diff --git a/src/.vuepress/sidebar/V1.3.3/en.ts b/src/.vuepress/sidebar/V1.3.3/en.ts
index 7e3eb8d65..23fd23dac 100644
--- a/src/.vuepress/sidebar/V1.3.3/en.ts
+++ b/src/.vuepress/sidebar/V1.3.3/en.ts
@@ -37,7 +37,7 @@ export const enSidebar = {
collapsible: true,
prefix: 'Background-knowledge/',
children: [
- { text: 'Cluster-related Concepts', link: 'Cluster-Concept' },
+ { text: 'Common Concepts', link: 'Cluster-Concept_apache' },
{ text: 'Data Type', link: 'Data-Type' },
],
},
diff --git a/src/.vuepress/sidebar/V1.3.3/zh.ts b/src/.vuepress/sidebar/V1.3.3/zh.ts
index 42ae0c252..075dbb2b2 100644
--- a/src/.vuepress/sidebar/V1.3.3/zh.ts
+++ b/src/.vuepress/sidebar/V1.3.3/zh.ts
@@ -38,7 +38,7 @@ export const zhSidebar = {
collapsible: true,
prefix: 'Background-knowledge/',
children: [
- { text: '集群相关概念', link: 'Cluster-Concept' },
+ { text: '常见概念', link: 'Cluster-Concept_apache' },
{ text: '数据类型', link: 'Data-Type' },
],
},
diff --git a/src/.vuepress/sidebar_timecho/V1.3.3/en.ts b/src/.vuepress/sidebar_timecho/V1.3.3/en.ts
index 207df6539..c59739813 100644
--- a/src/.vuepress/sidebar_timecho/V1.3.3/en.ts
+++ b/src/.vuepress/sidebar_timecho/V1.3.3/en.ts
@@ -37,7 +37,7 @@ export const enSidebar = {
collapsible: true,
prefix: 'Background-knowledge/',
children: [
- { text: 'Cluster-related Concepts', link: 'Cluster-Concept' },
+ { text: 'Common Concepts', link: 'Cluster-Concept_timecho' },
{ text: 'Data Type', link: 'Data-Type' },
],
},
diff --git a/src/.vuepress/sidebar_timecho/V1.3.3/zh.ts b/src/.vuepress/sidebar_timecho/V1.3.3/zh.ts
index ff86aaa3f..5127282bf 100644
--- a/src/.vuepress/sidebar_timecho/V1.3.3/zh.ts
+++ b/src/.vuepress/sidebar_timecho/V1.3.3/zh.ts
@@ -38,7 +38,7 @@ export const zhSidebar = {
collapsible: true,
prefix: 'Background-knowledge/',
children: [
- { text: '集群相关概念', link: 'Cluster-Concept' },
+ { text: '常见概念', link: 'Cluster-Concept_timecho' },
{ text: '数据类型', link: 'Data-Type' },
],
},
diff --git a/src/.vuepress/sidebar_timecho/V2.0.1/zh-Table.ts b/src/.vuepress/sidebar_timecho/V2.0.1/zh-Table.ts
index 4892142df..f5766bb7b 100644
--- a/src/.vuepress/sidebar_timecho/V2.0.1/zh-Table.ts
+++ b/src/.vuepress/sidebar_timecho/V2.0.1/zh-Table.ts
@@ -37,7 +37,7 @@ export const zhSidebar = {
collapsible: true,
prefix: 'Background-knowledge/',
children: [
- { text: '集群相关概念', link: 'Cluster-Concept' },
+ { text: '常见概念', link: 'Cluster-Concept_timecho' },
{ text: '数据类型', link: 'Data-Type' },
],
},
diff --git a/src/.vuepress/sidebar_timecho/V2.0.1/zh-Tree.ts b/src/.vuepress/sidebar_timecho/V2.0.1/zh-Tree.ts
index fde8e0193..3d12b386b 100644
--- a/src/.vuepress/sidebar_timecho/V2.0.1/zh-Tree.ts
+++ b/src/.vuepress/sidebar_timecho/V2.0.1/zh-Tree.ts
@@ -38,7 +38,7 @@ export const zhSidebar = {
collapsible: true,
prefix: 'Background-knowledge/',
children: [
- { text: '集群相关概念', link: 'Cluster-Concept' },
+ { text: '常见概念', link: 'Cluster-Concept_timecho' },
{ text: '数据类型', link: 'Data-Type' },
],
},
diff --git a/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md
index d6f57bf2a..b4631022f 100644
--- a/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md
+++ b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# Cluster-related Concepts
-The figure below illustrates a typical IoTDB 3C3D1A cluster deployment mode, comprising 3 ConfigNodes, 3 DataNodes, and 1 AINode:
-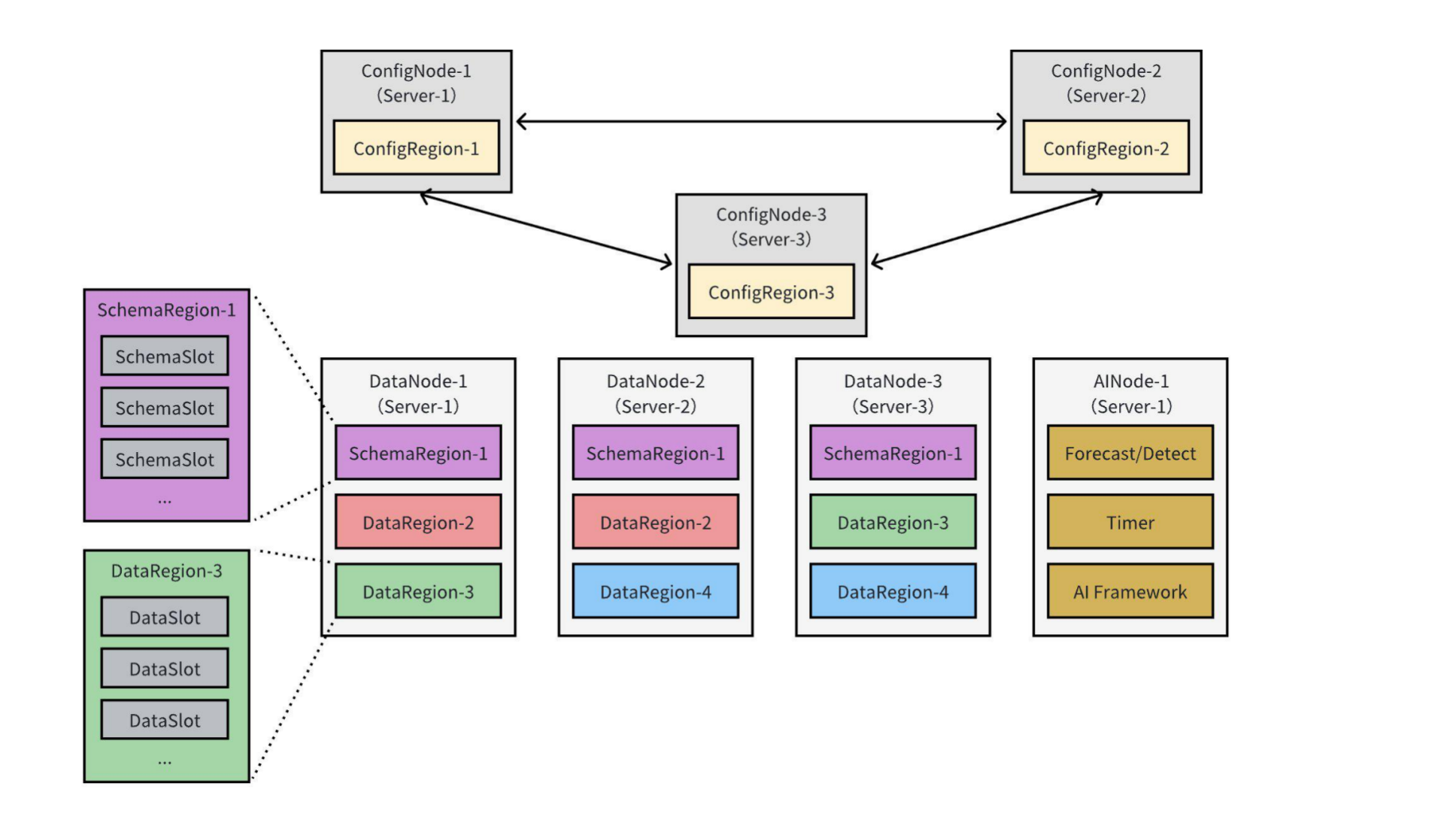 -
-This deployment involves several key concepts that users commonly encounter when working with IoTDB clusters, including:
-- **Nodes** (ConfigNode, DataNode, AINode);
-- **Slots** (SchemaSlot, DataSlot);
-- **Regions** (SchemaRegion, DataRegion);
-- **Replica Groups**.
-
-The following sections will provide a detailed introduction to these concepts.
-
-## Nodes
-
-An IoTDB cluster consists of three types of nodes (processes): **ConfigNode** (the main node), **DataNode**, and **AINode**, as detailed below:
-- **ConfigNode:** ConfigNodes store cluster configurations, database metadata, the routing information of time series' schema and data. They also monitor cluster nodes and conduct load balancing. All ConfigNodes maintain full mutual backups, as shown in the figure with ConfigNode-1, ConfigNode-2, and ConfigNode-3. ConfigNodes do not directly handle client read or write requests. Instead, they guide the distribution of time series' schema and data within the cluster using a series of [load balancing algorithms](../Technical-Insider/Cluster-data-partitioning.md).
