diff --git a/.ci/ignore_treon_docker.txt b/.ci/ignore_treon_docker.txt
index 6803c637d09..40537e09838 100644
--- a/.ci/ignore_treon_docker.txt
+++ b/.ci/ignore_treon_docker.txt
@@ -90,4 +90,5 @@ notebooks/kokoro/kokoro.ipynb
notebooks/qwen2.5-omni-chatbot/qwen2.5-omni-chatbot.ipynb
notebooks/intern-video2-classiciation/intern-video2-classification.ipynb
notebooks/flex.2-image-generation/flex.2-image-generation.ipynb
-notebooks/wan2.1-text-to-video/wan2.1-text-to-video.ipynb
\ No newline at end of file
+notebooks/wan2.1-text-to-video/wan2.1-text-to-video.ipynb
+notebooks/ace-step-music-generation/ace-step-music-generation.ipynb
\ No newline at end of file
diff --git a/.ci/skipped_notebooks.yml b/.ci/skipped_notebooks.yml
index 88ae13df2f9..f72a44859e6 100644
--- a/.ci/skipped_notebooks.yml
+++ b/.ci/skipped_notebooks.yml
@@ -574,3 +574,9 @@
skips:
- os:
- macos-13
+- notebook: notebooks/ace-step-music-generation/ace-step-music-generation.ipynb
+ skips:
+ - os:
+ - macos-13
+ - ubuntu-22.04
+ - windows-2022
diff --git a/.ci/spellcheck/.pyspelling.wordlist.txt b/.ci/spellcheck/.pyspelling.wordlist.txt
index 317159d286c..ed4252687a6 100644
--- a/.ci/spellcheck/.pyspelling.wordlist.txt
+++ b/.ci/spellcheck/.pyspelling.wordlist.txt
@@ -52,6 +52,8 @@ autogenerated
AutoModelForXxx
autoregressive
autoregressively
+AutoEncoder
+AutoEncoders
AutoTokenizer
AWQ
awq
@@ -201,6 +203,7 @@ denoises
denoising
denormalization
denormalized
+demucs
depainting
deployable
DepthAnything
@@ -231,6 +234,7 @@ DIT
DiT
DiT’s
DiT’s
+DiTs
DL
DocLayNet
docling
@@ -291,6 +295,8 @@ FastDraft
FastSAM
FC
feedforward
+FeedForward
+FFN
FFmpeg
FIL
FEIL
@@ -608,6 +614,7 @@ MRPC
mRoPE
msi
MTVQA
+mT
multiarchitecture
Multiclass
multiclass
@@ -705,6 +712,7 @@ opset
optimizable
Orca
otsl
+OSNet
OTSL
OuteTTS
outpainting
@@ -780,6 +788,7 @@ PowerShell
PPYOLOv
PR
Prateek
+PLR
pre
Precisions
precomputed
@@ -945,6 +954,7 @@ SmolVLM
softmax
softvc
SoftVC
+SongGen
SOTA
SoTA
soundfile
@@ -1125,6 +1135,7 @@ Vladlen
VOC
Vocoder
vocoder
+vocoding
VQ
VQA
VQGAN
diff --git a/notebooks/ace-step-music-generation/README.md b/notebooks/ace-step-music-generation/README.md
new file mode 100644
index 00000000000..c21adb0534e
--- /dev/null
+++ b/notebooks/ace-step-music-generation/README.md
@@ -0,0 +1,33 @@
+# Music generation using ACE Step and OpenVINO
+
+[ACE-Step](https://ace-step.github.io/) is a novel open-source foundation model for music generation that overcomes key limitations of existing approaches and achieves state-of-the-art performance through a holistic architectural design. Current methods face inherent trade-offs between generation speed, musical coherence, and controllability. ACE-Step bridges this gap by integrating diffusion-based generation with Sana’s Deep Compression AutoEncoder (DCAE) and a lightweight linear transformer. The model achieving superior musical coherence and lyric alignment across melody, harmony, and rhythm metrics. Moreover, ACE-Step preserves fine-grained acoustic details, enabling advanced control mechanisms such as voice cloning, lyric editing, remixing, and track generation (e.g., lyric2vocal, singing2accompaniment).
+
+ACE-Step adapts a text-to-image diffusion framework for music generation. The core generative model is a diffusion model operating on a compressed mel spectrogram latent representation. This process is guided by conditioning information from three specialized encoders: a text prompt encoder, a lyric encoder, and a speaker encoder. Embeddings from these encoders are concatenated and integrated into the diffusion model via cross-attention mechanisms
+
+ACE-Step can be used for generating original music from text descriptions, music remixing and style transfer, edit song lyrics. The model offers a set of controllable features that allow users to precisely control the generation process and enable targeted modifications to existing audio material, as well as perform specialized generation tasks through fine-tuning.
+
+
+
+More details about the model can be found using the following resources: [project page](https://ace-step.github.io/), [paper](https://arxiv.org/abs/2506.00045), [original repository](https://github.com/ace-step/ACE-Step).
+
+
+## Notebook Contents
+
+This notebook demonstrates how to convert and run music generation or editing with ACE Step using OpenVINO.
