = Boxes(torch.empty((0, 6)), orig_shape=result.orig_shape)
+
+ annotated_image = result.plot()
+ try:
+ annotated_msg = self.bridge.cv2_to_imgmsg(annotated_image, encoding='bgr8')
+ annotated_msg.header = msg.header
+ self.annotated_image_pub.publish(annotated_msg)
+ except Exception as e:
+ self.get_logger().error(f'Annotated image conversion error: {e}')
+
+ for box in filtered_boxes:
+ detection_msg = Detection2D()
+ detection_msg.header = msg.header
+
+ hypothesis = ObjectHypothesisWithPose()
+ hypothesis.hypothesis.class_id = self.model.names[int(box.cls)]
+ hypothesis.hypothesis.score = float(box.conf)
+ detection_msg.results.append(hypothesis)
+
+ xywh = box.xywh.cpu().numpy().flatten()
+ detection_msg.bbox.center.position.x = float(xywh[0])
+ detection_msg.bbox.center.position.y = float(xywh[1])
+ detection_msg.bbox.size_x = float(xywh[2])
+ detection_msg.bbox.size_y = float(xywh[3])
+
+ detection_array_msg.detections.append(detection_msg)
+
+ self.detection_pub.publish(detection_array_msg)
+
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = YoloDetectorNode()
+ rclpy.spin(node)
+ node.destroy_node()
+ rclpy.shutdown()
+
+
+if __name__ == '__main__':
+ main()
diff --git a/Asjad/perception/resource/perception b/Asjad/perception/resource/perception
new file mode 100644
index 0000000..e69de29
diff --git a/Asjad/perception/rviz/pose_estimation.rviz b/Asjad/perception/rviz/pose_estimation.rviz
new file mode 100644
index 0000000..e7bf5cf
--- /dev/null
+++ b/Asjad/perception/rviz/pose_estimation.rviz
@@ -0,0 +1,219 @@
+Panels:
+ - Class: rviz_common/Displays
+ Help Height: 78
+ Name: Displays
+ Property Tree Widget:
+ Expanded:
+ - /Global Options1
+ - /Status1
+ - /PointCloud21
+ - /TF1
+ Splitter Ratio: 0.5
+ Tree Height: 348
+ - Class: rviz_common/Selection
+ Name: Selection
+ - Class: rviz_common/Tool Properties
+ Expanded:
+ - /2D Goal Pose1
+ - /Publish Point1
+ Name: Tool Properties
+ Splitter Ratio: 0.5886790156364441
+ - Class: rviz_common/Views
+ Expanded:
+ - /Current View1
+ Name: Views
+ Splitter Ratio: 0.5
+ - Class: rviz_common/Time
+ Experimental: false
+ Name: Time
+ SyncMode: 0
+ SyncSource: PointCloud2
+Visualization Manager:
+ Class: ""
+ Displays:
+ - Alpha: 0.5
+ Cell Size: 1
+ Class: rviz_default_plugins/Grid
+ Color: 160; 160; 164
+ Enabled: true
+ Line Style:
+ Line Width: 0.029999999329447746
+ Value: Lines
+ Name: Grid
+ Normal Cell Count: 0
+ Offset:
+ X: 0
+ Y: 0
+ Z: 0
+ Plane: XY
+ Plane Cell Count: 10
+ Reference Frame:
+ Value: true
+ - Class: rviz_default_plugins/Image
+ Enabled: true
+ Max Value: 1
+ Median window: 5
+ Min Value: 0
+ Name: Image
+ Normalize Range: true
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /annotated_image
+ Value: true
+ - Alpha: 1
+ Autocompute Intensity Bounds: true
+ Autocompute Value Bounds:
+ Max Value: 10
+ Min Value: -10
+ Value: true
+ Axis: Z
+ Channel Name: intensity
+ Class: rviz_default_plugins/PointCloud2
+ Color: 255; 255; 255
+ Color Transformer: RGB8
+ Decay Time: 0
+ Enabled: true
+ Invert Rainbow: false
+ Max Color: 255; 255; 255
+ Max Intensity: 4096
+ Min Color: 0; 0; 0
+ Min Intensity: 0
+ Name: PointCloud2
+ Position Transformer: XYZ
+ Selectable: true
+ Size (Pixels): 3
+ Size (m): 0.009999999776482582
+ Style: Flat Squares
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /cropped_pointcloud
+ Use Fixed Frame: true
+ Use rainbow: true
+ Value: true
+ - Class: rviz_default_plugins/TF
+ Enabled: true
+ Filter (blacklist): ""
+ Filter (whitelist): ""
+ Frame Timeout: 15
+ Frames:
+ All Enabled: true
+ camera_color_frame:
+ Value: true
+ camera_color_optical_frame:
+ Value: true
+ camera_depth_frame:
+ Value: true
+ camera_depth_optical_frame:
+ Value: true
+ camera_link:
+ Value: true
+ object_frame_0:
+ Value: true
+ Marker Scale: 1
+ Name: TF
+ Show Arrows: true
+ Show Axes: true
+ Show Names: false
+ Tree:
+ camera_link:
+ camera_color_frame:
+ camera_color_optical_frame:
+ {}
+ camera_depth_frame:
+ camera_depth_optical_frame:
+ object_frame_0:
+ {}
+ Update Interval: 0
+ Value: true
+ Enabled: true
+ Global Options:
+ Background Color: 48; 48; 48
+ Fixed Frame: camera_link
+ Frame Rate: 30
+ Name: root
+ Tools:
+ - Class: rviz_default_plugins/Interact
+ Hide Inactive Objects: true
+ - Class: rviz_default_plugins/MoveCamera
+ - Class: rviz_default_plugins/Select
+ - Class: rviz_default_plugins/FocusCamera
+ - Class: rviz_default_plugins/Measure
+ Line color: 128; 128; 0
+ - Class: rviz_default_plugins/SetInitialPose
+ Covariance x: 0.25
+ Covariance y: 0.25
+ Covariance yaw: 0.06853891909122467
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /initialpose
+ - Class: rviz_default_plugins/SetGoal
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /goal_pose
+ - Class: rviz_default_plugins/PublishPoint
+ Single click: true
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /clicked_point
+ Transformation:
+ Current:
+ Class: rviz_default_plugins/TF
+ Value: true
+ Views:
+ Current:
+ Class: rviz_default_plugins/Orbit
+ Distance: 2.855905532836914
+ Enable Stereo Rendering:
+ Stereo Eye Separation: 0.05999999865889549
+ Stereo Focal Distance: 1
+ Swap Stereo Eyes: false
+ Value: false
+ Focal Point:
+ X: 1.2362849712371826
+ Y: -0.21183088421821594
+ Z: -0.2512143552303314
+ Focal Shape Fixed Size: true
+ Focal Shape Size: 0.05000000074505806
+ Invert Z Axis: false
+ Name: Current View
+ Near Clip Distance: 0.009999999776482582
+ Pitch: -0.05460222065448761
+ Target Frame:
+ Value: Orbit (rviz)
+ Yaw: 3.0917561054229736
+ Saved: ~
+Window Geometry:
+ Displays:
+ collapsed: false
+ Height: 846
+ Hide Left Dock: false
+ Hide Right Dock: false
+ Image:
+ collapsed: false
+ QMainWindow State: 000000ff00000000fd000000040000000000000156000002acfc020000000afb0000001200530065006c0065006300740069006f006e00000001e10000009b0000005d00fffffffb0000001e0054006f006f006c002000500072006f007000650072007400690065007302000001ed000001df00000185000000a3fb000000120056006900650077007300200054006f006f02000001df000002110000018500000122fb000000200054006f006f006c002000500072006f0070006500720074006900650073003203000002880000011d000002210000017afb000000100044006900730070006c006100790073010000003f000001ea000000cc00fffffffb0000002000730065006c0065006300740069006f006e00200062007500660066006500720200000138000000aa0000023a00000294fb00000014005700690064006500530074006500720065006f02000000e6000000d2000003ee0000030bfb0000000c004b0069006e0065006300740200000186000001060000030c00000261fb0000000c00430061006d006500720061010000022f000000bc0000000000000000fb0000000a0049006d006100670065010000022f000000bc0000001700ffffff000000010000010f000002acfc0200000003fb0000001e0054006f006f006c002000500072006f00700065007200740069006500730100000041000000780000000000000000fb0000000a00560069006500770073010000003f000002ac000000a900fffffffb0000001200530065006c0065006300740069006f006e010000025a000000b200000000000000000000000200000490000000a9fc0100000001fb0000000a00560069006500770073030000004e00000080000002e10000019700000003000004b00000003efc0100000002fb0000000800540069006d00650100000000000004b00000026f00fffffffb0000000800540069006d006501000000000000045000000000000000000000023f000002ac00000004000000040000000800000008fc0000000100000002000000010000000a0054006f006f006c00730100000000ffffffff0000000000000000
+ Selection:
+ collapsed: false
+ Time:
+ collapsed: false
+ Tool Properties:
+ collapsed: false
+ Views:
+ collapsed: false
+ Width: 1200
+ X: 66
+ Y: 60
diff --git a/Asjad/perception/setup.cfg b/Asjad/perception/setup.cfg
new file mode 100644
index 0000000..be4fcdb
--- /dev/null
+++ b/Asjad/perception/setup.cfg
@@ -0,0 +1,6 @@
+[develop]
+script_dir=$base/lib/perception
+[install]
+install_scripts=$base/lib/perception
+[build_scripts]
+executable = /usr/bin/env python3
diff --git a/Asjad/perception/setup.py b/Asjad/perception/setup.py
new file mode 100644
index 0000000..f537b6d
--- /dev/null
+++ b/Asjad/perception/setup.py
@@ -0,0 +1,33 @@
+from setuptools import find_packages, setup
+from glob import glob
+import os
+
+package_name = 'perception'
+
+setup(
+ name=package_name,
+ version='0.0.0',
+ packages=find_packages(exclude=['test']),
+ data_files=[
+ ('share/ament_index/resource_index/packages',
+ ['resource/' + package_name]),
+ ('share/' + package_name, ['package.xml']),
+ (os.path.join('share', package_name, 'launch'), glob('launch/*.launch.py')),
+ ],
+ install_requires=['setuptools'],
+ zip_safe=True,
+ maintainer='mohsin',
+ maintainer_email='',
+ description='TODO: Package description',
+ license='Apache-2.0',
+ tests_require=['pytest'],
+ entry_points={
+ 'console_scripts': [
+ "yolo_node = perception.yolo_object_detection:main",
+ "pose_node = perception.pose_pca:main",
+ "opencv_camera_node = perception.opencv_camera_feed:main",
+ "opencv_yolo = perception.opencv_yolo_object_detection:main",
+ "mock_depth_node = perception.mock_depth_publisher:main",
+ ],
+ },
+)
diff --git a/Asjad/scripts/demos/test_realsense_windows.py b/Asjad/scripts/demos/test_realsense_windows.py
new file mode 100644
index 0000000..85927f1
--- /dev/null
+++ b/Asjad/scripts/demos/test_realsense_windows.py
@@ -0,0 +1,65 @@
+import pyrealsense2 as rs
+import time
+
+def main():
+ print("---------------------------------------")
+ print("RealSense Windows Diagnostics")
+ print("---------------------------------------")
+
+ ctx = rs.context()
+ devices = ctx.query_devices()
+
+ if len(devices) == 0:
+ print("ERROR: No RealSense devices found!")
+ print("Check your USB connection.")
+ return
+
+ for dev in devices:
+ print(f"Device Found: {dev.get_info(rs.camera_info.name)}")
+ print(f" Serial: {dev.get_info(rs.camera_info.serial_number)}")
+ print(f" Firmware: {dev.get_info(rs.camera_info.firmware_version)}")
+
+ # Check USB Type
+ try:
+ usb_type = dev.get_info(rs.camera_info.usb_type_descriptor)
+ print(f" USB Connection: {usb_type}")
+ if "2." in usb_type:
+ print(" [WARNING] Connected via USB 2.0! Streaming capabilities will be limited.")
+ print(" Use a high-quality USB 3.0 (Type-C to Type-A/C) cable.")
+ except:
+ print(" USB Connection: Unknown")
+
+ print("\nAttempting to start stream...")
+ pipeline = rs.pipeline()
+ config = rs.config()
+
+ # Try a modest resolution that works on USB 2.0 and 3.0
+ config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30)
+ config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30)
+
+ try:
+ profile = pipeline.start(config)
+ print("SUCCESS: Stream started!")
+
+ # Check active profile
+ active_depth = profile.get_stream(rs.stream.depth)
+ print(f"Active Stream: {active_depth.as_video_stream_profile().width()}x{active_depth.as_video_stream_profile().height()} @ {active_depth.as_video_stream_profile().fps()}fps")
+
+ print("Streaming 50 frames...")
+ for i in range(50):
+ frames = pipeline.wait_for_frames()
+ if i % 10 == 0:
+ print(f" Frame {i}/50 received...")
+
+ pipeline.stop()
+ print("SUCCESS: Test Complete. Hardware is working.")
+ print("---------------------------------------")
+
+ except Exception as e:
+ print(f"\n[ERROR] Failed to stream: {e}")
+ print("Possible causes:")
+ print("1. USB Bandwidth (Try a different port/cable)")
+ print("2. Camera is in a bad state (Unplug/Replug)")
+
+if __name__ == "__main__":
+ main()
diff --git a/Asjad/scripts/demos/webcam_demo.py b/Asjad/scripts/demos/webcam_demo.py
new file mode 100644
index 0000000..0aa023f
--- /dev/null
+++ b/Asjad/scripts/demos/webcam_demo.py
@@ -0,0 +1,36 @@
+import torch
+import cv2
+from ultralytics import YOLO
+
+# Monkeypatch torch.load to disable weights_only enforcement
+# This is necessary because we are using PyTorch 2.6+ with Ultralytics 8.1.0
+if hasattr(torch, 'load'):
+ original_load = torch.load
+ def safe_load(*args, **kwargs):
+ if 'weights_only' not in kwargs:
+ kwargs['weights_only'] = False
+ return original_load(*args, **kwargs)
+ torch.load = safe_load
+
+def main():
+ # Load the trained model
+ model_path = 'models/tools.pt'
+ print(f"Loading model from {model_path}...")
+ try:
+ model = YOLO(model_path)
+ except Exception as e:
+ print(f"Error loading model: {e}")
+ return
+
+ # Run inference on the webcam (source=0)
+ # show=True opens a window with results
+ # conf=0.6 sets confidence threshold
+ print("Starting webcam... Press 'q' to exit (if window allows) or Ctrl+C in terminal.")
+ results = model.predict(source='0', show=True, conf=0.6, stream=True)
+
+ # We iterate over the stream to keep the script running
+ for r in results:
+ pass # The show=True handles the display
+
+if __name__ == '__main__':
+ main()
diff --git a/Asjad/scripts/training/train_tool_model.py b/Asjad/scripts/training/train_tool_model.py
new file mode 100644
index 0000000..f6bb9b6
--- /dev/null
+++ b/Asjad/scripts/training/train_tool_model.py
@@ -0,0 +1,26 @@
+import torch
+import os
+
+# Monkeypatch torch.load to disable weights_only enforcement by default
+# This is necessary because PyTorch 2.6+ defaults weights_only=True,
+# but Ultralytics 8.1.0 (legacy req) relies on the old behavior for loading yolov8s.pt
+original_load = torch.load
+def safe_load(*args, **kwargs):
+ if 'weights_only' not in kwargs:
+ kwargs['weights_only'] = False
+ return original_load(*args, **kwargs)
+torch.load = safe_load
+
+from ultralytics import YOLO
+
+def main():
+ print("Starting YOLOv8 training with patched torch.load...")
+ # Load model
+ model = YOLO('yolov8s.pt')
+
+ # Train
+ # data path must be correct relative to cwd
+ model.train(data='datasets/tools/data.yaml', epochs=50, imgsz=640)
+
+if __name__ == '__main__':
+ main()
diff --git a/Feature_Readme/Action_Server_Readme/README.md b/Feature_Readme/Action_Server_Readme/README.md
new file mode 100644
index 0000000..67582b2
--- /dev/null
+++ b/Feature_Readme/Action_Server_Readme/README.md
@@ -0,0 +1,19 @@
+Terminal 1
+```bash
+ros2 launch perception action_launch.py input_source:=robot
+```
+
+Terminal 2
+
+```bash
+cd src/perception/perception
+python3 action_vision_manager.py
+```
+
+Terminal 3
+
+```bash
+ros2 action send_goal /run_vision_pipeline my_robot_interfaces/action/RunVision "{duration_seconds: 20.0}" --feedback
+```
+
+So it also implements a lifecycle such that it keeps the Yolo and Pose node on Standby. Only when the action is sent does it start to publish the frames for the duration specified.
diff --git a/Feature_Readme/Table_Height_Readme/README.md b/Feature_Readme/Table_Height_Readme/README.md
new file mode 100644
index 0000000..8ccb6b8
--- /dev/null
+++ b/Feature_Readme/Table_Height_Readme/README.md
@@ -0,0 +1,22 @@
+### Running Table Height
+```code
+ros2 run table_height_predictor table_heigt
+```
+### Running Floor Detection
+```
+ros2 run table_height_predictor detect_floor
+```
+Although this node isnt useful to the table height but, it can help us to separate objects from the floor. This could be useful if one wishes to only
+segment the floor. Moreover, it also helps to estimate the angle of depression of the robot's camera.
