- | Number of timeseries (frequency<=1HZ) |
+ Number of timeseries (frequency<=1HZ) |
Memory |
Number of nodes |
diff --git a/src/zh/UserGuide/Master/Table/API/Programming-JDBC.md b/src/zh/UserGuide/Master/Table/API/Programming-JDBC.md
new file mode 100644
index 000000000..c5b57096e
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/API/Programming-JDBC.md
@@ -0,0 +1,191 @@
+
+
+# JDBC接口
+
+## 1 功能介绍
+
+IoTDB JDBC接口提供了一种标准的方式来与IoTDB数据库进行交互,允许用户通过Java程序执行SQL语句来管理数据库和时间序列数据。它支持数据库的连接、创建、查询、更新和删除操作,以及时间序列数据的批量插入和查询。
+
+**注意**: 目前的JDBC实现仅是为与第三方工具连接使用的。使用JDBC(执行插入语句时)无法提供高性能写入。
+
+对于Java应用,我们推荐使用Java 原生接口。
+
+## 2 使用方式
+
+**环境要求:**
+
+- JDK >= 1.8
+- Maven >= 3.6
+
+**在maven中添加依赖:**
+
+```XML
+
+
+ com.timecho.iotdb
+ iotdb-jdbc
+ 2.0.1.1
+
+
+```
+
+## 3 读写操作
+
+### 3.1 功能说明
+
+- **写操作**:通过execute方法执行插入、创建数据库、创建时间序列等操作。
+- **读操作**:通过executeQuery方法执行查询操作,并使用ResultSet对象获取查询结果。
+
+### 3.2 **方法列表**
+
+| **方法名** | **描述** | **参数** | **返回值** |
+| ------------------------------------------------------------ | ---------------------------------- | ---------------------------------------------------------- | ----------------------------------- |
+| Class.forName(String driver) | 加载JDBC驱动类 | driver: JDBC驱动类的名称 | Class: 加载的类对象 |
+| DriverManager.getConnection(String url, String username, String password) | 建立数据库连接 | url: 数据库的URLusername: 数据库用户名password: 数据库密码 | Connection: 数据库连接对象 |
+| Connection.createStatement() | 创建Statement对象,用于执行SQL语句 | 无 | Statement: SQL语句执行对象 |
+| Statement.execute(String sql) | 执行SQL语句,对于非查询语句 | sql: 要执行的SQL语句 | boolean: 指示是否返回ResultSet对象 |
+| Statement.executeQuery(String sql) | 执行查询SQL语句并返回结果集 | sql: 要执行的查询SQL语句 | ResultSet: 查询结果集 |
+| ResultSet.getMetaData() | 获取结果集的元数据 | 无 | ResultSetMetaData: 结果集元数据对象 |
+| ResultSet.next() | 移动到结果集的下一行 | 无 | boolean: 是否成功移动到下一行 |
+| ResultSet.getString(int columnIndex) | 获取指定列的字符串值 | columnIndex: 列索引(从1开始) | String: 列的字符串值 |
+
+## 4 示例代码
+
+**注意:使用表模型,必须在 url 中指定 sql_dialect 参数为 table。**
+
+```Java
+String url = "jdbc:iotdb://127.0.0.1:6667?sql_dialect=table";
+```
+
+JDBC接口示例代码:[src/main/java/org/apache/iotdb/TableModelJDBCExample.java](https://github.com/apache/iotdb/blob/master/example/jdbc/src/main/java/org/apache/iotdb/TableModelJDBCExample.java)
+
+
+```Java
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iotdb;
+
+import org.apache.iotdb.jdbc.IoTDBSQLException;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.sql.Connection;
+import java.sql.DriverManager;
+import java.sql.ResultSet;
+import java.sql.ResultSetMetaData;
+import java.sql.SQLException;
+import java.sql.Statement;
+
+public class TableModelJDBCExample {
+
+ private static final Logger LOGGER = LoggerFactory.getLogger(TableModelJDBCExample.class);
+
+ public static void main(String[] args) throws ClassNotFoundException, SQLException {
+ Class.forName("org.apache.iotdb.jdbc.IoTDBDriver");
+
+ // don't specify database in url
+ try (Connection connection =
+ DriverManager.getConnection(
+ "jdbc:iotdb://127.0.0.1:6667?sql_dialect=table", "root", "root");
+ Statement statement = connection.createStatement()) {
+
+ statement.execute("CREATE DATABASE test1");
+ statement.execute("CREATE DATABASE test2");
+
+ statement.execute("use test2");
+
+ // or use full qualified table name
+ statement.execute(
+ "create table test1.table1(region_id STRING ID, plant_id STRING ID, device_id STRING ID, model STRING ATTRIBUTE, temperature FLOAT MEASUREMENT, humidity DOUBLE MEASUREMENT) with (TTL=3600000)");
+
+ statement.execute(
+ "create table table2(region_id STRING ID, plant_id STRING ID, color STRING ATTRIBUTE, temperature FLOAT MEASUREMENT, speed DOUBLE MEASUREMENT) with (TTL=6600000)");
+
+ // show tables from current database
+ try (ResultSet resultSet = statement.executeQuery("SHOW TABLES")) {
+ ResultSetMetaData metaData = resultSet.getMetaData();
+ System.out.println(metaData.getColumnCount());
+ while (resultSet.next()) {
+ System.out.println(resultSet.getString(1) + ", " + resultSet.getInt(2));
+ }
+ }
+
+ // show tables by specifying another database
+ // using SHOW tables FROM
+ try (ResultSet resultSet = statement.executeQuery("SHOW TABLES FROM test1")) {
+ ResultSetMetaData metaData = resultSet.getMetaData();
+ System.out.println(metaData.getColumnCount());
+ while (resultSet.next()) {
+ System.out.println(resultSet.getString(1) + ", " + resultSet.getInt(2));
+ }
+ }
+
+ } catch (IoTDBSQLException e) {
+ LOGGER.error("IoTDB Jdbc example error", e);
+ }
+
+ // specify database in url
+ try (Connection connection =
+ DriverManager.getConnection(
+ "jdbc:iotdb://127.0.0.1:6667/test1?sql_dialect=table", "root", "root");
+ Statement statement = connection.createStatement()) {
+ // show tables from current database test1
+ try (ResultSet resultSet = statement.executeQuery("SHOW TABLES")) {
+ ResultSetMetaData metaData = resultSet.getMetaData();
+ System.out.println(metaData.getColumnCount());
+ while (resultSet.next()) {
+ System.out.println(resultSet.getString(1) + ", " + resultSet.getInt(2));
+ }
+ }
+
+ // change database to test2
+ statement.execute("use test2");
+
+ try (ResultSet resultSet = statement.executeQuery("SHOW TABLES")) {
+ ResultSetMetaData metaData = resultSet.getMetaData();
+ System.out.println(metaData.getColumnCount());
+ while (resultSet.next()) {
+ System.out.println(resultSet.getString(1) + ", " + resultSet.getInt(2));
+ }
+ }
+ }
+ }
+}
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/API/Programming-Java-Native-API.md b/src/zh/UserGuide/Master/Table/API/Programming-Java-Native-API.md
new file mode 100644
index 000000000..e97273103
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/API/Programming-Java-Native-API.md
@@ -0,0 +1,860 @@
+
+
+# Java Session原生接口
+
+## 1 功能介绍
+
+IoTDB具备Java原生客户端驱动和对应的连接池,提供对象化接口,可以直接组装时序对象进行写入,无需拼装 SQL。推荐使用连接池,多线程并行操作数据库。
+
+## 2 使用方式
+
+**环境要求:**
+
+- JDK >= 1.8
+- Maven >= 3.6
+
+**在maven中添加依赖:**
+
+```XML
+
+
+ com.timecho.iotdb
+ iotdb-session
+ 2.0.1.1
+
+
+```
+
+## 3 读写操作
+
+### 3.1 ITableSession接口
+
+#### 3.1.1 功能描述
+
+ITableSession接口定义了与IoTDB交互的基本操作,可以执行数据插入、查询操作以及关闭会话等,非线程安全。
+
+#### 3.1.2 方法列表
+
+以下是ITableSession接口中定义的方法及其详细说明:
+
+| **方法名** | **描述** | **参数** | **返回值** | **返回异常** |
+| --------------------------------------------------- | ------------------------------------------------------------ | ----------------------------------------------------------- | -------------- | --------------------------------------------------- |
+| insert(Tablet tablet) | 将一个包含时间序列数据的Tablet 对象插入到数据库中 | tablet: 要插入的Tablet对象 | 无 | StatementExecutionExceptionIoTDBConnectionException |
+| executeNonQueryStatement(String sql) | 执行非查询SQL语句,如DDL(数据定义语言)或DML(数据操作语言)命令 | sql: 要执行的SQL语句。 | 无 | StatementExecutionExceptionIoTDBConnectionException |
+| executeQueryStatement(String sql) | 执行查询SQL语句,并返回包含查询结果的SessionDataSet对象 | sql: 要执行的查询SQL语句。 | SessionDataSet | StatementExecutionExceptionIoTDBConnectionException |
+| executeQueryStatement(String sql, long timeoutInMs) | 执行查询SQL语句,并设置查询超时时间(以毫秒为单位) | sql: 要执行的查询SQL语句。timeoutInMs: 查询超时时间(毫秒) | SessionDataSet | StatementExecutionException |
+| close() | 关闭会话,释放所持有的资源 | 无 | 无 | IoTDBConnectionException |
+
+#### 3.1.2 接口展示
+
+``` java
+/**
+ * This interface defines a session for interacting with IoTDB tables.
+ * It supports operations such as data insertion, executing queries, and closing the session.
+ * Implementations of this interface are expected to manage connections and ensure
+ * proper resource cleanup.
+ *
+ * Each method may throw exceptions to indicate issues such as connection errors or
+ * execution failures.
+ *
+ *
Since this interface extends {@link AutoCloseable}, it is recommended to use
+ * try-with-resources to ensure the session is properly closed.
+ */
+public interface ITableSession extends AutoCloseable {
+
+ /**
+ * Inserts a {@link Tablet} into the database.
+ *
+ * @param tablet the tablet containing time-series data to be inserted.
+ * @throws StatementExecutionException if an error occurs while executing the statement.
+ * @throws IoTDBConnectionException if there is an issue with the IoTDB connection.
+ */
+ void insert(Tablet tablet) throws StatementExecutionException, IoTDBConnectionException;
+
+ /**
+ * Executes a non-query SQL statement, such as a DDL or DML command.
+ *
+ * @param sql the SQL statement to execute.
+ * @throws IoTDBConnectionException if there is an issue with the IoTDB connection.
+ * @throws StatementExecutionException if an error occurs while executing the statement.
+ */
+ void executeNonQueryStatement(String sql) throws IoTDBConnectionException, StatementExecutionException;
+
+ /**
+ * Executes a query SQL statement and returns the result set.
+ *
+ * @param sql the SQL query statement to execute.
+ * @return a {@link SessionDataSet} containing the query results.
+ * @throws StatementExecutionException if an error occurs while executing the statement.
+ * @throws IoTDBConnectionException if there is an issue with the IoTDB connection.
+ */
+ SessionDataSet executeQueryStatement(String sql)
+ throws StatementExecutionException, IoTDBConnectionException;
+
+ /**
+ * Executes a query SQL statement with a specified timeout and returns the result set.
+ *
+ * @param sql the SQL query statement to execute.
+ * @param timeoutInMs the timeout duration in milliseconds for the query execution.
+ * @return a {@link SessionDataSet} containing the query results.
+ * @throws StatementExecutionException if an error occurs while executing the statement.
+ * @throws IoTDBConnectionException if there is an issue with the IoTDB connection.
+ */
+ SessionDataSet executeQueryStatement(String sql, long timeoutInMs)
+ throws StatementExecutionException, IoTDBConnectionException;
+
+ /**
+ * Closes the session, releasing any held resources.
+ *
+ * @throws IoTDBConnectionException if there is an issue with closing the IoTDB connection.
+ */
+ @Override
+ void close() throws IoTDBConnectionException;
+}
+```
+
+### 3.2 TableSessionBuilder类
+
+#### 3.2.1 功能描述
+
+TableSessionBuilder类是一个构建器,用于配置和创建ITableSession接口的实例。它允许开发者设置连接参数、查询参数和安全特性等。
+
+#### 3.2.2 配置选项
+
+以下是TableSessionBuilder类中可用的配置选项及其默认值:
+
+| **配置项** | **描述** | **默认值** |
+| ---------------------------------------------------- | ---------------------------------------- | ------------------------------------------- |
+| nodeUrls(List`` nodeUrls) | 设置IoTDB集群的节点URL列表 | Collections.singletonList("localhost:6667") |
+| username(String username) | 设置连接的用户名 | "root" |
+| password(String password) | 设置连接的密码 | "root" |
+| database(String database) | 设置目标数据库名称 | null |
+| queryTimeoutInMs(long queryTimeoutInMs) | 设置查询超时时间(毫秒) | 60000(1分钟) |
+| fetchSize(int fetchSize) | 设置查询结果的获取大小 | 5000 |
+| zoneId(ZoneId zoneId) | 设置时区相关的ZoneId | ZoneId.systemDefault() |
+| thriftDefaultBufferSize(int thriftDefaultBufferSize) | 设置Thrift客户端的默认缓冲区大小(字节) | 1024(1KB) |
+| thriftMaxFrameSize(int thriftMaxFrameSize) | 设置Thrift客户端的最大帧大小(字节) | 64 * 1024 * 1024(64MB) |
+| enableRedirection(boolean enableRedirection) | 是否启用集群节点的重定向 | true |
+| enableAutoFetch(boolean enableAutoFetch) | 是否启用自动获取可用DataNodes | true |
+| maxRetryCount(int maxRetryCount) | 设置连接尝试的最大重试次数 | 60 |
+| retryIntervalInMs(long retryIntervalInMs) | 设置重试间隔时间(毫秒) | 500 |
+| useSSL(boolean useSSL) | 是否启用SSL安全连接 | false |
+| trustStore(String keyStore) | 设置SSL连接的信任库路径 | null |
+| trustStorePwd(String keyStorePwd) | 设置SSL连接的信任库密码 | null |
+| enableCompression(boolean enableCompression) | 是否启用RPC压缩 | false |
+| connectionTimeoutInMs(int connectionTimeoutInMs) | 设置连接超时时间(毫秒) | 0(无超时) |
+
+#### 3.2.3 接口展示
+
+``` java
+/**
+ * A builder class for constructing instances of {@link ITableSession}.
+ *
+ * This builder provides a fluent API for configuring various options such as connection
+ * settings, query parameters, and security features.
+ *
+ *
All configurations have reasonable default values, which can be overridden as needed.
+ */
+public class TableSessionBuilder {
+
+ /**
+ * Builds and returns a configured {@link ITableSession} instance.
+ *
+ * @return a fully configured {@link ITableSession}.
+ * @throws IoTDBConnectionException if an error occurs while establishing the connection.
+ */
+ public ITableSession build() throws IoTDBConnectionException;
+
+ /**
+ * Sets the list of node URLs for the IoTDB cluster.
+ *
+ * @param nodeUrls a list of node URLs.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue Collection.singletonList("localhost:6667")
+ */
+ public TableSessionBuilder nodeUrls(List nodeUrls);
+
+ /**
+ * Sets the username for the connection.
+ *
+ * @param username the username.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionBuilder username(String username);
+
+ /**
+ * Sets the password for the connection.
+ *
+ * @param password the password.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionBuilder password(String password);
+
+ /**
+ * Sets the target database name.
+ *
+ * @param database the database name.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionBuilder database(String database);
+
+ /**
+ * Sets the query timeout in milliseconds.
+ *
+ * @param queryTimeoutInMs the query timeout in milliseconds.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 60000 (1 minute)
+ */
+ public TableSessionBuilder queryTimeoutInMs(long queryTimeoutInMs);
+
+ /**
+ * Sets the fetch size for query results.
+ *
+ * @param fetchSize the fetch size.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 5000
+ */
+ public TableSessionBuilder fetchSize(int fetchSize);
+
+ /**
+ * Sets the {@link ZoneId} for timezone-related operations.
+ *
+ * @param zoneId the {@link ZoneId}.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue ZoneId.systemDefault()
+ */
+ public TableSessionBuilder zoneId(ZoneId zoneId);
+
+ /**
+ * Sets the default init buffer size for the Thrift client.
+ *
+ * @param thriftDefaultBufferSize the buffer size in bytes.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 1024 (1 KB)
+ */
+ public TableSessionBuilder thriftDefaultBufferSize(int thriftDefaultBufferSize);
+
+ /**
+ * Sets the maximum frame size for the Thrift client.
+ *
+ * @param thriftMaxFrameSize the maximum frame size in bytes.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 64 * 1024 * 1024 (64 MB)
+ */
+ public TableSessionBuilder thriftMaxFrameSize(int thriftMaxFrameSize);
+
+ /**
+ * Enables or disables redirection for cluster nodes.
+ *
+ * @param enableRedirection whether to enable redirection.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue true
+ */
+ public TableSessionBuilder enableRedirection(boolean enableRedirection);
+
+ /**
+ * Enables or disables automatic fetching of available DataNodes.
+ *
+ * @param enableAutoFetch whether to enable automatic fetching.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue true
+ */
+ public TableSessionBuilder enableAutoFetch(boolean enableAutoFetch);
+
+ /**
+ * Sets the maximum number of retries for connection attempts.
+ *
+ * @param maxRetryCount the maximum retry count.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 60
+ */
+ public TableSessionBuilder maxRetryCount(int maxRetryCount);
+
+ /**
+ * Sets the interval between retries in milliseconds.
+ *
+ * @param retryIntervalInMs the interval in milliseconds.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 500 milliseconds
+ */
+ public TableSessionBuilder retryIntervalInMs(long retryIntervalInMs);
+
+ /**
+ * Enables or disables SSL for secure connections.
+ *
+ * @param useSSL whether to enable SSL.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue false
+ */
+ public TableSessionBuilder useSSL(boolean useSSL);
+
+ /**
+ * Sets the trust store path for SSL connections.
+ *
+ * @param keyStore the trust store path.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionBuilder trustStore(String keyStore);
+
+ /**
+ * Sets the trust store password for SSL connections.
+ *
+ * @param keyStorePwd the trust store password.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionBuilder trustStorePwd(String keyStorePwd);
+
+ /**
+ * Enables or disables rpc compression for the connection.
+ *
+ * @param enableCompression whether to enable compression.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue false
+ */
+ public TableSessionBuilder enableCompression(boolean enableCompression);
+
+ /**
+ * Sets the connection timeout in milliseconds.
+ *
+ * @param connectionTimeoutInMs the connection timeout in milliseconds.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 0 (no timeout)
+ */
+ public TableSessionBuilder connectionTimeoutInMs(int connectionTimeoutInMs);
+}
+```
+
+## 4 客户端连接池
+
+### 4.1 ITableSessionPool 接口
+
+#### 4.1.1 功能描述
+
+ITableSessionPool 是一个用于管理 ITableSession实例的池。这个池可以帮助我们高效地重用连接,并且在不需要时正确地清理资源, 该接口定义了如何从池中获取会话以及如何关闭池的基本操作。
+
+#### 4.1.2 方法列表
+
+| **方法名** | **描述** | **返回值** | **返回异常** |
+| ------------ | ------------------------------------------------------------ | ------------------ | ------------------------ |
+| getSession() | 从池中获取一个 ITableSession 实例,用于与 IoTDB 交互。 | ITableSession 实例 | IoTDBConnectionException |
+| close() | 关闭会话池,释放任何持有的资源。关闭后,不能再从池中获取新的会话。 | 无 | 无 |
+
+#### 4.1.3 接口展示
+
+```Java
+/**
+ * This interface defines a pool for managing {@link ITableSession} instances.
+ * It provides methods to acquire a session from the pool and to close the pool.
+ *
+ * The implementation should handle the lifecycle of sessions, ensuring efficient
+ * reuse and proper cleanup of resources.
+ */
+public interface ITableSessionPool {
+
+ /**
+ * Acquires an {@link ITableSession} instance from the pool.
+ *
+ * @return an {@link ITableSession} instance for interacting with the IoTDB.
+ * @throws IoTDBConnectionException if there is an issue obtaining a session from the pool.
+ */
+ ITableSession getSession() throws IoTDBConnectionException;
+
+ /**
+ * Closes the session pool, releasing any held resources.
+ *
+ *
Once the pool is closed, no further sessions can be acquired.
+ */
+ void close();
+}
+```
+
+### 4.2 TableSessionPoolBuilder 类
+
+#### 4.2.1 功能描述
+
+TableSessionPool 的构造器,用于配置和创建 ITableSessionPool 的实例。允许开发者配置连接参数、会话参数和池化行为等。
+
+#### 4.2.2 配置选项
+
+以下是 TableSessionPoolBuilder 类的可用配置选项及其默认值:
+
+| **配置项** | **描述** | **默认值** |
+| ------------------------------------------------------------ | -------------------------------------------- | ------------------------------------------- |
+| nodeUrls(List`` nodeUrls) | 设置IoTDB集群的节点URL列表 | Collections.singletonList("localhost:6667") |
+| maxSize(int maxSize) | 设置会话池的最大大小,即池中允许的最大会话数 | 5 |
+| user(String user) | 设置连接的用户名 | "root" |
+| password(String password) | 设置连接的密码 | "root" |
+| database(String database) | 设置目标数据库名称 | "root" |
+| queryTimeoutInMs(long queryTimeoutInMs) | 设置查询超时时间(毫秒) | 60000(1分钟) |
+| fetchSize(int fetchSize) | 设置查询结果的获取大小 | 5000 |
+| zoneId(ZoneId zoneId) | 设置时区相关的 ZoneId | ZoneId.systemDefault() |
+| waitToGetSessionTimeoutInMs(long waitToGetSessionTimeoutInMs) | 设置从池中获取会话的超时时间(毫秒) | 30000(30秒) |
+| thriftDefaultBufferSize(int thriftDefaultBufferSize) | 设置Thrift客户端的默认缓冲区大小(字节) | 1024(1KB) |
+| thriftMaxFrameSize(int thriftMaxFrameSize) | 设置Thrift客户端的最大帧大小(字节) | 64 * 1024 * 1024(64MB) |
+| enableCompression(boolean enableCompression) | 是否启用连接的压缩 | false |
+| enableRedirection(boolean enableRedirection) | 是否启用集群节点的重定向 | true |
+| connectionTimeoutInMs(int connectionTimeoutInMs) | 设置连接超时时间(毫秒) | 10000(10秒) |
+| enableAutoFetch(boolean enableAutoFetch) | 是否启用自动获取可用DataNodes | true |
+| maxRetryCount(int maxRetryCount) | 设置连接尝试的最大重试次数 | 60 |
+| retryIntervalInMs(long retryIntervalInMs) | 设置重试间隔时间(毫秒) | 500 |
+| useSSL(boolean useSSL) | 是否启用SSL安全连接 | false |
+| trustStore(String keyStore) | 设置SSL连接的信任库路径 | null |
+| trustStorePwd(String keyStorePwd) | 设置SSL连接的信任库密码 | null |
+
+#### 4.1.3 接口展示
+
+```Java
+/**
+ * A builder class for constructing instances of {@link ITableSessionPool}.
+ *
+ * This builder provides a fluent API for configuring a session pool, including
+ * connection settings, session parameters, and pool behavior.
+ *
+ *
All configurations have reasonable default values, which can be overridden as needed.
+ */
+public class TableSessionPoolBuilder {
+
+ /**
+ * Builds and returns a configured {@link ITableSessionPool} instance.
+ *
+ * @return a fully configured {@link ITableSessionPool}.
+ */
+ public ITableSessionPool build();
+
+ /**
+ * Sets the list of node URLs for the IoTDB cluster.
+ *
+ * @param nodeUrls a list of node URLs.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue Collection.singletonList("localhost:6667")
+ */
+ public TableSessionPoolBuilder nodeUrls(List nodeUrls);
+
+ /**
+ * Sets the maximum size of the session pool.
+ *
+ * @param maxSize the maximum number of sessions allowed in the pool.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 5
+ */
+ public TableSessionPoolBuilder maxSize(int maxSize);
+
+ /**
+ * Sets the username for the connection.
+ *
+ * @param user the username.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionPoolBuilder user(String user);
+
+ /**
+ * Sets the password for the connection.
+ *
+ * @param password the password.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionPoolBuilder password(String password);
+
+ /**
+ * Sets the target database name.
+ *
+ * @param database the database name.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionPoolBuilder database(String database);
+
+ /**
+ * Sets the query timeout in milliseconds.
+ *
+ * @param queryTimeoutInMs the query timeout in milliseconds.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 60000 (1 minute)
+ */
+ public TableSessionPoolBuilder queryTimeoutInMs(long queryTimeoutInMs);
+
+ /**
+ * Sets the fetch size for query results.
+ *
+ * @param fetchSize the fetch size.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 5000
+ */
+ public TableSessionPoolBuilder fetchSize(int fetchSize);
+
+ /**
+ * Sets the {@link ZoneId} for timezone-related operations.
+ *
+ * @param zoneId the {@link ZoneId}.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue ZoneId.systemDefault()
+ */
+ public TableSessionPoolBuilder zoneId(ZoneId zoneId);
+
+ /**
+ * Sets the timeout for waiting to acquire a session from the pool.
+ *
+ * @param waitToGetSessionTimeoutInMs the timeout duration in milliseconds.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 30000 (30 seconds)
+ */
+ public TableSessionPoolBuilder waitToGetSessionTimeoutInMs(long waitToGetSessionTimeoutInMs);
+
+ /**
+ * Sets the default buffer size for the Thrift client.
+ *
+ * @param thriftDefaultBufferSize the buffer size in bytes.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 1024 (1 KB)
+ */
+ public TableSessionPoolBuilder thriftDefaultBufferSize(int thriftDefaultBufferSize);
+
+ /**
+ * Sets the maximum frame size for the Thrift client.
+ *
+ * @param thriftMaxFrameSize the maximum frame size in bytes.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 64 * 1024 * 1024 (64 MB)
+ */
+ public TableSessionPoolBuilder thriftMaxFrameSize(int thriftMaxFrameSize);
+
+ /**
+ * Enables or disables compression for the connection.
+ *
+ * @param enableCompression whether to enable compression.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue false
+ */
+ public TableSessionPoolBuilder enableCompression(boolean enableCompression);
+
+ /**
+ * Enables or disables redirection for cluster nodes.
+ *
+ * @param enableRedirection whether to enable redirection.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue true
+ */
+ public TableSessionPoolBuilder enableRedirection(boolean enableRedirection);
+
+ /**
+ * Sets the connection timeout in milliseconds.
+ *
+ * @param connectionTimeoutInMs the connection timeout in milliseconds.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 10000 (10 seconds)
+ */
+ public TableSessionPoolBuilder connectionTimeoutInMs(int connectionTimeoutInMs);
+
+ /**
+ * Enables or disables automatic fetching of available DataNodes.
+ *
+ * @param enableAutoFetch whether to enable automatic fetching.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue true
+ */
+ public TableSessionPoolBuilder enableAutoFetch(boolean enableAutoFetch);
+
+ /**
+ * Sets the maximum number of retries for connection attempts.
+ *
+ * @param maxRetryCount the maximum retry count.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 60
+ */
+ public TableSessionPoolBuilder maxRetryCount(int maxRetryCount);
+
+ /**
+ * Sets the interval between retries in milliseconds.
+ *
+ * @param retryIntervalInMs the interval in milliseconds.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 500 milliseconds
+ */
+ public TableSessionPoolBuilder retryIntervalInMs(long retryIntervalInMs);
+
+ /**
+ * Enables or disables SSL for secure connections.
+ *
+ * @param useSSL whether to enable SSL.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue false
+ */
+ public TableSessionPoolBuilder useSSL(boolean useSSL);
+
+ /**
+ * Sets the trust store path for SSL connections.
+ *
+ * @param keyStore the trust store path.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionPoolBuilder trustStore(String keyStore);
+
+ /**
+ * Sets the trust store password for SSL connections.
+ *
+ * @param keyStorePwd the trust store password.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionPoolBuilder trustStorePwd(String keyStorePwd);
+}
+```
+
+## 5 示例代码
+
+Session 示例代码:[src/main/java/org/apache/iotdb/TableModelSessionExample.java](https://github.com/apache/iotdb/blob/master/example/session/src/main/java/org/apache/iotdb/TableModelSessionExample.java)
+
+SessionPool 示例代码:[src/main/java/org/apache/iotdb/TableModelSessionPoolExample.java](https://github.com/apache/iotdb/blob/master/example/session/src/main/java/org/apache/iotdb/TableModelSessionPoolExample.java)
+
+```Java
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iotdb;
+
+import org.apache.iotdb.isession.ITableSession;
+import org.apache.iotdb.isession.SessionDataSet;
+import org.apache.iotdb.isession.pool.ITableSessionPool;
+import org.apache.iotdb.rpc.IoTDBConnectionException;
+import org.apache.iotdb.rpc.StatementExecutionException;
+import org.apache.iotdb.session.pool.TableSessionPoolBuilder;
+
+import org.apache.tsfile.enums.TSDataType;
+import org.apache.tsfile.write.record.Tablet;
+import org.apache.tsfile.write.record.Tablet.ColumnCategory;
+import org.apache.tsfile.write.schema.IMeasurementSchema;
+import org.apache.tsfile.write.schema.MeasurementSchema;
+
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+
+public class TableModelSessionPoolExample {
+
+ private static final String LOCAL_URL = "127.0.0.1:6667";
+
+ public static void main(String[] args) {
+
+ // don't specify database in constructor
+ ITableSessionPool tableSessionPool =
+ new TableSessionPoolBuilder()
+ .nodeUrls(Collections.singletonList(LOCAL_URL))
+ .user("root")
+ .password("root")
+ .maxSize(1)
+ .build();
+
+ try (ITableSession session = tableSessionPool.getSession()) {
+
+ session.executeNonQueryStatement("CREATE DATABASE test1");
+ session.executeNonQueryStatement("CREATE DATABASE test2");
+
+ session.executeNonQueryStatement("use test2");
+
+ // or use full qualified table name
+ session.executeNonQueryStatement(
+ "create table test1.table1("
+ + "region_id STRING ID, "
+ + "plant_id STRING ID, "
+ + "device_id STRING ID, "
+ + "model STRING ATTRIBUTE, "
+ + "temperature FLOAT MEASUREMENT, "
+ + "humidity DOUBLE MEASUREMENT) with (TTL=3600000)");
+
+ session.executeNonQueryStatement(
+ "create table table2("
+ + "region_id STRING ID, "
+ + "plant_id STRING ID, "
+ + "color STRING ATTRIBUTE, "
+ + "temperature FLOAT MEASUREMENT, "
+ + "speed DOUBLE MEASUREMENT) with (TTL=6600000)");
+
+ // show tables from current database
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ // show tables by specifying another database
+ // using SHOW tables FROM
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES FROM test1")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ // insert table data by tablet
+ List measurementSchemaList =
+ new ArrayList<>(
+ Arrays.asList(
+ new MeasurementSchema("region_id", TSDataType.STRING),
+ new MeasurementSchema("plant_id", TSDataType.STRING),
+ new MeasurementSchema("device_id", TSDataType.STRING),
+ new MeasurementSchema("model", TSDataType.STRING),
+ new MeasurementSchema("temperature", TSDataType.FLOAT),
+ new MeasurementSchema("humidity", TSDataType.DOUBLE)));
+ List columnTypeList =
+ new ArrayList<>(
+ Arrays.asList(
+ ColumnCategory.ID,
+ ColumnCategory.ID,
+ ColumnCategory.ID,
+ ColumnCategory.ATTRIBUTE,
+ ColumnCategory.MEASUREMENT,
+ ColumnCategory.MEASUREMENT));
+ Tablet tablet =
+ new Tablet(
+ "test1",
+ IMeasurementSchema.getMeasurementNameList(measurementSchemaList),
+ IMeasurementSchema.getDataTypeList(measurementSchemaList),
+ columnTypeList,
+ 100);
+ for (long timestamp = 0; timestamp < 100; timestamp++) {
+ int rowIndex = tablet.getRowSize();
+ tablet.addTimestamp(rowIndex, timestamp);
+ tablet.addValue("region_id", rowIndex, "1");
+ tablet.addValue("plant_id", rowIndex, "5");
+ tablet.addValue("device_id", rowIndex, "3");
+ tablet.addValue("model", rowIndex, "A");
+ tablet.addValue("temperature", rowIndex, 37.6F);
+ tablet.addValue("humidity", rowIndex, 111.1);
+ if (tablet.getRowSize() == tablet.getMaxRowNumber()) {
+ session.insert(tablet);
+ tablet.reset();
+ }
+ }
+ if (tablet.getRowSize() != 0) {
+ session.insert(tablet);
+ tablet.reset();
+ }
+
+ // query table data
+ try (SessionDataSet dataSet =
+ session.executeQueryStatement(
+ "select * from test1 "
+ + "where region_id = '1' and plant_id in ('3', '5') and device_id = '3'")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ } catch (IoTDBConnectionException e) {
+ e.printStackTrace();
+ } catch (StatementExecutionException e) {
+ e.printStackTrace();
+ } finally {
+ tableSessionPool.close();
+ }
+
+ // specify database in constructor
+ tableSessionPool =
+ new TableSessionPoolBuilder()
+ .nodeUrls(Collections.singletonList(LOCAL_URL))
+ .user("root")
+ .password("root")
+ .maxSize(1)
+ .database("test1")
+ .build();
+
+ try (ITableSession session = tableSessionPool.getSession()) {
+
+ // show tables from current database
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ // change database to test2
+ session.executeNonQueryStatement("use test2");
+
+ // show tables by specifying another database
+ // using SHOW tables FROM
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ } catch (IoTDBConnectionException e) {
+ e.printStackTrace();
+ } catch (StatementExecutionException e) {
+ e.printStackTrace();
+ }
+
+ try (ITableSession session = tableSessionPool.getSession()) {
+
+ // show tables from default database test1
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ } catch (IoTDBConnectionException e) {
+ e.printStackTrace();
+ } catch (StatementExecutionException e) {
+ e.printStackTrace();
+ } finally {
+ tableSessionPool.close();
+ }
+ }
+}
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/API/Programming-Python-Native-API.md b/src/zh/UserGuide/Master/Table/API/Programming-Python-Native-API.md
new file mode 100644
index 000000000..28f92880a
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/API/Programming-Python-Native-API.md
@@ -0,0 +1,457 @@
+
+
+# Python 原生接口
+
+## 1 使用方式
+
+安装依赖包:
+
+```Java
+pip3 install apache-iotdb
+```
+
+## 2 读写操作
+
+### 2.1 TableSession
+
+#### 2.1.1 功能描述
+
+TableSession是IoTDB的一个核心类,用于与IoTDB数据库进行交互。通过这个类,用户可以执行SQL语句、插入数据以及管理数据库会话。
+
+#### 2.1.2 方法列表
+
+| **方法名称** | **描述** | **参数类型** | **返回类型** |
+| --------------------------- | ---------------------------------- | ---------------------------------- | -------------- |
+| insert | 写入数据 | tablet: Union[Tablet, NumpyTablet] | None |
+| execute_non_query_statement | 执行非查询 SQL 语句,如 DDL 和 DML | sql: str | None |
+| execute_query_statement | 执行查询 SQL 语句并返回结果集 | sql: str | SessionDataSet |
+| close | 关闭会话并释放资源 | None | None |
+
+#### 2.1.3 接口展示
+
+**TableSession:**
+
+
+```Java
+class TableSession(object):
+def insert(self, tablet: Union[Tablet, NumpyTablet]):
+ """
+ Insert data into the database.
+
+ Parameters:
+ tablet (Tablet | NumpyTablet): The tablet containing the data to be inserted.
+ Accepts either a `Tablet` or `NumpyTablet`.
+
+ Raises:
+ IoTDBConnectionException: If there is an issue with the database connection.
+ """
+ pass
+
+def execute_non_query_statement(self, sql: str):
+ """
+ Execute a non-query SQL statement.
+
+ Parameters:
+ sql (str): The SQL statement to execute. Typically used for commands
+ such as INSERT, DELETE, or UPDATE.
+
+ Raises:
+ IoTDBConnectionException: If there is an issue with the database connection.
+ """
+ pass
+
+def execute_query_statement(self, sql: str, timeout_in_ms: int = 0) -> "SessionDataSet":
+ """
+ Execute a query SQL statement and return the result set.
+
+ Parameters:
+ sql (str): The SQL query to execute.
+ timeout_in_ms (int, optional): Timeout for the query in milliseconds. Defaults to 0,
+ which means no timeout.
+
+ Returns:
+ SessionDataSet: The result set of the query.
+
+ Raises:
+ IoTDBConnectionException: If there is an issue with the database connection.
+ """
+ pass
+
+def close(self):
+ """
+ Close the session and release resources.
+
+ Raises:
+ IoTDBConnectionException: If there is an issue closing the connection.
+ """
+ pass
+```
+
+### 2.2 TableSessionConfig
+
+#### 2.2.1 功能描述
+
+TableSessionConfig是一个配置类,用于设置和创建TableSession 实例。它定义了连接到IoTDB数据库所需的各种参数。
+
+#### 2.2.2 配置选项
+
+| **配置项** | **描述** | **类型** | **默认值** |
+| ------------------ | ------------------------- | -------- | ----------------------- |
+| node_urls | 数据库连接的节点 URL 列表 | list | ["localhost:6667"] |
+| username | 数据库连接用户名 | str | "root" |
+| password | 数据库连接密码 | str | "root" |
+| database | 要连接的目标数据库 | str | None |
+| fetch_size | 每次查询获取的行数 | int | 5000 |
+| time_zone | 会话的默认时区 | str | Session.DEFAULT_ZONE_ID |
+| enable_compression | 是否启用数据压缩 | bool | False |
+
+#### 2.2.3 接口展示
+
+```Java
+class TableSessionConfig(object):
+ """
+ Configuration class for a TableSession.
+
+ This class defines various parameters for connecting to and interacting
+ with the IoTDB tables.
+ """
+
+ def __init__(
+ self,
+ node_urls: list = None,
+ username: str = Session.DEFAULT_USER,
+ password: str = Session.DEFAULT_PASSWORD,
+ database: str = None,
+ fetch_size: int = 5000,
+ time_zone: str = Session.DEFAULT_ZONE_ID,
+ enable_compression: bool = False,
+ ):
+ """
+ Initialize a TableSessionConfig object with the provided parameters.
+
+ Parameters:
+ node_urls (list, optional): A list of node URLs for the database connection.
+ Defaults to ["localhost:6667"].
+ username (str, optional): The username for the database connection.
+ Defaults to "root".
+ password (str, optional): The password for the database connection.
+ Defaults to "root".
+ database (str, optional): The target database to connect to. Defaults to None.
+ fetch_size (int, optional): The number of rows to fetch per query. Defaults to 5000.
+ time_zone (str, optional): The default time zone for the session.
+ Defaults to Session.DEFAULT_ZONE_ID.
+ enable_compression (bool, optional): Whether to enable data compression.
+ Defaults to False.
+ """
+```
+
+**注意事项:**
+
+在使用完 TableSession 后,务必调用 close 方法来释放资源。
+
+## 3 客户端连接池
+
+### 3.1 TableSessionPool
+
+#### 3.1.1 功能描述
+
+TableSessionPool 是一个会话池管理类,用于管理 TableSession 实例的创建和销毁。它提供了从池中获取会话和关闭会话池的功能。
+
+#### 3.1.2 方法列表
+
+| **方法名称** | **描述** | **返回类型** | **异常** |
+| ------------ | ---------------------------------------- | ------------ | -------- |
+| get_session | 从会话池中检索一个新的 TableSession 实例 | TableSession | 无 |
+| close | 关闭会话池并释放所有资源 | None | 无 |
+
+#### 3.1.3 接口展示
+
+**TableSessionPool:**
+
+```Java
+def get_session(self) -> TableSession:
+ """
+ Retrieve a new TableSession instance.
+
+ Returns:
+ TableSession: A new session object configured with the session pool.
+
+ Notes:
+ The session is initialized with the underlying session pool for managing
+ connections. Ensure proper usage of the session's lifecycle.
+ """
+
+def close(self):
+ """
+ Close the session pool and release all resources.
+
+ This method closes the underlying session pool, ensuring that all
+ resources associated with it are properly released.
+
+ Notes:
+ After calling this method, the session pool cannot be used to retrieve
+ new sessions, and any attempt to do so may raise an exception.
+ """
+```
+
+### 3.2 TableSessionPoolConfig
+
+#### 3.2.1 功能描述
+
+TableSessionPoolConfig是一个配置类,用于设置和创建 TableSessionPool 实例。它定义了初始化和管理 IoTDB 数据库会话池所需的参数。
+
+#### 3.2.2 配置选项
+
+| **配置项** | **描述** | **类型** | **默认值** |
+| ------------------ | ------------------------------ | -------- | ------------------------ |
+| node_urls | 数据库连接的节点 URL 列表 | list | None |
+| max_pool_size | 会话池中的最大会话数 | int | 5 |
+| username | 数据库连接用户名 | str | Session.DEFAULT_USER |
+| password | 数据库连接密码 | str | Session.DEFAULT_PASSWORD |
+| database | 要连接的目标数据库 | str | None |
+| fetch_size | 每次查询获取的行数 | int | 5000 |
+| time_zone | 会话池的默认时区 | str | Session.DEFAULT_ZONE_ID |
+| enable_redirection | 是否启用重定向 | bool | False |
+| enable_compression | 是否启用数据压缩 | bool | False |
+| wait_timeout_in_ms | 等待会话可用的最大时间(毫秒) | int | 10000 |
+| max_retry | 操作的最大重试次数 | int | 3 |
+
+#### 3.2.3 接口展示
+
+
+```Java
+class TableSessionPoolConfig(object):
+ """
+ Configuration class for a TableSessionPool.
+
+ This class defines the parameters required to initialize and manage
+ a session pool for interacting with the IoTDB database.
+ """
+ def __init__(
+ self,
+ node_urls: list = None,
+ max_pool_size: int = 5,
+ username: str = Session.DEFAULT_USER,
+ password: str = Session.DEFAULT_PASSWORD,
+ database: str = None,
+ fetch_size: int = 5000,
+ time_zone: str = Session.DEFAULT_ZONE_ID,
+ enable_redirection: bool = False,
+ enable_compression: bool = False,
+ wait_timeout_in_ms: int = 10000,
+ max_retry: int = 3,
+ ):
+ """
+ Initialize a TableSessionPoolConfig object with the provided parameters.
+
+ Parameters:
+ node_urls (list, optional): A list of node URLs for the database connection.
+ Defaults to None.
+ max_pool_size (int, optional): The maximum number of sessions in the pool.
+ Defaults to 5.
+ username (str, optional): The username for the database connection.
+ Defaults to Session.DEFAULT_USER.
+ password (str, optional): The password for the database connection.
+ Defaults to Session.DEFAULT_PASSWORD.
+ database (str, optional): The target database to connect to. Defaults to None.
+ fetch_size (int, optional): The number of rows to fetch per query. Defaults to 5000.
+ time_zone (str, optional): The default time zone for the session pool.
+ Defaults to Session.DEFAULT_ZONE_ID.
+ enable_redirection (bool, optional): Whether to enable redirection.
+ Defaults to False.
+ enable_compression (bool, optional): Whether to enable data compression.
+ Defaults to False.
+ wait_timeout_in_ms (int, optional): The maximum time (in milliseconds) to wait for a session
+ to become available. Defaults to 10000.
+ max_retry (int, optional): The maximum number of retry attempts for operations. Defaults to 3.
+
+ """
+```
+
+## 4 示例代码
+
+Session示例代码:[iotdb/blob/master/iotdb-client/client-py/table_model_session_example.py](https://github.com/apache/iotdb/blob/master/iotdb-client/client-py/table_model_session_example.py)
+
+SessionPool示例代码:[iotdb/blob/master/iotdb-client/client-py/table_model_session_pool_example.py](https://github.com/apache/iotdb/blob/master/iotdb-client/client-py/table_model_session_pool_example.py)
+
+```Java
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+#
+import threading
+
+import numpy as np
+
+from iotdb.table_session_pool import TableSessionPool, TableSessionPoolConfig
+from iotdb.utils.IoTDBConstants import TSDataType
+from iotdb.utils.NumpyTablet import NumpyTablet
+from iotdb.utils.Tablet import ColumnType, Tablet
+
+
+def prepare_data():
+ print("create database")
+ # Get a session from the pool
+ session = session_pool.get_session()
+ session.execute_non_query_statement("CREATE DATABASE IF NOT EXISTS db1")
+ session.execute_non_query_statement('USE "db1"')
+ session.execute_non_query_statement(
+ "CREATE TABLE table0 (id1 string id, attr1 string attribute, "
+ + "m1 double "
+ + "measurement)"
+ )
+ session.execute_non_query_statement(
+ "CREATE TABLE table1 (id1 string id, attr1 string attribute, "
+ + "m1 double "
+ + "measurement)"
+ )
+
+ print("now the tables are:")
+ # show result
+ res = session.execute_query_statement("SHOW TABLES")
+ while res.has_next():
+ print(res.next())
+
+ session.close()
+
+
+def insert_data(num: int):
+ print("insert data for table" + str(num))
+ # Get a session from the pool
+ session = session_pool.get_session()
+ column_names = [
+ "id1",
+ "attr1",
+ "m1",
+ ]
+ data_types = [
+ TSDataType.STRING,
+ TSDataType.STRING,
+ TSDataType.DOUBLE,
+ ]
+ column_types = [ColumnType.ID, ColumnType.ATTRIBUTE, ColumnType.MEASUREMENT]
+ timestamps = []
+ values = []
+ for row in range(15):
+ timestamps.append(row)
+ values.append(["id:" + str(row), "attr:" + str(row), row * 1.0])
+ tablet = Tablet(
+ "table" + str(num), column_names, data_types, values, timestamps, column_types
+ )
+ session.insert(tablet)
+ session.execute_non_query_statement("FLush")
+
+ np_timestamps = np.arange(15, 30, dtype=np.dtype(">i8"))
+ np_values = [
+ np.array(["id:{}".format(i) for i in range(15, 30)]),
+ np.array(["attr:{}".format(i) for i in range(15, 30)]),
+ np.linspace(15.0, 29.0, num=15, dtype=TSDataType.DOUBLE.np_dtype()),
+ ]
+
+ np_tablet = NumpyTablet(
+ "table" + str(num),
+ column_names,
+ data_types,
+ np_values,
+ np_timestamps,
+ column_types=column_types,
+ )
+ session.insert(np_tablet)
+ session.close()
+
+
+def query_data():
+ # Get a session from the pool
+ session = session_pool.get_session()
+
+ print("get data from table0")
+ res = session.execute_query_statement("select * from table0")
+ while res.has_next():
+ print(res.next())
+
+ print("get data from table1")
+ res = session.execute_query_statement("select * from table0")
+ while res.has_next():
+ print(res.next())
+
+ session.close()
+
+
+def delete_data():
+ session = session_pool.get_session()
+ session.execute_non_query_statement("drop database db1")
+ print("data has been deleted. now the databases are:")
+ res = session.execute_query_statement("show databases")
+ while res.has_next():
+ print(res.next())
+ session.close()
+
+
+# Create a session pool
+username = "root"
+password = "root"
+node_urls = ["127.0.0.1:6667", "127.0.0.1:6668", "127.0.0.1:6669"]
+fetch_size = 1024
+database = "db1"
+max_pool_size = 5
+wait_timeout_in_ms = 3000
+config = TableSessionPoolConfig(
+ node_urls=node_urls,
+ username=username,
+ password=password,
+ database=database,
+ max_pool_size=max_pool_size,
+ fetch_size=fetch_size,
+ wait_timeout_in_ms=wait_timeout_in_ms,
+)
+session_pool = TableSessionPool(config)
+
+prepare_data()
+
+insert_thread1 = threading.Thread(target=insert_data, args=(0,))
+insert_thread2 = threading.Thread(target=insert_data, args=(1,))
+
+insert_thread1.start()
+insert_thread2.start()
+
+insert_thread1.join()
+insert_thread2.join()
+
+query_data()
+delete_data()
+session_pool.close()
+print("example is finished!")
+```
+
diff --git a/src/zh/UserGuide/Master/Table/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/Master/Table/Background-knowledge/Cluster-Concept.md
new file mode 100644
index 000000000..ebd6a800e
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Background-knowledge/Cluster-Concept.md
@@ -0,0 +1,55 @@
+
+
+# 集群相关概念
+下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
+ +
+其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
+- **节点**(ConfigNode、DataNode、AINode);
+- **槽**(SchemaSlot、DataSlot);
+- **Region**(SchemaRegion、DataRegion);
+- ***副本组***。
+
+下文将重点对以上概念进行介绍。
+
+## 节点
+IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
+- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
+- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
+- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
+
+## 槽
+IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
+- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
+- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
+
+## Region
+在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
+- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+
+## 副本组
+Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
+| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
+| :-: | :-: | :-: | :-: |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/Background-knowledge/Data-Type.md b/src/zh/UserGuide/Master/Table/Background-knowledge/Data-Type.md
new file mode 100644
index 000000000..3584aabb1
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Background-knowledge/Data-Type.md
@@ -0,0 +1,184 @@
+
+
+# 数据类型
+
+## 基本数据类型
+
+IoTDB 支持以下十种数据类型:
+
+* BOOLEAN(布尔值)
+* INT32(整型)
+* INT64(长整型)
+* FLOAT(单精度浮点数)
+* DOUBLE(双精度浮点数)
+* TEXT(长字符串)
+* STRING(字符串)
+* BLOB(大二进制对象)
+* TIMESTAMP(时间戳)
+* DATE(日期)
+
+其中,STRING 和 TEXT 类型的区别在于,STRING 类型具有更多的统计信息,能够用于优化值过滤查询。TEXT 类型适合用于存储长字符串。
+
+### 浮点数精度配置
+
+对于 **FLOAT** 与 **DOUBLE** 类型的序列,如果编码方式采用 `RLE`或 `TS_2DIFF`,可以在创建序列时通过 `MAX_POINT_NUMBER` 属性指定浮点数的小数点后位数。
+
+例如,
+```sql
+CREATE TIMESERIES root.vehicle.d0.s0 WITH DATATYPE=FLOAT, ENCODING=RLE, 'MAX_POINT_NUMBER'='2';
+```
+
+若不指定,系统会按照配置文件 `iotdb-system.properties` 中的 [float_precision](../Reference/Common-Config-Manual.md) 项配置(默认为 2 位)。
+
+### 数据类型兼容性
+
+当写入数据的类型与序列注册的数据类型不一致时,
+- 如果序列数据类型不兼容写入数据类型,系统会给出错误提示。
+- 如果序列数据类型兼容写入数据类型,系统会进行数据类型的自动转换,将写入的数据类型更正为注册序列的类型。
+
+各数据类型的兼容情况如下表所示:
+
+| 序列数据类型 | 支持的写入数据类型 |
+|--------------|--------------------------|
+| BOOLEAN | BOOLEAN |
+| INT32 | INT32 |
+| INT64 | INT32 INT64 |
+| FLOAT | INT32 FLOAT |
+| DOUBLE | INT32 INT64 FLOAT DOUBLE |
+| TEXT | TEXT |
+
+## 时间戳类型
+
+时间戳是一个数据到来的时间点,其中包括绝对时间戳和相对时间戳。
+
+### 绝对时间戳
+
+IOTDB 中绝对时间戳分为二种,一种为 LONG 类型,一种为 DATETIME 类型(包含 DATETIME-INPUT, DATETIME-DISPLAY 两个小类)。
+
+在用户在输入时间戳时,可以使用 LONG 类型的时间戳或 DATETIME-INPUT 类型的时间戳,其中 DATETIME-INPUT 类型的时间戳支持格式如表所示:
+
+
+
+其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
+- **节点**(ConfigNode、DataNode、AINode);
+- **槽**(SchemaSlot、DataSlot);
+- **Region**(SchemaRegion、DataRegion);
+- ***副本组***。
+
+下文将重点对以上概念进行介绍。
+
+## 节点
+IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
+- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
+- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
+- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
+
+## 槽
+IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
+- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
+- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
+
+## Region
+在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
+- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+
+## 副本组
+Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
+| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
+| :-: | :-: | :-: | :-: |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/Background-knowledge/Data-Type.md b/src/zh/UserGuide/Master/Table/Background-knowledge/Data-Type.md
new file mode 100644
index 000000000..3584aabb1
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Background-knowledge/Data-Type.md
@@ -0,0 +1,184 @@
+
+
+# 数据类型
+
+## 基本数据类型
+
+IoTDB 支持以下十种数据类型:
+
+* BOOLEAN(布尔值)
+* INT32(整型)
+* INT64(长整型)
+* FLOAT(单精度浮点数)
+* DOUBLE(双精度浮点数)
+* TEXT(长字符串)
+* STRING(字符串)
+* BLOB(大二进制对象)
+* TIMESTAMP(时间戳)
+* DATE(日期)
+
+其中,STRING 和 TEXT 类型的区别在于,STRING 类型具有更多的统计信息,能够用于优化值过滤查询。TEXT 类型适合用于存储长字符串。
+
+### 浮点数精度配置
+
+对于 **FLOAT** 与 **DOUBLE** 类型的序列,如果编码方式采用 `RLE`或 `TS_2DIFF`,可以在创建序列时通过 `MAX_POINT_NUMBER` 属性指定浮点数的小数点后位数。
+
+例如,
+```sql
+CREATE TIMESERIES root.vehicle.d0.s0 WITH DATATYPE=FLOAT, ENCODING=RLE, 'MAX_POINT_NUMBER'='2';
+```
+
+若不指定,系统会按照配置文件 `iotdb-system.properties` 中的 [float_precision](../Reference/Common-Config-Manual.md) 项配置(默认为 2 位)。
+
+### 数据类型兼容性
+
+当写入数据的类型与序列注册的数据类型不一致时,
+- 如果序列数据类型不兼容写入数据类型,系统会给出错误提示。
+- 如果序列数据类型兼容写入数据类型,系统会进行数据类型的自动转换,将写入的数据类型更正为注册序列的类型。
+
+各数据类型的兼容情况如下表所示:
+
+| 序列数据类型 | 支持的写入数据类型 |
+|--------------|--------------------------|
+| BOOLEAN | BOOLEAN |
+| INT32 | INT32 |
+| INT64 | INT32 INT64 |
+| FLOAT | INT32 FLOAT |
+| DOUBLE | INT32 INT64 FLOAT DOUBLE |
+| TEXT | TEXT |
+
+## 时间戳类型
+
+时间戳是一个数据到来的时间点,其中包括绝对时间戳和相对时间戳。
+
+### 绝对时间戳
+
+IOTDB 中绝对时间戳分为二种,一种为 LONG 类型,一种为 DATETIME 类型(包含 DATETIME-INPUT, DATETIME-DISPLAY 两个小类)。
+
+在用户在输入时间戳时,可以使用 LONG 类型的时间戳或 DATETIME-INPUT 类型的时间戳,其中 DATETIME-INPUT 类型的时间戳支持格式如表所示:
+
+
+
+**DATETIME-INPUT 类型支持格式**
+
+
+| format |
+| :--------------------------- |
+| yyyy-MM-dd HH:mm:ss |
+| yyyy/MM/dd HH:mm:ss |
+| yyyy.MM.dd HH:mm:ss |
+| yyyy-MM-dd HH:mm:ssZZ |
+| yyyy/MM/dd HH:mm:ssZZ |
+| yyyy.MM.dd HH:mm:ssZZ |
+| yyyy/MM/dd HH:mm:ss.SSS |
+| yyyy-MM-dd HH:mm:ss.SSS |
+| yyyy.MM.dd HH:mm:ss.SSS |
+| yyyy-MM-dd HH:mm:ss.SSSZZ |
+| yyyy/MM/dd HH:mm:ss.SSSZZ |
+| yyyy.MM.dd HH:mm:ss.SSSZZ |
+| ISO8601 standard time format |
+
+
+
+
+
+IoTDB 在显示时间戳时可以支持 LONG 类型以及 DATETIME-DISPLAY 类型,其中 DATETIME-DISPLAY 类型可以支持用户自定义时间格式。自定义时间格式的语法如表所示:
+
+
+
+**DATETIME-DISPLAY 自定义时间格式的语法**
+
+
+| Symbol | Meaning | Presentation | Examples |
+| :----: | :-------------------------: | :----------: | :--------------------------------: |
+| G | era | era | era |
+| C | century of era (>=0) | number | 20 |
+| Y | year of era (>=0) | year | 1996 |
+| | | | |
+| x | weekyear | year | 1996 |
+| w | week of weekyear | number | 27 |
+| e | day of week | number | 2 |
+| E | day of week | text | Tuesday; Tue |
+| | | | |
+| y | year | year | 1996 |
+| D | day of year | number | 189 |
+| M | month of year | month | July; Jul; 07 |
+| d | day of month | number | 10 |
+| | | | |
+| a | halfday of day | text | PM |
+| K | hour of halfday (0~11) | number | 0 |
+| h | clockhour of halfday (1~12) | number | 12 |
+| | | | |
+| H | hour of day (0~23) | number | 0 |
+| k | clockhour of day (1~24) | number | 24 |
+| m | minute of hour | number | 30 |
+| s | second of minute | number | 55 |
+| S | fraction of second | millis | 978 |
+| | | | |
+| z | time zone | text | Pacific Standard Time; PST |
+| Z | time zone offset/id | zone | -0800; -08:00; America/Los_Angeles |
+| | | | |
+| ' | escape for text | delimiter | |
+| '' | single quote | literal | ' |
+
+
+
+### 相对时间戳
+
+ 相对时间是指与服务器时间```now()```和```DATETIME```类型时间相差一定时间间隔的时间。
+ 形式化定义为:
+
+ ```
+ Duration = (Digit+ ('Y'|'MO'|'W'|'D'|'H'|'M'|'S'|'MS'|'US'|'NS'))+
+ RelativeTime = (now() | DATETIME) ((+|-) Duration)+
+ ```
+
+
+
+ **The syntax of the duration unit**
+
+
+ | Symbol | Meaning | Presentation | Examples |
+ | :----: | :---------: | :----------------------: | :------: |
+ | y | year | 1y=365 days | 1y |
+ | mo | month | 1mo=30 days | 1mo |
+ | w | week | 1w=7 days | 1w |
+ | d | day | 1d=1 day | 1d |
+ | | | | |
+ | h | hour | 1h=3600 seconds | 1h |
+ | m | minute | 1m=60 seconds | 1m |
+ | s | second | 1s=1 second | 1s |
+ | | | | |
+ | ms | millisecond | 1ms=1000_000 nanoseconds | 1ms |
+ | us | microsecond | 1us=1000 nanoseconds | 1us |
+ | ns | nanosecond | 1ns=1 nanosecond | 1ns |
+
+
+
+ 例子:
+
+ ```
+ now() - 1d2h //比服务器时间早 1 天 2 小时的时间
+ now() - 1w //比服务器时间早 1 周的时间
+ ```
+
+ > 注意:'+'和'-'的左右两边必须有空格
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/Basic-Concept/Data-Model-and-Terminology.md b/src/zh/UserGuide/Master/Table/Basic-Concept/Data-Model-and-Terminology.md
new file mode 100644
index 000000000..166401607
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Basic-Concept/Data-Model-and-Terminology.md
@@ -0,0 +1,161 @@
+
+
+# 建模方案设计
+
+本章节主要介绍如何将时序数据应用场景转化为IoTDB时序建模。
+
+## 1 时序数据模型
+
+在构建IoTDB建模方案前,需要先了解时序数据和时序数据模型,详细内容见此页面:[时序数据模型](../Basic-Concept/Navigating_Time_Series_Data.md)
+
+## 2 IoTDB 的两种时序模型
+
+> IoTDB 提供了两种数据建模方式——树模型和表模型,以满足用户多样化的应用需求。
+
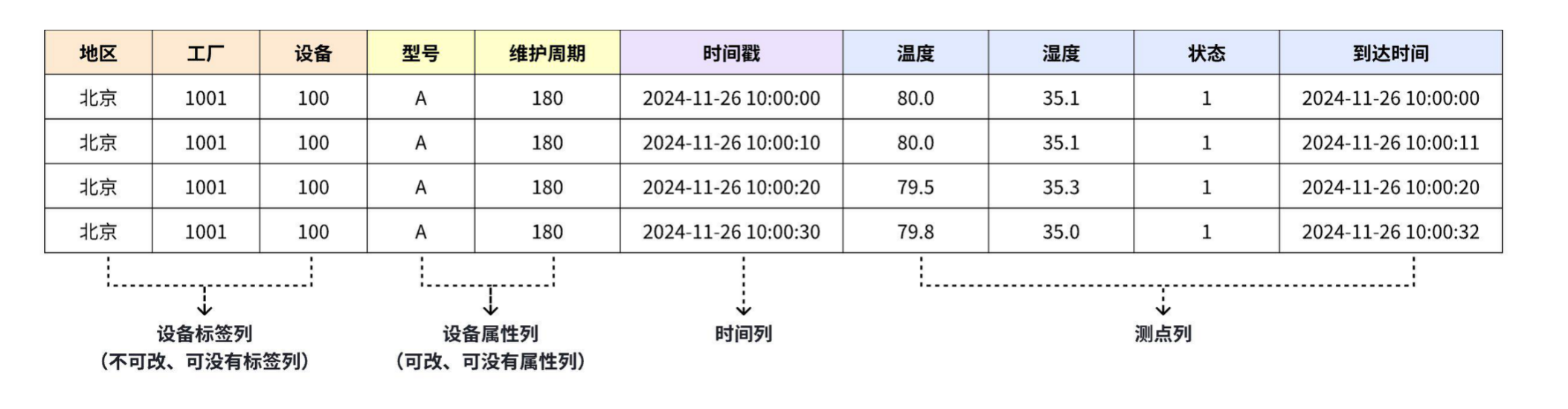
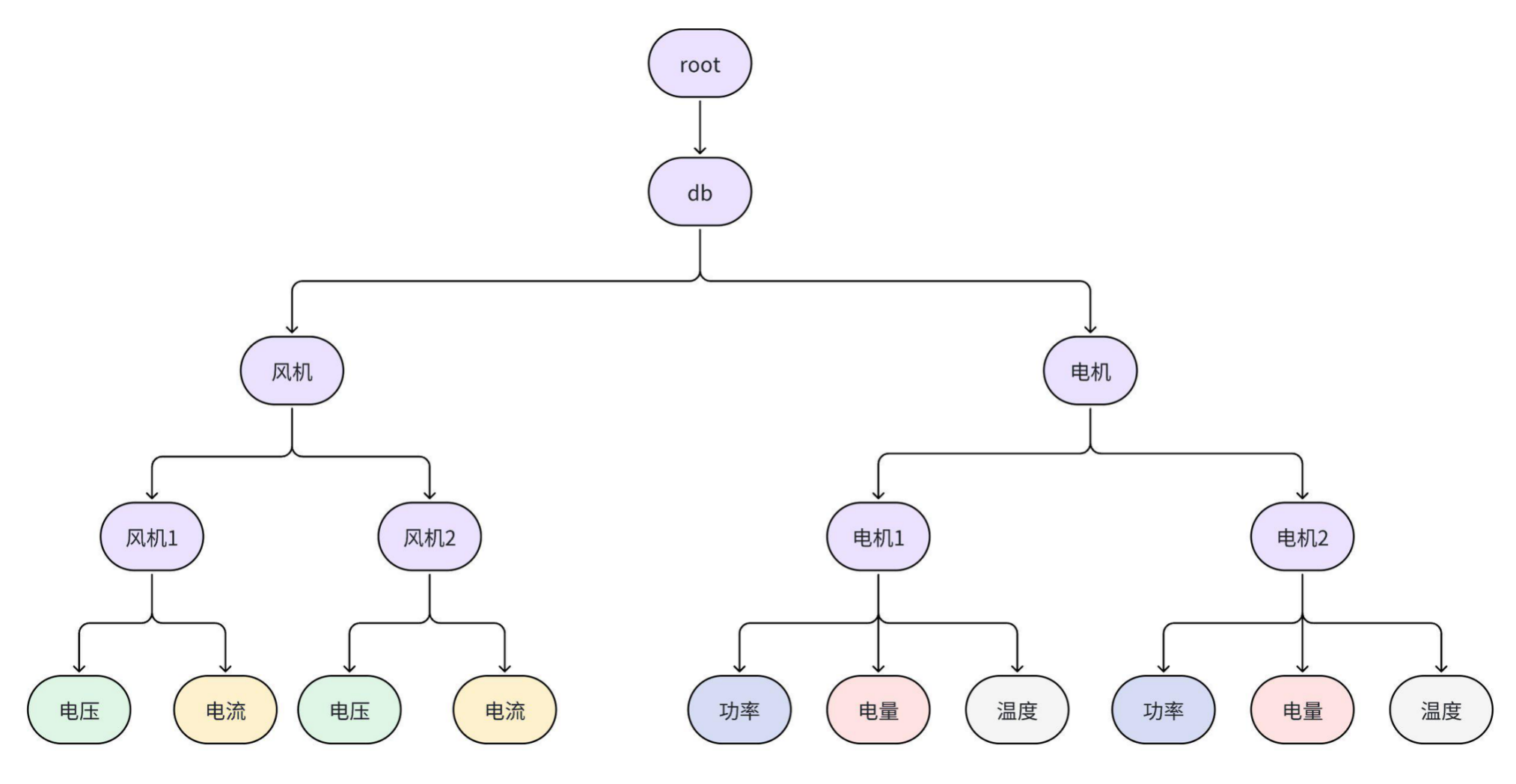
+### 2.1 树模型(测点管理模型):一条路径管理一个测点
+
+以测点为单元进行管理,每个测点对应一条时间序列,测点名按逗号分割可看作一个树形目录结构,与物理世界一一对应,简单直观。
+
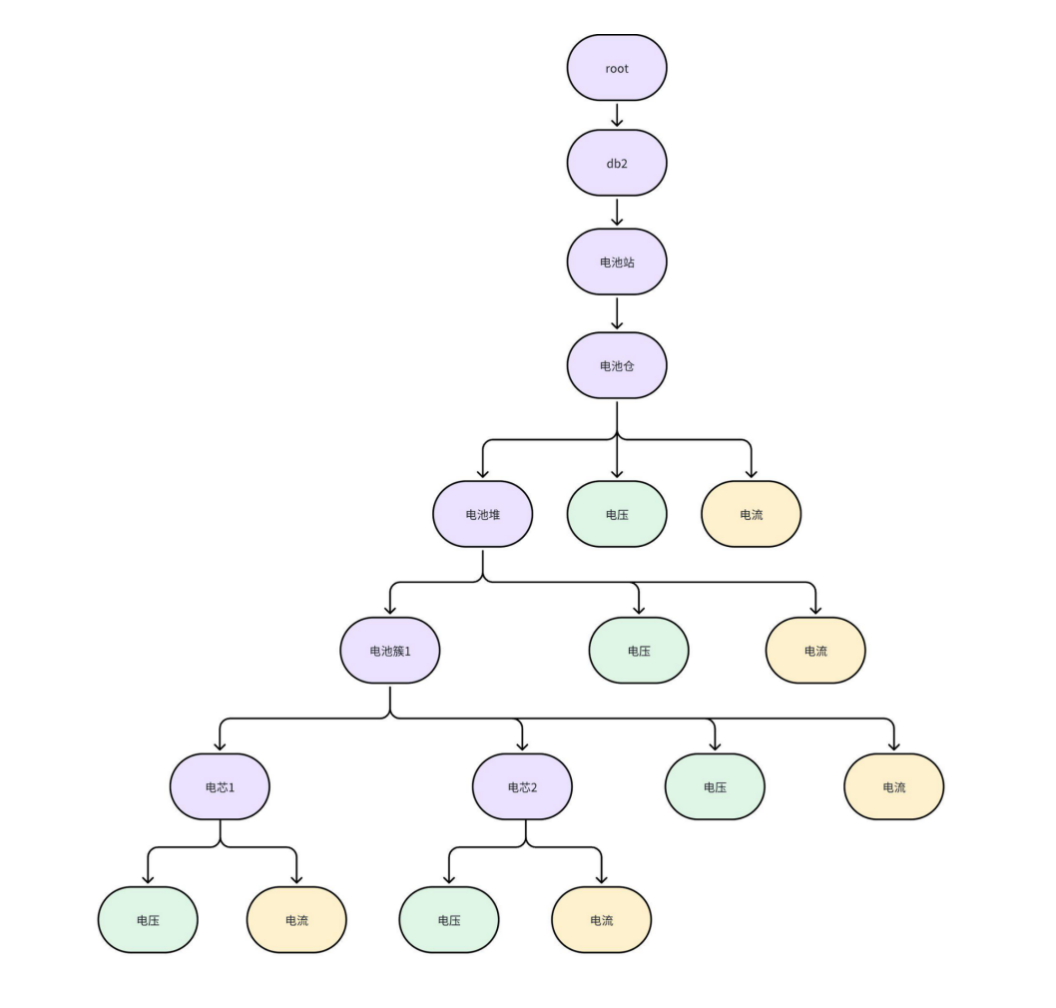
+示例:下图是一个风电场的建模管理,通过多个层级【集团】-【风电场】-【风机】-【物理量】可以唯一确定一个实体测点。
+
+
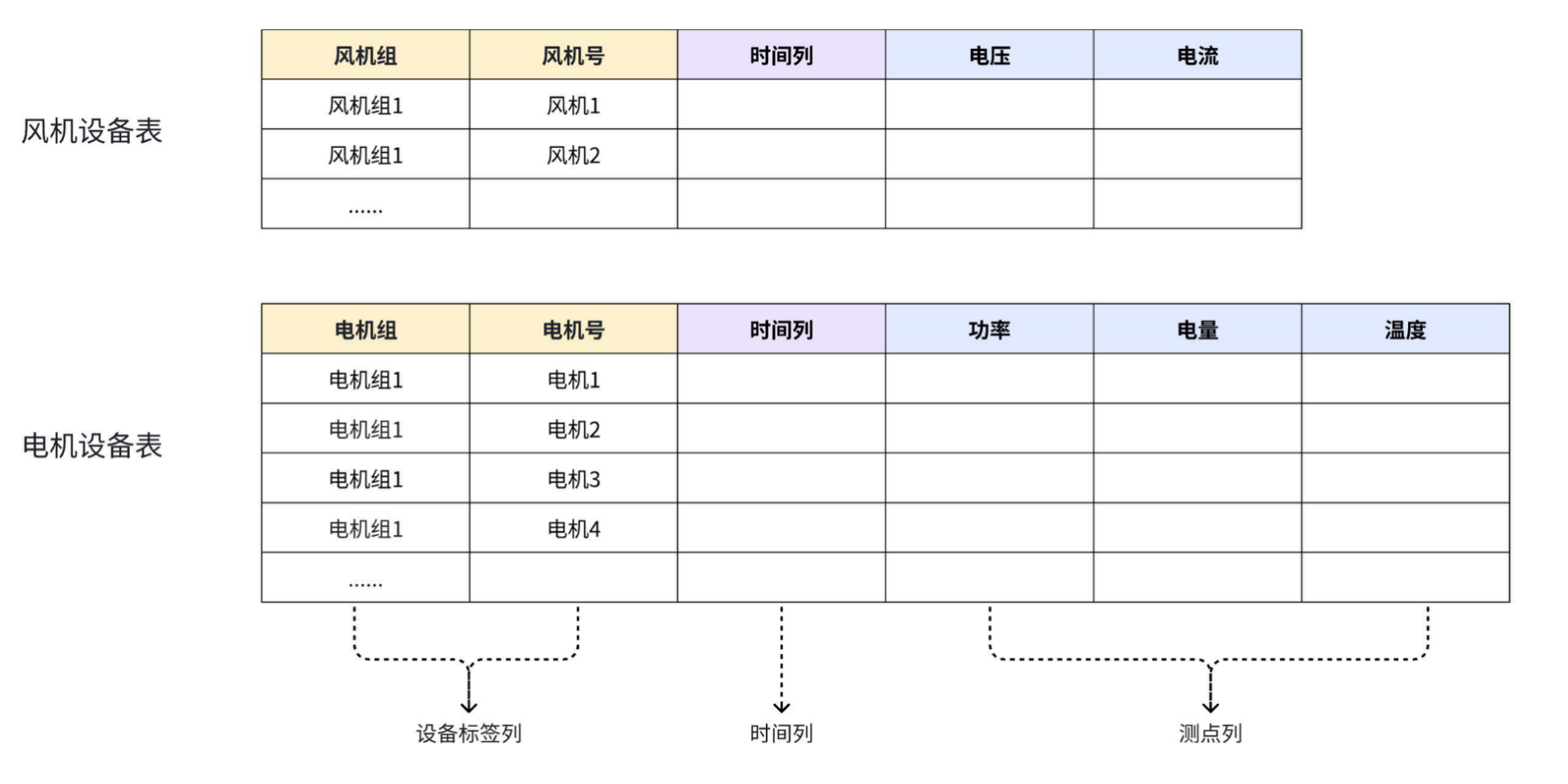
+
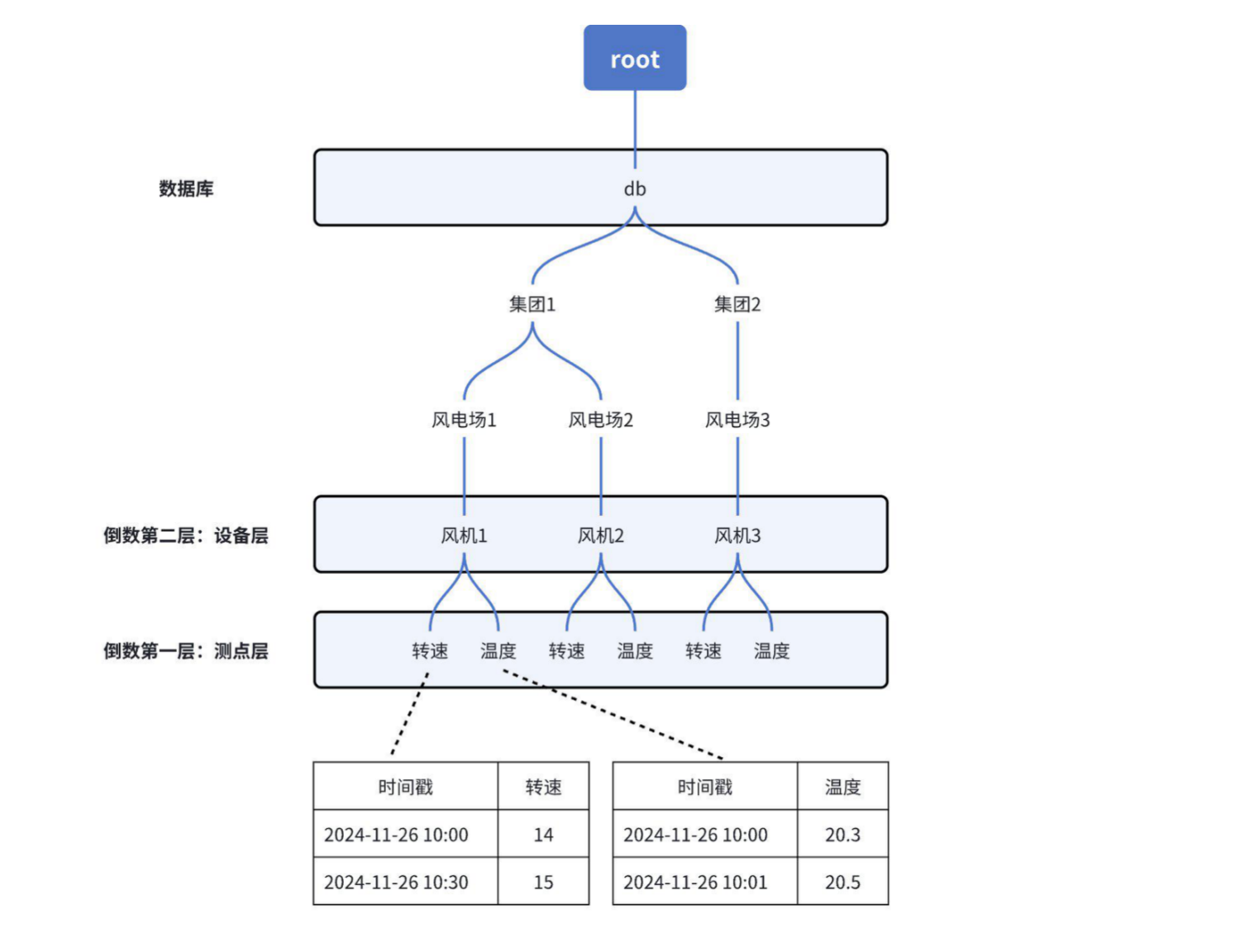
+
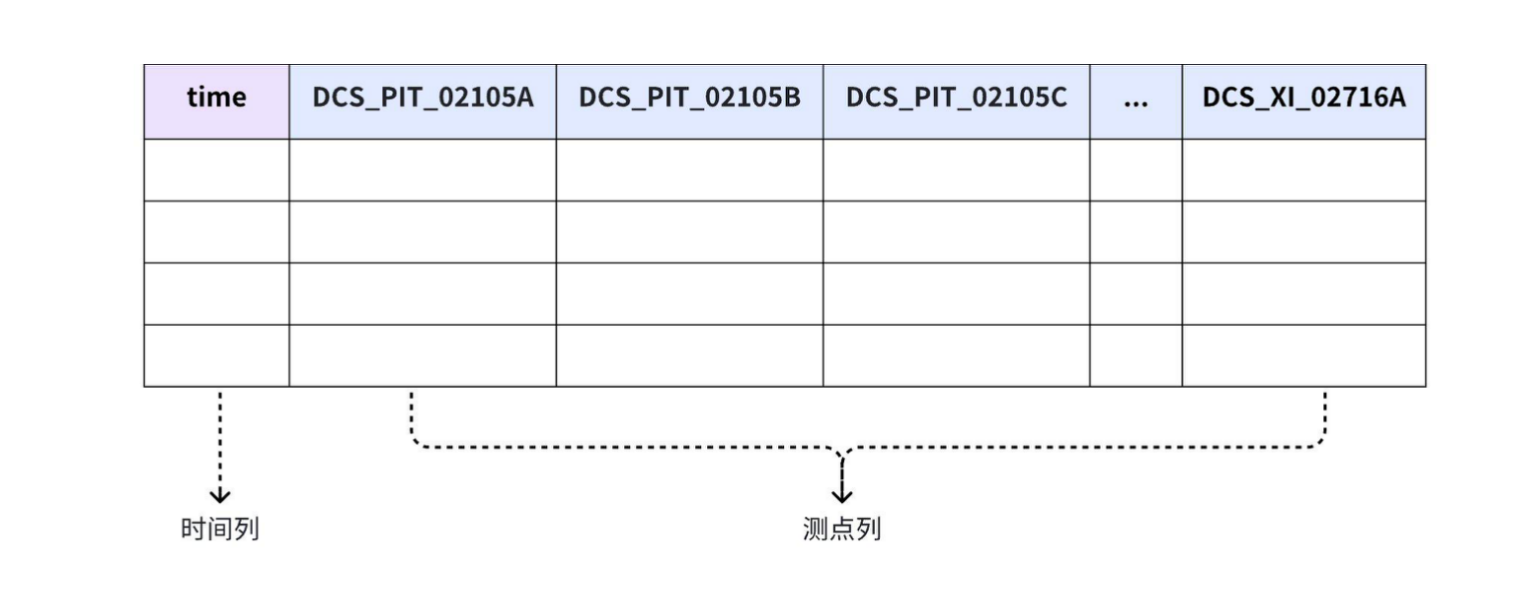
+
+
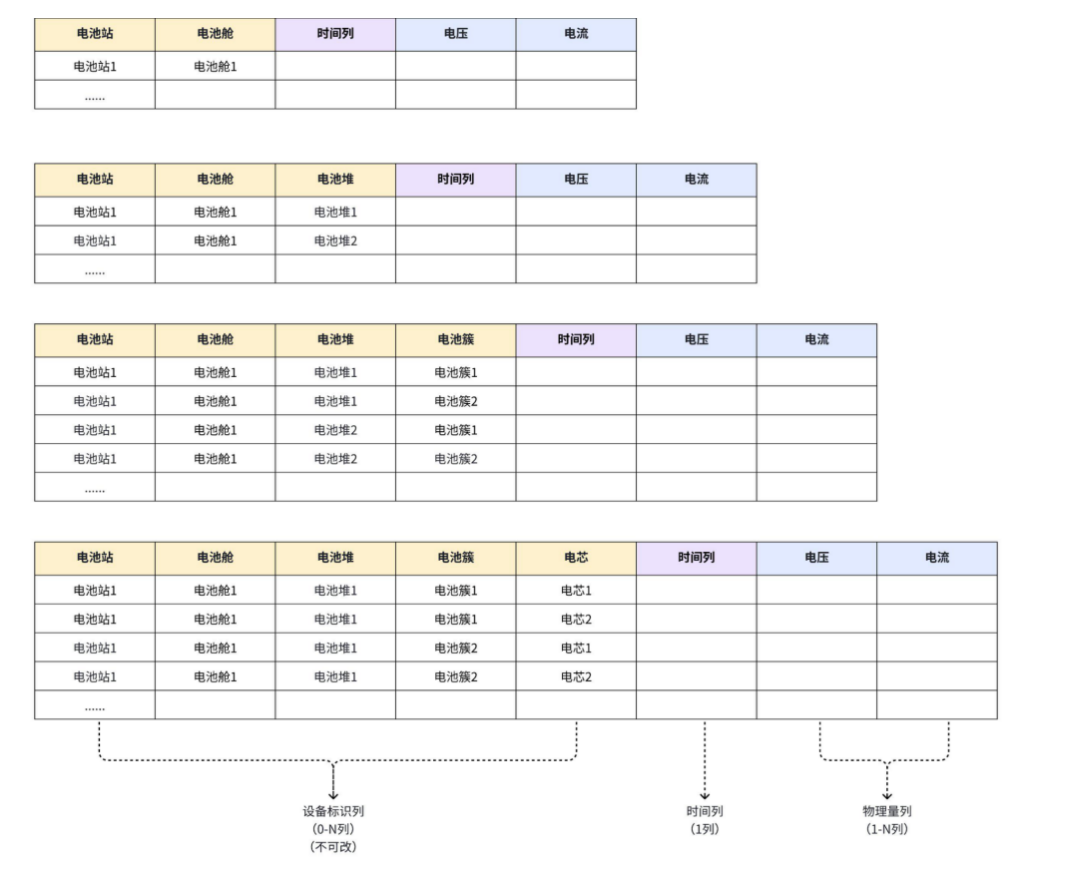
+
+
+
+
+
+
+
+
+
+
+
+
+

+
 -## 注意事项
+## 1 注意事项
1. 安装前请确认系统已参照[系统配置](../Deployment-and-Maintenance/Environment-Requirements.md)准备完成。
@@ -52,12 +52,12 @@
6. 推荐部署监控面板,可以对重要运行指标进行监控,随时掌握数据库运行状态,监控面板可以联系商务获取,部署监控面板步骤可以参考:[监控面板部署](./Monitoring-panel-deployment.md)
-## 准备步骤
+## 2 准备步骤
1. 准备IoTDB数据库安装包 :timechodb-{version}-bin.zip(安装包获取见:[链接](./IoTDB-Package_timecho.md))
2. 按环境要求配置好操作系统环境(系统环境配置见:[链接](./Environment-Requirements.md))
-## 安装步骤
+## 3 安装步骤
假设现在有3台linux服务器,IP地址和服务角色分配如下:
@@ -67,7 +67,7 @@
| 11.101.17.225 | iotdb-2 | ConfigNode、DataNode |
| 11.101.17.226 | iotdb-3 | ConfigNode、DataNode |
-### 设置主机名
+### 3.1 设置主机名
在3台机器上分别配置主机名,设置主机名需要在目标服务器上配置/etc/hosts,使用如下命令:
@@ -77,7 +77,7 @@ echo "11.101.17.225 iotdb-2" >> /etc/hosts
echo "11.101.17.226 iotdb-3" >> /etc/hosts
```
-### 参数配置
+### 3.2 参数配置
解压安装包并进入安装目录
@@ -86,7 +86,7 @@ unzip timechodb-{version}-bin.zip
cd timechodb-{version}-bin
```
-#### 环境脚本配置
+#### 3.2.1 环境脚本配置
- ./conf/confignode-env.sh配置
@@ -100,7 +100,7 @@ cd timechodb-{version}-bin
| :---------- | :----------------------------------- | :--------- | :----------------------------------------------- | :----------- |
| MEMORY_SIZE | IoTDB DataNode节点可以使用的内存总量 | 空 | 可按需填写,填写后系统会根据填写的数值来分配内存 | 重启服务生效 |
-#### 通用配置(./conf/iotdb-system.properties)
+#### 3.2.2 通用配置(./conf/iotdb-system.properties)
- 集群配置
@@ -110,7 +110,7 @@ cd timechodb-{version}-bin
| schema_replication_factor | 元数据副本数,DataNode数量不应少于此数目 | 3 | 3 | 3 |
| data_replication_factor | 数据副本数,DataNode数量不应少于此数目 | 2 | 2 | 2 |
-#### ConfigNode 配置
+#### 3.2.3 ConfigNode 配置
| 配置项 | 说明 | 默认 | 推荐值 | 11.101.17.224 | 11.101.17.225 | 11.101.17.226 | 备注 |
| ------------------- | ------------------------------------------------------------ | --------------- | ------------------------------------------------------- | ------------- | ------------- | ------------- | ------------------ |
@@ -119,7 +119,7 @@ cd timechodb-{version}-bin
| cn_consensus_port | ConfigNode副本组共识协议通信使用的端口 | 10720 | 10720 | 10720 | 10720 | 10720 | 首次启动后不能修改 |
| cn_seed_config_node | 节点注册加入集群时连接的ConfigNode 的地址,cn_internal_address:cn_internal_port | 127.0.0.1:10710 | 第一个CongfigNode的cn_internal_address:cn_internal_port | iotdb-1:10710 | iotdb-1:10710 | iotdb-1:10710 | 首次启动后不能修改 |
-#### DataNode 配置
+#### 3.2.4 DataNode 配置
| 配置项 | 说明 | 默认 | 推荐值 | 11.101.17.224 | 11.101.17.225 | 11.101.17.226 | 备注 |
| ------------------------------- | ------------------------------------------------------------ | --------------- | ------------------------------------------------------- | ------------- | ------------- | ------------- | ------------------ |
@@ -134,7 +134,7 @@ cd timechodb-{version}-bin
> ❗️注意:VSCode Remote等编辑器无自动保存配置功能,请确保修改的文件被持久化保存,否则配置项无法生效
-### 启动ConfigNode节点
+### 3.3 启动ConfigNode节点
先启动第一个iotdb-1的confignode, 保证种子confignode节点先启动,然后依次启动第2和第3个confignode节点
@@ -145,7 +145,7 @@ cd sbin
如果启动失败,请参考下[常见问题](#常见问题)
-### 启动DataNode 节点
+### 3.4 启动DataNode 节点
分别进入iotdb的sbin目录下,依次启动3个datanode节点:
@@ -154,7 +154,7 @@ cd sbin
./start-datanode.sh -d #-d参数将在后台进行启动
```
-### 激活数据库
+### 3.5 激活数据库
#### 方式一:激活文件拷贝激活
@@ -214,15 +214,15 @@ cd sbin
IoTDB> activate '01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOMN7-NB2E4BHI-7ZKGFVK6-GCIFXA4T-UG3XJTTD-SHJV6F2P-Q27B4OMJ-R47ZDIM3-UUASUXG2-OQXGVZCO-MMYKICZU-TWFQYYAO-ZOAGOKJA-NYHQTA5U-EWAR4EP5-MRC6R2CI-PKUTKRCT-7UDGRH3F-7BYV4P5D-6KKIA===,01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOMN7-NB2E4BHI-7ZKGFVK6-GCIFXA4T-UG3XJTTD-SHJV6F2P-Q27B4OMJ-R47ZDIM3-UUASUXG2-OQXGVZCO-MMYKICZU-TWFQYYAO-ZOAGOKJA-NYHQTA5U-EWAR4EP5-MRC6R2CI-PKUTKRCT-7UDGRH3F-7BYV4P5D-6KKIA===,01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOMN7-NB2E4BHI-7ZKGFVK6-GCIFXA4T-UG3XJTTD-SHJV6F2P-Q27B4OMJ-R47ZDIM3-UUASUXG2-OQXGVZCO-MMYKICZU-TWFQYYAO-ZOAGOKJA-NYHQTA5U-EWAR4EP5-MRC6R2CI-PKUTKRCT-7UDGRH3F-7BYV4P5D-6KKIA==='
```
-### 验证激活
+### 3.6 验证激活
当看到“Result”字段状态显示为success表示激活成功
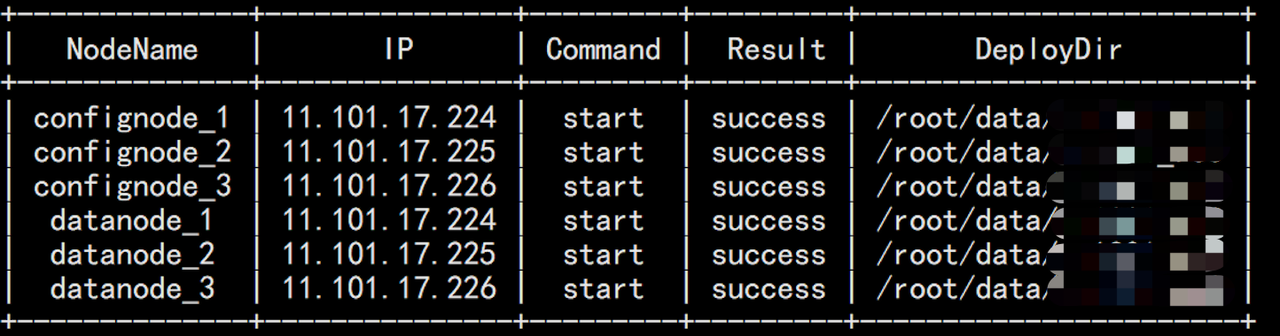
-## 节点维护步骤
+## 4 节点维护步骤
-### ConfigNode节点维护
+### 4.1 ConfigNode节点维护
ConfigNode节点维护分为ConfigNode添加和移除两种操作,有两个常见使用场景:
@@ -231,7 +231,7 @@ ConfigNode节点维护分为ConfigNode添加和移除两种操作,有两个常
> ❗️注意,在完成ConfigNode节点维护后,需要保证集群中有1或者3个正常运行的ConfigNode。2个ConfigNode不具备高可用性,超过3个ConfigNode会导致性能损失。
-#### 添加ConfigNode节点
+#### 4.1.1 添加ConfigNode节点
脚本命令:
@@ -245,7 +245,7 @@ sbin/start-confignode.sh
sbin/start-confignode.bat
```
-#### 移除ConfigNode节点
+#### 4.1.2 移除ConfigNode节点
首先通过CLI连接集群,通过`show confignodes`确认想要移除ConfigNode的内部地址与端口号:
@@ -276,7 +276,7 @@ sbin/remove-confignode.bat [confignode_id]
./sbin/remove-confignode.bat [cn_internal_address:cn_internal_port]
```
-### DataNode节点维护
+### 4.2 DataNode节点维护
DataNode节点维护有两个常见场景:
@@ -285,7 +285,7 @@ DataNode节点维护有两个常见场景:
> ❗️注意,为了使集群能正常工作,在DataNode节点维护过程中以及维护完成后,正常运行的DataNode总数不得少于数据副本数(通常为2),也不得少于元数据副本数(通常为3)。
-#### 添加DataNode节点
+#### 4.2.1 添加DataNode节点
脚本命令:
@@ -301,7 +301,7 @@ sbin/start-datanode.bat
说明:在添加DataNode后,随着新的写入到来(以及旧数据过期,如果设置了TTL),集群负载会逐渐向新的DataNode均衡,最终在所有节点上达到存算资源的均衡。
-#### 移除DataNode节点
+#### 4.2.2 移除DataNode节点
首先通过CLI连接集群,通过`show datanodes`确认想要移除的DataNode的RPC地址与端口号:
@@ -328,7 +328,7 @@ sbin/remove-datanode.sh [dn_rpc_address:dn_rpc_port]
sbin/remove-datanode.bat [dn_rpc_address:dn_rpc_port]
```
-## 常见问题
+## 5 常见问题
1. 部署过程中多次提示激活失败
- 使用 `ls -al` 命令:使用 `ls -al` 命令检查安装包根目录的所有者信息是否为当前用户。
@@ -360,15 +360,15 @@ sbin/remove-datanode.bat [dn_rpc_address:dn_rpc_port]
```shell
cd /data/iotdb rm -rf data logs
```
-## 附录
+## 6 附录
-### Confignode节点参数介绍
+### 6.1 Confignode节点参数介绍
| 参数 | 描述 | 是否为必填项 |
| :--- | :------------------------------- | :----------- |
| -d | 以守护进程模式启动,即在后台运行 | 否 |
-### Datanode节点参数介绍
+### 6.2 Datanode节点参数介绍
| 缩写 | 描述 | 是否为必填项 |
| :--- | :--------------------------------------------- | :----------- |
diff --git a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Database-Resources.md b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Database-Resources.md
index 5b85630b4..fe6133025 100644
--- a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Database-Resources.md
+++ b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Database-Resources.md
@@ -19,7 +19,8 @@
-->
# 资源规划
-## CPU
+
+## 1 CPU
-## 内存
+## 2 内存
-## 存储(磁盘)
-### 存储空间
+## 3 存储(磁盘)
+### 3.1 存储空间
计算公式:测点数量 * 采样频率(Hz)* 每个数据点大小(Byte,不同数据类型不一样,见下表)
-## 注意事项
+## 1 注意事项
1. 安装前请确认系统已参照[系统配置](../Deployment-and-Maintenance/Environment-Requirements.md)准备完成。
@@ -52,12 +52,12 @@
6. 推荐部署监控面板,可以对重要运行指标进行监控,随时掌握数据库运行状态,监控面板可以联系商务获取,部署监控面板步骤可以参考:[监控面板部署](./Monitoring-panel-deployment.md)
-## 准备步骤
+## 2 准备步骤
1. 准备IoTDB数据库安装包 :timechodb-{version}-bin.zip(安装包获取见:[链接](./IoTDB-Package_timecho.md))
2. 按环境要求配置好操作系统环境(系统环境配置见:[链接](./Environment-Requirements.md))
-## 安装步骤
+## 3 安装步骤
假设现在有3台linux服务器,IP地址和服务角色分配如下:
@@ -67,7 +67,7 @@
| 11.101.17.225 | iotdb-2 | ConfigNode、DataNode |
| 11.101.17.226 | iotdb-3 | ConfigNode、DataNode |
-### 设置主机名
+### 3.1 设置主机名
在3台机器上分别配置主机名,设置主机名需要在目标服务器上配置/etc/hosts,使用如下命令:
@@ -77,7 +77,7 @@ echo "11.101.17.225 iotdb-2" >> /etc/hosts
echo "11.101.17.226 iotdb-3" >> /etc/hosts
```
-### 参数配置
+### 3.2 参数配置
解压安装包并进入安装目录
@@ -86,7 +86,7 @@ unzip timechodb-{version}-bin.zip
cd timechodb-{version}-bin
```
-#### 环境脚本配置
+#### 3.2.1 环境脚本配置
- ./conf/confignode-env.sh配置
@@ -100,7 +100,7 @@ cd timechodb-{version}-bin
| :---------- | :----------------------------------- | :--------- | :----------------------------------------------- | :----------- |
| MEMORY_SIZE | IoTDB DataNode节点可以使用的内存总量 | 空 | 可按需填写,填写后系统会根据填写的数值来分配内存 | 重启服务生效 |
-#### 通用配置(./conf/iotdb-system.properties)
+#### 3.2.2 通用配置(./conf/iotdb-system.properties)
- 集群配置
@@ -110,7 +110,7 @@ cd timechodb-{version}-bin
| schema_replication_factor | 元数据副本数,DataNode数量不应少于此数目 | 3 | 3 | 3 |
| data_replication_factor | 数据副本数,DataNode数量不应少于此数目 | 2 | 2 | 2 |
-#### ConfigNode 配置
+#### 3.2.3 ConfigNode 配置
| 配置项 | 说明 | 默认 | 推荐值 | 11.101.17.224 | 11.101.17.225 | 11.101.17.226 | 备注 |
| ------------------- | ------------------------------------------------------------ | --------------- | ------------------------------------------------------- | ------------- | ------------- | ------------- | ------------------ |
@@ -119,7 +119,7 @@ cd timechodb-{version}-bin
| cn_consensus_port | ConfigNode副本组共识协议通信使用的端口 | 10720 | 10720 | 10720 | 10720 | 10720 | 首次启动后不能修改 |
| cn_seed_config_node | 节点注册加入集群时连接的ConfigNode 的地址,cn_internal_address:cn_internal_port | 127.0.0.1:10710 | 第一个CongfigNode的cn_internal_address:cn_internal_port | iotdb-1:10710 | iotdb-1:10710 | iotdb-1:10710 | 首次启动后不能修改 |
-#### DataNode 配置
+#### 3.2.4 DataNode 配置
| 配置项 | 说明 | 默认 | 推荐值 | 11.101.17.224 | 11.101.17.225 | 11.101.17.226 | 备注 |
| ------------------------------- | ------------------------------------------------------------ | --------------- | ------------------------------------------------------- | ------------- | ------------- | ------------- | ------------------ |
@@ -134,7 +134,7 @@ cd timechodb-{version}-bin
> ❗️注意:VSCode Remote等编辑器无自动保存配置功能,请确保修改的文件被持久化保存,否则配置项无法生效
-### 启动ConfigNode节点
+### 3.3 启动ConfigNode节点
先启动第一个iotdb-1的confignode, 保证种子confignode节点先启动,然后依次启动第2和第3个confignode节点
@@ -145,7 +145,7 @@ cd sbin
如果启动失败,请参考下[常见问题](#常见问题)
-### 启动DataNode 节点
+### 3.4 启动DataNode 节点
分别进入iotdb的sbin目录下,依次启动3个datanode节点:
@@ -154,7 +154,7 @@ cd sbin
./start-datanode.sh -d #-d参数将在后台进行启动
```
-### 激活数据库
+### 3.5 激活数据库
#### 方式一:激活文件拷贝激活
@@ -214,15 +214,15 @@ cd sbin
IoTDB> activate '01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOMN7-NB2E4BHI-7ZKGFVK6-GCIFXA4T-UG3XJTTD-SHJV6F2P-Q27B4OMJ-R47ZDIM3-UUASUXG2-OQXGVZCO-MMYKICZU-TWFQYYAO-ZOAGOKJA-NYHQTA5U-EWAR4EP5-MRC6R2CI-PKUTKRCT-7UDGRH3F-7BYV4P5D-6KKIA===,01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOMN7-NB2E4BHI-7ZKGFVK6-GCIFXA4T-UG3XJTTD-SHJV6F2P-Q27B4OMJ-R47ZDIM3-UUASUXG2-OQXGVZCO-MMYKICZU-TWFQYYAO-ZOAGOKJA-NYHQTA5U-EWAR4EP5-MRC6R2CI-PKUTKRCT-7UDGRH3F-7BYV4P5D-6KKIA===,01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOMN7-NB2E4BHI-7ZKGFVK6-GCIFXA4T-UG3XJTTD-SHJV6F2P-Q27B4OMJ-R47ZDIM3-UUASUXG2-OQXGVZCO-MMYKICZU-TWFQYYAO-ZOAGOKJA-NYHQTA5U-EWAR4EP5-MRC6R2CI-PKUTKRCT-7UDGRH3F-7BYV4P5D-6KKIA==='
```
-### 验证激活
+### 3.6 验证激活
当看到“Result”字段状态显示为success表示激活成功

-## 节点维护步骤
+## 4 节点维护步骤
-### ConfigNode节点维护
+### 4.1 ConfigNode节点维护
ConfigNode节点维护分为ConfigNode添加和移除两种操作,有两个常见使用场景:
@@ -231,7 +231,7 @@ ConfigNode节点维护分为ConfigNode添加和移除两种操作,有两个常
> ❗️注意,在完成ConfigNode节点维护后,需要保证集群中有1或者3个正常运行的ConfigNode。2个ConfigNode不具备高可用性,超过3个ConfigNode会导致性能损失。
-#### 添加ConfigNode节点
+#### 4.1.1 添加ConfigNode节点
脚本命令:
@@ -245,7 +245,7 @@ sbin/start-confignode.sh
sbin/start-confignode.bat
```
-#### 移除ConfigNode节点
+#### 4.1.2 移除ConfigNode节点
首先通过CLI连接集群,通过`show confignodes`确认想要移除ConfigNode的内部地址与端口号:
@@ -276,7 +276,7 @@ sbin/remove-confignode.bat [confignode_id]
./sbin/remove-confignode.bat [cn_internal_address:cn_internal_port]
```
-### DataNode节点维护
+### 4.2 DataNode节点维护
DataNode节点维护有两个常见场景:
@@ -285,7 +285,7 @@ DataNode节点维护有两个常见场景:
> ❗️注意,为了使集群能正常工作,在DataNode节点维护过程中以及维护完成后,正常运行的DataNode总数不得少于数据副本数(通常为2),也不得少于元数据副本数(通常为3)。
-#### 添加DataNode节点
+#### 4.2.1 添加DataNode节点
脚本命令:
@@ -301,7 +301,7 @@ sbin/start-datanode.bat
说明:在添加DataNode后,随着新的写入到来(以及旧数据过期,如果设置了TTL),集群负载会逐渐向新的DataNode均衡,最终在所有节点上达到存算资源的均衡。
-#### 移除DataNode节点
+#### 4.2.2 移除DataNode节点
首先通过CLI连接集群,通过`show datanodes`确认想要移除的DataNode的RPC地址与端口号:
@@ -328,7 +328,7 @@ sbin/remove-datanode.sh [dn_rpc_address:dn_rpc_port]
sbin/remove-datanode.bat [dn_rpc_address:dn_rpc_port]
```
-## 常见问题
+## 5 常见问题
1. 部署过程中多次提示激活失败
- 使用 `ls -al` 命令:使用 `ls -al` 命令检查安装包根目录的所有者信息是否为当前用户。
@@ -360,15 +360,15 @@ sbin/remove-datanode.bat [dn_rpc_address:dn_rpc_port]
```shell
cd /data/iotdb rm -rf data logs
```
-## 附录
+## 6 附录
-### Confignode节点参数介绍
+### 6.1 Confignode节点参数介绍
| 参数 | 描述 | 是否为必填项 |
| :--- | :------------------------------- | :----------- |
| -d | 以守护进程模式启动,即在后台运行 | 否 |
-### Datanode节点参数介绍
+### 6.2 Datanode节点参数介绍
| 缩写 | 描述 | 是否为必填项 |
| :--- | :--------------------------------------------- | :----------- |
diff --git a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Database-Resources.md b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Database-Resources.md
index 5b85630b4..fe6133025 100644
--- a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Database-Resources.md
+++ b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Database-Resources.md
@@ -19,7 +19,8 @@
-->
# 资源规划
-## CPU
+
+## 1 CPU
-## 内存
+## 2 内存
-## 存储(磁盘)
-### 存储空间
+## 3 存储(磁盘)
+### 3.1 存储空间
计算公式:测点数量 * 采样频率(Hz)* 每个数据点大小(Byte,不同数据类型不一样,见下表)
@@ -187,13 +188,13 @@
示例:1000设备,每个设备100 测点,共 100000 序列,INT32 类型。采样频率1Hz(每秒一次),存储1年,3副本。
- 完整计算公式:1000设备 * 100测点 * 12字节每数据点 * 86400秒每天 * 365天每年 * 3副本/10压缩比 / 1024 / 1024 / 1024 / 1024 =11T
- 简版计算公式:1000 * 100 * 12 * 86400 * 365 * 3 / 10 / 1024 / 1024 / 1024 / 1024 = 11T
-### 存储配置
+### 3.2 存储配置
1000w 点位以上或查询负载较大,推荐配置 SSD。
-## 网络(网卡)
+## 4 网络(网卡)
在写入吞吐不超过1000万点/秒时,需配置千兆网卡;当写入吞吐超过 1000万点/秒时,需配置万兆网卡。
| **写入吞吐(数据点/秒)** | **网卡速率** |
| ------------------- | ------------- |
| <1000万 | 1Gbps(千兆) |
| >=1000万 | 10Gbps(万兆) |
-## 其他说明
+## 5 其他说明
IoTDB 具有集群秒级扩容能力,扩容节点数据可不迁移,因此您无需担心按现有数据情况估算的集群能力有限,未来您可在需要扩容时为集群加入新的节点。
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Docker-Deployment_apache.md b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Docker-Deployment_apache.md
new file mode 100644
index 000000000..c3f9029c4
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Docker-Deployment_apache.md
@@ -0,0 +1,412 @@
+
+# Docker部署
+
+## 1 环境准备
+
+### 1.1 Docker安装
+
+```SQL
+#以ubuntu为例,其他操作系统可以自行搜索安装方法
+#step1: 安装一些必要的系统工具
+sudo apt-get update
+sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
+#step2: 安装GPG证书
+curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
+#step3: 写入软件源信息
+sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
+#step4: 更新并安装Docker-CE
+sudo apt-get -y update
+sudo apt-get -y install docker-ce
+#step5: 设置docker开机自启动
+sudo systemctl enable docker
+#step6: 验证docker是否安装成功
+docker --version #显示版本信息,即安装成功
+```
+
+### 1.2 docker-compose安装
+
+```SQL
+#安装命令
+curl -L "https://github.com/docker/compose/releases/download/v2.20.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
+chmod +x /usr/local/bin/docker-compose
+ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
+#验证是否安装成功
+docker-compose --version #显示版本信息即安装成功
+```
+
+## 2 单机版
+
+本节演示如何部署1C1D的docker单机版。
+
+### 2.1 拉取镜像文件
+
+Apache IoTDB的Docker镜像已经上传至https://hub.docker.com/r/apache/iotdb。
+
+以获取1.3.2版本为例,拉取镜像命令:
+
+```bash
+docker pull apache/iotdb:1.3.2-standalone
+```
+
+查看镜像:
+
+```bash
+docker images
+```
+
+
+
+### 2.2 创建docker bridge网络
+
+```Bash
+docker network create --driver=bridge --subnet=172.18.0.0/16 --gateway=172.18.0.1 iotdb
+```
+
+### 2.3 编写docker-compose的yml文件
+
+这里我们以把IoTDB安装目录和yml文件统一放在`/docker-iotdb`文件夹下为例:
+
+文件目录结构为:`/docker-iotdb/iotdb`, `/docker-iotdb/docker-compose-standalone.yml `
+
+```bash
+docker-iotdb:
+├── iotdb #iotdb安装目录
+│── docker-compose-standalone.yml #单机版docker-compose的yml文件
+```
+
+完整的docker-compose-standalone.yml 内容如下:
+
+```bash
+version: "3"
+services:
+ iotdb-service:
+ image: apache/iotdb:1.3.2-standalone #使用的镜像
+ hostname: iotdb
+ container_name: iotdb
+ restart: always
+ ports:
+ - "6667:6667"
+ environment:
+ - cn_internal_address=iotdb
+ - cn_internal_port=10710
+ - cn_consensus_port=10720
+ - cn_seed_config_node=iotdb:10710
+ - dn_rpc_address=iotdb
+ - dn_internal_address=iotdb
+ - dn_rpc_port=6667
+ - dn_internal_port=10730
+ - dn_mpp_data_exchange_port=10740
+ - dn_schema_region_consensus_port=10750
+ - dn_data_region_consensus_port=10760
+ - dn_seed_config_node=iotdb:10710
+ privileged: true
+ volumes:
+ - ./iotdb/data:/iotdb/data
+ - ./iotdb/logs:/iotdb/logs
+ networks:
+ iotdb:
+ ipv4_address: 172.18.0.6
+networks:
+ iotdb:
+ external: true
+```
+
+### 2.4 启动IoTDB
+
+使用下面的命令启动:
+
+```bash
+cd /docker-iotdb
+docker-compose -f docker-compose-standalone.yml up -d #后台启动
+```
+
+### 2.5 验证部署
+
+- 查看日志,有如下字样,表示启动成功
+
+ ```SQL
+ docker logs -f iotdb-datanode #查看日志命令
+ 2024-07-21 08:22:38,457 [main] INFO o.a.i.db.service.DataNode:227 - Congratulations, IoTDB DataNode is set up successfully. Now, enjoy yourself!
+ ```
+
+ 
+
+- 进入容器,查看服务运行状态
+
+ 查看启动的容器
+
+ ```SQL
+ docker ps
+ ```
+
+ 
+
+ 进入容器, 通过cli登录数据库, 使用show cluster命令查看服务状态
+
+ ```SQL
+ docker exec -it iotdb /bin/bash #进入容器
+ ./start-cli.sh -h iotdb #登录数据库
+ IoTDB> show cluster #查看服务状态
+ ```
+
+ 可以看到服务状态都是running, 说明IoTDB部署成功。
+
+ 
+
+### 2.6 映射/conf目录(可选)
+
+后续如果想在物理机中直接修改配置文件,可以把容器中的/conf文件夹映射出来,分三步:
+
+步骤一:拷贝容器中的/conf目录到`/docker-iotdb/iotdb/conf`
+
+```bash
+docker cp iotdb:/iotdb/conf /docker-iotdb/iotdb/conf
+```
+
+步骤二:在`docker-compose-standalone.yml`中添加映射
+
+```bash
+ volumes:
+ - ./iotdb/conf:/iotdb/conf #增加这个/conf文件夹的映射
+ - ./iotdb/data:/iotdb/data
+ - ./iotdb/logs:/iotdb/logs
+```
+
+步骤三:重新启动IoTDB
+
+```bash
+docker-compose -f docker-compose-standalone.yml up -d
+```
+
+## 3 集群版
+
+本小节描述如何手动部署包括3个ConfigNode和3个DataNode的实例,即通常所说的3C3D集群。
+
+
+
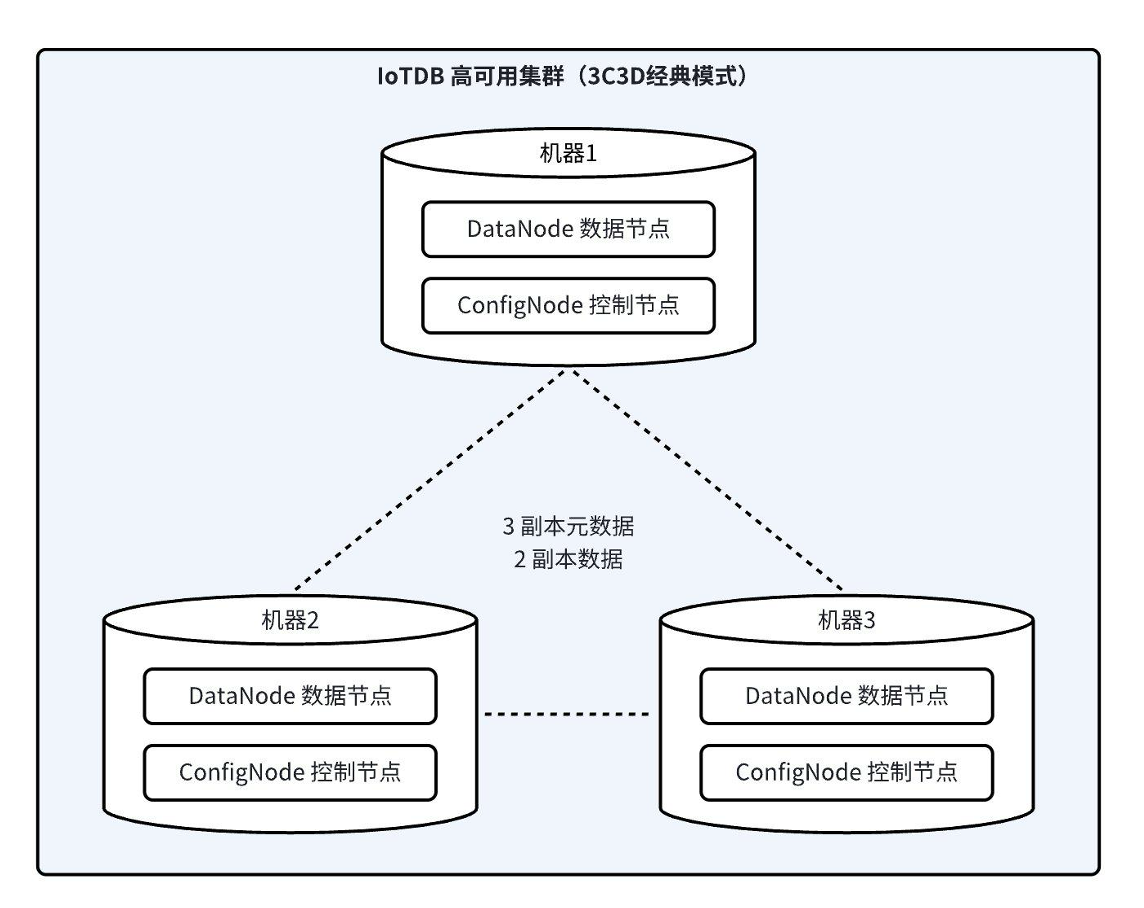
+
+
+
-### 网络配置
+### 2.3 网络配置
1. 关闭防火墙
@@ -163,7 +163,7 @@ systemctl start sshd #启用22号端口
3. 保证服务器之间的网络相互连通
-### 其他配置
+### 2.4 其他配置
1. 关闭系统 swap 内存
@@ -192,7 +192,7 @@ echo "* hard nofile 65535" >> /etc/security/limits.conf
ulimit -n
```
-## 软件依赖
+## 3 软件依赖
安装 Java 运行环境 ,Java 版本 >= 1.8,请确保已设置 jdk 环境变量。(V1.3.2.2 及之上版本推荐直接部署JDK17,老版本JDK部分场景下性能有问题,且datanode会出现stop不掉的问题)
diff --git a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md
index 6c66c7fb9..23758abf0 100644
--- a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md
+++ b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md
@@ -19,11 +19,11 @@
-->
# 安装包获取
-## 获取方式
+## 1 获取方式
企业版安装包可通过产品试用申请,或直接联系与您对接的工作人员获取。
-## 安装包结构
+## 2 安装包结构
安装包解压后目录结构如下:
diff --git a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md
index c7fba837e..51dd0f19e 100644
--- a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md
+++ b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md
@@ -22,12 +22,12 @@
IoTDB配套监控面板是IoTDB企业版配套工具之一。它旨在解决IoTDB及其所在操作系统的监控问题,主要包括:操作系统资源监控、IoTDB性能监控,及上百项内核监控指标,从而帮助用户监控集群健康状态,并进行集群调优和运维。本文将以常见的3C3D集群(3个Confignode和3个Datanode)为例,为您介绍如何在IoTDB的实例中开启系统监控模块,并且使用Prometheus + Grafana的方式完成对系统监控指标的可视化。
-## 安装准备
+## 1 安装准备
1. 安装 IoTDB:需先安装IoTDB V1.0 版本及以上企业版,您可联系商务或技术支持获取
2. 获取 IoTDB 监控面板安装包:基于企业版 IoTDB 的数据库监控面板,您可联系商务或技术支持获取
-## 安装步骤
+## 2 安装步骤
### 步骤一:IoTDB开启监控指标采集
@@ -184,13 +184,13 @@ cd grafana-*
-## 附录、监控指标详解
+## 3 附录、监控指标详解
-### 系统面板(System Dashboard)
+### 3.1 系统面板(System Dashboard)
该面板展示了当前系统CPU、内存、磁盘、网络资源的使用情况已经JVM的部分状况。
-#### CPU
+#### 3.1.1 CPU
- CPU Core:CPU 核数
- CPU Load:
@@ -198,7 +198,7 @@ cd grafana-*
- Process CPU Load:IoTDB 进程在采样时间内占用的 CPU 比例
- CPU Time Per Minute:系统每分钟内所有进程的 CPU 时间总和
-#### Memory
+#### 3.1.2 Memory
- System Memory:当前系统内存的使用情况。
- Commited vm size: 操作系统分配给正在运行的进程使用的虚拟内存的大小。
@@ -210,7 +210,7 @@ cd grafana-*
- Total Memory:IoTDB 进程当前已经从操作系统中请求到的内存总量。
- Used Memory:IoTDB 进程当前已经使用的内存总量。
-#### Disk
+#### 3.1.3 Disk
- Disk Space:
- Total disk space:IoTDB 可使用的最大磁盘空间。
@@ -237,7 +237,7 @@ cd grafana-*
- I/O System Call Rate:进程调用读写系统调用的频率,类似于 IOPS。
- I/O Throughput:进程进行 I/O 的吞吐量,分为 actual_read/write 和 attempt_read/write 两类。actual read 和 actual write 指的是进程实际导致块设备进行 I/O 的字节数,不包含被 Page Cache 处理的部分。
-#### JVM
+#### 3.1.4 JVM
- GC Time Percentage:节点 JVM 在过去一分钟的时间窗口内,GC 耗时所占的比例
- GC Allocated/Promoted Size Detail: 节点 JVM 平均每分钟晋升到老年代的对象大小,新生代/老年代和非分代新申请的对象大小
@@ -263,7 +263,7 @@ cd grafana-*
- unloaded:系统启动至今 JVM 卸载的类的数量
- The Number of Java Thread:IoTDB 目前存活的线程数。各子项分别为各状态的线程数。
-#### Network
+#### 3.1.5 Network
eno 指的是到公网的网卡,lo 是虚拟网卡。
@@ -272,9 +272,9 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Packet Speed:网卡发送和接收数据包的速度,一次 RPC 请求可以对应一个或者多个数据包
- Connection Num:当前选定进程的 socket 连接数(IoTDB只有 TCP)
-### 整体性能面板(Performance Overview Dashboard)
+### 3.2 整体性能面板(Performance Overview Dashboard)
-#### Cluster Overview
+#### 3.2.1 Cluster Overview
- Total CPU Core: 集群机器 CPU 总核数
- DataNode CPU Load: 集群各DataNode 节点的 CPU 使用率
@@ -295,7 +295,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Total DataRegion: 集群管理的 DataRegion 总数
- Total SchemaRegion: 集群管理的 SchemaRegion 总数
-#### Node Overview
+#### 3.2.2 Node Overview
- CPU Core: 节点所在机器的 CPU 核数
- Disk Space: 节点所在机器的磁盘大小
@@ -306,7 +306,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Swap Memory: 节点所在机器的交换内存大小
- File Number: 节点管理的文件数
-#### Performance
+#### 3.2.3 Performance
- Session Idle Time: 节点的 session 连接的总空闲时间和总忙碌时间
- Client Connection: 节点的客户端连接情况,包括总连接数和活跃连接数
@@ -338,7 +338,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Average Time Consumed Of Engine Stage: 节点的 engine 阶段各子阶段平均耗时
- P99 Time Consumed Of Engine Stage: 节点 engine 阶段各子阶段的 P99 耗时
-#### System
+#### 3.2.4 System
- CPU Load: 节点的 CPU 负载
- CPU Time Per Minute: 节点的每分钟 CPU 时间,最大值和 CPU 核数相关
@@ -350,11 +350,11 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- File Size: 节点管理文件大小情况
- Log Number Per Minute: 节点的每分钟不同类型日志情况
-### ConfigNode 面板(ConfigNode Dashboard)
+### 3.3 ConfigNode 面板(ConfigNode Dashboard)
该面板展示了集群中所有管理节点的表现情况,包括分区、节点信息、客户端连接情况统计等。
-#### Node Overview
+#### 3.3.1 Node Overview
- Database Count: 节点的数据库数量
- Region
@@ -368,7 +368,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- DataNodes: 节点所在集群的 DataNode 情况
- System Overview: 节点的系统概述,包括系统内存、磁盘使用、进程内存以及CPU负载
-#### NodeInfo
+#### 3.3.2 NodeInfo
- Node Count: 节点所在集群的节点数量,包括 ConfigNode 和 DataNode
- ConfigNode Status: 节点所在集群的 ConfigNode 节点的状态
@@ -378,7 +378,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- DataRegion Distribution: 节点所在集群的 DataRegion 的分布情况
- DataRegionGroup Leader Distribution: 节点所在集群的 DataRegionGroup 的 Leader 分布情况
-#### Protocol
+#### 3.3.3 Protocol
- 客户端数量统计
- Active Client Num: 节点各线程池的活跃客户端数量
@@ -391,7 +391,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Client Mean Borrow Wait Time: 节点各线程池的客户端平均借用等待时间
- Client Mean Idle Time: 节点各线程池的客户端平均空闲时间
-#### Partition Table
+#### 3.3.4 Partition Table
- SchemaRegionGroup Count: 节点所在集群的 Database 的 SchemaRegionGroup 的数量
- DataRegionGroup Count: 节点所在集群的 Database 的 DataRegionGroup 的数量
@@ -400,7 +400,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- DataRegion Status: 节点所在集群的 DataRegion 状态
- SchemaRegion Status: 节点所在集群的 SchemaRegion 的状态
-#### Consensus
+#### 3.3.5 Consensus
- Ratis Stage Time: 节点的 Ratis 各阶段耗时
- Write Log Entry: 节点的 Ratis 写 Log 的耗时
@@ -408,17 +408,17 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Remote / Local Write QPS: 节点 Ratis 的远程和本地写入的 QPS
- RatisConsensus Memory: 节点 Ratis 共识协议的内存使用
-### DataNode 面板(DataNode Dashboard)
+### 3.4 DataNode 面板(DataNode Dashboard)
该面板展示了集群中所有数据节点的监控情况,包含写入耗时、查询耗时、存储文件数等。
-#### Node Overview
+#### 3.4.1 Node Overview
- The Number Of Entity: 节点管理的实体情况
- Write Point Per Second: 节点的每秒写入速度
- Memory Usage: 节点的内存使用情况,包括 IoT Consensus 各部分内存占用、SchemaRegion内存总占用和各个数据库的内存占用。
-#### Protocol
+#### 3.4.2 Protocol
- 节点操作耗时
- The Time Consumed Of Operation (avg): 节点的各项操作的平均耗时
@@ -439,7 +439,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Client Mean Borrow Wait Time: 节点各线程池的客户端平均借用等待时间
- Client Mean Idle Time: 节点各线程池的客户端平均空闲时间
-#### Storage Engine
+#### 3.4.3 Storage Engine
- File Count: 节点管理的各类型文件数量
- File Size: 节点管理的各类型文件大小
@@ -455,7 +455,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Compaction Process Chunk Status: 节点合并不同状态的 Chunk 的数量
- Compacted Point Num Per Minute: 节点每分钟合并的点数
-#### Write Performance
+#### 3.4.4 Write Performance
- Write Cost(avg): 节点写入耗时平均值,包括写入 wal 和 memtable
- Write Cost(50%): 节点写入耗时中位数,包括写入 wal 和 memtable
@@ -491,7 +491,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Series Num Of Flushing MemTable: 节点的不同 DataRegion 的 Memtable 刷盘时的时间序列数
- Average Point Num Of Flushing MemChunk: 节点 MemChunk 刷盘的平均点数
-#### Schema Engine
+#### 3.4.5 Schema Engine
- Schema Engine Mode: 节点的元数据引擎模式
- Schema Consensus Protocol: 节点的元数据共识协议
@@ -520,7 +520,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Time Consumed of Relead and Flush (avg): 节点触发 cache 释放和 buffer 刷盘耗时的平均值
- Time Consumed of Relead and Flush (99%): 节点触发 cache 释放和 buffer 刷盘的耗时的 P99
-#### Query Engine
+#### 3.4.6 Query Engine
- 各阶段耗时
- The time consumed of query plan stages(avg): 节点查询各阶段耗时的平均值
@@ -563,7 +563,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- The time consumed of query schedule time(50%): 节点查询任务调度耗时的中位数
- The time consumed of query schedule time(99%): 节点查询任务调度耗时的P99
-#### Query Interface
+#### 3.4.7 Query Interface
- 加载时间序列元数据
- The time consumed of load timeseries metadata(avg): 节点查询加载时间序列元数据耗时的平均值
@@ -610,7 +610,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- The time consumed of build tsblock from merge reader(50%): 节点查询通过 Merge Reader 构造 TsBlock 耗时的中位数
- The time consumed of build tsblock from merge reader(99%): 节点查询通过 Merge Reader 构造 TsBlock 耗时的P99
-#### Query Data Exchange
+#### 3.4.8 Query Data Exchange
查询的数据交换耗时。
@@ -635,7 +635,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- The time consumed of get data block task(50%): 节点查询获取 data block task 耗时的中位数
- The time consumed of get data block task(99%): 节点查询获取 data block task 耗时的 P99
-#### Query Related Resource
+#### 3.4.9 Query Related Resource
- MppDataExchangeManager: 节点查询时 shuffle sink handle 和 source handle 的数量
- LocalExecutionPlanner: 节点可分配给查询分片的剩余内存
@@ -645,7 +645,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- MemoryPool Capacity: 节点查询相关的内存池的大小情况,包括最大值和剩余可用值
- DriverScheduler: 节点查询相关的队列任务数量
-#### Consensus - IoT Consensus
+#### 3.4.10 Consensus - IoT Consensus
- 内存使用
- IoTConsensus Used Memory: 节点的 IoT Consensus 的内存使用情况,包括总使用内存大小、队列使用内存大小、同步使用内存大小
@@ -665,7 +665,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- The Time Consumed Of Different Stages (50%): 节点 IoT Consensus 不同执行阶段的耗时的中位数
- The Time Consumed Of Different Stages (99%): 节点 IoT Consensus 不同执行阶段的耗时的P99
-#### Consensus - DataRegion Ratis Consensus
+#### 3.4.11 Consensus - DataRegion Ratis Consensus
- Ratis Stage Time: 节点 Ratis 不同阶段的耗时
- Write Log Entry: 节点 Ratis 写 Log 不同阶段的耗时
@@ -673,7 +673,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Remote / Local Write QPS: 节点 Ratis 在本地或者远端写入的 QPS
- RatisConsensus Memory: 节点 Ratis 的内存使用情况
-#### Consensus - SchemaRegion Ratis Consensus
+#### 3.4.12 Consensus - SchemaRegion Ratis Consensus
- Ratis Stage Time: 节点 Ratis 不同阶段的耗时
- Write Log Entry: 节点 Ratis 写 Log 各阶段的耗时
diff --git a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md
index 5344fd9ed..8421d9f57 100644
--- a/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md
+++ b/src/zh/UserGuide/Master/Table/Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md
@@ -22,7 +22,7 @@
本章将介绍如何启动IoTDB单机实例,IoTDB单机实例包括 1 个ConfigNode 和1个DataNode(即通常所说的1C1D)。
-## 注意事项
+## 1 注意事项
1. 安装前请确认系统已参照[系统配置](../Deployment-and-Maintenance/Environment-Requirements.md)准备完成。
2. 推荐使用`hostname`进行IP配置,可避免后期修改主机ip导致数据库无法启动的问题。设置hostname需要在服务器上配置`/etc/hosts`,如本机ip是192.168.1.3,hostname是iotdb-1,则可以使用以下命令设置服务器的 hostname,并使用hostname配置IoTDB的 `cn_internal_address`、`dn_internal_address`。
@@ -40,18 +40,18 @@
- 避免使用 sudo:使用 sudo 命令会以 root 用户权限执行命令,可能会引起权限混淆或安全问题。
6. 推荐部署监控面板,可以对重要运行指标进行监控,随时掌握数据库运行状态,监控面板可以联系工作人员获取,部署监控面板步骤可以参考:[监控面板部署](../Deployment-and-Maintenance/Monitoring-panel-deployment.md)
-## 安装步骤
+## 2 安装步骤
-### 1、解压安装包并进入安装目录
+### 2.1 解压安装包并进入安装目录
```Plain
unzip timechodb-{version}-bin.zip
cd timechodb-{version}-bin
```
-### 2、参数配置
+### 2.2 参数配置
-#### 内存配置
+#### 2.2.1 内存配置
- conf/confignode-env.sh(或 .bat)
@@ -65,7 +65,7 @@ cd timechodb-{version}-bin
| :---------- | :----------------------------------- | :--------- | :----------------------------------------------- | :----------- |
| MEMORY_SIZE | IoTDB DataNode节点可以使用的内存总量 | 空 | 可按需填写,填写后系统会根据填写的数值来分配内存 | 重启服务生效 |
-#### 功能配置
+#### 2.2.2 功能配置
系统实际生效的参数在文件 conf/iotdb-system.properties 中,启动需设置以下参数,可以从 conf/iotdb-system.properties.template 文件中查看全部参数
@@ -99,7 +99,7 @@ DataNode 配置
| dn_schema_region_consensus_port | DataNode用于元数据副本共识协议通信使用的端口 | 10760 | 10760 | 首次启动后不能修改 |
| dn_seed_config_node | 节点注册加入集群时连接的ConfigNode地址,即cn_internal_address:cn_internal_port | 127.0.0.1:10710 | cn_internal_address:cn_internal_port | 首次启动后不能修改 |
-### 3、启动 ConfigNode 节点
+### 2.3 启动 ConfigNode 节点
进入iotdb的sbin目录下,启动confignode
@@ -109,7 +109,7 @@ DataNode 配置
如果启动失败,请参考下方[常见问题](#常见问题)。
-### 4、启动 DataNode 节点
+### 2.4 启动 DataNode 节点
进入iotdb的sbin目录下,启动datanode:
@@ -117,7 +117,7 @@ DataNode 配置
./sbin/start-datanode.sh -d #“-d”参数将在后台进行启动
```
-### 5、激活数据库
+### 2.5 激活数据库
#### 方式一:文件激活
@@ -145,7 +145,7 @@ DataNode 配置
./start-cli.bat
```
- 执行以下内容获取激活所需机器码:
- - 注:当前仅支持在树模型中进行激活
+ - 注:当前仅支持在树模型中进行激活
```Bash
show system info
@@ -170,13 +170,13 @@ It costs 0.030s
IoTDB> activate '01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOMN7-NB2E4BHI-7ZKGFVK6-GCIFXA4T-UG3XJTTD-SHJV6F2P-Q27B4OMJ-R47ZDIM3-UUASUXG2-OQXGVZCO-MMYKICZU-TWFQYYAO-ZOAGOKJA-NYHQTA5U-EWAR4EP5-MRC6R2CI-PKUTKRCT-7UDGRH3F-7BYV4P5D-6KKIA==='
```
-### 6、验证激活
+### 2.6 验证激活
当看到“ClusterActivationStatus”字段状态显示为ACTIVATED表示激活成功
-## 常见问题
+## 3 常见问题
1. 部署过程中多次提示激活失败
- 使用 `ls -al` 命令:使用 `ls -al` 命令检查安装包根目录的所有者信息是否为当前用户。
@@ -208,15 +208,15 @@ IoTDB> activate '01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOM
cd /data/iotdb rm -rf data logs
```
-## 附录
+## 4 附录
-### Confignode节点参数介绍
+### 4.1 Confignode节点参数介绍
| 参数 | 描述 | 是否为必填项 |
| :--- | :------------------------------- | :----------- |
| -d | 以守护进程模式启动,即在后台运行 | 否 |
-### Datanode节点参数介绍
+### 4.2 Datanode节点参数介绍
| 缩写 | 描述 | 是否为必填项 |
| :--- | :--------------------------------------------- | :----------- |
diff --git a/src/zh/UserGuide/Master/Table/IoTDB-Introduction/IoTDB-Introduction_apache.md b/src/zh/UserGuide/Master/Table/IoTDB-Introduction/IoTDB-Introduction_apache.md
new file mode 100644
index 000000000..2fc384714
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/IoTDB-Introduction/IoTDB-Introduction_apache.md
@@ -0,0 +1,76 @@
+
+
+# 产品介绍
+
+Apache IoTDB 是一款低成本、高性能的物联网原生时序数据库。它可以解决企业组建物联网大数据平台管理时序数据时所遇到的应用场景复杂、数据体量大、采样频率高、数据乱序多、数据处理耗时长、分析需求多样、存储与运维成本高等多种问题。
+
+- Github仓库链接:https://github.com/apache/iotdb
+
+- 开源安装包下载:https://iotdb.apache.org/zh/Download/
+
+- 安装部署与使用文档:[快速上手](../QuickStart/QuickStart_apache.md)
+
+
+## 产品体系
+
+IoTDB 体系由若干个组件构成,帮助用户高效地管理和分析物联网产生的海量时序数据。
+
+
+
+
+
+
+
+ | 功能 |
+ Apache IoTDB |
+ TimechoDB |
+
+
+ | 部署模式 |
+ 单机部署 |
+ √ |
+ √ |
+
+
+ | 分布式部署 |
+ √ |
+ √ |
+
+
+ | 双活部署 |
+ × |
+ √ |
+
+
+ | 容器部署 |
+ 部分支持 |
+ √ |
+
+
+ | 数据库功能 |
+ 测点管理 |
+ √ |
+ √ |
+
+
+ | 数据写入 |
+ √ |
+ √ |
+
+
+ | 数据查询 |
+ √ |
+ √ |
+
+
+ | 连续查询 |
+ √ |
+ √ |
+
+
+ | 触发器 |
+ √ |
+ √ |
+
+
+ | 用户自定义函数 |
+ √ |
+ √ |
+
+
+ | 权限管理 |
+ √ |
+ √ |
+
+
+ | 数据同步 |
+ 仅文件同步,无内置插件 |
+ 实时同步+文件同步,丰富内置插件 |
+
+
+ | 流处理 |
+ 仅框架,无内置插件 |
+ 框架+丰富内置插件 |
+
+
+ | 多级存储 |
+ × |
+ √ |
+
+
+ | 视图 |
+ × |
+ √ |
+
+
+ | 白名单 |
+ × |
+ √ |
+
+
+ | 审计日志 |
+ × |
+ √ |
+
+
+ | 配套工具 |
+ 可视化控制台 |
+ × |
+ √ |
+
+
+ | 集群管理工具 |
+ × |
+ √ |
+
+
+ | 系统监控工具 |
+ × |
+ √ |
+
+
+ | 国产化 |
+ 国产化兼容性认证 |
+ × |
+ √ |
+
+
+ | 技术支持 |
+ 最佳实践 |
+ × |
+ √ |
+
+
+ | 使用培训 |
+ × |
+ √ |
+
+
+
+
+### 更高效/稳定的产品性能
+
+TimechoDB 在开源版的基础上优化了稳定性与性能,经过企业版技术支持,能够实现10倍以上性能提升,并具有故障及时恢复的性能优势。
+
+### 更用户友好的工具体系
+
+TimechoDB 将为用户提供更简单、易用的工具体系,通过集群监控面板(IoTDB Grafana)、数据库控制台(IoTDB Workbench)、集群管理工具(IoTDB Deploy Tool,简称 IoTD)等产品帮助用户快速部署、管理、监控数据库集群,降低运维人员工作/学习成本,简化数据库运维工作,使运维过程更加方便、快捷。
+
+- 集群监控面板:旨在解决 IoTDB 及其所在操作系统的监控问题,主要包括:操作系统资源监控、IoTDB 性能监控,及上百项内核监控指标,从而帮助用户监控集群健康状态,并进行集群调优和运维。
+
+
+
总体概览
+
操作系统资源监控
+
IoTDB 性能监控
+
+

+
1. SequenceStrategy:IoTDB 按顺序选择目录,依次遍历 data_dirs 中的所有目录,并不断轮循;
2. MaxDiskUsableSpaceFirstStrategy:IoTDB 优先选择 data_dirs 中对应磁盘空余空间最大的目录;
您可以通过以下方法完成用户自定义策略:
1. 继承 org.apache.iotdb.db.storageengine.rescon.disk.strategy.DirectoryStrategy 类并实现自身的 Strategy 方法;
2. 将实现的类的完整类名(包名加类名,UserDefineStrategyPackage)填写到该配置项;
3. 将该类 jar 包添加到工程中。 |
+| 类型 | String |
+| 默认值 | SequenceStrategy |
+| 改后生效方式 | 热加载 |
+
+- dn_consensus_dir
+
+| 名字 | dn_consensus_dir |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTDB 共识层日志存储路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/consensus(Windows:data\\datanode\\consensus) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_wal_dirs
+
+| 名字 | dn_wal_dirs |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTDB 写前日志存储路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/wal(Windows:data\\datanode\\wal) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_tracing_dir
+
+| 名字 | dn_tracing_dir |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTDB 追踪根目录路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。 |
+| 类型 | String |
+| 默认值 | datanode/tracing(Windows:datanode\\tracing) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_sync_dir
+
+| 名字 | dn_sync_dir |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTDB sync 存储路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/sync(Windows:data\\datanode\\sync) |
+| 改后生效方式 | 重启服务生效 |
+
+- sort_tmp_dir
+
+| 名字 | sort_tmp_dir |
+| ------------ | ------------------------------------------------- |
+| 描述 | 用于配置排序操作的临时目录。 |
+| 类型 | String |
+| 默认值 | data/datanode/tmp(Windows:data\\datanode\\tmp) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_pipe_receiver_file_dirs
+
+| 名字 | dn_pipe_receiver_file_dirs |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | DataNode中pipe接收者用于存储文件的目录路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/system/pipe/receiver(Windows:data\\datanode\\system\\pipe\\receiver) |
+| 改后生效方式 | 重启服务生效 |
+
+- iot_consensus_v2_receiver_file_dirs
+
+| 名字 | iot_consensus_v2_receiver_file_dirs |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTConsensus V2中接收者用于存储文件的目录路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/system/pipe/consensus/receiver(Windows:data\\datanode\\system\\pipe\\consensus\\receiver) |
+| 改后生效方式 | 重启服务生效 |
+
+- iot_consensus_v2_deletion_file_dir
+
+| 名字 | iot_consensus_v2_deletion_file_dir |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTConsensus V2中删除操作用于存储文件的目录路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/system/pipe/consensus/deletion(Windows:data\\datanode\\system\\pipe\\consensus\\deletion) |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.6 监控配置
+
+- cn_metric_reporter_list
+
+| 名字 | cn_metric_reporter_list |
+| ------------ | -------------------------------------------------- |
+| 描述 | confignode中用于配置监控模块的数据需要报告的系统。 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_metric_level
+
+| 名字 | cn_metric_level |
+| ------------ | ------------------------------------------ |
+| 描述 | confignode中控制监控模块收集数据的详细程度 |
+| 类型 | String |
+| 默认值 | IMPORTANT |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_metric_async_collect_period
+
+| 名字 | cn_metric_async_collect_period |
+| ------------ | -------------------------------------------------- |
+| 描述 | confignode中某些监控数据异步收集的周期,单位是秒。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_metric_prometheus_reporter_port
+
+| 名字 | cn_metric_prometheus_reporter_port |
+| ------------ | ------------------------------------------------------ |
+| 描述 | confignode中Prometheus报告者用于监控数据报告的端口号。 |
+| 类型 | int |
+| 默认值 | 9091 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_reporter_list
+
+| 名字 | dn_metric_reporter_list |
+| ------------ | ------------------------------------------------ |
+| 描述 | DataNode中用于配置监控模块的数据需要报告的系统。 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_level
+
+| 名字 | dn_metric_level |
+| ------------ | ---------------------------------------- |
+| 描述 | DataNode中控制监控模块收集数据的详细程度 |
+| 类型 | String |
+| 默认值 | IMPORTANT |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_async_collect_period
+
+| 名字 | dn_metric_async_collect_period |
+| ------------ | ------------------------------------------------ |
+| 描述 | DataNode中某些监控数据异步收集的周期,单位是秒。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_prometheus_reporter_port
+
+| 名字 | dn_metric_prometheus_reporter_port |
+| ------------ | ---------------------------------------------------- |
+| 描述 | DataNode中Prometheus报告者用于监控数据报告的端口号。 |
+| 类型 | int |
+| 默认值 | 9092 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_internal_reporter_type
+
+| 名字 | dn_metric_internal_reporter_type |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | DataNode中监控模块内部报告者的种类,用于内部监控和检查数据是否已经成功写入和刷新。 |
+| 类型 | String |
+| 默认值 | IOTDB |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.7 SSL 配置
+
+- enable_thrift_ssl
+
+| 名字 | enable_thrift_ssl |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当enable_thrift_ssl配置为true时,将通过dn_rpc_port使用 SSL 加密进行通信 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_https
+
+| 名字 | enable_https |
+| ------------ | ------------------------------ |
+| 描述 | REST Service 是否开启 SSL 配置 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- key_store_path
+
+| 名字 | key_store_path |
+| ------------ | -------------- |
+| 描述 | ssl证书路径 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- key_store_pwd
+
+| 名字 | key_store_pwd |
+| ------------ | ------------- |
+| 描述 | ssl证书密码 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.8 连接配置
+
+- cn_rpc_thrift_compression_enable
+
+| 名字 | cn_rpc_thrift_compression_enable |
+| ------------ | -------------------------------- |
+| 描述 | 是否启用 thrift 的压缩机制。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_rpc_max_concurrent_client_num
+
+| 名字 | cn_rpc_max_concurrent_client_num |
+| ------------ | -------------------------------- |
+| 描述 | 最大连接数。 |
+| 类型 | Short Int : [0,65535] |
+| 默认值 | 65535 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_connection_timeout_ms
+
+| 名字 | cn_connection_timeout_ms |
+| ------------ | ------------------------ |
+| 描述 | 节点连接超时时间 |
+| 类型 | int |
+| 默认值 | 60000 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_selector_thread_nums_of_client_manager
+
+| 名字 | cn_selector_thread_nums_of_client_manager |
+| ------------ | ----------------------------------------- |
+| 描述 | 客户端异步线程管理的选择器线程数量 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_max_client_count_for_each_node_in_client_manager
+
+| 名字 | cn_max_client_count_for_each_node_in_client_manager |
+| ------------ | --------------------------------------------------- |
+| 描述 | 单 ClientManager 中路由到每个节点的最大 Client 个数 |
+| 类型 | int |
+| 默认值 | 300 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_session_timeout_threshold
+
+| 名字 | dn_session_timeout_threshold |
+| ------------ | ---------------------------- |
+| 描述 | 最大的会话空闲时间 |
+| 类型 | int |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_thrift_compression_enable
+
+| 名字 | dn_rpc_thrift_compression_enable |
+| ------------ | -------------------------------- |
+| 描述 | 是否启用 thrift 的压缩机制 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_advanced_compression_enable
+
+| 名字 | dn_rpc_advanced_compression_enable |
+| ------------ | ---------------------------------- |
+| 描述 | 是否启用 thrift 的自定制压缩机制 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_selector_thread_count
+
+| 名字 | rpc_selector_thread_count |
+| ------------ | ------------------------- |
+| 描述 | rpc 选择器线程数量 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_min_concurrent_client_num
+
+| 名字 | rpc_min_concurrent_client_num |
+| ------------ | ----------------------------- |
+| 描述 | 最小连接数 |
+| 类型 | Short Int : [0,65535] |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_max_concurrent_client_num
+
+| 名字 | dn_rpc_max_concurrent_client_num |
+| ------------ | -------------------------------- |
+| 描述 | 最大连接数 |
+| 类型 | Short Int : [0,65535] |
+| 默认值 | 65535 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_thrift_max_frame_size
+
+| 名字 | dn_thrift_max_frame_size |
+| ------------ | ------------------------------------------------------ |
+| 描述 | RPC 请求/响应的最大字节数 |
+| 类型 | long |
+| 默认值 | 536870912 (默认值512MB,应大于等于 512 * 1024 * 1024) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_thrift_init_buffer_size
+
+| 名字 | dn_thrift_init_buffer_size |
+| ------------ | -------------------------- |
+| 描述 | 字节数 |
+| 类型 | long |
+| 默认值 | 1024 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_connection_timeout_ms
+
+| 名字 | dn_connection_timeout_ms |
+| ------------ | ------------------------ |
+| 描述 | 节点连接超时时间 |
+| 类型 | int |
+| 默认值 | 60000 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_selector_thread_count_of_client_manager
+
+| 名字 | dn_selector_thread_count_of_client_manager |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | selector thread (TAsyncClientManager) nums for async thread in a clientManagerclientManager中异步线程的选择器线程(TAsyncClientManager)编号 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_max_client_count_for_each_node_in_client_manager
+
+| 名字 | dn_max_client_count_for_each_node_in_client_manager |
+| ------------ | --------------------------------------------------- |
+| 描述 | 单 ClientManager 中路由到每个节点的最大 Client 个数 |
+| 类型 | int |
+| 默认值 | 300 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.9 对象存储管理
+
+- remote_tsfile_cache_dirs
+
+| 名字 | remote_tsfile_cache_dirs |
+| ------------ | ------------------------ |
+| 描述 | 云端存储在本地的缓存目录 |
+| 类型 | String |
+| 默认值 | data/datanode/data/cache |
+| 改后生效方式 | 重启服务生效 |
+
+- remote_tsfile_cache_page_size_in_kb
+
+| 名字 | remote_tsfile_cache_page_size_in_kb |
+| ------------ | ----------------------------------- |
+| 描述 | 云端存储在本地缓存文件的块大小 |
+| 类型 | int |
+| 默认值 | 20480 |
+| 改后生效方式 | 重启服务生效 |
+
+- remote_tsfile_cache_max_disk_usage_in_mb
+
+| 名字 | remote_tsfile_cache_max_disk_usage_in_mb |
+| ------------ | ---------------------------------------- |
+| 描述 | 云端存储本地缓存的最大磁盘占用大小 |
+| 类型 | long |
+| 默认值 | 51200 |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_type
+
+| 名字 | object_storage_type |
+| ------------ | ------------------- |
+| 描述 | 云端存储类型 |
+| 类型 | String |
+| 默认值 | AWS_S3 |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_endpoint
+
+| 名字 | object_storage_endpoint |
+| ------------ | ----------------------- |
+| 描述 | 云端存储的 endpoint |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_bucket
+
+| 名字 | object_storage_bucket |
+| ------------ | ---------------------- |
+| 描述 | 云端存储 bucket 的名称 |
+| 类型 | String |
+| 默认值 | iotdb_data |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_access_key
+
+| 名字 | object_storage_access_key |
+| ------------ | ------------------------- |
+| 描述 | 云端存储的验证信息 key |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_access_secret
+
+| 名字 | object_storage_access_secret |
+| ------------ | ---------------------------- |
+| 描述 | 云端存储的验证信息 secret |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.10 多级管理
+
+- dn_default_space_usage_thresholds
+
+| 名字 | dn_default_space_usage_thresholds |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 定义每个层级数据目录的最小剩余空间比例;当剩余空间少于该比例时,数据会被自动迁移至下一个层级;当最后一个层级的剩余存储空间到低于此阈值时,会将系统置为 READ_ONLY |
+| 类型 | double |
+| 默认值 | 0.85 |
+| 改后生效方式 | 热加载 |
+
+- dn_tier_full_policy
+
+| 名字 | dn_tier_full_policy |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 如何处理最后一层数据,当其已用空间高于其dn_default_space_usage_threshold时。 |
+| 类型 | String |
+| 默认值 | NULL |
+| 改后生效方式 | 热加载 |
+
+- migrate_thread_count
+
+| 名字 | migrate_thread_count |
+| ------------ | ---------------------------------------- |
+| 描述 | DataNode数据目录中迁移操作的线程池大小。 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 热加载 |
+
+- tiered_storage_migrate_speed_limit_bytes_per_sec
+
+| 名字 | tiered_storage_migrate_speed_limit_bytes_per_sec |
+| ------------ | ------------------------------------------------ |
+| 描述 | 限制不同存储层级之间的数据迁移速度。 |
+| 类型 | int |
+| 默认值 | 10485760 |
+| 改后生效方式 | 热加载 |
+
+### 3.11 REST服务配置
+
+- enable_rest_service
+
+| 名字 | enable_rest_service |
+| ------------ | ------------------- |
+| 描述 | 是否开启Rest服务。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- rest_service_port
+
+| 名字 | rest_service_port |
+| ------------ | ------------------ |
+| 描述 | Rest服务监听端口号 |
+| 类型 | int32 |
+| 默认值 | 18080 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_swagger
+
+| 名字 | enable_swagger |
+| ------------ | --------------------------------- |
+| 描述 | 是否启用swagger来展示rest接口信息 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- rest_query_default_row_size_limit
+
+| 名字 | rest_query_default_row_size_limit |
+| ------------ | --------------------------------- |
+| 描述 | 一次查询能返回的结果集最大行数 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- cache_expire_in_seconds
+
+| 名字 | cache_expire_in_seconds |
+| ------------ | -------------------------------- |
+| 描述 | 用户登录信息缓存的过期时间(秒) |
+| 类型 | int32 |
+| 默认值 | 28800 |
+| 改后生效方式 | 重启服务生效 |
+
+- cache_max_num
+
+| 名字 | cache_max_num |
+| ------------ | ------------------------ |
+| 描述 | 缓存中存储的最大用户数量 |
+| 类型 | int32 |
+| 默认值 | 100 |
+| 改后生效方式 | 重启服务生效 |
+
+- cache_init_num
+
+| 名字 | cache_init_num |
+| ------------ | -------------- |
+| 描述 | 缓存初始容量 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- client_auth
+
+| 名字 | client_auth |
+| ------------ | ---------------------- |
+| 描述 | 是否需要客户端身份验证 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- trust_store_path
+
+| 名字 | trust_store_path |
+| ------------ | ----------------------- |
+| 描述 | keyStore 密码(非必填) |
+| 类型 | String |
+| 默认值 | "" |
+| 改后生效方式 | 重启服务生效 |
+
+- trust_store_pwd
+
+| 名字 | trust_store_pwd |
+| ------------ | ------------------------- |
+| 描述 | trustStore 密码(非必填) |
+| 类型 | String |
+| 默认值 | "" |
+| 改后生效方式 | 重启服务生效 |
+
+- idle_timeout_in_seconds
+
+| 名字 | idle_timeout_in_seconds |
+| ------------ | ----------------------- |
+| 描述 | SSL 超时时间,单位为秒 |
+| 类型 | int32 |
+| 默认值 | 5000 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.12 负载均衡配置
+
+- series_slot_num
+
+| 名字 | series_slot_num |
+| ------------ | ---------------------------- |
+| 描述 | 序列分区槽数 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- series_partition_executor_class
+
+| 名字 | series_partition_executor_class |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 序列分区哈希函数 |
+| 类型 | String |
+| 默认值 | org.apache.iotdb.commons.partition.executor.hash.BKDRHashExecutor |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- schema_region_group_extension_policy
+
+| 名字 | schema_region_group_extension_policy |
+| ------------ | ------------------------------------ |
+| 描述 | SchemaRegionGroup 的扩容策略 |
+| 类型 | string |
+| 默认值 | AUTO |
+| 改后生效方式 | 重启服务生效 |
+
+- default_schema_region_group_num_per_database
+
+| 名字 | default_schema_region_group_num_per_database |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当选用 CUSTOM-SchemaRegionGroup 扩容策略时,此参数为每个 Database 拥有的 SchemaRegionGroup 数量;当选用 AUTO-SchemaRegionGroup 扩容策略时,此参数为每个 Database 最少拥有的 SchemaRegionGroup 数量 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_per_data_node
+
+| 名字 | schema_region_per_data_node |
+| ------------ | -------------------------------------------------- |
+| 描述 | 期望每个 DataNode 可管理的 SchemaRegion 的最大数量 |
+| 类型 | double |
+| 默认值 | 1.0 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_group_extension_policy
+
+| 名字 | data_region_group_extension_policy |
+| ------------ | ---------------------------------- |
+| 描述 | DataRegionGroup 的扩容策略 |
+| 类型 | string |
+| 默认值 | AUTO |
+| 改后生效方式 | 重启服务生效 |
+
+- default_data_region_group_num_per_database
+
+| 名字 | default_data_region_group_per_database |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当选用 CUSTOM-DataRegionGroup 扩容策略时,此参数为每个 Database 拥有的 DataRegionGroup 数量;当选用 AUTO-DataRegionGroup 扩容策略时,此参数为每个 Database 最少拥有的 DataRegionGroup 数量 |
+| 类型 | int |
+| 默认值 | 2 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_per_data_node
+
+| 名字 | data_region_per_data_node |
+| ------------ | ------------------------------------------------ |
+| 描述 | 期望每个 DataNode 可管理的 DataRegion 的最大数量 |
+| 类型 | double |
+| 默认值 | 5.0 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_auto_leader_balance_for_ratis_consensus
+
+| 名字 | enable_auto_leader_balance_for_ratis_consensus |
+| ------------ | ---------------------------------------------- |
+| 描述 | 是否为 Ratis 共识协议开启自动均衡 leader 策略 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_auto_leader_balance_for_iot_consensus
+
+| 名字 | enable_auto_leader_balance_for_iot_consensus |
+| ------------ | -------------------------------------------- |
+| 描述 | 是否为 IoT 共识协议开启自动均衡 leader 策略 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.13 集群管理
+
+- time_partition_origin
+
+| 名字 | time_partition_origin |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | Database 数据时间分区的起始点,即从哪个时间点开始计算时间分区。 |
+| 类型 | Long |
+| 单位 | 毫秒 |
+| 默认值 | 0 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- time_partition_interval
+
+| 名字 | time_partition_interval |
+| ------------ | ------------------------------- |
+| 描述 | Database 默认的数据时间分区间隔 |
+| 类型 | Long |
+| 单位 | 毫秒 |
+| 默认值 | 604800000 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- heartbeat_interval_in_ms
+
+| 名字 | heartbeat_interval_in_ms |
+| ------------ | ------------------------ |
+| 描述 | 集群节点间的心跳间隔 |
+| 类型 | Long |
+| 单位 | ms |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- disk_space_warning_threshold
+
+| 名字 | disk_space_warning_threshold |
+| ------------ | ---------------------------- |
+| 描述 | DataNode 磁盘剩余阈值 |
+| 类型 | double(percentage) |
+| 默认值 | 0.05 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.14 内存控制配置
+
+- datanode_memory_proportion
+
+| 名字 | datanode_memory_proportion |
+| ------------ | ---------------------------------------------------- |
+| 描述 | 存储,查询,元数据,流处理引擎,共识层,空闲内存比例 |
+| 类型 | Ratio |
+| 默认值 | 3:3:1:1:1:1 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_memory_proportion
+
+| 名字 | schema_memory_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | Schema 相关的内存如何在 SchemaRegion、SchemaCache 和 PartitionCache 之间分配 |
+| 类型 | Ratio |
+| 默认值 | 5:4:1 |
+| 改后生效方式 | 重启服务生效 |
+
+- storage_engine_memory_proportion
+
+| 名字 | storage_engine_memory_proportion |
+| ------------ | -------------------------------- |
+| 描述 | 写入和合并占存储内存比例 |
+| 类型 | Ratio |
+| 默认值 | 8:2 |
+| 改后生效方式 | 重启服务生效 |
+
+- write_memory_proportion
+
+| 名字 | write_memory_proportion |
+| ------------ | -------------------------------------------- |
+| 描述 | Memtable 和 TimePartitionInfo 占写入内存比例 |
+| 类型 | Ratio |
+| 默认值 | 19:1 |
+| 改后生效方式 | 重启服务生效 |
+
+- primitive_array_size
+
+| 名字 | primitive_array_size |
+| ------------ | ---------------------------------------- |
+| 描述 | 数组池中的原始数组大小(每个数组的长度) |
+| 类型 | int32 |
+| 默认值 | 64 |
+| 改后生效方式 | 重启服务生效 |
+
+- chunk_metadata_size_proportion
+
+| 名字 | chunk_metadata_size_proportion |
+| ------------ | -------------------------------------------- |
+| 描述 | 在数据压缩过程中,用于存储块元数据的内存比例 |
+| 类型 | Double |
+| 默认值 | 0.1 |
+| 改后生效方式 | 重启服务生效 |
+
+- flush_proportion
+
+| 名字 | flush_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 调用flush disk的写入内存比例,默认0.4,若有极高的写入负载力(比如batch=1000),可以设置为低于默认值,比如0.2 |
+| 类型 | Double |
+| 默认值 | 0.4 |
+| 改后生效方式 | 重启服务生效 |
+
+- buffered_arrays_memory_proportion
+
+| 名字 | buffered_arrays_memory_proportion |
+| ------------ | --------------------------------------- |
+| 描述 | 为缓冲数组分配的写入内存比例,默认为0.6 |
+| 类型 | Double |
+| 默认值 | 0.6 |
+| 改后生效方式 | 重启服务生效 |
+
+- reject_proportion
+
+| 名字 | reject_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 拒绝插入的写入内存比例,默认0.8,若有极高的写入负载力(比如batch=1000)并且物理内存足够大,它可以设置为高于默认值,如0.9 |
+| 类型 | Double |
+| 默认值 | 0.8 |
+| 改后生效方式 | 重启服务生效 |
+
+- device_path_cache_proportion
+
+| 名字 | device_path_cache_proportion |
+| ------------ | --------------------------------------------------- |
+| 描述 | 在内存中分配给设备路径缓存(DevicePathCache)的比例 |
+| 类型 | Double |
+| 默认值 | 0.05 |
+| 改后生效方式 | 重启服务生效 |
+
+- write_memory_variation_report_proportion
+
+| 名字 | write_memory_variation_report_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 如果 DataRegion 的内存增加超过写入可用内存的一定比例,则向系统报告。默认值为0.001 |
+| 类型 | Double |
+| 默认值 | 0.001 |
+| 改后生效方式 | 重启服务生效 |
+
+- check_period_when_insert_blocked
+
+| 名字 | check_period_when_insert_blocked |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当插入被拒绝时,等待时间(以毫秒为单位)去再次检查系统,默认为50。若插入被拒绝,读取负载低,可以设置大一些。 |
+| 类型 | int32 |
+| 默认值 | 50 |
+| 改后生效方式 | 重启服务生效 |
+
+- io_task_queue_size_for_flushing
+
+| 名字 | io_task_queue_size_for_flushing |
+| ------------ | -------------------------------- |
+| 描述 | ioTaskQueue 的大小。默认值为10。 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_query_memory_estimation
+
+| 名字 | enable_query_memory_estimation |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 开启后会预估每次查询的内存使用量,如果超过可用内存,会拒绝本次查询 |
+| 类型 | bool |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+### 3.15 元数据引擎配置
+
+- schema_engine_mode
+
+| 名字 | schema_engine_mode |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 元数据引擎的运行模式,支持 Memory 和 PBTree;PBTree 模式下支持将内存中暂时不用的序列元数据实时置换到磁盘上,需要使用时再加载进内存;此参数在集群中所有的 DataNode 上务必保持相同。 |
+| 类型 | string |
+| 默认值 | Memory |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- partition_cache_size
+
+| 名字 | partition_cache_size |
+| ------------ | ------------------------------ |
+| 描述 | 分区信息缓存的最大缓存条目数。 |
+| 类型 | Int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- sync_mlog_period_in_ms
+
+| 名字 | sync_mlog_period_in_ms |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | mlog定期刷新到磁盘的周期,单位毫秒。如果该参数为0,则表示每次对元数据的更新操作都会被立即写到磁盘上。 |
+| 类型 | Int64 |
+| 默认值 | 100 |
+| 改后生效方式 | 重启服务生效 |
+
+- tag_attribute_flush_interval
+
+| 名字 | tag_attribute_flush_interval |
+| ------------ | -------------------------------------------------- |
+| 描述 | 标签和属性记录的间隔数,达到此记录数量时将强制刷盘 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- tag_attribute_total_size
+
+| 名字 | tag_attribute_total_size |
+| ------------ | ---------------------------------------- |
+| 描述 | 每个时间序列标签和属性的最大持久化字节数 |
+| 类型 | int32 |
+| 默认值 | 700 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- max_measurement_num_of_internal_request
+
+| 名字 | max_measurement_num_of_internal_request |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 一次注册序列请求中若物理量过多,在系统内部执行时将被拆分为若干个轻量级的子请求,每个子请求中的物理量数目不超过此参数设置的最大值。 |
+| 类型 | Int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- datanode_schema_cache_eviction_policy
+
+| 名字 | datanode_schema_cache_eviction_policy |
+| ------------ | ----------------------------------------------------- |
+| 描述 | 当 Schema 缓存达到其最大容量时,Schema 缓存的淘汰策略 |
+| 类型 | String |
+| 默认值 | FIFO |
+| 改后生效方式 | 重启服务生效 |
+
+- cluster_timeseries_limit_threshold
+
+| 名字 | cluster_timeseries_limit_threshold |
+| ------------ | ---------------------------------- |
+| 描述 | 集群中可以创建的时间序列的最大数量 |
+| 类型 | Int32 |
+| 默认值 | -1 |
+| 改后生效方式 | 重启服务生效 |
+
+- cluster_device_limit_threshold
+
+| 名字 | cluster_device_limit_threshold |
+| ------------ | ------------------------------ |
+| 描述 | 集群中可以创建的最大设备数量 |
+| 类型 | Int32 |
+| 默认值 | -1 |
+| 改后生效方式 | 重启服务生效 |
+
+- database_limit_threshold
+
+| 名字 | database_limit_threshold |
+| ------------ | ------------------------------ |
+| 描述 | 集群中可以创建的最大数据库数量 |
+| 类型 | Int32 |
+| 默认值 | -1 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.16 自动推断数据类型
+
+- enable_auto_create_schema
+
+| 名字 | enable_auto_create_schema |
+| ------------ | -------------------------------------- |
+| 描述 | 当写入的序列不存在时,是否自动创建序列 |
+| 取值 | true or false |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- default_storage_group_level
+
+| 名字 | default_storage_group_level |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当写入的数据不存在且自动创建序列时,若需要创建相应的 database,将序列路径的哪一层当做 database。例如,如果我们接到一个新序列 root.sg0.d1.s2, 并且 level=1, 那么 root.sg0 被视为database(因为 root 是 level 0 层) |
+| 取值 | int32 |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- boolean_string_infer_type
+
+| 名字 | boolean_string_infer_type |
+| ------------ | ------------------------------------------ |
+| 描述 | "true" 或者 "false" 字符串被推断的数据类型 |
+| 取值 | BOOLEAN 或者 TEXT |
+| 默认值 | BOOLEAN |
+| 改后生效方式 | 重启服务生效 |
+
+- integer_string_infer_type
+
+| 名字 | integer_string_infer_type |
+| ------------ | --------------------------------- |
+| 描述 | 整型字符串推断的数据类型 |
+| 取值 | INT32, INT64, FLOAT, DOUBLE, TEXT |
+| 默认值 | DOUBLE |
+| 改后生效方式 | 重启服务生效 |
+
+- floating_string_infer_type
+
+| 名字 | floating_string_infer_type |
+| ------------ | ----------------------------- |
+| 描述 | "6.7"等字符串被推断的数据类型 |
+| 取值 | DOUBLE, FLOAT or TEXT |
+| 默认值 | DOUBLE |
+| 改后生效方式 | 重启服务生效 |
+
+- nan_string_infer_type
+
+| 名字 | nan_string_infer_type |
+| ------------ | ---------------------------- |
+| 描述 | "NaN" 字符串被推断的数据类型 |
+| 取值 | DOUBLE, FLOAT or TEXT |
+| 默认值 | DOUBLE |
+| 改后生效方式 | 重启服务生效 |
+
+- default_boolean_encoding
+
+| 名字 | default_boolean_encoding |
+| ------------ | ------------------------ |
+| 描述 | BOOLEAN 类型编码格式 |
+| 取值 | PLAIN, RLE |
+| 默认值 | RLE |
+| 改后生效方式 | 重启服务生效 |
+
+- default_int32_encoding
+
+| 名字 | default_int32_encoding |
+| ------------ | -------------------------------------- |
+| 描述 | int32 类型编码格式 |
+| 取值 | PLAIN, RLE, TS_2DIFF, REGULAR, GORILLA |
+| 默认值 | TS_2DIFF |
+| 改后生效方式 | 重启服务生效 |
+
+- default_int64_encoding
+
+| 名字 | default_int64_encoding |
+| ------------ | -------------------------------------- |
+| 描述 | int64 类型编码格式 |
+| 取值 | PLAIN, RLE, TS_2DIFF, REGULAR, GORILLA |
+| 默认值 | TS_2DIFF |
+| 改后生效方式 | 重启服务生效 |
+
+- default_float_encoding
+
+| 名字 | default_float_encoding |
+| ------------ | ----------------------------- |
+| 描述 | float 类型编码格式 |
+| 取值 | PLAIN, RLE, TS_2DIFF, GORILLA |
+| 默认值 | GORILLA |
+| 改后生效方式 | 重启服务生效 |
+
+- default_double_encoding
+
+| 名字 | default_double_encoding |
+| ------------ | ----------------------------- |
+| 描述 | double 类型编码格式 |
+| 取值 | PLAIN, RLE, TS_2DIFF, GORILLA |
+| 默认值 | GORILLA |
+| 改后生效方式 | 重启服务生效 |
+
+- default_text_encoding
+
+| 名字 | default_text_encoding |
+| ------------ | --------------------- |
+| 描述 | text 类型编码格式 |
+| 取值 | PLAIN |
+| 默认值 | PLAIN |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.17 查询配置
+
+- read_consistency_level
+
+| 名字 | read_consistency_level |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 查询一致性等级,取值 “strong” 时从 Leader 副本查询,取值 “weak” 时随机查询一个副本。 |
+| 类型 | String |
+| 默认值 | strong |
+| 改后生效方式 | 重启服务生效 |
+
+- meta_data_cache_enable
+
+| 名字 | meta_data_cache_enable |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 是否缓存元数据(包括 BloomFilter、Chunk Metadata 和 TimeSeries Metadata。) |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- chunk_timeseriesmeta_free_memory_proportion
+
+| 名字 | chunk_timeseriesmeta_free_memory_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 读取内存分配比例,BloomFilterCache、ChunkCache、TimeseriesMetadataCache、数据集查询的内存和可用内存的查询。参数形式为a : b : c : d : e,其中a、b、c、d、e为整数。 例如“1 : 1 : 1 : 1 : 1” ,“1 : 100 : 200 : 300 : 400” 。 |
+| 类型 | String |
+| 默认值 | 1 : 100 : 200 : 300 : 400 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_last_cache
+
+| 名字 | enable_last_cache |
+| ------------ | ------------------ |
+| 描述 | 是否开启最新点缓存 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- mpp_data_exchange_core_pool_size
+
+| 名字 | mpp_data_exchange_core_pool_size |
+| ------------ | -------------------------------- |
+| 描述 | MPP 数据交换线程池核心线程数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- mpp_data_exchange_max_pool_size
+
+| 名字 | mpp_data_exchange_max_pool_size |
+| ------------ | ------------------------------- |
+| 描述 | MPP 数据交换线程池最大线程数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- mpp_data_exchange_keep_alive_time_in_ms
+
+| 名字 | mpp_data_exchange_keep_alive_time_in_ms |
+| ------------ | --------------------------------------- |
+| 描述 | MPP 数据交换最大等待时间 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- driver_task_execution_time_slice_in_ms
+
+| 名字 | driver_task_execution_time_slice_in_ms |
+| ------------ | -------------------------------------- |
+| 描述 | 单个 DriverTask 最长执行时间(ms) |
+| 类型 | int32 |
+| 默认值 | 200 |
+| 改后生效方式 | 重启服务生效 |
+
+- max_tsblock_size_in_bytes
+
+| 名字 | max_tsblock_size_in_bytes |
+| ------------ | ------------------------------- |
+| 描述 | 单个 TsBlock 的最大容量(byte) |
+| 类型 | int32 |
+| 默认值 | 131072 |
+| 改后生效方式 | 重启服务生效 |
+
+- max_tsblock_line_numbers
+
+| 名字 | max_tsblock_line_numbers |
+| ------------ | ------------------------ |
+| 描述 | 单个 TsBlock 的最大行数 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- slow_query_threshold
+
+| 名字 | slow_query_threshold |
+| ------------ | ------------------------------ |
+| 描述 | 慢查询的时间阈值。单位:毫秒。 |
+| 类型 | long |
+| 默认值 | 10000 |
+| 改后生效方式 | 热加载 |
+
+- query_timeout_threshold
+
+| 名字 | query_timeout_threshold |
+| ------------ | -------------------------------- |
+| 描述 | 查询的最大执行时间。单位:毫秒。 |
+| 类型 | Int32 |
+| 默认值 | 60000 |
+| 改后生效方式 | 重启服务生效 |
+
+- max_allowed_concurrent_queries
+
+| 名字 | max_allowed_concurrent_queries |
+| ------------ | ------------------------------ |
+| 描述 | 允许的最大并发查询数量。 |
+| 类型 | Int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- query_thread_count
+
+| 名字 | query_thread_count |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当 IoTDB 对内存中的数据进行查询时,最多启动多少个线程来执行该操作。如果该值小于等于 0,那么采用机器所安装的 CPU 核的数量。 |
+| 类型 | Int32 |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- degree_of_query_parallelism
+
+| 名字 | degree_of_query_parallelism |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 设置单个查询片段实例将创建的 pipeline 驱动程序数量,也就是查询操作的并行度。 |
+| 类型 | Int32 |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- mode_map_size_threshold
+
+| 名字 | mode_map_size_threshold |
+| ------------ | ---------------------------------------------- |
+| 描述 | 计算 MODE 聚合函数时,计数映射可以增长到的阈值 |
+| 类型 | Int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- batch_size
+
+| 名字 | batch_size |
+| ------------ | ---------------------------------------------------------- |
+| 描述 | 服务器中每次迭代的数据量(数据条目,即不同时间戳的数量。) |
+| 类型 | Int32 |
+| 默认值 | 100000 |
+| 改后生效方式 | 重启服务生效 |
+
+- sort_buffer_size_in_bytes
+
+| 名字 | sort_buffer_size_in_bytes |
+| ------------ | -------------------------------------- |
+| 描述 | 设置外部排序操作中使用的内存缓冲区大小 |
+| 类型 | long |
+| 默认值 | 1048576 |
+| 改后生效方式 | 重启服务生效 |
+
+- merge_threshold_of_explain_analyze
+
+| 名字 | merge_threshold_of_explain_analyze |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 用于设置在 `EXPLAIN ANALYZE` 语句的结果集中操作符(operator)数量的合并阈值。 |
+| 类型 | int |
+| 默认值 | 10 |
+| 改后生效方式 | 热加载 |
+
+### 3.18 TTL配置
+
+- ttl_check_interval
+
+| 名字 | ttl_check_interval |
