 +
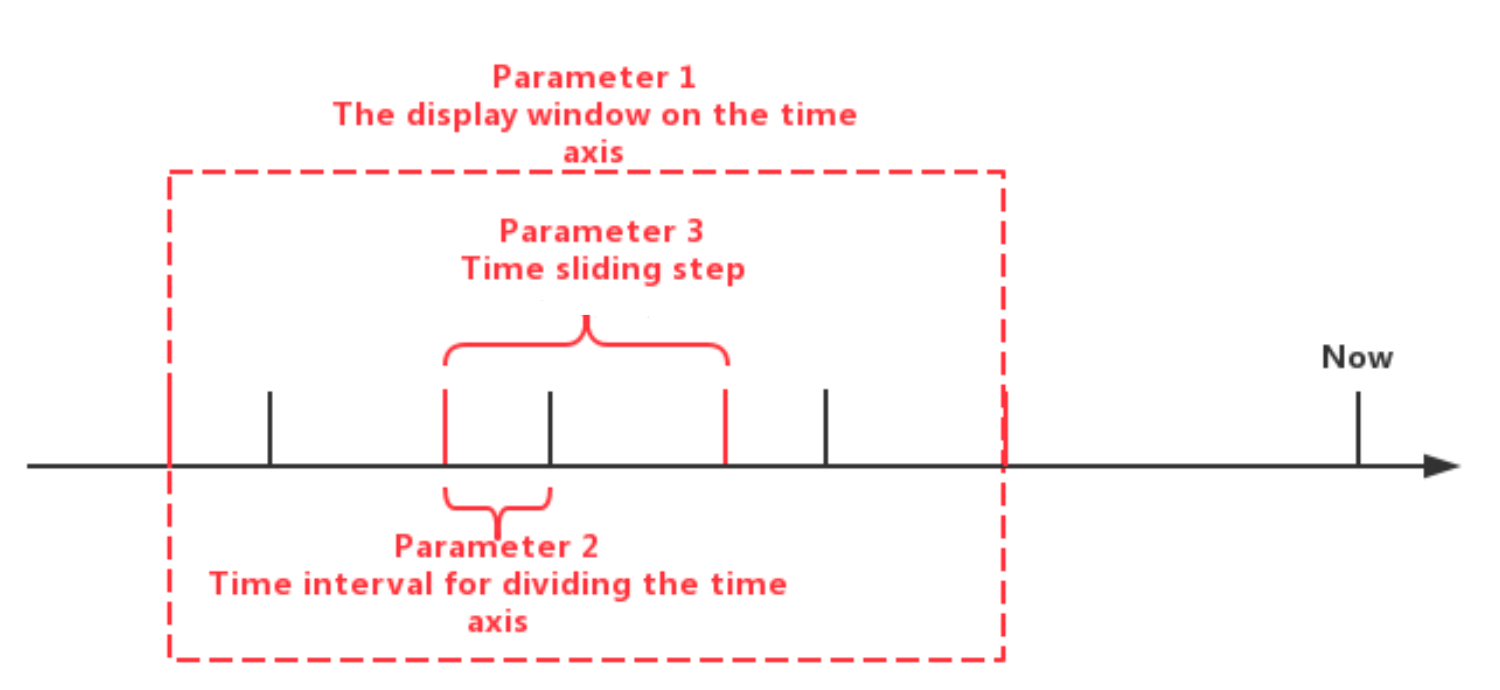
+`SlidingTimeWindowAccessStrategy`: `SlidingTimeWindowAccessStrategy` has many constructors, you can pass 3 types of parameters to them:
+
+- Parameter 1: The display window on the time axis
+
+The first type of parameters are optional. If the parameters are not provided, the beginning time of the display window will be set to the same as the minimum timestamp of the query result set, and the ending time of the display window will be set to the same as the maximum timestamp of the query result set.
+
+- Parameter 2: Time interval for dividing the time axis (should be positive)
+- Parameter 3: Time sliding step (not required to be greater than or equal to the time interval, but must be a positive number)
+
+The sliding step parameter is also optional. If the parameter is not provided, the sliding step will be set to the same as the time interval for dividing the time axis.
+
+The relationship between the three types of parameters can be seen in the figure below. Please see the Javadoc for more details.
+
+
+
+`SlidingTimeWindowAccessStrategy`: `SlidingTimeWindowAccessStrategy` has many constructors, you can pass 3 types of parameters to them:
+
+- Parameter 1: The display window on the time axis
+
+The first type of parameters are optional. If the parameters are not provided, the beginning time of the display window will be set to the same as the minimum timestamp of the query result set, and the ending time of the display window will be set to the same as the maximum timestamp of the query result set.
+
+- Parameter 2: Time interval for dividing the time axis (should be positive)
+- Parameter 3: Time sliding step (not required to be greater than or equal to the time interval, but must be a positive number)
+
+The sliding step parameter is also optional. If the parameter is not provided, the sliding step will be set to the same as the time interval for dividing the time axis.
+
+The relationship between the three types of parameters can be seen in the figure below. Please see the Javadoc for more details.
+
+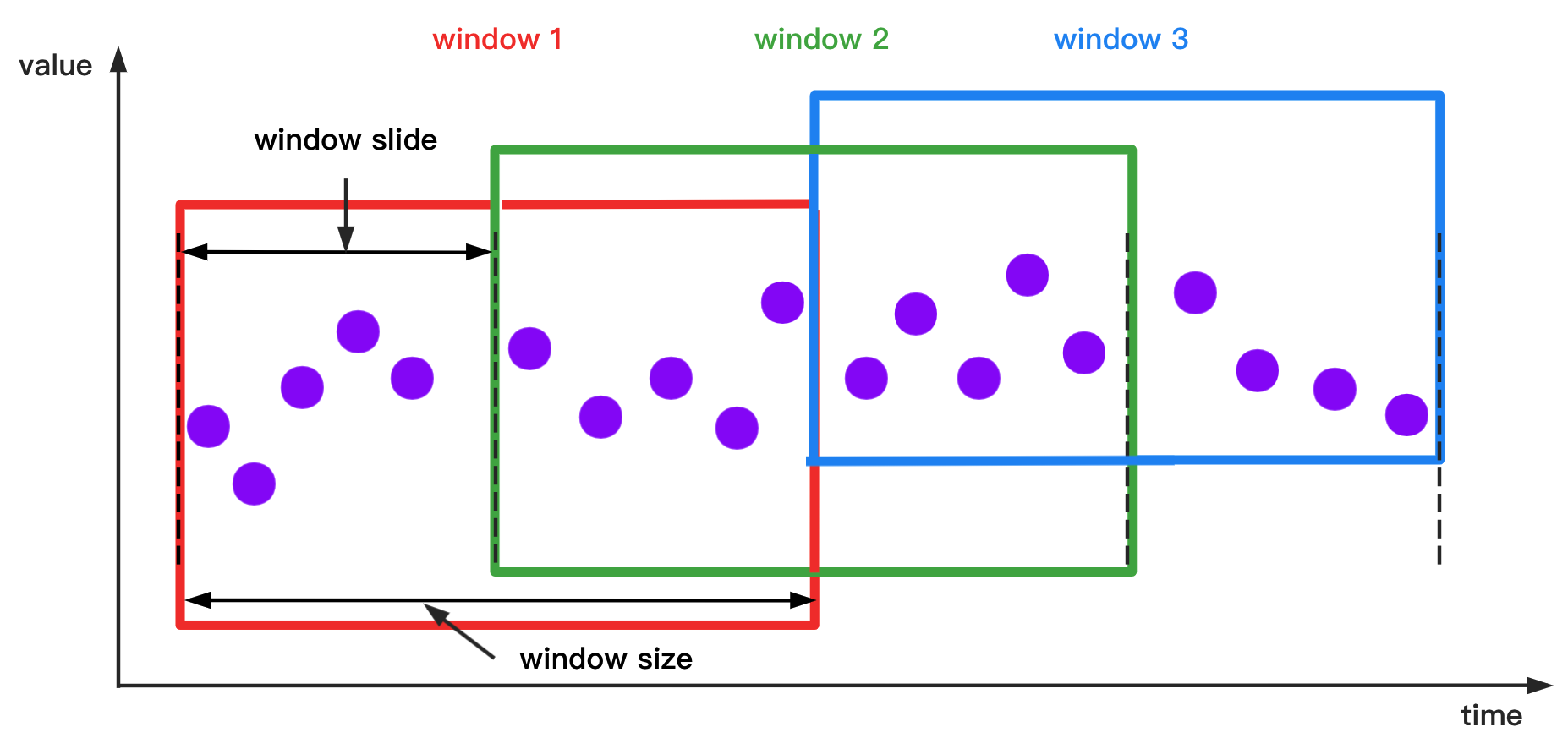 +
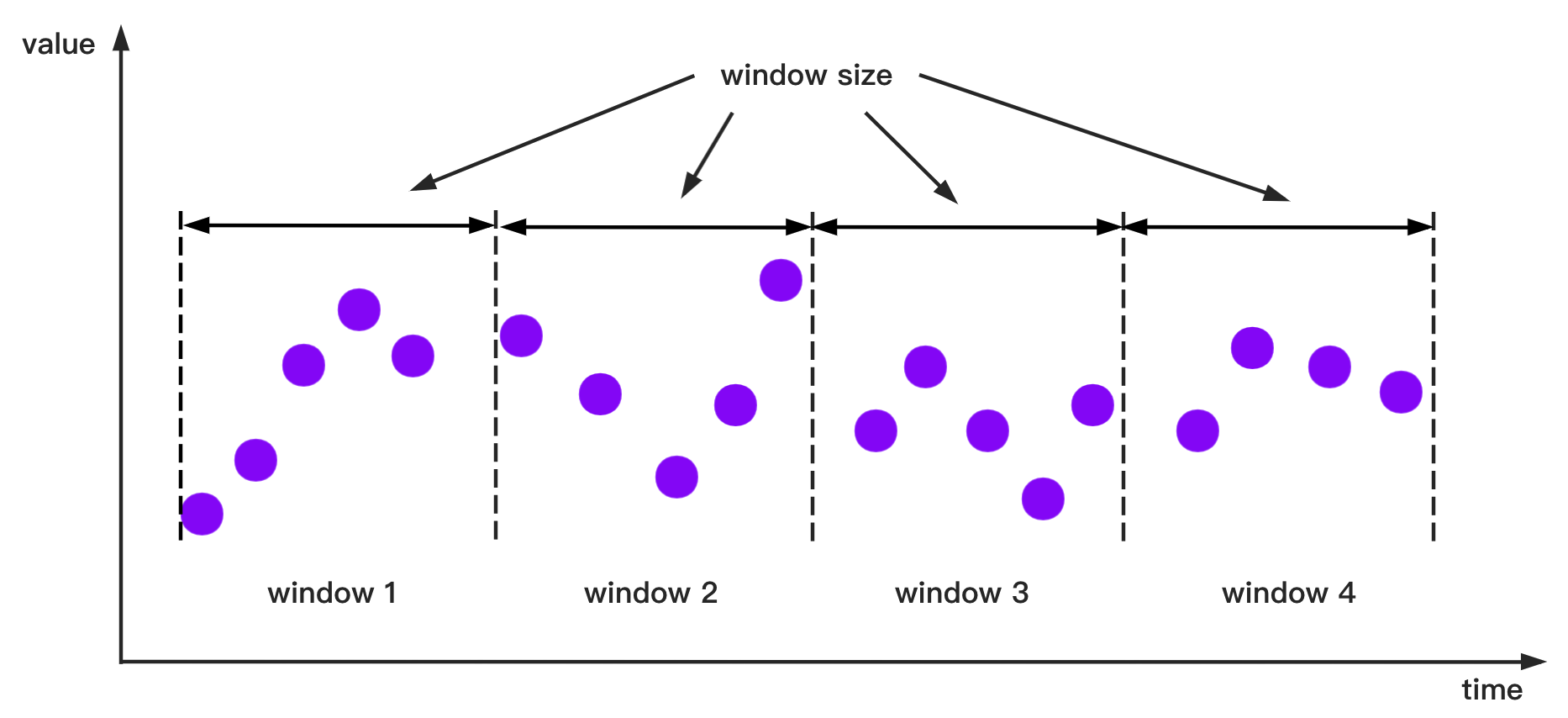
+`SlidingSizeWindowAccessStrategy`: `SlidingSizeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
+
+* Parameter 1: Window size. This parameter specifies the number of data rows contained in a data processing window. Note that the number of data rows in some of the last time windows may be less than the specified number of data rows.
+* Parameter 2: Sliding step. This parameter means the number of rows between the first point of the next window and the first point of the current window. (This parameter is not required to be greater than or equal to the window size, but must be a positive number)
+
+The sliding step parameter is optional. If the parameter is not provided, the sliding step will be set to the same as the window size.
+
+- `SessionTimeWindowAccessStrategy`
+
+Window opening diagram: **Time intervals less than or equal to the given minimum time interval `sessionGap` are assigned in one group.**
+
+
+
+`SlidingSizeWindowAccessStrategy`: `SlidingSizeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
+
+* Parameter 1: Window size. This parameter specifies the number of data rows contained in a data processing window. Note that the number of data rows in some of the last time windows may be less than the specified number of data rows.
+* Parameter 2: Sliding step. This parameter means the number of rows between the first point of the next window and the first point of the current window. (This parameter is not required to be greater than or equal to the window size, but must be a positive number)
+
+The sliding step parameter is optional. If the parameter is not provided, the sliding step will be set to the same as the window size.
+
+- `SessionTimeWindowAccessStrategy`
+
+Window opening diagram: **Time intervals less than or equal to the given minimum time interval `sessionGap` are assigned in one group.**
+
+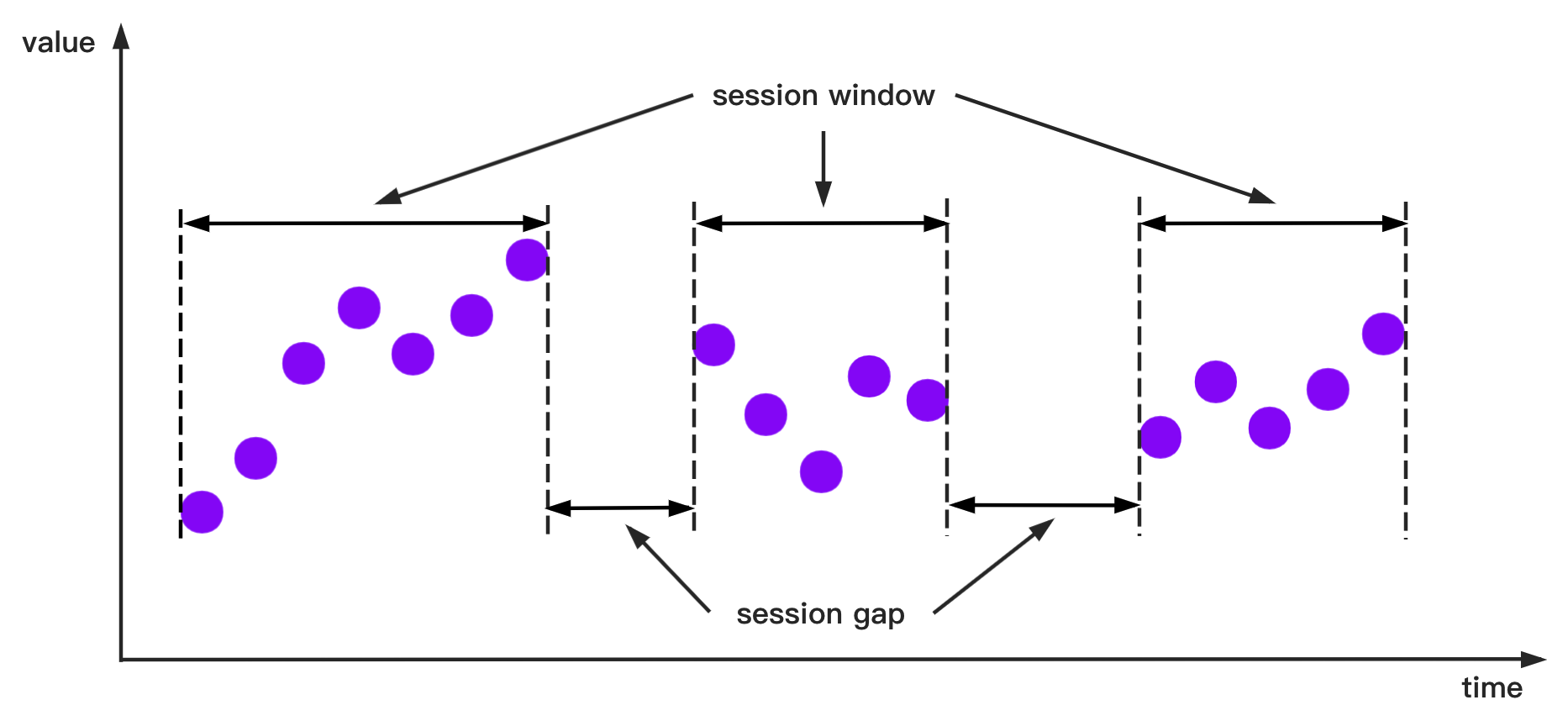 +
+`SessionTimeWindowAccessStrategy`: `SessionTimeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
+
+- Parameter 1: The display window on the time axis.
+- Parameter 2: The minimum time interval `sessionGap` of two adjacent windows.
+
+- `StateWindowAccessStrategy`
+
+Window opening diagram: **For numerical data, if the state difference is less than or equal to the given threshold `delta`, it will be assigned in one group.**
+
+
+
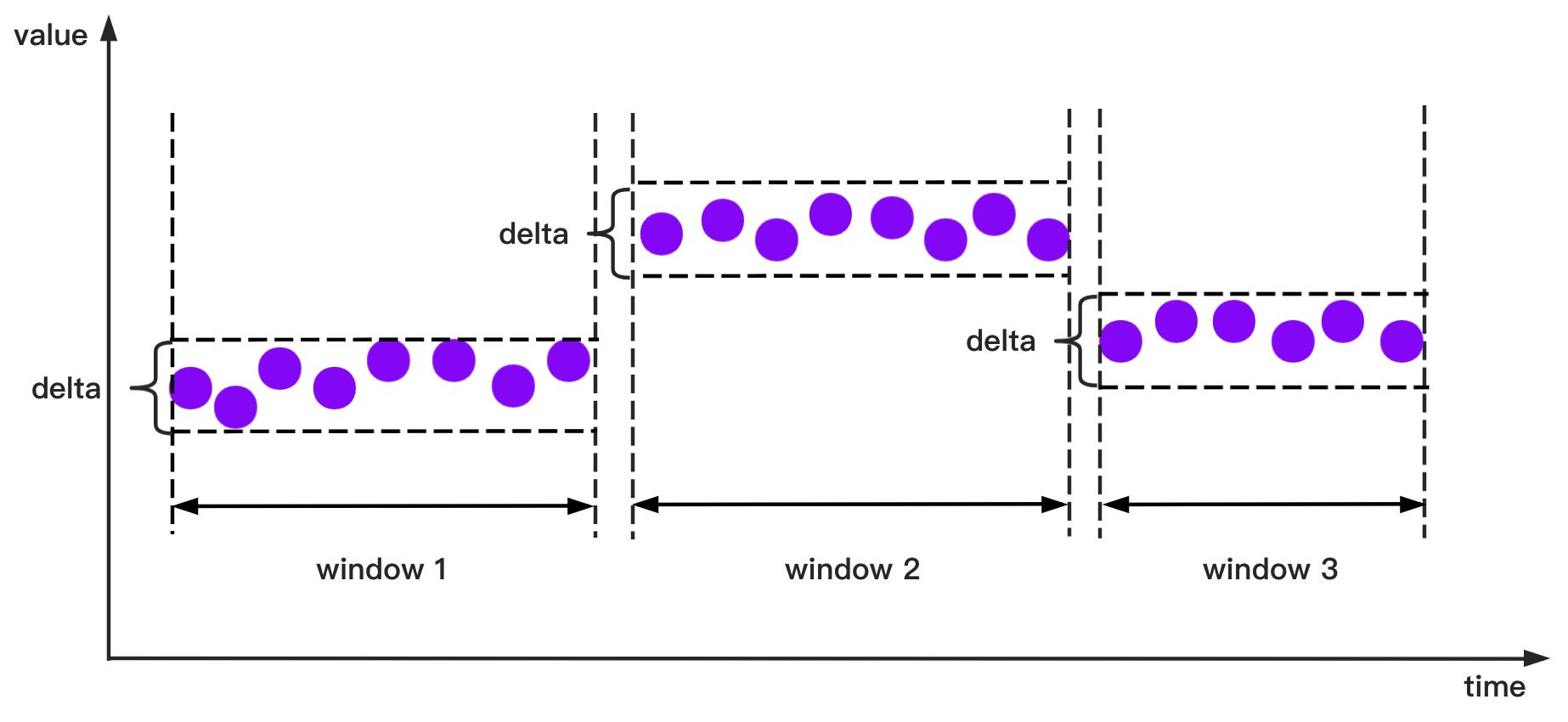
+`SessionTimeWindowAccessStrategy`: `SessionTimeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
+
+- Parameter 1: The display window on the time axis.
+- Parameter 2: The minimum time interval `sessionGap` of two adjacent windows.
+
+- `StateWindowAccessStrategy`
+
+Window opening diagram: **For numerical data, if the state difference is less than or equal to the given threshold `delta`, it will be assigned in one group.**
+
+ +
+`StateWindowAccessStrategy` has four constructors.
+
+- Constructor 1: For numerical data, there are 3 parameters: the time axis can display the start and end time of the time window and the threshold `delta` for the allowable change within a single window.
+- Constructor 2: For text data and boolean data, there are 3 parameters: the time axis can be provided to display the start and end time of the time window. For both data types, the data within a single window is same, and there is no need to provide an allowable change threshold.
+- Constructor 3: For numerical data, there are 1 parameters: you can only provide the threshold delta that is allowed to change within a single window. The start time of the time axis display time window will be defined as the smallest timestamp in the entire query result set, and the time axis display time window end time will be defined as The largest timestamp in the entire query result set.
+- Constructor 4: For text data and boolean data, you can provide no parameter. The start and end timestamps are explained in Constructor 3.
+
+StateWindowAccessStrategy can only take one column as input for now.
+
+Please see the Javadoc for more details.
+
+ 2.2.2 **setOutputDataType**
+
+Note that the type of output sequence you set here determines the type of data that the `PointCollector` can actually receive in the `transform` method. The relationship between the output data type set in `setOutputDataType` and the actual data output type that `PointCollector` can receive is as follows:
+
+| Output Data Type Set in `setOutputDataType` | Data Type that `PointCollector` Can Receive |
+| :------------------------------------------ | :----------------------------------------------------------- |
+| INT32 | int |
+| INT64 | long |
+| FLOAT | float |
+| DOUBLE | double |
+| BOOLEAN | boolean |
+| TEXT | java.lang.String and org.apache.iotdb.udf.api.type.Binar` |
+
+The type of output time series of a UDTF is determined at runtime, which means that a UDTF can dynamically determine the type of output time series according to the type of input time series.
+Here is a simple example:
+
+```java
+void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
+ // do something
+ // ...
+
+ configurations
+ .setAccessStrategy(new RowByRowAccessStrategy())
+ .setOutputDataType(parameters.getDataType(0));
+}
+```
+
+3. **void transform(Row row, PointCollector collector) throws Exception**
+
+You need to implement this method when you specify the strategy of UDF to read the original data as `RowByRowAccessStrategy`.
+
+This method processes the raw data one row at a time. The raw data is input from `Row` and output by `PointCollector`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
+
+The following is a complete UDF example that implements the `void transform(Row row, PointCollector collector) throws Exception` method. It is an adder that receives two columns of time series as input. When two data points in a row are not `null`, this UDF will output the algebraic sum of these two data points.
