Search the Web with AI


This article is based on PrAIvateSearch
v2.0-beta.0, a privacy-first, AI-powered, user-centered and data-safe application aimed at providing a local and open-source alternative to big AI search engines such as SearchGPT or Perplexity AI.
1. Introduction
In the last blog post we introduced PrAIvateSearch v1.0-beta.0, a data-safe and private AI-powered search engine: despite being a fully functional solution, there were still hassles that made it under-perform, specifically:
- Content scraping from the URLs resulting from the web search was unreliable and sometimes did not produce correct results.
- We extracted a series of key-words from web-based contents: keywords were then formatted into JSON and injected into the user prompt as context. This, despite being a viable solution to lighten the prompt, only gave the LLM a partial contextual information.
- We used RAG for context augmentation, but it often proved inefficient as the retrieved context was passed directly into the user's prompt, making inference computationally intense and time-requiring.
- Our interface was basic and essential, lacking the dynamic and modern flows of other web applications.
- The use of Google Search API to search the web was not optimal under a privacy-wise point of view
In this sense, we decided to apply a way simpler and direct workflow, synthesized in the following image:
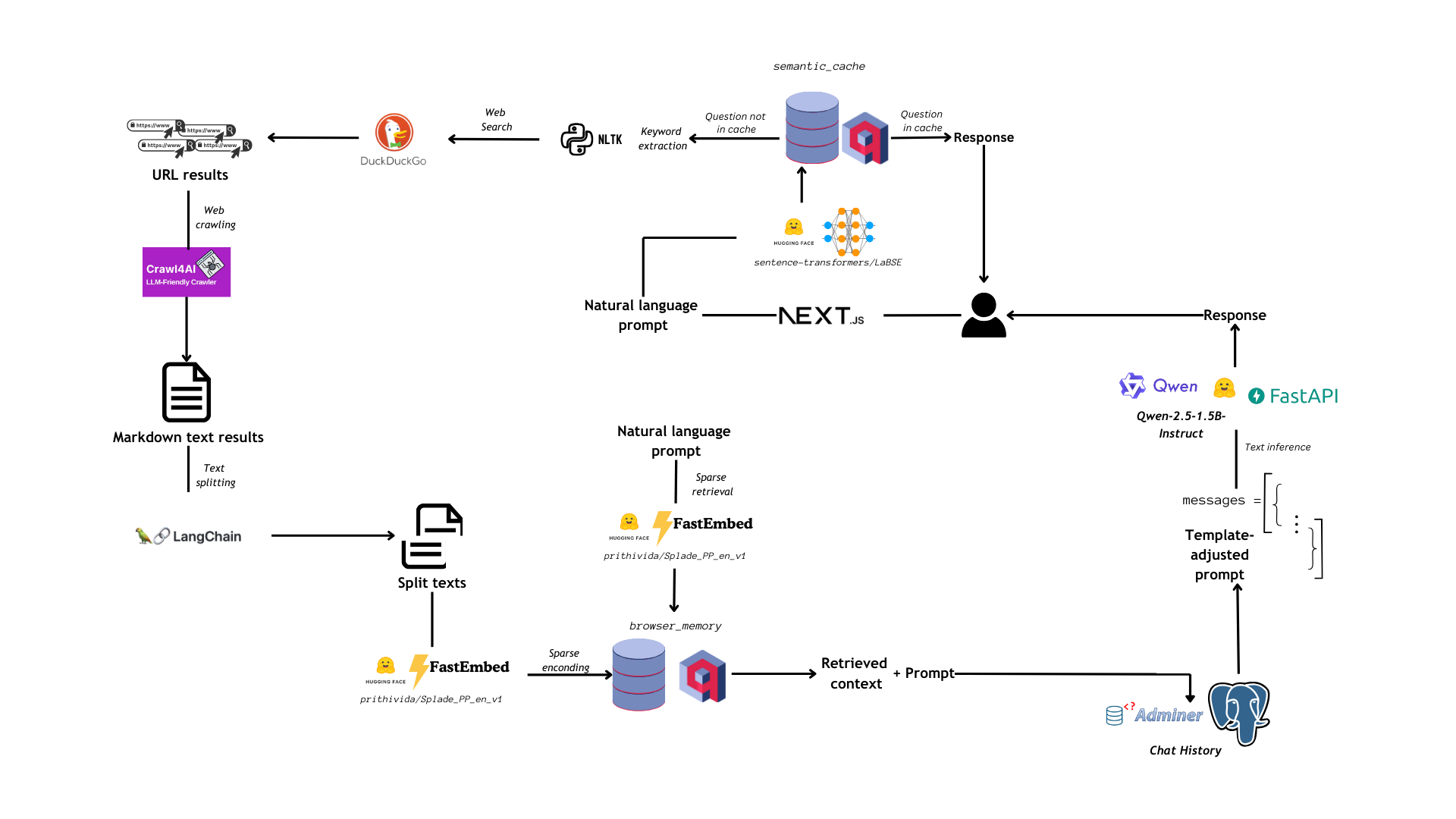
2. Building Blocks
The application is made up by three important building blocks:
- A dynamic, chat-like user interface built with NextJS (launched via docker compose)
- Third-party local database services: Postgres and Qdrant (launched via docker compose)
- An API service, which is built with FastAPI and served with Uvicorn (launched in an isolated conda environment): this service is responsible for connecting the frontend with the backend third party services, web search and all the functions related to finding an answer to the user's query.
We'll go through all these building blocks, but first let's have a look on what are the pre-requirements and the first steps to get the code to build PrAIvateSearch v2.0-beta.0.
2a. First steps
To get the necessary code and build the environment to run it, you will need:
gittoolset to get the code from the GitHub repositorycondapackage manager to build the environment from which the API will be launcheddockeranddocker composeto serve the UI and the third-party local databases.
Now, to get the code, you can simply run:
git clone https://github.com/AstraBert/PrAIvateSearch.git
cd PrAIvateSearch
First of all move .env.example to .env...
mv .env.example .env
...and specify PostgreSQL related variables:
# .env file
pgql_db="postgres"
pgql_user="localhost"
pgql_psw="
You will then need to build the API environment with:
# create the environment
conda env create -f conda_environment.yaml
# activate the environment
conda activate praivatesearch
# run crawl4ai post-installation setup
crawl4ai-setup
# run crawl4ai health checks
crawl4ai-doctor
# deactivate the environment
conda deactivate
And, finally, you will be able to launch the frontend and the databases with:
# The use of the -d option is not mandatory
docker compose up [-d]
3. User Interface
The user interface is now based on a NextJS implementation of a modern, dynamic chat interface. The interface is inspired to ChatGPT, and aims at giving the user a similar experience to that of using OpenAI's product.
Whenever the user interacts with the UI by sending a message, the NextJS app backend sends a GET request to http://localhost:8000/messages/, where our FastAPI/Uvicorn managed API runs (see below). Once the request is fulfilled, the applications displays the message it got back, which is the answer to the user's query.
The NextJS application runs on http://localhost:3000 and is launched through docker compose.
4. Database Services
Database services are run locally thanks to docker compose: they are completely user-managed and can be easily monitored. This gives the user complete control over the data flow inside the application.
4a. Qdrant
Qdrant is a vector database service that plays a core role inside PrAIvateSearch. Thanks to Qdrant, we:
- Create and manage a semantic cache, in which we store questions that the user already asked and answers that the LLM gave to them, so that we can use the same answer if the user inputs the same question or a similar one. We use semantic search to find similar questions and use a cut-off threshold of 75% similarity to filter out non-relevant hits: that's why our cache is not just a cache, but it is also semantic.
- Store the content scraped from the web during the web searching and crawling step: we use a sparse collection for this purpose. We then perform sparse retrieval with Splade, loaded with FastEmbed (a python library managed by Qdrant itself): this first retrieval step yields the 5 top hits for the user's prompt inside the database of contents scraped from the web.
Qdrant is accessible for monitoring, thanks to a complete and easy-to-use interface, on http://localhost:6333/dashboard
4b. Postgres
Postgres is a relational database, and it is employed here essentially as a manager for chat memory.
Thanks to a SQLAlchemy-based custom client, we can load all the messages sent during the conversation in the messages table: this table is structured in such a way that it is compatible with the chat template that we set for our LLM, and so the retrieval of the chat history at inference time already provides the language model with the full number of previously sent messages.
