-
-
-
-
-
-  +
diff --git a/Module3_Labs/Lab2_CarDealershipLab/311 2.md b/Module3_Labs/Lab2_CarDealershipLab/311 2.md
new file mode 100644
index 00000000..acc1dfca
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/311 2.md
@@ -0,0 +1,47 @@
+
+
+
+
+
+
+Sets are nice for getting unique values, so you should be using one as your data structure.
+
+Iterate through all the Vehicle instances in `vehicles` and use an **if statement** to check whether `attribute` matches either "Make", "Model", or "Year":
+
+```python
+unique_attributes = set()
+for vehicle in vehicles:
+ if (attribute == "Make"):
+ elif (attribute == "Model"):
+ elif (attribute == "Year"):
+```
+
+Only add that vehicle's attribute (not the vehicle itself) to your set, if it matches `attribute`.
+
+```python
+unique_attributes = set()
+for vehicle in vehicles:
+ if (attribute == "Make"):
+ unique_attributes.add(vehicle.make)
+ elif (attribute == "Model"):
+ unique_attributes.add(vehicle.model)
+ elif (attribute == "Year"):
+ unique_attributes.add(vehicle.year)
+```
+
+Sorting can be done with the `sorted` function. Also, print the unique attributes out for the user.
+
+```python
+# print out attributes sorted
+attr_sorted = sorted(unique_attributes)
+for attr in attr_sorted:
+ print(attr)
+print("")
+```
+
+Return the unique attributes at the end.
+
+```python
+return unique_attributes
+```
+
diff --git a/Module3_Labs/Lab2_CarDealershipLab/4 2.md b/Module3_Labs/Lab2_CarDealershipLab/4 2.md
new file mode 100644
index 00000000..1f7c8d73
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/4 2.md
@@ -0,0 +1,9 @@
+
+
+
+
+
+
+Finish writing `print_matching()` that prints all the vehicles to satisfy the attribute `user_attr`. The type of attribute is stored in `attribute` as a string. `print_matching()` is an extremely useful function for a car dealership because it allows for customers to print out cars in the lot that match the criterion, or `attribute`, they are looking for. It helps customers find cars they are interested in.
+
+
+
diff --git a/Module3_Labs/Lab2_CarDealershipLab/311 2.md b/Module3_Labs/Lab2_CarDealershipLab/311 2.md
new file mode 100644
index 00000000..acc1dfca
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/311 2.md
@@ -0,0 +1,47 @@
+
+
+
+
+
+
+Sets are nice for getting unique values, so you should be using one as your data structure.
+
+Iterate through all the Vehicle instances in `vehicles` and use an **if statement** to check whether `attribute` matches either "Make", "Model", or "Year":
+
+```python
+unique_attributes = set()
+for vehicle in vehicles:
+ if (attribute == "Make"):
+ elif (attribute == "Model"):
+ elif (attribute == "Year"):
+```
+
+Only add that vehicle's attribute (not the vehicle itself) to your set, if it matches `attribute`.
+
+```python
+unique_attributes = set()
+for vehicle in vehicles:
+ if (attribute == "Make"):
+ unique_attributes.add(vehicle.make)
+ elif (attribute == "Model"):
+ unique_attributes.add(vehicle.model)
+ elif (attribute == "Year"):
+ unique_attributes.add(vehicle.year)
+```
+
+Sorting can be done with the `sorted` function. Also, print the unique attributes out for the user.
+
+```python
+# print out attributes sorted
+attr_sorted = sorted(unique_attributes)
+for attr in attr_sorted:
+ print(attr)
+print("")
+```
+
+Return the unique attributes at the end.
+
+```python
+return unique_attributes
+```
+
diff --git a/Module3_Labs/Lab2_CarDealershipLab/4 2.md b/Module3_Labs/Lab2_CarDealershipLab/4 2.md
new file mode 100644
index 00000000..1f7c8d73
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/4 2.md
@@ -0,0 +1,9 @@
+
+
+
+
+
+
+Finish writing `print_matching()` that prints all the vehicles to satisfy the attribute `user_attr`. The type of attribute is stored in `attribute` as a string. `print_matching()` is an extremely useful function for a car dealership because it allows for customers to print out cars in the lot that match the criterion, or `attribute`, they are looking for. It helps customers find cars they are interested in.
+
+ \ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/41 2.md b/Module3_Labs/Lab2_CarDealershipLab/41 2.md
new file mode 100644
index 00000000..a3efd470
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/41 2.md
@@ -0,0 +1,7 @@
+
+
+
+
+
+
+When a vehicle has the user's attribute `user_attr`, call `print_info()`.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/41 3.md b/Module3_Labs/Lab2_CarDealershipLab/41 3.md
new file mode 100644
index 00000000..a3efd470
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/41 3.md
@@ -0,0 +1,7 @@
+
+
+
+
+
+
+When a vehicle has the user's attribute `user_attr`, call `print_info()`.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/411 2.md b/Module3_Labs/Lab2_CarDealershipLab/411 2.md
new file mode 100644
index 00000000..bb1c2832
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/411 2.md
@@ -0,0 +1,20 @@
+
+
+
+
+
+
+Iterate through all vehicles using a **for loop**. We need to know which attribute we should be comparing for to `user_attr`. This is our first condition in the **if statement**. Then, we need to actually compare the appropriate instance variable to `user_attr`. If both are `True`, then call `print_info()` by typing the variable holding the instance (variable), a dot, then `print_info()`.
+
+****
+
+```python
+for vehicle in vehicles:
+ if (attribute == "Make" and vehicle.make == user_attr or
+ attribute == "Model" and vehicle.model == user_attr or
+ attribute == "Year" and vehicle.year == user_attr):
+ vehicle.print_info()
+```
+
+
+
diff --git a/Module3_Labs/Lab2_CarDealershipLab/411 3.md b/Module3_Labs/Lab2_CarDealershipLab/411 3.md
new file mode 100644
index 00000000..bb1c2832
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/411 3.md
@@ -0,0 +1,20 @@
+
+
+
+
+
+
+Iterate through all vehicles using a **for loop**. We need to know which attribute we should be comparing for to `user_attr`. This is our first condition in the **if statement**. Then, we need to actually compare the appropriate instance variable to `user_attr`. If both are `True`, then call `print_info()` by typing the variable holding the instance (variable), a dot, then `print_info()`.
+
+****
+
+```python
+for vehicle in vehicles:
+ if (attribute == "Make" and vehicle.make == user_attr or
+ attribute == "Model" and vehicle.model == user_attr or
+ attribute == "Year" and vehicle.year == user_attr):
+ vehicle.print_info()
+```
+
+
+
diff --git a/Module3_Labs/Lab2_CarDealershipLab/5 2.md b/Module3_Labs/Lab2_CarDealershipLab/5 2.md
new file mode 100644
index 00000000..55dbb086
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/5 2.md
@@ -0,0 +1,24 @@
+
+
+
+
+
+
+`print_vehicles()` communicates directly with `main()`.
+
+This function that runs all the other lower-level functions to print the correct vehicles.
+
+It has three parts:
+
+1. Handling choice 1 (Printing all vehicles)
+2. Handling choices 2-4 (Printing by an attribute)
+
+ * Choice 2: Prints unique make
+ * Choice 3: Prints unique model
+ * Choice 4: Prints unique year
+3. Handling choices 5-7 (Printing by type of vehicle)
+ * Choice 5: Prints `user_attr` make
+ * Choice 6: Prints `user_attr` model
+ * Choice 7: Prints `user_attr` year
+
+Write the complete function.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/5 3.md b/Module3_Labs/Lab2_CarDealershipLab/5 3.md
new file mode 100644
index 00000000..55dbb086
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/5 3.md
@@ -0,0 +1,24 @@
+
+
+
+
+
+
+`print_vehicles()` communicates directly with `main()`.
+
+This function that runs all the other lower-level functions to print the correct vehicles.
+
+It has three parts:
+
+1. Handling choice 1 (Printing all vehicles)
+2. Handling choices 2-4 (Printing by an attribute)
+
+ * Choice 2: Prints unique make
+ * Choice 3: Prints unique model
+ * Choice 4: Prints unique year
+3. Handling choices 5-7 (Printing by type of vehicle)
+ * Choice 5: Prints `user_attr` make
+ * Choice 6: Prints `user_attr` model
+ * Choice 7: Prints `user_attr` year
+
+Write the complete function.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/51 2.md b/Module3_Labs/Lab2_CarDealershipLab/51 2.md
new file mode 100644
index 00000000..1d3f234b
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/51 2.md
@@ -0,0 +1,11 @@
+
+
+
+
+
+
+Utilize the `print_info()` function.
+
+Choices 2-4 are mostly utilizing your already written functions appropriately as well as the `choices` dictionary to convert between choice number (integer) to choice name (string)/
+
+Choices 5-7 require calling instance methods based on `vehicle_type()`'s return value.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/51 3.md b/Module3_Labs/Lab2_CarDealershipLab/51 3.md
new file mode 100644
index 00000000..1d3f234b
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/51 3.md
@@ -0,0 +1,11 @@
+
+
+
+
+
+
+Utilize the `print_info()` function.
+
+Choices 2-4 are mostly utilizing your already written functions appropriately as well as the `choices` dictionary to convert between choice number (integer) to choice name (string)/
+
+Choices 5-7 require calling instance methods based on `vehicle_type()`'s return value.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/511 2.md b/Module3_Labs/Lab2_CarDealershipLab/511 2.md
new file mode 100644
index 00000000..f7aa9757
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/511 2.md
@@ -0,0 +1,36 @@
+
+
+
+
+
+
+Check that choice is 1 first, then iterate through all the vehicles and call `print_info()`.
+
+```python
+if (choice == 1):
+ for vehicle in vehicles:
+ vehicle.print_info()
+```
+
+
+
+For choices 2-4, call `print_unique()`, get the user's name of the attribute using `input()`, and call `print_matching()` to print out the matching vehicles based on the user's specific attribute name.
+
+This should all be done in an **elif** statement for choices 2-4 only.
+
+```python
+elif (choice >= 2 and choice <= 4):
+ print_unique(vehicles, choices[choice])
+ user_attr = input(f"Enter a {choices[choice]}: ")
+ print_matching(vehicles, choices[choice], user_attr)
+```
+
+For choices 5-7, check the return type of `vehicle_type()` for each instance. This means you have to iterate through all class instances in `vehicles`.
+
+```python
+else:
+ for vehicle in vehicles:
+ if (vehicle.vehicle_type() == choices[choice]):
+ vehicle.print_info()
+```
+
diff --git a/Module3_Labs/Lab2_CarDealershipLab/511 3.md b/Module3_Labs/Lab2_CarDealershipLab/511 3.md
new file mode 100644
index 00000000..f7aa9757
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/511 3.md
@@ -0,0 +1,36 @@
+
+
+
+
+
+
+Check that choice is 1 first, then iterate through all the vehicles and call `print_info()`.
+
+```python
+if (choice == 1):
+ for vehicle in vehicles:
+ vehicle.print_info()
+```
+
+
+
+For choices 2-4, call `print_unique()`, get the user's name of the attribute using `input()`, and call `print_matching()` to print out the matching vehicles based on the user's specific attribute name.
+
+This should all be done in an **elif** statement for choices 2-4 only.
+
+```python
+elif (choice >= 2 and choice <= 4):
+ print_unique(vehicles, choices[choice])
+ user_attr = input(f"Enter a {choices[choice]}: ")
+ print_matching(vehicles, choices[choice], user_attr)
+```
+
+For choices 5-7, check the return type of `vehicle_type()` for each instance. This means you have to iterate through all class instances in `vehicles`.
+
+```python
+else:
+ for vehicle in vehicles:
+ if (vehicle.vehicle_type() == choices[choice]):
+ vehicle.print_info()
+```
+
diff --git a/Module3_Labs/Lab3_Minesweeper/README 2.md b/Module3_Labs/Lab3_Minesweeper/README 2.md
new file mode 100644
index 00000000..4b69eb6c
--- /dev/null
+++ b/Module3_Labs/Lab3_Minesweeper/README 2.md
@@ -0,0 +1,26 @@
+# Activity/Lab Name
+
+Minesweeper
+
+# Long Summary
+
+Students will use object-oriented structure to build the game, Mine Sweeper, while implementing an interactive interface between user and the program.
+
+# Short Summary
+
+Utilize object oriented programming concepts to build the game, Mine Sweeper.
+
+# Criteria
+
+1. On a very macro scale, how do you use Object-Oriented Programming concepts (inheritance, encapsulation, polymorphism) to solve this problem? Describe the general progression of your program.
+2. What are the possible events that can happen when you click on a cell? Describe in terms of your defined objects.
+3. What kinds of inputs are invalid and how do you account for them?
+
+# Difficulty
+
+Hard
+
+# Image
+
+
+
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act1_TimeAndSpaceComplexity/README 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act1_TimeAndSpaceComplexity/README 2.md
new file mode 100644
index 00000000..792adb8f
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act1_TimeAndSpaceComplexity/README 2.md
@@ -0,0 +1,25 @@
+# Time and Space Complexity
+
+# Long Summary
+
+Algorithms require an input to run. As the input grows, learn about what happens to the memory usage and space usage. Learn about how to describe this rate.
+
+# Short Summary
+
+Learn about the different rates at which algorithm's memory usage and runtime increase
+
+# Criteria
+
+-Know what Time Complexity is, and the different rates of growth a function can have.
+
+-What is Space Complexity? If one has to choose, what is of higher priority: space or time? Why?
+
+-Create a function with O(n^2) time. How is it O(n^2)?
+
+# Difficulty
+
+Easy
+
+
+
+
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act2_HashTables/README 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act2_HashTables/README 2.md
new file mode 100644
index 00000000..40dcff20
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act2_HashTables/README 2.md
@@ -0,0 +1,20 @@
+# Hash Tables
+
+# Long Summary
+
+Learn about hash Tables and how to use Hash Functions. Also learn about the implementation of Hash functions in Python by using dictionaries. The usage and implementation of Dictionaries in Python is then explained.
+# Short Summary
+
+Learn about the basics of Dictionaries and Hash Tables
+
+# Criteria
+
+- Know what a Hash Table is
+
+-Understand the importance of hash functions
+
+-How do you implement hash Tables in python by using dictionaries?
+
+# Difficulty
+
+Easy
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act3_Queues/README 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act3_Queues/README 2.md
new file mode 100644
index 00000000..32f30ec3
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act3_Queues/README 2.md
@@ -0,0 +1,22 @@
+# Queues
+
+# Long Summary
+
+Understand how Queues work in Python. Learn to push and pop elements from queues and what queues are used for.
+
+# Short Summary
+
+Learning about the Queue Data Structure and its implementations
+
+# Criteria
+
+- How is a queue in Python similar to standing in a line to buy coffee?
+
+- Explain what the two functions for enqueuing and dequeuing respectively are and how they work.
+
+- Explain how to create a queue.
+
+# Difficulty
+
+Easy
+
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/5 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/5 2.md
new file mode 100644
index 00000000..f83007e9
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/5 2.md
@@ -0,0 +1,170 @@
+We're now going to explain the programming concept behind the Tower of Hanoi.
+
+**Step 0) Initialize**
+
+Let's initialize all the items we need and properly set up our puzzle.
+
+```python
+sourcePole = Stack()
+auxPole = Stack()
+destPole = Stack()
+
+smallDisk = 1
+avgDisk = 2
+largeDisk = 3
+
+sourcePole.push(largeDisk)
+sourcePole.push(avgDisk)
+sourcePole.push(smallDisk)
+
+print(sourcePole.stack) # print the Initial state of 3 poles
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/41 2.md b/Module3_Labs/Lab2_CarDealershipLab/41 2.md
new file mode 100644
index 00000000..a3efd470
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/41 2.md
@@ -0,0 +1,7 @@
+
+
+
+
+
+
+When a vehicle has the user's attribute `user_attr`, call `print_info()`.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/41 3.md b/Module3_Labs/Lab2_CarDealershipLab/41 3.md
new file mode 100644
index 00000000..a3efd470
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/41 3.md
@@ -0,0 +1,7 @@
+
+
+
+
+
+
+When a vehicle has the user's attribute `user_attr`, call `print_info()`.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/411 2.md b/Module3_Labs/Lab2_CarDealershipLab/411 2.md
new file mode 100644
index 00000000..bb1c2832
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/411 2.md
@@ -0,0 +1,20 @@
+
+
+
+
+
+
+Iterate through all vehicles using a **for loop**. We need to know which attribute we should be comparing for to `user_attr`. This is our first condition in the **if statement**. Then, we need to actually compare the appropriate instance variable to `user_attr`. If both are `True`, then call `print_info()` by typing the variable holding the instance (variable), a dot, then `print_info()`.
+
+****
+
+```python
+for vehicle in vehicles:
+ if (attribute == "Make" and vehicle.make == user_attr or
+ attribute == "Model" and vehicle.model == user_attr or
+ attribute == "Year" and vehicle.year == user_attr):
+ vehicle.print_info()
+```
+
+
+
diff --git a/Module3_Labs/Lab2_CarDealershipLab/411 3.md b/Module3_Labs/Lab2_CarDealershipLab/411 3.md
new file mode 100644
index 00000000..bb1c2832
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/411 3.md
@@ -0,0 +1,20 @@
+
+
+
+
+
+
+Iterate through all vehicles using a **for loop**. We need to know which attribute we should be comparing for to `user_attr`. This is our first condition in the **if statement**. Then, we need to actually compare the appropriate instance variable to `user_attr`. If both are `True`, then call `print_info()` by typing the variable holding the instance (variable), a dot, then `print_info()`.
+
+****
+
+```python
+for vehicle in vehicles:
+ if (attribute == "Make" and vehicle.make == user_attr or
+ attribute == "Model" and vehicle.model == user_attr or
+ attribute == "Year" and vehicle.year == user_attr):
+ vehicle.print_info()
+```
+
+
+
diff --git a/Module3_Labs/Lab2_CarDealershipLab/5 2.md b/Module3_Labs/Lab2_CarDealershipLab/5 2.md
new file mode 100644
index 00000000..55dbb086
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/5 2.md
@@ -0,0 +1,24 @@
+
+
+
+
+
+
+`print_vehicles()` communicates directly with `main()`.
+
+This function that runs all the other lower-level functions to print the correct vehicles.
+
+It has three parts:
+
+1. Handling choice 1 (Printing all vehicles)
+2. Handling choices 2-4 (Printing by an attribute)
+
+ * Choice 2: Prints unique make
+ * Choice 3: Prints unique model
+ * Choice 4: Prints unique year
+3. Handling choices 5-7 (Printing by type of vehicle)
+ * Choice 5: Prints `user_attr` make
+ * Choice 6: Prints `user_attr` model
+ * Choice 7: Prints `user_attr` year
+
+Write the complete function.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/5 3.md b/Module3_Labs/Lab2_CarDealershipLab/5 3.md
new file mode 100644
index 00000000..55dbb086
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/5 3.md
@@ -0,0 +1,24 @@
+
+
+
+
+
+
+`print_vehicles()` communicates directly with `main()`.
+
+This function that runs all the other lower-level functions to print the correct vehicles.
+
+It has three parts:
+
+1. Handling choice 1 (Printing all vehicles)
+2. Handling choices 2-4 (Printing by an attribute)
+
+ * Choice 2: Prints unique make
+ * Choice 3: Prints unique model
+ * Choice 4: Prints unique year
+3. Handling choices 5-7 (Printing by type of vehicle)
+ * Choice 5: Prints `user_attr` make
+ * Choice 6: Prints `user_attr` model
+ * Choice 7: Prints `user_attr` year
+
+Write the complete function.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/51 2.md b/Module3_Labs/Lab2_CarDealershipLab/51 2.md
new file mode 100644
index 00000000..1d3f234b
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/51 2.md
@@ -0,0 +1,11 @@
+
+
+
+
+
+
+Utilize the `print_info()` function.
+
+Choices 2-4 are mostly utilizing your already written functions appropriately as well as the `choices` dictionary to convert between choice number (integer) to choice name (string)/
+
+Choices 5-7 require calling instance methods based on `vehicle_type()`'s return value.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/51 3.md b/Module3_Labs/Lab2_CarDealershipLab/51 3.md
new file mode 100644
index 00000000..1d3f234b
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/51 3.md
@@ -0,0 +1,11 @@
+
+
+
+
+
+
+Utilize the `print_info()` function.
+
+Choices 2-4 are mostly utilizing your already written functions appropriately as well as the `choices` dictionary to convert between choice number (integer) to choice name (string)/
+
+Choices 5-7 require calling instance methods based on `vehicle_type()`'s return value.
\ No newline at end of file
diff --git a/Module3_Labs/Lab2_CarDealershipLab/511 2.md b/Module3_Labs/Lab2_CarDealershipLab/511 2.md
new file mode 100644
index 00000000..f7aa9757
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/511 2.md
@@ -0,0 +1,36 @@
+
+
+
+
+
+
+Check that choice is 1 first, then iterate through all the vehicles and call `print_info()`.
+
+```python
+if (choice == 1):
+ for vehicle in vehicles:
+ vehicle.print_info()
+```
+
+
+
+For choices 2-4, call `print_unique()`, get the user's name of the attribute using `input()`, and call `print_matching()` to print out the matching vehicles based on the user's specific attribute name.
+
+This should all be done in an **elif** statement for choices 2-4 only.
+
+```python
+elif (choice >= 2 and choice <= 4):
+ print_unique(vehicles, choices[choice])
+ user_attr = input(f"Enter a {choices[choice]}: ")
+ print_matching(vehicles, choices[choice], user_attr)
+```
+
+For choices 5-7, check the return type of `vehicle_type()` for each instance. This means you have to iterate through all class instances in `vehicles`.
+
+```python
+else:
+ for vehicle in vehicles:
+ if (vehicle.vehicle_type() == choices[choice]):
+ vehicle.print_info()
+```
+
diff --git a/Module3_Labs/Lab2_CarDealershipLab/511 3.md b/Module3_Labs/Lab2_CarDealershipLab/511 3.md
new file mode 100644
index 00000000..f7aa9757
--- /dev/null
+++ b/Module3_Labs/Lab2_CarDealershipLab/511 3.md
@@ -0,0 +1,36 @@
+
+
+
+
+
+
+Check that choice is 1 first, then iterate through all the vehicles and call `print_info()`.
+
+```python
+if (choice == 1):
+ for vehicle in vehicles:
+ vehicle.print_info()
+```
+
+
+
+For choices 2-4, call `print_unique()`, get the user's name of the attribute using `input()`, and call `print_matching()` to print out the matching vehicles based on the user's specific attribute name.
+
+This should all be done in an **elif** statement for choices 2-4 only.
+
+```python
+elif (choice >= 2 and choice <= 4):
+ print_unique(vehicles, choices[choice])
+ user_attr = input(f"Enter a {choices[choice]}: ")
+ print_matching(vehicles, choices[choice], user_attr)
+```
+
+For choices 5-7, check the return type of `vehicle_type()` for each instance. This means you have to iterate through all class instances in `vehicles`.
+
+```python
+else:
+ for vehicle in vehicles:
+ if (vehicle.vehicle_type() == choices[choice]):
+ vehicle.print_info()
+```
+
diff --git a/Module3_Labs/Lab3_Minesweeper/README 2.md b/Module3_Labs/Lab3_Minesweeper/README 2.md
new file mode 100644
index 00000000..4b69eb6c
--- /dev/null
+++ b/Module3_Labs/Lab3_Minesweeper/README 2.md
@@ -0,0 +1,26 @@
+# Activity/Lab Name
+
+Minesweeper
+
+# Long Summary
+
+Students will use object-oriented structure to build the game, Mine Sweeper, while implementing an interactive interface between user and the program.
+
+# Short Summary
+
+Utilize object oriented programming concepts to build the game, Mine Sweeper.
+
+# Criteria
+
+1. On a very macro scale, how do you use Object-Oriented Programming concepts (inheritance, encapsulation, polymorphism) to solve this problem? Describe the general progression of your program.
+2. What are the possible events that can happen when you click on a cell? Describe in terms of your defined objects.
+3. What kinds of inputs are invalid and how do you account for them?
+
+# Difficulty
+
+Hard
+
+# Image
+
+
+
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act1_TimeAndSpaceComplexity/README 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act1_TimeAndSpaceComplexity/README 2.md
new file mode 100644
index 00000000..792adb8f
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act1_TimeAndSpaceComplexity/README 2.md
@@ -0,0 +1,25 @@
+# Time and Space Complexity
+
+# Long Summary
+
+Algorithms require an input to run. As the input grows, learn about what happens to the memory usage and space usage. Learn about how to describe this rate.
+
+# Short Summary
+
+Learn about the different rates at which algorithm's memory usage and runtime increase
+
+# Criteria
+
+-Know what Time Complexity is, and the different rates of growth a function can have.
+
+-What is Space Complexity? If one has to choose, what is of higher priority: space or time? Why?
+
+-Create a function with O(n^2) time. How is it O(n^2)?
+
+# Difficulty
+
+Easy
+
+
+
+
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act2_HashTables/README 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act2_HashTables/README 2.md
new file mode 100644
index 00000000..40dcff20
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act2_HashTables/README 2.md
@@ -0,0 +1,20 @@
+# Hash Tables
+
+# Long Summary
+
+Learn about hash Tables and how to use Hash Functions. Also learn about the implementation of Hash functions in Python by using dictionaries. The usage and implementation of Dictionaries in Python is then explained.
+# Short Summary
+
+Learn about the basics of Dictionaries and Hash Tables
+
+# Criteria
+
+- Know what a Hash Table is
+
+-Understand the importance of hash functions
+
+-How do you implement hash Tables in python by using dictionaries?
+
+# Difficulty
+
+Easy
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act3_Queues/README 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act3_Queues/README 2.md
new file mode 100644
index 00000000..32f30ec3
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act3_Queues/README 2.md
@@ -0,0 +1,22 @@
+# Queues
+
+# Long Summary
+
+Understand how Queues work in Python. Learn to push and pop elements from queues and what queues are used for.
+
+# Short Summary
+
+Learning about the Queue Data Structure and its implementations
+
+# Criteria
+
+- How is a queue in Python similar to standing in a line to buy coffee?
+
+- Explain what the two functions for enqueuing and dequeuing respectively are and how they work.
+
+- Explain how to create a queue.
+
+# Difficulty
+
+Easy
+
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/5 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/5 2.md
new file mode 100644
index 00000000..f83007e9
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/5 2.md
@@ -0,0 +1,170 @@
+We're now going to explain the programming concept behind the Tower of Hanoi.
+
+**Step 0) Initialize**
+
+Let's initialize all the items we need and properly set up our puzzle.
+
+```python
+sourcePole = Stack()
+auxPole = Stack()
+destPole = Stack()
+
+smallDisk = 1
+avgDisk = 2
+largeDisk = 3
+
+sourcePole.push(largeDisk)
+sourcePole.push(avgDisk)
+sourcePole.push(smallDisk)
+
+print(sourcePole.stack) # print the Initial state of 3 poles
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+ +
+> Note: remember that stack is LIFO so we must `push()` our elements in the appropriate order, the source pole has the `largeDisk` at the bottom and `smallDisk` at the top.
+
+---
+
+**Step 1)**
+
+Now let's proceed to solving this puzzle! For our first move, we can only remove the top disk which is `smallDisk`. We will place the `smallDisk` on the destination pole.
+
+```python
+disk = sourcePole.pop() #remove the top disk of source pole to destination pole
+destPole.push(disk)
+
+print(sourcePole.stack) #print the state now
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+
+
+> Note: remember that stack is LIFO so we must `push()` our elements in the appropriate order, the source pole has the `largeDisk` at the bottom and `smallDisk` at the top.
+
+---
+
+**Step 1)**
+
+Now let's proceed to solving this puzzle! For our first move, we can only remove the top disk which is `smallDisk`. We will place the `smallDisk` on the destination pole.
+
+```python
+disk = sourcePole.pop() #remove the top disk of source pole to destination pole
+destPole.push(disk)
+
+print(sourcePole.stack) #print the state now
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+ +
+---
+
+**Step 2)**
+
+Next, we will put the `avgDisk` onto the auxililary pole. Each pole will now have exactly 1 disk.
+
+```python
+disk = sourcePole.pop() #remove the top disk of source pole now to destination pole
+auxPole.push(disk)
+
+print(sourcePole.stack) #print the state now
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+
+
+---
+
+**Step 2)**
+
+Next, we will put the `avgDisk` onto the auxililary pole. Each pole will now have exactly 1 disk.
+
+```python
+disk = sourcePole.pop() #remove the top disk of source pole now to destination pole
+auxPole.push(disk)
+
+print(sourcePole.stack) #print the state now
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+ +
+---
+
+**Step 3)**
+
+Knowing that we want to put the `largeDisk` first into the destination pole, we need to move the `smallDisk`. So let's put the `smallDisk` on top of the `avgDisk` on the auxiliary pole.
+
+```python
+disk=destPole.pop()
+auxPole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+
+
+---
+
+**Step 3)**
+
+Knowing that we want to put the `largeDisk` first into the destination pole, we need to move the `smallDisk`. So let's put the `smallDisk` on top of the `avgDisk` on the auxiliary pole.
+
+```python
+disk=destPole.pop()
+auxPole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+ +
+---
+
+**Step 4)**
+
+Now the destination pole is free for us to put the `largeDisk` in first.
+
+```python
+disk=sourcePole.pop()
+destPole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+
+
+---
+
+**Step 4)**
+
+Now the destination pole is free for us to put the `largeDisk` in first.
+
+```python
+disk=sourcePole.pop()
+destPole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+ +
+---
+
+**Step 5)**
+
+Our goal now is to get the `avgDisk` on top of the `largeDisk` in the destination pole, but `smallDisk` is in the way so let's move that back to the source pole.
+
+```python
+disk=auxPole.pop()
+sourcePole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+
+
+---
+
+**Step 5)**
+
+Our goal now is to get the `avgDisk` on top of the `largeDisk` in the destination pole, but `smallDisk` is in the way so let's move that back to the source pole.
+
+```python
+disk=auxPole.pop()
+sourcePole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+ +
+---
+
+**Step 6)**
+
+The `avgDisk` is now free to be put on top of the `largeDisk` in the destination pole so we will do so now.
+
+```python
+disk=auxPole.pop()
+destPole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+ **result of the code :**
+
+
+
+---
+
+**Step 6)**
+
+The `avgDisk` is now free to be put on top of the `largeDisk` in the destination pole so we will do so now.
+
+```python
+disk=auxPole.pop()
+destPole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+ **result of the code :**
+
+ +
+---
+
+**Step 7)**
+
+Finally, we just need to put the `smallDisk` onto our destination pole and we will have completed our Tower of Hanoi puzzle!
+
+```python
+disk=sourcePole.pop()
+destPole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+
+
+---
+
+**Step 7)**
+
+Finally, we just need to put the `smallDisk` onto our destination pole and we will have completed our Tower of Hanoi puzzle!
+
+```python
+disk=sourcePole.pop()
+destPole.push(disk)
+
+print(sourcePole.stack)
+print(auxPole.stack)
+print(destPole.stack)
+```
+
+**result of the code :**
+
+ +
+---
+
+For a visual representation of the steps that we took to complete our Tower of Hanoi programatically, you can take a look below:
+
+
+
+If you guys really want to solve the tower of Hanoi in an automatic way, you can develop a stack class that would take account of the size of each disk to be added into the pole for the stack and then you can pop each disk out of the stack and then you create new towers (stacks really) to input any of the disks in a different order no matter the size.
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/README 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/README 2.md
new file mode 100644
index 00000000..fd861057
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/README 2.md
@@ -0,0 +1,22 @@
+# Stacks
+
+# Long Summary
+
+Learn about stacks and how to implement them in Python. Then use stacks to solve a fun mathematical puzzle!
+
+# Short Summary
+
+Understand what a stack is and how to use it.
+
+# Criteria
+
+- How is a stack similar to a pile of books?
+
+- How do you remove and add elements to a stack?
+
+- How would you implement removing and adding elements from a stack in Python?
+
+
+# Difficulty
+
+Easy
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act1_LinkedLists/README 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act1_LinkedLists/README 2.md
new file mode 100644
index 00000000..ebddb558
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act1_LinkedLists/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Linked Lists
+
+# Long Summary
+Students will learn about the essential data structure linked lists. They will learn the critical operations that will allow them to interact with linked lists. At the end, they will be given a scenario in which linked lists can be implemented.
+
+# Short Summary
+Students will learn about the linked list data structure.
+
+# Criteria
+1. What do we use the `next_node` pointer for?
+2. What is the purpose of keeping track of the head of the linked list?
+3. Give a scenario where a linked list is better to use than an array.
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/InsertBefore3 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/InsertBefore3 2.md
new file mode 100644
index 00000000..bc5f693c
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/InsertBefore3 2.md
@@ -0,0 +1,68 @@
+
+
+
+
+# Recursion with Binary Search Trees
+
+Recursion is a common coding strategy where we write a function that calls itself until it reaches a base case.
+Below is a code example where recursion is implemented to find the factorial of a number.
+The function takes in a number and it should return the factorial of the number.
+When writing a recursive function, the first thing we want to establish is a base case. In this case, the mathematical relationship of the factorial of 7 would be ...
+```
+7*6*5*4*3*2*1
+```
+It multiplies every number from 7*1 and after it multiplies by 1, all the calculation is finished. Hence, our **base case** will be when number == 1.
+Right now, it may seem confusing but it will make sense when all the pieces come together.
+``` python
+def fact(number):
+ if(number == 1) //base case
+ return product;
+```
+Now, lets write the rest of our recursive function. Since `number == 7` (in our example), it would not fall into our if-statement. We will write an `else` statement
+that accounts for when `number` != 1.
+```python
+ else
+ product = number*(fact(number-1)) // this is where the recursion occurs
+```
+This is the rest of the function. We will multiply `number *fact(number-1)`. When `Fact` is called, `number` will not equal 1.
+The pseudo code will look like this
+```
+product = number*(number-1)*(fact(number-1)).
+Using our example of fact(7), the computation of our program will look like:
+`7*6*fact(number-1)`.
+
+When fact is called again, `number` == 5, and the pattern will repeat until `number` == 1.
+Eventually the computation will look like:
+7*6*5*4*3*2*1
+Since the last `number` multiplied is 1, the base case is reached and `product` is returned.
+
+### Another Example
+Recursion is an incredibly confusing topic so lets take a look at another example before we implement it into our Binary Search Tree.
+The general outline we want to approach recursion is:
+1. Simplify the problem into something smaller.
+ - Our problem is adding `num1` to the number above it.
+2. Solve the simpler problem with an algorithm.
+ - To solve our problem, we can solve it by calling our function multiple times.
+ In this case, calling the same function with a `num1+1`
+3. Putting Everything Together
+
+Lets write a recursive function to find the sum of an interval of numbers. We will want two inputs and every number between those inputs will be added.
+```python
+def interval(num1, num2):
+```
+First lets write our base case. If `num1 == num2`, then that means the interval is zero and there are no more numbers to add. So our base case looks like this:
+Sum is simply the number that is the sum of the interval of numbers.
+```python
+if (num1 == num2)
+ return sum
+```
+
+Now lets incorporate our logic. In our else statement, we want to be calling the same function but with `num1+1` as our input.
+```python
+else
+ sum = num1 + interval(num1+1, num2)
+```
+Eventually, after enough calls, num1 will equal num2 and our function will return sum.
+
+Recursion has an incredible wide use of applications that we can implment and its that we can look into.
+
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/README 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/README 2.md
new file mode 100644
index 00000000..73f344ba
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Trees
+
+# Long Summary
+Students will learn about the tree data structure. They will learn all the necessary terminology associated with trees. Then, they will learn about specific types of trees, such as Binary Search Trees.
+
+# Short Summary
+Students will learn about the tree data structure and different types of trees.
+
+# Criteria
+1. What makes a tree be considered a Binary Search Tree?
+2. Give an example of some data that would work well with a tree data structure.
+3. What are the operations that you can perform on a Binary Search Tree?
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act3_Binary Heaps/README 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act3_Binary Heaps/README 2.md
new file mode 100644
index 00000000..7e2dd737
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act3_Binary Heaps/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Binary Heaps
+
+# Long Summary
+Students will learn about the Binary Heap data structure. They will explore the different operations that can be performed on a binary heap. They will also learn how to build a binary heap given a set of keys.
+
+# Short Summary
+Students will learn about the binary heap data structure.
+
+# Criteria
+1. Which key is put at the root of a max heap?
+2. Give a scenario where a binary heap would help you solve a problem.
+3. What are the operations you can perform on a binary heap?
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act4_Graphs/README 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act4_Graphs/README 2.md
new file mode 100644
index 00000000..3e2910a1
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act4_Graphs/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Graphs
+
+# Long Summary
+Students will learn about graph data structures. They become familiar with different types of graphs that are commonly used. They will then learn popular graph algorithms.
+
+# Short Summary
+Students will learn about graphs and different ways computer scientists use graphs.
+
+# Criteria
+1. What does Dijkstra's algorithm do?
+2. What is the difference between a directed and undirected graph?
+3. What is a Hamiltonian path?
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/3-checkpoint 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/3-checkpoint 2.md
new file mode 100644
index 00000000..b257260c
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/3-checkpoint 2.md
@@ -0,0 +1,5 @@
+**Name**: BFS code checkup
+
+**Instruction**: Take a screenshot of your code and submit it.
+
+**Type**: Image Checkpoint
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/5-checkpoint 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/5-checkpoint 2.md
new file mode 100644
index 00000000..84599e08
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/5-checkpoint 2.md
@@ -0,0 +1,5 @@
+**Name**: BFS and DFS comparison
+
+**Instruction**: How is the Depth-First Search different from the Breadth-First Search?
+
+**Type**: Short answer
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7 2.md
new file mode 100644
index 00000000..3cb50fc8
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7 2.md
@@ -0,0 +1,167 @@
+
+
+
+
+
+
+Here is a binary search algorithm coded in Python:
+
+```python
+# Python Program for recursive binary search.
+
+# Returns index of x in arr if present, else -1
+def binarySearch(arr, l, r, x):
+
+ # Check base case
+ if r >= l:
+
+ mid = l + (r - l)/2
+
+ # If element is present at the middle itself
+ if arr[mid] == x:
+ return mid
+
+ # If element is smaller than mid, then it
+ # can only be present in left subarray
+ elif arr[mid] > x:
+ return binarySearch(arr, l, mid-1, x)
+
+ # Else the element can only be present
+ # in right subarray
+ else:
+ return binarySearch(arr, mid + 1, r, x)
+
+ else:
+ # Element is not present in the array
+ return -1
+
+# Test array
+arr = [ 2, 3, 4, 10, 40 ]
+x = 10
+
+# Function call
+result = binarySearch(arr, 0, len(arr)-1, x)
+
+if result != -1:
+ print "Element is present at index % d" % result
+else:
+ print "Element is not present in array"
+
+```
+
+That was probably a mouthful of code. Let's break it down.
+
+Binary Search takes as arguments an array `arr` and three integers, `l`, `r`, and `x`. `l` is the leftmost index of the array we are searching and `r` is the rightmost index of the array we are searching. `x` is the element we are looking for.
+
+``` python
+# Function call
+result = binarySearch(arr, 0, len(arr)-1, x)
+```
+
+This is why the first function call passes in 0 for `l` and `len(arr) - 1` for `r` as we are searching the entire array. `l` and `r` will become important in the recursive calls made in the function.
+
+We start our binary search function by setting up a base case.
+
+```python
+ def binarySearch(arr, l, r, x):
+ if r >= l:
+
+ mid = l + (r - l)/2
+
+ if arr[mid] == x:
+ return mid
+
+
+ elif arr[mid] > x:
+ return binarySearch(arr, l, mid-1, x)
+
+ else:
+ return binarySearch(arr, mid + 1, r, x)
+```
+
+We only proceed with the algorithm if the right index is greater than a left index (`if r >= l`). When `r < l`, then we know that the element is not in the array, as the start of the array (represented by `l`) must always be before the end of the array (represented by `r`)
+
+If we pass this test, we find the index of the middle element using the formula:
+
+```python
+mid = l + (r - l) / 2
+```
+
+This is analogous to the formula shown in the previous section:
+
+```
+mid = low + (high - low) / 2
+```
+
+Note that the formula uses integer division, meaning that any decimal places are truncated. For example,
+
+```
+mid = 5 + (4-1) / 2 = 5 + 3/2 = 5 + 1 = 6
+```
+
+We then proceed if the element we are looking for (`x`) is indeed the middle element. If this is the case, we have found the element and the algorithm returns the middle index and terminates. This is seen here:
+
+```python
+if arr[mid] == x:
+ return mid
+```
+
+If the target element's value is less than the middle element's value, that implies that the target element should be on the left side of the array (remember, the array is sorted). This case is handled by the following `elif` statement.