+| ------------ | -------------------------------------- |
+| 描述 | ttl 检查任务的间隔,单位 ms,默认为 2h |
+| 类型 | int |
+| 默认值 | 7200000 |
+| 改后生效方式 | 重启服务生效 |
+
+- max_expired_time
+
+| 名字 | max_expired_time |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 如果一个文件中存在设备已经过期超过此时间,那么这个文件将被立即整理。单位 ms,默认为一个月 |
+| 类型 | int |
+| 默认值 | 2592000000 |
+| 改后生效方式 | 重启服务生效 |
+
+- expired_data_ratio
+
+| 名字 | expired_data_ratio |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 过期设备比例。如果一个文件中过期设备的比率超过这个值,那么这个文件中的过期数据将通过 compaction 清理。 |
+| 类型 | float |
+| 默认值 | 0.3 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.19 存储引擎配置
+
+- timestamp_precision
+
+| 名字 | timestamp_precision |
+| ------------ | ---------------------------- |
+| 描述 | 时间戳精度,支持 ms、us、ns |
+| 类型 | String |
+| 默认值 | ms |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- timestamp_precision_check_enabled
+
+| 名字 | timestamp_precision_check_enabled |
+| ------------ | --------------------------------- |
+| 描述 | 用于控制是否启用时间戳精度检查 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- max_waiting_time_when_insert_blocked
+
+| 名字 | max_waiting_time_when_insert_blocked |
+| ------------ | ----------------------------------------------- |
+| 描述 | 当插入请求等待超过这个时间,则抛出异常,单位 ms |
+| 类型 | Int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- handle_system_error
+
+| 名字 | handle_system_error |
+| ------------ | ------------------------------------ |
+| 描述 | 当系统遇到不可恢复的错误时的处理方法 |
+| 类型 | String |
+| 默认值 | CHANGE_TO_READ_ONLY |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_timed_flush_seq_memtable
+
+| 名字 | enable_timed_flush_seq_memtable |
+| ------------ | ------------------------------- |
+| 描述 | 是否开启定时刷盘顺序 memtable |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- seq_memtable_flush_interval_in_ms
+
+| 名字 | seq_memtable_flush_interval_in_ms |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当 memTable 的创建时间小于当前时间减去该值时,该 memtable 需要被刷盘 |
+| 类型 | long |
+| 默认值 | 600000 |
+| 改后生效方式 | 热加载 |
+
+- seq_memtable_flush_check_interval_in_ms
+
+| 名字 | seq_memtable_flush_check_interval_in_ms |
+| ------------ | ---------------------------------------- |
+| 描述 | 检查顺序 memtable 是否需要刷盘的时间间隔 |
+| 类型 | long |
+| 默认值 | 30000 |
+| 改后生效方式 | 热加载 |
+
+- enable_timed_flush_unseq_memtable
+
+| 名字 | enable_timed_flush_unseq_memtable |
+| ------------ | --------------------------------- |
+| 描述 | 是否开启定时刷新乱序 memtable |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- unseq_memtable_flush_interval_in_ms
+
+| 名字 | unseq_memtable_flush_interval_in_ms |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当 memTable 的创建时间小于当前时间减去该值时,该 memtable 需要被刷盘 |
+| 类型 | long |
+| 默认值 | 600000 |
+| 改后生效方式 | 热加载 |
+
+- unseq_memtable_flush_check_interval_in_ms
+
+| 名字 | unseq_memtable_flush_check_interval_in_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | 检查乱序 memtable 是否需要刷盘的时间间隔 |
+| 类型 | long |
+| 默认值 | 30000 |
+| 改后生效方式 | 热加载 |
+
+- tvlist_sort_algorithm
+
+| 名字 | tvlist_sort_algorithm |
+| ------------ | ------------------------ |
+| 描述 | memtable中数据的排序方法 |
+| 类型 | String |
+| 默认值 | TIM |
+| 改后生效方式 | 重启服务生效 |
+
+- avg_series_point_number_threshold
+
+| 名字 | avg_series_point_number_threshold |
+| ------------ | ------------------------------------------------ |
+| 描述 | 内存中平均每个时间序列点数最大值,达到触发 flush |
+| 类型 | int32 |
+| 默认值 | 100000 |
+| 改后生效方式 | 重启服务生效 |
+
+- flush_thread_count
+
+| 名字 | flush_thread_count |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当 IoTDB 将内存中的数据写入磁盘时,最多启动多少个线程来执行该操作。如果该值小于等于 0,那么采用机器所安装的 CPU 核的数量。默认值为 0。 |
+| 类型 | int32 |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_partial_insert
+
+| 名字 | enable_partial_insert |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在一次 insert 请求中,如果部分测点写入失败,是否继续写入其他测点。 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- recovery_log_interval_in_ms
+
+| 名字 | recovery_log_interval_in_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | data region的恢复过程中打印日志信息的间隔 |
+| 类型 | Int32 |
+| 默认值 | 5000 |
+| 改后生效方式 | 重启服务生效 |
+
+- 0.13_data_insert_adapt
+
+| 名字 | 0.13_data_insert_adapt |
+| ------------ | ------------------------------------------------------- |
+| 描述 | 如果 0.13 版本客户端进行写入,需要将此配置项设置为 true |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_tsfile_validation
+
+| 名字 | enable_tsfile_validation |
+| ------------ | -------------------------------------- |
+| 描述 | Flush, Load 或合并后验证 tsfile 正确性 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 热加载 |
+
+- tier_ttl_in_ms
+
+| 名字 | tier_ttl_in_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | 定义每个层级负责的数据范围,通过 TTL 表示 |
+| 类型 | long |
+| 默认值 | -1 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.20 合并配置
+
+- enable_seq_space_compaction
+
+| 名字 | enable_seq_space_compaction |
+| ------------ | -------------------------------------- |
+| 描述 | 顺序空间内合并,开启顺序文件之间的合并 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- enable_unseq_space_compaction
+
+| 名字 | enable_unseq_space_compaction |
+| ------------ | -------------------------------------- |
+| 描述 | 乱序空间内合并,开启乱序文件之间的合并 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- enable_cross_space_compaction
+
+| 名字 | enable_cross_space_compaction |
+| ------------ | ------------------------------------------ |
+| 描述 | 跨空间合并,开启将乱序文件合并到顺序文件中 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- enable_auto_repair_compaction
+
+| 名字 | enable_auto_repair_compaction |
+| ------------ | ----------------------------- |
+| 描述 | 修复文件的合并任务 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- cross_selector
+
+| 名字 | cross_selector |
+| ------------ | -------------------------- |
+| 描述 | 跨空间合并任务选择器的类型 |
+| 类型 | String |
+| 默认值 | rewrite |
+| 改后生效方式 | 重启服务生效 |
+
+- cross_performer
+
+| 名字 | cross_performer |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 跨空间合并任务执行器的类型,可选项是read_point和fast,默认是read_point,fast还在测试中 |
+| 类型 | String |
+| 默认值 | read_point |
+| 改后生效方式 | 重启服务生效 |
+
+- inner_seq_selector
+
+| 名字 | inner_seq_selector |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 顺序空间内合并任务选择器的类型,可选 size_tiered_single_\target,size_tiered_multi_target |
+| 类型 | String |
+| 默认值 | size_tiered_multi_target |
+| 改后生效方式 | 热加载 |
+
+- inner_seq_performer
+
+| 名字 | inner_seq_performer |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 顺序空间内合并任务执行器的类型,可选项是read_chunk和fast,默认是read_chunk,fast还在测试中 |
+| 类型 | String |
+| 默认值 | read_chunk |
+| 改后生效方式 | 重启服务生效 |
+
+- inner_unseq_selector
+
+| 名字 | inner_unseq_selector |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 乱序空间内合并任务选择器的类型,可选 size_tiered_single_\target,size_tiered_multi_target |
+| 类型 | String |
+| 默认值 | size_tiered_multi_target |
+| 改后生效方式 | 热加载 |
+
+- inner_unseq_performer
+
+| 名字 | inner_unseq_performer |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 乱序空间内合并任务执行器的类型,可选项是read_point和fast,默认是read_point,fast还在测试中 |
+| 类型 | String |
+| 默认值 | read_point |
+| 改后生效方式 | 重启服务生效 |
+
+- compaction_priority
+
+| 名字 | compaction_priority |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 合并时的优先级,BALANCE 各种合并平等,INNER_CROSS 优先进行顺序文件和顺序文件或乱序文件和乱序文件的合并,CROSS_INNER 优先将乱序文件合并到顺序文件中 |
+| 类型 | String |
+| 默认值 | INNER_CROSS |
+| 改后生效方式 | 重启服务生效 |
+
+- candidate_compaction_task_queue_size
+
+| 名字 | candidate_compaction_task_queue_size |
+| ------------ | ------------------------------------ |
+| 描述 | 合并任务优先级队列的大小 |
+| 类型 | int32 |
+| 默认值 | 50 |
+| 改后生效方式 | 重启服务生效 |
+
+- target_compaction_file_size
+
+| 名字 | target_compaction_file_size |
+| ------------ | --------------------------- |
+| 描述 | 合并后的目标文件大小 |
+| 类型 | Int64 |
+| 默认值 | 2147483648 |
+| 改后生效方式 | 热加载 |
+
+- inner_compaction_total_file_size_threshold
+
+| 名字 | inner_compaction_total_file_size_threshold |
+| ------------ | -------------------------------------------- |
+| 描述 | 空间内合并任务最大选中文件总大小,单位:byte |
+| 类型 | int64 |
+| 默认值 | 10737418240 |
+| 改后生效方式 | 热加载 |
+
+- inner_compaction_total_file_num_threshold
+
+| 名字 | inner_compaction_total_file_num_threshold |
+| ------------ | ----------------------------------------- |
+| 描述 | 空间内合并中一次合并最多参与的文件数 |
+| 类型 | int32 |
+| 默认值 | 100 |
+| 改后生效方式 | 热加载 |
+
+- max_level_gap_in_inner_compaction
+
+| 名字 | max_level_gap_in_inner_compaction |
+| ------------ | -------------------------------------- |
+| 描述 | 空间内合并选文件时最大允许跨的文件层级 |
+| 类型 | int32 |
+| 默认值 | 2 |
+| 改后生效方式 | 热加载 |
+
+- target_chunk_size
+
+| 名字 | target_chunk_size |
+| ------------ | ----------------------- |
+| 描述 | 合并时 Chunk 的目标大小 |
+| 类型 | Int64 |
+| 默认值 | 1048576 |
+| 改后生效方式 | 重启服务生效 |
+
+- target_chunk_point_num
+
+| 名字 | target_chunk_point_num |
+| ------------ | ----------------------- |
+| 描述 | 合并时 Chunk 的目标点数 |
+| 类型 | int32 |
+| 默认值 | 100000 |
+| 改后生效方式 | 重启服务生效 |
+
+- chunk_size_lower_bound_in_compaction
+
+| 名字 | chunk_size_lower_bound_in_compaction |
+| ------------ | ----------------------------------------------------- |
+| 描述 | 合并时源 Chunk 的大小小于这个值,将被解开成点进行合并 |
+| 类型 | Int64 |
+| 默认值 | 10240 |
+| 改后生效方式 | 重启服务生效 |
+
+- chunk_point_num_lower_bound_in_compaction
+
+| 名字 | chunk_point_num_lower_bound_in_compaction |
+| ------------ | ----------------------------------------------------- |
+| 描述 | 合并时源 Chunk 的点数小于这个值,将被解开成点进行合并 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- inner_compaction_candidate_file_num
+
+| 名字 | inner_compaction_candidate_file_num |
+| ------------ | ---------------------------------------- |
+| 描述 | 符合构成一个空间内合并任务的候选文件数量 |
+| 类型 | int32 |
+| 默认值 | 30 |
+| 改后生效方式 | 热加载 |
+
+- max_cross_compaction_candidate_file_num
+
+| 名字 | max_cross_compaction_candidate_file_num |
+| ------------ | --------------------------------------- |
+| 描述 | 跨空间合并中一次合并最多参与的文件数 |
+| 类型 | int32 |
+| 默认值 | 500 |
+| 改后生效方式 | 热加载 |
+
+- max_cross_compaction_candidate_file_size
+
+| 名字 | max_cross_compaction_candidate_file_size |
+| ------------ | ---------------------------------------- |
+| 描述 | 跨空间合并中一次合并最多参与的文件总大小 |
+| 类型 | Int64 |
+| 默认值 | 5368709120 |
+| 改后生效方式 | 热加载 |
+
+- min_cross_compaction_unseq_file_level
+
+| 名字 | min_cross_compaction_unseq_file_level |
+| ------------ | ---------------------------------------------- |
+| 描述 | 乱序空间中跨空间合并中文件的最小内部压缩级别。 |
+| 类型 | int32 |
+| 默认值 | 1 |
+| 改后生效方式 | 热加载 |
+
+- compaction_thread_count
+
+| 名字 | compaction_thread_count |
+| ------------ | ----------------------- |
+| 描述 | 执行合并任务的线程数目 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 热加载 |
+
+- compaction_max_aligned_series_num_in_one_batch
+
+| 名字 | compaction_max_aligned_series_num_in_one_batch |
+| ------------ | ---------------------------------------------- |
+| 描述 | 对齐序列合并一次执行时处理的值列数量 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 热加载 |
+
+- compaction_schedule_interval_in_ms
+
+| 名字 | compaction_schedule_interval_in_ms |
+| ------------ | ---------------------------------- |
+| 描述 | 合并调度的时间间隔 |
+| 类型 | Int64 |
+| 默认值 | 60000 |
+| 改后生效方式 | 重启服务生效 |
+
+- compaction_write_throughput_mb_per_sec
+
+| 名字 | compaction_write_throughput_mb_per_sec |
+| ------------ | -------------------------------------- |
+| 描述 | 每秒可达到的写入吞吐量合并限制。 |
+| 类型 | int32 |
+| 默认值 | 16 |
+| 改后生效方式 | 重启服务生效 |
+
+- compaction_read_throughput_mb_per_sec
+
+| 名字 | compaction_read_throughput_mb_per_sec |
+| --------- | ---------------------------------------------------- |
+| 描述 | 合并每秒读吞吐限制,单位为 byte,设置为 0 代表不限制 |
+| 类型 | int32 |
+| 默认值 | 0 |
+| Effective | 热加载 |
+
+- compaction_read_operation_per_sec
+
+| 名字 | compaction_read_operation_per_sec |
+| --------- | ------------------------------------------- |
+| 描述 | 合并每秒读操作数量限制,设置为 0 代表不限制 |
+| 类型 | int32 |
+| 默认值 | 0 |
+| Effective | 热加载 |
+
+- sub_compaction_thread_count
+
+| 名字 | sub_compaction_thread_count |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 每个合并任务的子任务线程数,只对跨空间合并和乱序空间内合并生效 |
+| 类型 | int32 |
+| 默认值 | 4 |
+| 改后生效方式 | 热加载 |
+
+- inner_compaction_task_selection_disk_redundancy
+
+| 名字 | inner_compaction_task_selection_disk_redundancy |
+| ------------ | ----------------------------------------------- |
+| 描述 | 定义了磁盘可用空间的冗余值,仅用于内部压缩 |
+| 类型 | double |
+| 默认值 | 0.05 |
+| 改后生效方式 | 热加载 |
+
+- inner_compaction_task_selection_mods_file_threshold
+
+| 名字 | inner_compaction_task_selection_mods_file_threshold |
+| ------------ | --------------------------------------------------- |
+| 描述 | 定义了mods文件大小的阈值,仅用于内部压缩。 |
+| 类型 | long |
+| 默认值 | 131072 |
+| 改后生效方式 | 热加载 |
+
+- compaction_schedule_thread_num
+
+| 名字 | compaction_schedule_thread_num |
+| ------------ | ------------------------------ |
+| 描述 | 选择合并任务的线程数量 |
+| 类型 | int32 |
+| 默认值 | 4 |
+| 改后生效方式 | 热加载 |
+
+### 3.21 写前日志配置
+
+- wal_mode
+
+| 名字 | wal_mode |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 写前日志的写入模式. DISABLE 模式下会关闭写前日志;SYNC 模式下写入请求会在成功写入磁盘后返回; ASYNC 模式下写入请求返回时可能尚未成功写入磁盘后。 |
+| 类型 | String |
+| 默认值 | ASYNC |
+| 改后生效方式 | 重启服务生效 |
+
+- max_wal_nodes_num
+
+| 名字 | max_wal_nodes_num |
+| ------------ | ----------------------------------------------------- |
+| 描述 | 写前日志节点的最大数量,默认值 0 表示数量由系统控制。 |
+| 类型 | int32 |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- wal_async_mode_fsync_delay_in_ms
+
+| 名字 | wal_async_mode_fsync_delay_in_ms |
+| ------------ | ------------------------------------------- |
+| 描述 | async 模式下写前日志调用 fsync 前的等待时间 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 热加载 |
+
+- wal_sync_mode_fsync_delay_in_ms
+
+| 名字 | wal_sync_mode_fsync_delay_in_ms |
+| ------------ | ------------------------------------------ |
+| 描述 | sync 模式下写前日志调用 fsync 前的等待时间 |
+| 类型 | int32 |
+| 默认值 | 3 |
+| 改后生效方式 | 热加载 |
+
+- wal_buffer_size_in_byte
+
+| 名字 | wal_buffer_size_in_byte |
+| ------------ | ----------------------- |
+| 描述 | 写前日志的 buffer 大小 |
+| 类型 | int32 |
+| 默认值 | 33554432 |
+| 改后生效方式 | 重启服务生效 |
+
+- wal_buffer_queue_capacity
+
+| 名字 | wal_buffer_queue_capacity |
+| ------------ | ------------------------- |
+| 描述 | 写前日志阻塞队列大小上限 |
+| 类型 | int32 |
+| 默认值 | 500 |
+| 改后生效方式 | 重启服务生效 |
+
+- wal_file_size_threshold_in_byte
+
+| 名字 | wal_file_size_threshold_in_byte |
+| ------------ | ------------------------------- |
+| 描述 | 写前日志文件封口阈值 |
+| 类型 | int32 |
+| 默认值 | 31457280 |
+| 改后生效方式 | 热加载 |
+
+- wal_min_effective_info_ratio
+
+| 名字 | wal_min_effective_info_ratio |
+| ------------ | ---------------------------- |
+| 描述 | 写前日志最小有效信息比 |
+| 类型 | double |
+| 默认值 | 0.1 |
+| 改后生效方式 | 热加载 |
+
+- wal_memtable_snapshot_threshold_in_byte
+
+| 名字 | wal_memtable_snapshot_threshold_in_byte |
+| ------------ | ---------------------------------------- |
+| 描述 | 触发写前日志中内存表快照的内存表大小阈值 |
+| 类型 | int64 |
+| 默认值 | 8388608 |
+| 改后生效方式 | 热加载 |
+
+- max_wal_memtable_snapshot_num
+
+| 名字 | max_wal_memtable_snapshot_num |
+| ------------ | ------------------------------ |
+| 描述 | 写前日志中内存表的最大数量上限 |
+| 类型 | int32 |
+| 默认值 | 1 |
+| 改后生效方式 | 热加载 |
+
+- delete_wal_files_period_in_ms
+
+| 名字 | delete_wal_files_period_in_ms |
+| ------------ | ----------------------------- |
+| 描述 | 删除写前日志的检查间隔 |
+| 类型 | int64 |
+| 默认值 | 20000 |
+| 改后生效方式 | 热加载 |
+
+- wal_throttle_threshold_in_byte
+
+| 名字 | wal_throttle_threshold_in_byte |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在IoTConsensus中,当WAL文件的大小达到一定阈值时,会开始对写入操作进行节流,以控制写入速度。 |
+| 类型 | long |
+| 默认值 | 53687091200 |
+| 改后生效方式 | 热加载 |
+
+- iot_consensus_cache_window_time_in_ms
+
+| 名字 | iot_consensus_cache_window_time_in_ms |
+| ------------ | ---------------------------------------- |
+| 描述 | 在IoTConsensus中,写缓存的最大等待时间。 |
+| 类型 | long |
+| 默认值 | -1 |
+| 改后生效方式 | 热加载 |
+
+- enable_wal_compression
+
+| 名字 | iot_consensus_cache_window_time_in_ms |
+| ------------ | ------------------------------------- |
+| 描述 | 用于控制是否启用WAL的压缩。 |
+| 类型 | boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+### 3.22 IoT 共识协议配置
+
+当Region配置了IoTConsensus共识协议之后,下述的配置项才会生效
+
+- data_region_iot_max_log_entries_num_per_batch
+
+| 名字 | data_region_iot_max_log_entries_num_per_batch |
+| ------------ | --------------------------------------------- |
+| 描述 | IoTConsensus batch 的最大日志条数 |
+| 类型 | int32 |
+| 默认值 | 1024 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_iot_max_size_per_batch
+
+| 名字 | data_region_iot_max_size_per_batch |
+| ------------ | ---------------------------------- |
+| 描述 | IoTConsensus batch 的最大大小 |
+| 类型 | int32 |
+| 默认值 | 16777216 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_iot_max_pending_batches_num
+
+| 名字 | data_region_iot_max_pending_batches_num |
+| ------------ | --------------------------------------- |
+| 描述 | IoTConsensus batch 的流水线并发阈值 |
+| 类型 | int32 |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_iot_max_memory_ratio_for_queue
+
+| 名字 | data_region_iot_max_memory_ratio_for_queue |
+| ------------ | ------------------------------------------ |
+| 描述 | IoTConsensus 队列内存分配比例 |
+| 类型 | double |
+| 默认值 | 0.6 |
+| 改后生效方式 | 重启服务生效 |
+
+- region_migration_speed_limit_bytes_per_second
+
+| 名字 | region_migration_speed_limit_bytes_per_second |
+| ------------ | --------------------------------------------- |
+| 描述 | 定义了在region迁移过程中,数据传输的最大速率 |
+| 类型 | long |
+| 默认值 | 33554432 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.23 TsFile配置
+
+- group_size_in_byte
+
+| 名字 | group_size_in_byte |
+| ------------ | ---------------------------------------------- |
+| 描述 | 每次将内存中的数据写入到磁盘时的最大写入字节数 |
+| 类型 | int32 |
+| 默认值 | 134217728 |
+| 改后生效方式 | 热加载 |
+
+- page_size_in_byte
+
+| 名字 | page_size_in_byte |
+| ------------ | ---------------------------------------------------- |
+| 描述 | 内存中每个列写出时,写成的单页最大的大小,单位为字节 |
+| 类型 | int32 |
+| 默认值 | 65536 |
+| 改后生效方式 | 热加载 |
+
+- max_number_of_points_in_page
+
+| 名字 | max_number_of_points_in_page |
+| ------------ | ------------------------------------------------- |
+| 描述 | 一个页中最多包含的数据点(时间戳-值的二元组)数量 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 热加载 |
+
+- pattern_matching_threshold
+
+| 名字 | pattern_matching_threshold |
+| ------------ | ------------------------------ |
+| 描述 | 正则表达式匹配时最大的匹配次数 |
+| 类型 | int32 |
+| 默认值 | 1000000 |
+| 改后生效方式 | 热加载 |
+
+- float_precision
+
+| 名字 | float_precision |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 浮点数精度,为小数点后数字的位数 |
+| 类型 | int32 |
+| 默认值 | 默认为 2 位。注意:32 位浮点数的十进制精度为 7 位,64 位浮点数的十进制精度为 15 位。如果设置超过机器精度将没有实际意义。 |
+| 改后生效方式 | 热加载 |
+
+- value_encoder
+
+| 名字 | value_encoder |
+| ------------ | ------------------------------------- |
+| 描述 | value 列编码方式 |
+| 类型 | 枚举 String: “TS_2DIFF”,“PLAIN”,“RLE” |
+| 默认值 | PLAIN |
+| 改后生效方式 | 热加载 |
+
+- compressor
+
+| 名字 | compressor |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 数据压缩方法; 对齐序列中时间列的压缩方法 |
+| 类型 | 枚举 String : "UNCOMPRESSED", "SNAPPY", "LZ4", "ZSTD", "LZMA2" |
+| 默认值 | LZ4 |
+| 改后生效方式 | 热加载 |
+
+- encrypt_flag
+
+| 名字 | compressor |
+| ------------ | ---------------------------- |
+| 描述 | 用于开启或关闭数据加密功能。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- encrypt_type
+
+| 名字 | compressor |
+| ------------ | ------------------------------------- |
+| 描述 | 数据加密的方法。 |
+| 类型 | String |
+| 默认值 | org.apache.tsfile.encrypt.UNENCRYPTED |
+| 改后生效方式 | 重启服务生效 |
+
+- encrypt_key_path
+
+| 名字 | encrypt_key_path |
+| ------------ | ---------------------------- |
+| 描述 | 数据加密使用的密钥来源路径。 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.24 授权配置
+
+- authorizer_provider_class
+
+| 名字 | authorizer_provider_class |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 权限服务的类名 |
+| 类型 | String |
+| 默认值 | org.apache.iotdb.commons.auth.authorizer.LocalFileAuthorizer |
+| 改后生效方式 | 重启服务生效 |
+| 其他可选值 | org.apache.iotdb.commons.auth.authorizer.OpenIdAuthorizer |
+
+- openID_url
+
+| 名字 | openID_url |
+| ------------ | ---------------------------------------------------------- |
+| 描述 | openID 服务器地址 (当 OpenIdAuthorizer 被启用时必须设定) |
+| 类型 | String(一个 http 地址) |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- iotdb_server_encrypt_decrypt_provider
+
+| 名字 | iotdb_server_encrypt_decrypt_provider |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 用于用户密码加密的类 |
+| 类型 | String |
+| 默认值 | org.apache.iotdb.commons.security.encrypt.MessageDigestEncrypt |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- iotdb_server_encrypt_decrypt_provider_parameter
+
+| 名字 | iotdb_server_encrypt_decrypt_provider_parameter |
+| ------------ | ----------------------------------------------- |
+| 描述 | 用于初始化用户密码加密类的参数 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- author_cache_size
+
+| 名字 | author_cache_size |
+| ------------ | ------------------------ |
+| 描述 | 用户缓存与角色缓存的大小 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- author_cache_expire_time
+
+| 名字 | author_cache_expire_time |
+| ------------ | -------------------------------------- |
+| 描述 | 用户缓存与角色缓存的有效期,单位为分钟 |
+| 类型 | int32 |
+| 默认值 | 30 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.25 UDF配置
+
+- udf_initial_byte_array_length_for_memory_control
+
+| 名字 | udf_initial_byte_array_length_for_memory_control |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 用于评估UDF查询中文本字段的内存使用情况。建议将此值设置为略大于所有文本的平均长度记录。 |
+| 类型 | int32 |
+| 默认值 | 48 |
+| 改后生效方式 | 重启服务生效 |
+
+- udf_memory_budget_in_mb
+
+| 名字 | udf_memory_budget_in_mb |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在一个UDF查询中使用多少内存(以 MB 为单位)。上限为已分配内存的 20% 用于读取。 |
+| 类型 | Float |
+| 默认值 | 30.0 |
+| 改后生效方式 | 重启服务生效 |
+
+- udf_reader_transformer_collector_memory_proportion
+
+| 名字 | udf_reader_transformer_collector_memory_proportion |
+| ------------ | --------------------------------------------------------- |
+| 描述 | UDF内存分配比例。参数形式为a : b : c,其中a、b、c为整数。 |
+| 类型 | String |
+| 默认值 | 1:1:1 |
+| 改后生效方式 | 重启服务生效 |
+
+- udf_lib_dir
+
+| 名字 | udf_lib_dir |
+| ------------ | ---------------------------- |
+| 描述 | UDF 日志及jar文件存储路径 |
+| 类型 | String |
+| 默认值 | ext/udf(Windows:ext\\udf) |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.26 触发器配置
+
+- trigger_lib_dir
+
+| 名字 | trigger_lib_dir |
+| ------------ | ----------------------- |
+| 描述 | 触发器 JAR 包存放的目录 |
+| 类型 | String |
+| 默认值 | ext/trigger |
+| 改后生效方式 | 重启服务生效 |
+
+- stateful_trigger_retry_num_when_not_found
+
+| 名字 | stateful_trigger_retry_num_when_not_found |
+| ------------ | ---------------------------------------------- |
+| 描述 | 有状态触发器触发无法找到触发器实例时的重试次数 |
+| 类型 | Int32 |
+| 默认值 | 3 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.27 SELECT-INTO配置
+
+- into_operation_buffer_size_in_byte
+
+| 名字 | into_operation_buffer_size_in_byte |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 执行 select-into 语句时,待写入数据占用的最大内存(单位:Byte) |
+| 类型 | long |
+| 默认值 | 104857600 |
+| 改后生效方式 | 热加载 |
+
+- select_into_insert_tablet_plan_row_limit
+
+| 名字 | select_into_insert_tablet_plan_row_limit |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 执行 select-into 语句时,一个 insert-tablet-plan 中可以处理的最大行数 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 热加载 |
+
+- into_operation_execution_thread_count
+
+| 名字 | into_operation_execution_thread_count |
+| ------------ | ------------------------------------------ |
+| 描述 | SELECT INTO 中执行写入任务的线程池的线程数 |
+| 类型 | int32 |
+| 默认值 | 2 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.28 连续查询配置
+- continuous_query_submit_thread_count
+
+| 名字 | continuous_query_execution_thread |
+| ------------ | --------------------------------- |
+| 描述 | 执行连续查询任务的线程池的线程数 |
+| 类型 | int32 |
+| 默认值 | 2 |
+| 改后生效方式 | 重启服务生效 |
+
+- continuous_query_min_every_interval_in_ms
+
+| 名字 | continuous_query_min_every_interval_in_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | 连续查询执行时间间隔的最小值 |
+| 类型 | long (duration) |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.29 PIPE配置
+
+- pipe_lib_dir
+
+| 名字 | pipe_lib_dir |
+| ------------ | -------------------------- |
+| 描述 | 自定义 Pipe 插件的存放目录 |
+| 类型 | string |
+| 默认值 | ext/pipe |
+| 改后生效方式 | 暂不支持修改 |
+
+- pipe_subtask_executor_max_thread_num
+
+| 名字 | pipe_subtask_executor_max_thread_num |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | pipe 子任务 processor、sink 中各自可以使用的最大线程数。实际值将是 min(pipe_subtask_executor_max_thread_num, max(1, CPU核心数 / 2))。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_sink_timeout_ms
+
+| 名字 | pipe_sink_timeout_ms |
+| ------------ | --------------------------------------------- |
+| 描述 | thrift 客户端的连接超时时间(以毫秒为单位)。 |
+| 类型 | int |
+| 默认值 | 900000 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_sink_selector_number
+
+| 名字 | pipe_sink_selector_number |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在 iotdb-thrift-async-sink 插件中可以使用的最大执行结果处理线程数量。 建议将此值设置为小于或等于 pipe_sink_max_client_number。 |
+| 类型 | int |
+| 默认值 | 4 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_sink_max_client_number
+
+| 名字 | pipe_sink_max_client_number |
+| ------------ | ----------------------------------------------------------- |
+| 描述 | 在 iotdb-thrift-async-sink 插件中可以使用的最大客户端数量。 |
+| 类型 | int |
+| 默认值 | 16 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_air_gap_receiver_enabled
+
+| 名字 | pipe_air_gap_receiver_enabled |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 是否启用通过网闸接收 pipe 数据。接收器只能在 tcp 模式下返回 0 或 1,以指示数据是否成功接收。 \| |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_air_gap_receiver_port
+
+| 名字 | pipe_air_gap_receiver_port |
+| ------------ | ------------------------------------ |
+| 描述 | 服务器通过网闸接收 pipe 数据的端口。 |
+| 类型 | int |
+| 默认值 | 9780 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_all_sinks_rate_limit_bytes_per_second
+
+| 名字 | pipe_all_sinks_rate_limit_bytes_per_second |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 所有 pipe sink 每秒可以传输的总字节数。当给定的值小于或等于 0 时,表示没有限制。默认值是 -1,表示没有限制。 |
+| 类型 | double |
+| 默认值 | -1 |
+| 改后生效方式 | 热加载 |
+
+### 3.30 Ratis共识协议配置
+
+当Region配置了RatisConsensus共识协议之后,下述的配置项才会生效
+
+- config_node_ratis_log_appender_buffer_size_max
+
+| 名字 | config_node_ratis_log_appender_buffer_size_max |
+| ------------ | ---------------------------------------------- |
+| 描述 | confignode 一次同步日志RPC最大的传输字节限制 |
+| 类型 | int32 |
+| 默认值 | 16777216 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_appender_buffer_size_max
+
+| 名字 | schema_region_ratis_log_appender_buffer_size_max |
+| ------------ | ------------------------------------------------ |
+| 描述 | schema region 一次同步日志RPC最大的传输字节限制 |
+| 类型 | int32 |
+| 默认值 | 16777216 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_appender_buffer_size_max
+
+| 名字 | data_region_ratis_log_appender_buffer_size_max |
+| ------------ | ---------------------------------------------- |
+| 描述 | data region 一次同步日志RPC最大的传输字节限制 |
+| 类型 | int32 |
+| 默认值 | 16777216 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_snapshot_trigger_threshold
+
+| 名字 | config_node_ratis_snapshot_trigger_threshold |
+| ------------ | -------------------------------------------- |
+| 描述 | confignode 触发snapshot需要的日志条数 |
+| 类型 | int32 |
+| 默认值 | 400,000 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_snapshot_trigger_threshold
+
+| 名字 | schema_region_ratis_snapshot_trigger_threshold |
+| ------------ | ---------------------------------------------- |
+| 描述 | schema region 触发snapshot需要的日志条数 |
+| 类型 | int32 |
+| 默认值 | 400,000 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_snapshot_trigger_threshold
+
+| 名字 | data_region_ratis_snapshot_trigger_threshold |
+| ------------ | -------------------------------------------- |
+| 描述 | data region 触发snapshot需要的日志条数 |
+| 类型 | int32 |
+| 默认值 | 400,000 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_log_unsafe_flush_enable
+
+| 名字 | config_node_ratis_log_unsafe_flush_enable |
+| ------------ | ----------------------------------------- |
+| 描述 | confignode 是否允许Raft日志异步刷盘 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_unsafe_flush_enable
+
+| 名字 | schema_region_ratis_log_unsafe_flush_enable |
+| ------------ | ------------------------------------------- |
+| 描述 | schema region 是否允许Raft日志异步刷盘 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_unsafe_flush_enable
+
+| 名字 | data_region_ratis_log_unsafe_flush_enable |
+| ------------ | ----------------------------------------- |
+| 描述 | data region 是否允许Raft日志异步刷盘 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_log_segment_size_max_in_byte
+
+| 名字 | config_node_ratis_log_segment_size_max_in_byte |
+| ------------ | ---------------------------------------------- |
+| 描述 | confignode 一个RaftLog日志段文件的大小 |
+| 类型 | int32 |
+| 默认值 | 25165824 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_segment_size_max_in_byte
+
+| 名字 | schema_region_ratis_log_segment_size_max_in_byte |
+| ------------ | ------------------------------------------------ |
+| 描述 | schema region 一个RaftLog日志段文件的大小 |
+| 类型 | int32 |
+| 默认值 | 25165824 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_segment_size_max_in_byte
+
+| 名字 | data_region_ratis_log_segment_size_max_in_byte |
+| ------------ | ---------------------------------------------- |
+| 描述 | data region 一个RaftLog日志段文件的大小 |
+| 类型 | int32 |
+| 默认值 | 25165824 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_simple_consensus_log_segment_size_max_in_byte
+
+| 名字 | data_region_ratis_log_segment_size_max_in_byte |
+| ------------ | ---------------------------------------------- |
+| 描述 | Confignode 简单共识协议一个Log日志段文件的大小 |
+| 类型 | int32 |
+| 默认值 | 25165824 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_grpc_flow_control_window
+
+| 名字 | config_node_ratis_grpc_flow_control_window |
+| ------------ | ------------------------------------------ |
+| 描述 | confignode grpc 流式拥塞窗口大小 |
+| 类型 | int32 |
+| 默认值 | 4194304 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_grpc_flow_control_window
+
+| 名字 | schema_region_ratis_grpc_flow_control_window |
+| ------------ | -------------------------------------------- |
+| 描述 | schema region grpc 流式拥塞窗口大小 |
+| 类型 | int32 |
+| 默认值 | 4194304 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_grpc_flow_control_window
+
+| 名字 | data_region_ratis_grpc_flow_control_window |
+| ------------ | ------------------------------------------ |
+| 描述 | data region grpc 流式拥塞窗口大小 |
+| 类型 | int32 |
+| 默认值 | 4194304 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_grpc_leader_outstanding_appends_max
+
+| 名字 | config_node_ratis_grpc_leader_outstanding_appends_max |
+| ------------ | ----------------------------------------------------- |
+| 描述 | config node grpc 流水线并发阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_grpc_leader_outstanding_appends_max
+
+| 名字 | schema_region_ratis_grpc_leader_outstanding_appends_max |
+| ------------ | ------------------------------------------------------- |
+| 描述 | schema region grpc 流水线并发阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_grpc_leader_outstanding_appends_max
+
+| 名字 | data_region_ratis_grpc_leader_outstanding_appends_max |
+| ------------ | ----------------------------------------------------- |
+| 描述 | data region grpc 流水线并发阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_log_force_sync_num
+
+| 名字 | config_node_ratis_log_force_sync_num |
+| ------------ | ------------------------------------ |
+| 描述 | config node fsync 阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_force_sync_num
+
+| 名字 | schema_region_ratis_log_force_sync_num |
+| ------------ | -------------------------------------- |
+| 描述 | schema region fsync 阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_force_sync_num
+
+| 名字 | data_region_ratis_log_force_sync_num |
+| ------------ | ------------------------------------ |
+| 描述 | data region fsync 阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_rpc_leader_election_timeout_min_ms
+
+| 名字 | config_node_ratis_rpc_leader_election_timeout_min_ms |
+| ------------ | ---------------------------------------------------- |
+| 描述 | confignode leader 选举超时最小值 |
+| 类型 | int32 |
+| 默认值 | 2000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_rpc_leader_election_timeout_min_ms
+
+| 名字 | schema_region_ratis_rpc_leader_election_timeout_min_ms |
+| ------------ | ------------------------------------------------------ |
+| 描述 | schema region leader 选举超时最小值 |
+| 类型 | int32 |
+| 默认值 | 2000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_rpc_leader_election_timeout_min_ms
+
+| 名字 | data_region_ratis_rpc_leader_election_timeout_min_ms |
+| ------------ | ---------------------------------------------------- |
+| 描述 | data region leader 选举超时最小值 |
+| 类型 | int32 |
+| 默认值 | 2000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_rpc_leader_election_timeout_max_ms
+
+| 名字 | config_node_ratis_rpc_leader_election_timeout_max_ms |
+| ------------ | ---------------------------------------------------- |
+| 描述 | confignode leader 选举超时最大值 |
+| 类型 | int32 |
+| 默认值 | 4000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_rpc_leader_election_timeout_max_ms
+
+| 名字 | schema_region_ratis_rpc_leader_election_timeout_max_ms |
+| ------------ | ------------------------------------------------------ |
+| 描述 | schema region leader 选举超时最大值 |
+| 类型 | int32 |
+| 默认值 | 4000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_rpc_leader_election_timeout_max_ms
+
+| 名字 | data_region_ratis_rpc_leader_election_timeout_max_ms |
+| ------------ | ---------------------------------------------------- |
+| 描述 | data region leader 选举超时最大值 |
+| 类型 | int32 |
+| 默认值 | 4000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_request_timeout_ms
+
+| 名字 | config_node_ratis_request_timeout_ms |
+| ------------ | ------------------------------------ |
+| 描述 | confignode Raft 客户端重试超时 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_request_timeout_ms
+
+| 名字 | schema_region_ratis_request_timeout_ms |
+| ------------ | -------------------------------------- |
+| 描述 | schema region Raft 客户端重试超时 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_request_timeout_ms
+
+| 名字 | data_region_ratis_request_timeout_ms |
+| ------------ | ------------------------------------ |
+| 描述 | data region Raft 客户端重试超时 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_max_retry_attempts
+
+| 名字 | config_node_ratis_max_retry_attempts |
+| ------------ | ------------------------------------ |
+| 描述 | confignode Raft客户端最大重试次数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_initial_sleep_time_ms
+
+| 名字 | config_node_ratis_initial_sleep_time_ms |
+| ------------ | --------------------------------------- |
+| 描述 | confignode Raft客户端初始重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 100ms |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_max_sleep_time_ms
+
+| 名字 | config_node_ratis_max_sleep_time_ms |
+| ------------ | ------------------------------------- |
+| 描述 | confignode Raft客户端最大重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_max_retry_attempts
+
+| 名字 | schema_region_ratis_max_retry_attempts |
+| ------------ | -------------------------------------- |
+| 描述 | schema region Raft客户端最大重试次数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_initial_sleep_time_ms
+
+| 名字 | schema_region_ratis_initial_sleep_time_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | schema region Raft客户端初始重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 100ms |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_max_sleep_time_ms
+
+| 名字 | schema_region_ratis_max_sleep_time_ms |
+| ------------ | ---------------------------------------- |
+| 描述 | schema region Raft客户端最大重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_max_retry_attempts
+
+| 名字 | data_region_ratis_max_retry_attempts |
+| ------------ | ------------------------------------ |
+| 描述 | data region Raft客户端最大重试次数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_initial_sleep_time_ms
+
+| 名字 | data_region_ratis_initial_sleep_time_ms |
+| ------------ | --------------------------------------- |
+| 描述 | data region Raft客户端初始重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 100ms |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_max_sleep_time_ms
+
+| 名字 | data_region_ratis_max_sleep_time_ms |
+| ------------ | -------------------------------------- |
+| 描述 | data region Raft客户端最大重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- ratis_first_election_timeout_min_ms
+
+| 名字 | ratis_first_election_timeout_min_ms |
+| ------------ | ----------------------------------- |
+| 描述 | Ratis协议首次选举最小超时时间 |
+| 类型 | int64 |
+| 默认值 | 50 (ms) |
+| 改后生效方式 | 重启服务生效 |
+
+- ratis_first_election_timeout_max_ms
+
+| 名字 | ratis_first_election_timeout_max_ms |
+| ------------ | ----------------------------------- |
+| 描述 | Ratis协议首次选举最大超时时间 |
+| 类型 | int64 |
+| 默认值 | 150 (ms) |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_preserve_logs_num_when_purge
+
+| 名字 | config_node_ratis_preserve_logs_num_when_purge |
+| ------------ | ---------------------------------------------- |
+| 描述 | confignode snapshot后保持一定数量日志不删除 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_preserve_logs_num_when_purge
+
+| 名字 | schema_region_ratis_preserve_logs_num_when_purge |
+| ------------ | ------------------------------------------------ |
+| 描述 | schema region snapshot后保持一定数量日志不删除 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_preserve_logs_num_when_purge
+
+| 名字 | data_region_ratis_preserve_logs_num_when_purge |
+| ------------ | ---------------------------------------------- |
+| 描述 | data region snapshot后保持一定数量日志不删除 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_log_max_size
+
+| 名字 | config_node_ratis_log_max_size |
+| ------------ | ----------------------------------- |
+| 描述 | config node磁盘Raft Log最大占用空间 |
+| 类型 | int64 |
+| 默认值 | 2147483648 (2GB) |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_max_size
+
+| 名字 | schema_region_ratis_log_max_size |
+| ------------ | -------------------------------------- |
+| 描述 | schema region 磁盘Raft Log最大占用空间 |
+| 类型 | int64 |
+| 默认值 | 2147483648 (2GB) |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_max_size
+
+| 名字 | data_region_ratis_log_max_size |
+| ------------ | ------------------------------------ |
+| 描述 | data region 磁盘Raft Log最大占用空间 |
+| 类型 | int64 |
+| 默认值 | 21474836480 (20GB) |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_periodic_snapshot_interval
+
+| 名字 | config_node_ratis_periodic_snapshot_interval |
+| ------------ | -------------------------------------------- |
+| 描述 | config node定期snapshot的间隔时间 |
+| 类型 | int64 |
+| 默认值 | 86400 (秒) |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_periodic_snapshot_interval
+
+| 名字 | schema_region_ratis_preserve_logs_num_when_purge |
+| ------------ | ------------------------------------------------ |
+| 描述 | schema region定期snapshot的间隔时间 |
+| 类型 | int64 |
+| 默认值 | 86400 (秒) |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_periodic_snapshot_interval
+
+| 名字 | data_region_ratis_preserve_logs_num_when_purge |
+| ------------ | ---------------------------------------------- |
+| 描述 | data region定期snapshot的间隔时间 |
+| 类型 | int64 |
+| 默认值 | 86400 (秒) |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.31 IoTConsensusV2配置
+
+- iot_consensus_v2_pipeline_size
+
+| 名字 | iot_consensus_v2_pipeline_size |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTConsensus V2中连接器(connector)和接收器(receiver)的默认事件缓冲区大小。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- iot_consensus_v2_mode
+
+| 名字 | iot_consensus_v2_pipeline_size |
+| ------------ | ----------------------------------- |
+| 描述 | IoTConsensus V2使用的共识协议模式。 |
+| 类型 | String |
+| 默认值 | batch |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.32 Procedure 配置
+
+- procedure_core_worker_thread_count
+
+| 名字 | procedure_core_worker_thread_count |
+| ------------ | ---------------------------------- |
+| 描述 | 工作线程数量 |
+| 类型 | int32 |
+| 默认值 | 4 |
+| 改后生效方式 | 重启服务生效 |
+
+- procedure_completed_clean_interval
+
+| 名字 | procedure_completed_clean_interval |
+| ------------ | ---------------------------------- |
+| 描述 | 清理已完成的 procedure 时间间隔 |
+| 类型 | int32 |
+| 默认值 | 30(s) |
+| 改后生效方式 | 重启服务生效 |
+
+- procedure_completed_evict_ttl
+
+| 名字 | procedure_completed_evict_ttl |
+| ------------ | --------------------------------- |
+| 描述 | 已完成的 procedure 的数据保留时间 |
+| 类型 | int32 |
+| 默认值 | 60(s) |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.33 MQTT代理配置
+
+- enable_mqtt_service
+
+| 名字 | enable_mqtt_service。 |
+| ------------ | --------------------- |
+| 描述 | 是否开启MQTT服务 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 热加载 |
+
+- mqtt_host
+
+| 名字 | mqtt_host |
+| ------------ | -------------------- |
+| 描述 | MQTT服务绑定的host。 |
+| 类型 | String |
+| 默认值 | 127.0.0.1 |
+| 改后生效方式 | 热加载 |
+
+- mqtt_port
+
+| 名字 | mqtt_port |
+| ------------ | -------------------- |
+| 描述 | MQTT服务绑定的port。 |
+| 类型 | int32 |
+| 默认值 | 1883 |
+| 改后生效方式 | 热加载 |
+
+- mqtt_handler_pool_size
+
+| 名字 | mqtt_handler_pool_size |
+| ------------ | ---------------------------------- |
+| 描述 | 用于处理MQTT消息的处理程序池大小。 |
+| 类型 | int32 |
+| 默认值 | 1 |
+| 改后生效方式 | 热加载 |
+
+- mqtt_payload_formatter
+
+| 名字 | mqtt_payload_formatter |
+| ------------ | ---------------------------- |
+| 描述 | MQTT消息有效负载格式化程序。 |
+| 类型 | String |
+| 默认值 | json |
+| 改后生效方式 | 热加载 |
+
+- mqtt_max_message_size
+
+| 名字 | mqtt_max_message_size |
+| ------------ | ------------------------------------ |
+| 描述 | MQTT消息的最大长度(以字节为单位)。 |
+| 类型 | int32 |
+| 默认值 | 1048576 |
+| 改后生效方式 | 热加载 |
+
+### 3.34 审计日志配置
+
+- enable_audit_log
+
+| 名字 | enable_audit_log |
+| ------------ | ------------------------------ |
+| 描述 | 用于控制是否启用审计日志功能。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- audit_log_storage
+
+| 名字 | audit_log_storage |
+| ------------ | -------------------------- |
+| 描述 | 定义了审计日志的输出位置。 |
+| 类型 | String |
+| 默认值 | IOTDB,LOGGER |
+| 改后生效方式 | 重启服务生效 |
+
+- audit_log_operation
+
+| 名字 | audit_log_operation |
+| ------------ | -------------------------------------- |
+| 描述 | 定义了哪些类型的操作需要记录审计日志。 |
+| 类型 | String |
+| 默认值 | DML,DDL,QUERY |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_audit_log_for_native_insert_api
+
+| 名字 | enable_audit_log_for_native_insert_api |
+| ------------ | -------------------------------------- |
+| 描述 | 用于控制本地写入API是否记录审计日志。 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.35 白名单配置
+- enable_white_list
+
+| 名字 | enable_white_list |
+| ------------ | ----------------- |
+| 描述 | 是否启用白名单。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 热加载 |
+
+### 3.36 IoTDB-AI 配置
+
+- model_inference_execution_thread_count
+
+| 名字 | model_inference_execution_thread_count |
+| ------------ | -------------------------------------- |
+| 描述 | 用于模型推理操作的线程数。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.37 TsFile 主动监听&加载功能配置
+
+- load_clean_up_task_execution_delay_time_seconds
+
+| 名字 | load_clean_up_task_execution_delay_time_seconds |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在加载TsFile失败后,系统将等待多长时间才会执行清理任务来清除这些未成功加载的TsFile。 |
+| 类型 | int |
+| 默认值 | 1800 |
+| 改后生效方式 | 热加载 |
+
+- load_write_throughput_bytes_per_second
+
+| 名字 | load_write_throughput_bytes_per_second |
+| ------------ | -------------------------------------- |
+| 描述 | 加载TsFile时磁盘写入的最大字节数每秒。 |
+| 类型 | int |
+| 默认值 | -1 |
+| 改后生效方式 | 热加载 |
+
+- load_active_listening_enable
+
+| 名字 | load_active_listening_enable |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 是否开启 DataNode 主动监听并且加载 tsfile 的功能(默认开启)。 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- load_active_listening_dirs
+
+| 名字 | load_active_listening_dirs |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 需要监听的目录(自动包括目录中的子目录),如有多个使用 “,“ 隔开默认的目录为 ext/load/pending(支持热装载)。 |
+| 类型 | String |
+| 默认值 | ext/load/pending |
+| 改后生效方式 | 热加载 |
+
+- load_active_listening_fail_dir
+
+| 名字 | load_active_listening_fail_dir |
+| ------------ | ---------------------------------------------------------- |
+| 描述 | 执行加载 tsfile 文件失败后将文件转存的目录,只能配置一个。 |
+| 类型 | String |
+| 默认值 | ext/load/failed |
+| 改后生效方式 | 热加载 |
+
+- load_active_listening_max_thread_num
+
+| 名字 | load_active_listening_max_thread_num |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 同时执行加载 tsfile 任务的最大线程数,参数被注释掉时的默值为 max(1, CPU 核心数 / 2),当用户设置的值不在这个区间[1, CPU核心数 /2]内时,会设置为默认值 (1, CPU 核心数 / 2)。 |
+| 类型 | Long |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- load_active_listening_check_interval_seconds
+
+| 名字 | load_active_listening_check_interval_seconds |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 主动监听轮询间隔,单位秒。主动监听 tsfile 的功能是通过轮询检查文件夹实现的。该配置指定了两次检查 load_active_listening_dirs 的时间间隔,每次检查完成 load_active_listening_check_interval_seconds 秒后,会执行下一次检查。当用户设置的轮询间隔小于 1 时,会被设置为默认值 5 秒。 |
+| 类型 | Long |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.38 分发重试配置
+
+- enable_retry_for_unknown_error
+
+| 名字 | enable_retry_for_unknown_error |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在遇到未知错误时,写请求远程分发的最大重试时间,单位是毫秒。 |
+| 类型 | Long |
+| 默认值 | 60000 |
+| 改后生效方式 | 热加载 |
+
+- enable_retry_for_unknown_error
+
+| 名字 | enable_retry_for_unknown_error |
+| ------------ | -------------------------------- |
+| 描述 | 用于控制是否对未知错误进行重试。 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 热加载 |
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/Fill-Clause.md b/src/zh/UserGuide/Master/Table/SQL-Manual/Fill-Clause.md
new file mode 100644
index 000000000..e8797f836
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/Fill-Clause.md
@@ -0,0 +1,466 @@
+
+
+# FILL 子句
+
+## 1 功能介绍
+
+在执行数据查询时,可能会遇到某些列在某些行中没有数据,导致结果集中出现 NULL 值。这些 NULL 值不利于数据的可视化展示和分析,因此 IoTDB 提供了 FILL 子句来填充这些 NULL 值。
+
+当查询中包含 ORDER BY 子句时,FILL 子句会在 ORDER BY 之前执行。而如果存在 GAPFILL( date_bin_gapfill 函数)操作,则 FILL 子句会在 GAPFILL 之后执行。
+
+## 2 语法概览
+
+```sql
+fillClause
+ : FILL METHOD fillMethod
+ ;
+
+fillMethod
+ : LINEAR timeColumnClause? fillGroupClause? #linearFill
+ | PREVIOUS timeBoundClause? timeColumnClause? fillGroupClause? #previousFill
+ | CONSTANT literalExpression #valueFill
+ ;
+
+timeColumnClause
+ : TIME_COLUMN INTEGER_VALUE
+ ;
+
+fillGroupClause
+ : FILL_GROUP INTEGER_VALUE (',' INTEGER_VALUE)*
+ ;
+
+timeBoundClause
+ : TIME_BOUND duration=timeDuration
+ ;
+
+timeDuration
+ : (INTEGER_VALUE intervalField)+
+ ;
+intervalField
+ : YEAR | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND | MILLISECOND | MICROSECOND | NANOSECOND
+ ;
+```
+
+### 2.1 填充方式
+
+IoTDB 支持以下三种空值填充方式:
+
+1. **`PREVIOUS`填充**:使用该列前一个非空值进行填充。
+2. **`LINEAR`填充**:使用该列前一个非空值和下一个非空值的线性插值进行填充。
+3. **`Constant`填充**:使用指定的常量值进行填充。
+
+只能指定一种填充方法,且该方法会作用于结果集的全部列。
+
+### 2.2 数据类型与支持的填充方法
+
+| Data Type | Previous | Linear | Constant |
+| :-------- | :------- | :----- | :------- |
+| boolean | √ | - | √ |
+| int32 | √ | √ | √ |
+| int64 | √ | √ | √ |
+| float | √ | √ | √ |
+| double | √ | √ | √ |
+| text | √ | - | √ |
+| string | √ | - | √ |
+| blob | √ | - | √ |
+| timestamp | √ | √ | √ |
+| date | √ | √ | √ |
+
+注意:对于数据类型不支持指定填充方法的列,既不进行填充,也不抛出异常,只是保持原样。
+
+## 3 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+### 3.1 PREVIOUS 填充:
+
+对于查询结果集中的空值,使用该列的前一个非空值进行填充。
+
+#### 3.1.1 参数介绍:
+
+- TIME_BOUND(可选):向前查看的时间阈值。如果当前空值的时间戳与前一个非空值的时间戳之间的间隔超过了此阈值,则不会进行填充。默认选择查询结果中第一个 TIMESTAMP 类型的列来确定是否超出了时间阈值。
+ - 时间阈值参数格式为时间间隔,数值部分需要为整数,单位部分 y 表示年,mo 表示月,w 表示周,d 表示天,h 表示小时,m 表示分钟,s 表示秒,ms 表示毫秒,µs 表示微秒,ns 表示纳秒,如1d1h。
+- TIME_COLUMN(可选):若需手动指定用于判断时间阈值的 TIMESTAMP 列,可通过在 `TIME_COLUMN` 参数后指定数字(从1开始)来确定列的顺序位置,该数字代表在原始表中 TIMESTAMP 列的具体位置。
+
+#### 3.1.2 示例
+
+不使用任何填充方法:
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101';
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| null| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| null|
+|2024-11-27T16:40:00.000+08:00| 85.0| null|
+|2024-11-27T16:41:00.000+08:00| 85.0| null|
+|2024-11-27T16:42:00.000+08:00| null| false|
+|2024-11-27T16:43:00.000+08:00| null| false|
+|2024-11-27T16:44:00.000+08:00| null| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.088s
+```
+
+使用 PREVIOUS 填充方法(结果将使用前一个非空值填充 NULL 值):
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD PREVIOUS;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| null| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| true|
+|2024-11-27T16:40:00.000+08:00| 85.0| true|
+|2024-11-27T16:41:00.000+08:00| 85.0| true|
+|2024-11-27T16:42:00.000+08:00| 85.0| false|
+|2024-11-27T16:43:00.000+08:00| 85.0| false|
+|2024-11-27T16:44:00.000+08:00| 85.0| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.091s
+```
+
+使用 PREVIOUS 填充方法(指定时间阈值):
+
+```sql
+# 不指定时间列
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD PREVIOUS TIME_BOUND 1m;
+
+# 手动指定时间列
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD PREVIOUS 1m TIME_COLUMN 1;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| null| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| true|
+|2024-11-27T16:40:00.000+08:00| 85.0| null|
+|2024-11-27T16:41:00.000+08:00| 85.0| null|
+|2024-11-27T16:42:00.000+08:00| 85.0| false|
+|2024-11-27T16:43:00.000+08:00| null| false|
+|2024-11-27T16:44:00.000+08:00| null| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.075s
+```
+
+### 3.2 LINEAR 填充
+
+对于查询结果集中的空值,用该列的前一个非空值和后一个非空值的线性插值填充。
+
+#### 3.2.1 线性填充规则:
+
+- 如果之前都是空值,或者之后都是空值,则不进行填充。
+- 如果列的数据类型是 boolean/string/blob/text,则不会进行填充,也不会抛出异常。
+- 若没有指定时间列,默认选择 SELECT 子句中第一个数据类型为 TIMESTAMP 类型的列作为辅助时间列进行线性插值。如果不存在数据类型为TIMESTAMP的列,系统将抛出异常。
+
+#### 3.2.2 参数介绍:
+
+- TIME_COLUMN(可选):可以通过在`TIME_COLUMN`参数后指定数字(从1开始)来手动指定用于判断时间阈值的`TIMESTAMP`列,作为线性插值的辅助列,该数字代表原始表中`TIMESTAMP`列的具体位置。
+
+注意:不强制要求线性插值的辅助列一定是 time 列,任何类型为 TIMESTAMP 的表达式都可以,不过因为线性插值只有在辅助列是升序或者降序的时候,才有意义,所以用户如果指定了其他的列,需要自行保证结果集是按照那一列升序或降序排列的。
+
+#### 3.2.3 示例
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD LINEAR;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| null| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| null|
+|2024-11-27T16:40:00.000+08:00| 85.0| null|
+|2024-11-27T16:41:00.000+08:00| 85.0| null|
+|2024-11-27T16:42:00.000+08:00| null| false|
+|2024-11-27T16:43:00.000+08:00| null| false|
+|2024-11-27T16:44:00.000+08:00| null| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.053s
+```
+
+### 3.3 Constant 填充:
+
+对于查询结果集中的空值,使用指定的常量进行填充。
+
+#### 3.3.1 常量填充规则:
+
+- 若数据类型与输入的常量不匹配,IoTDB 不会填充查询结果,也不会抛出异常。
+- 若插入的常量值超出了其数据类型所能表示的最大值,IoTDB 不会填充查询结果,也不会抛出异常。
+
+#### 3.3.2 示例
+
+使用`FLOAT`常量填充时,SQL 语句如下所示:
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD CONSTANT 80.0;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| 80.0| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| true|
+|2024-11-27T16:40:00.000+08:00| 85.0| true|
+|2024-11-27T16:41:00.000+08:00| 85.0| true|
+|2024-11-27T16:42:00.000+08:00| 80.0| false|
+|2024-11-27T16:43:00.000+08:00| 80.0| false|
+|2024-11-27T16:44:00.000+08:00| 80.0| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.242s
+```
+
+使用`BOOLEAN`常量填充时,SQL 语句如下所示:
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD CONSTANT true;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| 1.0| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| true|
+|2024-11-27T16:40:00.000+08:00| 85.0| true|
+|2024-11-27T16:41:00.000+08:00| 85.0| true|
+|2024-11-27T16:42:00.000+08:00| 1.0| false|
+|2024-11-27T16:43:00.000+08:00| 1.0| false|
+|2024-11-27T16:44:00.000+08:00| 1.0| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.073s
+```
+
+## 4 高阶用法
+
+使用 `PREVIOUS` 和 `LINEAR` FILL 时,还支持额外的 `FILL_GROUP` 参数,来进行分组内填充。
+
+在使用 group by 子句 + fill 时,想在分组内进行填充,而不受其他分组的影响。
+
+例如:对每个 `device_id` 内部的空值进行填充,而不使用其他设备的值:
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, plant_id, device_id, avg(temperature) AS avg_temp
+ FROM table1
+ WHERE time >= 2024-11-28 08:00:00 AND time < 2024-11-30 14:30:00
+ group by 1, plant_id, device_id;
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+
+| hour_time|plant_id|device_id|avg_temp|
++-----------------------------+--------+---------+--------+
+|2024-11-28T08:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 3001| 100| null|
+|2024-11-28T10:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 3001| 100| 88.0|
+|2024-11-29T10:00:00.000+08:00| 3001| 101| 85.0|
+|2024-11-29T11:00:00.000+08:00| 3002| 100| null|
+|2024-11-29T18:00:00.000+08:00| 3002| 100| 90.0|
+|2024-11-30T09:00:00.000+08:00| 3002| 101| 90.0|
++-----------------------------+--------+---------+--------+
+Total line number = 8
+It costs 0.110s
+```
+
+若没有指定 FILL_GROUP 参数时,`100` 的空值会被 `101` 的值填充:
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, plant_id, device_id, avg(temperature) AS avg_temp
+ FROM table1
+ WHERE time >= 2024-11-28 08:00:00 AND time < 2024-11-30 14:30:00
+ group by 1, plant_id, device_id
+ FILL METHOD PREVIOUS;
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+
+| hour_time|plant_id|device_id|avg_temp|
++-----------------------------+--------+---------+--------+
+|2024-11-28T08:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T10:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 3001| 100| 88.0|
+|2024-11-29T10:00:00.000+08:00| 3001| 101| 85.0|
+|2024-11-29T11:00:00.000+08:00| 3002| 100| 85.0|
+|2024-11-29T18:00:00.000+08:00| 3002| 100| 90.0|
+|2024-11-30T09:00:00.000+08:00| 3002| 101| 90.0|
++-----------------------------+--------+---------+--------+
+Total line number = 8
+It costs 0.066s
+```
+
+指定了 FILL_GROUP 为第 2 列后,填充只会发生在以第二列`device_id`为分组键的分组中,`100` 的空值不会被 `101` 的值填充,因为它们属于不同的分组。
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, plant_id, device_id, avg(temperature) AS avg_temp
+ FROM table1
+ WHERE time >= 2024-11-28 08:00:00 AND time < 2024-11-30 14:30:00
+ group by 1, plant_id, device_id
+ FILL METHOD PREVIOUS FILL_GROUP 2;
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+
+| hour_time|plant_id|device_id|avg_temp|
++-----------------------------+--------+---------+--------+
+|2024-11-28T08:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T10:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 3001| 100| 88.0|
+|2024-11-29T10:00:00.000+08:00| 3001| 101| 85.0|
+|2024-11-29T11:00:00.000+08:00| 3002| 100| null|
+|2024-11-29T18:00:00.000+08:00| 3002| 100| 90.0|
+|2024-11-30T09:00:00.000+08:00| 3002| 101| 90.0|
++-----------------------------+--------+---------+--------+
+Total line number = 8
+It costs 0.089s
+```
+
+## 5 特别说明
+
+在使用 `LINEAR FILL` 或 `PREVIOUS FILL` 时,如果辅助时间列(用于确定填充逻辑的时间列)中存在 NULL 值,IoTDB 将遵循以下规则:
+
+- 不对辅助时间列为 NULL 的行进行填充。
+- 这些行也不会参与到填充逻辑的计算中。
+
+以 `PREVIOUS FILL`为例,原始数据如下所示:
+
+```sql
+SELECT time, plant_id, device_id, humidity, arrival_time
+ FROM table1
+ WHERE time >= 2024-11-26 16:37:00 and time <= 2024-11-28 08:00:00
+ AND plant_id='1001' and device_id='101';
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+-----------------------------+
+| time|plant_id|device_id|humidity| arrival_time|
++-----------------------------+--------+---------+--------+-----------------------------+
+|2024-11-27T16:38:00.000+08:00| 1001| 101| 35.1|2024-11-27T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 1001| 101| 35.3| null|
+|2024-11-27T16:40:00.000+08:00| 1001| 101| null|2024-11-27T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 1001| 101| null|2024-11-27T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 1001| 101| 35.2| null|
+|2024-11-27T16:43:00.000+08:00| 1001| 101| null| null|
+|2024-11-27T16:44:00.000+08:00| 1001| 101| null|2024-11-27T16:37:08.000+08:00|
++-----------------------------+--------+---------+--------+-----------------------------+
+Total line number = 7
+It costs 0.119s
+```
+
+使用 arrival_time 列作为辅助时间列,并设置时间间隔(TIME_BOUND)为 2 ms(前值距离当前值超过 2ms 就不填充):
+
+```sql
+SELECT time, plant_id, device_id, humidity, arrival_time
+ FROM table1
+ WHERE time >= 2024-11-26 16:37:00 and time <= 2024-11-28 08:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD PREVIOUS TIME_BOUND 2s TIME_COLUMN 5;
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+-----------------------------+
+| time|plant_id|device_id|humidity| arrival_time|
++-----------------------------+--------+---------+--------+-----------------------------+
+|2024-11-27T16:38:00.000+08:00| 1001| 101| 35.1|2024-11-27T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 1001| 101| 35.3| null|
+|2024-11-27T16:40:00.000+08:00| 1001| 101| 35.1|2024-11-27T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 1001| 101| null|2024-11-27T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 1001| 101| 35.2| null|
+|2024-11-27T16:43:00.000+08:00| 1001| 101| null| null|
+|2024-11-27T16:44:00.000+08:00| 1001| 101| null|2024-11-27T16:37:08.000+08:00|
++-----------------------------+--------+---------+--------+-----------------------------+
+Total line number = 7
+It costs 0.049s
+```
+
+填充结果详情:
+
+- 16:39、16:42、16:43 的 humidity 列,由于辅助列 arrival_time 为 NULL,所以不进行填充。
+- 16:40 的 humidity 列,由于辅助列 arrival_time 非 NULL ,为 `1970-01-01T08:00:00.003+08:00`且与前一个非 NULL 值 `1970-01-01T08:00:00.001+08:00`的时间差未超过 2ms,因此使用第一行 s1 的值 1 进行填充。
+- 16:41 的 humidity 列,尽管 arrival_time 非 NULL,但与前一个非 NULL 值的时间差超过 2ms,因此不进行填充。第七行同理。
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/From-Join-Clause.md b/src/zh/UserGuide/Master/Table/SQL-Manual/From-Join-Clause.md
new file mode 100644
index 000000000..47367651f
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/From-Join-Clause.md
@@ -0,0 +1,387 @@
+
+
+# FROM & JOIN 子句
+
+## 1 语法概览
+
+```sql
+FROM relation (',' relation)*
+
+relation
+ : relation joinType JOIN relation joinCriteria
+ | aliasedRelation
+ ;
+
+joinType
+ : INNER?
+ | FULL OUTER?
+ ;
+
+joinCriteria
+ : ON booleanExpression
+ | USING '(' identifier (',' identifier)* ')'
+ ;
+
+aliasedRelation
+ : relationPrimary (AS? identifier columnAliases?)?