+
+``` java
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Adder implements UDTF {
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT64)
+ .setAccessStrategy(new RowByRowAccessStrategy());
+ }
+
+ @Override
+ public void transform(Row row, PointCollector collector) throws Exception {
+ if (row.isNull(0) || row.isNull(1)) {
+ return;
+ }
+ collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
+ }
+}
+```
+
+4. **void transform(RowWindow rowWindow, PointCollector collector) throws Exception**
+
+You need to implement this method when you specify the strategy of UDF to read the original data as `SlidingTimeWindowAccessStrategy` or `SlidingSizeWindowAccessStrategy`.
+
+This method processes a batch of data in a fixed number of rows or a fixed time interval each time, and we call the container containing this batch of data a window. The raw data is input from `RowWindow` and output by `PointCollector`. `RowWindow` can help you access a batch of `Row`, it provides a set of interfaces for random access and iterative access to this batch of `Row`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
+
+Below is a complete UDF example that implements the `void transform(RowWindow rowWindow, PointCollector collector) throws Exception` method. It is a counter that receives any number of time series as input, and its function is to count and output the number of data rows in each time window within a specified time range.
+
+```java
+import java.io.IOException;
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.access.RowWindow;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Counter implements UDTF {
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT32)
+ .setAccessStrategy(new SlidingTimeWindowAccessStrategy(
+ parameters.getLong("time_interval"),
+ parameters.getLong("sliding_step"),
+ parameters.getLong("display_window_begin"),
+ parameters.getLong("display_window_end")));
+ }
+
+ @Override
+ public void transform(RowWindow rowWindow, PointCollector collector) {
+ if (rowWindow.windowSize() != 0) {
+ collector.putInt(rowWindow.windowStartTime(), rowWindow.windowSize());
+ }
+ }
+}
+```
+
+5. **void terminate(PointCollector collector) throws Exception**
+
+In some scenarios, a UDF needs to traverse all the original data to calculate the final output data points. The `terminate` interface provides support for those scenarios.
+
+This method is called after all `transform` calls are executed and before the `beforeDestory` method is executed. You can implement the `transform` method to perform pure data processing (without outputting any data points), and implement the `terminate` method to output the processing results.
+
+The processing results need to be output by the `PointCollector`. You can output any number of data points in one `terminate` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
+
+Below is a complete UDF example that implements the `void terminate(PointCollector collector) throws Exception` method. It takes one time series whose data type is `INT32` as input, and outputs the maximum value point of the series.
+
+```java
+import java.io.IOException;
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Max implements UDTF {
+
+ private Long time;
+ private int value;
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT32)
+ .setAccessStrategy(new RowByRowAccessStrategy());
+ }
+
+ @Override
+ public void transform(Row row, PointCollector collector) {
+ if (row.isNull(0)) {
+ return;
+ }
+ int candidateValue = row.getInt(0);
+ if (time == null || value < candidateValue) {
+ time = row.getTime();
+ value = candidateValue;
+ }
+ }
+
+ @Override
+ public void terminate(PointCollector collector) throws IOException {
+ if (time != null) {
+ collector.putInt(time, value);
+ }
+ }
+}
+```
+
+6. **void beforeDestroy()**
+
+The method for terminating a UDF.
+
+This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
+
+
+
+### UDAF (User Defined Aggregation Function)
+
+A complete definition of UDAF involves two classes, `State` and `UDAF`.
+
+#### State Class
+
+To write your own `State`, you need to implement the `org.apache.iotdb.udf.api.State` interface.
+
+#### Interface Description:
+
+| Interface Definition | Description | Required to Implement |
+| -------------------------------- | ------------------------------------------------------------ | --------------------- |
+| void reset() | To reset the `State` object to its initial state, you need to fill in the initial values of the fields in the `State` class within this method as if you were writing a constructor. | Required |
+| byte[] serialize() | Serializes `State` to binary data. This method is used for IoTDB internal `State` passing. Note that the order of serialization must be consistent with the following deserialization methods. | Required |
+| void deserialize(byte[] bytes) | Deserializes binary data to `State`. This method is used for IoTDB internal `State` passing. Note that the order of deserialization must be consistent with the serialization method above. | Required |
+
+#### Detailed interface introduction:
+
+1. **void reset()**
+
+This method resets the `State` to its initial state, you need to fill in the initial values of the fields in the `State` object in this method. For optimization reasons, IoTDB reuses `State` as much as possible internally, rather than creating a new `State` for each group, which would introduce unnecessary overhead. When `State` has finished updating the data in a group, this method is called to reset to the initial state as a way to process the next group.
+
+In the case of `State` for averaging (aka `avg`), for example, you would need the sum of the data, `sum`, and the number of entries in the data, `count`, and initialize both to 0 in the `reset()` method.
+
+```java
+class AvgState implements State {
+ double sum;
+
+ long count;
+
+ @Override
+ public void reset() {
+ sum = 0;
+ count = 0;
+ }
+
+ // other methods
+}
+```
+
+2. **byte[] serialize()/void deserialize(byte[] bytes)**
+
+These methods serialize the `State` into binary data, and deserialize the `State` from the binary data. IoTDB, as a distributed database, involves passing data among different nodes, so you need to write these two methods to enable the passing of the State among different nodes. Note that the order of serialization and deserialization must be the consistent.
+
+In the case of `State` for averaging (aka `avg`), for example, you can convert the content of State to `byte[]` array and read out the content of State from `byte[]` array in any way you want, the following shows the code for serialization/deserialization using `ByteBuffer` introduced by Java8:
+
+```java
+@Override
+public byte[] serialize() {
+ ByteBuffer buffer = ByteBuffer.allocate(Double.BYTES + Long.BYTES);
+ buffer.putDouble(sum);
+ buffer.putLong(count);
+
+ return buffer.array();
+}
+
+@Override
+public void deserialize(byte[] bytes) {
+ ByteBuffer buffer = ByteBuffer.wrap(bytes);
+ sum = buffer.getDouble();
+ count = buffer.getLong();
+}
+```
+
+
+
+#### UDAF Classes
+
+To write a UDAF, you need to implement the `org.apache.iotdb.udf.api.UDAF` interface.
+
+#### Interface Description:
+
+| Interface definition | Description | Required to Implement |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | --------------------- |
+| void validate(UDFParameterValidator validator) throws Exception | This method is mainly used to validate `UDFParameters` and it is executed before `beforeStart(UDFParameters, UDTFConfigurations)` is called. | Optional |
+| void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception | Initialization method that invokes user-defined initialization behavior before UDAF processes the input data. Unlike UDTF, configuration is of type `UDAFConfiguration`. | Required |
+| State createState() | To create a `State` object, usually just call the default constructor and modify the default initial value as needed. | Required |
+| void addInput(State state, Column[] columns, BitMap bitMap) | Update `State` object according to the incoming data `Column[]` in batch, note that last column `columns[columns.length - 1]` always represents the time column. In addition, `BitMap` represents the data that has been filtered out before, you need to manually determine whether the corresponding data has been filtered out when writing this method. | Required |
+| void combineState(State state, State rhs) | Merge `rhs` state into `state` state. In a distributed scenario, the same set of data may be distributed on different nodes, IoTDB generates a `State` object for the partial data on each node, and then calls this method to merge it into the complete `State`. | Required |
+| void outputFinal(State state, ResultValue resultValue) | Computes the final aggregated result based on the data in `State`. Note that according to the semantics of the aggregation, only one value can be output per group. | Required |
+| void beforeDestroy() | This method is called by the framework after the last input data is processed, and will only be called once in the life cycle of each UDF instance. | Optional |
+
+In the life cycle of a UDAF instance, the calling sequence of each method is as follows:
+
+1. State createState()
+2. void validate(UDFParameterValidator validator) throws Exception
+3. void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception
+4. void addInput(State state, Column[] columns, BitMap bitMap)
+5. void combineState(State state, State rhs)
+6. void outputFinal(State state, ResultValue resultValue)
+7. void beforeDestroy()
+
+Similar to UDTF, every time the framework executes a UDAF query, a new UDF instance will be constructed. When the query ends, the corresponding instance will be destroyed. Therefore, the internal data of the instances in different UDAF queries (even in the same SQL statement) are isolated. You can maintain some state data in the UDAF without considering the influence of concurrency and other factors.
+
+#### Detailed interface introduction:
+
+
+1. **void validate(UDFParameterValidator validator) throws Exception**
+
+Same as UDTF, the `validate` method is used to validate the parameters entered by the user.
+
+In this method, you can limit the number and types of input time series, check the attributes of user input, or perform any custom verification.
+
+2. **void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception**
+
+ The `beforeStart` method does the same thing as the UDAF:
+
+1. Use UDFParameters to get the time series paths and parse key-value pair attributes entered by the user.
+2. Set the strategy to access the raw data and set the output data type in UDAFConfigurations.
+3. Create resources, such as establishing external connections, opening files, etc.
+
+The role of the `UDFParameters` type can be seen above.
+
+2.2 **UDTFConfigurations**
+
+The difference from UDTF is that UDAF uses `UDAFConfigurations` as the type of `configuration` object.
+
+Currently, this class only supports setting the type of output data.
+
+```java
+void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
+ // parameters
+ // ...
+
+ // configurations
+ configurations
+ .setOutputDataType(Type.INT32); }
+}
+```
+
+The relationship between the output type set in `setOutputDataType` and the type of data output that `ResultValue` can actually receive is as follows:
+
+| The output type set in `setOutputDataType` | The output type that `ResultValue` can actually receive |
+| ------------------------------------------ | ------------------------------------------------------- |
+| INT32 | int |
+| INT64 | long |
+| FLOAT | float |
+| DOUBLE | double |
+| BOOLEAN | boolean |
+| TEXT | org.apache.iotdb.udf.api.type.Binary |
+
+The output type of the UDAF is determined at runtime. You can dynamically determine the output sequence type based on the input type.
+
+Here is a simple example:
+
+```java
+void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
+ // do something
+ // ...
+
+ configurations
+ .setOutputDataType(parameters.getDataType(0));
+}
+```
+
+3. **State createState()**
+
+
+This method creates and initializes a `State` object for UDAF. Due to the limitations of the Java language, you can only call the default constructor for the `State` class. The default constructor assigns a default initial value to all the fields in the class, and if that initial value does not meet your requirements, you need to initialize them manually within this method.
+
+The following is an example that includes manual initialization. Suppose you want to implement an aggregate function that multiply all numbers in the group, then your initial `State` value should be set to 1, but the default constructor initializes it to 0, so you need to initialize `State` manually after calling the default constructor:
+
+```java
+public State createState() {
+ MultiplyState state = new MultiplyState();
+ state.result = 1;
+ return state;
+}
+```
+
+4. **void addInput(State state, Column[] columns, BitMap bitMap)**
+
+This method updates the `State` object with the raw input data. For performance reasons, also to align with the IoTDB vectorized query engine, the raw input data is no longer a data point, but an array of columns ``Column[]``. Note that the last column (i.e. `columns[columns.length - 1]`) is always the time column, so you can also do different operations in UDAF depending on the time.
+
+Since the input parameter is not of a single data point type, but of multiple columns, you need to manually filter some of the data in the columns, which is why the third parameter, `BitMap`, exists. It identifies which of these columns have been filtered out, so you don't have to think about the filtered data in any case.
+
+Here's an example of `addInput()` that counts the number of items (aka count). It shows how you can use `BitMap` to ignore data that has been filtered out. Note that due to the limitations of the Java language, you need to do the explicit cast the `State` object from type defined in the interface to a custom `State` type at the beginning of the method, otherwise you won't be able to use the `State` object.
+
+```java
+public void addInput(State state, Column[] columns, BitMap bitMap) {
+ CountState countState = (CountState) state;
+
+ int count = columns[0].getPositionCount();
+ for (int i = 0; i < count; i++) {
+ if (bitMap != null && !bitMap.isMarked(i)) {
+ continue;
+ }
+ if (!columns[0].isNull(i)) {
+ countState.count++;
+ }
+ }
+}
+```
+
+5. **void combineState(State state, State rhs)**
+
+
+This method combines two `State`s, or more precisely, updates the first `State` object with the second `State` object. IoTDB is a distributed database, and the data of the same group may be distributed on different nodes. For performance reasons, IoTDB will first aggregate some of the data on each node into `State`, and then merge the `State`s on different nodes that belong to the same group, which is what `combineState` does.
+
+Here's an example of `combineState()` for averaging (aka avg). Similar to `addInput`, you need to do an explicit type conversion for the two `State`s at the beginning. Also note that you are updating the value of the first `State` with the contents of the second `State`.
+
+```java
+public void combineState(State state, State rhs) {
+ AvgState avgState = (AvgState) state;
+ AvgState avgRhs = (AvgState) rhs;
+
+ avgState.count += avgRhs.count;
+ avgState.sum += avgRhs.sum;
+}
+```
+
+6. **void outputFinal(State state, ResultValue resultValue)**
+
+This method works by calculating the final result from `State`. You need to access the various fields in `State`, derive the final result, and set the final result into the `ResultValue` object.IoTDB internally calls this method once at the end for each group. Note that according to the semantics of aggregation, the final result can only be one value.
+
+Here is another `outputFinal` example for averaging (aka avg). In addition to the forced type conversion at the beginning, you will also see a specific use of the `ResultValue` object, where the final result is set by `setXXX` (where `XXX` is the type name).
+
+```java
+public void outputFinal(State state, ResultValue resultValue) {
+ AvgState avgState = (AvgState) state;
+
+ if (avgState.count != 0) {
+ resultValue.setDouble(avgState.sum / avgState.count);
+ } else {
+ resultValue.setNull();
+ }
+}
+```
+
+7. **void beforeDestroy()**
+
+
+The method for terminating a UDF.
+
+This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
+
+
+### Maven Project Example
+
+If you use Maven, you can build your own UDF project referring to our **udf-example** module. You can find the project [here](https://github.com/apache/iotdb/tree/master/example/udf).
+
+
+## Contribute universal built-in UDF functions to iotdb
+
+This part mainly introduces how external users can contribute their own UDFs to the IoTDB community.
+
+#### Prerequisites
+
+1. UDFs must be universal.
+
+ The "universal" mentioned here refers to: UDFs can be widely used in some scenarios. In other words, the UDF function must have reuse value and may be directly used by other users in the community.
+
+ If you are not sure whether the UDF you want to contribute is universal, you can send an email to `dev@iotdb.apache.org` or create an issue to initiate a discussion.
+
+2. The UDF you are going to contribute has been well tested and can run normally in the production environment.
+
+
+#### What you need to prepare
+
+1. UDF source code
+2. Test cases
+3. Instructions
+
+#### UDF Source Code
+
+1. Create the UDF main class and related classes in `iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/udf/builtin` or in its subfolders.
+2. Register your UDF in `iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/udf/builtin/BuiltinTimeSeriesGeneratingFunction.java`.
+
+#### Test Cases
+
+At a minimum, you need to write integration tests for the UDF.
+
+You can add a test class in `integration-test/src/test/java/org/apache/iotdb/db/it/udf`.
+
+
+#### Instructions
+
+The instructions need to include: the name and the function of the UDF, the attribute parameters that must be provided when the UDF is executed, the applicable scenarios, and the usage examples, etc.
+
+The instructions for use should include both Chinese and English versions. Instructions for use should be added separately in `docs/zh/UserGuide/Operation Manual/DML Data Manipulation Language.md` and `docs/UserGuide/Operation Manual/DML Data Manipulation Language.md`.
+
+#### Submit a PR
+
+When you have prepared the UDF source code, test cases, and instructions, you are ready to submit a Pull Request (PR) on [Github](https://github.com/apache/iotdb). You can refer to our code contribution guide to submit a PR: [Development Guide](https://iotdb.apache.org/Community/Development-Guide.html).
+
+
+After the PR review is approved and merged, your UDF has already contributed to the IoTDB community!
diff --git a/src/UserGuide/Master/User-Manual/Database-Programming.md b/src/UserGuide/Master/User-Manual/Database-Programming.md
index 98f097c2d..9367c865e 100644
--- a/src/UserGuide/Master/User-Manual/Database-Programming.md
+++ b/src/UserGuide/Master/User-Manual/Database-Programming.md
@@ -1037,889 +1037,3 @@ SELECT avg(count_s1) from root.sg_count.d;
| `continuous_query_submit_thread` | The number of threads in the scheduled thread pool that submit continuous query tasks periodically | int32 | 2 |
| `continuous_query_min_every_interval_in_ms` | The minimum value of the continuous query execution time interval | duration | 1000 |
-## USER-DEFINED FUNCTION (UDF)
-
-IoTDB provides a variety of built-in functions to meet your computing needs, and you can also create user defined functions to meet more computing needs.
-
-This document describes how to write, register and use a UDF.
-
-
-### UDF Types
-
-In IoTDB, you can expand two types of UDF:
-
-| UDF Class | Description |
-| --------------------------------------------------- | ------------------------------------------------------------ |
-| UDTF(User Defined Timeseries Generating Function) | This type of function can take **multiple** time series as input, and output **one** time series, which can have any number of data points. |
-| UDAF(User Defined Aggregation Function) | Custom Aggregation Functions. This type of function can take one time series as input, and output **one** aggregated data point for each group based on the GROUP BY type. |
-
-### UDF Development Dependencies
-
-If you use [Maven](http://search.maven.org/), you can search for the development dependencies listed below from the [Maven repository](http://search.maven.org/) . Please note that you must select the same dependency version as the target IoTDB server version for development.
-
-``` xml
-
-
-`SlidingTimeWindowAccessStrategy`: `SlidingTimeWindowAccessStrategy` has many constructors, you can pass 3 types of parameters to them:
-
-- Parameter 1: The display window on the time axis
-- Parameter 2: Time interval for dividing the time axis (should be positive)
-- Parameter 3: Time sliding step (not required to be greater than or equal to the time interval, but must be a positive number)
-
-The first type of parameters are optional. If the parameters are not provided, the beginning time of the display window will be set to the same as the minimum timestamp of the query result set, and the ending time of the display window will be set to the same as the maximum timestamp of the query result set.
-
-The sliding step parameter is also optional. If the parameter is not provided, the sliding step will be set to the same as the time interval for dividing the time axis.
-
-The relationship between the three types of parameters can be seen in the figure below. Please see the Javadoc for more details.
-
-
-
-`SlidingSizeWindowAccessStrategy`: `SlidingSizeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
-
-* Parameter 1: Window size. This parameter specifies the number of data rows contained in a data processing window. Note that the number of data rows in some of the last time windows may be less than the specified number of data rows.
-* Parameter 2: Sliding step. This parameter means the number of rows between the first point of the next window and the first point of the current window. (This parameter is not required to be greater than or equal to the window size, but must be a positive number)
-
-The sliding step parameter is optional. If the parameter is not provided, the sliding step will be set to the same as the window size.
-
-The `SessionTimeWindowAccessStrategy` is shown schematically below. **Time intervals less than or equal to the given minimum time interval `sessionGap` are assigned in one group**
-
-
-`SessionTimeWindowAccessStrategy`: `SessionTimeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
-
-- Parameter 1: The display window on the time axis.
-- Parameter 2: The minimum time interval `sessionGap` of two adjacent windows.
-
-
-The `StateWindowAccessStrategy` is shown schematically below. **For numerical data, if the state difference is less than or equal to the given threshold `delta`, it will be assigned in one group. **
-
-
-`StateWindowAccessStrategy` has four constructors.
-
-- Constructor 1: For numerical data, there are 3 parameters: the time axis can display the start and end time of the time window and the threshold `delta` for the allowable change within a single window.
-- Constructor 2: For text data and boolean data, there are 3 parameters: the time axis can be provided to display the start and end time of the time window. For both data types, the data within a single window is same, and there is no need to provide an allowable change threshold.
-- Constructor 3: For numerical data, there are 1 parameters: you can only provide the threshold delta that is allowed to change within a single window. The start time of the time axis display time window will be defined as the smallest timestamp in the entire query result set, and the time axis display time window end time will be defined as The largest timestamp in the entire query result set.
-- Constructor 4: For text data and boolean data, you can provide no parameter. The start and end timestamps are explained in Constructor 3.
-
-StateWindowAccessStrategy can only take one column as input for now.
-
-Please see the Javadoc for more details.
-
-
-
-###### setOutputDataType
-
-Note that the type of output sequence you set here determines the type of data that the `PointCollector` can actually receive in the `transform` method. The relationship between the output data type set in `setOutputDataType` and the actual data output type that `PointCollector` can receive is as follows:
-
-| Output Data Type Set in `setOutputDataType` | Data Type that `PointCollector` Can Receive |
-| :------------------------------------------ | :----------------------------------------------------------- |
-| `INT32` | `int` |
-| `INT64` | `long` |
-| `FLOAT` | `float` |
-| `DOUBLE` | `double` |
-| `BOOLEAN` | `boolean` |
-| `TEXT` | `java.lang.String` and `org.apache.iotdb.udf.api.type.Binary` |
-
-The type of output time series of a UDTF is determined at runtime, which means that a UDTF can dynamically determine the type of output time series according to the type of input time series.
-Here is a simple example:
-
-```java
-void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
- // do something
- // ...
-
- configurations
- .setAccessStrategy(new RowByRowAccessStrategy())
- .setOutputDataType(parameters.getDataType(0));
-}
-```
-
-
-
-#### void transform(Row row, PointCollector collector) throws Exception
-
-You need to implement this method when you specify the strategy of UDF to read the original data as `RowByRowAccessStrategy`.
-
-This method processes the raw data one row at a time. The raw data is input from `Row` and output by `PointCollector`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
-
-The following is a complete UDF example that implements the `void transform(Row row, PointCollector collector) throws Exception` method. It is an adder that receives two columns of time series as input. When two data points in a row are not `null`, this UDF will output the algebraic sum of these two data points.
-
-``` java
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Adder implements UDTF {
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT64)
- .setAccessStrategy(new RowByRowAccessStrategy());
- }
-
- @Override
- public void transform(Row row, PointCollector collector) throws Exception {
- if (row.isNull(0) || row.isNull(1)) {
- return;
- }
- collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
- }
-}
-```
-
-
-
-#### void transform(RowWindow rowWindow, PointCollector collector) throws Exception
-
-You need to implement this method when you specify the strategy of UDF to read the original data as `SlidingTimeWindowAccessStrategy` or `SlidingSizeWindowAccessStrategy`.
-
-This method processes a batch of data in a fixed number of rows or a fixed time interval each time, and we call the container containing this batch of data a window. The raw data is input from `RowWindow` and output by `PointCollector`. `RowWindow` can help you access a batch of `Row`, it provides a set of interfaces for random access and iterative access to this batch of `Row`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
-
-Below is a complete UDF example that implements the `void transform(RowWindow rowWindow, PointCollector collector) throws Exception` method. It is a counter that receives any number of time series as input, and its function is to count and output the number of data rows in each time window within a specified time range.
-
-```java
-import java.io.IOException;
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.access.RowWindow;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Counter implements UDTF {
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT32)
- .setAccessStrategy(new SlidingTimeWindowAccessStrategy(
- parameters.getLong("time_interval"),
- parameters.getLong("sliding_step"),
- parameters.getLong("display_window_begin"),
- parameters.getLong("display_window_end")));
- }
-
- @Override
- public void transform(RowWindow rowWindow, PointCollector collector) {
- if (rowWindow.windowSize() != 0) {
- collector.putInt(rowWindow.windowStartTime(), rowWindow.windowSize());
- }
- }
-}
-```
-
-
-
-#### void terminate(PointCollector collector) throws Exception
-
-In some scenarios, a UDF needs to traverse all the original data to calculate the final output data points. The `terminate` interface provides support for those scenarios.