-- **DataNode:** DataNodes are responsible for reading and writing time series' schema and data. Each DataNode can accept client read and write requests and provide corresponding services, as illustrated with DataNode-1, DataNode-2, and DataNode-3 in the above figure. When a DataNode receives client requests, it can process them directly or forward them if it has the relevant routing information cached locally. Otherwise, it queries the ConfigNode for routing details and caches the information to improve the efficiency of subsequent requests.
-- **AINode:** AINodes interact with ConfigNodes and DataNodes to extend IoTDB's capabilities for data intelligence analysis on time series data. They support registering pre-trained machine learning models from external sources and performing time series analysis tasks using simple SQL statements on specified data. This process integrates model creation, management, and inference within the database engine. Currently, the system provides built-in algorithms or self-training models for common time series analysis scenarios, such as forecasting and anomaly detection.
-
-## Slots
-
-IoTDB divides time series' schema and data into smaller, more manageable units called **slots**. Slots are logical entities, and in an IoTDB cluster, the **SchemaSlots** and **DataSlots** are defined as follows:
-- **SchemaSlot:** A SchemaSlot represents a subset of the time series' schema collection. The total number of SchemaSlots is fixed, with a default value of 1000. IoTDB uses a hashing algorithm to evenly distribute all devices across these SchemaSlots.
-- **DataSlot:** A DataSlot represents a subset of the time series' data collection. Based on the SchemaSlots, the data for corresponding devices is further divided into DataSlots by a fixed time interval. The default time interval for a DataSlot is 7 days.
-
-## Region
-
-In IoTDB, time series' schema and data are replicated across DataNodes to ensure high availability in the cluster. However, replicating data at the slot level can increase management complexity and reduce write throughput. To address this, IoTDB introduces the concept of **Region**, which groups SchemaSlots and DataSlots into **SchemaRegions** and **DataRegions** respectively. Replication is then performed at the Region level. The definitions of SchemaRegion and DataRegion are as follows:
-- **SchemaRegion**: A SchemaRegion is the basic unit for storing and replicating time series' schema. All SchemaSlots in a database are evenly distributed across the database's SchemaRegions. SchemaRegions with the same RegionID are replicas of each other. For example, in the figure above, SchemaRegion-1 has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
-- **DataRegion**: A DataRegion is the basic unit for storing and replicating time series' data. All DataSlots in a database are evenly distributed across the database's DataRegions. DataRegions with the same RegionID are replicas of each other. For instance, in the figure above, DataRegion-2 has two replicas located on DataNode-1 and DataNode-2.
-
-## Replica Groups
-Region replicas are critical for the fault tolerance of the cluster. Each Region's replicas are organized into **replica groups**, where the replicas are assigned roles as either **leader** or **follower**, working together to provide read and write services. Recommended replica group configurations under different architectures are as follows:
-
-| Category | Parameter | Single-node Recommended Configuration | Distributed Recommended Configuration |
-|:------------:|:-----------------------:|:------------------------------------:|:-------------------------------------:|
-| Schema | `schema_replication_factor` | 1 | 3 |
-| Data | `data_replication_factor` | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..1edc7c292
--- /dev/null
+++ b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,105 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
-
-This deployment involves several key concepts that users commonly encounter when working with IoTDB clusters, including:
-- **Nodes** (ConfigNode, DataNode, AINode);
-- **Slots** (SchemaSlot, DataSlot);
-- **Regions** (SchemaRegion, DataRegion);
-- **Replica Groups**.
-
-The following sections will provide a detailed introduction to these concepts.
-
-## Nodes
-
-An IoTDB cluster consists of three types of nodes (processes): **ConfigNode** (the main node), **DataNode**, and **AINode**, as detailed below:
-- **ConfigNode:** ConfigNodes store cluster configurations, database metadata, the routing information of time series' schema and data. They also monitor cluster nodes and conduct load balancing. All ConfigNodes maintain full mutual backups, as shown in the figure with ConfigNode-1, ConfigNode-2, and ConfigNode-3. ConfigNodes do not directly handle client read or write requests. Instead, they guide the distribution of time series' schema and data within the cluster using a series of [load balancing algorithms](../Technical-Insider/Cluster-data-partitioning.md).
-- **DataNode:** DataNodes are responsible for reading and writing time series' schema and data. Each DataNode can accept client read and write requests and provide corresponding services, as illustrated with DataNode-1, DataNode-2, and DataNode-3 in the above figure. When a DataNode receives client requests, it can process them directly or forward them if it has the relevant routing information cached locally. Otherwise, it queries the ConfigNode for routing details and caches the information to improve the efficiency of subsequent requests.
-- **AINode:** AINodes interact with ConfigNodes and DataNodes to extend IoTDB's capabilities for data intelligence analysis on time series data. They support registering pre-trained machine learning models from external sources and performing time series analysis tasks using simple SQL statements on specified data. This process integrates model creation, management, and inference within the database engine. Currently, the system provides built-in algorithms or self-training models for common time series analysis scenarios, such as forecasting and anomaly detection.
-
-## Slots
-
-IoTDB divides time series' schema and data into smaller, more manageable units called **slots**. Slots are logical entities, and in an IoTDB cluster, the **SchemaSlots** and **DataSlots** are defined as follows:
-- **SchemaSlot:** A SchemaSlot represents a subset of the time series' schema collection. The total number of SchemaSlots is fixed, with a default value of 1000. IoTDB uses a hashing algorithm to evenly distribute all devices across these SchemaSlots.
-- **DataSlot:** A DataSlot represents a subset of the time series' data collection. Based on the SchemaSlots, the data for corresponding devices is further divided into DataSlots by a fixed time interval. The default time interval for a DataSlot is 7 days.
-
-## Region
-
-In IoTDB, time series' schema and data are replicated across DataNodes to ensure high availability in the cluster. However, replicating data at the slot level can increase management complexity and reduce write throughput. To address this, IoTDB introduces the concept of **Region**, which groups SchemaSlots and DataSlots into **SchemaRegions** and **DataRegions** respectively. Replication is then performed at the Region level. The definitions of SchemaRegion and DataRegion are as follows:
-- **SchemaRegion**: A SchemaRegion is the basic unit for storing and replicating time series' schema. All SchemaSlots in a database are evenly distributed across the database's SchemaRegions. SchemaRegions with the same RegionID are replicas of each other. For example, in the figure above, SchemaRegion-1 has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
-- **DataRegion**: A DataRegion is the basic unit for storing and replicating time series' data. All DataSlots in a database are evenly distributed across the database's DataRegions. DataRegions with the same RegionID are replicas of each other. For instance, in the figure above, DataRegion-2 has two replicas located on DataNode-1 and DataNode-2.
-
-## Replica Groups
-Region replicas are critical for the fault tolerance of the cluster. Each Region's replicas are organized into **replica groups**, where the replicas are assigned roles as either **leader** or **follower**, working together to provide read and write services. Recommended replica group configurations under different architectures are as follows:
-
-| Category | Parameter | Single-node Recommended Configuration | Distributed Recommended Configuration |
-|:------------:|:-----------------------:|:------------------------------------:|:-------------------------------------:|
-| Schema | `schema_replication_factor` | 1 | 3 |
-| Data | `data_replication_factor` | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..1edc7c292
--- /dev/null
+++ b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,105 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+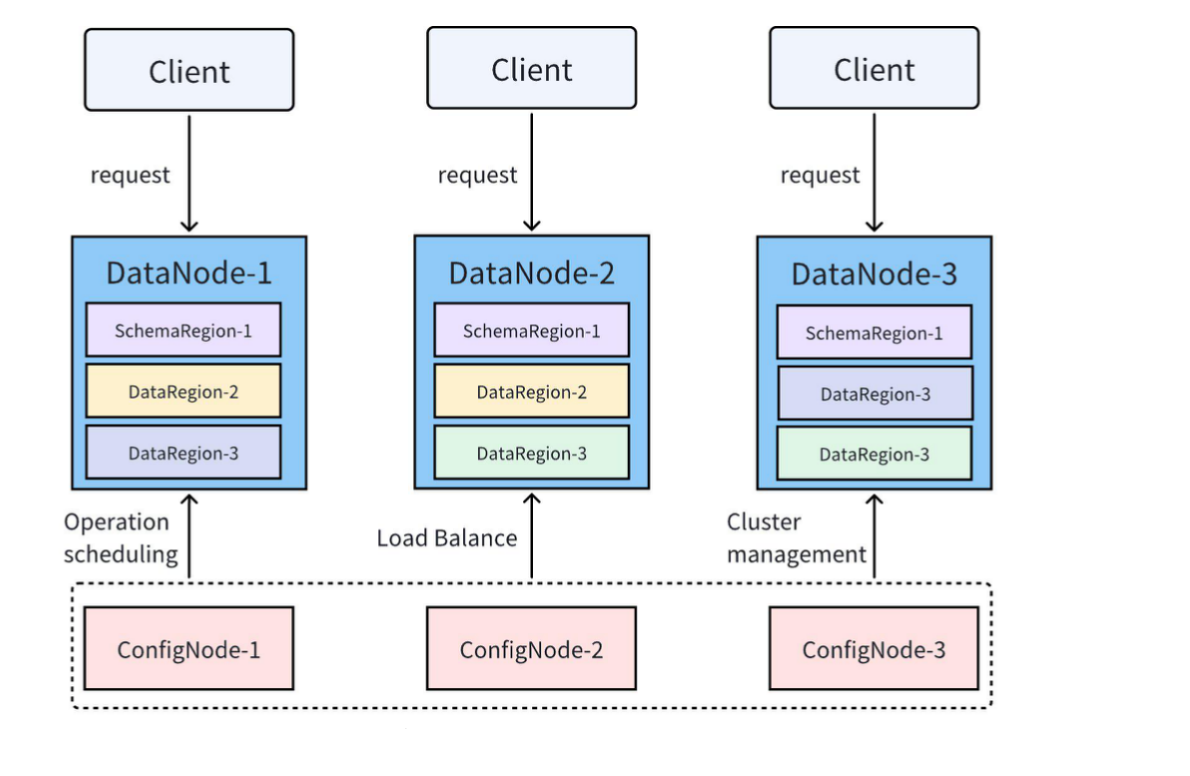 +
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+## Deployment Related Concepts
+
+IoTDB has two operating modes: Stand-Alone mode and Cluster mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..af669a6d6
--- /dev/null
+++ b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,118 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+
+## Deployment Related Concepts
+
+IoTDB has three operating modes: Stand-Alone mode, Cluster mode, and Dual-Active mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### Dual-Active Mode
+
+Dual-active deployment is a feature of TimechoDB Enterprise Edition, which refers to two independent instances performing bidirectional synchronization and can provide services simultaneously. When one instance is restarted after a shutdown, the other instance will resume transmission of the missing data.