+
+````python
+elif arr[mid] > x:
+ return binarySearch(arr, l, mid-1, x)
+````
+
+The body of the `elif` statement performs a recursive call to `binarySearch`, changing the right endpoint (`r`) to `mid - 1`. This is done as we had determined that `x` must be on the left side of the array (that is, between the `l` and `mid - 1` indices). By doing this recursive call, we have essentially split our problem in half.
+
+Our else case tells us that if the target element is not in the middle and it is not to the left, it must be on the right (and greater in value than the middle element's value).
+
+```python
+else:
+ return binarySearch(arr, mid + 1, r, x)
+```
+
+The body of the `else` statement performs a recursive call to `binarySearch` for a similar reason to that of the `elif` statement. The difference here is that we had determined that `x` must be on the right side of the array and would be contained between the indices `mid + 1` and `r`. By doing this recursive call, the problem is split in half.
+
+This diagram shows how the recursive calls work in finding an element `x`.
+
+
+
+The last case is reserved for when the element cannot be found. As stated earlier, this occurs when `r` < `l`. In this case, we return `-1` to signify that we could not find `x`.
+
+```python
+ else:
+ return -1
+```
+
+When does `r < l` occur? To understand this, let's go back to our recursive calls
+
+```python
+elif arr[mid] > x:
+ return binarySearch(arr, l, mid-1, x)
+
+ else:
+ return binarySearch(arr, mid + 1, r, x)
+```
+
+In the first possible recursive call, we decrement `mid` and pass it to the argument `r`, without changing `l`. In the second possible recursive call, we increment `mid` and pass it to the argument `l`, without changing `r`. One can see that if the target element is not the middle element everytime we shrink the size of the array (by adjusting `l` and `r`), eventually, we could have `l` cross (be greater than) `r` (either by passing in `mid - 1` for `r` or `mid + 1` for `l`).
+
+Here is how the algorithm would proceed when you are unable to find an element:
+
+
+
+This block of code is what we use to test if our function is working properly. Feel free to twink with it.
+
+```python
+arr = [ 2, 3, 4, 10, 40 ]
+x = 10
+
+# Function call
+result = binarySearch(arr, 0, len(arr)-1, x)
+
+if result != -1:
+ print "Element is present at index % d" % result
+else:
+ print "Element is not present in array"
+```
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7-checkpoint 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7-checkpoint 2.md
new file mode 100644
index 00000000..746f2e37
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7-checkpoint 2.md
@@ -0,0 +1,5 @@
+**Name**: Binary search implementation
+
+**Instruction**: How is recursion used in the binary search function to find the target?
+
+**Type**: Short Answer
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/10 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/10 2.md
new file mode 100644
index 00000000..d02bcbf6
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/10 2.md
@@ -0,0 +1,69 @@
+
+## Quick Sort Implementation in Python
+
+```python
+def partition(arr,low,high):
+ i = ( low-1 )
+ pivot = arr[high]
+```
+
+The **partition** function will be responsible for actually placing our pivot point (always the last element of the list in this version) in its proper place. Notice what this means. There is no "right side" of the list as far as our pivot is concerned. Only a "left side". The goal remains the same however: all the numbers smaller than the pivot need to be to its left, and all larger numbers need to be to its right.
+
+In this system, we will attempt to always keep track of two elements : a smaller element and a bigger element. Here, we use `i` to represent the smaller element, specifically its position. We use the last element of the list as our pivot.
+
+```python
+ for j in range(low, high):
+ if arr[j] < pivot:
+ i = i+1
+ arr[i],arr[j] = arr[j],arr[i]
+```
+
+`j` will represent the larger element. The `i`'th element should always be smaller than the `j`'th element. This means that we want the elements of the list to be in increasing order as we pass through it. We iterate through our list using `j`, doing nothing if the `j`'th element is bigger than the pivot.
+
+If the `j`'th element is smaller than our pivot, we increment `i`. Notice what happens! The `i`'th element is now *bigger* than the `j`'th element. So, we need to swap them.
+
+```python
+ arr[i+1], arr[high] = arr[high], arr[i+1]
+ return ( i+1 )
+```
+
+After we have finished iterating through our list, we should have sorted every element we could in this pass. All that's left is to put the pivot element into its proper place within our list. With the way we decided when to increment `i` in our algorithm, all elements to the right of the `i`'th element will be *bigger* than the pivot element. So, the place to insert our pivot element will be immediately to the right of the `i`'th element, or at the `i+1`'th position. We return this number to be used when we run **quickSort** again.
+
+```python
+def quickSort(arr,low,high):
+ if low < high:
+ pi = partition(arr,low,high)
+ quickSort(arr, low, pi-1)
+ quickSort(arr, pi+1, high)
+```
+
+This is where we define the actual **quickSort** function. Notice the role of `pi` here. By the time we call the **partition** function and get the value of `pi`, we have placed the pivot element in its proper place. This means we only need to worry about sorting all the elements *before* it and *after* it. That's why we use `pi` to split our list into two and call **quicksort** on both halves.
+
+```python
+def partition(arr,low,high):
+ i = low - 1
+ pivot = arr[high]
+ for j in range(low, high):
+ if arr[j] < pivot:
+ i = i+1
+ arr[i],arr[j] = arr[j],arr[i]
+ arr[i+1],arr[high] = arr[high],arr[i+1]
+ return i+1
+
+def quickSort(arr,low,high):
+ if low < high:
+ pi = partition(arr,low,high)
+
+ quickSort(arr, low, pi-1)
+ quickSort(arr, pi+1, high)
+
+# Driver Code
+arr = [10, 7, 8, 9, 1, 5]
+n = len(arr)
+quickSort(arr,0,n-1)
+print ("Sorted array is:")
+for i in range(n):
+ print ("%d" %arr[i])
+```
+
+Use this code to call our functions and ensure they work properly.
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/7 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/7 2.md
new file mode 100644
index 00000000..98c399b4
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/7 2.md
@@ -0,0 +1,23 @@
+### Merge Sort in Python (Part I)
+
+```python
+def mergeSort(alist):
+ if len(alist) > 1:
+ mid = len(alist) // 2 # integer division
+```
+
+Let's start off with creating a function. If the length of the list we are looking at is greater than 1, we know it might need sorting. We first create a variable called `mid` which finds the middle position of the list. We need this to be able to do the initial splitting of the list into two equal groups.
+
+```python
+ lefthalf = alist[:mid]
+ righthalf = alist[mid:]
+```
+
+These two lines split the list into two equal groups, if possible. `lefthalf` holds all the elements of our original list from the beginning up to (*but not including*) `mid`. `righthalf` then holds all of the elements from the `mid`, or middle, position all the way to the end.
+
+```
+ mergeSort(lefthalf)
+ mergeSort(righthalf)
+```
+
+Here we use recursion to split up the two halves of our list. We simply treat each part as another list and put it through the same splitting process we just went through. We keep doing this until we get to the place where we have each element on its own and ready to be placed into pairs. The code for actually sorting the elements and combining them into groups comes next.
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/8 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/8 2.md
new file mode 100644
index 00000000..7edd020b
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/8 2.md
@@ -0,0 +1,89 @@
+
+
+
+
+
+
+### Merge Sort in Python (Part II)
+
+```python
+ i = j = k = 0
+ while i < len(lefthalf) and j < len(righthalf):
+ if lefthalf[i] <= righthalf[j]:
+ alist[k]=lefthalf[i]
+ i=i+1
+ else:
+ alist[k]=righthalf[j]
+ j=j+1
+ k=k+1
+```
+
+At this point, we're ready to start combining elements. We have `lefthalf`,`righthalf`, and the original `alist` from where these two halves came from. (Note: when we say "original", it only means the list which was passed to *this* particular iteration of the **mergesort** function. We could be at any step in the overall splitting-sorting-combining process).
+
+We create three new variables: `i`, `j`, and `k`, to keep track of our position within `lefthalf`, `righthalf`, and `alist` respectively. Now we start iterating through both `lefthalf` and `righthalf`, comparing them element-by-element. Whichever element is the smaller of the two gets placed in the appropriate position in our `alist`. We keep doing this until we finish sorting and combining all elements in both halves.
+
+```python
+ while i < len(lefthalf):
+ alist[k]=lefthalf[i]
+ i=i+1
+ k=k+1
+
+ while j < len(righthalf):
+ alist[k]=righthalf[j]
+ j=j+1
+ k=k+1
+```
+
+There might be situations where we still have elements "left over" after this combining process. These elements haven't been sorted and combined yet. The most common example of this happening is when we have an odd number of elements in our main list and the two halves aren't equal. In this case, we simply tack on these elements to the end of our main list. We'll deal with them in a later step.
+
+```python
+def printList(arr):
+ for i in range(len(arr)):
+ print(arr[i],end=" ")
+ print()
+```
+
+We use this function for when we want to print a list without any brackets or commas showing up in our output.
+
+```python
+def mergeSort(alist):
+ if len(alist) > 1:
+ mid = len(alist) // 2 # integer division
+ lefthalf = alist[:mid]
+ righthalf = alist[mid:]
+ mergeSort(lefthalf)
+ mergeSort(righthalf)
+
+ i = 0
+ j = 0
+ k = 0
+ while i < len(lefthalf) and j < len(righthalf):
+ if lefthalf[i] <= righthalf[j]:
+ alist[k]=lefthalf[i]
+ i=i+1
+ else:
+ alist[k]=righthalf[j]
+ j=j+1
+ k=k+1
+
+ while i < len(lefthalf):
+ alist[k]=lefthalf[i]
+ i=i+1
+ k=k+1
+
+ while j < len(righthalf):
+ alist[k]=righthalf[j]
+ j=j+1
+ k=k+1
+
+def printList(arr):
+ for i in range(len(arr)):
+ print(arr[i],end=" ")
+ print()
+
+alist = [14,46,43,27,57,41,45,21,70]
+mergeSort(alist)
+printList(alist)
+```
+
+Use this code to call our functions and ensure they work properly.
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/9 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/9 2.md
new file mode 100644
index 00000000..9ee84b90
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/9 2.md
@@ -0,0 +1,39 @@
+
+
+
+
+
+
+# Quicksort Theory
+
+Quick sort may be the hardest of the 4 to understand as it relies on something called a "pivot value" to compare and swap numbers around.
+
+
+
+We will use a sample list to demonstrate each step of the algorithm. This is the same list that we saw in our Bubble Sort and Insertion Sort examples:
+
+
+
+---
+
+For a visual representation of the steps that we took to complete our Tower of Hanoi programatically, you can take a look below:
+
+
+
+If you guys really want to solve the tower of Hanoi in an automatic way, you can develop a stack class that would take account of the size of each disk to be added into the pole for the stack and then you can pop each disk out of the stack and then you create new towers (stacks really) to input any of the disks in a different order no matter the size.
diff --git a/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/README 2.md b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/README 2.md
new file mode 100644
index 00000000..fd861057
--- /dev/null
+++ b/Module4.1_Intro_to_Data_Structures_and_Algos/activities/Act4_Stacks/README 2.md
@@ -0,0 +1,22 @@
+# Stacks
+
+# Long Summary
+
+Learn about stacks and how to implement them in Python. Then use stacks to solve a fun mathematical puzzle!
+
+# Short Summary
+
+Understand what a stack is and how to use it.
+
+# Criteria
+
+- How is a stack similar to a pile of books?
+
+- How do you remove and add elements to a stack?
+
+- How would you implement removing and adding elements from a stack in Python?
+
+
+# Difficulty
+
+Easy
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act1_LinkedLists/README 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act1_LinkedLists/README 2.md
new file mode 100644
index 00000000..ebddb558
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act1_LinkedLists/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Linked Lists
+
+# Long Summary
+Students will learn about the essential data structure linked lists. They will learn the critical operations that will allow them to interact with linked lists. At the end, they will be given a scenario in which linked lists can be implemented.
+
+# Short Summary
+Students will learn about the linked list data structure.
+
+# Criteria
+1. What do we use the `next_node` pointer for?
+2. What is the purpose of keeping track of the head of the linked list?
+3. Give a scenario where a linked list is better to use than an array.
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/InsertBefore3 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/InsertBefore3 2.md
new file mode 100644
index 00000000..bc5f693c
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/InsertBefore3 2.md
@@ -0,0 +1,68 @@
+
+
+
+
+# Recursion with Binary Search Trees
+
+Recursion is a common coding strategy where we write a function that calls itself until it reaches a base case.
+Below is a code example where recursion is implemented to find the factorial of a number.
+The function takes in a number and it should return the factorial of the number.
+When writing a recursive function, the first thing we want to establish is a base case. In this case, the mathematical relationship of the factorial of 7 would be ...
+```
+7*6*5*4*3*2*1
+```
+It multiplies every number from 7*1 and after it multiplies by 1, all the calculation is finished. Hence, our **base case** will be when number == 1.
+Right now, it may seem confusing but it will make sense when all the pieces come together.
+``` python
+def fact(number):
+ if(number == 1) //base case
+ return product;
+```
+Now, lets write the rest of our recursive function. Since `number == 7` (in our example), it would not fall into our if-statement. We will write an `else` statement
+that accounts for when `number` != 1.
+```python
+ else
+ product = number*(fact(number-1)) // this is where the recursion occurs
+```
+This is the rest of the function. We will multiply `number *fact(number-1)`. When `Fact` is called, `number` will not equal 1.
+The pseudo code will look like this
+```
+product = number*(number-1)*(fact(number-1)).
+Using our example of fact(7), the computation of our program will look like:
+`7*6*fact(number-1)`.
+
+When fact is called again, `number` == 5, and the pattern will repeat until `number` == 1.
+Eventually the computation will look like:
+7*6*5*4*3*2*1
+Since the last `number` multiplied is 1, the base case is reached and `product` is returned.
+
+### Another Example
+Recursion is an incredibly confusing topic so lets take a look at another example before we implement it into our Binary Search Tree.
+The general outline we want to approach recursion is:
+1. Simplify the problem into something smaller.
+ - Our problem is adding `num1` to the number above it.
+2. Solve the simpler problem with an algorithm.
+ - To solve our problem, we can solve it by calling our function multiple times.
+ In this case, calling the same function with a `num1+1`
+3. Putting Everything Together
+
+Lets write a recursive function to find the sum of an interval of numbers. We will want two inputs and every number between those inputs will be added.
+```python
+def interval(num1, num2):
+```
+First lets write our base case. If `num1 == num2`, then that means the interval is zero and there are no more numbers to add. So our base case looks like this:
+Sum is simply the number that is the sum of the interval of numbers.
+```python
+if (num1 == num2)
+ return sum
+```
+
+Now lets incorporate our logic. In our else statement, we want to be calling the same function but with `num1+1` as our input.
+```python
+else
+ sum = num1 + interval(num1+1, num2)
+```
+Eventually, after enough calls, num1 will equal num2 and our function will return sum.
+
+Recursion has an incredible wide use of applications that we can implment and its that we can look into.
+
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/README 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/README 2.md
new file mode 100644
index 00000000..73f344ba
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act2_Trees/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Trees
+
+# Long Summary
+Students will learn about the tree data structure. They will learn all the necessary terminology associated with trees. Then, they will learn about specific types of trees, such as Binary Search Trees.
+
+# Short Summary
+Students will learn about the tree data structure and different types of trees.
+
+# Criteria
+1. What makes a tree be considered a Binary Search Tree?
+2. Give an example of some data that would work well with a tree data structure.
+3. What are the operations that you can perform on a Binary Search Tree?
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act3_Binary Heaps/README 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act3_Binary Heaps/README 2.md
new file mode 100644
index 00000000..7e2dd737
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act3_Binary Heaps/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Binary Heaps
+
+# Long Summary
+Students will learn about the Binary Heap data structure. They will explore the different operations that can be performed on a binary heap. They will also learn how to build a binary heap given a set of keys.
+
+# Short Summary
+Students will learn about the binary heap data structure.
+
+# Criteria
+1. Which key is put at the root of a max heap?
+2. Give a scenario where a binary heap would help you solve a problem.
+3. What are the operations you can perform on a binary heap?
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module4.2_Intermediate_Data_Structures/activities/Act4_Graphs/README 2.md b/Module4.2_Intermediate_Data_Structures/activities/Act4_Graphs/README 2.md
new file mode 100644
index 00000000..3e2910a1
--- /dev/null
+++ b/Module4.2_Intermediate_Data_Structures/activities/Act4_Graphs/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Graphs
+
+# Long Summary
+Students will learn about graph data structures. They become familiar with different types of graphs that are commonly used. They will then learn popular graph algorithms.
+
+# Short Summary
+Students will learn about graphs and different ways computer scientists use graphs.
+
+# Criteria
+1. What does Dijkstra's algorithm do?
+2. What is the difference between a directed and undirected graph?
+3. What is a Hamiltonian path?
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/3-checkpoint 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/3-checkpoint 2.md
new file mode 100644
index 00000000..b257260c
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/3-checkpoint 2.md
@@ -0,0 +1,5 @@
+**Name**: BFS code checkup
+
+**Instruction**: Take a screenshot of your code and submit it.
+
+**Type**: Image Checkpoint
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/5-checkpoint 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/5-checkpoint 2.md
new file mode 100644
index 00000000..84599e08
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/5-checkpoint 2.md
@@ -0,0 +1,5 @@
+**Name**: BFS and DFS comparison
+
+**Instruction**: How is the Depth-First Search different from the Breadth-First Search?
+
+**Type**: Short answer
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7 2.md
new file mode 100644
index 00000000..3cb50fc8
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7 2.md
@@ -0,0 +1,167 @@
+
+
+
+
+
+
+Here is a binary search algorithm coded in Python:
+
+```python
+# Python Program for recursive binary search.
+
+# Returns index of x in arr if present, else -1
+def binarySearch(arr, l, r, x):
+
+ # Check base case
+ if r >= l:
+
+ mid = l + (r - l)/2
+
+ # If element is present at the middle itself
+ if arr[mid] == x:
+ return mid
+
+ # If element is smaller than mid, then it
+ # can only be present in left subarray
+ elif arr[mid] > x:
+ return binarySearch(arr, l, mid-1, x)
+
+ # Else the element can only be present
+ # in right subarray
+ else:
+ return binarySearch(arr, mid + 1, r, x)
+
+ else:
+ # Element is not present in the array
+ return -1
+
+# Test array
+arr = [ 2, 3, 4, 10, 40 ]
+x = 10
+
+# Function call
+result = binarySearch(arr, 0, len(arr)-1, x)
+
+if result != -1:
+ print "Element is present at index % d" % result
+else:
+ print "Element is not present in array"
+
+```
+
+That was probably a mouthful of code. Let's break it down.
+
+Binary Search takes as arguments an array `arr` and three integers, `l`, `r`, and `x`. `l` is the leftmost index of the array we are searching and `r` is the rightmost index of the array we are searching. `x` is the element we are looking for.
+
+``` python
+# Function call
+result = binarySearch(arr, 0, len(arr)-1, x)
+```
+
+This is why the first function call passes in 0 for `l` and `len(arr) - 1` for `r` as we are searching the entire array. `l` and `r` will become important in the recursive calls made in the function.
+
+We start our binary search function by setting up a base case.
+
+```python
+ def binarySearch(arr, l, r, x):
+ if r >= l:
+
+ mid = l + (r - l)/2
+
+ if arr[mid] == x:
+ return mid
+
+
+ elif arr[mid] > x:
+ return binarySearch(arr, l, mid-1, x)
+
+ else:
+ return binarySearch(arr, mid + 1, r, x)
+```
+
+We only proceed with the algorithm if the right index is greater than a left index (`if r >= l`). When `r < l`, then we know that the element is not in the array, as the start of the array (represented by `l`) must always be before the end of the array (represented by `r`)
+
+If we pass this test, we find the index of the middle element using the formula:
+
+```python
+mid = l + (r - l) / 2
+```
+
+This is analogous to the formula shown in the previous section:
+
+```
+mid = low + (high - low) / 2
+```
+
+Note that the formula uses integer division, meaning that any decimal places are truncated. For example,
+
+```
+mid = 5 + (4-1) / 2 = 5 + 3/2 = 5 + 1 = 6
+```
+
+We then proceed if the element we are looking for (`x`) is indeed the middle element. If this is the case, we have found the element and the algorithm returns the middle index and terminates. This is seen here:
+
+```python
+if arr[mid] == x:
+ return mid
+```
+
+If the target element's value is less than the middle element's value, that implies that the target element should be on the left side of the array (remember, the array is sorted). This case is handled by the following `elif` statement.
+
+````python
+elif arr[mid] > x:
+ return binarySearch(arr, l, mid-1, x)
+````
+
+The body of the `elif` statement performs a recursive call to `binarySearch`, changing the right endpoint (`r`) to `mid - 1`. This is done as we had determined that `x` must be on the left side of the array (that is, between the `l` and `mid - 1` indices). By doing this recursive call, we have essentially split our problem in half.
+
+Our else case tells us that if the target element is not in the middle and it is not to the left, it must be on the right (and greater in value than the middle element's value).
+
+```python
+else:
+ return binarySearch(arr, mid + 1, r, x)
+```
+
+The body of the `else` statement performs a recursive call to `binarySearch` for a similar reason to that of the `elif` statement. The difference here is that we had determined that `x` must be on the right side of the array and would be contained between the indices `mid + 1` and `r`. By doing this recursive call, the problem is split in half.
+
+This diagram shows how the recursive calls work in finding an element `x`.
+
+
+
+The last case is reserved for when the element cannot be found. As stated earlier, this occurs when `r` < `l`. In this case, we return `-1` to signify that we could not find `x`.
+
+```python
+ else:
+ return -1
+```
+
+When does `r < l` occur? To understand this, let's go back to our recursive calls
+
+```python
+elif arr[mid] > x:
+ return binarySearch(arr, l, mid-1, x)
+
+ else:
+ return binarySearch(arr, mid + 1, r, x)
+```
+
+In the first possible recursive call, we decrement `mid` and pass it to the argument `r`, without changing `l`. In the second possible recursive call, we increment `mid` and pass it to the argument `l`, without changing `r`. One can see that if the target element is not the middle element everytime we shrink the size of the array (by adjusting `l` and `r`), eventually, we could have `l` cross (be greater than) `r` (either by passing in `mid - 1` for `r` or `mid + 1` for `l`).
+
+Here is how the algorithm would proceed when you are unable to find an element:
+
+
+
+This block of code is what we use to test if our function is working properly. Feel free to twink with it.
+
+```python
+arr = [ 2, 3, 4, 10, 40 ]
+x = 10
+
+# Function call
+result = binarySearch(arr, 0, len(arr)-1, x)
+
+if result != -1:
+ print "Element is present at index % d" % result
+else:
+ print "Element is not present in array"
+```
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7-checkpoint 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7-checkpoint 2.md
new file mode 100644
index 00000000..746f2e37
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act1_SearchingAndSorting/7-checkpoint 2.md
@@ -0,0 +1,5 @@
+**Name**: Binary search implementation
+
+**Instruction**: How is recursion used in the binary search function to find the target?
+
+**Type**: Short Answer
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/10 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/10 2.md
new file mode 100644
index 00000000..d02bcbf6
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/10 2.md
@@ -0,0 +1,69 @@
+
+## Quick Sort Implementation in Python
+
+```python
+def partition(arr,low,high):
+ i = ( low-1 )
+ pivot = arr[high]
+```
+
+The **partition** function will be responsible for actually placing our pivot point (always the last element of the list in this version) in its proper place. Notice what this means. There is no "right side" of the list as far as our pivot is concerned. Only a "left side". The goal remains the same however: all the numbers smaller than the pivot need to be to its left, and all larger numbers need to be to its right.
+
+In this system, we will attempt to always keep track of two elements : a smaller element and a bigger element. Here, we use `i` to represent the smaller element, specifically its position. We use the last element of the list as our pivot.
+
+```python
+ for j in range(low, high):
+ if arr[j] < pivot:
+ i = i+1
+ arr[i],arr[j] = arr[j],arr[i]
+```
+
+`j` will represent the larger element. The `i`'th element should always be smaller than the `j`'th element. This means that we want the elements of the list to be in increasing order as we pass through it. We iterate through our list using `j`, doing nothing if the `j`'th element is bigger than the pivot.
+
+If the `j`'th element is smaller than our pivot, we increment `i`. Notice what happens! The `i`'th element is now *bigger* than the `j`'th element. So, we need to swap them.
+
+```python
+ arr[i+1], arr[high] = arr[high], arr[i+1]
+ return ( i+1 )
+```
+
+After we have finished iterating through our list, we should have sorted every element we could in this pass. All that's left is to put the pivot element into its proper place within our list. With the way we decided when to increment `i` in our algorithm, all elements to the right of the `i`'th element will be *bigger* than the pivot element. So, the place to insert our pivot element will be immediately to the right of the `i`'th element, or at the `i+1`'th position. We return this number to be used when we run **quickSort** again.
+
+```python
+def quickSort(arr,low,high):
+ if low < high:
+ pi = partition(arr,low,high)
+ quickSort(arr, low, pi-1)
+ quickSort(arr, pi+1, high)
+```
+
+This is where we define the actual **quickSort** function. Notice the role of `pi` here. By the time we call the **partition** function and get the value of `pi`, we have placed the pivot element in its proper place. This means we only need to worry about sorting all the elements *before* it and *after* it. That's why we use `pi` to split our list into two and call **quicksort** on both halves.
+
+```python
+def partition(arr,low,high):
+ i = low - 1
+ pivot = arr[high]
+ for j in range(low, high):
+ if arr[j] < pivot:
+ i = i+1
+ arr[i],arr[j] = arr[j],arr[i]
+ arr[i+1],arr[high] = arr[high],arr[i+1]
+ return i+1
+
+def quickSort(arr,low,high):
+ if low < high:
+ pi = partition(arr,low,high)
+
+ quickSort(arr, low, pi-1)
+ quickSort(arr, pi+1, high)
+
+# Driver Code
+arr = [10, 7, 8, 9, 1, 5]
+n = len(arr)
+quickSort(arr,0,n-1)
+print ("Sorted array is:")
+for i in range(n):
+ print ("%d" %arr[i])
+```
+
+Use this code to call our functions and ensure they work properly.
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/7 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/7 2.md
new file mode 100644
index 00000000..98c399b4
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/7 2.md
@@ -0,0 +1,23 @@
+### Merge Sort in Python (Part I)
+
+```python
+def mergeSort(alist):
+ if len(alist) > 1:
+ mid = len(alist) // 2 # integer division
+```
+
+Let's start off with creating a function. If the length of the list we are looking at is greater than 1, we know it might need sorting. We first create a variable called `mid` which finds the middle position of the list. We need this to be able to do the initial splitting of the list into two equal groups.
+
+```python
+ lefthalf = alist[:mid]
+ righthalf = alist[mid:]
+```
+
+These two lines split the list into two equal groups, if possible. `lefthalf` holds all the elements of our original list from the beginning up to (*but not including*) `mid`. `righthalf` then holds all of the elements from the `mid`, or middle, position all the way to the end.
+
+```
+ mergeSort(lefthalf)
+ mergeSort(righthalf)
+```
+
+Here we use recursion to split up the two halves of our list. We simply treat each part as another list and put it through the same splitting process we just went through. We keep doing this until we get to the place where we have each element on its own and ready to be placed into pairs. The code for actually sorting the elements and combining them into groups comes next.
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/8 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/8 2.md
new file mode 100644
index 00000000..7edd020b
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/8 2.md
@@ -0,0 +1,89 @@
+
+
+
+
+
+
+### Merge Sort in Python (Part II)
+
+```python
+ i = j = k = 0
+ while i < len(lefthalf) and j < len(righthalf):
+ if lefthalf[i] <= righthalf[j]:
+ alist[k]=lefthalf[i]
+ i=i+1
+ else:
+ alist[k]=righthalf[j]
+ j=j+1
+ k=k+1
+```
+
+At this point, we're ready to start combining elements. We have `lefthalf`,`righthalf`, and the original `alist` from where these two halves came from. (Note: when we say "original", it only means the list which was passed to *this* particular iteration of the **mergesort** function. We could be at any step in the overall splitting-sorting-combining process).
+
+We create three new variables: `i`, `j`, and `k`, to keep track of our position within `lefthalf`, `righthalf`, and `alist` respectively. Now we start iterating through both `lefthalf` and `righthalf`, comparing them element-by-element. Whichever element is the smaller of the two gets placed in the appropriate position in our `alist`. We keep doing this until we finish sorting and combining all elements in both halves.
+
+```python
+ while i < len(lefthalf):
+ alist[k]=lefthalf[i]
+ i=i+1
+ k=k+1
+
+ while j < len(righthalf):
+ alist[k]=righthalf[j]
+ j=j+1
+ k=k+1
+```
+
+There might be situations where we still have elements "left over" after this combining process. These elements haven't been sorted and combined yet. The most common example of this happening is when we have an odd number of elements in our main list and the two halves aren't equal. In this case, we simply tack on these elements to the end of our main list. We'll deal with them in a later step.
+
+```python
+def printList(arr):
+ for i in range(len(arr)):
+ print(arr[i],end=" ")
+ print()
+```
+
+We use this function for when we want to print a list without any brackets or commas showing up in our output.
+
+```python
+def mergeSort(alist):
+ if len(alist) > 1:
+ mid = len(alist) // 2 # integer division
+ lefthalf = alist[:mid]
+ righthalf = alist[mid:]
+ mergeSort(lefthalf)
+ mergeSort(righthalf)
+
+ i = 0
+ j = 0
+ k = 0
+ while i < len(lefthalf) and j < len(righthalf):
+ if lefthalf[i] <= righthalf[j]:
+ alist[k]=lefthalf[i]
+ i=i+1
+ else:
+ alist[k]=righthalf[j]
+ j=j+1
+ k=k+1
+
+ while i < len(lefthalf):
+ alist[k]=lefthalf[i]
+ i=i+1
+ k=k+1
+
+ while j < len(righthalf):
+ alist[k]=righthalf[j]
+ j=j+1
+ k=k+1
+
+def printList(arr):
+ for i in range(len(arr)):
+ print(arr[i],end=" ")
+ print()
+
+alist = [14,46,43,27,57,41,45,21,70]
+mergeSort(alist)
+printList(alist)
+```
+
+Use this code to call our functions and ensure they work properly.
\ No newline at end of file
diff --git a/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/9 2.md b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/9 2.md
new file mode 100644
index 00000000..9ee84b90
--- /dev/null
+++ b/Module4.3_Search_and_Sorting_Algorithms/activities/Act2_Sorting/9 2.md
@@ -0,0 +1,39 @@
+
+
+
+
+
+
+# Quicksort Theory
+
+Quick sort may be the hardest of the 4 to understand as it relies on something called a "pivot value" to compare and swap numbers around.
+
+
+
+We will use a sample list to demonstrate each step of the algorithm. This is the same list that we saw in our Bubble Sort and Insertion Sort examples:
+
+ +
+1. We first choose an element to be our "pivot point". There are many different strategies on how to pick the pivot point. For our example, we will choose a random element, `3` as our pivot. The code below chooses to always pick the last element in a list as the pivot.
+
+
+
+1. We first choose an element to be our "pivot point". There are many different strategies on how to pick the pivot point. For our example, we will choose a random element, `3` as our pivot. The code below chooses to always pick the last element in a list as the pivot.
+
+  +
+2. Start at the left of the list and continue through until you come across a value higher than that of the pivot. In our case, we didn't need to move. The first element `6` is already larger than our pivot.
+
+
+
+2. Start at the left of the list and continue through until you come across a value higher than that of the pivot. In our case, we didn't need to move. The first element `6` is already larger than our pivot.
+
+  +
+3. Do the same starting from the right end of the list. Move left until you come across a value smaller than that the pivot. That would be the `2` in our example, the second-to-last element in the list.
+
+
+
+3. Do the same starting from the right end of the list. Move left until you come across a value smaller than that the pivot. That would be the `2` in our example, the second-to-last element in the list.
+
+  +
+4. Swap these two values.
+
+
+
+4. Swap these two values.
+
+  +
+5. Continue moving in through the list, repeating steps 2-4 until both sides meet the pivot point. At this point, our list should look like this:
+
+
+
+5. Continue moving in through the list, repeating steps 2-4 until both sides meet the pivot point. At this point, our list should look like this:
+
+  +
+6. We're done with `3`. Now we select a different pivot and repeat the process all over again. We keep doing this until we get a fully sorted list, as shown below:
+
+
+
+6. We're done with `3`. Now we select a different pivot and repeat the process all over again. We keep doing this until we get a fully sorted list, as shown below:
+
+  diff --git a/Module4_Labs/Bubblesort 2.md b/Module4_Labs/Bubblesort 2.md
new file mode 100644
index 00000000..d64b104a
--- /dev/null
+++ b/Module4_Labs/Bubblesort 2.md
@@ -0,0 +1,23 @@
+
+
+# Bubblesort Algorithm
+
+Bubblesort is one of our four types of basic sorting algorithms in Python. The purpose of Bubblesort is to sort through a series of numbers and sort the values out such that the largest values are first and the lower values are last.
+
+### How to do this?
+
+1. Compare the first two numbers, if they are not in order (larger number is on the left) then swap the two.
+2. Move on from the first and compare the second and third values, swap if necessary.
+3. Continue down the list until reaching the last index. At this point the largest value has been sorted.
+4. Repeat from the first number and continue to the last unsorted index.
+
+#### Why is it Useful?
+
+* Use Bubblesort to quickly rearrange values
+* A teacher could use Bubblesort to quickly shift through a large amount of test scores to find the highest and lowest scores
+* A consumer looking for a new TV could sort a list of items to check for price
+
+
+
+
+
diff --git a/Module4_Labs/Insertionsort 2.md b/Module4_Labs/Insertionsort 2.md
new file mode 100644
index 00000000..3f72614e
--- /dev/null
+++ b/Module4_Labs/Insertionsort 2.md
@@ -0,0 +1,17 @@
+
+
+# Insertion Sort
+
+Insertion Sort is another one of our four basic sorting algorithms in Python. As with all sorting algorithms in Python, the purpose of Insertion is to work with groups of data. For example, if we are trying to sort a list of values from Biggest to smallest; Insertion Sort works by grabbing one element, and comparing it the element next to it. If the element is smaller, we pass that element and keep passing elements until we reach an element that is greater than the element we grabbed. We then insert that element in that place holder, and grab a new one.
+
+##### Visual Example
+
+
+
+### When should I use Insertion Sort?
+
+* insertion sort is most useful when working with data sets that are partially sorted through and only have a few misplaced items. Insertion sort is also useful when the data set is small.
+* Note that Insertion Sort runs in O(n^2^) time.
+
+
+
diff --git a/Module4_Labs/Lab1_BFS_Maze/Cards/5 2.md b/Module4_Labs/Lab1_BFS_Maze/Cards/5 2.md
new file mode 100644
index 00000000..d2859520
--- /dev/null
+++ b/Module4_Labs/Lab1_BFS_Maze/Cards/5 2.md
@@ -0,0 +1,60 @@
+# Time and Space Analysis of Breath First Search
+
+In this section we are going to perform an analysis of the runtime and space complexity of the BFS search.
+
+## Time complexity of BFS
+
+We can perform an analysis of the BFS search by removing all unnecessary details of implementation and focus on what BFS is doing at its core. This would simplify and help get the higher level overview of the BFS.
+
+There are three things that define the time complexity of BFS:
+
+* In the beginning we had to create a list to track of visited nodes. This will take O(n) runtime.
+
+
+* Also, since we will be visitting each node in the graph there will be at most O(n) queue and dequeue operations each which takes O(1) cost. Therefore this step is also O(n)
+
+
+* For every node we visit, we have to iterate through all its neighbors. At first glance this seemed to be O(n^2) because we are looping through all the neighbors of the nodes. This may be right, but O(n^2) is too big of an upper bound and we can find a tighter upper bound for this.
+
+We see that for every node we will have to check its neighbors. The number of edges (neighbors) that a node has is called the degree of that node.
+
+*Let us denote the degree of node i to Di* .
+
+Therefore we can see that the total number of iterations we have to perform is the sum of all the degrees of each nodes. So the total number of iterations is *D0 + D1 + D2 + ... Dn*. What does this number sum to? Well i will be straightforward and tell you that this equals to 2|E|, where E is the number of edges in the graph. This is proven by the [*Handshaking lemma*](https://en.wikipedia.org/wiki/Handshaking_lemma).
+
+Therefore the complexity of looping through the nodes and its neighbors is actually O(2E) = O(E) rather than O(N^2).
+
+Finally our runtime is therefore O(E + N) , E is number of edges and N is number of nodes.
+
+## Space (Auxiliary) Complexity
+
+For this we just need an additional O(N) space to store our visited nodes array. So our space auxiliary complexity is O(N).
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/Module4_Labs/Lab1_BFS_Maze/Cards/5-Checkpoint 2.md b/Module4_Labs/Lab1_BFS_Maze/Cards/5-Checkpoint 2.md
new file mode 100644
index 00000000..c9a200c9
--- /dev/null
+++ b/Module4_Labs/Lab1_BFS_Maze/Cards/5-Checkpoint 2.md
@@ -0,0 +1,7 @@
+### Checkpoint
+
+Name: BFS Time Complexity
+
+Instruction: Could you answer why the complexity of looping through the neighbors of the nodes in the graph is O(E) instead of O(N^2) ?
+
+Type: Short Answer
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/2-CHECKPOINT 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/2-CHECKPOINT 2.md
new file mode 100644
index 00000000..2c757e05
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/2-CHECKPOINT 2.md
@@ -0,0 +1,37 @@
+
+## Multiple Choice Checkpoint
+
+Description: What would `printList()` look like ?
+
+Choices:
+```python
+def printList(self, node):
+ while node != None:
+ print(node.data)
+ node = node.next
+```
+
+
+```python
+def printList(self, node):
+ for i in range(len(node)):
+ print(node[i].data)
+```
+
+```python
+def printList(self, node):
+ print(node)
+ printList(node.next)
+```
+
+
+
+
+Correct Choice:
+
+```python
+def printList(self, node):
+ while node != None:
+ print(node.data)
+ node = node.next
+```
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/4-CHECKPOINT 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/4-CHECKPOINT 2.md
new file mode 100644
index 00000000..9d1221d7
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/4-CHECKPOINT 2.md
@@ -0,0 +1,3 @@
+## Checkpoint `push`, `pushback` , `insertAfter` , `insertBefore`
+
+Implement the following functions and submit your code. `main()` functions were provided to test those functions
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/42 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/42 2.md
new file mode 100644
index 00000000..98c7db7c
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/42 2.md
@@ -0,0 +1,16 @@
+
+
+
+
+
+
+**Step 1: Normal Operations of push()**
+
+Expanding from the function **push()** which you just defined for inserting the item into an empty list.
+
+You already have the initial coniditon checks in this function. Now, you need to complete the condition when the list is not empty.
+
+If this is not an empty list, then you need to update the pointers of the orignial head node with the new node. Hint: what would happen to the previous pointer of the old head node if you add a new head node into the list, and what about the pointers of the new head node?
+
+
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/421 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/421 2.md
new file mode 100644
index 00000000..eeb42afc
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/421 2.md
@@ -0,0 +1,92 @@
+
+
+
+
+
+
+**Step 1: Making the node**
+
+The first function that will be made for this class is `push(self, newData)` which adds a new node to the **head** of the list.
+
+We are going to create a new node with any `newData` that we want and insert it at the `head` of the list.
+
+First, we call the `Node` method to make the incoming data a node that we can add to the linked list.
+
+```python
+def push(self, newData):
+ newNode = Node(newData)
+```
+
+**Step 2: Pointing to self.head**
+
+The function `push()` relies on `self.head` to keep track of the first node. You can think of this process as cutting to the front of the line. You are the `newNode` and you insert yourself infront of the first person in line.