-
-This method is called after all `transform` calls are executed and before the `beforeDestory` method is executed. You can implement the `transform` method to perform pure data processing (without outputting any data points), and implement the `terminate` method to output the processing results.
-
-The processing results need to be output by the `PointCollector`. You can output any number of data points in one `terminate` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
-
-Below is a complete UDF example that implements the `void terminate(PointCollector collector) throws Exception` method. It takes one time series whose data type is `INT32` as input, and outputs the maximum value point of the series.
-
-```java
-import java.io.IOException;
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Max implements UDTF {
-
- private Long time;
- private int value;
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT32)
- .setAccessStrategy(new RowByRowAccessStrategy());
- }
-
- @Override
- public void transform(Row row, PointCollector collector) {
- if (row.isNull(0)) {
- return;
- }
- int candidateValue = row.getInt(0);
- if (time == null || value < candidateValue) {
- time = row.getTime();
- value = candidateValue;
- }
- }
-
- @Override
- public void terminate(PointCollector collector) throws IOException {
- if (time != null) {
- collector.putInt(time, value);
- }
- }
-}
-```
-
-
-
-#### void beforeDestroy()
-
-The method for terminating a UDF.
-
-This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
-
-
-
-### UDAF (User Defined Aggregation Function)
-
-A complete definition of UDAF involves two classes, `State` and `UDAF`.
-
-#### State Class
-
-To write your own `State`, you need to implement the `org.apache.iotdb.udf.api.State` interface.
-
-The following table shows all the interfaces available for user implementation.
-
-| Interface Definition | Description | Required to Implement |
-| -------------------------------- | ------------------------------------------------------------ | --------------------- |
-| `void reset()` | To reset the `State` object to its initial state, you need to fill in the initial values of the fields in the `State` class within this method as if you were writing a constructor. | Required |
-| `byte[] serialize()` | Serializes `State` to binary data. This method is used for IoTDB internal `State` passing. Note that the order of serialization must be consistent with the following deserialization methods. | Required |
-| `void deserialize(byte[] bytes)` | Deserializes binary data to `State`. This method is used for IoTDB internal `State` passing. Note that the order of deserialization must be consistent with the serialization method above. | Required |
-
-The following section describes the usage of each interface in detail.
-
-
-
-##### void reset()
-
-This method resets the `State` to its initial state, you need to fill in the initial values of the fields in the `State` object in this method. For optimization reasons, IoTDB reuses `State` as much as possible internally, rather than creating a new `State` for each group, which would introduce unnecessary overhead. When `State` has finished updating the data in a group, this method is called to reset to the initial state as a way to process the next group.
-
-In the case of `State` for averaging (aka `avg`), for example, you would need the sum of the data, `sum`, and the number of entries in the data, `count`, and initialize both to 0 in the `reset()` method.
-
-```java
-class AvgState implements State {
- double sum;
-
- long count;
-
- @Override
- public void reset() {
- sum = 0;
- count = 0;
- }
-
- // other methods
-}
-```
-
-
-
-##### byte[] serialize()/void deserialize(byte[] bytes)
-
-These methods serialize the `State` into binary data, and deserialize the `State` from the binary data. IoTDB, as a distributed database, involves passing data among different nodes, so you need to write these two methods to enable the passing of the State among different nodes. Note that the order of serialization and deserialization must be the consistent.
-
-In the case of `State` for averaging (aka `avg`), for example, you can convert the content of State to `byte[]` array and read out the content of State from `byte[]` array in any way you want, the following shows the code for serialization/deserialization using `ByteBuffer` introduced by Java8:
-
-```java
-@Override
-public byte[] serialize() {
- ByteBuffer buffer = ByteBuffer.allocate(Double.BYTES + Long.BYTES);
- buffer.putDouble(sum);
- buffer.putLong(count);
-
- return buffer.array();
-}
-
-@Override
-public void deserialize(byte[] bytes) {
- ByteBuffer buffer = ByteBuffer.wrap(bytes);
- sum = buffer.getDouble();
- count = buffer.getLong();
-}
-```
-
-
-
-#### UDAF Classes
-
-To write a UDAF, you need to implement the `org.apache.iotdb.udf.api.UDAF` interface.
-
-The following table shows all the interfaces available for user implementation.
-
-| Interface definition | Description | Required to Implement |
-| ------------------------------------------------------------ | ------------------------------------------------------------ | --------------------- |
-| `void validate(UDFParameterValidator validator) throws Exception` | This method is mainly used to validate `UDFParameters` and it is executed before `beforeStart(UDFParameters, UDTFConfigurations)` is called. | Optional |
-| `void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception` | Initialization method that invokes user-defined initialization behavior before UDAF processes the input data. Unlike UDTF, configuration is of type `UDAFConfiguration`. | Required |
-| `State createState()` | To create a `State` object, usually just call the default constructor and modify the default initial value as needed. | Required |
-| `void addInput(State state, Column[] columns, BitMap bitMap)` | Update `State` object according to the incoming data `Column[]` in batch, note that last column `columns[columns.length - 1]` always represents the time column. In addition, `BitMap` represents the data that has been filtered out before, you need to manually determine whether the corresponding data has been filtered out when writing this method. | Required |
-| `void combineState(State state, State rhs)` | Merge `rhs` state into `state` state. In a distributed scenario, the same set of data may be distributed on different nodes, IoTDB generates a `State` object for the partial data on each node, and then calls this method to merge it into the complete `State`. | Required |
-| `void outputFinal(State state, ResultValue resultValue)` | Computes the final aggregated result based on the data in `State`. Note that according to the semantics of the aggregation, only one value can be output per group. | Required |
-| `void beforeDestroy() ` | This method is called by the framework after the last input data is processed, and will only be called once in the life cycle of each UDF instance. | Optional |
-
-In the life cycle of a UDAF instance, the calling sequence of each method is as follows:
-
-1. `State createState()`
-2. `void validate(UDFParameterValidator validator) throws Exception`
-3. `void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception`
-4. `void addInput(State state, Column[] columns, BitMap bitMap)`
-5. `void combineState(State state, State rhs)`
-6. `void outputFinal(State state, ResultValue resultValue)`
-7. `void beforeDestroy()`
-
-Similar to UDTF, every time the framework executes a UDAF query, a new UDF instance will be constructed. When the query ends, the corresponding instance will be destroyed. Therefore, the internal data of the instances in different UDAF queries (even in the same SQL statement) are isolated. You can maintain some state data in the UDAF without considering the influence of concurrency and other factors.
-
-The usage of each interface will be described in detail below.
-
-
-
-##### void validate(UDFParameterValidator validator) throws Exception
-
-Same as UDTF, the `validate` method is used to validate the parameters entered by the user.
-
-In this method, you can limit the number and types of input time series, check the attributes of user input, or perform any custom verification.
-
-
-
-##### void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception
-
- The `beforeStart` method does the same thing as the UDAF:
-
-1. Use UDFParameters to get the time series paths and parse key-value pair attributes entered by the user.
-2. Set the strategy to access the raw data and set the output data type in UDAFConfigurations.
-3. Create resources, such as establishing external connections, opening files, etc.
-
-The role of the `UDFParameters` type can be seen above.
-
-###### UDAFConfigurations
-
-The difference from UDTF is that UDAF uses `UDAFConfigurations` as the type of `configuration` object.
-
-Currently, this class only supports setting the type of output data.
-
-```java
-void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
- // parameters
- // ...
-
- // configurations
- configurations
- .setOutputDataType(Type.INT32); }
-}
-```
-
-The relationship between the output type set in `setOutputDataType` and the type of data output that `ResultValue` can actually receive is as follows:
-
-| The output type set in `setOutputDataType` | The output type that `ResultValue` can actually receive |
-| ------------------------------------------ | ------------------------------------------------------- |
-| `INT32` | `int` |
-| `INT64` | `long` |
-| `FLOAT` | `float` |
-| `DOUBLE` | `double` |
-| `BOOLEAN` | `boolean` |
-| `TEXT` | `org.apache.iotdb.udf.api.type.Binary` |
-
-The output type of the UDAF is determined at runtime. You can dynamically determine the output sequence type based on the input type.
-
-Here is a simple example:
-
-```java
-void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
- // do something
- // ...
-
- configurations
- .setOutputDataType(parameters.getDataType(0));
-}
-```
-
-
-
-##### State createState()
-
-This method creates and initializes a `State` object for UDAF. Due to the limitations of the Java language, you can only call the default constructor for the `State` class. The default constructor assigns a default initial value to all the fields in the class, and if that initial value does not meet your requirements, you need to initialize them manually within this method.
-
-The following is an example that includes manual initialization. Suppose you want to implement an aggregate function that multiply all numbers in the group, then your initial `State` value should be set to 1, but the default constructor initializes it to 0, so you need to initialize `State` manually after calling the default constructor:
-
-```java
-public State createState() {
- MultiplyState state = new MultiplyState();
- state.result = 1;
- return state;
-}
-```
-
-
-
-##### void addInput(State state, Column[] columns, BitMap bitMap)
-
-This method updates the `State` object with the raw input data. For performance reasons, also to align with the IoTDB vectorized query engine, the raw input data is no longer a data point, but an array of columns ``Column[]``. Note that the last column (i.e. `columns[columns.length - 1]`) is always the time column, so you can also do different operations in UDAF depending on the time.
-
-Since the input parameter is not of a single data point type, but of multiple columns, you need to manually filter some of the data in the columns, which is why the third parameter, `BitMap`, exists. It identifies which of these columns have been filtered out, so you don't have to think about the filtered data in any case.
-
-Here's an example of `addInput()` that counts the number of items (aka count). It shows how you can use `BitMap` to ignore data that has been filtered out. Note that due to the limitations of the Java language, you need to do the explicit cast the `State` object from type defined in the interface to a custom `State` type at the beginning of the method, otherwise you won't be able to use the `State` object.
-
-```java
-public void addInput(State state, Column[] columns, BitMap bitMap) {
- CountState countState = (CountState) state;
-
- int count = columns[0].getPositionCount();
- for (int i = 0; i < count; i++) {
- if (bitMap != null && !bitMap.isMarked(i)) {
- continue;
- }
- if (!columns[0].isNull(i)) {
- countState.count++;
- }
- }
-}
-```
-
-
-
-##### void combineState(State state, State rhs)
-
-This method combines two `State`s, or more precisely, updates the first `State` object with the second `State` object. IoTDB is a distributed database, and the data of the same group may be distributed on different nodes. For performance reasons, IoTDB will first aggregate some of the data on each node into `State`, and then merge the `State`s on different nodes that belong to the same group, which is what `combineState` does.
-
-Here's an example of `combineState()` for averaging (aka avg). Similar to `addInput`, you need to do an explicit type conversion for the two `State`s at the beginning. Also note that you are updating the value of the first `State` with the contents of the second `State`.
-
-```java
-public void combineState(State state, State rhs) {
- AvgState avgState = (AvgState) state;
- AvgState avgRhs = (AvgState) rhs;
-
- avgState.count += avgRhs.count;
- avgState.sum += avgRhs.sum;
-}
-```
-
-
-
-##### void outputFinal(State state, ResultValue resultValue)
-
-This method works by calculating the final result from `State`. You need to access the various fields in `State`, derive the final result, and set the final result into the `ResultValue` object.IoTDB internally calls this method once at the end for each group. Note that according to the semantics of aggregation, the final result can only be one value.
-
-Here is another `outputFinal` example for averaging (aka avg). In addition to the forced type conversion at the beginning, you will also see a specific use of the `ResultValue` object, where the final result is set by `setXXX` (where `XXX` is the type name).
-
-```java
-public void outputFinal(State state, ResultValue resultValue) {
- AvgState avgState = (AvgState) state;
-
- if (avgState.count != 0) {
- resultValue.setDouble(avgState.sum / avgState.count);
- } else {
- resultValue.setNull();
- }
-}
-```
-
-
-
-##### void beforeDestroy()
-
-The method for terminating a UDF.
-
-This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
-
-
-
-### Maven Project Example
-
-If you use Maven, you can build your own UDF project referring to our **udf-example** module. You can find the project [here](https://github.com/apache/iotdb/tree/master/example/udf).
-
-
-
-### UDF Registration
-
-The process of registering a UDF in IoTDB is as follows:
-
-1. Implement a complete UDF class, assuming the full class name of this class is `org.apache.iotdb.udf.ExampleUDTF`.
-2. Package your project into a JAR. If you use Maven to manage your project, you can refer to the Maven project example above.
-3. Make preparations for registration according to the registration mode. For details, see the following example.
-4. You can use following SQL to register UDF.
-
-```sql
-CREATE FUNCTION
+
+`StateWindowAccessStrategy` has four constructors.
+
+- Constructor 1: For numerical data, there are 3 parameters: the time axis can display the start and end time of the time window and the threshold `delta` for the allowable change within a single window.
+- Constructor 2: For text data and boolean data, there are 3 parameters: the time axis can be provided to display the start and end time of the time window. For both data types, the data within a single window is same, and there is no need to provide an allowable change threshold.
+- Constructor 3: For numerical data, there are 1 parameters: you can only provide the threshold delta that is allowed to change within a single window. The start time of the time axis display time window will be defined as the smallest timestamp in the entire query result set, and the time axis display time window end time will be defined as The largest timestamp in the entire query result set.
+- Constructor 4: For text data and boolean data, you can provide no parameter. The start and end timestamps are explained in Constructor 3.
+
+StateWindowAccessStrategy can only take one column as input for now.
+
+Please see the Javadoc for more details.
+
+ 2.2.2 **setOutputDataType**
+
+Note that the type of output sequence you set here determines the type of data that the `PointCollector` can actually receive in the `transform` method. The relationship between the output data type set in `setOutputDataType` and the actual data output type that `PointCollector` can receive is as follows:
+
+| Output Data Type Set in `setOutputDataType` | Data Type that `PointCollector` Can Receive |
+| :------------------------------------------ | :----------------------------------------------------------- |
+| INT32 | int |
+| INT64 | long |
+| FLOAT | float |
+| DOUBLE | double |
+| BOOLEAN | boolean |
+| TEXT | java.lang.String and org.apache.iotdb.udf.api.type.Binar` |
+
+The type of output time series of a UDTF is determined at runtime, which means that a UDTF can dynamically determine the type of output time series according to the type of input time series.
+Here is a simple example:
+
+```java
+void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
+ // do something
+ // ...
+
+ configurations
+ .setAccessStrategy(new RowByRowAccessStrategy())
+ .setOutputDataType(parameters.getDataType(0));
+}
+```
+
+3. **void transform(Row row, PointCollector collector) throws Exception**
+
+You need to implement this method when you specify the strategy of UDF to read the original data as `RowByRowAccessStrategy`.
+
+This method processes the raw data one row at a time. The raw data is input from `Row` and output by `PointCollector`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
+
+The following is a complete UDF example that implements the `void transform(Row row, PointCollector collector) throws Exception` method. It is an adder that receives two columns of time series as input. When two data points in a row are not `null`, this UDF will output the algebraic sum of these two data points.
+
+``` java
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Adder implements UDTF {
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT64)
+ .setAccessStrategy(new RowByRowAccessStrategy());
+ }
+
+ @Override
+ public void transform(Row row, PointCollector collector) throws Exception {
+ if (row.isNull(0) || row.isNull(1)) {
+ return;
+ }
+ collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
+ }
+}
+```
+
+4. **void transform(RowWindow rowWindow, PointCollector collector) throws Exception**
+
+You need to implement this method when you specify the strategy of UDF to read the original data as `SlidingTimeWindowAccessStrategy` or `SlidingSizeWindowAccessStrategy`.
+
+This method processes a batch of data in a fixed number of rows or a fixed time interval each time, and we call the container containing this batch of data a window. The raw data is input from `RowWindow` and output by `PointCollector`. `RowWindow` can help you access a batch of `Row`, it provides a set of interfaces for random access and iterative access to this batch of `Row`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
+
+Below is a complete UDF example that implements the `void transform(RowWindow rowWindow, PointCollector collector) throws Exception` method. It is a counter that receives any number of time series as input, and its function is to count and output the number of data rows in each time window within a specified time range.
+
+```java
+import java.io.IOException;
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.access.RowWindow;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Counter implements UDTF {
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT32)
+ .setAccessStrategy(new SlidingTimeWindowAccessStrategy(
+ parameters.getLong("time_interval"),
+ parameters.getLong("sliding_step"),
+ parameters.getLong("display_window_begin"),
+ parameters.getLong("display_window_end")));
+ }
+
+ @Override
+ public void transform(RowWindow rowWindow, PointCollector collector) {
+ if (rowWindow.windowSize() != 0) {
+ collector.putInt(rowWindow.windowStartTime(), rowWindow.windowSize());
+ }
+ }
+}
+```
+
+5. **void terminate(PointCollector collector) throws Exception**
+
+In some scenarios, a UDF needs to traverse all the original data to calculate the final output data points. The `terminate` interface provides support for those scenarios.
+
+This method is called after all `transform` calls are executed and before the `beforeDestory` method is executed. You can implement the `transform` method to perform pure data processing (without outputting any data points), and implement the `terminate` method to output the processing results.
+
+The processing results need to be output by the `PointCollector`. You can output any number of data points in one `terminate` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
+
+Below is a complete UDF example that implements the `void terminate(PointCollector collector) throws Exception` method. It takes one time series whose data type is `INT32` as input, and outputs the maximum value point of the series.
+
+```java
+import java.io.IOException;
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Max implements UDTF {
+
+ private Long time;
+ private int value;
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT32)
+ .setAccessStrategy(new RowByRowAccessStrategy());
+ }
+
+ @Override
+ public void transform(Row row, PointCollector collector) {
+ if (row.isNull(0)) {
+ return;
+ }
+ int candidateValue = row.getInt(0);
+ if (time == null || value < candidateValue) {
+ time = row.getTime();
+ value = candidateValue;
+ }
+ }
+
+ @Override
+ public void terminate(PointCollector collector) throws IOException {
+ if (time != null) {
+ collector.putInt(time, value);
+ }
+ }
+}
+```
+
+6. **void beforeDestroy()**
+
+The method for terminating a UDF.
+
+This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
+
+
+
+### UDAF (User Defined Aggregation Function)
+
+A complete definition of UDAF involves two classes, `State` and `UDAF`.
+
+#### State Class
+
+To write your own `State`, you need to implement the `org.apache.iotdb.udf.api.State` interface.
+
+#### Interface Description:
+
+| Interface Definition | Description | Required to Implement |
+| -------------------------------- | ------------------------------------------------------------ | --------------------- |
+| void reset() | To reset the `State` object to its initial state, you need to fill in the initial values of the fields in the `State` class within this method as if you were writing a constructor. | Required |
+| byte[] serialize() | Serializes `State` to binary data. This method is used for IoTDB internal `State` passing. Note that the order of serialization must be consistent with the following deserialization methods. | Required |
+| void deserialize(byte[] bytes) | Deserializes binary data to `State`. This method is used for IoTDB internal `State` passing. Note that the order of deserialization must be consistent with the serialization method above. | Required |
+
+#### Detailed interface introduction:
+
+1. **void reset()**
+
+This method resets the `State` to its initial state, you need to fill in the initial values of the fields in the `State` object in this method. For optimization reasons, IoTDB reuses `State` as much as possible internally, rather than creating a new `State` for each group, which would introduce unnecessary overhead. When `State` has finished updating the data in a group, this method is called to reset to the initial state as a way to process the next group.
+
+In the case of `State` for averaging (aka `avg`), for example, you would need the sum of the data, `sum`, and the number of entries in the data, `count`, and initialize both to 0 in the `reset()` method.
+
+```java
+class AvgState implements State {
+ double sum;
+
+ long count;
+
+ @Override
+ public void reset() {
+ sum = 0;
+ count = 0;
+ }
+
+ // other methods
+}
+```
+
+2. **byte[] serialize()/void deserialize(byte[] bytes)**
+
+These methods serialize the `State` into binary data, and deserialize the `State` from the binary data. IoTDB, as a distributed database, involves passing data among different nodes, so you need to write these two methods to enable the passing of the State among different nodes. Note that the order of serialization and deserialization must be the consistent.
+
+In the case of `State` for averaging (aka `avg`), for example, you can convert the content of State to `byte[]` array and read out the content of State from `byte[]` array in any way you want, the following shows the code for serialization/deserialization using `ByteBuffer` introduced by Java8:
+
+```java
+@Override
+public byte[] serialize() {
+ ByteBuffer buffer = ByteBuffer.allocate(Double.BYTES + Long.BYTES);
+ buffer.putDouble(sum);
+ buffer.putLong(count);
+
+ return buffer.array();
+}
+
+@Override
+public void deserialize(byte[] bytes) {
+ ByteBuffer buffer = ByteBuffer.wrap(bytes);
+ sum = buffer.getDouble();
+ count = buffer.getLong();
+}
+```
+
+
+
+#### UDAF Classes
+
+To write a UDAF, you need to implement the `org.apache.iotdb.udf.api.UDAF` interface.
+
+#### Interface Description:
+
+| Interface definition | Description | Required to Implement |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | --------------------- |
+| void validate(UDFParameterValidator validator) throws Exception | This method is mainly used to validate `UDFParameters` and it is executed before `beforeStart(UDFParameters, UDTFConfigurations)` is called. | Optional |
+| void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception | Initialization method that invokes user-defined initialization behavior before UDAF processes the input data. Unlike UDTF, configuration is of type `UDAFConfiguration`. | Required |
+| State createState() | To create a `State` object, usually just call the default constructor and modify the default initial value as needed. | Required |
+| void addInput(State state, Column[] columns, BitMap bitMap) | Update `State` object according to the incoming data `Column[]` in batch, note that last column `columns[columns.length - 1]` always represents the time column. In addition, `BitMap` represents the data that has been filtered out before, you need to manually determine whether the corresponding data has been filtered out when writing this method. | Required |
+| void combineState(State state, State rhs) | Merge `rhs` state into `state` state. In a distributed scenario, the same set of data may be distributed on different nodes, IoTDB generates a `State` object for the partial data on each node, and then calls this method to merge it into the complete `State`. | Required |
+| void outputFinal(State state, ResultValue resultValue) | Computes the final aggregated result based on the data in `State`. Note that according to the semantics of the aggregation, only one value can be output per group. | Required |
+| void beforeDestroy() | This method is called by the framework after the last input data is processed, and will only be called once in the life cycle of each UDF instance. | Optional |
+
+In the life cycle of a UDAF instance, the calling sequence of each method is as follows:
+
+1. State createState()
+2. void validate(UDFParameterValidator validator) throws Exception
+3. void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception
+4. void addInput(State state, Column[] columns, BitMap bitMap)
+5. void combineState(State state, State rhs)
+6. void outputFinal(State state, ResultValue resultValue)
+7. void beforeDestroy()
+
+Similar to UDTF, every time the framework executes a UDAF query, a new UDF instance will be constructed. When the query ends, the corresponding instance will be destroyed. Therefore, the internal data of the instances in different UDAF queries (even in the same SQL statement) are isolated. You can maintain some state data in the UDAF without considering the influence of concurrency and other factors.
+
+#### Detailed interface introduction:
+
+
+1. **void validate(UDFParameterValidator validator) throws Exception**
+
+Same as UDTF, the `validate` method is used to validate the parameters entered by the user.
+
+In this method, you can limit the number and types of input time series, check the attributes of user input, or perform any custom verification.
+
+2. **void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception**
+
+ The `beforeStart` method does the same thing as the UDAF:
+
+1. Use UDFParameters to get the time series paths and parse key-value pair attributes entered by the user.
+2. Set the strategy to access the raw data and set the output data type in UDAFConfigurations.
+3. Create resources, such as establishing external connections, opening files, etc.
+
+The role of the `UDFParameters` type can be seen above.