+
+
+## Results
+
+- It uses Yolo World Model with SAM (Segmentation Anything Meta) using Zero Shot learning and prompt like white "standing desk" to segment the table.
+
+- It then uses RANSAC algorithim to identify the plane of the floor. It then draws a line between the line between the floor plane and the top of the
+desk.
+
+- It has an error rate of +-5cm to the actual height so it should be used with a safety margin. In the example above the actual height was 58cm.
+- This can work with varying heights of the table.
+
diff --git a/Feature_Readme/Table_Segmentation_Readme/README.md b/Feature_Readme/Table_Segmentation_Readme/README.md
new file mode 100644
index 0000000..8447cdf
--- /dev/null
+++ b/Feature_Readme/Table_Segmentation_Readme/README.md
@@ -0,0 +1,42 @@
+### Run Object Segmentation
+```bash
+ros2 run perception segment_object
+```
+
+### Run Table Segmentation
+
+Applies segmentation on the table and detects empty spaces.
+
+```bash
+ros2 run perception table_segmentation_node --ros-args -p mode:=test -p test_radius:=0.08
+```
+- `input_mode`: `robot`(default) or `realsense`
+- `mode`: `test` or `actual` (`actual`=listening to publisher msg, `test`=random test radius values default 0.07 or 7cm)
+- `safety_margin`: float, default `0.02`. (2cm)
+
+**Publish object radius:**
+
+If running in `mode:=actual`, to change radius of object:
+
+In another terminal, run:
+```bash
+ros2 topic pub --once /perception/detected_object_radius std_msgs/msg/Float32 "{data: }"
+```
+
+For example, could be 0.07.
+
+## Results
+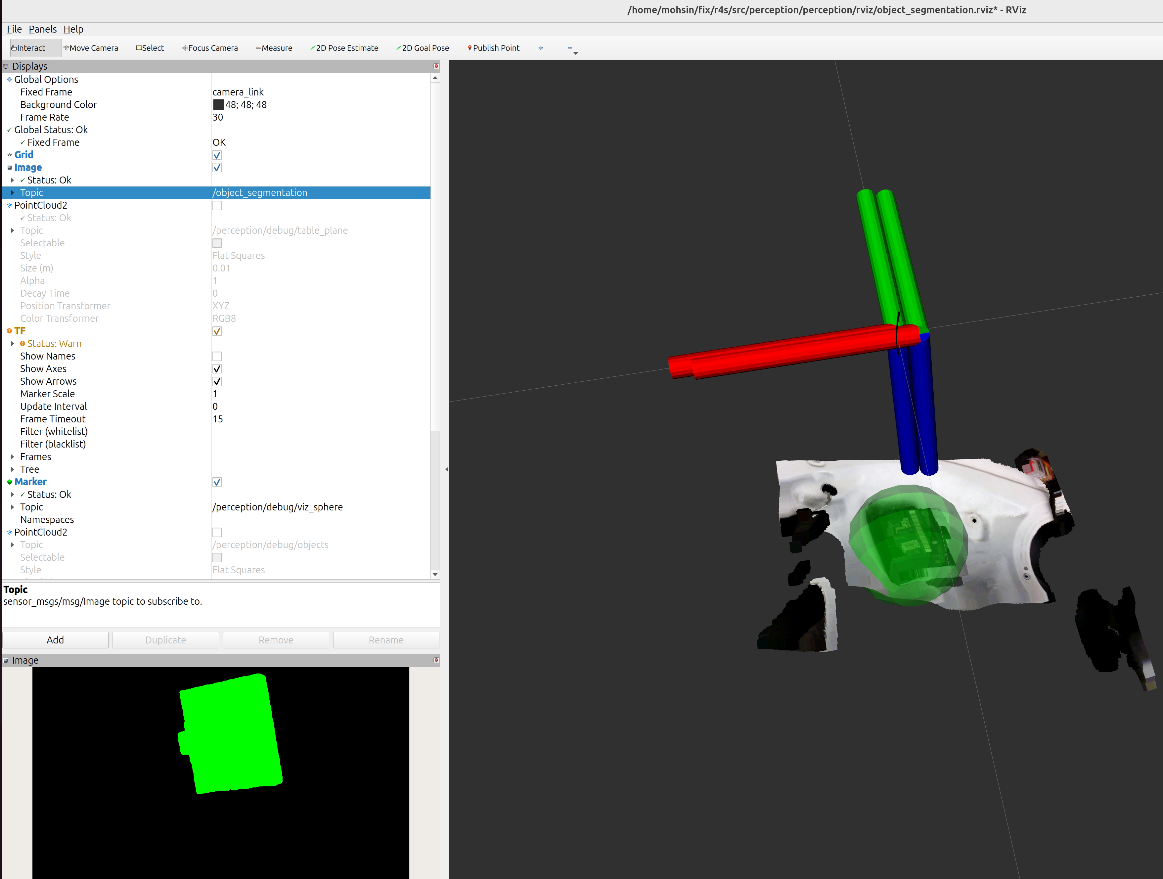
+The above image is highlighting segmentation of the car parts which is then estimated to a sphere. This float sphere radius will be then published as msg to table_segemntation node,
+which will look at empty space and decide whether this sphere is possible to be placed on the table without colliding with other objects.
+
+Object Segemntation->Sphere Approximation->(passed the radius)->Table_segementation
+
+**Place Object**
+
+The results of running the table segmentation node will look like:
+
+
+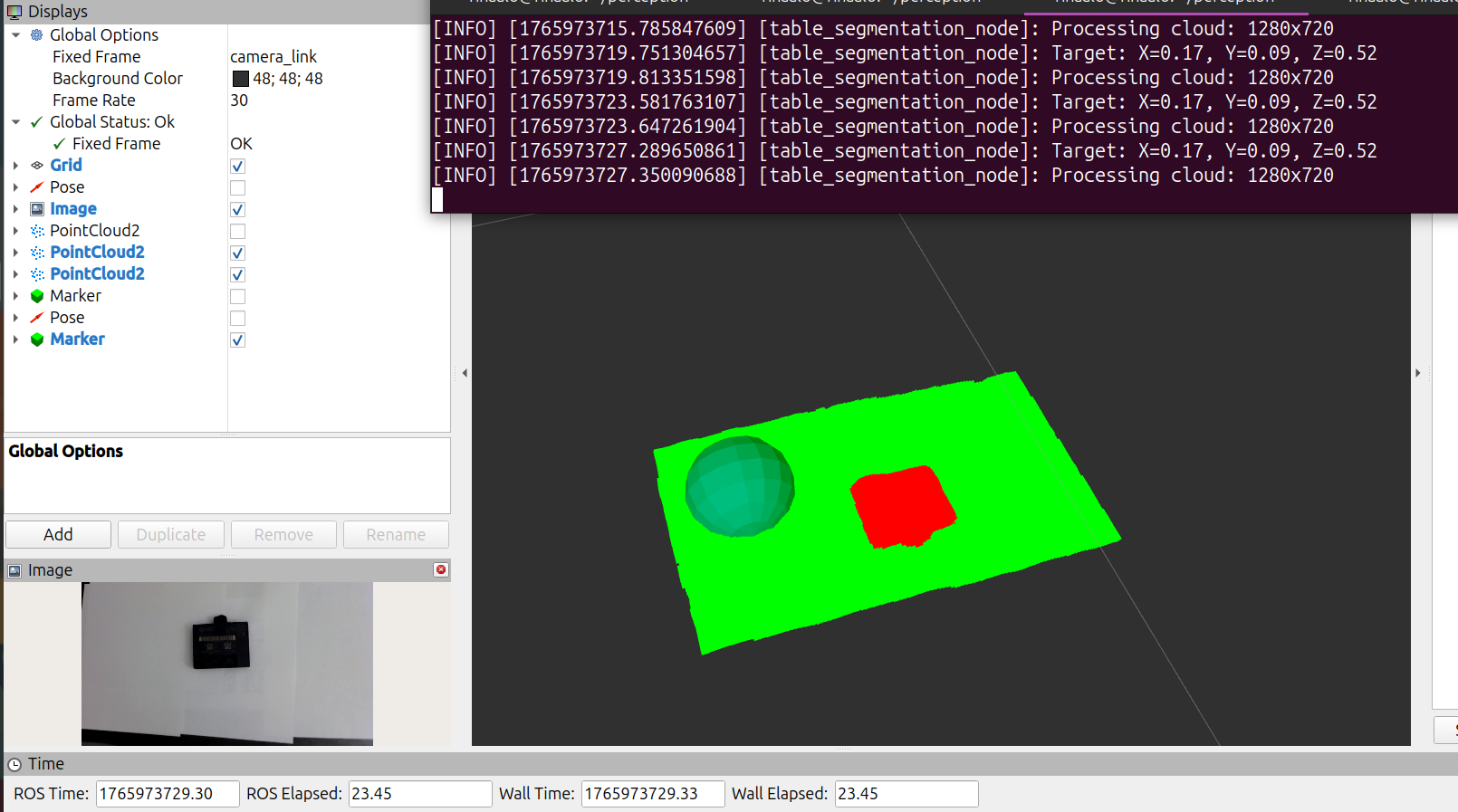
+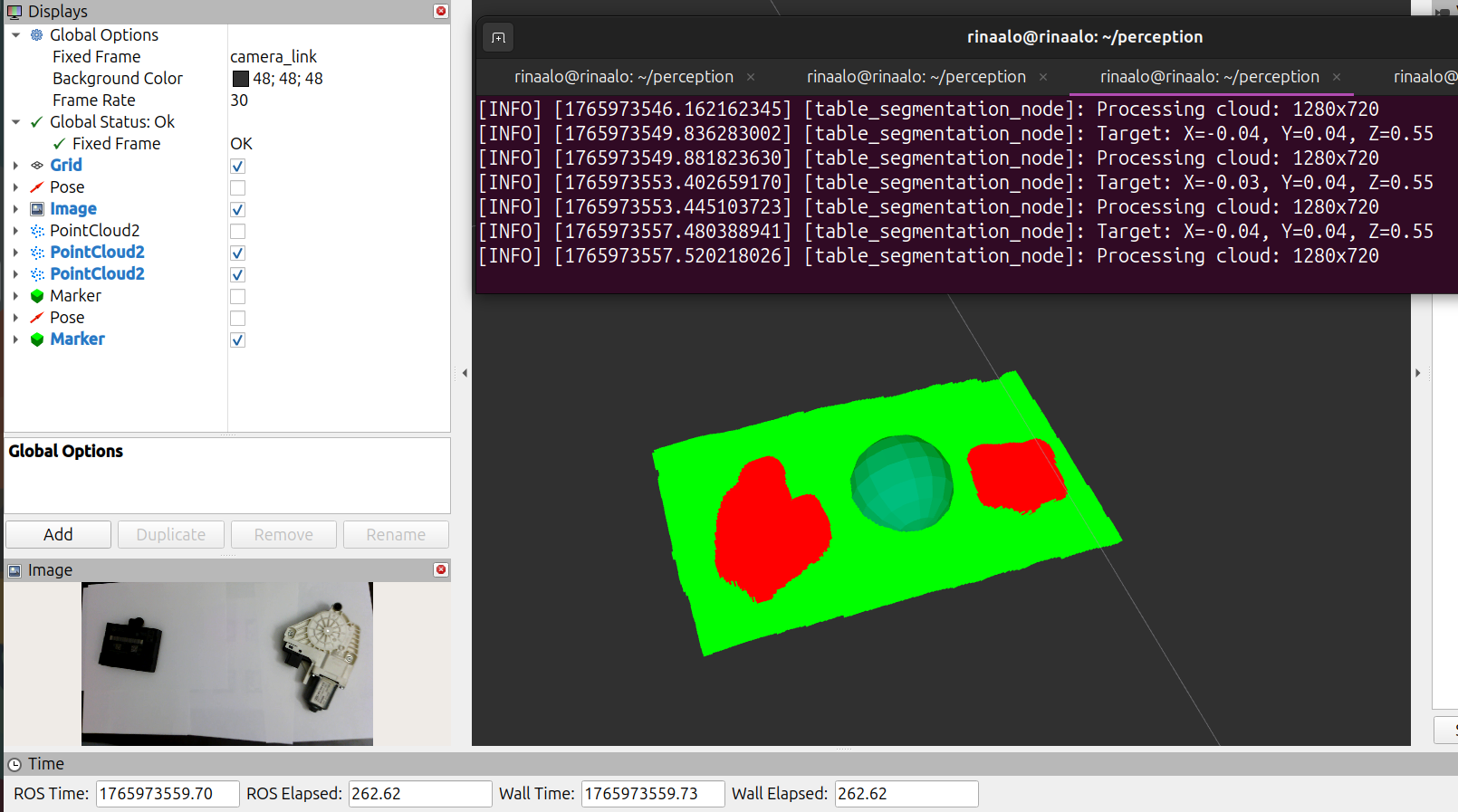
+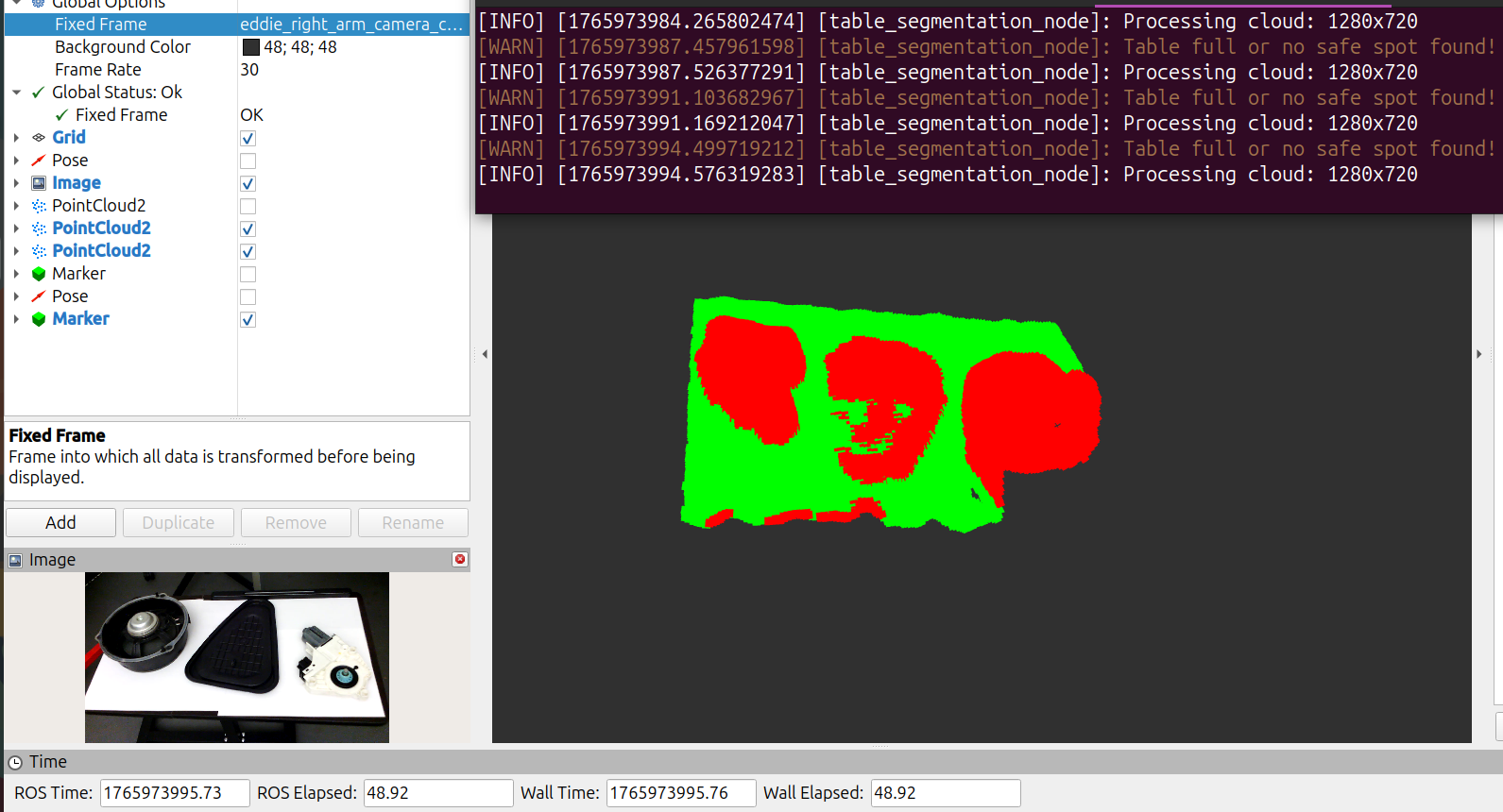
diff --git a/Feature_Readme/Tool_Detection/README.md b/Feature_Readme/Tool_Detection/README.md
new file mode 100644
index 0000000..3c77bd3
--- /dev/null
+++ b/Feature_Readme/Tool_Detection/README.md
@@ -0,0 +1,18 @@
+## Tool Detection Model Training
+
+We use a YOLOv8-small model trained on the specific tools dataset.