+
+Here we're using **dot notation**, which allows us to access and reset variables in the constructor methods of classes. We set our new node to point to the current head of the list by using `.next` from our `Node()` class and `self.head` from our `DoublyLinkedList()` class, where the first node in the list is stored.
+
+```python
+ # newNode -> self.head
+ newNode.next = self.head
+```
+
+**Step 3: Pointing back to the new node**
+
+Next, we set `self.head`'s previous pointer to our new node, so now `newNode` is ahead of the value at `self.head`. Again, we use dot notation with `.prev` from the `Node` class. Note that we only do this if the list is **not** empty, since we can't set pointers in an empty list.
+
+```python
+ # If the list is not empty
+ if self.head != None:
+ self.head.prev = newNode
+```
+
+**Step 4: Pushing to an empty list**
+
+In the case of pushing to an empty list, you can just make the head and the tail the new node. We use dot notation once again, setting `newNode` to both self variables. We need to set both head and tail, so if another method is used on the list afterwards, both can be accessed for adding or removing nodes.
+
+```python
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+```
+
+**Step 5: Finalizing the new head**
+
+The last two steps are crucial for the viability of our linked list. First, we must set the `self.head` pointer to `newNode`, so it becomes the new head of the list. You are now at the **front** of the line, with the `head` pointing at you and the person behind you being `next`.
+
+**Step 6: Incrementing the list size**
+
+Lastly, we increment the size of the list by one by editing the size variable in our `DoublyLinkedList` class constructor method.
+
+```python
+ # The head is now the new node
+ self.head = newNode
+ self.size += 1
+```
+
+Here is a graphic that illustrates the changes in the pointers at the front of the linked list when we call the push method.
+
+
diff --git a/Module4_Labs/Bubblesort 2.md b/Module4_Labs/Bubblesort 2.md
new file mode 100644
index 00000000..d64b104a
--- /dev/null
+++ b/Module4_Labs/Bubblesort 2.md
@@ -0,0 +1,23 @@
+
+
+# Bubblesort Algorithm
+
+Bubblesort is one of our four types of basic sorting algorithms in Python. The purpose of Bubblesort is to sort through a series of numbers and sort the values out such that the largest values are first and the lower values are last.
+
+### How to do this?
+
+1. Compare the first two numbers, if they are not in order (larger number is on the left) then swap the two.
+2. Move on from the first and compare the second and third values, swap if necessary.
+3. Continue down the list until reaching the last index. At this point the largest value has been sorted.
+4. Repeat from the first number and continue to the last unsorted index.
+
+#### Why is it Useful?
+
+* Use Bubblesort to quickly rearrange values
+* A teacher could use Bubblesort to quickly shift through a large amount of test scores to find the highest and lowest scores
+* A consumer looking for a new TV could sort a list of items to check for price
+
+
+
+
+
diff --git a/Module4_Labs/Insertionsort 2.md b/Module4_Labs/Insertionsort 2.md
new file mode 100644
index 00000000..3f72614e
--- /dev/null
+++ b/Module4_Labs/Insertionsort 2.md
@@ -0,0 +1,17 @@
+
+
+# Insertion Sort
+
+Insertion Sort is another one of our four basic sorting algorithms in Python. As with all sorting algorithms in Python, the purpose of Insertion is to work with groups of data. For example, if we are trying to sort a list of values from Biggest to smallest; Insertion Sort works by grabbing one element, and comparing it the element next to it. If the element is smaller, we pass that element and keep passing elements until we reach an element that is greater than the element we grabbed. We then insert that element in that place holder, and grab a new one.
+
+##### Visual Example
+
+
+
+### When should I use Insertion Sort?
+
+* insertion sort is most useful when working with data sets that are partially sorted through and only have a few misplaced items. Insertion sort is also useful when the data set is small.
+* Note that Insertion Sort runs in O(n^2^) time.
+
+
+
diff --git a/Module4_Labs/Lab1_BFS_Maze/Cards/5 2.md b/Module4_Labs/Lab1_BFS_Maze/Cards/5 2.md
new file mode 100644
index 00000000..d2859520
--- /dev/null
+++ b/Module4_Labs/Lab1_BFS_Maze/Cards/5 2.md
@@ -0,0 +1,60 @@
+# Time and Space Analysis of Breath First Search
+
+In this section we are going to perform an analysis of the runtime and space complexity of the BFS search.
+
+## Time complexity of BFS
+
+We can perform an analysis of the BFS search by removing all unnecessary details of implementation and focus on what BFS is doing at its core. This would simplify and help get the higher level overview of the BFS.
+
+There are three things that define the time complexity of BFS:
+
+* In the beginning we had to create a list to track of visited nodes. This will take O(n) runtime.
+
+
+* Also, since we will be visitting each node in the graph there will be at most O(n) queue and dequeue operations each which takes O(1) cost. Therefore this step is also O(n)
+
+
+* For every node we visit, we have to iterate through all its neighbors. At first glance this seemed to be O(n^2) because we are looping through all the neighbors of the nodes. This may be right, but O(n^2) is too big of an upper bound and we can find a tighter upper bound for this.
+
+We see that for every node we will have to check its neighbors. The number of edges (neighbors) that a node has is called the degree of that node.
+
+*Let us denote the degree of node i to Di* .
+
+Therefore we can see that the total number of iterations we have to perform is the sum of all the degrees of each nodes. So the total number of iterations is *D0 + D1 + D2 + ... Dn*. What does this number sum to? Well i will be straightforward and tell you that this equals to 2|E|, where E is the number of edges in the graph. This is proven by the [*Handshaking lemma*](https://en.wikipedia.org/wiki/Handshaking_lemma).
+
+Therefore the complexity of looping through the nodes and its neighbors is actually O(2E) = O(E) rather than O(N^2).
+
+Finally our runtime is therefore O(E + N) , E is number of edges and N is number of nodes.
+
+## Space (Auxiliary) Complexity
+
+For this we just need an additional O(N) space to store our visited nodes array. So our space auxiliary complexity is O(N).
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
+
diff --git a/Module4_Labs/Lab1_BFS_Maze/Cards/5-Checkpoint 2.md b/Module4_Labs/Lab1_BFS_Maze/Cards/5-Checkpoint 2.md
new file mode 100644
index 00000000..c9a200c9
--- /dev/null
+++ b/Module4_Labs/Lab1_BFS_Maze/Cards/5-Checkpoint 2.md
@@ -0,0 +1,7 @@
+### Checkpoint
+
+Name: BFS Time Complexity
+
+Instruction: Could you answer why the complexity of looping through the neighbors of the nodes in the graph is O(E) instead of O(N^2) ?
+
+Type: Short Answer
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/2-CHECKPOINT 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/2-CHECKPOINT 2.md
new file mode 100644
index 00000000..2c757e05
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/2-CHECKPOINT 2.md
@@ -0,0 +1,37 @@
+
+## Multiple Choice Checkpoint
+
+Description: What would `printList()` look like ?
+
+Choices:
+```python
+def printList(self, node):
+ while node != None:
+ print(node.data)
+ node = node.next
+```
+
+
+```python
+def printList(self, node):
+ for i in range(len(node)):
+ print(node[i].data)
+```
+
+```python
+def printList(self, node):
+ print(node)
+ printList(node.next)
+```
+
+
+
+
+Correct Choice:
+
+```python
+def printList(self, node):
+ while node != None:
+ print(node.data)
+ node = node.next
+```
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/4-CHECKPOINT 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/4-CHECKPOINT 2.md
new file mode 100644
index 00000000..9d1221d7
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/4-CHECKPOINT 2.md
@@ -0,0 +1,3 @@
+## Checkpoint `push`, `pushback` , `insertAfter` , `insertBefore`
+
+Implement the following functions and submit your code. `main()` functions were provided to test those functions
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/42 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/42 2.md
new file mode 100644
index 00000000..98c7db7c
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/42 2.md
@@ -0,0 +1,16 @@
+
+
+
+
+
+
+**Step 1: Normal Operations of push()**
+
+Expanding from the function **push()** which you just defined for inserting the item into an empty list.
+
+You already have the initial coniditon checks in this function. Now, you need to complete the condition when the list is not empty.
+
+If this is not an empty list, then you need to update the pointers of the orignial head node with the new node. Hint: what would happen to the previous pointer of the old head node if you add a new head node into the list, and what about the pointers of the new head node?
+
+
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/421 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/421 2.md
new file mode 100644
index 00000000..eeb42afc
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/421 2.md
@@ -0,0 +1,92 @@
+
+
+
+
+
+
+**Step 1: Making the node**
+
+The first function that will be made for this class is `push(self, newData)` which adds a new node to the **head** of the list.
+
+We are going to create a new node with any `newData` that we want and insert it at the `head` of the list.
+
+First, we call the `Node` method to make the incoming data a node that we can add to the linked list.
+
+```python
+def push(self, newData):
+ newNode = Node(newData)
+```
+
+**Step 2: Pointing to self.head**
+
+The function `push()` relies on `self.head` to keep track of the first node. You can think of this process as cutting to the front of the line. You are the `newNode` and you insert yourself infront of the first person in line.
+
+Here we're using **dot notation**, which allows us to access and reset variables in the constructor methods of classes. We set our new node to point to the current head of the list by using `.next` from our `Node()` class and `self.head` from our `DoublyLinkedList()` class, where the first node in the list is stored.
+
+```python
+ # newNode -> self.head
+ newNode.next = self.head
+```
+
+**Step 3: Pointing back to the new node**
+
+Next, we set `self.head`'s previous pointer to our new node, so now `newNode` is ahead of the value at `self.head`. Again, we use dot notation with `.prev` from the `Node` class. Note that we only do this if the list is **not** empty, since we can't set pointers in an empty list.
+
+```python
+ # If the list is not empty
+ if self.head != None:
+ self.head.prev = newNode
+```
+
+**Step 4: Pushing to an empty list**
+
+In the case of pushing to an empty list, you can just make the head and the tail the new node. We use dot notation once again, setting `newNode` to both self variables. We need to set both head and tail, so if another method is used on the list afterwards, both can be accessed for adding or removing nodes.
+
+```python
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+```
+
+**Step 5: Finalizing the new head**
+
+The last two steps are crucial for the viability of our linked list. First, we must set the `self.head` pointer to `newNode`, so it becomes the new head of the list. You are now at the **front** of the line, with the `head` pointing at you and the person behind you being `next`.
+
+**Step 6: Incrementing the list size**
+
+Lastly, we increment the size of the list by one by editing the size variable in our `DoublyLinkedList` class constructor method.
+
+```python
+ # The head is now the new node
+ self.head = newNode
+ self.size += 1
+```
+
+Here is a graphic that illustrates the changes in the pointers at the front of the linked list when we call the push method.
+
+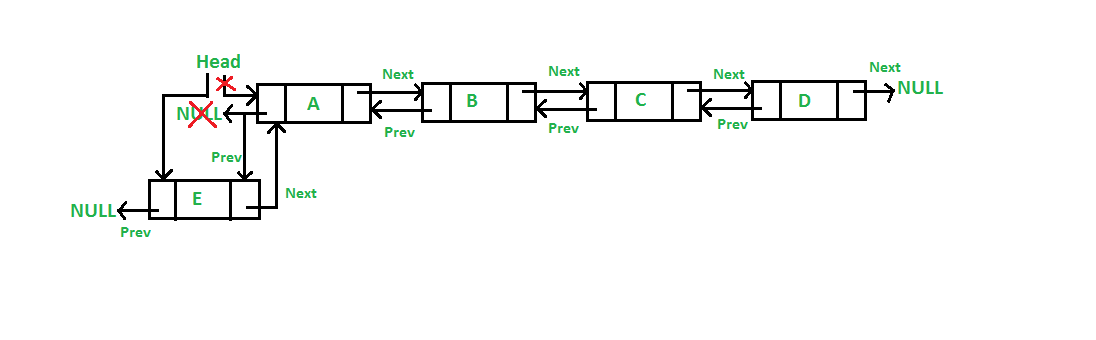 +
+Here is the completed code for the `push(self, newData)` method:
+
+```python
+def push(self, newData):
+ newNode = Node(newData)
+
+ # newNode -> self.head
+ newNode.next = self.head
+
+ # If the list is not empty
+ if self.head != None:
+ self.head.prev = newNode
+
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # The head is now the new node
+ self.head = newNode
+ self.size += 1
+```
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/43 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/43 2.md
new file mode 100644
index 00000000..17ca7bf3
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/43 2.md
@@ -0,0 +1,14 @@
+
+
+
+
+
+
+**Step 1: pushback()**
+
+Define a function called **pushback()** which will also takes a value as the parameter for initializing the element of new node. Of course, as you might have guessed, we need to check the empty list again! If the list is empty, simply make a new head node with the given value.
+
+If this list already contains some elements, we need to traverse through the list until the tail pointer of the list. The next pointer of the tail will be `None`, so this is your base case to stop your while loop.
+
+As you come to the last node of the list, simply apply the logic as you insert a new node at the front. However, we are inserting at the end so the pointers adjustment will be a little bit different.
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/431 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/431 2.md
new file mode 100644
index 00000000..ebae043c
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/431 2.md
@@ -0,0 +1,82 @@
+
+
+
+
+
+
+**Step 1: Making the node**
+
+The next function we will work on is `pushback(self, newData)`
+
+Just like `push(self, newData`), the function `pushback(self, newData)` adds a new node to the list, but it adds it to the **back** or `tail` of the list. It is similar to the `append()` function on a normal list.
+
+Just like in the push method, we first make turn our data into a new node.
+
+```python
+def pushback(self, newData):
+
+ # Initialize new node
+ newNode = Node(newData)
+```
+
+**Step 2: The temp pointer**
+
+The function relies on `self.tail` to keep track of the last node. For this example, you can think of this as going to the back of the line. If the list is not empty, then we have a `temp` pointer pointing to the last node, `self.tail`. We make `temp.next` point to `newNode` and `newNode.prev` point back to temp. This establishes the `next` and `prev` connection between `temp` and `newNode`, so `newNode` is now at the end of the list. Now we just have to set `newNode` as the new tail.
+
+```python
+ # If the list is not empty
+ if self.head != None:
+ temp = self.tail
+ temp.next = newNode
+ newNode.prev = temp
+ self.tail = self.tail.next
+```
+
+Note the order of setting the values in the body of the if statement. We have to set the temp variable first, so we can manipulate the pointers to and from the original tail of the list, all before setting the new node as the new tail using `self.tail`.
+
+**Step 4: Pushing to an empty list**
+
+In the case of using `pushback` on an empty list, you just make `newNode` the head and tail.
+
+**Step 5: Incrementing the list size**
+
+Lastly, we increment the size of the list by one, just like we did with the push function.
+
+```python
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # Increment size
+ self.size += 1
+```
+
+This image depicts how the pointers change when you use the method to add a new tail.
+
+
+
+Here is the completed code for the `push(self, newData)` method:
+
+```python
+def push(self, newData):
+ newNode = Node(newData)
+
+ # newNode -> self.head
+ newNode.next = self.head
+
+ # If the list is not empty
+ if self.head != None:
+ self.head.prev = newNode
+
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # The head is now the new node
+ self.head = newNode
+ self.size += 1
+```
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/43 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/43 2.md
new file mode 100644
index 00000000..17ca7bf3
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/43 2.md
@@ -0,0 +1,14 @@
+
+
+
+
+
+
+**Step 1: pushback()**
+
+Define a function called **pushback()** which will also takes a value as the parameter for initializing the element of new node. Of course, as you might have guessed, we need to check the empty list again! If the list is empty, simply make a new head node with the given value.
+
+If this list already contains some elements, we need to traverse through the list until the tail pointer of the list. The next pointer of the tail will be `None`, so this is your base case to stop your while loop.
+
+As you come to the last node of the list, simply apply the logic as you insert a new node at the front. However, we are inserting at the end so the pointers adjustment will be a little bit different.
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/431 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/431 2.md
new file mode 100644
index 00000000..ebae043c
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/431 2.md
@@ -0,0 +1,82 @@
+
+
+
+
+
+
+**Step 1: Making the node**
+
+The next function we will work on is `pushback(self, newData)`
+
+Just like `push(self, newData`), the function `pushback(self, newData)` adds a new node to the list, but it adds it to the **back** or `tail` of the list. It is similar to the `append()` function on a normal list.
+
+Just like in the push method, we first make turn our data into a new node.
+
+```python
+def pushback(self, newData):
+
+ # Initialize new node
+ newNode = Node(newData)
+```
+
+**Step 2: The temp pointer**
+
+The function relies on `self.tail` to keep track of the last node. For this example, you can think of this as going to the back of the line. If the list is not empty, then we have a `temp` pointer pointing to the last node, `self.tail`. We make `temp.next` point to `newNode` and `newNode.prev` point back to temp. This establishes the `next` and `prev` connection between `temp` and `newNode`, so `newNode` is now at the end of the list. Now we just have to set `newNode` as the new tail.
+
+```python
+ # If the list is not empty
+ if self.head != None:
+ temp = self.tail
+ temp.next = newNode
+ newNode.prev = temp
+ self.tail = self.tail.next
+```
+
+Note the order of setting the values in the body of the if statement. We have to set the temp variable first, so we can manipulate the pointers to and from the original tail of the list, all before setting the new node as the new tail using `self.tail`.
+
+**Step 4: Pushing to an empty list**
+
+In the case of using `pushback` on an empty list, you just make `newNode` the head and tail.
+
+**Step 5: Incrementing the list size**
+
+Lastly, we increment the size of the list by one, just like we did with the push function.
+
+```python
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # Increment size
+ self.size += 1
+```
+
+This image depicts how the pointers change when you use the method to add a new tail.
+
+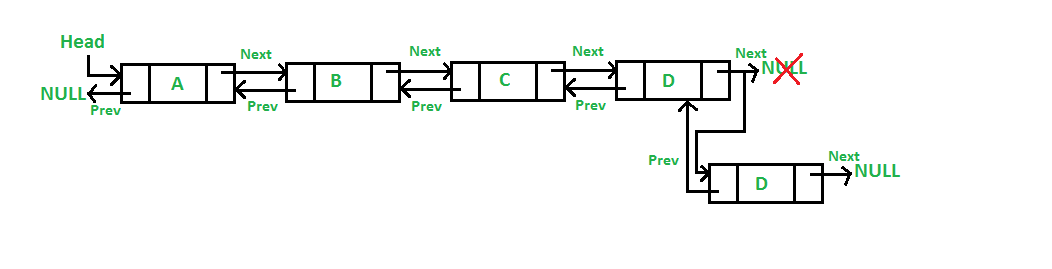 +
+This is the completed code for the `pushback(self, newData)` method:
+
+```python
+def pushback(self, newData):
+
+ # Initialize new node
+ newNode = Node(newData)
+
+ # If the list is not empty
+ if self.head != None:
+ temp = self.tail
+ temp.next = newNode
+ newNode.prev = temp
+ self.tail = self.tail.next
+
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # Increment size
+ self.size += 1
+```
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/44 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/44 2.md
new file mode 100644
index 00000000..164eb939
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/44 2.md
@@ -0,0 +1,23 @@
+
+
+
+
+
+
+**Step 1: Empty List Check**
+
+The **insertAfter()** method takes two parameters: the value you want to insert, and the node that you want to insert it after. We can not insert a node after another node if the list contains no nodes, and this is again why we need the empty list check!
+
+If the list is empty, you can return.
+
+**Step 2: Traversal**
+
+Otherwise, you will do something similar to **pushback()** where you traverse the list until you find the node that you want to insert the value after.
+
+**Step 3: Pointers and Insertion**
+
+If you don't find the node after the tail node, you should insert the new node into the tail node.
+
+Else if the node exists in the list, insert the new node after the selected node. To do this, you need to adjust the next and previous pointers to the new node, the node (A) that it'll be inserted after, and the node after the node A.
+
+Make sure your pointers are set up properly because this is the key to this function.
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/441 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/441 2.md
new file mode 100644
index 00000000..8c79c00e
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/441 2.md
@@ -0,0 +1,120 @@
+
+
+
+
+
+
+**Step 1: Check for an empty list**
+
+We learned how to insert at the front and back of the list, but what about the middle? Or after a certain value?
+
+This next function, `insertAfter(target, newData)` will allow us to do just that. `target` is the node you want to insert after, and `newData` will be the new node proceeding `target`. If we wanted to insert a new node after the node containing the value 17, we would call `insertAfter(17, newData)`.
+
+First, we will check if the list is empty.
+
+**Step 2: Setting up the curr variable**
+
+If it's not, then we set a variable `curr` to the head (first node) of the list, which we will later use to find the target.
+
+```python
+def insertAfter(self, target, newData):
+
+ # 1. If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+```
+
+**Step 3: Iterating through the list to find the target**
+
+Next, we use a while loop to iterate through the linked list in search of the target value. So long as the value at `curr` is not the value of the target, we set `curr` to the following node using `next` and dot notation. Once the data at `curr` is equal to `target`, we exit the while loop. If we get to the end of the list and we haven't found the target, then `curr` will equal None in the last iteration of the while loop. The if statement will then be evaluated, and we will exit the method.
+
+```python
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+
+ if curr == None:
+ print("Target not found.")
+ return
+```
+
+**Step 4: Inserting the new node after the target**
+
+If `target` is found, we skip the if statement, initialize a `newNode` with the `newData` and establish connections for `next` and `prev` between the new node and `curr`. We have to first set the new node to point back at `curr`, and then set `newNode` to point towards the node after `curr`.
+
+```python
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr
+ newNode.next = curr.next
+```
+
+**Step 5: Pointing back at the new node**
+
+Now check that the new node is not the last node in the list. If it's not, then we set the node after `curr` to point back at `newNode`. If we inserted after the last node in the list, `newNode.next` will already point to `None`, so we can just set the new node as `self.tail`, shown in the else statement.
+
+```python
+ # 4. If curr is not the last node
+ if curr.next is not None:
+ curr.next.prev = newNode
+
+ else:
+ self.tail = newNode
+```
+
+**Step 6: Pointing towards the new node**
+
+To finalize the position of `newNode`, we set `curr` to point to `newNode`, which completes the connection between `newNode` and the values before and after it.
+
+Lastly, we increment `self.size` by 1 to track the addition of the new node.
+
+```python
+ # 5. Connect the current node with the new node
+ curr.next = newNode
+
+ # Increment size
+ self.size += 1
+```
+
+Here is the complete code for `insertAfter(self, target, newData)`:
+
+```python
+def insertAfter(self, target, newData):
+
+ # 1. If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr
+ newNode.next = curr.next
+
+ # 4. If curr is not the last node
+ if curr.next is not None:
+ curr.next.prev = newNode
+
+ else:
+ self.tail = newNode
+
+ # 5. Connect the current node with the new node
+ curr.next = newNode
+
+ # Increment size
+ self.size += 1
+```
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/45 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/45 2.md
new file mode 100644
index 00000000..0038a43d
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/45 2.md
@@ -0,0 +1,17 @@
+
+
+
+
+
+
+**Step 1: insertBefore()**
+
+This is the last method for inserting the item, and this item will be inserted before another one in the list. In **insertBefore()**, you will take in two parameters which are the value and the node to be inserted before.
+
+If this is an empty list, you should simply return.
+
+Otherwise, we will iterate through all the nodes in the doubly linked list. In case the node before which we want to insert the new node is not found, just print he message, "Target not Found." and return.
+
+Else if the selected node exists in the list, break out your traversing loop and insert the new node in before the selected node.
+
+Note that you will need to adjust the pointers for both nodes after the insertion. If the node to be inserted before is the head node, what would the previous pointer of the new node be?
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/451 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/451 2.md
new file mode 100644
index 00000000..02c95d10
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/451 2.md
@@ -0,0 +1,112 @@
+
+
+
+
+
+
+**Step 1: Check for an empty list and set curr**
+
+The function `insertBefore(target, newData)` is very similar to the previous function we did. If we wanted to insert a new node before the node containing the value 17, we would call `insertBefore(17, newData)`.
+
+We start out the same way as `insertAfter`, checking that the list is not empty. We set `curr` to the head of the list.
+
+```python
+def insertBefore(self, target, newData):
+
+ # If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+```
+
+**Step 2: Iterating through the list to find the target**
+
+We use the same while loop and if statement as the insert after function as well. We iterate through the linked list by continuously setting `curr` to the node after it, until the data at that node equals the target value. If `curr` is equal to `None`, that means we were not able to find the target in the list, so we exit the method after printing.
+
+```python
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+```
+
+**Step 4: Inserting the new node before the target**
+
+Once the data at `curr` equals `target`, we can insert `newData`. We make a node out of that value, and then set the pointers accordingly. First, set `newNode` to point back to the value before `curr`. Then, set `newNode` to point to `curr`. This positions the new node before `curr`.
+
+```python
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr.prev
+ newNode.next = curr
+```
+
+**Step 5: Pointing to the new node**
+
+Now check to see if we inserted before the head of the list. If not, then we can set the node before `curr` to point to the new node. Otherwise, `newNode` is already at the start of the list, and `newNode.prev` will already point to `None`. If we are at the first node, we will set the new node as `self.head`.
+
+```python
+ # 4. If curr is not the first node
+ if curr.prev != None:
+ curr.prev.next = newNode
+
+ else:
+ self.head = newNode
+```
+
+**Step 6: Pointing back at the new node**
+
+The last step in situating the new node is to set the node before `curr` as `newNode`, by making the current node's `prev` point to the new node. Now `newNode` is before `curr`, and after the node that was originally before `curr`.
+
+Finally, we increment the size of the linked list by one.
+
+```python
+ # 5. Connect the current node with the new node
+ curr.prev = newNode
+
+ # Increment size
+ self.size += 1
+```
+
+This is the completed code for `insertBefore(self, target, newData)`:
+
+```python
+def insertBefore(self, target, newData):
+
+ # If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr.prev
+ newNode.next = curr
+
+ # 4. If curr is not the first node
+ if curr.prev != None:
+ curr.prev.next = newNode
+
+ else:
+ self.head = newNode
+
+ # 5. Connect the current node with the new node
+ curr.prev = newNode
+
+ # Increment size
+ self.size += 1
+```
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/511 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/511 2.md
new file mode 100644
index 00000000..4bb01665
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/511 2.md
@@ -0,0 +1,37 @@
+
+
+
+
+
+
+**Step 1: popFront()**
+
+Now that we know how to add nodes to the list, let's learn how to *remove* nodes from the list.
+
+First, let's look at how to remove from the **head** of the list. We will be relying on `self.head` since it points to the first node in the list.
+
+This function will be called `popFront()`
+
+```python
+def popFront(self):
+
+ # 1. If the list is not empty
+ if self.head == None:
+ return
+
+ else:
+ # 2. If there ISN'T only onde node
+ if self.head.next != None:
+ self.head = self.head.next
+ self.head.prev = None
+
+ # 3. If there's only one node
+ else:
+ self.head = None
+ self.tail = None
+
+ # Decrement size
+ self.size -= 1
+```
+
+For `popFront()`, we will (1) check if the list is empty, then (2) check if there is more than one node in the list and set `self.head` to the next node. Now that `self.head` is the second node in the list, we can now get get rid of the connection the previous node. In the case that there is only one node in the list, we would just make the head and the tail point to `None`.
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/612 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/612 2.md
new file mode 100644
index 00000000..1c710270
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/612 2.md
@@ -0,0 +1,62 @@
+
+
+
+
+
+
+**Step 1: Regular Operation**
+
+Now, if the list is not empty, let's continue coding the removing process.
+
+We can first check if there is more than one node in the list and set `self.head` to the next node. Now that `self.head` is the second node in the list, we can now get get rid of the connection the previous node.
+
+```python
+ else:
+ # 2. If there ISN'T only one node
+ if self.head.next != None:
+ self.head = self.head.next
+ self.head.prev = None
+```
+
+**Step 2: Checking the Edge Case**
+
+In the case that there is only one node in the list, we would just make the head and the tail point to `None`.
+
+```python
+ # 3. If there IS only one node
+ else:
+ self.head = None
+ self.tail = None
+```
+Then, after we remove a node from our list, we have remember to decrease the size of the list.
+
+```python
+ # Decrement size
+ self.size -= 1
+```
+
+**Step 3: Putting it Together**
+
+With that, our `popFront()` function is complete!
+
+```python
+def popFront(self):
+
+ # 1. If the list is not empty
+ if self.head == None:
+ return
+
+ else:
+ # 2. If there ISN'T only one node
+ if self.head.next != None:
+ self.head = self.head.next
+ self.head.prev = None
+
+ # 3. If there IS only one node
+ else:
+ self.head = None
+ self.tail = None
+
+ # Decrement size
+ self.size -= 1
+```
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/622 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/622 2.md
new file mode 100644
index 00000000..01d3c213
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/622 2.md
@@ -0,0 +1,37 @@
+
+
+
+
+
+
+**Step 1: Regular Operation**
+
+If the list is not empty, let's continue coding the popping process.
+
+Similar to method we used for `popFront()`, we can first check if there is more than one node in the list and set `self.tail` to the previous node. Now that `self.tail` is the second-last node in the list, we can now get get rid of the connection the next node.
+
+```python
+ else:
+ # 2. If there ISN'T only one node
+ if self.head != None:
+ self.tail = self.tail.prev
+ self.tail.next = None
+```
+
+**Step 2: Checking the Edge Case**
+
+In the case that there is only one node in the list, we would just make the head and the tail point to `None`.
+
+```python
+ # 3. If there IS only one node
+ else:
+ self.head = None
+ self.tail = None
+```
+
+Then, after we remove a node from our list, we have remember to decrease the size of the list.
+
+```python
+ # Decrement size
+ self.size -= 1
+```
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/623 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/623 2.md
new file mode 100644
index 00000000..16159a32
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/623 2.md
@@ -0,0 +1,42 @@
+
+
+
+
+
+
+**Step 1: Putting it Together & Final Notes**
+
+With that, our `popBack()` function is complete!
+
+```python
+def popBack(self):
+
+ # 1. If the list isn't empty
+ if self.head == None:
+ return
+
+ else:
+ # 2. If there ISN'T only one node
+ if self.head != None:
+ self.tail = self.tail.prev
+ self.tail.next = None
+
+ # 3. If there IS only one node
+ else:
+ self.head = None
+ self.tail = None
+
+ # Decrement size
+ self.size -= 1
+
+```
+
+Overall, you can think of this process as removing the last person in the line. As you can see in the picture below, `self.tail` is the node with the value **1**, let's call this **Node(1)**. `self.tail.next` is None and `self.tail.prev` is **Node(45)**
+
+
+
+This is the completed code for the `pushback(self, newData)` method:
+
+```python
+def pushback(self, newData):
+
+ # Initialize new node
+ newNode = Node(newData)
+
+ # If the list is not empty
+ if self.head != None:
+ temp = self.tail
+ temp.next = newNode
+ newNode.prev = temp
+ self.tail = self.tail.next
+
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # Increment size
+ self.size += 1
+```
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/44 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/44 2.md
new file mode 100644
index 00000000..164eb939
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/44 2.md
@@ -0,0 +1,23 @@
+
+
+
+
+
+
+**Step 1: Empty List Check**
+
+The **insertAfter()** method takes two parameters: the value you want to insert, and the node that you want to insert it after. We can not insert a node after another node if the list contains no nodes, and this is again why we need the empty list check!
+
+If the list is empty, you can return.
+
+**Step 2: Traversal**
+
+Otherwise, you will do something similar to **pushback()** where you traverse the list until you find the node that you want to insert the value after.
+
+**Step 3: Pointers and Insertion**
+
+If you don't find the node after the tail node, you should insert the new node into the tail node.
+
+Else if the node exists in the list, insert the new node after the selected node. To do this, you need to adjust the next and previous pointers to the new node, the node (A) that it'll be inserted after, and the node after the node A.
+
+Make sure your pointers are set up properly because this is the key to this function.
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/441 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/441 2.md
new file mode 100644
index 00000000..8c79c00e
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/441 2.md
@@ -0,0 +1,120 @@
+
+
+
+
+
+
+**Step 1: Check for an empty list**
+
+We learned how to insert at the front and back of the list, but what about the middle? Or after a certain value?
+
+This next function, `insertAfter(target, newData)` will allow us to do just that. `target` is the node you want to insert after, and `newData` will be the new node proceeding `target`. If we wanted to insert a new node after the node containing the value 17, we would call `insertAfter(17, newData)`.
+
+First, we will check if the list is empty.
+
+**Step 2: Setting up the curr variable**
+
+If it's not, then we set a variable `curr` to the head (first node) of the list, which we will later use to find the target.
+
+```python
+def insertAfter(self, target, newData):
+
+ # 1. If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+```
+
+**Step 3: Iterating through the list to find the target**
+
+Next, we use a while loop to iterate through the linked list in search of the target value. So long as the value at `curr` is not the value of the target, we set `curr` to the following node using `next` and dot notation. Once the data at `curr` is equal to `target`, we exit the while loop. If we get to the end of the list and we haven't found the target, then `curr` will equal None in the last iteration of the while loop. The if statement will then be evaluated, and we will exit the method.
+
+```python
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+
+ if curr == None:
+ print("Target not found.")
+ return
+```
+
+**Step 4: Inserting the new node after the target**
+
+If `target` is found, we skip the if statement, initialize a `newNode` with the `newData` and establish connections for `next` and `prev` between the new node and `curr`. We have to first set the new node to point back at `curr`, and then set `newNode` to point towards the node after `curr`.
+
+```python
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr
+ newNode.next = curr.next
+```
+
+**Step 5: Pointing back at the new node**
+
+Now check that the new node is not the last node in the list. If it's not, then we set the node after `curr` to point back at `newNode`. If we inserted after the last node in the list, `newNode.next` will already point to `None`, so we can just set the new node as `self.tail`, shown in the else statement.
+
+```python
+ # 4. If curr is not the last node
+ if curr.next is not None:
+ curr.next.prev = newNode
+
+ else:
+ self.tail = newNode
+```
+
+**Step 6: Pointing towards the new node**
+
+To finalize the position of `newNode`, we set `curr` to point to `newNode`, which completes the connection between `newNode` and the values before and after it.
+
+Lastly, we increment `self.size` by 1 to track the addition of the new node.
+
+```python
+ # 5. Connect the current node with the new node
+ curr.next = newNode
+
+ # Increment size
+ self.size += 1
+```
+
+Here is the complete code for `insertAfter(self, target, newData)`:
+
+```python
+def insertAfter(self, target, newData):
+
+ # 1. If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr
+ newNode.next = curr.next
+
+ # 4. If curr is not the last node
+ if curr.next is not None:
+ curr.next.prev = newNode
+
+ else:
+ self.tail = newNode
+
+ # 5. Connect the current node with the new node
+ curr.next = newNode
+
+ # Increment size
+ self.size += 1
+```
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/45 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/45 2.md
new file mode 100644
index 00000000..0038a43d
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/45 2.md
@@ -0,0 +1,17 @@
+
+
+
+
+
+
+**Step 1: insertBefore()**
+
+This is the last method for inserting the item, and this item will be inserted before another one in the list. In **insertBefore()**, you will take in two parameters which are the value and the node to be inserted before.
+
+If this is an empty list, you should simply return.
+
+Otherwise, we will iterate through all the nodes in the doubly linked list. In case the node before which we want to insert the new node is not found, just print he message, "Target not Found." and return.
+
+Else if the selected node exists in the list, break out your traversing loop and insert the new node in before the selected node.
+
+Note that you will need to adjust the pointers for both nodes after the insertion. If the node to be inserted before is the head node, what would the previous pointer of the new node be?
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/451 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/451 2.md
new file mode 100644
index 00000000..02c95d10
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/451 2.md
@@ -0,0 +1,112 @@
+
+
+
+
+
+
+**Step 1: Check for an empty list and set curr**
+
+The function `insertBefore(target, newData)` is very similar to the previous function we did. If we wanted to insert a new node before the node containing the value 17, we would call `insertBefore(17, newData)`.
+
+We start out the same way as `insertAfter`, checking that the list is not empty. We set `curr` to the head of the list.
+
+```python
+def insertBefore(self, target, newData):
+
+ # If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+```
+
+**Step 2: Iterating through the list to find the target**
+
+We use the same while loop and if statement as the insert after function as well. We iterate through the linked list by continuously setting `curr` to the node after it, until the data at that node equals the target value. If `curr` is equal to `None`, that means we were not able to find the target in the list, so we exit the method after printing.
+
+```python
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+```
+
+**Step 4: Inserting the new node before the target**
+
+Once the data at `curr` equals `target`, we can insert `newData`. We make a node out of that value, and then set the pointers accordingly. First, set `newNode` to point back to the value before `curr`. Then, set `newNode` to point to `curr`. This positions the new node before `curr`.
+
+```python
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr.prev
+ newNode.next = curr
+```
+
+**Step 5: Pointing to the new node**
+
+Now check to see if we inserted before the head of the list. If not, then we can set the node before `curr` to point to the new node. Otherwise, `newNode` is already at the start of the list, and `newNode.prev` will already point to `None`. If we are at the first node, we will set the new node as `self.head`.
+
+```python
+ # 4. If curr is not the first node
+ if curr.prev != None:
+ curr.prev.next = newNode
+
+ else:
+ self.head = newNode
+```
+
+**Step 6: Pointing back at the new node**
+
+The last step in situating the new node is to set the node before `curr` as `newNode`, by making the current node's `prev` point to the new node. Now `newNode` is before `curr`, and after the node that was originally before `curr`.
+
+Finally, we increment the size of the linked list by one.
+
+```python
+ # 5. Connect the current node with the new node
+ curr.prev = newNode
+
+ # Increment size
+ self.size += 1
+```
+
+This is the completed code for `insertBefore(self, target, newData)`:
+
+```python
+def insertBefore(self, target, newData):
+
+ # If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr.prev
+ newNode.next = curr
+
+ # 4. If curr is not the first node
+ if curr.prev != None:
+ curr.prev.next = newNode
+
+ else:
+ self.head = newNode
+
+ # 5. Connect the current node with the new node
+ curr.prev = newNode
+
+ # Increment size
+ self.size += 1
+```
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/511 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/511 2.md
new file mode 100644
index 00000000..4bb01665
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/511 2.md
@@ -0,0 +1,37 @@
+
+
+
+
+
+
+**Step 1: popFront()**
+
+Now that we know how to add nodes to the list, let's learn how to *remove* nodes from the list.
+
+First, let's look at how to remove from the **head** of the list. We will be relying on `self.head` since it points to the first node in the list.
+
+This function will be called `popFront()`
+
+```python
+def popFront(self):
+
+ # 1. If the list is not empty
+ if self.head == None:
+ return
+
+ else:
+ # 2. If there ISN'T only onde node
+ if self.head.next != None:
+ self.head = self.head.next
+ self.head.prev = None
+
+ # 3. If there's only one node
+ else:
+ self.head = None
+ self.tail = None
+
+ # Decrement size
+ self.size -= 1
+```
+
+For `popFront()`, we will (1) check if the list is empty, then (2) check if there is more than one node in the list and set `self.head` to the next node. Now that `self.head` is the second node in the list, we can now get get rid of the connection the previous node. In the case that there is only one node in the list, we would just make the head and the tail point to `None`.
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/612 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/612 2.md
new file mode 100644
index 00000000..1c710270
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/612 2.md
@@ -0,0 +1,62 @@
+
+
+
+
+
+
+**Step 1: Regular Operation**
+
+Now, if the list is not empty, let's continue coding the removing process.
+
+We can first check if there is more than one node in the list and set `self.head` to the next node. Now that `self.head` is the second node in the list, we can now get get rid of the connection the previous node.
+
+```python
+ else:
+ # 2. If there ISN'T only one node
+ if self.head.next != None:
+ self.head = self.head.next
+ self.head.prev = None
+```
+
+**Step 2: Checking the Edge Case**
+
+In the case that there is only one node in the list, we would just make the head and the tail point to `None`.
+
+```python
+ # 3. If there IS only one node
+ else:
+ self.head = None
+ self.tail = None
+```
+Then, after we remove a node from our list, we have remember to decrease the size of the list.
+
+```python
+ # Decrement size
+ self.size -= 1
+```
+
+**Step 3: Putting it Together**
+
+With that, our `popFront()` function is complete!