+
+The tutorial consists of the following steps:
+
+- Install prerequisites
+- Download and run inference of ACE Step model
+- Convert the model to IR format and run inference with OpenVINO
+- Download, apply and generate audio with LoRA
+- Interactive demo
+
+
+## Installation Instructions
+
+This is a self-contained example that relies solely on its own code.
+We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
+For details, please refer to [Installation Guide](../../README.md).
+
+
diff --git a/notebooks/ace-step-music-generation/ace-step-music-generation.ipynb b/notebooks/ace-step-music-generation/ace-step-music-generation.ipynb
new file mode 100644
index 00000000000..9d9b9f185ba
--- /dev/null
+++ b/notebooks/ace-step-music-generation/ace-step-music-generation.ipynb
@@ -0,0 +1,881 @@
+{
+ "cells": [
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "b464bcb6-cff9-46e7-bd86-fa40bdd3ad18",
+ "metadata": {},
+ "source": [
+ "# Music generation using ACE Step and OpenVINO\n",
+ "\n",
+ "
Important note: This notebook requires python >= 3.10. Please make sure that your environment fulfill to this requirement before running it
\n",
+ "\n",
+ "[ACE-Step](https://ace-step.github.io/) is a novel open-source foundation model for music generation that overcomes key limitations of existing approaches and achieves state-of-the-art performance through a holistic architectural design. Current methods face inherent trade-offs between generation speed, musical coherence, and controllability. ACE-Step bridges this gap by integrating diffusion-based generation with Sana’s Deep Compression AutoEncoder (DCAE) and a lightweight linear transformer. The model achieving superior musical coherence and lyric alignment across melody, harmony, and rhythm metrics. Moreover, ACE-Step preserves fine-grained acoustic details, enabling advanced control mechanisms such as voice cloning, lyric editing, remixing, and track generation (e.g., lyric2vocal, singing2accompaniment). \n",
+ "\n",
+ "\n",
+ "ACE-Step adapts a text-to-image diffusion framework for music generation. The core generative model is a diffusion model operating on a compressed mel spectrogram latent representation. This process is guided by conditioning information from three specialized encoders: a text prompt encoder, a lyric encoder, and a speaker encoder. Embeddings from these encoders are concatenated and integrated into the diffusion model via cross-attention mechanisms\n",
+ "\n",
+ "\n",
+ "ACE-Step can be used for generating original music from text descriptions, music remixing and style transfer, edit song lyrics. The model offers a set of controllable features that allow users to precisely control the generation process and enable targeted modifications to existing audio material, as well as perform specialized generation tasks through fine-tuning.\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "More details about the model can be found using the following resources: [project page](https://ace-step.github.io/), [paper](https://arxiv.org/abs/2506.00045), [original repository](https://github.com/ace-step/ACE-Step).\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Installation Instructions\n",
+ "\n",
+ "This is a self-contained example that relies solely on its own code.\n",
+ "\n",
+ "We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.\n",
+ "For details, please refer to [Installation Guide](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/README.md#-installation-guide).\n",
+ "\n",
+ "\n",
+ "\n",
+ "#### Table of contents:\n",
+ "\n",
+ "- [Prerequisites](#Prerequisites)\n",
+ "- [Music generation with ACE Step Pipeline via PyTorch](#Music-generation-with-ACE-Step-Pipeline-via-PyTorch)\n",
+ " - [Download checkpoints and load PyTorch models](#Download-checkpoints-and-load-PyTorch-models)\n",
+ " - [Configure parameters and generate audio](#Configure-parameters-and-generate-audio)\n",
+ " - [Update audio](#Update-audio)\n",
+ "- [Music Generation with ACE Step via OpenVINO](#Music-Generation-with-ACE-Step-via-OpenVINO)\n",
+ " - [Convert model to OpenVINO](#Convert-model-to-OpenVINO)\n",
+ " - [Select inference device](#Select-inference-device)\n",
+ " - [Create pipeline, read and compile models](#Create-pipeline,-read-and-compile-models)\n",
+ " - [Generate audio](#Generate-audio)\n",
+ " - [Update audio](#Update-audio)\n",
+ "- [ACE Step with LoRA](#ACE-Step-with-LoRA)\n",
+ " - [Load LoRA and apply for Transformer models for ACE Step pipeline](#Load-LoRA-and-apply-for-Transformer-models-for-ACE-Step-pipeline)\n",
+ " - [Convert models with LoRA and load to OpenVINO pipeline](#Convert-models-with-LoRA-and-load-to-OpenVINO-pipeline)\n",