+
+
+> An IoTDB dual-active instance usually consists of 2 single-machine nodes, i.e., 2 sets of 1C1D. Each instance can also be a cluster.
+
+- **Features**:The most resource-efficient high-availability solution.
+- **Applicable Scenarios**:Scenarios with limited resources (only two servers) but requiring high-availability capabilities.
+- **Deployment Method**:[Dual-Active-Deployment](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Dual-Active Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | 2 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Each instance can be expanded as needed | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Same as the performance of one of the instances | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
index d6f57bf2a..b4631022f 100644
--- a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
+++ b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# Cluster-related Concepts
-The figure below illustrates a typical IoTDB 3C3D1A cluster deployment mode, comprising 3 ConfigNodes, 3 DataNodes, and 1 AINode:
-
-
-This deployment involves several key concepts that users commonly encounter when working with IoTDB clusters, including:
-- **Nodes** (ConfigNode, DataNode, AINode);
-- **Slots** (SchemaSlot, DataSlot);
-- **Regions** (SchemaRegion, DataRegion);
-- **Replica Groups**.
-
-The following sections will provide a detailed introduction to these concepts.
-
-## Nodes
-
-An IoTDB cluster consists of three types of nodes (processes): **ConfigNode** (the main node), **DataNode**, and **AINode**, as detailed below:
-- **ConfigNode:** ConfigNodes store cluster configurations, database metadata, the routing information of time series' schema and data. They also monitor cluster nodes and conduct load balancing. All ConfigNodes maintain full mutual backups, as shown in the figure with ConfigNode-1, ConfigNode-2, and ConfigNode-3. ConfigNodes do not directly handle client read or write requests. Instead, they guide the distribution of time series' schema and data within the cluster using a series of [load balancing algorithms](../Technical-Insider/Cluster-data-partitioning.md).
-- **DataNode:** DataNodes are responsible for reading and writing time series' schema and data. Each DataNode can accept client read and write requests and provide corresponding services, as illustrated with DataNode-1, DataNode-2, and DataNode-3 in the above figure. When a DataNode receives client requests, it can process them directly or forward them if it has the relevant routing information cached locally. Otherwise, it queries the ConfigNode for routing details and caches the information to improve the efficiency of subsequent requests.
-- **AINode:** AINodes interact with ConfigNodes and DataNodes to extend IoTDB's capabilities for data intelligence analysis on time series data. They support registering pre-trained machine learning models from external sources and performing time series analysis tasks using simple SQL statements on specified data. This process integrates model creation, management, and inference within the database engine. Currently, the system provides built-in algorithms or self-training models for common time series analysis scenarios, such as forecasting and anomaly detection.
-
-## Slots
-
-IoTDB divides time series' schema and data into smaller, more manageable units called **slots**. Slots are logical entities, and in an IoTDB cluster, the **SchemaSlots** and **DataSlots** are defined as follows:
-- **SchemaSlot:** A SchemaSlot represents a subset of the time series' schema collection. The total number of SchemaSlots is fixed, with a default value of 1000. IoTDB uses a hashing algorithm to evenly distribute all devices across these SchemaSlots.
-- **DataSlot:** A DataSlot represents a subset of the time series' data collection. Based on the SchemaSlots, the data for corresponding devices is further divided into DataSlots by a fixed time interval. The default time interval for a DataSlot is 7 days.
-
-## Region
-
-In IoTDB, time series' schema and data are replicated across DataNodes to ensure high availability in the cluster. However, replicating data at the slot level can increase management complexity and reduce write throughput. To address this, IoTDB introduces the concept of **Region**, which groups SchemaSlots and DataSlots into **SchemaRegions** and **DataRegions** respectively. Replication is then performed at the Region level. The definitions of SchemaRegion and DataRegion are as follows:
-- **SchemaRegion**: A SchemaRegion is the basic unit for storing and replicating time series' schema. All SchemaSlots in a database are evenly distributed across the database's SchemaRegions. SchemaRegions with the same RegionID are replicas of each other. For example, in the figure above, SchemaRegion-1 has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
-- **DataRegion**: A DataRegion is the basic unit for storing and replicating time series' data. All DataSlots in a database are evenly distributed across the database's DataRegions. DataRegions with the same RegionID are replicas of each other. For instance, in the figure above, DataRegion-2 has two replicas located on DataNode-1 and DataNode-2.
-
-## Replica Groups
-Region replicas are critical for the fault tolerance of the cluster. Each Region's replicas are organized into **replica groups**, where the replicas are assigned roles as either **leader** or **follower**, working together to provide read and write services. Recommended replica group configurations under different architectures are as follows:
-
-| Category | Parameter | Single-node Recommended Configuration | Distributed Recommended Configuration |
-|:------------:|:-----------------------:|:------------------------------------:|:-------------------------------------:|
-| Schema | `schema_replication_factor` | 1 | 3 |
-| Data | `data_replication_factor` | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..1edc7c292
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,105 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+## Deployment Related Concepts
+
+IoTDB has two operating modes: Stand-Alone mode and Cluster mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..af669a6d6
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,118 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+
+## Deployment Related Concepts
+
+IoTDB has three operating modes: Stand-Alone mode, Cluster mode, and Dual-Active mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### Dual-Active Mode
+
+Dual-active deployment is a feature of TimechoDB Enterprise Edition, which refers to two independent instances performing bidirectional synchronization and can provide services simultaneously. When one instance is restarted after a shutdown, the other instance will resume transmission of the missing data.
+
+
+> An IoTDB dual-active instance usually consists of 2 single-machine nodes, i.e., 2 sets of 1C1D. Each instance can also be a cluster.
+
+- **Features**:The most resource-efficient high-availability solution.
+- **Applicable Scenarios**:Scenarios with limited resources (only two servers) but requiring high-availability capabilities.
+- **Deployment Method**:[Dual-Active-Deployment](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Dual-Active Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | 2 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Each instance can be expanded as needed | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Same as the performance of one of the instances | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/latest/Background-knowledge/Cluster-Concept.md b/src/UserGuide/latest/Background-knowledge/Cluster-Concept.md
index 6b6bb7c8a..b4631022f 100644
--- a/src/UserGuide/latest/Background-knowledge/Cluster-Concept.md
+++ b/src/UserGuide/latest/Background-knowledge/Cluster-Concept.md
@@ -1,63 +1,23 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-# Cluster-related Concepts
-
-The figure below illustrates a typical IoTDB 3C3D1A cluster deployment mode, comprising 3 ConfigNodes, 3 DataNodes, and 1 AINode:
-
-
-
-This deployment involves several key concepts that users commonly encounter when working with IoTDB clusters, including:
-
-- **Nodes** (ConfigNode, DataNode, AINode);
-- **Slots** (SchemaSlot, DataSlot);
-- **Regions** (SchemaRegion, DataRegion);
-- **Replica Groups**.
-
-The following sections will provide a detailed introduction to these concepts.
-
-## Nodes
-
-An IoTDB cluster consists of three types of nodes (processes): **ConfigNode** (the main node), **DataNode**, and **AINode**, as detailed below:
-
-- **ConfigNode:** ConfigNodes store cluster configurations, database metadata, the routing information of time series' schema and data. They also monitor cluster nodes and conduct load balancing. All ConfigNodes maintain full mutual backups, as shown in the figure with ConfigNode-1, ConfigNode-2, and ConfigNode-3. ConfigNodes do not directly handle client read or write requests. Instead, they guide the distribution of time series' schema and data within the cluster using a series of [load balancing algorithms](../Technical-Insider/Cluster-data-partitioning.md).