+
+```python
+def popFront(self):
+
+ # 1. If the list is not empty
+ if self.head == None:
+ return
+
+ else:
+ # 2. If there ISN'T only one node
+ if self.head.next != None:
+ self.head = self.head.next
+ self.head.prev = None
+
+ # 3. If there IS only one node
+ else:
+ self.head = None
+ self.tail = None
+
+ # Decrement size
+ self.size -= 1
+```
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/622 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/622 2.md
new file mode 100644
index 00000000..01d3c213
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/622 2.md
@@ -0,0 +1,37 @@
+
+
+
+
+
+
+**Step 1: Regular Operation**
+
+If the list is not empty, let's continue coding the popping process.
+
+Similar to method we used for `popFront()`, we can first check if there is more than one node in the list and set `self.tail` to the previous node. Now that `self.tail` is the second-last node in the list, we can now get get rid of the connection the next node.
+
+```python
+ else:
+ # 2. If there ISN'T only one node
+ if self.head != None:
+ self.tail = self.tail.prev
+ self.tail.next = None
+```
+
+**Step 2: Checking the Edge Case**
+
+In the case that there is only one node in the list, we would just make the head and the tail point to `None`.
+
+```python
+ # 3. If there IS only one node
+ else:
+ self.head = None
+ self.tail = None
+```
+
+Then, after we remove a node from our list, we have remember to decrease the size of the list.
+
+```python
+ # Decrement size
+ self.size -= 1
+```
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/623 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/623 2.md
new file mode 100644
index 00000000..16159a32
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/623 2.md
@@ -0,0 +1,42 @@
+
+
+
+
+
+
+**Step 1: Putting it Together & Final Notes**
+
+With that, our `popBack()` function is complete!
+
+```python
+def popBack(self):
+
+ # 1. If the list isn't empty
+ if self.head == None:
+ return
+
+ else:
+ # 2. If there ISN'T only one node
+ if self.head != None:
+ self.tail = self.tail.prev
+ self.tail.next = None
+
+ # 3. If there IS only one node
+ else:
+ self.head = None
+ self.tail = None
+
+ # Decrement size
+ self.size -= 1
+
+```
+
+Overall, you can think of this process as removing the last person in the line. As you can see in the picture below, `self.tail` is the node with the value **1**, let's call this **Node(1)**. `self.tail.next` is None and `self.tail.prev` is **Node(45)**
+
+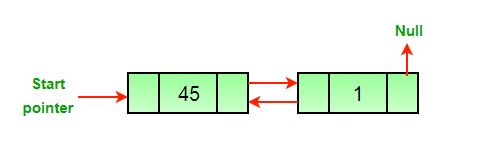 +
+In order to delete the last node, you must make `self.tail` the previous node, or else we will lose the address of the previous node.
+
+Now, **Node(45)** is `self.tail`. Since the node is `self.tail`, we can point `self.tail.next` to be None. **Node(1)** is now deleted after we call Python's built in garbage collector because **Node(1)** does not point to anything anymore.
+
+
+
+In order to delete the last node, you must make `self.tail` the previous node, or else we will lose the address of the previous node.
+
+Now, **Node(45)** is `self.tail`. Since the node is `self.tail`, we can point `self.tail.next` to be None. **Node(1)** is now deleted after we call Python's built in garbage collector because **Node(1)** does not point to anything anymore.
+
+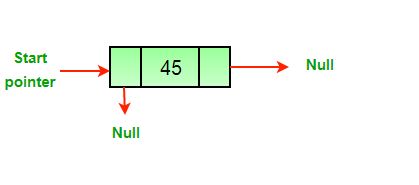 diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/632 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/632 2.md
new file mode 100644
index 00000000..f7be11d8
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/632 2.md
@@ -0,0 +1,71 @@
+
+
+
+
+
+
+**Step 1: Regular Operation**
+
+If the list is not empty, then we shall proceed with the popping process by first searching for the node that we want to pop. Using a while loop, we will traverse through the list with `curr`, and if `curr` reaches the end of the list and equals `None`, then print out "Target not found." and `return` to exit the loop.
+
+```python
+ else:
+ # 2. Search for target
+ while curr.data != target:
+ curr = curr.next
+
+ if curr == None:
+ print("Target not found.")
+ return
+```
+
+**Step 2: Putting it Together & Note**
+
+Once we find the target, we check if it's not the last node because the process in deleting a middle node and the last node are different. If the target node is not the last node, then we would create a `temp` pointer to the `next` node and point the node before the target, `curr.prev.next`, to `temp`. Now we can set temp's `prev` pointer to `curr`'s `prev`.
+
+If the target node is the last node, then we can just use our `popBack()` function to remove it from the list.
+
+Note that the order in which the variables are assigned does matter because the values and pointers of the variables, `temp` and `curr` change throughout the if statement. If one is misplaced, then the values may be assigned incorrectly.
+
+```python
+ # 3. If curr is not the last node
+ if curr.next != None:
+ temp = curr.next
+ curr.prev.next = temp
+ temp.prev = curr.prev
+
+ # 4. If curr is the last node, use popBack()
+ else:
+ self.popBack()
+```
+
+Then, after we remove a node from our list, we have remember to decrease the size of the list.
+
+```python
+ # Decrement size
+ self.size -= 1
+```
+
+---
+
+With that, we have completed our `pop()` function!
+
+```python
+def pop(self, target):
+
+ # 1. Check if the list is empty
+ if self.head == None:
+ return
+
+ else:
+ # 2. Search for target
+ while curr.data != target:
+ curr = curr.next
+
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # Decrement size
+ self.size -= 1
+```
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/712 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/712 2.md
new file mode 100644
index 00000000..6ef9632c
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/712 2.md
@@ -0,0 +1,56 @@
+
+
+
+
+
+
+**Step 1: Looping Through the List**
+
+Now, let's starting coding the actual reversing process.
+
+To move through the entire list, we will create a while loop, which will iterate through each node and halt when `curr` reaches the very end of the list. For instance, if we were at the second node in a list of five, we would set `temp` as a pointer to first node, then switch the second node's pointers, which can be see in the first to third line under the while loop.
+
+The final step in the while loop is very interesting! We would think that we would want `curr = curr.next`, but remember that we just swapped the `next` and`prev` pointers, so instead we would set `curr = curr.prev`. Now `prev` is now pointing in the direction of `next`.
+
+```python
+ # Swap next and prev for all nodes of
+ # doubly linked list
+ while curr is not None:
+ temp = curr.prev
+ curr.prev = curr.next
+ curr.next = temp
+ curr = curr.prev
+```
+**Step 2: Checking for Edge Cases**
+
+Before finish coding our reverse() function, we need to check for certain cases.
+
+If the list is either empty or only has one node, then the reversing process is not needed/ will not work because there is nothing left that can be reversed! So, we need to make sure that check for these cases before proceeding.
+
+```python
+ # Before changing head, check for the cases like
+ # empty list and list with only one node
+ if temp is not None:
+ self.head = temp.prev
+```
+With that, your reverse() function is complete!
+
+```python
+def reverse(self):
+ temp = None
+ curr = self.head
+ self.tail = curr
+
+ # Swap next and prev for all nodes of
+ # doubly linked list
+ while curr is not None:
+ temp = curr.prev
+ curr.prev = curr.next
+ curr.next = temp
+ curr = curr.prev
+
+ # Before changing head, check for the cases like
+ # empty list and list with only one node
+ if temp is not None:
+ self.head = temp.prev
+```
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 2.py b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 2.py
new file mode 100644
index 00000000..5e8479a0
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 2.py
@@ -0,0 +1,132 @@
+
+class Node:
+ def __init__(self, data):
+ self.data = data
+ self.next = None
+ self.prev = None
+
+
+class DoublyLinkedList:
+ def __init__(self):
+ self.head = None
+ self.tail = None
+ self.size = 0
+
+ def printList(self, node):
+ while node != None:
+ print(node.data)
+ # Get next node
+ node = node.next
+
+ def push(self, newData):
+ newNode = Node(newData)
+
+ # newNode -> self.head
+ newNode.next = self.head
+
+ # If the list is not empty
+ if self.head != None:
+ self.head.prev = newNode
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # The head is now the new node
+ self.head = newNode
+ self.size += 1
+
+ def pushback(self, newData):
+ #Initialize new node
+ newNode = Node(newData)
+
+ # If the list is not empty
+
+
+ if self.head != None:
+ temp = self.tail
+ temp.next = newNode
+ newNode.prev = temp
+ self.tail = self.tail.next
+
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # Increment size
+ self.size += 1
+
+ def insertAfter(self, target, newData):
+ # 1. If the list is empty
+ if self.head == None:
+ return
+ else:
+ curr = self.head
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr
+ newNode.next = curr.next
+ # 4. If curr is not the last node
+ if curr.next is not None:
+ curr.next.prev = newNode
+
+ else:
+ self.tail = newNode
+
+ # 5. Connect the current node with the new node
+ curr.next = newNode
+ # Increment size
+ self.size += 1
+
+ def insertBefore(self, target, newData):
+
+ # If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr.prev
+ newNode.next = curr
+
+ # 4. If curr is not the first node
+ if curr.prev != None:
+ curr.prev.next = newNode
+
+ else:
+ self.head = newNode
+
+ # 5. Connect the current node with the new node
+ curr.prev = newNode
+ # Increment size
+ self.size += 1
+
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.insertAfter(2,3)
+ LL.insertAfter(1,4)
+ LL.insertBefore(4,9)
+ LL.printList(LL.head)
+
+main()
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 3.py b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 3.py
new file mode 100644
index 00000000..5e8479a0
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 3.py
@@ -0,0 +1,132 @@
+
+class Node:
+ def __init__(self, data):
+ self.data = data
+ self.next = None
+ self.prev = None
+
+
+class DoublyLinkedList:
+ def __init__(self):
+ self.head = None
+ self.tail = None
+ self.size = 0
+
+ def printList(self, node):
+ while node != None:
+ print(node.data)
+ # Get next node
+ node = node.next
+
+ def push(self, newData):
+ newNode = Node(newData)
+
+ # newNode -> self.head
+ newNode.next = self.head
+
+ # If the list is not empty
+ if self.head != None:
+ self.head.prev = newNode
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # The head is now the new node
+ self.head = newNode
+ self.size += 1
+
+ def pushback(self, newData):
+ #Initialize new node
+ newNode = Node(newData)
+
+ # If the list is not empty
+
+
+ if self.head != None:
+ temp = self.tail
+ temp.next = newNode
+ newNode.prev = temp
+ self.tail = self.tail.next
+
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # Increment size
+ self.size += 1
+
+ def insertAfter(self, target, newData):
+ # 1. If the list is empty
+ if self.head == None:
+ return
+ else:
+ curr = self.head
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr
+ newNode.next = curr.next
+ # 4. If curr is not the last node
+ if curr.next is not None:
+ curr.next.prev = newNode
+
+ else:
+ self.tail = newNode
+
+ # 5. Connect the current node with the new node
+ curr.next = newNode
+ # Increment size
+ self.size += 1
+
+ def insertBefore(self, target, newData):
+
+ # If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr.prev
+ newNode.next = curr
+
+ # 4. If curr is not the first node
+ if curr.prev != None:
+ curr.prev.next = newNode
+
+ else:
+ self.head = newNode
+
+ # 5. Connect the current node with the new node
+ curr.prev = newNode
+ # Increment size
+ self.size += 1
+
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.insertAfter(2,3)
+ LL.insertAfter(1,4)
+ LL.insertBefore(4,9)
+ LL.printList(LL.head)
+
+main()
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 2.py b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 2.py
new file mode 100644
index 00000000..85df80df
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 2.py
@@ -0,0 +1,98 @@
+"""
+Test Case 1
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.push(5)
+ LL.push(9)
+ LL.printList(LL.head)
+"""
+"""
+Test Case 1 - Results
+9
+5
+3
+2
+1
+"""
+
+"""
+Test Case 2
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.pushback(5)
+ LL.pushback(9)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 2 - Results
+3
+2
+1
+5
+9
+"""
+
+
+"""
+Test Case 3
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.pushback(5)
+ LL.insertAfter(5,10)
+ LL.pushback(9)
+ LL.insertAfter(9,11)
+ LL.insertAfter(10,12)
+ LL.insertAfter(3,4)
+ LL.insertAfter(11,14)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 3 - Results
+3
+4
+2
+1
+5
+10
+12
+9
+11
+14
+"""
+
+"""
+Test Case 4
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.insertBefore(3,4)
+ LL.insertBefore(4,5)
+ LL.insertBefore(4,4.5)
+ LL.insertBefore(1,10)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 4 - Results
+5
+4.5
+4
+3
+2
+10
+1
+"""
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 3.py b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 3.py
new file mode 100644
index 00000000..85df80df
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 3.py
@@ -0,0 +1,98 @@
+"""
+Test Case 1
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.push(5)
+ LL.push(9)
+ LL.printList(LL.head)
+"""
+"""
+Test Case 1 - Results
+9
+5
+3
+2
+1
+"""
+
+"""
+Test Case 2
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.pushback(5)
+ LL.pushback(9)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 2 - Results
+3
+2
+1
+5
+9
+"""
+
+
+"""
+Test Case 3
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.pushback(5)
+ LL.insertAfter(5,10)
+ LL.pushback(9)
+ LL.insertAfter(9,11)
+ LL.insertAfter(10,12)
+ LL.insertAfter(3,4)
+ LL.insertAfter(11,14)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 3 - Results
+3
+4
+2
+1
+5
+10
+12
+9
+11
+14
+"""
+
+"""
+Test Case 4
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.insertBefore(3,4)
+ LL.insertBefore(4,5)
+ LL.insertBefore(4,4.5)
+ LL.insertBefore(1,10)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 4 - Results
+5
+4.5
+4
+3
+2
+10
+1
+"""
+
diff --git a/Module4_Labs/Lab3_File_System/Cards/README 2.md b/Module4_Labs/Lab3_File_System/Cards/README 2.md
new file mode 100644
index 00000000..22b12a9e
--- /dev/null
+++ b/Module4_Labs/Lab3_File_System/Cards/README 2.md
@@ -0,0 +1,20 @@
+# File System
+
+# Long Summary
+
+Students will have to parse through a file that contains information about a folder/file's "structural position" within the file structure and its name. After extracting the relevant information in relation to directed graphs, they will store it in a graph that they implement themselves. Students will use the networkx library to help them visual the graph with a GUI and then write the ordered file structure to an output file using DFS.
+# Short Summary
+
+Students will understand graphs better by implementing a directed graph that represents a small file structure and printing its ordered structure in a file.
+
+# Criteria
+
+- The edges in these graphs have directions. Generalize what objects in the file system are the "from" objects, which are the "to" objects, and why?
+
+- Is a graph useful if it just contains a list of nodes? Why or why not?
+
+- When performing a DFS, what is the significance of using a queue (or in this lab's case, a queue)?
+
+# Difficulty
+
+Medium
diff --git a/Module4_Labs/Lab4_Maze_Solver_With_Stack/README 2.md b/Module4_Labs/Lab4_Maze_Solver_With_Stack/README 2.md
new file mode 100644
index 00000000..df086741
--- /dev/null
+++ b/Module4_Labs/Lab4_Maze_Solver_With_Stack/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Maze Solver with Stack
+
+# Long Summary
+Students will use a stack data structure to create a program that can solve a maze. This lab gives students practice with essential data structures. They will learn how to apply stacks to an interesting problem scenario.
+
+# Short Summary
+Students will learn to implement a stack data structure with the purpose of solving a maze.
+
+# Criteria
+1. What are the essential operations we perform on a stack?
+2. How is the maze setup in the maze.txt file and why do we do it this way?
+3. How is the `gotoxy()` function implemented?
+
+# Difficulty
+Medium
+
+# Image
+
\ No newline at end of file
diff --git a/Module4_Labs/Lab5_nColorable/README 2.md b/Module4_Labs/Lab5_nColorable/README 2.md
new file mode 100644
index 00000000..dc596aa8
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+nColorable
+
+# Long Summary
+Students will learn to solve the classic n-Colorable graph problem. They will be using Depth First Search (DFS) to solve the problem. They will also learn about Backtracking Search and implement that into their solution.
+
+# Short Summary
+Students will solve the n-Colorable problem using Depth First Search and Backtracking Search.
+
+# Criteria
+1. Why are we using Depth First Search instead of Breadth First Search?
+2. What is the purpose of using Backtracking Search?
+3. Why do we represent the graph as an adjacency matrix?
+
+# Difficulty
+Medium/Hard
+
+# Image
+
\ No newline at end of file
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 2.py
new file mode 100644
index 00000000..b16725e3
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 1
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 3.py
new file mode 100644
index 00000000..b16725e3
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 1
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 2.py
new file mode 100644
index 00000000..bb9473a2
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 2
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 3.py
new file mode 100644
index 00000000..bb9473a2
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 2
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 2.py
new file mode 100644
index 00000000..59881da9
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 3
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 3.py
new file mode 100644
index 00000000..59881da9
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 3
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 2.py
new file mode 100644
index 00000000..1b445d8e
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 4
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 3.py
new file mode 100644
index 00000000..1b445d8e
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 4
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 2.py
new file mode 100644
index 00000000..da82c900
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 5
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 3.py
new file mode 100644
index 00000000..da82c900
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 5
diff --git a/Module4_Labs/Lab6_Sudoku_Solver/Cards/712 2.md b/Module4_Labs/Lab6_Sudoku_Solver/Cards/712 2.md
new file mode 100644
index 00000000..256d086e
--- /dev/null
+++ b/Module4_Labs/Lab6_Sudoku_Solver/Cards/712 2.md
@@ -0,0 +1,103 @@
+
+
+
+
+
+
+# testPossible()
+
+In our code, we name the variable storing the grid copy `duplicate`.
+
+Once we input the user's guess into `duplicate`, we need to check if `duplicate` will succeed. This is done through our function `complete()`, which takes as arguments the grid (`duplicate` in this case) and the integer `depth`. We will do this in an if-statement as seen below:
+
+```python
+ if complete(duplicate,depth):
+```
+
+As of now, our function will look like this altogether:
+
+```python
+def testPossible(grid,r,c,n,depth,finish):
+ duplicate = copy.deepcopy(grid)
+ duplicate[r][c] = n
+ if complete(duplicate,depth):
+```
+
+If the condition above succeeds, then all we need to do left is check if `finish` is true. If so, then we will copy `duplicate` back to grid since we now have a solution!
+
+At this point, we are attempting to test solutions to solve our Sudoku puzzle. It is in in our best interests to create a duplicate board in order to not infringe on our current board. If the solution is true, then we know we should copy our duplicate board to the original board. Otherwise if we just tested solutions on our original board, then the code becomes much more complicated.
+
+On the condition that `complete()` returns True in our if-statement, we will check if `finish` evaluates to True also:
+
+```python
+ if complete(duplicate,depth):
+ if finish:
+```
+
+
+Then we know that `duplicate` was successful in regards to completion, so we now want `dup` to be our `grid` since `dup` is now the solution. If the possible solution we are testing works, then finish will be true. We simply need to check if finish is true, which means the solution we are testing is true and we can copy over our duplicate board. Thus we will use a nested for-loop to overwrite all the values in `grid` with `dup`:
+
+
+```python
+ for r in range(0,9): //Iterate through each row and column
+ for c in range(0,9):
+
+ grid[r][c] = dup[r][c] //Copy our duplicate grid to our actual grid
+
+```
+
+In the end of that we just return True if we succeeded and otherwise False. Therefore, our final `testPossible()` function will appear as below:
+
+```python
+# Checks if it can find a solution given a grid, and then a row-column pair with a value to try.
+# If it finds a solution and finish is true, then it sets the grid to the solution so as to speed it up.
+def testPossible(grid,r,c,n,depth,finish):
+ dup = copy.deepcopy(grid) //Copies our actual grid and makes a duplicate
+ dup[r][c] = n
+ if complete(dup,depth):
+ if finish: //If successful, we want to copy the duplicate board to our actual board
+ for r in range(0,9):
+ for c in range(0,9):
+ grid[r][c] = duplicate[r][c]
+ return True
+ else: //If false, then we don't want to copy it over.
+ return False
+```
+
+On the condition that `complete()` returns True in our if-statement, we will check if `finish` evaluates to True also:
+
+```python
+ if complete(duplicate,depth):
+ if finish:
+```
+
+
+Then we know that `duplicate` was successful in regards to completion, so we now want `dup` to be our `grid` since `dup` is now the solution. If the possible solution we are testing works, then finish will be true. We simply need to check if finish is true, which means the solution we are testing is true and we can copy over our duplicate board. Thus we will use a nested for-loop to overwrite all the values in `grid` with `dup`:
+
+
+```python
+ for r in range(0,9): //Iterate through each row and column
+ for c in range(0,9):
+
+ grid[r][c] = dup[r][c] //Copy our duplicate grid to our actual grid
+
+```
+
+In the end of that we just return True if we succeeded and otherwise False. Therefore, our final `testPossible()` function will appear as below:
+
+```python
+# Checks if it can find a solution given a grid, and then a row-column pair with a value to try.
+# If it finds a solution and finish is true, then it sets the grid to the solution so as to speed it up.
+def testPossible(grid,r,c,n,depth,finish):
+ dup = copy.deepcopy(grid) //Copies our actual grid and makes a duplicate
+ dup[r][c] = n
+ if complete(dup,depth):
+ if finish: //If successful, we want to copy the duplicate board to our actual board
+ for r in range(0,9):
+ for c in range(0,9):
+ grid[r][c] = duplicate[r][c]
+ return True
+ else: //If false, then we don't want to copy it over.
+ return False
+```
+
diff --git a/Module4_Labs/Lab6_Sudoku_Solver/Cards/812 2.md b/Module4_Labs/Lab6_Sudoku_Solver/Cards/812 2.md
new file mode 100644
index 00000000..dc63f5e9
--- /dev/null
+++ b/Module4_Labs/Lab6_Sudoku_Solver/Cards/812 2.md
@@ -0,0 +1,62 @@
+
+
+
+
+
+
+# main() Part 1
+
+Now that we know we have a total of 81 characters, we need to verify is this is even a valid Sudoku board. To do so we need to create the structure of our board which will be stored into `tempGrid`. Remember that programmatically, our Sudoku board is a list of of 9 lists where each list contains 9 elements (numbers). Thus, we will define an empty list called `r` and fill up each list with 9 elements at a time and append it to `tempGrid` such that `r` will be appended to `tempGrid` 9 times to get our entire Sudoku board:
+
+```python
+ else:
+ for row in range(0,9):
+ r = []
+ for col in range(0,9):
+ r.append(int(data[row*9+col]))
+ tempGrid.append(r)
+```
+
+> Note: remember that the user input (stored in `data`) is a string, so we must type cast it to an int
+
+Now that `data` is formatted into a 9x9 grid that was stored into `tempGrid` we can now verify if the user's inputted grid is valid by using our `isValid()` function. If `isValid()` returns True, we simply can do the assignment `grid = tempGrid`. Else, if `isValid()` returns False, we will print `"Invalid grid."` and reset `data` but assigning it as an empty string:
+
+```python
+ if not isValid(tempGrid):
+ data = ""
+ print("Invalid grid.")
+ printGrid(tempGrid)
+
+
+ grid = tempGrid
+```
+
+Thus, we have finished the first part of our UI for accepting the first user input from the user as seen below:
+
+```python
+# The UI, with options for entering grids, finding next moves, printing the current grid, finishing the grid, and printing out
+# possible values for a row and column index
+if len(grid) == 0:
+ tempGrid = []
+
+ data = ""
+ while len(data) != 81:
+ tempGrid = []
+ data = input("Type in the grid, going left to right row by row, 0 = empty: ")
+ if len(data) != 81:
+ print("Not 81 characters.")
+ else:
+ for row in range(0,9):
+ r = []
+ for col in range(0,9):
+ r.append(int(data[row*9+col]))
+ tempGrid.append(r)
+ if not isValid(tempGrid):
+ data = ""
+ print("Invalid grid.")
+ printGrid(tempGrid)
+
+
+ grid = tempGrid
+```
+
diff --git a/Module4_Labs/Lab6_Sudoku_Solver/Cards/913 2.md b/Module4_Labs/Lab6_Sudoku_Solver/Cards/913 2.md
new file mode 100644
index 00000000..5f2bd358
--- /dev/null
+++ b/Module4_Labs/Lab6_Sudoku_Solver/Cards/913 2.md
@@ -0,0 +1,53 @@
+
+
+
+
+
+
+# main() Part 2
+
+In the else statement when we've determined that the `grid` is complete, we will need to stop our timer and compute the elapsed time. Also we will print our now complete `grid`:
+
+```python
+ else:
+ time2 = time.time()
+ printGrid(grid)
+ if time1 != 0:
+ print("Solved in %0.2fs!" % (time2-time1))
+ else:
+ print("Solved!")
+```
+
+We assign `time2` to `time.time()` as this will give us the current time when we have reached inside this else statement. Then once we check that `time1 != 0` to confirm that there was a time recorded for `time1`, we then can compute the time it took to complete the Sudoku board with the computation `time2 - time1` which gives us the total time that it took to complete. We also will call `printGrid(grid)` in order to print our final grid.
+
+Now we have finally finished our Sudoku Solver! This will how our logic will appear for user input options during the process of solving their valid Sudoku board:
+
+```python
+time1 = 0
+
+c = input("Controls:\n\t'Enter': Display the next move\n\t'p': Print the current grid (small)\n\t'c': Complete the grid (or attempt to)\n\t'(r,c)': Prints the possible options for that row, column\n")
+while hasMoves(grid) and (len(c) == 0 or c == "p" or c == "c" or c[0] == "("):
+ if c == "p":
+ printGrid(grid)
+ elif c == "c":
+ time1 = time.time()
+ if not complete(grid):
+ print("Failed to complete. Please improve algorithm. :)")
+ #break
+ elif len(c) > 0 and c[0] == "(":
+ print(findPossible(int(c[1])-1,int(c[3])-1,grid))
+ else:
+ nextMove(grid)
+
+ if hasMoves(grid):
+ c = input("Controls:\n\t'Enter': Display the next move\n\t'p': Print the current grid (small)\n\t'c': Complete the grid (or attempt to)\n\t'(r,c)': Prints the possible options for that row, column\n")
+ else:
+ time2 = time.time()
+ printGrid(grid)
+ if time1 != 0:
+ print("Solved in %0.2fs!" % (time2-time1))
+ else:
+ print("Solved!")
+```
+
+That's it! We are done! Congratulations on completing the Sudoku Solver Lab!
\ No newline at end of file
diff --git a/Module4_Labs/Lab6_Sudoku_Solver/Cards/README 2.md b/Module4_Labs/Lab6_Sudoku_Solver/Cards/README 2.md
new file mode 100644
index 00000000..2a957d04
--- /dev/null
+++ b/Module4_Labs/Lab6_Sudoku_Solver/Cards/README 2.md
@@ -0,0 +1,22 @@
+# Sudoku Solver
+
+# Long Summary
+
+In this lab, student will create a program to solve a sudoku challenge by taking in user input and indexing through a 2D list.
+
+# Short Summary
+
+Student will create a program to solve a sudoku game using a 2D List.
+
+# Criteria
+
+1. Explain how to use a nested for loop to iterate through a 2D List.
+
+2. How does the function testPossible() work?
+
+3. How does the function nextMove() word?
+
+# Difficulty
+
+Hard
+
diff --git a/Module4_Labs/Lab7_Zoologist/Cards/3-CHECKPOINT 2.md b/Module4_Labs/Lab7_Zoologist/Cards/3-CHECKPOINT 2.md
new file mode 100644
index 00000000..2ea0a759
--- /dev/null
+++ b/Module4_Labs/Lab7_Zoologist/Cards/3-CHECKPOINT 2.md
@@ -0,0 +1,3 @@
+## Checkpoint 1: For `array` explanation
+
+In a video, please explain how you created the `array` and how you edited the print statements for the sort methods: Bubble Sort, Insertion Sort, and Selection Sort. What does each sort method do and how are they different from each other?
\ No newline at end of file
diff --git a/Module4_Labs/Mergesort 2.md b/Module4_Labs/Mergesort 2.md
new file mode 100644
index 00000000..0e76b19f
--- /dev/null
+++ b/Module4_Labs/Mergesort 2.md
@@ -0,0 +1,34 @@
+
+
+# Merge Sort
+
+Merge Sort is a sorting algorithm that uses recursion, which means it calls upon itself, and we use sorting algorithms like Merge Sort to make our data more manageable.
+
+When given an array of elements, Merge Sort starts by dividing the array into two separate sections. Then, it will divide those two sections in half and will continue to do so until it reaches its base case (each element is standing on its own). Once this is done, Merge Sort begins to *merge* the adjacent elements together into pairs, sorts them, and repeats this merging process with the resulting pairs and so on until a sorted list remains. A visual demonstration is shown below:
+
+
+
+Now that we understand how Merge Sort works, let's look at some pseudocode, modified from the GeeksforGeeks website, that demonstrates an implementation of this sorting algorithm:
+
+```
+mergesort(array):
+ if length of array > l: # base case
+
+ # dividing array into elements
+ find the middle point (m)
+ divide the array into two halves
+
+ # sort elements in array
+ call mergesort for first half # sort first half
+ call mergesort for second half # sort second half
+
+ # merging elements in array
+ merge the two halves sorted
+```
+
+### Important Characteristics of Merge Sort:
+
+- Merge Sort is useful for sorting linked lists.
+- The time complexity of Merge Sort is Θ(nlogn) for worst, average, and best case because dividing the array takes logn times and each pass through the array is proportional to its number of elements, n.
+- The space complexity of Merge Sort is O(n), which shows that this algorithm takes a lot of space and may slow down operations for its last data sets.
+
diff --git a/Module4_Labs/Quicksort 2.md b/Module4_Labs/Quicksort 2.md
new file mode 100644
index 00000000..0ba79690
--- /dev/null
+++ b/Module4_Labs/Quicksort 2.md
@@ -0,0 +1,16 @@
+
+
+# Quick Sort
+
+Quick Sort is one of our four basic sorting algorithims in Python. It is known as the most efficient and fastest of the four.
+
+Quick Sort in two basic simple steps would be:
+
+1. Quicksort determines a **pivot** point which would be an element in the dataset.
+2. Next, using the pivot point, it ***partitions\*** (or divides) the larger unsorted collection into two, smaller lists. It then sorts the unsorted collection into two groups. Everything smaller is moved to the right/or left of the pivot point, and everything greater would be moved to the opposite direction of the pivot point.
+
+Quick sort uses a *divide and conquer* strategy when working with data. After it creates two subgroups, it will then choose another pivot point with in that subgroup. The process then repeats until the entire data structure is organized. It then recombines all the subgroups back into one big group so the data structure is now organized.
+
+Here is a Visual Aide to demonstrate just how effective Quicksort is:
+
+
\ No newline at end of file
diff --git a/Module4_Labs/concepts/Concepts/.Big O Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Big O Concept 2.mdx.icloud
new file mode 100644
index 00000000..6ca688d0
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Big O Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Big O Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Big O Concept 3.mdx.icloud
new file mode 100644
index 00000000..d8abe45f
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Big O Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 2.mdx.icloud
new file mode 100644
index 00000000..ff073bc3
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 3.mdx.icloud
new file mode 100644
index 00000000..eac778e6
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Queue-Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Queue-Concept 2.mdx.icloud
new file mode 100644
index 00000000..c12d3949
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Queue-Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Queue-Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Queue-Concept 3.mdx.icloud
new file mode 100644
index 00000000..48ad1af6
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Queue-Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Space Complexity - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Space Complexity - Concept 2.mdx.icloud
new file mode 100644
index 00000000..ce92bf55
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Space Complexity - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks - Concept 2.mdx.icloud
new file mode 100644
index 00000000..5301933c
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks - Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks - Concept 3.mdx.icloud
new file mode 100644
index 00000000..612eb7b4
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks - Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks_PushPop - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks_PushPop - Concept 2.mdx.icloud
new file mode 100644
index 00000000..23c0e53a
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks_PushPop - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 2.mdx.icloud
new file mode 100644
index 00000000..e3d41a09
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 3.mdx.icloud
new file mode 100644
index 00000000..1bb91028
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 2.mdx.icloud
new file mode 100644
index 00000000..95200d1e
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 3.mdx.icloud
new file mode 100644
index 00000000..0a622325
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/Updating dictionary 2.md b/Module4_Labs/concepts/Concepts/Updating dictionary 2.md
new file mode 100644
index 00000000..9d16e624
--- /dev/null
+++ b/Module4_Labs/concepts/Concepts/Updating dictionary 2.md
@@ -0,0 +1,20 @@
+
+
+Dictionary are mutable. We can add new items or change the value of existing items using assignment operator.
+
+You can update a dictionary by adding a new entry or a key-value pair, modifying an existing entry, or deleting an existing entry as shown below in the simple example −
+
+```python
+# Declare a dictionary
+dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
+
+dict['Age'] = 8; # update existing entry
+dict['School'] = "DPS School"; # Add new entry
+
+print("dict['Age']: ", dict['Age'])
+print("dict['School']: ", dict['School'])
+```
+
+> Note: a dictionary allows you to dynamically add new keys with corresponding values or redefine values to an existing key following initialization.
+
+The code snippet above should reflect the appropriate changes on _dict_ such that it contains a new key _'School'_ and that _'Age'_ no longer has value _'7'_.
\ No newline at end of file
diff --git a/Module4_Labs/concepts/Concepts/Updating dictionary 3.md b/Module4_Labs/concepts/Concepts/Updating dictionary 3.md
new file mode 100644
index 00000000..9d16e624
--- /dev/null
+++ b/Module4_Labs/concepts/Concepts/Updating dictionary 3.md
@@ -0,0 +1,20 @@
+
+
+Dictionary are mutable. We can add new items or change the value of existing items using assignment operator.
+
+You can update a dictionary by adding a new entry or a key-value pair, modifying an existing entry, or deleting an existing entry as shown below in the simple example −
+
+```python
+# Declare a dictionary
+dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
+
+dict['Age'] = 8; # update existing entry
+dict['School'] = "DPS School"; # Add new entry
+
+print("dict['Age']: ", dict['Age'])
+print("dict['School']: ", dict['School'])
+```
+
+> Note: a dictionary allows you to dynamically add new keys with corresponding values or redefine values to an existing key following initialization.
+
+The code snippet above should reflect the appropriate changes on _dict_ such that it contains a new key _'School'_ and that _'Age'_ no longer has value _'7'_.
\ No newline at end of file
diff --git a/Module_Postman/.DS_Store b/Module_Postman/.DS_Store
new file mode 100644
index 00000000..8b3a63f4
Binary files /dev/null and b/Module_Postman/.DS_Store differ
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/.git 2.keep.icloud b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/api 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/api 2.md
new file mode 100644
index 00000000..c4fe8a05
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/api 2.md
@@ -0,0 +1,7 @@
+# API
+
+Application Programming Interface (API) is a set of functions and procedures that allow applications to access the contents of another developer's server.
+
+They let servers communicate with each other and transfer data securely back and forth.
+
+Exposing source code to a third-party server is dangerous and could compromise the entire server providing the access, so APIs allow authentication keys to ensure safe transfer.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/client 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/client 2.md
new file mode 100644
index 00000000..649b236f
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/client 2.md
@@ -0,0 +1,3 @@
+# client
+
+The client of a server or website is the web browser viewing it. They send http requests to the server under the assumption that the server is functioning well and will return the requested page based on the URL.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/crud 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/crud 2.md
new file mode 100644
index 00000000..bf0c3f76
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/crud 2.md
@@ -0,0 +1,19 @@
+# CRUD
+
+Many servers need to store data persistently. When dealing with persistent data storage, they generally need to be able to allow four basic operations to be performed.
+
+- **C**reate data in the server
+- **R**etrieve data from the server
+- **U**pdate and replace existing data in the server
+- **D**elete data from the server
+
+These operations can be used in SQL (Structured Query Language), HTTP (Hypertext Transfer Protocol), RESTful API (Representational State Transfer), and DDS (Data Distribution)
+
+| Operation | SQL | HTTP | RESTful API | DDS |
+| ---------------- | ------ | -------------- | ----------- | --------- |
+| Create | Insert | Put/Post | Post | Write |
+| Read (Retrieve) | Select | Get | Get | Read/Take |
+| Update (Modify) | Update | Put/Post/Patch | Put | Write |
+| Delete (Destroy) | Delete | Delete | Delete | Dispose |
+
+Without these four operations, the software is not considered complete.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/delete 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/delete 2.md
new file mode 100644
index 00000000..f3b7d399
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/delete 2.md
@@ -0,0 +1,5 @@
+# DELETE Request
+
+A DELETE request is used to remove a specific object that already exists in the database. You would usually use this request when you no longer need a specific instance of an object in your database.
+
+Lets say that we no longer need the movie Thor in our database. In order to get rid of the movie, we would send a DELETE request to delete Thor. After that request, Thor will no longer exist in our database.
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/endpoint 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/endpoint 2.md
new file mode 100644
index 00000000..8dc6acb4
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/endpoint 2.md
@@ -0,0 +1,6 @@
+# Endpoint
+
+An endpoint is the URL where your service can be accessed by a client
+application.
+
+If application A wants to reach application B's data stored in a page called data, they would send a GET request to `
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/632 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/632 2.md
new file mode 100644
index 00000000..f7be11d8
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/632 2.md
@@ -0,0 +1,71 @@
+
+
+
+
+
+
+**Step 1: Regular Operation**
+
+If the list is not empty, then we shall proceed with the popping process by first searching for the node that we want to pop. Using a while loop, we will traverse through the list with `curr`, and if `curr` reaches the end of the list and equals `None`, then print out "Target not found." and `return` to exit the loop.
+
+```python
+ else:
+ # 2. Search for target
+ while curr.data != target:
+ curr = curr.next
+
+ if curr == None:
+ print("Target not found.")
+ return
+```
+
+**Step 2: Putting it Together & Note**
+
+Once we find the target, we check if it's not the last node because the process in deleting a middle node and the last node are different. If the target node is not the last node, then we would create a `temp` pointer to the `next` node and point the node before the target, `curr.prev.next`, to `temp`. Now we can set temp's `prev` pointer to `curr`'s `prev`.
+
+If the target node is the last node, then we can just use our `popBack()` function to remove it from the list.
+
+Note that the order in which the variables are assigned does matter because the values and pointers of the variables, `temp` and `curr` change throughout the if statement. If one is misplaced, then the values may be assigned incorrectly.
+
+```python
+ # 3. If curr is not the last node
+ if curr.next != None:
+ temp = curr.next
+ curr.prev.next = temp
+ temp.prev = curr.prev
+
+ # 4. If curr is the last node, use popBack()
+ else:
+ self.popBack()
+```
+
+Then, after we remove a node from our list, we have remember to decrease the size of the list.
+
+```python
+ # Decrement size
+ self.size -= 1
+```
+
+---
+
+With that, we have completed our `pop()` function!
+
+```python
+def pop(self, target):
+
+ # 1. Check if the list is empty
+ if self.head == None:
+ return
+
+ else:
+ # 2. Search for target
+ while curr.data != target:
+ curr = curr.next
+
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # Decrement size
+ self.size -= 1
+```
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Cards/712 2.md b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/712 2.md
new file mode 100644
index 00000000..6ef9632c
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Cards/712 2.md
@@ -0,0 +1,56 @@
+
+
+
+
+
+
+**Step 1: Looping Through the List**
+
+Now, let's starting coding the actual reversing process.
+
+To move through the entire list, we will create a while loop, which will iterate through each node and halt when `curr` reaches the very end of the list. For instance, if we were at the second node in a list of five, we would set `temp` as a pointer to first node, then switch the second node's pointers, which can be see in the first to third line under the while loop.
+
+The final step in the while loop is very interesting! We would think that we would want `curr = curr.next`, but remember that we just swapped the `next` and`prev` pointers, so instead we would set `curr = curr.prev`. Now `prev` is now pointing in the direction of `next`.
+
+```python
+ # Swap next and prev for all nodes of
+ # doubly linked list
+ while curr is not None:
+ temp = curr.prev
+ curr.prev = curr.next
+ curr.next = temp
+ curr = curr.prev
+```
+**Step 2: Checking for Edge Cases**
+
+Before finish coding our reverse() function, we need to check for certain cases.