+
+### Training Command
+```bash
+yolo task=detect mode=train model=yolov8s.pt data=datasets/tools/data.yaml epochs=50 imgsz=640
+```
+
+### Metrics
+* **mAP@0.5**: 0.9813 (Target: > 0.95)
+* **Precision**: 0.9907
+* **Recall**: 0.9755
+
+To run the trained model:
+```bash
+ros2 launch perception tool_pipeline.launch.py model_path:=models/tools.pt
+```
diff --git a/Feature_Readme/ignore.html b/Feature_Readme/ignore.html
new file mode 100644
index 0000000..8b13789
--- /dev/null
+++ b/Feature_Readme/ignore.html
@@ -0,0 +1 @@
+
diff --git a/Plan for Perception Team.pdf b/Plan for Perception Team.pdf
deleted file mode 100644
index 4faca85..0000000
Binary files a/Plan for Perception Team.pdf and /dev/null differ
diff --git a/README.md b/README.md
index ea56045..81b0966 100644
--- a/README.md
+++ b/README.md
@@ -1,3 +1,11 @@
+# Release_3 Feature Readmes
+- [Table_Segmentation](https://github.com/Robots4Sustainability/perception/tree/dev/Feature_Readme/Table_Segmentation_Readme)
+- [Table_Height](https://github.com/Robots4Sustainability/perception/blob/dev/Feature_Readme/Table_Height_Readme/README.md)
+- [Action_Server](https://github.com/Robots4Sustainability/perception/blob/dev/Feature_Readme/Action_Server_Readme/README.md)
+- [Tool_Detection](https://github.com/Robots4Sustainability/perception/blob/dev/Feature_Readme/Tool_Detection/README.md)
+
+---
+
# Vision-Based Object Detection and Pose Estimation Framework
This repository provides a complete vision pipeline that supports object detection with YOLOv8 and 6D pose estimation. The project is structured to support fine-tuning, inference, and integration with robotic systems using ROS 2.
@@ -8,7 +16,6 @@ This repository provides a complete vision pipeline that supports object detecti
---
## Table of Contents
-
- [Cloning the Repository](#cloning-the-repository)
- [Project Structure](#project-structure)
- [Pose Estimation Setup](#pose-estimation-setup)
diff --git a/no_place.png b/no_place.png
new file mode 100644
index 0000000..d643b10
Binary files /dev/null and b/no_place.png differ
diff --git a/place_object_1.png b/place_object_1.png
new file mode 100644
index 0000000..8e6e390
Binary files /dev/null and b/place_object_1.png differ
diff --git a/place_object_2.png b/place_object_2.png
new file mode 100644
index 0000000..6ad8aa4
Binary files /dev/null and b/place_object_2.png differ
diff --git a/requirements.txt b/requirements.txt
index 304cb77..862d048 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,3 +1,8 @@
numpy==1.26.4 ; python_version >= "3.12"
transforms3d==0.4.2 ; python_version >= "3.12"
ultralytics==8.3.236 ; python_version >= "3.12"
+open3d==0.19.0 ; python_version >= "3.12"
+empy==4.2 ; python_version >= "3.12"
+lark-parser==0.12.0 ; python_version >= "3.12"
+setuptools==80.9.0 ; python_version >= "3.12"
+catkin_pkg==1.1.0 ; python_version >= "3.12"
diff --git a/results/object_segmentation.png b/results/object_segmentation.png
new file mode 100644
index 0000000..97a5661
Binary files /dev/null and b/results/object_segmentation.png differ
diff --git a/src/my_robot_interfaces/CMakeLists.txt b/src/my_robot_interfaces/CMakeLists.txt
new file mode 100644
index 0000000..a25777e
--- /dev/null
+++ b/src/my_robot_interfaces/CMakeLists.txt
@@ -0,0 +1,19 @@
+cmake_minimum_required(VERSION 3.8)
+project(my_robot_interfaces)
+
+if(CMAKE_COMPILER_IS_GNUCXX OR CMAKE_CXX_COMPILER_ID MATCHES "Clang")
+ add_compile_options(-Wall -Wextra -Wpedantic)
+endif()
+
+find_package(ament_cmake REQUIRED)
+find_package(rosidl_default_generators REQUIRED)
+# 1. ADD THIS LINE:
+find_package(geometry_msgs REQUIRED)
+
+rosidl_generate_interfaces(${PROJECT_NAME}
+ "action/RunVision.action"
+ # 2. ADD THIS DEPENDENCIES SECTION:
+ DEPENDENCIES geometry_msgs
+)
+
+ament_package()
\ No newline at end of file
diff --git a/src/my_robot_interfaces/action/RunVision.action b/src/my_robot_interfaces/action/RunVision.action
new file mode 100644
index 0000000..a475110
--- /dev/null
+++ b/src/my_robot_interfaces/action/RunVision.action
@@ -0,0 +1,11 @@
+# Goal: What we send to start the task
+float32 duration_seconds
+---
+# Result: What we get back when finished/canceled
+bool success
+string message
+geometry_msgs/PoseStamped pose
+---
+# Feedback: What we receive continuously while running
+float32 time_elapsed
+string status
\ No newline at end of file
diff --git a/src/my_robot_interfaces/package.xml b/src/my_robot_interfaces/package.xml
new file mode 100644
index 0000000..a55c4d5
--- /dev/null
+++ b/src/my_robot_interfaces/package.xml
@@ -0,0 +1,19 @@
+
+ my_robot_interfaces
+ 0.0.0
+ Custom interfaces for my robot
+ user
+ TODO
+
+ ament_cmake
+
+ rosidl_default_generators
+ rosidl_default_runtime
+ rosidl_interface_packages
+ geometry_msgs
+ action_msgs
+
+
+ ament_cmake
+
+
\ No newline at end of file
diff --git a/src/perception/launch/action_launch.py b/src/perception/launch/action_launch.py
new file mode 100644
index 0000000..feab7f1
--- /dev/null
+++ b/src/perception/launch/action_launch.py
@@ -0,0 +1,51 @@
+from launch import LaunchDescription
+from launch.actions import DeclareLaunchArgument
+from launch.substitutions import LaunchConfiguration
+from launch_ros.actions import Node
+
+def generate_launch_description():
+ """Generates a launch description that can switch between robot and realsense inputs."""
+
+ # 1. Declare a launch argument 'input_source'
+ # This creates a variable that you can set from the command line.
+ # We'll set 'realsense' as the default value.
+ input_source_arg = DeclareLaunchArgument(
+ 'input_source',
+ default_value='realsense',
+ description='Input source for perception nodes. Can be "realsense" or "robot".'
+ )
+
+ # 2. YOLO Node
+ yolo_node = Node(
+ package='perception',
+ executable='action_yolo_node',
+ name='action_yolo_node',
+ output='screen',
+ parameters=[{
+ # Use the value of the 'input_source' launch argument here
+ 'input_mode': LaunchConfiguration('input_source'),
+ 'model_type': 'fine_tuned',
+ 'conf_threshold': 0.6,
+ 'device': 'cuda'
+ }]
+ )
+
+ # 3. Pose Node
+ pose_node = Node(
+ package='perception',
+ executable='action_pose_node',
+ name='action_pose_node',
+ output='screen',
+ parameters=[{
+ # Use the same 'input_source' launch argument here
+ 'input_mode': LaunchConfiguration('input_source')
+ }]
+ )
+
+
+ # Return the LaunchDescription, including the argument and all nodes
+ return LaunchDescription([
+ input_source_arg,
+ yolo_node,
+ pose_node,
+ ])
diff --git a/src/perception/perception/action_pose_pca.py b/src/perception/perception/action_pose_pca.py
new file mode 100644
index 0000000..fef1b2a
--- /dev/null
+++ b/src/perception/perception/action_pose_pca.py
@@ -0,0 +1,232 @@
+import rclpy
+from rclpy.node import Node
+from sensor_msgs.msg import PointCloud2, PointField, Image
+from vision_msgs.msg import Detection2DArray
+from geometry_msgs.msg import PoseStamped, TransformStamped
+from std_msgs.msg import Header
+
+import message_filters
+from cv_bridge import CvBridge
+import numpy as np
+import struct
+import sensor_msgs_py.point_cloud2 as pc2
+from transforms3d.quaternions import mat2quat
+from tf2_ros import TransformBroadcaster
+from std_srvs.srv import SetBool # <-- NEW: Service Import
+
+
+class PointCloudCropperNode(Node):
+ def __init__(self):
+ super().__init__('pointcloud_cropper_node')
+
+ self.bridge = CvBridge()
+
+ # --- PARAMETERS ---
+ self.declare_parameter('input_mode', 'realsense')
+ input_mode = self.get_parameter('input_mode').get_parameter_value().string_value
+
+ # Determine topics based on mode
+ if input_mode == 'robot':
+ self.pc_topic = '/camera/depth/color/points'
+ self.img_topic = '/camera/color/image_raw'
+ elif input_mode == 'realsense':
+ self.pc_topic = '/camera/camera/depth/color/points'
+ self.img_topic = '/camera/camera/color/image_raw'
+ else:
+ self.get_logger().warn(f"Unknown input_mode '{input_mode}', defaulting to 'realsense'")
+ self.pc_topic = '/camera/camera/depth/color/points'
+ self.img_topic = '/camera/camera/color/image_raw'
+
+ self.get_logger().info(f"Using input mode: '{input_mode}' with topics: {self.pc_topic}, {self.img_topic}")
+
+ # --- 1. SETUP PUBLISHERS (Always Active) ---
+ self.pc_pub = self.create_publisher(PointCloud2, '/cropped_pointcloud', 10)
+ self.pose_pub = self.create_publisher(PoseStamped, '/object_pose', 10)
+ self.tf_broadcaster = TransformBroadcaster(self)
+
+ # --- 2. OPTIMIZATION: INITIALIZE STATE ---
+ # We do NOT create subscribers or synchronizers here.
+ self.pc_sub = None
+ self.img_sub = None
+ self.det_sub = None
+ self.ts = None
+ self.is_active = False
+
+ # --- 3. CREATE TOGGLE SERVICE ---
+ self.srv = self.create_service(SetBool, 'toggle_pose', self.toggle_callback)
+
+ self.get_logger().info('PointCloud Cropper Node Ready in STANDBY mode.')
+ self.get_logger().info('Send "True" to /toggle_pose to start synchronization.')
+
+ def toggle_callback(self, request, response):
+ """Service to Turn Processing ON or OFF"""
+ if request.data: # ENABLE
+ if not self.is_active:
+ self.get_logger().info("ACTIVATING: Starting Time Synchronizer...")
+
+ # Create the message filters
+ self.pc_sub = message_filters.Subscriber(self, PointCloud2, self.pc_topic)
+ self.img_sub = message_filters.Subscriber(self, Image, self.img_topic)
+ self.det_sub = message_filters.Subscriber(self, Detection2DArray, '/detections')
+
+ # Create the Synchronizer
+ self.ts = message_filters.ApproximateTimeSynchronizer(
+ [self.pc_sub, self.det_sub, self.img_sub],
+ queue_size=10,
+ slop=0.1
+ )
+ self.ts.registerCallback(self.sync_callback)
+
+ self.is_active = True
+ response.message = "Pose Node Activated"
+ response.success = True
+ else:
+ response.message = "Already Active"
+ response.success = True
+
+ else: # DISABLE
+ if self.is_active:
+ self.get_logger().info("DEACTIVATING: Destroying Synchronizer to save CPU...")
+
+ # message_filters.Subscriber wrappers don't have a clean 'destroy' method
+ # exposed easily, but destroying the underlying subscription works.
+ # However, dropping the reference to the synchronizer stops the callbacks.
+
+ # Best practice: explicitly destroy the underlying rclpy subscriptions
+ if self.pc_sub: self.destroy_subscription(self.pc_sub.sub)
+ if self.img_sub: self.destroy_subscription(self.img_sub.sub)
+ if self.det_sub: self.destroy_subscription(self.det_sub.sub)
+
+ self.pc_sub = None
+ self.img_sub = None
+ self.det_sub = None
+ self.ts = None
+
+ self.is_active = False
+ response.message = "Pose Node Deactivated"
+ response.success = True
+ else:
+ response.message = "Already Inactive"
+ response.success = True
+
+ return response
+
+ def sync_callback(self, cloud_msg, detection_msg, image_msg):
+ # This callback logic remains EXACTLY the same as your original code
+ try:
+ color_image = self.bridge.imgmsg_to_cv2(image_msg, desired_encoding='bgr8')
+ except Exception as e:
+ self.get_logger().error(f"Image conversion error: {e}")
+ return
+
+ pc_width = cloud_msg.width
+ pc_height = cloud_msg.height
+
+ cloud_points = np.array([
+ [x, y, z]
+ for x, y, z in pc2.read_points(cloud_msg, field_names=("x", "y", "z"), skip_nans=False)
+ ]).reshape((pc_height, pc_width, 3))
+
+ all_colored_points = []
+
+ for idx, detection in enumerate(detection_msg.detections):
+ detected_class = detection.results[0].hypothesis.class_id
+
+ cx = int(detection.bbox.center.position.x)
+ cy = int(detection.bbox.center.position.y)
+ w = int(detection.bbox.size_x)
+ h = int(detection.bbox.size_y)
+
+ xmin = max(cx - w // 2, 0)
+ xmax = min(cx + w // 2, pc_width)
+ ymin = max(cy - h // 2, 0)
+ ymax = min(cy + h // 2, pc_height)
+
+ cropped_points = cloud_points[ymin:ymax, xmin:xmax, :].reshape(-1, 3)
+ cropped_colors = color_image[ymin:ymax, xmin:xmax, :].reshape(-1, 3)
+
+ valid_mask = ~np.isnan(cropped_points).any(axis=1)
+ cropped_points = cropped_points[valid_mask]
+ cropped_colors = cropped_colors[valid_mask]
+
+ for pt, color in zip(cropped_points, cropped_colors):
+ x, y, z = pt
+ b, g, r = color
+ rgb = struct.unpack('f', struct.pack('I', (int(r) << 16) | (int(g) << 8) | int(b)))[0]
+ all_colored_points.append([x, y, z, rgb])
+
+ self.get_logger().info(
+ f"Cropped '{detected_class}' object {idx}: [{xmin}:{xmax}, {ymin}:{ymax}] -> {len(cropped_points)} valid points"
+ )
+
+ if len(cropped_points) >= 3:
+ centroid = np.mean(cropped_points, axis=0)
+ centered = cropped_points - centroid
+ _, _, vh = np.linalg.svd(centered, full_matrices=False)
+ R = vh.T
+
+ T = np.eye(4)
+ T[:3, :3] = R
+ T[:3, 3] = centroid
+
+ quat_wxyz = mat2quat(T[:3, :3])
+ quat = [quat_wxyz[1], quat_wxyz[2], quat_wxyz[3], quat_wxyz[0]]
+
+ pose_msg = PoseStamped()
+ pose_msg.header.stamp = self.get_clock().now().to_msg()
+ pose_msg.header.frame_id = cloud_msg.header.frame_id
+ pose_msg.pose.position.x = float(centroid[0])
+ pose_msg.pose.position.y = float(centroid[1])
+ pose_msg.pose.position.z = float(centroid[2])
+ pose_msg.pose.orientation.x = float(quat[0])
+ pose_msg.pose.orientation.y = float(quat[1])
+ pose_msg.pose.orientation.z = float(quat[2])
+ pose_msg.pose.orientation.w = float(quat[3])
+
+ self.pose_pub.publish(pose_msg)
+
+ t = TransformStamped()
+ t.header.stamp = self.get_clock().now().to_msg()
+ t.header.frame_id = cloud_msg.header.frame_id
+ t.child_frame_id = f'object_frame_{idx}'
+ t.transform.translation.x = float(centroid[0])
+ t.transform.translation.y = float(centroid[1])
+ t.transform.translation.z = float(centroid[2])
+ t.transform.rotation.x = float(quat[0])
+ t.transform.rotation.y = float(quat[1])
+ t.transform.rotation.z = float(quat[2])
+ t.transform.rotation.w = float(quat[3])
+
+ self.tf_broadcaster.sendTransform(t)
+ self.get_logger().info(f"Published pose and TF for '{detected_class}' object {idx}")
+
+ if all_colored_points:
+ header = Header()
+ header.stamp = self.get_clock().now().to_msg()
+ header.frame_id = cloud_msg.header.frame_id
+
+ fields = [
+ PointField(name='x', offset=0, datatype=PointField.FLOAT32, count=1),
+ PointField(name='y', offset=4, datatype=PointField.FLOAT32, count=1),
+ PointField(name='z', offset=8, datatype=PointField.FLOAT32, count=1),
+ PointField(name='rgb', offset=12, datatype=PointField.FLOAT32, count=1),
+ ]
+
+ cropped_pc = pc2.create_cloud(header, fields, all_colored_points)
+ self.pc_pub.publish(cropped_pc)
+
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = PointCloudCropperNode()
+ try:
+ rclpy.spin(node)
+ except KeyboardInterrupt:
+ pass
+ finally:
+ node.destroy_node()
+ rclpy.shutdown()
+
+
+if __name__ == '__main__':
+ main()
\ No newline at end of file
diff --git a/src/perception/perception/action_vision_manager.py b/src/perception/perception/action_vision_manager.py
new file mode 100644
index 0000000..fba49b3
--- /dev/null
+++ b/src/perception/perception/action_vision_manager.py
@@ -0,0 +1,249 @@
+import time
+import rclpy
+from rclpy.node import Node
+from rclpy.action import ActionServer, CancelResponse, GoalResponse
+from rclpy.callback_groups import ReentrantCallbackGroup
+from rclpy.executors import MultiThreadedExecutor
+from std_srvs.srv import SetBool
+from geometry_msgs.msg import PoseStamped
+from rclpy.qos import QoSProfile, ReliabilityPolicy, HistoryPolicy
+import statistics
+
+from my_robot_interfaces.action import RunVision
+
+class VisionManager(Node):
+ def __init__(self):
+ super().__init__('vision_manager')
+
+ # We use a ReentrantCallbackGroup to allow the Action Loop and the
+ # Subscriber Callback to run in parallel on the MultiThreadedExecutor
+ self.group = ReentrantCallbackGroup()
+
+ # --- 1. ACTION SERVER ---
+ self._action_server = ActionServer(
+ self,
+ RunVision,
+ 'run_vision_pipeline',
+ execute_callback=self.execute_callback,
+ goal_callback=self.goal_callback,
+ cancel_callback=self.cancel_callback,
+ callback_group=self.group
+ )
+
+ # --- 2. SERVICE CLIENTS (Talks to YOLO and Pose nodes) ---
+ self.yolo_client = self.create_client(SetBool, '/toggle_yolo', callback_group=self.group)
+ self.pose_client = self.create_client(SetBool, '/toggle_pose', callback_group=self.group)
+
+ # --- 3. STATE MANAGEMENT ---
+ self.captured_poses = []
+ self.collection_active = False # The "Gate" flag
+
+ # --- 4. SUBSCRIBER ---
+ # Reliable QoS ensures we don't miss packets if they are sent correctly
+ qos_profile = QoSProfile(
+ reliability=ReliabilityPolicy.RELIABLE,
+ history=HistoryPolicy.KEEP_LAST,
+ depth=10
+ )
+
+ self.pose_sub = self.create_subscription(
+ PoseStamped,
+ '/object_pose',
+ self.pose_callback,
+ qos_profile,
+ callback_group=self.group
+ )
+
+ self.vis_pub = self.create_publisher(
+ PoseStamped,
+ '/visualized_average_pose',
+ 10
+ )
+
+ self.get_logger().info("Vision Manager Ready. Initializing sensors to OFF state...")