+
+2.2 **UDTFConfigurations**
+
+The difference from UDTF is that UDAF uses `UDAFConfigurations` as the type of `configuration` object.
+
+Currently, this class only supports setting the type of output data.
+
+```java
+void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
+ // parameters
+ // ...
+
+ // configurations
+ configurations
+ .setOutputDataType(Type.INT32); }
+}
+```
+
+The relationship between the output type set in `setOutputDataType` and the type of data output that `ResultValue` can actually receive is as follows:
+
+| The output type set in `setOutputDataType` | The output type that `ResultValue` can actually receive |
+| ------------------------------------------ | ------------------------------------------------------- |
+| INT32 | int |
+| INT64 | long |
+| FLOAT | float |
+| DOUBLE | double |
+| BOOLEAN | boolean |
+| TEXT | org.apache.iotdb.udf.api.type.Binary |
+
+The output type of the UDAF is determined at runtime. You can dynamically determine the output sequence type based on the input type.
+
+Here is a simple example:
+
+```java
+void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
+ // do something
+ // ...
+
+ configurations
+ .setOutputDataType(parameters.getDataType(0));
+}
+```
+
+3. **State createState()**
+
+
+This method creates and initializes a `State` object for UDAF. Due to the limitations of the Java language, you can only call the default constructor for the `State` class. The default constructor assigns a default initial value to all the fields in the class, and if that initial value does not meet your requirements, you need to initialize them manually within this method.
+
+The following is an example that includes manual initialization. Suppose you want to implement an aggregate function that multiply all numbers in the group, then your initial `State` value should be set to 1, but the default constructor initializes it to 0, so you need to initialize `State` manually after calling the default constructor:
+
+```java
+public State createState() {
+ MultiplyState state = new MultiplyState();
+ state.result = 1;
+ return state;
+}
+```
+
+4. **void addInput(State state, Column[] columns, BitMap bitMap)**
+
+This method updates the `State` object with the raw input data. For performance reasons, also to align with the IoTDB vectorized query engine, the raw input data is no longer a data point, but an array of columns ``Column[]``. Note that the last column (i.e. `columns[columns.length - 1]`) is always the time column, so you can also do different operations in UDAF depending on the time.
+
+Since the input parameter is not of a single data point type, but of multiple columns, you need to manually filter some of the data in the columns, which is why the third parameter, `BitMap`, exists. It identifies which of these columns have been filtered out, so you don't have to think about the filtered data in any case.
+
+Here's an example of `addInput()` that counts the number of items (aka count). It shows how you can use `BitMap` to ignore data that has been filtered out. Note that due to the limitations of the Java language, you need to do the explicit cast the `State` object from type defined in the interface to a custom `State` type at the beginning of the method, otherwise you won't be able to use the `State` object.
+
+```java
+public void addInput(State state, Column[] columns, BitMap bitMap) {
+ CountState countState = (CountState) state;
+
+ int count = columns[0].getPositionCount();
+ for (int i = 0; i < count; i++) {
+ if (bitMap != null && !bitMap.isMarked(i)) {
+ continue;
+ }
+ if (!columns[0].isNull(i)) {
+ countState.count++;
+ }
+ }
+}
+```
+
+5. **void combineState(State state, State rhs)**
+
+
+This method combines two `State`s, or more precisely, updates the first `State` object with the second `State` object. IoTDB is a distributed database, and the data of the same group may be distributed on different nodes. For performance reasons, IoTDB will first aggregate some of the data on each node into `State`, and then merge the `State`s on different nodes that belong to the same group, which is what `combineState` does.
+
+Here's an example of `combineState()` for averaging (aka avg). Similar to `addInput`, you need to do an explicit type conversion for the two `State`s at the beginning. Also note that you are updating the value of the first `State` with the contents of the second `State`.
+
+```java
+public void combineState(State state, State rhs) {
+ AvgState avgState = (AvgState) state;
+ AvgState avgRhs = (AvgState) rhs;
+
+ avgState.count += avgRhs.count;
+ avgState.sum += avgRhs.sum;
+}
+```
+
+6. **void outputFinal(State state, ResultValue resultValue)**
+
+This method works by calculating the final result from `State`. You need to access the various fields in `State`, derive the final result, and set the final result into the `ResultValue` object.IoTDB internally calls this method once at the end for each group. Note that according to the semantics of aggregation, the final result can only be one value.
+
+Here is another `outputFinal` example for averaging (aka avg). In addition to the forced type conversion at the beginning, you will also see a specific use of the `ResultValue` object, where the final result is set by `setXXX` (where `XXX` is the type name).
+
+```java
+public void outputFinal(State state, ResultValue resultValue) {
+ AvgState avgState = (AvgState) state;
+
+ if (avgState.count != 0) {
+ resultValue.setDouble(avgState.sum / avgState.count);
+ } else {
+ resultValue.setNull();
+ }
+}
+```
+
+7. **void beforeDestroy()**
+
+
+The method for terminating a UDF.
+
+This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
+
+
+### Maven Project Example
+
+If you use Maven, you can build your own UDF project referring to our **udf-example** module. You can find the project [here](https://github.com/apache/iotdb/tree/master/example/udf).
+
+
+## Contribute universal built-in UDF functions to iotdb
+
+This part mainly introduces how external users can contribute their own UDFs to the IoTDB community.
+
+#### Prerequisites
+
+1. UDFs must be universal.
+
+ The "universal" mentioned here refers to: UDFs can be widely used in some scenarios. In other words, the UDF function must have reuse value and may be directly used by other users in the community.
+
+ If you are not sure whether the UDF you want to contribute is universal, you can send an email to `dev@iotdb.apache.org` or create an issue to initiate a discussion.
+
+2. The UDF you are going to contribute has been well tested and can run normally in the production environment.
+
+
+#### What you need to prepare
+
+1. UDF source code
+2. Test cases
+3. Instructions
+
+#### UDF Source Code
+
+1. Create the UDF main class and related classes in `iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/udf/builtin` or in its subfolders.
+2. Register your UDF in `iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/udf/builtin/BuiltinTimeSeriesGeneratingFunction.java`.
+
+#### Test Cases
+
+At a minimum, you need to write integration tests for the UDF.
+
+You can add a test class in `integration-test/src/test/java/org/apache/iotdb/db/it/udf`.
+
+
+#### Instructions
+
+The instructions need to include: the name and the function of the UDF, the attribute parameters that must be provided when the UDF is executed, the applicable scenarios, and the usage examples, etc.
+
+The instructions for use should include both Chinese and English versions. Instructions for use should be added separately in `docs/zh/UserGuide/Operation Manual/DML Data Manipulation Language.md` and `docs/UserGuide/Operation Manual/DML Data Manipulation Language.md`.
+
+#### Submit a PR
+
+When you have prepared the UDF source code, test cases, and instructions, you are ready to submit a Pull Request (PR) on [Github](https://github.com/apache/iotdb). You can refer to our code contribution guide to submit a PR: [Development Guide](https://iotdb.apache.org/Community/Development-Guide.html).
+
+
+After the PR review is approved and merged, your UDF has already contributed to the IoTDB community!
diff --git a/src/UserGuide/Master/User-Manual/Database-Programming.md b/src/UserGuide/Master/User-Manual/Database-Programming.md
index 98f097c2d..9367c865e 100644
--- a/src/UserGuide/Master/User-Manual/Database-Programming.md
+++ b/src/UserGuide/Master/User-Manual/Database-Programming.md
@@ -1037,889 +1037,3 @@ SELECT avg(count_s1) from root.sg_count.d;
| `continuous_query_submit_thread` | The number of threads in the scheduled thread pool that submit continuous query tasks periodically | int32 | 2 |
| `continuous_query_min_every_interval_in_ms` | The minimum value of the continuous query execution time interval | duration | 1000 |
-## USER-DEFINED FUNCTION (UDF)
-
-IoTDB provides a variety of built-in functions to meet your computing needs, and you can also create user defined functions to meet more computing needs.
-
-This document describes how to write, register and use a UDF.
-
-
-### UDF Types
-
-In IoTDB, you can expand two types of UDF:
-
-| UDF Class | Description |
-| --------------------------------------------------- | ------------------------------------------------------------ |
-| UDTF(User Defined Timeseries Generating Function) | This type of function can take **multiple** time series as input, and output **one** time series, which can have any number of data points. |
-| UDAF(User Defined Aggregation Function) | Custom Aggregation Functions. This type of function can take one time series as input, and output **one** aggregated data point for each group based on the GROUP BY type. |
-
-### UDF Development Dependencies
-
-If you use [Maven](http://search.maven.org/), you can search for the development dependencies listed below from the [Maven repository](http://search.maven.org/) . Please note that you must select the same dependency version as the target IoTDB server version for development.
-
-``` xml
-
-
-`SlidingTimeWindowAccessStrategy`: `SlidingTimeWindowAccessStrategy` has many constructors, you can pass 3 types of parameters to them:
-
-- Parameter 1: The display window on the time axis
-- Parameter 2: Time interval for dividing the time axis (should be positive)
-- Parameter 3: Time sliding step (not required to be greater than or equal to the time interval, but must be a positive number)
-
-The first type of parameters are optional. If the parameters are not provided, the beginning time of the display window will be set to the same as the minimum timestamp of the query result set, and the ending time of the display window will be set to the same as the maximum timestamp of the query result set.
-
-The sliding step parameter is also optional. If the parameter is not provided, the sliding step will be set to the same as the time interval for dividing the time axis.
-
-The relationship between the three types of parameters can be seen in the figure below. Please see the Javadoc for more details.
-
-
-
-`SlidingSizeWindowAccessStrategy`: `SlidingSizeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
-
-* Parameter 1: Window size. This parameter specifies the number of data rows contained in a data processing window. Note that the number of data rows in some of the last time windows may be less than the specified number of data rows.
-* Parameter 2: Sliding step. This parameter means the number of rows between the first point of the next window and the first point of the current window. (This parameter is not required to be greater than or equal to the window size, but must be a positive number)
-
-The sliding step parameter is optional. If the parameter is not provided, the sliding step will be set to the same as the window size.
-
-The `SessionTimeWindowAccessStrategy` is shown schematically below. **Time intervals less than or equal to the given minimum time interval `sessionGap` are assigned in one group**
-
-
-`SessionTimeWindowAccessStrategy`: `SessionTimeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
-
-- Parameter 1: The display window on the time axis.
-- Parameter 2: The minimum time interval `sessionGap` of two adjacent windows.
-
-
-The `StateWindowAccessStrategy` is shown schematically below. **For numerical data, if the state difference is less than or equal to the given threshold `delta`, it will be assigned in one group. **
-
-
-`StateWindowAccessStrategy` has four constructors.
-
-- Constructor 1: For numerical data, there are 3 parameters: the time axis can display the start and end time of the time window and the threshold `delta` for the allowable change within a single window.
-- Constructor 2: For text data and boolean data, there are 3 parameters: the time axis can be provided to display the start and end time of the time window. For both data types, the data within a single window is same, and there is no need to provide an allowable change threshold.
-- Constructor 3: For numerical data, there are 1 parameters: you can only provide the threshold delta that is allowed to change within a single window. The start time of the time axis display time window will be defined as the smallest timestamp in the entire query result set, and the time axis display time window end time will be defined as The largest timestamp in the entire query result set.
-- Constructor 4: For text data and boolean data, you can provide no parameter. The start and end timestamps are explained in Constructor 3.
-
-StateWindowAccessStrategy can only take one column as input for now.
-
-Please see the Javadoc for more details.
-
-
-
-###### setOutputDataType
-
-Note that the type of output sequence you set here determines the type of data that the `PointCollector` can actually receive in the `transform` method. The relationship between the output data type set in `setOutputDataType` and the actual data output type that `PointCollector` can receive is as follows:
-
-| Output Data Type Set in `setOutputDataType` | Data Type that `PointCollector` Can Receive |
-| :------------------------------------------ | :----------------------------------------------------------- |
-| `INT32` | `int` |
-| `INT64` | `long` |
-| `FLOAT` | `float` |
-| `DOUBLE` | `double` |
-| `BOOLEAN` | `boolean` |
-| `TEXT` | `java.lang.String` and `org.apache.iotdb.udf.api.type.Binary` |
-
-The type of output time series of a UDTF is determined at runtime, which means that a UDTF can dynamically determine the type of output time series according to the type of input time series.
-Here is a simple example:
-
-```java
-void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
- // do something
- // ...
-
- configurations
- .setAccessStrategy(new RowByRowAccessStrategy())
- .setOutputDataType(parameters.getDataType(0));
-}
-```
-
-
-
-#### void transform(Row row, PointCollector collector) throws Exception
-
-You need to implement this method when you specify the strategy of UDF to read the original data as `RowByRowAccessStrategy`.
-
-This method processes the raw data one row at a time. The raw data is input from `Row` and output by `PointCollector`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
-
-The following is a complete UDF example that implements the `void transform(Row row, PointCollector collector) throws Exception` method. It is an adder that receives two columns of time series as input. When two data points in a row are not `null`, this UDF will output the algebraic sum of these two data points.
-
-``` java
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Adder implements UDTF {
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT64)
- .setAccessStrategy(new RowByRowAccessStrategy());
- }
-
- @Override
- public void transform(Row row, PointCollector collector) throws Exception {
- if (row.isNull(0) || row.isNull(1)) {
- return;
- }
- collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
- }
-}
-```
-
-
-
-#### void transform(RowWindow rowWindow, PointCollector collector) throws Exception
-
-You need to implement this method when you specify the strategy of UDF to read the original data as `SlidingTimeWindowAccessStrategy` or `SlidingSizeWindowAccessStrategy`.
-
-This method processes a batch of data in a fixed number of rows or a fixed time interval each time, and we call the container containing this batch of data a window. The raw data is input from `RowWindow` and output by `PointCollector`. `RowWindow` can help you access a batch of `Row`, it provides a set of interfaces for random access and iterative access to this batch of `Row`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
-
-Below is a complete UDF example that implements the `void transform(RowWindow rowWindow, PointCollector collector) throws Exception` method. It is a counter that receives any number of time series as input, and its function is to count and output the number of data rows in each time window within a specified time range.
-
-```java
-import java.io.IOException;
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.access.RowWindow;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Counter implements UDTF {
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT32)
- .setAccessStrategy(new SlidingTimeWindowAccessStrategy(
- parameters.getLong("time_interval"),
- parameters.getLong("sliding_step"),
- parameters.getLong("display_window_begin"),
- parameters.getLong("display_window_end")));
- }
-
- @Override
- public void transform(RowWindow rowWindow, PointCollector collector) {
- if (rowWindow.windowSize() != 0) {
- collector.putInt(rowWindow.windowStartTime(), rowWindow.windowSize());
- }
- }
-}
-```
-
-
-
-#### void terminate(PointCollector collector) throws Exception
-
-In some scenarios, a UDF needs to traverse all the original data to calculate the final output data points. The `terminate` interface provides support for those scenarios.
-
-This method is called after all `transform` calls are executed and before the `beforeDestory` method is executed. You can implement the `transform` method to perform pure data processing (without outputting any data points), and implement the `terminate` method to output the processing results.
-
-The processing results need to be output by the `PointCollector`. You can output any number of data points in one `terminate` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
-
-Below is a complete UDF example that implements the `void terminate(PointCollector collector) throws Exception` method. It takes one time series whose data type is `INT32` as input, and outputs the maximum value point of the series.
-
-```java
-import java.io.IOException;
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Max implements UDTF {
-
- private Long time;
- private int value;
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT32)
- .setAccessStrategy(new RowByRowAccessStrategy());
- }
-
- @Override
- public void transform(Row row, PointCollector collector) {
- if (row.isNull(0)) {
- return;
- }
- int candidateValue = row.getInt(0);
- if (time == null || value < candidateValue) {
- time = row.getTime();
- value = candidateValue;
- }
- }
-
- @Override
- public void terminate(PointCollector collector) throws IOException {
- if (time != null) {
- collector.putInt(time, value);
- }
- }
-}
-```
-
-
-
-#### void beforeDestroy()
-
-The method for terminating a UDF.
-
-This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
-
-
-
-### UDAF (User Defined Aggregation Function)
-
-A complete definition of UDAF involves two classes, `State` and `UDAF`.
-
-#### State Class
-
-To write your own `State`, you need to implement the `org.apache.iotdb.udf.api.State` interface.
-
-The following table shows all the interfaces available for user implementation.
-
-| Interface Definition | Description | Required to Implement |
-| -------------------------------- | ------------------------------------------------------------ | --------------------- |
-| `void reset()` | To reset the `State` object to its initial state, you need to fill in the initial values of the fields in the `State` class within this method as if you were writing a constructor. | Required |
-| `byte[] serialize()` | Serializes `State` to binary data. This method is used for IoTDB internal `State` passing. Note that the order of serialization must be consistent with the following deserialization methods. | Required |
-| `void deserialize(byte[] bytes)` | Deserializes binary data to `State`. This method is used for IoTDB internal `State` passing. Note that the order of deserialization must be consistent with the serialization method above. | Required |
-
-The following section describes the usage of each interface in detail.
-
-
-
-##### void reset()
-
-This method resets the `State` to its initial state, you need to fill in the initial values of the fields in the `State` object in this method. For optimization reasons, IoTDB reuses `State` as much as possible internally, rather than creating a new `State` for each group, which would introduce unnecessary overhead. When `State` has finished updating the data in a group, this method is called to reset to the initial state as a way to process the next group.
-
-In the case of `State` for averaging (aka `avg`), for example, you would need the sum of the data, `sum`, and the number of entries in the data, `count`, and initialize both to 0 in the `reset()` method.
-
-```java
-class AvgState implements State {
- double sum;
-
- long count;
-
- @Override
- public void reset() {
- sum = 0;
- count = 0;
- }
-
- // other methods
-}
-```
-
-
-
-##### byte[] serialize()/void deserialize(byte[] bytes)
-
-These methods serialize the `State` into binary data, and deserialize the `State` from the binary data. IoTDB, as a distributed database, involves passing data among different nodes, so you need to write these two methods to enable the passing of the State among different nodes. Note that the order of serialization and deserialization must be the consistent.
-
-In the case of `State` for averaging (aka `avg`), for example, you can convert the content of State to `byte[]` array and read out the content of State from `byte[]` array in any way you want, the following shows the code for serialization/deserialization using `ByteBuffer` introduced by Java8:
-
-```java
-@Override
-public byte[] serialize() {
- ByteBuffer buffer = ByteBuffer.allocate(Double.BYTES + Long.BYTES);
- buffer.putDouble(sum);
- buffer.putLong(count);
-
- return buffer.array();
-}
-
-@Override
-public void deserialize(byte[] bytes) {
- ByteBuffer buffer = ByteBuffer.wrap(bytes);
- sum = buffer.getDouble();
- count = buffer.getLong();
-}
-```
-
-
-
-#### UDAF Classes
-
-To write a UDAF, you need to implement the `org.apache.iotdb.udf.api.UDAF` interface.
-
-The following table shows all the interfaces available for user implementation.
-
-| Interface definition | Description | Required to Implement |
-| ------------------------------------------------------------ | ------------------------------------------------------------ | --------------------- |
-| `void validate(UDFParameterValidator validator) throws Exception` | This method is mainly used to validate `UDFParameters` and it is executed before `beforeStart(UDFParameters, UDTFConfigurations)` is called. | Optional |
-| `void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception` | Initialization method that invokes user-defined initialization behavior before UDAF processes the input data. Unlike UDTF, configuration is of type `UDAFConfiguration`. | Required |
-| `State createState()` | To create a `State` object, usually just call the default constructor and modify the default initial value as needed. | Required |
-| `void addInput(State state, Column[] columns, BitMap bitMap)` | Update `State` object according to the incoming data `Column[]` in batch, note that last column `columns[columns.length - 1]` always represents the time column. In addition, `BitMap` represents the data that has been filtered out before, you need to manually determine whether the corresponding data has been filtered out when writing this method. | Required |
-| `void combineState(State state, State rhs)` | Merge `rhs` state into `state` state. In a distributed scenario, the same set of data may be distributed on different nodes, IoTDB generates a `State` object for the partial data on each node, and then calls this method to merge it into the complete `State`. | Required |
-| `void outputFinal(State state, ResultValue resultValue)` | Computes the final aggregated result based on the data in `State`. Note that according to the semantics of the aggregation, only one value can be output per group. | Required |
-| `void beforeDestroy() ` | This method is called by the framework after the last input data is processed, and will only be called once in the life cycle of each UDF instance. | Optional |
-
-In the life cycle of a UDAF instance, the calling sequence of each method is as follows:
-
-1. `State createState()`
-2. `void validate(UDFParameterValidator validator) throws Exception`
-3. `void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception`
-4. `void addInput(State state, Column[] columns, BitMap bitMap)`
-5. `void combineState(State state, State rhs)`
-6. `void outputFinal(State state, ResultValue resultValue)`
-7. `void beforeDestroy()`
-
-Similar to UDTF, every time the framework executes a UDAF query, a new UDF instance will be constructed. When the query ends, the corresponding instance will be destroyed. Therefore, the internal data of the instances in different UDAF queries (even in the same SQL statement) are isolated. You can maintain some state data in the UDAF without considering the influence of concurrency and other factors.
-
-The usage of each interface will be described in detail below.
-
-
-
-##### void validate(UDFParameterValidator validator) throws Exception
-
-Same as UDTF, the `validate` method is used to validate the parameters entered by the user.
-
-In this method, you can limit the number and types of input time series, check the attributes of user input, or perform any custom verification.
-
-
-
-##### void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception
-
- The `beforeStart` method does the same thing as the UDAF:
-
-1. Use UDFParameters to get the time series paths and parse key-value pair attributes entered by the user.
-2. Set the strategy to access the raw data and set the output data type in UDAFConfigurations.
-3. Create resources, such as establishing external connections, opening files, etc.
-
-The role of the `UDFParameters` type can be seen above.
-
-###### UDAFConfigurations
-
-The difference from UDTF is that UDAF uses `UDAFConfigurations` as the type of `configuration` object.
-
-Currently, this class only supports setting the type of output data.
-
-```java
-void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
- // parameters
- // ...
-
- // configurations
- configurations
- .setOutputDataType(Type.INT32); }
-}
-```
-
-The relationship between the output type set in `setOutputDataType` and the type of data output that `ResultValue` can actually receive is as follows:
-
-| The output type set in `setOutputDataType` | The output type that `ResultValue` can actually receive |
-| ------------------------------------------ | ------------------------------------------------------- |
-| `INT32` | `int` |
-| `INT64` | `long` |
-| `FLOAT` | `float` |
-| `DOUBLE` | `double` |
-| `BOOLEAN` | `boolean` |
-| `TEXT` | `org.apache.iotdb.udf.api.type.Binary` |
-
-The output type of the UDAF is determined at runtime. You can dynamically determine the output sequence type based on the input type.
-
-Here is a simple example:
-
-```java
-void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
- // do something
- // ...
-
- configurations
- .setOutputDataType(parameters.getDataType(0));
-}
-```
-
-
-
-##### State createState()
-
-This method creates and initializes a `State` object for UDAF. Due to the limitations of the Java language, you can only call the default constructor for the `State` class. The default constructor assigns a default initial value to all the fields in the class, and if that initial value does not meet your requirements, you need to initialize them manually within this method.
-
-The following is an example that includes manual initialization. Suppose you want to implement an aggregate function that multiply all numbers in the group, then your initial `State` value should be set to 1, but the default constructor initializes it to 0, so you need to initialize `State` manually after calling the default constructor:
-
-```java
-public State createState() {
- MultiplyState state = new MultiplyState();
- state.result = 1;
- return state;
-}
-```
-
-
-
-##### void addInput(State state, Column[] columns, BitMap bitMap)
-
-This method updates the `State` object with the raw input data. For performance reasons, also to align with the IoTDB vectorized query engine, the raw input data is no longer a data point, but an array of columns ``Column[]``. Note that the last column (i.e. `columns[columns.length - 1]`) is always the time column, so you can also do different operations in UDAF depending on the time.