+
+If the list is either empty or only has one node, then the reversing process is not needed/ will not work because there is nothing left that can be reversed! So, we need to make sure that check for these cases before proceeding.
+
+```python
+ # Before changing head, check for the cases like
+ # empty list and list with only one node
+ if temp is not None:
+ self.head = temp.prev
+```
+With that, your reverse() function is complete!
+
+```python
+def reverse(self):
+ temp = None
+ curr = self.head
+ self.tail = curr
+
+ # Swap next and prev for all nodes of
+ # doubly linked list
+ while curr is not None:
+ temp = curr.prev
+ curr.prev = curr.next
+ curr.next = temp
+ curr = curr.prev
+
+ # Before changing head, check for the cases like
+ # empty list and list with only one node
+ if temp is not None:
+ self.head = temp.prev
+```
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 2.py b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 2.py
new file mode 100644
index 00000000..5e8479a0
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 2.py
@@ -0,0 +1,132 @@
+
+class Node:
+ def __init__(self, data):
+ self.data = data
+ self.next = None
+ self.prev = None
+
+
+class DoublyLinkedList:
+ def __init__(self):
+ self.head = None
+ self.tail = None
+ self.size = 0
+
+ def printList(self, node):
+ while node != None:
+ print(node.data)
+ # Get next node
+ node = node.next
+
+ def push(self, newData):
+ newNode = Node(newData)
+
+ # newNode -> self.head
+ newNode.next = self.head
+
+ # If the list is not empty
+ if self.head != None:
+ self.head.prev = newNode
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # The head is now the new node
+ self.head = newNode
+ self.size += 1
+
+ def pushback(self, newData):
+ #Initialize new node
+ newNode = Node(newData)
+
+ # If the list is not empty
+
+
+ if self.head != None:
+ temp = self.tail
+ temp.next = newNode
+ newNode.prev = temp
+ self.tail = self.tail.next
+
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # Increment size
+ self.size += 1
+
+ def insertAfter(self, target, newData):
+ # 1. If the list is empty
+ if self.head == None:
+ return
+ else:
+ curr = self.head
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr
+ newNode.next = curr.next
+ # 4. If curr is not the last node
+ if curr.next is not None:
+ curr.next.prev = newNode
+
+ else:
+ self.tail = newNode
+
+ # 5. Connect the current node with the new node
+ curr.next = newNode
+ # Increment size
+ self.size += 1
+
+ def insertBefore(self, target, newData):
+
+ # If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr.prev
+ newNode.next = curr
+
+ # 4. If curr is not the first node
+ if curr.prev != None:
+ curr.prev.next = newNode
+
+ else:
+ self.head = newNode
+
+ # 5. Connect the current node with the new node
+ curr.prev = newNode
+ # Increment size
+ self.size += 1
+
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.insertAfter(2,3)
+ LL.insertAfter(1,4)
+ LL.insertBefore(4,9)
+ LL.printList(LL.head)
+
+main()
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 3.py b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 3.py
new file mode 100644
index 00000000..5e8479a0
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/checkpoint4_ans 3.py
@@ -0,0 +1,132 @@
+
+class Node:
+ def __init__(self, data):
+ self.data = data
+ self.next = None
+ self.prev = None
+
+
+class DoublyLinkedList:
+ def __init__(self):
+ self.head = None
+ self.tail = None
+ self.size = 0
+
+ def printList(self, node):
+ while node != None:
+ print(node.data)
+ # Get next node
+ node = node.next
+
+ def push(self, newData):
+ newNode = Node(newData)
+
+ # newNode -> self.head
+ newNode.next = self.head
+
+ # If the list is not empty
+ if self.head != None:
+ self.head.prev = newNode
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # The head is now the new node
+ self.head = newNode
+ self.size += 1
+
+ def pushback(self, newData):
+ #Initialize new node
+ newNode = Node(newData)
+
+ # If the list is not empty
+
+
+ if self.head != None:
+ temp = self.tail
+ temp.next = newNode
+ newNode.prev = temp
+ self.tail = self.tail.next
+
+ # If the list is empty
+ else:
+ self.head = newNode
+ self.tail = newNode
+
+ # Increment size
+ self.size += 1
+
+ def insertAfter(self, target, newData):
+ # 1. If the list is empty
+ if self.head == None:
+ return
+ else:
+ curr = self.head
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr
+ newNode.next = curr.next
+ # 4. If curr is not the last node
+ if curr.next is not None:
+ curr.next.prev = newNode
+
+ else:
+ self.tail = newNode
+
+ # 5. Connect the current node with the new node
+ curr.next = newNode
+ # Increment size
+ self.size += 1
+
+ def insertBefore(self, target, newData):
+
+ # If the list is empty
+ if self.head == None:
+ return
+
+ else:
+ curr = self.head
+
+ # 2. Search for target node
+ while curr.data != target:
+ curr = curr.next
+ if curr == None:
+ print("Target not found.")
+ return
+
+ # 3. If target was found, curr != None
+ newNode = Node(newData)
+ newNode.prev = curr.prev
+ newNode.next = curr
+
+ # 4. If curr is not the first node
+ if curr.prev != None:
+ curr.prev.next = newNode
+
+ else:
+ self.head = newNode
+
+ # 5. Connect the current node with the new node
+ curr.prev = newNode
+ # Increment size
+ self.size += 1
+
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.insertAfter(2,3)
+ LL.insertAfter(1,4)
+ LL.insertBefore(4,9)
+ LL.printList(LL.head)
+
+main()
\ No newline at end of file
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 2.py b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 2.py
new file mode 100644
index 00000000..85df80df
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 2.py
@@ -0,0 +1,98 @@
+"""
+Test Case 1
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.push(5)
+ LL.push(9)
+ LL.printList(LL.head)
+"""
+"""
+Test Case 1 - Results
+9
+5
+3
+2
+1
+"""
+
+"""
+Test Case 2
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.pushback(5)
+ LL.pushback(9)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 2 - Results
+3
+2
+1
+5
+9
+"""
+
+
+"""
+Test Case 3
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.pushback(5)
+ LL.insertAfter(5,10)
+ LL.pushback(9)
+ LL.insertAfter(9,11)
+ LL.insertAfter(10,12)
+ LL.insertAfter(3,4)
+ LL.insertAfter(11,14)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 3 - Results
+3
+4
+2
+1
+5
+10
+12
+9
+11
+14
+"""
+
+"""
+Test Case 4
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.insertBefore(3,4)
+ LL.insertBefore(4,5)
+ LL.insertBefore(4,4.5)
+ LL.insertBefore(1,10)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 4 - Results
+5
+4.5
+4
+3
+2
+10
+1
+"""
+
diff --git a/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 3.py b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 3.py
new file mode 100644
index 00000000..85df80df
--- /dev/null
+++ b/Module4_Labs/Lab2_Doubly_Linked_List/Student Starter/Checkpoint/test_cases_check4 3.py
@@ -0,0 +1,98 @@
+"""
+Test Case 1
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.push(5)
+ LL.push(9)
+ LL.printList(LL.head)
+"""
+"""
+Test Case 1 - Results
+9
+5
+3
+2
+1
+"""
+
+"""
+Test Case 2
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.pushback(5)
+ LL.pushback(9)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 2 - Results
+3
+2
+1
+5
+9
+"""
+
+
+"""
+Test Case 3
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.pushback(5)
+ LL.insertAfter(5,10)
+ LL.pushback(9)
+ LL.insertAfter(9,11)
+ LL.insertAfter(10,12)
+ LL.insertAfter(3,4)
+ LL.insertAfter(11,14)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 3 - Results
+3
+4
+2
+1
+5
+10
+12
+9
+11
+14
+"""
+
+"""
+Test Case 4
+def main():
+ LL = DoublyLinkedList()
+ LL.push(1)
+ LL.push(2)
+ LL.push(3)
+ LL.insertBefore(3,4)
+ LL.insertBefore(4,5)
+ LL.insertBefore(4,4.5)
+ LL.insertBefore(1,10)
+ LL.printList(LL.head)
+"""
+
+"""
+Test Case 4 - Results
+5
+4.5
+4
+3
+2
+10
+1
+"""
+
diff --git a/Module4_Labs/Lab3_File_System/Cards/README 2.md b/Module4_Labs/Lab3_File_System/Cards/README 2.md
new file mode 100644
index 00000000..22b12a9e
--- /dev/null
+++ b/Module4_Labs/Lab3_File_System/Cards/README 2.md
@@ -0,0 +1,20 @@
+# File System
+
+# Long Summary
+
+Students will have to parse through a file that contains information about a folder/file's "structural position" within the file structure and its name. After extracting the relevant information in relation to directed graphs, they will store it in a graph that they implement themselves. Students will use the networkx library to help them visual the graph with a GUI and then write the ordered file structure to an output file using DFS.
+# Short Summary
+
+Students will understand graphs better by implementing a directed graph that represents a small file structure and printing its ordered structure in a file.
+
+# Criteria
+
+- The edges in these graphs have directions. Generalize what objects in the file system are the "from" objects, which are the "to" objects, and why?
+
+- Is a graph useful if it just contains a list of nodes? Why or why not?
+
+- When performing a DFS, what is the significance of using a queue (or in this lab's case, a queue)?
+
+# Difficulty
+
+Medium
diff --git a/Module4_Labs/Lab4_Maze_Solver_With_Stack/README 2.md b/Module4_Labs/Lab4_Maze_Solver_With_Stack/README 2.md
new file mode 100644
index 00000000..df086741
--- /dev/null
+++ b/Module4_Labs/Lab4_Maze_Solver_With_Stack/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+Maze Solver with Stack
+
+# Long Summary
+Students will use a stack data structure to create a program that can solve a maze. This lab gives students practice with essential data structures. They will learn how to apply stacks to an interesting problem scenario.
+
+# Short Summary
+Students will learn to implement a stack data structure with the purpose of solving a maze.
+
+# Criteria
+1. What are the essential operations we perform on a stack?
+2. How is the maze setup in the maze.txt file and why do we do it this way?
+3. How is the `gotoxy()` function implemented?
+
+# Difficulty
+Medium
+
+# Image
+
\ No newline at end of file
diff --git a/Module4_Labs/Lab5_nColorable/README 2.md b/Module4_Labs/Lab5_nColorable/README 2.md
new file mode 100644
index 00000000..dc596aa8
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+nColorable
+
+# Long Summary
+Students will learn to solve the classic n-Colorable graph problem. They will be using Depth First Search (DFS) to solve the problem. They will also learn about Backtracking Search and implement that into their solution.
+
+# Short Summary
+Students will solve the n-Colorable problem using Depth First Search and Backtracking Search.
+
+# Criteria
+1. Why are we using Depth First Search instead of Breadth First Search?
+2. What is the purpose of using Backtracking Search?
+3. Why do we represent the graph as an adjacency matrix?
+
+# Difficulty
+Medium/Hard
+
+# Image
+
\ No newline at end of file
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 2.py
new file mode 100644
index 00000000..b16725e3
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 1
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 3.py
new file mode 100644
index 00000000..b16725e3
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_1 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 1
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 2.py
new file mode 100644
index 00000000..bb9473a2
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 2
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 3.py
new file mode 100644
index 00000000..bb9473a2
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_2 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 2
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 2.py
new file mode 100644
index 00000000..59881da9
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 3
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 3.py
new file mode 100644
index 00000000..59881da9
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_3 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 3
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 2.py
new file mode 100644
index 00000000..1b445d8e
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 4
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 3.py
new file mode 100644
index 00000000..1b445d8e
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_4 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 4
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 2.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 2.py
new file mode 100644
index 00000000..da82c900
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 2.py
@@ -0,0 +1,2 @@
+"""
+Test Case 5
diff --git a/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 3.py b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 3.py
new file mode 100644
index 00000000..da82c900
--- /dev/null
+++ b/Module4_Labs/Lab5_nColorable/Student-Starter/Overall/test_case_5 3.py
@@ -0,0 +1,2 @@
+"""
+Test Case 5
diff --git a/Module4_Labs/Lab6_Sudoku_Solver/Cards/712 2.md b/Module4_Labs/Lab6_Sudoku_Solver/Cards/712 2.md
new file mode 100644
index 00000000..256d086e
--- /dev/null
+++ b/Module4_Labs/Lab6_Sudoku_Solver/Cards/712 2.md
@@ -0,0 +1,103 @@
+
+
+
+
+
+
+# testPossible()
+
+In our code, we name the variable storing the grid copy `duplicate`.
+
+Once we input the user's guess into `duplicate`, we need to check if `duplicate` will succeed. This is done through our function `complete()`, which takes as arguments the grid (`duplicate` in this case) and the integer `depth`. We will do this in an if-statement as seen below:
+
+```python
+ if complete(duplicate,depth):
+```
+
+As of now, our function will look like this altogether:
+
+```python
+def testPossible(grid,r,c,n,depth,finish):
+ duplicate = copy.deepcopy(grid)
+ duplicate[r][c] = n
+ if complete(duplicate,depth):
+```
+
+If the condition above succeeds, then all we need to do left is check if `finish` is true. If so, then we will copy `duplicate` back to grid since we now have a solution!
+
+At this point, we are attempting to test solutions to solve our Sudoku puzzle. It is in in our best interests to create a duplicate board in order to not infringe on our current board. If the solution is true, then we know we should copy our duplicate board to the original board. Otherwise if we just tested solutions on our original board, then the code becomes much more complicated.
+
+On the condition that `complete()` returns True in our if-statement, we will check if `finish` evaluates to True also:
+
+```python
+ if complete(duplicate,depth):
+ if finish:
+```
+
+
+Then we know that `duplicate` was successful in regards to completion, so we now want `dup` to be our `grid` since `dup` is now the solution. If the possible solution we are testing works, then finish will be true. We simply need to check if finish is true, which means the solution we are testing is true and we can copy over our duplicate board. Thus we will use a nested for-loop to overwrite all the values in `grid` with `dup`:
+
+
+```python
+ for r in range(0,9): //Iterate through each row and column
+ for c in range(0,9):
+
+ grid[r][c] = dup[r][c] //Copy our duplicate grid to our actual grid
+
+```
+
+In the end of that we just return True if we succeeded and otherwise False. Therefore, our final `testPossible()` function will appear as below:
+
+```python
+# Checks if it can find a solution given a grid, and then a row-column pair with a value to try.
+# If it finds a solution and finish is true, then it sets the grid to the solution so as to speed it up.
+def testPossible(grid,r,c,n,depth,finish):
+ dup = copy.deepcopy(grid) //Copies our actual grid and makes a duplicate
+ dup[r][c] = n
+ if complete(dup,depth):
+ if finish: //If successful, we want to copy the duplicate board to our actual board
+ for r in range(0,9):
+ for c in range(0,9):
+ grid[r][c] = duplicate[r][c]
+ return True
+ else: //If false, then we don't want to copy it over.
+ return False
+```
+
+On the condition that `complete()` returns True in our if-statement, we will check if `finish` evaluates to True also:
+
+```python
+ if complete(duplicate,depth):
+ if finish:
+```
+
+
+Then we know that `duplicate` was successful in regards to completion, so we now want `dup` to be our `grid` since `dup` is now the solution. If the possible solution we are testing works, then finish will be true. We simply need to check if finish is true, which means the solution we are testing is true and we can copy over our duplicate board. Thus we will use a nested for-loop to overwrite all the values in `grid` with `dup`:
+
+
+```python
+ for r in range(0,9): //Iterate through each row and column
+ for c in range(0,9):
+
+ grid[r][c] = dup[r][c] //Copy our duplicate grid to our actual grid
+
+```
+
+In the end of that we just return True if we succeeded and otherwise False. Therefore, our final `testPossible()` function will appear as below:
+
+```python
+# Checks if it can find a solution given a grid, and then a row-column pair with a value to try.
+# If it finds a solution and finish is true, then it sets the grid to the solution so as to speed it up.
+def testPossible(grid,r,c,n,depth,finish):
+ dup = copy.deepcopy(grid) //Copies our actual grid and makes a duplicate
+ dup[r][c] = n
+ if complete(dup,depth):
+ if finish: //If successful, we want to copy the duplicate board to our actual board
+ for r in range(0,9):
+ for c in range(0,9):
+ grid[r][c] = duplicate[r][c]
+ return True
+ else: //If false, then we don't want to copy it over.
+ return False
+```
+
diff --git a/Module4_Labs/Lab6_Sudoku_Solver/Cards/812 2.md b/Module4_Labs/Lab6_Sudoku_Solver/Cards/812 2.md
new file mode 100644
index 00000000..dc63f5e9
--- /dev/null
+++ b/Module4_Labs/Lab6_Sudoku_Solver/Cards/812 2.md
@@ -0,0 +1,62 @@
+
+
+
+
+
+
+# main() Part 1
+
+Now that we know we have a total of 81 characters, we need to verify is this is even a valid Sudoku board. To do so we need to create the structure of our board which will be stored into `tempGrid`. Remember that programmatically, our Sudoku board is a list of of 9 lists where each list contains 9 elements (numbers). Thus, we will define an empty list called `r` and fill up each list with 9 elements at a time and append it to `tempGrid` such that `r` will be appended to `tempGrid` 9 times to get our entire Sudoku board:
+
+```python
+ else:
+ for row in range(0,9):
+ r = []
+ for col in range(0,9):
+ r.append(int(data[row*9+col]))
+ tempGrid.append(r)
+```
+
+> Note: remember that the user input (stored in `data`) is a string, so we must type cast it to an int
+
+Now that `data` is formatted into a 9x9 grid that was stored into `tempGrid` we can now verify if the user's inputted grid is valid by using our `isValid()` function. If `isValid()` returns True, we simply can do the assignment `grid = tempGrid`. Else, if `isValid()` returns False, we will print `"Invalid grid."` and reset `data` but assigning it as an empty string:
+
+```python
+ if not isValid(tempGrid):
+ data = ""
+ print("Invalid grid.")
+ printGrid(tempGrid)
+
+
+ grid = tempGrid
+```
+
+Thus, we have finished the first part of our UI for accepting the first user input from the user as seen below:
+
+```python
+# The UI, with options for entering grids, finding next moves, printing the current grid, finishing the grid, and printing out
+# possible values for a row and column index
+if len(grid) == 0:
+ tempGrid = []
+
+ data = ""
+ while len(data) != 81:
+ tempGrid = []
+ data = input("Type in the grid, going left to right row by row, 0 = empty: ")
+ if len(data) != 81:
+ print("Not 81 characters.")
+ else:
+ for row in range(0,9):
+ r = []
+ for col in range(0,9):
+ r.append(int(data[row*9+col]))
+ tempGrid.append(r)
+ if not isValid(tempGrid):
+ data = ""
+ print("Invalid grid.")
+ printGrid(tempGrid)
+
+
+ grid = tempGrid
+```
+
diff --git a/Module4_Labs/Lab6_Sudoku_Solver/Cards/913 2.md b/Module4_Labs/Lab6_Sudoku_Solver/Cards/913 2.md
new file mode 100644
index 00000000..5f2bd358
--- /dev/null
+++ b/Module4_Labs/Lab6_Sudoku_Solver/Cards/913 2.md
@@ -0,0 +1,53 @@
+
+
+
+
+
+
+# main() Part 2
+
+In the else statement when we've determined that the `grid` is complete, we will need to stop our timer and compute the elapsed time. Also we will print our now complete `grid`:
+
+```python
+ else:
+ time2 = time.time()
+ printGrid(grid)
+ if time1 != 0:
+ print("Solved in %0.2fs!" % (time2-time1))
+ else:
+ print("Solved!")
+```
+
+We assign `time2` to `time.time()` as this will give us the current time when we have reached inside this else statement. Then once we check that `time1 != 0` to confirm that there was a time recorded for `time1`, we then can compute the time it took to complete the Sudoku board with the computation `time2 - time1` which gives us the total time that it took to complete. We also will call `printGrid(grid)` in order to print our final grid.
+
+Now we have finally finished our Sudoku Solver! This will how our logic will appear for user input options during the process of solving their valid Sudoku board:
+
+```python
+time1 = 0
+
+c = input("Controls:\n\t'Enter': Display the next move\n\t'p': Print the current grid (small)\n\t'c': Complete the grid (or attempt to)\n\t'(r,c)': Prints the possible options for that row, column\n")
+while hasMoves(grid) and (len(c) == 0 or c == "p" or c == "c" or c[0] == "("):
+ if c == "p":
+ printGrid(grid)
+ elif c == "c":
+ time1 = time.time()
+ if not complete(grid):
+ print("Failed to complete. Please improve algorithm. :)")
+ #break
+ elif len(c) > 0 and c[0] == "(":
+ print(findPossible(int(c[1])-1,int(c[3])-1,grid))
+ else:
+ nextMove(grid)
+
+ if hasMoves(grid):
+ c = input("Controls:\n\t'Enter': Display the next move\n\t'p': Print the current grid (small)\n\t'c': Complete the grid (or attempt to)\n\t'(r,c)': Prints the possible options for that row, column\n")
+ else:
+ time2 = time.time()
+ printGrid(grid)
+ if time1 != 0:
+ print("Solved in %0.2fs!" % (time2-time1))
+ else:
+ print("Solved!")
+```
+
+That's it! We are done! Congratulations on completing the Sudoku Solver Lab!
\ No newline at end of file
diff --git a/Module4_Labs/Lab6_Sudoku_Solver/Cards/README 2.md b/Module4_Labs/Lab6_Sudoku_Solver/Cards/README 2.md
new file mode 100644
index 00000000..2a957d04
--- /dev/null
+++ b/Module4_Labs/Lab6_Sudoku_Solver/Cards/README 2.md
@@ -0,0 +1,22 @@
+# Sudoku Solver
+
+# Long Summary
+
+In this lab, student will create a program to solve a sudoku challenge by taking in user input and indexing through a 2D list.
+
+# Short Summary
+
+Student will create a program to solve a sudoku game using a 2D List.
+
+# Criteria
+
+1. Explain how to use a nested for loop to iterate through a 2D List.
+
+2. How does the function testPossible() work?
+
+3. How does the function nextMove() word?
+
+# Difficulty
+
+Hard
+
diff --git a/Module4_Labs/Lab7_Zoologist/Cards/3-CHECKPOINT 2.md b/Module4_Labs/Lab7_Zoologist/Cards/3-CHECKPOINT 2.md
new file mode 100644
index 00000000..2ea0a759
--- /dev/null
+++ b/Module4_Labs/Lab7_Zoologist/Cards/3-CHECKPOINT 2.md
@@ -0,0 +1,3 @@
+## Checkpoint 1: For `array` explanation
+
+In a video, please explain how you created the `array` and how you edited the print statements for the sort methods: Bubble Sort, Insertion Sort, and Selection Sort. What does each sort method do and how are they different from each other?
\ No newline at end of file
diff --git a/Module4_Labs/Mergesort 2.md b/Module4_Labs/Mergesort 2.md
new file mode 100644
index 00000000..0e76b19f
--- /dev/null
+++ b/Module4_Labs/Mergesort 2.md
@@ -0,0 +1,34 @@
+
+
+# Merge Sort
+
+Merge Sort is a sorting algorithm that uses recursion, which means it calls upon itself, and we use sorting algorithms like Merge Sort to make our data more manageable.
+
+When given an array of elements, Merge Sort starts by dividing the array into two separate sections. Then, it will divide those two sections in half and will continue to do so until it reaches its base case (each element is standing on its own). Once this is done, Merge Sort begins to *merge* the adjacent elements together into pairs, sorts them, and repeats this merging process with the resulting pairs and so on until a sorted list remains. A visual demonstration is shown below:
+
+
+
+Now that we understand how Merge Sort works, let's look at some pseudocode, modified from the GeeksforGeeks website, that demonstrates an implementation of this sorting algorithm:
+
+```
+mergesort(array):
+ if length of array > l: # base case
+
+ # dividing array into elements
+ find the middle point (m)
+ divide the array into two halves
+
+ # sort elements in array
+ call mergesort for first half # sort first half
+ call mergesort for second half # sort second half
+
+ # merging elements in array
+ merge the two halves sorted
+```
+
+### Important Characteristics of Merge Sort:
+
+- Merge Sort is useful for sorting linked lists.
+- The time complexity of Merge Sort is Θ(nlogn) for worst, average, and best case because dividing the array takes logn times and each pass through the array is proportional to its number of elements, n.
+- The space complexity of Merge Sort is O(n), which shows that this algorithm takes a lot of space and may slow down operations for its last data sets.
+
diff --git a/Module4_Labs/Quicksort 2.md b/Module4_Labs/Quicksort 2.md
new file mode 100644
index 00000000..0ba79690
--- /dev/null
+++ b/Module4_Labs/Quicksort 2.md
@@ -0,0 +1,16 @@
+
+
+# Quick Sort
+
+Quick Sort is one of our four basic sorting algorithims in Python. It is known as the most efficient and fastest of the four.
+
+Quick Sort in two basic simple steps would be:
+
+1. Quicksort determines a **pivot** point which would be an element in the dataset.
+2. Next, using the pivot point, it ***partitions\*** (or divides) the larger unsorted collection into two, smaller lists. It then sorts the unsorted collection into two groups. Everything smaller is moved to the right/or left of the pivot point, and everything greater would be moved to the opposite direction of the pivot point.
+
+Quick sort uses a *divide and conquer* strategy when working with data. After it creates two subgroups, it will then choose another pivot point with in that subgroup. The process then repeats until the entire data structure is organized. It then recombines all the subgroups back into one big group so the data structure is now organized.
+
+Here is a Visual Aide to demonstrate just how effective Quicksort is:
+
+
\ No newline at end of file
diff --git a/Module4_Labs/concepts/Concepts/.Big O Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Big O Concept 2.mdx.icloud
new file mode 100644
index 00000000..6ca688d0
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Big O Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Big O Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Big O Concept 3.mdx.icloud
new file mode 100644
index 00000000..d8abe45f
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Big O Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 2.mdx.icloud
new file mode 100644
index 00000000..ff073bc3
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 3.mdx.icloud
new file mode 100644
index 00000000..eac778e6
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Queue-Add,Remove,View- Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Queue-Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Queue-Concept 2.mdx.icloud
new file mode 100644
index 00000000..c12d3949
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Queue-Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Queue-Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Queue-Concept 3.mdx.icloud
new file mode 100644
index 00000000..48ad1af6
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Queue-Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Space Complexity - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Space Complexity - Concept 2.mdx.icloud
new file mode 100644
index 00000000..ce92bf55
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Space Complexity - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks - Concept 2.mdx.icloud
new file mode 100644
index 00000000..5301933c
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks - Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks - Concept 3.mdx.icloud
new file mode 100644
index 00000000..612eb7b4
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks - Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks_PushPop - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks_PushPop - Concept 2.mdx.icloud
new file mode 100644
index 00000000..23c0e53a
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks_PushPop - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 2.mdx.icloud
new file mode 100644
index 00000000..e3d41a09
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 3.mdx.icloud
new file mode 100644
index 00000000..1bb91028
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Stacks_Return information - Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 2.mdx.icloud b/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 2.mdx.icloud
new file mode 100644
index 00000000..95200d1e
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 2.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 3.mdx.icloud b/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 3.mdx.icloud
new file mode 100644
index 00000000..0a622325
Binary files /dev/null and b/Module4_Labs/concepts/Concepts/.Time Complexity - Concept 3.mdx.icloud differ
diff --git a/Module4_Labs/concepts/Concepts/Updating dictionary 2.md b/Module4_Labs/concepts/Concepts/Updating dictionary 2.md
new file mode 100644
index 00000000..9d16e624
--- /dev/null
+++ b/Module4_Labs/concepts/Concepts/Updating dictionary 2.md
@@ -0,0 +1,20 @@
+
+
+Dictionary are mutable. We can add new items or change the value of existing items using assignment operator.
+
+You can update a dictionary by adding a new entry or a key-value pair, modifying an existing entry, or deleting an existing entry as shown below in the simple example −
+
+```python
+# Declare a dictionary
+dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
+
+dict['Age'] = 8; # update existing entry
+dict['School'] = "DPS School"; # Add new entry
+
+print("dict['Age']: ", dict['Age'])
+print("dict['School']: ", dict['School'])
+```
+
+> Note: a dictionary allows you to dynamically add new keys with corresponding values or redefine values to an existing key following initialization.
+
+The code snippet above should reflect the appropriate changes on _dict_ such that it contains a new key _'School'_ and that _'Age'_ no longer has value _'7'_.
\ No newline at end of file
diff --git a/Module4_Labs/concepts/Concepts/Updating dictionary 3.md b/Module4_Labs/concepts/Concepts/Updating dictionary 3.md
new file mode 100644
index 00000000..9d16e624
--- /dev/null
+++ b/Module4_Labs/concepts/Concepts/Updating dictionary 3.md
@@ -0,0 +1,20 @@
+
+
+Dictionary are mutable. We can add new items or change the value of existing items using assignment operator.
+
+You can update a dictionary by adding a new entry or a key-value pair, modifying an existing entry, or deleting an existing entry as shown below in the simple example −
+
+```python
+# Declare a dictionary
+dict = {'Name': 'Zara', 'Age': 7, 'Class': 'First'}
+
+dict['Age'] = 8; # update existing entry
+dict['School'] = "DPS School"; # Add new entry
+
+print("dict['Age']: ", dict['Age'])
+print("dict['School']: ", dict['School'])
+```
+
+> Note: a dictionary allows you to dynamically add new keys with corresponding values or redefine values to an existing key following initialization.
+
+The code snippet above should reflect the appropriate changes on _dict_ such that it contains a new key _'School'_ and that _'Age'_ no longer has value _'7'_.
\ No newline at end of file
diff --git a/Module_Postman/.DS_Store b/Module_Postman/.DS_Store
new file mode 100644
index 00000000..8b3a63f4
Binary files /dev/null and b/Module_Postman/.DS_Store differ
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/.git 2.keep.icloud b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/api 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/api 2.md
new file mode 100644
index 00000000..c4fe8a05
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/api 2.md
@@ -0,0 +1,7 @@
+# API
+
+Application Programming Interface (API) is a set of functions and procedures that allow applications to access the contents of another developer's server.
+
+They let servers communicate with each other and transfer data securely back and forth.
+
+Exposing source code to a third-party server is dangerous and could compromise the entire server providing the access, so APIs allow authentication keys to ensure safe transfer.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/client 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/client 2.md
new file mode 100644
index 00000000..649b236f
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/client 2.md
@@ -0,0 +1,3 @@
+# client
+
+The client of a server or website is the web browser viewing it. They send http requests to the server under the assumption that the server is functioning well and will return the requested page based on the URL.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/crud 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/crud 2.md
new file mode 100644
index 00000000..bf0c3f76
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/crud 2.md
@@ -0,0 +1,19 @@
+# CRUD
+
+Many servers need to store data persistently. When dealing with persistent data storage, they generally need to be able to allow four basic operations to be performed.
+
+- **C**reate data in the server
+- **R**etrieve data from the server
+- **U**pdate and replace existing data in the server
+- **D**elete data from the server
+
+These operations can be used in SQL (Structured Query Language), HTTP (Hypertext Transfer Protocol), RESTful API (Representational State Transfer), and DDS (Data Distribution)
+
+| Operation | SQL | HTTP | RESTful API | DDS |
+| ---------------- | ------ | -------------- | ----------- | --------- |
+| Create | Insert | Put/Post | Post | Write |
+| Read (Retrieve) | Select | Get | Get | Read/Take |
+| Update (Modify) | Update | Put/Post/Patch | Put | Write |
+| Delete (Destroy) | Delete | Delete | Delete | Dispose |
+
+Without these four operations, the software is not considered complete.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/delete 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/delete 2.md
new file mode 100644
index 00000000..f3b7d399
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/delete 2.md
@@ -0,0 +1,5 @@
+# DELETE Request
+
+A DELETE request is used to remove a specific object that already exists in the database. You would usually use this request when you no longer need a specific instance of an object in your database.
+
+Lets say that we no longer need the movie Thor in our database. In order to get rid of the movie, we would send a DELETE request to delete Thor. After that request, Thor will no longer exist in our database.
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/endpoint 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/endpoint 2.md
new file mode 100644
index 00000000..8dc6acb4
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/endpoint 2.md
@@ -0,0 +1,6 @@
+# Endpoint
+
+An endpoint is the URL where your service can be accessed by a client
+application.
+
+If application A wants to reach application B's data stored in a page called data, they would send a GET request to ` \ No newline at end of file
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/url 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/url 2.md
new file mode 100644
index 00000000..bf43829e
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/url 2.md
@@ -0,0 +1,21 @@
+
+
+# URL Components
+
+When you see a URL, such as "http://www.example.com:88/home?item=book", it's comprised of several components. We can break this URL into 5 parts:
+
+- `http`: The **scheme**. It always comes before the colon and two forward slashes and tells the web client how to access the resource. In this case it tells the web client to use the Hypertext Transfer Protocol or HTTP to make a request. Other popular URL schemes are `ftp`, `mailto` or `git`.
+- `www.example.com`: The **host**. It tells the client where the resource is hosted or located.
+- `:88` : The **port** or port number. It is only required if you want to use a port other than the default.
+- `/home/`: The **path**. It shows what local resource is being requested. This part of the URL is optional.
+- `?item=book` : The **query string**, which is made up of **query parameters**. It is used to send data to the server. This part of the URL is also optional.
+
+
+
+
+
+
+
+Sometimes, the path can point to a specific resource on the host. For instance, [www.example.com/home/index.html](http://www.example.com/home/index.html) points to an HTML file located on the example.com server.
+
+Sometimes, we may want to include a port number which the host uses to listen to HTTP requests. A URL in the form of: http://localhost:3000/profile is using the port number `3000` to listen to HTTP requests. The default port number for HTTP is port `80`. Even though this port number is not always specified, it's assumed to be part of every URL. **Unless a different port number is specified, port `80` will be used by default in normal HTTP requests.** To use anything other than the default, one has to specify it in the URL.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.DS_Store b/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.DS_Store
new file mode 100644
index 00000000..d7fd20db
Binary files /dev/null and b/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.DS_Store differ
diff --git a/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.git 2.keep.icloud b/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act3_Creating_Postman_Collections/.DS_Store b/Module_Postman/activities/Act3_Creating_Postman_Collections/.DS_Store
new file mode 100644
index 00000000..5008ddfc
Binary files /dev/null and b/Module_Postman/activities/Act3_Creating_Postman_Collections/.DS_Store differ
diff --git a/Module_Postman/activities/Act3_Creating_Postman_Collections/.git 2.keep.icloud b/Module_Postman/activities/Act3_Creating_Postman_Collections/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act3_Creating_Postman_Collections/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act4_Collection_Runners/.DS_Store b/Module_Postman/activities/Act4_Collection_Runners/.DS_Store
new file mode 100644
index 00000000..1f7ddd00
Binary files /dev/null and b/Module_Postman/activities/Act4_Collection_Runners/.DS_Store differ
diff --git a/Module_Postman/activities/Act4_Collection_Runners/.git 2.keep.icloud b/Module_Postman/activities/Act4_Collection_Runners/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act4_Collection_Runners/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act4_Collection_Runners/ReadMe 2.md b/Module_Postman/activities/Act4_Collection_Runners/ReadMe 2.md
new file mode 100644
index 00000000..6523b4af
--- /dev/null
+++ b/Module_Postman/activities/Act4_Collection_Runners/ReadMe 2.md
@@ -0,0 +1,24 @@
+# Activity/Lab Name
+
+Collection Runner
+
+# Long Summary
+
+Students will learn how to use the Postman Collection Runner function to clear the entire BitBloxs board. They will construct their own data file to pass into Collection Runner and learn how to use requests based on data files to automate the process of testing.
+
+# Short Summary
+
+Students will learn how to use the Runner function in Postman.
+
+# Criteria
+
+1. How can we use the collection runner to automate our testing process?
+2. Why is it helpful to have a datafile uploaded to assist in during the run?
+3. How can you change the other requests we have to take inputs from a data file too?
+
+# Difficulty
+
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module_Postman/activities/Act5_Mock_Servers/.DS_Store b/Module_Postman/activities/Act5_Mock_Servers/.DS_Store
new file mode 100644
index 00000000..5008ddfc
Binary files /dev/null and b/Module_Postman/activities/Act5_Mock_Servers/.DS_Store differ
diff --git a/Module_Postman/activities/Act5_Mock_Servers/.git 2.keep.icloud b/Module_Postman/activities/Act5_Mock_Servers/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act5_Mock_Servers/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.DS_Store b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.DS_Store
new file mode 100644
index 00000000..5008ddfc
Binary files /dev/null and b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.DS_Store differ
diff --git a/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.git 2.keep.icloud b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/README 2.md b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/README 2.md
new file mode 100644
index 00000000..3d075618
--- /dev/null
+++ b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+APIs for Front-End Devs
+
+# Long Summary
+Students will be using NASA's API on Postman with the goal of implementing the API's requests into their own website. They will test different HTTP requests and use the API's documentation on Postman. They will then create code to implement the request into their website.
+
+# Short Summary
+Students will practice using Postman's documentation to test API calls in Postman to implement them in their own website.
+
+# Criteria
+1. What is the advantage of looking through documentation instead of using websites like Stack Overflow?
+2. Where do you modify the parameters for the HTTP request in Postman?
+3. Why is it important to tests HTTP requests instead of solely relying on documentation?
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/.DS_Store b/Module_Postman/activities/Act7_API_Documentation_in_Postman/.DS_Store
new file mode 100644
index 00000000..5008ddfc
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/.DS_Store differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/.git 2.keep.icloud b/Module_Postman/activities/Act7_API_Documentation_in_Postman/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/4 2.md b/Module_Postman/activities/Act7_API_Documentation_in_Postman/4 2.md
new file mode 100644
index 00000000..a9abd20b
--- /dev/null
+++ b/Module_Postman/activities/Act7_API_Documentation_in_Postman/4 2.md
@@ -0,0 +1,15 @@
+
+
+
+
+
+
+To document the APIs we used, simply copy and paste the API link onto the url box. Then you will want to write a nice, thoughtful description of the API in order for other developers to understand what the API is and how to use it.
+
+
\ No newline at end of file
diff --git a/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/url 2.md b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/url 2.md
new file mode 100644
index 00000000..bf43829e
--- /dev/null
+++ b/Module_Postman/activities/Act1_Intro_to_APIs_Endpoints/Concepts/url 2.md
@@ -0,0 +1,21 @@
+
+
+# URL Components
+
+When you see a URL, such as "http://www.example.com:88/home?item=book", it's comprised of several components. We can break this URL into 5 parts:
+
+- `http`: The **scheme**. It always comes before the colon and two forward slashes and tells the web client how to access the resource. In this case it tells the web client to use the Hypertext Transfer Protocol or HTTP to make a request. Other popular URL schemes are `ftp`, `mailto` or `git`.
+- `www.example.com`: The **host**. It tells the client where the resource is hosted or located.
+- `:88` : The **port** or port number. It is only required if you want to use a port other than the default.
+- `/home/`: The **path**. It shows what local resource is being requested. This part of the URL is optional.
+- `?item=book` : The **query string**, which is made up of **query parameters**. It is used to send data to the server. This part of the URL is also optional.
+
+
+
+
+
+
+
+Sometimes, the path can point to a specific resource on the host. For instance, [www.example.com/home/index.html](http://www.example.com/home/index.html) points to an HTML file located on the example.com server.