Postgres can be easily monitored through Adminer, a simple and intuitive database management tool: you just need to provide the database type (PostgreSQL), the database name, the username and the password (variables that are passed to Docker and that you can define inside your .env file) . Also Adminer runs locally and is served through docker compose: it is accessible at http://localhost:8080.
5. API Services
As we said, we built a local API service thanks to FastAPI and Uvicorn, two intuitive and easy-to-use tools that make API development seamless.
The API endpoint is up at http://localhost:8000/messages/ and receives the user messages from the NextJS application. The workflow from receiving a message to returning a response is straightforward:
- We check if the user's prompt corresponds to an already asked question thanks to the semantic cache: this cache is basically a dense Qdrant collection, with 768-dimensional vectors produced by LaBSE. If there is a significant match within the semantic cache, we return the same answer used for that match, otherwise we proceed with handling the request
- If the user's query did not yield a significant match from the semantic cache, we proceed to extracting keywords from the user's natural language prompt with the RAKE (Rapid Automatic Keyword Extraction) algorithm. These keywords will be used to search the web
- We search the web through DuckDuckGo Search API: using DuckDuckGo ensures more privacy in surfing the net than exploiting Google. This is part of the effort that PrAIvateSearch makes to ensure that the user's data are safe and not indexed by Big Techs for secondary (not-always-so-transparent) purposes.
- We scrape content using the URLs returned by the web search: to do this, we use Crawl4AI asynchronous web crawler, and we return all the scraped content in markdown format
- We split the markdown texts from the previous step with LangChain
MarkdownTextSplitter: after this step, we will have 1000-charachters long text chunks - The chunks are encoded into sparse vectors with Splade and uploaded to a Qdrant sparse collection
- We search the sparse collection with the user's original query and retrieve the top 5 most relevant documents
- These 5 relevant documents are then re-ranked: we employ LaBSE to encode the relevant documents into dense vectors and we evaluate their cosine similarity with the vectorized user's prompt. The most similar document gets retrieved as a context
- The context is passed as a user's message, and the prompt is passed right after it as a user's message too. In this sense, the LLM only has to reply to the user's prompt, but can access, through chat memory, the web-based context for it
- Qwen-2.5-1.5B-Instruct performs inference on the user's prompt and generates an answer to it: this answer is then returned as the API final response, and will be displayed in the UI.
6. Usage
6a. Usage note
The NextJS application was successfully developed and tested on a Ubuntu 22.04.3 machine, with 32GB RAM, 22 cores CPU and Nvidia GEFORCE RTX4050 GPU (6GB, cuda version 12.3), python version 3.11.11 (packaged by conda 24.11.0)
Although being at a good stage of development, the application is a beta and might still contain bugs and have OS/hardware/python version incompatibilities.
6b. Getting PrAIvateSearch Up and Running
To get PrAIvateSearch up and running you need to have already executed the first steps
Once we have launched (from within the PrAIVateSearch folder) the databases backend services and the frontend applications via docker compose with this command :
docker compose up
We can head over to the conda environment we set up in the first steps, and launch the API:
# activate the environment
conda activate praivatesearch
# head over to the qwen-on-api folder
cd qwen-on-api/
# launch the application
uvicorn main:app --host 0.0.0.0 --port 8000
After loading the several AI models involved in the development of the application, you will see that the API is up and ready to receive requests.
If you want to test the API prior to sending requests through the frontend, you can simply use this curl command:
curl "http://0.0.0.0:8000/messages/What%20is%20the%20capital%20of%20France"
If everything went smoothly, you should receive a response like this:
{"response": "The capital of France is **Paris**."}
And that's all! Now head over to http://localhost:3000 and start playing around with PrAIvateSearch!🪿
7. Conclusion
The aim behind PrAIvateSearch is to provide an open-source, private and data-safe alternative to Big Tech solutions. The application is still a beta, so, although its workflow may seem solid, there may still be hiccups, untackled errors and imprecisions. If you want to contribute to the project, report issues and help developing the OSS AI community and environment, feel free to do so on GitHub and to help it with funding.
Thanks!🤗