+ " - [Run Inference with LoRA](#Run-Inference-with-LoRA)\n",
+ " - [Deactivate LoRA](#Deactivate-LoRA)\n",
+ "- [Interactive demo](#Interactive-demo)\n",
+ "\n"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "915b561b-3a13-4deb-8a61-9bab9abb6faa",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "[back to top ⬆️](#Table-of-contents:)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16f5d8e3-87e7-4396-97c1-147b6b82d0f8",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import requests\n",
+ "import platform\n",
+ "from pathlib import Path\n",
+ "\n",
+ "if not Path(\"ov_ace_helper.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/ace-step-music-generation/ov_ace_helper.py\")\n",
+ " open(\"ov_ace_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"gradio_helper.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/ace-step-music-generation/gradio_helper.py\")\n",
+ " open(\"gradio_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"notebook_utils.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\")\n",
+ " open(\"notebook_utils.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"pip_helper.py\").exists():\n",
+ " r = requests.get(\n",
+ " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/pip_helper.py\",\n",
+ " )\n",
+ " open(\"pip_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "from pip_helper import pip_install\n",
+ "\n",
+ "pip_install(\"gradio>=4.19\")\n",
+ "if platform.system() == \"Darwin\":\n",
+ " pip_install(\"numpy<2.0\")\n",
+ "\n",
+ "pip_install(\n",
+ " \"git+https://github.com/ace-step/ACE-Step.git@6ae0852b1388de6dc0cca26b31a86d711f723cb3\", \"--extra-index-url\", \"https://download.pytorch.org/whl/cpu\"\n",
+ ")\n",
+ "\n",
+ "pip_install(\"openvino>=2025.1.0\", \"openvino-tokenizers>=2025.1.0\", \"nncf>=2.16.0\")\n",
+ "\n",
+ "# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry\n",
+ "from notebook_utils import collect_telemetry\n",
+ "\n",
+ "collect_telemetry(\"ace-step-music-generation.ipynb\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "358dd910",
+ "metadata": {},
+ "source": [
+ "## Music generation with ACE Step Pipeline via PyTorch\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cc3880f0",
+ "metadata": {},
+ "source": [
+ "### Download checkpoints and load PyTorch models\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "The architecture of ACE Step consists of following components.\n",
+ "\n",
+ "Linear Diffusion Transformer.\n",
+ "\n",
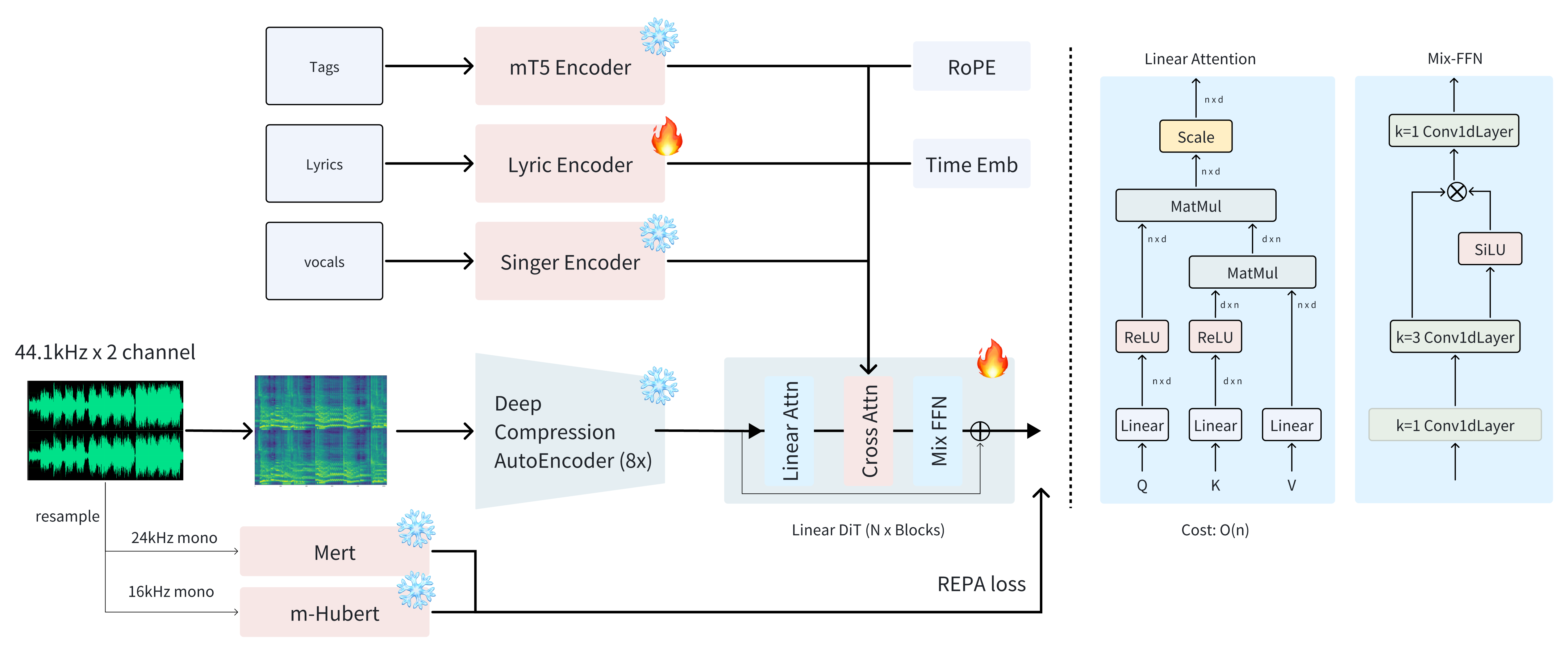
+ "Core Diffusion Model is a Linear Diffusion Transformer (DiT). DiT architecture adapts the Transformer to serve as the backbone for diffusion models, primarily replacing U-Net structures common in image generation. DiTs treat latent representations (e.g., image patches or segments of audio features) as sequences of tokens. These tokens, along with embeddings for the diffusion timestep and any conditioning information, are processed by a series of Transformer blocks. ACE-Step adapt the Linear DiT structure from Sana with several modifications. This significantly reduces model size and memory consumption; And added 1D Convolutional FeedForward Layers (FFN).\n",
+ "\n",
+ "Conditioning Encoders.\n",
+ "\n",
+ "To guide the generation process, the Linear DiT is conditioned on embeddings from the following encoders:\n",
+ "- Text Encoder: It is a mT5-base model, which generate 768-dimensional embeddings from textual prompts.\n",
+ "- Lyric Encoder: The lyric encoder architecture and hyperparameters are adopted from SongGen.\n",
+ "- Speaker Encoder: The speaker encoder processes a 10 - second unaccompanied vocal segment, which is separated by demucs, into a 512 - dimensional embedding. For full songs with vocals, embeddings from multiple such segments are averaged. A zero vector is used as the speaker embedding for instrumental tracks. The encoder, pre-trained on a large and diverse singing voice corpus, draws architectural inspiration from\n",
+ "PLR-OSNet, originally designed for face recognition. The model was tuned to prevents the model from over-relying on timbre information for stylistic interpretation, thereby enabling reasonable timbre generation even without explicit speaker input.\n",
+ "\n",
+ "Deep Compression AutoEncoders.\n",
+ "\n",