+
+Sometimes, we may want to include a port number which the host uses to listen to HTTP requests. A URL in the form of: http://localhost:3000/profile is using the port number `3000` to listen to HTTP requests. The default port number for HTTP is port `80`. Even though this port number is not always specified, it's assumed to be part of every URL. **Unless a different port number is specified, port `80` will be used by default in normal HTTP requests.** To use anything other than the default, one has to specify it in the URL.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.DS_Store b/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.DS_Store
new file mode 100644
index 00000000..d7fd20db
Binary files /dev/null and b/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.DS_Store differ
diff --git a/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.git 2.keep.icloud b/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act2_Creating_and_Testing_BitBloxs/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act3_Creating_Postman_Collections/.DS_Store b/Module_Postman/activities/Act3_Creating_Postman_Collections/.DS_Store
new file mode 100644
index 00000000..5008ddfc
Binary files /dev/null and b/Module_Postman/activities/Act3_Creating_Postman_Collections/.DS_Store differ
diff --git a/Module_Postman/activities/Act3_Creating_Postman_Collections/.git 2.keep.icloud b/Module_Postman/activities/Act3_Creating_Postman_Collections/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act3_Creating_Postman_Collections/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act4_Collection_Runners/.DS_Store b/Module_Postman/activities/Act4_Collection_Runners/.DS_Store
new file mode 100644
index 00000000..1f7ddd00
Binary files /dev/null and b/Module_Postman/activities/Act4_Collection_Runners/.DS_Store differ
diff --git a/Module_Postman/activities/Act4_Collection_Runners/.git 2.keep.icloud b/Module_Postman/activities/Act4_Collection_Runners/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act4_Collection_Runners/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act4_Collection_Runners/ReadMe 2.md b/Module_Postman/activities/Act4_Collection_Runners/ReadMe 2.md
new file mode 100644
index 00000000..6523b4af
--- /dev/null
+++ b/Module_Postman/activities/Act4_Collection_Runners/ReadMe 2.md
@@ -0,0 +1,24 @@
+# Activity/Lab Name
+
+Collection Runner
+
+# Long Summary
+
+Students will learn how to use the Postman Collection Runner function to clear the entire BitBloxs board. They will construct their own data file to pass into Collection Runner and learn how to use requests based on data files to automate the process of testing.
+
+# Short Summary
+
+Students will learn how to use the Runner function in Postman.
+
+# Criteria
+
+1. How can we use the collection runner to automate our testing process?
+2. Why is it helpful to have a datafile uploaded to assist in during the run?
+3. How can you change the other requests we have to take inputs from a data file too?
+
+# Difficulty
+
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module_Postman/activities/Act5_Mock_Servers/.DS_Store b/Module_Postman/activities/Act5_Mock_Servers/.DS_Store
new file mode 100644
index 00000000..5008ddfc
Binary files /dev/null and b/Module_Postman/activities/Act5_Mock_Servers/.DS_Store differ
diff --git a/Module_Postman/activities/Act5_Mock_Servers/.git 2.keep.icloud b/Module_Postman/activities/Act5_Mock_Servers/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act5_Mock_Servers/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.DS_Store b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.DS_Store
new file mode 100644
index 00000000..5008ddfc
Binary files /dev/null and b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.DS_Store differ
diff --git a/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.git 2.keep.icloud b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/README 2.md b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/README 2.md
new file mode 100644
index 00000000..3d075618
--- /dev/null
+++ b/Module_Postman/activities/Act6_APIs_for_Front-End_Devs/README 2.md
@@ -0,0 +1,19 @@
+# Activity/Lab Name
+APIs for Front-End Devs
+
+# Long Summary
+Students will be using NASA's API on Postman with the goal of implementing the API's requests into their own website. They will test different HTTP requests and use the API's documentation on Postman. They will then create code to implement the request into their website.
+
+# Short Summary
+Students will practice using Postman's documentation to test API calls in Postman to implement them in their own website.
+
+# Criteria
+1. What is the advantage of looking through documentation instead of using websites like Stack Overflow?
+2. Where do you modify the parameters for the HTTP request in Postman?
+3. Why is it important to tests HTTP requests instead of solely relying on documentation?
+
+# Difficulty
+Easy
+
+# Image
+
\ No newline at end of file
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/.DS_Store b/Module_Postman/activities/Act7_API_Documentation_in_Postman/.DS_Store
new file mode 100644
index 00000000..5008ddfc
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/.DS_Store differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/.git 2.keep.icloud b/Module_Postman/activities/Act7_API_Documentation_in_Postman/.git 2.keep.icloud
new file mode 100644
index 00000000..b17d495e
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/.git 2.keep.icloud differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/4 2.md b/Module_Postman/activities/Act7_API_Documentation_in_Postman/4 2.md
new file mode 100644
index 00000000..a9abd20b
--- /dev/null
+++ b/Module_Postman/activities/Act7_API_Documentation_in_Postman/4 2.md
@@ -0,0 +1,15 @@
+
+
+
+
+
+
+To document the APIs we used, simply copy and paste the API link onto the url box. Then you will want to write a nice, thoughtful description of the API in order for other developers to understand what the API is and how to use it.
+
+ +
+Once the following is done, we can now move on to the next step, which is to name our collection and give it a description like what we did for the various individual APIs.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/6 2.md b/Module_Postman/activities/Act7_API_Documentation_in_Postman/6 2.md
new file mode 100644
index 00000000..a3e8baa9
--- /dev/null
+++ b/Module_Postman/activities/Act7_API_Documentation_in_Postman/6 2.md
@@ -0,0 +1,11 @@
+
+
+
+
+
+
+To add the headers and parameters needed for our APIs, we can simply click on an API and add a key and value to the header and/or parameter. As an example, our parameters for the NEOWS feed API should look like the following:
+
+
+
+Once you do this for all 5 APIs, we can be considered to have finished creating our API documentation
\ No newline at end of file
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/7 2.md b/Module_Postman/activities/Act7_API_Documentation_in_Postman/7 2.md
new file mode 100644
index 00000000..ddc0637b
--- /dev/null
+++ b/Module_Postman/activities/Act7_API_Documentation_in_Postman/7 2.md
@@ -0,0 +1,23 @@
+
+
+
+
+
+
+Now that we have finally finished creating our API documentation, we can head on over to the postman website and check and see what our it looks like. To do so, simply click on the arrow button next to our collection name and click the view in web button.
+
+
+
+Once the following is done, we can now move on to the next step, which is to name our collection and give it a description like what we did for the various individual APIs.
\ No newline at end of file
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/6 2.md b/Module_Postman/activities/Act7_API_Documentation_in_Postman/6 2.md
new file mode 100644
index 00000000..a3e8baa9
--- /dev/null
+++ b/Module_Postman/activities/Act7_API_Documentation_in_Postman/6 2.md
@@ -0,0 +1,11 @@
+
+
+
+
+
+
+To add the headers and parameters needed for our APIs, we can simply click on an API and add a key and value to the header and/or parameter. As an example, our parameters for the NEOWS feed API should look like the following:
+
+
+
+Once you do this for all 5 APIs, we can be considered to have finished creating our API documentation
\ No newline at end of file
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/7 2.md b/Module_Postman/activities/Act7_API_Documentation_in_Postman/7 2.md
new file mode 100644
index 00000000..ddc0637b
--- /dev/null
+++ b/Module_Postman/activities/Act7_API_Documentation_in_Postman/7 2.md
@@ -0,0 +1,23 @@
+
+
+
+
+
+
+Now that we have finally finished creating our API documentation, we can head on over to the postman website and check and see what our it looks like. To do so, simply click on the arrow button next to our collection name and click the view in web button.
+
+ +
+This should link you to the following API documentation we made:
+
+
+
+This should link you to the following API documentation we made:
+
+ +
+It looks nice doesn't it! However, we are not quite done yet. Despite how beautiful our API documentation looks like, it'll be pointless if no one can see it. Therefore, as the last step, click on the publish button on the top right of our API documentation. Once you do that, you should see the following screen:
+
+
+
+It looks nice doesn't it! However, we are not quite done yet. Despite how beautiful our API documentation looks like, it'll be pointless if no one can see it. Therefore, as the last step, click on the publish button on the top right of our API documentation. Once you do that, you should see the following screen:
+
+ +
+At the very bottom of that page lies another publish button that you have to click. Once you do so, your API documentation will be visible for all to see and marvel at!
+
+Also Postman allows us to edit our documentation in the browser. Clicking on a section of the documentation will allow you to do it.
+
+
\ No newline at end of file
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.09.10 PM 2.png b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.09.10 PM 2.png
new file mode 100644
index 00000000..3005aee6
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.09.10 PM 2.png differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.20.50 PM 2.png b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.20.50 PM 2.png
new file mode 100644
index 00000000..78ca4cc3
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.20.50 PM 2.png differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.46.11 PM 2.png b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.46.11 PM 2.png
new file mode 100644
index 00000000..c1eaac46
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.46.11 PM 2.png differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/edit_browser 2.PNG b/Module_Postman/activities/Act7_API_Documentation_in_Postman/edit_browser 2.PNG
new file mode 100644
index 00000000..0c8fd04a
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/edit_browser 2.PNG differ
diff --git a/Module_Twitter_API/.DS_Store b/Module_Twitter_API/.DS_Store
index efd0171a..073a6fd9 100644
Binary files a/Module_Twitter_API/.DS_Store and b/Module_Twitter_API/.DS_Store differ
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 6.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 6.md
new file mode 100644
index 00000000..2b04a661
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 6.md
@@ -0,0 +1,51 @@
+# Bag Of Words
+
+We first train our Bag of Words with some sample text
+
+Let's say we have the following string
+
+```python
+s1 = "The apple is red"
+```
+
+We store this phrase into our corpus (our known words).
+
+
+
+Now we want to transform other strings into vectors based on the first sentence.
+
+Let's say we want a vectorized version of:
+
+```python
+s2 = "The orange is not red"
+```
+
+Our corpus knows the words "The", "apple", "is", and "red".
+
+The words in `s2` that are also in our corpus (currently only `s1`) are "The", "is", and "red". These words have a value of 1 in the final vector, while the other two words "orange" and "not" have a value of 0 because they are not in our corpus (`s1`).
+
+```
+Corpus: ["The", "apple", "is", "red"]
+# s2 was "The orange is not red"
+# after Bag of Words, it is [1, 0, 1, 0, 1]
+
+[ 1 0 1 0 1 ]
+ The orange is not red
+```
+
+"The" → inside corpus → 1
+
+"orange" → not inside corpus → 0
+
+"is" → inside corpus → 1
+
+"not" → inside corpus → 0
+
+"red" → not inside corpus → 1
+
+So our final vector for "The orange is not red" is
+
+```python
+[1, 0, 1, 0, 1]
+```
+
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 7.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 7.md
new file mode 100644
index 00000000..2b04a661
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 7.md
@@ -0,0 +1,51 @@
+# Bag Of Words
+
+We first train our Bag of Words with some sample text
+
+Let's say we have the following string
+
+```python
+s1 = "The apple is red"
+```
+
+We store this phrase into our corpus (our known words).
+
+
+
+Now we want to transform other strings into vectors based on the first sentence.
+
+Let's say we want a vectorized version of:
+
+```python
+s2 = "The orange is not red"
+```
+
+Our corpus knows the words "The", "apple", "is", and "red".
+
+The words in `s2` that are also in our corpus (currently only `s1`) are "The", "is", and "red". These words have a value of 1 in the final vector, while the other two words "orange" and "not" have a value of 0 because they are not in our corpus (`s1`).
+
+```
+Corpus: ["The", "apple", "is", "red"]
+# s2 was "The orange is not red"
+# after Bag of Words, it is [1, 0, 1, 0, 1]
+
+[ 1 0 1 0 1 ]
+ The orange is not red
+```
+
+"The" → inside corpus → 1
+
+"orange" → not inside corpus → 0
+
+"is" → inside corpus → 1
+
+"not" → inside corpus → 0
+
+"red" → not inside corpus → 1
+
+So our final vector for "The orange is not red" is
+
+```python
+[1, 0, 1, 0, 1]
+```
+
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 6.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 6.md
new file mode 100644
index 00000000..3f4db139
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 6.md
@@ -0,0 +1,9 @@
+# Grid Search
+
+In supervised learning, we make models, train them, then use them to predict values given an input.
+
+However, which hyperparameters yields the model with the highest accuracy?
+
+Instead of guessing each combination of hyperparameters (which could take a long time), we can use grid search in a programmatic way.
+
+Grid Search goes through each combination of hyperparameters we provide it and returns the score or accuracy of the prediction.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 7.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 7.md
new file mode 100644
index 00000000..3f4db139
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 7.md
@@ -0,0 +1,9 @@
+# Grid Search
+
+In supervised learning, we make models, train them, then use them to predict values given an input.
+
+However, which hyperparameters yields the model with the highest accuracy?
+
+Instead of guessing each combination of hyperparameters (which could take a long time), we can use grid search in a programmatic way.
+
+Grid Search goes through each combination of hyperparameters we provide it and returns the score or accuracy of the prediction.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 8.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 8.md
new file mode 100644
index 00000000..3f4db139
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 8.md
@@ -0,0 +1,9 @@
+# Grid Search
+
+In supervised learning, we make models, train them, then use them to predict values given an input.
+
+However, which hyperparameters yields the model with the highest accuracy?
+
+Instead of guessing each combination of hyperparameters (which could take a long time), we can use grid search in a programmatic way.
+
+Grid Search goes through each combination of hyperparameters we provide it and returns the score or accuracy of the prediction.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 4.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 4.md
new file mode 100644
index 00000000..26adf073
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 4.md
@@ -0,0 +1,6 @@
+# Data Splitting
+
+Generally, in supervised learning, we need to train our models with some portion of the entire data, and use the rest of it to see how well it learned.
+
+We need both a training set and a testing set.
+
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 5.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 5.md
new file mode 100644
index 00000000..26adf073
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 5.md
@@ -0,0 +1,6 @@
+# Data Splitting
+
+Generally, in supervised learning, we need to train our models with some portion of the entire data, and use the rest of it to see how well it learned.
+
+We need both a training set and a testing set.
+
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 4.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 4.md
new file mode 100644
index 00000000..f7bb06f1
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 4.md
@@ -0,0 +1,5 @@
+# Hyperparameters
+
+Hyperparameters are parameters we set for our machine learning models before they begin learning.
+
+We can tune how well our models perform by tweaking the values of each hyperparameters, meaning each combination of hyperparameters yield a different model.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 5.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 5.md
new file mode 100644
index 00000000..f7bb06f1
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 5.md
@@ -0,0 +1,5 @@
+# Hyperparameters
+
+Hyperparameters are parameters we set for our machine learning models before they begin learning.
+
+We can tune how well our models perform by tweaking the values of each hyperparameters, meaning each combination of hyperparameters yield a different model.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/json 4.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/json 4.md
new file mode 100644
index 00000000..4bf4eed8
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/json 4.md
@@ -0,0 +1,28 @@
+
+
+
+
+At the very bottom of that page lies another publish button that you have to click. Once you do so, your API documentation will be visible for all to see and marvel at!
+
+Also Postman allows us to edit our documentation in the browser. Clicking on a section of the documentation will allow you to do it.
+
+
\ No newline at end of file
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.09.10 PM 2.png b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.09.10 PM 2.png
new file mode 100644
index 00000000..3005aee6
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.09.10 PM 2.png differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.20.50 PM 2.png b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.20.50 PM 2.png
new file mode 100644
index 00000000..78ca4cc3
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.20.50 PM 2.png differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.46.11 PM 2.png b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.46.11 PM 2.png
new file mode 100644
index 00000000..c1eaac46
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/Screen Shot 2020-02-19 at 11.46.11 PM 2.png differ
diff --git a/Module_Postman/activities/Act7_API_Documentation_in_Postman/edit_browser 2.PNG b/Module_Postman/activities/Act7_API_Documentation_in_Postman/edit_browser 2.PNG
new file mode 100644
index 00000000..0c8fd04a
Binary files /dev/null and b/Module_Postman/activities/Act7_API_Documentation_in_Postman/edit_browser 2.PNG differ
diff --git a/Module_Twitter_API/.DS_Store b/Module_Twitter_API/.DS_Store
index efd0171a..073a6fd9 100644
Binary files a/Module_Twitter_API/.DS_Store and b/Module_Twitter_API/.DS_Store differ
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 6.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 6.md
new file mode 100644
index 00000000..2b04a661
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 6.md
@@ -0,0 +1,51 @@
+# Bag Of Words
+
+We first train our Bag of Words with some sample text
+
+Let's say we have the following string
+
+```python
+s1 = "The apple is red"
+```
+
+We store this phrase into our corpus (our known words).
+
+
+
+Now we want to transform other strings into vectors based on the first sentence.
+
+Let's say we want a vectorized version of:
+
+```python
+s2 = "The orange is not red"
+```
+
+Our corpus knows the words "The", "apple", "is", and "red".
+
+The words in `s2` that are also in our corpus (currently only `s1`) are "The", "is", and "red". These words have a value of 1 in the final vector, while the other two words "orange" and "not" have a value of 0 because they are not in our corpus (`s1`).
+
+```
+Corpus: ["The", "apple", "is", "red"]
+# s2 was "The orange is not red"
+# after Bag of Words, it is [1, 0, 1, 0, 1]
+
+[ 1 0 1 0 1 ]
+ The orange is not red
+```
+
+"The" → inside corpus → 1
+
+"orange" → not inside corpus → 0
+
+"is" → inside corpus → 1
+
+"not" → inside corpus → 0
+
+"red" → not inside corpus → 1
+
+So our final vector for "The orange is not red" is
+
+```python
+[1, 0, 1, 0, 1]
+```
+
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 7.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 7.md
new file mode 100644
index 00000000..2b04a661
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/BagOfWords 7.md
@@ -0,0 +1,51 @@
+# Bag Of Words
+
+We first train our Bag of Words with some sample text
+
+Let's say we have the following string
+
+```python
+s1 = "The apple is red"
+```
+
+We store this phrase into our corpus (our known words).
+
+
+
+Now we want to transform other strings into vectors based on the first sentence.
+
+Let's say we want a vectorized version of:
+
+```python
+s2 = "The orange is not red"
+```
+
+Our corpus knows the words "The", "apple", "is", and "red".
+
+The words in `s2` that are also in our corpus (currently only `s1`) are "The", "is", and "red". These words have a value of 1 in the final vector, while the other two words "orange" and "not" have a value of 0 because they are not in our corpus (`s1`).
+
+```
+Corpus: ["The", "apple", "is", "red"]
+# s2 was "The orange is not red"
+# after Bag of Words, it is [1, 0, 1, 0, 1]
+
+[ 1 0 1 0 1 ]
+ The orange is not red
+```
+
+"The" → inside corpus → 1
+
+"orange" → not inside corpus → 0
+
+"is" → inside corpus → 1
+
+"not" → inside corpus → 0
+
+"red" → not inside corpus → 1
+
+So our final vector for "The orange is not red" is
+
+```python
+[1, 0, 1, 0, 1]
+```
+
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 6.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 6.md
new file mode 100644
index 00000000..3f4db139
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 6.md
@@ -0,0 +1,9 @@
+# Grid Search
+
+In supervised learning, we make models, train them, then use them to predict values given an input.
+
+However, which hyperparameters yields the model with the highest accuracy?
+
+Instead of guessing each combination of hyperparameters (which could take a long time), we can use grid search in a programmatic way.
+
+Grid Search goes through each combination of hyperparameters we provide it and returns the score or accuracy of the prediction.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 7.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 7.md
new file mode 100644
index 00000000..3f4db139
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 7.md
@@ -0,0 +1,9 @@
+# Grid Search
+
+In supervised learning, we make models, train them, then use them to predict values given an input.
+
+However, which hyperparameters yields the model with the highest accuracy?
+
+Instead of guessing each combination of hyperparameters (which could take a long time), we can use grid search in a programmatic way.
+
+Grid Search goes through each combination of hyperparameters we provide it and returns the score or accuracy of the prediction.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 8.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 8.md
new file mode 100644
index 00000000..3f4db139
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/GridSearch 8.md
@@ -0,0 +1,9 @@
+# Grid Search
+
+In supervised learning, we make models, train them, then use them to predict values given an input.
+
+However, which hyperparameters yields the model with the highest accuracy?
+
+Instead of guessing each combination of hyperparameters (which could take a long time), we can use grid search in a programmatic way.
+
+Grid Search goes through each combination of hyperparameters we provide it and returns the score or accuracy of the prediction.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 4.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 4.md
new file mode 100644
index 00000000..26adf073
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 4.md
@@ -0,0 +1,6 @@
+# Data Splitting
+
+Generally, in supervised learning, we need to train our models with some portion of the entire data, and use the rest of it to see how well it learned.
+
+We need both a training set and a testing set.
+
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 5.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 5.md
new file mode 100644
index 00000000..26adf073
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/datasplitting 5.md
@@ -0,0 +1,6 @@
+# Data Splitting
+
+Generally, in supervised learning, we need to train our models with some portion of the entire data, and use the rest of it to see how well it learned.
+
+We need both a training set and a testing set.
+
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 4.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 4.md
new file mode 100644
index 00000000..f7bb06f1
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 4.md
@@ -0,0 +1,5 @@
+# Hyperparameters
+
+Hyperparameters are parameters we set for our machine learning models before they begin learning.
+
+We can tune how well our models perform by tweaking the values of each hyperparameters, meaning each combination of hyperparameters yield a different model.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 5.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 5.md
new file mode 100644
index 00000000..f7bb06f1
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/hyperparameters 5.md
@@ -0,0 +1,5 @@
+# Hyperparameters
+
+Hyperparameters are parameters we set for our machine learning models before they begin learning.
+
+We can tune how well our models perform by tweaking the values of each hyperparameters, meaning each combination of hyperparameters yield a different model.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/json 4.md b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/json 4.md
new file mode 100644
index 00000000..4bf4eed8
--- /dev/null
+++ b/Module_Twitter_API/activities/Act11_Intro to ML with Sci-kit Learn/Concepts/json 4.md
@@ -0,0 +1,28 @@
+
+
+ +
+JSON stands for JavaScript Object Notation. All API data is returned in JSON format. JSON data looks a lot like a Python dictionary where you have a key on the left and a value on the right.
+
+Example: Lets say we have the following data returned from a movie API.
+
+ `"movies": {
+ "Thor": {
+ "Rating": 4,
+ },
+ "Spiderman": {
+ "Rating": 5,
+ },
+ "Superman": {
+ "Rating": 3,
+ }
+ }`
+
+Assume that the above JSON data is stored in a variable called `movie_list`.
+
+To get the rating data about Thor, we need to use square brackets to get specific data that we need. To get the rating on Thor we would need to do:
+
+`movie_list["Thor"]["Rating"]` to get Thor's movie rating. `movie_list["Thor"]["Rating"]` yields a value of 4.
+
+If we only wanted to get Thor's object we would use:
+`movie_list["Thor"]` to get the Thor object.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act12_Intro to NLP/.11.html.icloud b/Module_Twitter_API/activities/Act12_Intro to NLP/.11.html.icloud
new file mode 100644
index 00000000..d79aeaba
Binary files /dev/null and b/Module_Twitter_API/activities/Act12_Intro to NLP/.11.html.icloud differ
diff --git a/Module_Twitter_API/activities/Act12_Intro to NLP/11.html b/Module_Twitter_API/activities/Act12_Intro to NLP/11.html
deleted file mode 100644
index 676a1a12..00000000
--- a/Module_Twitter_API/activities/Act12_Intro to NLP/11.html
+++ /dev/null
@@ -1,21404 +0,0 @@
-
-
-
+
+JSON stands for JavaScript Object Notation. All API data is returned in JSON format. JSON data looks a lot like a Python dictionary where you have a key on the left and a value on the right.
+
+Example: Lets say we have the following data returned from a movie API.
+
+ `"movies": {
+ "Thor": {
+ "Rating": 4,
+ },
+ "Spiderman": {
+ "Rating": 5,
+ },
+ "Superman": {
+ "Rating": 3,
+ }
+ }`
+
+Assume that the above JSON data is stored in a variable called `movie_list`.
+
+To get the rating data about Thor, we need to use square brackets to get specific data that we need. To get the rating on Thor we would need to do:
+
+`movie_list["Thor"]["Rating"]` to get Thor's movie rating. `movie_list["Thor"]["Rating"]` yields a value of 4.
+
+If we only wanted to get Thor's object we would use:
+`movie_list["Thor"]` to get the Thor object.
\ No newline at end of file
diff --git a/Module_Twitter_API/activities/Act12_Intro to NLP/.11.html.icloud b/Module_Twitter_API/activities/Act12_Intro to NLP/.11.html.icloud
new file mode 100644
index 00000000..d79aeaba
Binary files /dev/null and b/Module_Twitter_API/activities/Act12_Intro to NLP/.11.html.icloud differ
diff --git a/Module_Twitter_API/activities/Act12_Intro to NLP/11.html b/Module_Twitter_API/activities/Act12_Intro to NLP/11.html
deleted file mode 100644
index 676a1a12..00000000
--- a/Module_Twitter_API/activities/Act12_Intro to NLP/11.html
+++ /dev/null
@@ -1,21404 +0,0 @@
-
-
-[[item.1]]
-[[item.2]]
-[[menuStrings_.RESTRICTED_MODE_TEXT_LINE_1]]
- -[[menuStrings_.RESTRICTED_MODE_TEXT_LINE_2]]
- -[[formattedAmount]]
- -[[getSimpleString(data.title)]]
-[[getSimpleString(data.text)]]
-|
- [[item.timeDate]]
- |
-
-
-
-
- [[item.timeWeekday]][[item.timeTime]]
-
- |
-
-
-
-
-
- [[item.subtitle2]]
- ·
-
- [[item.linkText]]
-
- |
-
-
-
 \ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/112.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/112.md
new file mode 100644
index 00000000..ea6a3ca5
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/112.md
@@ -0,0 +1,12 @@
+
+
+The Twitter developer application process starts at this page, please complete the form. Once you click 'student', proceed to the rest of the Application.
+
+When you're prompted to explain your use, you can explain that you'll be using Twitter to perform sentiment analysis for learning purposes.
+
+
+
+You will also be analyzing Twitter data, you can say this is also part of the exercise.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/113.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/113.md
new file mode 100644
index 00000000..26b8f934
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/113.md
@@ -0,0 +1,5 @@
+
+
+After finishing your application, confirm your email and your account should be processed and reviewed swiftly.
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/12.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/12.md
new file mode 100644
index 00000000..11b31eef
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/12.md
@@ -0,0 +1,12 @@
+
+
+When you have finished configuring your account, head back to Twitter Developer [here](https://developer.twitter.com/en/apps), your app menu should look like this:
+
+Click on “Create an app”. Fill out app details; for the website URL field, you can input any website, we used https://bitproject.org. Leave the OAuth Callback URL, TOS and Privacy Policy fields blank.
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key. Copy these keys for later use. (these keys in the picture have been erased)
+
+
+
+There is also an area to generate an access token and access secret token, please generate them and keep track of those as well.
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/121.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/121.md
new file mode 100644
index 00000000..3d3abcc6
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/121.md
@@ -0,0 +1,6 @@
+
+
+Head back to Twitter Developer website [here](https://developer.twitter.com/en/apps), and your app menu should look like this:
+
+Click on “Create an app”.
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/122.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/122.md
new file mode 100644
index 00000000..3f94fc25
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/122.md
@@ -0,0 +1,6 @@
+
+
+In the creation of your app, fill out all the required information for your app details. For the website URL field, you can input any website, we used https://bitproject.org. Leave the OAuth Callback URL, TOS and Privacy Policy fields blank.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/123.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/123.md
new file mode 100644
index 00000000..4e4adbf5
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/123.md
@@ -0,0 +1,21 @@
+
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key.
+
+
+
+
+
+Below the consumer API keys, there is also an area to generate an access token and access secret token, please generate them and keep track of those as well.
+
+
+
+Copy these keys into your starter code where the example is:
+
+```python
+consumer_key = "Your key goes here!"
+consumer_secret = "Your key goes here!"
+access_token = "Your key goes here!"
+access_token_secret = "Your key goes here!
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/2.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/2.md
new file mode 100644
index 00000000..36c87dc6
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/2.md
@@ -0,0 +1,11 @@
+
+
+The goal of this card is to set up authentication so your application can use Tweet information. You should:
+
+* Configure OAuth authentication with your consumer key and secret key
+* Set your access tokens and create a API object in `tweepy` to fetch tweets.
+
+You'll be using the `us_search` dictionary provided in the starter code for the rest of this lab.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/21.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/21.md
new file mode 100644
index 00000000..021a24a3
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/21.md
@@ -0,0 +1,9 @@
+
+
+Paste your keys and tokens in the allocated space. You'll want to authenticate in three steps:
+
+1. Configure OAuth authentication with your consumer key and secret with the `OAuthHandler(consumer_key, consumer_secret)` call. This should create an `auth` object
+2. Set your access tokens with `auth.set_access_token()`
+3. Create a API object in `tweepy` to fetch tweets: `tweepy.API(auth, wait_on_rate_limit=True)`
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/211.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/211.md
new file mode 100644
index 00000000..2cad02d2
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/211.md
@@ -0,0 +1,23 @@
+
+
+
+We're now going to authenticate using our app credentials.
+
+```python
+auth = OAuthHandler(consumer_key, consumer_secret)
+```
+
+The above line generates an authentication object using our consumer key and secret.
+
+```python
+auth.set_access_token(access_token, access_token_secret)
+```
+
+This line enables access to our authentication object with our access token and access secret token.
+
+
+
+Setting the above tokens is telling the Twitter API that you are the one using the application! Great job!
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/212.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/212.md
new file mode 100644
index 00000000..b2fc0a15
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/212.md
@@ -0,0 +1,15 @@
+
+
+The `tweepy` package allows us to very easily use Twitter's API within a Python environment. The line below will give us an API object that will allow us to fetch tweets.
+
+```python
+api = tw.API(auth, wait_on_rate_limit=True)
+```
+
+We're setting up our `api` object to use the authentication object `auth` we set up just before this.
+
+
+
+The Twitter API has a limit of how many times you can request for an hour. The `wait_on_rate_limit` parameter is telling our Twitter request object to automatically wait for the rate limit to refresh for the hour.
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/3.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/3.md
new file mode 100644
index 00000000..8168a52d
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/3.md
@@ -0,0 +1,24 @@
+
+
+Now that our application is set up, we're going to produce a dataframe that stores two items: the data, and the sentiment of each tweet found.
+
+
+
+Complete the function `produce_dataframe(search_dict, num_tweets)`, with the following descriptions of the parameters:
+
+* `search_dict` - a dictionary that has a {key, value} pair in the items category. The `key` is the date you will be searching for, and the `value` is the name of the airline you will search for.
+* `num_tweets` - the number of tweets in the search dictionary
+
+
+
+The function `produce_dataframe(search_dict, num_tweets)` should complete the following checklist:
+
+* Return a dataframe using the `pandas` library, the column names should be 'date', and 'sentiment'. Set rownames to 'positive', 'neutral', and 'negative.'
+* Fill the returning dataframe with
+
+
+
+You are not allowed to change any function definition or code that was given to you. The end result should look like this:
+
+![image]()
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/31.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/31.md
new file mode 100644
index 00000000..857614b8
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/31.md
@@ -0,0 +1,17 @@
+
+
+
+
+In order to add items to the dataframe, we first need to create dataframe. We can use the `pandas` library to create a dataframe.
+
+The function we want to use is `pandas.Dataframe(arguments)`. Use the argument:
+
+* `index` to set the rownames to 'positive', 'neutral', and 'negative.'
+* `columns` to set the columnnames to `date` and `sentiment`
+
+
+
+If you run your code before inserting any data, your graph should look like this:
+
+![image]()
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/311.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/311.md
new file mode 100644
index 00000000..2e74590e
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/311.md
@@ -0,0 +1,24 @@
+
+
+
+
+We can create a `pandas` dataframe with the function `pd.DataFrame()`. If we want a dataframe with the following structure (it currently has :
+
+| | Airline_0 | Airline_1 | ... |
+| -------- | --------- | --------- | ---- |
+| positive | ... | ... | ... |
+| neutral | ... | ... | ... |
+| negative | ... | ... | ... |
+
+We need the arguments:
+
+* `data` - this argument is defaulted to None, we define it to an explicit `[]`
+* `Index` - We'll set this to a list of []'positive', 'neutral', 'negative']
+
+Our final code looks like:
+
+```python
+df = pd.DataFrame([], index=['positive', 'neutral', 'negative'])
+```
+
+Now we need to get the tweets from the cursor object
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/312.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/312.md
new file mode 100644
index 00000000..f32b7d59
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/312.md
@@ -0,0 +1,17 @@
+
+
+The `Cursor` in `tweepy` will allow us to find `num_tweets` tweets given a search query `val`.
+
+```python
+# Collect tweets
+tweets = tw.Cursor(api.search, q=val, lang="en", since=date_since).items(num_tweets)
+```
+
+Because we are given a dictionary with search queries, we want to iterate through this dictionary and call the above line for each search query (each query corresponds to one airline):
+
+```python
+for key, val in search_dict.items():
+ # Collect tweets
+ tweets = tw.Cursor(api.search, q=val, lang="en", since=date_since).items(num_tweets)
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/32.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/32.md
new file mode 100644
index 00000000..91cab110
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/32.md
@@ -0,0 +1,13 @@
+
+
+
+
+Now that we've created our Dataframe, we need to fill our dataframe. Recall the parameter `search_dict` is a dictionary that has a {key, value} pair in the items category. The `key` is the date you will be searching for, and the `value` is the name of the airline you will search for.
+
+
+
+After producing the dataframe you should iterate through the `search_dict` and call the `tweepy.Cursor()` object to get the tweets with the search query.
+
+
+
+![image]()
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/321.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/321.md
new file mode 100644
index 00000000..6a27d795
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/321.md
@@ -0,0 +1,30 @@
+
+
+
+
+For each tweet object in the cursor, we can use the `.text` attribute to get the text of the tweet itself. Then for each text, we make a `TextBlob` object out of that text.
+
+From there, simply check the values of the `.sentiment.polarity` attribute. Positive polarity indicates positive sentiment, zero polarity indicates neutral sentiment and neutral polarity indicates negative sentiment.
+
+We keep track of positive, neutral and negative tweets with counter variables. At the end, we add the acquired sentiment data to the dataframe.
+
+Return `df` at the end.
+
+```python
+for key, val in search_dict.items():
+ # ...
+
+ positive = 0
+ neutral = 0
+ negative = 0
+ for t in tweets:
+ analysis = TextBlob(t.text)
+ if analysis.sentiment.polarity > 0:
+ positive += 1
+ elif analysis.sentiment.polarity == 0:
+ neutral += 1
+ else:
+ negative += 1
+ df[key] = [positive, neutral, negative]
+return df
+```
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/33.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/33.md
new file mode 100644
index 00000000..69b0311c
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/33.md
@@ -0,0 +1,13 @@
+
+
+Now that we've got the tweets, we need to iterate through the tweets to find the sentiments.
+
+
+
+We also want to keep track of how many of each sentiments you have. Make sure to initialize the number of sentiments of each 'positive', 'neutral' or 'negative' first.
+
+
+
+You need to use the `TextBlob` module to get the `sentiment.polarity` attribute. For each item in the Tweets we have, set the item in the dataframe date to the sentiment.
+
+![image]()
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/4.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/4.md
new file mode 100644
index 00000000..e419a958
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/4.md
@@ -0,0 +1,13 @@
+
+
+We currently have a dataframe containing the dates and sentiments for the airlines we searched for. We now want to calculate the total tweets and the percentages of positive/neutral/negative tweets for a specific airline
+
+
+The goal for this card is to create a *new* dataframe that's columns are the dates of the tweets, and the rows are labeled `positive`, `neutral`, `negative`, and `total`. The rows `positive`, `neutral`, and `negative` will be the percentage of tweets across the day, and `total` will be an integer, the number of tweetsfor that day.
+
+
+
+To do this, choose just *one* airline whose data you will perform analysis on, and create a dataframe that looks like the one below:
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/41.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/41.md
new file mode 100644
index 00000000..b60fdcc0
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/41.md
@@ -0,0 +1,11 @@
+
+
+Our first step is to create a dataframe with the raw dates and sentiments for each tweets. You can follow this process:
+
+1. Pick an airline from the `search_dict` dictionary (we chose United Airlines!) and get the related tweets using the Twitter API. You can search for the tweet since the variable `date_since`, which has an already calculated value of 3 days ago.
+2. Create the empty Time Series Dataframe. Name the columns `date`, and `sentiment`.
+3. Fill the time series dataframe by analyzing each tweet. Like before, tweets should be categorized into `postive`, `neutral`, or `negative`.
+
+Once we've created the time series dataframe, we can create percentages of tweets from that!
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/411.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/411.md
new file mode 100644
index 00000000..b5e18318
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/411.md
@@ -0,0 +1,18 @@
+
+
+We can search for the tweets related to an airline the same way we did before. The only thing we're changing here is we're picking on airline to search for instead of all of the airlines in the search dictionary.
+
+```python
+tweets = tw.Cursor(api.search,
+ q="united airlines",
+ lang="en",
+ since=date_since).items(1000)
+```
+
+Again, we're getting a list of tweets through the Tweepy cursor object.
+
+
+
+In the background, the Tweepy cursor object is creating a loop that uses your API keys to get up to 1000 tweets as we set it with the parameter.
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/412.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/412.md
new file mode 100644
index 00000000..a1dfa588
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/412.md
@@ -0,0 +1,21 @@
+```python
+text_create = []
+text_sentiment = []
+time_series_df = pd.DataFrame(pd.np.empty((0, 2)))
+time_series_df.columns = ['date', 'sentiment']
+
+for t in tweets:
+ text_create.append(t.created_at)
+ analysis = TextBlob(t.text)
+
+ if analysis.sentiment.polarity > 0:
+ text_sentiment.append('positive')
+ elif analysis.sentiment.polarity == 0:
+ text_sentiment.append('neutral')
+ else:
+ text_sentiment.append('negative')
+
+time_series_df['date'] = text_create
+time_series_df['sentiment'] = text_sentiment
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/42.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/42.md
new file mode 100644
index 00000000..a3a38400
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/42.md
@@ -0,0 +1,9 @@
+
+
+Now that we have our time series dataframe with each tweet and it's corresponding sentiment, we can create a dataframe with the percentages of each tweet per day. Try this process:
+
+1. Create the dataframe. The dataframe columns should be each day since `date_since`, and the row names should be `positive`, `neutral`, `negative`, and `total`.
+2. Calculate the total number of tweets for each day. The numbers will be in the row `total`.
+3. Calculate the percentage of `positive`, `neutral`, and `negative` for each day.
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/5.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/5.md
new file mode 100644
index 00000000..cdcbc47b
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/5.md
@@ -0,0 +1,12 @@
+# Graphing
+
+Now that we have our dataframe with the number of positive, neutral, and negative tweets for each candidate, it's time to graph!
+
+We'll be graphing a bar graph representing the total number of tweets per day for
+
+Inside of the function `produce_graph(df, keys)`, create a bar graph, with each bar labelled with an appropriate date for the tick. Then on top of that bar graph, create a line graph with three lines for the positive, neutral, and negative sentiment on *each day*.
+
+Data presentation is everything - without putting your due diligence into your presentation, less people will read your analytics! So make sure your graph is properly titled, with a legend, x-axes, y-axes, and x and y labels. Don't forget to have 2 y-axes! (one for your bar graph and one for your line graph). As a reminder this is what your graph should look like:
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/51.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/51.md
new file mode 100644
index 00000000..49a59138
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/51.md
@@ -0,0 +1,12 @@
+# Setting Up Bars
+
+Remember that even though this is a stacked bar graph, you are still essentially graphing numbers on a bar graph, with the caveat that the bars are on top of each other, and so the location of the bars needs to be controlled.
+
+To make your bars on your graph, there are two steps you need to take:
+
+* Locate the positive, neutral and negative lists in your data frame. That is the data you will be graphing.
+* Use `plt.bar` to graph bar graphs.
+ * Start off with just graphing the positive bars and making sure those work.
+ * Then graph the neutral bars, setting the **bottom** to be the positive bars.
+ * Do the same for negative bars.
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/52.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/52.md
new file mode 100644
index 00000000..65ab6ddc
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/52.md
@@ -0,0 +1,22 @@
+# Making Graph Pretty
+
+Now that your bars are set up, your graph most likely looks unorganized. To organize our graph better, we can set margins to the x ticks to space them out. Because the specifics of how to space out x tick labels can get quite complicated and out of the scope of this bootcamp, I'll provide a chunk of code for you here:
+
+```python
+# space out x ticks and give margins
+plt.gca().margins(x=0)
+plt.gcf().canvas.draw()
+tl = plt.gca().get_xticklabels()
+maxsize = max([t.get_window_extent().width for t in tl])
+m = 0.1 # inch margin
+s = maxsize/plt.gcf().dpi*7+2*m
+margin = m/plt.gcf().get_size_inches()[0]
+
+plt.gcf().subplots_adjust(left=margin, right=1.-margin)
+plt.gcf().set_size_inches(s, plt.gcf().get_size_inches()[1])
+```
+
+This code should space out your x ticks and set margins.