+
+ # --- 5. INITIAL CLEANUP TIMER ---
+ # We run this ONCE to ensure sensors start in a clean "Standby" state.
+ self.init_timer = self.create_timer(1.0, self.initial_cleanup)
+
+ async def initial_cleanup(self):
+ """Forces connected nodes to sleep on startup so we start fresh."""
+
+ # CRITICAL FIX: Cancel the timer so this function NEVER runs again
+ if self.init_timer:
+ self.init_timer.cancel()
+ self.init_timer = None
+
+ self.get_logger().info("System Startup: Ensuring sensors are in STANDBY mode...")
+ await self.set_nodes_state(False)
+
+ def pose_callback(self, msg):
+ """
+ Only process data if the Action is running (collection_active is True).
+ Otherwise, ignore the noise to prevent log spam and dirty data.
+ """
+ if not self.collection_active:
+ return # IGNORE BACKGROUND NOISE
+
+ self.get_logger().info(f"Received Pose: x={msg.pose.position.x:.2f}")
+ self.captured_poses.append(msg)
+
+ def goal_callback(self, goal_request):
+ return GoalResponse.ACCEPT
+
+ def cancel_callback(self, goal_handle):
+ return CancelResponse.ACCEPT
+
+ async def execute_callback(self, goal_handle):
+ self.get_logger().info('Goal Received. Opening the Gate...')
+
+ # 1. Reset Buffer for new run
+ self.captured_poses = []
+ result = RunVision.Result()
+ feedback = RunVision.Feedback()
+ duration = goal_handle.request.duration_seconds
+
+ # 2. Wake up nodes
+ if not await self.set_nodes_state(True):
+ goal_handle.abort()
+ result.success = False
+ result.message = "Failed to wake sensors"
+ return result
+
+ # 3. Enable Collection (Open Gate)
+ self.collection_active = True
+
+ # 4. Run Timer Loop
+ start_time = time.time()
+ feedback.status = "Collecting Poses"
+
+ while (time.time() - start_time) < duration:
+ # Check Cancel
+ if goal_handle.is_cancel_requested:
+ self.collection_active = False # Close gate
+ await self.set_nodes_state(False)
+ goal_handle.canceled()
+ result.success = False
+ result.message = "Canceled"
+ return result
+
+ # Publish Feedback
+ feedback.time_elapsed = time.time() - start_time
+ goal_handle.publish_feedback(feedback)
+ time.sleep(0.1)
+
+ # 5. Disable Collection (Close Gate)
+ self.collection_active = False
+
+ # 6. Shut Down Sensors
+ await self.set_nodes_state(False)
+
+ # 7. Process Data
+ if len(self.captured_poses) > 0:
+ final_pose = self.calculate_average_pose(self.captured_poses)
+
+ # Publish to RViz so we can see the result
+ self.vis_pub.publish(final_pose)
+ self.get_logger().info("Published final median pose to /visualized_average_pose")
+
+ result.success = True
+ result.message = f"Success. Calculated Median of {len(self.captured_poses)} frames."
+ result.pose = final_pose
+ goal_handle.succeed()
+ else:
+ result.success = False
+ result.message = "Time finished, but no objects were detected."
+ self.get_logger().warn("Finished with 0 poses.")
+ goal_handle.abort()
+
+ return result
+
+ def calculate_average_pose(self, poses):
+ """
+ Calculates the 'Truncated Mean' (Interquartile Mean).
+ 1. Sorts data.
+ 2. Removes top 25% and bottom 25% (outliers).
+ 3. Averages the remaining middle 50%.
+ """
+ if not poses: return PoseStamped()
+
+ # Helper function to get truncated mean of a list of numbers
+ def get_truncated_mean(data):
+ if not data: return 0.0
+ n = len(data)
+ if n < 3: return statistics.mean(data) # Too few to truncate
+
+ sorted_data = sorted(data)
+ # Remove top and bottom 25%
+ cut_amount = int(n * 0.25)
+ # Slice the middle
+ middle_data = sorted_data[cut_amount : n - cut_amount]
+
+ return statistics.mean(middle_data)
+
+ # 1. Calculate Truncated Mean for Position
+ final_x = get_truncated_mean([p.pose.position.x for p in poses])
+ final_y = get_truncated_mean([p.pose.position.y for p in poses])
+ final_z = get_truncated_mean([p.pose.position.z for p in poses])
+
+ # 2. Find the orientation from the pose closest to this new calculated position
+ # (We still shouldn't average quaternions simply, so we pick the best representative)
+ best_idx = 0
+ min_dist = float('inf')
+
+ for i, p in enumerate(poses):
+ dist = (p.pose.position.x - final_x)**2 + \
+ (p.pose.position.y - final_y)**2 + \
+ (p.pose.position.z - final_z)**2
+ if dist < min_dist:
+ min_dist = dist
+ best_idx = i
+
+ # 3. Construct Final Pose
+ final_pose = PoseStamped()
+ final_pose.header = poses[best_idx].header
+ final_pose.header.stamp = self.get_clock().now().to_msg()
+
+ final_pose.pose.position.x = final_x
+ final_pose.pose.position.y = final_y
+ final_pose.pose.position.z = final_z
+ final_pose.pose.orientation = poses[best_idx].pose.orientation
+
+ return final_pose
+
+ async def set_nodes_state(self, active: bool):
+ """Helper to call services asynchronously."""
+ req = SetBool.Request()
+ req.data = active
+
+ # Small timeout check to avoid blocking if nodes aren't up
+ if not self.yolo_client.wait_for_service(timeout_sec=1.0):
+ self.get_logger().warn("YOLO Service not available")
+ return False
+ if not self.pose_client.wait_for_service(timeout_sec=1.0):
+ self.get_logger().warn("Pose Service not available")
+ return False
+
+ future_yolo = self.yolo_client.call_async(req)
+ future_pose = self.pose_client.call_async(req)
+
+ try:
+ await future_yolo
+ await future_pose
+ return True
+ except Exception as e:
+ self.get_logger().error(f"Service toggle failed: {e}")
+ return False
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = VisionManager()
+
+ # CRITICAL: MultiThreadedExecutor is required for Callbacks to run
+ # while the Action Loop is active.
+ executor = MultiThreadedExecutor()
+ rclpy.spin(node, executor=executor)
+ rclpy.shutdown()
+
+if __name__ == '__main__':
+ main()
\ No newline at end of file
diff --git a/src/perception/perception/action_yolo_object_detection.py b/src/perception/perception/action_yolo_object_detection.py
new file mode 100644
index 0000000..303069f
--- /dev/null
+++ b/src/perception/perception/action_yolo_object_detection.py
@@ -0,0 +1,197 @@
+import rclpy
+from rclpy.node import Node
+from sensor_msgs.msg import Image
+from vision_msgs.msg import Detection2DArray, Detection2D, ObjectHypothesisWithPose
+from cv_bridge import CvBridge
+from ultralytics import YOLO
+from ultralytics.engine.results import Boxes
+import torch
+import cv2
+import os
+from ament_index_python.packages import get_package_share_directory
+from pathlib import Path
+from std_srvs.srv import SetBool # Required for the toggle service
+
+def get_package_name_from_path(file_path):
+ """Dynamically find the package name from the file path."""
+ p = Path(file_path)
+ try:
+ package_parts = p.parts[p.parts.index('site-packages') + 1:]
+ return package_parts[0]
+ except ValueError:
+ # Fallback if not installed in site-packages (e.g. running from source)
+ return 'perception'
+
+class YoloDetectorNode(Node):
+ def __init__(self):
+ super().__init__('yolo_detector_node')
+ self.package_name = get_package_name_from_path(__file__)
+ self.bridge = CvBridge()
+
+ # --- PARAMETERS ---
+ self.declare_parameter('model_type', 'default')
+ self.declare_parameter('input_mode', 'realsense')
+ self.declare_parameter('model_path', '')
+ self.declare_parameter('conf_threshold', 0.6)
+ self.declare_parameter('device', '')
+ self.declare_parameter('class_names', [])
+
+ model_type = self.get_parameter('model_type').get_parameter_value().string_value
+ input_mode = self.get_parameter('input_mode').get_parameter_value().string_value
+ explicit_model_path = self.get_parameter('model_path').get_parameter_value().string_value
+ self.conf_threshold = self.get_parameter('conf_threshold').get_parameter_value().double_value
+ device_param = self.get_parameter('device').get_parameter_value().string_value
+ class_names_param = self.get_parameter('class_names').get_parameter_value().string_array_value
+
+ # --- MODEL PATH LOGIC ---
+ if explicit_model_path:
+ model_path = explicit_model_path
+ else:
+ try:
+ package_share_directory = get_package_share_directory(self.package_name)
+ if model_type == 'fine_tuned':
+ model_path = os.path.join(package_share_directory, 'models', 'fine_tuned.pt')
+ else:
+ model_path = os.path.join(package_share_directory, 'models', 'yolov8n.pt')
+ except Exception:
+ # Fallback for when running locally/testing without full install
+ model_path = 'yolov8n.pt'
+ self.get_logger().warn(f"Could not find package share directory. Defaulting model path to: {model_path}")
+
+ self.get_logger().info(f"Using model type '{model_type}' from: {model_path}")
+
+ # --- 1. LOAD MODEL (Heavy operation, done ONCE at startup) ---
+ self.get_logger().info("Loading YOLO model... (This stays in RAM)")
+ try:
+ if device_param:
+ self.model = YOLO(model_path)
+ try:
+ self.model.to(device_param)
+ self.get_logger().info(f"Model moved to device: {device_param}")
+ except Exception as e:
+ self.get_logger().warn(f"Failed to move model to device '{device_param}': {e}")
+ else:
+ self.model = YOLO(model_path)
+ except Exception as e:
+ self.get_logger().error(f"Failed to load YOLO model from '{model_path}': {e}")
+ raise
+
+ # Optional override for class names
+ self.class_names = None
+ if class_names_param:
+ self.class_names = list(class_names_param)
+
+ # --- 2. DETERMINE TOPIC (Save for later) ---
+ if input_mode == 'robot':
+ self.image_topic = '/camera/color/image_raw'
+ elif input_mode == 'realsense':
+ self.image_topic = '/camera/camera/color/image_raw'
+ else:
+ self.get_logger().warn(f"Unknown input_mode '{input_mode}', defaulting to 'realsense'")
+ self.image_topic = '/camera/camera/color/image_raw'
+
+ # --- 3. SETUP PUBLISHERS ---
+ self.annotated_image_pub = self.create_publisher(Image, '/annotated_image', 10)
+ self.detection_pub = self.create_publisher(Detection2DArray, '/detections', 10)
+
+ # --- 4. OPTIMIZATION / SOFT LIFECYCLE ---
+ # We do NOT subscribe here. We start in "Standby" mode.
+ self.image_sub = None
+
+ # Create the service to wake up the node
+ self.srv = self.create_service(SetBool, 'toggle_yolo', self.toggle_callback)
+
+ self.get_logger().info(f"YOLOv8 Node Initialized in STANDBY mode.")
+ self.get_logger().info(f"Send 'True' to service '/toggle_yolo' to start processing {self.image_topic}")
+
+ def toggle_callback(self, request, response):
+ """Service callback to Turn processing ON or OFF"""
+ if request.data: # REQUEST: ENABLE
+ if self.image_sub is None:
+ self.get_logger().info(f"ACTIVATING: Subscribing to {self.image_topic}...")
+ self.image_sub = self.create_subscription(
+ Image, self.image_topic, self.image_callback, 10
+ )
+ response.message = "YOLO Activated"
+ response.success = True
+ else:
+ response.message = "Already Active"
+ response.success = True
+ else: # REQUEST: DISABLE
+ if self.image_sub is not None:
+ self.get_logger().info("DEACTIVATING: Unsubscribing to save CPU...")