-
-Since the input parameter is not of a single data point type, but of multiple columns, you need to manually filter some of the data in the columns, which is why the third parameter, `BitMap`, exists. It identifies which of these columns have been filtered out, so you don't have to think about the filtered data in any case.
-
-Here's an example of `addInput()` that counts the number of items (aka count). It shows how you can use `BitMap` to ignore data that has been filtered out. Note that due to the limitations of the Java language, you need to do the explicit cast the `State` object from type defined in the interface to a custom `State` type at the beginning of the method, otherwise you won't be able to use the `State` object.
-
-```java
-public void addInput(State state, Column[] columns, BitMap bitMap) {
- CountState countState = (CountState) state;
-
- int count = columns[0].getPositionCount();
- for (int i = 0; i < count; i++) {
- if (bitMap != null && !bitMap.isMarked(i)) {
- continue;
- }
- if (!columns[0].isNull(i)) {
- countState.count++;
- }
- }
-}
-```
-
-
-
-##### void combineState(State state, State rhs)
-
-This method combines two `State`s, or more precisely, updates the first `State` object with the second `State` object. IoTDB is a distributed database, and the data of the same group may be distributed on different nodes. For performance reasons, IoTDB will first aggregate some of the data on each node into `State`, and then merge the `State`s on different nodes that belong to the same group, which is what `combineState` does.
-
-Here's an example of `combineState()` for averaging (aka avg). Similar to `addInput`, you need to do an explicit type conversion for the two `State`s at the beginning. Also note that you are updating the value of the first `State` with the contents of the second `State`.
-
-```java
-public void combineState(State state, State rhs) {
- AvgState avgState = (AvgState) state;
- AvgState avgRhs = (AvgState) rhs;
-
- avgState.count += avgRhs.count;
- avgState.sum += avgRhs.sum;
-}
-```
-
-
-
-##### void outputFinal(State state, ResultValue resultValue)
-
-This method works by calculating the final result from `State`. You need to access the various fields in `State`, derive the final result, and set the final result into the `ResultValue` object.IoTDB internally calls this method once at the end for each group. Note that according to the semantics of aggregation, the final result can only be one value.
-
-Here is another `outputFinal` example for averaging (aka avg). In addition to the forced type conversion at the beginning, you will also see a specific use of the `ResultValue` object, where the final result is set by `setXXX` (where `XXX` is the type name).
-
-```java
-public void outputFinal(State state, ResultValue resultValue) {
- AvgState avgState = (AvgState) state;
-
- if (avgState.count != 0) {
- resultValue.setDouble(avgState.sum / avgState.count);
- } else {
- resultValue.setNull();
- }
-}
-```
-
-
-
-##### void beforeDestroy()
-
-The method for terminating a UDF.
-
-This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
-
-
-
-### Maven Project Example
-
-If you use Maven, you can build your own UDF project referring to our **udf-example** module. You can find the project [here](https://github.com/apache/iotdb/tree/master/example/udf).
-
-
-
-### UDF Registration
-
-The process of registering a UDF in IoTDB is as follows:
-
-1. Implement a complete UDF class, assuming the full class name of this class is `org.apache.iotdb.udf.ExampleUDTF`.
-2. Package your project into a JAR. If you use Maven to manage your project, you can refer to the Maven project example above.
-3. Make preparations for registration according to the registration mode. For details, see the following example.
-4. You can use following SQL to register UDF.
-
-```sql
-CREATE FUNCTION | UDF Class | +AccessStrategy | +Description | +
|---|---|---|
| UDTF | +MAPPABLE_ROW_BY_ROW | +Custom scalar function, input k columns of time series and 1 row of data, output 1 column of time series and 1 row of data, can be used in any clause and expression that appears in the scalar function, such as select clause, where clause, etc. | +
| ROW_BY_ROW SLIDING_TIME_WINDOW SLIDING_SIZE_WINDOW SESSION_TIME_WINDOW STATE_WINDOW |
+ Custom time series generation function, input k columns of time series m rows of data, output 1 column of time series n rows of data, the number of input rows m can be different from the number of output rows n, and can only be used in SELECT clauses. | +|
| UDAF | +- | +Custom aggregation function, input k columns of time series m rows of data, output 1 column of time series 1 row of data, can be used in any clause and expression that appears in the aggregation function, such as select clause, having clause, etc. | +
+
+`SlidingTimeWindowAccessStrategy`: `SlidingTimeWindowAccessStrategy` has many constructors, you can pass 3 types of parameters to them:
+
+- Parameter 1: The display window on the time axis
+
+The first type of parameters are optional. If the parameters are not provided, the beginning time of the display window will be set to the same as the minimum timestamp of the query result set, and the ending time of the display window will be set to the same as the maximum timestamp of the query result set.
+
+- Parameter 2: Time interval for dividing the time axis (should be positive)
+- Parameter 3: Time sliding step (not required to be greater than or equal to the time interval, but must be a positive number)
+
+The sliding step parameter is also optional. If the parameter is not provided, the sliding step will be set to the same as the time interval for dividing the time axis.
+
+The relationship between the three types of parameters can be seen in the figure below. Please see the Javadoc for more details.
+
+
+
+`SlidingSizeWindowAccessStrategy`: `SlidingSizeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
+
+* Parameter 1: Window size. This parameter specifies the number of data rows contained in a data processing window. Note that the number of data rows in some of the last time windows may be less than the specified number of data rows.
+* Parameter 2: Sliding step. This parameter means the number of rows between the first point of the next window and the first point of the current window. (This parameter is not required to be greater than or equal to the window size, but must be a positive number)
+
+The sliding step parameter is optional. If the parameter is not provided, the sliding step will be set to the same as the window size.
+
+- `SessionTimeWindowAccessStrategy`
+
+Window opening diagram: **Time intervals less than or equal to the given minimum time interval `sessionGap` are assigned in one group.**
+
+
+
+`SessionTimeWindowAccessStrategy`: `SessionTimeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
+
+- Parameter 1: The display window on the time axis.
+- Parameter 2: The minimum time interval `sessionGap` of two adjacent windows.
+
+- `StateWindowAccessStrategy`
+
+Window opening diagram: **For numerical data, if the state difference is less than or equal to the given threshold `delta`, it will be assigned in one group.**
+
+
+
+`StateWindowAccessStrategy` has four constructors.
+
+- Constructor 1: For numerical data, there are 3 parameters: the time axis can display the start and end time of the time window and the threshold `delta` for the allowable change within a single window.
+- Constructor 2: For text data and boolean data, there are 3 parameters: the time axis can be provided to display the start and end time of the time window. For both data types, the data within a single window is same, and there is no need to provide an allowable change threshold.
+- Constructor 3: For numerical data, there are 1 parameters: you can only provide the threshold delta that is allowed to change within a single window. The start time of the time axis display time window will be defined as the smallest timestamp in the entire query result set, and the time axis display time window end time will be defined as The largest timestamp in the entire query result set.
+- Constructor 4: For text data and boolean data, you can provide no parameter. The start and end timestamps are explained in Constructor 3.
+
+StateWindowAccessStrategy can only take one column as input for now.
+
+Please see the Javadoc for more details.
+
+ 2.2.2 **setOutputDataType**
+
+Note that the type of output sequence you set here determines the type of data that the `PointCollector` can actually receive in the `transform` method. The relationship between the output data type set in `setOutputDataType` and the actual data output type that `PointCollector` can receive is as follows:
+
+| Output Data Type Set in `setOutputDataType` | Data Type that `PointCollector` Can Receive |
+| :------------------------------------------ | :----------------------------------------------------------- |
+| INT32 | int |
+| INT64 | long |
+| FLOAT | float |
+| DOUBLE | double |
+| BOOLEAN | boolean |
+| TEXT | java.lang.String and org.apache.iotdb.udf.api.type.Binar` |
+
+The type of output time series of a UDTF is determined at runtime, which means that a UDTF can dynamically determine the type of output time series according to the type of input time series.
+Here is a simple example:
+
+```java
+void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
+ // do something
+ // ...
+
+ configurations
+ .setAccessStrategy(new RowByRowAccessStrategy())
+ .setOutputDataType(parameters.getDataType(0));
+}
+```
+
+3. **void transform(Row row, PointCollector collector) throws Exception**
+
+You need to implement this method when you specify the strategy of UDF to read the original data as `RowByRowAccessStrategy`.
+
+This method processes the raw data one row at a time. The raw data is input from `Row` and output by `PointCollector`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
+
+The following is a complete UDF example that implements the `void transform(Row row, PointCollector collector) throws Exception` method. It is an adder that receives two columns of time series as input. When two data points in a row are not `null`, this UDF will output the algebraic sum of these two data points.
+
+``` java
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Adder implements UDTF {
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT64)
+ .setAccessStrategy(new RowByRowAccessStrategy());
+ }
+
+ @Override
+ public void transform(Row row, PointCollector collector) throws Exception {
+ if (row.isNull(0) || row.isNull(1)) {
+ return;
+ }
+ collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
+ }
+}
+```
+
+4. **void transform(RowWindow rowWindow, PointCollector collector) throws Exception**
+
+You need to implement this method when you specify the strategy of UDF to read the original data as `SlidingTimeWindowAccessStrategy` or `SlidingSizeWindowAccessStrategy`.
+
+This method processes a batch of data in a fixed number of rows or a fixed time interval each time, and we call the container containing this batch of data a window. The raw data is input from `RowWindow` and output by `PointCollector`. `RowWindow` can help you access a batch of `Row`, it provides a set of interfaces for random access and iterative access to this batch of `Row`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
+
+Below is a complete UDF example that implements the `void transform(RowWindow rowWindow, PointCollector collector) throws Exception` method. It is a counter that receives any number of time series as input, and its function is to count and output the number of data rows in each time window within a specified time range.
+
+```java
+import java.io.IOException;
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.access.RowWindow;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Counter implements UDTF {
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT32)
+ .setAccessStrategy(new SlidingTimeWindowAccessStrategy(
+ parameters.getLong("time_interval"),
+ parameters.getLong("sliding_step"),
+ parameters.getLong("display_window_begin"),
+ parameters.getLong("display_window_end")));
+ }
+
+ @Override
+ public void transform(RowWindow rowWindow, PointCollector collector) {
+ if (rowWindow.windowSize() != 0) {
+ collector.putInt(rowWindow.windowStartTime(), rowWindow.windowSize());
+ }
+ }
+}
+```
+
+5. **void terminate(PointCollector collector) throws Exception**
+
+In some scenarios, a UDF needs to traverse all the original data to calculate the final output data points. The `terminate` interface provides support for those scenarios.
+
+This method is called after all `transform` calls are executed and before the `beforeDestory` method is executed. You can implement the `transform` method to perform pure data processing (without outputting any data points), and implement the `terminate` method to output the processing results.
+
+The processing results need to be output by the `PointCollector`. You can output any number of data points in one `terminate` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
+
+Below is a complete UDF example that implements the `void terminate(PointCollector collector) throws Exception` method. It takes one time series whose data type is `INT32` as input, and outputs the maximum value point of the series.
+
+```java
+import java.io.IOException;
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Max implements UDTF {
+
+ private Long time;
+ private int value;
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT32)
+ .setAccessStrategy(new RowByRowAccessStrategy());
+ }
+
+ @Override
+ public void transform(Row row, PointCollector collector) {
+ if (row.isNull(0)) {
+ return;
+ }
+ int candidateValue = row.getInt(0);
+ if (time == null || value < candidateValue) {
+ time = row.getTime();
+ value = candidateValue;
+ }
+ }
+
+ @Override
+ public void terminate(PointCollector collector) throws IOException {
+ if (time != null) {
+ collector.putInt(time, value);
+ }
+ }
+}
+```
+
+6. **void beforeDestroy()**
+
+The method for terminating a UDF.
+
+This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
+
+
+
+### UDAF (User Defined Aggregation Function)
+
+A complete definition of UDAF involves two classes, `State` and `UDAF`.
+
+#### State Class
+
+To write your own `State`, you need to implement the `org.apache.iotdb.udf.api.State` interface.
+
+#### Interface Description:
+
+| Interface Definition | Description | Required to Implement |
+| -------------------------------- | ------------------------------------------------------------ | --------------------- |
+| void reset() | To reset the `State` object to its initial state, you need to fill in the initial values of the fields in the `State` class within this method as if you were writing a constructor. | Required |
+| byte[] serialize() | Serializes `State` to binary data. This method is used for IoTDB internal `State` passing. Note that the order of serialization must be consistent with the following deserialization methods. | Required |
+| void deserialize(byte[] bytes) | Deserializes binary data to `State`. This method is used for IoTDB internal `State` passing. Note that the order of deserialization must be consistent with the serialization method above. | Required |
+
+#### Detailed interface introduction:
+
+1. **void reset()**
+
+This method resets the `State` to its initial state, you need to fill in the initial values of the fields in the `State` object in this method. For optimization reasons, IoTDB reuses `State` as much as possible internally, rather than creating a new `State` for each group, which would introduce unnecessary overhead. When `State` has finished updating the data in a group, this method is called to reset to the initial state as a way to process the next group.
+
+In the case of `State` for averaging (aka `avg`), for example, you would need the sum of the data, `sum`, and the number of entries in the data, `count`, and initialize both to 0 in the `reset()` method.
+
+```java
+class AvgState implements State {
+ double sum;
+
+ long count;
+
+ @Override
+ public void reset() {
+ sum = 0;
+ count = 0;
+ }
+
+ // other methods
+}
+```
+
+2. **byte[] serialize()/void deserialize(byte[] bytes)**
+
+These methods serialize the `State` into binary data, and deserialize the `State` from the binary data. IoTDB, as a distributed database, involves passing data among different nodes, so you need to write these two methods to enable the passing of the State among different nodes. Note that the order of serialization and deserialization must be the consistent.
+
+In the case of `State` for averaging (aka `avg`), for example, you can convert the content of State to `byte[]` array and read out the content of State from `byte[]` array in any way you want, the following shows the code for serialization/deserialization using `ByteBuffer` introduced by Java8:
+
+```java
+@Override
+public byte[] serialize() {
+ ByteBuffer buffer = ByteBuffer.allocate(Double.BYTES + Long.BYTES);
+ buffer.putDouble(sum);
+ buffer.putLong(count);
+
+ return buffer.array();
+}
+
+@Override
+public void deserialize(byte[] bytes) {
+ ByteBuffer buffer = ByteBuffer.wrap(bytes);
+ sum = buffer.getDouble();
+ count = buffer.getLong();
+}
+```
+
+
+
+#### UDAF Classes
+
+To write a UDAF, you need to implement the `org.apache.iotdb.udf.api.UDAF` interface.
+
+#### Interface Description:
+
+| Interface definition | Description | Required to Implement |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | --------------------- |
+| void validate(UDFParameterValidator validator) throws Exception | This method is mainly used to validate `UDFParameters` and it is executed before `beforeStart(UDFParameters, UDTFConfigurations)` is called. | Optional |
+| void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception | Initialization method that invokes user-defined initialization behavior before UDAF processes the input data. Unlike UDTF, configuration is of type `UDAFConfiguration`. | Required |
+| State createState() | To create a `State` object, usually just call the default constructor and modify the default initial value as needed. | Required |
+| void addInput(State state, Column[] columns, BitMap bitMap) | Update `State` object according to the incoming data `Column[]` in batch, note that last column `columns[columns.length - 1]` always represents the time column. In addition, `BitMap` represents the data that has been filtered out before, you need to manually determine whether the corresponding data has been filtered out when writing this method. | Required |
+| void combineState(State state, State rhs) | Merge `rhs` state into `state` state. In a distributed scenario, the same set of data may be distributed on different nodes, IoTDB generates a `State` object for the partial data on each node, and then calls this method to merge it into the complete `State`. | Required |
+| void outputFinal(State state, ResultValue resultValue) | Computes the final aggregated result based on the data in `State`. Note that according to the semantics of the aggregation, only one value can be output per group. | Required |
+| void beforeDestroy() | This method is called by the framework after the last input data is processed, and will only be called once in the life cycle of each UDF instance. | Optional |
+
+In the life cycle of a UDAF instance, the calling sequence of each method is as follows:
+
+1. State createState()
+2. void validate(UDFParameterValidator validator) throws Exception
+3. void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception
+4. void addInput(State state, Column[] columns, BitMap bitMap)
+5. void combineState(State state, State rhs)
+6. void outputFinal(State state, ResultValue resultValue)
+7. void beforeDestroy()
+
+Similar to UDTF, every time the framework executes a UDAF query, a new UDF instance will be constructed. When the query ends, the corresponding instance will be destroyed. Therefore, the internal data of the instances in different UDAF queries (even in the same SQL statement) are isolated. You can maintain some state data in the UDAF without considering the influence of concurrency and other factors.
+
+#### Detailed interface introduction:
+
+
+1. **void validate(UDFParameterValidator validator) throws Exception**
+
+Same as UDTF, the `validate` method is used to validate the parameters entered by the user.
+
+In this method, you can limit the number and types of input time series, check the attributes of user input, or perform any custom verification.
+
+2. **void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception**
+
+ The `beforeStart` method does the same thing as the UDAF:
+
+1. Use UDFParameters to get the time series paths and parse key-value pair attributes entered by the user.
+2. Set the strategy to access the raw data and set the output data type in UDAFConfigurations.
+3. Create resources, such as establishing external connections, opening files, etc.
+
+The role of the `UDFParameters` type can be seen above.
+
+2.2 **UDTFConfigurations**
+
+The difference from UDTF is that UDAF uses `UDAFConfigurations` as the type of `configuration` object.
+
+Currently, this class only supports setting the type of output data.
+
+```java
+void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
+ // parameters
+ // ...
+
+ // configurations
+ configurations
+ .setOutputDataType(Type.INT32); }
+}
+```
+
+The relationship between the output type set in `setOutputDataType` and the type of data output that `ResultValue` can actually receive is as follows:
+
+| The output type set in `setOutputDataType` | The output type that `ResultValue` can actually receive |
+| ------------------------------------------ | ------------------------------------------------------- |
+| INT32 | int |
+| INT64 | long |
+| FLOAT | float |
+| DOUBLE | double |
+| BOOLEAN | boolean |
+| TEXT | org.apache.iotdb.udf.api.type.Binary |
+
+The output type of the UDAF is determined at runtime. You can dynamically determine the output sequence type based on the input type.
+
+Here is a simple example:
+
+```java
+void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
+ // do something
+ // ...
+
+ configurations
+ .setOutputDataType(parameters.getDataType(0));
+}
+```
+
+3. **State createState()**
+
+
+This method creates and initializes a `State` object for UDAF. Due to the limitations of the Java language, you can only call the default constructor for the `State` class. The default constructor assigns a default initial value to all the fields in the class, and if that initial value does not meet your requirements, you need to initialize them manually within this method.
+
+The following is an example that includes manual initialization. Suppose you want to implement an aggregate function that multiply all numbers in the group, then your initial `State` value should be set to 1, but the default constructor initializes it to 0, so you need to initialize `State` manually after calling the default constructor:
+
+```java
+public State createState() {
+ MultiplyState state = new MultiplyState();
+ state.result = 1;
+ return state;
+}
+```
+
+4. **void addInput(State state, Column[] columns, BitMap bitMap)**
+
+This method updates the `State` object with the raw input data. For performance reasons, also to align with the IoTDB vectorized query engine, the raw input data is no longer a data point, but an array of columns ``Column[]``. Note that the last column (i.e. `columns[columns.length - 1]`) is always the time column, so you can also do different operations in UDAF depending on the time.
+
+Since the input parameter is not of a single data point type, but of multiple columns, you need to manually filter some of the data in the columns, which is why the third parameter, `BitMap`, exists. It identifies which of these columns have been filtered out, so you don't have to think about the filtered data in any case.
+
+Here's an example of `addInput()` that counts the number of items (aka count). It shows how you can use `BitMap` to ignore data that has been filtered out. Note that due to the limitations of the Java language, you need to do the explicit cast the `State` object from type defined in the interface to a custom `State` type at the beginning of the method, otherwise you won't be able to use the `State` object.
+
+```java
+public void addInput(State state, Column[] columns, BitMap bitMap) {
+ CountState countState = (CountState) state;
+
+ int count = columns[0].getPositionCount();
+ for (int i = 0; i < count; i++) {
+ if (bitMap != null && !bitMap.isMarked(i)) {
+ continue;
+ }
+ if (!columns[0].isNull(i)) {
+ countState.count++;
+ }
+ }
+}
+```
+
+5. **void combineState(State state, State rhs)**
+
+
+This method combines two `State`s, or more precisely, updates the first `State` object with the second `State` object. IoTDB is a distributed database, and the data of the same group may be distributed on different nodes. For performance reasons, IoTDB will first aggregate some of the data on each node into `State`, and then merge the `State`s on different nodes that belong to the same group, which is what `combineState` does.
+
+Here's an example of `combineState()` for averaging (aka avg). Similar to `addInput`, you need to do an explicit type conversion for the two `State`s at the beginning. Also note that you are updating the value of the first `State` with the contents of the second `State`.
+
+```java
+public void combineState(State state, State rhs) {
+ AvgState avgState = (AvgState) state;
+ AvgState avgRhs = (AvgState) rhs;
+
+ avgState.count += avgRhs.count;
+ avgState.sum += avgRhs.sum;
+}
+```
+
+6. **void outputFinal(State state, ResultValue resultValue)**
+
+This method works by calculating the final result from `State`. You need to access the various fields in `State`, derive the final result, and set the final result into the `ResultValue` object.IoTDB internally calls this method once at the end for each group. Note that according to the semantics of aggregation, the final result can only be one value.
+
+Here is another `outputFinal` example for averaging (aka avg). In addition to the forced type conversion at the beginning, you will also see a specific use of the `ResultValue` object, where the final result is set by `setXXX` (where `XXX` is the type name).
+
+```java
+public void outputFinal(State state, ResultValue resultValue) {
+ AvgState avgState = (AvgState) state;
+
+ if (avgState.count != 0) {
+ resultValue.setDouble(avgState.sum / avgState.count);
+ } else {
+ resultValue.setNull();
+ }
+}
+```
+
+7. **void beforeDestroy()**
+
+
+The method for terminating a UDF.
+
+This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
+
+
+### Maven Project Example
+
+If you use Maven, you can build your own UDF project referring to our **udf-example** module. You can find the project [here](https://github.com/apache/iotdb/tree/master/example/udf).
+
+
+## Contribute universal built-in UDF functions to iotdb
+
+This part mainly introduces how external users can contribute their own UDFs to the IoTDB community.
+
+#### Prerequisites
+
+1. UDFs must be universal.
+
+ The "universal" mentioned here refers to: UDFs can be widely used in some scenarios. In other words, the UDF function must have reuse value and may be directly used by other users in the community.
+
+ If you are not sure whether the UDF you want to contribute is universal, you can send an email to `dev@iotdb.apache.org` or create an issue to initiate a discussion.
+
+2. The UDF you are going to contribute has been well tested and can run normally in the production environment.
+
+
+#### What you need to prepare
+
+1. UDF source code
+2. Test cases
+3. Instructions
+
+#### UDF Source Code
+
+1. Create the UDF main class and related classes in `iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/udf/builtin` or in its subfolders.
+2. Register your UDF in `iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/udf/builtin/BuiltinTimeSeriesGeneratingFunction.java`.
+
+#### Test Cases
+
+At a minimum, you need to write integration tests for the UDF.
+
+You can add a test class in `integration-test/src/test/java/org/apache/iotdb/db/it/udf`.