+ ;
+
+columnAliases
+ : '(' identifier (',' identifier)* ')'
+ ;
+
+relationPrimary
+ : qualifiedName #tableName
+ | '(' query ')' #subqueryRelation
+ | '(' relation ')' #parenthesizedRelation
+ ;
+
+qualifiedName
+ : identifier ('.' identifier)*
+ ;
+```
+
+## 2 FROM 子句
+
+FROM 子句指定了查询操作的数据源。在逻辑上,查询的执行从 FROM 子句开始。FROM 子句可以包含单个表、使用 JOIN 子句连接的多个表的组合,或者子查询中的另一个 SELECT 查询。
+
+## 3 JOIN 子句
+
+JOIN 用于将两个表基于某些条件连接起来,通常,连接条件是一个谓词,但也可以指定其他隐含的规则。
+
+在当前版本的 IoTDB 中,支持内连接(Inner Join)和全外连接(Full Outer Join),并且连接条件只能是时间列的等值连接。
+
+### 3.1 内连接(Inner Join)
+
+INNER JOIN 表示内连接,其中 INNER 关键字可以省略。它返回两个表中满足连接条件的记录,舍弃不满足的记录,等同于两个表的交集。
+
+#### 3.1.1 显式指定连接条件(推荐)
+
+显式连接需要使用 JOIN + ON 或 JOIN + USING 语法,在 ON 或 USING 关键字后指定连接条件。
+
+SQL语法如下所示:
+
+```sql
+// 显式连接, 在ON关键字后指定连接条件或在Using关键字后指定连接列
+SELECT selectExpr [, selectExpr] ... FROM [INNER] JOIN joinCriteria [WHERE whereCondition]
+
+joinCriteria
+ : ON booleanExpression
+ | USING '(' identifier (',' identifier)* ')'
+ ;
+```
+
+__注意:USING 和 ON 的区别__
+
+USING 是显式连接条件的缩写语法,它接收一个用逗号分隔的字段名列表,这些字段必须是连接表共有的字段。例如,USING (time) 等效于 ON (t1.time = t2.time)。当使用 `ON` 关键字时,两个表中的 `time` 字段在逻辑上是区分的,分别表示为 `t1.time` 和 `t2.time`。而当使用 `USING` 关键字时,逻辑上只会有一个 `time` 字段。而最终的查询结果取决于 `SELECT` 语句中指定的字段。
+
+#### 3.1.2 隐式指定连接条件
+
+隐式连接不需要出现 JOIN、ON、USING 关键字,而是通过在 WHERE 子句中指定条件来实现表与表之间的连接。
+
+SQL语法如下所示:
+
+```sql
+// 隐式连接, 在WHERE子句里指定连接条件
+SELECT selectExpr [, selectExpr] ... FROM [, ] ... [WHERE whereCondition]
+```
+
+### 3.2 外连接(Outer Join)
+
+如果没有匹配的行,仍然可以通过指定外连接返回行。外连接可以是:
+
+- LEFT(左侧表的所有行至少出现一次)
+- RIGHT(右侧表的所有行至少出现一次)
+- FULL(两个表的所有行至少出现一次)
+
+在当前版本的 IoTDB 中,只支持 FULL [OUTER] JOIN,即全外连接,返回左表和右表连接后的所有记录。如果某个表中的记录没有与另一个表中的记录匹配,则会返回 NULL 值。__FULL JOIN 只能使用显式连接方式。__
+
+## 4 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+### 4.1 From 示例
+
+#### 4.1.1 从单个表查询
+
+示例 1:此查询将返回 `table1` 中的所有记录,并按时间排序。
+
+```sql
+SELECT * FROM table1 ORDER BY time;
+```
+
+查询结果:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| arrival_time|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-27T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-27T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-27T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-27T16:37:08.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-29T11:00:00.000+08:00| 上海| 3002| 100| E| 180| null| 45.1| true| null|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 18
+It costs 0.085s
+```
+
+示例 2:此查询将返回 `table1`中`device`为`101`的记录,并按时间排序。
+
+```sql
+SELECT * FROM table1 t1 where t1.device_id='101' order by time;
+```
+
+查询结果:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| arrival_time|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-27T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-27T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-27T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-27T16:37:08.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 10
+It costs 0.061s
+```
+
+#### 4.1.2 从子查询中查询
+
+示例 1:此查询将返回 `table1` 中的记录总数。
+
+```sql
+SELECT COUNT(*) AS count FROM (SELECT * FROM table1);
+```
+
+查询结果:
+
+```sql
++-----+
+|count|
++-----+
+| 18|
++-----+
+Total line number = 1
+It costs 0.072s
+```
+
+### 4.2 Join 示例
+
+#### 4.2.1 Inner Join
+
+示例 1:显式连接
+
+```sql
+SELECT
+ t1.time,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+ table1 t1 JOIN table2 t2
+ON t1.time = t2.time
+```
+
+查询结果:
+
+```sql
++-----------------------------+-------+------------+-------+------------+
+| time|device1|temperature1|device2|temperature2|
++-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
++-----------------------------+-------+------------+-------+------------+
+Total line number = 3
+It costs 0.076s
+```
+
+示例 2:显式连接
+
+```sql
+SELECT time,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+ table1 t1 JOIN table2 t2
+USING(time)
+```
+
+查询结果:
+
+```sql
++-----------------------------+-------+------------+-------+------------+
+| time|device1|temperature1|device2|temperature2|
++-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
++-----------------------------+-------+------------+-------+------------+
+Total line number = 3
+It costs 0.081s
+```
+
+示例 3:隐式连接
+
+```sql
+SELECT t1.time,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+table1 t1, table2 t2
+WHERE
+t1.time=t2.time
+```
+
+查询结果:
+
+```sql
++-----------------------------+-------+------------+-------+------------+
+| time|device1|temperature1|device2|temperature2|
++-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
++-----------------------------+-------+------------+-------+------------+
+Total line number = 3
+It costs 0.082s
+```
+
+#### 4.2.2 Outer Join
+
+示例 1:显式连接
+
+```sql
+SELECT
+ t1.time as time1, t2.time as time2,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+ table1 t1 FULL JOIN table2 t2
+ON t1.time = t2.time
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------------------------+-------+------------+-------+------------+
+| time1| time2|device1|temperature1|device2|temperature2|
++-----------------------------+-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-26T13:38:00.000+08:00| null| 100| 90.0| null| null|
+| null|2024-11-27T00:00:00.000+08:00| null| null| 101| 85.0|
+|2024-11-27T16:38:00.000+08:00| null| 101| null| null| null|
+|2024-11-27T16:39:00.000+08:00| null| 101| 85.0| null| null|
+|2024-11-27T16:40:00.000+08:00| null| 101| 85.0| null| null|
+|2024-11-27T16:41:00.000+08:00| null| 101| 85.0| null| null|
+|2024-11-27T16:42:00.000+08:00| null| 101| null| null| null|
+|2024-11-27T16:43:00.000+08:00| null| 101| null| null| null|
+|2024-11-27T16:44:00.000+08:00| null| 101| null| null| null|
+|2024-11-28T08:00:00.000+08:00|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| null| 100| null| null| null|
+|2024-11-28T10:00:00.000+08:00| null| 100| 85.0| null| null|
+|2024-11-28T11:00:00.000+08:00| null| 100| 88.0| null| null|
+| null|2024-11-29T00:00:00.000+08:00| null| null| 101| 85.0|
+|2024-11-29T10:00:00.000+08:00| null| 101| 85.0| null| null|
+|2024-11-29T11:00:00.000+08:00|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
+|2024-11-29T18:30:00.000+08:00| null| 100| 90.0| null| null|
+| null|2024-11-30T00:00:00.000+08:00| null| null| 101| 90.0|
+|2024-11-30T09:30:00.000+08:00| null| 101| 90.0| null| null|
+|2024-11-30T14:30:00.000+08:00| null| 101| 90.0| null| null|
++-----------------------------+-----------------------------+-------+------------+-------+------------+
+Total line number = 21
+It costs 0.071s
+```
+
+示例 2:显式连接
+
+```sql
+SELECT
+ time,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+ table1 t1 FULL JOIN table2 t2
+USING(time)
+```
+
+查询结果:
+
+```sql
++-----------------------------+-------+------------+-------+------------+
+| time|device1|temperature1|device2|temperature2|
++-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-26T13:38:00.000+08:00| 100| 90.0| null| null|
+|2024-11-27T00:00:00.000+08:00| null| null| 101| 85.0|
+|2024-11-27T16:38:00.000+08:00| 101| null| null| null|
+|2024-11-27T16:39:00.000+08:00| 101| 85.0| null| null|
+|2024-11-27T16:40:00.000+08:00| 101| 85.0| null| null|
+|2024-11-27T16:41:00.000+08:00| 101| 85.0| null| null|
+|2024-11-27T16:42:00.000+08:00| 101| null| null| null|
+|2024-11-27T16:43:00.000+08:00| 101| null| null| null|
+|2024-11-27T16:44:00.000+08:00| 101| null| null| null|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 100| null| null| null|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0| null| null|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0| null| null|
+|2024-11-29T00:00:00.000+08:00| null| null| 101| 85.0|
+|2024-11-29T10:00:00.000+08:00| 101| 85.0| null| null|
+|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
+|2024-11-29T18:30:00.000+08:00| 100| 90.0| null| null|
+|2024-11-30T00:00:00.000+08:00| null| null| 101| 90.0|
+|2024-11-30T09:30:00.000+08:00| 101| 90.0| null| null|
+|2024-11-30T14:30:00.000+08:00| 101| 90.0| null| null|
++-----------------------------+-------+------------+-------+------------+
+Total line number = 21
+It costs 0.073s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/GroupBy-Clause.md b/src/zh/UserGuide/Master/Table/SQL-Manual/GroupBy-Clause.md
new file mode 100644
index 000000000..c36c93840
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/GroupBy-Clause.md
@@ -0,0 +1,364 @@
+
+
+# GROUP BY 子句
+
+## 1 语法概览
+
+```sql
+GROUP BY expression (',' expression)*
+```
+
+- GROUP BY 子句用于将 SELECT 语句的结果集按指定的列值进行分组计算。这些分组列的值在结果中保持原样,其他列中具备相同分组列值的所有记录通过指定的聚合函数(例如 COUNT、AVG)进行计算。
+
+
+
+
+## 2 注意事项
+
+- 在 SELECT 子句中的项必须包含聚合函数或由出现在 GROUP BY 子句中的列组成。
+
+合法示例:
+
+```sql
+SELECT concat(device_id, model_id), avg(temperature)
+ FROM table1
+ GROUP BY device_id, model_id; -- 合法
+```
+
+执行结果如下:
+
+```sql
++-----+-----+
+|_col0|_col1|
++-----+-----+
+| 100A| 90.0|
+| 100C| 86.0|
+| 100E| 90.0|
+| 101B| 85.0|
+| 101D| 85.0|
+| 101F| 90.0|
++-----+-----+
+Total line number = 6
+It costs 0.094s
+```
+
+不合法示例1:
+
+```sql
+SELECT device_id, temperature
+ FROM table1
+ GROUP BY device_id;-- 不合法
+```
+
+执行结果如下:
+
+```sql
+Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701:
+ 'temperature' must be an aggregate expression or appear in GROUP BY clause
+```
+
+不合法示例2:
+
+```sql
+SELECT device_id, avg(temperature)
+ FROM table1
+ GROUP BY model; -- 不合法
+```
+
+执行结果如下:
+
+```sql
+Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701:
+ Column 'model' cannot be resolved
+```
+
+- 如果没有 GROUP BY 子句,则 SELECT 子句中的所有项要么都包含聚合函数,要么都不包含聚合函数。
+
+合法示例:
+
+```sql
+SELECT COUNT(*), avg(temperature)
+ FROM table1; -- 合法
+```
+
+执行结果如下:
+
+```sql
++-----+-----------------+
+|_col0| _col1|
++-----+-----------------+
+| 18|87.33333333333333|
++-----+-----------------+
+Total line number = 1
+It costs 0.094s
+```
+
+不合法示例:
+
+```sql
+SELECT humidity, avg(temperature) FROM table1; -- 不合法
+```
+
+执行结果如下:
+
+```sql
+Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701:
+ 'humidity' must be an aggregate expression or appear in GROUP BY clause
+```
+
+- group by子句可以使用从 1 开始的常量整数来引用 SELECT 子句中的项,如果常量整数小于1或大于选择项列表的大小,则会抛出错误。
+
+```sql
+SELECT date_bin(1h, time), device_id, avg(temperature)
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ GROUP BY 1, device_id;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------+-----+
+| _col0|device_id|_col2|
++-----------------------------+---------+-----+
+|2024-11-28T08:00:00.000+08:00| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 100| null|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0|
+|2024-11-27T16:00:00.000+08:00| 101| 85.0|
++-----------------------------+---------+-----+
+Total line number = 5
+It costs 0.092s
+```
+
+- 不支持在 group by 子句中使用 select item 的别名。以下 SQL 将抛出错误,可以使用上述 SQL 代替。
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, device_id, avg(temperature)
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ GROUP BY date_bin(1h, time), device_id;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------+-----+
+| hour_time|device_id|_col2|
++-----------------------------+---------+-----+
+|2024-11-28T08:00:00.000+08:00| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 100| null|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0|
+|2024-11-27T16:00:00.000+08:00| 101| 85.0|
++-----------------------------+---------+-----+
+Total line number = 5
+It costs 0.092s
+```
+
+- 只有 COUNT 函数可以与星号(*)一起使用,用于计算表中的总行数。其他聚合函数与`*`一起使用,将抛出错误。
+
+```sql
+SELECT count(*) FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----+
+|_col0|
++-----+
+| 18|
++-----+
+Total line number = 1
+It costs 0.047s
+```
+
+## 3 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例 1:降采样时间序列数据
+
+对设备 101 下述时间范围的温度进行降采样,每小时返回一个平均温度。
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, AVG(temperature) AS avg_temperature
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-30 00:00:00
+ AND device_id='101'
+ GROUP BY 1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------------+
+| hour_time|avg_temperature|
++-----------------------------+---------------+
+|2024-11-29T10:00:00.000+08:00| 85.0|
+|2024-11-27T16:00:00.000+08:00| 85.0|
++-----------------------------+---------------+
+Total line number = 2
+It costs 0.054s
+```
+
+对每个设备过去一天的温度进行降采样,每小时返回一个平均温度。
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, device_id, AVG(temperature) AS avg_temperature
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-30 00:00:00
+ GROUP BY 1, device_id;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------+---------------+
+| hour_time|device_id|avg_temperature|
++-----------------------------+---------+---------------+
+|2024-11-29T11:00:00.000+08:00| 100| null|
+|2024-11-29T18:00:00.000+08:00| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 100| null|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0|
+|2024-11-29T10:00:00.000+08:00| 101| 85.0|
+|2024-11-27T16:00:00.000+08:00| 101| 85.0|
++-----------------------------+---------+---------------+
+Total line number = 8
+It costs 0.081s
+```
+
+有关date_bin函数的更多详细信息可以参见 date_bin (时间分桶规整)函数功能定义
+
+#### 示例 2:查询每个设备的最新数据点
+
+```sql
+SELECT device_id, LAST(temperature), LAST_BY(time, temperature)
+ FROM table1
+ GROUP BY device_id;
+```
+
+执行结果如下:
+
+```sql
++---------+-----+-----------------------------+
+|device_id|_col1| _col2|
++---------+-----+-----------------------------+
+| 100| 90.0|2024-11-29T18:30:00.000+08:00|
+| 101| 90.0|2024-11-30T14:30:00.000+08:00|
++---------+-----+-----------------------------+
+Total line number = 2
+It costs 0.078s
+```
+
+#### 示例 3:计算总行数
+
+计算所有设备的总行数:
+
+```sql
+SELECT COUNT(*) FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----+
+|_col0|
++-----+
+| 18|
++-----+
+Total line number = 1
+It costs 0.060s
+```
+
+计算每个设备的总行数:
+
+```sql
+SELECT device_id, COUNT(*) AS total_rows
+ FROM table1
+ GROUP BY device_id;
+```
+
+执行结果如下:
+
+```sql
++---------+----------+
+|device_id|total_rows|
++---------+----------+
+| 100| 8|
+| 101| 10|
++---------+----------+
+Total line number = 2
+It costs 0.060s
+```
+
+#### 示例 4:没有 group by 子句的聚合
+
+查询所有设备中的最大温度:
+
+```sql
+SELECT MAX(temperature)
+FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----+
+|_col0|
++-----+
+| 90.0|
++-----+
+Total line number = 1
+It costs 0.086s
+```
+
+#### 示例 5:对子查询的结果进行聚合
+
+查询在指定时间段内平均温度超过 80.0 且至少有两次记录的设备和工厂组合:
+
+```sql
+SELECT plant_id, device_id
+FROM (
+ SELECT date_bin(10m, time) AS time, plant_id, device_id, AVG(temperature) AS temp FROM table1 WHERE time >= 2024-11-26 00:00:00 AND time <= 2024-11-29 00:00:00
+ GROUP BY 1, plant_id, device_id
+)
+WHERE temp > 80.0
+GROUP BY plant_id, device_id
+HAVING COUNT(*) > 1;
+```
+
+执行结果如下:
+
+```sql
++--------+---------+
+|plant_id|device_id|
++--------+---------+
+| 1001| 101|
+| 3001| 100|
++--------+---------+
+Total line number = 2
+It costs 0.073s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/Having-Clause.md b/src/zh/UserGuide/Master/Table/SQL-Manual/Having-Clause.md
new file mode 100644
index 000000000..d02911d4a
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/Having-Clause.md
@@ -0,0 +1,95 @@
+
+
+# HAVING 子句
+
+## 1 语法概览
+
+```sql
+HAVING booleanExpression
+```
+
+### 1.1 HAVING 子句
+
+用于在数据分组聚合(GROUP BY)完成后,对聚合结果进行筛选。
+
+#### 注意事项
+
+- 就语法而言,`HAVING`子句与`WHERE`子句相同,WHERE子句在分组聚合之前对数据进行过滤,HAVING子句是对分组聚合后的结果进行过滤。
+
+## 2 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例 1:过滤计数低于特定值的设备
+
+查询将计算 `table1` 表中每个 `device_id` 的条目数,并过滤掉那些计数低于 5 的设备。
+
+```sql
+SELECT device_id, COUNT(*)
+ FROM table1
+ GROUP BY device_id
+ HAVING COUNT(*) >= 5;
+```
+
+执行结果如下:
+
+```sql
++---------+-----+
+|device_id|_col1|
++---------+-----+
+| 100| 8|
+| 101| 10|
++---------+-----+
+Total line number = 2
+It costs 0.063s
+```
+
+### 示例 2:计算每个设备的每小时平均温度并过滤
+
+查询将计算 `table1` 表中每个设备每小时的平均温度,并过滤掉那些平均温度低于 27.2 的设备。
+
+```sql
+SELECT date_bin(1h, time) as hour_time, device_id, AVG(temperature) as avg_temp
+ FROM table1
+ GROUP BY date_bin(1h, time), device_id
+ HAVING AVG(temperature) >= 85.0;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------+--------+
+| hour_time|device_id|avg_temp|
++-----------------------------+---------+--------+
+|2024-11-29T18:00:00.000+08:00| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0|
+|2024-11-26T13:00:00.000+08:00| 100| 90.0|
+|2024-11-30T09:00:00.000+08:00| 101| 90.0|
+|2024-11-30T14:00:00.000+08:00| 101| 90.0|
+|2024-11-29T10:00:00.000+08:00| 101| 85.0|
+|2024-11-27T16:00:00.000+08:00| 101| 85.0|
++-----------------------------+---------+--------+
+Total line number = 9
+It costs 0.079s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/Identifier.md b/src/zh/UserGuide/Master/Table/SQL-Manual/Identifier.md
new file mode 100644
index 000000000..fcb5fa61c
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/Identifier.md
@@ -0,0 +1,83 @@
+
+
+# 标识符
+
+在 IoTDB 中,标识符用于标识 database、table、column、function 或其他对象名称。
+
+## 1 命名规则
+
+- __开头字符__:标识符必须以字母开头。
+- __后续字符__:可以包含字母、数字和下划线。
+- __特殊字符__:如果标识符包含除字母、数字和下划线之外的其他字符,必须用双引号(`"`)括起来。
+- __转义字符__:在双引号定界的标识符中,使用两个连续的双引号(`""`)来表示一个双引号字符。
+
+### 1.1 示例
+
+以下是一些有效的标识符示例:
+
+```sql
+test
+"table$partitions"
+"identifierWith"
+"double"
+"quotes"
+```
+
+无效的标识符示例,使用时必须用双引号引用:
+
+```sql
+table-name // 包含短横线
+123SchemaName // 以数字开头
+colum$name@field // 包含特殊字符且未用双引号括起
+```
+
+## 2 大小写敏感性
+
+标识符不区分大小写,且系统存储标识符时不保留原始大小写,查询结果会根据用户在`SELECT`子句中指定的大小写显示列名。
+
+> 双引号括起来的标识符也不区分大小写。
+
+### 2.1 示例
+
+当创建了一个名为 `Device_id` 的列,在查看表时看到为 `device_id`,但返回的结果列与用户查询时指定的格式保持相同为`Device_ID`:
+
+```sql
+IoTDB> create table table1(Device_id STRING TAG, Model STRING ATTRIBUTE, TemPerature FLOAT FIELD, Humidity DOUBLE FIELD)
+
+IoTDB> desc table1;
++-----------+---------+-----------+
+| ColumnName| DataType| Category|
++-----------+---------+-----------+
+| time|TIMESTAMP| TIME|
+| device_id| STRING| TAG|
+| model| STRING| ATTRIBUTE|
+|temperature| FLOAT| FIELD|
+| humidity| DOUBLE| FIELD|
++-----------+---------+-----------+
+
+IoTDB> select TiMe, Device_ID, MoDEL, TEMPerature, HUMIdity from table1;
++-----------------------------+---------+------+-----------+--------+
+| TiMe|Device_ID| MoDEL|TEMPerature|HUMIdity|
++-----------------------------+---------+------+-----------+--------+
+|1970-01-01T08:00:00.001+08:00| d1|modelY| 27.2| 67.0|
++-----------------------------+---------+------+-----------+--------+
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/Keywords.md b/src/zh/UserGuide/Master/Table/SQL-Manual/Keywords.md
new file mode 100644
index 000000000..80a16414e
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/Keywords.md
@@ -0,0 +1,107 @@
+
+
+# 保留字&关键字
+
+保留关键字必须被双引号(`"`)引用才能用作标识符。以下是 IoTDB 表模型中的所有保留字:
+
+- ALTER
+- AND
+- AS
+- BETWEEN
+- BY
+- CASE
+- CAST
+- CONSTRAINT
+- CREATE
+- CROSS
+- CUBE
+- CURRENT_CATALOG
+- CURRENT_DATE
+- CURRENT_PATH
+- CURRENT_ROLE
+- CURRENT_SCHEMA
+- CURRENT_TIME
+- CURRENT_TIMESTAMP
+- CURRENT_USER
+- DEALLOCATE
+- DELETE
+- DESCRIBE
+- DISTINCT
+- DROP
+- ELSE
+- END
+- ESCAPE
+- EXCEPT
+- EXISTS
+- EXTRACT
+- FALSE
+- FOR
+- FROM
+- FULL
+- GROUP
+- GROUPING
+- HAVING
+- IN
+- INNER
+- INSERT
+- INTERSECT
+- INTO
+- IS
+- JOIN
+- JSON_ARRAY
+- JSON_EXISTS
+- JSON_OBJECT
+- JSON_QUERY
+- JSON_TABLE
+- JSON_VALUE
+- LEFT
+- LIKE
+- LISTAGG
+- LOCALTIME
+- LOCALTIMESTAMP
+- NATURAL
+- NORMALIZE
+- NOT
+- NULL
+- ON
+- OR
+- ORDER
+- OUTER
+- PREPARE
+- RECURSIVE
+- RIGHT
+- ROLLUP
+- SELECT
+- SKIP
+- TABLE
+- THEN
+- TRIM
+- TRUE
+- UESCAPE
+- UNION
+- UNNEST
+- USING
+- VALUES
+- WHEN
+- WHERE
+- WITH
+- FILL
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/Limit-Offset-Clause.md b/src/zh/UserGuide/Master/Table/SQL-Manual/Limit-Offset-Clause.md
new file mode 100644
index 000000000..4a18e7632
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/Limit-Offset-Clause.md
@@ -0,0 +1,128 @@
+
+
+# LIMIT 和 OFFSET 子句
+
+## 1 语法概览
+
+```sql
+OFFSET INTEGER_VALUE LIMIT INTEGER_VALUE
+```
+
+### 1.1 LIMIT 子句
+
+LIMIT 子句应用在查询的最后阶段,用于限制返回的行数。
+
+#### 注意事项
+
+- 在没有 ORDER BY 子句的情况下使用 LIMIT,查询结果的顺序可能是不确定的。
+- LIMIT 子句必须使用非负整数。
+
+### 1.2 OFFSET 子句
+
+OFFSET 子句与 LIMIT 子句配合使用,用于指定查询结果跳过前 OFFSET 行,以实现分页或特定位置的数据检索。
+
+#### 注意事项
+
+- OFFSET 子句必须接一个非负整数。
+- 如果总记录数`n >= OFFSET+LIMIT`之和,返回`LIMIT`数量的记录。
+- 如果总记录数`n < OFFSET+LIMIT`之和,返回从`OFFSET`开始到末尾的所有记录,最多`n-offset`条。
+
+## 2 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例 1:查询设备的最新行
+
+```sql
+SELECT *
+ FROM table1
+ ORDER BY time DESC
+ LIMIT 1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 1
+It costs 0.103s
+```
+
+#### 示例 2:查询温度最高的前10行数据
+
+```sql
+SELECT *
+ FROM table1
+ ORDER BY temperature DESC NULLS LAST
+ LIMIT 10;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 10
+It costs 0.063s
+```
+
+#### 示例 3:从特定位置选择5行数据
+
+```sql
+SELECT *
+ FROM table1
+ ORDER BY TIME
+ OFFSET 5
+ LIMIT 5;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 5
+It costs 0.069s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/OrderBy-Clause.md b/src/zh/UserGuide/Master/Table/SQL-Manual/OrderBy-Clause.md
new file mode 100644
index 000000000..f5be7a4f8
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/OrderBy-Clause.md
@@ -0,0 +1,135 @@
+
+
+# ORDER BY 子句
+
+## 1 语法概览
+
+```sql
+ORDER BY sortItem (',' sortItem)*
+
+sortItem
+ : expression (ASC | DESC)? (NULLS (FIRST | LAST))?
+ ;
+```
+
+### 1.1 ORDER BY 子句
+
+- 用于在查询的最后阶段对结果集进行排序,能够根据指定的排序条件,将查询结果中的行按照升序(ASC)或降序(DESC)进行排列。
+- 提供了对 NULL 值排序位置的控制,允许用户指定 NULL 值是排在结果的开头(NULLS FIRST)还是结尾(NULLS LAST)。
+- 默认情况下, 将采用 ASC NULLS LAST排序,即值按升序排序,空值放在最后。可以通过手动指定其他参数更改默认排序顺序。
+- ORDER BY 子句的执行顺序排在 LIMIT 或 OFFSET 子句之前。
+
+## 2 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例 1: 按时间降序查询过去一小时的数据
+
+```sql
+SELECT *
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ ORDER BY time DESC;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 11
+It costs 0.148s
+```
+
+#### 示例 2: 按 `device_id` 升序和时间降序查询所有设备过去一小时的数据,空 `temperature` 优先显示
+
+```sql
+SELECT *
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ ORDER BY temperature NULLS FIRST, time DESC;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 11
+It costs 0.060s
+```
+
+#### 示例 3: 查询温度最高的前10行数据
+
+```sql
+SELECT *
+ FROM table1
+ ORDER BY temperature DESC NULLS LAST
+ LIMIT 10;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 10
+It costs 0.069s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/Select-Clause.md b/src/zh/UserGuide/Master/Table/SQL-Manual/Select-Clause.md
new file mode 100644
index 000000000..ebf97c93a
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/Select-Clause.md
@@ -0,0 +1,250 @@
+
+
+# SELECT 子句
+
+## 1 语法概览
+
+```sql
+SELECT selectItem (',' selectItem)*
+
+selectItem
+ : expression (AS? identifier)? #selectSingle
+ | tableName '.' ASTERISK (AS columnAliases)? #selectAll
+ | ASTERISK #selectAll
+ ;
+```
+
+- __SELECT 子句__: 指定了查询结果应包含的列,包含聚合函数(如 SUM、AVG、COUNT 等)以及窗口函数,在逻辑上最后执行。
+
+## 2 语法详释:
+
+每个 `selectItem` 可以是以下形式之一:
+
+- __表达式__: `expression [ [ AS ] column_alias ]` 定义单个输出列,可以指定列别名。
+- __选择某个关系的所有列__: `relation.*` 选择某个关系的所有列,不允许使用列别名。
+- __选择结果集中的所有列__: `*` 选择查询的所有列,不允许使用列别名。
+
+## 3 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+### 3.1 选择列表
+
+#### 3.1.1 星表达式
+
+使用星号(*)可以选取表中的所有列,__注意__,星号表达式不能被大多数函数转换,除了`count(*)`的情况。
+
+示例:从表中选择所有列
+
+```sql
+SELECT * FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-29T11:00:00.000+08:00| 上海| 3002| 100| E| 180| null| 45.1| true| null|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 18
+It costs 0.653s
+```
+
+#### 3.1.2 聚合函数
+
+聚合函数将多行数据汇总为单个值。当 SELECT 子句中存在聚合函数时,查询将被视为聚合查询。在聚合查询中,所有表达式必须是聚合函数的一部分或由[GROUP BY子句](../SQL-Manual/GroupBy-Clause.md)指定的分组的一部分。
+
+示例1:返回地址表中的总行数:
+
+```sql
+SELECT count(*) FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----+
+|_col0|
++-----+
+| 18|
++-----+
+Total line number = 1
+It costs 0.091s
+```
+
+示例2:返回按城市分组的地址表中的总行数:
+
+```sql
+SELECT region, count(*)
+ FROM table1
+ GROUP BY region;
+```
+
+执行结果如下:
+
+```sql
++------+-----+
+|region|_col1|
++------+-----+
+| 上海| 9|
+| 北京| 9|
++------+-----+
+Total line number = 2
+It costs 0.071s
+```
+
+#### 3.1.3 别名
+
+关键字`AS`:为选定的列指定别名,别名将覆盖已存在的列名,以提高查询结果的可读性。
+
+示例1:原始表格:
+
+```sql
+IoTDB> SELECT * FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-29T11:00:00.000+08:00| 上海| 3002| 100| E| 180| null| 45.1| true| null|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 18
+It costs 0.653s
+```
+
+示例2:单列设置别名:
+
+```sql
+IoTDB> SELECT device_id
+ AS device
+ FROM table1;
+```
+
+执行结果如下:
+
+```sql
++------+
+|device|
++------+
+| 100|
+| 100|
+| 100|
+| 100|
+| 100|
+| 100|
+| 100|
+| 100|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
++------+
+Total line number = 18
+It costs 0.053s
+```
+
+示例3:所有列的别名:
+
+```sql
+IoTDB> SELECT table1.*
+ AS (timestamp, Reg, Pl, DevID, Mod, Mnt, Temp, Hum, Stat,MTime)
+ FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+----+----+-----+---+---+----+----+-----+-----------------------------+
+| TIMESTAMP| REG| PL|DEVID|MOD|MNT|TEMP| HUM| STAT| MTIME|
++-----------------------------+----+----+-----+---+---+----+----+-----+-----------------------------+
+|2024-11-29T11:00:00.000+08:00|上海|3002| 100| E|180|null|45.1| true| null|
+|2024-11-29T18:30:00.000+08:00|上海|3002| 100| E|180|90.0|35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T08:00:00.000+08:00|上海|3001| 100| C| 90|85.0|null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00|上海|3001| 100| C| 90|null|40.9| true| null|
+|2024-11-28T10:00:00.000+08:00|上海|3001| 100| C| 90|85.0|35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00|上海|3001| 100| C| 90|88.0|45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-26T13:37:00.000+08:00|北京|1001| 100| A|180|90.0|35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00|北京|1001| 100| A|180|90.0|35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T09:30:00.000+08:00|上海|3002| 101| F|360|90.0|35.2| true| null|
+|2024-11-30T14:30:00.000+08:00|上海|3002| 101| F|360|90.0|34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-29T10:00:00.000+08:00|上海|3001| 101| D|360|85.0|null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:38:00.000+08:00|北京|1001| 101| B|180|null|35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00|北京|1001| 101| B|180|85.0|35.3| null| null|
+|2024-11-27T16:40:00.000+08:00|北京|1001| 101| B|180|85.0|null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00|北京|1001| 101| B|180|85.0|null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00|北京|1001| 101| B|180|null|35.2|false| null|
+|2024-11-27T16:43:00.000+08:00|北京|1001| 101| B|180|null|null|false| null|
+|2024-11-27T16:44:00.000+08:00|北京|1001| 101| B|180|null|null|false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+----+----+-----+---+---+----+----+-----+-----------------------------+
+Total line number = 18
+It costs 0.189s
+```
+
+## 4 结果集列顺序
+
+- __列顺序__: 结果集中的列顺序与 SELECT 子句中指定的顺序相同。
+- __多列排序__: 如果选择表达式返回多个列,它们的排序方式与源关系中的排序方式相同
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/Where-Clause.md b/src/zh/UserGuide/Master/Table/SQL-Manual/Where-Clause.md
new file mode 100644
index 000000000..82c4d2cc4
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/Where-Clause.md
@@ -0,0 +1,112 @@
+
+
+# WHERE 子句
+
+## 1 语法概览
+
+```sql
+WHERE booleanExpression
+```
+
+__WHERE 子句__:用于在 SQL 查询中指定筛选条件,WHERE 子句在 FROM 子句之后立即执行。
+
+## 2 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例1:选择特定 ID 的行
+
+```sql
+SELECT * FROM table1 WHERE plant_id = '1001';
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 9
+It costs 0.091s
+```
+
+#### 示例2:选择使用 LIKE 表达式匹配
+
+```sql
+SELECT * FROM table1 WHERE plant_id LIKE '300%';
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-29T11:00:00.000+08:00| 上海| 3002| 100| E| 180| null| 45.1| true| null|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 9
+It costs 0.261s
+```
+
+#### 示例3:选择使用复合表达式筛选
+
+```sql
+SELECT * FROM table1 WHERE time >= 2024-11-28 00:00:00 and (plant_id = '3001' OR plant_id = '3002');
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 9
+It costs 0.091s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/SQL-Manual/overview.md b/src/zh/UserGuide/Master/Table/SQL-Manual/overview.md
new file mode 100644
index 000000000..afe7a9d58
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/SQL-Manual/overview.md
@@ -0,0 +1,60 @@
+
+
+# 概览
+
+## 1 语法概览
+
+```SQL
+SELECT ⟨select_list⟩
+ FROM ⟨tables⟩
+ [WHERE ⟨condition⟩]
+ [GROUP BY ⟨groups⟩]
+ [HAVING ⟨group_filter⟩]
+ [FILL ⟨fill_methods⟩]
+ [ORDER BY ⟨order_expression⟩]
+ [OFFSET ⟨n⟩]
+ [LIMIT ⟨n⟩];
+```
+
+IoTDB 查询语法提供以下子句:
+
+- SELECT 子句:查询结果应包含的列。详细语法见:[SELECT子句](../SQL-Manual/Select-Clause.md)
+- FROM 子句:指出查询的数据源,可以是单个表、多个通过 `JOIN` 子句连接的表,或者是一个子查询。详细语法见:[FROM & JOIN 子句](../SQL-Manual/From-Join-Clause.md)
+- WHERE 子句:用于过滤数据,只选择满足特定条件的数据行。这个子句在逻辑上紧跟在 FROM 子句之后执行。详细语法见:[WHERE 子句](../SQL-Manual/Where-Clause.md)
+- GROUP BY 子句:当需要对数据进行聚合时使用,指定了用于分组的列。详细语法见:[GROUP BY 子句](../SQL-Manual/GroupBy-Clause.md)
+- HAVING 子句:在 GROUP BY 子句之后使用,用于对已经分组的数据进行过滤。与 WHERE 子句类似,但 HAVING 子句在分组后执行。详细语法见:[HAVING 子句](../SQL-Manual/Having-Clause.md)
+- FILL 子句:用于处理查询结果中的空值,用户可以使用 FILL 子句来指定数据缺失时的填充模式(如前一个非空值或线性插值)来填充 null 值,以便于数据可视化和分析。 详细语法见:[FILL 子句](../SQL-Manual/Fill-Clause.md)
+- ORDER BY 子句:对查询结果进行排序,可以指定升序(ASC)或降序(DESC),以及 NULL 值的处理方式(NULLS FIRST 或 NULLS LAST)。详细语法见:[ORDER BY 子句](../SQL-Manual/OrderBy-Clause.md)
+- OFFSET 子句:用于指定查询结果的起始位置,即跳过前 OFFSET 行。与 LIMIT 子句配合使用。详细语法见:[LIMIT 和 OFFSET 子句](../SQL-Manual/Limit-Offset-Clause.md)
+- LIMIT 子句:限制查询结果的行数,通常与 OFFSET 子句一起使用以实现分页功能。详细语法见:[LIMIT 和 OFFSET 子句](../SQL-Manual/Limit-Offset-Clause.md)
+
+## 2 子句执行顺序
+
+1. FROM(表名)
+2. WHERE(条件过滤)
+3. SELECT(列名/表达式)
+4. GROUP BY (分组)
+5. HAVING(分组后的条件过滤)
+6. FILL(空值填充)
+7. ORDER BY(排序)
+8. OFFSET(偏移量)
+9. LIMIT(限制数量)
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/Technical-Insider/Cluster-data-partitioning.md b/src/zh/UserGuide/Master/Table/Technical-Insider/Cluster-data-partitioning.md
new file mode 100644
index 000000000..6b5c017c9
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Technical-Insider/Cluster-data-partitioning.md
@@ -0,0 +1,111 @@
+
+
+# 数据分区和负载均衡
+
+本文档介绍 IoTDB 中的分区策略和负载均衡策略。根据时序数据的特性,IoTDB 按序列和时间维度对其进行分区。结合序列分区与时间分区创建一个分区,作为划分的基本单元。为了提高吞吐量并降低管理成本,这些分区被均匀分配到分片(Region)中,分片是复制的基本单元。分片的副本决定了数据的存储位置,主副本负责主要负载的管理。在此过程中,副本放置算法决定哪些节点将持有分片副本,而主副本选择算法则指定哪个副本将成为主副本。
+
+## 1 分区策略和分区分配
+IoTDB 为时间序列数据实现了量身定制的分区算法。在此基础上,缓存于配置节点和数据节点上的分区信息不仅易于管理,而且能够清晰区分冷热数据。随后,平衡的分区被均匀分配到集群的分片中,以实现存储均衡。
+
+### 1.1 分区策略
+IoTDB 将生产环境中的每个传感器映射为一个时间序列。然后,使用序列分区算法对时间序列进行分区以管理其元数据,再结合时间分区算法来管理其数据。下图展示了 IoTDB 如何对时序数据进行分区。
+
+ +
+#### 1.1.1 分区算法
+由于生产环境中通常部署大量设备和传感器,IoTDB 使用序列分区算法以确保分区信息的大小可控。由于生成的时间序列与时间戳相关联,IoTDB 使用时间分区算法来清晰区分冷热分区。
+
+##### 1.1.1.1 序列分区算法
+默认情况下,IoTDB 将序列分区的数量限制为 1000,并将序列分区算法配置为哈希分区算法。这带来以下收益:
++ 由于序列分区的数量是固定常量,序列与序列分区之间的映射保持稳定。因此,IoTDB 不需要频繁进行数据迁移。
++ 序列分区的负载相对均衡,因为序列分区的数量远小于生产环境中部署的传感器数量。
+
+更进一步,如果能够更准确地估计生产环境中的实际负载情况,序列分区算法可以配置为自定义的哈希分区或列表分区,以在所有序列分区中实现更均匀的负载分布。
+
+##### 1.1.1.2 时间分区算法
+时间分区算法通过下式将给定的时间戳转换为相应的时间分区
+
+$$\left\lfloor\frac{\text{Timestamp}-\text{StartTimestamp}}{\text{TimePartitionInterval}}\right\rfloor\text{。}$$
+
+在此式中,$\text{StartTimestamp}$ 和 $\text{TimePartitionInterval}$ 都是可配置参数,以适应不同的生产环境。$\text{StartTimestamp}$ 表示第一个时间分区的起始时间,而 $\text{TimePartitionInterval}$ 定义了每个时间分区的持续时间。默认情况下,$\text{TimePartitionInterval}$ 设置为七天。
+
+#### 1.1.2 元数据分区
+由于序列分区算法对时间序列进行了均匀分区,每个序列分区对应一个元数据分区。这些元数据分区随后被均匀分配到 元数据分片 中,以实现元数据的均衡分布。
+
+#### 1.1.3 数据分区
+结合序列分区与时间分区创建数据分区。由于序列分区算法对时间序列进行了均匀分区,特定时间分区内的数据分区负载保持均衡。这些数据分区随后被均匀分配到数据分片中,以实现数据的均衡分布。
+
+### 1.2 分区分配
+IoTDB 使用分片来实现时间序列的弹性存储,集群中分片的数量由所有数据节点的总资源决定。由于分片的数量是动态的,IoTDB 可以轻松扩展。元数据分片和数据分片都遵循相同的分区分配算法,即均匀划分所有序列分区。下图展示了分区分配过程,其中动态扩展的分片匹配不断扩展的时间序列和集群。
+
+
+
+#### 1.1.1 分区算法
+由于生产环境中通常部署大量设备和传感器,IoTDB 使用序列分区算法以确保分区信息的大小可控。由于生成的时间序列与时间戳相关联,IoTDB 使用时间分区算法来清晰区分冷热分区。
+
+##### 1.1.1.1 序列分区算法
+默认情况下,IoTDB 将序列分区的数量限制为 1000,并将序列分区算法配置为哈希分区算法。这带来以下收益:
++ 由于序列分区的数量是固定常量,序列与序列分区之间的映射保持稳定。因此,IoTDB 不需要频繁进行数据迁移。
++ 序列分区的负载相对均衡,因为序列分区的数量远小于生产环境中部署的传感器数量。
+
+更进一步,如果能够更准确地估计生产环境中的实际负载情况,序列分区算法可以配置为自定义的哈希分区或列表分区,以在所有序列分区中实现更均匀的负载分布。
+
+##### 1.1.1.2 时间分区算法
+时间分区算法通过下式将给定的时间戳转换为相应的时间分区
+
+$$\left\lfloor\frac{\text{Timestamp}-\text{StartTimestamp}}{\text{TimePartitionInterval}}\right\rfloor\text{。}$$
+
+在此式中,$\text{StartTimestamp}$ 和 $\text{TimePartitionInterval}$ 都是可配置参数,以适应不同的生产环境。$\text{StartTimestamp}$ 表示第一个时间分区的起始时间,而 $\text{TimePartitionInterval}$ 定义了每个时间分区的持续时间。默认情况下,$\text{TimePartitionInterval}$ 设置为七天。
+
+#### 1.1.2 元数据分区
+由于序列分区算法对时间序列进行了均匀分区,每个序列分区对应一个元数据分区。这些元数据分区随后被均匀分配到 元数据分片 中,以实现元数据的均衡分布。
+
+#### 1.1.3 数据分区
+结合序列分区与时间分区创建数据分区。由于序列分区算法对时间序列进行了均匀分区,特定时间分区内的数据分区负载保持均衡。这些数据分区随后被均匀分配到数据分片中,以实现数据的均衡分布。
+
+### 1.2 分区分配
+IoTDB 使用分片来实现时间序列的弹性存储,集群中分片的数量由所有数据节点的总资源决定。由于分片的数量是动态的,IoTDB 可以轻松扩展。元数据分片和数据分片都遵循相同的分区分配算法,即均匀划分所有序列分区。下图展示了分区分配过程,其中动态扩展的分片匹配不断扩展的时间序列和集群。
+
+ +
+#### 1.2.1 分片扩容
+分片的数量由下式给出
+
+$$\text{RegionGroupNumber}=\left\lfloor\frac{\sum_{i=1}^{DataNodeNumber}\text{RegionNumber}_i}{\text{ReplicationFactor}}\right\rfloor\text{。}$$
+
+在此式中,$\text{RegionNumber}_i$ 表示期望在第 $i$ 个数据节点上放置的副本数量,而 $\text{ReplicationFactor}$ 表示每个分片中的副本数量。$\text{RegionNumber}_i$ 和 $\text{ReplicationFactor}$ 都是可配置的参数。$\text{RegionNumber}_i$ 可以根据第 $i$ 个数据节点上的可用硬件资源(如 CPU 核心数量、内存大小等)确定,以适应不同的物理服务器。$\text{ReplicationFactor}$ 可以调整以确保不同级别的容错能力。
+
+#### 1.2.2 分配策略
+元数据分片和数据分片都遵循相同的分配策略,即均匀划分所有序列分区。因此,每个元数据分片持有相同数量的元数据分区,以确保元数据存储均衡。同样,对于每个时间分区,每个数据分片 获取与其持有的序列分区对应的数据分区。因此,时间分区内的数据分区均匀分布在所有数据分片中,确保每个时间分区内的数据存储均衡。
+
+值得注意的是,IoTDB 有效利用了时序数据的特性。当配置了 TTL(生存时间)时,IoTDB 可实现无需迁移的时序数据弹性存储,该功能在集群扩展时最小化了对在线操作的影响。上图展示了该功能的一个实例:新生成的数据分区被均匀分配到每个数据分片,过期数据会自动归档。因此,集群的存储最终将保持平衡。
+
+## 2 均衡策略
+为了提高集群的可用性和性能,IoTDB 采用了精心设计的存储均衡和计算均衡算法。
+
+### 2.1 存储均衡
+数据节点持有的副本数量反映了它的存储负载。如果数据节点之间的副本数量差异较大,拥有更多副本的数据节点可能成为存储瓶颈。尽管简单的轮询(Round Robin)放置算法可以通过确保每个数据节点持有等量副本来实现存储均衡,但它会降低集群的容错能力,如下所示:
+
+
+
+#### 1.2.1 分片扩容
+分片的数量由下式给出
+
+$$\text{RegionGroupNumber}=\left\lfloor\frac{\sum_{i=1}^{DataNodeNumber}\text{RegionNumber}_i}{\text{ReplicationFactor}}\right\rfloor\text{。}$$
+
+在此式中,$\text{RegionNumber}_i$ 表示期望在第 $i$ 个数据节点上放置的副本数量,而 $\text{ReplicationFactor}$ 表示每个分片中的副本数量。$\text{RegionNumber}_i$ 和 $\text{ReplicationFactor}$ 都是可配置的参数。$\text{RegionNumber}_i$ 可以根据第 $i$ 个数据节点上的可用硬件资源(如 CPU 核心数量、内存大小等)确定,以适应不同的物理服务器。$\text{ReplicationFactor}$ 可以调整以确保不同级别的容错能力。
+
+#### 1.2.2 分配策略
+元数据分片和数据分片都遵循相同的分配策略,即均匀划分所有序列分区。因此,每个元数据分片持有相同数量的元数据分区,以确保元数据存储均衡。同样,对于每个时间分区,每个数据分片 获取与其持有的序列分区对应的数据分区。因此,时间分区内的数据分区均匀分布在所有数据分片中,确保每个时间分区内的数据存储均衡。
+
+值得注意的是,IoTDB 有效利用了时序数据的特性。当配置了 TTL(生存时间)时,IoTDB 可实现无需迁移的时序数据弹性存储,该功能在集群扩展时最小化了对在线操作的影响。上图展示了该功能的一个实例:新生成的数据分区被均匀分配到每个数据分片,过期数据会自动归档。因此,集群的存储最终将保持平衡。
+
+## 2 均衡策略
+为了提高集群的可用性和性能,IoTDB 采用了精心设计的存储均衡和计算均衡算法。
+
+### 2.1 存储均衡
+数据节点持有的副本数量反映了它的存储负载。如果数据节点之间的副本数量差异较大,拥有更多副本的数据节点可能成为存储瓶颈。尽管简单的轮询(Round Robin)放置算法可以通过确保每个数据节点持有等量副本来实现存储均衡,但它会降低集群的容错能力,如下所示:
+
+ +
++ 假设集群有 4 个数据节点,4 个分片,并且副本因子为 2。
++ 将分片 $r_1$ 的 2 个副本放置在数据节点 $n_1$ 和 $n_2$ 上。
++ 将分片 $r_2$ 的 2 个副本放置在数据节点 $n_3$ 和 $n_4$ 上。
++ 将分片 $r_3$ 的 2 个副本放置在数据节点 $n_1$ 和 $n_3$ 上。
++ 将分片 $r_4$ 的 2 个副本放置在数据节点 $n_2$ 和 $n_4$ 上。
+
+在这种情况下,如果数据节点 $n_2$ 发生故障,由它先前负责的负载将只能全部转移到数据节点 $n_1$,可能导致其过载。
+
+为了解决这个问题,IoTDB 采用了一种副本放置算法,该算法不仅将副本均匀放置到所有数据节点上,还确保每个 数据节点在发生故障时,能够将其负载转移到足够多的其他数据节点。因此,集群实现了存储分布的均衡,并具备较高的容错能力,从而确保其可用性。
+
+### 2.2 计算均衡
+数据节点持有的主副本数量反映了它的计算负载。如果数据节点之间持有主副本数量差异较大,拥有更多主副本的数据节点可能成为计算瓶颈。如果主副本选择过程使用直观的贪心算法,当副本以容错算法放置时,可能会导致主副本分布不均,如下所示:
+
+
+
++ 假设集群有 4 个数据节点,4 个分片,并且副本因子为 2。
++ 将分片 $r_1$ 的 2 个副本放置在数据节点 $n_1$ 和 $n_2$ 上。
++ 将分片 $r_2$ 的 2 个副本放置在数据节点 $n_3$ 和 $n_4$ 上。
++ 将分片 $r_3$ 的 2 个副本放置在数据节点 $n_1$ 和 $n_3$ 上。
++ 将分片 $r_4$ 的 2 个副本放置在数据节点 $n_2$ 和 $n_4$ 上。
+
+在这种情况下,如果数据节点 $n_2$ 发生故障,由它先前负责的负载将只能全部转移到数据节点 $n_1$,可能导致其过载。
+
+为了解决这个问题,IoTDB 采用了一种副本放置算法,该算法不仅将副本均匀放置到所有数据节点上,还确保每个 数据节点在发生故障时,能够将其负载转移到足够多的其他数据节点。因此,集群实现了存储分布的均衡,并具备较高的容错能力,从而确保其可用性。
+
+### 2.2 计算均衡
+数据节点持有的主副本数量反映了它的计算负载。如果数据节点之间持有主副本数量差异较大,拥有更多主副本的数据节点可能成为计算瓶颈。如果主副本选择过程使用直观的贪心算法,当副本以容错算法放置时,可能会导致主副本分布不均,如下所示:
+
+ +
++ 假设集群有 4 个数据节点,4 个分片,并且副本因子为 2。
++ 选择分片 $r_5$ 在数据节点 $n_5$ 上的副本作为主副本。
++ 选择分片 $r_6$ 在数据节点 $n_7$ 上的副本作为主副本。
++ 选择分片 $r_7$ 在数据节点 $n_7$ 上的副本作为主副本。
++ 选择分片 $r_8$ 在数据节点 $n_8$ 上的副本作为主副本。
+
+请注意,以上步骤严格遵循贪心算法。然而,到第 3 步时,无论在数据节点 $n_5$ 或 $n_7$ 上选择分片 $r_7$ 的主副本,都会导致主副本分布不均衡。根本原因在于每一步贪心选择都缺乏全局视角,最终导致局部最优解。
+
+为了解决这个问题,IoTDB 采用了一种主副本选择算法,能够持续平衡集群中的主副本分布。因此,集群实现了计算负载的均衡分布,确保了其性能。
+
+## 3 Source Code
++ [数据分区](https://github.com/apache/iotdb/tree/master/iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/partition)
++ [分区分配](https://github.com/apache/iotdb/tree/master/iotdb-core/confignode/src/main/java/org/apache/iotdb/confignode/manager/load/balancer/partition)
++ [副本放置](https://github.com/apache/iotdb/tree/master/iotdb-core/confignode/src/main/java/org/apache/iotdb/confignode/manager/load/balancer/副本)
++ [主副本选择](https://github.com/apache/iotdb/tree/master/iotdb-core/confignode/src/main/java/org/apache/iotdb/confignode/manager/load/balancer/router/主副本)
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/Technical-Insider/Encoding-and-Compression.md b/src/zh/UserGuide/Master/Table/Technical-Insider/Encoding-and-Compression.md
new file mode 100644
index 000000000..2a4885b3d
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Technical-Insider/Encoding-and-Compression.md
@@ -0,0 +1,123 @@
+
+
+# 编码和压缩
+
+## 1 编码方式
+
+### 1.1 基本编码方式
+
+为了提高数据的存储效率,需要在数据写入的过程中对数据进行编码,从而减少磁盘空间的使用量。在写数据以及读数据的过程中都能够减少 I/O 操作的数据量从而提高性能。IoTDB 支持多种针对不同类型的数据的编码方法:
+
+1. PLAIN 编码(PLAIN)
+
+ PLAIN 编码,默认的编码方式,即不编码,支持多种数据类型,压缩和解压缩的时间效率较高,但空间存储效率较低。
+
+2. 二阶差分编码(TS_2DIFF)
+
+ 二阶差分编码,比较适合编码单调递增或者递减的序列数据,不适合编码波动较大的数据。
+
+3. 游程编码(RLE)
+
+ 游程编码,比较适合存储某些数值连续出现的序列,不适合编码大部分情况下前后值不一样的序列数据。
+
+ 游程编码也可用于对浮点数进行编码,但在创建时间序列的时候需指定保留小数位数。比较适合存储某些浮点数值连续出现的序列数据,不适合存储对小数点后精度要求较高以及前后波动较大的序列数据。
+
+ > 游程编码(RLE)和二阶差分编码(TS_2DIFF)对 float 和 double 的编码是有精度限制的,默认保留 2 位小数。推荐使用 GORILLA。
+
+4. GORILLA 编码(GORILLA)
+
+ GORILLA 编码是一种无损编码,它比较适合编码前后值比较接近的数值序列,不适合编码前后波动较大的数据。
+
+ 当前系统中存在两个版本的 GORILLA 编码实现,推荐使用`GORILLA`,不推荐使用`GORILLA_V1`(已过时)。
+
+ 使用限制:使用 Gorilla 编码 INT32 数据时,需要保证序列中不存在值为`Integer.MIN_VALUE`的数据点;使用 Gorilla 编码 INT64 数据时,需要保证序列中不存在值为`Long.MIN_VALUE`的数据点。
+
+5. 字典编码 (DICTIONARY)
+
+ 字典编码是一种无损编码。它适合编码基数小的数据(即数据去重后唯一值数量小)。不推荐用于基数大的数据。
+
+6. ZIGZAG 编码
+
+ ZigZag编码将有符号整型映射到无符号整型,适合比较小的整数。
+
+7. CHIMP 编码
+
+ CHIMP 是一种无损编码。它是一种新的流式浮点数据压缩算法,可以节省存储空间。这个编码适用于前后值比较接近的数值序列,对波动小和随机噪声少的序列数据更加友好。
+
+ 使用限制:如果对 INT32 类型数据使用 CHIMP 编码,需要确保数据点中没有 `Integer.MIN_VALUE`。 如果对 INT64 类型数据使用 CHIMP 编码,需要确保数据点中没有 `Long.MIN_VALUE`。
+
+8. SPRINTZ 编码
+
+ SPRINTZ编码是一种无损编码,将原始时序数据分别进行预测、Zigzag编码、位填充和游程编码。SPRINTZ编码适合差分值的绝对值较小(即波动较小)的时序数据,不适合差分值较大(即波动较大)的时序数据。
+
+9. RLBE 编码
+
+ RLBE编码是一种无损编码,将差分编码,位填充编码,游程长度,斐波那契编码和拼接等编码思想结合到一起。RLBE编码适合递增且递增值较小的时序数据,不适合波动较大的时序数据。
+
+### 1.2 数据类型与编码的对应关系
+
+前文介绍的五种编码适用于不同的数据类型,若对应关系错误,则无法正确创建时间序列。数据类型与支持其编码的编码方式对应关系总结如下表所示。
+
+| **数据类型** | **推荐编码(默认)** | **支持的编码** |
+| ------------ | ---------------------- | ----------------------------------------------------------- |
+| BOOLEAN | RLE | PLAIN, RLE |
+| INT32 | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| DATE | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| INT64 | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| TIMESTAMP | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| FLOAT | GORILLA | PLAIN, RLE, TS_2DIFF, GORILLA, CHIMP, SPRINTZ, RLBE |
+| DOUBLE | GORILLA | PLAIN, RLE, TS_2DIFF, GORILLA, CHIMP, SPRINTZ, RLBE |
+| TEXT | PLAIN | PLAIN, DICTIONARY |
+| STRING | PLAIN | PLAIN, DICTIONARY |
+| BLOB | PLAIN | PLAIN |
+
+当用户输入的数据类型与编码方式不对应时,系统会提示错误。如下所示,二阶差分编码不支持布尔类型:
+
+```
+IoTDB> create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
+Msg: 507: encoding TS_2DIFF does not support BOOLEAN
+```
+
+## 2 压缩方式
+
+当时间序列写入并按照指定的类型编码为二进制数据后,IoTDB 会使用压缩技术对该数据进行压缩,进一步提升空间存储效率。虽然编码和压缩都旨在提升存储效率,但编码技术通常只适合特定的数据类型(如二阶差分编码只适合与 INT32 或者 INT64 编码,存储浮点数需要先将他们乘以 10m 以转换为整数),然后将它们转换为二进制流。压缩方式(SNAPPY)针对二进制流进行压缩,因此压缩方式的使用不再受数据类型的限制。
+
+### 2.1 基本压缩方式
+
+IoTDB 允许在创建一个时间序列的时候指定该列的压缩方式。现阶段 IoTDB 支持以下几种压缩方式:
+
+* UNCOMPRESSED(不压缩)
+* SNAPPY 压缩
+* LZ4 压缩(推荐压缩方式)
+* GZIP 压缩
+* ZSTD 压缩
+* LZMA2 压缩
+
+
+### 2.2 压缩比统计信息
+
+压缩比统计信息文件:data/datanode/system/compression_ratio
+
+* ratio_sum: memtable压缩比的总和
+* memtable_flush_time: memtable刷盘的总次数
+
+通过 `ratio_sum / memtable_flush_time` 可以计算出平均压缩比
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/Tools-System/CLI.md b/src/zh/UserGuide/Master/Table/Tools-System/CLI.md
new file mode 100644
index 000000000..fa72ab417
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Tools-System/CLI.md
@@ -0,0 +1,107 @@
+
+
+# CLI 命令行工具
+
+IoTDB 为用户提供 CLI 工具用于和服务端程序进行交互操作。在使用 CLI 工具连接 IoTDB 前,请保证 IoTDB 服务已经正常启动。下面介绍 CLI 工具的运行方式和相关参数。
+
+> 本文中 $IoTDB_HOME 表示 IoTDB 的安装目录所在路径。
+
+## 1 CLI 启动
+
+CLI 客户端脚本是 $IoTDB_HOME/sbin 文件夹下的`start-cli`脚本。启动命令为:
+
+- Linux/MacOS 系统常用启动命令为:
+
+```Shell
+Shell> bash sbin/start-cli.sh -sql_dialect table
+或
+Shell> bash sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root -sql_dialect table
+```
+
+- Windows 系统常用启动命令为:
+
+```Shell
+Shell> sbin\start-cli.bat -sql_dialect table
+或
+Shell> sbin\start-cli.bat -h 127.0.0.1 -p 6667 -u root -pw root -sql_dialect table
+```
+
+其中:
+
+- -h 和-p 项是 IoTDB 所在的 IP 和 RPC 端口号(本机未修改 IP 和 RPC 端口号默认为 127.0.0.1、6667)
+- -u 和-pw 是 IoTDB 登录的用户名密码(安装后IoTDB有一个默认用户,用户名密码均为`root`)
+- -sql_dialect 是登录的数据模型(表模型或树模型),此处指定为 table 代表进入表模型模式
+
+更多参数见:
+
+| **参数名** | **参数类型** | **是否为必需参数** | **说明** | **示例** |
+| :------------------------- | :----------- | :----------------- | :----------------------------------------------------------- | :------------------ |
+| -h `` | string 类型 | 否 | IoTDB 客户端连接 IoTDB 服务器的 IP 地址, 默认使用:127.0.0.1。 | -h 127.0.0.1 |
+| -p `` | int 类型 | 否 | IoTDB 客户端连接服务器的端口号,IoTDB 默认使用 6667。 | -p 6667 |
+| -u `` | string 类型 | 否 | IoTDB 客户端连接服务器所使用的用户名,默认使用 root。 | -u root |
+| -pw `` | string 类型 | 否 | IoTDB 客户端连接服务器所使用的密码,默认使用 root。 | -pw root |
+| -sql_dialect `` | string 类型 | 否 | 目前可选 tree(树模型) 、table(表模型),默认 tree | -sql_dialect table |
+| -e `` | string 类型 | 否 | 在不进入客户端输入模式的情况下,批量操作 IoTDB。 | -e "show databases" |
+| -c | 空 | 否 | 如果服务器设置了 rpc_thrift_compression_enable=true, 则 CLI 必须使用 -c | -c |
+| -disableISO8601 | 空 | 否 | 如果设置了这个参数,IoTDB 将以数字的形式打印时间戳 (timestamp)。 | -disableISO8601 |
+| -help | 空 | 否 | 打印 IoTDB 的帮助信息。 | -help |
+
+启动后出现如图提示即为启动成功。
+
+
+
+
+## 2 在 CLI 中执行语句
+
+进入 CLI 后,用户可以直接在对话中输入 SQL 语句进行交互。如:
+
+- 创建数据库
+
+```Java
+create database test
+```
+
+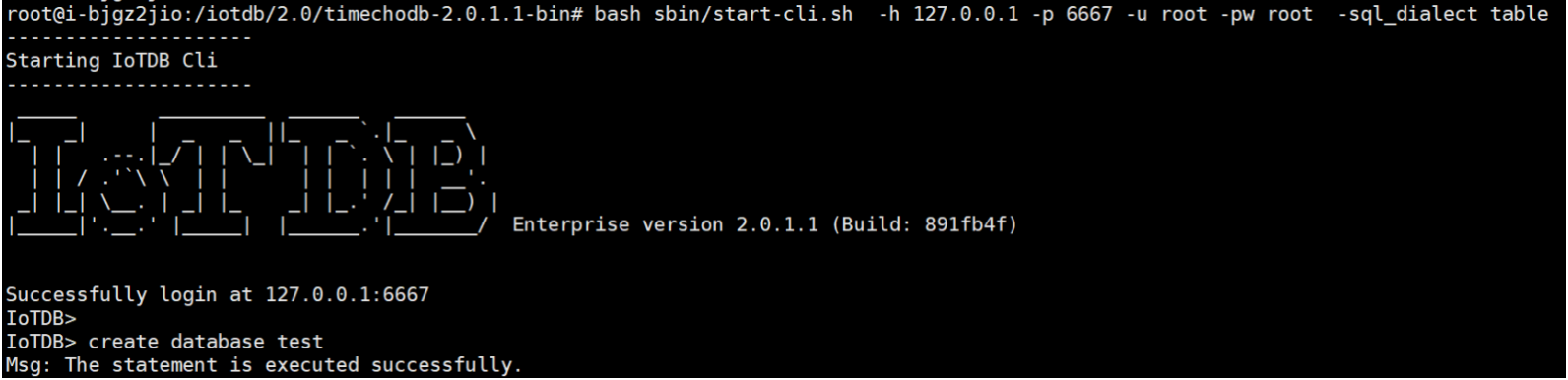
+
+
+- 查看数据库
+
+```Java
+show databases
+```
+
+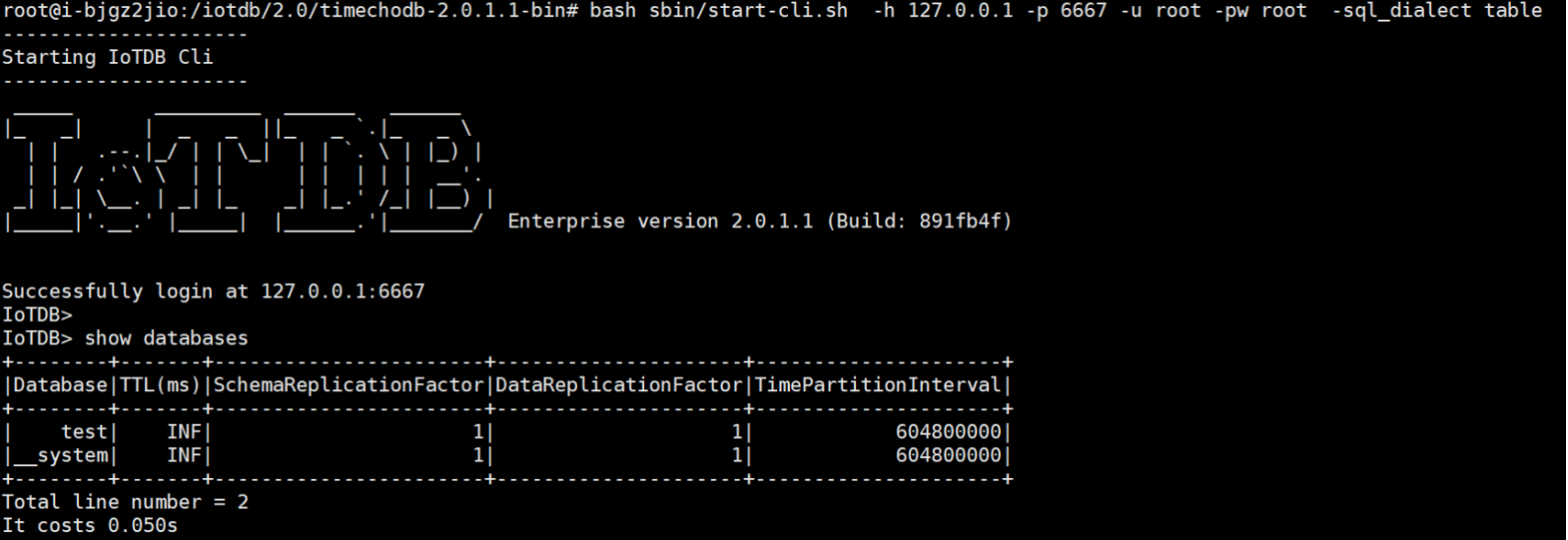
+
+
+## 3 CLI 退出
+
+在 CLI 中输入`quit`或`exit`可退出 CLI 结束本次会话。
+
+## 4 其他说明
+
+CLI中使用命令小技巧:
+
+(1)快速切换历史命令: 上下箭头
+
+(2)历史命令自动补全:右箭头
+
+(3)中断执行命令: CTRL+C
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/User-Manual/Data-Sync_timecho.md b/src/zh/UserGuide/Master/Table/User-Manual/Data-Sync_timecho.md
new file mode 100644
index 000000000..97df7cae6
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/User-Manual/Data-Sync_timecho.md
@@ -0,0 +1,557 @@
+
+
+# 数据同步
+数据同步是工业物联网的典型需求,通过数据同步机制,可实现 IoTDB 之间的数据共享,搭建完整的数据链路来满足内网外网数据互通、端边云同步、数据迁移、数据备份等需求。
+
+## 1 功能概述
+
+### 1.1 数据同步
+
+一个数据同步任务包含 3 个阶段:
+
+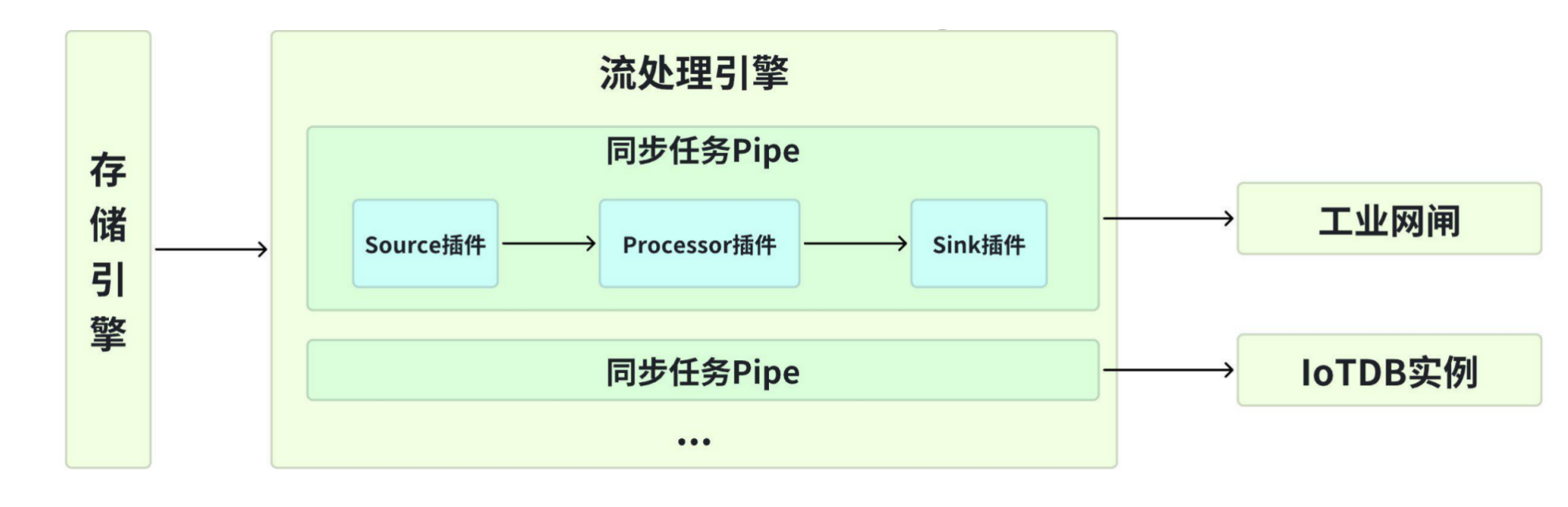
+
+- 抽取(Source)阶段:该部分用于从源 IoTDB 抽取数据,在 SQL 语句中的 source 部分定义
+- 处理(Process)阶段:该部分用于处理从源 IoTDB 抽取出的数据,在 SQL 语句中的 processor 部分定义
+- 发送(Sink)阶段:该部分用于向目标 IoTDB 发送数据,在 SQL 语句中的 sink 部分定义
+
+通过 SQL 语句声明式地配置 3 个部分的具体内容,可实现灵活的数据同步能力。
+
+### 1.2 功能限制及说明
+
+- 支持 1.x 系列版本 IoTDB 数据同步到 2.x 以及以上系列版本版本的 IoTDB。
+- 不支持 2.x 系列版本 IoTDB 数据同步到 1.x 系列版本版本的 IoTDB。
+- 在进行数据同步任务时,请避免执行任何删除操作,防止两端状态不一致。
+
+## 2 使用说明
+
+数据同步任务有三种状态:RUNNING、STOPPED 和 DROPPED。任务状态转换如下图所示:
+
+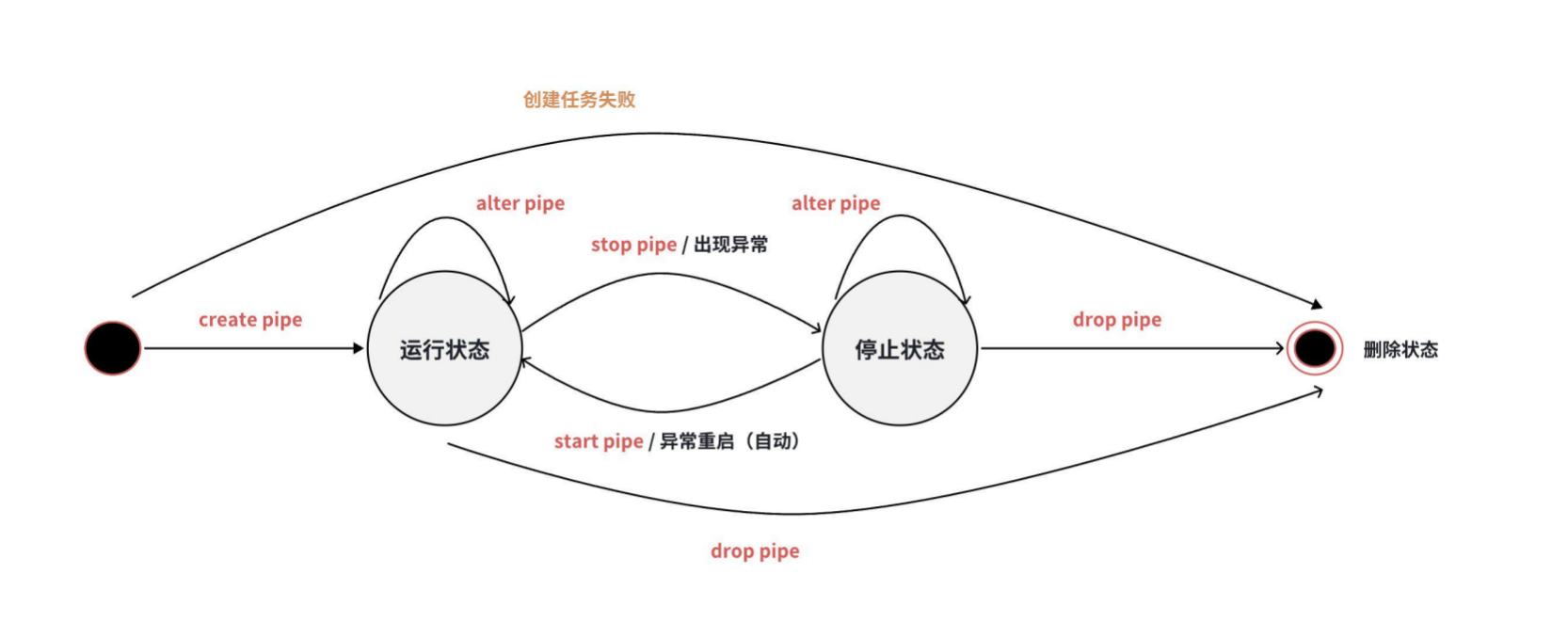
+
+创建后任务会直接启动,同时当任务发生异常停止后,系统会自动尝试重启任务。
+
+提供以下 SQL 语句对同步任务进行状态管理。
+
+### 2.1 创建任务
+
+使用 `CREATE PIPE` 语句来创建一条数据同步任务,下列属性中`PipeId`和`sink`必填,`source`和`processor`为选填项,输入 SQL 时注意 `SOURCE`与 `SINK` 插件顺序不能替换。
+
+SQL 示例如下:
+
+```SQL
+CREATE PIPE [IF NOT EXISTS] -- PipeId 是能够唯一标定任务的名字
+-- 数据抽取插件,可选插件
+WITH SOURCE (
+ [ = ,],
+)
+-- 数据处理插件,可选插件
+WITH PROCESSOR (
+ [ = ,],
+)
+-- 数据连接插件,必填插件
+WITH SINK (
+ [ = ,],
+)
+```
+
+**IF NOT EXISTS 语义**:用于创建操作中,确保当指定 Pipe 不存在时,执行创建命令,防止因尝试创建已存在的 Pipe 而导致报错。
+
+### 2.2 开始任务
+
+创建之后,任务直接进入运行状态,不需要执行启动任务。当使用`STOP PIPE`语句停止任务时需手动使用`START PIPE`语句来启动任务,PIPE 发生异常情况停止后会自动重新启动任务,从而开始处理数据:
+
+```SQL
+START PIPE
+```
+
+### 2.3 停止任务
+
+停止处理数据:
+
+```SQL
+STOP PIPE
+```
+
+### 2.4 删除任务
+
+删除指定任务:
+
+```SQL
+DROP PIPE [IF EXISTS]
+```
+
+**IF EXISTS 语义**:用于删除操作中,确保当指定 Pipe 存在时,执行删除命令,防止因尝试删除不存在的 Pipe 而导致报错。
+
+删除任务不需要先停止同步任务。
+
+### 2.5 查看任务
+
+查看全部任务:
+
+```SQL
+SHOW PIPES
+```
+
+查看指定任务:
+
+```SQL
+SHOW PIPE
+```
+
+ pipe 的 show pipes 结果示例:
+
+```SQL
++--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
+| ID| CreationTime| State|PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
++--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
+|59abf95db892428b9d01c5fa318014ea|2024-06-17T14:03:44.189|RUNNING| {}| {}|{sink=iotdb-thrift-sink, sink.ip=127.0.0.1, sink.port=6668}| | 128| 1.03|
++--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
+```
+
+其中各列含义如下:
+
+- **ID**:同步任务的唯一标识符
+- **CreationTime**:同步任务的创建的时间
+- **State**:同步任务的状态
+- **PipeSource**:同步数据流的来源
+- **PipeProcessor**:同步数据流在传输过程中的处理逻辑
+- **PipeSink**:同步数据流的目的地
+- **ExceptionMessage**:显示同步任务的异常信息
+- **RemainingEventCount(统计存在延迟)**:剩余 event 数,当前数据同步任务中的所有 event 总数,包括数据同步的 event,以及系统和用户自定义的 event。
+- **EstimatedRemainingSeconds(统计存在延迟)**:剩余时间,基于当前 event 个数和 pipe 处速率,预估完成传输的剩余时间。
+
+### 2.6 同步插件
+
+为了使得整体架构更加灵活以匹配不同的同步场景需求,我们支持在同步任务框架中进行插件组装。系统为您预置了一些常用插件可直接使用,同时您也可以自定义 processor 插件 和 Sink 插件,并加载至 IoTDB 系统进行使用。查看系统中的插件(含自定义与内置插件)可以用以下语句:
+
+```SQL
+SHOW PIPEPLUGINS
+```
+
+返回结果如下:
+
+```SQL
+IoTDB> SHOW PIPEPLUGINS
++------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
+| PluginName|PluginType| ClassName| PluginJar|
++------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
+| DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.donothing.DoNothingProcessor| |
+| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.donothing.DoNothingConnector| |
+| IOTDB-AIR-GAP-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.airgap.IoTDBAirGapConnector| |
+| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.extractor.iotdb.IoTDBExtractor| |
+| IOTDB-THRIFT-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftConnector| |
+| IOTDB-THRIFT-SSL-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftSslConnector| |
++------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
+```
+
+预置插件详细介绍如下(各插件的详细参数可参考本文[参数说明](#参考参数说明)):
+
+
+
+
++ 假设集群有 4 个数据节点,4 个分片,并且副本因子为 2。
++ 选择分片 $r_5$ 在数据节点 $n_5$ 上的副本作为主副本。
++ 选择分片 $r_6$ 在数据节点 $n_7$ 上的副本作为主副本。
++ 选择分片 $r_7$ 在数据节点 $n_7$ 上的副本作为主副本。
++ 选择分片 $r_8$ 在数据节点 $n_8$ 上的副本作为主副本。
+
+请注意,以上步骤严格遵循贪心算法。然而,到第 3 步时,无论在数据节点 $n_5$ 或 $n_7$ 上选择分片 $r_7$ 的主副本,都会导致主副本分布不均衡。根本原因在于每一步贪心选择都缺乏全局视角,最终导致局部最优解。
+
+为了解决这个问题,IoTDB 采用了一种主副本选择算法,能够持续平衡集群中的主副本分布。因此,集群实现了计算负载的均衡分布,确保了其性能。
+
+## 3 Source Code
++ [数据分区](https://github.com/apache/iotdb/tree/master/iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/partition)
++ [分区分配](https://github.com/apache/iotdb/tree/master/iotdb-core/confignode/src/main/java/org/apache/iotdb/confignode/manager/load/balancer/partition)
++ [副本放置](https://github.com/apache/iotdb/tree/master/iotdb-core/confignode/src/main/java/org/apache/iotdb/confignode/manager/load/balancer/副本)
++ [主副本选择](https://github.com/apache/iotdb/tree/master/iotdb-core/confignode/src/main/java/org/apache/iotdb/confignode/manager/load/balancer/router/主副本)
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/Technical-Insider/Encoding-and-Compression.md b/src/zh/UserGuide/Master/Table/Technical-Insider/Encoding-and-Compression.md
new file mode 100644
index 000000000..2a4885b3d
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Technical-Insider/Encoding-and-Compression.md
@@ -0,0 +1,123 @@
+
+
+# 编码和压缩
+
+## 1 编码方式
+
+### 1.1 基本编码方式
+
+为了提高数据的存储效率,需要在数据写入的过程中对数据进行编码,从而减少磁盘空间的使用量。在写数据以及读数据的过程中都能够减少 I/O 操作的数据量从而提高性能。IoTDB 支持多种针对不同类型的数据的编码方法:
+
+1. PLAIN 编码(PLAIN)
+
+ PLAIN 编码,默认的编码方式,即不编码,支持多种数据类型,压缩和解压缩的时间效率较高,但空间存储效率较低。
+
+2. 二阶差分编码(TS_2DIFF)
+
+ 二阶差分编码,比较适合编码单调递增或者递减的序列数据,不适合编码波动较大的数据。
+
+3. 游程编码(RLE)
+
+ 游程编码,比较适合存储某些数值连续出现的序列,不适合编码大部分情况下前后值不一样的序列数据。
+
+ 游程编码也可用于对浮点数进行编码,但在创建时间序列的时候需指定保留小数位数。比较适合存储某些浮点数值连续出现的序列数据,不适合存储对小数点后精度要求较高以及前后波动较大的序列数据。
+
+ > 游程编码(RLE)和二阶差分编码(TS_2DIFF)对 float 和 double 的编码是有精度限制的,默认保留 2 位小数。推荐使用 GORILLA。
+
+4. GORILLA 编码(GORILLA)
+
+ GORILLA 编码是一种无损编码,它比较适合编码前后值比较接近的数值序列,不适合编码前后波动较大的数据。
+
+ 当前系统中存在两个版本的 GORILLA 编码实现,推荐使用`GORILLA`,不推荐使用`GORILLA_V1`(已过时)。
+
+ 使用限制:使用 Gorilla 编码 INT32 数据时,需要保证序列中不存在值为`Integer.MIN_VALUE`的数据点;使用 Gorilla 编码 INT64 数据时,需要保证序列中不存在值为`Long.MIN_VALUE`的数据点。
+
+5. 字典编码 (DICTIONARY)
+
+ 字典编码是一种无损编码。它适合编码基数小的数据(即数据去重后唯一值数量小)。不推荐用于基数大的数据。
+
+6. ZIGZAG 编码
+
+ ZigZag编码将有符号整型映射到无符号整型,适合比较小的整数。
+
+7. CHIMP 编码
+
+ CHIMP 是一种无损编码。它是一种新的流式浮点数据压缩算法,可以节省存储空间。这个编码适用于前后值比较接近的数值序列,对波动小和随机噪声少的序列数据更加友好。
+
+ 使用限制:如果对 INT32 类型数据使用 CHIMP 编码,需要确保数据点中没有 `Integer.MIN_VALUE`。 如果对 INT64 类型数据使用 CHIMP 编码,需要确保数据点中没有 `Long.MIN_VALUE`。
+
+8. SPRINTZ 编码
+
+ SPRINTZ编码是一种无损编码,将原始时序数据分别进行预测、Zigzag编码、位填充和游程编码。SPRINTZ编码适合差分值的绝对值较小(即波动较小)的时序数据,不适合差分值较大(即波动较大)的时序数据。
+
+9. RLBE 编码
+
+ RLBE编码是一种无损编码,将差分编码,位填充编码,游程长度,斐波那契编码和拼接等编码思想结合到一起。RLBE编码适合递增且递增值较小的时序数据,不适合波动较大的时序数据。
+
+### 1.2 数据类型与编码的对应关系
+
+前文介绍的五种编码适用于不同的数据类型,若对应关系错误,则无法正确创建时间序列。数据类型与支持其编码的编码方式对应关系总结如下表所示。
+
+| **数据类型** | **推荐编码(默认)** | **支持的编码** |
+| ------------ | ---------------------- | ----------------------------------------------------------- |
+| BOOLEAN | RLE | PLAIN, RLE |
+| INT32 | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| DATE | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| INT64 | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| TIMESTAMP | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| FLOAT | GORILLA | PLAIN, RLE, TS_2DIFF, GORILLA, CHIMP, SPRINTZ, RLBE |
+| DOUBLE | GORILLA | PLAIN, RLE, TS_2DIFF, GORILLA, CHIMP, SPRINTZ, RLBE |
+| TEXT | PLAIN | PLAIN, DICTIONARY |
+| STRING | PLAIN | PLAIN, DICTIONARY |
+| BLOB | PLAIN | PLAIN |
+
+当用户输入的数据类型与编码方式不对应时,系统会提示错误。如下所示,二阶差分编码不支持布尔类型:
+
+```
+IoTDB> create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
+Msg: 507: encoding TS_2DIFF does not support BOOLEAN
+```
+
+## 2 压缩方式
+
+当时间序列写入并按照指定的类型编码为二进制数据后,IoTDB 会使用压缩技术对该数据进行压缩,进一步提升空间存储效率。虽然编码和压缩都旨在提升存储效率,但编码技术通常只适合特定的数据类型(如二阶差分编码只适合与 INT32 或者 INT64 编码,存储浮点数需要先将他们乘以 10m 以转换为整数),然后将它们转换为二进制流。压缩方式(SNAPPY)针对二进制流进行压缩,因此压缩方式的使用不再受数据类型的限制。
+
+### 2.1 基本压缩方式
+
+IoTDB 允许在创建一个时间序列的时候指定该列的压缩方式。现阶段 IoTDB 支持以下几种压缩方式:
+
+* UNCOMPRESSED(不压缩)
+* SNAPPY 压缩
+* LZ4 压缩(推荐压缩方式)
+* GZIP 压缩
+* ZSTD 压缩
+* LZMA2 压缩
+
+
+### 2.2 压缩比统计信息
+
+压缩比统计信息文件:data/datanode/system/compression_ratio
+
+* ratio_sum: memtable压缩比的总和
+* memtable_flush_time: memtable刷盘的总次数
+
+通过 `ratio_sum / memtable_flush_time` 可以计算出平均压缩比
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/Tools-System/CLI.md b/src/zh/UserGuide/Master/Table/Tools-System/CLI.md
new file mode 100644
index 000000000..fa72ab417
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/Tools-System/CLI.md
@@ -0,0 +1,107 @@
+
+
+# CLI 命令行工具
+
+IoTDB 为用户提供 CLI 工具用于和服务端程序进行交互操作。在使用 CLI 工具连接 IoTDB 前,请保证 IoTDB 服务已经正常启动。下面介绍 CLI 工具的运行方式和相关参数。
+
+> 本文中 $IoTDB_HOME 表示 IoTDB 的安装目录所在路径。
+
+## 1 CLI 启动
+
+CLI 客户端脚本是 $IoTDB_HOME/sbin 文件夹下的`start-cli`脚本。启动命令为:
+
+- Linux/MacOS 系统常用启动命令为:
+
+```Shell
+Shell> bash sbin/start-cli.sh -sql_dialect table
+或
+Shell> bash sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root -sql_dialect table
+```
+
+- Windows 系统常用启动命令为:
+
+```Shell
+Shell> sbin\start-cli.bat -sql_dialect table
+或
+Shell> sbin\start-cli.bat -h 127.0.0.1 -p 6667 -u root -pw root -sql_dialect table
+```
+
+其中:
+
+- -h 和-p 项是 IoTDB 所在的 IP 和 RPC 端口号(本机未修改 IP 和 RPC 端口号默认为 127.0.0.1、6667)
+- -u 和-pw 是 IoTDB 登录的用户名密码(安装后IoTDB有一个默认用户,用户名密码均为`root`)
+- -sql_dialect 是登录的数据模型(表模型或树模型),此处指定为 table 代表进入表模型模式
+
+更多参数见:
+
+| **参数名** | **参数类型** | **是否为必需参数** | **说明** | **示例** |
+| :------------------------- | :----------- | :----------------- | :----------------------------------------------------------- | :------------------ |
+| -h `` | string 类型 | 否 | IoTDB 客户端连接 IoTDB 服务器的 IP 地址, 默认使用:127.0.0.1。 | -h 127.0.0.1 |
+| -p `` | int 类型 | 否 | IoTDB 客户端连接服务器的端口号,IoTDB 默认使用 6667。 | -p 6667 |
+| -u `` | string 类型 | 否 | IoTDB 客户端连接服务器所使用的用户名,默认使用 root。 | -u root |
+| -pw `` | string 类型 | 否 | IoTDB 客户端连接服务器所使用的密码,默认使用 root。 | -pw root |
+| -sql_dialect `` | string 类型 | 否 | 目前可选 tree(树模型) 、table(表模型),默认 tree | -sql_dialect table |
+| -e `` | string 类型 | 否 | 在不进入客户端输入模式的情况下,批量操作 IoTDB。 | -e "show databases" |
+| -c | 空 | 否 | 如果服务器设置了 rpc_thrift_compression_enable=true, 则 CLI 必须使用 -c | -c |
+| -disableISO8601 | 空 | 否 | 如果设置了这个参数,IoTDB 将以数字的形式打印时间戳 (timestamp)。 | -disableISO8601 |
+| -help | 空 | 否 | 打印 IoTDB 的帮助信息。 | -help |
+
+启动后出现如图提示即为启动成功。
+
+
+
+
+## 2 在 CLI 中执行语句
+
+进入 CLI 后,用户可以直接在对话中输入 SQL 语句进行交互。如:
+
+- 创建数据库
+
+```Java
+create database test
+```
+
+
+
+
+- 查看数据库
+
+```Java
+show databases
+```
+
+
+
+
+## 3 CLI 退出
+
+在 CLI 中输入`quit`或`exit`可退出 CLI 结束本次会话。
+
+## 4 其他说明
+
+CLI中使用命令小技巧:
+
+(1)快速切换历史命令: 上下箭头
+
+(2)历史命令自动补全:右箭头
+
+(3)中断执行命令: CTRL+C
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Table/User-Manual/Data-Sync_timecho.md b/src/zh/UserGuide/Master/Table/User-Manual/Data-Sync_timecho.md
new file mode 100644
index 000000000..97df7cae6
--- /dev/null
+++ b/src/zh/UserGuide/Master/Table/User-Manual/Data-Sync_timecho.md
@@ -0,0 +1,557 @@
+
+
+# 数据同步
+数据同步是工业物联网的典型需求,通过数据同步机制,可实现 IoTDB 之间的数据共享,搭建完整的数据链路来满足内网外网数据互通、端边云同步、数据迁移、数据备份等需求。
+
+## 1 功能概述
+
+### 1.1 数据同步
+
+一个数据同步任务包含 3 个阶段:
+
+
+
+- 抽取(Source)阶段:该部分用于从源 IoTDB 抽取数据,在 SQL 语句中的 source 部分定义
+- 处理(Process)阶段:该部分用于处理从源 IoTDB 抽取出的数据,在 SQL 语句中的 processor 部分定义
+- 发送(Sink)阶段:该部分用于向目标 IoTDB 发送数据,在 SQL 语句中的 sink 部分定义
+
+通过 SQL 语句声明式地配置 3 个部分的具体内容,可实现灵活的数据同步能力。
+
+### 1.2 功能限制及说明
+
+- 支持 1.x 系列版本 IoTDB 数据同步到 2.x 以及以上系列版本版本的 IoTDB。
+- 不支持 2.x 系列版本 IoTDB 数据同步到 1.x 系列版本版本的 IoTDB。
+- 在进行数据同步任务时,请避免执行任何删除操作,防止两端状态不一致。
+
+## 2 使用说明
+
+数据同步任务有三种状态:RUNNING、STOPPED 和 DROPPED。任务状态转换如下图所示:
+
+
+
+创建后任务会直接启动,同时当任务发生异常停止后,系统会自动尝试重启任务。
+
+提供以下 SQL 语句对同步任务进行状态管理。
+
+### 2.1 创建任务
+
+使用 `CREATE PIPE` 语句来创建一条数据同步任务,下列属性中`PipeId`和`sink`必填,`source`和`processor`为选填项,输入 SQL 时注意 `SOURCE`与 `SINK` 插件顺序不能替换。
+
+SQL 示例如下:
+
+```SQL
+CREATE PIPE [IF NOT EXISTS] -- PipeId 是能够唯一标定任务的名字
+-- 数据抽取插件,可选插件
+WITH SOURCE (
+ [ = ,],
+)
+-- 数据处理插件,可选插件
+WITH PROCESSOR (
+ [ = ,],
+)
+-- 数据连接插件,必填插件
+WITH SINK (
+ [ = ,],
+)
+```
+
+**IF NOT EXISTS 语义**:用于创建操作中,确保当指定 Pipe 不存在时,执行创建命令,防止因尝试创建已存在的 Pipe 而导致报错。
+
+### 2.2 开始任务
+
+创建之后,任务直接进入运行状态,不需要执行启动任务。当使用`STOP PIPE`语句停止任务时需手动使用`START PIPE`语句来启动任务,PIPE 发生异常情况停止后会自动重新启动任务,从而开始处理数据:
+
+```SQL
+START PIPE
+```
+
+### 2.3 停止任务
+
+停止处理数据:
+
+```SQL
+STOP PIPE
+```
+
+### 2.4 删除任务
+
+删除指定任务:
+
+```SQL
+DROP PIPE [IF EXISTS]
+```
+
+**IF EXISTS 语义**:用于删除操作中,确保当指定 Pipe 存在时,执行删除命令,防止因尝试删除不存在的 Pipe 而导致报错。
+
+删除任务不需要先停止同步任务。
+
+### 2.5 查看任务
+
+查看全部任务:
+
+```SQL
+SHOW PIPES
+```
+
+查看指定任务:
+
+```SQL
+SHOW PIPE
+```
+
+ pipe 的 show pipes 结果示例:
+
+```SQL
++--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
+| ID| CreationTime| State|PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
++--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
+|59abf95db892428b9d01c5fa318014ea|2024-06-17T14:03:44.189|RUNNING| {}| {}|{sink=iotdb-thrift-sink, sink.ip=127.0.0.1, sink.port=6668}| | 128| 1.03|
++--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
+```
+
+其中各列含义如下:
+
+- **ID**:同步任务的唯一标识符
+- **CreationTime**:同步任务的创建的时间
+- **State**:同步任务的状态
+- **PipeSource**:同步数据流的来源
+- **PipeProcessor**:同步数据流在传输过程中的处理逻辑
+- **PipeSink**:同步数据流的目的地
+- **ExceptionMessage**:显示同步任务的异常信息