+ self.destroy_subscription(self.image_sub)
+ self.image_sub = None
+ response.message = "YOLO Deactivated"
+ response.success = True
+ else:
+ response.message = "Already Inactive"
+ response.success = True
+ return response
+
+ def image_callback(self, msg):
+ """This function ONLY runs when the node is Activated"""
+ try:
+ cv_image = self.bridge.imgmsg_to_cv2(msg, 'bgr8')
+ except Exception as e:
+ self.get_logger().error(f'Image conversion error: {e}')
+ return
+
+ # Inference
+ results = self.model(cv_image, verbose=False) # verbose=False keeps terminal clean
+ detection_array_msg = Detection2DArray()
+ detection_array_msg.header = msg.header
+
+ for result in results:
+ filtered_boxes = [box for box in result.boxes if float(box.conf) >= self.conf_threshold]
+
+ # 1. Publish Annotated Image
+ annotated_image = result.plot()
+ try:
+ annotated_msg = self.bridge.cv2_to_imgmsg(annotated_image, encoding='bgr8')
+ annotated_msg.header = msg.header
+ self.annotated_image_pub.publish(annotated_msg)
+ except Exception as e:
+ self.get_logger().error(f'Annotated image conversion error: {e}')
+
+ # 2. Publish Detections
+ for box in filtered_boxes:
+ detection_msg = Detection2D()
+ detection_msg.header = msg.header
+
+ hypothesis = ObjectHypothesisWithPose()
+ try:
+ if self.class_names and int(box.cls) < len(self.class_names):
+ class_name = self.class_names[int(box.cls)]
+ else:
+ class_name = self.model.names[int(box.cls)]
+ except Exception:
+ class_name = str(int(box.cls))
+
+ hypothesis.hypothesis.class_id = class_name
+ hypothesis.hypothesis.score = float(box.conf)
+ detection_msg.results.append(hypothesis)
+
+ xywh = box.xywh.cpu().numpy().flatten()
+ detection_msg.bbox.center.position.x = float(xywh[0])
+ detection_msg.bbox.center.position.y = float(xywh[1])
+ detection_msg.bbox.size_x = float(xywh[2])
+ detection_msg.bbox.size_y = float(xywh[3])
+
+ detection_array_msg.detections.append(detection_msg)
+
+ self.detection_pub.publish(detection_array_msg)
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = YoloDetectorNode()
+ try:
+ rclpy.spin(node)
+ except KeyboardInterrupt:
+ pass
+ finally:
+ node.destroy_node()
+ rclpy.shutdown()
+
+if __name__ == '__main__':
+ main()
\ No newline at end of file
diff --git a/src/perception/perception/opencv_camera_feed.py b/src/perception/perception/opencv_camera_feed.py
deleted file mode 100644
index b9d8c7d..0000000
--- a/src/perception/perception/opencv_camera_feed.py
+++ /dev/null
@@ -1,37 +0,0 @@
-import rclpy
-from rclpy.node import Node
-from sensor_msgs.msg import Image
-from cv_bridge import CvBridge
-import cv2
-
-class SimpleCameraNode(Node):
- def __init__(self):
- super().__init__('simple_camera_node')
- self.publisher = self.create_publisher(Image, 'image_raw', 10)
- self.bridge = CvBridge()
- self.cap = cv2.VideoCapture(4) # Video4Linux device
-
- timer_period = 0.03 # 30ms ~ 33 FPS
- self.timer = self.create_timer(timer_period, self.timer_callback)
-
- def timer_callback(self):
- ret, frame = self.cap.read()
- if not ret:
- self.get_logger().warn('Failed to capture frame')
- return
-
- msg = self.bridge.cv2_to_imgmsg(frame, encoding='bgr8')
- self.publisher.publish(msg)
-
-
-def main(args=None):
- rclpy.init(args=args)
- node = SimpleCameraNode()
- rclpy.spin(node)
- node.cap.release()
- node.destroy_node()
- rclpy.shutdown()
-
-
-if __name__ == '__main__':
- main()
diff --git a/src/perception/perception/opencv_yolo_object_detection.py b/src/perception/perception/opencv_yolo_object_detection.py
deleted file mode 100644
index 60677af..0000000
--- a/src/perception/perception/opencv_yolo_object_detection.py
+++ /dev/null
@@ -1,37 +0,0 @@
-import rclpy
-from rclpy.node import Node
-from sensor_msgs.msg import Image
-from cv_bridge import CvBridge
-from ultralytics import YOLO
-import cv2
-import os
-
-class YOLOv8Node(Node):
- def __init__(self):
- super().__init__('yolov8_node')
- self.bridge = CvBridge()
- model_path = os.path.expanduser('~/ros2_ws/models/yolov8n.pt')
- self.model = YOLO(model_path) # Replace with your model if custom
-
- self.subscription = self.create_subscription(
- Image,
- '/image_raw',
- self.image_callback,
- 10)
-
- self.publisher = self.create_publisher(Image, '/yolov8/image_annotated', 10)
-
- def image_callback(self, msg):
- frame = self.bridge.imgmsg_to_cv2(msg, desired_encoding='bgr8')
- results = self.model(frame)
- annotated_frame = results[0].plot()
- out_msg = self.bridge.cv2_to_imgmsg(annotated_frame, encoding='bgr8')
- self.publisher.publish(out_msg)
-
-
-def main(args=None):
- rclpy.init(args=args)
- node = YOLOv8Node()
- rclpy.spin(node)
- node.destroy_node()
- rclpy.shutdown()
diff --git a/src/perception/perception/rviz/place_object.rviz b/src/perception/perception/rviz/place_object.rviz
new file mode 100644
index 0000000..7c7716f
--- /dev/null
+++ b/src/perception/perception/rviz/place_object.rviz
@@ -0,0 +1,314 @@
+Panels:
+ - Class: rviz_common/Displays
+ Help Height: 0
+ Name: Displays
+ Property Tree Widget:
+ Expanded:
+ - /Global Options1
+ - /Status1
+ Splitter Ratio: 0.5
+ Tree Height: 751
+ - Class: rviz_common/Selection
+ Name: Selection
+ - Class: rviz_common/Tool Properties
+ Expanded:
+ - /2D Goal Pose1
+ - /Publish Point1
+ Name: Tool Properties
+ Splitter Ratio: 0.5886790156364441
+ - Class: rviz_common/Views
+ Expanded:
+ - /Current View1
+ Name: Views
+ Splitter Ratio: 0.5
+ - Class: rviz_common/Time
+ Experimental: false
+ Name: Time
+ SyncMode: 0
+ SyncSource: PointCloud2
+Visualization Manager:
+ Class: ""
+ Displays:
+ - Alpha: 0.5
+ Cell Size: 1
+ Class: rviz_default_plugins/Grid
+ Color: 160; 160; 164
+ Enabled: true
+ Line Style:
+ Line Width: 0.029999999329447746
+ Value: Lines
+ Name: Grid
+ Normal Cell Count: 0
+ Offset:
+ X: 0
+ Y: 0
+ Z: 0
+ Plane: XY
+ Plane Cell Count: 10
+ Reference Frame:
+ Value: true
+ - Alpha: 1
+ Axes Length: 1
+ Axes Radius: 0.10000000149011612
+ Class: rviz_default_plugins/Pose
+ Color: 255; 25; 0
+ Enabled: false
+ Head Length: 0.30000001192092896
+ Head Radius: 0.10000000149011612
+ Name: Pose
+ Shaft Length: 1
+ Shaft Radius: 0.05000000074505806
+ Shape: Arrow
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ Filter size: 10
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /perception/target_place_pose
+ Value: false
+ - Class: rviz_default_plugins/Image
+ Enabled: false
+ Max Value: 1
+ Median window: 5
+ Min Value: 0
+ Name: Image
+ Normalize Range: true
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /camera/color/image_raw
+ Value: false
+ - Alpha: 1
+ Autocompute Intensity Bounds: true
+ Autocompute Value Bounds:
+ Max Value: 10
+ Min Value: -10
+ Value: true
+ Axis: Z
+ Channel Name: intensity
+ Class: rviz_default_plugins/PointCloud2
+ Color: 255; 255; 255
+ Color Transformer: RGB8
+ Decay Time: 0
+ Enabled: false
+ Invert Rainbow: false
+ Max Color: 255; 255; 255
+ Max Intensity: 4096
+ Min Color: 0; 0; 0
+ Min Intensity: 0
+ Name: PointCloud2
+ Position Transformer: XYZ
+ Selectable: true
+ Size (Pixels): 3
+ Size (m): 0.009999999776482582
+ Style: Flat Squares
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /camera/depth/color/points
+ Use Fixed Frame: true
+ Use rainbow: true
+ Value: false
+ - Alpha: 1
+ Autocompute Intensity Bounds: true
+ Autocompute Value Bounds:
+ Max Value: 10
+ Min Value: -10
+ Value: true
+ Axis: Z
+ Channel Name: intensity
+ Class: rviz_default_plugins/PointCloud2
+ Color: 255; 255; 255
+ Color Transformer: RGB8
+ Decay Time: 0
+ Enabled: true
+ Invert Rainbow: false
+ Max Color: 255; 255; 255
+ Max Intensity: 4096
+ Min Color: 0; 0; 0
+ Min Intensity: 0
+ Name: PointCloud2
+ Position Transformer: XYZ
+ Selectable: true
+ Size (Pixels): 3
+ Size (m): 0.009999999776482582
+ Style: Flat Squares
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /perception/debug/table_plane
+ Use Fixed Frame: true
+ Use rainbow: true
+ Value: true
+ - Alpha: 1
+ Autocompute Intensity Bounds: true
+ Autocompute Value Bounds:
+ Max Value: 10
+ Min Value: -10
+ Value: true
+ Axis: Z
+ Channel Name: intensity
+ Class: rviz_default_plugins/PointCloud2
+ Color: 255; 255; 255
+ Color Transformer: RGB8
+ Decay Time: 0
+ Enabled: true
+ Invert Rainbow: false
+ Max Color: 255; 255; 255
+ Max Intensity: 4096
+ Min Color: 0; 0; 0
+ Min Intensity: 0
+ Name: PointCloud2
+ Position Transformer: XYZ
+ Selectable: true
+ Size (Pixels): 3
+ Size (m): 0.009999999776482582
+ Style: Flat Squares
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /perception/debug/objects
+ Use Fixed Frame: true
+ Use rainbow: true
+ Value: true
+ - Class: rviz_default_plugins/Marker
+ Enabled: false
+ Name: Marker
+ Namespaces:
+ {}
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ Filter size: 10
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /perception/debug/viz_arrow
+ Value: false
+ - Alpha: 1
+ Axes Length: 1
+ Axes Radius: 0.10000000149011612
+ Class: rviz_default_plugins/Pose
+ Color: 255; 25; 0
+ Enabled: false
+ Head Length: 0.30000001192092896
+ Head Radius: 0.10000000149011612
+ Name: Pose
+ Shaft Length: 1
+ Shaft Radius: 0.05000000074505806
+ Shape: Arrow
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ Filter size: 10
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /perception/target_place_pose
+ Value: false
+ - Class: rviz_default_plugins/Marker
+ Enabled: true
+ Name: Marker
+ Namespaces:
+ safety_sphere: true
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ Filter size: 10
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /perception/debug/viz_sphere
+ Value: true
+ Enabled: true
+ Global Options:
+ Background Color: 48; 48; 48
+ Fixed Frame: camera_link
+ Frame Rate: 30
+ Name: root
+ Tools:
+ - Class: rviz_default_plugins/Interact
+ Hide Inactive Objects: true
+ - Class: rviz_default_plugins/MoveCamera
+ - Class: rviz_default_plugins/Select
+ - Class: rviz_default_plugins/FocusCamera
+ - Class: rviz_default_plugins/Measure
+ Line color: 128; 128; 0
+ - Class: rviz_default_plugins/SetInitialPose
+ Covariance x: 0.25
+ Covariance y: 0.25
+ Covariance yaw: 0.06853891909122467
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /initialpose
+ - Class: rviz_default_plugins/SetGoal
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /goal_pose
+ - Class: rviz_default_plugins/PublishPoint
+ Single click: true
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /clicked_point
+ Transformation:
+ Current:
+ Class: rviz_default_plugins/TF
+ Value: true
+ Views:
+ Current:
+ Class: rviz_default_plugins/Orbit
+ Distance: 2.601862668991089
+ Enable Stereo Rendering:
+ Stereo Eye Separation: 0.05999999865889549
+ Stereo Focal Distance: 1
+ Swap Stereo Eyes: false
+ Value: false
+ Focal Point:
+ X: -0.18230421841144562
+ Y: 0.2078571617603302
+ Z: 0.9030411839485168
+ Focal Shape Fixed Size: true
+ Focal Shape Size: 0.05000000074505806
+ Invert Z Axis: true
+ Name: Current View
+ Near Clip Distance: 0.009999999776482582
+ Pitch: 0.9502022862434387
+ Target Frame:
+ Value: Orbit (rviz)
+ Yaw: 1.5285863876342773
+ Saved: ~
+Window Geometry:
+ Displays:
+ collapsed: false
+ Height: 1003
+ Hide Left Dock: false
+ Hide Right Dock: false
+ Image:
+ collapsed: false
+ QMainWindow State: 000000ff00000000fd0000000400000000000002e400000338fc020000000bfb0000001200530065006c0065006300740069006f006e00000001e10000009b0000006f00fffffffb0000001e0054006f006f006c002000500072006f007000650072007400690065007302000001ed000001df00000185000000a3fb000000120056006900650077007300200054006f006f02000001df000002110000018500000122fb000000200054006f006f006c002000500072006f0070006500720074006900650073003203000002880000011d000002210000017afb000000100044006900730070006c006100790073010000004800000338000000f300fffffffb0000002000730065006c0065006300740069006f006e00200062007500660066006500720200000138000000aa0000023a00000294fb00000014005700690064006500530074006500720065006f02000000e6000000d2000003ee0000030bfb0000000c004b0069006e0065006300740200000186000001060000030c00000261fb0000000a0049006d0061006700650000000269000001170000001a00fffffffb0000000a0049006d006100670065010000022f000001510000000000000000fb0000000a0049006d00610067006501000002110000016f0000000000000000000000010000011500000338fc0200000003fb0000001e0054006f006f006c002000500072006f00700065007200740069006500730100000041000000780000000000000000fb0000000a00560069006500770073010000004800000338000000c500fffffffb0000001200530065006c0065006300740069006f006e010000025a000000b200000000000000000000000200000490000000a9fc0100000001fb0000000a00560069006500770073030000004e00000080000002e100000197000000030000073e00000042fc0100000002fb0000000800540069006d006501000000000000073e000002dc00fffffffb0000000800540069006d00650100000000000004500000000000000000000003370000033800000004000000040000000800000008fc0000000100000002000000010000000a0054006f006f006c00730100000000ffffffff0000000000000000
+ Selection:
+ collapsed: false
+ Time:
+ collapsed: false
+ Tool Properties:
+ collapsed: false
+ Views:
+ collapsed: false
+ Width: 1854
+ X: 66
+ Y: 40
diff --git a/src/perception/perception/segment_object.py b/src/perception/perception/segment_object.py
new file mode 100644
index 0000000..77a212d
--- /dev/null
+++ b/src/perception/perception/segment_object.py
@@ -0,0 +1,190 @@
+import rclpy
+from rclpy.node import Node
+from rclpy.qos import QoSProfile, ReliabilityPolicy, HistoryPolicy
+import message_filters
+from sensor_msgs.msg import Image, PointCloud2
+from visualization_msgs.msg import Marker, MarkerArray
+from vision_msgs.msg import Detection3D, Detection3DArray, ObjectHypothesisWithPose
+from std_msgs.msg import Float32 # <--- NEW: Import for the radius topic
+from cv_bridge import CvBridge
+from sensor_msgs_py import point_cloud2 as pc2
+import numpy as np
+import cv2
+import torch
+from ultralytics import YOLO, SAM
+
+class ObjectSphereNode(Node):
+ def __init__(self):
+ super().__init__('object_sphere_node')
+
+ # --- CONFIGURATION ---
+ self.img_topic = '/camera/color/image_raw'
+ self.pc_topic = '/camera/depth/color/points'
+ self.yolo_model = '/home/mohsin/fix/r4s/models/fine_tuned.pt'
+ self.sam_model = "sam_b.pt"
+ self.target_classes = ["unit", "motor"]
+ # Define BGR colors for classes (Green for unit, Blue for motor)
+ self.class_colors = {"unit": (0, 255, 0), "motor": (255, 0, 0)}
+ self.min_points_threshold = 50 # Minimum valid points needed for 3D calculation
+
+ # --- MODELS ---
+ self.bridge = CvBridge()
+ self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
+ self.get_logger().info(f"Loading Models on {self.device}...")
+ self.yolo = YOLO(self.yolo_model).to(self.device)
+ self.sam = SAM(self.sam_model).to(self.device)
+
+ # --- PUBLISHERS ---
+ # 1. 3D Markers for RViz Visualization
+ self.marker_pub = self.create_publisher(MarkerArray, '/object_markers', 10)
+ # 2. 3D Data for other nodes (position/size)
+ self.detect_pub = self.create_publisher(Detection3DArray, '/object_detections', 10)
+ # 3. 2D Segmentation visualization image
+ self.seg_pub = self.create_publisher(Image, '/object_segmentation', 10)
+ # 4. NEW: Single float radius publisher for external node
+ self.radius_pub = self.create_publisher(Float32, '/perception/detected_object_radius', 10)
+
+ # --- SUBSCRIBERS ---
+ qos = QoSProfile(reliability=ReliabilityPolicy.BEST_EFFORT, history=HistoryPolicy.KEEP_LAST, depth=1)
+ self.img_sub = message_filters.Subscriber(self, Image, self.img_topic, qos_profile=qos)
+ self.pc_sub = message_filters.Subscriber(self, PointCloud2, self.pc_topic, qos_profile=qos)
+
+ # Sync RGB and Depth
+ self.ts = message_filters.ApproximateTimeSynchronizer(
+ [self.img_sub, self.pc_sub], queue_size=5, slop=0.1
+ )
+ self.ts.registerCallback(self.callback)
+ self.get_logger().info("Node ready.")