+ "For efficient latent space modeling, ACE-Step uses Deep Compression AutoEncoder (DCAE). A DCAE is an encoder to map high-dimensional input (e.g., mel-spectrograms) to a much lower-dimensional latent representation, and a decoder to reconstruct the original input from this latent code. The \"deep compression\" aspect implies a focus on achieving a highly compact latent space while minimizing reconstruction error. For audio, this means capturing salient acoustic features essential for perception and quality within a small number of latent variables. This not only reduces the computational burden for subsequent generative models operating in this latent space but also encourages the generative model to focus on higher-level structural and semantic aspects rather than low-level waveform details. The specific architecture of DCAE (e.g., convolutional layers, quantization if used) is optimized for this trade-off. For converting the generated mel-spectrograms back to waveform (vocoding), ACE-Step utilizes a pre-trained universal music vocoder from Fish Audio."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b542df6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from acestep.pipeline_ace_step import ACEStepPipeline\n",
+ "\n",
+ "checkpoint_dir = \"\"\n",
+ "pipeline = ACEStepPipeline(checkpoint_dir=checkpoint_dir, dtype=\"float32\", cpu_offload=False)\n",
+ "pipeline.load_checkpoint(checkpoint_dir)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e23dd34c",
+ "metadata": {},
+ "source": [
+ "### Configure parameters and generate audio\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "We will specify some parameters: `prompt`, `lyrics`, `infer_step` `save_path`, `audio_duration` in second, `task` and parameters related to the Entropy Rectifying Guidance `use_erg_tag`, `use_erg_lyric`, `use_erg_diffusion`, if these parameters are enabled, the temperature will be multiply to the attention to make a weaker, for example with `use_erg_lyric`, lyric condition and make better diversity.\n",
+ "\n",
+ "Some other options which can be specified: `guidance_scale`, `guidance_scale_text`, `guidance_scale_lyric`, `guidance_interval` - guidance interval for the generation, `min_guidance_scale`, `guidance_interval_decay` - guidance interval decay for the generation, guidance scale will decay from guidance_scale to min_guidance_scale in the interval, `omega_scale` - Granularity scale for the generation. Higher values can reduce artifacts, `oss_steps` - optimal Steps for the generation, `audio2audio_enable` - enable Audio-to-Audio generation using a reference audio, `ref_audio_input` - reference audio for audio2audio task, `ref_audio_strength`.\n",
+ "\n",
+ "More information about parameters can be found in [ACE Step repo](https://github.com/ace-step/ACE-Step)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "359fabcb",
+ "metadata": {
+ "test_replace": {
+ " \"audio_duration\": 15.0,\n": " \"audio_duration\": 5.0,\n",
+ " \"infer_step\": 25,\n": " \"infer_step\": 10,\n",
+ " \"lyrics\": \"[verse]\\nWoke up to the sunrise glow\\nTook my heart and hit the road[inst]\",\n": " \"lyrics\": \"[verse]\\nWoke up \\n[inst]\",\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "inputs = {\n",
+ " \"prompt\": \"country rock, folk rock, southern rock, bluegrass, country pop\",\n",
+ " \"lyrics\": \"[verse]\\nWoke up to the sunrise glow\\nTook my heart and hit the road[inst]\",\n",
+ " \"audio_duration\": 15.0,\n",
+ " \"infer_step\": 25,\n",
+ " \"use_erg_tag\": False,\n",
+ " \"use_erg_lyric\": True,\n",
+ " \"use_erg_diffusion\": True,\n",
+ " \"save_path\": Path(\"outputs\").absolute().as_posix(),\n",
+ " \"task\": \"text2music\",\n",
+ "}\n",
+ "\n",
+ "if not Path(inputs[\"save_path\"]).exists():\n",
+ " os.mkdir(inputs[\"save_path\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "f559c85c",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\u001b[32m2025-08-18 21:08:31.631\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36m__call__\u001b[0m:\u001b[36m1488\u001b[0m - \u001b[1mModel loaded in 0.00 seconds.\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:08:31.682\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mtext2music_diffusion_process\u001b[0m:\u001b[36m847\u001b[0m - \u001b[1mcfg_type: apg, guidance_scale: 15.0, omega_scale: 10.0\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:08:31.684\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mtext2music_diffusion_process\u001b[0m:\u001b[36m1072\u001b[0m - \u001b[1mstart_idx: 6, end_idx: 18, num_inference_steps: 25\u001b[0m\n",
+ "100%|███████████████████████████████████████████| 25/25 [00:33<00:00, 1.35s/it]\n",
+ " 0%| | 0/1 [00:00\n",
+ " \n",
+ " Your browser does not support the audio element.\n",
+ " \n",
+ " "
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "import IPython.display as ipd\n",
+ "\n",
+ "result = pipeline(**inputs)\n",
+ "\n",
+ "output_path = result[0]\n",