-- **DataNode:** DataNodes are responsible for reading and writing time series' schema and data. Each DataNode can accept client read and write requests and provide corresponding services, as illustrated with DataNode-1, DataNode-2, and DataNode-3 in the above figure. When a DataNode receives client requests, it can process them directly or forward them if it has the relevant routing information cached locally. Otherwise, it queries the ConfigNode for routing details and caches the information to improve the efficiency of subsequent requests.
-- **AINode:** AINodes interact with ConfigNodes and DataNodes to extend IoTDB's capabilities for data intelligence analysis on time series data. They support registering pre-trained machine learning models from external sources and performing time series analysis tasks using simple SQL statements on specified data. This process integrates model creation, management, and inference within the database engine. Currently, the system provides built-in algorithms or self-training models for common time series analysis scenarios, such as forecasting and anomaly detection.
-
-## Slots
-
-IoTDB divides time series' schema and data into smaller, more manageable units called **slots**. Slots are logical entities, and in an IoTDB cluster, the **SchemaSlots** and **DataSlots** are defined as follows:
-
-- **SchemaSlot:** A SchemaSlot represents a subset of the time series' schema collection. The total number of SchemaSlots is fixed, with a default value of 1000. IoTDB uses a hashing algorithm to evenly distribute all devices across these SchemaSlots.
-- **DataSlot:** A DataSlot represents a subset of the time series' data collection. Based on the SchemaSlots, the data for corresponding devices is further divided into DataSlots by a fixed time interval. The default time interval for a DataSlot is 7 days.
-
-## Region
-
-In IoTDB, time series' schema and data are replicated across DataNodes to ensure high availability in the cluster. However, replicating data at the slot level can increase management complexity and reduce write throughput. To address this, IoTDB introduces the concept of **Region**, which groups SchemaSlots and DataSlots into **SchemaRegions** and **DataRegions** respectively. Replication is then performed at the Region level. The definitions of SchemaRegion and DataRegion are as follows:
-
-- **SchemaRegion**: A SchemaRegion is the basic unit for storing and replicating time series' schema. All SchemaSlots in a database are evenly distributed across the database's SchemaRegions. SchemaRegions with the same RegionID are replicas of each other. For example, in the figure above, SchemaRegion-1 has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
-- **DataRegion**: A DataRegion is the basic unit for storing and replicating time series' data. All DataSlots in a database are evenly distributed across the database's DataRegions. DataRegions with the same RegionID are replicas of each other. For instance, in the figure above, DataRegion-2 has two replicas located on DataNode-1 and DataNode-2.
-
-## Replica Groups
-
-Region replicas are critical for the fault tolerance of the cluster. Each Region's replicas are organized into **replica groups**, where the replicas are assigned roles as either **leader** or **follower**, working together to provide read and write services. Recommended replica group configurations under different architectures are as follows:
-
-| Category | Parameter | Single-node Recommended Configuration | Distributed Recommended Configuration |
-| :------: | :-------------------------: | :-----------------------------------: | :-----------------------------------: |
-| Schema | `schema_replication_factor` | 1 | 3 |
-| Data | `data_replication_factor` | 1 | 2 |
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
\ No newline at end of file
diff --git a/src/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md b/src/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..1edc7c292
--- /dev/null
+++ b/src/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,105 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+## Deployment Related Concepts
+
+IoTDB has two operating modes: Stand-Alone mode and Cluster mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md b/src/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..af669a6d6
--- /dev/null
+++ b/src/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,118 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+
+## Deployment Related Concepts
+
+IoTDB has three operating modes: Stand-Alone mode, Cluster mode, and Dual-Active mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### Dual-Active Mode
+
+Dual-active deployment is a feature of TimechoDB Enterprise Edition, which refers to two independent instances performing bidirectional synchronization and can provide services simultaneously. When one instance is restarted after a shutdown, the other instance will resume transmission of the missing data.
+
+
+> An IoTDB dual-active instance usually consists of 2 single-machine nodes, i.e., 2 sets of 1C1D. Each instance can also be a cluster.
+
+- **Features**:The most resource-efficient high-availability solution.
+- **Applicable Scenarios**:Scenarios with limited resources (only two servers) but requiring high-availability capabilities.
+- **Deployment Method**:[Dual-Active-Deployment](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Dual-Active Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | 2 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Each instance can be expanded as needed | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Same as the performance of one of the instances | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md
index ebd6a800e..b4631022f 100644
--- a/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md
+++ b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# 集群相关概念
-下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
-
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+## Deployment Related Concepts
+
+IoTDB has two operating modes: Stand-Alone mode and Cluster mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..af669a6d6
--- /dev/null
+++ b/src/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,118 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+
+## Deployment Related Concepts
+
+IoTDB has three operating modes: Stand-Alone mode, Cluster mode, and Dual-Active mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### Dual-Active Mode
+
+Dual-active deployment is a feature of TimechoDB Enterprise Edition, which refers to two independent instances performing bidirectional synchronization and can provide services simultaneously. When one instance is restarted after a shutdown, the other instance will resume transmission of the missing data.
+
+
+> An IoTDB dual-active instance usually consists of 2 single-machine nodes, i.e., 2 sets of 1C1D. Each instance can also be a cluster.
+
+- **Features**:The most resource-efficient high-availability solution.
+- **Applicable Scenarios**:Scenarios with limited resources (only two servers) but requiring high-availability capabilities.
+- **Deployment Method**:[Dual-Active-Deployment](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Dual-Active Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | 2 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Each instance can be expanded as needed | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Same as the performance of one of the instances | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
index d6f57bf2a..b4631022f 100644
--- a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
+++ b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# Cluster-related Concepts
-The figure below illustrates a typical IoTDB 3C3D1A cluster deployment mode, comprising 3 ConfigNodes, 3 DataNodes, and 1 AINode:
-
-
-This deployment involves several key concepts that users commonly encounter when working with IoTDB clusters, including:
-- **Nodes** (ConfigNode, DataNode, AINode);
-- **Slots** (SchemaSlot, DataSlot);
-- **Regions** (SchemaRegion, DataRegion);
-- **Replica Groups**.
-
-The following sections will provide a detailed introduction to these concepts.
-
-## Nodes
-
-An IoTDB cluster consists of three types of nodes (processes): **ConfigNode** (the main node), **DataNode**, and **AINode**, as detailed below:
-- **ConfigNode:** ConfigNodes store cluster configurations, database metadata, the routing information of time series' schema and data. They also monitor cluster nodes and conduct load balancing. All ConfigNodes maintain full mutual backups, as shown in the figure with ConfigNode-1, ConfigNode-2, and ConfigNode-3. ConfigNodes do not directly handle client read or write requests. Instead, they guide the distribution of time series' schema and data within the cluster using a series of [load balancing algorithms](../Technical-Insider/Cluster-data-partitioning.md).
-- **DataNode:** DataNodes are responsible for reading and writing time series' schema and data. Each DataNode can accept client read and write requests and provide corresponding services, as illustrated with DataNode-1, DataNode-2, and DataNode-3 in the above figure. When a DataNode receives client requests, it can process them directly or forward them if it has the relevant routing information cached locally. Otherwise, it queries the ConfigNode for routing details and caches the information to improve the efficiency of subsequent requests.
-- **AINode:** AINodes interact with ConfigNodes and DataNodes to extend IoTDB's capabilities for data intelligence analysis on time series data. They support registering pre-trained machine learning models from external sources and performing time series analysis tasks using simple SQL statements on specified data. This process integrates model creation, management, and inference within the database engine. Currently, the system provides built-in algorithms or self-training models for common time series analysis scenarios, such as forecasting and anomaly detection.
-
-## Slots
-
-IoTDB divides time series' schema and data into smaller, more manageable units called **slots**. Slots are logical entities, and in an IoTDB cluster, the **SchemaSlots** and **DataSlots** are defined as follows:
-- **SchemaSlot:** A SchemaSlot represents a subset of the time series' schema collection. The total number of SchemaSlots is fixed, with a default value of 1000. IoTDB uses a hashing algorithm to evenly distribute all devices across these SchemaSlots.
-- **DataSlot:** A DataSlot represents a subset of the time series' data collection. Based on the SchemaSlots, the data for corresponding devices is further divided into DataSlots by a fixed time interval. The default time interval for a DataSlot is 7 days.
-
-## Region
-
-In IoTDB, time series' schema and data are replicated across DataNodes to ensure high availability in the cluster. However, replicating data at the slot level can increase management complexity and reduce write throughput. To address this, IoTDB introduces the concept of **Region**, which groups SchemaSlots and DataSlots into **SchemaRegions** and **DataRegions** respectively. Replication is then performed at the Region level. The definitions of SchemaRegion and DataRegion are as follows:
-- **SchemaRegion**: A SchemaRegion is the basic unit for storing and replicating time series' schema. All SchemaSlots in a database are evenly distributed across the database's SchemaRegions. SchemaRegions with the same RegionID are replicas of each other. For example, in the figure above, SchemaRegion-1 has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
-- **DataRegion**: A DataRegion is the basic unit for storing and replicating time series' data. All DataSlots in a database are evenly distributed across the database's DataRegions. DataRegions with the same RegionID are replicas of each other. For instance, in the figure above, DataRegion-2 has two replicas located on DataNode-1 and DataNode-2.