+
+ def callback(self, img_msg, pc_msg):
+ # 1. Image Conversion
+ try:
+ cv_img = self.bridge.imgmsg_to_cv2(img_msg, desired_encoding='bgr8')
+ except Exception as e:
+ self.get_logger().error(f"CV Bridge Error: {e}")
+ return
+
+ # 2. YOLO Inference
+ yolo_res = self.yolo(cv_img, verbose=False, conf=0.5)[0]
+ boxes, labels = [], []
+ for box in yolo_res.boxes:
+ cls_id = int(box.cls[0])
+ name = yolo_res.names[cls_id]
+ if name in self.target_classes:
+ boxes.append(box.xyxy[0].cpu().numpy())
+ labels.append(name)
+
+ if not boxes: return
+
+ # 3. SAM Inference
+ boxes_np = np.array(boxes)
+ sam_res = self.sam(cv_img, bboxes=boxes_np, verbose=False)[0]
+ if sam_res.masks is None: return
+ masks_data = sam_res.masks.data.cpu().numpy()
+
+ # 4. Point Cloud Prep
+ if pc_msg.height <= 1: return
+ points = pc2.read_points_numpy(pc_msg, field_names=("x", "y", "z"), skip_nans=False)
+ try:
+ points_3d = points.reshape((pc_msg.height, pc_msg.width, 3))
+ except ValueError: return
+
+ # --- Initialize Outputs ---
+ marker_array = MarkerArray()
+ detection_array = Detection3DArray()
+ detection_array.header = pc_msg.header
+
+ # Create a black background image for segmentation visualization
+ seg_overlay_img = np.zeros((cv_img.shape[0], cv_img.shape[1], 3), dtype=np.uint8)
+
+ # NEW: Flag to track if the radius has been published in this frame
+ radius_published = False
+
+ # 5. Iterate Results
+ for i, (mask_small, label) in enumerate(zip(masks_data, labels)):
+ # A. Resize Mask
+ mask_uint8 = mask_small.astype(np.uint8)
+ # Resize to match the original image/pointcloud dimensions
+ mask_resized = cv2.resize(mask_uint8, (pc_msg.width, pc_msg.height), interpolation=cv2.INTER_NEAREST)
+ full_mask_bool = mask_resized.astype(bool)
+
+ # --- Paint Segmentation Image ---
+ # Get BGR color for this class
+ color_bgr = self.class_colors.get(label, (255, 255, 255))
+ # Use boolean indexing to color the pixels where the mask is True
+ seg_overlay_img[full_mask_bool] = color_bgr
+
+ # B. Extract 3D Points based on mask
+ obj_points = points_3d[full_mask_bool]
+ valid_obj_points = obj_points[~np.isnan(obj_points).any(axis=1)]
+
+ if len(valid_obj_points) < self.min_points_threshold: continue
+
+ # C. Calculate Sphere
+ centroid = np.mean(valid_obj_points, axis=0)
+ distances = np.linalg.norm(valid_obj_points - centroid, axis=1)
+ radius = np.max(distances)
+ diameter = radius * 2.0
+
+ # D. NEW: Publish radius for the first valid object
+ if not radius_published:
+ radius_msg = Float32()
+ radius_msg.data = float(radius)
+ self.radius_pub.publish(radius_msg)
+ self.get_logger().debug(f"Published radius for {label}: {radius:.4f} m")
+ radius_published = True
+
+ # E. Create Marker (RViz)
+ sphere = Marker()
+ sphere.header = pc_msg.header
+ sphere.ns = "detections"
+ sphere.id = i
+ sphere.type = Marker.SPHERE
+ sphere.action = Marker.ADD
+ sphere.pose.position.x = float(centroid[0])
+ sphere.pose.position.y = float(centroid[1])
+ sphere.pose.position.z = float(centroid[2])
+ sphere.scale.x = float(diameter); sphere.scale.y = float(diameter); sphere.scale.z = float(diameter)
+ # Set color based on class, matching segmentation color but semi-transparent
+ sphere.color.r = color_bgr[2] / 255.0 # BGR to RGB normalized
+ sphere.color.g = color_bgr[1] / 255.0
+ sphere.color.b = color_bgr[0] / 255.0
+ sphere.color.a = 0.5
+ marker_array.markers.append(sphere)
+
+ # F. Create Detection Message (Data)
+ detection = Detection3D()
+ detection.header = pc_msg.header
+ hypothesis = ObjectHypothesisWithPose()
+ hypothesis.hypothesis.class_id = label
+ hypothesis.hypothesis.score = 1.0
+ detection.results.append(hypothesis)
+ detection.bbox.center.position.x = float(centroid[0])
+ detection.bbox.center.position.y = float(centroid[1])
+ detection.bbox.center.position.z = float(centroid[2])
+ detection.bbox.size.x = float(diameter); detection.bbox.size.y = float(diameter); detection.bbox.size.z = float(diameter)
+ detection_array.detections.append(detection)
+
+ # --- Publish All outputs ---
+ self.marker_pub.publish(marker_array)
+ self.detect_pub.publish(detection_array)
+
+ # Publish Segmentation Image
+ try:
+ # Convert numpy array back to ROS Image message
+ seg_msg = self.bridge.cv2_to_imgmsg(seg_overlay_img, encoding="bgr8")
+ # IMPORTANT: Copy header from input to ensure sync in RViz
+ seg_msg.header = img_msg.header
+ self.seg_pub.publish(seg_msg)
+ except Exception as e:
+ self.get_logger().error(f"Could not publish segmentation image: {e}")
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = ObjectSphereNode()
+ rclpy.spin(node)
+ node.destroy_node()
+ rclpy.shutdown()
+
+if __name__ == '__main__':
+ main()
\ No newline at end of file
diff --git a/src/perception/perception/table_segmentation.py b/src/perception/perception/table_segmentation.py
new file mode 100644
index 0000000..4f08041
--- /dev/null
+++ b/src/perception/perception/table_segmentation.py
@@ -0,0 +1,428 @@
+import rclpy
+from rclpy.node import Node
+from sensor_msgs.msg import PointCloud2, PointField
+from geometry_msgs.msg import PoseStamped
+from visualization_msgs.msg import Marker
+from std_msgs.msg import Float32, Header
+import sensor_msgs_py.point_cloud2 as pc2
+import open3d as o3d
+import numpy as np
+import struct
+
+class TableSegmentationNode(Node):
+ def __init__(self):
+ super().__init__('table_segmentation_node')
+
+ # Declare Parameters
+ self.declare_parameter('input_mode', 'robot')
+ self.declare_parameter('debug_viz', True)
+
+ self.declare_parameter('mode', 'test') # 'test' or 'actual'
+ self.declare_parameter('test_radius', 0.07) # Default radius for test mode (7cm)
+ self.declare_parameter('safety_margin', 0.02) # Default safety margin (2cm)
+
+ # Get Parameters
+ input_mode = self.get_parameter('input_mode').get_parameter_value().string_value
+ self.debug_viz = self.get_parameter('debug_viz').get_parameter_value().bool_value
+ self.op_mode = self.get_parameter('mode').get_parameter_value().string_value
+ self.current_radius = self.get_parameter('test_radius').get_parameter_value().double_value
+ self.safety_margin = self.get_parameter('safety_margin').get_parameter_value().double_value
+
+ self.get_logger().info(f"Starting in MODE: {self.op_mode}")
+ self.get_logger().info(f"Initial Radius: {self.current_radius}m | Safety Margin: {self.safety_margin}m")
+
+ if input_mode == 'robot':
+ pc_topic = '/camera/depth/color/points'
+ elif input_mode == 'realsense':
+ pc_topic = '/camera/camera/depth/color/points'
+ else:
+ pc_topic = '/camera/depth/color/points'
+
+ self.get_logger().info(f"Subscribing to: {pc_topic}")
+
+ self.pc_sub = self.create_subscription(PointCloud2, pc_topic, self.cloud_callback, 10)
+
+ # Radius Subscriber (Only active in actual mode)
+ if self.op_mode == 'actual':
+ self.radius_sub = self.create_subscription(
+ Float32,
+ '/perception/detected_object_radius',
+ self.radius_callback,
+ 10
+ )
+ self.get_logger().info("Listening to /perception/detected_object_radius for updates...")
+
+ # Publishers
+ self.place_pose_pub = self.create_publisher(PoseStamped, '/perception/target_place_pose', 10)
+ self.viz_sphere_pub = self.create_publisher(Marker, '/perception/debug/viz_sphere', 10) # Publisher for the Safety Sphere
+
+ # Debug Publishers
+ self.table_cloud_pub = self.create_publisher(PointCloud2, '/perception/debug/table_plane', 10)
+ self.object_cloud_pub = self.create_publisher(PointCloud2, '/perception/debug/objects', 10)
+ self.viz_pub = self.create_publisher(Marker, '/perception/debug/viz_arrow', 10) # For RViz - Visual Offset above the table
+
+ def radius_callback(self, msg):
+ """Called only in actual mode when a new object size is detected."""
+ if msg.data > 0.01: # Minimum 1cm radius
+ self.current_radius = float(msg.data)
+ self.get_logger().info(f"Updated Object Radius to: {self.current_radius:.3f}m")
+
+ def cloud_callback(self, ros_cloud_msg):
+ self.get_logger().info(f"Processing cloud: {ros_cloud_msg.width}x{ros_cloud_msg.height}")
+
+ pcd = self.convert_ros_to_o3d(ros_cloud_msg)
+ if pcd is None:
+ return
+
+ max_depth = 1.2 # 1.2 meters
+
+ points = np.asarray(pcd.points)
+ if len(points) > 0:
+ # Keep points where Z is less than max_depth
+ mask = points[:, 2] < max_depth
+ pcd = pcd.select_by_index(np.where(mask)[0])
+
+ if len(pcd.points) < 100:
+ self.get_logger().warn("No points left after depth filtering!")
+ return
+
+ pcd_down = pcd.voxel_down_sample(voxel_size=0.005)
+
+ try:
+ plane_model, inliers = pcd_down.segment_plane(distance_threshold=0.008,
+ ransac_n=3,
+ num_iterations=1000)
+ except Exception as e:
+ self.get_logger().warn("Could not find a plane (table) in view.")
+ return
+
+ table_cloud = pcd_down.select_by_index(inliers)
+ raw_object_cloud = pcd_down.select_by_index(inliers, invert=True)
+
+ # Filter objects above the table
+ object_cloud = self.filter_objects_above_table(raw_object_cloud, plane_model)
+
+ total_check_radius = self.current_radius + self.safety_margin
+ target_point = self.find_empty_spot(table_cloud, object_cloud, total_check_radius, plane_model)
+
+ if target_point is not None:
+ quat, arrow_vector = self.get_orientation_from_plane(plane_model)
+
+ self.get_logger().info(
+ f"Target: X={target_point[0]:.2f}, Y={target_point[1]:.2f}, Z={target_point[2]:.2f}"
+ )
+
+ # Publish the real target pose for the robot
+ real_pose = PoseStamped()
+ real_pose.header = ros_cloud_msg.header
+ real_pose.pose.position.x = float(target_point[0])
+ real_pose.pose.position.y = float(target_point[1])
+ real_pose.pose.position.z = float(target_point[2])
+ real_pose.pose.orientation.x = float(quat[0])
+ real_pose.pose.orientation.y = float(quat[1])
+ real_pose.pose.orientation.z = float(quat[2])
+ real_pose.pose.orientation.w = float(quat[3])
+
+ self.place_pose_pub.publish(real_pose)
+
+ # Publish a visualization pose slightly above the table for RViz
+ viz_len = 0.15
+ hover_point = target_point - (arrow_vector * viz_len)
+
+ viz_pose = PoseStamped()
+ viz_pose.header = ros_cloud_msg.header
+ viz_pose.pose.position.x = float(hover_point[0])
+ viz_pose.pose.position.y = float(hover_point[1])
+ viz_pose.pose.position.z = float(hover_point[2])
+ viz_pose.pose.orientation = real_pose.pose.orientation
+
+ self.publish_arrow_marker(viz_pose)
+
+ self.publish_safety_sphere(real_pose, self.current_radius)
+ else:
+ self.get_logger().warn("Table full or no safe spot found!")
+
+ if self.debug_viz:
+ # Paint Green and Red
+ table_cloud.paint_uniform_color([0, 1, 0])
+ object_cloud.paint_uniform_color([1, 0, 0])
+
+ # Publish with Color support
+ self.publish_o3d(table_cloud, self.table_cloud_pub, ros_cloud_msg.header)
+ self.publish_o3d(object_cloud, self.object_cloud_pub, ros_cloud_msg.header)
+
+ def publish_safety_sphere(self, pose_stamped, radius):
+ marker = Marker()
+ marker.header = pose_stamped.header
+ marker.ns = "safety_sphere"
+ marker.id = 1
+ marker.type = Marker.SPHERE
+ marker.action = Marker.ADD
+ marker.pose = pose_stamped.pose
+
+ diameter = radius * 2.0
+ marker.scale.x = diameter
+ marker.scale.y = diameter
+ marker.scale.z = diameter
+
+ marker.color.r = 0.0
+ marker.color.g = 0.5
+ marker.color.b = 1.0
+ marker.color.a = 0.5
+
+ self.viz_sphere_pub.publish(marker)
+
+ def publish_arrow_marker(self, pose_stamped):
+ marker = Marker()
+ marker.header = pose_stamped.header
+ marker.ns = "target_arrow"
+ marker.id = 0
+ marker.type = Marker.ARROW
+ marker.action = Marker.ADD
+
+ marker.pose = pose_stamped.pose
+
+ marker.scale.x = 0.15 # 15cm Long
+ marker.scale.y = 0.01 # 1cm Wide
+ marker.scale.z = 0.02 # 2cm Head
+
+ marker.color.r = 0.0
+ marker.color.g = 1.0
+ marker.color.b = 1.0
+ marker.color.a = 1.0
+
+ self.viz_pub.publish(marker)
+
+ def filter_objects_above_table(self, object_cloud, plane_model):
+ """
+ Removes points that are on the wrong side of the table.
+ Also removes points that are too high to be relevant objects.
+ """
+ if len(object_cloud.points) == 0:
+ return object_cloud
+
+ a, b, c, d = plane_model
+
+ # Determine camera side sign
+ camera_sign = np.sign(d)
+
+ points = np.asarray(object_cloud.points)
+ colors = np.asarray(object_cloud.colors) if object_cloud.has_colors() else None
+
+ # Calculate signed distance for all points
+ distances = (points[:,0] * a) + (points[:,1] * b) + (points[:,2] * c) + d
+
+ # Filter
+ # - Must be on the same side as camera (Above table)
+ # - Must be within 50cm of the table surface (Ignore ceiling/high noise)
+ valid_mask = (np.sign(distances) == camera_sign) & (np.abs(distances) < 0.5)
+
+ filtered_cloud = o3d.geometry.PointCloud()
+ filtered_cloud.points = o3d.utility.Vector3dVector(points[valid_mask])
+ if colors is not None:
+ filtered_cloud.colors = o3d.utility.Vector3dVector(colors[valid_mask])
+
+ return filtered_cloud
+
+ def get_orientation_from_plane(self, plane_model):
+ """
+ Calculates a quaternion where the X-AXIS points into the table.
+ """
+ # Get the Normal Vector [a,b,c]
+ normal = np.array(plane_model[:3])
+ normal = normal / np.linalg.norm(normal)
+
+ # Define the arrow direction (X-axis)
+ if normal[1] < 0: # If Y is negative (pointing up)
+ target_x = -normal # Flip it to point down/table
+ else:
+ target_x = normal
+
+ # Construct Orthogonal Axes
+ ref_vector = np.array([0, 1, 0])
+
+ # If too close to parallel, use World X (1,0,0)
+ if np.abs(np.dot(target_x, ref_vector)) > 0.9:
+ ref_vector = np.array([1, 0, 0])
+
+ # Z = X cross Ref
+ z_axis = np.cross(target_x, ref_vector)
+ z_axis = z_axis / np.linalg.norm(z_axis)
+
+ # Y = Z cross X (Ensure orthogonality)
+ y_axis = np.cross(z_axis, target_x)
+ y_axis = y_axis / np.linalg.norm(y_axis)
+
+ # Create Rotation Matrix [ X Y Z ]
+ R = np.array([target_x, y_axis, z_axis]).T
+
+ # Convert to Quaternion [x, y, z, w]
+ tr = np.trace(R)
+ if tr > 0:
+ S = np.sqrt(tr + 1.0) * 2
+ qw = 0.25 * S
+ qx = (R[2,1] - R[1,2]) / S
+ qy = (R[0,2] - R[2,0]) / S
+ qz = (R[1,0] - R[0,1]) / S
+ elif (R[0,0] > R[1,1]) and (R[0,0] > R[2,2]):
+ S = np.sqrt(1.0 + R[0,0] - R[1,1] - R[2,2]) * 2
+ qw = (R[2,1] - R[1,2]) / S
+ qx = 0.25 * S
+ qy = (R[0,1] + R[1,0]) / S
+ qz = (R[0,2] + R[2,0]) / S
+ elif (R[1,1] > R[2,2]):
+ S = np.sqrt(1.0 + R[1,1] - R[0,0] - R[2,2]) * 2
+ qw = (R[0,2] - R[2,0]) / S
+ qx = (R[0,1] + R[1,0]) / S
+ qy = 0.25 * S
+ qz = (R[1,2] + R[2,1]) / S
+ else:
+ S = np.sqrt(1.0 + R[2,2] - R[0,0] - R[1,1]) * 2
+ qw = (R[1,0] - R[0,1]) / S
+ qx = (R[0,2] + R[2,0]) / S
+ qy = (R[1,2] + R[2,1]) / S
+ qz = 0.25 * S
+
+ return [qx, qy, qz, qw], target_x
+
+ def find_empty_spot(self, table_cloud, object_cloud, radius_to_check, plane_model):
+ if len(table_cloud.points) == 0: return None
+
+ a, b, c, d = plane_model
+
+ # Get table geometry statistics
+ table_pts = np.asarray(table_cloud.points)
+ min_x, min_y = np.min(table_pts[:,0]), np.min(table_pts[:,1])
+ max_x, max_y = np.max(table_pts[:,0]), np.max(table_pts[:,1])
+
+ avg_z = np.mean(table_pts[:,2]) # The height of the table plane
+ center_x, center_y = np.mean(table_pts[:,0]), np.mean(table_pts[:,1])
+
+ table_tree = o3d.geometry.KDTreeFlann(table_cloud)
+
+ has_objects = len(object_cloud.points) > 0
+ object_tree = None
+
+ if has_objects:
+ # Create a shadow cloud where all object points are projected onto the table plane (Z = avg_z).
+ # This ensures that tall objects block the grid points underneath them.