+
+
+#### Instructions
+
+The instructions need to include: the name and the function of the UDF, the attribute parameters that must be provided when the UDF is executed, the applicable scenarios, and the usage examples, etc.
+
+The instructions for use should include both Chinese and English versions. Instructions for use should be added separately in `docs/zh/UserGuide/Operation Manual/DML Data Manipulation Language.md` and `docs/UserGuide/Operation Manual/DML Data Manipulation Language.md`.
+
+#### Submit a PR
+
+When you have prepared the UDF source code, test cases, and instructions, you are ready to submit a Pull Request (PR) on [Github](https://github.com/apache/iotdb). You can refer to our code contribution guide to submit a PR: [Development Guide](https://iotdb.apache.org/Community/Development-Guide.html).
+
+
+After the PR review is approved and merged, your UDF has already contributed to the IoTDB community!
diff --git a/src/UserGuide/latest/User-Manual/Database-Programming.md b/src/UserGuide/latest/User-Manual/Database-Programming.md
index ce100e750..2386a55b4 100644
--- a/src/UserGuide/latest/User-Manual/Database-Programming.md
+++ b/src/UserGuide/latest/User-Manual/Database-Programming.md
@@ -1036,890 +1036,3 @@ SELECT avg(count_s1) from root.sg_count.d;
| :------------------------------------------ | ------------------------------------------------------------ | --------- | ------------- |
| `continuous_query_submit_thread` | The number of threads in the scheduled thread pool that submit continuous query tasks periodically | int32 | 2 |
| `continuous_query_min_every_interval_in_ms` | The minimum value of the continuous query execution time interval | duration | 1000 |
-
-## USER-DEFINED FUNCTION (UDF)
-
-IoTDB provides a variety of built-in functions to meet your computing needs, and you can also create user defined functions to meet more computing needs.
-
-This document describes how to write, register and use a UDF.
-
-
-### UDF Types
-
-In IoTDB, you can expand two types of UDF:
-
-| UDF Class | Description |
-| --------------------------------------------------- | ------------------------------------------------------------ |
-| UDTF(User Defined Timeseries Generating Function) | This type of function can take **multiple** time series as input, and output **one** time series, which can have any number of data points. |
-| UDAF(User Defined Aggregation Function) | Custom Aggregation Functions. This type of function can take one time series as input, and output **one** aggregated data point for each group based on the GROUP BY type. |
-
-### UDF Development Dependencies
-
-If you use [Maven](http://search.maven.org/), you can search for the development dependencies listed below from the [Maven repository](http://search.maven.org/) . Please note that you must select the same dependency version as the target IoTDB server version for development.
-
-``` xml
-
-
-`SlidingTimeWindowAccessStrategy`: `SlidingTimeWindowAccessStrategy` has many constructors, you can pass 3 types of parameters to them:
-
-- Parameter 1: The display window on the time axis
-- Parameter 2: Time interval for dividing the time axis (should be positive)
-- Parameter 3: Time sliding step (not required to be greater than or equal to the time interval, but must be a positive number)
-
-The first type of parameters are optional. If the parameters are not provided, the beginning time of the display window will be set to the same as the minimum timestamp of the query result set, and the ending time of the display window will be set to the same as the maximum timestamp of the query result set.
-
-The sliding step parameter is also optional. If the parameter is not provided, the sliding step will be set to the same as the time interval for dividing the time axis.
-
-The relationship between the three types of parameters can be seen in the figure below. Please see the Javadoc for more details.
-
-
-
-`SlidingSizeWindowAccessStrategy`: `SlidingSizeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
-
-* Parameter 1: Window size. This parameter specifies the number of data rows contained in a data processing window. Note that the number of data rows in some of the last time windows may be less than the specified number of data rows.
-* Parameter 2: Sliding step. This parameter means the number of rows between the first point of the next window and the first point of the current window. (This parameter is not required to be greater than or equal to the window size, but must be a positive number)
-
-The sliding step parameter is optional. If the parameter is not provided, the sliding step will be set to the same as the window size.
-
-The `SessionTimeWindowAccessStrategy` is shown schematically below. **Time intervals less than or equal to the given minimum time interval `sessionGap` are assigned in one group**
-
-
-`SessionTimeWindowAccessStrategy`: `SessionTimeWindowAccessStrategy` has many constructors, you can pass 2 types of parameters to them:
-
-- Parameter 1: The display window on the time axis.
-- Parameter 2: The minimum time interval `sessionGap` of two adjacent windows.
-
-
-The `StateWindowAccessStrategy` is shown schematically below. **For numerical data, if the state difference is less than or equal to the given threshold `delta`, it will be assigned in one group. **
-
-
-`StateWindowAccessStrategy` has four constructors.
-
-- Constructor 1: For numerical data, there are 3 parameters: the time axis can display the start and end time of the time window and the threshold `delta` for the allowable change within a single window.
-- Constructor 2: For text data and boolean data, there are 3 parameters: the time axis can be provided to display the start and end time of the time window. For both data types, the data within a single window is same, and there is no need to provide an allowable change threshold.
-- Constructor 3: For numerical data, there are 1 parameters: you can only provide the threshold delta that is allowed to change within a single window. The start time of the time axis display time window will be defined as the smallest timestamp in the entire query result set, and the time axis display time window end time will be defined as The largest timestamp in the entire query result set.
-- Constructor 4: For text data and boolean data, you can provide no parameter. The start and end timestamps are explained in Constructor 3.
-
-StateWindowAccessStrategy can only take one column as input for now.
-
-Please see the Javadoc for more details.
-
-
-
-###### setOutputDataType
-
-Note that the type of output sequence you set here determines the type of data that the `PointCollector` can actually receive in the `transform` method. The relationship between the output data type set in `setOutputDataType` and the actual data output type that `PointCollector` can receive is as follows:
-
-| Output Data Type Set in `setOutputDataType` | Data Type that `PointCollector` Can Receive |
-| :------------------------------------------ | :----------------------------------------------------------- |
-| `INT32` | `int` |
-| `INT64` | `long` |
-| `FLOAT` | `float` |
-| `DOUBLE` | `double` |
-| `BOOLEAN` | `boolean` |
-| `TEXT` | `java.lang.String` and `org.apache.iotdb.udf.api.type.Binary` |
-
-The type of output time series of a UDTF is determined at runtime, which means that a UDTF can dynamically determine the type of output time series according to the type of input time series.
-Here is a simple example:
-
-```java
-void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
- // do something
- // ...
-
- configurations
- .setAccessStrategy(new RowByRowAccessStrategy())
- .setOutputDataType(parameters.getDataType(0));
-}
-```
-
-
-
-#### void transform(Row row, PointCollector collector) throws Exception
-
-You need to implement this method when you specify the strategy of UDF to read the original data as `RowByRowAccessStrategy`.
-
-This method processes the raw data one row at a time. The raw data is input from `Row` and output by `PointCollector`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
-
-The following is a complete UDF example that implements the `void transform(Row row, PointCollector collector) throws Exception` method. It is an adder that receives two columns of time series as input. When two data points in a row are not `null`, this UDF will output the algebraic sum of these two data points.
-
-``` java
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Adder implements UDTF {
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT64)
- .setAccessStrategy(new RowByRowAccessStrategy());
- }
-
- @Override
- public void transform(Row row, PointCollector collector) throws Exception {
- if (row.isNull(0) || row.isNull(1)) {
- return;
- }
- collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
- }
-}
-```
-
-
-
-#### void transform(RowWindow rowWindow, PointCollector collector) throws Exception
-
-You need to implement this method when you specify the strategy of UDF to read the original data as `SlidingTimeWindowAccessStrategy` or `SlidingSizeWindowAccessStrategy`.
-
-This method processes a batch of data in a fixed number of rows or a fixed time interval each time, and we call the container containing this batch of data a window. The raw data is input from `RowWindow` and output by `PointCollector`. `RowWindow` can help you access a batch of `Row`, it provides a set of interfaces for random access and iterative access to this batch of `Row`. You can output any number of data points in one `transform` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
-
-Below is a complete UDF example that implements the `void transform(RowWindow rowWindow, PointCollector collector) throws Exception` method. It is a counter that receives any number of time series as input, and its function is to count and output the number of data rows in each time window within a specified time range.
-
-```java
-import java.io.IOException;
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.access.RowWindow;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Counter implements UDTF {
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT32)
- .setAccessStrategy(new SlidingTimeWindowAccessStrategy(
- parameters.getLong("time_interval"),
- parameters.getLong("sliding_step"),
- parameters.getLong("display_window_begin"),
- parameters.getLong("display_window_end")));
- }
-
- @Override
- public void transform(RowWindow rowWindow, PointCollector collector) {
- if (rowWindow.windowSize() != 0) {
- collector.putInt(rowWindow.windowStartTime(), rowWindow.windowSize());
- }
- }
-}
-```
-
-
-
-#### void terminate(PointCollector collector) throws Exception
-
-In some scenarios, a UDF needs to traverse all the original data to calculate the final output data points. The `terminate` interface provides support for those scenarios.
-
-This method is called after all `transform` calls are executed and before the `beforeDestory` method is executed. You can implement the `transform` method to perform pure data processing (without outputting any data points), and implement the `terminate` method to output the processing results.
-
-The processing results need to be output by the `PointCollector`. You can output any number of data points in one `terminate` method call. It should be noted that the type of output data points must be the same as you set in the `beforeStart` method, and the timestamps of output data points must be strictly monotonically increasing.
-
-Below is a complete UDF example that implements the `void terminate(PointCollector collector) throws Exception` method. It takes one time series whose data type is `INT32` as input, and outputs the maximum value point of the series.
-
-```java
-import java.io.IOException;
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Max implements UDTF {
-
- private Long time;
- private int value;
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT32)
- .setAccessStrategy(new RowByRowAccessStrategy());
- }
-
- @Override
- public void transform(Row row, PointCollector collector) {
- if (row.isNull(0)) {
- return;
- }
- int candidateValue = row.getInt(0);
- if (time == null || value < candidateValue) {
- time = row.getTime();
- value = candidateValue;
- }
- }
-
- @Override
- public void terminate(PointCollector collector) throws IOException {
- if (time != null) {
- collector.putInt(time, value);
- }
- }
-}
-```
-
-
-
-#### void beforeDestroy()
-
-The method for terminating a UDF.
-
-This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
-
-
-
-### UDAF (User Defined Aggregation Function)
-
-A complete definition of UDAF involves two classes, `State` and `UDAF`.
-
-#### State Class
-
-To write your own `State`, you need to implement the `org.apache.iotdb.udf.api.State` interface.
-
-The following table shows all the interfaces available for user implementation.
-
-| Interface Definition | Description | Required to Implement |
-| -------------------------------- | ------------------------------------------------------------ | --------------------- |
-| `void reset()` | To reset the `State` object to its initial state, you need to fill in the initial values of the fields in the `State` class within this method as if you were writing a constructor. | Required |
-| `byte[] serialize()` | Serializes `State` to binary data. This method is used for IoTDB internal `State` passing. Note that the order of serialization must be consistent with the following deserialization methods. | Required |
-| `void deserialize(byte[] bytes)` | Deserializes binary data to `State`. This method is used for IoTDB internal `State` passing. Note that the order of deserialization must be consistent with the serialization method above. | Required |
-
-The following section describes the usage of each interface in detail.
-
-
-
-##### void reset()
-
-This method resets the `State` to its initial state, you need to fill in the initial values of the fields in the `State` object in this method. For optimization reasons, IoTDB reuses `State` as much as possible internally, rather than creating a new `State` for each group, which would introduce unnecessary overhead. When `State` has finished updating the data in a group, this method is called to reset to the initial state as a way to process the next group.
-
-In the case of `State` for averaging (aka `avg`), for example, you would need the sum of the data, `sum`, and the number of entries in the data, `count`, and initialize both to 0 in the `reset()` method.
-
-```java
-class AvgState implements State {
- double sum;
-
- long count;
-
- @Override
- public void reset() {
- sum = 0;
- count = 0;
- }
-
- // other methods
-}
-```
-
-
-
-##### byte[] serialize()/void deserialize(byte[] bytes)
-
-These methods serialize the `State` into binary data, and deserialize the `State` from the binary data. IoTDB, as a distributed database, involves passing data among different nodes, so you need to write these two methods to enable the passing of the State among different nodes. Note that the order of serialization and deserialization must be the consistent.
-
-In the case of `State` for averaging (aka `avg`), for example, you can convert the content of State to `byte[]` array and read out the content of State from `byte[]` array in any way you want, the following shows the code for serialization/deserialization using `ByteBuffer` introduced by Java8:
-
-```java
-@Override
-public byte[] serialize() {
- ByteBuffer buffer = ByteBuffer.allocate(Double.BYTES + Long.BYTES);
- buffer.putDouble(sum);
- buffer.putLong(count);
-
- return buffer.array();
-}
-
-@Override
-public void deserialize(byte[] bytes) {
- ByteBuffer buffer = ByteBuffer.wrap(bytes);
- sum = buffer.getDouble();
- count = buffer.getLong();
-}
-```
-
-
-
-#### UDAF Classes
-
-To write a UDAF, you need to implement the `org.apache.iotdb.udf.api.UDAF` interface.
-
-The following table shows all the interfaces available for user implementation.
-
-| Interface definition | Description | Required to Implement |
-| ------------------------------------------------------------ | ------------------------------------------------------------ | --------------------- |
-| `void validate(UDFParameterValidator validator) throws Exception` | This method is mainly used to validate `UDFParameters` and it is executed before `beforeStart(UDFParameters, UDTFConfigurations)` is called. | Optional |
-| `void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception` | Initialization method that invokes user-defined initialization behavior before UDAF processes the input data. Unlike UDTF, configuration is of type `UDAFConfiguration`. | Required |
-| `State createState()` | To create a `State` object, usually just call the default constructor and modify the default initial value as needed. | Required |
-| `void addInput(State state, Column[] columns, BitMap bitMap)` | Update `State` object according to the incoming data `Column[]` in batch, note that last column `columns[columns.length - 1]` always represents the time column. In addition, `BitMap` represents the data that has been filtered out before, you need to manually determine whether the corresponding data has been filtered out when writing this method. | Required |
-| `void combineState(State state, State rhs)` | Merge `rhs` state into `state` state. In a distributed scenario, the same set of data may be distributed on different nodes, IoTDB generates a `State` object for the partial data on each node, and then calls this method to merge it into the complete `State`. | Required |
-| `void outputFinal(State state, ResultValue resultValue)` | Computes the final aggregated result based on the data in `State`. Note that according to the semantics of the aggregation, only one value can be output per group. | Required |
-| `void beforeDestroy() ` | This method is called by the framework after the last input data is processed, and will only be called once in the life cycle of each UDF instance. | Optional |
-
-In the life cycle of a UDAF instance, the calling sequence of each method is as follows:
-
-1. `State createState()`
-2. `void validate(UDFParameterValidator validator) throws Exception`
-3. `void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception`
-4. `void addInput(State state, Column[] columns, BitMap bitMap)`
-5. `void combineState(State state, State rhs)`
-6. `void outputFinal(State state, ResultValue resultValue)`
-7. `void beforeDestroy()`
-
-Similar to UDTF, every time the framework executes a UDAF query, a new UDF instance will be constructed. When the query ends, the corresponding instance will be destroyed. Therefore, the internal data of the instances in different UDAF queries (even in the same SQL statement) are isolated. You can maintain some state data in the UDAF without considering the influence of concurrency and other factors.
-
-The usage of each interface will be described in detail below.
-
-
-
-##### void validate(UDFParameterValidator validator) throws Exception
-
-Same as UDTF, the `validate` method is used to validate the parameters entered by the user.
-
-In this method, you can limit the number and types of input time series, check the attributes of user input, or perform any custom verification.
-
-
-
-##### void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception
-
- The `beforeStart` method does the same thing as the UDAF:
-
-1. Use UDFParameters to get the time series paths and parse key-value pair attributes entered by the user.
-2. Set the strategy to access the raw data and set the output data type in UDAFConfigurations.
-3. Create resources, such as establishing external connections, opening files, etc.
-
-The role of the `UDFParameters` type can be seen above.
-
-###### UDAFConfigurations
-
-The difference from UDTF is that UDAF uses `UDAFConfigurations` as the type of `configuration` object.
-
-Currently, this class only supports setting the type of output data.
-
-```java
-void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
- // parameters
- // ...
-
- // configurations
- configurations
- .setOutputDataType(Type.INT32); }
-}
-```
-
-The relationship between the output type set in `setOutputDataType` and the type of data output that `ResultValue` can actually receive is as follows:
-
-| The output type set in `setOutputDataType` | The output type that `ResultValue` can actually receive |
-| ------------------------------------------ | ------------------------------------------------------- |
-| `INT32` | `int` |
-| `INT64` | `long` |
-| `FLOAT` | `float` |
-| `DOUBLE` | `double` |
-| `BOOLEAN` | `boolean` |
-| `TEXT` | `org.apache.iotdb.udf.api.type.Binary` |
-
-The output type of the UDAF is determined at runtime. You can dynamically determine the output sequence type based on the input type.
-
-Here is a simple example:
-
-```java
-void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
- // do something
- // ...
-
- configurations
- .setOutputDataType(parameters.getDataType(0));
-}
-```
-
-
-
-##### State createState()
-
-This method creates and initializes a `State` object for UDAF. Due to the limitations of the Java language, you can only call the default constructor for the `State` class. The default constructor assigns a default initial value to all the fields in the class, and if that initial value does not meet your requirements, you need to initialize them manually within this method.
-
-The following is an example that includes manual initialization. Suppose you want to implement an aggregate function that multiply all numbers in the group, then your initial `State` value should be set to 1, but the default constructor initializes it to 0, so you need to initialize `State` manually after calling the default constructor:
-
-```java
-public State createState() {
- MultiplyState state = new MultiplyState();
- state.result = 1;
- return state;
-}
-```
-
-
-
-##### void addInput(State state, Column[] columns, BitMap bitMap)
-
-This method updates the `State` object with the raw input data. For performance reasons, also to align with the IoTDB vectorized query engine, the raw input data is no longer a data point, but an array of columns ``Column[]``. Note that the last column (i.e. `columns[columns.length - 1]`) is always the time column, so you can also do different operations in UDAF depending on the time.
-
-Since the input parameter is not of a single data point type, but of multiple columns, you need to manually filter some of the data in the columns, which is why the third parameter, `BitMap`, exists. It identifies which of these columns have been filtered out, so you don't have to think about the filtered data in any case.
-
-Here's an example of `addInput()` that counts the number of items (aka count). It shows how you can use `BitMap` to ignore data that has been filtered out. Note that due to the limitations of the Java language, you need to do the explicit cast the `State` object from type defined in the interface to a custom `State` type at the beginning of the method, otherwise you won't be able to use the `State` object.
-
-```java
-public void addInput(State state, Column[] columns, BitMap bitMap) {
- CountState countState = (CountState) state;
-
- int count = columns[0].getPositionCount();
- for (int i = 0; i < count; i++) {
- if (bitMap != null && !bitMap.isMarked(i)) {
- continue;
- }
- if (!columns[0].isNull(i)) {
- countState.count++;
- }
- }
-}
-```
-
-
-
-##### void combineState(State state, State rhs)
-
-This method combines two `State`s, or more precisely, updates the first `State` object with the second `State` object. IoTDB is a distributed database, and the data of the same group may be distributed on different nodes. For performance reasons, IoTDB will first aggregate some of the data on each node into `State`, and then merge the `State`s on different nodes that belong to the same group, which is what `combineState` does.
-
-Here's an example of `combineState()` for averaging (aka avg). Similar to `addInput`, you need to do an explicit type conversion for the two `State`s at the beginning. Also note that you are updating the value of the first `State` with the contents of the second `State`.
-
-```java
-public void combineState(State state, State rhs) {
- AvgState avgState = (AvgState) state;
- AvgState avgRhs = (AvgState) rhs;
-
- avgState.count += avgRhs.count;
- avgState.sum += avgRhs.sum;
-}
-```
-
-
-
-##### void outputFinal(State state, ResultValue resultValue)
-
-This method works by calculating the final result from `State`. You need to access the various fields in `State`, derive the final result, and set the final result into the `ResultValue` object.IoTDB internally calls this method once at the end for each group. Note that according to the semantics of aggregation, the final result can only be one value.
-
-Here is another `outputFinal` example for averaging (aka avg). In addition to the forced type conversion at the beginning, you will also see a specific use of the `ResultValue` object, where the final result is set by `setXXX` (where `XXX` is the type name).
-
-```java
-public void outputFinal(State state, ResultValue resultValue) {
- AvgState avgState = (AvgState) state;
-
- if (avgState.count != 0) {
- resultValue.setDouble(avgState.sum / avgState.count);
- } else {
- resultValue.setNull();
- }
-}
-```
-
-
-
-##### void beforeDestroy()
-
-The method for terminating a UDF.
-
-This method is called by the framework. For a UDF instance, `beforeDestroy` will be called after the last record is processed. In the entire life cycle of the instance, `beforeDestroy` will only be called once.
-
-
-
-### Maven Project Example
-
-If you use Maven, you can build your own UDF project referring to our **udf-example** module. You can find the project [here](https://github.com/apache/iotdb/tree/master/example/udf).
-
-
-
-### UDF Registration
-
-The process of registering a UDF in IoTDB is as follows:
-
-1. Implement a complete UDF class, assuming the full class name of this class is `org.apache.iotdb.udf.ExampleUDTF`.
-2. Package your project into a JAR. If you use Maven to manage your project, you can refer to the Maven project example above.
-3. Make preparations for registration according to the registration mode. For details, see the following example.
-4. You can use following SQL to register UDF.