+- **RemainingEventCount(统计存在延迟)**:剩余 event 数,当前数据同步任务中的所有 event 总数,包括数据同步的 event,以及系统和用户自定义的 event。
+- **EstimatedRemainingSeconds(统计存在延迟)**:剩余时间,基于当前 event 个数和 pipe 处速率,预估完成传输的剩余时间。
+
+### 2.6 同步插件
+
+为了使得整体架构更加灵活以匹配不同的同步场景需求,我们支持在同步任务框架中进行插件组装。系统为您预置了一些常用插件可直接使用,同时您也可以自定义 processor 插件 和 Sink 插件,并加载至 IoTDB 系统进行使用。查看系统中的插件(含自定义与内置插件)可以用以下语句:
+
+```SQL
+SHOW PIPEPLUGINS
+```
+
+返回结果如下:
+
+```SQL
+IoTDB> SHOW PIPEPLUGINS
++------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
+| PluginName|PluginType| ClassName| PluginJar|
++------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
+| DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.donothing.DoNothingProcessor| |
+| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.donothing.DoNothingConnector| |
+| IOTDB-AIR-GAP-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.airgap.IoTDBAirGapConnector| |
+| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.extractor.iotdb.IoTDBExtractor| |
+| IOTDB-THRIFT-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftConnector| |
+| IOTDB-THRIFT-SSL-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftSslConnector| |
++------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
+```
+
+预置插件详细介绍如下(各插件的详细参数可参考本文[参数说明](#参考参数说明)):
+
+
+
+
+
+ | 类型 |
+ 自定义插件 |
+ 插件名称 |
+ 介绍 |
+
+
+ | source 插件 |
+ 不支持 |
+ iotdb-source |
+ 默认的 extractor 插件,用于抽取 IoTDB 历史或实时数据 |
+
+
+ | processor 插件 |
+ 支持 |
+ do-nothing-processor |
+ 默认的 processor 插件,不对传入的数据做任何的处理 |
+
+
+ | sink 插件 |
+ 支持 |
+ do-nothing-sink |
+ 不对发送出的数据做任何的处理 |
+
+
+ | iotdb-thrift-sink |
+ 默认的 sink 插件,用于 IoTDB 到 IoTDB(V2.0.0 及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景 |
+
+
+ | iotdb-air-gap-sink |
+ 用于 IoTDB 向 IoTDB(V2.0.0 及以上)跨单向数据网闸的数据同步。支持的网闸型号包括南瑞 Syskeeper 2000 等 |
+
+
+ | iotdb-thrift-ssl-sink |
+ 用于 IoTDB 与 IoTDB(V2.0.0 及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 sync blocking IO 模型,适用于安全需求较高的场景 |
+
+
+
+
+
+## 3 使用示例
+
+### 3.1 全量数据同步
+
+本例子用来演示将一个 IoTDB 的所有数据同步至另一个 IoTDB,数据链路如下图所示:
+
+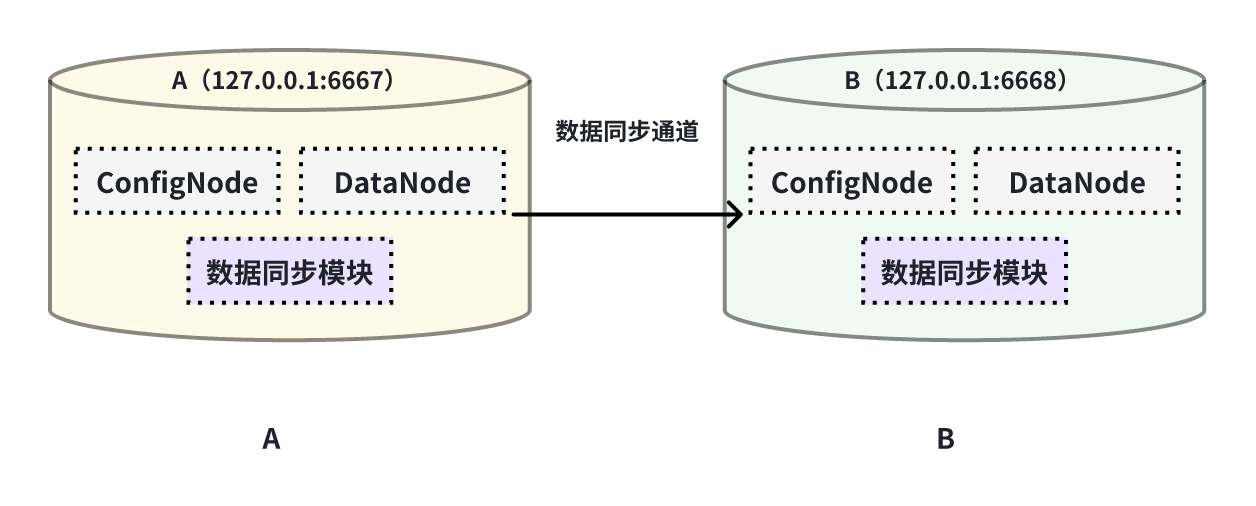
+
+在这个例子中,我们可以创建一个名为 A2B 的同步任务,用来同步 A IoTDB 到 B IoTDB 间的全量数据,这里需要用到用到 sink 的 iotdb-thrift-sink 插件(内置插件),需通过 node-urls 配置目标端 IoTDB 中 DataNode 节点的数据服务端口的 url,如下面的示例语句:
+
+```SQL
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.2 部分数据同步
+
+本例子用来演示同步某个历史时间范围( 2023 年 8 月 23 日 8 点到 2023 年 10 月 23 日 8 点)的数据至另一个 IoTDB,数据链路如下图所示:
+
+
+
+在这个例子中,我们可以创建一个名为 A2B 的同步任务。首先我们需要在 source 中定义传输数据的范围,由于传输的是历史数据(历史数据是指同步任务创建之前存在的数据),需要配置数据的起止时间 start-time 和 end-time 以及传输的模式 mode.streaming。通过 node-urls 配置目标端 IoTDB 中 DataNode 节点的数据服务端口的 url。
+
+详细语句如下:
+
+```SQL
+create pipe A2B
+WITH SOURCE (
+ 'source'= 'iotdb-source',
+ 'mode.streaming' = 'true' -- 新插入数据(pipe创建后)的抽取模式:是否按流式抽取(false 时为批式)
+ 'start-time' = '2023.08.23T08:00:00+00:00', -- 同步所有数据的开始 event time,包含 start-time
+ 'end-time' = '2023.10.23T08:00:00+00:00' -- 同步所有数据的结束 event time,包含 end-time
+)
+with SINK (
+ 'sink'='iotdb-thrift-async-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.3 双向数据传输
+
+本例子用来演示两个 IoTDB 之间互为双活的场景,数据链路如下图所示:
+
+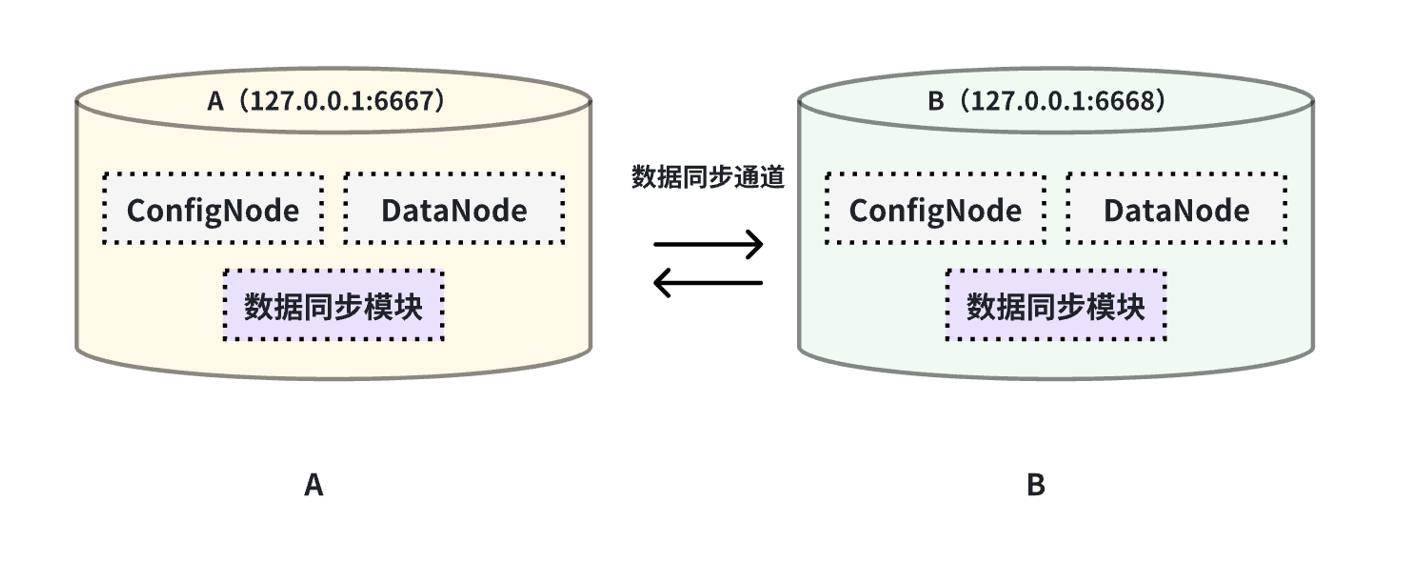
+
+在这个例子中,为了避免数据无限循环,需要将 A 和 B 上的参数`source.mode.double-living` 均设置为 `true`,表示不转发从另一 pipe 传输而来的数据。
+
+详细语句如下:
+
+在 A IoTDB 上执行下列语句:
+
+```SQL
+create pipe AB
+with source (
+ 'source.mode.double-living' ='true' --不转发由其他 Pipe 写入的数据
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+在 B IoTDB 上执行下列语句:
+
+```SQL
+create pipe BA
+with source (
+ 'source.mode.double-living' ='true' --不转发由其他 Pipe 写入的数据
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6667', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+### 3.4 边云数据传输
+
+本例子用来演示多个 IoTDB 之间边云传输数据的场景,数据由 B 、C、D 集群分别都同步至 A 集群,数据链路如下图所示:
+
+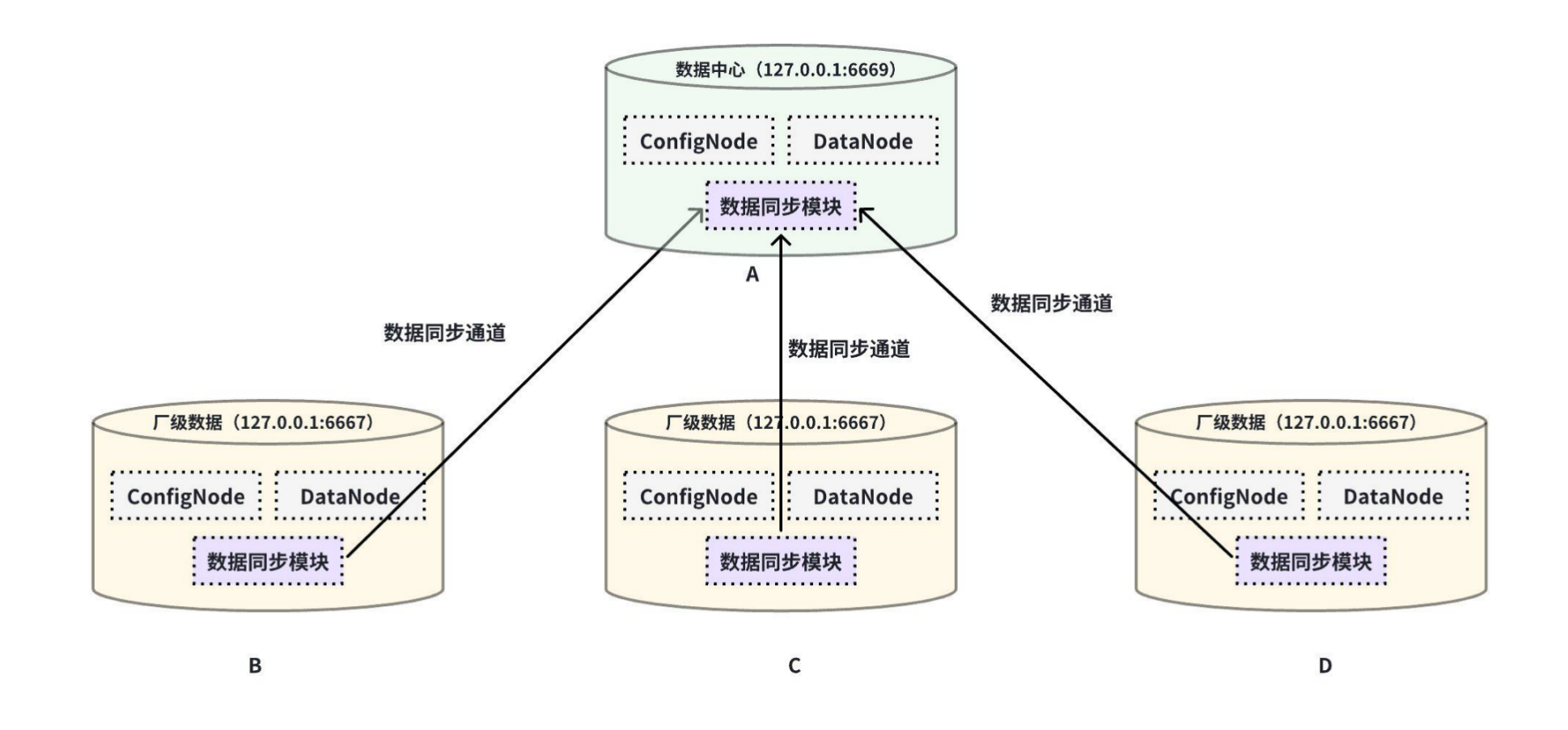
+
+在这个例子中,为了将 B 、C、D 集群的数据同步至 A,在 BA 、CA、DA 之间的 pipe 需要配置database-name 和 table-name 限制范围,详细语句如下:
+
+在 B IoTDB 上执行下列语句,将 B 中数据同步至 A:
+
+```SQL
+create pipe BA
+with source (
+ 'database-name'='db_b.*', -- 限制范围
+ 'table-name'='.*', -- 可选择匹配所有
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6667', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+在 C IoTDB 上执行下列语句,将 C 中数据同步至 A:
+
+```SQL
+create pipe CA
+with source (
+ 'database-name'='db_c.*', -- 限制范围
+ 'table-name'='.*', -- 可选择匹配所有
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+在 D IoTDB 上执行下列语句,将 D 中数据同步至 A:
+
+```SQL
+create pipe DA
+with source (
+ 'database-name'='db_d.*', -- 限制范围
+ 'table-name'='.*', -- 可选择匹配所有
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6669', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.5 级联数据传输
+
+本例子用来演示多个 IoTDB 之间级联传输数据的场景,数据由 A 集群同步至 B 集群,再同步至 C 集群,数据链路如下图所示:
+
+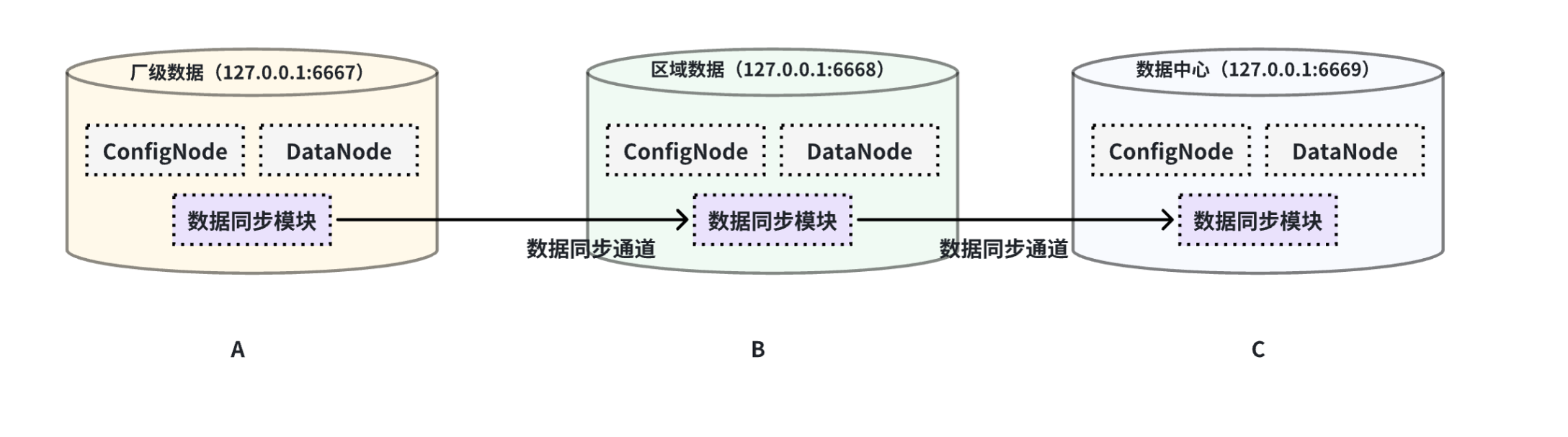
+
+在这个例子中,为了将 A 集群的数据同步至 C,在 BC 之间的 pipe 需要将 `source.mode.double-living` 配置为`true`,详细语句如下:
+
+在 A IoTDB 上执行下列语句,将 A 中数据同步至 B:
+
+```SQL
+create pipe AB
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+在 B IoTDB 上执行下列语句,将 B 中数据同步至 C:
+
+```SQL
+create pipe BC
+with source (
+ 'source.mode.double-living' ='true' --不转发由其他 Pipe 写入的数据
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6669', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.6 跨网闸数据传输
+
+本例子用来演示将一个 IoTDB 的数据,经过单向网闸,同步至另一个 IoTDB 的场景,数据链路如下图所示:
+
+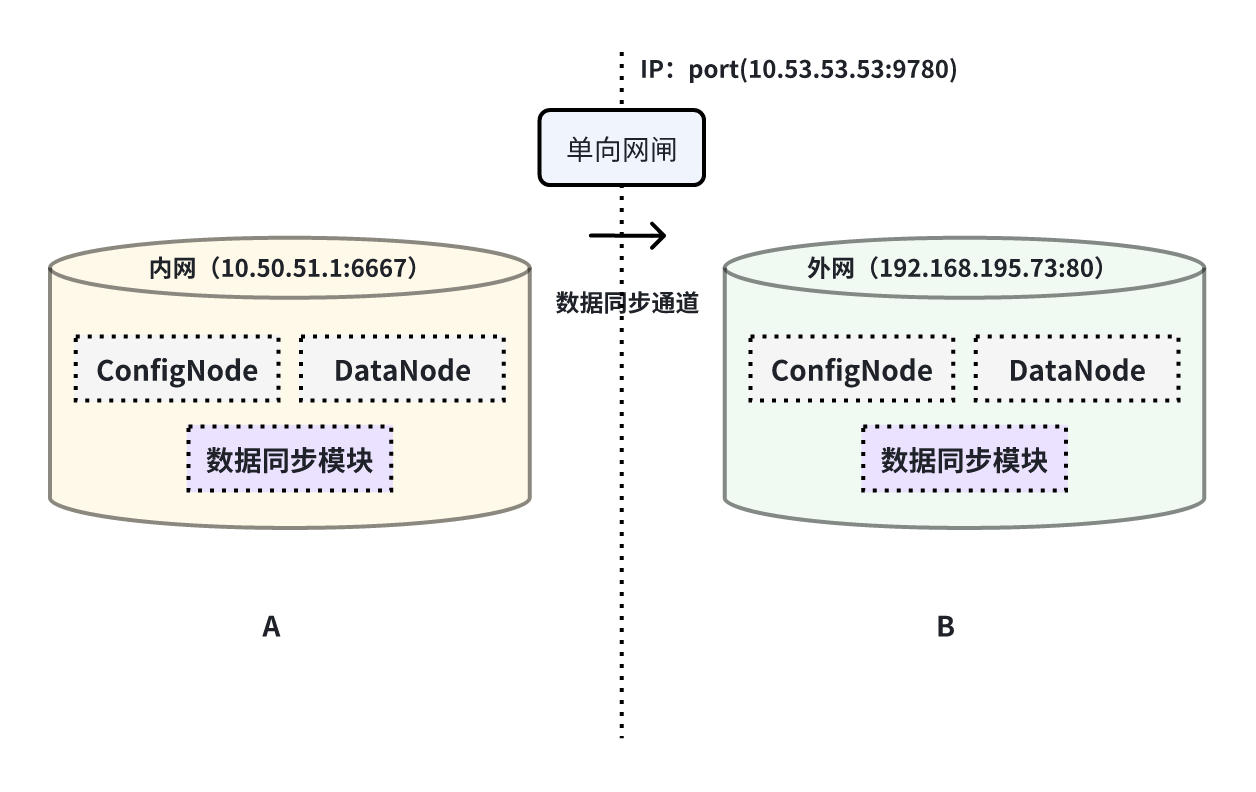
+
+在这个例子中,需要使用 sink 任务中的 iotdb-air-gap-sink 插件(目前支持部分型号网闸,具体型号请联系天谋科技工作人员确认),配置网闸后,在 A IoTDB 上执行下列语句,其中 node-urls 填写网闸配置的目标端 IoTDB 中 DataNode 节点的数据服务端口的 url,详细语句如下:
+
+```SQL
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'node-urls' = '10.53.53.53:9780', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.7 压缩同步
+
+IoTDB 支持在同步过程中指定数据压缩方式。可通过配置 `compressor` 参数,实现数据的实时压缩和传输。`compressor`目前支持 snappy / gzip / lz4 / zstd / lzma2 5 种可选算法,且可以选择多种压缩算法组合,按配置的顺序进行压缩。`rate-limit-bytes-per-second`(V1.3.3 及以后版本支持)每秒最大允许传输的byte数,计算压缩后的byte,若小于0则不限制。
+
+如创建一个名为 A2B 的同步任务:
+
+```SQL
+create pipe A2B
+with sink (
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+ 'compressor' = 'snappy,lz4' --
+ 'rate-limit-bytes-per-second'='1048576' -- 每秒最大允许传输的byte数
+)
+```
+
+### 3.8 加密同步
+
+IoTDB 支持在同步过程中使用 SSL 加密,从而在不同的 IoTDB 实例之间安全地传输数据。通过配置 SSL 相关的参数,如证书地址和密码(`ssl.trust-store-path`)、(`ssl.trust-store-pwd`)可以确保数据在同步过程中被 SSL 加密所保护。
+
+如创建名为 A2B 的同步任务:
+
+```SQL
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-ssl-sink',
+ 'node-urls'='127.0.0.1:6667', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+ 'ssl.trust-store-path'='pki/trusted', -- 连接目标端 DataNode 所需的 trust store 证书路径
+ 'ssl.trust-store-pwd'='root' -- 连接目标端 DataNode 所需的 trust store 证书密码
+)
+```
+
+## 参考:注意事项
+
+可通过修改 IoTDB 配置文件(`iotdb-system.properties`)以调整数据同步的参数,如同步数据存储目录等。完整配置如下::
+
+```Properties
+# pipe_receiver_file_dir
+# If this property is unset, system will save the data in the default relative path directory under the IoTDB folder(i.e., %IOTDB_HOME%/${cn_system_dir}/pipe/receiver).
+# If it is absolute, system will save the data in the exact location it points to.
+# If it is relative, system will save the data in the relative path directory it indicates under the IoTDB folder.
+# Note: If pipe_receiver_file_dir is assigned an empty string(i.e.,zero-size), it will be handled as a relative path.
+# effectiveMode: restart
+# For windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is absolute. Otherwise, it is relative.
+# pipe_receiver_file_dir=data\\confignode\\system\\pipe\\receiver
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+pipe_receiver_file_dir=data/confignode/system/pipe/receiver
+
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# effectiveMode: first_start
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# effectiveMode: restart
+# Datatype: int
+pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# effectiveMode: restart
+# Datatype: int
+pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# effectiveMode: restart
+# Datatype: int
+pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# effectiveMode: restart
+# Datatype: int
+pipe_sink_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# effectiveMode: restart
+# Datatype: Boolean
+pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# Datatype: int
+# effectiveMode: restart
+pipe_air_gap_receiver_port=9780
+
+# The total bytes that all pipe sinks can transfer per second.
+# When given a value less than or equal to 0, it means no limit.
+# default value is -1, which means no limit.
+# effectiveMode: hot_reload
+# Datatype: double
+pipe_all_sinks_rate_limit_bytes_per_second=-1
+```
+
+## 参考:参数说明
+
+### source 参数
+
+| **参数** | **描述** | **value 取值范围** | **是否必填** | **默认取值** |
+| ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------ | ------------------------------- |
+| source | iotdb-source | String: iotdb-source | 必填 | - |
+| mode.streaming | 此参数指定时序数据写入的捕获来源。适用于 `mode.streaming`为 `false` 模式下的场景,决定`inclusion`中`data.insert`数据的捕获来源。提供两种捕获策略:true: 动态选择捕获的类型。系统将根据下游处理速度,自适应地选择是捕获每个写入请求还是仅捕获 TsFile 文件的封口请求。当下游处理速度快时,优先捕获写入请求以减少延迟;当处理速度慢时,仅捕获文件封口请求以避免处理堆积。这种模式适用于大多数场景,能够实现处理延迟和吞吐量的最优平衡。false:固定按批捕获方式。仅捕获 TsFile 文件的封口请求,适用于资源受限的应用场景,以降低系统负载。注意,pipe 启动时捕获的快照数据只会以文件的方式供下游处理。 | Boolean: true / false | 否 | true |
+| mode.strict | 在使用 time / path / database-name / table-name 参数过滤数据时,是否需要严格按照条件筛选:`true`: 严格筛选。系统将完全按照给定条件过滤筛选被捕获的数据,确保只有符合条件的数据被选中。`false`:非严格筛选。系统在筛选被捕获的数据时可能会包含一些额外的数据,适用于性能敏感的场景,可降低 CPU 和 IO 消耗。 | Boolean: true / false | 否 | true |
+| mode.snapshot | 此参数决定时序数据的捕获方式,影响`inclusion`中的`data`数据。提供两种模式:`true`:静态数据捕获。启动 pipe 时,会进行一次性的数据快照捕获。当快照数据被完全消费后,**pipe 将自动终止(DROP PIPE SQL 会自动执行)**。`false`:动态数据捕获。除了在 pipe 启动时捕获快照数据外,还会持续捕获后续的数据变更。pipe 将持续运行以处理动态数据流。 | Boolean: true / false | 否 | false |
+| database-name | 当用户连接指定的 sql_dialect 为 table 时可以指定。此参数决定时序数据的捕获范围,影响`inclusion`中的`data`数据。表示要过滤的数据库的名称。它可以是具体的数据库名,也可以是 Java 风格正则表达式来匹配多个数据库。默认情况下,匹配所有的库。 | String:数据库名或数据库正则模式串,可以匹配未创建的、不存在的库 | 否 | ".*" |
+| table-name | 当用户连接指定的 sql_dialect 为 table 时可以指定。此参数决定时序数据的捕获范围,影响`inclusion`中的`data`数据。表示要过滤的表的名称。它可以是具体的表名,也可以是 Java 风格正则表达式来匹配多个表。默认情况下,匹配所有的表。 | String:数据表名或数据表正则模式串,可以是未创建的、不存在的表 | 否 | ".*" |
+| start-time | 此参数决定时序数据的捕获范围,影响`inclusion`中的`data`数据。当数据的 event time 大于等于该参数时,数据会被筛选出来进入流处理 pipe。 | Long: [Long.MIN_VALUE, Long.MAX_VALUE] (unix 裸时间戳)或 String:IoTDB 支持的 ISO 格式时间戳 | 否 | Long.MIN_VALUE(unix 裸时间戳) |
+| end-time | 此参数决定时序数据的捕获范围,影响`inclusion`中的`data`数据。当数据的 event time 小于等于该参数时,数据会被筛选出来进入流处理 pipe。 | Long: [Long.MIN_VALUE, Long.MAX_VALUE](unix 裸时间戳)或String:IoTDB 支持的 ISO 格式时间戳 | 否 | Long.MAX_VALUE(unix 裸时间戳) |
+| forwarding-pipe-requests | 是否转发由 pipe 数据同步而来的集群外的数据。一般供搭建双活集群时使用,双活集群模式下该参数为 false,以此避免无限的环形同步。 | Boolean: true / false | 否 | true |
+
+> 💎 **说明:数据抽取模式 mode.streaming 取值 true 和 false 的差异**
+> - **true(推荐)**:该取值下,任务将对数据进行实时处理、发送,其特点是高时效、低吞吐
+> - **false**:该取值下,任务将对数据进行批量(按底层数据文件)处理、发送,其特点是低时效、高吞吐
+
+
+## sink 参数
+
+#### iotdb-thrift-sink
+
+| **参数** | **描述** | **value 取值范围** | **是否必填** | **默认取值** |
+| --------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------ |
+| sink | iotdb-thrift-sink 或 iotdb-thrift-async-sink | String: iotdb-thrift-sink 或 iotdb-thrift-async-sink | 必填 | - |
+| node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String. 例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
+| user/usename | 连接接收端使用的用户名,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| password | 连接接收端使用的用户名对应的密码,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
+| batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
+| batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | 16*1024*1024 |
+| compressor | 所选取的 rpc 压缩算法,可配置多个,对每个请求顺序采用 | String: snappy / gzip / lz4 / zstd / lzma2 | 选填 | "" |
+| compressor.zstd.level | 所选取的 rpc 压缩算法为 zstd 时,可使用该参数额外配置 zstd 算法的压缩等级 | Int: [-131072, 22] | 选填 | 3 |
+| rate-limit-bytes-per-second | 每秒最大允许传输的 byte 数,计算压缩后的 byte(如压缩),若小于 0 则不限制 | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | 选填 | -1 |
+
+
+#### iotdb-air-gap-sink
+
+| **参数** | **描述** | **value 取值范围** | **是否必填** | **默认取值** |
+| ---------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | -------- |
+| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | 必填 | - |
+| node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String. 例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
+| user/usename | 连接接收端使用的用户名,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| password | 连接接收端使用的用户名对应的密码,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| compressor | 所选取的 rpc 压缩算法,可配置多个,对每个请求顺序采用 | String: snappy / gzip / lz4 / zstd / lzma2 | 选填 | "" |
+| compressor.zstd.level | 所选取的 rpc 压缩算法为 zstd 时,可使用该参数额外配置 zstd 算法的压缩等级 | Int: [-131072, 22] | 选填 | 3 |
+| rate-limit-bytes-per-second | 每秒最大允许传输的 byte 数,计算压缩后的 byte(如压缩),若小于 0 则不限制 | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | 选填 | -1 |
+| air-gap.handshake-timeout-ms | 发送端与接收端在首次尝试建立连接时握手请求的超时时长,单位:毫秒 | Integer | 选填 | 5000 |
+
+#### iotdb-thrift-ssl-sink
+
+| **参数** | **描述** | **value 取值范围** | **是否必填** | **默认取值** |
+| --------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------ |
+| sink | iotdb-thrift-ssl-sink | String: iotdb-thrift-ssl-sink | 必填 | - |
+| node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String. 例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
+| user/usename | 连接接收端使用的用户名,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| password | 连接接收端使用的用户名对应的密码,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
+| batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
+| batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | 16*1024*1024 |
+| compressor | 所选取的 rpc 压缩算法,可配置多个,对每个请求顺序采用 | String: snappy / gzip / lz4 / zstd / lzma2 | 选填 | "" |
+| compressor.zstd.level | 所选取的 rpc 压缩算法为 zstd 时,可使用该参数额外配置 zstd 算法的压缩等级 | Int: [-131072, 22] | 选填 | 3 |
+| rate-limit-bytes-per-second | 每秒最大允许传输的 byte 数,计算压缩后的 byte(如压缩),若小于 0 则不限制 | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | 选填 | -1 |
+| ssl.trust-store-path | 连接目标端 DataNode 所需的 trust store 证书路径 | String.Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
+| ssl.trust-store-pwd | 连接目标端 DataNode 所需的 trust store 证书密码 | Integer | 必填 | - |
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/API/Programming-JDBC.md b/src/zh/UserGuide/V2.0.1/Table/API/Programming-JDBC.md
new file mode 100644
index 000000000..c5b57096e
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/API/Programming-JDBC.md
@@ -0,0 +1,191 @@
+
+
+# JDBC接口
+
+## 1 功能介绍
+
+IoTDB JDBC接口提供了一种标准的方式来与IoTDB数据库进行交互,允许用户通过Java程序执行SQL语句来管理数据库和时间序列数据。它支持数据库的连接、创建、查询、更新和删除操作,以及时间序列数据的批量插入和查询。
+
+**注意**: 目前的JDBC实现仅是为与第三方工具连接使用的。使用JDBC(执行插入语句时)无法提供高性能写入。
+
+对于Java应用,我们推荐使用Java 原生接口。
+
+## 2 使用方式
+
+**环境要求:**
+
+- JDK >= 1.8
+- Maven >= 3.6
+
+**在maven中添加依赖:**
+
+```XML
+
+
+ com.timecho.iotdb
+ iotdb-jdbc
+ 2.0.1.1
+
+
+```
+
+## 3 读写操作
+
+### 3.1 功能说明
+
+- **写操作**:通过execute方法执行插入、创建数据库、创建时间序列等操作。
+- **读操作**:通过executeQuery方法执行查询操作,并使用ResultSet对象获取查询结果。
+
+### 3.2 **方法列表**
+
+| **方法名** | **描述** | **参数** | **返回值** |
+| ------------------------------------------------------------ | ---------------------------------- | ---------------------------------------------------------- | ----------------------------------- |
+| Class.forName(String driver) | 加载JDBC驱动类 | driver: JDBC驱动类的名称 | Class: 加载的类对象 |
+| DriverManager.getConnection(String url, String username, String password) | 建立数据库连接 | url: 数据库的URLusername: 数据库用户名password: 数据库密码 | Connection: 数据库连接对象 |
+| Connection.createStatement() | 创建Statement对象,用于执行SQL语句 | 无 | Statement: SQL语句执行对象 |
+| Statement.execute(String sql) | 执行SQL语句,对于非查询语句 | sql: 要执行的SQL语句 | boolean: 指示是否返回ResultSet对象 |
+| Statement.executeQuery(String sql) | 执行查询SQL语句并返回结果集 | sql: 要执行的查询SQL语句 | ResultSet: 查询结果集 |
+| ResultSet.getMetaData() | 获取结果集的元数据 | 无 | ResultSetMetaData: 结果集元数据对象 |
+| ResultSet.next() | 移动到结果集的下一行 | 无 | boolean: 是否成功移动到下一行 |
+| ResultSet.getString(int columnIndex) | 获取指定列的字符串值 | columnIndex: 列索引(从1开始) | String: 列的字符串值 |
+
+## 4 示例代码
+
+**注意:使用表模型,必须在 url 中指定 sql_dialect 参数为 table。**
+
+```Java
+String url = "jdbc:iotdb://127.0.0.1:6667?sql_dialect=table";
+```
+
+JDBC接口示例代码:[src/main/java/org/apache/iotdb/TableModelJDBCExample.java](https://github.com/apache/iotdb/blob/master/example/jdbc/src/main/java/org/apache/iotdb/TableModelJDBCExample.java)
+
+
+```Java
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iotdb;
+
+import org.apache.iotdb.jdbc.IoTDBSQLException;
+
+import org.slf4j.Logger;
+import org.slf4j.LoggerFactory;
+
+import java.sql.Connection;
+import java.sql.DriverManager;
+import java.sql.ResultSet;
+import java.sql.ResultSetMetaData;
+import java.sql.SQLException;
+import java.sql.Statement;
+
+public class TableModelJDBCExample {
+
+ private static final Logger LOGGER = LoggerFactory.getLogger(TableModelJDBCExample.class);
+
+ public static void main(String[] args) throws ClassNotFoundException, SQLException {
+ Class.forName("org.apache.iotdb.jdbc.IoTDBDriver");
+
+ // don't specify database in url
+ try (Connection connection =
+ DriverManager.getConnection(
+ "jdbc:iotdb://127.0.0.1:6667?sql_dialect=table", "root", "root");
+ Statement statement = connection.createStatement()) {
+
+ statement.execute("CREATE DATABASE test1");
+ statement.execute("CREATE DATABASE test2");
+
+ statement.execute("use test2");
+
+ // or use full qualified table name
+ statement.execute(
+ "create table test1.table1(region_id STRING ID, plant_id STRING ID, device_id STRING ID, model STRING ATTRIBUTE, temperature FLOAT MEASUREMENT, humidity DOUBLE MEASUREMENT) with (TTL=3600000)");
+
+ statement.execute(
+ "create table table2(region_id STRING ID, plant_id STRING ID, color STRING ATTRIBUTE, temperature FLOAT MEASUREMENT, speed DOUBLE MEASUREMENT) with (TTL=6600000)");
+
+ // show tables from current database
+ try (ResultSet resultSet = statement.executeQuery("SHOW TABLES")) {
+ ResultSetMetaData metaData = resultSet.getMetaData();
+ System.out.println(metaData.getColumnCount());
+ while (resultSet.next()) {
+ System.out.println(resultSet.getString(1) + ", " + resultSet.getInt(2));
+ }
+ }
+
+ // show tables by specifying another database
+ // using SHOW tables FROM
+ try (ResultSet resultSet = statement.executeQuery("SHOW TABLES FROM test1")) {
+ ResultSetMetaData metaData = resultSet.getMetaData();
+ System.out.println(metaData.getColumnCount());
+ while (resultSet.next()) {
+ System.out.println(resultSet.getString(1) + ", " + resultSet.getInt(2));
+ }
+ }
+
+ } catch (IoTDBSQLException e) {
+ LOGGER.error("IoTDB Jdbc example error", e);
+ }
+
+ // specify database in url
+ try (Connection connection =
+ DriverManager.getConnection(
+ "jdbc:iotdb://127.0.0.1:6667/test1?sql_dialect=table", "root", "root");
+ Statement statement = connection.createStatement()) {
+ // show tables from current database test1
+ try (ResultSet resultSet = statement.executeQuery("SHOW TABLES")) {
+ ResultSetMetaData metaData = resultSet.getMetaData();
+ System.out.println(metaData.getColumnCount());
+ while (resultSet.next()) {
+ System.out.println(resultSet.getString(1) + ", " + resultSet.getInt(2));
+ }
+ }
+
+ // change database to test2
+ statement.execute("use test2");
+
+ try (ResultSet resultSet = statement.executeQuery("SHOW TABLES")) {
+ ResultSetMetaData metaData = resultSet.getMetaData();
+ System.out.println(metaData.getColumnCount());
+ while (resultSet.next()) {
+ System.out.println(resultSet.getString(1) + ", " + resultSet.getInt(2));
+ }
+ }
+ }
+ }
+}
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/API/Programming-Java-Native-API.md b/src/zh/UserGuide/V2.0.1/Table/API/Programming-Java-Native-API.md
new file mode 100644
index 000000000..e97273103
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/API/Programming-Java-Native-API.md
@@ -0,0 +1,860 @@
+
+
+# Java Session原生接口
+
+## 1 功能介绍
+
+IoTDB具备Java原生客户端驱动和对应的连接池,提供对象化接口,可以直接组装时序对象进行写入,无需拼装 SQL。推荐使用连接池,多线程并行操作数据库。
+
+## 2 使用方式
+
+**环境要求:**
+
+- JDK >= 1.8
+- Maven >= 3.6
+
+**在maven中添加依赖:**
+
+```XML
+
+
+ com.timecho.iotdb
+ iotdb-session
+ 2.0.1.1
+
+
+```
+
+## 3 读写操作
+
+### 3.1 ITableSession接口
+
+#### 3.1.1 功能描述
+
+ITableSession接口定义了与IoTDB交互的基本操作,可以执行数据插入、查询操作以及关闭会话等,非线程安全。
+
+#### 3.1.2 方法列表
+
+以下是ITableSession接口中定义的方法及其详细说明:
+
+| **方法名** | **描述** | **参数** | **返回值** | **返回异常** |
+| --------------------------------------------------- | ------------------------------------------------------------ | ----------------------------------------------------------- | -------------- | --------------------------------------------------- |
+| insert(Tablet tablet) | 将一个包含时间序列数据的Tablet 对象插入到数据库中 | tablet: 要插入的Tablet对象 | 无 | StatementExecutionExceptionIoTDBConnectionException |
+| executeNonQueryStatement(String sql) | 执行非查询SQL语句,如DDL(数据定义语言)或DML(数据操作语言)命令 | sql: 要执行的SQL语句。 | 无 | StatementExecutionExceptionIoTDBConnectionException |
+| executeQueryStatement(String sql) | 执行查询SQL语句,并返回包含查询结果的SessionDataSet对象 | sql: 要执行的查询SQL语句。 | SessionDataSet | StatementExecutionExceptionIoTDBConnectionException |
+| executeQueryStatement(String sql, long timeoutInMs) | 执行查询SQL语句,并设置查询超时时间(以毫秒为单位) | sql: 要执行的查询SQL语句。timeoutInMs: 查询超时时间(毫秒) | SessionDataSet | StatementExecutionException |
+| close() | 关闭会话,释放所持有的资源 | 无 | 无 | IoTDBConnectionException |
+
+#### 3.1.2 接口展示
+
+``` java
+/**
+ * This interface defines a session for interacting with IoTDB tables.
+ * It supports operations such as data insertion, executing queries, and closing the session.
+ * Implementations of this interface are expected to manage connections and ensure
+ * proper resource cleanup.
+ *
+ * Each method may throw exceptions to indicate issues such as connection errors or
+ * execution failures.
+ *
+ *
Since this interface extends {@link AutoCloseable}, it is recommended to use
+ * try-with-resources to ensure the session is properly closed.
+ */
+public interface ITableSession extends AutoCloseable {
+
+ /**
+ * Inserts a {@link Tablet} into the database.
+ *
+ * @param tablet the tablet containing time-series data to be inserted.
+ * @throws StatementExecutionException if an error occurs while executing the statement.
+ * @throws IoTDBConnectionException if there is an issue with the IoTDB connection.
+ */
+ void insert(Tablet tablet) throws StatementExecutionException, IoTDBConnectionException;
+
+ /**
+ * Executes a non-query SQL statement, such as a DDL or DML command.
+ *
+ * @param sql the SQL statement to execute.
+ * @throws IoTDBConnectionException if there is an issue with the IoTDB connection.
+ * @throws StatementExecutionException if an error occurs while executing the statement.
+ */
+ void executeNonQueryStatement(String sql) throws IoTDBConnectionException, StatementExecutionException;
+
+ /**
+ * Executes a query SQL statement and returns the result set.
+ *
+ * @param sql the SQL query statement to execute.
+ * @return a {@link SessionDataSet} containing the query results.
+ * @throws StatementExecutionException if an error occurs while executing the statement.
+ * @throws IoTDBConnectionException if there is an issue with the IoTDB connection.
+ */
+ SessionDataSet executeQueryStatement(String sql)
+ throws StatementExecutionException, IoTDBConnectionException;
+
+ /**
+ * Executes a query SQL statement with a specified timeout and returns the result set.
+ *
+ * @param sql the SQL query statement to execute.
+ * @param timeoutInMs the timeout duration in milliseconds for the query execution.
+ * @return a {@link SessionDataSet} containing the query results.
+ * @throws StatementExecutionException if an error occurs while executing the statement.
+ * @throws IoTDBConnectionException if there is an issue with the IoTDB connection.
+ */
+ SessionDataSet executeQueryStatement(String sql, long timeoutInMs)
+ throws StatementExecutionException, IoTDBConnectionException;
+
+ /**
+ * Closes the session, releasing any held resources.
+ *
+ * @throws IoTDBConnectionException if there is an issue with closing the IoTDB connection.
+ */
+ @Override
+ void close() throws IoTDBConnectionException;
+}
+```
+
+### 3.2 TableSessionBuilder类
+
+#### 3.2.1 功能描述
+
+TableSessionBuilder类是一个构建器,用于配置和创建ITableSession接口的实例。它允许开发者设置连接参数、查询参数和安全特性等。
+
+#### 3.2.2 配置选项
+
+以下是TableSessionBuilder类中可用的配置选项及其默认值:
+
+| **配置项** | **描述** | **默认值** |
+| ---------------------------------------------------- | ---------------------------------------- | ------------------------------------------- |
+| nodeUrls(List`` nodeUrls) | 设置IoTDB集群的节点URL列表 | Collections.singletonList("localhost:6667") |
+| username(String username) | 设置连接的用户名 | "root" |
+| password(String password) | 设置连接的密码 | "root" |
+| database(String database) | 设置目标数据库名称 | null |
+| queryTimeoutInMs(long queryTimeoutInMs) | 设置查询超时时间(毫秒) | 60000(1分钟) |
+| fetchSize(int fetchSize) | 设置查询结果的获取大小 | 5000 |
+| zoneId(ZoneId zoneId) | 设置时区相关的ZoneId | ZoneId.systemDefault() |
+| thriftDefaultBufferSize(int thriftDefaultBufferSize) | 设置Thrift客户端的默认缓冲区大小(字节) | 1024(1KB) |
+| thriftMaxFrameSize(int thriftMaxFrameSize) | 设置Thrift客户端的最大帧大小(字节) | 64 * 1024 * 1024(64MB) |
+| enableRedirection(boolean enableRedirection) | 是否启用集群节点的重定向 | true |
+| enableAutoFetch(boolean enableAutoFetch) | 是否启用自动获取可用DataNodes | true |
+| maxRetryCount(int maxRetryCount) | 设置连接尝试的最大重试次数 | 60 |
+| retryIntervalInMs(long retryIntervalInMs) | 设置重试间隔时间(毫秒) | 500 |
+| useSSL(boolean useSSL) | 是否启用SSL安全连接 | false |
+| trustStore(String keyStore) | 设置SSL连接的信任库路径 | null |
+| trustStorePwd(String keyStorePwd) | 设置SSL连接的信任库密码 | null |
+| enableCompression(boolean enableCompression) | 是否启用RPC压缩 | false |
+| connectionTimeoutInMs(int connectionTimeoutInMs) | 设置连接超时时间(毫秒) | 0(无超时) |
+
+#### 3.2.3 接口展示
+
+``` java
+/**
+ * A builder class for constructing instances of {@link ITableSession}.
+ *
+ * This builder provides a fluent API for configuring various options such as connection
+ * settings, query parameters, and security features.
+ *
+ *
All configurations have reasonable default values, which can be overridden as needed.
+ */
+public class TableSessionBuilder {
+
+ /**
+ * Builds and returns a configured {@link ITableSession} instance.
+ *
+ * @return a fully configured {@link ITableSession}.
+ * @throws IoTDBConnectionException if an error occurs while establishing the connection.
+ */
+ public ITableSession build() throws IoTDBConnectionException;
+
+ /**
+ * Sets the list of node URLs for the IoTDB cluster.
+ *
+ * @param nodeUrls a list of node URLs.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue Collection.singletonList("localhost:6667")
+ */
+ public TableSessionBuilder nodeUrls(List nodeUrls);
+
+ /**
+ * Sets the username for the connection.
+ *
+ * @param username the username.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionBuilder username(String username);
+
+ /**
+ * Sets the password for the connection.
+ *
+ * @param password the password.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionBuilder password(String password);
+
+ /**
+ * Sets the target database name.
+ *
+ * @param database the database name.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionBuilder database(String database);
+
+ /**
+ * Sets the query timeout in milliseconds.
+ *
+ * @param queryTimeoutInMs the query timeout in milliseconds.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 60000 (1 minute)
+ */
+ public TableSessionBuilder queryTimeoutInMs(long queryTimeoutInMs);
+
+ /**
+ * Sets the fetch size for query results.
+ *
+ * @param fetchSize the fetch size.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 5000
+ */
+ public TableSessionBuilder fetchSize(int fetchSize);
+
+ /**
+ * Sets the {@link ZoneId} for timezone-related operations.
+ *
+ * @param zoneId the {@link ZoneId}.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue ZoneId.systemDefault()
+ */
+ public TableSessionBuilder zoneId(ZoneId zoneId);
+
+ /**
+ * Sets the default init buffer size for the Thrift client.
+ *
+ * @param thriftDefaultBufferSize the buffer size in bytes.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 1024 (1 KB)
+ */
+ public TableSessionBuilder thriftDefaultBufferSize(int thriftDefaultBufferSize);
+
+ /**
+ * Sets the maximum frame size for the Thrift client.
+ *
+ * @param thriftMaxFrameSize the maximum frame size in bytes.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 64 * 1024 * 1024 (64 MB)
+ */
+ public TableSessionBuilder thriftMaxFrameSize(int thriftMaxFrameSize);
+
+ /**
+ * Enables or disables redirection for cluster nodes.
+ *
+ * @param enableRedirection whether to enable redirection.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue true
+ */
+ public TableSessionBuilder enableRedirection(boolean enableRedirection);
+
+ /**
+ * Enables or disables automatic fetching of available DataNodes.
+ *
+ * @param enableAutoFetch whether to enable automatic fetching.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue true
+ */
+ public TableSessionBuilder enableAutoFetch(boolean enableAutoFetch);
+
+ /**
+ * Sets the maximum number of retries for connection attempts.
+ *
+ * @param maxRetryCount the maximum retry count.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 60
+ */
+ public TableSessionBuilder maxRetryCount(int maxRetryCount);
+
+ /**
+ * Sets the interval between retries in milliseconds.
+ *
+ * @param retryIntervalInMs the interval in milliseconds.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 500 milliseconds
+ */
+ public TableSessionBuilder retryIntervalInMs(long retryIntervalInMs);
+
+ /**
+ * Enables or disables SSL for secure connections.
+ *
+ * @param useSSL whether to enable SSL.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue false
+ */
+ public TableSessionBuilder useSSL(boolean useSSL);
+
+ /**
+ * Sets the trust store path for SSL connections.
+ *
+ * @param keyStore the trust store path.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionBuilder trustStore(String keyStore);
+
+ /**
+ * Sets the trust store password for SSL connections.
+ *
+ * @param keyStorePwd the trust store password.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionBuilder trustStorePwd(String keyStorePwd);
+
+ /**
+ * Enables or disables rpc compression for the connection.
+ *
+ * @param enableCompression whether to enable compression.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue false
+ */
+ public TableSessionBuilder enableCompression(boolean enableCompression);
+
+ /**
+ * Sets the connection timeout in milliseconds.
+ *
+ * @param connectionTimeoutInMs the connection timeout in milliseconds.
+ * @return the current {@link TableSessionBuilder} instance.
+ * @defaultValue 0 (no timeout)
+ */
+ public TableSessionBuilder connectionTimeoutInMs(int connectionTimeoutInMs);
+}
+```
+
+## 4 客户端连接池
+
+### 4.1 ITableSessionPool 接口
+
+#### 4.1.1 功能描述
+
+ITableSessionPool 是一个用于管理 ITableSession实例的池。这个池可以帮助我们高效地重用连接,并且在不需要时正确地清理资源, 该接口定义了如何从池中获取会话以及如何关闭池的基本操作。
+
+#### 4.1.2 方法列表
+
+| **方法名** | **描述** | **返回值** | **返回异常** |
+| ------------ | ------------------------------------------------------------ | ------------------ | ------------------------ |
+| getSession() | 从池中获取一个 ITableSession 实例,用于与 IoTDB 交互。 | ITableSession 实例 | IoTDBConnectionException |
+| close() | 关闭会话池,释放任何持有的资源。关闭后,不能再从池中获取新的会话。 | 无 | 无 |
+
+#### 4.1.3 接口展示
+
+```Java
+/**
+ * This interface defines a pool for managing {@link ITableSession} instances.
+ * It provides methods to acquire a session from the pool and to close the pool.
+ *
+ * The implementation should handle the lifecycle of sessions, ensuring efficient
+ * reuse and proper cleanup of resources.
+ */
+public interface ITableSessionPool {
+
+ /**
+ * Acquires an {@link ITableSession} instance from the pool.
+ *
+ * @return an {@link ITableSession} instance for interacting with the IoTDB.
+ * @throws IoTDBConnectionException if there is an issue obtaining a session from the pool.
+ */
+ ITableSession getSession() throws IoTDBConnectionException;
+
+ /**
+ * Closes the session pool, releasing any held resources.
+ *
+ *
Once the pool is closed, no further sessions can be acquired.
+ */
+ void close();
+}
+```
+
+### 4.2 TableSessionPoolBuilder 类
+
+#### 4.2.1 功能描述
+
+TableSessionPool 的构造器,用于配置和创建 ITableSessionPool 的实例。允许开发者配置连接参数、会话参数和池化行为等。
+
+#### 4.2.2 配置选项
+
+以下是 TableSessionPoolBuilder 类的可用配置选项及其默认值:
+
+| **配置项** | **描述** | **默认值** |
+| ------------------------------------------------------------ | -------------------------------------------- | ------------------------------------------- |
+| nodeUrls(List`` nodeUrls) | 设置IoTDB集群的节点URL列表 | Collections.singletonList("localhost:6667") |
+| maxSize(int maxSize) | 设置会话池的最大大小,即池中允许的最大会话数 | 5 |
+| user(String user) | 设置连接的用户名 | "root" |
+| password(String password) | 设置连接的密码 | "root" |
+| database(String database) | 设置目标数据库名称 | "root" |
+| queryTimeoutInMs(long queryTimeoutInMs) | 设置查询超时时间(毫秒) | 60000(1分钟) |
+| fetchSize(int fetchSize) | 设置查询结果的获取大小 | 5000 |
+| zoneId(ZoneId zoneId) | 设置时区相关的 ZoneId | ZoneId.systemDefault() |
+| waitToGetSessionTimeoutInMs(long waitToGetSessionTimeoutInMs) | 设置从池中获取会话的超时时间(毫秒) | 30000(30秒) |
+| thriftDefaultBufferSize(int thriftDefaultBufferSize) | 设置Thrift客户端的默认缓冲区大小(字节) | 1024(1KB) |
+| thriftMaxFrameSize(int thriftMaxFrameSize) | 设置Thrift客户端的最大帧大小(字节) | 64 * 1024 * 1024(64MB) |
+| enableCompression(boolean enableCompression) | 是否启用连接的压缩 | false |
+| enableRedirection(boolean enableRedirection) | 是否启用集群节点的重定向 | true |
+| connectionTimeoutInMs(int connectionTimeoutInMs) | 设置连接超时时间(毫秒) | 10000(10秒) |
+| enableAutoFetch(boolean enableAutoFetch) | 是否启用自动获取可用DataNodes | true |
+| maxRetryCount(int maxRetryCount) | 设置连接尝试的最大重试次数 | 60 |
+| retryIntervalInMs(long retryIntervalInMs) | 设置重试间隔时间(毫秒) | 500 |
+| useSSL(boolean useSSL) | 是否启用SSL安全连接 | false |
+| trustStore(String keyStore) | 设置SSL连接的信任库路径 | null |
+| trustStorePwd(String keyStorePwd) | 设置SSL连接的信任库密码 | null |
+
+#### 4.1.3 接口展示
+
+```Java
+/**
+ * A builder class for constructing instances of {@link ITableSessionPool}.
+ *
+ * This builder provides a fluent API for configuring a session pool, including
+ * connection settings, session parameters, and pool behavior.
+ *
+ *
All configurations have reasonable default values, which can be overridden as needed.
+ */
+public class TableSessionPoolBuilder {
+
+ /**
+ * Builds and returns a configured {@link ITableSessionPool} instance.
+ *
+ * @return a fully configured {@link ITableSessionPool}.
+ */
+ public ITableSessionPool build();
+
+ /**
+ * Sets the list of node URLs for the IoTDB cluster.
+ *
+ * @param nodeUrls a list of node URLs.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue Collection.singletonList("localhost:6667")
+ */
+ public TableSessionPoolBuilder nodeUrls(List nodeUrls);
+
+ /**
+ * Sets the maximum size of the session pool.
+ *
+ * @param maxSize the maximum number of sessions allowed in the pool.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 5
+ */
+ public TableSessionPoolBuilder maxSize(int maxSize);
+
+ /**
+ * Sets the username for the connection.
+ *
+ * @param user the username.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionPoolBuilder user(String user);
+
+ /**
+ * Sets the password for the connection.
+ *
+ * @param password the password.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionPoolBuilder password(String password);
+
+ /**
+ * Sets the target database name.
+ *
+ * @param database the database name.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue "root"
+ */
+ public TableSessionPoolBuilder database(String database);
+
+ /**
+ * Sets the query timeout in milliseconds.
+ *
+ * @param queryTimeoutInMs the query timeout in milliseconds.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 60000 (1 minute)
+ */
+ public TableSessionPoolBuilder queryTimeoutInMs(long queryTimeoutInMs);
+
+ /**
+ * Sets the fetch size for query results.
+ *
+ * @param fetchSize the fetch size.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 5000
+ */
+ public TableSessionPoolBuilder fetchSize(int fetchSize);
+
+ /**
+ * Sets the {@link ZoneId} for timezone-related operations.
+ *
+ * @param zoneId the {@link ZoneId}.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue ZoneId.systemDefault()
+ */
+ public TableSessionPoolBuilder zoneId(ZoneId zoneId);
+
+ /**
+ * Sets the timeout for waiting to acquire a session from the pool.
+ *
+ * @param waitToGetSessionTimeoutInMs the timeout duration in milliseconds.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 30000 (30 seconds)
+ */
+ public TableSessionPoolBuilder waitToGetSessionTimeoutInMs(long waitToGetSessionTimeoutInMs);
+
+ /**
+ * Sets the default buffer size for the Thrift client.
+ *
+ * @param thriftDefaultBufferSize the buffer size in bytes.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 1024 (1 KB)
+ */
+ public TableSessionPoolBuilder thriftDefaultBufferSize(int thriftDefaultBufferSize);
+
+ /**
+ * Sets the maximum frame size for the Thrift client.
+ *
+ * @param thriftMaxFrameSize the maximum frame size in bytes.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 64 * 1024 * 1024 (64 MB)
+ */
+ public TableSessionPoolBuilder thriftMaxFrameSize(int thriftMaxFrameSize);
+
+ /**
+ * Enables or disables compression for the connection.
+ *
+ * @param enableCompression whether to enable compression.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue false
+ */
+ public TableSessionPoolBuilder enableCompression(boolean enableCompression);
+
+ /**
+ * Enables or disables redirection for cluster nodes.
+ *
+ * @param enableRedirection whether to enable redirection.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue true
+ */
+ public TableSessionPoolBuilder enableRedirection(boolean enableRedirection);
+
+ /**
+ * Sets the connection timeout in milliseconds.
+ *
+ * @param connectionTimeoutInMs the connection timeout in milliseconds.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 10000 (10 seconds)
+ */
+ public TableSessionPoolBuilder connectionTimeoutInMs(int connectionTimeoutInMs);
+
+ /**
+ * Enables or disables automatic fetching of available DataNodes.
+ *
+ * @param enableAutoFetch whether to enable automatic fetching.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue true
+ */
+ public TableSessionPoolBuilder enableAutoFetch(boolean enableAutoFetch);
+
+ /**
+ * Sets the maximum number of retries for connection attempts.
+ *
+ * @param maxRetryCount the maximum retry count.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 60
+ */
+ public TableSessionPoolBuilder maxRetryCount(int maxRetryCount);
+
+ /**
+ * Sets the interval between retries in milliseconds.
+ *
+ * @param retryIntervalInMs the interval in milliseconds.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue 500 milliseconds
+ */
+ public TableSessionPoolBuilder retryIntervalInMs(long retryIntervalInMs);
+
+ /**
+ * Enables or disables SSL for secure connections.
+ *
+ * @param useSSL whether to enable SSL.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue false
+ */
+ public TableSessionPoolBuilder useSSL(boolean useSSL);
+
+ /**
+ * Sets the trust store path for SSL connections.
+ *
+ * @param keyStore the trust store path.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionPoolBuilder trustStore(String keyStore);
+
+ /**
+ * Sets the trust store password for SSL connections.
+ *
+ * @param keyStorePwd the trust store password.
+ * @return the current {@link TableSessionPoolBuilder} instance.
+ * @defaultValue null
+ */
+ public TableSessionPoolBuilder trustStorePwd(String keyStorePwd);
+}
+```
+
+## 5 示例代码
+
+Session 示例代码:[src/main/java/org/apache/iotdb/TableModelSessionExample.java](https://github.com/apache/iotdb/blob/master/example/session/src/main/java/org/apache/iotdb/TableModelSessionExample.java)
+
+SessionPool 示例代码:[src/main/java/org/apache/iotdb/TableModelSessionPoolExample.java](https://github.com/apache/iotdb/blob/master/example/session/src/main/java/org/apache/iotdb/TableModelSessionPoolExample.java)
+
+```Java
+/*
+ * Licensed to the Apache Software Foundation (ASF) under one
+ * or more contributor license agreements. See the NOTICE file
+ * distributed with this work for additional information
+ * regarding copyright ownership. The ASF licenses this file
+ * to you under the Apache License, Version 2.0 (the
+ * "License"); you may not use this file except in compliance
+ * with the License. You may obtain a copy of the License at
+ *
+ * http://www.apache.org/licenses/LICENSE-2.0
+ *
+ * Unless required by applicable law or agreed to in writing,
+ * software distributed under the License is distributed on an
+ * "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ * KIND, either express or implied. See the License for the
+ * specific language governing permissions and limitations
+ * under the License.
+ */
+
+package org.apache.iotdb;
+
+import org.apache.iotdb.isession.ITableSession;
+import org.apache.iotdb.isession.SessionDataSet;
+import org.apache.iotdb.isession.pool.ITableSessionPool;
+import org.apache.iotdb.rpc.IoTDBConnectionException;
+import org.apache.iotdb.rpc.StatementExecutionException;
+import org.apache.iotdb.session.pool.TableSessionPoolBuilder;
+
+import org.apache.tsfile.enums.TSDataType;
+import org.apache.tsfile.write.record.Tablet;
+import org.apache.tsfile.write.record.Tablet.ColumnCategory;
+import org.apache.tsfile.write.schema.IMeasurementSchema;
+import org.apache.tsfile.write.schema.MeasurementSchema;
+
+import java.util.ArrayList;
+import java.util.Arrays;
+import java.util.Collections;
+import java.util.List;
+
+public class TableModelSessionPoolExample {
+
+ private static final String LOCAL_URL = "127.0.0.1:6667";
+
+ public static void main(String[] args) {
+
+ // don't specify database in constructor
+ ITableSessionPool tableSessionPool =
+ new TableSessionPoolBuilder()
+ .nodeUrls(Collections.singletonList(LOCAL_URL))
+ .user("root")
+ .password("root")
+ .maxSize(1)
+ .build();
+
+ try (ITableSession session = tableSessionPool.getSession()) {
+
+ session.executeNonQueryStatement("CREATE DATABASE test1");
+ session.executeNonQueryStatement("CREATE DATABASE test2");
+
+ session.executeNonQueryStatement("use test2");
+
+ // or use full qualified table name
+ session.executeNonQueryStatement(
+ "create table test1.table1("
+ + "region_id STRING ID, "
+ + "plant_id STRING ID, "
+ + "device_id STRING ID, "
+ + "model STRING ATTRIBUTE, "
+ + "temperature FLOAT MEASUREMENT, "
+ + "humidity DOUBLE MEASUREMENT) with (TTL=3600000)");
+
+ session.executeNonQueryStatement(
+ "create table table2("
+ + "region_id STRING ID, "
+ + "plant_id STRING ID, "
+ + "color STRING ATTRIBUTE, "
+ + "temperature FLOAT MEASUREMENT, "
+ + "speed DOUBLE MEASUREMENT) with (TTL=6600000)");
+
+ // show tables from current database
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ // show tables by specifying another database
+ // using SHOW tables FROM
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES FROM test1")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ // insert table data by tablet
+ List measurementSchemaList =
+ new ArrayList<>(
+ Arrays.asList(
+ new MeasurementSchema("region_id", TSDataType.STRING),
+ new MeasurementSchema("plant_id", TSDataType.STRING),
+ new MeasurementSchema("device_id", TSDataType.STRING),
+ new MeasurementSchema("model", TSDataType.STRING),
+ new MeasurementSchema("temperature", TSDataType.FLOAT),
+ new MeasurementSchema("humidity", TSDataType.DOUBLE)));
+ List columnTypeList =
+ new ArrayList<>(
+ Arrays.asList(
+ ColumnCategory.ID,
+ ColumnCategory.ID,
+ ColumnCategory.ID,
+ ColumnCategory.ATTRIBUTE,
+ ColumnCategory.MEASUREMENT,
+ ColumnCategory.MEASUREMENT));
+ Tablet tablet =
+ new Tablet(
+ "test1",
+ IMeasurementSchema.getMeasurementNameList(measurementSchemaList),
+ IMeasurementSchema.getDataTypeList(measurementSchemaList),
+ columnTypeList,
+ 100);
+ for (long timestamp = 0; timestamp < 100; timestamp++) {
+ int rowIndex = tablet.getRowSize();
+ tablet.addTimestamp(rowIndex, timestamp);
+ tablet.addValue("region_id", rowIndex, "1");
+ tablet.addValue("plant_id", rowIndex, "5");
+ tablet.addValue("device_id", rowIndex, "3");
+ tablet.addValue("model", rowIndex, "A");
+ tablet.addValue("temperature", rowIndex, 37.6F);
+ tablet.addValue("humidity", rowIndex, 111.1);
+ if (tablet.getRowSize() == tablet.getMaxRowNumber()) {
+ session.insert(tablet);
+ tablet.reset();
+ }
+ }
+ if (tablet.getRowSize() != 0) {
+ session.insert(tablet);
+ tablet.reset();
+ }
+
+ // query table data
+ try (SessionDataSet dataSet =
+ session.executeQueryStatement(
+ "select * from test1 "
+ + "where region_id = '1' and plant_id in ('3', '5') and device_id = '3'")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ } catch (IoTDBConnectionException e) {
+ e.printStackTrace();
+ } catch (StatementExecutionException e) {
+ e.printStackTrace();
+ } finally {
+ tableSessionPool.close();
+ }
+
+ // specify database in constructor
+ tableSessionPool =
+ new TableSessionPoolBuilder()
+ .nodeUrls(Collections.singletonList(LOCAL_URL))
+ .user("root")
+ .password("root")
+ .maxSize(1)
+ .database("test1")
+ .build();
+
+ try (ITableSession session = tableSessionPool.getSession()) {
+
+ // show tables from current database
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ // change database to test2
+ session.executeNonQueryStatement("use test2");
+
+ // show tables by specifying another database
+ // using SHOW tables FROM
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ } catch (IoTDBConnectionException e) {
+ e.printStackTrace();
+ } catch (StatementExecutionException e) {
+ e.printStackTrace();
+ }
+
+ try (ITableSession session = tableSessionPool.getSession()) {
+
+ // show tables from default database test1
+ try (SessionDataSet dataSet = session.executeQueryStatement("SHOW TABLES")) {
+ System.out.println(dataSet.getColumnNames());
+ System.out.println(dataSet.getColumnTypes());
+ while (dataSet.hasNext()) {
+ System.out.println(dataSet.next());
+ }
+ }
+
+ } catch (IoTDBConnectionException e) {
+ e.printStackTrace();
+ } catch (StatementExecutionException e) {
+ e.printStackTrace();
+ } finally {
+ tableSessionPool.close();
+ }
+ }
+}
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/API/Programming-Python-Native-API.md b/src/zh/UserGuide/V2.0.1/Table/API/Programming-Python-Native-API.md
new file mode 100644
index 000000000..28f92880a
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/API/Programming-Python-Native-API.md
@@ -0,0 +1,457 @@
+
+
+# Python 原生接口
+
+## 1 使用方式
+
+安装依赖包:
+
+```Java
+pip3 install apache-iotdb
+```
+
+## 2 读写操作
+
+### 2.1 TableSession
+
+#### 2.1.1 功能描述
+
+TableSession是IoTDB的一个核心类,用于与IoTDB数据库进行交互。通过这个类,用户可以执行SQL语句、插入数据以及管理数据库会话。
+
+#### 2.1.2 方法列表
+
+| **方法名称** | **描述** | **参数类型** | **返回类型** |
+| --------------------------- | ---------------------------------- | ---------------------------------- | -------------- |
+| insert | 写入数据 | tablet: Union[Tablet, NumpyTablet] | None |
+| execute_non_query_statement | 执行非查询 SQL 语句,如 DDL 和 DML | sql: str | None |
+| execute_query_statement | 执行查询 SQL 语句并返回结果集 | sql: str | SessionDataSet |
+| close | 关闭会话并释放资源 | None | None |
+
+#### 2.1.3 接口展示
+
+**TableSession:**
+
+
+```Java
+class TableSession(object):
+def insert(self, tablet: Union[Tablet, NumpyTablet]):
+ """
+ Insert data into the database.
+
+ Parameters:
+ tablet (Tablet | NumpyTablet): The tablet containing the data to be inserted.
+ Accepts either a `Tablet` or `NumpyTablet`.
+
+ Raises:
+ IoTDBConnectionException: If there is an issue with the database connection.
+ """
+ pass
+
+def execute_non_query_statement(self, sql: str):
+ """
+ Execute a non-query SQL statement.
+
+ Parameters:
+ sql (str): The SQL statement to execute. Typically used for commands
+ such as INSERT, DELETE, or UPDATE.
+
+ Raises:
+ IoTDBConnectionException: If there is an issue with the database connection.
+ """
+ pass
+
+def execute_query_statement(self, sql: str, timeout_in_ms: int = 0) -> "SessionDataSet":
+ """
+ Execute a query SQL statement and return the result set.
+
+ Parameters:
+ sql (str): The SQL query to execute.
+ timeout_in_ms (int, optional): Timeout for the query in milliseconds. Defaults to 0,
+ which means no timeout.
+
+ Returns:
+ SessionDataSet: The result set of the query.
+
+ Raises:
+ IoTDBConnectionException: If there is an issue with the database connection.
+ """
+ pass
+
+def close(self):
+ """
+ Close the session and release resources.
+
+ Raises:
+ IoTDBConnectionException: If there is an issue closing the connection.
+ """
+ pass
+```
+
+### 2.2 TableSessionConfig
+
+#### 2.2.1 功能描述
+
+TableSessionConfig是一个配置类,用于设置和创建TableSession 实例。它定义了连接到IoTDB数据库所需的各种参数。
+
+#### 2.2.2 配置选项
+
+| **配置项** | **描述** | **类型** | **默认值** |
+| ------------------ | ------------------------- | -------- | ----------------------- |
+| node_urls | 数据库连接的节点 URL 列表 | list | ["localhost:6667"] |
+| username | 数据库连接用户名 | str | "root" |
+| password | 数据库连接密码 | str | "root" |
+| database | 要连接的目标数据库 | str | None |
+| fetch_size | 每次查询获取的行数 | int | 5000 |
+| time_zone | 会话的默认时区 | str | Session.DEFAULT_ZONE_ID |
+| enable_compression | 是否启用数据压缩 | bool | False |
+
+#### 2.2.3 接口展示
+
+```Java
+class TableSessionConfig(object):
+ """
+ Configuration class for a TableSession.
+
+ This class defines various parameters for connecting to and interacting
+ with the IoTDB tables.
+ """
+
+ def __init__(
+ self,
+ node_urls: list = None,
+ username: str = Session.DEFAULT_USER,
+ password: str = Session.DEFAULT_PASSWORD,
+ database: str = None,
+ fetch_size: int = 5000,
+ time_zone: str = Session.DEFAULT_ZONE_ID,
+ enable_compression: bool = False,
+ ):
+ """
+ Initialize a TableSessionConfig object with the provided parameters.
+
+ Parameters:
+ node_urls (list, optional): A list of node URLs for the database connection.
+ Defaults to ["localhost:6667"].
+ username (str, optional): The username for the database connection.
+ Defaults to "root".
+ password (str, optional): The password for the database connection.
+ Defaults to "root".
+ database (str, optional): The target database to connect to. Defaults to None.
+ fetch_size (int, optional): The number of rows to fetch per query. Defaults to 5000.
+ time_zone (str, optional): The default time zone for the session.
+ Defaults to Session.DEFAULT_ZONE_ID.
+ enable_compression (bool, optional): Whether to enable data compression.
+ Defaults to False.
+ """
+```
+
+**注意事项:**
+
+在使用完 TableSession 后,务必调用 close 方法来释放资源。
+
+## 3 客户端连接池
+
+### 3.1 TableSessionPool
+
+#### 3.1.1 功能描述
+
+TableSessionPool 是一个会话池管理类,用于管理 TableSession 实例的创建和销毁。它提供了从池中获取会话和关闭会话池的功能。
+
+#### 3.1.2 方法列表
+
+| **方法名称** | **描述** | **返回类型** | **异常** |
+| ------------ | ---------------------------------------- | ------------ | -------- |
+| get_session | 从会话池中检索一个新的 TableSession 实例 | TableSession | 无 |
+| close | 关闭会话池并释放所有资源 | None | 无 |
+
+#### 3.1.3 接口展示
+
+**TableSessionPool:**
+
+```Java
+def get_session(self) -> TableSession:
+ """
+ Retrieve a new TableSession instance.
+
+ Returns:
+ TableSession: A new session object configured with the session pool.
+
+ Notes:
+ The session is initialized with the underlying session pool for managing
+ connections. Ensure proper usage of the session's lifecycle.
+ """
+
+def close(self):
+ """
+ Close the session pool and release all resources.
+
+ This method closes the underlying session pool, ensuring that all
+ resources associated with it are properly released.
+
+ Notes:
+ After calling this method, the session pool cannot be used to retrieve
+ new sessions, and any attempt to do so may raise an exception.
+ """
+```
+
+### 3.2 TableSessionPoolConfig
+
+#### 3.2.1 功能描述
+
+TableSessionPoolConfig是一个配置类,用于设置和创建 TableSessionPool 实例。它定义了初始化和管理 IoTDB 数据库会话池所需的参数。
+
+#### 3.2.2 配置选项
+
+| **配置项** | **描述** | **类型** | **默认值** |
+| ------------------ | ------------------------------ | -------- | ------------------------ |
+| node_urls | 数据库连接的节点 URL 列表 | list | None |
+| max_pool_size | 会话池中的最大会话数 | int | 5 |
+| username | 数据库连接用户名 | str | Session.DEFAULT_USER |
+| password | 数据库连接密码 | str | Session.DEFAULT_PASSWORD |
+| database | 要连接的目标数据库 | str | None |
+| fetch_size | 每次查询获取的行数 | int | 5000 |
+| time_zone | 会话池的默认时区 | str | Session.DEFAULT_ZONE_ID |
+| enable_redirection | 是否启用重定向 | bool | False |
+| enable_compression | 是否启用数据压缩 | bool | False |
+| wait_timeout_in_ms | 等待会话可用的最大时间(毫秒) | int | 10000 |
+| max_retry | 操作的最大重试次数 | int | 3 |
+
+#### 3.2.3 接口展示
+
+
+```Java
+class TableSessionPoolConfig(object):
+ """
+ Configuration class for a TableSessionPool.
+
+ This class defines the parameters required to initialize and manage
+ a session pool for interacting with the IoTDB database.
+ """
+ def __init__(
+ self,
+ node_urls: list = None,
+ max_pool_size: int = 5,
+ username: str = Session.DEFAULT_USER,
+ password: str = Session.DEFAULT_PASSWORD,
+ database: str = None,
+ fetch_size: int = 5000,
+ time_zone: str = Session.DEFAULT_ZONE_ID,
+ enable_redirection: bool = False,
+ enable_compression: bool = False,
+ wait_timeout_in_ms: int = 10000,
+ max_retry: int = 3,
+ ):
+ """
+ Initialize a TableSessionPoolConfig object with the provided parameters.
+
+ Parameters:
+ node_urls (list, optional): A list of node URLs for the database connection.
+ Defaults to None.
+ max_pool_size (int, optional): The maximum number of sessions in the pool.
+ Defaults to 5.
+ username (str, optional): The username for the database connection.
+ Defaults to Session.DEFAULT_USER.
+ password (str, optional): The password for the database connection.
+ Defaults to Session.DEFAULT_PASSWORD.
+ database (str, optional): The target database to connect to. Defaults to None.
+ fetch_size (int, optional): The number of rows to fetch per query. Defaults to 5000.
+ time_zone (str, optional): The default time zone for the session pool.
+ Defaults to Session.DEFAULT_ZONE_ID.
+ enable_redirection (bool, optional): Whether to enable redirection.
+ Defaults to False.
+ enable_compression (bool, optional): Whether to enable data compression.
+ Defaults to False.
+ wait_timeout_in_ms (int, optional): The maximum time (in milliseconds) to wait for a session
+ to become available. Defaults to 10000.
+ max_retry (int, optional): The maximum number of retry attempts for operations. Defaults to 3.
+
+ """
+```
+
+## 4 示例代码
+
+Session示例代码:[iotdb/blob/master/iotdb-client/client-py/table_model_session_example.py](https://github.com/apache/iotdb/blob/master/iotdb-client/client-py/table_model_session_example.py)
+
+SessionPool示例代码:[iotdb/blob/master/iotdb-client/client-py/table_model_session_pool_example.py](https://github.com/apache/iotdb/blob/master/iotdb-client/client-py/table_model_session_pool_example.py)
+
+```Java
+# Licensed to the Apache Software Foundation (ASF) under one
+# or more contributor license agreements. See the NOTICE file
+# distributed with this work for additional information
+# regarding copyright ownership. The ASF licenses this file
+# to you under the Apache License, Version 2.0 (the
+# "License"); you may not use this file except in compliance
+# with the License. You may obtain a copy of the License at
+#
+# http://www.apache.org/licenses/LICENSE-2.0
+#
+# Unless required by applicable law or agreed to in writing,
+# software distributed under the License is distributed on an
+# "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+# KIND, either express or implied. See the License for the
+# specific language governing permissions and limitations
+# under the License.