+ "display(ipd.Audio(output_path))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "216b725c",
+ "metadata": {},
+ "source": [
+ "### Update audio\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "ACE Step provides functions for updating audio. The following tasks are available in ACE Step for that: `retake`, `repaint`, `edit` and `extend`.\n",
+ "For retaking `retake_variance` and `retake_seeds` can be specified. We can edit prompt with `edit_target_prompt` or lyrics with `edit_target_lyrics`, also we can set `edit_n_min`,`edit_n_max` and `edit_n_avg`. For repainting it is possible to setup `retake_variance`, `retake_seeds`, `repaint_start` and `repaint_end` times. And extend can be configured with `repaint_start` and `repaint_end` options in seconds. Also source audio should be provided via `src_audio_path`.\n",
+ "\n",
+ "Let's try to edit style of generated audio."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 5,
+ "id": "02c814a4",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "import copy\n",
+ "\n",
+ "inputs_update_audio = copy.deepcopy(inputs)\n",
+ "inputs_update_audio.update(\n",
+ " {\n",
+ " \"edit_target_prompt\": \"classical, orchestral, strings, piano, 60 bpm, elegant, emotive, timeless, instrumental\",\n",
+ " \"edit_target_lyrics\": inputs[\"lyrics\"],\n",
+ " \"edit_n_min\": 0.2,\n",
+ " \"edit_n_max\": 0.4,\n",
+ " \"task\": \"edit\",\n",
+ " \"src_audio_path\": output_path,\n",
+ " }\n",
+ ")"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 7,
+ "id": "34d73ee0",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\u001b[32m2025-08-18 21:14:15.309\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36m__call__\u001b[0m:\u001b[36m1488\u001b[0m - \u001b[1mModel loaded in 0.00 seconds.\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:14:16.593\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mtokenize_lyrics\u001b[0m:\u001b[36m465\u001b[0m - \u001b[1mdebbug [verse] --> zh --> ['[en]', '[verse]']\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:14:16.594\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mtokenize_lyrics\u001b[0m:\u001b[36m465\u001b[0m - \u001b[1mdebbug Woke up to the sunrise glow --> en --> ['[en]', 'w', 'ok', 'e', ' ', 'up', ' ', 'to', ' ', 'the', ' ', 'sun', 'ris', 'e', ' ', 'gl', 'ow']\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:14:16.596\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mtokenize_lyrics\u001b[0m:\u001b[36m465\u001b[0m - \u001b[1mdebbug Took my heart and hit the road[inst] --> en --> ['[en]', 'to', 'ok', ' ', 'my', ' ', 'he', 'a', 'rt', ' ', 'and', ' ', 'h', 'it', ' ', 'the', ' ', 'ro', 'ad', '[inst]']\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:14:16.598\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mflowedit_diffusion_process\u001b[0m:\u001b[36m658\u001b[0m - \u001b[1mflowedit start from 5 to 10\u001b[0m\n",
+ "100%|███████████████████████████████████████████| 25/25 [00:44<00:00, 1.79s/it]\n",
+ " 0%| | 0/1 [00:00\n",
+ " \n",
+ " Your browser does not support the audio element.\n",
+ " \n",
+ " "
+ ],
+ "text/plain": [
+ ""
+ ]
+ },
+ "metadata": {},
+ "output_type": "display_data"
+ }
+ ],
+ "source": [
+ "result = pipeline(**inputs_update_audio)\n",
+ "\n",
+ "display(ipd.Audio(result[0]))"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "448566eb",
+ "metadata": {},
+ "source": [
+ "## Music Generation with ACE Step via OpenVINO\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "ff826412",
+ "metadata": {},
+ "source": [
+ "### Convert model to OpenVINO\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "OpenVINO supports PyTorch models via conversion to OpenVINO Intermediate Representation (IR). [OpenVINO model conversion API](https://docs.openvino.ai/2024/openvino-workflow/model-preparation.html#convert-a-model-with-python-convert-model) can be used for these purposes. `ov.convert_model` function accepts original PyTorch model instance and example input for tracing and returns `ov.Model` representing this model in OpenVINO framework. Converted model can be saved on disk using `ov.save_model` function or loading on device using `core.complie_model`.\n",
+ "\n",
+ "`ov_ace_helper.py` script contains helper function for model conversion, please check its content if you interested in conversion details. \n",
+ "\n",
+ "Let's convert models to IR format. In output folder you will find tokenizer - `openvino_tokenizer.xml`, text encoder model - `ov_text_encoder_model.xml`. Lyric encoder and speaker encoder will be part of transformer models. DCAE decoder and encoder models: `ov_dcae_encoder_model.xml`, `ov_dcae_decoder_model.xml`, vocoder decoder and mel_transform models: `ov_vocoder_decode_model.xml`, `ov_vocoder_mel_transform_model.xml`. And transformer models: `ov_transformer_decoder_model.xml`, `ov_transformer_encoder_model.xml`."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "14c01092",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from gradio_helper import get_model_compression_format_widgets\n",