-
-```sql
-CREATE FUNCTION | UDF Class | +AccessStrategy | +Description | +
|---|---|---|
| UDTF | +MAPPABLE_ROW_BY_ROW | +Custom scalar function, input k columns of time series and 1 row of data, output 1 column of time series and 1 row of data, can be used in any clause and expression that appears in the scalar function, such as select clause, where clause, etc. | +
| ROW_BY_ROW SLIDING_TIME_WINDOW SLIDING_SIZE_WINDOW SESSION_TIME_WINDOW STATE_WINDOW |
+ Custom time series generation function, input k columns of time series m rows of data, output 1 column of time series n rows of data, the number of input rows m can be different from the number of output rows n, and can only be used in SELECT clauses. | +|
| UDAF | +- | +Custom aggregation function, input k columns of time series m rows of data, output 1 column of time series 1 row of data, can be used in any clause and expression that appears in the aggregation function, such as select clause, having clause, etc. | +
| UDF 分类 | +数据访问策略 | +描述 | +
|---|---|---|
| UDTF | +MAPPABLE_ROW_BY_ROW | +自定义标量函数,输入 k 列时间序列 1 行数据,输出 1 列时间序列 1 行数据,可用于标量函数出现的任何子句和表达式中,如select子句、where子句等。 | +
| ROW_BY_ROW SLIDING_TIME_WINDOW SLIDING_SIZE_WINDOW SESSION_TIME_WINDOW STATE_WINDOW |
+ 自定义时间序列生成函数,输入 k 列时间序列 m 行数据,输出 1 列时间序列 n 行数据,输入行数 m 可以与输出行数 n 不相同,只能用于SELECT子句中。 | +|
| UDAF | +- | +自定义聚合函数,输入 k 列时间序列 m 行数据,输出 1 列时间序列 1 行数据,可用于聚合函数出现的任何子句和表达式中,如select子句、having子句等。 | +
+
+`SlidingTimeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供 3 类参数:
+
+1. 时间轴显示时间窗开始和结束时间
+
+时间轴显示时间窗开始和结束时间不是必须要提供的。当您不提供这类参数时,时间轴显示时间窗开始时间会被定义为整个查询结果集中最小的时间戳,时间轴显示时间窗结束时间会被定义为整个查询结果集中最大的时间戳。
+
+2. 划分时间轴的时间间隔参数(必须为正数)
+3. 滑动步长(不要求大于等于时间间隔,但是必须为正数)
+
+滑动步长参数也不是必须的。当您不提供滑动步长参数时,滑动步长会被设定为划分时间轴的时间间隔。
+
+3 类参数的关系可见下图。策略的构造方法详见 Javadoc。
+
+
+
+> 注意,最后的一些时间窗口的实际时间间隔可能小于规定的时间间隔参数。另外,可能存在某些时间窗口内数据行数量为 0 的情况,这种情况框架也会为该窗口调用一次`transform`方法。
+
+- `SlidingSizeWindowAccessStrategy`
+
+开窗示意图:
+
+
+
+`SlidingSizeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供 2 个参数:
+
+1. 窗口大小,即一个数据处理窗口包含的数据行数。注意,最后一些窗口的数据行数可能少于规定的数据行数。
+2. 滑动步长,即下一窗口第一个数据行与当前窗口第一个数据行间的数据行数(不要求大于等于窗口大小,但是必须为正数)
+
+滑动步长参数不是必须的。当您不提供滑动步长参数时,滑动步长会被设定为窗口大小。
+
+- `SessionTimeWindowAccessStrategy`
+
+开窗示意图:**时间间隔小于等于给定的最小时间间隔 sessionGap 则分为一组。**
+
+
+
+
+`SessionTimeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供 2 类参数:
+
+1. 时间轴显示时间窗开始和结束时间。
+2. 会话窗口之间的最小时间间隔。
+
+- `StateWindowAccessStrategy`
+
+开窗示意图:**对于数值型数据,状态差值小于等于给定的阈值 delta 则分为一组。**
+
+
+
+`StateWindowAccessStrategy`有四种构造方法:
+
+1. 针对数值型数据,可以提供时间轴显示时间窗开始和结束时间以及对于单个窗口内部允许变化的阈值delta。
+2. 针对文本数据以及布尔数据,可以提供时间轴显示时间窗开始和结束时间。对于这两种数据类型,单个窗口内的数据是相同的,不需要提供变化阈值。
+3. 针对数值型数据,可以只提供单个窗口内部允许变化的阈值delta,时间轴显示时间窗开始时间会被定义为整个查询结果集中最小的时间戳,时间轴显示时间窗结束时间会被定义为整个查询结果集中最大的时间戳。
+4. 针对文本数据以及布尔数据,可以不提供任何参数,开始与结束时间戳见3中解释。
+
+StateWindowAccessStrategy 目前只能接收一列输入。策略的构造方法详见 Javadoc。
+
+ 2.2.2 **setOutputDataType**
+
+注意,您在此处设定的输出结果序列的类型,决定了`transform`方法中`PointCollector`实际能够接收的数据类型。`setOutputDataType`中设定的输出类型和`PointCollector`实际能够接收的数据输出类型关系如下:
+
+| `setOutputDataType`中设定的输出类型 | `PointCollector`实际能够接收的输出类型 |
+| :---------------------------------- | :----------------------------------------------------------- |
+| INT32 | int |
+| INT64 | long |
+| FLOAT | float |
+| DOUBLE | double |
+| BOOLEAN | boolean |
+| TEXT | java.lang.String 和 org.apache.iotdb.udf.api.type.Binary |
+
+UDTF 输出序列的类型是运行时决定的。您可以根据输入序列类型动态决定输出序列类型。
+
+示例:
+
+```java
+void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
+ // do something
+ // ...
+
+ configurations
+ .setAccessStrategy(new RowByRowAccessStrategy())
+ .setOutputDataType(parameters.getDataType(0));
+}
+```
+
+3. **void transform(Row row, PointCollector collector) throws Exception**
+
+当您在`beforeStart`方法中指定 UDF 读取原始数据的策略为 `RowByRowAccessStrategy`,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
+
+该方法每次处理原始数据的一行。原始数据由`Row`读入,由`PointCollector`输出。您可以选择在一次`transform`方法调用中输出任意数量的数据点。需要注意的是,输出数据点的类型必须与您在`beforeStart`方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
+
+下面是一个实现了`void transform(Row row, PointCollector collector) throws Exception`方法的完整 UDF 示例。它是一个加法器,接收两列时间序列输入,当这两个数据点都不为`null`时,输出这两个数据点的代数和。
+
+``` java
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Adder implements UDTF {
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(Type.INT64)
+ .setAccessStrategy(new RowByRowAccessStrategy());
+ }
+
+ @Override
+ public void transform(Row row, PointCollector collector) throws Exception {
+ if (row.isNull(0) || row.isNull(1)) {
+ return;
+ }
+ collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
+ }
+}
+```
+
+4. **void transform(RowWindow rowWindow, PointCollector collector) throws Exception**
+
+当您在`beforeStart`方法中指定 UDF 读取原始数据的策略为 `SlidingTimeWindowAccessStrategy`或者`SlidingSizeWindowAccessStrategy`时,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
+
+该方法每次处理固定行数或者固定时间间隔内的一批数据,我们称包含这一批数据的容器为窗口。原始数据由`RowWindow`读入,由`PointCollector`输出。`RowWindow`能够帮助您访问某一批次的`Row`,它提供了对这一批次的`Row`进行随机访问和迭代访问的接口。您可以选择在一次`transform`方法调用中输出任意数量的数据点,需要注意的是,输出数据点的类型必须与您在`beforeStart`方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
+
+下面是一个实现了`void transform(RowWindow rowWindow, PointCollector collector) throws Exception`方法的完整 UDF 示例。它是一个计数器,接收任意列数的时间序列输入,作用是统计并输出指定时间范围内每一个时间窗口中的数据行数。
+
+```java
+import java.io.IOException;
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.RowWindow;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Counter implements UDTF {
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(Type.INT32)
+ .setAccessStrategy(new SlidingTimeWindowAccessStrategy(
+ parameters.getLong("time_interval"),
+ parameters.getLong("sliding_step"),
+ parameters.getLong("display_window_begin"),
+ parameters.getLong("display_window_end")));
+ }
+
+ @Override
+ public void transform(RowWindow rowWindow, PointCollector collector) throws Exception {
+ if (rowWindow.windowSize() != 0) {
+ collector.putInt(rowWindow.windowStartTime(), rowWindow.windowSize());
+ }
+ }
+}
+```
+
+5. **void terminate(PointCollector collector) throws Exception**
+
+在一些场景下,UDF 需要遍历完所有的原始数据后才能得到最后的输出结果。`terminate`接口为这类 UDF 提供了支持。
+
+该方法会在所有的`transform`调用执行完成后,在`beforeDestory`方法执行前被调用。您可以选择使用`transform`方法进行单纯的数据处理,最后使用`terminate`将处理结果输出。
+
+结果需要由`PointCollector`输出。您可以选择在一次`terminate`方法调用中输出任意数量的数据点。需要注意的是,输出数据点的类型必须与您在`beforeStart`方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
+
+下面是一个实现了`void terminate(PointCollector collector) throws Exception`方法的完整 UDF 示例。它接收一个`INT32`类型的时间序列输入,作用是输出该序列的最大值点。
+
+```java
+import java.io.IOException;
+import org.apache.iotdb.udf.api.UDTF;
+import org.apache.iotdb.udf.api.access.Row;
+import org.apache.iotdb.udf.api.collector.PointCollector;
+import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
+import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
+import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
+import org.apache.iotdb.udf.api.type.Type;
+
+public class Max implements UDTF {
+
+ private Long time;
+ private int value;
+
+ @Override
+ public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
+ configurations
+ .setOutputDataType(TSDataType.INT32)
+ .setAccessStrategy(new RowByRowAccessStrategy());
+ }
+
+ @Override
+ public void transform(Row row, PointCollector collector) {
+ if (row.isNull(0)) {
+ return;
+ }
+ int candidateValue = row.getInt(0);
+ if (time == null || value < candidateValue) {
+ time = row.getTime();
+ value = candidateValue;
+ }
+ }
+
+ @Override
+ public void terminate(PointCollector collector) throws IOException {
+ if (time != null) {
+ collector.putInt(time, value);
+ }
+ }
+}
+```
+
+6. **void beforeDestroy()**
+
+UDTF 的结束方法,您可以在此方法中进行一些资源释放等的操作。
+
+此方法由框架调用。对于一个 UDF 类实例而言,生命周期中会且只会被调用一次,即在处理完最后一条记录之后被调用。
+
+### UDAF(User Defined Aggregation Function)
+
+一个完整的 UDAF 定义涉及到 State 和 UDAF 两个类。
+
+#### State 类
+
+编写一个 State 类需要实现`org.apache.iotdb.udf.api.State`接口,下表是需要实现的方法说明。
+
+#### 接口说明:
+
+| 接口定义 | 描述 | 是否必须 |
+| -------------------------------- | ------------------------------------------------------------ | -------- |
+| void reset() | 将 `State` 对象重置为初始的状态,您需要像编写构造函数一样,在该方法内填入 `State` 类中各个字段的初始值。 | 是 |
+| byte[] serialize() | 将 `State` 序列化为二进制数据。该方法用于 IoTDB 内部的 `State` 对象传递,注意序列化的顺序必须和下面的反序列化方法一致。 | 是 |
+| void deserialize(byte[] bytes) | 将二进制数据反序列化为 `State`。该方法用于 IoTDB 内部的 `State` 对象传递,注意反序列化的顺序必须和上面的序列化方法一致。 | 是 |
+
+#### 接口详细介绍:
+
+1. **void reset()**
+
+该方法的作用是将 `State` 重置为初始的状态,您需要在该方法内填写 `State` 对象中各个字段的初始值。出于优化上的考量,IoTDB 在内部会尽可能地复用 `State`,而不是为每一个组创建一个新的 `State`,这样会引入不必要的开销。当 `State` 更新完一个组中的数据之后,就会调用这个方法重置为初始状态,以此来处理下一个组。
+
+以求平均数(也就是 `avg`)的 `State` 为例,您需要数据的总和 `sum` 与数据的条数 `count`,并在 `reset()` 方法中将二者初始化为 0。
+
+```java
+class AvgState implements State {
+ double sum;
+
+ long count;
+
+ @Override
+ public void reset() {
+ sum = 0;
+ count = 0;
+ }
+
+ // other methods
+}
+```
+
+2. **byte[] serialize()/void deserialize(byte[] bytes)**
+
+该方法的作用是将 State 序列化为二进制数据,和从二进制数据中反序列化出 State。IoTDB 作为分布式数据库,涉及到在不同节点中传递数据,因此您需要编写这两个方法,来实现 State 在不同节点中的传递。注意序列化和反序列的顺序必须一致。
+
+还是以求平均数(也就是求 avg)的 State 为例,您可以通过任意途径将 State 的内容转化为 `byte[]` 数组,以及从 `byte[]` 数组中读取出 State 的内容,下面展示的是用 Java8 引入的 `ByteBuffer` 进行序列化/反序列的代码:
+
+```java
+@Override
+public byte[] serialize() {
+ ByteBuffer buffer = ByteBuffer.allocate(Double.BYTES + Long.BYTES);
+ buffer.putDouble(sum);
+ buffer.putLong(count);
+
+ return buffer.array();
+}
+
+@Override
+public void deserialize(byte[] bytes) {
+ ByteBuffer buffer = ByteBuffer.wrap(bytes);
+ sum = buffer.getDouble();
+ count = buffer.getLong();
+}
+```
+
+#### UDAF 类
+
+编写一个 UDAF 类需要实现`org.apache.iotdb.udf.api.UDAF`接口,下表是需要实现的方法说明。
+
+#### 接口说明:
+
+| 接口定义 | 描述 | 是否必须 |
+| ------------------------------------------------------------ | ------------------------------------------------------------ | -------- |
+| void validate(UDFParameterValidator validator) throws Exception | 在初始化方法`beforeStart`调用前执行,用于检测`UDFParameters`中用户输入的参数是否合法。该方法与 UDTF 的`validate`相同。 | 否 |
+| void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception | 初始化方法,在 UDAF 处理输入数据前,调用用户自定义的初始化行为。与 UDTF 不同的是,这里的 configuration 是 `UDAFConfiguration` 类型。 | 是 |
+| State createState() | 创建`State`对象,一般只需要调用默认构造函数,然后按需修改默认的初始值即可。 | 是 |
+| void addInput(State state, Column[] columns, BitMap bitMap) | 根据传入的数据`Column[]`批量地更新`State`对象,注意最后一列,也就是 `columns[columns.length - 1]` 总是代表时间列。另外`BitMap`表示之前已经被过滤掉的数据,您在编写该方法时需要手动判断对应的数据是否被过滤掉。 | 是 |
+| void combineState(State state, State rhs) | 将`rhs`状态合并至`state`状态中。在分布式场景下,同一组的数据可能分布在不同节点上,IoTDB 会为每个节点上的部分数据生成一个`State`对象,然后调用该方法合并成完整的`State`。 | 是 |
+| void outputFinal(State state, ResultValue resultValue) | 根据`State`中的数据,计算出最终的聚合结果。注意根据聚合的语义,每一组只能输出一个值。 | 是 |
+| void beforeDestroy() | UDAF 的结束方法。此方法由框架调用,并且只会被调用一次,即在处理完最后一条记录之后被调用。 | 否 |
+
+在一个完整的 UDAF 实例生命周期中,各个方法的调用顺序如下:
+
+1. State createState()
+2. void validate(UDFParameterValidator validator) throws Exception
+3. void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception
+4. void addInput(State state, Column[] columns, BitMap bitMap)
+5. void combineState(State state, State rhs)
+6. void outputFinal(State state, ResultValue resultValue)
+7. void beforeDestroy()
+
+和 UDTF 类似,框架每执行一次 UDAF 查询,都会构造一个全新的 UDF 类实例,查询结束时,对应的 UDF 类实例即被销毁,因此不同 UDAF 查询(即使是在同一个 SQL 语句中)UDF 类实例内部的数据都是隔离的。您可以放心地在 UDAF 中维护一些状态数据,无需考虑并发对 UDF 类实例内部状态数据的影响。
+
+#### 接口详细介绍:
+
+1. **void validate(UDFParameterValidator validator) throws Exception**
+
+同 UDTF, `validate`方法能够对用户输入的参数进行验证。
+
+您可以在该方法中限制输入序列的数量和类型,检查用户输入的属性或者进行自定义逻辑的验证。
+
+2. **void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception**
+
+ `beforeStart`方法的作用 UDAF 相同:
+
+ 1. 帮助用户解析 SQL 语句中的 UDF 参数
+ 2. 配置 UDF 运行时必要的信息,即指定 UDF 访问原始数据时采取的策略和输出结果序列的类型
+ 3. 创建资源,比如建立外部链接,打开文件等。
+
+其中,`UDFParameters` 类型的作用可以参照上文。
+
+2.2 **UDTFConfigurations**
+
+和 UDTF 的区别在于,UDAF 使用了 `UDAFConfigurations` 作为 `configuration` 对象的类型。
+
+目前,该类仅支持设置输出数据的类型。
+
+```java
+void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
+ // parameters
+ // ...
+
+ // configurations
+ configurations
+ .setOutputDataType(Type.INT32);
+}
+```
+
+`setOutputDataType` 中设定的输出类型和 `ResultValue` 实际能够接收的数据输出类型关系如下:
+
+| `setOutputDataType`中设定的输出类型 | `ResultValue`实际能够接收的输出类型 |
+| :---------------------------------- | :------------------------------------- |
+| INT32 | int |
+| INT64 | long |
+| FLOAT | float |
+| DOUBLE | double |
+| BOOLEAN | boolean |
+| TEXT | org.apache.iotdb.udf.api.type.Binary |
+
+UDAF 输出序列的类型也是运行时决定的。您可以根据输入序列类型动态决定输出序列类型。
+
+示例:
+
+```java
+void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
+ // do something
+ // ...
+
+ configurations
+ .setOutputDataType(parameters.getDataType(0));
+}
+```
+
+3. **State createState()**
+
+为 UDAF 创建并初始化 `State`。由于 Java 语言本身的限制,您只能调用 `State` 类的默认构造函数。默认构造函数会为类中所有的字段赋一个默认的初始值,如果该初始值并不符合您的要求,您需要在这个方法内进行手动的初始化。
+
+下面是一个包含手动初始化的例子。假设您要实现一个累乘的聚合函数,`State` 的初始值应该设置为 1,但是默认构造函数会初始化为 0,因此您需要在调用默认构造函数之后,手动对 `State` 进行初始化:
+
+```java
+public State createState() {
+ MultiplyState state = new MultiplyState();
+ state.result = 1;
+ return state;
+}
+```
+
+4. **void addInput(State state, Column[] columns, BitMap bitMap)**
+
+该方法的作用是,通过原始的输入数据来更新 `State` 对象。出于性能上的考量,也是为了和 IoTDB 向量化的查询引擎相对齐,原始的输入数据不再是一个数据点,而是列的数组 `Column[]`。注意最后一列(也就是 `columns[columns.length - 1]` )总是时间列,因此您也可以在 UDAF 中根据时间进行不同的操作。
+
+由于输入参数的类型不是一个数据点,而是多个列,您需要手动对列中的部分数据进行过滤处理,这就是第三个参数 `BitMap` 存在的意义。它用来标识这些列中哪些数据被过滤掉了,您在任何情况下都无需考虑被过滤掉的数据。
+
+下面是一个用于统计数据条数(也就是 count)的 `addInput()` 示例。它展示了您应该如何使用 `BitMap` 来忽视那些已经被过滤掉的数据。注意还是由于 Java 语言本身的限制,您需要在方法的开头将接口中定义的 `State` 类型强制转化为自定义的 `State` 类型,不然后续无法正常使用该 `State` 对象。
+
+```java
+public void addInput(State state, Column[] columns, BitMap bitMap) {
+ CountState countState = (CountState) state;
+
+ int count = columns[0].getPositionCount();
+ for (int i = 0; i < count; i++) {
+ if (bitMap != null && !bitMap.isMarked(i)) {
+ continue;
+ }
+ if (!columns[0].isNull(i)) {
+ countState.count++;
+ }
+ }
+}
+```
+
+5. **void combineState(State state, State rhs)**
+
+该方法的作用是合并两个 `State`,更加准确的说,是用第二个 `State` 对象来更新第一个 `State` 对象。IoTDB 是分布式数据库,同一组的数据可能分布在多个不同的节点上。出于性能考虑,IoTDB 会为每个节点上的部分数据先进行聚合成 `State`,然后再将不同节点上的、属于同一个组的 `State` 进行合并,这就是 `combineState` 的作用。
+
+下面是一个用于求平均数(也就是 avg)的 `combineState()` 示例。和 `addInput` 类似,您都需要在开头对两个 `State` 进行强制类型转换。另外需要注意是用第二个 `State` 的内容来更新第一个 `State` 的值。
+
+```java
+public void combineState(State state, State rhs) {
+ AvgState avgState = (AvgState) state;
+ AvgState avgRhs = (AvgState) rhs;
+
+ avgState.count += avgRhs.count;
+ avgState.sum += avgRhs.sum;
+}
+```
+
+6. **void outputFinal(State state, ResultValue resultValue)**
+
+该方法的作用是从 `State` 中计算出最终的结果。您需要访问 `State` 中的各个字段,求出最终的结果,并将最终的结果设置到 `ResultValue` 对象中。IoTDB 内部会为每个组在最后调用一次这个方法。注意根据聚合的语义,最终的结果只能是一个值。
+
+下面还是一个用于求平均数(也就是 avg)的 `outputFinal` 示例。除了开头的强制类型转换之外,您还将看到 `ResultValue` 对象的具体用法,即通过 `setXXX`(其中 `XXX` 是类型名)来设置最后的结果。
+
+```java
+public void outputFinal(State state, ResultValue resultValue) {
+ AvgState avgState = (AvgState) state;
+
+ if (avgState.count != 0) {
+ resultValue.setDouble(avgState.sum / avgState.count);
+ } else {
+ resultValue.setNull();
+ }
+}
+```
+
+7. **void beforeDestroy()**
+
+UDAF 的结束方法,您可以在此方法中进行一些资源释放等的操作。
+
+此方法由框架调用。对于一个 UDF 类实例而言,生命周期中会且只会被调用一次,即在处理完最后一条记录之后被调用。
+
+### 完整 Maven 项目示例
+
+如果您使用 [Maven](http://search.maven.org/),可以参考我们编写的示例项目**udf-example**。您可以在 [这里](https://github.com/apache/iotdb/tree/master/example/udf) 找到它。
+
+
+## 为iotdb贡献通用的内置UDF函数
+
+该部分主要讲述了外部用户如何将自己编写的 UDF 贡献给 IoTDB 社区。
+
+#### 前提条件
+
+1. UDF 具有通用性。
+
+ 通用性主要指的是:UDF 在某些业务场景下,可以被广泛使用。换言之,就是 UDF 具有复用价值,可被社区内其他用户直接使用。
+
+ 如果不确定自己写的 UDF 是否具有通用性,可以发邮件到 `dev@iotdb.apache.org` 或直接创建 ISSUE 发起讨论。
+
+2. UDF 已经完成测试,且能够正常运行在用户的生产环境中。
+
+#### 贡献清单
+
+1. UDF 的源代码
+2. UDF 的测试用例
+3. UDF 的使用说明
+
+#### 源代码
+
+1. 在`iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/udf/builtin`中创建 UDF 主类和相关的辅助类。
+2. 在`iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/udf/builtin/BuiltinTimeSeriesGeneratingFunction.java`中注册编写的 UDF。
+
+#### 测试用例
+
+至少需要为贡献的 UDF 编写集成测试。
+
+可以在`integration-test/src/test/java/org/apache/iotdb/db/it/udf`中为贡献的 UDF 新增一个测试类进行测试。
+
+#### 使用说明
+
+使用说明需要包含:UDF 的名称、UDF 的作用、执行函数必须的属性参数、函数的适用的场景以及使用示例等。
+
+使用说明需包含中英文两个版本。应分别在 `docs/zh/UserGuide/Operation Manual/DML Data Manipulation Language.md` 和 `docs/UserGuide/Operation Manual/DML Data Manipulation Language.md` 中新增使用说明。
+
+#### 提交 PR
+
+当准备好源代码、测试用例和使用说明后,就可以将 UDF 贡献到 IoTDB 社区了。在 [Github](https://github.com/apache/iotdb) 上面提交 Pull Request (PR) 即可。具体提交方式见:[贡献指南](https://iotdb.apache.org/zh/Community/Development-Guide.html)。
+
+当 PR 评审通过并被合并后, UDF 就已经贡献给 IoTDB 社区了!