+#
+import threading
+
+import numpy as np
+
+from iotdb.table_session_pool import TableSessionPool, TableSessionPoolConfig
+from iotdb.utils.IoTDBConstants import TSDataType
+from iotdb.utils.NumpyTablet import NumpyTablet
+from iotdb.utils.Tablet import ColumnType, Tablet
+
+
+def prepare_data():
+ print("create database")
+ # Get a session from the pool
+ session = session_pool.get_session()
+ session.execute_non_query_statement("CREATE DATABASE IF NOT EXISTS db1")
+ session.execute_non_query_statement('USE "db1"')
+ session.execute_non_query_statement(
+ "CREATE TABLE table0 (id1 string id, attr1 string attribute, "
+ + "m1 double "
+ + "measurement)"
+ )
+ session.execute_non_query_statement(
+ "CREATE TABLE table1 (id1 string id, attr1 string attribute, "
+ + "m1 double "
+ + "measurement)"
+ )
+
+ print("now the tables are:")
+ # show result
+ res = session.execute_query_statement("SHOW TABLES")
+ while res.has_next():
+ print(res.next())
+
+ session.close()
+
+
+def insert_data(num: int):
+ print("insert data for table" + str(num))
+ # Get a session from the pool
+ session = session_pool.get_session()
+ column_names = [
+ "id1",
+ "attr1",
+ "m1",
+ ]
+ data_types = [
+ TSDataType.STRING,
+ TSDataType.STRING,
+ TSDataType.DOUBLE,
+ ]
+ column_types = [ColumnType.ID, ColumnType.ATTRIBUTE, ColumnType.MEASUREMENT]
+ timestamps = []
+ values = []
+ for row in range(15):
+ timestamps.append(row)
+ values.append(["id:" + str(row), "attr:" + str(row), row * 1.0])
+ tablet = Tablet(
+ "table" + str(num), column_names, data_types, values, timestamps, column_types
+ )
+ session.insert(tablet)
+ session.execute_non_query_statement("FLush")
+
+ np_timestamps = np.arange(15, 30, dtype=np.dtype(">i8"))
+ np_values = [
+ np.array(["id:{}".format(i) for i in range(15, 30)]),
+ np.array(["attr:{}".format(i) for i in range(15, 30)]),
+ np.linspace(15.0, 29.0, num=15, dtype=TSDataType.DOUBLE.np_dtype()),
+ ]
+
+ np_tablet = NumpyTablet(
+ "table" + str(num),
+ column_names,
+ data_types,
+ np_values,
+ np_timestamps,
+ column_types=column_types,
+ )
+ session.insert(np_tablet)
+ session.close()
+
+
+def query_data():
+ # Get a session from the pool
+ session = session_pool.get_session()
+
+ print("get data from table0")
+ res = session.execute_query_statement("select * from table0")
+ while res.has_next():
+ print(res.next())
+
+ print("get data from table1")
+ res = session.execute_query_statement("select * from table0")
+ while res.has_next():
+ print(res.next())
+
+ session.close()
+
+
+def delete_data():
+ session = session_pool.get_session()
+ session.execute_non_query_statement("drop database db1")
+ print("data has been deleted. now the databases are:")
+ res = session.execute_query_statement("show databases")
+ while res.has_next():
+ print(res.next())
+ session.close()
+
+
+# Create a session pool
+username = "root"
+password = "root"
+node_urls = ["127.0.0.1:6667", "127.0.0.1:6668", "127.0.0.1:6669"]
+fetch_size = 1024
+database = "db1"
+max_pool_size = 5
+wait_timeout_in_ms = 3000
+config = TableSessionPoolConfig(
+ node_urls=node_urls,
+ username=username,
+ password=password,
+ database=database,
+ max_pool_size=max_pool_size,
+ fetch_size=fetch_size,
+ wait_timeout_in_ms=wait_timeout_in_ms,
+)
+session_pool = TableSessionPool(config)
+
+prepare_data()
+
+insert_thread1 = threading.Thread(target=insert_data, args=(0,))
+insert_thread2 = threading.Thread(target=insert_data, args=(1,))
+
+insert_thread1.start()
+insert_thread2.start()
+
+insert_thread1.join()
+insert_thread2.join()
+
+query_data()
+delete_data()
+session_pool.close()
+print("example is finished!")
+```
+
diff --git a/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md
new file mode 100644
index 000000000..ebd6a800e
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md
@@ -0,0 +1,55 @@
+
+
+# 集群相关概念
+下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
+
+
+其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
+- **节点**(ConfigNode、DataNode、AINode);
+- **槽**(SchemaSlot、DataSlot);
+- **Region**(SchemaRegion、DataRegion);
+- ***副本组***。
+
+下文将重点对以上概念进行介绍。
+
+## 节点
+IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
+- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
+- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
+- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
+
+## 槽
+IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
+- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
+- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
+
+## Region
+在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
+- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+
+## 副本组
+Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
+| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
+| :-: | :-: | :-: | :-: |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Data-Type.md b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Data-Type.md
new file mode 100644
index 000000000..3584aabb1
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Data-Type.md
@@ -0,0 +1,184 @@
+
+
+# 数据类型
+
+## 基本数据类型
+
+IoTDB 支持以下十种数据类型:
+
+* BOOLEAN(布尔值)
+* INT32(整型)
+* INT64(长整型)
+* FLOAT(单精度浮点数)
+* DOUBLE(双精度浮点数)
+* TEXT(长字符串)
+* STRING(字符串)
+* BLOB(大二进制对象)
+* TIMESTAMP(时间戳)
+* DATE(日期)
+
+其中,STRING 和 TEXT 类型的区别在于,STRING 类型具有更多的统计信息,能够用于优化值过滤查询。TEXT 类型适合用于存储长字符串。
+
+### 浮点数精度配置
+
+对于 **FLOAT** 与 **DOUBLE** 类型的序列,如果编码方式采用 `RLE`或 `TS_2DIFF`,可以在创建序列时通过 `MAX_POINT_NUMBER` 属性指定浮点数的小数点后位数。
+
+例如,
+```sql
+CREATE TIMESERIES root.vehicle.d0.s0 WITH DATATYPE=FLOAT, ENCODING=RLE, 'MAX_POINT_NUMBER'='2';
+```
+
+若不指定,系统会按照配置文件 `iotdb-system.properties` 中的 [float_precision](../Reference/Common-Config-Manual.md) 项配置(默认为 2 位)。
+
+### 数据类型兼容性
+
+当写入数据的类型与序列注册的数据类型不一致时,
+- 如果序列数据类型不兼容写入数据类型,系统会给出错误提示。
+- 如果序列数据类型兼容写入数据类型,系统会进行数据类型的自动转换,将写入的数据类型更正为注册序列的类型。
+
+各数据类型的兼容情况如下表所示:
+
+| 序列数据类型 | 支持的写入数据类型 |
+|--------------|--------------------------|
+| BOOLEAN | BOOLEAN |
+| INT32 | INT32 |
+| INT64 | INT32 INT64 |
+| FLOAT | INT32 FLOAT |
+| DOUBLE | INT32 INT64 FLOAT DOUBLE |
+| TEXT | TEXT |
+
+## 时间戳类型
+
+时间戳是一个数据到来的时间点,其中包括绝对时间戳和相对时间戳。
+
+### 绝对时间戳
+
+IOTDB 中绝对时间戳分为二种,一种为 LONG 类型,一种为 DATETIME 类型(包含 DATETIME-INPUT, DATETIME-DISPLAY 两个小类)。
+
+在用户在输入时间戳时,可以使用 LONG 类型的时间戳或 DATETIME-INPUT 类型的时间戳,其中 DATETIME-INPUT 类型的时间戳支持格式如表所示:
+
+
+
+**DATETIME-INPUT 类型支持格式**
+
+
+| format |
+| :--------------------------- |
+| yyyy-MM-dd HH:mm:ss |
+| yyyy/MM/dd HH:mm:ss |
+| yyyy.MM.dd HH:mm:ss |
+| yyyy-MM-dd HH:mm:ssZZ |
+| yyyy/MM/dd HH:mm:ssZZ |
+| yyyy.MM.dd HH:mm:ssZZ |
+| yyyy/MM/dd HH:mm:ss.SSS |
+| yyyy-MM-dd HH:mm:ss.SSS |
+| yyyy.MM.dd HH:mm:ss.SSS |
+| yyyy-MM-dd HH:mm:ss.SSSZZ |
+| yyyy/MM/dd HH:mm:ss.SSSZZ |
+| yyyy.MM.dd HH:mm:ss.SSSZZ |
+| ISO8601 standard time format |
+
+
+
+
+
+IoTDB 在显示时间戳时可以支持 LONG 类型以及 DATETIME-DISPLAY 类型,其中 DATETIME-DISPLAY 类型可以支持用户自定义时间格式。自定义时间格式的语法如表所示:
+
+
+
+**DATETIME-DISPLAY 自定义时间格式的语法**
+
+
+| Symbol | Meaning | Presentation | Examples |
+| :----: | :-------------------------: | :----------: | :--------------------------------: |
+| G | era | era | era |
+| C | century of era (>=0) | number | 20 |
+| Y | year of era (>=0) | year | 1996 |
+| | | | |
+| x | weekyear | year | 1996 |
+| w | week of weekyear | number | 27 |
+| e | day of week | number | 2 |
+| E | day of week | text | Tuesday; Tue |
+| | | | |
+| y | year | year | 1996 |
+| D | day of year | number | 189 |
+| M | month of year | month | July; Jul; 07 |
+| d | day of month | number | 10 |
+| | | | |
+| a | halfday of day | text | PM |
+| K | hour of halfday (0~11) | number | 0 |
+| h | clockhour of halfday (1~12) | number | 12 |
+| | | | |
+| H | hour of day (0~23) | number | 0 |
+| k | clockhour of day (1~24) | number | 24 |
+| m | minute of hour | number | 30 |
+| s | second of minute | number | 55 |
+| S | fraction of second | millis | 978 |
+| | | | |
+| z | time zone | text | Pacific Standard Time; PST |
+| Z | time zone offset/id | zone | -0800; -08:00; America/Los_Angeles |
+| | | | |
+| ' | escape for text | delimiter | |
+| '' | single quote | literal | ' |
+
+
+
+### 相对时间戳
+
+ 相对时间是指与服务器时间```now()```和```DATETIME```类型时间相差一定时间间隔的时间。
+ 形式化定义为:
+
+ ```
+ Duration = (Digit+ ('Y'|'MO'|'W'|'D'|'H'|'M'|'S'|'MS'|'US'|'NS'))+
+ RelativeTime = (now() | DATETIME) ((+|-) Duration)+
+ ```
+
+
+
+ **The syntax of the duration unit**
+
+
+ | Symbol | Meaning | Presentation | Examples |
+ | :----: | :---------: | :----------------------: | :------: |
+ | y | year | 1y=365 days | 1y |
+ | mo | month | 1mo=30 days | 1mo |
+ | w | week | 1w=7 days | 1w |
+ | d | day | 1d=1 day | 1d |
+ | | | | |
+ | h | hour | 1h=3600 seconds | 1h |
+ | m | minute | 1m=60 seconds | 1m |
+ | s | second | 1s=1 second | 1s |
+ | | | | |
+ | ms | millisecond | 1ms=1000_000 nanoseconds | 1ms |
+ | us | microsecond | 1us=1000 nanoseconds | 1us |
+ | ns | nanosecond | 1ns=1 nanosecond | 1ns |
+
+
+
+ 例子:
+
+ ```
+ now() - 1d2h //比服务器时间早 1 天 2 小时的时间
+ now() - 1w //比服务器时间早 1 周的时间
+ ```
+
+ > 注意:'+'和'-'的左右两边必须有空格
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Basic-Concept/Data-Model-and-Terminology.md b/src/zh/UserGuide/V2.0.1/Table/Basic-Concept/Data-Model-and-Terminology.md
new file mode 100644
index 000000000..166401607
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/Basic-Concept/Data-Model-and-Terminology.md
@@ -0,0 +1,161 @@
+
+
+# 建模方案设计
+
+本章节主要介绍如何将时序数据应用场景转化为IoTDB时序建模。
+
+## 1 时序数据模型
+
+在构建IoTDB建模方案前,需要先了解时序数据和时序数据模型,详细内容见此页面:[时序数据模型](../Basic-Concept/Navigating_Time_Series_Data.md)
+
+## 2 IoTDB 的两种时序模型
+
+> IoTDB 提供了两种数据建模方式——树模型和表模型,以满足用户多样化的应用需求。
+
+### 2.1 树模型(测点管理模型):一条路径管理一个测点
+
+以测点为单元进行管理,每个测点对应一条时间序列,测点名按逗号分割可看作一个树形目录结构,与物理世界一一对应,简单直观。
+
+示例:下图是一个风电场的建模管理,通过多个层级【集团】-【风电场】-【风机】-【物理量】可以唯一确定一个实体测点。
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
@@ -187,13 +188,13 @@
示例:1000设备,每个设备100 测点,共 100000 序列,INT32 类型。采样频率1Hz(每秒一次),存储1年,3副本。
- 完整计算公式:1000设备 * 100测点 * 12字节每数据点 * 86400秒每天 * 365天每年 * 3副本/10压缩比 / 1024 / 1024 / 1024 / 1024 =11T
- 简版计算公式:1000 * 100 * 12 * 86400 * 365 * 3 / 10 / 1024 / 1024 / 1024 / 1024 = 11T
-### 存储配置
+### 3.2 存储配置
1000w 点位以上或查询负载较大,推荐配置 SSD。
-## 网络(网卡)
+## 4 网络(网卡)
在写入吞吐不超过1000万点/秒时,需配置千兆网卡;当写入吞吐超过 1000万点/秒时,需配置万兆网卡。
| **写入吞吐(数据点/秒)** | **网卡速率** |
| ------------------- | ------------- |
| <1000万 | 1Gbps(千兆) |
| >=1000万 | 10Gbps(万兆) |
-## 其他说明
+## 5 其他说明
IoTDB 具有集群秒级扩容能力,扩容节点数据可不迁移,因此您无需担心按现有数据情况估算的集群能力有限,未来您可在需要扩容时为集群加入新的节点。
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Docker-Deployment_apache.md b/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Docker-Deployment_apache.md
new file mode 100644
index 000000000..c3f9029c4
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Docker-Deployment_apache.md
@@ -0,0 +1,412 @@
+
+# Docker部署
+
+## 1 环境准备
+
+### 1.1 Docker安装
+
+```SQL
+#以ubuntu为例,其他操作系统可以自行搜索安装方法
+#step1: 安装一些必要的系统工具
+sudo apt-get update
+sudo apt-get -y install apt-transport-https ca-certificates curl software-properties-common
+#step2: 安装GPG证书
+curl -fsSL https://mirrors.aliyun.com/docker-ce/linux/ubuntu/gpg | sudo apt-key add -
+#step3: 写入软件源信息
+sudo add-apt-repository "deb [arch=amd64] https://mirrors.aliyun.com/docker-ce/linux/ubuntu $(lsb_release -cs) stable"
+#step4: 更新并安装Docker-CE
+sudo apt-get -y update
+sudo apt-get -y install docker-ce
+#step5: 设置docker开机自启动
+sudo systemctl enable docker
+#step6: 验证docker是否安装成功
+docker --version #显示版本信息,即安装成功
+```
+
+### 1.2 docker-compose安装
+
+```SQL
+#安装命令
+curl -L "https://github.com/docker/compose/releases/download/v2.20.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
+chmod +x /usr/local/bin/docker-compose
+ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
+#验证是否安装成功
+docker-compose --version #显示版本信息即安装成功
+```
+
+## 2 单机版
+
+本节演示如何部署1C1D的docker单机版。
+
+### 2.1 拉取镜像文件
+
+Apache IoTDB的Docker镜像已经上传至https://hub.docker.com/r/apache/iotdb。
+
+以获取1.3.2版本为例,拉取镜像命令:
+
+```bash
+docker pull apache/iotdb:1.3.2-standalone
+```
+
+查看镜像:
+
+```bash
+docker images
+```
+
+
+
+### 2.2 创建docker bridge网络
+
+```Bash
+docker network create --driver=bridge --subnet=172.18.0.0/16 --gateway=172.18.0.1 iotdb
+```
+
+### 2.3 编写docker-compose的yml文件
+
+这里我们以把IoTDB安装目录和yml文件统一放在`/docker-iotdb`文件夹下为例:
+
+文件目录结构为:`/docker-iotdb/iotdb`, `/docker-iotdb/docker-compose-standalone.yml `
+
+```bash
+docker-iotdb:
+├── iotdb #iotdb安装目录
+│── docker-compose-standalone.yml #单机版docker-compose的yml文件
+```
+
+完整的docker-compose-standalone.yml 内容如下:
+
+```bash
+version: "3"
+services:
+ iotdb-service:
+ image: apache/iotdb:1.3.2-standalone #使用的镜像
+ hostname: iotdb
+ container_name: iotdb
+ restart: always
+ ports:
+ - "6667:6667"
+ environment:
+ - cn_internal_address=iotdb
+ - cn_internal_port=10710
+ - cn_consensus_port=10720
+ - cn_seed_config_node=iotdb:10710
+ - dn_rpc_address=iotdb
+ - dn_internal_address=iotdb
+ - dn_rpc_port=6667
+ - dn_internal_port=10730
+ - dn_mpp_data_exchange_port=10740
+ - dn_schema_region_consensus_port=10750
+ - dn_data_region_consensus_port=10760
+ - dn_seed_config_node=iotdb:10710
+ privileged: true
+ volumes:
+ - ./iotdb/data:/iotdb/data
+ - ./iotdb/logs:/iotdb/logs
+ networks:
+ iotdb:
+ ipv4_address: 172.18.0.6
+networks:
+ iotdb:
+ external: true
+```
+
+### 2.4 启动IoTDB
+
+使用下面的命令启动:
+
+```bash
+cd /docker-iotdb
+docker-compose -f docker-compose-standalone.yml up -d #后台启动
+```
+
+### 2.5 验证部署
+
+- 查看日志,有如下字样,表示启动成功
+
+ ```SQL
+ docker logs -f iotdb-datanode #查看日志命令
+ 2024-07-21 08:22:38,457 [main] INFO o.a.i.db.service.DataNode:227 - Congratulations, IoTDB DataNode is set up successfully. Now, enjoy yourself!
+ ```
+
+ 
+
+- 进入容器,查看服务运行状态
+
+ 查看启动的容器
+
+ ```SQL
+ docker ps
+ ```
+
+ 
+
+ 进入容器, 通过cli登录数据库, 使用show cluster命令查看服务状态
+
+ ```SQL
+ docker exec -it iotdb /bin/bash #进入容器
+ ./start-cli.sh -h iotdb #登录数据库
+ IoTDB> show cluster #查看服务状态
+ ```
+
+ 可以看到服务状态都是running, 说明IoTDB部署成功。
+
+ 
+
+### 2.6 映射/conf目录(可选)
+
+后续如果想在物理机中直接修改配置文件,可以把容器中的/conf文件夹映射出来,分三步:
+
+步骤一:拷贝容器中的/conf目录到`/docker-iotdb/iotdb/conf`
+
+```bash
+docker cp iotdb:/iotdb/conf /docker-iotdb/iotdb/conf
+```
+
+步骤二:在`docker-compose-standalone.yml`中添加映射
+
+```bash
+ volumes:
+ - ./iotdb/conf:/iotdb/conf #增加这个/conf文件夹的映射
+ - ./iotdb/data:/iotdb/data
+ - ./iotdb/logs:/iotdb/logs
+```
+
+步骤三:重新启动IoTDB
+
+```bash
+docker-compose -f docker-compose-standalone.yml up -d
+```
+
+## 3 集群版
+
+本小节描述如何手动部署包括3个ConfigNode和3个DataNode的实例,即通常所说的3C3D集群。
+
+
+
+
+
+
-### 网络配置
+### 2.3 网络配置
1. 关闭防火墙
@@ -163,7 +163,7 @@ systemctl start sshd #启用22号端口
3. 保证服务器之间的网络相互连通
-### 其他配置
+### 2.4 其他配置
1. 关闭系统 swap 内存
@@ -192,7 +192,7 @@ echo "* hard nofile 65535" >> /etc/security/limits.conf
ulimit -n
```
-## 软件依赖
+## 3 软件依赖
安装 Java 运行环境 ,Java 版本 >= 1.8,请确保已设置 jdk 环境变量。(V1.3.2.2 及之上版本推荐直接部署JDK17,老版本JDK部分场景下性能有问题,且datanode会出现stop不掉的问题)
diff --git a/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md b/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md
index 6c66c7fb9..23758abf0 100644
--- a/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md
+++ b/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/IoTDB-Package_timecho.md
@@ -19,11 +19,11 @@
-->
# 安装包获取
-## 获取方式
+## 1 获取方式
企业版安装包可通过产品试用申请,或直接联系与您对接的工作人员获取。
-## 安装包结构
+## 2 安装包结构
安装包解压后目录结构如下:
diff --git a/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md b/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md
index c7fba837e..51dd0f19e 100644
--- a/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md
+++ b/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Monitoring-panel-deployment.md
@@ -22,12 +22,12 @@
IoTDB配套监控面板是IoTDB企业版配套工具之一。它旨在解决IoTDB及其所在操作系统的监控问题,主要包括:操作系统资源监控、IoTDB性能监控,及上百项内核监控指标,从而帮助用户监控集群健康状态,并进行集群调优和运维。本文将以常见的3C3D集群(3个Confignode和3个Datanode)为例,为您介绍如何在IoTDB的实例中开启系统监控模块,并且使用Prometheus + Grafana的方式完成对系统监控指标的可视化。
-## 安装准备
+## 1 安装准备
1. 安装 IoTDB:需先安装IoTDB V1.0 版本及以上企业版,您可联系商务或技术支持获取
2. 获取 IoTDB 监控面板安装包:基于企业版 IoTDB 的数据库监控面板,您可联系商务或技术支持获取
-## 安装步骤
+## 2 安装步骤
### 步骤一:IoTDB开启监控指标采集
@@ -184,13 +184,13 @@ cd grafana-*

-## 附录、监控指标详解
+## 3 附录、监控指标详解
-### 系统面板(System Dashboard)
+### 3.1 系统面板(System Dashboard)
该面板展示了当前系统CPU、内存、磁盘、网络资源的使用情况已经JVM的部分状况。
-#### CPU
+#### 3.1.1 CPU
- CPU Core:CPU 核数
- CPU Load:
@@ -198,7 +198,7 @@ cd grafana-*
- Process CPU Load:IoTDB 进程在采样时间内占用的 CPU 比例
- CPU Time Per Minute:系统每分钟内所有进程的 CPU 时间总和
-#### Memory
+#### 3.1.2 Memory
- System Memory:当前系统内存的使用情况。
- Commited vm size: 操作系统分配给正在运行的进程使用的虚拟内存的大小。
@@ -210,7 +210,7 @@ cd grafana-*
- Total Memory:IoTDB 进程当前已经从操作系统中请求到的内存总量。
- Used Memory:IoTDB 进程当前已经使用的内存总量。
-#### Disk
+#### 3.1.3 Disk
- Disk Space:
- Total disk space:IoTDB 可使用的最大磁盘空间。
@@ -237,7 +237,7 @@ cd grafana-*
- I/O System Call Rate:进程调用读写系统调用的频率,类似于 IOPS。
- I/O Throughput:进程进行 I/O 的吞吐量,分为 actual_read/write 和 attempt_read/write 两类。actual read 和 actual write 指的是进程实际导致块设备进行 I/O 的字节数,不包含被 Page Cache 处理的部分。
-#### JVM
+#### 3.1.4 JVM
- GC Time Percentage:节点 JVM 在过去一分钟的时间窗口内,GC 耗时所占的比例
- GC Allocated/Promoted Size Detail: 节点 JVM 平均每分钟晋升到老年代的对象大小,新生代/老年代和非分代新申请的对象大小
@@ -263,7 +263,7 @@ cd grafana-*
- unloaded:系统启动至今 JVM 卸载的类的数量
- The Number of Java Thread:IoTDB 目前存活的线程数。各子项分别为各状态的线程数。
-#### Network
+#### 3.1.5 Network
eno 指的是到公网的网卡,lo 是虚拟网卡。
@@ -272,9 +272,9 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Packet Speed:网卡发送和接收数据包的速度,一次 RPC 请求可以对应一个或者多个数据包
- Connection Num:当前选定进程的 socket 连接数(IoTDB只有 TCP)
-### 整体性能面板(Performance Overview Dashboard)
+### 3.2 整体性能面板(Performance Overview Dashboard)
-#### Cluster Overview
+#### 3.2.1 Cluster Overview
- Total CPU Core: 集群机器 CPU 总核数
- DataNode CPU Load: 集群各DataNode 节点的 CPU 使用率
@@ -295,7 +295,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Total DataRegion: 集群管理的 DataRegion 总数
- Total SchemaRegion: 集群管理的 SchemaRegion 总数
-#### Node Overview
+#### 3.2.2 Node Overview
- CPU Core: 节点所在机器的 CPU 核数
- Disk Space: 节点所在机器的磁盘大小
@@ -306,7 +306,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Swap Memory: 节点所在机器的交换内存大小
- File Number: 节点管理的文件数
-#### Performance
+#### 3.2.3 Performance
- Session Idle Time: 节点的 session 连接的总空闲时间和总忙碌时间
- Client Connection: 节点的客户端连接情况,包括总连接数和活跃连接数
@@ -338,7 +338,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Average Time Consumed Of Engine Stage: 节点的 engine 阶段各子阶段平均耗时
- P99 Time Consumed Of Engine Stage: 节点 engine 阶段各子阶段的 P99 耗时
-#### System
+#### 3.2.4 System
- CPU Load: 节点的 CPU 负载
- CPU Time Per Minute: 节点的每分钟 CPU 时间,最大值和 CPU 核数相关
@@ -350,11 +350,11 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- File Size: 节点管理文件大小情况
- Log Number Per Minute: 节点的每分钟不同类型日志情况
-### ConfigNode 面板(ConfigNode Dashboard)
+### 3.3 ConfigNode 面板(ConfigNode Dashboard)
该面板展示了集群中所有管理节点的表现情况,包括分区、节点信息、客户端连接情况统计等。
-#### Node Overview
+#### 3.3.1 Node Overview
- Database Count: 节点的数据库数量
- Region
@@ -368,7 +368,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- DataNodes: 节点所在集群的 DataNode 情况
- System Overview: 节点的系统概述,包括系统内存、磁盘使用、进程内存以及CPU负载
-#### NodeInfo
+#### 3.3.2 NodeInfo
- Node Count: 节点所在集群的节点数量,包括 ConfigNode 和 DataNode
- ConfigNode Status: 节点所在集群的 ConfigNode 节点的状态
@@ -378,7 +378,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- DataRegion Distribution: 节点所在集群的 DataRegion 的分布情况
- DataRegionGroup Leader Distribution: 节点所在集群的 DataRegionGroup 的 Leader 分布情况
-#### Protocol
+#### 3.3.3 Protocol
- 客户端数量统计
- Active Client Num: 节点各线程池的活跃客户端数量
@@ -391,7 +391,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Client Mean Borrow Wait Time: 节点各线程池的客户端平均借用等待时间
- Client Mean Idle Time: 节点各线程池的客户端平均空闲时间
-#### Partition Table
+#### 3.3.4 Partition Table
- SchemaRegionGroup Count: 节点所在集群的 Database 的 SchemaRegionGroup 的数量
- DataRegionGroup Count: 节点所在集群的 Database 的 DataRegionGroup 的数量
@@ -400,7 +400,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- DataRegion Status: 节点所在集群的 DataRegion 状态
- SchemaRegion Status: 节点所在集群的 SchemaRegion 的状态
-#### Consensus
+#### 3.3.5 Consensus
- Ratis Stage Time: 节点的 Ratis 各阶段耗时
- Write Log Entry: 节点的 Ratis 写 Log 的耗时
@@ -408,17 +408,17 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Remote / Local Write QPS: 节点 Ratis 的远程和本地写入的 QPS
- RatisConsensus Memory: 节点 Ratis 共识协议的内存使用
-### DataNode 面板(DataNode Dashboard)
+### 3.4 DataNode 面板(DataNode Dashboard)
该面板展示了集群中所有数据节点的监控情况,包含写入耗时、查询耗时、存储文件数等。
-#### Node Overview
+#### 3.4.1 Node Overview
- The Number Of Entity: 节点管理的实体情况
- Write Point Per Second: 节点的每秒写入速度
- Memory Usage: 节点的内存使用情况,包括 IoT Consensus 各部分内存占用、SchemaRegion内存总占用和各个数据库的内存占用。
-#### Protocol
+#### 3.4.2 Protocol
- 节点操作耗时
- The Time Consumed Of Operation (avg): 节点的各项操作的平均耗时
@@ -439,7 +439,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Client Mean Borrow Wait Time: 节点各线程池的客户端平均借用等待时间
- Client Mean Idle Time: 节点各线程池的客户端平均空闲时间
-#### Storage Engine
+#### 3.4.3 Storage Engine
- File Count: 节点管理的各类型文件数量
- File Size: 节点管理的各类型文件大小
@@ -455,7 +455,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Compaction Process Chunk Status: 节点合并不同状态的 Chunk 的数量
- Compacted Point Num Per Minute: 节点每分钟合并的点数
-#### Write Performance
+#### 3.4.4 Write Performance
- Write Cost(avg): 节点写入耗时平均值,包括写入 wal 和 memtable
- Write Cost(50%): 节点写入耗时中位数,包括写入 wal 和 memtable
@@ -491,7 +491,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Series Num Of Flushing MemTable: 节点的不同 DataRegion 的 Memtable 刷盘时的时间序列数
- Average Point Num Of Flushing MemChunk: 节点 MemChunk 刷盘的平均点数
-#### Schema Engine
+#### 3.4.5 Schema Engine
- Schema Engine Mode: 节点的元数据引擎模式
- Schema Consensus Protocol: 节点的元数据共识协议
@@ -520,7 +520,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Time Consumed of Relead and Flush (avg): 节点触发 cache 释放和 buffer 刷盘耗时的平均值
- Time Consumed of Relead and Flush (99%): 节点触发 cache 释放和 buffer 刷盘的耗时的 P99
-#### Query Engine
+#### 3.4.6 Query Engine
- 各阶段耗时
- The time consumed of query plan stages(avg): 节点查询各阶段耗时的平均值
@@ -563,7 +563,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- The time consumed of query schedule time(50%): 节点查询任务调度耗时的中位数
- The time consumed of query schedule time(99%): 节点查询任务调度耗时的P99
-#### Query Interface
+#### 3.4.7 Query Interface
- 加载时间序列元数据
- The time consumed of load timeseries metadata(avg): 节点查询加载时间序列元数据耗时的平均值
@@ -610,7 +610,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- The time consumed of build tsblock from merge reader(50%): 节点查询通过 Merge Reader 构造 TsBlock 耗时的中位数
- The time consumed of build tsblock from merge reader(99%): 节点查询通过 Merge Reader 构造 TsBlock 耗时的P99
-#### Query Data Exchange
+#### 3.4.8 Query Data Exchange
查询的数据交换耗时。
@@ -635,7 +635,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- The time consumed of get data block task(50%): 节点查询获取 data block task 耗时的中位数
- The time consumed of get data block task(99%): 节点查询获取 data block task 耗时的 P99
-#### Query Related Resource
+#### 3.4.9 Query Related Resource
- MppDataExchangeManager: 节点查询时 shuffle sink handle 和 source handle 的数量
- LocalExecutionPlanner: 节点可分配给查询分片的剩余内存
@@ -645,7 +645,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- MemoryPool Capacity: 节点查询相关的内存池的大小情况,包括最大值和剩余可用值
- DriverScheduler: 节点查询相关的队列任务数量
-#### Consensus - IoT Consensus
+#### 3.4.10 Consensus - IoT Consensus
- 内存使用
- IoTConsensus Used Memory: 节点的 IoT Consensus 的内存使用情况,包括总使用内存大小、队列使用内存大小、同步使用内存大小
@@ -665,7 +665,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- The Time Consumed Of Different Stages (50%): 节点 IoT Consensus 不同执行阶段的耗时的中位数
- The Time Consumed Of Different Stages (99%): 节点 IoT Consensus 不同执行阶段的耗时的P99
-#### Consensus - DataRegion Ratis Consensus
+#### 3.4.11 Consensus - DataRegion Ratis Consensus
- Ratis Stage Time: 节点 Ratis 不同阶段的耗时
- Write Log Entry: 节点 Ratis 写 Log 不同阶段的耗时
@@ -673,7 +673,7 @@ eno 指的是到公网的网卡,lo 是虚拟网卡。
- Remote / Local Write QPS: 节点 Ratis 在本地或者远端写入的 QPS
- RatisConsensus Memory: 节点 Ratis 的内存使用情况
-#### Consensus - SchemaRegion Ratis Consensus
+#### 3.4.12 Consensus - SchemaRegion Ratis Consensus
- Ratis Stage Time: 节点 Ratis 不同阶段的耗时
- Write Log Entry: 节点 Ratis 写 Log 各阶段的耗时
diff --git a/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md b/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md
index 3e6fc34e1..8421d9f57 100644
--- a/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md
+++ b/src/zh/UserGuide/V2.0.1/Table/Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md
@@ -22,7 +22,7 @@
本章将介绍如何启动IoTDB单机实例,IoTDB单机实例包括 1 个ConfigNode 和1个DataNode(即通常所说的1C1D)。
-## 注意事项
+## 1 注意事项
1. 安装前请确认系统已参照[系统配置](../Deployment-and-Maintenance/Environment-Requirements.md)准备完成。
2. 推荐使用`hostname`进行IP配置,可避免后期修改主机ip导致数据库无法启动的问题。设置hostname需要在服务器上配置`/etc/hosts`,如本机ip是192.168.1.3,hostname是iotdb-1,则可以使用以下命令设置服务器的 hostname,并使用hostname配置IoTDB的 `cn_internal_address`、`dn_internal_address`。
@@ -40,18 +40,18 @@
- 避免使用 sudo:使用 sudo 命令会以 root 用户权限执行命令,可能会引起权限混淆或安全问题。
6. 推荐部署监控面板,可以对重要运行指标进行监控,随时掌握数据库运行状态,监控面板可以联系工作人员获取,部署监控面板步骤可以参考:[监控面板部署](../Deployment-and-Maintenance/Monitoring-panel-deployment.md)
-## 安装步骤
+## 2 安装步骤
-### 1、解压安装包并进入安装目录
+### 2.1 解压安装包并进入安装目录
```Plain
unzip timechodb-{version}-bin.zip
cd timechodb-{version}-bin
```
-### 2、参数配置
+### 2.2 参数配置
-#### 内存配置
+#### 2.2.1 内存配置
- conf/confignode-env.sh(或 .bat)
@@ -65,7 +65,7 @@ cd timechodb-{version}-bin
| :---------- | :----------------------------------- | :--------- | :----------------------------------------------- | :----------- |
| MEMORY_SIZE | IoTDB DataNode节点可以使用的内存总量 | 空 | 可按需填写,填写后系统会根据填写的数值来分配内存 | 重启服务生效 |
-#### 功能配置
+#### 2.2.2 功能配置
系统实际生效的参数在文件 conf/iotdb-system.properties 中,启动需设置以下参数,可以从 conf/iotdb-system.properties.template 文件中查看全部参数
@@ -99,7 +99,7 @@ DataNode 配置
| dn_schema_region_consensus_port | DataNode用于元数据副本共识协议通信使用的端口 | 10760 | 10760 | 首次启动后不能修改 |
| dn_seed_config_node | 节点注册加入集群时连接的ConfigNode地址,即cn_internal_address:cn_internal_port | 127.0.0.1:10710 | cn_internal_address:cn_internal_port | 首次启动后不能修改 |
-### 3、启动 ConfigNode 节点
+### 2.3 启动 ConfigNode 节点
进入iotdb的sbin目录下,启动confignode
@@ -109,7 +109,7 @@ DataNode 配置
如果启动失败,请参考下方[常见问题](#常见问题)。
-### 4、启动 DataNode 节点
+### 2.4 启动 DataNode 节点
进入iotdb的sbin目录下,启动datanode:
@@ -117,7 +117,7 @@ DataNode 配置
./sbin/start-datanode.sh -d #“-d”参数将在后台进行启动
```
-### 5、激活数据库
+### 2.5 激活数据库
#### 方式一:文件激活
@@ -170,13 +170,13 @@ It costs 0.030s
IoTDB> activate '01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOMN7-NB2E4BHI-7ZKGFVK6-GCIFXA4T-UG3XJTTD-SHJV6F2P-Q27B4OMJ-R47ZDIM3-UUASUXG2-OQXGVZCO-MMYKICZU-TWFQYYAO-ZOAGOKJA-NYHQTA5U-EWAR4EP5-MRC6R2CI-PKUTKRCT-7UDGRH3F-7BYV4P5D-6KKIA==='
```
-### 6、验证激活
+### 2.6 验证激活
当看到“ClusterActivationStatus”字段状态显示为ACTIVATED表示激活成功

-## 常见问题
+## 3 常见问题
1. 部署过程中多次提示激活失败
- 使用 `ls -al` 命令:使用 `ls -al` 命令检查安装包根目录的所有者信息是否为当前用户。
@@ -208,15 +208,15 @@ IoTDB> activate '01-D4EYQGPZ-EAUJJODW-NUKRDR6F-TUQS3B75-EDZFLK3A-6BOKJFFZ-ALDHOM
cd /data/iotdb rm -rf data logs
```
-## 附录
+## 4 附录
-### Confignode节点参数介绍
+### 4.1 Confignode节点参数介绍
| 参数 | 描述 | 是否为必填项 |
| :--- | :------------------------------- | :----------- |
| -d | 以守护进程模式启动,即在后台运行 | 否 |
-### Datanode节点参数介绍
+### 4.2 Datanode节点参数介绍
| 缩写 | 描述 | 是否为必填项 |
| :--- | :--------------------------------------------- | :----------- |
diff --git a/src/zh/UserGuide/V2.0.1/Table/IoTDB-Introduction/IoTDB-Introduction_apache.md b/src/zh/UserGuide/V2.0.1/Table/IoTDB-Introduction/IoTDB-Introduction_apache.md
new file mode 100644
index 000000000..2fc384714
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/IoTDB-Introduction/IoTDB-Introduction_apache.md
@@ -0,0 +1,76 @@
+
+
+# 产品介绍
+
+Apache IoTDB 是一款低成本、高性能的物联网原生时序数据库。它可以解决企业组建物联网大数据平台管理时序数据时所遇到的应用场景复杂、数据体量大、采样频率高、数据乱序多、数据处理耗时长、分析需求多样、存储与运维成本高等多种问题。
+
+- Github仓库链接:https://github.com/apache/iotdb
+
+- 开源安装包下载:https://iotdb.apache.org/zh/Download/
+
+- 安装部署与使用文档:[快速上手](../QuickStart/QuickStart_apache.md)
+
+
+## 产品体系
+
+IoTDB 体系由若干个组件构成,帮助用户高效地管理和分析物联网产生的海量时序数据。
+
+
+
+
+
+
+
+ | 功能 |
+ Apache IoTDB |
+ TimechoDB |
+
+
+ | 部署模式 |
+ 单机部署 |
+ √ |
+ √ |
+
+
+ | 分布式部署 |
+ √ |
+ √ |
+
+
+ | 双活部署 |
+ × |
+ √ |
+
+
+ | 容器部署 |
+ 部分支持 |
+ √ |
+
+
+ | 数据库功能 |
+ 测点管理 |
+ √ |
+ √ |
+
+
+ | 数据写入 |
+ √ |
+ √ |
+
+
+ | 数据查询 |
+ √ |
+ √ |
+
+
+ | 连续查询 |
+ √ |
+ √ |
+
+
+ | 触发器 |
+ √ |
+ √ |
+
+
+ | 用户自定义函数 |
+ √ |
+ √ |
+
+
+ | 权限管理 |
+ √ |
+ √ |
+
+
+ | 数据同步 |
+ 仅文件同步,无内置插件 |
+ 实时同步+文件同步,丰富内置插件 |
+
+
+ | 流处理 |
+ 仅框架,无内置插件 |
+ 框架+丰富内置插件 |
+
+
+ | 多级存储 |
+ × |
+ √ |
+
+
+ | 视图 |
+ × |
+ √ |
+
+
+ | 白名单 |
+ × |
+ √ |
+
+
+ | 审计日志 |
+ × |
+ √ |
+
+
+ | 配套工具 |
+ 可视化控制台 |
+ × |
+ √ |
+
+
+ | 集群管理工具 |
+ × |
+ √ |
+
+
+ | 系统监控工具 |
+ × |
+ √ |
+
+
+ | 国产化 |
+ 国产化兼容性认证 |
+ × |
+ √ |
+
+
+ | 技术支持 |
+ 最佳实践 |
+ × |
+ √ |
+
+
+ | 使用培训 |
+ × |
+ √ |
+
+
+
+
+### 更高效/稳定的产品性能
+
+TimechoDB 在开源版的基础上优化了稳定性与性能,经过企业版技术支持,能够实现10倍以上性能提升,并具有故障及时恢复的性能优势。
+
+### 更用户友好的工具体系
+
+TimechoDB 将为用户提供更简单、易用的工具体系,通过集群监控面板(IoTDB Grafana)、数据库控制台(IoTDB Workbench)、集群管理工具(IoTDB Deploy Tool,简称 IoTD)等产品帮助用户快速部署、管理、监控数据库集群,降低运维人员工作/学习成本,简化数据库运维工作,使运维过程更加方便、快捷。
+
+- 集群监控面板:旨在解决 IoTDB 及其所在操作系统的监控问题,主要包括:操作系统资源监控、IoTDB 性能监控,及上百项内核监控指标,从而帮助用户监控集群健康状态,并进行集群调优和运维。
+
+
+
总体概览
+
操作系统资源监控
+
IoTDB 性能监控
+
+
+
1. SequenceStrategy:IoTDB 按顺序选择目录,依次遍历 data_dirs 中的所有目录,并不断轮循;
2. MaxDiskUsableSpaceFirstStrategy:IoTDB 优先选择 data_dirs 中对应磁盘空余空间最大的目录;
您可以通过以下方法完成用户自定义策略:
1. 继承 org.apache.iotdb.db.storageengine.rescon.disk.strategy.DirectoryStrategy 类并实现自身的 Strategy 方法;
2. 将实现的类的完整类名(包名加类名,UserDefineStrategyPackage)填写到该配置项;
3. 将该类 jar 包添加到工程中。 |
+| 类型 | String |
+| 默认值 | SequenceStrategy |
+| 改后生效方式 | 热加载 |
+
+- dn_consensus_dir
+
+| 名字 | dn_consensus_dir |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTDB 共识层日志存储路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/consensus(Windows:data\\datanode\\consensus) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_wal_dirs
+
+| 名字 | dn_wal_dirs |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTDB 写前日志存储路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/wal(Windows:data\\datanode\\wal) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_tracing_dir
+
+| 名字 | dn_tracing_dir |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTDB 追踪根目录路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。 |
+| 类型 | String |
+| 默认值 | datanode/tracing(Windows:datanode\\tracing) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_sync_dir
+
+| 名字 | dn_sync_dir |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTDB sync 存储路径,默认存放在和 sbin 目录同级的 data 目录下。相对路径的起始目录与操作系统相关,建议使用绝对路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/sync(Windows:data\\datanode\\sync) |
+| 改后生效方式 | 重启服务生效 |
+
+- sort_tmp_dir
+
+| 名字 | sort_tmp_dir |
+| ------------ | ------------------------------------------------- |
+| 描述 | 用于配置排序操作的临时目录。 |
+| 类型 | String |
+| 默认值 | data/datanode/tmp(Windows:data\\datanode\\tmp) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_pipe_receiver_file_dirs
+
+| 名字 | dn_pipe_receiver_file_dirs |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | DataNode中pipe接收者用于存储文件的目录路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/system/pipe/receiver(Windows:data\\datanode\\system\\pipe\\receiver) |
+| 改后生效方式 | 重启服务生效 |
+
+- iot_consensus_v2_receiver_file_dirs
+
+| 名字 | iot_consensus_v2_receiver_file_dirs |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTConsensus V2中接收者用于存储文件的目录路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/system/pipe/consensus/receiver(Windows:data\\datanode\\system\\pipe\\consensus\\receiver) |
+| 改后生效方式 | 重启服务生效 |
+
+- iot_consensus_v2_deletion_file_dir
+
+| 名字 | iot_consensus_v2_deletion_file_dir |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTConsensus V2中删除操作用于存储文件的目录路径。 |
+| 类型 | String |
+| 默认值 | data/datanode/system/pipe/consensus/deletion(Windows:data\\datanode\\system\\pipe\\consensus\\deletion) |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.6 监控配置
+
+- cn_metric_reporter_list
+
+| 名字 | cn_metric_reporter_list |
+| ------------ | -------------------------------------------------- |
+| 描述 | confignode中用于配置监控模块的数据需要报告的系统。 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_metric_level
+
+| 名字 | cn_metric_level |
+| ------------ | ------------------------------------------ |
+| 描述 | confignode中控制监控模块收集数据的详细程度 |
+| 类型 | String |
+| 默认值 | IMPORTANT |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_metric_async_collect_period
+
+| 名字 | cn_metric_async_collect_period |
+| ------------ | -------------------------------------------------- |
+| 描述 | confignode中某些监控数据异步收集的周期,单位是秒。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_metric_prometheus_reporter_port
+
+| 名字 | cn_metric_prometheus_reporter_port |
+| ------------ | ------------------------------------------------------ |
+| 描述 | confignode中Prometheus报告者用于监控数据报告的端口号。 |
+| 类型 | int |
+| 默认值 | 9091 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_reporter_list
+
+| 名字 | dn_metric_reporter_list |
+| ------------ | ------------------------------------------------ |
+| 描述 | DataNode中用于配置监控模块的数据需要报告的系统。 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_level
+
+| 名字 | dn_metric_level |
+| ------------ | ---------------------------------------- |
+| 描述 | DataNode中控制监控模块收集数据的详细程度 |
+| 类型 | String |
+| 默认值 | IMPORTANT |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_async_collect_period
+
+| 名字 | dn_metric_async_collect_period |
+| ------------ | ------------------------------------------------ |
+| 描述 | DataNode中某些监控数据异步收集的周期,单位是秒。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_prometheus_reporter_port
+
+| 名字 | dn_metric_prometheus_reporter_port |
+| ------------ | ---------------------------------------------------- |
+| 描述 | DataNode中Prometheus报告者用于监控数据报告的端口号。 |
+| 类型 | int |
+| 默认值 | 9092 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_metric_internal_reporter_type
+
+| 名字 | dn_metric_internal_reporter_type |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | DataNode中监控模块内部报告者的种类,用于内部监控和检查数据是否已经成功写入和刷新。 |
+| 类型 | String |
+| 默认值 | IOTDB |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.7 SSL 配置
+
+- enable_thrift_ssl
+
+| 名字 | enable_thrift_ssl |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当enable_thrift_ssl配置为true时,将通过dn_rpc_port使用 SSL 加密进行通信 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_https
+
+| 名字 | enable_https |
+| ------------ | ------------------------------ |
+| 描述 | REST Service 是否开启 SSL 配置 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- key_store_path
+
+| 名字 | key_store_path |
+| ------------ | -------------- |
+| 描述 | ssl证书路径 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- key_store_pwd
+
+| 名字 | key_store_pwd |
+| ------------ | ------------- |
+| 描述 | ssl证书密码 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.8 连接配置
+
+- cn_rpc_thrift_compression_enable
+
+| 名字 | cn_rpc_thrift_compression_enable |
+| ------------ | -------------------------------- |
+| 描述 | 是否启用 thrift 的压缩机制。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_rpc_max_concurrent_client_num
+
+| 名字 | cn_rpc_max_concurrent_client_num |
+| ------------ | -------------------------------- |
+| 描述 | 最大连接数。 |
+| 类型 | Short Int : [0,65535] |
+| 默认值 | 65535 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_connection_timeout_ms
+
+| 名字 | cn_connection_timeout_ms |
+| ------------ | ------------------------ |
+| 描述 | 节点连接超时时间 |
+| 类型 | int |
+| 默认值 | 60000 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_selector_thread_nums_of_client_manager
+
+| 名字 | cn_selector_thread_nums_of_client_manager |
+| ------------ | ----------------------------------------- |
+| 描述 | 客户端异步线程管理的选择器线程数量 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- cn_max_client_count_for_each_node_in_client_manager
+
+| 名字 | cn_max_client_count_for_each_node_in_client_manager |
+| ------------ | --------------------------------------------------- |
+| 描述 | 单 ClientManager 中路由到每个节点的最大 Client 个数 |
+| 类型 | int |
+| 默认值 | 300 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_session_timeout_threshold
+
+| 名字 | dn_session_timeout_threshold |
+| ------------ | ---------------------------- |
+| 描述 | 最大的会话空闲时间 |
+| 类型 | int |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_thrift_compression_enable
+
+| 名字 | dn_rpc_thrift_compression_enable |
+| ------------ | -------------------------------- |
+| 描述 | 是否启用 thrift 的压缩机制 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_advanced_compression_enable
+
+| 名字 | dn_rpc_advanced_compression_enable |
+| ------------ | ---------------------------------- |
+| 描述 | 是否启用 thrift 的自定制压缩机制 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_selector_thread_count
+
+| 名字 | rpc_selector_thread_count |
+| ------------ | ------------------------- |
+| 描述 | rpc 选择器线程数量 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_min_concurrent_client_num
+
+| 名字 | rpc_min_concurrent_client_num |
+| ------------ | ----------------------------- |
+| 描述 | 最小连接数 |
+| 类型 | Short Int : [0,65535] |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_rpc_max_concurrent_client_num
+
+| 名字 | dn_rpc_max_concurrent_client_num |
+| ------------ | -------------------------------- |
+| 描述 | 最大连接数 |
+| 类型 | Short Int : [0,65535] |
+| 默认值 | 65535 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_thrift_max_frame_size
+
+| 名字 | dn_thrift_max_frame_size |
+| ------------ | ------------------------------------------------------ |
+| 描述 | RPC 请求/响应的最大字节数 |
+| 类型 | long |
+| 默认值 | 536870912 (默认值512MB,应大于等于 512 * 1024 * 1024) |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_thrift_init_buffer_size
+
+| 名字 | dn_thrift_init_buffer_size |
+| ------------ | -------------------------- |
+| 描述 | 字节数 |
+| 类型 | long |
+| 默认值 | 1024 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_connection_timeout_ms
+
+| 名字 | dn_connection_timeout_ms |
+| ------------ | ------------------------ |
+| 描述 | 节点连接超时时间 |
+| 类型 | int |
+| 默认值 | 60000 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_selector_thread_count_of_client_manager
+
+| 名字 | dn_selector_thread_count_of_client_manager |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | selector thread (TAsyncClientManager) nums for async thread in a clientManagerclientManager中异步线程的选择器线程(TAsyncClientManager)编号 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- dn_max_client_count_for_each_node_in_client_manager
+
+| 名字 | dn_max_client_count_for_each_node_in_client_manager |
+| ------------ | --------------------------------------------------- |
+| 描述 | 单 ClientManager 中路由到每个节点的最大 Client 个数 |
+| 类型 | int |
+| 默认值 | 300 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.9 对象存储管理
+
+- remote_tsfile_cache_dirs
+
+| 名字 | remote_tsfile_cache_dirs |
+| ------------ | ------------------------ |
+| 描述 | 云端存储在本地的缓存目录 |
+| 类型 | String |
+| 默认值 | data/datanode/data/cache |
+| 改后生效方式 | 重启服务生效 |
+
+- remote_tsfile_cache_page_size_in_kb
+
+| 名字 | remote_tsfile_cache_page_size_in_kb |
+| ------------ | ----------------------------------- |
+| 描述 | 云端存储在本地缓存文件的块大小 |
+| 类型 | int |
+| 默认值 | 20480 |
+| 改后生效方式 | 重启服务生效 |
+
+- remote_tsfile_cache_max_disk_usage_in_mb
+
+| 名字 | remote_tsfile_cache_max_disk_usage_in_mb |
+| ------------ | ---------------------------------------- |
+| 描述 | 云端存储本地缓存的最大磁盘占用大小 |
+| 类型 | long |
+| 默认值 | 51200 |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_type
+
+| 名字 | object_storage_type |
+| ------------ | ------------------- |
+| 描述 | 云端存储类型 |
+| 类型 | String |
+| 默认值 | AWS_S3 |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_endpoint
+
+| 名字 | object_storage_endpoint |
+| ------------ | ----------------------- |
+| 描述 | 云端存储的 endpoint |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_bucket
+
+| 名字 | object_storage_bucket |
+| ------------ | ---------------------- |
+| 描述 | 云端存储 bucket 的名称 |
+| 类型 | String |
+| 默认值 | iotdb_data |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_access_key
+
+| 名字 | object_storage_access_key |
+| ------------ | ------------------------- |
+| 描述 | 云端存储的验证信息 key |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- object_storage_access_secret
+
+| 名字 | object_storage_access_secret |
+| ------------ | ---------------------------- |
+| 描述 | 云端存储的验证信息 secret |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.10 多级管理
+
+- dn_default_space_usage_thresholds
+
+| 名字 | dn_default_space_usage_thresholds |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 定义每个层级数据目录的最小剩余空间比例;当剩余空间少于该比例时,数据会被自动迁移至下一个层级;当最后一个层级的剩余存储空间到低于此阈值时,会将系统置为 READ_ONLY |
+| 类型 | double |
+| 默认值 | 0.85 |
+| 改后生效方式 | 热加载 |
+
+- dn_tier_full_policy
+
+| 名字 | dn_tier_full_policy |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 如何处理最后一层数据,当其已用空间高于其dn_default_space_usage_threshold时。|
+| 类型 | String |
+| 默认值 | NULL |
+| 改后生效方式 | 热加载 |
+
+- migrate_thread_count
+
+| 名字 | migrate_thread_count |
+| ------------ | ---------------------------------------- |
+| 描述 | DataNode数据目录中迁移操作的线程池大小。 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 热加载 |
+
+- tiered_storage_migrate_speed_limit_bytes_per_sec
+
+| 名字 | tiered_storage_migrate_speed_limit_bytes_per_sec |
+| ------------ | ------------------------------------------------ |
+| 描述 | 限制不同存储层级之间的数据迁移速度。 |
+| 类型 | int |
+| 默认值 | 10485760 |
+| 改后生效方式 | 热加载 |
+
+### 3.11 REST服务配置
+
+- enable_rest_service
+
+| 名字 | enable_rest_service |
+| ------------ | ------------------- |
+| 描述 | 是否开启Rest服务。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- rest_service_port
+
+| 名字 | rest_service_port |
+| ------------ | ------------------ |
+| 描述 | Rest服务监听端口号 |
+| 类型 | int32 |
+| 默认值 | 18080 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_swagger
+
+| 名字 | enable_swagger |
+| ------------ | --------------------------------- |
+| 描述 | 是否启用swagger来展示rest接口信息 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- rest_query_default_row_size_limit
+
+| 名字 | rest_query_default_row_size_limit |
+| ------------ | --------------------------------- |
+| 描述 | 一次查询能返回的结果集最大行数 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- cache_expire_in_seconds
+
+| 名字 | cache_expire_in_seconds |
+| ------------ | -------------------------------- |
+| 描述 | 用户登录信息缓存的过期时间(秒) |
+| 类型 | int32 |
+| 默认值 | 28800 |
+| 改后生效方式 | 重启服务生效 |
+
+- cache_max_num
+
+| 名字 | cache_max_num |
+| ------------ | ------------------------ |
+| 描述 | 缓存中存储的最大用户数量 |
+| 类型 | int32 |
+| 默认值 | 100 |
+| 改后生效方式 | 重启服务生效 |
+
+- cache_init_num
+
+| 名字 | cache_init_num |
+| ------------ | -------------- |
+| 描述 | 缓存初始容量 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- client_auth
+
+| 名字 | client_auth |
+| ------------ | ---------------------- |
+| 描述 | 是否需要客户端身份验证 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- trust_store_path
+
+| 名字 | trust_store_path |
+| ------------ | ----------------------- |
+| 描述 | keyStore 密码(非必填) |
+| 类型 | String |
+| 默认值 | "" |
+| 改后生效方式 | 重启服务生效 |
+
+- trust_store_pwd
+
+| 名字 | trust_store_pwd |
+| ------------ | ------------------------- |
+| 描述 | trustStore 密码(非必填) |
+| 类型 | String |
+| 默认值 | "" |
+| 改后生效方式 | 重启服务生效 |
+
+- idle_timeout_in_seconds
+
+| 名字 | idle_timeout_in_seconds |
+| ------------ | ----------------------- |
+| 描述 | SSL 超时时间,单位为秒 |
+| 类型 | int32 |
+| 默认值 | 5000 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.12 负载均衡配置
+
+- series_slot_num
+
+| 名字 | series_slot_num |
+| ------------ | ---------------------------- |
+| 描述 | 序列分区槽数 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- series_partition_executor_class
+
+| 名字 | series_partition_executor_class |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 序列分区哈希函数 |
+| 类型 | String |
+| 默认值 | org.apache.iotdb.commons.partition.executor.hash.BKDRHashExecutor |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- schema_region_group_extension_policy
+
+| 名字 | schema_region_group_extension_policy |
+| ------------ | ------------------------------------ |
+| 描述 | SchemaRegionGroup 的扩容策略 |
+| 类型 | string |
+| 默认值 | AUTO |
+| 改后生效方式 | 重启服务生效 |
+
+- default_schema_region_group_num_per_database
+
+| 名字 | default_schema_region_group_num_per_database |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当选用 CUSTOM-SchemaRegionGroup 扩容策略时,此参数为每个 Database 拥有的 SchemaRegionGroup 数量;当选用 AUTO-SchemaRegionGroup 扩容策略时,此参数为每个 Database 最少拥有的 SchemaRegionGroup 数量 |
+| 类型 | int |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_per_data_node
+
+| 名字 | schema_region_per_data_node |
+| ------------ | -------------------------------------------------- |
+| 描述 | 期望每个 DataNode 可管理的 SchemaRegion 的最大数量 |
+| 类型 | double |
+| 默认值 | 1.0 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_group_extension_policy
+
+| 名字 | data_region_group_extension_policy |
+| ------------ | ---------------------------------- |
+| 描述 | DataRegionGroup 的扩容策略 |
+| 类型 | string |
+| 默认值 | AUTO |
+| 改后生效方式 | 重启服务生效 |
+
+- default_data_region_group_num_per_database
+
+| 名字 | default_data_region_group_per_database |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当选用 CUSTOM-DataRegionGroup 扩容策略时,此参数为每个 Database 拥有的 DataRegionGroup 数量;当选用 AUTO-DataRegionGroup 扩容策略时,此参数为每个 Database 最少拥有的 DataRegionGroup 数量 |
+| 类型 | int |
+| 默认值 | 2 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_per_data_node
+
+| 名字 | data_region_per_data_node |
+| ------------ | ------------------------------------------------ |
+| 描述 | 期望每个 DataNode 可管理的 DataRegion 的最大数量 |
+| 类型 | double |
+| 默认值 | 5.0 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_auto_leader_balance_for_ratis_consensus
+
+| 名字 | enable_auto_leader_balance_for_ratis_consensus |
+| ------------ | ---------------------------------------------- |
+| 描述 | 是否为 Ratis 共识协议开启自动均衡 leader 策略 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_auto_leader_balance_for_iot_consensus
+
+| 名字 | enable_auto_leader_balance_for_iot_consensus |
+| ------------ | -------------------------------------------- |
+| 描述 | 是否为 IoT 共识协议开启自动均衡 leader 策略 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.13 集群管理
+
+- time_partition_origin
+
+| 名字 | time_partition_origin |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | Database 数据时间分区的起始点,即从哪个时间点开始计算时间分区。 |
+| 类型 | Long |
+| 单位 | 毫秒 |
+| 默认值 | 0 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- time_partition_interval
+
+| 名字 | time_partition_interval |
+| ------------ | ------------------------------- |
+| 描述 | Database 默认的数据时间分区间隔 |
+| 类型 | Long |
+| 单位 | 毫秒 |
+| 默认值 | 604800000 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- heartbeat_interval_in_ms
+
+| 名字 | heartbeat_interval_in_ms |
+| ------------ | ------------------------ |
+| 描述 | 集群节点间的心跳间隔 |
+| 类型 | Long |
+| 单位 | ms |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- disk_space_warning_threshold
+
+| 名字 | disk_space_warning_threshold |
+| ------------ | ---------------------------- |
+| 描述 | DataNode 磁盘剩余阈值 |
+| 类型 | double(percentage) |
+| 默认值 | 0.05 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.14 内存控制配置
+
+- datanode_memory_proportion
+
+| 名字 | datanode_memory_proportion |
+| ------------ | ---------------------------------------------------- |
+| 描述 | 存储,查询,元数据,流处理引擎,共识层,空闲内存比例 |
+| 类型 | Ratio |
+| 默认值 | 3:3:1:1:1:1 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_memory_proportion
+
+| 名字 | schema_memory_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | Schema 相关的内存如何在 SchemaRegion、SchemaCache 和 PartitionCache 之间分配 |
+| 类型 | Ratio |
+| 默认值 | 5:4:1 |
+| 改后生效方式 | 重启服务生效 |
+
+- storage_engine_memory_proportion
+
+| 名字 | storage_engine_memory_proportion |
+| ------------ | -------------------------------- |
+| 描述 | 写入和合并占存储内存比例 |
+| 类型 | Ratio |
+| 默认值 | 8:2 |
+| 改后生效方式 | 重启服务生效 |
+
+- write_memory_proportion
+
+| 名字 | write_memory_proportion |
+| ------------ | -------------------------------------------- |
+| 描述 | Memtable 和 TimePartitionInfo 占写入内存比例 |
+| 类型 | Ratio |
+| 默认值 | 19:1 |
+| 改后生效方式 | 重启服务生效 |
+
+- primitive_array_size
+
+| 名字 | primitive_array_size |
+| ------------ | ---------------------------------------- |
+| 描述 | 数组池中的原始数组大小(每个数组的长度) |
+| 类型 | int32 |
+| 默认值 | 64 |
+| 改后生效方式 | 重启服务生效 |
+
+- chunk_metadata_size_proportion
+
+| 名字 | chunk_metadata_size_proportion |
+| ------------ | -------------------------------------------- |
+| 描述 | 在数据压缩过程中,用于存储块元数据的内存比例 |
+| 类型 | Double |
+| 默认值 | 0.1 |
+| 改后生效方式 | 重启服务生效 |
+
+- flush_proportion
+
+| 名字 | flush_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 调用flush disk的写入内存比例,默认0.4,若有极高的写入负载力(比如batch=1000),可以设置为低于默认值,比如0.2 |
+| 类型 | Double |
+| 默认值 | 0.4 |
+| 改后生效方式 | 重启服务生效 |
+
+- buffered_arrays_memory_proportion
+
+| 名字 | buffered_arrays_memory_proportion |
+| ------------ | --------------------------------------- |
+| 描述 | 为缓冲数组分配的写入内存比例,默认为0.6 |
+| 类型 | Double |
+| 默认值 | 0.6 |
+| 改后生效方式 | 重启服务生效 |
+
+- reject_proportion
+
+| 名字 | reject_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 拒绝插入的写入内存比例,默认0.8,若有极高的写入负载力(比如batch=1000)并且物理内存足够大,它可以设置为高于默认值,如0.9 |
+| 类型 | Double |
+| 默认值 | 0.8 |
+| 改后生效方式 | 重启服务生效 |
+
+- device_path_cache_proportion
+
+| 名字 | device_path_cache_proportion |
+| ------------ | --------------------------------------------------- |
+| 描述 | 在内存中分配给设备路径缓存(DevicePathCache)的比例 |
+| 类型 | Double |
+| 默认值 | 0.05 |
+| 改后生效方式 | 重启服务生效 |
+
+- write_memory_variation_report_proportion
+
+| 名字 | write_memory_variation_report_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 如果 DataRegion 的内存增加超过写入可用内存的一定比例,则向系统报告。默认值为0.001 |
+| 类型 | Double |
+| 默认值 | 0.001 |
+| 改后生效方式 | 重启服务生效 |
+
+- check_period_when_insert_blocked
+
+| 名字 | check_period_when_insert_blocked |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当插入被拒绝时,等待时间(以毫秒为单位)去再次检查系统,默认为50。若插入被拒绝,读取负载低,可以设置大一些。 |
+| 类型 | int32 |
+| 默认值 | 50 |
+| 改后生效方式 | 重启服务生效 |
+
+- io_task_queue_size_for_flushing
+
+| 名字 | io_task_queue_size_for_flushing |
+| ------------ | -------------------------------- |
+| 描述 | ioTaskQueue 的大小。默认值为10。 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_query_memory_estimation
+
+| 名字 | enable_query_memory_estimation |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 开启后会预估每次查询的内存使用量,如果超过可用内存,会拒绝本次查询 |
+| 类型 | bool |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+### 3.15 元数据引擎配置
+
+- schema_engine_mode
+
+| 名字 | schema_engine_mode |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 元数据引擎的运行模式,支持 Memory 和 PBTree;PBTree 模式下支持将内存中暂时不用的序列元数据实时置换到磁盘上,需要使用时再加载进内存;此参数在集群中所有的 DataNode 上务必保持相同。 |
+| 类型 | string |
+| 默认值 | Memory |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- partition_cache_size
+
+| 名字 | partition_cache_size |
+| ------------ | ------------------------------ |
+| 描述 | 分区信息缓存的最大缓存条目数。 |
+| 类型 | Int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- sync_mlog_period_in_ms
+
+| 名字 | sync_mlog_period_in_ms |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | mlog定期刷新到磁盘的周期,单位毫秒。如果该参数为0,则表示每次对元数据的更新操作都会被立即写到磁盘上。 |
+| 类型 | Int64 |
+| 默认值 | 100 |
+| 改后生效方式 | 重启服务生效 |
+
+- tag_attribute_flush_interval
+
+| 名字 | tag_attribute_flush_interval |
+| ------------ | -------------------------------------------------- |
+| 描述 | 标签和属性记录的间隔数,达到此记录数量时将强制刷盘 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- tag_attribute_total_size
+
+| 名字 | tag_attribute_total_size |
+| ------------ | ---------------------------------------- |
+| 描述 | 每个时间序列标签和属性的最大持久化字节数 |
+| 类型 | int32 |
+| 默认值 | 700 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- max_measurement_num_of_internal_request
+
+| 名字 | max_measurement_num_of_internal_request |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 一次注册序列请求中若物理量过多,在系统内部执行时将被拆分为若干个轻量级的子请求,每个子请求中的物理量数目不超过此参数设置的最大值。 |
+| 类型 | Int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- datanode_schema_cache_eviction_policy
+
+| 名字 | datanode_schema_cache_eviction_policy |
+| ------------ | ----------------------------------------------------- |
+| 描述 | 当 Schema 缓存达到其最大容量时,Schema 缓存的淘汰策略 |
+| 类型 | String |
+| 默认值 | FIFO |
+| 改后生效方式 | 重启服务生效 |
+
+- cluster_timeseries_limit_threshold
+
+| 名字 | cluster_timeseries_limit_threshold |
+| ------------ | ---------------------------------- |
+| 描述 | 集群中可以创建的时间序列的最大数量 |
+| 类型 | Int32 |
+| 默认值 | -1 |
+| 改后生效方式 | 重启服务生效 |
+
+- cluster_device_limit_threshold
+
+| 名字 | cluster_device_limit_threshold |
+| ------------ | ------------------------------ |
+| 描述 | 集群中可以创建的最大设备数量 |
+| 类型 | Int32 |
+| 默认值 | -1 |
+| 改后生效方式 | 重启服务生效 |
+
+- database_limit_threshold
+
+| 名字 | database_limit_threshold |
+| ------------ | ------------------------------ |
+| 描述 | 集群中可以创建的最大数据库数量 |
+| 类型 | Int32 |
+| 默认值 | -1 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.16 自动推断数据类型
+
+- enable_auto_create_schema
+
+| 名字 | enable_auto_create_schema |
+| ------------ | -------------------------------------- |
+| 描述 | 当写入的序列不存在时,是否自动创建序列 |
+| 取值 | true or false |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- default_storage_group_level
+
+| 名字 | default_storage_group_level |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当写入的数据不存在且自动创建序列时,若需要创建相应的 database,将序列路径的哪一层当做 database。例如,如果我们接到一个新序列 root.sg0.d1.s2, 并且 level=1, 那么 root.sg0 被视为database(因为 root 是 level 0 层) |
+| 取值 | int32 |
+| 默认值 | 1 |
+| 改后生效方式 | 重启服务生效 |
+
+- boolean_string_infer_type
+
+| 名字 | boolean_string_infer_type |
+| ------------ | ------------------------------------------ |
+| 描述 | "true" 或者 "false" 字符串被推断的数据类型 |
+| 取值 | BOOLEAN 或者 TEXT |
+| 默认值 | BOOLEAN |
+| 改后生效方式 | 重启服务生效 |
+
+- integer_string_infer_type
+
+| 名字 | integer_string_infer_type |
+| ------------ | --------------------------------- |
+| 描述 | 整型字符串推断的数据类型 |
+| 取值 | INT32, INT64, FLOAT, DOUBLE, TEXT |
+| 默认值 | DOUBLE |
+| 改后生效方式 | 重启服务生效 |
+
+- floating_string_infer_type
+
+| 名字 | floating_string_infer_type |
+| ------------ | ----------------------------- |
+| 描述 | "6.7"等字符串被推断的数据类型 |
+| 取值 | DOUBLE, FLOAT or TEXT |
+| 默认值 | DOUBLE |
+| 改后生效方式 | 重启服务生效 |
+
+- nan_string_infer_type
+
+| 名字 | nan_string_infer_type |
+| ------------ | ---------------------------- |
+| 描述 | "NaN" 字符串被推断的数据类型 |
+| 取值 | DOUBLE, FLOAT or TEXT |
+| 默认值 | DOUBLE |
+| 改后生效方式 | 重启服务生效 |
+
+- default_boolean_encoding
+
+| 名字 | default_boolean_encoding |
+| ------------ | ------------------------ |
+| 描述 | BOOLEAN 类型编码格式 |
+| 取值 | PLAIN, RLE |
+| 默认值 | RLE |
+| 改后生效方式 | 重启服务生效 |
+
+- default_int32_encoding
+
+| 名字 | default_int32_encoding |
+| ------------ | -------------------------------------- |
+| 描述 | int32 类型编码格式 |
+| 取值 | PLAIN, RLE, TS_2DIFF, REGULAR, GORILLA |
+| 默认值 | TS_2DIFF |
+| 改后生效方式 | 重启服务生效 |
+
+- default_int64_encoding
+
+| 名字 | default_int64_encoding |
+| ------------ | -------------------------------------- |
+| 描述 | int64 类型编码格式 |
+| 取值 | PLAIN, RLE, TS_2DIFF, REGULAR, GORILLA |
+| 默认值 | TS_2DIFF |
+| 改后生效方式 | 重启服务生效 |
+
+- default_float_encoding
+
+| 名字 | default_float_encoding |
+| ------------ | ----------------------------- |
+| 描述 | float 类型编码格式 |
+| 取值 | PLAIN, RLE, TS_2DIFF, GORILLA |
+| 默认值 | GORILLA |
+| 改后生效方式 | 重启服务生效 |
+
+- default_double_encoding
+
+| 名字 | default_double_encoding |
+| ------------ | ----------------------------- |
+| 描述 | double 类型编码格式 |
+| 取值 | PLAIN, RLE, TS_2DIFF, GORILLA |
+| 默认值 | GORILLA |
+| 改后生效方式 | 重启服务生效 |
+
+- default_text_encoding
+
+| 名字 | default_text_encoding |
+| ------------ | --------------------- |
+| 描述 | text 类型编码格式 |
+| 取值 | PLAIN |
+| 默认值 | PLAIN |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.17 查询配置
+
+- read_consistency_level
+
+| 名字 | read_consistency_level |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 查询一致性等级,取值 “strong” 时从 Leader 副本查询,取值 “weak” 时随机查询一个副本。 |
+| 类型 | String |
+| 默认值 | strong |
+| 改后生效方式 | 重启服务生效 |
+
+- meta_data_cache_enable
+
+| 名字 | meta_data_cache_enable |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 是否缓存元数据(包括 BloomFilter、Chunk Metadata 和 TimeSeries Metadata。) |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- chunk_timeseriesmeta_free_memory_proportion
+
+| 名字 | chunk_timeseriesmeta_free_memory_proportion |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 读取内存分配比例,BloomFilterCache、ChunkCache、TimeseriesMetadataCache、数据集查询的内存和可用内存的查询。参数形式为a : b : c : d : e,其中a、b、c、d、e为整数。 例如“1 : 1 : 1 : 1 : 1” ,“1 : 100 : 200 : 300 : 400” 。 |
+| 类型 | String |
+| 默认值 | 1 : 100 : 200 : 300 : 400 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_last_cache
+
+| 名字 | enable_last_cache |
+| ------------ | ------------------ |
+| 描述 | 是否开启最新点缓存 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- mpp_data_exchange_core_pool_size
+
+| 名字 | mpp_data_exchange_core_pool_size |
+| ------------ | -------------------------------- |
+| 描述 | MPP 数据交换线程池核心线程数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- mpp_data_exchange_max_pool_size
+
+| 名字 | mpp_data_exchange_max_pool_size |
+| ------------ | ------------------------------- |
+| 描述 | MPP 数据交换线程池最大线程数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- mpp_data_exchange_keep_alive_time_in_ms
+
+| 名字 | mpp_data_exchange_keep_alive_time_in_ms |
+| ------------ | --------------------------------------- |
+| 描述 | MPP 数据交换最大等待时间 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- driver_task_execution_time_slice_in_ms
+
+| 名字 | driver_task_execution_time_slice_in_ms |
+| ------------ | -------------------------------------- |
+| 描述 | 单个 DriverTask 最长执行时间(ms) |
+| 类型 | int32 |
+| 默认值 | 200 |
+| 改后生效方式 | 重启服务生效 |
+
+- max_tsblock_size_in_bytes
+
+| 名字 | max_tsblock_size_in_bytes |
+| ------------ | ------------------------------- |
+| 描述 | 单个 TsBlock 的最大容量(byte) |
+| 类型 | int32 |
+| 默认值 | 131072 |
+| 改后生效方式 | 重启服务生效 |
+
+- max_tsblock_line_numbers
+
+| 名字 | max_tsblock_line_numbers |
+| ------------ | ------------------------ |
+| 描述 | 单个 TsBlock 的最大行数 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- slow_query_threshold
+
+| 名字 | slow_query_threshold |
+| ------------ | ------------------------------ |
+| 描述 | 慢查询的时间阈值。单位:毫秒。 |
+| 类型 | long |
+| 默认值 | 10000 |
+| 改后生效方式 | 热加载 |
+
+- query_timeout_threshold
+
+| 名字 | query_timeout_threshold |
+| ------------ | -------------------------------- |
+| 描述 | 查询的最大执行时间。单位:毫秒。 |
+| 类型 | Int32 |
+| 默认值 | 60000 |
+| 改后生效方式 | 重启服务生效 |
+
+- max_allowed_concurrent_queries
+
+| 名字 | max_allowed_concurrent_queries |
+| ------------ | ------------------------------ |
+| 描述 | 允许的最大并发查询数量。 |
+| 类型 | Int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- query_thread_count
+
+| 名字 | query_thread_count |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当 IoTDB 对内存中的数据进行查询时,最多启动多少个线程来执行该操作。如果该值小于等于 0,那么采用机器所安装的 CPU 核的数量。 |
+| 类型 | Int32 |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- degree_of_query_parallelism
+
+| 名字 | degree_of_query_parallelism |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 设置单个查询片段实例将创建的 pipeline 驱动程序数量,也就是查询操作的并行度。 |
+| 类型 | Int32 |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- mode_map_size_threshold
+
+| 名字 | mode_map_size_threshold |
+| ------------ | ---------------------------------------------- |
+| 描述 | 计算 MODE 聚合函数时,计数映射可以增长到的阈值 |
+| 类型 | Int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- batch_size
+
+| 名字 | batch_size |
+| ------------ | ---------------------------------------------------------- |
+| 描述 | 服务器中每次迭代的数据量(数据条目,即不同时间戳的数量。) |
+| 类型 | Int32 |
+| 默认值 | 100000 |
+| 改后生效方式 | 重启服务生效 |
+
+- sort_buffer_size_in_bytes
+
+| 名字 | sort_buffer_size_in_bytes |
+| ------------ | -------------------------------------- |
+| 描述 | 设置外部排序操作中使用的内存缓冲区大小 |
+| 类型 | long |
+| 默认值 | 1048576 |
+| 改后生效方式 | 重启服务生效 |
+
+- merge_threshold_of_explain_analyze
+
+| 名字 | merge_threshold_of_explain_analyze |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 用于设置在 `EXPLAIN ANALYZE` 语句的结果集中操作符(operator)数量的合并阈值。 |
+| 类型 | int |
+| 默认值 | 10 |
+| 改后生效方式 | 热加载 |
+
+### 3.18 TTL配置
+
+- ttl_check_interval
+
+| 名字 | ttl_check_interval |
+| ------------ | -------------------------------------- |
+| 描述 | ttl 检查任务的间隔,单位 ms,默认为 2h |
+| 类型 | int |
+| 默认值 | 7200000 |
+| 改后生效方式 | 重启服务生效 |
+
+- max_expired_time
+
+| 名字 | max_expired_time |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 如果一个文件中存在设备已经过期超过此时间,那么这个文件将被立即整理。单位 ms,默认为一个月 |
+| 类型 | int |
+| 默认值 | 2592000000 |
+| 改后生效方式 | 重启服务生效 |
+
+- expired_data_ratio
+
+| 名字 | expired_data_ratio |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 过期设备比例。如果一个文件中过期设备的比率超过这个值,那么这个文件中的过期数据将通过 compaction 清理。 |
+| 类型 | float |
+| 默认值 | 0.3 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.19 存储引擎配置
+
+- timestamp_precision
+
+| 名字 | timestamp_precision |
+| ------------ | ---------------------------- |
+| 描述 | 时间戳精度,支持 ms、us、ns |
+| 类型 | String |
+| 默认值 | ms |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- timestamp_precision_check_enabled
+
+| 名字 | timestamp_precision_check_enabled |
+| ------------ | --------------------------------- |
+| 描述 | 用于控制是否启用时间戳精度检查 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- max_waiting_time_when_insert_blocked
+
+| 名字 | max_waiting_time_when_insert_blocked |
+| ------------ | ----------------------------------------------- |
+| 描述 | 当插入请求等待超过这个时间,则抛出异常,单位 ms |
+| 类型 | Int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- handle_system_error
+
+| 名字 | handle_system_error |
+| ------------ | ------------------------------------ |
+| 描述 | 当系统遇到不可恢复的错误时的处理方法 |
+| 类型 | String |
+| 默认值 | CHANGE_TO_READ_ONLY |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_timed_flush_seq_memtable
+
+| 名字 | enable_timed_flush_seq_memtable |
+| ------------ | ------------------------------- |
+| 描述 | 是否开启定时刷盘顺序 memtable |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- seq_memtable_flush_interval_in_ms
+
+| 名字 | seq_memtable_flush_interval_in_ms |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当 memTable 的创建时间小于当前时间减去该值时,该 memtable 需要被刷盘 |
+| 类型 | long |
+| 默认值 | 600000 |
+| 改后生效方式 | 热加载 |
+
+- seq_memtable_flush_check_interval_in_ms
+
+| 名字 | seq_memtable_flush_check_interval_in_ms |
+| ------------ | ---------------------------------------- |
+| 描述 | 检查顺序 memtable 是否需要刷盘的时间间隔 |
+| 类型 | long |
+| 默认值 | 30000 |
+| 改后生效方式 | 热加载 |
+
+- enable_timed_flush_unseq_memtable
+
+| 名字 | enable_timed_flush_unseq_memtable |
+| ------------ | --------------------------------- |
+| 描述 | 是否开启定时刷新乱序 memtable |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- unseq_memtable_flush_interval_in_ms
+
+| 名字 | unseq_memtable_flush_interval_in_ms |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当 memTable 的创建时间小于当前时间减去该值时,该 memtable 需要被刷盘 |
+| 类型 | long |
+| 默认值 | 600000 |
+| 改后生效方式 | 热加载 |
+
+- unseq_memtable_flush_check_interval_in_ms
+
+| 名字 | unseq_memtable_flush_check_interval_in_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | 检查乱序 memtable 是否需要刷盘的时间间隔 |
+| 类型 | long |
+| 默认值 | 30000 |
+| 改后生效方式 | 热加载 |
+
+- tvlist_sort_algorithm
+
+| 名字 | tvlist_sort_algorithm |
+| ------------ | ------------------------ |
+| 描述 | memtable中数据的排序方法 |
+| 类型 | String |
+| 默认值 | TIM |
+| 改后生效方式 | 重启服务生效 |
+
+- avg_series_point_number_threshold
+
+| 名字 | avg_series_point_number_threshold |
+| ------------ | ------------------------------------------------ |
+| 描述 | 内存中平均每个时间序列点数最大值,达到触发 flush |
+| 类型 | int32 |
+| 默认值 | 100000 |
+| 改后生效方式 | 重启服务生效 |
+
+- flush_thread_count
+
+| 名字 | flush_thread_count |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 当 IoTDB 将内存中的数据写入磁盘时,最多启动多少个线程来执行该操作。如果该值小于等于 0,那么采用机器所安装的 CPU 核的数量。默认值为 0。 |
+| 类型 | int32 |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_partial_insert
+
+| 名字 | enable_partial_insert |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在一次 insert 请求中,如果部分测点写入失败,是否继续写入其他测点。 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+- recovery_log_interval_in_ms
+
+| 名字 | recovery_log_interval_in_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | data region的恢复过程中打印日志信息的间隔 |
+| 类型 | Int32 |
+| 默认值 | 5000 |
+| 改后生效方式 | 重启服务生效 |
+
+- 0.13_data_insert_adapt
+
+| 名字 | 0.13_data_insert_adapt |
+| ------------ | ------------------------------------------------------- |
+| 描述 | 如果 0.13 版本客户端进行写入,需要将此配置项设置为 true |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_tsfile_validation
+
+| 名字 | enable_tsfile_validation |
+| ------------ | -------------------------------------- |
+| 描述 | Flush, Load 或合并后验证 tsfile 正确性 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 热加载 |
+
+- tier_ttl_in_ms
+
+| 名字 | tier_ttl_in_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | 定义每个层级负责的数据范围,通过 TTL 表示 |
+| 类型 | long |
+| 默认值 | -1 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.20 合并配置
+
+- enable_seq_space_compaction
+
+| 名字 | enable_seq_space_compaction |
+| ------------ | -------------------------------------- |
+| 描述 | 顺序空间内合并,开启顺序文件之间的合并 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- enable_unseq_space_compaction
+
+| 名字 | enable_unseq_space_compaction |
+| ------------ | -------------------------------------- |
+| 描述 | 乱序空间内合并,开启乱序文件之间的合并 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- enable_cross_space_compaction
+
+| 名字 | enable_cross_space_compaction |
+| ------------ | ------------------------------------------ |
+| 描述 | 跨空间合并,开启将乱序文件合并到顺序文件中 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- enable_auto_repair_compaction
+
+| 名字 | enable_auto_repair_compaction |
+| ------------ | ----------------------------- |
+| 描述 | 修复文件的合并任务 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- cross_selector
+
+| 名字 | cross_selector |
+| ------------ | -------------------------- |
+| 描述 | 跨空间合并任务选择器的类型 |
+| 类型 | String |
+| 默认值 | rewrite |
+| 改后生效方式 | 重启服务生效 |
+
+- cross_performer
+
+| 名字 | cross_performer |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 跨空间合并任务执行器的类型,可选项是read_point和fast,默认是read_point,fast还在测试中 |
+| 类型 | String |
+| 默认值 | read_point |
+| 改后生效方式 | 重启服务生效 |
+
+- inner_seq_selector
+
+| 名字 | inner_seq_selector |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 顺序空间内合并任务选择器的类型,可选 size_tiered_single_\target,size_tiered_multi_target |
+| 类型 | String |
+| 默认值 | size_tiered_multi_target |
+| 改后生效方式 | 热加载 |
+
+- inner_seq_performer
+
+| 名字 | inner_seq_performer |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 顺序空间内合并任务执行器的类型,可选项是read_chunk和fast,默认是read_chunk,fast还在测试中 |
+| 类型 | String |
+| 默认值 | read_chunk |
+| 改后生效方式 | 重启服务生效 |
+
+- inner_unseq_selector
+
+| 名字 | inner_unseq_selector |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 乱序空间内合并任务选择器的类型,可选 size_tiered_single_\target,size_tiered_multi_target |
+| 类型 | String |
+| 默认值 | size_tiered_multi_target |
+| 改后生效方式 | 热加载 |
+
+- inner_unseq_performer
+
+| 名字 | inner_unseq_performer |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 乱序空间内合并任务执行器的类型,可选项是read_point和fast,默认是read_point,fast还在测试中 |
+| 类型 | String |
+| 默认值 | read_point |
+| 改后生效方式 | 重启服务生效 |
+
+- compaction_priority
+
+| 名字 | compaction_priority |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 合并时的优先级,BALANCE 各种合并平等,INNER_CROSS 优先进行顺序文件和顺序文件或乱序文件和乱序文件的合并,CROSS_INNER 优先将乱序文件合并到顺序文件中 |
+| 类型 | String |
+| 默认值 | INNER_CROSS |
+| 改后生效方式 | 重启服务生效 |
+
+- candidate_compaction_task_queue_size
+
+| 名字 | candidate_compaction_task_queue_size |
+| ------------ | ------------------------------------ |
+| 描述 | 合并任务优先级队列的大小 |
+| 类型 | int32 |
+| 默认值 | 50 |
+| 改后生效方式 | 重启服务生效 |
+
+- target_compaction_file_size
+
+| 名字 | target_compaction_file_size |
+| ------------ | --------------------------- |
+| 描述 | 合并后的目标文件大小 |
+| 类型 | Int64 |
+| 默认值 | 2147483648 |
+| 改后生效方式 | 热加载 |
+
+- inner_compaction_total_file_size_threshold
+
+| 名字 | inner_compaction_total_file_size_threshold |
+| ------------ | -------------------------------------------- |
+| 描述 | 空间内合并任务最大选中文件总大小,单位:byte |
+| 类型 | int64 |
+| 默认值 | 10737418240 |
+| 改后生效方式 | 热加载 |
+
+- inner_compaction_total_file_num_threshold
+
+| 名字 | inner_compaction_total_file_num_threshold |
+| ------------ | ----------------------------------------- |
+| 描述 | 空间内合并中一次合并最多参与的文件数 |
+| 类型 | int32 |
+| 默认值 | 100 |
+| 改后生效方式 | 热加载 |
+
+- max_level_gap_in_inner_compaction
+
+| 名字 | max_level_gap_in_inner_compaction |
+| ------------ | -------------------------------------- |
+| 描述 | 空间内合并选文件时最大允许跨的文件层级 |
+| 类型 | int32 |
+| 默认值 | 2 |
+| 改后生效方式 | 热加载 |
+
+- target_chunk_size
+
+| 名字 | target_chunk_size |
+| ------------ | ----------------------- |
+| 描述 | 合并时 Chunk 的目标大小 |
+| 类型 | Int64 |
+| 默认值 | 1048576 |
+| 改后生效方式 | 重启服务生效 |
+
+- target_chunk_point_num
+
+| 名字 | target_chunk_point_num |
+| ------------ | ----------------------- |
+| 描述 | 合并时 Chunk 的目标点数 |
+| 类型 | int32 |
+| 默认值 | 100000 |
+| 改后生效方式 | 重启服务生效 |
+
+- chunk_size_lower_bound_in_compaction
+
+| 名字 | chunk_size_lower_bound_in_compaction |
+| ------------ | ----------------------------------------------------- |
+| 描述 | 合并时源 Chunk 的大小小于这个值,将被解开成点进行合并 |
+| 类型 | Int64 |
+| 默认值 | 10240 |
+| 改后生效方式 | 重启服务生效 |
+
+- chunk_point_num_lower_bound_in_compaction
+
+| 名字 | chunk_point_num_lower_bound_in_compaction |
+| ------------ | ----------------------------------------------------- |
+| 描述 | 合并时源 Chunk 的点数小于这个值,将被解开成点进行合并 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- inner_compaction_candidate_file_num
+
+| 名字 | inner_compaction_candidate_file_num |
+| ------------ | ---------------------------------------- |
+| 描述 | 符合构成一个空间内合并任务的候选文件数量 |
+| 类型 | int32 |
+| 默认值 | 30 |
+| 改后生效方式 | 热加载 |
+
+- max_cross_compaction_candidate_file_num
+
+| 名字 | max_cross_compaction_candidate_file_num |
+| ------------ | --------------------------------------- |
+| 描述 | 跨空间合并中一次合并最多参与的文件数 |
+| 类型 | int32 |
+| 默认值 | 500 |
+| 改后生效方式 | 热加载 |
+
+- max_cross_compaction_candidate_file_size
+
+| 名字 | max_cross_compaction_candidate_file_size |
+| ------------ | ---------------------------------------- |