-
-## Replica Groups
-Region replicas are critical for the fault tolerance of the cluster. Each Region's replicas are organized into **replica groups**, where the replicas are assigned roles as either **leader** or **follower**, working together to provide read and write services. Recommended replica group configurations under different architectures are as follows:
-
-| Category | Parameter | Single-node Recommended Configuration | Distributed Recommended Configuration |
-|:------------:|:-----------------------:|:------------------------------------:|:-------------------------------------:|
-| Schema | `schema_replication_factor` | 1 | 3 |
-| Data | `data_replication_factor` | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..1edc7c292
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,105 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+## Deployment Related Concepts
+
+IoTDB has two operating modes: Stand-Alone mode and Cluster mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..af669a6d6
--- /dev/null
+++ b/src/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,118 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+
+## Deployment Related Concepts
+
+IoTDB has three operating modes: Stand-Alone mode, Cluster mode, and Dual-Active mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### Dual-Active Mode
+
+Dual-active deployment is a feature of TimechoDB Enterprise Edition, which refers to two independent instances performing bidirectional synchronization and can provide services simultaneously. When one instance is restarted after a shutdown, the other instance will resume transmission of the missing data.
+
+
+> An IoTDB dual-active instance usually consists of 2 single-machine nodes, i.e., 2 sets of 1C1D. Each instance can also be a cluster.
+
+- **Features**:The most resource-efficient high-availability solution.
+- **Applicable Scenarios**:Scenarios with limited resources (only two servers) but requiring high-availability capabilities.
+- **Deployment Method**:[Dual-Active-Deployment](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Dual-Active Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | 2 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Each instance can be expanded as needed | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Same as the performance of one of the instances | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/latest/Background-knowledge/Cluster-Concept.md b/src/UserGuide/latest/Background-knowledge/Cluster-Concept.md
index 6b6bb7c8a..b4631022f 100644
--- a/src/UserGuide/latest/Background-knowledge/Cluster-Concept.md
+++ b/src/UserGuide/latest/Background-knowledge/Cluster-Concept.md
@@ -1,63 +1,23 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-# Cluster-related Concepts
-
-The figure below illustrates a typical IoTDB 3C3D1A cluster deployment mode, comprising 3 ConfigNodes, 3 DataNodes, and 1 AINode:
-
-
-
-This deployment involves several key concepts that users commonly encounter when working with IoTDB clusters, including:
-
-- **Nodes** (ConfigNode, DataNode, AINode);
-- **Slots** (SchemaSlot, DataSlot);
-- **Regions** (SchemaRegion, DataRegion);
-- **Replica Groups**.
-
-The following sections will provide a detailed introduction to these concepts.
-
-## Nodes
-
-An IoTDB cluster consists of three types of nodes (processes): **ConfigNode** (the main node), **DataNode**, and **AINode**, as detailed below:
-
-- **ConfigNode:** ConfigNodes store cluster configurations, database metadata, the routing information of time series' schema and data. They also monitor cluster nodes and conduct load balancing. All ConfigNodes maintain full mutual backups, as shown in the figure with ConfigNode-1, ConfigNode-2, and ConfigNode-3. ConfigNodes do not directly handle client read or write requests. Instead, they guide the distribution of time series' schema and data within the cluster using a series of [load balancing algorithms](../Technical-Insider/Cluster-data-partitioning.md).
-- **DataNode:** DataNodes are responsible for reading and writing time series' schema and data. Each DataNode can accept client read and write requests and provide corresponding services, as illustrated with DataNode-1, DataNode-2, and DataNode-3 in the above figure. When a DataNode receives client requests, it can process them directly or forward them if it has the relevant routing information cached locally. Otherwise, it queries the ConfigNode for routing details and caches the information to improve the efficiency of subsequent requests.
-- **AINode:** AINodes interact with ConfigNodes and DataNodes to extend IoTDB's capabilities for data intelligence analysis on time series data. They support registering pre-trained machine learning models from external sources and performing time series analysis tasks using simple SQL statements on specified data. This process integrates model creation, management, and inference within the database engine. Currently, the system provides built-in algorithms or self-training models for common time series analysis scenarios, such as forecasting and anomaly detection.
-
-## Slots
-
-IoTDB divides time series' schema and data into smaller, more manageable units called **slots**. Slots are logical entities, and in an IoTDB cluster, the **SchemaSlots** and **DataSlots** are defined as follows:
-
-- **SchemaSlot:** A SchemaSlot represents a subset of the time series' schema collection. The total number of SchemaSlots is fixed, with a default value of 1000. IoTDB uses a hashing algorithm to evenly distribute all devices across these SchemaSlots.
-- **DataSlot:** A DataSlot represents a subset of the time series' data collection. Based on the SchemaSlots, the data for corresponding devices is further divided into DataSlots by a fixed time interval. The default time interval for a DataSlot is 7 days.
-
-## Region
-
-In IoTDB, time series' schema and data are replicated across DataNodes to ensure high availability in the cluster. However, replicating data at the slot level can increase management complexity and reduce write throughput. To address this, IoTDB introduces the concept of **Region**, which groups SchemaSlots and DataSlots into **SchemaRegions** and **DataRegions** respectively. Replication is then performed at the Region level. The definitions of SchemaRegion and DataRegion are as follows:
-
-- **SchemaRegion**: A SchemaRegion is the basic unit for storing and replicating time series' schema. All SchemaSlots in a database are evenly distributed across the database's SchemaRegions. SchemaRegions with the same RegionID are replicas of each other. For example, in the figure above, SchemaRegion-1 has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
-- **DataRegion**: A DataRegion is the basic unit for storing and replicating time series' data. All DataSlots in a database are evenly distributed across the database's DataRegions. DataRegions with the same RegionID are replicas of each other. For instance, in the figure above, DataRegion-2 has two replicas located on DataNode-1 and DataNode-2.
-
-## Replica Groups
-
-Region replicas are critical for the fault tolerance of the cluster. Each Region's replicas are organized into **replica groups**, where the replicas are assigned roles as either **leader** or **follower**, working together to provide read and write services. Recommended replica group configurations under different architectures are as follows:
-
-| Category | Parameter | Single-node Recommended Configuration | Distributed Recommended Configuration |
-| :------: | :-------------------------: | :-----------------------------------: | :-----------------------------------: |
-| Schema | `schema_replication_factor` | 1 | 3 |
-| Data | `data_replication_factor` | 1 | 2 |
+ Licensed to the Apache Software Foundation (ASF) under one
+ or more contributor license agreements. See the NOTICE file
+ distributed with this work for additional information
+ regarding copyright ownership. The ASF licenses this file
+ to you under the Apache License, Version 2.0 (the
+ "License"); you may not use this file except in compliance
+ with the License. You may obtain a copy of the License at
+
+ http://www.apache.org/licenses/LICENSE-2.0
+
+ Unless required by applicable law or agreed to in writing,
+ software distributed under the License is distributed on an
+ "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
+ KIND, either express or implied. See the License for the
+ specific language governing permissions and limitations
+ under the License.
+
+-->
\ No newline at end of file
diff --git a/src/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md b/src/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..1edc7c292
--- /dev/null
+++ b/src/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,105 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+## Deployment Related Concepts
+
+IoTDB has two operating modes: Stand-Alone mode and Cluster mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md b/src/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..af669a6d6
--- /dev/null
+++ b/src/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,118 @@
+
+
+# Common Concepts
+
+## Sql_dialect Related Concepts
+
+| Concept | Meaning |
+| ----------------------- | ------------------------------------------------------------ |
+| sql_dialect | IoTDB supports two time-series data models (SQL dialects), both managing devices and measurement points. Tree: Manages data in a hierarchical path manner, where one path corresponds to one measurement point of a device. Table: Manages data in a relational table manner, where one table corresponds to a category of devices. |
+| Schema | Schema is the data model information of the database, i.e., tree structure or table structure. It includes definitions such as the names and data types of measurement points. |
+| Device | Corresponds to a physical device in an actual scenario, usually containing multiple measurement points. |
+| Timeseries | Also known as: physical quantity, time series, timeline, point location, semaphore, indicator, measurement value, etc. It is a time series formed by arranging multiple data points in ascending order of timestamps. Usually, a Timeseries represents a collection point that can periodically collect physical quantities of the environment it is in. |
+| Encoding | Encoding is a compression technique that represents data in binary form to improve storage efficiency. IoTDB supports various encoding methods for different types of data. For more detailed information, please refer to:[Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+| Compression | After data encoding, IoTDB uses compression technology to further compress binary data to enhance storage efficiency. IoTDB supports multiple compression methods. For more detailed information, please refer to: [Encoding-and-Compression](../Technical-Insider/Encoding-and-Compression.md) |
+
+## Distributed Related Concepts
+
+The following figure shows a common IoTDB 3C3D (3 ConfigNodes, 3 DataNodes) cluster deployment pattern:
+
+
+
+IoTDB's cluster includes the following common concepts:
+
+- Nodes(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- Replica Groups
+
+The above concepts will be introduced in the following text.
+
+
+### Nodes
+
+IoTDB cluster includes three types of nodes (processes): ConfigNode (management node), DataNode (data node), and AINode (analysis node), as shown below:
+
+- ConfigNode: Manages cluster node information, configuration information, user permissions, metadata, partition information, etc., and is responsible for the scheduling of distributed operations and load balancing. All ConfigNodes are fully backed up with each other, as shown in ConfigNode-1, ConfigNode-2, and ConfigNode-3 in the figure above.
+- DataNode: Serves client requests and is responsible for data storage and computation, as shown in DataNode-1, DataNode-2, and DataNode-3 in the figure above.