\ No newline at end of file
diff --git a/src/zh/UserGuide/latest/User-Manual/Database-Programming.md b/src/zh/UserGuide/latest/User-Manual/Database-Programming.md
index 385319086..86b0c31a8 100644
--- a/src/zh/UserGuide/latest/User-Manual/Database-Programming.md
+++ b/src/zh/UserGuide/latest/User-Manual/Database-Programming.md
@@ -1030,812 +1030,3 @@ SELECT avg(count_s1) from root.sg_count.d;
| :---------------------------------- |----------------------|----------|---------------|
| `continuous_query_submit_thread` | 用于周期性提交连续查询执行任务的线程数 | int32 | 2 |
| `continuous_query_min_every_interval_in_ms` | 系统允许的连续查询最小的周期性时间间隔 | duration | 1000 |
-
-## 用户自定义函数
-
-UDF(User Defined Function)即用户自定义函数。IoTDB 提供多种内建函数来满足您的计算需求,同时您还可以通过创建自定义函数来满足更多的计算需求。
-
-根据此文档,您将会很快学会 UDF 的编写、注册、使用等操作。
-
-### UDF 类型
-
-IoTDB 支持两种类型的 UDF 函数,如下表所示。
-
-| UDF 分类 | 描述 |
-| --------------------------------------------------- | ------------------------------------------------------------ |
-| UDTF(User Defined Timeseries Generating Function) | 自定义时间序列生成函数。该类函数允许接收多条时间序列,最终会输出一条时间序列,生成的时间序列可以有任意多数量的数据点。 |
-| UDAF(User Defined Aggregation Function) | 自定义聚合函数。该类函数接受一条时间序列数据,最终会根据用户指定的 GROUP BY 类型,为每个组生成一个聚合后的数据点。 |
-
-### UDF 依赖
-
-如果您使用 [Maven](http://search.maven.org/) ,可以从 [Maven 库](http://search.maven.org/) 中搜索下面示例中的依赖。请注意选择和目标 IoTDB 服务器版本相同的依赖版本。
-
-``` xml
-
-
-`SlidingTimeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供 3 类参数:
-
-1. 时间轴显示时间窗开始和结束时间
-2. 划分时间轴的时间间隔参数(必须为正数)
-3. 滑动步长(不要求大于等于时间间隔,但是必须为正数)
-
-时间轴显示时间窗开始和结束时间不是必须要提供的。当您不提供这类参数时,时间轴显示时间窗开始时间会被定义为整个查询结果集中最小的时间戳,时间轴显示时间窗结束时间会被定义为整个查询结果集中最大的时间戳。
-
-滑动步长参数也不是必须的。当您不提供滑动步长参数时,滑动步长会被设定为划分时间轴的时间间隔。
-
-3 类参数的关系可见下图。策略的构造方法详见 Javadoc。
-
-
-
-注意,最后的一些时间窗口的实际时间间隔可能小于规定的时间间隔参数。另外,可能存在某些时间窗口内数据行数量为 0 的情况,这种情况框架也会为该窗口调用一次`transform`方法。
-
-如图是`SlidingSizeWindowAccessStrategy`的开窗示意图。
-
-
-`SlidingSizeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供 2 个参数:
-
-1. 窗口大小,即一个数据处理窗口包含的数据行数。注意,最后一些窗口的数据行数可能少于规定的数据行数。
-2. 滑动步长,即下一窗口第一个数据行与当前窗口第一个数据行间的数据行数(不要求大于等于窗口大小,但是必须为正数)
-
-滑动步长参数不是必须的。当您不提供滑动步长参数时,滑动步长会被设定为窗口大小。
-
-如图是`SessionTimeWindowAccessStrategy`的开窗示意图。**时间间隔小于等于给定的最小时间间隔 sessionGap 则分为一组。**
-
-
-`SessionTimeWindowAccessStrategy`有多种构造方法,您可以向构造方法提供 2 类参数:
-
-1. 时间轴显示时间窗开始和结束时间。
-2. 会话窗口之间的最小时间间隔。
-
-如图是`StateWindowAccessStrategy`的开窗示意图。**对于数值型数据,状态差值小于等于给定的阈值 delta 则分为一组。**
-
-
-`StateWindowAccessStrategy`有四种构造方法。
-
-1. 针对数值型数据,可以提供时间轴显示时间窗开始和结束时间以及对于单个窗口内部允许变化的阈值delta。
-2. 针对文本数据以及布尔数据,可以提供时间轴显示时间窗开始和结束时间。对于这两种数据类型,单个窗口内的数据是相同的,不需要提供变化阈值。
-3. 针对数值型数据,可以只提供单个窗口内部允许变化的阈值delta,时间轴显示时间窗开始时间会被定义为整个查询结果集中最小的时间戳,时间轴显示时间窗结束时间会被定义为整个查询结果集中最大的时间戳。
-4. 针对文本数据以及布尔数据,可以不提供任何参数,开始与结束时间戳见3中解释。
-
-StateWindowAccessStrategy 目前只能接收一列输入。策略的构造方法详见 Javadoc。
-
- * setOutputDataType
-
-注意,您在此处设定的输出结果序列的类型,决定了`transform`方法中`PointCollector`实际能够接收的数据类型。`setOutputDataType`中设定的输出类型和`PointCollector`实际能够接收的数据输出类型关系如下:
-
-| `setOutputDataType`中设定的输出类型 | `PointCollector`实际能够接收的输出类型 |
-| :---------------------------------- | :----------------------------------------------------------- |
-| `INT32` | `int` |
-| `INT64` | `long` |
-| `FLOAT` | `float` |
-| `DOUBLE` | `double` |
-| `BOOLEAN` | `boolean` |
-| `TEXT` | `java.lang.String` 和 `org.apache.iotdb.udf.api.type.Binary` |
-
-UDTF 输出序列的类型是运行时决定的。您可以根据输入序列类型动态决定输出序列类型。
-
-下面是一个简单的例子:
-
-```java
-void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) throws Exception {
- // do something
- // ...
-
- configurations
- .setAccessStrategy(new RowByRowAccessStrategy())
- .setOutputDataType(parameters.getDataType(0));
-}
-```
-
-* void transform(Row row, PointCollector collector) throws Exception
-
-当您在`beforeStart`方法中指定 UDF 读取原始数据的策略为 `RowByRowAccessStrategy`,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
-
-该方法每次处理原始数据的一行。原始数据由`Row`读入,由`PointCollector`输出。您可以选择在一次`transform`方法调用中输出任意数量的数据点。需要注意的是,输出数据点的类型必须与您在`beforeStart`方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
-
-下面是一个实现了`void transform(Row row, PointCollector collector) throws Exception`方法的完整 UDF 示例。它是一个加法器,接收两列时间序列输入,当这两个数据点都不为`null`时,输出这两个数据点的代数和。
-
-``` java
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Adder implements UDTF {
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(Type.INT64)
- .setAccessStrategy(new RowByRowAccessStrategy());
- }
-
- @Override
- public void transform(Row row, PointCollector collector) throws Exception {
- if (row.isNull(0) || row.isNull(1)) {
- return;
- }
- collector.putLong(row.getTime(), row.getLong(0) + row.getLong(1));
- }
-}
-```
-
- * void transform(RowWindow rowWindow, PointCollector collector) throws Exception
-
-当您在`beforeStart`方法中指定 UDF 读取原始数据的策略为 `SlidingTimeWindowAccessStrategy`或者`SlidingSizeWindowAccessStrategy`时,您就需要实现该方法,在该方法中增加对原始数据处理的逻辑。
-
-该方法每次处理固定行数或者固定时间间隔内的一批数据,我们称包含这一批数据的容器为窗口。原始数据由`RowWindow`读入,由`PointCollector`输出。`RowWindow`能够帮助您访问某一批次的`Row`,它提供了对这一批次的`Row`进行随机访问和迭代访问的接口。您可以选择在一次`transform`方法调用中输出任意数量的数据点,需要注意的是,输出数据点的类型必须与您在`beforeStart`方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
-
-下面是一个实现了`void transform(RowWindow rowWindow, PointCollector collector) throws Exception`方法的完整 UDF 示例。它是一个计数器,接收任意列数的时间序列输入,作用是统计并输出指定时间范围内每一个时间窗口中的数据行数。
-
-```java
-import java.io.IOException;
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.RowWindow;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.SlidingTimeWindowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Counter implements UDTF {
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(Type.INT32)
- .setAccessStrategy(new SlidingTimeWindowAccessStrategy(
- parameters.getLong("time_interval"),
- parameters.getLong("sliding_step"),
- parameters.getLong("display_window_begin"),
- parameters.getLong("display_window_end")));
- }
-
- @Override
- public void transform(RowWindow rowWindow, PointCollector collector) throws Exception {
- if (rowWindow.windowSize() != 0) {
- collector.putInt(rowWindow.windowStartTime(), rowWindow.windowSize());
- }
- }
-}
-```
-
- * void terminate(PointCollector collector) throws Exception
-
-在一些场景下,UDF 需要遍历完所有的原始数据后才能得到最后的输出结果。`terminate`接口为这类 UDF 提供了支持。
-
-该方法会在所有的`transform`调用执行完成后,在`beforeDestory`方法执行前被调用。您可以选择使用`transform`方法进行单纯的数据处理,最后使用`terminate`将处理结果输出。
-
-结果需要由`PointCollector`输出。您可以选择在一次`terminate`方法调用中输出任意数量的数据点。需要注意的是,输出数据点的类型必须与您在`beforeStart`方法中设置的一致,而输出数据点的时间戳必须是严格单调递增的。
-
-下面是一个实现了`void terminate(PointCollector collector) throws Exception`方法的完整 UDF 示例。它接收一个`INT32`类型的时间序列输入,作用是输出该序列的最大值点。
-
-```java
-import java.io.IOException;
-import org.apache.iotdb.udf.api.UDTF;
-import org.apache.iotdb.udf.api.access.Row;
-import org.apache.iotdb.udf.api.collector.PointCollector;
-import org.apache.iotdb.udf.api.customizer.config.UDTFConfigurations;
-import org.apache.iotdb.udf.api.customizer.parameter.UDFParameters;
-import org.apache.iotdb.udf.api.customizer.strategy.RowByRowAccessStrategy;
-import org.apache.iotdb.udf.api.type.Type;
-
-public class Max implements UDTF {
-
- private Long time;
- private int value;
-
- @Override
- public void beforeStart(UDFParameters parameters, UDTFConfigurations configurations) {
- configurations
- .setOutputDataType(TSDataType.INT32)
- .setAccessStrategy(new RowByRowAccessStrategy());
- }
-
- @Override
- public void transform(Row row, PointCollector collector) {
- if (row.isNull(0)) {
- return;
- }
- int candidateValue = row.getInt(0);
- if (time == null || value < candidateValue) {
- time = row.getTime();
- value = candidateValue;
- }
- }
-
- @Override
- public void terminate(PointCollector collector) throws IOException {
- if (time != null) {
- collector.putInt(time, value);
- }
- }
-}
-```
-
- * void beforeDestroy()
-
-UDTF 的结束方法,您可以在此方法中进行一些资源释放等的操作。
-
-此方法由框架调用。对于一个 UDF 类实例而言,生命周期中会且只会被调用一次,即在处理完最后一条记录之后被调用。
-
-### UDAF(User Defined Aggregation Function)
-
-一个完整的 UDAF 定义涉及到 State 和 UDAF 两个类。
-
-#### State 类
-
-编写一个 State 类需要实现`org.apache.iotdb.udf.api.State`接口,下表是需要实现的方法说明。
-
-| 接口定义 | 描述 | 是否必须 |
-| -------------------------------- | ------------------------------------------------------------ | -------- |
-| `void reset()` | 将 `State` 对象重置为初始的状态,您需要像编写构造函数一样,在该方法内填入 `State` 类中各个字段的初始值。 | 是 |
-| `byte[] serialize()` | 将 `State` 序列化为二进制数据。该方法用于 IoTDB 内部的 `State` 对象传递,注意序列化的顺序必须和下面的反序列化方法一致。 | 是 |
-| `void deserialize(byte[] bytes)` | 将二进制数据反序列化为 `State`。该方法用于 IoTDB 内部的 `State` 对象传递,注意反序列化的顺序必须和上面的序列化方法一致。 | 是 |
-
-下面将详细介绍各个接口的使用方法。
-
-- void reset()
-
-该方法的作用是将 `State` 重置为初始的状态,您需要在该方法内填写 `State` 对象中各个字段的初始值。出于优化上的考量,IoTDB 在内部会尽可能地复用 `State`,而不是为每一个组创建一个新的 `State`,这样会引入不必要的开销。当 `State` 更新完一个组中的数据之后,就会调用这个方法重置为初始状态,以此来处理下一个组。
-
-以求平均数(也就是 `avg`)的 `State` 为例,您需要数据的总和 `sum` 与数据的条数 `count`,并在 `reset()` 方法中将二者初始化为 0。
-
-```java
-class AvgState implements State {
- double sum;
-
- long count;
-
- @Override
- public void reset() {
- sum = 0;
- count = 0;
- }
-
- // other methods
-}
-```
-
-- byte[] serialize()/void deserialize(byte[] bytes)
-
-该方法的作用是将 State 序列化为二进制数据,和从二进制数据中反序列化出 State。IoTDB 作为分布式数据库,涉及到在不同节点中传递数据,因此您需要编写这两个方法,来实现 State 在不同节点中的传递。注意序列化和反序列的顺序必须一致。
-
-还是以求平均数(也就是求 avg)的 State 为例,您可以通过任意途径将 State 的内容转化为 `byte[]` 数组,以及从 `byte[]` 数组中读取出 State 的内容,下面展示的是用 Java8 引入的 `ByteBuffer` 进行序列化/反序列的代码:
-
-```java
-@Override
-public byte[] serialize() {
- ByteBuffer buffer = ByteBuffer.allocate(Double.BYTES + Long.BYTES);
- buffer.putDouble(sum);
- buffer.putLong(count);
-
- return buffer.array();
-}
-
-@Override
-public void deserialize(byte[] bytes) {
- ByteBuffer buffer = ByteBuffer.wrap(bytes);
- sum = buffer.getDouble();
- count = buffer.getLong();
-}
-```
-
-#### UDAF 类
-
-编写一个 UDAF 类需要实现`org.apache.iotdb.udf.api.UDAF`接口,下表是需要实现的方法说明。
-
-| 接口定义 | 描述 | 是否必须 |
-| ------------------------------------------------------------ | ------------------------------------------------------------ | -------- |
-| `void validate(UDFParameterValidator validator) throws Exception` | 在初始化方法`beforeStart`调用前执行,用于检测`UDFParameters`中用户输入的参数是否合法。该方法与 UDTF 的`validate`相同。 | 否 |
-| `void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception` | 初始化方法,在 UDAF 处理输入数据前,调用用户自定义的初始化行为。与 UDTF 不同的是,这里的 configuration 是 `UDAFConfiguration` 类型。 | 是 |
-| `State createState()` | 创建`State`对象,一般只需要调用默认构造函数,然后按需修改默认的初始值即可。 | 是 |
-| `void addInput(State state, Column[] columns, BitMap bitMap)` | 根据传入的数据`Column[]`批量地更新`State`对象,注意最后一列,也就是 `columns[columns.length - 1]` 总是代表时间列。另外`BitMap`表示之前已经被过滤掉的数据,您在编写该方法时需要手动判断对应的数据是否被过滤掉。 | 是 |
-| `void combineState(State state, State rhs)` | 将`rhs`状态合并至`state`状态中。在分布式场景下,同一组的数据可能分布在不同节点上,IoTDB 会为每个节点上的部分数据生成一个`State`对象,然后调用该方法合并成完整的`State`。 | 是 |
-| `void outputFinal(State state, ResultValue resultValue)` | 根据`State`中的数据,计算出最终的聚合结果。注意根据聚合的语义,每一组只能输出一个值。 | 是 |
-| `void beforeDestroy() ` | UDAF 的结束方法。此方法由框架调用,并且只会被调用一次,即在处理完最后一条记录之后被调用。 | 否 |
-
-在一个完整的 UDAF 实例生命周期中,各个方法的调用顺序如下:
-
-1. `State createState()`
-2. `void validate(UDFParameterValidator validator) throws Exception`
-3. `void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception`
-4. `void addInput(State state, Column[] columns, BitMap bitMap)`
-5. `void combineState(State state, State rhs)`
-6. `void outputFinal(State state, ResultValue resultValue)`
-7. `void beforeDestroy()`
-
-和 UDTF 类似,框架每执行一次 UDAF 查询,都会构造一个全新的 UDF 类实例,查询结束时,对应的 UDF 类实例即被销毁,因此不同 UDAF 查询(即使是在同一个 SQL 语句中)UDF 类实例内部的数据都是隔离的。您可以放心地在 UDAF 中维护一些状态数据,无需考虑并发对 UDF 类实例内部状态数据的影响。
-
-下面将详细介绍各个接口的使用方法。
-
- * void validate(UDFParameterValidator validator) throws Exception
-
-同 UDTF, `validate`方法能够对用户输入的参数进行验证。
-
-您可以在该方法中限制输入序列的数量和类型,检查用户输入的属性或者进行自定义逻辑的验证。
-
- * void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception
-
- `beforeStart`方法的作用 UDAF 相同:
-
- 1. 帮助用户解析 SQL 语句中的 UDF 参数
- 2. 配置 UDF 运行时必要的信息,即指定 UDF 访问原始数据时采取的策略和输出结果序列的类型
- 3. 创建资源,比如建立外部链接,打开文件等。
-
-其中,`UDFParameters` 类型的作用可以参照上文。
-
-##### UDAFConfigurations
-
-和 UDTF 的区别在于,UDAF 使用了 `UDAFConfigurations` 作为 `configuration` 对象的类型。
-
-目前,该类仅支持设置输出数据的类型。
-
-```java
-void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
- // parameters
- // ...
-
- // configurations
- configurations
- .setOutputDataType(Type.INT32);
-}
-```
-
-`setOutputDataType` 中设定的输出类型和 `ResultValue` 实际能够接收的数据输出类型关系如下:
-
-| `setOutputDataType`中设定的输出类型 | `ResultValue`实际能够接收的输出类型 |
-| :---------------------------------- | :------------------------------------- |
-| `INT32` | `int` |
-| `INT64` | `long` |
-| `FLOAT` | `float` |
-| `DOUBLE` | `double` |
-| `BOOLEAN` | `boolean` |
-| `TEXT` | `org.apache.iotdb.udf.api.type.Binary` |
-
-UDAF 输出序列的类型也是运行时决定的。您可以根据输入序列类型动态决定输出序列类型。
-
-下面是一个简单的例子:
-
-```java
-void beforeStart(UDFParameters parameters, UDAFConfigurations configurations) throws Exception {
- // do something
- // ...
-
- configurations
- .setOutputDataType(parameters.getDataType(0));
-}
-```
-
-- State createState()
-
-为 UDAF 创建并初始化 `State`。由于 Java 语言本身的限制,您只能调用 `State` 类的默认构造函数。默认构造函数会为类中所有的字段赋一个默认的初始值,如果该初始值并不符合您的要求,您需要在这个方法内进行手动的初始化。
-
-下面是一个包含手动初始化的例子。假设您要实现一个累乘的聚合函数,`State` 的初始值应该设置为 1,但是默认构造函数会初始化为 0,因此您需要在调用默认构造函数之后,手动对 `State` 进行初始化:
-
-```java
-public State createState() {
- MultiplyState state = new MultiplyState();
- state.result = 1;
- return state;
-}
-```
-
-- void addInput(State state, Column[] columns, BitMap bitMap)
-
-该方法的作用是,通过原始的输入数据来更新 `State` 对象。出于性能上的考量,也是为了和 IoTDB 向量化的查询引擎相对齐,原始的输入数据不再是一个数据点,而是列的数组 `Column[]`。注意最后一列(也就是 `columns[columns.length - 1]` )总是时间列,因此您也可以在 UDAF 中根据时间进行不同的操作。
-
-由于输入参数的类型不是一个数据点,而是多个列,您需要手动对列中的部分数据进行过滤处理,这就是第三个参数 `BitMap` 存在的意义。它用来标识这些列中哪些数据被过滤掉了,您在任何情况下都无需考虑被过滤掉的数据。
-
-下面是一个用于统计数据条数(也就是 count)的 `addInput()` 示例。它展示了您应该如何使用 `BitMap` 来忽视那些已经被过滤掉的数据。注意还是由于 Java 语言本身的限制,您需要在方法的开头将接口中定义的 `State` 类型强制转化为自定义的 `State` 类型,不然后续无法正常使用该 `State` 对象。
-
-```java
-public void addInput(State state, Column[] columns, BitMap bitMap) {
- CountState countState = (CountState) state;
-
- int count = columns[0].getPositionCount();
- for (int i = 0; i < count; i++) {
- if (bitMap != null && !bitMap.isMarked(i)) {
- continue;
- }
- if (!columns[0].isNull(i)) {
- countState.count++;
- }
- }
-}
-```
-
-- void combineState(State state, State rhs)
-
-该方法的作用是合并两个 `State`,更加准确的说,是用第二个 `State` 对象来更新第一个 `State` 对象。IoTDB 是分布式数据库,同一组的数据可能分布在多个不同的节点上。出于性能考虑,IoTDB 会为每个节点上的部分数据先进行聚合成 `State`,然后再将不同节点上的、属于同一个组的 `State` 进行合并,这就是 `combineState` 的作用。
-
-下面是一个用于求平均数(也就是 avg)的 `combineState()` 示例。和 `addInput` 类似,您都需要在开头对两个 `State` 进行强制类型转换。另外需要注意是用第二个 `State` 的内容来更新第一个 `State` 的值。
-
-```java
-public void combineState(State state, State rhs) {
- AvgState avgState = (AvgState) state;
- AvgState avgRhs = (AvgState) rhs;
-
- avgState.count += avgRhs.count;
- avgState.sum += avgRhs.sum;
-}
-```
-
-- void outputFinal(State state, ResultValue resultValue)
-
-该方法的作用是从 `State` 中计算出最终的结果。您需要访问 `State` 中的各个字段,求出最终的结果,并将最终的结果设置到 `ResultValue` 对象中。IoTDB 内部会为每个组在最后调用一次这个方法。注意根据聚合的语义,最终的结果只能是一个值。
-
-下面还是一个用于求平均数(也就是 avg)的 `outputFinal` 示例。除了开头的强制类型转换之外,您还将看到 `ResultValue` 对象的具体用法,即通过 `setXXX`(其中 `XXX` 是类型名)来设置最后的结果。
-
-```java
-public void outputFinal(State state, ResultValue resultValue) {
- AvgState avgState = (AvgState) state;
-
- if (avgState.count != 0) {
- resultValue.setDouble(avgState.sum / avgState.count);
- } else {
- resultValue.setNull();
- }
-}
-```
-
- * void beforeDestroy()
-
-UDAF 的结束方法,您可以在此方法中进行一些资源释放等的操作。
-
-此方法由框架调用。对于一个 UDF 类实例而言,生命周期中会且只会被调用一次,即在处理完最后一条记录之后被调用。
-
-### 完整 Maven 项目示例
-
-如果您使用 [Maven](http://search.maven.org/),可以参考我们编写的示例项目**udf-example**。您可以在 [这里](https://github.com/apache/iotdb/tree/master/example/udf) 找到它。
-
-### UDF 注册
-
-注册一个 UDF 可以按如下流程进行:
-
-1. 实现一个完整的 UDF 类,假定这个类的全类名为`org.apache.iotdb.udf.UDTFExample`
-2. 将项目打成 JAR 包,如果您使用 Maven 管理项目,可以参考上述 Maven 项目示例的写法
-3. 进行注册前的准备工作,根据注册方式的不同需要做不同的准备,具体可参考以下例子
-4. 使用以下 SQL 语句注册 UDF
-
-```sql
-CREATE FUNCTION | UDF 分类 | +数据访问策略 | +描述 | +
|---|---|---|
| UDTF | +MAPPABLE_ROW_BY_ROW | +自定义标量函数,输入 k 列时间序列 1 行数据,输出 1 列时间序列 1 行数据,可用于标量函数出现的任何子句和表达式中,如select子句、where子句等。 | +
| ROW_BY_ROW SLIDING_TIME_WINDOW SLIDING_SIZE_WINDOW SESSION_TIME_WINDOW STATE_WINDOW |
+ 自定义时间序列生成函数,输入 k 列时间序列 m 行数据,输出 1 列时间序列 n 行数据,输入行数 m 可以与输出行数 n 不相同,只能用于SELECT子句中。 | +|
| UDAF | +- | +自定义聚合函数,输入 k 列时间序列 m 行数据,输出 1 列时间序列 1 行数据,可用于聚合函数出现的任何子句和表达式中,如select子句、having子句等。 | +