+ obj_points = np.asarray(object_cloud.points).copy()
+ obj_points[:, 2] = avg_z # Force Z to match table height
+
+ flat_object_cloud = o3d.geometry.PointCloud()
+ flat_object_cloud.points = o3d.utility.Vector3dVector(obj_points)
+
+ # Build tree on the flattened cloud
+ object_tree = o3d.geometry.KDTreeFlann(flat_object_cloud)
+
+ # Grid search
+ step = 0.05
+ best_pt = None
+ best_score = -float('inf')
+
+ for x in np.arange(min_x, max_x, step):
+ for y in np.arange(min_y , max_y, step):
+
+ if abs(c) < 0.001: # Avoid division by zero (vertical plane)
+ z_plane = avg_z
+ else:
+ z_plane = -(a*x + b*y + d) / c
+
+ # The candidate point follows the table tilt
+ cand = np.array([x, y, z_plane])
+
+ # use a temp candidate at avg_z for the KDTree checks
+ # (the tree and objects are built around avg_z for simplicity)
+ check_cand = np.array([x, y, avg_z])
+
+ # Check if it is this actually on the table
+ [k, _, _] = table_tree.search_radius_vector_3d(check_cand, 0.05)
+ if k == 0: continue
+
+ dist_center = np.sqrt((x - center_x)**2 + (y - center_y)**2)
+
+ # Check collision with flattened objects
+ if has_objects:
+ # Finds distance to the nearest object shadow
+ [_, _, d_sq] = object_tree.search_knn_vector_3d(check_cand, 1)
+ dist_obj = np.sqrt(d_sq[0])
+
+ # Radius Check
+ if dist_obj < radius_to_check:
+ continue
+
+ # Score: Maximize distance to object, minimize distance to center
+ score = dist_obj - (0.8 * dist_center)
+ else:
+ score = -dist_center
+
+ # Check if object radius fits on table
+ if (x - radius_to_check < min_x) or (x + radius_to_check > max_x):
+ continue
+ if (y - radius_to_check < min_y) or (y + radius_to_check > max_y):
+ continue
+
+ if score > best_score:
+ best_score = score
+ best_pt = cand
+
+ return best_pt
+
+ def convert_ros_to_o3d(self, ros_cloud):
+ try:
+ pcd_as_numpy = np.array([
+ [x, y, z]
+ for x, y, z in pc2.read_points(ros_cloud, field_names=("x", "y", "z"), skip_nans=True)
+ ])
+
+ if pcd_as_numpy.shape[0] == 0:
+ return None
+
+ pcd = o3d.geometry.PointCloud()
+ pcd.points = o3d.utility.Vector3dVector(pcd_as_numpy)
+ return pcd
+ except Exception as e:
+ self.get_logger().error(f'Conversion error: {e}')
+ return None
+
+ def publish_o3d(self, o3d_cloud, publisher, header):
+ points = np.asarray(o3d_cloud.points)
+ if len(points) == 0:
+ return
+
+ # If no colors, just send XYZ
+ if not o3d_cloud.has_colors():
+ msg = pc2.create_cloud_xyz32(header, points)
+ publisher.publish(msg)
+ return
+
+ # Pack RGB color into the message
+ colors = np.asarray(o3d_cloud.colors)
+ points_with_color = []
+
+ for i in range(len(points)):
+ x, y, z = points[i]
+ r, g, b = colors[i]
+ rgb_int = (int(r * 255) << 16) | (int(g * 255) << 8) | int(b * 255)
+ rgb_float = struct.unpack('f', struct.pack('I', rgb_int))[0]
+ points_with_color.append([x, y, z, rgb_float])
+
+ fields = [
+ PointField(name='x', offset=0, datatype=PointField.FLOAT32, count=1),
+ PointField(name='y', offset=4, datatype=PointField.FLOAT32, count=1),
+ PointField(name='z', offset=8, datatype=PointField.FLOAT32, count=1),
+ PointField(name='rgb', offset=12, datatype=PointField.FLOAT32, count=1),
+ ]
+
+ msg = pc2.create_cloud(header, fields, points_with_color)
+ publisher.publish(msg)
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = TableSegmentationNode()
+ rclpy.spin(node)
+ node.destroy_node()
+ rclpy.shutdown()
+
+if __name__ == '__main__':
+ main()
diff --git a/src/perception/setup.py b/src/perception/setup.py
index 9985fa8..fc8bb06 100644
--- a/src/perception/setup.py
+++ b/src/perception/setup.py
@@ -30,8 +30,14 @@
"yolo_node = perception.yolo_object_detection:main",
"classifier_node = perception.object_classifier_node:main",
"pose_node = perception.pose_pca:main",
- "opencv_camera_node = perception.opencv_camera_feed:main",
- "opencv_yolo = perception.opencv_yolo_object_detection:main",
+ "action_pose_node = perception.action_pose_pca:main",
+ "action_yolo_node = perception.action_yolo_object_detection:main",
+ "vision_manager_node = perception.action_vision_manager:main",
+ "table_segmentation_node = perception.table_segmentation:main",
+ "segment_object = perception.segment_object:main",
+
+
+
],
},
)
diff --git a/src/table_height_predictor/package.xml b/src/table_height_predictor/package.xml
new file mode 100644
index 0000000..08125a4
--- /dev/null
+++ b/src/table_height_predictor/package.xml
@@ -0,0 +1,26 @@
+
+
+
+ table_height_predictor
+ 0.0.0
+ TODO: Package description
+ mohsin
+ TODO: License declaration
+
+ sensor_msgs
+ std_msgs
+ rclpy
+ image_transport
+ cv_bridge
+ python3-opencv
+ opencv4
+
+ ament_copyright
+ ament_flake8
+ ament_pep257
+ python3-pytest
+
+
+ ament_python
+
+
\ No newline at end of file
diff --git a/src/table_height_predictor/resource/table_height_predictor b/src/table_height_predictor/resource/table_height_predictor
new file mode 100644
index 0000000..e69de29
diff --git a/src/table_height_predictor/rviz/table_height.rviz b/src/table_height_predictor/rviz/table_height.rviz
new file mode 100644
index 0000000..203a42a
--- /dev/null
+++ b/src/table_height_predictor/rviz/table_height.rviz
@@ -0,0 +1,258 @@
+Panels:
+ - Class: rviz_common/Displays
+ Help Height: 138
+ Name: Displays
+ Property Tree Widget:
+ Expanded:
+ - /Global Options1
+ - /Status1
+ - /Image1
+ - /PointCloud21
+ - /TF1
+ - /PointCloud22
+ Splitter Ratio: 0.5
+ Tree Height: 1531
+ - Class: rviz_common/Selection
+ Name: Selection
+ - Class: rviz_common/Tool Properties
+ Expanded:
+ - /2D Goal Pose1
+ - /Publish Point1
+ Name: Tool Properties
+ Splitter Ratio: 0.5886790156364441
+ - Class: rviz_common/Views
+ Expanded:
+ - /Current View1
+ Name: Views
+ Splitter Ratio: 0.5
+ - Class: rviz_common/Time
+ Experimental: false
+ Name: Time
+ SyncMode: 0
+ SyncSource: PointCloud2
+Visualization Manager:
+ Class: ""
+ Displays:
+ - Alpha: 0.5
+ Cell Size: 1
+ Class: rviz_default_plugins/Grid
+ Color: 160; 160; 164
+ Enabled: true
+ Line Style:
+ Line Width: 0.029999999329447746
+ Value: Lines
+ Name: Grid
+ Normal Cell Count: 0
+ Offset:
+ X: 0
+ Y: 0
+ Z: 0
+ Plane: XY
+ Plane Cell Count: 10
+ Reference Frame:
+ Value: true
+ - Class: rviz_default_plugins/Image
+ Enabled: true
+ Max Value: 1
+ Median window: 5
+ Min Value: 0
+ Name: Image
+ Normalize Range: true
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /table_segmentation_image
+ Value: true
+ - Alpha: 1
+ Autocompute Intensity Bounds: true
+ Autocompute Value Bounds:
+ Max Value: 10
+ Min Value: -10
+ Value: true
+ Axis: Z
+ Channel Name: intensity
+ Class: rviz_default_plugins/PointCloud2
+ Color: 255; 255; 255
+ Color Transformer: RGB8
+ Decay Time: 0
+ Enabled: false
+ Invert Rainbow: false
+ Max Color: 255; 255; 255
+ Max Intensity: 4096
+ Min Color: 0; 0; 0
+ Min Intensity: 0
+ Name: PointCloud2
+ Position Transformer: XYZ
+ Selectable: true
+ Size (Pixels): 3
+ Size (m): 0.009999999776482582
+ Style: Flat Squares
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /camera/depth/color/points
+ Use Fixed Frame: true
+ Use rainbow: true
+ Value: false
+ - Class: rviz_default_plugins/TF
+ Enabled: true
+ Filter (blacklist): ""
+ Filter (whitelist): ""
+ Frame Timeout: 15
+ Frames:
+ All Enabled: true
+ camera_color_frame:
+ Value: true
+ camera_depth_frame:
+ Value: true
+ camera_link:
+ Value: true
+ Marker Scale: 1
+ Name: TF
+ Show Arrows: true
+ Show Axes: true
+ Show Names: false
+ Tree:
+ camera_link:
+ camera_color_frame:
+ {}
+ camera_depth_frame:
+ {}
+ Update Interval: 0
+ Value: true
+ - Class: rviz_default_plugins/Marker
+ Enabled: true
+ Name: Marker
+ Namespaces:
+ table_center: true
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ Filter size: 10
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /table_marker
+ Value: true
+ - Alpha: 1
+ Autocompute Intensity Bounds: true
+ Autocompute Value Bounds:
+ Max Value: 3.0160000324249268
+ Min Value: 1.0190000534057617
+ Value: true
+ Axis: Z
+ Channel Name: intensity
+ Class: rviz_default_plugins/PointCloud2
+ Color: 255; 255; 255
+ Color Transformer: AxisColor
+ Decay Time: 0
+ Enabled: true
+ Invert Rainbow: false
+ Max Color: 255; 255; 255
+ Max Intensity: 4096
+ Min Color: 0; 0; 0
+ Min Intensity: 0
+ Name: PointCloud2
+ Position Transformer: XYZ
+ Selectable: true
+ Size (Pixels): 3
+ Size (m): 0.009999999776482582
+ Style: Flat Squares
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /table_points_debug
+ Use Fixed Frame: true
+ Use rainbow: true
+ Value: true
+ Enabled: true
+ Global Options:
+ Background Color: 48; 48; 48
+ Fixed Frame: camera_link
+ Frame Rate: 30
+ Name: root
+ Tools:
+ - Class: rviz_default_plugins/Interact
+ Hide Inactive Objects: true
+ - Class: rviz_default_plugins/MoveCamera
+ - Class: rviz_default_plugins/Select
+ - Class: rviz_default_plugins/FocusCamera
+ - Class: rviz_default_plugins/Measure
+ Line color: 128; 128; 0
+ - Class: rviz_default_plugins/SetInitialPose
+ Covariance x: 0.25
+ Covariance y: 0.25
+ Covariance yaw: 0.06853891909122467
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /initialpose
+ - Class: rviz_default_plugins/SetGoal
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /goal_pose
+ - Class: rviz_default_plugins/PublishPoint
+ Single click: true
+ Topic:
+ Depth: 5
+ Durability Policy: Volatile
+ History Policy: Keep Last
+ Reliability Policy: Reliable
+ Value: /clicked_point
+ Transformation:
+ Current:
+ Class: rviz_default_plugins/TF
+ Value: true
+ Views:
+ Current:
+ Class: rviz_default_plugins/Orbit
+ Distance: 1.535581350326538
+ Enable Stereo Rendering:
+ Stereo Eye Separation: 0.05999999865889549
+ Stereo Focal Distance: 1
+ Swap Stereo Eyes: false
+ Value: false
+ Focal Point:
+ X: -0.1352316290140152
+ Y: 0.32156407833099365
+ Z: 0.4516058564186096
+ Focal Shape Fixed Size: true
+ Focal Shape Size: 0.05000000074505806
+ Invert Z Axis: true
+ Name: Current View
+ Near Clip Distance: 0.009999999776482582
+ Pitch: 1.4647964239120483
+ Target Frame:
+ Value: Orbit (rviz)
+ Yaw: 4.534939289093018
+ Saved: ~
+Window Geometry:
+ Displays:
+ collapsed: false
+ Height: 2742
+ Hide Left Dock: false
+ Hide Right Dock: false
+ Image:
+ collapsed: false
+ QMainWindow State: 000000ff00000000fd0000000400000000000003c0000009acfc020000000afb0000001200530065006c0065006300740069006f006e00000001e10000009b000000b200fffffffb0000001e0054006f006f006c002000500072006f007000650072007400690065007302000001ed000001df00000185000000a3fb000000120056006900650077007300200054006f006f02000001df000002110000018500000122fb000000200054006f006f006c002000500072006f0070006500720074006900650073003203000002880000011d000002210000017afb000000100044006900730070006c0061007900730100000070000006f70000018600fffffffb0000002000730065006c0065006300740069006f006e00200062007500660066006500720200000138000000aa0000023a00000294fb00000014005700690064006500530074006500720065006f02000000e6000000d2000003ee0000030bfb0000000c004b0069006e0065006300740200000186000001060000030c00000261fb0000000c00430061006d006500720061010000022f000000bc0000000000000000fb0000000a0049006d0061006700650100000773000002a90000002800ffffff000000010000015d000009acfc0200000003fb0000001e0054006f006f006c002000500072006f00700065007200740069006500730100000041000000780000000000000000fb0000000a005600690065007700730100000070000009ac0000013800fffffffb0000001200530065006c0065006300740069006f006e010000025a000000b200000000000000000000000200000490000000a9fc0100000001fb0000000a00560069006500770073030000004e00000080000002e100000197000000030000137c0000005efc0100000002fb0000000800540069006d006501000000000000137c0000047a00fffffffb0000000800540069006d0065010000000000000450000000000000000000000e47000009ac00000004000000040000000800000008fc0000000100000002000000010000000a0054006f006f006c00730100000000ffffffff0000000000000000
+ Selection:
+ collapsed: false
+ Time:
+ collapsed: false
+ Tool Properties:
+ collapsed: false
+ Views:
+ collapsed: false
+ Width: 4988
+ X: 132
+ Y: 64
diff --git a/src/table_height_predictor/setup.cfg b/src/table_height_predictor/setup.cfg
new file mode 100644
index 0000000..1d892df
--- /dev/null
+++ b/src/table_height_predictor/setup.cfg
@@ -0,0 +1,6 @@
+[develop]
+script_dir=$base/lib/table_height_predictor
+[install]
+install_scripts=$base/lib/table_height_predictor
+[build_scripts]
+executable = /usr/bin/env python3
diff --git a/src/table_height_predictor/setup.py b/src/table_height_predictor/setup.py
new file mode 100644
index 0000000..60af6e8
--- /dev/null
+++ b/src/table_height_predictor/setup.py
@@ -0,0 +1,27 @@
+from setuptools import find_packages, setup
+
+package_name = 'table_height_predictor'
+
+setup(
+ name=package_name,
+ version='0.0.0',
+ packages=find_packages(exclude=['test']),
+ data_files=[
+ ('share/ament_index/resource_index/packages',
+ ['resource/' + package_name]),
+ ('share/' + package_name, ['package.xml']),
+ ],
+ install_requires=['setuptools'],
+ zip_safe=True,
+ maintainer='mohsin',
+ maintainer_email='mohsinalimirxa@gmail.com',
+ description='TODO: Package description',
+ license='TODO: License declaration',
+ tests_require=['pytest'],
+ entry_points={
+ 'console_scripts': [
+ 'detect_floor = table_height_predictor.floor_detector_node:main',
+ 'table_height = table_height_predictor.table_height_node:main',
+ ],
+ },
+)
diff --git a/src/table_height_predictor/table_height_predictor/__init__.py b/src/table_height_predictor/table_height_predictor/__init__.py
new file mode 100644
index 0000000..e69de29
diff --git a/src/table_height_predictor/table_height_predictor/floor_detector_node.py b/src/table_height_predictor/table_height_predictor/floor_detector_node.py
new file mode 100644
index 0000000..a929385
--- /dev/null
+++ b/src/table_height_predictor/table_height_predictor/floor_detector_node.py
@@ -0,0 +1,160 @@
+import rclpy
+from rclpy.node import Node
+from sensor_msgs.msg import PointCloud2
+from std_msgs.msg import Header
+import numpy as np
+import open3d as o3d
+import sensor_msgs_py.point_cloud2 as pc2
+
+# Import QoS classes
+from rclpy.qos import QoSProfile, QoSReliabilityPolicy, QoSHistoryPolicy
+
+# --- FIX 1: Import traceback for correct error logging ---
+import traceback
+
+class FloorDetectorNode(Node):
+ def __init__(self):
+ super().__init__('floor_detector_node')
+
+ # --- Parameters ---
+ self.declare_parameter('input_topic', '/camera/depth/color/points')
+ self.declare_parameter('distance_threshold', 0.02) # 2cm
+ self.declare_parameter('angle_threshold_deg', 45.0) # 10 degrees from Z-axis
+
+ input_topic = self.get_parameter('input_topic').get_parameter_value().string_value
+ self.distance_threshold = self.get_parameter('distance_threshold').get_parameter_value().double_value
+ self.angle_threshold_rad = np.deg2rad(self.get_parameter('angle_threshold_deg').get_parameter_value().double_value)
+
+ # --- Define the Sensor QoS Profile ---
+ qos_profile = QoSProfile(
+ reliability=QoSReliabilityPolicy.BEST_EFFORT,
+ history=QoSHistoryPolicy.KEEP_LAST,
+ depth=1
+ )
+
+ # --- Subscriber ---
+ self.subscription = self.create_subscription(
+ PointCloud2,
+ input_topic,
+ self.cloud_callback,
+ qos_profile # Use the sensor-specific QoS
+ )
+
+ # --- Publishers ---
+ self.floor_pub = self.create_publisher(PointCloud2, '/floor_cloud', 10)
+ self.other_pub = self.create_publisher(PointCloud2, '/other_cloud', 10)
+
+ self.get_logger().info(f"Floor Detector Node started. Subscribing to '{input_topic}'")
+
+ def cloud_callback(self, msg):
+ """Main callback: receives a point cloud, finds the floor, and republishes."""
+ self.get_logger().info("Callback triggered! Processing cloud...")
+
+ try:
+ # --- FIX 2: Simplify the conversion ---
+ # We assume read_points_numpy with field_names gives us a simple (N, 3) array
+ xyz_data = pc2.read_points_numpy(
+ msg,
+ field_names=("x", "y", "z"),
+ skip_nans=True
+ )
+
+ if xyz_data.size == 0:
+ self.get_logger().warn("Point list is EMPTY. Is the camera covered or facing the sky?")