+
+Don't forget a title (`plt.title`) and a legend (`plt.legend`)!
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/53.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/53.md
new file mode 100644
index 00000000..224384de
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/53.md
@@ -0,0 +1,5 @@
+# Text Labels
+
+To add text labels, we'll have to iterate through all the bars and append an appropriate label to each one. So firstly, set up a list called `labels`, that has all the positive, neutral and negative data *in one list*.
+
+We can use `ax.patches` to find a list of all the bars currently in the graph. We can then `zip` the labels and patches together, iterate through that, and for each patch use `ax.text` to attribute a label to each bar. Make sure you have an appropriate location when using `ax.text`!
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/6.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/6.md
new file mode 100644
index 00000000..45f890d6
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/6.md
@@ -0,0 +1,3 @@
+# `main()`
+
+It's time to put all of our functions together into a program! Call `produce_dataframe()` and `produce_graph` inside of your main() function with the proper parameters, and run your main() to see your graphs made!
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/README.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/README.md
new file mode 100644
index 00000000..f9c64055
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/README.md
@@ -0,0 +1,20 @@
+# Activity/Lab Name
+
+Airline Sentiment Analysis
+
+# Long Summary
+
+Students will use the `tweepy` and `textblob` Python modules to utilize the Twitter API and perform sentiment analysis on tweets about airlines. Students will then use Python modules `pandas` and `matplotlib` to make a dataframe and graph the information appropriately.
+
+# Short Summary
+
+Students will use the Twitter API to analyze sentiments about airline tweets
+
+# Criteria
+
+1. How would you use a Tweepy cursor object to get Tweets from the Twitter API?
+2. What's the difference between a time series dataframe and a regular dataframe?
+
+# Difficulty
+
+Medium
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/starter_code.py b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/starter_code.py
new file mode 100644
index 00000000..16163c8a
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/starter_code.py
@@ -0,0 +1,28 @@
+# Import necessary modules
+import os
+import tweepy as tw
+import pandas as pd
+import numpy as np
+import matplotlib.pyplot as plt
+from scipy import stats
+from textblob import TextBlob
+from tweepy import OAuthHandler
+from IPython.display import display, HTML
+
+# 1.md and 2.md
+consumer_key = "Your key goes here!"
+consumer_secret = "Your key goes here!"
+access_token = "Your key goes here!"
+access_token_secret = "Your key goes here!"
+
+# Search dictionary to pass into produce_dataframe() as airlines to search for. DO NOT EDIT!
+search_dict = {"Spirit Airlines": "#spiritairlines","JetBlue": "#jetblue", "Frontier Airlines": "frontier airlines",
+ "Delta": "delta airlines", "United": "united airlines", "Southwest": "southwest airlines", "American":
+ "american airlines"
+ }
+
+# The date to search from
+date_since = "This date should be five days from now!"
+d = datetime.datetime.today()
+print(d)
+# Check that the tweepy object is working!
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/1.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/1.md
new file mode 100644
index 00000000..bd409861
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/1.md
@@ -0,0 +1,14 @@
+
+
+With the wealth of information at our disposal, American politics have increasingly become a game of misinformation and narrative twisting. To win elections, often times it doesn't matter what political candidates actually do or say, but how candidates can control the narrative surrounding their campaigns, and what the American people think of their candidates.
+
+Twitter reactions are a valuable source of political opinions from regular Americans, because anyone can tweet their honest feelings about political candidates. Using sentiment analysis on Americans' tweets can give us genuine insight on the sentiment behind every candidate in the race, outside of media spin or campaign biases. For this lab, we'll dive into the tweets during and after the 7th Democratic Debate to gauge how average Americans perceive political candidates, and graph our results in a stacked bar graph! Here is what the result should look like:
+
+
+
+To do this, we'll be gathering tweets referencing political candidates using Twitter's API as well as the `tweepy` and `TextBlob`packages to determine whether generated tweets have a positive, neutral or negative attitude towards the airlines.
+
+Proceed to Twitter Developer [here](https://developer.twitter.com/en/apps), and you'll need to make a new Twitter app and get four credentials for future use: consumer key, consumer token, access token and access secret token.
+
+Paste those credentials into the appropriate area in your starter code.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/11.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/11.md
new file mode 100644
index 00000000..20e2f2c8
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/11.md
@@ -0,0 +1,6 @@
+
+
+The Twitter developer application process starts here, please complete the form.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/111.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/111.md
new file mode 100644
index 00000000..6e78cbed
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/111.md
@@ -0,0 +1,6 @@
+
+
+Proceed to Twitter Developer [here](https://developer.twitter.com/en/apps). Implementing sign-in with Twitter requires a Twitter developer account, so click “Apply”.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/112.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/112.md
new file mode 100644
index 00000000..7c1b766b
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/112.md
@@ -0,0 +1,8 @@
+
+
+The Twitter developer application process starts here, please complete the form.
+
+As you are most likely a student, click on the student option to begin. If another option is more relevant, click on that instead.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/113.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/113.md
new file mode 100644
index 00000000..35d947ef
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/113.md
@@ -0,0 +1,7 @@
+
+
+After finishing your application, confirm your email and your account should be processed and reviewed swiftly.
+
+
+
+After you have been approved, you will then be able to access the neccessary API keys. Be patient! This process can lasrt up to 2 bussiness weeks.
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/12.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/12.md
new file mode 100644
index 00000000..03be66ab
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/12.md
@@ -0,0 +1,12 @@
+
+
+When you have finished configuring your account, head back to Twitter Developer [here](https://developer.twitter.com/en/apps), your app menu should look like this:
+
+
+
+Click on “Create an app” and fill out app details.
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key. Copy these keys for later use (these keys in the picture have been erased). The keys will be used to access Twitter's sentiment anlysis API and will be inserted into the starter code.
+
+There is also an area to generate an access token and access secret token, please generate them and keep track of those as well. They will be used in the starter code.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/121.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/121.md
new file mode 100644
index 00000000..b6f3eed0
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/121.md
@@ -0,0 +1,11 @@
+
+
+Head back to Twitter Developer [here](https://developer.twitter.com/en/apps), your app menu should look like this:
+
+Click on “Create an app”. Fill out app details; for the website URL field, you can input any website, we used https://bitproject.org. Leave the OAuth Callback URL, TOS and Privacy Policy fields blank.
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key. Copy these keys for later use. (these keys in the picture have been erased)
+
+
+
+There is also an area to generate an access token and access secret token, please generate them and keep track of those as well.
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/122.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/122.md
new file mode 100644
index 00000000..42c3898b
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/122.md
@@ -0,0 +1,12 @@
+
+
+In the creation of your app, fill out all the required information for your app details. For the website URL field, you can input any website, we used https://bitproject.org. Leave the OAuth Callback URL, TOS and Privacy Policy fields blank.
+
+ OAuth Callback URLs are used for providing directions on where a user should go after signing in with their Twitter credentials. They can even be used to redirect a user to a spcific page, which won't be neccessary for our lab.
+
+TOS stands for 'terms of service' which again, we don't need to specify here.
+
+Privacy Policy is similar to TOS, but would explain to users what the data collected from them would be used for. Since there will be no users other than yourself, it is not relevant.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/123.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/123.md
new file mode 100644
index 00000000..77467a79
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/123.md
@@ -0,0 +1,10 @@
+
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key. Copy these keys for later use. (these keys in the picture have been erased)
+
+
+
+
+
+Below the consumer API keys, there is also an area to generate an access token and access secret token, please generate them and keep track of those as well. Remember, these keys will be used to access Twitter's sentiment anlysis API and will be inserted into the starter code.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/2.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/2.md
new file mode 100644
index 00000000..bc1c754e
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/2.md
@@ -0,0 +1,6 @@
+
+
+Paste your keys and tokens in the allocated space. Then configure OAuth authentication with your consumer key and secret, set your access tokens and create a API object in `tweepy` to fetch tweets.
+
+Bear in mind we will be using the `dem_search` dictionary for the rest of this lab.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/21.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/21.md
new file mode 100644
index 00000000..77cae357
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/21.md
@@ -0,0 +1,8 @@
+
+
+Paste your keys and tokens in the allocated space. You'll want to authenticate in three steps:
+
+1. Configure OAuth authentication with your consumer key and secret with the `OAuthHandler(consumer_key, consumer_secret)` call. This should create an `auth` object
+2. Set your access tokens with `auth.set_access_token()`.
+3. Create a API object in `tweepy` to fetch tweets: `tweepy.API(auth, wait_on_rate_limit=True)`
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/211.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/211.md
new file mode 100644
index 00000000..e2315f0b
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/211.md
@@ -0,0 +1,11 @@
+
+
+Remember all those credentials you generated? Paste them appropriately in the starter code.
+
+```python
+consumer_key = 'xxx'
+consumer_secret = 'xxx'
+access_token = 'xxx'
+access_token_secret = 'xxx'
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/212.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/212.md
new file mode 100644
index 00000000..0d30563d
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/212.md
@@ -0,0 +1,16 @@
+
+
+We are now going to authenticate using our app credentials. Please look at the next two lines of code:
+
+```python
+auth = OAuthHandler(consumer_key, consumer_secret)
+```
+
+This line generates an authentication object using our consumer key and secret.
+
+```python
+auth.set_access_token(access_token, access_token_secret)
+```
+
+This line enables access to our authentication object with our access token and access secret token.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/213.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/213.md
new file mode 100644
index 00000000..e7466b3c
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/213.md
@@ -0,0 +1,8 @@
+
+
+The `tweepy` package allows us to very easily use Twitter's API within a Python environment. The line below will give us an API object that will allow us to fetch tweets.
+
+```python
+api = tw.API(auth, wait_on_rate_limit=True)
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/3.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/3.md
new file mode 100644
index 00000000..5e059159
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/3.md
@@ -0,0 +1,4 @@
+# Producing Dataframes
+
+First, we'll have to complete the function `produce_dataframe()`. Please reference the description in the starter code. Bear in mind we provide what will be passed into the `search_dict` parameter for you, and you are not allowed to change any function definition or given code.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/31.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/31.md
new file mode 100644
index 00000000..27371b7d
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/31.md
@@ -0,0 +1,12 @@
+
+
+
+
+Our end result is going to be a dataframe indexed by sentiment categories `['positive', 'neutral', 'negative']` and our columns being various airlines of a category. From this dataframe, one should be able to easily look up the number of positive/neutral/negative tweets regarding an airline.
+
+Firstly, make a empty dataframe `df` indexed by the array `['positive', 'neutral', 'negative']`.
+
+A `search_dict` simply is a dictionary with airline names mapped to appropriate search queries on Twitter. We can use `tweepy` to search for tweets including those search queries.
+
+For each search query, use the `Cursor` object from `tweepy` to generate n number of tweets including each query. (n corresponds to the parameter `num_tweets` in this case.)
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/311.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/311.md
new file mode 100644
index 00000000..4e41893f
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/311.md
@@ -0,0 +1,20 @@
+
+
+
+
+We want a dataframe with the following structure:
+
+
+
+| | Airline_0 | Airline_1 | ... |
+| -------- | --------------- | --------------- | ---- |
+| positive | 321 | 23 | ... |
+| neutral | 76 | 32 | ... |
+| negative | \# example data | \# example data | ... |
+
+Our dataframe `df` will do the trick:
+
+```
+df = pd.DataFrame([], index=['positive', 'neutral', 'negative'])
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/312.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/312.md
new file mode 100644
index 00000000..f32b7d59
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/312.md
@@ -0,0 +1,17 @@
+
+
+The `Cursor` in `tweepy` will allow us to find `num_tweets` tweets given a search query `val`.
+
+```python
+# Collect tweets
+tweets = tw.Cursor(api.search, q=val, lang="en", since=date_since).items(num_tweets)
+```
+
+Because we are given a dictionary with search queries, we want to iterate through this dictionary and call the above line for each search query (each query corresponds to one airline):
+
+```python
+for key, val in search_dict.items():
+ # Collect tweets
+ tweets = tw.Cursor(api.search, q=val, lang="en", since=date_since).items(num_tweets)
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/32.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/32.md
new file mode 100644
index 00000000..b96fa681
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/32.md
@@ -0,0 +1,15 @@
+
+
+
+
+In our `Cursor` object is a list of tweets with our search query.
+
+Iterate through this cursor object and find whether its sentiment is positive, neutral or negative.
+
+* You'll have to use `TextBlob` as well as the `sentiment.polarity` attribute.
+
+Keep track of a count of positive, neutral and negative tweets.
+
+When done iterating through the tweets, index the dataframe so that the sentiment data shows up in your dataframe.
+
+The function should return `df`.
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/321.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/321.md
new file mode 100644
index 00000000..6a27d795
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/321.md
@@ -0,0 +1,30 @@
+
+
+
+
+For each tweet object in the cursor, we can use the `.text` attribute to get the text of the tweet itself. Then for each text, we make a `TextBlob` object out of that text.
+
+From there, simply check the values of the `.sentiment.polarity` attribute. Positive polarity indicates positive sentiment, zero polarity indicates neutral sentiment and neutral polarity indicates negative sentiment.
+
+We keep track of positive, neutral and negative tweets with counter variables. At the end, we add the acquired sentiment data to the dataframe.
+
+Return `df` at the end.
+
+```python
+for key, val in search_dict.items():
+ # ...
+
+ positive = 0
+ neutral = 0
+ negative = 0
+ for t in tweets:
+ analysis = TextBlob(t.text)
+ if analysis.sentiment.polarity > 0:
+ positive += 1
+ elif analysis.sentiment.polarity == 0:
+ neutral += 1
+ else:
+ negative += 1
+ df[key] = [positive, neutral, negative]
+return df
+```
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/33.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/33.md
new file mode 100644
index 00000000..b5fc3605
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/33.md
@@ -0,0 +1,3 @@
+
+
+Now let's fill out `init_dataframes()`. Call your method `produce_dataframe` on the defined dictionaries `low_cost_search` and `luxury_search` to produce two dataframes which consist of sentiment data on low-cost airlines and luxury airlines. Print *the entirety* of these dataframes to the Python console and return *both* of them.
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/331.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/331.md
new file mode 100644
index 00000000..9d87b411
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/331.md
@@ -0,0 +1,14 @@
+
+
+To do this, call `produce_dataframe()` twice on `low_cost_search` and `luxury_search`, each with the 100 tweets as a parameter.
+
+Then we print the *entirety* of the dataframe using `.to_string()` and return the resulting dataframes.
+
+```python
+def init_dataframes():
+ low_cost_df = produce_dataframe(low_cost_search, 100)
+ luxury_cost_df = produce_dataframe(luxury_search, 100)
+ print(low_cost_df.to_string())
+ print(luxury_cost_df.to_string())
+ return low_cost_df, luxury_cost_df
+```
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/4.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/4.md
new file mode 100644
index 00000000..9cb3384a
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/4.md
@@ -0,0 +1,17 @@
+# Graphing
+
+Now that we have our dataframe with the number of positive, neutral, and negative tweets for each candidate, it's time to graph!
+
+Inside of the function `produce_graph(df, keys)`, create a stacked bar graph, with each bar labelled with the number of the positive/neutral/negative tweets. Data presentation is everything - without putting your due diligence into your presentation, less people will read your analytics! So make sure your graph is properly titled, with a legend, x-axes, y-axes, and x and y labels.
+
+Here are some formatting rules (and hints!) that were used in the graph below:
+
+* Width of bars is 0.40
+* The legend is placed outside the graph using `bbox_to_anchor`
+* 0.1 inch margin between x-axis labels
+* Think about what `matplotlib` function you would use to set up a bar graph. How would you set up bars so that the bottom of one bar is set at the same location as the top of another?
+* You can set up text labels by initializing a figure `fig` with `plt.figure`, then initializing a subplot `ax` with `fig.add_subplot` and adding text labels at a location `(x, y)` with `ax.text(x, y, ...)`
+
+Remember that this is the result you are aiming for:
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/41.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/41.md
new file mode 100644
index 00000000..49a59138
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/41.md
@@ -0,0 +1,12 @@
+# Setting Up Bars
+
+Remember that even though this is a stacked bar graph, you are still essentially graphing numbers on a bar graph, with the caveat that the bars are on top of each other, and so the location of the bars needs to be controlled.
+
+To make your bars on your graph, there are two steps you need to take:
+
+* Locate the positive, neutral and negative lists in your data frame. That is the data you will be graphing.
+* Use `plt.bar` to graph bar graphs.
+ * Start off with just graphing the positive bars and making sure those work.
+ * Then graph the neutral bars, setting the **bottom** to be the positive bars.
+ * Do the same for negative bars.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/42.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/42.md
new file mode 100644
index 00000000..65ab6ddc
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/42.md
@@ -0,0 +1,22 @@
+# Making Graph Pretty
+
+Now that your bars are set up, your graph most likely looks unorganized. To organize our graph better, we can set margins to the x ticks to space them out. Because the specifics of how to space out x tick labels can get quite complicated and out of the scope of this bootcamp, I'll provide a chunk of code for you here:
+
+```python
+# space out x ticks and give margins
+plt.gca().margins(x=0)
+plt.gcf().canvas.draw()
+tl = plt.gca().get_xticklabels()
+maxsize = max([t.get_window_extent().width for t in tl])
+m = 0.1 # inch margin
+s = maxsize/plt.gcf().dpi*7+2*m
+margin = m/plt.gcf().get_size_inches()[0]
+
+plt.gcf().subplots_adjust(left=margin, right=1.-margin)
+plt.gcf().set_size_inches(s, plt.gcf().get_size_inches()[1])
+```
+
+This code should space out your x ticks and set margins.
+
+Don't forget a title (`plt.title`) and a legend (`plt.legend`)!
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/43.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/43.md
new file mode 100644
index 00000000..224384de
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/43.md
@@ -0,0 +1,5 @@
+# Text Labels
+
+To add text labels, we'll have to iterate through all the bars and append an appropriate label to each one. So firstly, set up a list called `labels`, that has all the positive, neutral and negative data *in one list*.
+
+We can use `ax.patches` to find a list of all the bars currently in the graph. We can then `zip` the labels and patches together, iterate through that, and for each patch use `ax.text` to attribute a label to each bar. Make sure you have an appropriate location when using `ax.text`!
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/5.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/5.md
new file mode 100644
index 00000000..45f890d6
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/5.md
@@ -0,0 +1,3 @@
+# `main()`
+
+It's time to put all of our functions together into a program! Call `produce_dataframe()` and `produce_graph` inside of your main() function with the proper parameters, and run your main() to see your graphs made!
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/README.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/README.md
new file mode 100644
index 00000000..510698a9
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/README.md
@@ -0,0 +1,20 @@
+# Activity/Lab Name
+
+Democratic Debate Sentiment
+
+# Long Summary
+
+Students will use the `tweepy` and `textblob` Python modules to utilize the Twitter API and perform sentiment analysis on tweets about the Democratic Debates. Students will then use Python modules `pandas` and `matplotlib` to make a dataframe and graph the information appropriately.
+
+# Short Summary
+
+Students will use the Twitter API to analyze sentiments about Democratic Debate tweets
+
+# Criteria
+
+1. How would you use a Tweepy cursor object to get Tweets from the Twitter API?
+2. What's the difference between a time series dataframe and a regular dataframe?
+
+# Difficulty
+
+Medium
diff --git a/Node_Week_1/.DS_Store b/Node_Week_1/.DS_Store
new file mode 100644
index 00000000..8aa4ab2d
Binary files /dev/null and b/Node_Week_1/.DS_Store differ
diff --git a/Node_Week_1/javascripting/1 2.md b/Node_Week_1/javascripting/1 2.md
new file mode 100644
index 00000000..088566c0
--- /dev/null
+++ b/Node_Week_1/javascripting/1 2.md
@@ -0,0 +1,46 @@
+## Creat Your Folder
+
+To keep things organized, let's create a folder for this workshop.
+
+Run this command to make a directory called `javascripting` (or something else if you like):
+
+```bash
+mkdir javascripting
+```
+
+Change directory into the `javascripting` folder:
+
+```bash
+cd javascripting
+```
+
+Create a file named `introduction.js`:
+
+```bash
+touch introduction.js
+```
+
+Or if you're on **Windows**:
+```bash
+type NUL > introduction.js
+```
+ (**`type` is part of the command!**)
+
+Open the file in your favorite editor, and add this text:
+
+```js
+console.log('hello')
+```
+
+Save the file, then check to see if your program is correct by running this command:
+
+```bash
+javascripting verify introduction.js
+```
+
+By the way, throughout this tutorial, you can give the file you work with any name you like, so if you want to use something like `catsAreAwesome.js` file for every exercise, you can do that. Just make sure to run:
+
+```bash
+javascripting verify catsAreAwesome.js
+```
+
diff --git a/Node_Week_1/javascripting/2 2.md b/Node_Week_1/javascripting/2 2.md
new file mode 100644
index 00000000..e5e766ef
--- /dev/null
+++ b/Node_Week_1/javascripting/2 2.md
@@ -0,0 +1,39 @@
+## Variable
+
+A variable is a name that can **reference** a specific value. Variables are declared using `let` followed by the variable's name.
+
+Here's an example:
+
+```js
+let example
+```
+
+The above variable is **declared**, but it **isn't defined** (it does not yet reference a specific value).
+
+Here's an example of defining a variable, making it reference a specific value:
+
+```js
+const example = 'some string'
+```
+
+**Name** of the variable: example
+
+**Value** of the variable: `'some string'`
+
+# NOTE
+
+A variable is **declared** using `let` and uses the **equals sign** to **define** the value that it references. This is colloquially known as "Making a variable equal a value".
+
+## The challenge:
+
+Create a file named `variables.js`.
+
+In that file declare a variable named `example`.
+
+**Make the variable `example` equal to the value `'some string'`.**
+
+Then use `console.log()` to print the `example` variable to the console.
+
+Check to see if your program is correct by running this command:
+
+`javascripting verify variables.js`
diff --git a/Node_Week_1/javascripting/5 2.md b/Node_Week_1/javascripting/5 2.md
new file mode 100644
index 00000000..e970a428
--- /dev/null
+++ b/Node_Week_1/javascripting/5 2.md
@@ -0,0 +1,39 @@
+## String Length
+
+You will often need to know **how many** characters are in a string.
+
+For this you will use the `.length` property. Here's an example:
+
+```js
+const example = 'example string'
+example.length
+```
+
+Result:
+
+```js
+14
+```
+
+(' 'is also have a length of 1)
+
+## NOTE
+
+Make sure there is a period between `example` and `length`.
+
+The above code will return a **number** for the total number of characters in the string.
+
+
+## The challenge:
+
+Create a file named `string-length.js`.
+
+In that file, create a variable named `example`.
+
+**Assign the string `'example string'` to the variable `example`.**
+
+Use `console.log` to print the **length** of the string to the terminal.
+
+**Check to see if your program is correct by running this command:**
+
+`javascripting verify string-length.js`
diff --git a/Node_Week_1/javascripting/6 2.md b/Node_Week_1/javascripting/6 2.md
new file mode 100644
index 00000000..c66923e1
--- /dev/null
+++ b/Node_Week_1/javascripting/6 2.md
@@ -0,0 +1,17 @@
+## Number
+
+Numbers can be integers, like `2`, `14`, or `4353`, or they can be **ints**,
+also known as **floats**, like `3.14`, `1.5`, or `100.7893423`.
+Unlike Strings, Numbers **do not need to have quotes**.
+
+## The challenge:
+
+Create a file named `numbers.js`.
+
+In that file define a variable named `example` that references the integer `123456789`.
+
+Use `console.log()` to print that number to the terminal.
+
+Check to see if your program is correct by running this command:
+
+`javascripting verify numbers.js`
diff --git a/Node_Week_1/javascripting/8 2.md b/Node_Week_1/javascripting/8 2.md
new file mode 100644
index 00000000..574734cf
--- /dev/null
+++ b/Node_Week_1/javascripting/8 2.md
@@ -0,0 +1,34 @@
+## Number to String
+
+Sometimes you will need to turn a number into a string.
+
+In those instances you will use the `.toString()` method. Here's an example:
+
+```js
+let n = 256
+n = n.toString()
+```
+
+Result of n:
+
+```js
+'256'
+```
+
+
+
+## The challenge:
+
+Create a file named `number-to-string.js`.
+
+1.In that file define a variable named `n` that references the number `128`;
+
+2.Call the `.toString()` method on the `n` variable.
+
+3.Use `console.log()` to print the results of the `.toString()` method to the terminal.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify number-to-string.js
+```
diff --git a/Node_Week_1/javascripting/for_loop 2.md b/Node_Week_1/javascripting/for_loop 2.md
new file mode 100644
index 00000000..1be3cccb
--- /dev/null
+++ b/Node_Week_1/javascripting/for_loop 2.md
@@ -0,0 +1,59 @@
+## Statement : For loops
+
+For loops allow you to **repeatedly** run a block of code a certain number of times. This for loop logs to the console ten times:
+
+```js
+for (let i = 0; i < 10; i++) {
+ // log the numbers 0 through 9
+ console.log(i)
+}
+```
+
+Result:
+
+```js
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+```
+
+***
+
+The first part, `let i = 0`, is run once at the beginning of the loop. The variable `i` is used to track how many times the loop has run.
+
+The second part, `i < 10`, is checked at the beginning of every loop iteration before running the code inside the loop. If the **statement is true**, the code **inside** the loop is **executed**. If it is **false**, then the **loop is complete**. The statement `i < 10;` indicates that the loop will continue as long as `i` is less than `10`.
+
+The final part, `i++`, is **executed at the end of every loop**. This increases the variable `i` by 1 after each loop. Once `i` reaches `10`, the loop will exit.
+
+## The challenge:
+
+Create a file named `for-loop.js`.
+
+In that file define a variable named `total` and make it equal the number `0`.
+
+Define a second variable named `limit` and make it equal the number `10`.
+
+Create a for loop with a variable `i` starting at 0 and increasing by 1 each time through the loop. The loop should run as long as `i` is less than `limit`.
+
+On each iteration of the loop, add the number `i` to the `total` variable. To do this, you can use this statement:
+
+```js
+total += i
+```
+
+When this statement is used in a for loop, it can also be known as _an accumulator_. Think of it like a cash register's running total while each item is scanned and added up. For this challenge, you have 10 items and they just happen to be increasing in price by 1 each item (with the first item free!).
+
+After the for loop, use `console.log()` to print the `total` variable to the terminal.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify for-loop.js
+```
diff --git a/Node_Week_1/javascripting/function 2.md b/Node_Week_1/javascripting/function 2.md
new file mode 100644
index 00000000..a2f9a523
--- /dev/null
+++ b/Node_Week_1/javascripting/function 2.md
@@ -0,0 +1,57 @@
+## Function
+
+A **function** is a block of code that ***1. takes input***, ***2. processes that input***, and then ***3. produces output***.
+
+Here is an example:
+
+```js
+function example (x) {
+ y = x * 2
+ return y
+}
+```
+
+*Name* of function: **example**
+
+*Input* (*argument*): **x**
+
+*processes*: **x*2**
+
+*output* (*return value*): **y**
+
+*****
+
+We can ***call*** that function like this :
+
+```js
+example(5)
+```
+
+The **result** is :
+
+```js
+10
+```
+
+The above example assumes that the `example` function will take a number as an argument –– as input –– and will return that number multiplied by 2.
+
+## The challenge:
+
+Create a file named `functions.js`.
+
+In that file, define a function named `eat` that takes an argument named `food`
+that is expected to be a string.
+
+Inside the function return the `food` argument like this:
+
+```js
+return food + ' tasted really good.'
+```
+
+Inside of the parentheses of `console.log()`, call the `eat()` function with the string `bananas` as the argument.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify functions.js
+```
diff --git a/Node_Week_1/javascripting/function_argument 2.md b/Node_Week_1/javascripting/function_argument 2.md
new file mode 100644
index 00000000..40527f52
--- /dev/null
+++ b/Node_Week_1/javascripting/function_argument 2.md
@@ -0,0 +1,43 @@
+## Function Argument
+
+A function can be declared to receive any number of arguments. Arguments can be from any type. An argument could be a string, a number, an array, an object and even another function.
+
+Here is an example:
+
+```js
+function example (firstArg, secondArg) {
+ console.log(firstArg, secondArg)
+}
+```
+
+**Argument**: `firstArg`, `secondArg`
+
+We can **call** that function with two arguments like this:
+
+```js
+example('hello', 'world')
+```
+
+Result:
+
+```js
+hello world
+```
+
+## The challenge:
+
+Create a file named `function-arguments.js`.
+
+In that file, define a function named `math` that takes three arguments. It's important for you to understand that arguments names are only used to reference them.
+
+Name each argument as you like.
+
+Within the `math` function, return the value obtained from multiplying the second and third arguments and adding that result to the first argument.
+
+After that, inside the parentheses of `console.log()`, call the `math()` function with the number `53` as first argument, the number `61` as second and the number `67` as third argument.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify function-arguments.js
+```
diff --git a/Node_Week_1/javascripting/if 2.md b/Node_Week_1/javascripting/if 2.md
new file mode 100644
index 00000000..1318257e
--- /dev/null
+++ b/Node_Week_1/javascripting/if 2.md
@@ -0,0 +1,44 @@
+## Statement: If
+
+Conditional statements are used to **alter the control flow** of a program, **based** on a specified **boolean condition**.
+
+A conditional statement looks like this:
+
+```js
+if (n > 1) {
+ console.log('the variable n is greater than 1.')
+} else {
+ console.log('the variable n is less than or equal to 1.')
+}
+```
+
+In this example:
+
+**Logic statement**: `n>1`
+
+If n>1, the code will print `the variable n is greater than 1.`
+
+If n<=1, the code will print `the variable n is less than or equal to 1.`
+
+***
+
+Inside parentheses you must enter a logic statement, meaning that the result of the statement is either true or false.
+
+The else block is optional and contains the code that will be executed if the statement is false.
+
+## The challenge:
+
+Create a file named `if-statement.js`.
+
+In that file, declare a variable named `fruit`.
+
+Make the `fruit` variable reference the string value **"orange"**.
+
+Then use `console.log()` to print "**The fruit name has more than five characters."** if the length of the value of `fruit` is greater than five.
+Otherwise, print "**The fruit name has five characters or less.**"
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify if-statement.js
+```
diff --git a/Node_Week_1/javascripting/loop through array 2.md b/Node_Week_1/javascripting/loop through array 2.md
new file mode 100644
index 00000000..93dbe84f
--- /dev/null
+++ b/Node_Week_1/javascripting/loop through array 2.md
@@ -0,0 +1,53 @@
+## Loop Through The Array
+
+For this challenge we will use a **for loop** to access and manipulate a list of values in an array.
+
+Accessing array values can be done using an integer.
+
+Each item in an array is identified by a number, starting at `0`.
+
+So in this array `hi` is identified by the number `1`:
+
+```js
+const greetings = ['hello', 'hi', 'good morning']
+```
+
+It can be accessed like this:
+
+```js
+greetings[1]
+```
+
+So inside a **for loop** we would use the `i` variable inside the square brackets instead of directly using an integer.
+
+```
+
+```
+
+
+
+## The challenge:
+
+Create a file named `looping-through-arrays.js`.
+
+In that file, define a variable named `pets` that references this array:
+
+```js
+['cat', 'dog', 'rat']
+```
+
+Create a for loop that changes each string in the array so that they are plural.
+
+You will use a statement like this inside the for loop:
+
+```js
+pets[i] = pets[i] + 's'
+```
+
+After the for loop, use `console.log()` to print the `pets` array to the terminal.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify looping-through-arrays.js
+```
diff --git a/Node_Week_1/learnyouhtml/14 2.md b/Node_Week_1/learnyouhtml/14 2.md
new file mode 100644
index 00000000..481c5dbd
--- /dev/null
+++ b/Node_Week_1/learnyouhtml/14 2.md
@@ -0,0 +1,35 @@
+## LISTS
+
+### Unordered lists
+
+
+
+Unordered lists look similar to ordered ones. Describing of list items remains the same, keep using `
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/112.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/112.md
new file mode 100644
index 00000000..ea6a3ca5
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/112.md
@@ -0,0 +1,12 @@
+
+
+The Twitter developer application process starts at this page, please complete the form. Once you click 'student', proceed to the rest of the Application.
+
+When you're prompted to explain your use, you can explain that you'll be using Twitter to perform sentiment analysis for learning purposes.
+
+
+
+You will also be analyzing Twitter data, you can say this is also part of the exercise.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/113.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/113.md
new file mode 100644
index 00000000..26b8f934
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/113.md
@@ -0,0 +1,5 @@
+
+
+After finishing your application, confirm your email and your account should be processed and reviewed swiftly.
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/12.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/12.md
new file mode 100644
index 00000000..11b31eef
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/12.md
@@ -0,0 +1,12 @@
+
+
+When you have finished configuring your account, head back to Twitter Developer [here](https://developer.twitter.com/en/apps), your app menu should look like this:
+
+Click on “Create an app”. Fill out app details; for the website URL field, you can input any website, we used https://bitproject.org. Leave the OAuth Callback URL, TOS and Privacy Policy fields blank.
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key. Copy these keys for later use. (these keys in the picture have been erased)
+
+
+
+There is also an area to generate an access token and access secret token, please generate them and keep track of those as well.
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/121.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/121.md
new file mode 100644
index 00000000..3d3abcc6
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/121.md
@@ -0,0 +1,6 @@
+
+
+Head back to Twitter Developer website [here](https://developer.twitter.com/en/apps), and your app menu should look like this:
+
+Click on “Create an app”.
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/122.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/122.md
new file mode 100644
index 00000000..3f94fc25
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/122.md
@@ -0,0 +1,6 @@
+
+
+In the creation of your app, fill out all the required information for your app details. For the website URL field, you can input any website, we used https://bitproject.org. Leave the OAuth Callback URL, TOS and Privacy Policy fields blank.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/123.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/123.md
new file mode 100644
index 00000000..4e4adbf5
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/123.md
@@ -0,0 +1,21 @@
+
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key.
+
+
+
+
+
+Below the consumer API keys, there is also an area to generate an access token and access secret token, please generate them and keep track of those as well.
+
+
+
+Copy these keys into your starter code where the example is:
+
+```python
+consumer_key = "Your key goes here!"
+consumer_secret = "Your key goes here!"
+access_token = "Your key goes here!"
+access_token_secret = "Your key goes here!
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/2.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/2.md
new file mode 100644
index 00000000..36c87dc6
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/2.md
@@ -0,0 +1,11 @@
+
+
+The goal of this card is to set up authentication so your application can use Tweet information. You should:
+
+* Configure OAuth authentication with your consumer key and secret key
+* Set your access tokens and create a API object in `tweepy` to fetch tweets.
+
+You'll be using the `us_search` dictionary provided in the starter code for the rest of this lab.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/21.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/21.md
new file mode 100644
index 00000000..021a24a3
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/21.md
@@ -0,0 +1,9 @@
+
+
+Paste your keys and tokens in the allocated space. You'll want to authenticate in three steps:
+
+1. Configure OAuth authentication with your consumer key and secret with the `OAuthHandler(consumer_key, consumer_secret)` call. This should create an `auth` object
+2. Set your access tokens with `auth.set_access_token()`
+3. Create a API object in `tweepy` to fetch tweets: `tweepy.API(auth, wait_on_rate_limit=True)`
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/211.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/211.md
new file mode 100644
index 00000000..2cad02d2
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/211.md
@@ -0,0 +1,23 @@
+
+
+
+We're now going to authenticate using our app credentials.
+
+```python
+auth = OAuthHandler(consumer_key, consumer_secret)
+```
+
+The above line generates an authentication object using our consumer key and secret.
+
+```python
+auth.set_access_token(access_token, access_token_secret)
+```
+
+This line enables access to our authentication object with our access token and access secret token.
+
+
+
+Setting the above tokens is telling the Twitter API that you are the one using the application! Great job!
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/212.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/212.md
new file mode 100644
index 00000000..b2fc0a15
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/212.md
@@ -0,0 +1,15 @@
+
+
+The `tweepy` package allows us to very easily use Twitter's API within a Python environment. The line below will give us an API object that will allow us to fetch tweets.
+
+```python
+api = tw.API(auth, wait_on_rate_limit=True)
+```
+
+We're setting up our `api` object to use the authentication object `auth` we set up just before this.
+
+
+
+The Twitter API has a limit of how many times you can request for an hour. The `wait_on_rate_limit` parameter is telling our Twitter request object to automatically wait for the rate limit to refresh for the hour.
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/3.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/3.md
new file mode 100644
index 00000000..8168a52d
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/3.md
@@ -0,0 +1,24 @@
+
+
+Now that our application is set up, we're going to produce a dataframe that stores two items: the data, and the sentiment of each tweet found.
+
+
+
+Complete the function `produce_dataframe(search_dict, num_tweets)`, with the following descriptions of the parameters:
+
+* `search_dict` - a dictionary that has a {key, value} pair in the items category. The `key` is the date you will be searching for, and the `value` is the name of the airline you will search for.
+* `num_tweets` - the number of tweets in the search dictionary
+
+
+
+The function `produce_dataframe(search_dict, num_tweets)` should complete the following checklist:
+
+* Return a dataframe using the `pandas` library, the column names should be 'date', and 'sentiment'. Set rownames to 'positive', 'neutral', and 'negative.'
+* Fill the returning dataframe with
+
+
+
+You are not allowed to change any function definition or code that was given to you. The end result should look like this:
+
+![image]()
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/31.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/31.md
new file mode 100644
index 00000000..857614b8
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/31.md
@@ -0,0 +1,17 @@
+
+
+
+
+In order to add items to the dataframe, we first need to create dataframe. We can use the `pandas` library to create a dataframe.
+
+The function we want to use is `pandas.Dataframe(arguments)`. Use the argument:
+
+* `index` to set the rownames to 'positive', 'neutral', and 'negative.'
+* `columns` to set the columnnames to `date` and `sentiment`
+
+
+
+If you run your code before inserting any data, your graph should look like this:
+
+![image]()
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/311.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/311.md
new file mode 100644
index 00000000..2e74590e
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/311.md
@@ -0,0 +1,24 @@
+
+
+
+
+We can create a `pandas` dataframe with the function `pd.DataFrame()`. If we want a dataframe with the following structure (it currently has :
+
+| | Airline_0 | Airline_1 | ... |
+| -------- | --------- | --------- | ---- |
+| positive | ... | ... | ... |
+| neutral | ... | ... | ... |
+| negative | ... | ... | ... |
+
+We need the arguments:
+
+* `data` - this argument is defaulted to None, we define it to an explicit `[]`
+* `Index` - We'll set this to a list of []'positive', 'neutral', 'negative']
+
+Our final code looks like:
+
+```python
+df = pd.DataFrame([], index=['positive', 'neutral', 'negative'])
+```
+
+Now we need to get the tweets from the cursor object
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/312.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/312.md
new file mode 100644
index 00000000..f32b7d59
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/312.md
@@ -0,0 +1,17 @@
+
+
+The `Cursor` in `tweepy` will allow us to find `num_tweets` tweets given a search query `val`.
+
+```python
+# Collect tweets
+tweets = tw.Cursor(api.search, q=val, lang="en", since=date_since).items(num_tweets)
+```
+
+Because we are given a dictionary with search queries, we want to iterate through this dictionary and call the above line for each search query (each query corresponds to one airline):
+
+```python
+for key, val in search_dict.items():
+ # Collect tweets
+ tweets = tw.Cursor(api.search, q=val, lang="en", since=date_since).items(num_tweets)
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/32.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/32.md
new file mode 100644
index 00000000..91cab110
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/32.md
@@ -0,0 +1,13 @@
+
+
+
+
+Now that we've created our Dataframe, we need to fill our dataframe. Recall the parameter `search_dict` is a dictionary that has a {key, value} pair in the items category. The `key` is the date you will be searching for, and the `value` is the name of the airline you will search for.
+
+
+
+After producing the dataframe you should iterate through the `search_dict` and call the `tweepy.Cursor()` object to get the tweets with the search query.
+
+
+
+![image]()
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/321.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/321.md
new file mode 100644
index 00000000..6a27d795
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/321.md
@@ -0,0 +1,30 @@
+
+
+
+
+For each tweet object in the cursor, we can use the `.text` attribute to get the text of the tweet itself. Then for each text, we make a `TextBlob` object out of that text.