+| 描述 | 跨空间合并中一次合并最多参与的文件总大小 |
+| 类型 | Int64 |
+| 默认值 | 5368709120 |
+| 改后生效方式 | 热加载 |
+
+- min_cross_compaction_unseq_file_level
+
+| 名字 | min_cross_compaction_unseq_file_level |
+| ------------ | ---------------------------------------------- |
+| 描述 | 乱序空间中跨空间合并中文件的最小内部压缩级别。 |
+| 类型 | int32 |
+| 默认值 | 1 |
+| 改后生效方式 | 热加载 |
+
+- compaction_thread_count
+
+| 名字 | compaction_thread_count |
+| ------------ | ----------------------- |
+| 描述 | 执行合并任务的线程数目 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 热加载 |
+
+- compaction_max_aligned_series_num_in_one_batch
+
+| 名字 | compaction_max_aligned_series_num_in_one_batch |
+| ------------ | ---------------------------------------------- |
+| 描述 | 对齐序列合并一次执行时处理的值列数量 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 热加载 |
+
+- compaction_schedule_interval_in_ms
+
+| 名字 | compaction_schedule_interval_in_ms |
+| ------------ | ---------------------------------- |
+| 描述 | 合并调度的时间间隔 |
+| 类型 | Int64 |
+| 默认值 | 60000 |
+| 改后生效方式 | 重启服务生效 |
+
+- compaction_write_throughput_mb_per_sec
+
+| 名字 | compaction_write_throughput_mb_per_sec |
+| ------------ | -------------------------------------- |
+| 描述 | 每秒可达到的写入吞吐量合并限制。 |
+| 类型 | int32 |
+| 默认值 | 16 |
+| 改后生效方式 | 重启服务生效 |
+
+- compaction_read_throughput_mb_per_sec
+
+| 名字 | compaction_read_throughput_mb_per_sec |
+| --------- | ---------------------------------------------------- |
+| 描述 | 合并每秒读吞吐限制,单位为 byte,设置为 0 代表不限制 |
+| 类型 | int32 |
+| 默认值 | 0 |
+| Effective | 热加载 |
+
+- compaction_read_operation_per_sec
+
+| 名字 | compaction_read_operation_per_sec |
+| --------- | ------------------------------------------- |
+| 描述 | 合并每秒读操作数量限制,设置为 0 代表不限制 |
+| 类型 | int32 |
+| 默认值 | 0 |
+| Effective | 热加载 |
+
+- sub_compaction_thread_count
+
+| 名字 | sub_compaction_thread_count |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 每个合并任务的子任务线程数,只对跨空间合并和乱序空间内合并生效 |
+| 类型 | int32 |
+| 默认值 | 4 |
+| 改后生效方式 | 热加载 |
+
+- inner_compaction_task_selection_disk_redundancy
+
+| 名字 | inner_compaction_task_selection_disk_redundancy |
+| ------------ | ----------------------------------------------- |
+| 描述 | 定义了磁盘可用空间的冗余值,仅用于内部压缩 |
+| 类型 | double |
+| 默认值 | 0.05 |
+| 改后生效方式 | 热加载 |
+
+- inner_compaction_task_selection_mods_file_threshold
+
+| 名字 | inner_compaction_task_selection_mods_file_threshold |
+| ------------ | --------------------------------------------------- |
+| 描述 | 定义了mods文件大小的阈值,仅用于内部压缩。 |
+| 类型 | long |
+| 默认值 | 131072 |
+| 改后生效方式 | 热加载 |
+
+- compaction_schedule_thread_num
+
+| 名字 | compaction_schedule_thread_num |
+| ------------ | ------------------------------ |
+| 描述 | 选择合并任务的线程数量 |
+| 类型 | int32 |
+| 默认值 | 4 |
+| 改后生效方式 | 热加载 |
+
+### 3.21 写前日志配置
+
+- wal_mode
+
+| 名字 | wal_mode |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 写前日志的写入模式. DISABLE 模式下会关闭写前日志;SYNC 模式下写入请求会在成功写入磁盘后返回; ASYNC 模式下写入请求返回时可能尚未成功写入磁盘后。 |
+| 类型 | String |
+| 默认值 | ASYNC |
+| 改后生效方式 | 重启服务生效 |
+
+- max_wal_nodes_num
+
+| 名字 | max_wal_nodes_num |
+| ------------ | ----------------------------------------------------- |
+| 描述 | 写前日志节点的最大数量,默认值 0 表示数量由系统控制。 |
+| 类型 | int32 |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- wal_async_mode_fsync_delay_in_ms
+
+| 名字 | wal_async_mode_fsync_delay_in_ms |
+| ------------ | ------------------------------------------- |
+| 描述 | async 模式下写前日志调用 fsync 前的等待时间 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 热加载 |
+
+- wal_sync_mode_fsync_delay_in_ms
+
+| 名字 | wal_sync_mode_fsync_delay_in_ms |
+| ------------ | ------------------------------------------ |
+| 描述 | sync 模式下写前日志调用 fsync 前的等待时间 |
+| 类型 | int32 |
+| 默认值 | 3 |
+| 改后生效方式 | 热加载 |
+
+- wal_buffer_size_in_byte
+
+| 名字 | wal_buffer_size_in_byte |
+| ------------ | ----------------------- |
+| 描述 | 写前日志的 buffer 大小 |
+| 类型 | int32 |
+| 默认值 | 33554432 |
+| 改后生效方式 | 重启服务生效 |
+
+- wal_buffer_queue_capacity
+
+| 名字 | wal_buffer_queue_capacity |
+| ------------ | ------------------------- |
+| 描述 | 写前日志阻塞队列大小上限 |
+| 类型 | int32 |
+| 默认值 | 500 |
+| 改后生效方式 | 重启服务生效 |
+
+- wal_file_size_threshold_in_byte
+
+| 名字 | wal_file_size_threshold_in_byte |
+| ------------ | ------------------------------- |
+| 描述 | 写前日志文件封口阈值 |
+| 类型 | int32 |
+| 默认值 | 31457280 |
+| 改后生效方式 | 热加载 |
+
+- wal_min_effective_info_ratio
+
+| 名字 | wal_min_effective_info_ratio |
+| ------------ | ---------------------------- |
+| 描述 | 写前日志最小有效信息比 |
+| 类型 | double |
+| 默认值 | 0.1 |
+| 改后生效方式 | 热加载 |
+
+- wal_memtable_snapshot_threshold_in_byte
+
+| 名字 | wal_memtable_snapshot_threshold_in_byte |
+| ------------ | ---------------------------------------- |
+| 描述 | 触发写前日志中内存表快照的内存表大小阈值 |
+| 类型 | int64 |
+| 默认值 | 8388608 |
+| 改后生效方式 | 热加载 |
+
+- max_wal_memtable_snapshot_num
+
+| 名字 | max_wal_memtable_snapshot_num |
+| ------------ | ------------------------------ |
+| 描述 | 写前日志中内存表的最大数量上限 |
+| 类型 | int32 |
+| 默认值 | 1 |
+| 改后生效方式 | 热加载 |
+
+- delete_wal_files_period_in_ms
+
+| 名字 | delete_wal_files_period_in_ms |
+| ------------ | ----------------------------- |
+| 描述 | 删除写前日志的检查间隔 |
+| 类型 | int64 |
+| 默认值 | 20000 |
+| 改后生效方式 | 热加载 |
+
+- wal_throttle_threshold_in_byte
+
+| 名字 | wal_throttle_threshold_in_byte |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在IoTConsensus中,当WAL文件的大小达到一定阈值时,会开始对写入操作进行节流,以控制写入速度。 |
+| 类型 | long |
+| 默认值 | 53687091200 |
+| 改后生效方式 | 热加载 |
+
+- iot_consensus_cache_window_time_in_ms
+
+| 名字 | iot_consensus_cache_window_time_in_ms |
+| ------------ | ---------------------------------------- |
+| 描述 | 在IoTConsensus中,写缓存的最大等待时间。 |
+| 类型 | long |
+| 默认值 | -1 |
+| 改后生效方式 | 热加载 |
+
+- enable_wal_compression
+
+| 名字 | iot_consensus_cache_window_time_in_ms |
+| ------------ | ------------------------------------- |
+| 描述 | 用于控制是否启用WAL的压缩。 |
+| 类型 | boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+### 3.22 IoT 共识协议配置
+
+当Region配置了IoTConsensus共识协议之后,下述的配置项才会生效
+
+- data_region_iot_max_log_entries_num_per_batch
+
+| 名字 | data_region_iot_max_log_entries_num_per_batch |
+| ------------ | --------------------------------------------- |
+| 描述 | IoTConsensus batch 的最大日志条数 |
+| 类型 | int32 |
+| 默认值 | 1024 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_iot_max_size_per_batch
+
+| 名字 | data_region_iot_max_size_per_batch |
+| ------------ | ---------------------------------- |
+| 描述 | IoTConsensus batch 的最大大小 |
+| 类型 | int32 |
+| 默认值 | 16777216 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_iot_max_pending_batches_num
+
+| 名字 | data_region_iot_max_pending_batches_num |
+| ------------ | --------------------------------------- |
+| 描述 | IoTConsensus batch 的流水线并发阈值 |
+| 类型 | int32 |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_iot_max_memory_ratio_for_queue
+
+| 名字 | data_region_iot_max_memory_ratio_for_queue |
+| ------------ | ------------------------------------------ |
+| 描述 | IoTConsensus 队列内存分配比例 |
+| 类型 | double |
+| 默认值 | 0.6 |
+| 改后生效方式 | 重启服务生效 |
+
+- region_migration_speed_limit_bytes_per_second
+
+| 名字 | region_migration_speed_limit_bytes_per_second |
+| ------------ | --------------------------------------------- |
+| 描述 | 定义了在region迁移过程中,数据传输的最大速率 |
+| 类型 | long |
+| 默认值 | 33554432 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.23 TsFile配置
+
+- group_size_in_byte
+
+| 名字 | group_size_in_byte |
+| ------------ | ---------------------------------------------- |
+| 描述 | 每次将内存中的数据写入到磁盘时的最大写入字节数 |
+| 类型 | int32 |
+| 默认值 | 134217728 |
+| 改后生效方式 | 热加载 |
+
+- page_size_in_byte
+
+| 名字 | page_size_in_byte |
+| ------------ | ---------------------------------------------------- |
+| 描述 | 内存中每个列写出时,写成的单页最大的大小,单位为字节 |
+| 类型 | int32 |
+| 默认值 | 65536 |
+| 改后生效方式 | 热加载 |
+
+- max_number_of_points_in_page
+
+| 名字 | max_number_of_points_in_page |
+| ------------ | ------------------------------------------------- |
+| 描述 | 一个页中最多包含的数据点(时间戳-值的二元组)数量 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 热加载 |
+
+- pattern_matching_threshold
+
+| 名字 | pattern_matching_threshold |
+| ------------ | ------------------------------ |
+| 描述 | 正则表达式匹配时最大的匹配次数 |
+| 类型 | int32 |
+| 默认值 | 1000000 |
+| 改后生效方式 | 热加载 |
+
+- float_precision
+
+| 名字 | float_precision |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 浮点数精度,为小数点后数字的位数 |
+| 类型 | int32 |
+| 默认值 | 默认为 2 位。注意:32 位浮点数的十进制精度为 7 位,64 位浮点数的十进制精度为 15 位。如果设置超过机器精度将没有实际意义。 |
+| 改后生效方式 | 热加载 |
+
+- value_encoder
+
+| 名字 | value_encoder |
+| ------------ | ------------------------------------- |
+| 描述 | value 列编码方式 |
+| 类型 | 枚举 String: “TS_2DIFF”,“PLAIN”,“RLE” |
+| 默认值 | PLAIN |
+| 改后生效方式 | 热加载 |
+
+- compressor
+
+| 名字 | compressor |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 数据压缩方法; 对齐序列中时间列的压缩方法 |
+| 类型 | 枚举 String : "UNCOMPRESSED", "SNAPPY", "LZ4", "ZSTD", "LZMA2" |
+| 默认值 | LZ4 |
+| 改后生效方式 | 热加载 |
+
+- encrypt_flag
+
+| 名字 | compressor |
+| ------------ | ---------------------------- |
+| 描述 | 用于开启或关闭数据加密功能。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- encrypt_type
+
+| 名字 | compressor |
+| ------------ | ------------------------------------- |
+| 描述 | 数据加密的方法。 |
+| 类型 | String |
+| 默认值 | org.apache.tsfile.encrypt.UNENCRYPTED |
+| 改后生效方式 | 重启服务生效 |
+
+- encrypt_key_path
+
+| 名字 | encrypt_key_path |
+| ------------ | ---------------------------- |
+| 描述 | 数据加密使用的密钥来源路径。 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.24 授权配置
+
+- authorizer_provider_class
+
+| 名字 | authorizer_provider_class |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 权限服务的类名 |
+| 类型 | String |
+| 默认值 | org.apache.iotdb.commons.auth.authorizer.LocalFileAuthorizer |
+| 改后生效方式 | 重启服务生效 |
+| 其他可选值 | org.apache.iotdb.commons.auth.authorizer.OpenIdAuthorizer |
+
+- openID_url
+
+| 名字 | openID_url |
+| ------------ | ---------------------------------------------------------- |
+| 描述 | openID 服务器地址 (当 OpenIdAuthorizer 被启用时必须设定) |
+| 类型 | String(一个 http 地址) |
+| 默认值 | 无 |
+| 改后生效方式 | 重启服务生效 |
+
+- iotdb_server_encrypt_decrypt_provider
+
+| 名字 | iotdb_server_encrypt_decrypt_provider |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 用于用户密码加密的类 |
+| 类型 | String |
+| 默认值 | org.apache.iotdb.commons.security.encrypt.MessageDigestEncrypt |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- iotdb_server_encrypt_decrypt_provider_parameter
+
+| 名字 | iotdb_server_encrypt_decrypt_provider_parameter |
+| ------------ | ----------------------------------------------- |
+| 描述 | 用于初始化用户密码加密类的参数 |
+| 类型 | String |
+| 默认值 | 无 |
+| 改后生效方式 | 仅允许在第一次启动服务前修改 |
+
+- author_cache_size
+
+| 名字 | author_cache_size |
+| ------------ | ------------------------ |
+| 描述 | 用户缓存与角色缓存的大小 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- author_cache_expire_time
+
+| 名字 | author_cache_expire_time |
+| ------------ | -------------------------------------- |
+| 描述 | 用户缓存与角色缓存的有效期,单位为分钟 |
+| 类型 | int32 |
+| 默认值 | 30 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.25 UDF配置
+
+- udf_initial_byte_array_length_for_memory_control
+
+| 名字 | udf_initial_byte_array_length_for_memory_control |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 用于评估UDF查询中文本字段的内存使用情况。建议将此值设置为略大于所有文本的平均长度记录。 |
+| 类型 | int32 |
+| 默认值 | 48 |
+| 改后生效方式 | 重启服务生效 |
+
+- udf_memory_budget_in_mb
+
+| 名字 | udf_memory_budget_in_mb |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在一个UDF查询中使用多少内存(以 MB 为单位)。上限为已分配内存的 20% 用于读取。 |
+| 类型 | Float |
+| 默认值 | 30.0 |
+| 改后生效方式 | 重启服务生效 |
+
+- udf_reader_transformer_collector_memory_proportion
+
+| 名字 | udf_reader_transformer_collector_memory_proportion |
+| ------------ | --------------------------------------------------------- |
+| 描述 | UDF内存分配比例。参数形式为a : b : c,其中a、b、c为整数。 |
+| 类型 | String |
+| 默认值 | 1:1:1 |
+| 改后生效方式 | 重启服务生效 |
+
+- udf_lib_dir
+
+| 名字 | udf_lib_dir |
+| ------------ | ---------------------------- |
+| 描述 | UDF 日志及jar文件存储路径 |
+| 类型 | String |
+| 默认值 | ext/udf(Windows:ext\\udf) |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.26 触发器配置
+
+- trigger_lib_dir
+
+| 名字 | trigger_lib_dir |
+| ------------ | ----------------------- |
+| 描述 | 触发器 JAR 包存放的目录 |
+| 类型 | String |
+| 默认值 | ext/trigger |
+| 改后生效方式 | 重启服务生效 |
+
+- stateful_trigger_retry_num_when_not_found
+
+| 名字 | stateful_trigger_retry_num_when_not_found |
+| ------------ | ---------------------------------------------- |
+| 描述 | 有状态触发器触发无法找到触发器实例时的重试次数 |
+| 类型 | Int32 |
+| 默认值 | 3 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.27 SELECT-INTO配置
+
+- into_operation_buffer_size_in_byte
+
+| 名字 | into_operation_buffer_size_in_byte |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 执行 select-into 语句时,待写入数据占用的最大内存(单位:Byte) |
+| 类型 | long |
+| 默认值 | 104857600 |
+| 改后生效方式 | 热加载 |
+
+- select_into_insert_tablet_plan_row_limit
+
+| 名字 | select_into_insert_tablet_plan_row_limit |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 执行 select-into 语句时,一个 insert-tablet-plan 中可以处理的最大行数 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 热加载 |
+
+- into_operation_execution_thread_count
+
+| 名字 | into_operation_execution_thread_count |
+| ------------ | ------------------------------------------ |
+| 描述 | SELECT INTO 中执行写入任务的线程池的线程数 |
+| 类型 | int32 |
+| 默认值 | 2 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.28 连续查询配置
+- continuous_query_submit_thread_count
+
+| 名字 | continuous_query_execution_thread |
+| ------------ | --------------------------------- |
+| 描述 | 执行连续查询任务的线程池的线程数 |
+| 类型 | int32 |
+| 默认值 | 2 |
+| 改后生效方式 | 重启服务生效 |
+
+- continuous_query_min_every_interval_in_ms
+
+| 名字 | continuous_query_min_every_interval_in_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | 连续查询执行时间间隔的最小值 |
+| 类型 | long (duration) |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.29 PIPE配置
+
+- pipe_lib_dir
+
+| 名字 | pipe_lib_dir |
+| ------------ | -------------------------- |
+| 描述 | 自定义 Pipe 插件的存放目录 |
+| 类型 | string |
+| 默认值 | ext/pipe |
+| 改后生效方式 | 暂不支持修改 |
+
+- pipe_subtask_executor_max_thread_num
+
+| 名字 | pipe_subtask_executor_max_thread_num |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | pipe 子任务 processor、sink 中各自可以使用的最大线程数。实际值将是 min(pipe_subtask_executor_max_thread_num, max(1, CPU核心数 / 2))。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_sink_timeout_ms
+
+| 名字 | pipe_sink_timeout_ms |
+| ------------ | --------------------------------------------- |
+| 描述 | thrift 客户端的连接超时时间(以毫秒为单位)。 |
+| 类型 | int |
+| 默认值 | 900000 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_sink_selector_number
+
+| 名字 | pipe_sink_selector_number |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在 iotdb-thrift-async-sink 插件中可以使用的最大执行结果处理线程数量。 建议将此值设置为小于或等于 pipe_sink_max_client_number。 |
+| 类型 | int |
+| 默认值 | 4 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_sink_max_client_number
+
+| 名字 | pipe_sink_max_client_number |
+| ------------ | ----------------------------------------------------------- |
+| 描述 | 在 iotdb-thrift-async-sink 插件中可以使用的最大客户端数量。 |
+| 类型 | int |
+| 默认值 | 16 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_air_gap_receiver_enabled
+
+| 名字 | pipe_air_gap_receiver_enabled |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 是否启用通过网闸接收 pipe 数据。接收器只能在 tcp 模式下返回 0 或 1,以指示数据是否成功接收。 \| |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_air_gap_receiver_port
+
+| 名字 | pipe_air_gap_receiver_port |
+| ------------ | ------------------------------------ |
+| 描述 | 服务器通过网闸接收 pipe 数据的端口。 |
+| 类型 | int |
+| 默认值 | 9780 |
+| 改后生效方式 | 重启服务生效 |
+
+- pipe_all_sinks_rate_limit_bytes_per_second
+
+| 名字 | pipe_all_sinks_rate_limit_bytes_per_second |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 所有 pipe sink 每秒可以传输的总字节数。当给定的值小于或等于 0 时,表示没有限制。默认值是 -1,表示没有限制。 |
+| 类型 | double |
+| 默认值 | -1 |
+| 改后生效方式 | 热加载 |
+
+### 3.30 Ratis共识协议配置
+
+当Region配置了RatisConsensus共识协议之后,下述的配置项才会生效
+
+- config_node_ratis_log_appender_buffer_size_max
+
+| 名字 | config_node_ratis_log_appender_buffer_size_max |
+| ------------ | ---------------------------------------------- |
+| 描述 | confignode 一次同步日志RPC最大的传输字节限制 |
+| 类型 | int32 |
+| 默认值 | 16777216 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_appender_buffer_size_max
+
+| 名字 | schema_region_ratis_log_appender_buffer_size_max |
+| ------------ | ------------------------------------------------ |
+| 描述 | schema region 一次同步日志RPC最大的传输字节限制 |
+| 类型 | int32 |
+| 默认值 | 16777216 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_appender_buffer_size_max
+
+| 名字 | data_region_ratis_log_appender_buffer_size_max |
+| ------------ | ---------------------------------------------- |
+| 描述 | data region 一次同步日志RPC最大的传输字节限制 |
+| 类型 | int32 |
+| 默认值 | 16777216 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_snapshot_trigger_threshold
+
+| 名字 | config_node_ratis_snapshot_trigger_threshold |
+| ------------ | -------------------------------------------- |
+| 描述 | confignode 触发snapshot需要的日志条数 |
+| 类型 | int32 |
+| 默认值 | 400,000 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_snapshot_trigger_threshold
+
+| 名字 | schema_region_ratis_snapshot_trigger_threshold |
+| ------------ | ---------------------------------------------- |
+| 描述 | schema region 触发snapshot需要的日志条数 |
+| 类型 | int32 |
+| 默认值 | 400,000 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_snapshot_trigger_threshold
+
+| 名字 | data_region_ratis_snapshot_trigger_threshold |
+| ------------ | -------------------------------------------- |
+| 描述 | data region 触发snapshot需要的日志条数 |
+| 类型 | int32 |
+| 默认值 | 400,000 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_log_unsafe_flush_enable
+
+| 名字 | config_node_ratis_log_unsafe_flush_enable |
+| ------------ | ----------------------------------------- |
+| 描述 | confignode 是否允许Raft日志异步刷盘 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_unsafe_flush_enable
+
+| 名字 | schema_region_ratis_log_unsafe_flush_enable |
+| ------------ | ------------------------------------------- |
+| 描述 | schema region 是否允许Raft日志异步刷盘 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_unsafe_flush_enable
+
+| 名字 | data_region_ratis_log_unsafe_flush_enable |
+| ------------ | ----------------------------------------- |
+| 描述 | data region 是否允许Raft日志异步刷盘 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_log_segment_size_max_in_byte
+
+| 名字 | config_node_ratis_log_segment_size_max_in_byte |
+| ------------ | ---------------------------------------------- |
+| 描述 | confignode 一个RaftLog日志段文件的大小 |
+| 类型 | int32 |
+| 默认值 | 25165824 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_segment_size_max_in_byte
+
+| 名字 | schema_region_ratis_log_segment_size_max_in_byte |
+| ------------ | ------------------------------------------------ |
+| 描述 | schema region 一个RaftLog日志段文件的大小 |
+| 类型 | int32 |
+| 默认值 | 25165824 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_segment_size_max_in_byte
+
+| 名字 | data_region_ratis_log_segment_size_max_in_byte |
+| ------------ | ---------------------------------------------- |
+| 描述 | data region 一个RaftLog日志段文件的大小 |
+| 类型 | int32 |
+| 默认值 | 25165824 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_simple_consensus_log_segment_size_max_in_byte
+
+| 名字 | data_region_ratis_log_segment_size_max_in_byte |
+| ------------ | ---------------------------------------------- |
+| 描述 | Confignode 简单共识协议一个Log日志段文件的大小 |
+| 类型 | int32 |
+| 默认值 | 25165824 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_grpc_flow_control_window
+
+| 名字 | config_node_ratis_grpc_flow_control_window |
+| ------------ | ------------------------------------------ |
+| 描述 | confignode grpc 流式拥塞窗口大小 |
+| 类型 | int32 |
+| 默认值 | 4194304 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_grpc_flow_control_window
+
+| 名字 | schema_region_ratis_grpc_flow_control_window |
+| ------------ | -------------------------------------------- |
+| 描述 | schema region grpc 流式拥塞窗口大小 |
+| 类型 | int32 |
+| 默认值 | 4194304 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_grpc_flow_control_window
+
+| 名字 | data_region_ratis_grpc_flow_control_window |
+| ------------ | ------------------------------------------ |
+| 描述 | data region grpc 流式拥塞窗口大小 |
+| 类型 | int32 |
+| 默认值 | 4194304 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_grpc_leader_outstanding_appends_max
+
+| 名字 | config_node_ratis_grpc_leader_outstanding_appends_max |
+| ------------ | ----------------------------------------------------- |
+| 描述 | config node grpc 流水线并发阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_grpc_leader_outstanding_appends_max
+
+| 名字 | schema_region_ratis_grpc_leader_outstanding_appends_max |
+| ------------ | ------------------------------------------------------- |
+| 描述 | schema region grpc 流水线并发阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_grpc_leader_outstanding_appends_max
+
+| 名字 | data_region_ratis_grpc_leader_outstanding_appends_max |
+| ------------ | ----------------------------------------------------- |
+| 描述 | data region grpc 流水线并发阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_log_force_sync_num
+
+| 名字 | config_node_ratis_log_force_sync_num |
+| ------------ | ------------------------------------ |
+| 描述 | config node fsync 阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_force_sync_num
+
+| 名字 | schema_region_ratis_log_force_sync_num |
+| ------------ | -------------------------------------- |
+| 描述 | schema region fsync 阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_force_sync_num
+
+| 名字 | data_region_ratis_log_force_sync_num |
+| ------------ | ------------------------------------ |
+| 描述 | data region fsync 阈值 |
+| 类型 | int32 |
+| 默认值 | 128 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_rpc_leader_election_timeout_min_ms
+
+| 名字 | config_node_ratis_rpc_leader_election_timeout_min_ms |
+| ------------ | ---------------------------------------------------- |
+| 描述 | confignode leader 选举超时最小值 |
+| 类型 | int32 |
+| 默认值 | 2000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_rpc_leader_election_timeout_min_ms
+
+| 名字 | schema_region_ratis_rpc_leader_election_timeout_min_ms |
+| ------------ | ------------------------------------------------------ |
+| 描述 | schema region leader 选举超时最小值 |
+| 类型 | int32 |
+| 默认值 | 2000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_rpc_leader_election_timeout_min_ms
+
+| 名字 | data_region_ratis_rpc_leader_election_timeout_min_ms |
+| ------------ | ---------------------------------------------------- |
+| 描述 | data region leader 选举超时最小值 |
+| 类型 | int32 |
+| 默认值 | 2000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_rpc_leader_election_timeout_max_ms
+
+| 名字 | config_node_ratis_rpc_leader_election_timeout_max_ms |
+| ------------ | ---------------------------------------------------- |
+| 描述 | confignode leader 选举超时最大值 |
+| 类型 | int32 |
+| 默认值 | 4000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_rpc_leader_election_timeout_max_ms
+
+| 名字 | schema_region_ratis_rpc_leader_election_timeout_max_ms |
+| ------------ | ------------------------------------------------------ |
+| 描述 | schema region leader 选举超时最大值 |
+| 类型 | int32 |
+| 默认值 | 4000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_rpc_leader_election_timeout_max_ms
+
+| 名字 | data_region_ratis_rpc_leader_election_timeout_max_ms |
+| ------------ | ---------------------------------------------------- |
+| 描述 | data region leader 选举超时最大值 |
+| 类型 | int32 |
+| 默认值 | 4000ms |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_request_timeout_ms
+
+| 名字 | config_node_ratis_request_timeout_ms |
+| ------------ | ------------------------------------ |
+| 描述 | confignode Raft 客户端重试超时 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_request_timeout_ms
+
+| 名字 | schema_region_ratis_request_timeout_ms |
+| ------------ | -------------------------------------- |
+| 描述 | schema region Raft 客户端重试超时 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_request_timeout_ms
+
+| 名字 | data_region_ratis_request_timeout_ms |
+| ------------ | ------------------------------------ |
+| 描述 | data region Raft 客户端重试超时 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_max_retry_attempts
+
+| 名字 | config_node_ratis_max_retry_attempts |
+| ------------ | ------------------------------------ |
+| 描述 | confignode Raft客户端最大重试次数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_initial_sleep_time_ms
+
+| 名字 | config_node_ratis_initial_sleep_time_ms |
+| ------------ | --------------------------------------- |
+| 描述 | confignode Raft客户端初始重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 100ms |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_max_sleep_time_ms
+
+| 名字 | config_node_ratis_max_sleep_time_ms |
+| ------------ | ------------------------------------- |
+| 描述 | confignode Raft客户端最大重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 10000 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_max_retry_attempts
+
+| 名字 | schema_region_ratis_max_retry_attempts |
+| ------------ | -------------------------------------- |
+| 描述 | schema region Raft客户端最大重试次数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_initial_sleep_time_ms
+
+| 名字 | schema_region_ratis_initial_sleep_time_ms |
+| ------------ | ----------------------------------------- |
+| 描述 | schema region Raft客户端初始重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 100ms |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_max_sleep_time_ms
+
+| 名字 | schema_region_ratis_max_sleep_time_ms |
+| ------------ | ---------------------------------------- |
+| 描述 | schema region Raft客户端最大重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_max_retry_attempts
+
+| 名字 | data_region_ratis_max_retry_attempts |
+| ------------ | ------------------------------------ |
+| 描述 | data region Raft客户端最大重试次数 |
+| 类型 | int32 |
+| 默认值 | 10 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_initial_sleep_time_ms
+
+| 名字 | data_region_ratis_initial_sleep_time_ms |
+| ------------ | --------------------------------------- |
+| 描述 | data region Raft客户端初始重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 100ms |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_max_sleep_time_ms
+
+| 名字 | data_region_ratis_max_sleep_time_ms |
+| ------------ | -------------------------------------- |
+| 描述 | data region Raft客户端最大重试睡眠时长 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- ratis_first_election_timeout_min_ms
+
+| 名字 | ratis_first_election_timeout_min_ms |
+| ------------ | ----------------------------------- |
+| 描述 | Ratis协议首次选举最小超时时间 |
+| 类型 | int64 |
+| 默认值 | 50 (ms) |
+| 改后生效方式 | 重启服务生效 |
+
+- ratis_first_election_timeout_max_ms
+
+| 名字 | ratis_first_election_timeout_max_ms |
+| ------------ | ----------------------------------- |
+| 描述 | Ratis协议首次选举最大超时时间 |
+| 类型 | int64 |
+| 默认值 | 150 (ms) |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_preserve_logs_num_when_purge
+
+| 名字 | config_node_ratis_preserve_logs_num_when_purge |
+| ------------ | ---------------------------------------------- |
+| 描述 | confignode snapshot后保持一定数量日志不删除 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_preserve_logs_num_when_purge
+
+| 名字 | schema_region_ratis_preserve_logs_num_when_purge |
+| ------------ | ------------------------------------------------ |
+| 描述 | schema region snapshot后保持一定数量日志不删除 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_preserve_logs_num_when_purge
+
+| 名字 | data_region_ratis_preserve_logs_num_when_purge |
+| ------------ | ---------------------------------------------- |
+| 描述 | data region snapshot后保持一定数量日志不删除 |
+| 类型 | int32 |
+| 默认值 | 1000 |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_log_max_size
+
+| 名字 | config_node_ratis_log_max_size |
+| ------------ | ----------------------------------- |
+| 描述 | config node磁盘Raft Log最大占用空间 |
+| 类型 | int64 |
+| 默认值 | 2147483648 (2GB) |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_log_max_size
+
+| 名字 | schema_region_ratis_log_max_size |
+| ------------ | -------------------------------------- |
+| 描述 | schema region 磁盘Raft Log最大占用空间 |
+| 类型 | int64 |
+| 默认值 | 2147483648 (2GB) |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_log_max_size
+
+| 名字 | data_region_ratis_log_max_size |
+| ------------ | ------------------------------------ |
+| 描述 | data region 磁盘Raft Log最大占用空间 |
+| 类型 | int64 |
+| 默认值 | 21474836480 (20GB) |
+| 改后生效方式 | 重启服务生效 |
+
+- config_node_ratis_periodic_snapshot_interval
+
+| 名字 | config_node_ratis_periodic_snapshot_interval |
+| ------------ | -------------------------------------------- |
+| 描述 | config node定期snapshot的间隔时间 |
+| 类型 | int64 |
+| 默认值 | 86400 (秒) |
+| 改后生效方式 | 重启服务生效 |
+
+- schema_region_ratis_periodic_snapshot_interval
+
+| 名字 | schema_region_ratis_preserve_logs_num_when_purge |
+| ------------ | ------------------------------------------------ |
+| 描述 | schema region定期snapshot的间隔时间 |
+| 类型 | int64 |
+| 默认值 | 86400 (秒) |
+| 改后生效方式 | 重启服务生效 |
+
+- data_region_ratis_periodic_snapshot_interval
+
+| 名字 | data_region_ratis_preserve_logs_num_when_purge |
+| ------------ | ---------------------------------------------- |
+| 描述 | data region定期snapshot的间隔时间 |
+| 类型 | int64 |
+| 默认值 | 86400 (秒) |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.31 IoTConsensusV2配置
+
+- iot_consensus_v2_pipeline_size
+
+| 名字 | iot_consensus_v2_pipeline_size |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | IoTConsensus V2中连接器(connector)和接收器(receiver)的默认事件缓冲区大小。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+- iot_consensus_v2_mode
+
+| 名字 | iot_consensus_v2_pipeline_size |
+| ------------ | ----------------------------------- |
+| 描述 | IoTConsensus V2使用的共识协议模式。 |
+| 类型 | String |
+| 默认值 | batch |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.32 Procedure 配置
+
+- procedure_core_worker_thread_count
+
+| 名字 | procedure_core_worker_thread_count |
+| ------------ | ---------------------------------- |
+| 描述 | 工作线程数量 |
+| 类型 | int32 |
+| 默认值 | 4 |
+| 改后生效方式 | 重启服务生效 |
+
+- procedure_completed_clean_interval
+
+| 名字 | procedure_completed_clean_interval |
+| ------------ | ---------------------------------- |
+| 描述 | 清理已完成的 procedure 时间间隔 |
+| 类型 | int32 |
+| 默认值 | 30(s) |
+| 改后生效方式 | 重启服务生效 |
+
+- procedure_completed_evict_ttl
+
+| 名字 | procedure_completed_evict_ttl |
+| ------------ | --------------------------------- |
+| 描述 | 已完成的 procedure 的数据保留时间 |
+| 类型 | int32 |
+| 默认值 | 60(s) |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.33 MQTT代理配置
+
+- enable_mqtt_service
+
+| 名字 | enable_mqtt_service。 |
+| ------------ | --------------------- |
+| 描述 | 是否开启MQTT服务 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 热加载 |
+
+- mqtt_host
+
+| 名字 | mqtt_host |
+| ------------ | -------------------- |
+| 描述 | MQTT服务绑定的host。 |
+| 类型 | String |
+| 默认值 | 127.0.0.1 |
+| 改后生效方式 | 热加载 |
+
+- mqtt_port
+
+| 名字 | mqtt_port |
+| ------------ | -------------------- |
+| 描述 | MQTT服务绑定的port。 |
+| 类型 | int32 |
+| 默认值 | 1883 |
+| 改后生效方式 | 热加载 |
+
+- mqtt_handler_pool_size
+
+| 名字 | mqtt_handler_pool_size |
+| ------------ | ---------------------------------- |
+| 描述 | 用于处理MQTT消息的处理程序池大小。 |
+| 类型 | int32 |
+| 默认值 | 1 |
+| 改后生效方式 | 热加载 |
+
+- mqtt_payload_formatter
+
+| 名字 | mqtt_payload_formatter |
+| ------------ | ---------------------------- |
+| 描述 | MQTT消息有效负载格式化程序。 |
+| 类型 | String |
+| 默认值 | json |
+| 改后生效方式 | 热加载 |
+
+- mqtt_max_message_size
+
+| 名字 | mqtt_max_message_size |
+| ------------ | ------------------------------------ |
+| 描述 | MQTT消息的最大长度(以字节为单位)。 |
+| 类型 | int32 |
+| 默认值 | 1048576 |
+| 改后生效方式 | 热加载 |
+
+### 3.34 审计日志配置
+
+- enable_audit_log
+
+| 名字 | enable_audit_log |
+| ------------ | ------------------------------ |
+| 描述 | 用于控制是否启用审计日志功能。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 重启服务生效 |
+
+- audit_log_storage
+
+| 名字 | audit_log_storage |
+| ------------ | -------------------------- |
+| 描述 | 定义了审计日志的输出位置。 |
+| 类型 | String |
+| 默认值 | IOTDB,LOGGER |
+| 改后生效方式 | 重启服务生效 |
+
+- audit_log_operation
+
+| 名字 | audit_log_operation |
+| ------------ | -------------------------------------- |
+| 描述 | 定义了哪些类型的操作需要记录审计日志。 |
+| 类型 | String |
+| 默认值 | DML,DDL,QUERY |
+| 改后生效方式 | 重启服务生效 |
+
+- enable_audit_log_for_native_insert_api
+
+| 名字 | enable_audit_log_for_native_insert_api |
+| ------------ | -------------------------------------- |
+| 描述 | 用于控制本地写入API是否记录审计日志。 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.35 白名单配置
+- enable_white_list
+
+| 名字 | enable_white_list |
+| ------------ | ----------------- |
+| 描述 | 是否启用白名单。 |
+| 类型 | Boolean |
+| 默认值 | false |
+| 改后生效方式 | 热加载 |
+
+### 3.36 IoTDB-AI 配置
+
+- model_inference_execution_thread_count
+
+| 名字 | model_inference_execution_thread_count |
+| ------------ | -------------------------------------- |
+| 描述 | 用于模型推理操作的线程数。 |
+| 类型 | int |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.37 TsFile 主动监听&加载功能配置
+
+- load_clean_up_task_execution_delay_time_seconds
+
+| 名字 | load_clean_up_task_execution_delay_time_seconds |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在加载TsFile失败后,系统将等待多长时间才会执行清理任务来清除这些未成功加载的TsFile。 |
+| 类型 | int |
+| 默认值 | 1800 |
+| 改后生效方式 | 热加载 |
+
+- load_write_throughput_bytes_per_second
+
+| 名字 | load_write_throughput_bytes_per_second |
+| ------------ | -------------------------------------- |
+| 描述 | 加载TsFile时磁盘写入的最大字节数每秒。 |
+| 类型 | int |
+| 默认值 | -1 |
+| 改后生效方式 | 热加载 |
+
+- load_active_listening_enable
+
+| 名字 | load_active_listening_enable |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 是否开启 DataNode 主动监听并且加载 tsfile 的功能(默认开启)。 |
+| 类型 | Boolean |
+| 默认值 | true |
+| 改后生效方式 | 热加载 |
+
+- load_active_listening_dirs
+
+| 名字 | load_active_listening_dirs |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 需要监听的目录(自动包括目录中的子目录),如有多个使用 “,“ 隔开默认的目录为 ext/load/pending(支持热装载)。 |
+| 类型 | String |
+| 默认值 | ext/load/pending |
+| 改后生效方式 | 热加载 |
+
+- load_active_listening_fail_dir
+
+| 名字 | load_active_listening_fail_dir |
+| ------------ | ---------------------------------------------------------- |
+| 描述 | 执行加载 tsfile 文件失败后将文件转存的目录,只能配置一个。 |
+| 类型 | String |
+| 默认值 | ext/load/failed |
+| 改后生效方式 | 热加载 |
+
+- load_active_listening_max_thread_num
+
+| 名字 | load_active_listening_max_thread_num |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 同时执行加载 tsfile 任务的最大线程数,参数被注释掉时的默值为 max(1, CPU 核心数 / 2),当用户设置的值不在这个区间[1, CPU核心数 /2]内时,会设置为默认值 (1, CPU 核心数 / 2)。 |
+| 类型 | Long |
+| 默认值 | 0 |
+| 改后生效方式 | 重启服务生效 |
+
+- load_active_listening_check_interval_seconds
+
+| 名字 | load_active_listening_check_interval_seconds |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 主动监听轮询间隔,单位秒。主动监听 tsfile 的功能是通过轮询检查文件夹实现的。该配置指定了两次检查 load_active_listening_dirs 的时间间隔,每次检查完成 load_active_listening_check_interval_seconds 秒后,会执行下一次检查。当用户设置的轮询间隔小于 1 时,会被设置为默认值 5 秒。 |
+| 类型 | Long |
+| 默认值 | 5 |
+| 改后生效方式 | 重启服务生效 |
+
+### 3.38 分发重试配置
+
+- enable_retry_for_unknown_error
+
+| 名字 | enable_retry_for_unknown_error |
+| ------------ | ------------------------------------------------------------ |
+| 描述 | 在遇到未知错误时,写请求远程分发的最大重试时间,单位是毫秒。 |
+| 类型 | Long |
+| 默认值 | 60000 |
+| 改后生效方式 | 热加载 |
+
+- enable_retry_for_unknown_error
+
+| 名字 | enable_retry_for_unknown_error |
+| ------------ | -------------------------------- |
+| 描述 | 用于控制是否对未知错误进行重试。 |
+| 类型 | boolean |
+| 默认值 | false |
+| 改后生效方式 | 热加载 |
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Fill-Clause.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Fill-Clause.md
new file mode 100644
index 000000000..e8797f836
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Fill-Clause.md
@@ -0,0 +1,466 @@
+
+
+# FILL 子句
+
+## 1 功能介绍
+
+在执行数据查询时,可能会遇到某些列在某些行中没有数据,导致结果集中出现 NULL 值。这些 NULL 值不利于数据的可视化展示和分析,因此 IoTDB 提供了 FILL 子句来填充这些 NULL 值。
+
+当查询中包含 ORDER BY 子句时,FILL 子句会在 ORDER BY 之前执行。而如果存在 GAPFILL( date_bin_gapfill 函数)操作,则 FILL 子句会在 GAPFILL 之后执行。
+
+## 2 语法概览
+
+```sql
+fillClause
+ : FILL METHOD fillMethod
+ ;
+
+fillMethod
+ : LINEAR timeColumnClause? fillGroupClause? #linearFill
+ | PREVIOUS timeBoundClause? timeColumnClause? fillGroupClause? #previousFill
+ | CONSTANT literalExpression #valueFill
+ ;
+
+timeColumnClause
+ : TIME_COLUMN INTEGER_VALUE
+ ;
+
+fillGroupClause
+ : FILL_GROUP INTEGER_VALUE (',' INTEGER_VALUE)*
+ ;
+
+timeBoundClause
+ : TIME_BOUND duration=timeDuration
+ ;
+
+timeDuration
+ : (INTEGER_VALUE intervalField)+
+ ;
+intervalField
+ : YEAR | MONTH | WEEK | DAY | HOUR | MINUTE | SECOND | MILLISECOND | MICROSECOND | NANOSECOND
+ ;
+```
+
+### 2.1 填充方式
+
+IoTDB 支持以下三种空值填充方式:
+
+1. **`PREVIOUS`填充**:使用该列前一个非空值进行填充。
+2. **`LINEAR`填充**:使用该列前一个非空值和下一个非空值的线性插值进行填充。
+3. **`Constant`填充**:使用指定的常量值进行填充。
+
+只能指定一种填充方法,且该方法会作用于结果集的全部列。
+
+### 2.2 数据类型与支持的填充方法
+
+| Data Type | Previous | Linear | Constant |
+| :-------- | :------- | :----- | :------- |
+| boolean | √ | - | √ |
+| int32 | √ | √ | √ |
+| int64 | √ | √ | √ |
+| float | √ | √ | √ |
+| double | √ | √ | √ |
+| text | √ | - | √ |
+| string | √ | - | √ |
+| blob | √ | - | √ |
+| timestamp | √ | √ | √ |
+| date | √ | √ | √ |
+
+注意:对于数据类型不支持指定填充方法的列,既不进行填充,也不抛出异常,只是保持原样。
+
+## 3 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+### 3.1 PREVIOUS 填充:
+
+对于查询结果集中的空值,使用该列的前一个非空值进行填充。
+
+#### 3.1.1 参数介绍:
+
+- TIME_BOUND(可选):向前查看的时间阈值。如果当前空值的时间戳与前一个非空值的时间戳之间的间隔超过了此阈值,则不会进行填充。默认选择查询结果中第一个 TIMESTAMP 类型的列来确定是否超出了时间阈值。
+ - 时间阈值参数格式为时间间隔,数值部分需要为整数,单位部分 y 表示年,mo 表示月,w 表示周,d 表示天,h 表示小时,m 表示分钟,s 表示秒,ms 表示毫秒,µs 表示微秒,ns 表示纳秒,如1d1h。
+- TIME_COLUMN(可选):若需手动指定用于判断时间阈值的 TIMESTAMP 列,可通过在 `TIME_COLUMN` 参数后指定数字(从1开始)来确定列的顺序位置,该数字代表在原始表中 TIMESTAMP 列的具体位置。
+
+#### 3.1.2 示例
+
+不使用任何填充方法:
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101';
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| null| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| null|
+|2024-11-27T16:40:00.000+08:00| 85.0| null|
+|2024-11-27T16:41:00.000+08:00| 85.0| null|
+|2024-11-27T16:42:00.000+08:00| null| false|
+|2024-11-27T16:43:00.000+08:00| null| false|
+|2024-11-27T16:44:00.000+08:00| null| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.088s
+```
+
+使用 PREVIOUS 填充方法(结果将使用前一个非空值填充 NULL 值):
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD PREVIOUS;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| null| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| true|
+|2024-11-27T16:40:00.000+08:00| 85.0| true|
+|2024-11-27T16:41:00.000+08:00| 85.0| true|
+|2024-11-27T16:42:00.000+08:00| 85.0| false|
+|2024-11-27T16:43:00.000+08:00| 85.0| false|
+|2024-11-27T16:44:00.000+08:00| 85.0| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.091s
+```
+
+使用 PREVIOUS 填充方法(指定时间阈值):
+
+```sql
+# 不指定时间列
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD PREVIOUS TIME_BOUND 1m;
+
+# 手动指定时间列
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD PREVIOUS 1m TIME_COLUMN 1;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| null| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| true|
+|2024-11-27T16:40:00.000+08:00| 85.0| null|
+|2024-11-27T16:41:00.000+08:00| 85.0| null|
+|2024-11-27T16:42:00.000+08:00| 85.0| false|
+|2024-11-27T16:43:00.000+08:00| null| false|
+|2024-11-27T16:44:00.000+08:00| null| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.075s
+```
+
+### 3.2 LINEAR 填充
+
+对于查询结果集中的空值,用该列的前一个非空值和后一个非空值的线性插值填充。
+
+#### 3.2.1 线性填充规则:
+
+- 如果之前都是空值,或者之后都是空值,则不进行填充。
+- 如果列的数据类型是 boolean/string/blob/text,则不会进行填充,也不会抛出异常。
+- 若没有指定时间列,默认选择 SELECT 子句中第一个数据类型为 TIMESTAMP 类型的列作为辅助时间列进行线性插值。如果不存在数据类型为TIMESTAMP的列,系统将抛出异常。
+
+#### 3.2.2 参数介绍:
+
+- TIME_COLUMN(可选):可以通过在`TIME_COLUMN`参数后指定数字(从1开始)来手动指定用于判断时间阈值的`TIMESTAMP`列,作为线性插值的辅助列,该数字代表原始表中`TIMESTAMP`列的具体位置。
+
+注意:不强制要求线性插值的辅助列一定是 time 列,任何类型为 TIMESTAMP 的表达式都可以,不过因为线性插值只有在辅助列是升序或者降序的时候,才有意义,所以用户如果指定了其他的列,需要自行保证结果集是按照那一列升序或降序排列的。
+
+#### 3.2.3 示例
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD LINEAR;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| null| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| null|
+|2024-11-27T16:40:00.000+08:00| 85.0| null|
+|2024-11-27T16:41:00.000+08:00| 85.0| null|
+|2024-11-27T16:42:00.000+08:00| null| false|
+|2024-11-27T16:43:00.000+08:00| null| false|
+|2024-11-27T16:44:00.000+08:00| null| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.053s
+```
+
+### 3.3 Constant 填充:
+
+对于查询结果集中的空值,使用指定的常量进行填充。
+
+#### 3.3.1 常量填充规则:
+
+- 若数据类型与输入的常量不匹配,IoTDB 不会填充查询结果,也不会抛出异常。
+- 若插入的常量值超出了其数据类型所能表示的最大值,IoTDB 不会填充查询结果,也不会抛出异常。
+
+#### 3.3.2 示例
+
+使用`FLOAT`常量填充时,SQL 语句如下所示:
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD CONSTANT 80.0;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| 80.0| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| true|
+|2024-11-27T16:40:00.000+08:00| 85.0| true|
+|2024-11-27T16:41:00.000+08:00| 85.0| true|
+|2024-11-27T16:42:00.000+08:00| 80.0| false|
+|2024-11-27T16:43:00.000+08:00| 80.0| false|
+|2024-11-27T16:44:00.000+08:00| 80.0| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.242s
+```
+
+使用`BOOLEAN`常量填充时,SQL 语句如下所示:
+
+```sql
+SELECT time, temperature, status
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD CONSTANT true;
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------+------+
+| time|temperature|status|
++-----------------------------+-----------+------+
+|2024-11-27T16:38:00.000+08:00| 1.0| true|
+|2024-11-27T16:39:00.000+08:00| 85.0| true|
+|2024-11-27T16:40:00.000+08:00| 85.0| true|
+|2024-11-27T16:41:00.000+08:00| 85.0| true|
+|2024-11-27T16:42:00.000+08:00| 1.0| false|
+|2024-11-27T16:43:00.000+08:00| 1.0| false|
+|2024-11-27T16:44:00.000+08:00| 1.0| false|
++-----------------------------+-----------+------+
+Total line number = 7
+It costs 0.073s
+```
+
+## 4 高阶用法
+
+使用 `PREVIOUS` 和 `LINEAR` FILL 时,还支持额外的 `FILL_GROUP` 参数,来进行分组内填充。
+
+在使用 group by 子句 + fill 时,想在分组内进行填充,而不受其他分组的影响。
+
+例如:对每个 `device_id` 内部的空值进行填充,而不使用其他设备的值:
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, plant_id, device_id, avg(temperature) AS avg_temp
+ FROM table1
+ WHERE time >= 2024-11-28 08:00:00 AND time < 2024-11-30 14:30:00
+ group by 1, plant_id, device_id;
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+
+| hour_time|plant_id|device_id|avg_temp|
++-----------------------------+--------+---------+--------+
+|2024-11-28T08:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 3001| 100| null|
+|2024-11-28T10:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 3001| 100| 88.0|
+|2024-11-29T10:00:00.000+08:00| 3001| 101| 85.0|
+|2024-11-29T11:00:00.000+08:00| 3002| 100| null|
+|2024-11-29T18:00:00.000+08:00| 3002| 100| 90.0|
+|2024-11-30T09:00:00.000+08:00| 3002| 101| 90.0|
++-----------------------------+--------+---------+--------+
+Total line number = 8
+It costs 0.110s
+```
+
+若没有指定 FILL_GROUP 参数时,`100` 的空值会被 `101` 的值填充:
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, plant_id, device_id, avg(temperature) AS avg_temp
+ FROM table1
+ WHERE time >= 2024-11-28 08:00:00 AND time < 2024-11-30 14:30:00
+ group by 1, plant_id, device_id
+ FILL METHOD PREVIOUS;
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+
+| hour_time|plant_id|device_id|avg_temp|
++-----------------------------+--------+---------+--------+
+|2024-11-28T08:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T10:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 3001| 100| 88.0|
+|2024-11-29T10:00:00.000+08:00| 3001| 101| 85.0|
+|2024-11-29T11:00:00.000+08:00| 3002| 100| 85.0|
+|2024-11-29T18:00:00.000+08:00| 3002| 100| 90.0|
+|2024-11-30T09:00:00.000+08:00| 3002| 101| 90.0|
++-----------------------------+--------+---------+--------+
+Total line number = 8
+It costs 0.066s
+```
+
+指定了 FILL_GROUP 为第 2 列后,填充只会发生在以第二列`device_id`为分组键的分组中,`100` 的空值不会被 `101` 的值填充,因为它们属于不同的分组。
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, plant_id, device_id, avg(temperature) AS avg_temp
+ FROM table1
+ WHERE time >= 2024-11-28 08:00:00 AND time < 2024-11-30 14:30:00
+ group by 1, plant_id, device_id
+ FILL METHOD PREVIOUS FILL_GROUP 2;
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+
+| hour_time|plant_id|device_id|avg_temp|
++-----------------------------+--------+---------+--------+
+|2024-11-28T08:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T10:00:00.000+08:00| 3001| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 3001| 100| 88.0|
+|2024-11-29T10:00:00.000+08:00| 3001| 101| 85.0|
+|2024-11-29T11:00:00.000+08:00| 3002| 100| null|
+|2024-11-29T18:00:00.000+08:00| 3002| 100| 90.0|
+|2024-11-30T09:00:00.000+08:00| 3002| 101| 90.0|
++-----------------------------+--------+---------+--------+
+Total line number = 8
+It costs 0.089s
+```
+
+## 5 特别说明
+
+在使用 `LINEAR FILL` 或 `PREVIOUS FILL` 时,如果辅助时间列(用于确定填充逻辑的时间列)中存在 NULL 值,IoTDB 将遵循以下规则:
+
+- 不对辅助时间列为 NULL 的行进行填充。
+- 这些行也不会参与到填充逻辑的计算中。
+
+以 `PREVIOUS FILL`为例,原始数据如下所示:
+
+```sql
+SELECT time, plant_id, device_id, humidity, arrival_time
+ FROM table1
+ WHERE time >= 2024-11-26 16:37:00 and time <= 2024-11-28 08:00:00
+ AND plant_id='1001' and device_id='101';
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+-----------------------------+
+| time|plant_id|device_id|humidity| arrival_time|
++-----------------------------+--------+---------+--------+-----------------------------+
+|2024-11-27T16:38:00.000+08:00| 1001| 101| 35.1|2024-11-27T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 1001| 101| 35.3| null|
+|2024-11-27T16:40:00.000+08:00| 1001| 101| null|2024-11-27T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 1001| 101| null|2024-11-27T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 1001| 101| 35.2| null|
+|2024-11-27T16:43:00.000+08:00| 1001| 101| null| null|
+|2024-11-27T16:44:00.000+08:00| 1001| 101| null|2024-11-27T16:37:08.000+08:00|
++-----------------------------+--------+---------+--------+-----------------------------+
+Total line number = 7
+It costs 0.119s
+```
+
+使用 arrival_time 列作为辅助时间列,并设置时间间隔(TIME_BOUND)为 2 ms(前值距离当前值超过 2ms 就不填充):
+
+```sql
+SELECT time, plant_id, device_id, humidity, arrival_time
+ FROM table1
+ WHERE time >= 2024-11-26 16:37:00 and time <= 2024-11-28 08:00:00
+ AND plant_id='1001' and device_id='101'
+ FILL METHOD PREVIOUS TIME_BOUND 2s TIME_COLUMN 5;
+```
+
+查询结果:
+
+```sql
++-----------------------------+--------+---------+--------+-----------------------------+
+| time|plant_id|device_id|humidity| arrival_time|
++-----------------------------+--------+---------+--------+-----------------------------+
+|2024-11-27T16:38:00.000+08:00| 1001| 101| 35.1|2024-11-27T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 1001| 101| 35.3| null|
+|2024-11-27T16:40:00.000+08:00| 1001| 101| 35.1|2024-11-27T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 1001| 101| null|2024-11-27T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 1001| 101| 35.2| null|
+|2024-11-27T16:43:00.000+08:00| 1001| 101| null| null|
+|2024-11-27T16:44:00.000+08:00| 1001| 101| null|2024-11-27T16:37:08.000+08:00|
++-----------------------------+--------+---------+--------+-----------------------------+
+Total line number = 7
+It costs 0.049s
+```
+
+填充结果详情:
+
+- 16:39、16:42、16:43 的 humidity 列,由于辅助列 arrival_time 为 NULL,所以不进行填充。
+- 16:40 的 humidity 列,由于辅助列 arrival_time 非 NULL ,为 `1970-01-01T08:00:00.003+08:00`且与前一个非 NULL 值 `1970-01-01T08:00:00.001+08:00`的时间差未超过 2ms,因此使用第一行 s1 的值 1 进行填充。
+- 16:41 的 humidity 列,尽管 arrival_time 非 NULL,但与前一个非 NULL 值的时间差超过 2ms,因此不进行填充。第七行同理。
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/From-Join-Clause.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/From-Join-Clause.md
new file mode 100644
index 000000000..47367651f
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/From-Join-Clause.md
@@ -0,0 +1,387 @@
+
+
+# FROM & JOIN 子句
+
+## 1 语法概览
+
+```sql
+FROM relation (',' relation)*
+
+relation
+ : relation joinType JOIN relation joinCriteria
+ | aliasedRelation
+ ;
+
+joinType
+ : INNER?
+ | FULL OUTER?
+ ;
+
+joinCriteria
+ : ON booleanExpression
+ | USING '(' identifier (',' identifier)* ')'
+ ;
+
+aliasedRelation
+ : relationPrimary (AS? identifier columnAliases?)?
+ ;
+
+columnAliases
+ : '(' identifier (',' identifier)* ')'
+ ;
+
+relationPrimary
+ : qualifiedName #tableName
+ | '(' query ')' #subqueryRelation
+ | '(' relation ')' #parenthesizedRelation
+ ;
+
+qualifiedName
+ : identifier ('.' identifier)*
+ ;
+```
+
+## 2 FROM 子句
+
+FROM 子句指定了查询操作的数据源。在逻辑上,查询的执行从 FROM 子句开始。FROM 子句可以包含单个表、使用 JOIN 子句连接的多个表的组合,或者子查询中的另一个 SELECT 查询。
+
+## 3 JOIN 子句
+
+JOIN 用于将两个表基于某些条件连接起来,通常,连接条件是一个谓词,但也可以指定其他隐含的规则。
+
+在当前版本的 IoTDB 中,支持内连接(Inner Join)和全外连接(Full Outer Join),并且连接条件只能是时间列的等值连接。
+
+### 3.1 内连接(Inner Join)
+
+INNER JOIN 表示内连接,其中 INNER 关键字可以省略。它返回两个表中满足连接条件的记录,舍弃不满足的记录,等同于两个表的交集。
+
+#### 3.1.1 显式指定连接条件(推荐)
+
+显式连接需要使用 JOIN + ON 或 JOIN + USING 语法,在 ON 或 USING 关键字后指定连接条件。
+
+SQL语法如下所示:
+
+```sql
+// 显式连接, 在ON关键字后指定连接条件或在Using关键字后指定连接列
+SELECT selectExpr [, selectExpr] ... FROM [INNER] JOIN joinCriteria [WHERE whereCondition]
+
+joinCriteria
+ : ON booleanExpression
+ | USING '(' identifier (',' identifier)* ')'
+ ;
+```
+
+__注意:USING 和 ON 的区别__
+
+USING 是显式连接条件的缩写语法,它接收一个用逗号分隔的字段名列表,这些字段必须是连接表共有的字段。例如,USING (time) 等效于 ON (t1.time = t2.time)。当使用 `ON` 关键字时,两个表中的 `time` 字段在逻辑上是区分的,分别表示为 `t1.time` 和 `t2.time`。而当使用 `USING` 关键字时,逻辑上只会有一个 `time` 字段。而最终的查询结果取决于 `SELECT` 语句中指定的字段。
+
+#### 3.1.2 隐式指定连接条件
+
+隐式连接不需要出现 JOIN、ON、USING 关键字,而是通过在 WHERE 子句中指定条件来实现表与表之间的连接。
+
+SQL语法如下所示:
+
+```sql
+// 隐式连接, 在WHERE子句里指定连接条件
+SELECT selectExpr [, selectExpr] ... FROM [, ] ... [WHERE whereCondition]
+```
+
+### 3.2 外连接(Outer Join)
+
+如果没有匹配的行,仍然可以通过指定外连接返回行。外连接可以是:
+
+- LEFT(左侧表的所有行至少出现一次)
+- RIGHT(右侧表的所有行至少出现一次)
+- FULL(两个表的所有行至少出现一次)
+
+在当前版本的 IoTDB 中,只支持 FULL [OUTER] JOIN,即全外连接,返回左表和右表连接后的所有记录。如果某个表中的记录没有与另一个表中的记录匹配,则会返回 NULL 值。__FULL JOIN 只能使用显式连接方式。__
+
+## 4 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+### 4.1 From 示例
+
+#### 4.1.1 从单个表查询
+
+示例 1:此查询将返回 `table1` 中的所有记录,并按时间排序。
+
+```sql
+SELECT * FROM table1 ORDER BY time;
+```
+
+查询结果:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| arrival_time|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-27T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-27T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-27T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-27T16:37:08.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-29T11:00:00.000+08:00| 上海| 3002| 100| E| 180| null| 45.1| true| null|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 18
+It costs 0.085s
+```
+
+示例 2:此查询将返回 `table1`中`device`为`101`的记录,并按时间排序。
+
+```sql
+SELECT * FROM table1 t1 where t1.device_id='101' order by time;
+```
+
+查询结果:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| arrival_time|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-27T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-27T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-27T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-27T16:37:08.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 10
+It costs 0.061s
+```
+
+#### 4.1.2 从子查询中查询
+
+示例 1:此查询将返回 `table1` 中的记录总数。
+
+```sql
+SELECT COUNT(*) AS count FROM (SELECT * FROM table1);
+```
+
+查询结果:
+
+```sql
++-----+
+|count|
++-----+
+| 18|
++-----+
+Total line number = 1
+It costs 0.072s
+```
+
+### 4.2 Join 示例
+
+#### 4.2.1 Inner Join
+
+示例 1:显式连接
+
+```sql
+SELECT
+ t1.time,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+ table1 t1 JOIN table2 t2
+ON t1.time = t2.time
+```
+
+查询结果:
+
+```sql
++-----------------------------+-------+------------+-------+------------+
+| time|device1|temperature1|device2|temperature2|
++-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
++-----------------------------+-------+------------+-------+------------+
+Total line number = 3
+It costs 0.076s
+```
+
+示例 2:显式连接
+
+```sql
+SELECT time,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+ table1 t1 JOIN table2 t2
+USING(time)
+```
+
+查询结果:
+
+```sql
++-----------------------------+-------+------------+-------+------------+
+| time|device1|temperature1|device2|temperature2|
++-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
++-----------------------------+-------+------------+-------+------------+
+Total line number = 3
+It costs 0.081s
+```
+
+示例 3:隐式连接
+
+```sql
+SELECT t1.time,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+table1 t1, table2 t2
+WHERE
+t1.time=t2.time
+```
+
+查询结果:
+
+```sql
++-----------------------------+-------+------------+-------+------------+
+| time|device1|temperature1|device2|temperature2|
++-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
++-----------------------------+-------+------------+-------+------------+
+Total line number = 3
+It costs 0.082s
+```
+
+#### 4.2.2 Outer Join
+
+示例 1:显式连接
+
+```sql
+SELECT
+ t1.time as time1, t2.time as time2,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+ table1 t1 FULL JOIN table2 t2
+ON t1.time = t2.time
+```
+
+查询结果:
+
+```sql
++-----------------------------+-----------------------------+-------+------------+-------+------------+
+| time1| time2|device1|temperature1|device2|temperature2|
++-----------------------------+-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-26T13:38:00.000+08:00| null| 100| 90.0| null| null|
+| null|2024-11-27T00:00:00.000+08:00| null| null| 101| 85.0|
+|2024-11-27T16:38:00.000+08:00| null| 101| null| null| null|
+|2024-11-27T16:39:00.000+08:00| null| 101| 85.0| null| null|
+|2024-11-27T16:40:00.000+08:00| null| 101| 85.0| null| null|
+|2024-11-27T16:41:00.000+08:00| null| 101| 85.0| null| null|
+|2024-11-27T16:42:00.000+08:00| null| 101| null| null| null|
+|2024-11-27T16:43:00.000+08:00| null| 101| null| null| null|
+|2024-11-27T16:44:00.000+08:00| null| 101| null| null| null|
+|2024-11-28T08:00:00.000+08:00|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| null| 100| null| null| null|
+|2024-11-28T10:00:00.000+08:00| null| 100| 85.0| null| null|
+|2024-11-28T11:00:00.000+08:00| null| 100| 88.0| null| null|
+| null|2024-11-29T00:00:00.000+08:00| null| null| 101| 85.0|
+|2024-11-29T10:00:00.000+08:00| null| 101| 85.0| null| null|
+|2024-11-29T11:00:00.000+08:00|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
+|2024-11-29T18:30:00.000+08:00| null| 100| 90.0| null| null|
+| null|2024-11-30T00:00:00.000+08:00| null| null| 101| 90.0|
+|2024-11-30T09:30:00.000+08:00| null| 101| 90.0| null| null|
+|2024-11-30T14:30:00.000+08:00| null| 101| 90.0| null| null|
++-----------------------------+-----------------------------+-------+------------+-------+------------+
+Total line number = 21
+It costs 0.071s
+```
+
+示例 2:显式连接
+
+```sql
+SELECT
+ time,
+ t1.device_id as device1,
+ t1.temperature as temperature1,
+ t2.device_id as device2,
+ t2.temperature as temperature2
+FROM
+ table1 t1 FULL JOIN table2 t2
+USING(time)
+```
+
+查询结果:
+
+```sql
++-----------------------------+-------+------------+-------+------------+
+| time|device1|temperature1|device2|temperature2|
++-----------------------------+-------+------------+-------+------------+
+|2024-11-26T13:37:00.000+08:00| 100| 90.0| 100| 90.0|
+|2024-11-26T13:38:00.000+08:00| 100| 90.0| null| null|
+|2024-11-27T00:00:00.000+08:00| null| null| 101| 85.0|
+|2024-11-27T16:38:00.000+08:00| 101| null| null| null|
+|2024-11-27T16:39:00.000+08:00| 101| 85.0| null| null|
+|2024-11-27T16:40:00.000+08:00| 101| 85.0| null| null|
+|2024-11-27T16:41:00.000+08:00| 101| 85.0| null| null|
+|2024-11-27T16:42:00.000+08:00| 101| null| null| null|
+|2024-11-27T16:43:00.000+08:00| 101| null| null| null|
+|2024-11-27T16:44:00.000+08:00| 101| null| null| null|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 100| null| null| null|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0| null| null|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0| null| null|
+|2024-11-29T00:00:00.000+08:00| null| null| 101| 85.0|
+|2024-11-29T10:00:00.000+08:00| 101| 85.0| null| null|
+|2024-11-29T11:00:00.000+08:00| 100| null| 100| null|
+|2024-11-29T18:30:00.000+08:00| 100| 90.0| null| null|
+|2024-11-30T00:00:00.000+08:00| null| null| 101| 90.0|
+|2024-11-30T09:30:00.000+08:00| 101| 90.0| null| null|
+|2024-11-30T14:30:00.000+08:00| 101| 90.0| null| null|
++-----------------------------+-------+------------+-------+------------+
+Total line number = 21
+It costs 0.073s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/GroupBy-Clause.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/GroupBy-Clause.md
new file mode 100644
index 000000000..c36c93840
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/GroupBy-Clause.md
@@ -0,0 +1,364 @@
+
+
+# GROUP BY 子句
+
+## 1 语法概览
+
+```sql
+GROUP BY expression (',' expression)*
+```
+
+- GROUP BY 子句用于将 SELECT 语句的结果集按指定的列值进行分组计算。这些分组列的值在结果中保持原样,其他列中具备相同分组列值的所有记录通过指定的聚合函数(例如 COUNT、AVG)进行计算。
+
+
+
+
+## 2 注意事项
+
+- 在 SELECT 子句中的项必须包含聚合函数或由出现在 GROUP BY 子句中的列组成。
+
+合法示例:
+
+```sql
+SELECT concat(device_id, model_id), avg(temperature)
+ FROM table1
+ GROUP BY device_id, model_id; -- 合法
+```
+
+执行结果如下:
+
+```sql
++-----+-----+
+|_col0|_col1|
++-----+-----+
+| 100A| 90.0|
+| 100C| 86.0|
+| 100E| 90.0|
+| 101B| 85.0|
+| 101D| 85.0|
+| 101F| 90.0|
++-----+-----+
+Total line number = 6
+It costs 0.094s
+```
+
+不合法示例1:
+
+```sql
+SELECT device_id, temperature
+ FROM table1
+ GROUP BY device_id;-- 不合法
+```
+
+执行结果如下:
+
+```sql
+Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701:
+ 'temperature' must be an aggregate expression or appear in GROUP BY clause
+```
+
+不合法示例2:
+
+```sql
+SELECT device_id, avg(temperature)
+ FROM table1
+ GROUP BY model; -- 不合法
+```
+
+执行结果如下:
+
+```sql
+Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701:
+ Column 'model' cannot be resolved
+```
+
+- 如果没有 GROUP BY 子句,则 SELECT 子句中的所有项要么都包含聚合函数,要么都不包含聚合函数。
+
+合法示例:
+
+```sql
+SELECT COUNT(*), avg(temperature)
+ FROM table1; -- 合法
+```
+
+执行结果如下:
+
+```sql
++-----+-----------------+
+|_col0| _col1|
++-----+-----------------+
+| 18|87.33333333333333|
++-----+-----------------+
+Total line number = 1
+It costs 0.094s
+```
+
+不合法示例:
+
+```sql
+SELECT humidity, avg(temperature) FROM table1; -- 不合法
+```
+
+执行结果如下:
+
+```sql
+Msg: org.apache.iotdb.jdbc.IoTDBSQLException: 701:
+ 'humidity' must be an aggregate expression or appear in GROUP BY clause
+```
+
+- group by子句可以使用从 1 开始的常量整数来引用 SELECT 子句中的项,如果常量整数小于1或大于选择项列表的大小,则会抛出错误。
+
+```sql
+SELECT date_bin(1h, time), device_id, avg(temperature)
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ GROUP BY 1, device_id;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------+-----+
+| _col0|device_id|_col2|
++-----------------------------+---------+-----+
+|2024-11-28T08:00:00.000+08:00| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 100| null|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0|
+|2024-11-27T16:00:00.000+08:00| 101| 85.0|
++-----------------------------+---------+-----+
+Total line number = 5
+It costs 0.092s
+```
+
+- 不支持在 group by 子句中使用 select item 的别名。以下 SQL 将抛出错误,可以使用上述 SQL 代替。
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, device_id, avg(temperature)
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ GROUP BY date_bin(1h, time), device_id;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------+-----+
+| hour_time|device_id|_col2|
++-----------------------------+---------+-----+
+|2024-11-28T08:00:00.000+08:00| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 100| null|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0|
+|2024-11-27T16:00:00.000+08:00| 101| 85.0|
++-----------------------------+---------+-----+
+Total line number = 5
+It costs 0.092s
+```
+
+- 只有 COUNT 函数可以与星号(*)一起使用,用于计算表中的总行数。其他聚合函数与`*`一起使用,将抛出错误。
+
+```sql
+SELECT count(*) FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----+
+|_col0|
++-----+
+| 18|
++-----+
+Total line number = 1
+It costs 0.047s
+```
+
+## 3 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例 1:降采样时间序列数据
+
+对设备 101 下述时间范围的温度进行降采样,每小时返回一个平均温度。
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, AVG(temperature) AS avg_temperature
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-30 00:00:00
+ AND device_id='101'
+ GROUP BY 1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------------+
+| hour_time|avg_temperature|
++-----------------------------+---------------+
+|2024-11-29T10:00:00.000+08:00| 85.0|
+|2024-11-27T16:00:00.000+08:00| 85.0|
++-----------------------------+---------------+
+Total line number = 2
+It costs 0.054s
+```
+
+对每个设备过去一天的温度进行降采样,每小时返回一个平均温度。
+
+```sql
+SELECT date_bin(1h, time) AS hour_time, device_id, AVG(temperature) AS avg_temperature
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-30 00:00:00
+ GROUP BY 1, device_id;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------+---------------+
+| hour_time|device_id|avg_temperature|
++-----------------------------+---------+---------------+
+|2024-11-29T11:00:00.000+08:00| 100| null|
+|2024-11-29T18:00:00.000+08:00| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0|
+|2024-11-28T09:00:00.000+08:00| 100| null|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0|
+|2024-11-29T10:00:00.000+08:00| 101| 85.0|
+|2024-11-27T16:00:00.000+08:00| 101| 85.0|
++-----------------------------+---------+---------------+
+Total line number = 8
+It costs 0.081s
+```
+
+有关date_bin函数的更多详细信息可以参见 date_bin (时间分桶规整)函数功能定义
+
+#### 示例 2:查询每个设备的最新数据点
+
+```sql
+SELECT device_id, LAST(temperature), LAST_BY(time, temperature)
+ FROM table1
+ GROUP BY device_id;
+```
+
+执行结果如下:
+
+```sql
++---------+-----+-----------------------------+
+|device_id|_col1| _col2|
++---------+-----+-----------------------------+
+| 100| 90.0|2024-11-29T18:30:00.000+08:00|
+| 101| 90.0|2024-11-30T14:30:00.000+08:00|
++---------+-----+-----------------------------+
+Total line number = 2
+It costs 0.078s
+```
+
+#### 示例 3:计算总行数
+
+计算所有设备的总行数:
+
+```sql
+SELECT COUNT(*) FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----+
+|_col0|
++-----+
+| 18|
++-----+
+Total line number = 1
+It costs 0.060s
+```
+
+计算每个设备的总行数:
+
+```sql
+SELECT device_id, COUNT(*) AS total_rows
+ FROM table1
+ GROUP BY device_id;
+```
+
+执行结果如下:
+
+```sql
++---------+----------+
+|device_id|total_rows|
++---------+----------+
+| 100| 8|
+| 101| 10|
++---------+----------+
+Total line number = 2
+It costs 0.060s
+```
+
+#### 示例 4:没有 group by 子句的聚合
+
+查询所有设备中的最大温度:
+
+```sql
+SELECT MAX(temperature)
+FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----+
+|_col0|
++-----+
+| 90.0|
++-----+
+Total line number = 1
+It costs 0.086s
+```
+
+#### 示例 5:对子查询的结果进行聚合
+
+查询在指定时间段内平均温度超过 80.0 且至少有两次记录的设备和工厂组合:
+
+```sql
+SELECT plant_id, device_id
+FROM (
+ SELECT date_bin(10m, time) AS time, plant_id, device_id, AVG(temperature) AS temp FROM table1 WHERE time >= 2024-11-26 00:00:00 AND time <= 2024-11-29 00:00:00
+ GROUP BY 1, plant_id, device_id
+)
+WHERE temp > 80.0
+GROUP BY plant_id, device_id
+HAVING COUNT(*) > 1;
+```
+
+执行结果如下:
+
+```sql
++--------+---------+
+|plant_id|device_id|
++--------+---------+
+| 1001| 101|
+| 3001| 100|
++--------+---------+
+Total line number = 2
+It costs 0.073s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Having-Clause.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Having-Clause.md
new file mode 100644
index 000000000..d02911d4a
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Having-Clause.md
@@ -0,0 +1,95 @@
+
+
+# HAVING 子句
+
+## 1 语法概览
+
+```sql
+HAVING booleanExpression
+```
+
+### 1.1 HAVING 子句
+
+用于在数据分组聚合(GROUP BY)完成后,对聚合结果进行筛选。
+
+#### 注意事项
+
+- 就语法而言,`HAVING`子句与`WHERE`子句相同,WHERE子句在分组聚合之前对数据进行过滤,HAVING子句是对分组聚合后的结果进行过滤。
+
+## 2 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例 1:过滤计数低于特定值的设备
+
+查询将计算 `table1` 表中每个 `device_id` 的条目数,并过滤掉那些计数低于 5 的设备。
+
+```sql
+SELECT device_id, COUNT(*)
+ FROM table1
+ GROUP BY device_id
+ HAVING COUNT(*) >= 5;
+```
+
+执行结果如下:
+
+```sql
++---------+-----+
+|device_id|_col1|
++---------+-----+
+| 100| 8|
+| 101| 10|
++---------+-----+
+Total line number = 2
+It costs 0.063s
+```
+
+### 示例 2:计算每个设备的每小时平均温度并过滤
+
+查询将计算 `table1` 表中每个设备每小时的平均温度,并过滤掉那些平均温度低于 27.2 的设备。
+
+```sql
+SELECT date_bin(1h, time) as hour_time, device_id, AVG(temperature) as avg_temp
+ FROM table1
+ GROUP BY date_bin(1h, time), device_id
+ HAVING AVG(temperature) >= 85.0;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+---------+--------+
+| hour_time|device_id|avg_temp|
++-----------------------------+---------+--------+
+|2024-11-29T18:00:00.000+08:00| 100| 90.0|
+|2024-11-28T08:00:00.000+08:00| 100| 85.0|
+|2024-11-28T10:00:00.000+08:00| 100| 85.0|
+|2024-11-28T11:00:00.000+08:00| 100| 88.0|
+|2024-11-26T13:00:00.000+08:00| 100| 90.0|
+|2024-11-30T09:00:00.000+08:00| 101| 90.0|
+|2024-11-30T14:00:00.000+08:00| 101| 90.0|
+|2024-11-29T10:00:00.000+08:00| 101| 85.0|
+|2024-11-27T16:00:00.000+08:00| 101| 85.0|
++-----------------------------+---------+--------+
+Total line number = 9
+It costs 0.079s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Identifier.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Identifier.md
new file mode 100644
index 000000000..fcb5fa61c
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Identifier.md
@@ -0,0 +1,83 @@
+
+
+# 标识符
+
+在 IoTDB 中,标识符用于标识 database、table、column、function 或其他对象名称。
+
+## 1 命名规则
+
+- __开头字符__:标识符必须以字母开头。
+- __后续字符__:可以包含字母、数字和下划线。
+- __特殊字符__:如果标识符包含除字母、数字和下划线之外的其他字符,必须用双引号(`"`)括起来。
+- __转义字符__:在双引号定界的标识符中,使用两个连续的双引号(`""`)来表示一个双引号字符。
+
+### 1.1 示例
+
+以下是一些有效的标识符示例:
+
+```sql
+test
+"table$partitions"
+"identifierWith"
+"double"
+"quotes"
+```
+
+无效的标识符示例,使用时必须用双引号引用:
+
+```sql
+table-name // 包含短横线
+123SchemaName // 以数字开头
+colum$name@field // 包含特殊字符且未用双引号括起
+```
+
+## 2 大小写敏感性
+
+标识符不区分大小写,且系统存储标识符时不保留原始大小写,查询结果会根据用户在`SELECT`子句中指定的大小写显示列名。
+
+> 双引号括起来的标识符也不区分大小写。
+
+### 2.1 示例
+
+当创建了一个名为 `Device_id` 的列,在查看表时看到为 `device_id`,但返回的结果列与用户查询时指定的格式保持相同为`Device_ID`:
+
+```sql
+IoTDB> create table table1(Device_id STRING TAG, Model STRING ATTRIBUTE, TemPerature FLOAT FIELD, Humidity DOUBLE FIELD)
+
+IoTDB> desc table1;
++-----------+---------+-----------+
+| ColumnName| DataType| Category|
++-----------+---------+-----------+
+| time|TIMESTAMP| TIME|
+| device_id| STRING| TAG|
+| model| STRING| ATTRIBUTE|
+|temperature| FLOAT| FIELD|
+| humidity| DOUBLE| FIELD|
++-----------+---------+-----------+
+
+IoTDB> select TiMe, Device_ID, MoDEL, TEMPerature, HUMIdity from table1;
++-----------------------------+---------+------+-----------+--------+
+| TiMe|Device_ID| MoDEL|TEMPerature|HUMIdity|
++-----------------------------+---------+------+-----------+--------+
+|1970-01-01T08:00:00.001+08:00| d1|modelY| 27.2| 67.0|
++-----------------------------+---------+------+-----------+--------+
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Keywords.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Keywords.md
new file mode 100644
index 000000000..80a16414e
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Keywords.md
@@ -0,0 +1,107 @@
+
+
+# 保留字&关键字
+
+保留关键字必须被双引号(`"`)引用才能用作标识符。以下是 IoTDB 表模型中的所有保留字:
+
+- ALTER
+- AND
+- AS
+- BETWEEN
+- BY
+- CASE
+- CAST
+- CONSTRAINT
+- CREATE
+- CROSS
+- CUBE
+- CURRENT_CATALOG
+- CURRENT_DATE
+- CURRENT_PATH
+- CURRENT_ROLE
+- CURRENT_SCHEMA
+- CURRENT_TIME
+- CURRENT_TIMESTAMP
+- CURRENT_USER
+- DEALLOCATE
+- DELETE
+- DESCRIBE
+- DISTINCT
+- DROP
+- ELSE
+- END
+- ESCAPE
+- EXCEPT
+- EXISTS
+- EXTRACT
+- FALSE
+- FOR
+- FROM
+- FULL
+- GROUP
+- GROUPING
+- HAVING
+- IN
+- INNER
+- INSERT
+- INTERSECT
+- INTO
+- IS
+- JOIN
+- JSON_ARRAY
+- JSON_EXISTS
+- JSON_OBJECT
+- JSON_QUERY
+- JSON_TABLE
+- JSON_VALUE
+- LEFT
+- LIKE
+- LISTAGG
+- LOCALTIME
+- LOCALTIMESTAMP
+- NATURAL
+- NORMALIZE
+- NOT
+- NULL
+- ON
+- OR
+- ORDER
+- OUTER
+- PREPARE
+- RECURSIVE
+- RIGHT
+- ROLLUP
+- SELECT
+- SKIP
+- TABLE
+- THEN
+- TRIM
+- TRUE
+- UESCAPE
+- UNION
+- UNNEST
+- USING
+- VALUES
+- WHEN
+- WHERE
+- WITH
+- FILL
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Limit-Offset-Clause.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Limit-Offset-Clause.md
new file mode 100644
index 000000000..4a18e7632
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Limit-Offset-Clause.md
@@ -0,0 +1,128 @@
+
+
+# LIMIT 和 OFFSET 子句
+
+## 1 语法概览
+
+```sql
+OFFSET INTEGER_VALUE LIMIT INTEGER_VALUE
+```
+
+### 1.1 LIMIT 子句
+
+LIMIT 子句应用在查询的最后阶段,用于限制返回的行数。
+
+#### 注意事项
+
+- 在没有 ORDER BY 子句的情况下使用 LIMIT,查询结果的顺序可能是不确定的。
+- LIMIT 子句必须使用非负整数。
+
+### 1.2 OFFSET 子句
+
+OFFSET 子句与 LIMIT 子句配合使用,用于指定查询结果跳过前 OFFSET 行,以实现分页或特定位置的数据检索。
+
+#### 注意事项
+
+- OFFSET 子句必须接一个非负整数。
+- 如果总记录数`n >= OFFSET+LIMIT`之和,返回`LIMIT`数量的记录。
+- 如果总记录数`n < OFFSET+LIMIT`之和,返回从`OFFSET`开始到末尾的所有记录,最多`n-offset`条。
+
+## 2 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例 1:查询设备的最新行
+
+```sql
+SELECT *
+ FROM table1
+ ORDER BY time DESC
+ LIMIT 1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 1
+It costs 0.103s
+```
+
+#### 示例 2:查询温度最高的前10行数据
+
+```sql
+SELECT *
+ FROM table1
+ ORDER BY temperature DESC NULLS LAST
+ LIMIT 10;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 10
+It costs 0.063s
+```
+
+#### 示例 3:从特定位置选择5行数据
+
+```sql
+SELECT *
+ FROM table1
+ ORDER BY TIME
+ OFFSET 5
+ LIMIT 5;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 5
+It costs 0.069s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/OrderBy-Clause.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/OrderBy-Clause.md
new file mode 100644
index 000000000..f5be7a4f8
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/OrderBy-Clause.md
@@ -0,0 +1,135 @@
+
+
+# ORDER BY 子句
+
+## 1 语法概览
+
+```sql
+ORDER BY sortItem (',' sortItem)*
+
+sortItem
+ : expression (ASC | DESC)? (NULLS (FIRST | LAST))?