+ return
+
+ self.get_logger().info(f"Successfully converted to array with shape: {xyz_data.shape}")
+
+ except Exception as e:
+ # --- FIX 1: Correct error logging ---
+ self.get_logger().error(f"Failed to convert PointCloud2 to NumPy: {e}")
+ self.get_logger().error(f"TRACEBACK: {traceback.format_exc()}")
+ return
+ # --- End Fix 1 ---
+
+ if xyz_data.size == 0:
+ self.get_logger().info("Numpy array is empty. Skipping.")
+ return
+
+ # 3. Convert NumPy array to Open3D PointCloud object
+ pcd = o3d.geometry.PointCloud()
+
+ # Open3D's Vector3dVector expects float64, so we ensure the type is correct.
+ pcd.points = o3d.utility.Vector3dVector(xyz_data.astype(np.float64))
+
+ # 4. Run RANSAC to find the largest plane
+ self.get_logger().info("Running RANSAC...")
+ try:
+ plane_model, inlier_indices = pcd.segment_plane(
+ distance_threshold=self.distance_threshold,
+ ransac_n=3,
+ num_iterations=1000
+ )
+ except Exception as e:
+ self.get_logger().warn(f"RANSAC segmentation failed: {e}")
+ self.get_logger().warn(f"TRACEBACK: {traceback.format_exc()}")
+ return
+
+ if not inlier_indices:
+ self.get_logger().info("No plane found. Publishing all points as 'other'.")
+ self.other_pub.publish(msg) # Publish original cloud
+ return
+
+ # 5. Check if the plane is the "floor"
+ [a, b, c, d] = plane_model
+ normal = np.array([a, b, c])
+ normal = normal / np.linalg.norm(normal) # Normalize
+
+ ### --- THIS IS THE FIX --- ###
+ # "Up" in the camera frame is the Y-axis, not the Z-axis.
+ up_vector = np.array([0, 1, 0])
+
+ angle_rad = np.arccos(np.clip(np.abs(normal.dot(up_vector)), -1.0, 1.0))
+ ### --- END OF FIX --- ###
+
+ angle_deg = np.rad2deg(angle_rad)
+
+ # 6. Select points based on whether the floor was found
+ if angle_rad <= self.angle_threshold_rad:
+ # (rest of your code is correct)
+ self.get_logger().info(f"Floor plane found with {len(inlier_indices)} points. Angle: {angle_deg:.1f} deg")
+ floor_pcd = pcd.select_by_index(inlier_indices)
+ other_pcd = pcd.select_by_index(inlier_indices, invert=True)
+ floor_points = np.asarray(floor_pcd.points)
+ other_points = np.asarray(other_pcd.points)
+ else:
+ self.get_logger().info(f"Plane found (angle: {angle_deg:.1f} deg), but it's not the floor.")
+ floor_points = np.array([]) # Empty array
+ other_points = xyz_data # All points are "other"
+
+ # 7. Convert NumPy arrays back to ROS PointCloud2 messages
+ header = msg.header # Re-use the original header
+
+ if floor_points.size > 0:
+ floor_msg = self.create_point_cloud_msg(floor_points, header)
+ self.floor_pub.publish(floor_msg)
+
+ if other_points.size > 0:
+ other_msg = self.create_point_cloud_msg(other_points, header)
+ self.other_pub.publish(other_msg)
+
+ def create_point_cloud_msg(self, points, header: Header) -> PointCloud2:
+ """Helper function to create a PointCloud2 message from a NumPy array."""
+ # This function creates a PointCloud2 message for only XYZ data
+ # `points` is an (N, 3) NumPy array
+ return pc2.create_cloud_xyz32(header, points.astype(np.float32))
+
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = FloorDetectorNode()
+ try:
+ rclpy.spin(node)
+ except KeyboardInterrupt:
+ pass
+ finally:
+ node.destroy_node()
+ rclpy.shutdown()
+
+if __name__ == '__main__':
+ main()
\ No newline at end of file
diff --git a/src/table_height_predictor/table_height_predictor/table_height_node.py b/src/table_height_predictor/table_height_predictor/table_height_node.py
new file mode 100644
index 0000000..758f9df
--- /dev/null
+++ b/src/table_height_predictor/table_height_predictor/table_height_node.py
@@ -0,0 +1,242 @@
+import rclpy
+from rclpy.node import Node
+import message_filters
+from sensor_msgs.msg import Image, PointCloud2
+from visualization_msgs.msg import Marker, MarkerArray # Changed to MarkerArray
+from cv_bridge import CvBridge
+import sensor_msgs_py.point_cloud2 as pc2
+import numpy as np
+import cv2
+import torch
+from ultralytics import YOLOWorld, SAM
+from sklearn.linear_model import RANSACRegressor # Added for Floor Math
+
+class TableHeightNode(Node):
+ def __init__(self):
+ super().__init__('table_height_estimator')
+
+ # --- CONFIGURATION ---
+ self.img_topic = '/camera/color/image_raw'
+ self.pc_topic = '/camera/depth/color/points'
+ self.custom_classes = ["white standing desk", "white table surface"]
+ self.conf_threshold = 0.2
+ self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
+
+ # --- PUBLISHERS ---
+ # We use MarkerArray now to draw Table, Floor, Line, and Text all at once
+ self.marker_pub = self.create_publisher(MarkerArray, '/table_height_visualization', 10)
+ self.debug_pc_pub = self.create_publisher(PointCloud2, '/table_points_debug', 10)
+ self.seg_img_pub = self.create_publisher(Image, '/table_segmentation_image', 10)
+
+ # --- MODEL INITIALIZATION ---
+ self.get_logger().info(f"Loading models on {self.device}...")
+ self.det_model = YOLOWorld('yolov8l-worldv2.pt')
+ self.det_model.set_classes(self.custom_classes)
+ self.det_model.to(self.device)
+ self.seg_model = SAM('sam_b.pt')
+ self.seg_model.to(self.device)
+
+ # --- ROS SETUP ---
+ self.bridge = CvBridge()
+ self.img_sub = message_filters.Subscriber(self, Image, self.img_topic)
+ self.pc_sub = message_filters.Subscriber(self, PointCloud2, self.pc_topic)
+ self.ts = message_filters.ApproximateTimeSynchronizer(
+ [self.img_sub, self.pc_sub], queue_size=10, slop=0.1
+ )
+ self.ts.registerCallback(self.callback)
+
+ self.get_logger().info("Table Height Node Initialized.")
+
+ def callback(self, img_msg, pc_msg):
+ try:
+ cv_image = self.bridge.imgmsg_to_cv2(img_msg, desired_encoding='bgr8')
+ except Exception as e:
+ self.get_logger().error(f"CvBridge Error: {e}")
+ return
+
+ # 1. YOLO-World (Find Table)
+ det_results = self.det_model.predict(cv_image, conf=self.conf_threshold, verbose=False)
+ bboxes = det_results[0].boxes.xyxy.tolist()
+ if not bboxes: return
+
+ # 2. SAM (Segment Table)
+ table_box = [bboxes[0]]
+ seg_results = self.seg_model(cv_image, bboxes=table_box, verbose=False)
+ if seg_results[0].masks is None: return
+ table_mask = seg_results[0].masks.data[0].cpu().numpy()
+
+ # 3. Visualization Image
+ self.publish_debug_image(cv_image, table_mask, bboxes[0], img_msg.header)
+
+ # 4. Calculate Height Logic
+ self.process_point_cloud(pc_msg, table_mask)
+
+ def process_point_cloud(self, pc_msg, table_mask):
+ if pc_msg.height <= 1: return
+
+ # --- A. Parse PointCloud into (H, W, 3) Array ---
+ # (Optimized parsing logic)
+ raw_data = np.frombuffer(pc_msg.data, dtype=np.uint8)
+ try:
+ raw_data = raw_data.reshape(pc_msg.height, pc_msg.row_step)
+ except ValueError: return
+
+ bytes_per_pixel = pc_msg.point_step
+ raw_data = raw_data[:, :pc_msg.width * bytes_per_pixel]
+ pixel_chunks = raw_data.reshape(pc_msg.height, pc_msg.width, bytes_per_pixel)
+
+ # Get field offsets
+ off_x, off_y, off_z = 0, 4, 8
+ for field in pc_msg.fields:
+ if field.name == 'x': off_x = field.offset
+ if field.name == 'y': off_y = field.offset
+ if field.name == 'z': off_z = field.offset
+
+ x = pixel_chunks[:, :, off_x : off_x+4].view(dtype=np.float32).squeeze()
+ y = pixel_chunks[:, :, off_y : off_y+4].view(dtype=np.float32).squeeze()
+ z = pixel_chunks[:, :, off_z : off_z+4].view(dtype=np.float32).squeeze()
+
+ points_3d = np.dstack((x, y, z)) # Shape: (H, W, 3)
+
+ # --- B. Get Table Center ---
+ table_pts = points_3d[table_mask]
+ valid_table = table_pts[~np.isnan(table_pts).any(axis=1)]
+ if valid_table.shape[0] < 50: return
+
+ t_x = np.median(valid_table[:, 0])
+ t_y = np.median(valid_table[:, 1])
+ t_z = np.median(valid_table[:, 2])
+
+ # --- C. Get Floor Position (RANSAC) ---
+ # Strategy: Use points from bottom 50% of image that are NOT the table
+ h, w, _ = points_3d.shape
+ # Create a mask for "potential floor" (bottom half of image)
+ floor_region_mask = np.zeros((h, w), dtype=bool)
+ floor_region_mask[int(h*0.5):, :] = True
+
+ # Exclude the table itself from floor candidates
+ floor_candidates_mask = floor_region_mask & (~table_mask)
+
+ floor_pts = points_3d[floor_candidates_mask]
+ # Subsample for speed (take every 10th point)
+ floor_pts = floor_pts[::10]
+ valid_floor = floor_pts[~np.isnan(floor_pts).any(axis=1)]
+
+ floor_y_at_table = None
+
+ if valid_floor.shape[0] > 100:
+ # RANSAC: Fit plane y = f(x, z)
+ # We assume floor height (y) depends on horizontal (x) and depth (z)
+ X_in = valid_floor[:, [0, 2]] # Inputs: x, z
+ Y_out = valid_floor[:, 1] # Output: y (height)
+
+ ransac = RANSACRegressor(residual_threshold=0.05)
+ try:
+ ransac.fit(X_in, Y_out)
+
+ # KEY STEP: Predict floor Y specifically at Table's X and Z
+ floor_y_at_table = ransac.predict([[t_x, t_z]])[0]
+
+ # Sanity Check: Floor must be visibly lower (higher Y value) than table
+ if floor_y_at_table < t_y + 0.1:
+ floor_y_at_table = None # Invalid, floor appeared above table
+ except:
+ pass
+
+ # --- D. Visualize ---
+ self.publish_markers(t_x, t_y, t_z, floor_y_at_table, pc_msg.header)
+
+ # Publish Debug Cloud (Table Only)
+ debug_cloud = pc2.create_cloud_xyz32(pc_msg.header, valid_table)
+ self.debug_pc_pub.publish(debug_cloud)
+
+ def publish_markers(self, tx, ty, tz, fy, header):
+ marker_array = MarkerArray()
+
+ # 1. Table Marker (Red Sphere)
+ m_table = Marker()
+ m_table.header = header
+ m_table.ns = "table"
+ m_table.id = 0
+ m_table.type = Marker.SPHERE
+ m_table.action = Marker.ADD
+ m_table.pose.position.x, m_table.pose.position.y, m_table.pose.position.z = float(tx), float(ty), float(tz)
+ m_table.scale.x = m_table.scale.y = m_table.scale.z = 0.08
+ m_table.color.r, m_table.color.g, m_table.color.b, m_table.color.a = 1.0, 0.0, 0.0, 1.0
+ marker_array.markers.append(m_table)
+
+ log_msg = f"Table Z: {tz:.2f}m"
+
+ if fy is not None:
+ # Calculate Height
+ height_meters = abs(fy - ty)
+ log_msg += f" | Floor Est: {fy:.2f}m | HEIGHT: {height_meters:.3f}m"
+
+ # 2. Floor Marker (Green Flat Cube)
+ m_floor = Marker()
+ m_floor.header = header
+ m_floor.ns = "floor"
+ m_floor.id = 1
+ m_floor.type = Marker.CUBE
+ m_floor.action = Marker.ADD
+ # Uses Table X/Z but Floor Y
+ m_floor.pose.position.x, m_floor.pose.position.y, m_floor.pose.position.z = float(tx), float(fy), float(tz)
+ m_floor.scale.x, m_floor.scale.z = 0.2, 0.2
+ m_floor.scale.y = 0.005 # Thin
+ m_floor.color.r, m_floor.color.g, m_floor.color.b, m_floor.color.a = 0.0, 1.0, 0.0, 1.0
+ marker_array.markers.append(m_floor)
+
+ # 3. Connection Line (Yellow)
+ m_line = Marker()
+ m_line.header = header
+ m_line.ns = "line"
+ m_line.id = 2
+ m_line.type = Marker.LINE_LIST
+ m_line.action = Marker.ADD
+ m_line.scale.x = 0.005 # Line thickness
+ m_line.color.r, m_line.color.g, m_line.color.b, m_line.color.a = 1.0, 1.0, 0.0, 1.0
+ m_line.points.append(m_table.pose.position)
+ m_line.points.append(m_floor.pose.position)
+ marker_array.markers.append(m_line)
+
+ # 4. Text Label (Height Value)
+ m_text = Marker()
+ m_text.header = header
+ m_text.ns = "text"
+ m_text.id = 3
+ m_text.type = Marker.TEXT_VIEW_FACING
+ m_text.action = Marker.ADD
+ m_text.text = f"{height_meters:.2f}m"
+ m_text.pose.position.x = float(tx) + 0.15 # Offset text to right
+ m_text.pose.position.y = (ty + fy) / 2.0 # Center of line
+ m_text.pose.position.z = float(tz)
+ m_text.scale.z = 0.05 # Text size
+ m_text.color.r, m_text.color.g, m_text.color.b, m_text.color.a = 1.0, 1.0, 1.0, 1.0
+ marker_array.markers.append(m_text)
+
+ self.get_logger().info(log_msg)
+ self.marker_pub.publish(marker_array)
+
+ def publish_debug_image(self, cv_image, mask, bbox, header):
+ overlay = cv_image.copy()
+ overlay[mask] = [0, 255, 0]
+ blended = cv2.addWeighted(overlay, 0.4, cv_image, 0.6, 0)
+ x1, y1, x2, y2 = map(int, bbox)
+ cv2.rectangle(blended, (x1, y1), (x2, y2), (0,0,255), 2)
+
+ msg = self.bridge.cv2_to_imgmsg(blended, encoding="bgr8")
+ msg.header = header
+ self.seg_img_pub.publish(msg)
+
+def main(args=None):
+ rclpy.init(args=args)
+ node = TableHeightNode()
+ try:
+ rclpy.spin(node)
+ except KeyboardInterrupt: pass
+ finally:
+ node.destroy_node()
+ rclpy.shutdown()
+
+if __name__ == '__main__':
+ main()
\ No newline at end of file
diff --git a/src/table_height_predictor/test/test_copyright.py b/src/table_height_predictor/test/test_copyright.py
new file mode 100644
index 0000000..97a3919
--- /dev/null
+++ b/src/table_height_predictor/test/test_copyright.py
@@ -0,0 +1,25 @@
+# Copyright 2015 Open Source Robotics Foundation, Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from ament_copyright.main import main
+import pytest
+
+
+# Remove the `skip` decorator once the source file(s) have a copyright header
+@pytest.mark.skip(reason='No copyright header has been placed in the generated source file.')
+@pytest.mark.copyright
+@pytest.mark.linter
+def test_copyright():
+ rc = main(argv=['.', 'test'])
+ assert rc == 0, 'Found errors'
diff --git a/src/table_height_predictor/test/test_flake8.py b/src/table_height_predictor/test/test_flake8.py
new file mode 100644
index 0000000..27ee107
--- /dev/null
+++ b/src/table_height_predictor/test/test_flake8.py
@@ -0,0 +1,25 @@
+# Copyright 2017 Open Source Robotics Foundation, Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from ament_flake8.main import main_with_errors
+import pytest
+
+
+@pytest.mark.flake8
+@pytest.mark.linter
+def test_flake8():
+ rc, errors = main_with_errors(argv=[])
+ assert rc == 0, \
+ 'Found %d code style errors / warnings:\n' % len(errors) + \
+ '\n'.join(errors)
diff --git a/src/table_height_predictor/test/test_pep257.py b/src/table_height_predictor/test/test_pep257.py
new file mode 100644
index 0000000..b234a38
--- /dev/null
+++ b/src/table_height_predictor/test/test_pep257.py
@@ -0,0 +1,23 @@
+# Copyright 2015 Open Source Robotics Foundation, Inc.
+#
+# Licensed under the Apache License, Version 2.0 (the "License");
+# you may not use this file except in compliance with the License.
+# You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing, software
+# distributed under the License is distributed on an "AS IS" BASIS,
+# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
+# See the License for the specific language governing permissions and
+# limitations under the License.
+
+from ament_pep257.main import main
+import pytest
+
+
+@pytest.mark.linter
+@pytest.mark.pep257
+def test_pep257():
+ rc = main(argv=['.', 'test'])
+ assert rc == 0, 'Found code style errors / warnings'