+ "\n",
+ "model_format = get_model_compression_format_widgets()\n",
+ "model_format"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "f9db0d8a",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stdout",
+ "output_type": "stream",
+ "text": [
+ "⌛ Conversion started. Be patient, it may takes some time.\n",
+ "⌛ Convert Tokenizer\n",
+ "✅ Tokenizer is converted\n",
+ "⌛ Convert UMT5 Encoder model\n",
+ "✅ UMT5 Encoder model converted\n",
+ "⌛ Convert Sana's Deep Compression AutoEncoder model\n",
+ "✅ Sana's Deep Compression AutoEncoder model converted\n",
+ "⌛ Convert Sana's Deep Compression AutoEncoder Decoder model\n",
+ "✅ Sana's Deep Compression AutoEncoder Decoder model converted\n",
+ "⌛ Convert Vocoder Mel Tranform model\n",
+ "✅ Vocoder Mel Tranform model converted\n",
+ "⌛ Convert Vocoder Decoder model\n",
+ "✅ Vocoder Decoder model converted\n",
+ "⌛ Convert Transformer Encoder with Entropy Rectifying Guidance model\n",
+ "✅ Transformer Encoder with Entropy Rectifying Guidance model converted\n",
+ "⌛ Convert Transformer Decoder with Entropy Rectifying Guidance model\n",
+ "✅ Transformer Decoder with Entropy Rectifying Guidance model converted\n"
+ ]
+ }
+ ],
+ "source": [
+ "import nncf\n",
+ "from ov_ace_helper import convert_models\n",
+ "\n",
+ "ov_converted_model_dir = \"ov_models\"\n",
+ "if model_format.value == \"INT4\":\n",
+ " weights_compression_config = {\"mode\": nncf.CompressWeightsMode.INT4_ASYM, \"group_size\": 128, \"ratio\": 0.8}\n",
+ " ov_converted_model_dir += \"_int4\"\n",
+ "elif model_format.value == \"INT8\":\n",
+ " weights_compression_config = {\"mode\": nncf.CompressWeightsMode.INT8_ASYM}\n",
+ " ov_converted_model_dir += \"_int8\"\n",
+ "else:\n",
+ " weights_compression_config = None\n",
+ "\n",
+ "convert_models(pipeline, model_dir=ov_converted_model_dir, orig_checkpoint_path=checkpoint_dir, quantization_config=weights_compression_config)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "3154daae",
+ "metadata": {},
+ "source": [
+ "### Select inference device\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "Select device from dropdown list for running inference using OpenVINO"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "97f24bb1",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from notebook_utils import device_widget\n",
+ "\n",
+ "device = device_widget()\n",
+ "\n",
+ "device"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "b3b1d996",
+ "metadata": {},
+ "source": [
+ "### Create pipeline, read and compile models\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 11,
+ "id": "a3d15fff",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from ov_ace_helper import OVACEStepPipeline\n",
+ "\n",
+ "ov_pipeline = OVACEStepPipeline()\n",
+ "ov_pipeline.load_models(ov_models_path=ov_converted_model_dir, device=device.value)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "c2e4182b",
+ "metadata": {},
+ "source": [
+ "### Generate audio\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 12,
+ "id": "ae0c6914",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\u001b[32m2025-08-18 21:18:00.763\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36m__call__\u001b[0m:\u001b[36m1488\u001b[0m - \u001b[1mModel loaded in 0.00 seconds.\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:18:01.178\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36mov_ace_helper\u001b[0m:\u001b[36mtext2music_diffusion_process\u001b[0m:\u001b[36m571\u001b[0m - \u001b[1mcfg_type: apg, guidance_scale: 15.0, omega_scale: 10.0\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:18:01.180\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36mov_ace_helper\u001b[0m:\u001b[36mtext2music_diffusion_process\u001b[0m:\u001b[36m796\u001b[0m - \u001b[1mstart_idx: 6, end_idx: 18, num_inference_steps: 25\u001b[0m\n",
+ "100%|███████████████████████████████████████████| 25/25 [00:20<00:00, 1.20it/s]\n",
+ " 0%| | 0/1 [00:00\n",
+ "
 +
+More details about the model can be found using the following resources: [project page](https://ace-step.github.io/), [paper](https://arxiv.org/abs/2506.00045), [original repository](https://github.com/ace-step/ACE-Step).
+
+
+## Notebook Contents
+
+This notebook demonstrates how to convert and run music generation or editing with ACE Step using OpenVINO.