+ ;
+```
+
+### 1.1 ORDER BY 子句
+
+- 用于在查询的最后阶段对结果集进行排序,能够根据指定的排序条件,将查询结果中的行按照升序(ASC)或降序(DESC)进行排列。
+- 提供了对 NULL 值排序位置的控制,允许用户指定 NULL 值是排在结果的开头(NULLS FIRST)还是结尾(NULLS LAST)。
+- 默认情况下, 将采用 ASC NULLS LAST排序,即值按升序排序,空值放在最后。可以通过手动指定其他参数更改默认排序顺序。
+- ORDER BY 子句的执行顺序排在 LIMIT 或 OFFSET 子句之前。
+
+## 2 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例 1: 按时间降序查询过去一小时的数据
+
+```sql
+SELECT *
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ ORDER BY time DESC;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 11
+It costs 0.148s
+```
+
+#### 示例 2: 按 `device_id` 升序和时间降序查询所有设备过去一小时的数据,空 `temperature` 优先显示
+
+```sql
+SELECT *
+ FROM table1
+ WHERE time >= 2024-11-27 00:00:00 and time <= 2024-11-29 00:00:00
+ ORDER BY temperature NULLS FIRST, time DESC;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 11
+It costs 0.060s
+```
+
+#### 示例 3: 查询温度最高的前10行数据
+
+```sql
+SELECT *
+ FROM table1
+ ORDER BY temperature DESC NULLS LAST
+ LIMIT 10;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 10
+It costs 0.069s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Select-Clause.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Select-Clause.md
new file mode 100644
index 000000000..ebf97c93a
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Select-Clause.md
@@ -0,0 +1,250 @@
+
+
+# SELECT 子句
+
+## 1 语法概览
+
+```sql
+SELECT selectItem (',' selectItem)*
+
+selectItem
+ : expression (AS? identifier)? #selectSingle
+ | tableName '.' ASTERISK (AS columnAliases)? #selectAll
+ | ASTERISK #selectAll
+ ;
+```
+
+- __SELECT 子句__: 指定了查询结果应包含的列,包含聚合函数(如 SUM、AVG、COUNT 等)以及窗口函数,在逻辑上最后执行。
+
+## 2 语法详释:
+
+每个 `selectItem` 可以是以下形式之一:
+
+- __表达式__: `expression [ [ AS ] column_alias ]` 定义单个输出列,可以指定列别名。
+- __选择某个关系的所有列__: `relation.*` 选择某个关系的所有列,不允许使用列别名。
+- __选择结果集中的所有列__: `*` 选择查询的所有列,不允许使用列别名。
+
+## 3 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+### 3.1 选择列表
+
+#### 3.1.1 星表达式
+
+使用星号(*)可以选取表中的所有列,__注意__,星号表达式不能被大多数函数转换,除了`count(*)`的情况。
+
+示例:从表中选择所有列
+
+```sql
+SELECT * FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-29T11:00:00.000+08:00| 上海| 3002| 100| E| 180| null| 45.1| true| null|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 18
+It costs 0.653s
+```
+
+#### 3.1.2 聚合函数
+
+聚合函数将多行数据汇总为单个值。当 SELECT 子句中存在聚合函数时,查询将被视为聚合查询。在聚合查询中,所有表达式必须是聚合函数的一部分或由[GROUP BY子句](../SQL-Manual/GroupBy-Clause.md)指定的分组的一部分。
+
+示例1:返回地址表中的总行数:
+
+```sql
+SELECT count(*) FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----+
+|_col0|
++-----+
+| 18|
++-----+
+Total line number = 1
+It costs 0.091s
+```
+
+示例2:返回按城市分组的地址表中的总行数:
+
+```sql
+SELECT region, count(*)
+ FROM table1
+ GROUP BY region;
+```
+
+执行结果如下:
+
+```sql
++------+-----+
+|region|_col1|
++------+-----+
+| 上海| 9|
+| 北京| 9|
++------+-----+
+Total line number = 2
+It costs 0.071s
+```
+
+#### 3.1.3 别名
+
+关键字`AS`:为选定的列指定别名,别名将覆盖已存在的列名,以提高查询结果的可读性。
+
+示例1:原始表格:
+
+```sql
+IoTDB> SELECT * FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-29T11:00:00.000+08:00| 上海| 3002| 100| E| 180| null| 45.1| true| null|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 18
+It costs 0.653s
+```
+
+示例2:单列设置别名:
+
+```sql
+IoTDB> SELECT device_id
+ AS device
+ FROM table1;
+```
+
+执行结果如下:
+
+```sql
++------+
+|device|
++------+
+| 100|
+| 100|
+| 100|
+| 100|
+| 100|
+| 100|
+| 100|
+| 100|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
+| 101|
++------+
+Total line number = 18
+It costs 0.053s
+```
+
+示例3:所有列的别名:
+
+```sql
+IoTDB> SELECT table1.*
+ AS (timestamp, Reg, Pl, DevID, Mod, Mnt, Temp, Hum, Stat,MTime)
+ FROM table1;
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+----+----+-----+---+---+----+----+-----+-----------------------------+
+| TIMESTAMP| REG| PL|DEVID|MOD|MNT|TEMP| HUM| STAT| MTIME|
++-----------------------------+----+----+-----+---+---+----+----+-----+-----------------------------+
+|2024-11-29T11:00:00.000+08:00|上海|3002| 100| E|180|null|45.1| true| null|
+|2024-11-29T18:30:00.000+08:00|上海|3002| 100| E|180|90.0|35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T08:00:00.000+08:00|上海|3001| 100| C| 90|85.0|null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00|上海|3001| 100| C| 90|null|40.9| true| null|
+|2024-11-28T10:00:00.000+08:00|上海|3001| 100| C| 90|85.0|35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00|上海|3001| 100| C| 90|88.0|45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-26T13:37:00.000+08:00|北京|1001| 100| A|180|90.0|35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00|北京|1001| 100| A|180|90.0|35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-30T09:30:00.000+08:00|上海|3002| 101| F|360|90.0|35.2| true| null|
+|2024-11-30T14:30:00.000+08:00|上海|3002| 101| F|360|90.0|34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-29T10:00:00.000+08:00|上海|3001| 101| D|360|85.0|null| null|2024-11-29T10:00:13.000+08:00|
+|2024-11-27T16:38:00.000+08:00|北京|1001| 101| B|180|null|35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00|北京|1001| 101| B|180|85.0|35.3| null| null|
+|2024-11-27T16:40:00.000+08:00|北京|1001| 101| B|180|85.0|null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00|北京|1001| 101| B|180|85.0|null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00|北京|1001| 101| B|180|null|35.2|false| null|
+|2024-11-27T16:43:00.000+08:00|北京|1001| 101| B|180|null|null|false| null|
+|2024-11-27T16:44:00.000+08:00|北京|1001| 101| B|180|null|null|false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+----+----+-----+---+---+----+----+-----+-----------------------------+
+Total line number = 18
+It costs 0.189s
+```
+
+## 4 结果集列顺序
+
+- __列顺序__: 结果集中的列顺序与 SELECT 子句中指定的顺序相同。
+- __多列排序__: 如果选择表达式返回多个列,它们的排序方式与源关系中的排序方式相同
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Where-Clause.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Where-Clause.md
new file mode 100644
index 000000000..82c4d2cc4
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/Where-Clause.md
@@ -0,0 +1,112 @@
+
+
+# WHERE 子句
+
+## 1 语法概览
+
+```sql
+WHERE booleanExpression
+```
+
+__WHERE 子句__:用于在 SQL 查询中指定筛选条件,WHERE 子句在 FROM 子句之后立即执行。
+
+## 2 示例数据
+
+在[示例数据页面](../Basic-Concept/Sample-Data.md)中,包含了用于构建表结构和插入数据的SQL语句,下载并在IoTDB CLI中执行这些语句,即可将数据导入IoTDB,您可以使用这些数据来测试和执行示例中的SQL语句,并获得相应的结果。
+
+#### 示例1:选择特定 ID 的行
+
+```sql
+SELECT * FROM table1 WHERE plant_id = '1001';
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 9
+It costs 0.091s
+```
+
+#### 示例2:选择使用 LIKE 表达式匹配
+
+```sql
+SELECT * FROM table1 WHERE plant_id LIKE '300%';
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-29T11:00:00.000+08:00| 上海| 3002| 100| E| 180| null| 45.1| true| null|
+|2024-11-29T18:30:00.000+08:00| 上海| 3002| 100| E| 180| 90.0| 35.4| true|2024-11-29T18:30:15.000+08:00|
+|2024-11-28T08:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| null| null|2024-11-28T08:00:09.000+08:00|
+|2024-11-28T09:00:00.000+08:00| 上海| 3001| 100| C| 90| null| 40.9| true| null|
+|2024-11-28T10:00:00.000+08:00| 上海| 3001| 100| C| 90| 85.0| 35.2| null|2024-11-28T10:00:11.000+08:00|
+|2024-11-28T11:00:00.000+08:00| 上海| 3001| 100| C| 90| 88.0| 45.1| true|2024-11-28T11:00:12.000+08:00|
+|2024-11-30T09:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 35.2| true| null|
+|2024-11-30T14:30:00.000+08:00| 上海| 3002| 101| F| 360| 90.0| 34.8| true|2024-11-30T14:30:17.000+08:00|
+|2024-11-29T10:00:00.000+08:00| 上海| 3001| 101| D| 360| 85.0| null| null|2024-11-29T10:00:13.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 9
+It costs 0.261s
+```
+
+#### 示例3:选择使用复合表达式筛选
+
+```sql
+SELECT * FROM table1 WHERE time >= 2024-11-28 00:00:00 and (plant_id = '3001' OR plant_id = '3002');
+```
+
+执行结果如下:
+
+```sql
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+| time|region|plant_id|device_id|model_id|maintenance|temperature|humidity|status| modifytime|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+|2024-11-26T13:37:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:37:34.000+08:00|
+|2024-11-26T13:38:00.000+08:00| 北京| 1001| 100| A| 180| 90.0| 35.1| true|2024-11-26T13:38:25.000+08:00|
+|2024-11-27T16:38:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.1| true|2024-11-26T16:37:01.000+08:00|
+|2024-11-27T16:39:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| 35.3| null| null|
+|2024-11-27T16:40:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:03.000+08:00|
+|2024-11-27T16:41:00.000+08:00| 北京| 1001| 101| B| 180| 85.0| null| null|2024-11-26T16:37:04.000+08:00|
+|2024-11-27T16:42:00.000+08:00| 北京| 1001| 101| B| 180| null| 35.2| false| null|
+|2024-11-27T16:43:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false| null|
+|2024-11-27T16:44:00.000+08:00| 北京| 1001| 101| B| 180| null| null| false|2024-11-26T16:37:08.000+08:00|
++-----------------------------+------+--------+---------+--------+-----------+-----------+--------+------+-----------------------------+
+Total line number = 9
+It costs 0.091s
+```
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/overview.md b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/overview.md
new file mode 100644
index 000000000..afe7a9d58
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/SQL-Manual/overview.md
@@ -0,0 +1,60 @@
+
+
+# 概览
+
+## 1 语法概览
+
+```SQL
+SELECT ⟨select_list⟩
+ FROM ⟨tables⟩
+ [WHERE ⟨condition⟩]
+ [GROUP BY ⟨groups⟩]
+ [HAVING ⟨group_filter⟩]
+ [FILL ⟨fill_methods⟩]
+ [ORDER BY ⟨order_expression⟩]
+ [OFFSET ⟨n⟩]
+ [LIMIT ⟨n⟩];
+```
+
+IoTDB 查询语法提供以下子句:
+
+- SELECT 子句:查询结果应包含的列。详细语法见:[SELECT子句](../SQL-Manual/Select-Clause.md)
+- FROM 子句:指出查询的数据源,可以是单个表、多个通过 `JOIN` 子句连接的表,或者是一个子查询。详细语法见:[FROM & JOIN 子句](../SQL-Manual/From-Join-Clause.md)
+- WHERE 子句:用于过滤数据,只选择满足特定条件的数据行。这个子句在逻辑上紧跟在 FROM 子句之后执行。详细语法见:[WHERE 子句](../SQL-Manual/Where-Clause.md)
+- GROUP BY 子句:当需要对数据进行聚合时使用,指定了用于分组的列。详细语法见:[GROUP BY 子句](../SQL-Manual/GroupBy-Clause.md)
+- HAVING 子句:在 GROUP BY 子句之后使用,用于对已经分组的数据进行过滤。与 WHERE 子句类似,但 HAVING 子句在分组后执行。详细语法见:[HAVING 子句](../SQL-Manual/Having-Clause.md)
+- FILL 子句:用于处理查询结果中的空值,用户可以使用 FILL 子句来指定数据缺失时的填充模式(如前一个非空值或线性插值)来填充 null 值,以便于数据可视化和分析。 详细语法见:[FILL 子句](../SQL-Manual/Fill-Clause.md)
+- ORDER BY 子句:对查询结果进行排序,可以指定升序(ASC)或降序(DESC),以及 NULL 值的处理方式(NULLS FIRST 或 NULLS LAST)。详细语法见:[ORDER BY 子句](../SQL-Manual/OrderBy-Clause.md)
+- OFFSET 子句:用于指定查询结果的起始位置,即跳过前 OFFSET 行。与 LIMIT 子句配合使用。详细语法见:[LIMIT 和 OFFSET 子句](../SQL-Manual/Limit-Offset-Clause.md)
+- LIMIT 子句:限制查询结果的行数,通常与 OFFSET 子句一起使用以实现分页功能。详细语法见:[LIMIT 和 OFFSET 子句](../SQL-Manual/Limit-Offset-Clause.md)
+
+## 2 子句执行顺序
+
+1. FROM(表名)
+2. WHERE(条件过滤)
+3. SELECT(列名/表达式)
+4. GROUP BY (分组)
+5. HAVING(分组后的条件过滤)
+6. FILL(空值填充)
+7. ORDER BY(排序)
+8. OFFSET(偏移量)
+9. LIMIT(限制数量)
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Technical-Insider/Cluster-data-partitioning.md b/src/zh/UserGuide/V2.0.1/Table/Technical-Insider/Cluster-data-partitioning.md
new file mode 100644
index 000000000..6b5c017c9
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/Technical-Insider/Cluster-data-partitioning.md
@@ -0,0 +1,111 @@
+
+
+# 数据分区和负载均衡
+
+本文档介绍 IoTDB 中的分区策略和负载均衡策略。根据时序数据的特性,IoTDB 按序列和时间维度对其进行分区。结合序列分区与时间分区创建一个分区,作为划分的基本单元。为了提高吞吐量并降低管理成本,这些分区被均匀分配到分片(Region)中,分片是复制的基本单元。分片的副本决定了数据的存储位置,主副本负责主要负载的管理。在此过程中,副本放置算法决定哪些节点将持有分片副本,而主副本选择算法则指定哪个副本将成为主副本。
+
+## 1 分区策略和分区分配
+IoTDB 为时间序列数据实现了量身定制的分区算法。在此基础上,缓存于配置节点和数据节点上的分区信息不仅易于管理,而且能够清晰区分冷热数据。随后,平衡的分区被均匀分配到集群的分片中,以实现存储均衡。
+
+### 1.1 分区策略
+IoTDB 将生产环境中的每个传感器映射为一个时间序列。然后,使用序列分区算法对时间序列进行分区以管理其元数据,再结合时间分区算法来管理其数据。下图展示了 IoTDB 如何对时序数据进行分区。
+
+
+
+#### 1.1.1 分区算法
+由于生产环境中通常部署大量设备和传感器,IoTDB 使用序列分区算法以确保分区信息的大小可控。由于生成的时间序列与时间戳相关联,IoTDB 使用时间分区算法来清晰区分冷热分区。
+
+##### 1.1.1.1 序列分区算法
+默认情况下,IoTDB 将序列分区的数量限制为 1000,并将序列分区算法配置为哈希分区算法。这带来以下收益:
++ 由于序列分区的数量是固定常量,序列与序列分区之间的映射保持稳定。因此,IoTDB 不需要频繁进行数据迁移。
++ 序列分区的负载相对均衡,因为序列分区的数量远小于生产环境中部署的传感器数量。
+
+更进一步,如果能够更准确地估计生产环境中的实际负载情况,序列分区算法可以配置为自定义的哈希分区或列表分区,以在所有序列分区中实现更均匀的负载分布。
+
+##### 1.1.1.2 时间分区算法
+时间分区算法通过下式将给定的时间戳转换为相应的时间分区
+
+$$\left\lfloor\frac{\text{Timestamp}-\text{StartTimestamp}}{\text{TimePartitionInterval}}\right\rfloor\text{。}$$
+
+在此式中,$\text{StartTimestamp}$ 和 $\text{TimePartitionInterval}$ 都是可配置参数,以适应不同的生产环境。$\text{StartTimestamp}$ 表示第一个时间分区的起始时间,而 $\text{TimePartitionInterval}$ 定义了每个时间分区的持续时间。默认情况下,$\text{TimePartitionInterval}$ 设置为七天。
+
+#### 1.1.2 元数据分区
+由于序列分区算法对时间序列进行了均匀分区,每个序列分区对应一个元数据分区。这些元数据分区随后被均匀分配到 元数据分片 中,以实现元数据的均衡分布。
+
+#### 1.1.3 数据分区
+结合序列分区与时间分区创建数据分区。由于序列分区算法对时间序列进行了均匀分区,特定时间分区内的数据分区负载保持均衡。这些数据分区随后被均匀分配到数据分片中,以实现数据的均衡分布。
+
+### 1.2 分区分配
+IoTDB 使用分片来实现时间序列的弹性存储,集群中分片的数量由所有数据节点的总资源决定。由于分片的数量是动态的,IoTDB 可以轻松扩展。元数据分片和数据分片都遵循相同的分区分配算法,即均匀划分所有序列分区。下图展示了分区分配过程,其中动态扩展的分片匹配不断扩展的时间序列和集群。
+
+
+
+#### 1.2.1 分片扩容
+分片的数量由下式给出
+
+$$\text{RegionGroupNumber}=\left\lfloor\frac{\sum_{i=1}^{DataNodeNumber}\text{RegionNumber}_i}{\text{ReplicationFactor}}\right\rfloor\text{。}$$
+
+在此式中,$\text{RegionNumber}_i$ 表示期望在第 $i$ 个数据节点上放置的副本数量,而 $\text{ReplicationFactor}$ 表示每个分片中的副本数量。$\text{RegionNumber}_i$ 和 $\text{ReplicationFactor}$ 都是可配置的参数。$\text{RegionNumber}_i$ 可以根据第 $i$ 个数据节点上的可用硬件资源(如 CPU 核心数量、内存大小等)确定,以适应不同的物理服务器。$\text{ReplicationFactor}$ 可以调整以确保不同级别的容错能力。
+
+#### 1.2.2 分配策略
+元数据分片和数据分片都遵循相同的分配策略,即均匀划分所有序列分区。因此,每个元数据分片持有相同数量的元数据分区,以确保元数据存储均衡。同样,对于每个时间分区,每个数据分片 获取与其持有的序列分区对应的数据分区。因此,时间分区内的数据分区均匀分布在所有数据分片中,确保每个时间分区内的数据存储均衡。
+
+值得注意的是,IoTDB 有效利用了时序数据的特性。当配置了 TTL(生存时间)时,IoTDB 可实现无需迁移的时序数据弹性存储,该功能在集群扩展时最小化了对在线操作的影响。上图展示了该功能的一个实例:新生成的数据分区被均匀分配到每个数据分片,过期数据会自动归档。因此,集群的存储最终将保持平衡。
+
+## 2 均衡策略
+为了提高集群的可用性和性能,IoTDB 采用了精心设计的存储均衡和计算均衡算法。
+
+### 2.1 存储均衡
+数据节点持有的副本数量反映了它的存储负载。如果数据节点之间的副本数量差异较大,拥有更多副本的数据节点可能成为存储瓶颈。尽管简单的轮询(Round Robin)放置算法可以通过确保每个数据节点持有等量副本来实现存储均衡,但它会降低集群的容错能力,如下所示:
+
+
+
++ 假设集群有 4 个数据节点,4 个分片,并且副本因子为 2。
++ 将分片 $r_1$ 的 2 个副本放置在数据节点 $n_1$ 和 $n_2$ 上。
++ 将分片 $r_2$ 的 2 个副本放置在数据节点 $n_3$ 和 $n_4$ 上。
++ 将分片 $r_3$ 的 2 个副本放置在数据节点 $n_1$ 和 $n_3$ 上。
++ 将分片 $r_4$ 的 2 个副本放置在数据节点 $n_2$ 和 $n_4$ 上。
+
+在这种情况下,如果数据节点 $n_2$ 发生故障,由它先前负责的负载将只能全部转移到数据节点 $n_1$,可能导致其过载。
+
+为了解决这个问题,IoTDB 采用了一种副本放置算法,该算法不仅将副本均匀放置到所有数据节点上,还确保每个 数据节点在发生故障时,能够将其负载转移到足够多的其他数据节点。因此,集群实现了存储分布的均衡,并具备较高的容错能力,从而确保其可用性。
+
+### 2.2 计算均衡
+数据节点持有的主副本数量反映了它的计算负载。如果数据节点之间持有主副本数量差异较大,拥有更多主副本的数据节点可能成为计算瓶颈。如果主副本选择过程使用直观的贪心算法,当副本以容错算法放置时,可能会导致主副本分布不均,如下所示:
+
+
+
++ 假设集群有 4 个数据节点,4 个分片,并且副本因子为 2。
++ 选择分片 $r_5$ 在数据节点 $n_5$ 上的副本作为主副本。
++ 选择分片 $r_6$ 在数据节点 $n_7$ 上的副本作为主副本。
++ 选择分片 $r_7$ 在数据节点 $n_7$ 上的副本作为主副本。
++ 选择分片 $r_8$ 在数据节点 $n_8$ 上的副本作为主副本。
+
+请注意,以上步骤严格遵循贪心算法。然而,到第 3 步时,无论在数据节点 $n_5$ 或 $n_7$ 上选择分片 $r_7$ 的主副本,都会导致主副本分布不均衡。根本原因在于每一步贪心选择都缺乏全局视角,最终导致局部最优解。
+
+为了解决这个问题,IoTDB 采用了一种主副本选择算法,能够持续平衡集群中的主副本分布。因此,集群实现了计算负载的均衡分布,确保了其性能。
+
+## 3 Source Code
++ [数据分区](https://github.com/apache/iotdb/tree/master/iotdb-core/node-commons/src/main/java/org/apache/iotdb/commons/partition)
++ [分区分配](https://github.com/apache/iotdb/tree/master/iotdb-core/confignode/src/main/java/org/apache/iotdb/confignode/manager/load/balancer/partition)
++ [副本放置](https://github.com/apache/iotdb/tree/master/iotdb-core/confignode/src/main/java/org/apache/iotdb/confignode/manager/load/balancer/副本)
++ [主副本选择](https://github.com/apache/iotdb/tree/master/iotdb-core/confignode/src/main/java/org/apache/iotdb/confignode/manager/load/balancer/router/主副本)
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Technical-Insider/Encoding-and-Compression.md b/src/zh/UserGuide/V2.0.1/Table/Technical-Insider/Encoding-and-Compression.md
new file mode 100644
index 000000000..2a4885b3d
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/Technical-Insider/Encoding-and-Compression.md
@@ -0,0 +1,123 @@
+
+
+# 编码和压缩
+
+## 1 编码方式
+
+### 1.1 基本编码方式
+
+为了提高数据的存储效率,需要在数据写入的过程中对数据进行编码,从而减少磁盘空间的使用量。在写数据以及读数据的过程中都能够减少 I/O 操作的数据量从而提高性能。IoTDB 支持多种针对不同类型的数据的编码方法:
+
+1. PLAIN 编码(PLAIN)
+
+ PLAIN 编码,默认的编码方式,即不编码,支持多种数据类型,压缩和解压缩的时间效率较高,但空间存储效率较低。
+
+2. 二阶差分编码(TS_2DIFF)
+
+ 二阶差分编码,比较适合编码单调递增或者递减的序列数据,不适合编码波动较大的数据。
+
+3. 游程编码(RLE)
+
+ 游程编码,比较适合存储某些数值连续出现的序列,不适合编码大部分情况下前后值不一样的序列数据。
+
+ 游程编码也可用于对浮点数进行编码,但在创建时间序列的时候需指定保留小数位数。比较适合存储某些浮点数值连续出现的序列数据,不适合存储对小数点后精度要求较高以及前后波动较大的序列数据。
+
+ > 游程编码(RLE)和二阶差分编码(TS_2DIFF)对 float 和 double 的编码是有精度限制的,默认保留 2 位小数。推荐使用 GORILLA。
+
+4. GORILLA 编码(GORILLA)
+
+ GORILLA 编码是一种无损编码,它比较适合编码前后值比较接近的数值序列,不适合编码前后波动较大的数据。
+
+ 当前系统中存在两个版本的 GORILLA 编码实现,推荐使用`GORILLA`,不推荐使用`GORILLA_V1`(已过时)。
+
+ 使用限制:使用 Gorilla 编码 INT32 数据时,需要保证序列中不存在值为`Integer.MIN_VALUE`的数据点;使用 Gorilla 编码 INT64 数据时,需要保证序列中不存在值为`Long.MIN_VALUE`的数据点。
+
+5. 字典编码 (DICTIONARY)
+
+ 字典编码是一种无损编码。它适合编码基数小的数据(即数据去重后唯一值数量小)。不推荐用于基数大的数据。
+
+6. ZIGZAG 编码
+
+ ZigZag编码将有符号整型映射到无符号整型,适合比较小的整数。
+
+7. CHIMP 编码
+
+ CHIMP 是一种无损编码。它是一种新的流式浮点数据压缩算法,可以节省存储空间。这个编码适用于前后值比较接近的数值序列,对波动小和随机噪声少的序列数据更加友好。
+
+ 使用限制:如果对 INT32 类型数据使用 CHIMP 编码,需要确保数据点中没有 `Integer.MIN_VALUE`。 如果对 INT64 类型数据使用 CHIMP 编码,需要确保数据点中没有 `Long.MIN_VALUE`。
+
+8. SPRINTZ 编码
+
+ SPRINTZ编码是一种无损编码,将原始时序数据分别进行预测、Zigzag编码、位填充和游程编码。SPRINTZ编码适合差分值的绝对值较小(即波动较小)的时序数据,不适合差分值较大(即波动较大)的时序数据。
+
+9. RLBE 编码
+
+ RLBE编码是一种无损编码,将差分编码,位填充编码,游程长度,斐波那契编码和拼接等编码思想结合到一起。RLBE编码适合递增且递增值较小的时序数据,不适合波动较大的时序数据。
+
+### 1.2 数据类型与编码的对应关系
+
+前文介绍的五种编码适用于不同的数据类型,若对应关系错误,则无法正确创建时间序列。数据类型与支持其编码的编码方式对应关系总结如下表所示。
+
+| **数据类型** | **推荐编码(默认)** | **支持的编码** |
+| ------------ | ---------------------- | ----------------------------------------------------------- |
+| BOOLEAN | RLE | PLAIN, RLE |
+| INT32 | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| DATE | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| INT64 | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| TIMESTAMP | TS_2DIFF | PLAIN, RLE, TS_2DIFF, GORILLA, ZIGZAG, CHIMP, SPRINTZ, RLBE |
+| FLOAT | GORILLA | PLAIN, RLE, TS_2DIFF, GORILLA, CHIMP, SPRINTZ, RLBE |
+| DOUBLE | GORILLA | PLAIN, RLE, TS_2DIFF, GORILLA, CHIMP, SPRINTZ, RLBE |
+| TEXT | PLAIN | PLAIN, DICTIONARY |
+| STRING | PLAIN | PLAIN, DICTIONARY |
+| BLOB | PLAIN | PLAIN |
+
+当用户输入的数据类型与编码方式不对应时,系统会提示错误。如下所示,二阶差分编码不支持布尔类型:
+
+```
+IoTDB> create timeseries root.ln.wf02.wt02.status WITH DATATYPE=BOOLEAN, ENCODING=TS_2DIFF
+Msg: 507: encoding TS_2DIFF does not support BOOLEAN
+```
+
+## 2 压缩方式
+
+当时间序列写入并按照指定的类型编码为二进制数据后,IoTDB 会使用压缩技术对该数据进行压缩,进一步提升空间存储效率。虽然编码和压缩都旨在提升存储效率,但编码技术通常只适合特定的数据类型(如二阶差分编码只适合与 INT32 或者 INT64 编码,存储浮点数需要先将他们乘以 10m 以转换为整数),然后将它们转换为二进制流。压缩方式(SNAPPY)针对二进制流进行压缩,因此压缩方式的使用不再受数据类型的限制。
+
+### 2.1 基本压缩方式
+
+IoTDB 允许在创建一个时间序列的时候指定该列的压缩方式。现阶段 IoTDB 支持以下几种压缩方式:
+
+* UNCOMPRESSED(不压缩)
+* SNAPPY 压缩
+* LZ4 压缩(推荐压缩方式)
+* GZIP 压缩
+* ZSTD 压缩
+* LZMA2 压缩
+
+
+### 2.2 压缩比统计信息
+
+压缩比统计信息文件:data/datanode/system/compression_ratio
+
+* ratio_sum: memtable压缩比的总和
+* memtable_flush_time: memtable刷盘的总次数
+
+通过 `ratio_sum / memtable_flush_time` 可以计算出平均压缩比
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Tools-System/CLI.md b/src/zh/UserGuide/V2.0.1/Table/Tools-System/CLI.md
new file mode 100644
index 000000000..fa72ab417
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/Tools-System/CLI.md
@@ -0,0 +1,107 @@
+
+
+# CLI 命令行工具
+
+IoTDB 为用户提供 CLI 工具用于和服务端程序进行交互操作。在使用 CLI 工具连接 IoTDB 前,请保证 IoTDB 服务已经正常启动。下面介绍 CLI 工具的运行方式和相关参数。
+
+> 本文中 $IoTDB_HOME 表示 IoTDB 的安装目录所在路径。
+
+## 1 CLI 启动
+
+CLI 客户端脚本是 $IoTDB_HOME/sbin 文件夹下的`start-cli`脚本。启动命令为:
+
+- Linux/MacOS 系统常用启动命令为:
+
+```Shell
+Shell> bash sbin/start-cli.sh -sql_dialect table
+或
+Shell> bash sbin/start-cli.sh -h 127.0.0.1 -p 6667 -u root -pw root -sql_dialect table
+```
+
+- Windows 系统常用启动命令为:
+
+```Shell
+Shell> sbin\start-cli.bat -sql_dialect table
+或
+Shell> sbin\start-cli.bat -h 127.0.0.1 -p 6667 -u root -pw root -sql_dialect table
+```
+
+其中:
+
+- -h 和-p 项是 IoTDB 所在的 IP 和 RPC 端口号(本机未修改 IP 和 RPC 端口号默认为 127.0.0.1、6667)
+- -u 和-pw 是 IoTDB 登录的用户名密码(安装后IoTDB有一个默认用户,用户名密码均为`root`)
+- -sql_dialect 是登录的数据模型(表模型或树模型),此处指定为 table 代表进入表模型模式
+
+更多参数见:
+
+| **参数名** | **参数类型** | **是否为必需参数** | **说明** | **示例** |
+| :------------------------- | :----------- | :----------------- | :----------------------------------------------------------- | :------------------ |
+| -h `` | string 类型 | 否 | IoTDB 客户端连接 IoTDB 服务器的 IP 地址, 默认使用:127.0.0.1。 | -h 127.0.0.1 |
+| -p `` | int 类型 | 否 | IoTDB 客户端连接服务器的端口号,IoTDB 默认使用 6667。 | -p 6667 |
+| -u `` | string 类型 | 否 | IoTDB 客户端连接服务器所使用的用户名,默认使用 root。 | -u root |
+| -pw `` | string 类型 | 否 | IoTDB 客户端连接服务器所使用的密码,默认使用 root。 | -pw root |
+| -sql_dialect `` | string 类型 | 否 | 目前可选 tree(树模型) 、table(表模型),默认 tree | -sql_dialect table |
+| -e `` | string 类型 | 否 | 在不进入客户端输入模式的情况下,批量操作 IoTDB。 | -e "show databases" |
+| -c | 空 | 否 | 如果服务器设置了 rpc_thrift_compression_enable=true, 则 CLI 必须使用 -c | -c |
+| -disableISO8601 | 空 | 否 | 如果设置了这个参数,IoTDB 将以数字的形式打印时间戳 (timestamp)。 | -disableISO8601 |
+| -help | 空 | 否 | 打印 IoTDB 的帮助信息。 | -help |
+
+启动后出现如图提示即为启动成功。
+
+
+
+
+## 2 在 CLI 中执行语句
+
+进入 CLI 后,用户可以直接在对话中输入 SQL 语句进行交互。如:
+
+- 创建数据库
+
+```Java
+create database test
+```
+
+
+
+
+- 查看数据库
+
+```Java
+show databases
+```
+
+
+
+
+## 3 CLI 退出
+
+在 CLI 中输入`quit`或`exit`可退出 CLI 结束本次会话。
+
+## 4 其他说明
+
+CLI中使用命令小技巧:
+
+(1)快速切换历史命令: 上下箭头
+
+(2)历史命令自动补全:右箭头
+
+(3)中断执行命令: CTRL+C
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/User-Manual/Data-Sync_timecho.md b/src/zh/UserGuide/V2.0.1/Table/User-Manual/Data-Sync_timecho.md
new file mode 100644
index 000000000..97df7cae6
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/User-Manual/Data-Sync_timecho.md
@@ -0,0 +1,557 @@
+
+
+# 数据同步
+数据同步是工业物联网的典型需求,通过数据同步机制,可实现 IoTDB 之间的数据共享,搭建完整的数据链路来满足内网外网数据互通、端边云同步、数据迁移、数据备份等需求。
+
+## 1 功能概述
+
+### 1.1 数据同步
+
+一个数据同步任务包含 3 个阶段:
+
+
+
+- 抽取(Source)阶段:该部分用于从源 IoTDB 抽取数据,在 SQL 语句中的 source 部分定义
+- 处理(Process)阶段:该部分用于处理从源 IoTDB 抽取出的数据,在 SQL 语句中的 processor 部分定义
+- 发送(Sink)阶段:该部分用于向目标 IoTDB 发送数据,在 SQL 语句中的 sink 部分定义
+
+通过 SQL 语句声明式地配置 3 个部分的具体内容,可实现灵活的数据同步能力。
+
+### 1.2 功能限制及说明
+
+- 支持 1.x 系列版本 IoTDB 数据同步到 2.x 以及以上系列版本版本的 IoTDB。
+- 不支持 2.x 系列版本 IoTDB 数据同步到 1.x 系列版本版本的 IoTDB。
+- 在进行数据同步任务时,请避免执行任何删除操作,防止两端状态不一致。
+
+## 2 使用说明
+
+数据同步任务有三种状态:RUNNING、STOPPED 和 DROPPED。任务状态转换如下图所示:
+
+
+
+创建后任务会直接启动,同时当任务发生异常停止后,系统会自动尝试重启任务。
+
+提供以下 SQL 语句对同步任务进行状态管理。
+
+### 2.1 创建任务
+
+使用 `CREATE PIPE` 语句来创建一条数据同步任务,下列属性中`PipeId`和`sink`必填,`source`和`processor`为选填项,输入 SQL 时注意 `SOURCE`与 `SINK` 插件顺序不能替换。
+
+SQL 示例如下:
+
+```SQL
+CREATE PIPE [IF NOT EXISTS] -- PipeId 是能够唯一标定任务的名字
+-- 数据抽取插件,可选插件
+WITH SOURCE (
+ [ = ,],
+)
+-- 数据处理插件,可选插件
+WITH PROCESSOR (
+ [ = ,],
+)
+-- 数据连接插件,必填插件
+WITH SINK (
+ [ = ,],
+)
+```
+
+**IF NOT EXISTS 语义**:用于创建操作中,确保当指定 Pipe 不存在时,执行创建命令,防止因尝试创建已存在的 Pipe 而导致报错。
+
+### 2.2 开始任务
+
+创建之后,任务直接进入运行状态,不需要执行启动任务。当使用`STOP PIPE`语句停止任务时需手动使用`START PIPE`语句来启动任务,PIPE 发生异常情况停止后会自动重新启动任务,从而开始处理数据:
+
+```SQL
+START PIPE
+```
+
+### 2.3 停止任务
+
+停止处理数据:
+
+```SQL
+STOP PIPE
+```
+
+### 2.4 删除任务
+
+删除指定任务:
+
+```SQL
+DROP PIPE [IF EXISTS]
+```
+
+**IF EXISTS 语义**:用于删除操作中,确保当指定 Pipe 存在时,执行删除命令,防止因尝试删除不存在的 Pipe 而导致报错。
+
+删除任务不需要先停止同步任务。
+
+### 2.5 查看任务
+
+查看全部任务:
+
+```SQL
+SHOW PIPES
+```
+
+查看指定任务:
+
+```SQL
+SHOW PIPE
+```
+
+ pipe 的 show pipes 结果示例:
+
+```SQL
++--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
+| ID| CreationTime| State|PipeSource|PipeProcessor| PipeSink|ExceptionMessage|RemainingEventCount|EstimatedRemainingSeconds|
++--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
+|59abf95db892428b9d01c5fa318014ea|2024-06-17T14:03:44.189|RUNNING| {}| {}|{sink=iotdb-thrift-sink, sink.ip=127.0.0.1, sink.port=6668}| | 128| 1.03|
++--------------------------------+-----------------------+-------+----------+-------------+-----------------------------------------------------------+----------------+-------------------+-------------------------+
+```
+
+其中各列含义如下:
+
+- **ID**:同步任务的唯一标识符
+- **CreationTime**:同步任务的创建的时间
+- **State**:同步任务的状态
+- **PipeSource**:同步数据流的来源
+- **PipeProcessor**:同步数据流在传输过程中的处理逻辑
+- **PipeSink**:同步数据流的目的地
+- **ExceptionMessage**:显示同步任务的异常信息
+- **RemainingEventCount(统计存在延迟)**:剩余 event 数,当前数据同步任务中的所有 event 总数,包括数据同步的 event,以及系统和用户自定义的 event。
+- **EstimatedRemainingSeconds(统计存在延迟)**:剩余时间,基于当前 event 个数和 pipe 处速率,预估完成传输的剩余时间。
+
+### 2.6 同步插件
+
+为了使得整体架构更加灵活以匹配不同的同步场景需求,我们支持在同步任务框架中进行插件组装。系统为您预置了一些常用插件可直接使用,同时您也可以自定义 processor 插件 和 Sink 插件,并加载至 IoTDB 系统进行使用。查看系统中的插件(含自定义与内置插件)可以用以下语句:
+
+```SQL
+SHOW PIPEPLUGINS
+```
+
+返回结果如下:
+
+```SQL
+IoTDB> SHOW PIPEPLUGINS
++------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
+| PluginName|PluginType| ClassName| PluginJar|
++------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
+| DO-NOTHING-PROCESSOR| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.processor.donothing.DoNothingProcessor| |
+| DO-NOTHING-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.donothing.DoNothingConnector| |
+| IOTDB-AIR-GAP-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.airgap.IoTDBAirGapConnector| |
+| IOTDB-SOURCE| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.extractor.iotdb.IoTDBExtractor| |
+| IOTDB-THRIFT-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftConnector| |
+| IOTDB-THRIFT-SSL-SINK| Builtin| org.apache.iotdb.commons.pipe.plugin.builtin.connector.iotdb.thrift.IoTDBThriftSslConnector| |
++------------------------------+----------+--------------------------------------------------------------------------------------------------+----------------------------------------------------+
+```
+
+预置插件详细介绍如下(各插件的详细参数可参考本文[参数说明](#参考参数说明)):
+
+
+
+
+
+ | 类型 |
+ 自定义插件 |
+ 插件名称 |
+ 介绍 |
+
+
+ | source 插件 |
+ 不支持 |
+ iotdb-source |
+ 默认的 extractor 插件,用于抽取 IoTDB 历史或实时数据 |
+
+
+ | processor 插件 |
+ 支持 |
+ do-nothing-processor |
+ 默认的 processor 插件,不对传入的数据做任何的处理 |
+
+
+ | sink 插件 |
+ 支持 |
+ do-nothing-sink |
+ 不对发送出的数据做任何的处理 |
+
+
+ | iotdb-thrift-sink |
+ 默认的 sink 插件,用于 IoTDB 到 IoTDB(V2.0.0 及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 async non-blocking IO 模型,传输性能高,尤其适用于目标端为分布式时的场景 |
+
+
+ | iotdb-air-gap-sink |
+ 用于 IoTDB 向 IoTDB(V2.0.0 及以上)跨单向数据网闸的数据同步。支持的网闸型号包括南瑞 Syskeeper 2000 等 |
+
+
+ | iotdb-thrift-ssl-sink |
+ 用于 IoTDB 与 IoTDB(V2.0.0 及以上)之间的数据传输。使用 Thrift RPC 框架传输数据,多线程 sync blocking IO 模型,适用于安全需求较高的场景 |
+
+
+
+
+
+## 3 使用示例
+
+### 3.1 全量数据同步
+
+本例子用来演示将一个 IoTDB 的所有数据同步至另一个 IoTDB,数据链路如下图所示:
+
+
+
+在这个例子中,我们可以创建一个名为 A2B 的同步任务,用来同步 A IoTDB 到 B IoTDB 间的全量数据,这里需要用到用到 sink 的 iotdb-thrift-sink 插件(内置插件),需通过 node-urls 配置目标端 IoTDB 中 DataNode 节点的数据服务端口的 url,如下面的示例语句:
+
+```SQL
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.2 部分数据同步
+
+本例子用来演示同步某个历史时间范围( 2023 年 8 月 23 日 8 点到 2023 年 10 月 23 日 8 点)的数据至另一个 IoTDB,数据链路如下图所示:
+
+
+
+在这个例子中,我们可以创建一个名为 A2B 的同步任务。首先我们需要在 source 中定义传输数据的范围,由于传输的是历史数据(历史数据是指同步任务创建之前存在的数据),需要配置数据的起止时间 start-time 和 end-time 以及传输的模式 mode.streaming。通过 node-urls 配置目标端 IoTDB 中 DataNode 节点的数据服务端口的 url。
+
+详细语句如下:
+
+```SQL
+create pipe A2B
+WITH SOURCE (
+ 'source'= 'iotdb-source',
+ 'mode.streaming' = 'true' -- 新插入数据(pipe创建后)的抽取模式:是否按流式抽取(false 时为批式)
+ 'start-time' = '2023.08.23T08:00:00+00:00', -- 同步所有数据的开始 event time,包含 start-time
+ 'end-time' = '2023.10.23T08:00:00+00:00' -- 同步所有数据的结束 event time,包含 end-time
+)
+with SINK (
+ 'sink'='iotdb-thrift-async-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.3 双向数据传输
+
+本例子用来演示两个 IoTDB 之间互为双活的场景,数据链路如下图所示:
+
+
+
+在这个例子中,为了避免数据无限循环,需要将 A 和 B 上的参数`source.mode.double-living` 均设置为 `true`,表示不转发从另一 pipe 传输而来的数据。
+
+详细语句如下:
+
+在 A IoTDB 上执行下列语句:
+
+```SQL
+create pipe AB
+with source (
+ 'source.mode.double-living' ='true' --不转发由其他 Pipe 写入的数据
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+在 B IoTDB 上执行下列语句:
+
+```SQL
+create pipe BA
+with source (
+ 'source.mode.double-living' ='true' --不转发由其他 Pipe 写入的数据
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6667', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+### 3.4 边云数据传输
+
+本例子用来演示多个 IoTDB 之间边云传输数据的场景,数据由 B 、C、D 集群分别都同步至 A 集群,数据链路如下图所示:
+
+
+
+在这个例子中,为了将 B 、C、D 集群的数据同步至 A,在 BA 、CA、DA 之间的 pipe 需要配置database-name 和 table-name 限制范围,详细语句如下:
+
+在 B IoTDB 上执行下列语句,将 B 中数据同步至 A:
+
+```SQL
+create pipe BA
+with source (
+ 'database-name'='db_b.*', -- 限制范围
+ 'table-name'='.*', -- 可选择匹配所有
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6667', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+在 C IoTDB 上执行下列语句,将 C 中数据同步至 A:
+
+```SQL
+create pipe CA
+with source (
+ 'database-name'='db_c.*', -- 限制范围
+ 'table-name'='.*', -- 可选择匹配所有
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+在 D IoTDB 上执行下列语句,将 D 中数据同步至 A:
+
+```SQL
+create pipe DA
+with source (
+ 'database-name'='db_d.*', -- 限制范围
+ 'table-name'='.*', -- 可选择匹配所有
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6669', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.5 级联数据传输
+
+本例子用来演示多个 IoTDB 之间级联传输数据的场景,数据由 A 集群同步至 B 集群,再同步至 C 集群,数据链路如下图所示:
+
+
+
+在这个例子中,为了将 A 集群的数据同步至 C,在 BC 之间的 pipe 需要将 `source.mode.double-living` 配置为`true`,详细语句如下:
+
+在 A IoTDB 上执行下列语句,将 A 中数据同步至 B:
+
+```SQL
+create pipe AB
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+在 B IoTDB 上执行下列语句,将 B 中数据同步至 C:
+
+```SQL
+create pipe BC
+with source (
+ 'source.mode.double-living' ='true' --不转发由其他 Pipe 写入的数据
+)
+with sink (
+ 'sink'='iotdb-thrift-sink',
+ 'node-urls' = '127.0.0.1:6669', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.6 跨网闸数据传输
+
+本例子用来演示将一个 IoTDB 的数据,经过单向网闸,同步至另一个 IoTDB 的场景,数据链路如下图所示:
+
+
+
+在这个例子中,需要使用 sink 任务中的 iotdb-air-gap-sink 插件(目前支持部分型号网闸,具体型号请联系天谋科技工作人员确认),配置网闸后,在 A IoTDB 上执行下列语句,其中 node-urls 填写网闸配置的目标端 IoTDB 中 DataNode 节点的数据服务端口的 url,详细语句如下:
+
+```SQL
+create pipe A2B
+with sink (
+ 'sink'='iotdb-air-gap-sink',
+ 'node-urls' = '10.53.53.53:9780', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+)
+```
+
+### 3.7 压缩同步
+
+IoTDB 支持在同步过程中指定数据压缩方式。可通过配置 `compressor` 参数,实现数据的实时压缩和传输。`compressor`目前支持 snappy / gzip / lz4 / zstd / lzma2 5 种可选算法,且可以选择多种压缩算法组合,按配置的顺序进行压缩。`rate-limit-bytes-per-second`(V1.3.3 及以后版本支持)每秒最大允许传输的byte数,计算压缩后的byte,若小于0则不限制。
+
+如创建一个名为 A2B 的同步任务:
+
+```SQL
+create pipe A2B
+with sink (
+ 'node-urls' = '127.0.0.1:6668', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+ 'compressor' = 'snappy,lz4' --
+ 'rate-limit-bytes-per-second'='1048576' -- 每秒最大允许传输的byte数
+)
+```
+
+### 3.8 加密同步
+
+IoTDB 支持在同步过程中使用 SSL 加密,从而在不同的 IoTDB 实例之间安全地传输数据。通过配置 SSL 相关的参数,如证书地址和密码(`ssl.trust-store-path`)、(`ssl.trust-store-pwd`)可以确保数据在同步过程中被 SSL 加密所保护。
+
+如创建名为 A2B 的同步任务:
+
+```SQL
+create pipe A2B
+with sink (
+ 'sink'='iotdb-thrift-ssl-sink',
+ 'node-urls'='127.0.0.1:6667', -- 目标端 IoTDB 中 DataNode 节点的数据服务端口的 url
+ 'ssl.trust-store-path'='pki/trusted', -- 连接目标端 DataNode 所需的 trust store 证书路径
+ 'ssl.trust-store-pwd'='root' -- 连接目标端 DataNode 所需的 trust store 证书密码
+)
+```
+
+## 参考:注意事项
+
+可通过修改 IoTDB 配置文件(`iotdb-system.properties`)以调整数据同步的参数,如同步数据存储目录等。完整配置如下::
+
+```Properties
+# pipe_receiver_file_dir
+# If this property is unset, system will save the data in the default relative path directory under the IoTDB folder(i.e., %IOTDB_HOME%/${cn_system_dir}/pipe/receiver).
+# If it is absolute, system will save the data in the exact location it points to.
+# If it is relative, system will save the data in the relative path directory it indicates under the IoTDB folder.
+# Note: If pipe_receiver_file_dir is assigned an empty string(i.e.,zero-size), it will be handled as a relative path.
+# effectiveMode: restart
+# For windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is absolute. Otherwise, it is relative.
+# pipe_receiver_file_dir=data\\confignode\\system\\pipe\\receiver
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+pipe_receiver_file_dir=data/confignode/system/pipe/receiver
+
+####################
+### Pipe Configuration
+####################
+
+# Uncomment the following field to configure the pipe lib directory.
+# effectiveMode: first_start
+# For Windows platform
+# If its prefix is a drive specifier followed by "\\", or if its prefix is "\\\\", then the path is
+# absolute. Otherwise, it is relative.
+# pipe_lib_dir=ext\\pipe
+# For Linux platform
+# If its prefix is "/", then the path is absolute. Otherwise, it is relative.
+pipe_lib_dir=ext/pipe
+
+# The maximum number of threads that can be used to execute the pipe subtasks in PipeSubtaskExecutor.
+# The actual value will be min(pipe_subtask_executor_max_thread_num, max(1, CPU core number / 2)).
+# effectiveMode: restart
+# Datatype: int
+pipe_subtask_executor_max_thread_num=5
+
+# The connection timeout (in milliseconds) for the thrift client.
+# effectiveMode: restart
+# Datatype: int
+pipe_sink_timeout_ms=900000
+
+# The maximum number of selectors that can be used in the sink.
+# Recommend to set this value to less than or equal to pipe_sink_max_client_number.
+# effectiveMode: restart
+# Datatype: int
+pipe_sink_selector_number=4
+
+# The maximum number of clients that can be used in the sink.
+# effectiveMode: restart
+# Datatype: int
+pipe_sink_max_client_number=16
+
+# Whether to enable receiving pipe data through air gap.
+# The receiver can only return 0 or 1 in tcp mode to indicate whether the data is received successfully.
+# effectiveMode: restart
+# Datatype: Boolean
+pipe_air_gap_receiver_enabled=false
+
+# The port for the server to receive pipe data through air gap.
+# Datatype: int
+# effectiveMode: restart
+pipe_air_gap_receiver_port=9780
+
+# The total bytes that all pipe sinks can transfer per second.
+# When given a value less than or equal to 0, it means no limit.
+# default value is -1, which means no limit.
+# effectiveMode: hot_reload
+# Datatype: double
+pipe_all_sinks_rate_limit_bytes_per_second=-1
+```
+
+## 参考:参数说明
+
+### source 参数
+
+| **参数** | **描述** | **value 取值范围** | **是否必填** | **默认取值** |
+| ------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------ | ------------------------------- |
+| source | iotdb-source | String: iotdb-source | 必填 | - |
+| mode.streaming | 此参数指定时序数据写入的捕获来源。适用于 `mode.streaming`为 `false` 模式下的场景,决定`inclusion`中`data.insert`数据的捕获来源。提供两种捕获策略:true: 动态选择捕获的类型。系统将根据下游处理速度,自适应地选择是捕获每个写入请求还是仅捕获 TsFile 文件的封口请求。当下游处理速度快时,优先捕获写入请求以减少延迟;当处理速度慢时,仅捕获文件封口请求以避免处理堆积。这种模式适用于大多数场景,能够实现处理延迟和吞吐量的最优平衡。false:固定按批捕获方式。仅捕获 TsFile 文件的封口请求,适用于资源受限的应用场景,以降低系统负载。注意,pipe 启动时捕获的快照数据只会以文件的方式供下游处理。 | Boolean: true / false | 否 | true |
+| mode.strict | 在使用 time / path / database-name / table-name 参数过滤数据时,是否需要严格按照条件筛选:`true`: 严格筛选。系统将完全按照给定条件过滤筛选被捕获的数据,确保只有符合条件的数据被选中。`false`:非严格筛选。系统在筛选被捕获的数据时可能会包含一些额外的数据,适用于性能敏感的场景,可降低 CPU 和 IO 消耗。 | Boolean: true / false | 否 | true |
+| mode.snapshot | 此参数决定时序数据的捕获方式,影响`inclusion`中的`data`数据。提供两种模式:`true`:静态数据捕获。启动 pipe 时,会进行一次性的数据快照捕获。当快照数据被完全消费后,**pipe 将自动终止(DROP PIPE SQL 会自动执行)**。`false`:动态数据捕获。除了在 pipe 启动时捕获快照数据外,还会持续捕获后续的数据变更。pipe 将持续运行以处理动态数据流。 | Boolean: true / false | 否 | false |
+| database-name | 当用户连接指定的 sql_dialect 为 table 时可以指定。此参数决定时序数据的捕获范围,影响`inclusion`中的`data`数据。表示要过滤的数据库的名称。它可以是具体的数据库名,也可以是 Java 风格正则表达式来匹配多个数据库。默认情况下,匹配所有的库。 | String:数据库名或数据库正则模式串,可以匹配未创建的、不存在的库 | 否 | ".*" |
+| table-name | 当用户连接指定的 sql_dialect 为 table 时可以指定。此参数决定时序数据的捕获范围,影响`inclusion`中的`data`数据。表示要过滤的表的名称。它可以是具体的表名,也可以是 Java 风格正则表达式来匹配多个表。默认情况下,匹配所有的表。 | String:数据表名或数据表正则模式串,可以是未创建的、不存在的表 | 否 | ".*" |
+| start-time | 此参数决定时序数据的捕获范围,影响`inclusion`中的`data`数据。当数据的 event time 大于等于该参数时,数据会被筛选出来进入流处理 pipe。 | Long: [Long.MIN_VALUE, Long.MAX_VALUE] (unix 裸时间戳)或 String:IoTDB 支持的 ISO 格式时间戳 | 否 | Long.MIN_VALUE(unix 裸时间戳) |
+| end-time | 此参数决定时序数据的捕获范围,影响`inclusion`中的`data`数据。当数据的 event time 小于等于该参数时,数据会被筛选出来进入流处理 pipe。 | Long: [Long.MIN_VALUE, Long.MAX_VALUE](unix 裸时间戳)或String:IoTDB 支持的 ISO 格式时间戳 | 否 | Long.MAX_VALUE(unix 裸时间戳) |
+| forwarding-pipe-requests | 是否转发由 pipe 数据同步而来的集群外的数据。一般供搭建双活集群时使用,双活集群模式下该参数为 false,以此避免无限的环形同步。 | Boolean: true / false | 否 | true |
+
+> 💎 **说明:数据抽取模式 mode.streaming 取值 true 和 false 的差异**
+> - **true(推荐)**:该取值下,任务将对数据进行实时处理、发送,其特点是高时效、低吞吐
+> - **false**:该取值下,任务将对数据进行批量(按底层数据文件)处理、发送,其特点是低时效、高吞吐
+
+
+## sink 参数
+
+#### iotdb-thrift-sink
+
+| **参数** | **描述** | **value 取值范围** | **是否必填** | **默认取值** |
+| --------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------ |
+| sink | iotdb-thrift-sink 或 iotdb-thrift-async-sink | String: iotdb-thrift-sink 或 iotdb-thrift-async-sink | 必填 | - |
+| node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String. 例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
+| user/usename | 连接接收端使用的用户名,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| password | 连接接收端使用的用户名对应的密码,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
+| batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
+| batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | 16*1024*1024 |
+| compressor | 所选取的 rpc 压缩算法,可配置多个,对每个请求顺序采用 | String: snappy / gzip / lz4 / zstd / lzma2 | 选填 | "" |
+| compressor.zstd.level | 所选取的 rpc 压缩算法为 zstd 时,可使用该参数额外配置 zstd 算法的压缩等级 | Int: [-131072, 22] | 选填 | 3 |
+| rate-limit-bytes-per-second | 每秒最大允许传输的 byte 数,计算压缩后的 byte(如压缩),若小于 0 则不限制 | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | 选填 | -1 |
+
+
+#### iotdb-air-gap-sink
+
+| **参数** | **描述** | **value 取值范围** | **是否必填** | **默认取值** |
+| ---------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | -------- |
+| sink | iotdb-air-gap-sink | String: iotdb-air-gap-sink | 必填 | - |
+| node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url | String. 例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
+| user/usename | 连接接收端使用的用户名,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| password | 连接接收端使用的用户名对应的密码,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| compressor | 所选取的 rpc 压缩算法,可配置多个,对每个请求顺序采用 | String: snappy / gzip / lz4 / zstd / lzma2 | 选填 | "" |
+| compressor.zstd.level | 所选取的 rpc 压缩算法为 zstd 时,可使用该参数额外配置 zstd 算法的压缩等级 | Int: [-131072, 22] | 选填 | 3 |
+| rate-limit-bytes-per-second | 每秒最大允许传输的 byte 数,计算压缩后的 byte(如压缩),若小于 0 则不限制 | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | 选填 | -1 |
+| air-gap.handshake-timeout-ms | 发送端与接收端在首次尝试建立连接时握手请求的超时时长,单位:毫秒 | Integer | 选填 | 5000 |
+
+#### iotdb-thrift-ssl-sink
+
+| **参数** | **描述** | **value 取值范围** | **是否必填** | **默认取值** |
+| --------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ | -------- | ------------ |
+| sink | iotdb-thrift-ssl-sink | String: iotdb-thrift-ssl-sink | 必填 | - |
+| node-urls | 目标端 IoTDB 任意多个 DataNode 节点的数据服务端口的 url(请注意同步任务不支持向自身服务进行转发) | String. 例:'127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
+| user/usename | 连接接收端使用的用户名,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| password | 连接接收端使用的用户名对应的密码,同步要求该用户具备相应的操作权限 | String | 选填 | root |
+| batch.enable | 是否开启日志攒批发送模式,用于提高传输吞吐,降低 IOPS | Boolean: true, false | 选填 | true |
+| batch.max-delay-seconds | 在开启日志攒批发送模式时生效,表示一批数据在发送前的最长等待时间(单位:s) | Integer | 选填 | 1 |
+| batch.size-bytes | 在开启日志攒批发送模式时生效,表示一批数据最大的攒批大小(单位:byte) | Long | 选填 | 16*1024*1024 |
+| compressor | 所选取的 rpc 压缩算法,可配置多个,对每个请求顺序采用 | String: snappy / gzip / lz4 / zstd / lzma2 | 选填 | "" |
+| compressor.zstd.level | 所选取的 rpc 压缩算法为 zstd 时,可使用该参数额外配置 zstd 算法的压缩等级 | Int: [-131072, 22] | 选填 | 3 |
+| rate-limit-bytes-per-second | 每秒最大允许传输的 byte 数,计算压缩后的 byte(如压缩),若小于 0 则不限制 | Double: [Double.MIN_VALUE, Double.MAX_VALUE] | 选填 | -1 |
+| ssl.trust-store-path | 连接目标端 DataNode 所需的 trust store 证书路径 | String.Example: '127.0.0.1:6667,127.0.0.1:6668,127.0.0.1:6669', '127.0.0.1:6667' | 必填 | - |
+| ssl.trust-store-pwd | 连接目标端 DataNode 所需的 trust store 证书密码 | Integer | 必填 | - |
\ No newline at end of file
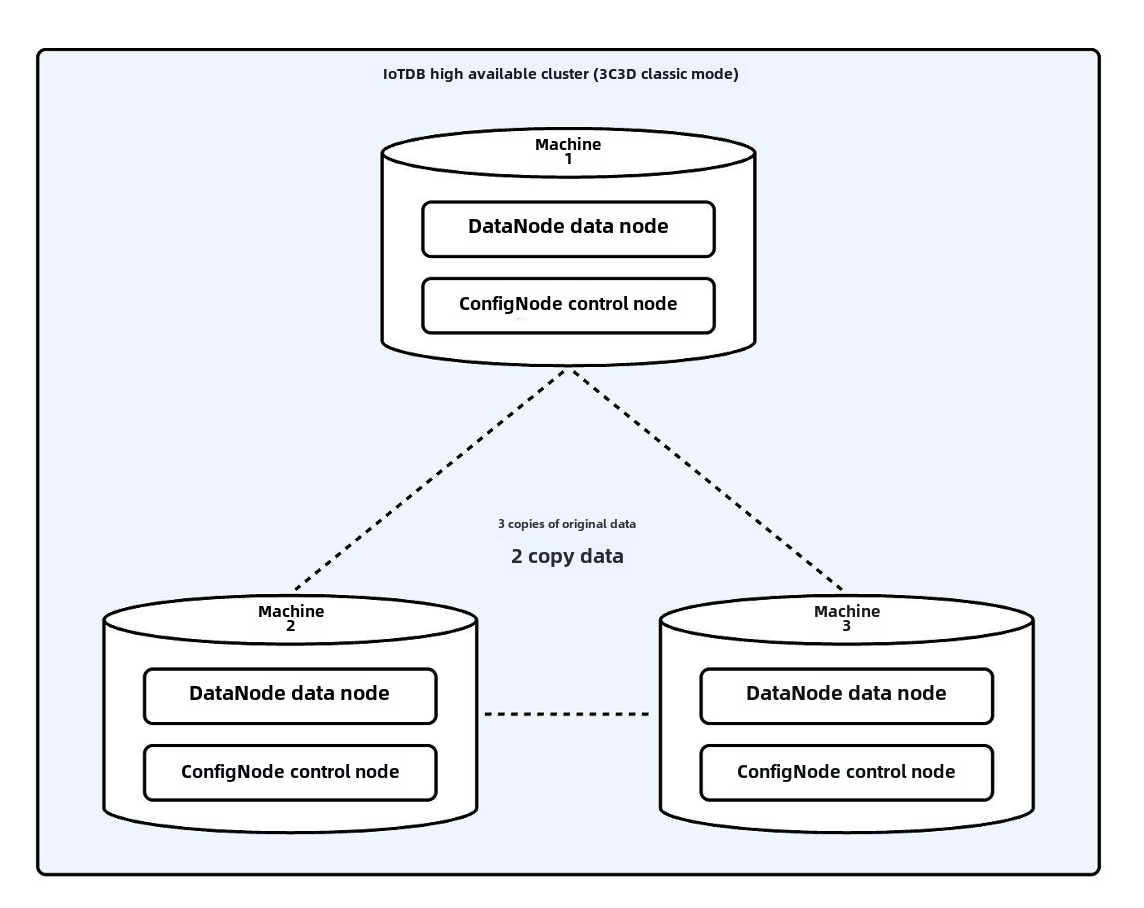 +
+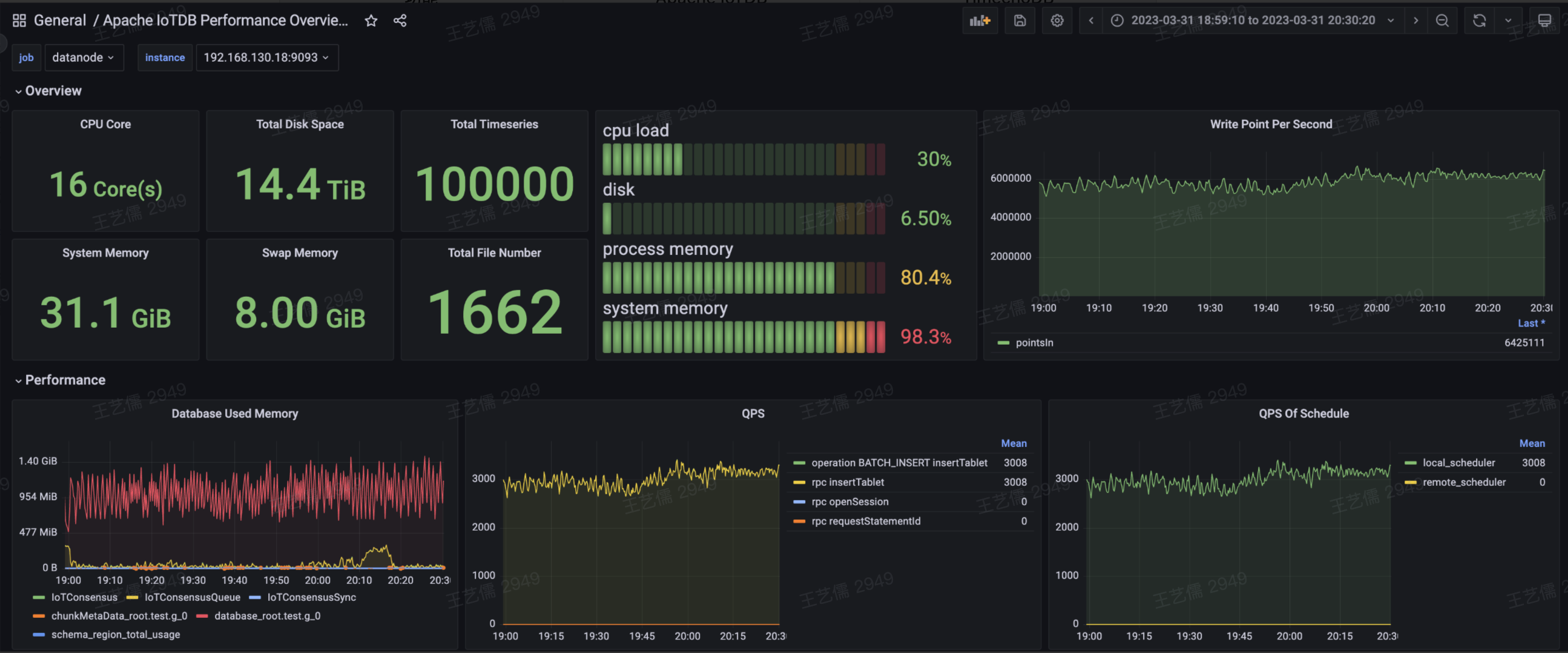 +
+ 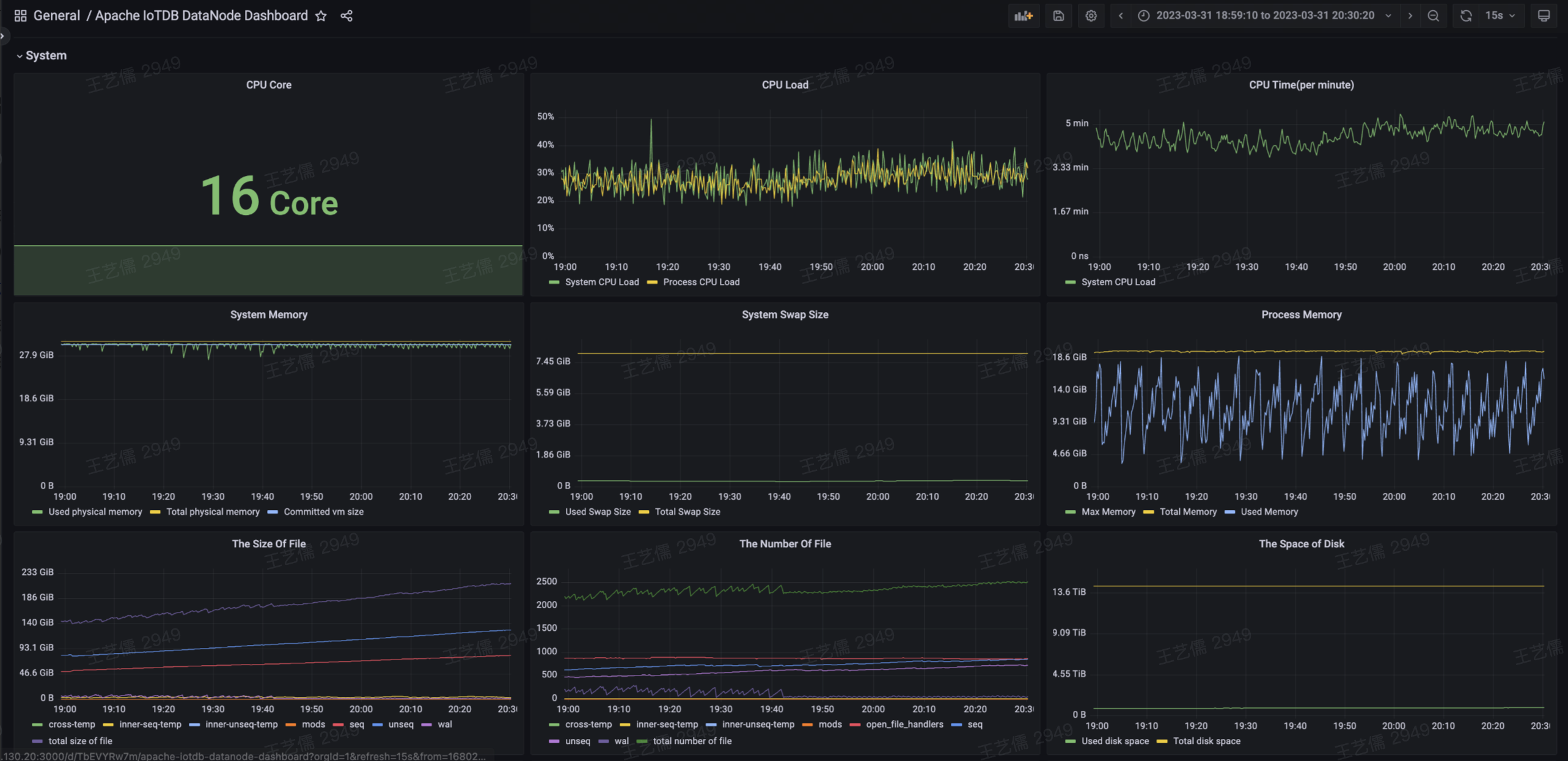 +
+ 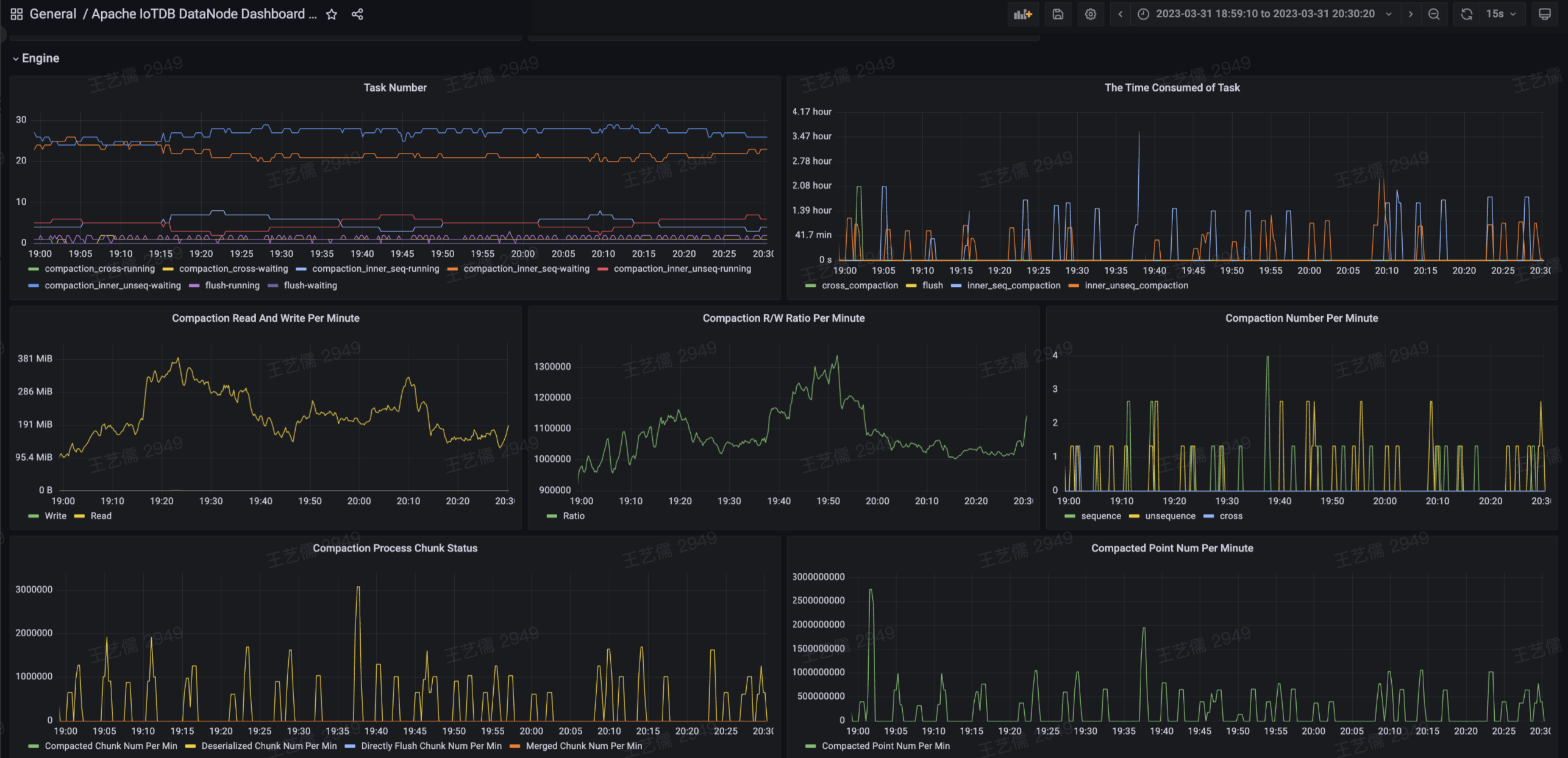 +
+ +
+  +
+  +
+