+- AINode: Provides machine learning capabilities, supports the registration of trained machine learning models, and allows model inference through SQL calls. It has already built-in self-developed time-series large models and common machine learning algorithms (such as prediction and anomaly detection).
+
+### Data Partitioning
+
+In IoTDB, both metadata and data are divided into small partitions, namely Regions, which are managed by various DataNodes in the cluster.
+
+- SchemaRegion: Metadata partition, managing the metadata of a part of devices and measurement points. SchemaRegions with the same RegionID on different DataNodes are mutual replicas, as shown in SchemaRegion-1 in the figure above, which has three replicas located on DataNode-1, DataNode-2, and DataNode-3.
+- DataRegion: Data partition, managing the data of a part of devices for a certain period of time. DataRegions with the same RegionID on different DataNodes are mutual replicas, as shown in DataRegion-2 in the figure above, which has two replicas located on DataNode-1 and DataNode-2.
+- For specific partitioning algorithms, please refer to: [Data Partitioning](../Technical-Insider/Cluster-data-partitioning.md)
+
+### Replica Groups
+
+The number of replicas for data and metadata can be configured. The recommended configurations for different deployment modes are as follows, where multi-replication can provide high-availability services.
+
+| Category | Parameter | Stand-Alone Recommended Configuration | Cluster Recommended Configuration |
+| :----- | :------------------------ | :----------- | :----------- |
+| Schema | schema_replication_factor | 1 | 3 |
+| Data | data_replication_factor | 1 | 2 |
+
+
+## Deployment Related Concepts
+
+IoTDB has three operating modes: Stand-Alone mode, Cluster mode, and Dual-Active mode.
+
+### Stand-Alone Mode
+
+An IoTDB Stand-Alone instance includes 1 ConfigNode and 1 DataNode, i.e., 1C1D;
+
+
+- **Features**:Easy for developers to install and deploy, with low deployment and maintenance costs and convenient operations.
+- **Applicable Scenarios**:Scenarios with limited resources or low requirements for high availability, such as edge-side servers.
+- **Deployment Method**:[Stand-Alone-Deployment](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### Dual-Active Mode
+
+Dual-active deployment is a feature of TimechoDB Enterprise Edition, which refers to two independent instances performing bidirectional synchronization and can provide services simultaneously. When one instance is restarted after a shutdown, the other instance will resume transmission of the missing data.
+
+
+> An IoTDB dual-active instance usually consists of 2 single-machine nodes, i.e., 2 sets of 1C1D. Each instance can also be a cluster.
+
+- **Features**:The most resource-efficient high-availability solution.
+- **Applicable Scenarios**:Scenarios with limited resources (only two servers) but requiring high-availability capabilities.
+- **Deployment Method**:[Dual-Active-Deployment](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### Cluster Mode
+
+An IoTDB cluster instance consists of 3 ConfigNodes and no less than 3 DataNodes, usually 3 DataNodes, i.e., 3C3D; when some nodes fail, the remaining nodes can still provide services, ensuring the high availability of the database service, and the database performance can be improved with the addition of nodes.
+
+- **Features**:High availability and scalability, and the system performance can be improved by adding DataNodes.
+- **Applicable Scenarios**:Enterprise-level application scenarios requiring high availability and reliability.
+- **Deployment Method**:[Cluster-Deployment](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### Summary of Features
+
+| Dimension | Stand-Alone Mode | Dual-Active Mode | Cluster Mode |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| Applicable Scenarios | Edge-side deployment, scenarios with low requirements for high availability | High-availability business, disaster recovery scenarios, etc. | High-availability business, disaster recovery scenarios, etc. |
+| Number of Machines Required | 1 | 2 | ≥3 |
+| Security and Reliability | Cannot tolerate single-point failures | High, can tolerate single-point failures | High, can tolerate single-point failures |
+| Scalability | Can expand DataNodes to improve performance | Each instance can be expanded as needed | Can expand DataNodes to improve performance |
+| Performance | Can be expanded with the number of DataNodes | Same as the performance of one of the instances | Can be expanded with the number of DataNodes |
+
+- The deployment steps for single-machine mode and cluster mode are similar (adding ConfigNodes and DataNodes one by one), with only the number of replicas and the minimum number of nodes that can provide services being different.
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md
index ebd6a800e..b4631022f 100644
--- a/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md
+++ b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# 集群相关概念
-下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
- -
-其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
-- **节点**(ConfigNode、DataNode、AINode);
-- **槽**(SchemaSlot、DataSlot);
-- **Region**(SchemaRegion、DataRegion);
-- ***副本组***。
-
-下文将重点对以上概念进行介绍。
-
-## 节点
-IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
-- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
-- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
-- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
-
-## 槽
-IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
-- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
-- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
-
-## Region
-在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
-- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
-- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
-
-## 副本组
-Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
-| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
-| :-: | :-: | :-: | :-: |
-| 元数据 | schema_replication_factor | 1 | 3 |
-| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..98c6050cc
--- /dev/null
+++ b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,106 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
-
-其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
-- **节点**(ConfigNode、DataNode、AINode);
-- **槽**(SchemaSlot、DataSlot);
-- **Region**(SchemaRegion、DataRegion);
-- ***副本组***。
-
-下文将重点对以上概念进行介绍。
-
-## 节点
-IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
-- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
-- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
-- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
-
-## 槽
-IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
-- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
-- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
-
-## Region
-在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
-- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
-- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
-
-## 副本组
-Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
-| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
-| :-: | :-: | :-: | :-: |
-| 元数据 | schema_replication_factor | 1 | 3 |
-| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..98c6050cc
--- /dev/null
+++ b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,106 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+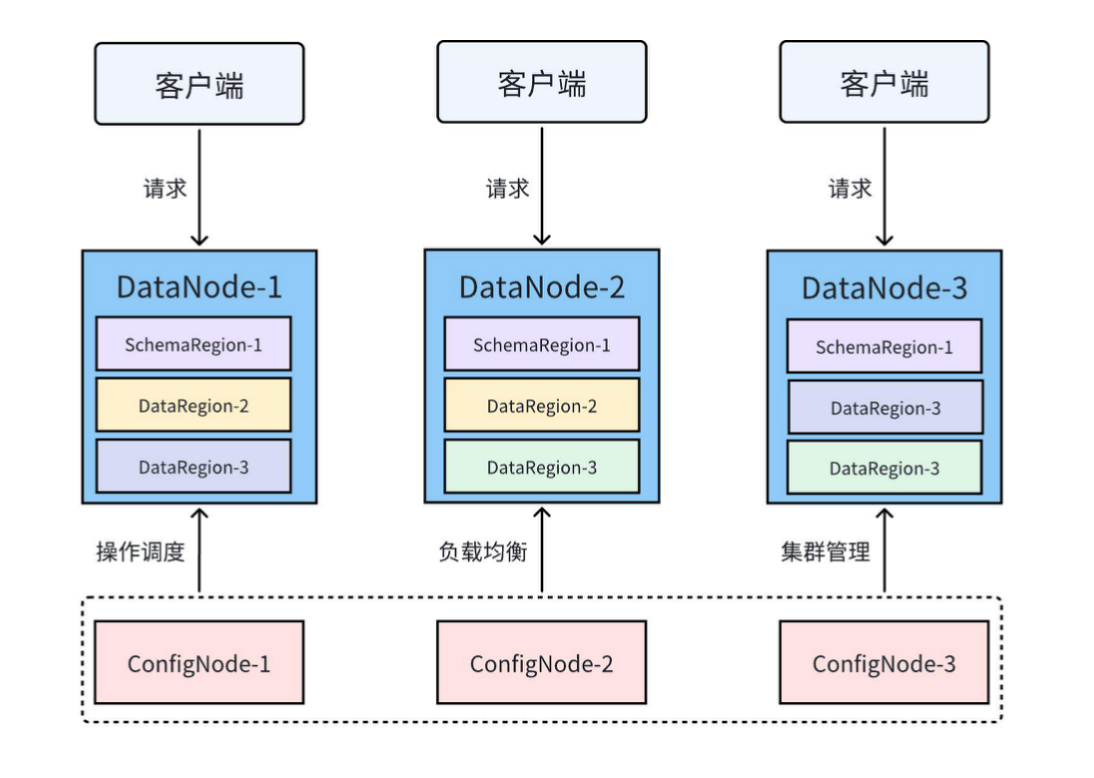 +
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有两种运行模式:单机模式、集群模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..77edf9ebb
--- /dev/null
+++ b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,116 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有三种运行模式:单机模式、集群模式和双活模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### 双活模式
+
+双活版部署为 TimechoDB 企业版功能,是指两个独立的实例进行双向同步,能同时对外提供服务。当一台停机重启后,另一个实例会将缺失数据断点续传。
+
+> IoTDB 双活实例通常为2个单机节点,即2套1C1D。每个实例也可以为集群。
+
+- **特点**:资源占用最低的高可用解决方案。
+- **适用场景**:资源有限(仅有两台服务器),但希望获得高可用能力。
+- **部署方法**:[双活版部署](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 双活模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | 2 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 每个实例可按需扩展 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 与其中一个实例性能相同 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md
index ebd6a800e..b4631022f 100644
--- a/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md
+++ b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# 集群相关概念
-下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
-
-
-其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
-- **节点**(ConfigNode、DataNode、AINode);
-- **槽**(SchemaSlot、DataSlot);
-- **Region**(SchemaRegion、DataRegion);