+
+The tutorial consists of the following steps:
+
+- Install prerequisites
+- Download and run inference of ACE Step model
+- Convert the model to IR format and run inference with OpenVINO
+- Download, apply and generate audio with LoRA
+- Interactive demo
+
+
+## Installation Instructions
+
+This is a self-contained example that relies solely on its own code.
+We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
+For details, please refer to [Installation Guide](../../README.md).
+
+
+
+More details about the model can be found using the following resources: [project page](https://ace-step.github.io/), [paper](https://arxiv.org/abs/2506.00045), [original repository](https://github.com/ace-step/ACE-Step).
+
+
+## Notebook Contents
+
+This notebook demonstrates how to convert and run music generation or editing with ACE Step using OpenVINO.
+
+The tutorial consists of the following steps:
+
+- Install prerequisites
+- Download and run inference of ACE Step model
+- Convert the model to IR format and run inference with OpenVINO
+- Download, apply and generate audio with LoRA
+- Interactive demo
+
+
+## Installation Instructions
+
+This is a self-contained example that relies solely on its own code.
+We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.
+For details, please refer to [Installation Guide](../../README.md).
+
+ diff --git a/notebooks/ace-step-music-generation/ace-step-music-generation.ipynb b/notebooks/ace-step-music-generation/ace-step-music-generation.ipynb
new file mode 100644
index 00000000000..9d9b9f185ba
--- /dev/null
+++ b/notebooks/ace-step-music-generation/ace-step-music-generation.ipynb
@@ -0,0 +1,881 @@
+{
+ "cells": [
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "b464bcb6-cff9-46e7-bd86-fa40bdd3ad18",
+ "metadata": {},
+ "source": [
+ "# Music generation using ACE Step and OpenVINO\n",
+ "\n",
+ "
diff --git a/notebooks/ace-step-music-generation/ace-step-music-generation.ipynb b/notebooks/ace-step-music-generation/ace-step-music-generation.ipynb
new file mode 100644
index 00000000000..9d9b9f185ba
--- /dev/null
+++ b/notebooks/ace-step-music-generation/ace-step-music-generation.ipynb
@@ -0,0 +1,881 @@
+{
+ "cells": [
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "b464bcb6-cff9-46e7-bd86-fa40bdd3ad18",
+ "metadata": {},
+ "source": [
+ "# Music generation using ACE Step and OpenVINO\n",
+ "\n",
+ " \n",
+ "\n",
+ "More details about the model can be found using the following resources: [project page](https://ace-step.github.io/), [paper](https://arxiv.org/abs/2506.00045), [original repository](https://github.com/ace-step/ACE-Step).\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Installation Instructions\n",
+ "\n",
+ "This is a self-contained example that relies solely on its own code.\n",
+ "\n",
+ "We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.\n",
+ "For details, please refer to [Installation Guide](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/README.md#-installation-guide).\n",
+ "\n",
+ "
\n",
+ "\n",
+ "More details about the model can be found using the following resources: [project page](https://ace-step.github.io/), [paper](https://arxiv.org/abs/2506.00045), [original repository](https://github.com/ace-step/ACE-Step).\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "### Installation Instructions\n",
+ "\n",
+ "This is a self-contained example that relies solely on its own code.\n",
+ "\n",
+ "We recommend running the notebook in a virtual environment. You only need a Jupyter server to start.\n",
+ "For details, please refer to [Installation Guide](https://github.com/openvinotoolkit/openvino_notebooks/blob/latest/README.md#-installation-guide).\n",
+ "\n",
+ " \n",
+ "\n",
+ "#### Table of contents:\n",
+ "\n",
+ "- [Prerequisites](#Prerequisites)\n",
+ "- [Music generation with ACE Step Pipeline via PyTorch](#Music-generation-with-ACE-Step-Pipeline-via-PyTorch)\n",
+ " - [Download checkpoints and load PyTorch models](#Download-checkpoints-and-load-PyTorch-models)\n",
+ " - [Configure parameters and generate audio](#Configure-parameters-and-generate-audio)\n",
+ " - [Update audio](#Update-audio)\n",
+ "- [Music Generation with ACE Step via OpenVINO](#Music-Generation-with-ACE-Step-via-OpenVINO)\n",
+ " - [Convert model to OpenVINO](#Convert-model-to-OpenVINO)\n",
+ " - [Select inference device](#Select-inference-device)\n",
+ " - [Create pipeline, read and compile models](#Create-pipeline,-read-and-compile-models)\n",
+ " - [Generate audio](#Generate-audio)\n",
+ " - [Update audio](#Update-audio)\n",
+ "- [ACE Step with LoRA](#ACE-Step-with-LoRA)\n",
+ " - [Load LoRA and apply for Transformer models for ACE Step pipeline](#Load-LoRA-and-apply-for-Transformer-models-for-ACE-Step-pipeline)\n",
+ " - [Convert models with LoRA and load to OpenVINO pipeline](#Convert-models-with-LoRA-and-load-to-OpenVINO-pipeline)\n",
+ " - [Run Inference with LoRA](#Run-Inference-with-LoRA)\n",
+ " - [Deactivate LoRA](#Deactivate-LoRA)\n",
+ "- [Interactive demo](#Interactive-demo)\n",
+ "\n"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "915b561b-3a13-4deb-8a61-9bab9abb6faa",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "[back to top ⬆️](#Table-of-contents:)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16f5d8e3-87e7-4396-97c1-147b6b82d0f8",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import requests\n",
+ "import platform\n",
+ "from pathlib import Path\n",
+ "\n",