+
+From there, simply check the values of the `.sentiment.polarity` attribute. Positive polarity indicates positive sentiment, zero polarity indicates neutral sentiment and neutral polarity indicates negative sentiment.
+
+We keep track of positive, neutral and negative tweets with counter variables. At the end, we add the acquired sentiment data to the dataframe.
+
+Return `df` at the end.
+
+```python
+for key, val in search_dict.items():
+ # ...
+
+ positive = 0
+ neutral = 0
+ negative = 0
+ for t in tweets:
+ analysis = TextBlob(t.text)
+ if analysis.sentiment.polarity > 0:
+ positive += 1
+ elif analysis.sentiment.polarity == 0:
+ neutral += 1
+ else:
+ negative += 1
+ df[key] = [positive, neutral, negative]
+return df
+```
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/33.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/33.md
new file mode 100644
index 00000000..69b0311c
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/33.md
@@ -0,0 +1,13 @@
+
+
+Now that we've got the tweets, we need to iterate through the tweets to find the sentiments.
+
+
+
+We also want to keep track of how many of each sentiments you have. Make sure to initialize the number of sentiments of each 'positive', 'neutral' or 'negative' first.
+
+
+
+You need to use the `TextBlob` module to get the `sentiment.polarity` attribute. For each item in the Tweets we have, set the item in the dataframe date to the sentiment.
+
+![image]()
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/4.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/4.md
new file mode 100644
index 00000000..e419a958
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/4.md
@@ -0,0 +1,13 @@
+
+
+We currently have a dataframe containing the dates and sentiments for the airlines we searched for. We now want to calculate the total tweets and the percentages of positive/neutral/negative tweets for a specific airline
+
+
+The goal for this card is to create a *new* dataframe that's columns are the dates of the tweets, and the rows are labeled `positive`, `neutral`, `negative`, and `total`. The rows `positive`, `neutral`, and `negative` will be the percentage of tweets across the day, and `total` will be an integer, the number of tweetsfor that day.
+
+
+
+To do this, choose just *one* airline whose data you will perform analysis on, and create a dataframe that looks like the one below:
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/41.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/41.md
new file mode 100644
index 00000000..b60fdcc0
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/41.md
@@ -0,0 +1,11 @@
+
+
+Our first step is to create a dataframe with the raw dates and sentiments for each tweets. You can follow this process:
+
+1. Pick an airline from the `search_dict` dictionary (we chose United Airlines!) and get the related tweets using the Twitter API. You can search for the tweet since the variable `date_since`, which has an already calculated value of 3 days ago.
+2. Create the empty Time Series Dataframe. Name the columns `date`, and `sentiment`.
+3. Fill the time series dataframe by analyzing each tweet. Like before, tweets should be categorized into `postive`, `neutral`, or `negative`.
+
+Once we've created the time series dataframe, we can create percentages of tweets from that!
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/411.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/411.md
new file mode 100644
index 00000000..b5e18318
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/411.md
@@ -0,0 +1,18 @@
+
+
+We can search for the tweets related to an airline the same way we did before. The only thing we're changing here is we're picking on airline to search for instead of all of the airlines in the search dictionary.
+
+```python
+tweets = tw.Cursor(api.search,
+ q="united airlines",
+ lang="en",
+ since=date_since).items(1000)
+```
+
+Again, we're getting a list of tweets through the Tweepy cursor object.
+
+
+
+In the background, the Tweepy cursor object is creating a loop that uses your API keys to get up to 1000 tweets as we set it with the parameter.
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/412.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/412.md
new file mode 100644
index 00000000..a1dfa588
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/412.md
@@ -0,0 +1,21 @@
+```python
+text_create = []
+text_sentiment = []
+time_series_df = pd.DataFrame(pd.np.empty((0, 2)))
+time_series_df.columns = ['date', 'sentiment']
+
+for t in tweets:
+ text_create.append(t.created_at)
+ analysis = TextBlob(t.text)
+
+ if analysis.sentiment.polarity > 0:
+ text_sentiment.append('positive')
+ elif analysis.sentiment.polarity == 0:
+ text_sentiment.append('neutral')
+ else:
+ text_sentiment.append('negative')
+
+time_series_df['date'] = text_create
+time_series_df['sentiment'] = text_sentiment
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/42.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/42.md
new file mode 100644
index 00000000..a3a38400
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/42.md
@@ -0,0 +1,9 @@
+
+
+Now that we have our time series dataframe with each tweet and it's corresponding sentiment, we can create a dataframe with the percentages of each tweet per day. Try this process:
+
+1. Create the dataframe. The dataframe columns should be each day since `date_since`, and the row names should be `positive`, `neutral`, `negative`, and `total`.
+2. Calculate the total number of tweets for each day. The numbers will be in the row `total`.
+3. Calculate the percentage of `positive`, `neutral`, and `negative` for each day.
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/5.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/5.md
new file mode 100644
index 00000000..cdcbc47b
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/5.md
@@ -0,0 +1,12 @@
+# Graphing
+
+Now that we have our dataframe with the number of positive, neutral, and negative tweets for each candidate, it's time to graph!
+
+We'll be graphing a bar graph representing the total number of tweets per day for
+
+Inside of the function `produce_graph(df, keys)`, create a bar graph, with each bar labelled with an appropriate date for the tick. Then on top of that bar graph, create a line graph with three lines for the positive, neutral, and negative sentiment on *each day*.
+
+Data presentation is everything - without putting your due diligence into your presentation, less people will read your analytics! So make sure your graph is properly titled, with a legend, x-axes, y-axes, and x and y labels. Don't forget to have 2 y-axes! (one for your bar graph and one for your line graph). As a reminder this is what your graph should look like:
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/51.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/51.md
new file mode 100644
index 00000000..49a59138
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/51.md
@@ -0,0 +1,12 @@
+# Setting Up Bars
+
+Remember that even though this is a stacked bar graph, you are still essentially graphing numbers on a bar graph, with the caveat that the bars are on top of each other, and so the location of the bars needs to be controlled.
+
+To make your bars on your graph, there are two steps you need to take:
+
+* Locate the positive, neutral and negative lists in your data frame. That is the data you will be graphing.
+* Use `plt.bar` to graph bar graphs.
+ * Start off with just graphing the positive bars and making sure those work.
+ * Then graph the neutral bars, setting the **bottom** to be the positive bars.
+ * Do the same for negative bars.
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/52.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/52.md
new file mode 100644
index 00000000..65ab6ddc
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/52.md
@@ -0,0 +1,22 @@
+# Making Graph Pretty
+
+Now that your bars are set up, your graph most likely looks unorganized. To organize our graph better, we can set margins to the x ticks to space them out. Because the specifics of how to space out x tick labels can get quite complicated and out of the scope of this bootcamp, I'll provide a chunk of code for you here:
+
+```python
+# space out x ticks and give margins
+plt.gca().margins(x=0)
+plt.gcf().canvas.draw()
+tl = plt.gca().get_xticklabels()
+maxsize = max([t.get_window_extent().width for t in tl])
+m = 0.1 # inch margin
+s = maxsize/plt.gcf().dpi*7+2*m
+margin = m/plt.gcf().get_size_inches()[0]
+
+plt.gcf().subplots_adjust(left=margin, right=1.-margin)
+plt.gcf().set_size_inches(s, plt.gcf().get_size_inches()[1])
+```
+
+This code should space out your x ticks and set margins.
+
+Don't forget a title (`plt.title`) and a legend (`plt.legend`)!
+
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/53.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/53.md
new file mode 100644
index 00000000..224384de
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/53.md
@@ -0,0 +1,5 @@
+# Text Labels
+
+To add text labels, we'll have to iterate through all the bars and append an appropriate label to each one. So firstly, set up a list called `labels`, that has all the positive, neutral and negative data *in one list*.
+
+We can use `ax.patches` to find a list of all the bars currently in the graph. We can then `zip` the labels and patches together, iterate through that, and for each patch use `ax.text` to attribute a label to each bar. Make sure you have an appropriate location when using `ax.text`!
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/6.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/6.md
new file mode 100644
index 00000000..45f890d6
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/6.md
@@ -0,0 +1,3 @@
+# `main()`
+
+It's time to put all of our functions together into a program! Call `produce_dataframe()` and `produce_graph` inside of your main() function with the proper parameters, and run your main() to see your graphs made!
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/README.md b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/README.md
new file mode 100644
index 00000000..f9c64055
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/README.md
@@ -0,0 +1,20 @@
+# Activity/Lab Name
+
+Airline Sentiment Analysis
+
+# Long Summary
+
+Students will use the `tweepy` and `textblob` Python modules to utilize the Twitter API and perform sentiment analysis on tweets about airlines. Students will then use Python modules `pandas` and `matplotlib` to make a dataframe and graph the information appropriately.
+
+# Short Summary
+
+Students will use the Twitter API to analyze sentiments about airline tweets
+
+# Criteria
+
+1. How would you use a Tweepy cursor object to get Tweets from the Twitter API?
+2. What's the difference between a time series dataframe and a regular dataframe?
+
+# Difficulty
+
+Medium
diff --git a/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/starter_code.py b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/starter_code.py
new file mode 100644
index 00000000..16163c8a
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Airline Sentiment Analysis/starter_code.py
@@ -0,0 +1,28 @@
+# Import necessary modules
+import os
+import tweepy as tw
+import pandas as pd
+import numpy as np
+import matplotlib.pyplot as plt
+from scipy import stats
+from textblob import TextBlob
+from tweepy import OAuthHandler
+from IPython.display import display, HTML
+
+# 1.md and 2.md
+consumer_key = "Your key goes here!"
+consumer_secret = "Your key goes here!"
+access_token = "Your key goes here!"
+access_token_secret = "Your key goes here!"
+
+# Search dictionary to pass into produce_dataframe() as airlines to search for. DO NOT EDIT!
+search_dict = {"Spirit Airlines": "#spiritairlines","JetBlue": "#jetblue", "Frontier Airlines": "frontier airlines",
+ "Delta": "delta airlines", "United": "united airlines", "Southwest": "southwest airlines", "American":
+ "american airlines"
+ }
+
+# The date to search from
+date_since = "This date should be five days from now!"
+d = datetime.datetime.today()
+print(d)
+# Check that the tweepy object is working!
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/1.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/1.md
new file mode 100644
index 00000000..bd409861
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/1.md
@@ -0,0 +1,14 @@
+
+
+With the wealth of information at our disposal, American politics have increasingly become a game of misinformation and narrative twisting. To win elections, often times it doesn't matter what political candidates actually do or say, but how candidates can control the narrative surrounding their campaigns, and what the American people think of their candidates.
+
+Twitter reactions are a valuable source of political opinions from regular Americans, because anyone can tweet their honest feelings about political candidates. Using sentiment analysis on Americans' tweets can give us genuine insight on the sentiment behind every candidate in the race, outside of media spin or campaign biases. For this lab, we'll dive into the tweets during and after the 7th Democratic Debate to gauge how average Americans perceive political candidates, and graph our results in a stacked bar graph! Here is what the result should look like:
+
+
+
+To do this, we'll be gathering tweets referencing political candidates using Twitter's API as well as the `tweepy` and `TextBlob`packages to determine whether generated tweets have a positive, neutral or negative attitude towards the airlines.
+
+Proceed to Twitter Developer [here](https://developer.twitter.com/en/apps), and you'll need to make a new Twitter app and get four credentials for future use: consumer key, consumer token, access token and access secret token.
+
+Paste those credentials into the appropriate area in your starter code.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/11.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/11.md
new file mode 100644
index 00000000..20e2f2c8
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/11.md
@@ -0,0 +1,6 @@
+
+
+The Twitter developer application process starts here, please complete the form.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/111.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/111.md
new file mode 100644
index 00000000..6e78cbed
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/111.md
@@ -0,0 +1,6 @@
+
+
+Proceed to Twitter Developer [here](https://developer.twitter.com/en/apps). Implementing sign-in with Twitter requires a Twitter developer account, so click “Apply”.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/112.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/112.md
new file mode 100644
index 00000000..7c1b766b
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/112.md
@@ -0,0 +1,8 @@
+
+
+The Twitter developer application process starts here, please complete the form.
+
+As you are most likely a student, click on the student option to begin. If another option is more relevant, click on that instead.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/113.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/113.md
new file mode 100644
index 00000000..35d947ef
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/113.md
@@ -0,0 +1,7 @@
+
+
+After finishing your application, confirm your email and your account should be processed and reviewed swiftly.
+
+
+
+After you have been approved, you will then be able to access the neccessary API keys. Be patient! This process can lasrt up to 2 bussiness weeks.
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/12.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/12.md
new file mode 100644
index 00000000..03be66ab
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/12.md
@@ -0,0 +1,12 @@
+
+
+When you have finished configuring your account, head back to Twitter Developer [here](https://developer.twitter.com/en/apps), your app menu should look like this:
+
+
+
+Click on “Create an app” and fill out app details.
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key. Copy these keys for later use (these keys in the picture have been erased). The keys will be used to access Twitter's sentiment anlysis API and will be inserted into the starter code.
+
+There is also an area to generate an access token and access secret token, please generate them and keep track of those as well. They will be used in the starter code.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/121.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/121.md
new file mode 100644
index 00000000..b6f3eed0
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/121.md
@@ -0,0 +1,11 @@
+
+
+Head back to Twitter Developer [here](https://developer.twitter.com/en/apps), your app menu should look like this:
+
+Click on “Create an app”. Fill out app details; for the website URL field, you can input any website, we used https://bitproject.org. Leave the OAuth Callback URL, TOS and Privacy Policy fields blank.
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key. Copy these keys for later use. (these keys in the picture have been erased)
+
+
+
+There is also an area to generate an access token and access secret token, please generate them and keep track of those as well.
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/122.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/122.md
new file mode 100644
index 00000000..42c3898b
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/122.md
@@ -0,0 +1,12 @@
+
+
+In the creation of your app, fill out all the required information for your app details. For the website URL field, you can input any website, we used https://bitproject.org. Leave the OAuth Callback URL, TOS and Privacy Policy fields blank.
+
+ OAuth Callback URLs are used for providing directions on where a user should go after signing in with their Twitter credentials. They can even be used to redirect a user to a spcific page, which won't be neccessary for our lab.
+
+TOS stands for 'terms of service' which again, we don't need to specify here.
+
+Privacy Policy is similar to TOS, but would explain to users what the data collected from them would be used for. Since there will be no users other than yourself, it is not relevant.
+
+
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/123.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/123.md
new file mode 100644
index 00000000..77467a79
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/123.md
@@ -0,0 +1,10 @@
+
+
+After creating your app, head to its “Keys and tokens” section, where you will find an API key and API secret key. Copy these keys for later use. (these keys in the picture have been erased)
+
+
+
+
+
+Below the consumer API keys, there is also an area to generate an access token and access secret token, please generate them and keep track of those as well. Remember, these keys will be used to access Twitter's sentiment anlysis API and will be inserted into the starter code.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/2.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/2.md
new file mode 100644
index 00000000..bc1c754e
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/2.md
@@ -0,0 +1,6 @@
+
+
+Paste your keys and tokens in the allocated space. Then configure OAuth authentication with your consumer key and secret, set your access tokens and create a API object in `tweepy` to fetch tweets.
+
+Bear in mind we will be using the `dem_search` dictionary for the rest of this lab.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/21.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/21.md
new file mode 100644
index 00000000..77cae357
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/21.md
@@ -0,0 +1,8 @@
+
+
+Paste your keys and tokens in the allocated space. You'll want to authenticate in three steps:
+
+1. Configure OAuth authentication with your consumer key and secret with the `OAuthHandler(consumer_key, consumer_secret)` call. This should create an `auth` object
+2. Set your access tokens with `auth.set_access_token()`.
+3. Create a API object in `tweepy` to fetch tweets: `tweepy.API(auth, wait_on_rate_limit=True)`
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/211.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/211.md
new file mode 100644
index 00000000..e2315f0b
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/211.md
@@ -0,0 +1,11 @@
+
+
+Remember all those credentials you generated? Paste them appropriately in the starter code.
+
+```python
+consumer_key = 'xxx'
+consumer_secret = 'xxx'
+access_token = 'xxx'
+access_token_secret = 'xxx'
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/212.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/212.md
new file mode 100644
index 00000000..0d30563d
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/212.md
@@ -0,0 +1,16 @@
+
+
+We are now going to authenticate using our app credentials. Please look at the next two lines of code:
+
+```python
+auth = OAuthHandler(consumer_key, consumer_secret)
+```
+
+This line generates an authentication object using our consumer key and secret.
+
+```python
+auth.set_access_token(access_token, access_token_secret)
+```
+
+This line enables access to our authentication object with our access token and access secret token.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/213.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/213.md
new file mode 100644
index 00000000..e7466b3c
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/213.md
@@ -0,0 +1,8 @@
+
+
+The `tweepy` package allows us to very easily use Twitter's API within a Python environment. The line below will give us an API object that will allow us to fetch tweets.
+
+```python
+api = tw.API(auth, wait_on_rate_limit=True)
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/3.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/3.md
new file mode 100644
index 00000000..5e059159
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/3.md
@@ -0,0 +1,4 @@
+# Producing Dataframes
+
+First, we'll have to complete the function `produce_dataframe()`. Please reference the description in the starter code. Bear in mind we provide what will be passed into the `search_dict` parameter for you, and you are not allowed to change any function definition or given code.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/31.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/31.md
new file mode 100644
index 00000000..27371b7d
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/31.md
@@ -0,0 +1,12 @@
+
+
+
+
+Our end result is going to be a dataframe indexed by sentiment categories `['positive', 'neutral', 'negative']` and our columns being various airlines of a category. From this dataframe, one should be able to easily look up the number of positive/neutral/negative tweets regarding an airline.
+
+Firstly, make a empty dataframe `df` indexed by the array `['positive', 'neutral', 'negative']`.
+
+A `search_dict` simply is a dictionary with airline names mapped to appropriate search queries on Twitter. We can use `tweepy` to search for tweets including those search queries.
+
+For each search query, use the `Cursor` object from `tweepy` to generate n number of tweets including each query. (n corresponds to the parameter `num_tweets` in this case.)
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/311.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/311.md
new file mode 100644
index 00000000..4e41893f
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/311.md
@@ -0,0 +1,20 @@
+
+
+
+
+We want a dataframe with the following structure:
+
+
+
+| | Airline_0 | Airline_1 | ... |
+| -------- | --------------- | --------------- | ---- |
+| positive | 321 | 23 | ... |
+| neutral | 76 | 32 | ... |
+| negative | \# example data | \# example data | ... |
+
+Our dataframe `df` will do the trick:
+
+```
+df = pd.DataFrame([], index=['positive', 'neutral', 'negative'])
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/312.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/312.md
new file mode 100644
index 00000000..f32b7d59
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/312.md
@@ -0,0 +1,17 @@
+
+
+The `Cursor` in `tweepy` will allow us to find `num_tweets` tweets given a search query `val`.
+
+```python
+# Collect tweets
+tweets = tw.Cursor(api.search, q=val, lang="en", since=date_since).items(num_tweets)
+```
+
+Because we are given a dictionary with search queries, we want to iterate through this dictionary and call the above line for each search query (each query corresponds to one airline):
+
+```python
+for key, val in search_dict.items():
+ # Collect tweets
+ tweets = tw.Cursor(api.search, q=val, lang="en", since=date_since).items(num_tweets)
+```
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/32.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/32.md
new file mode 100644
index 00000000..b96fa681
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/32.md
@@ -0,0 +1,15 @@
+
+
+
+
+In our `Cursor` object is a list of tweets with our search query.
+
+Iterate through this cursor object and find whether its sentiment is positive, neutral or negative.
+
+* You'll have to use `TextBlob` as well as the `sentiment.polarity` attribute.
+
+Keep track of a count of positive, neutral and negative tweets.
+
+When done iterating through the tweets, index the dataframe so that the sentiment data shows up in your dataframe.
+
+The function should return `df`.
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/321.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/321.md
new file mode 100644
index 00000000..6a27d795
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/321.md
@@ -0,0 +1,30 @@
+
+
+
+
+For each tweet object in the cursor, we can use the `.text` attribute to get the text of the tweet itself. Then for each text, we make a `TextBlob` object out of that text.
+
+From there, simply check the values of the `.sentiment.polarity` attribute. Positive polarity indicates positive sentiment, zero polarity indicates neutral sentiment and neutral polarity indicates negative sentiment.
+
+We keep track of positive, neutral and negative tweets with counter variables. At the end, we add the acquired sentiment data to the dataframe.
+
+Return `df` at the end.
+
+```python
+for key, val in search_dict.items():
+ # ...
+
+ positive = 0
+ neutral = 0
+ negative = 0
+ for t in tweets:
+ analysis = TextBlob(t.text)
+ if analysis.sentiment.polarity > 0:
+ positive += 1
+ elif analysis.sentiment.polarity == 0:
+ neutral += 1
+ else:
+ negative += 1
+ df[key] = [positive, neutral, negative]
+return df
+```
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/33.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/33.md
new file mode 100644
index 00000000..b5fc3605
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/33.md
@@ -0,0 +1,3 @@
+
+
+Now let's fill out `init_dataframes()`. Call your method `produce_dataframe` on the defined dictionaries `low_cost_search` and `luxury_search` to produce two dataframes which consist of sentiment data on low-cost airlines and luxury airlines. Print *the entirety* of these dataframes to the Python console and return *both* of them.
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/331.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/331.md
new file mode 100644
index 00000000..9d87b411
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/331.md
@@ -0,0 +1,14 @@
+
+
+To do this, call `produce_dataframe()` twice on `low_cost_search` and `luxury_search`, each with the 100 tweets as a parameter.
+
+Then we print the *entirety* of the dataframe using `.to_string()` and return the resulting dataframes.
+
+```python
+def init_dataframes():
+ low_cost_df = produce_dataframe(low_cost_search, 100)
+ luxury_cost_df = produce_dataframe(luxury_search, 100)
+ print(low_cost_df.to_string())
+ print(luxury_cost_df.to_string())
+ return low_cost_df, luxury_cost_df
+```
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/4.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/4.md
new file mode 100644
index 00000000..9cb3384a
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/4.md
@@ -0,0 +1,17 @@
+# Graphing
+
+Now that we have our dataframe with the number of positive, neutral, and negative tweets for each candidate, it's time to graph!
+
+Inside of the function `produce_graph(df, keys)`, create a stacked bar graph, with each bar labelled with the number of the positive/neutral/negative tweets. Data presentation is everything - without putting your due diligence into your presentation, less people will read your analytics! So make sure your graph is properly titled, with a legend, x-axes, y-axes, and x and y labels.
+
+Here are some formatting rules (and hints!) that were used in the graph below:
+
+* Width of bars is 0.40
+* The legend is placed outside the graph using `bbox_to_anchor`
+* 0.1 inch margin between x-axis labels
+* Think about what `matplotlib` function you would use to set up a bar graph. How would you set up bars so that the bottom of one bar is set at the same location as the top of another?
+* You can set up text labels by initializing a figure `fig` with `plt.figure`, then initializing a subplot `ax` with `fig.add_subplot` and adding text labels at a location `(x, y)` with `ax.text(x, y, ...)`
+
+Remember that this is the result you are aiming for:
+
+
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/41.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/41.md
new file mode 100644
index 00000000..49a59138
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/41.md
@@ -0,0 +1,12 @@
+# Setting Up Bars
+
+Remember that even though this is a stacked bar graph, you are still essentially graphing numbers on a bar graph, with the caveat that the bars are on top of each other, and so the location of the bars needs to be controlled.
+
+To make your bars on your graph, there are two steps you need to take:
+
+* Locate the positive, neutral and negative lists in your data frame. That is the data you will be graphing.
+* Use `plt.bar` to graph bar graphs.
+ * Start off with just graphing the positive bars and making sure those work.
+ * Then graph the neutral bars, setting the **bottom** to be the positive bars.
+ * Do the same for negative bars.
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/42.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/42.md
new file mode 100644
index 00000000..65ab6ddc
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/42.md
@@ -0,0 +1,22 @@
+# Making Graph Pretty
+
+Now that your bars are set up, your graph most likely looks unorganized. To organize our graph better, we can set margins to the x ticks to space them out. Because the specifics of how to space out x tick labels can get quite complicated and out of the scope of this bootcamp, I'll provide a chunk of code for you here:
+
+```python
+# space out x ticks and give margins
+plt.gca().margins(x=0)
+plt.gcf().canvas.draw()
+tl = plt.gca().get_xticklabels()
+maxsize = max([t.get_window_extent().width for t in tl])
+m = 0.1 # inch margin
+s = maxsize/plt.gcf().dpi*7+2*m
+margin = m/plt.gcf().get_size_inches()[0]
+
+plt.gcf().subplots_adjust(left=margin, right=1.-margin)
+plt.gcf().set_size_inches(s, plt.gcf().get_size_inches()[1])
+```
+
+This code should space out your x ticks and set margins.
+
+Don't forget a title (`plt.title`) and a legend (`plt.legend`)!
+
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/43.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/43.md
new file mode 100644
index 00000000..224384de
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/43.md
@@ -0,0 +1,5 @@
+# Text Labels
+
+To add text labels, we'll have to iterate through all the bars and append an appropriate label to each one. So firstly, set up a list called `labels`, that has all the positive, neutral and negative data *in one list*.
+
+We can use `ax.patches` to find a list of all the bars currently in the graph. We can then `zip` the labels and patches together, iterate through that, and for each patch use `ax.text` to attribute a label to each bar. Make sure you have an appropriate location when using `ax.text`!
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/5.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/5.md
new file mode 100644
index 00000000..45f890d6
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/5.md
@@ -0,0 +1,3 @@
+# `main()`
+
+It's time to put all of our functions together into a program! Call `produce_dataframe()` and `produce_graph` inside of your main() function with the proper parameters, and run your main() to see your graphs made!
\ No newline at end of file
diff --git a/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/README.md b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/README.md
new file mode 100644
index 00000000..510698a9
--- /dev/null
+++ b/Module_Twitter_API/labs/Week 3/Democratic Debate Sentiment/README.md
@@ -0,0 +1,20 @@
+# Activity/Lab Name
+
+Democratic Debate Sentiment
+
+# Long Summary
+
+Students will use the `tweepy` and `textblob` Python modules to utilize the Twitter API and perform sentiment analysis on tweets about the Democratic Debates. Students will then use Python modules `pandas` and `matplotlib` to make a dataframe and graph the information appropriately.
+
+# Short Summary
+
+Students will use the Twitter API to analyze sentiments about Democratic Debate tweets
+
+# Criteria
+
+1. How would you use a Tweepy cursor object to get Tweets from the Twitter API?
+2. What's the difference between a time series dataframe and a regular dataframe?
+
+# Difficulty
+
+Medium
diff --git a/Node_Week_1/.DS_Store b/Node_Week_1/.DS_Store
new file mode 100644
index 00000000..8aa4ab2d
Binary files /dev/null and b/Node_Week_1/.DS_Store differ
diff --git a/Node_Week_1/javascripting/1 2.md b/Node_Week_1/javascripting/1 2.md
new file mode 100644
index 00000000..088566c0
--- /dev/null
+++ b/Node_Week_1/javascripting/1 2.md
@@ -0,0 +1,46 @@
+## Creat Your Folder
+
+To keep things organized, let's create a folder for this workshop.
+
+Run this command to make a directory called `javascripting` (or something else if you like):
+
+```bash
+mkdir javascripting
+```
+
+Change directory into the `javascripting` folder:
+
+```bash
+cd javascripting
+```
+
+Create a file named `introduction.js`:
+
+```bash
+touch introduction.js
+```
+
+Or if you're on **Windows**:
+```bash
+type NUL > introduction.js
+```
+ (**`type` is part of the command!**)
+
+Open the file in your favorite editor, and add this text:
+
+```js
+console.log('hello')
+```
+
+Save the file, then check to see if your program is correct by running this command:
+
+```bash
+javascripting verify introduction.js
+```
+
+By the way, throughout this tutorial, you can give the file you work with any name you like, so if you want to use something like `catsAreAwesome.js` file for every exercise, you can do that. Just make sure to run:
+
+```bash
+javascripting verify catsAreAwesome.js
+```
+
diff --git a/Node_Week_1/javascripting/2 2.md b/Node_Week_1/javascripting/2 2.md
new file mode 100644
index 00000000..e5e766ef
--- /dev/null
+++ b/Node_Week_1/javascripting/2 2.md
@@ -0,0 +1,39 @@
+## Variable
+
+A variable is a name that can **reference** a specific value. Variables are declared using `let` followed by the variable's name.
+
+Here's an example:
+
+```js
+let example
+```
+
+The above variable is **declared**, but it **isn't defined** (it does not yet reference a specific value).
+
+Here's an example of defining a variable, making it reference a specific value:
+
+```js
+const example = 'some string'
+```
+
+**Name** of the variable: example
+
+**Value** of the variable: `'some string'`
+
+# NOTE
+
+A variable is **declared** using `let` and uses the **equals sign** to **define** the value that it references. This is colloquially known as "Making a variable equal a value".
+
+## The challenge:
+
+Create a file named `variables.js`.
+
+In that file declare a variable named `example`.
+
+**Make the variable `example` equal to the value `'some string'`.**
+
+Then use `console.log()` to print the `example` variable to the console.
+
+Check to see if your program is correct by running this command:
+
+`javascripting verify variables.js`
diff --git a/Node_Week_1/javascripting/5 2.md b/Node_Week_1/javascripting/5 2.md
new file mode 100644
index 00000000..e970a428
--- /dev/null
+++ b/Node_Week_1/javascripting/5 2.md
@@ -0,0 +1,39 @@
+## String Length
+
+You will often need to know **how many** characters are in a string.
+
+For this you will use the `.length` property. Here's an example:
+
+```js
+const example = 'example string'
+example.length
+```
+
+Result:
+
+```js
+14
+```
+
+(' 'is also have a length of 1)
+
+## NOTE
+
+Make sure there is a period between `example` and `length`.
+
+The above code will return a **number** for the total number of characters in the string.
+
+
+## The challenge:
+
+Create a file named `string-length.js`.
+
+In that file, create a variable named `example`.
+
+**Assign the string `'example string'` to the variable `example`.**
+
+Use `console.log` to print the **length** of the string to the terminal.
+
+**Check to see if your program is correct by running this command:**
+
+`javascripting verify string-length.js`
diff --git a/Node_Week_1/javascripting/6 2.md b/Node_Week_1/javascripting/6 2.md
new file mode 100644
index 00000000..c66923e1
--- /dev/null
+++ b/Node_Week_1/javascripting/6 2.md
@@ -0,0 +1,17 @@
+## Number
+
+Numbers can be integers, like `2`, `14`, or `4353`, or they can be **ints**,
+also known as **floats**, like `3.14`, `1.5`, or `100.7893423`.
+Unlike Strings, Numbers **do not need to have quotes**.
+
+## The challenge:
+
+Create a file named `numbers.js`.
+
+In that file define a variable named `example` that references the integer `123456789`.
+
+Use `console.log()` to print that number to the terminal.
+
+Check to see if your program is correct by running this command:
+
+`javascripting verify numbers.js`
diff --git a/Node_Week_1/javascripting/8 2.md b/Node_Week_1/javascripting/8 2.md
new file mode 100644
index 00000000..574734cf
--- /dev/null
+++ b/Node_Week_1/javascripting/8 2.md
@@ -0,0 +1,34 @@
+## Number to String
+
+Sometimes you will need to turn a number into a string.
+
+In those instances you will use the `.toString()` method. Here's an example:
+
+```js
+let n = 256
+n = n.toString()
+```
+
+Result of n:
+
+```js
+'256'
+```
+
+
+
+## The challenge:
+
+Create a file named `number-to-string.js`.
+
+1.In that file define a variable named `n` that references the number `128`;
+
+2.Call the `.toString()` method on the `n` variable.
+
+3.Use `console.log()` to print the results of the `.toString()` method to the terminal.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify number-to-string.js
+```
diff --git a/Node_Week_1/javascripting/for_loop 2.md b/Node_Week_1/javascripting/for_loop 2.md
new file mode 100644
index 00000000..1be3cccb
--- /dev/null
+++ b/Node_Week_1/javascripting/for_loop 2.md
@@ -0,0 +1,59 @@
+## Statement : For loops
+
+For loops allow you to **repeatedly** run a block of code a certain number of times. This for loop logs to the console ten times:
+
+```js
+for (let i = 0; i < 10; i++) {
+ // log the numbers 0 through 9
+ console.log(i)
+}
+```
+
+Result:
+
+```js
+0
+1
+2
+3
+4
+5
+6
+7
+8
+9
+```
+
+***
+
+The first part, `let i = 0`, is run once at the beginning of the loop. The variable `i` is used to track how many times the loop has run.
+
+The second part, `i < 10`, is checked at the beginning of every loop iteration before running the code inside the loop. If the **statement is true**, the code **inside** the loop is **executed**. If it is **false**, then the **loop is complete**. The statement `i < 10;` indicates that the loop will continue as long as `i` is less than `10`.
+
+The final part, `i++`, is **executed at the end of every loop**. This increases the variable `i` by 1 after each loop. Once `i` reaches `10`, the loop will exit.
+
+## The challenge:
+
+Create a file named `for-loop.js`.
+
+In that file define a variable named `total` and make it equal the number `0`.
+
+Define a second variable named `limit` and make it equal the number `10`.
+
+Create a for loop with a variable `i` starting at 0 and increasing by 1 each time through the loop. The loop should run as long as `i` is less than `limit`.
+
+On each iteration of the loop, add the number `i` to the `total` variable. To do this, you can use this statement:
+
+```js
+total += i
+```
+
+When this statement is used in a for loop, it can also be known as _an accumulator_. Think of it like a cash register's running total while each item is scanned and added up. For this challenge, you have 10 items and they just happen to be increasing in price by 1 each item (with the first item free!).
+
+After the for loop, use `console.log()` to print the `total` variable to the terminal.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify for-loop.js
+```
diff --git a/Node_Week_1/javascripting/function 2.md b/Node_Week_1/javascripting/function 2.md
new file mode 100644
index 00000000..a2f9a523
--- /dev/null
+++ b/Node_Week_1/javascripting/function 2.md
@@ -0,0 +1,57 @@
+## Function
+
+A **function** is a block of code that ***1. takes input***, ***2. processes that input***, and then ***3. produces output***.
+
+Here is an example:
+
+```js
+function example (x) {
+ y = x * 2
+ return y
+}
+```
+
+*Name* of function: **example**
+
+*Input* (*argument*): **x**
+
+*processes*: **x*2**
+
+*output* (*return value*): **y**
+
+*****
+
+We can ***call*** that function like this :
+
+```js
+example(5)
+```
+
+The **result** is :
+
+```js
+10
+```
+
+The above example assumes that the `example` function will take a number as an argument –– as input –– and will return that number multiplied by 2.
+
+## The challenge:
+
+Create a file named `functions.js`.
+
+In that file, define a function named `eat` that takes an argument named `food`
+that is expected to be a string.
+
+Inside the function return the `food` argument like this:
+
+```js
+return food + ' tasted really good.'
+```
+
+Inside of the parentheses of `console.log()`, call the `eat()` function with the string `bananas` as the argument.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify functions.js
+```
diff --git a/Node_Week_1/javascripting/function_argument 2.md b/Node_Week_1/javascripting/function_argument 2.md
new file mode 100644
index 00000000..40527f52
--- /dev/null
+++ b/Node_Week_1/javascripting/function_argument 2.md
@@ -0,0 +1,43 @@
+## Function Argument
+
+A function can be declared to receive any number of arguments. Arguments can be from any type. An argument could be a string, a number, an array, an object and even another function.
+
+Here is an example:
+
+```js
+function example (firstArg, secondArg) {
+ console.log(firstArg, secondArg)
+}
+```
+
+**Argument**: `firstArg`, `secondArg`
+
+We can **call** that function with two arguments like this:
+
+```js
+example('hello', 'world')
+```
+
+Result:
+
+```js
+hello world
+```
+
+## The challenge:
+
+Create a file named `function-arguments.js`.
+
+In that file, define a function named `math` that takes three arguments. It's important for you to understand that arguments names are only used to reference them.
+
+Name each argument as you like.
+
+Within the `math` function, return the value obtained from multiplying the second and third arguments and adding that result to the first argument.
+
+After that, inside the parentheses of `console.log()`, call the `math()` function with the number `53` as first argument, the number `61` as second and the number `67` as third argument.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify function-arguments.js
+```
diff --git a/Node_Week_1/javascripting/if 2.md b/Node_Week_1/javascripting/if 2.md
new file mode 100644
index 00000000..1318257e
--- /dev/null
+++ b/Node_Week_1/javascripting/if 2.md
@@ -0,0 +1,44 @@
+## Statement: If
+
+Conditional statements are used to **alter the control flow** of a program, **based** on a specified **boolean condition**.
+
+A conditional statement looks like this:
+
+```js
+if (n > 1) {
+ console.log('the variable n is greater than 1.')
+} else {
+ console.log('the variable n is less than or equal to 1.')
+}
+```
+
+In this example:
+
+**Logic statement**: `n>1`
+
+If n>1, the code will print `the variable n is greater than 1.`
+
+If n<=1, the code will print `the variable n is less than or equal to 1.`
+
+***
+
+Inside parentheses you must enter a logic statement, meaning that the result of the statement is either true or false.
+
+The else block is optional and contains the code that will be executed if the statement is false.
+
+## The challenge:
+
+Create a file named `if-statement.js`.
+
+In that file, declare a variable named `fruit`.
+
+Make the `fruit` variable reference the string value **"orange"**.
+
+Then use `console.log()` to print "**The fruit name has more than five characters."** if the length of the value of `fruit` is greater than five.
+Otherwise, print "**The fruit name has five characters or less.**"
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify if-statement.js
+```
diff --git a/Node_Week_1/javascripting/loop through array 2.md b/Node_Week_1/javascripting/loop through array 2.md
new file mode 100644
index 00000000..93dbe84f
--- /dev/null
+++ b/Node_Week_1/javascripting/loop through array 2.md
@@ -0,0 +1,53 @@
+## Loop Through The Array
+
+For this challenge we will use a **for loop** to access and manipulate a list of values in an array.
+
+Accessing array values can be done using an integer.
+
+Each item in an array is identified by a number, starting at `0`.
+
+So in this array `hi` is identified by the number `1`:
+
+```js
+const greetings = ['hello', 'hi', 'good morning']
+```
+
+It can be accessed like this:
+
+```js
+greetings[1]
+```
+
+So inside a **for loop** we would use the `i` variable inside the square brackets instead of directly using an integer.
+
+```
+
+```
+
+
+
+## The challenge:
+
+Create a file named `looping-through-arrays.js`.
+
+In that file, define a variable named `pets` that references this array:
+
+```js
+['cat', 'dog', 'rat']
+```
+
+Create a for loop that changes each string in the array so that they are plural.
+
+You will use a statement like this inside the for loop:
+
+```js
+pets[i] = pets[i] + 's'
+```
+
+After the for loop, use `console.log()` to print the `pets` array to the terminal.
+
+Check to see if your program is correct by running this command:
+
+```bash
+javascripting verify looping-through-arrays.js
+```
diff --git a/Node_Week_1/learnyouhtml/14 2.md b/Node_Week_1/learnyouhtml/14 2.md
new file mode 100644
index 00000000..481c5dbd
--- /dev/null
+++ b/Node_Week_1/learnyouhtml/14 2.md
@@ -0,0 +1,35 @@
+## LISTS
+
+### Unordered lists
+
+
+
+Unordered lists look similar to ordered ones. Describing of list items remains the same, keep using `| 1.1 | +1.2 | +
| 2.1 | +2.2 | +
` (table data) tag.
+
+Here is the markup for the table above:
+
+```html
+
| ` (table head) tags. Just create a row with ` | ` cells, like so:
+
+```html
+ Simple table with header +
Simple table with header +
| ` tags will be displayed as bolder text.
+
+
+
+Each of those tags has a lot of special attributes. Read more here:
+
+* [`
|
|---|





























 -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  -
-  +
+