-- ***副本组***。
-
-下文将重点对以上概念进行介绍。
-
-## 节点
-IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
-- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
-- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
-- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
-
-## 槽
-IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
-- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
-- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
-
-## Region
-在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
-- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
-- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
-
-## 副本组
-Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
-| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
-| :-: | :-: | :-: | :-: |
-| 元数据 | schema_replication_factor | 1 | 3 |
-| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept_timecho.md b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..77edf9ebb
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,116 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有三种运行模式:单机模式、集群模式和双活模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### 双活模式
+
+双活版部署为 TimechoDB 企业版功能,是指两个独立的实例进行双向同步,能同时对外提供服务。当一台停机重启后,另一个实例会将缺失数据断点续传。
+
+> IoTDB 双活实例通常为2个单机节点,即2套1C1D。每个实例也可以为集群。
+
+- **特点**:资源占用最低的高可用解决方案。
+- **适用场景**:资源有限(仅有两台服务器),但希望获得高可用能力。
+- **部署方法**:[双活版部署](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 双活模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | 2 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 每个实例可按需扩展 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 与其中一个实例性能相同 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
index ebd6a800e..b4631022f 100644
--- a/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
+++ b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# 集群相关概念
-下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
-
-
-其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
-- **节点**(ConfigNode、DataNode、AINode);
-- **槽**(SchemaSlot、DataSlot);
-- **Region**(SchemaRegion、DataRegion);
-- ***副本组***。
-
-下文将重点对以上概念进行介绍。
-
-## 节点
-IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
-- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
-- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
-- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
-
-## 槽
-IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
-- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
-- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
-
-## Region
-在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
-- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
-- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
-
-## 副本组
-Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
-| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
-| :-: | :-: | :-: | :-: |
-| 元数据 | schema_replication_factor | 1 | 3 |
-| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..98c6050cc
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,106 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有两种运行模式:单机模式、集群模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..77edf9ebb
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,116 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有三种运行模式:单机模式、集群模式和双活模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### 双活模式
+
+双活版部署为 TimechoDB 企业版功能,是指两个独立的实例进行双向同步,能同时对外提供服务。当一台停机重启后,另一个实例会将缺失数据断点续传。
+
+> IoTDB 双活实例通常为2个单机节点,即2套1C1D。每个实例也可以为集群。
+
+- **特点**:资源占用最低的高可用解决方案。
+- **适用场景**:资源有限(仅有两台服务器),但希望获得高可用能力。
+- **部署方法**:[双活版部署](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 双活模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | 2 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 每个实例可按需扩展 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 与其中一个实例性能相同 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept.md
index ebd6a800e..b4631022f 100644
--- a/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept.md
+++ b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# 集群相关概念
-下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
-
-
-其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
-- **节点**(ConfigNode、DataNode、AINode);
-- **槽**(SchemaSlot、DataSlot);
-- **Region**(SchemaRegion、DataRegion);
-- ***副本组***。
-
-下文将重点对以上概念进行介绍。
-
-## 节点
-IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
-- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
-- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
-- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
-
-## 槽
-IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
-- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
-- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
-
-## Region
-在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
-- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
-- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
-
-## 副本组
-Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
-| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
-| :-: | :-: | :-: | :-: |
-| 元数据 | schema_replication_factor | 1 | 3 |
-| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..98c6050cc
--- /dev/null
+++ b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,106 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有两种运行模式:单机模式、集群模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..77edf9ebb
--- /dev/null
+++ b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,116 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有三种运行模式:单机模式、集群模式和双活模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### 双活模式
+
+双活版部署为 TimechoDB 企业版功能,是指两个独立的实例进行双向同步,能同时对外提供服务。当一台停机重启后,另一个实例会将缺失数据断点续传。
+
+> IoTDB 双活实例通常为2个单机节点,即2套1C1D。每个实例也可以为集群。
+
+- **特点**:资源占用最低的高可用解决方案。
+- **适用场景**:资源有限(仅有两台服务器),但希望获得高可用能力。
+- **部署方法**:[双活版部署](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 双活模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | 2 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 每个实例可按需扩展 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 与其中一个实例性能相同 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有两种运行模式:单机模式、集群模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..77edf9ebb
--- /dev/null
+++ b/src/zh/UserGuide/Master/Tree/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,116 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有三种运行模式:单机模式、集群模式和双活模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### 双活模式
+
+双活版部署为 TimechoDB 企业版功能,是指两个独立的实例进行双向同步,能同时对外提供服务。当一台停机重启后,另一个实例会将缺失数据断点续传。
+
+> IoTDB 双活实例通常为2个单机节点,即2套1C1D。每个实例也可以为集群。
+
+- **特点**:资源占用最低的高可用解决方案。
+- **适用场景**:资源有限(仅有两台服务器),但希望获得高可用能力。
+- **部署方法**:[双活版部署](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 双活模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | 2 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 每个实例可按需扩展 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 与其中一个实例性能相同 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md
index ebd6a800e..b4631022f 100644
--- a/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md
+++ b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# 集群相关概念
-下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
-
-
-其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
-- **节点**(ConfigNode、DataNode、AINode);
-- **槽**(SchemaSlot、DataSlot);
-- **Region**(SchemaRegion、DataRegion);
-- ***副本组***。
-
-下文将重点对以上概念进行介绍。
-
-## 节点
-IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
-- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
-- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
-- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
-
-## 槽
-IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
-- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
-- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
-
-## Region
-在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
-- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
-- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
-
-## 副本组
-Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
-| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
-| :-: | :-: | :-: | :-: |
-| 元数据 | schema_replication_factor | 1 | 3 |
-| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept_timecho.md b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..77edf9ebb
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Table/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,116 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有三种运行模式:单机模式、集群模式和双活模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### 双活模式
+
+双活版部署为 TimechoDB 企业版功能,是指两个独立的实例进行双向同步,能同时对外提供服务。当一台停机重启后,另一个实例会将缺失数据断点续传。
+
+> IoTDB 双活实例通常为2个单机节点,即2套1C1D。每个实例也可以为集群。
+
+- **特点**:资源占用最低的高可用解决方案。
+- **适用场景**:资源有限(仅有两台服务器),但希望获得高可用能力。
+- **部署方法**:[双活版部署](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 双活模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | 2 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 每个实例可按需扩展 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 与其中一个实例性能相同 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
index ebd6a800e..b4631022f 100644
--- a/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
+++ b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# 集群相关概念
-下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
-
-
-其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
-- **节点**(ConfigNode、DataNode、AINode);
-- **槽**(SchemaSlot、DataSlot);
-- **Region**(SchemaRegion、DataRegion);
-- ***副本组***。
-
-下文将重点对以上概念进行介绍。
-
-## 节点
-IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
-- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
-- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
-- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
-
-## 槽
-IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
-- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
-- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
-
-## Region
-在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
-- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
-- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
-
-## 副本组
-Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
-| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
-| :-: | :-: | :-: | :-: |
-| 元数据 | schema_replication_factor | 1 | 3 |
-| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..98c6050cc
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,106 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有两种运行模式:单机模式、集群模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..77edf9ebb
--- /dev/null
+++ b/src/zh/UserGuide/V2.0.1/Tree/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,116 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有三种运行模式:单机模式、集群模式和双活模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### 双活模式
+
+双活版部署为 TimechoDB 企业版功能,是指两个独立的实例进行双向同步,能同时对外提供服务。当一台停机重启后,另一个实例会将缺失数据断点续传。
+
+> IoTDB 双活实例通常为2个单机节点,即2套1C1D。每个实例也可以为集群。
+
+- **特点**:资源占用最低的高可用解决方案。
+- **适用场景**:资源有限(仅有两台服务器),但希望获得高可用能力。
+- **部署方法**:[双活版部署](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 双活模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | 2 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 每个实例可按需扩展 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 与其中一个实例性能相同 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept.md b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept.md
index ebd6a800e..b4631022f 100644
--- a/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept.md
+++ b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept.md
@@ -1,3 +1,6 @@
+---
+redirectTo: Cluster-Concept_apache.html
+---
-
-# 集群相关概念
-下图展示了一个常见的 IoTDB 3C3D1A(3 个 ConfigNode、3 个 DataNode 和 1 个 AINode)的集群部署模式:
-
-
-其中包括了 IoTDB 集群使用中用户常接触到的几个概念,包括:
-- **节点**(ConfigNode、DataNode、AINode);
-- **槽**(SchemaSlot、DataSlot);
-- **Region**(SchemaRegion、DataRegion);
-- ***副本组***。
-
-下文将重点对以上概念进行介绍。
-
-## 节点
-IoTDB 集群包括三种节点(进程),**ConfigNode**(管理节点),**DataNode**(数据节点)和 **AINode**(分析节点),如下所示:
-- **ConfigNode**:存储集群的配置信息、数据库的元数据、时间序列元数据和数据的路由信息,监控集群节点并实施负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。ConfigNode 不直接接收客户端读写请求,它会通过一系列[负载均衡算法](../Technical-Insider/Cluster-data-partitioning.md)对集群中元数据和数据的分布提供指导。
-- **DataNode**:负责时间序列元数据和数据的读写,每个 DataNode 都能接收客户端读写请求并提供相应服务,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。接收客户端读写请求时,若 DataNode 缓存有对应的路由信息,它能直接在本地执行或是转发这些请求;否则它会向 ConfigNode 询问并缓存路由信息,以加速后续请求的服务效率。
-- **AINode**:负责与 ConfigNode 和 DataNode 交互来扩展 IoTDB 集群对时间序列进行智能分析的能力,支持从外部引入已有机器学习模型进行注册,并使用注册的模型在指定时序数据上通过简单 SQL 语句完成时序分析任务的过程,将模型的创建、管理及推理融合在数据库引擎中。目前已提供常见时序分析场景(例如预测与异常检测)的机器学习算法或自研模型。
-
-## 槽
-IoTDB 内部将元数据和数据划分成多个更小的、更易于管理的单元,每个单元称为一个**槽**。槽是一个逻辑概念,在 IoTDB 集群中,**元数据槽**和**数据槽**定义如下:
-- **元数据槽**(SchemaSlot):一部分元数据集合,元数据槽总数固定,默认数量为 1000,IoTDB 使用哈希算法将所有设备均匀地分配到这些元数据槽中。
-- **数据槽**(DataSlot):一部分数据集合,在元数据槽的基础上,将对应设备的数据按时间范围划分为数据槽,默认的时间范围为 7 天。
-
-## Region
-在 IoTDB 中,元数据和数据被复制到各个 DataNode 以获得集群高可用性。然而以槽为粒度进行复制会增加集群管理成本、降低写入吞吐。因此 IoTDB 引入 **Region** 这一概念,将元数据槽和数据槽分别分配给 SchemaRegion 和 DataRegion 后,以 Region 为单位进行复制。**SchemRegion** 和 **DataRegion** 的详细定义如下:
-- **SchemaRegion**:元数据存储和复制的基本单元,集群每个数据库的所有元数据槽会被均匀分配给该数据库的所有 SchemaRegion。拥有相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
-- **DataRegion**:数据存储和复制的基本单元,集群每个数据库的所有数据槽会被均匀分配给该数据库的所有 DataRegion。拥有相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
-
-## 副本组
-Region 的副本对集群的容灾能力至关重要。对于每个 Region 的所有副本,它们的角色分为 **leader** 和 **follower**,共同提供读写服务。不同架构下的副本组配置推荐如下:
-| 类别 | 配置项 | 单机推荐配置 | 分布式推荐配置 |
-| :-: | :-: | :-: | :-: |
-| 元数据 | schema_replication_factor | 1 | 3 |
-| 数据 | data_replication_factor | 1 | 2 |
\ No newline at end of file
+-->
\ No newline at end of file
diff --git a/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md
new file mode 100644
index 000000000..98c6050cc
--- /dev/null
+++ b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_apache.md
@@ -0,0 +1,106 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有两种运行模式:单机模式、集群模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_apache.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_apache.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file
diff --git a/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md
new file mode 100644
index 000000000..77edf9ebb
--- /dev/null
+++ b/src/zh/UserGuide/latest/Background-knowledge/Cluster-Concept_timecho.md
@@ -0,0 +1,116 @@
+
+
+# 常见概念
+
+## 数据模型相关概念
+
+| 概念 | 含义 |
+| ----------------------- | ------------------------------------------------------------ |
+| 数据模型(sql_dialect) | IoTDB 支持两种时序数据模型(SQL语法),管理的对象均为设备和测点树:以层级路径的方式管理数据,一条路径对应一个设备的一个测点表:以关系表的方式管理数据,一张表对应一类设备 |
+| 元数据(Schema) | 元数据是数据库的数据模型信息,即树形结构或表结构。包括测点的名称、数据类型等定义。 |
+| 设备(Device) | 对应一个实际场景中的物理设备,通常包含多个测点。 |
+| 测点(Timeseries) | 又名:物理量、时间序列、时间线、点位、信号量、指标、测量值等。是多个数据点按时间戳递增排列形成的一个时间序列。通常一个测点代表一个采集点位,能够定期采集所在环境的物理量。 |
+| 编码(Encoding) | 编码是一种压缩技术,将数据以二进制的形式进行表示,可以提高存储效率。IoTDB 支持多种针对不同类型的数据的编码方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+| 压缩(Compression) | IoTDB 在数据编码后,使用压缩技术进一步压缩二进制数据,提升存储效率。IoTDB 支持多种压缩方法,详细信息请查看:[压缩和编码](../Technical-Insider/Encoding-and-Compression.md) |
+
+## 分布式相关概念
+
+下图展示了一个常见的 IoTDB 3C3D(3 个 ConfigNode、3 个 DataNode)的集群部署模式:
+
+
+
+IoTDB 的集群包括如下常见概念:
+
+- 节点(ConfigNode、DataNode、AINode)
+- Region(SchemaRegion、DataRegion)
+- 多副本
+
+下文将对以上概念进行介绍。
+
+
+### 节点
+
+IoTDB 集群包括三种节点(进程):ConfigNode(管理节点),DataNode(数据节点)和 AINode(分析节点),如下所示:
+
+- ConfigNode:管理集群的节点信息、配置信息、用户权限、元数据、分区信息等,负责分布式操作的调度和负载均衡,所有 ConfigNode 之间互为全量备份,如上图中的 ConfigNode-1,ConfigNode-2 和 ConfigNode-3 所示。
+- DataNode:服务客户端请求,负责数据的存储和计算,如上图中的 DataNode-1,DataNode-2 和 DataNode-3 所示。
+- AINode:负责提供机器学习能力,支持注册已训练好的机器学习模型,并通过 SQL 调用模型进行推理,目前已内置自研时序大模型和常见的机器学习算法(如预测与异常检测)。
+
+### 数据分区
+
+在 IoTDB 中,元数据和数据都被分为小的分区,即 Region,由集群的各个 DataNode 进行管理。
+
+- SchemaRegion:元数据分区,管理一部分设备和测点的元数据。不同 DataNode 相同 RegionID 的 SchemaRegion 互为副本,如上图中 SchemaRegion-1 拥有三个副本,分别放置于 DataNode-1,DataNode-2 和 DataNode-3。
+- DataRegion:数据分区,管理一部分设备的一段时间的数据。不同 DataNode 相同 RegionID 的 DataRegion 互为副本,如上图中 DataRegion-2 拥有两个副本,分别放置于 DataNode-1 和 DataNode-2。
+- 具体分区算法可参考:[数据分区](../Technical-Insider/Cluster-data-partitioning.md)
+
+### 多副本
+
+数据和元数据的副本数可配置,不同部署模式下的副本数推荐如下配置,其中多副本时可提供高可用服务。
+
+| 类别 | 配置项 | 单机推荐配置 | 集群推荐配置 |
+| :----- | :------------------------ | :----------- | :----------- |
+| 元数据 | schema_replication_factor | 1 | 3 |
+| 数据 | data_replication_factor | 1 | 2 |
+
+
+## 部署相关概念
+
+IoTDB 有三种运行模式:单机模式、集群模式和双活模式。
+
+### 单机模式
+
+IoTDB单机实例包括 1 个ConfigNode、1个DataNode,即1C1D;
+
+- **特点**:便于开发者安装部署,部署和维护成本较低,操作方便。
+- **适用场景**:资源有限或对高可用要求不高的场景,例如边缘端服务器。
+- **部署方法**:[单机版部署](../Deployment-and-Maintenance/Stand-Alone-Deployment_timecho.md)
+
+### 双活模式
+
+双活版部署为 TimechoDB 企业版功能,是指两个独立的实例进行双向同步,能同时对外提供服务。当一台停机重启后,另一个实例会将缺失数据断点续传。
+
+> IoTDB 双活实例通常为2个单机节点,即2套1C1D。每个实例也可以为集群。
+
+- **特点**:资源占用最低的高可用解决方案。
+- **适用场景**:资源有限(仅有两台服务器),但希望获得高可用能力。
+- **部署方法**:[双活版部署](../Deployment-and-Maintenance/Dual-Active-Deployment_timecho.md)
+
+### 集群模式
+
+IoTDB 集群实例为 3 个ConfigNode 和不少于 3 个 DataNode,通常为 3 个 DataNode,即3C3D;当部分节点出现故障时,剩余节点仍然能对外提供服务,保证数据库服务的高可用性,且可随节点增加提升数据库性能。
+
+- **特点**:具有高可用性、高扩展性,可通过增加 DataNode 提高系统性能。
+- **适用场景**:需要提供高可用和可靠性的企业级应用场景。
+- **部署方法**:[集群版部署](../Deployment-and-Maintenance/Cluster-Deployment_timecho.md)
+
+### 特点总结
+
+| 维度 | 单机模式 | 双活模式 | 集群模式 |
+| ------------ | ---------------------------- | ------------------------ | ------------------------ |
+| 适用场景 | 边缘侧部署、对高可用要求不高 | 高可用性业务、容灾场景等 | 高可用性业务、容灾场景等 |
+| 所需机器数量 | 1 | 2 | ≥3 |
+| 安全可靠性 | 无法容忍单点故障 | 高,可容忍单点故障 | 高,可容忍单点故障 |
+| 扩展性 | 可扩展 DataNode 提升性能 | 每个实例可按需扩展 | 可扩展 DataNode 提升性能 |
+| 性能 | 可随 DataNode 数量扩展 | 与其中一个实例性能相同 | 可随 DataNode 数量扩展 |
+
+- 单机模式和集群模式,部署步骤类似(逐个增加 ConfigNode 和 DataNode),仅副本数和可提供服务的最少节点数不同。
\ No newline at end of file