+ "if not Path(\"ov_ace_helper.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/ace-step-music-generation/ov_ace_helper.py\")\n",
+ " open(\"ov_ace_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"gradio_helper.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/ace-step-music-generation/gradio_helper.py\")\n",
+ " open(\"gradio_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"notebook_utils.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\")\n",
+ " open(\"notebook_utils.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"pip_helper.py\").exists():\n",
+ " r = requests.get(\n",
+ " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/pip_helper.py\",\n",
+ " )\n",
+ " open(\"pip_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "from pip_helper import pip_install\n",
+ "\n",
+ "pip_install(\"gradio>=4.19\")\n",
+ "if platform.system() == \"Darwin\":\n",
+ " pip_install(\"numpy<2.0\")\n",
+ "\n",
+ "pip_install(\n",
+ " \"git+https://github.com/ace-step/ACE-Step.git@6ae0852b1388de6dc0cca26b31a86d711f723cb3\", \"--extra-index-url\", \"https://download.pytorch.org/whl/cpu\"\n",
+ ")\n",
+ "\n",
+ "pip_install(\"openvino>=2025.1.0\", \"openvino-tokenizers>=2025.1.0\", \"nncf>=2.16.0\")\n",
+ "\n",
+ "# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry\n",
+ "from notebook_utils import collect_telemetry\n",
+ "\n",
+ "collect_telemetry(\"ace-step-music-generation.ipynb\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "358dd910",
+ "metadata": {},
+ "source": [
+ "## Music generation with ACE Step Pipeline via PyTorch\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cc3880f0",
+ "metadata": {},
+ "source": [
+ "### Download checkpoints and load PyTorch models\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "The architecture of ACE Step consists of following components.\n",
+ "\n",
+ "Linear Diffusion Transformer.\n",
+ "\n",
+ "Core Diffusion Model is a Linear Diffusion Transformer (DiT). DiT architecture adapts the Transformer to serve as the backbone for diffusion models, primarily replacing U-Net structures common in image generation. DiTs treat latent representations (e.g., image patches or segments of audio features) as sequences of tokens. These tokens, along with embeddings for the diffusion timestep and any conditioning information, are processed by a series of Transformer blocks. ACE-Step adapt the Linear DiT structure from Sana with several modifications. This significantly reduces model size and memory consumption; And added 1D Convolutional FeedForward Layers (FFN).\n",
+ "\n",
+ "Conditioning Encoders.\n",
+ "\n",
+ "To guide the generation process, the Linear DiT is conditioned on embeddings from the following encoders:\n",
+ "- Text Encoder: It is a mT5-base model, which generate 768-dimensional embeddings from textual prompts.\n",
+ "- Lyric Encoder: The lyric encoder architecture and hyperparameters are adopted from SongGen.\n",
+ "- Speaker Encoder: The speaker encoder processes a 10 - second unaccompanied vocal segment, which is separated by demucs, into a 512 - dimensional embedding. For full songs with vocals, embeddings from multiple such segments are averaged. A zero vector is used as the speaker embedding for instrumental tracks. The encoder, pre-trained on a large and diverse singing voice corpus, draws architectural inspiration from\n",
+ "PLR-OSNet, originally designed for face recognition. The model was tuned to prevents the model from over-relying on timbre information for stylistic interpretation, thereby enabling reasonable timbre generation even without explicit speaker input.\n",
+ "\n",
+ "Deep Compression AutoEncoders.\n",
+ "\n",
+ "For efficient latent space modeling, ACE-Step uses Deep Compression AutoEncoder (DCAE). A DCAE is an encoder to map high-dimensional input (e.g., mel-spectrograms) to a much lower-dimensional latent representation, and a decoder to reconstruct the original input from this latent code. The \"deep compression\" aspect implies a focus on achieving a highly compact latent space while minimizing reconstruction error. For audio, this means capturing salient acoustic features essential for perception and quality within a small number of latent variables. This not only reduces the computational burden for subsequent generative models operating in this latent space but also encourages the generative model to focus on higher-level structural and semantic aspects rather than low-level waveform details. The specific architecture of DCAE (e.g., convolutional layers, quantization if used) is optimized for this trade-off. For converting the generated mel-spectrograms back to waveform (vocoding), ACE-Step utilizes a pre-trained universal music vocoder from Fish Audio."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b542df6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from acestep.pipeline_ace_step import ACEStepPipeline\n",
+ "\n",
+ "checkpoint_dir = \"\"\n",
+ "pipeline = ACEStepPipeline(checkpoint_dir=checkpoint_dir, dtype=\"float32\", cpu_offload=False)\n",
+ "pipeline.load_checkpoint(checkpoint_dir)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e23dd34c",
+ "metadata": {},
+ "source": [
+ "### Configure parameters and generate audio\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "We will specify some parameters: `prompt`, `lyrics`, `infer_step` `save_path`, `audio_duration` in second, `task` and parameters related to the Entropy Rectifying Guidance `use_erg_tag`, `use_erg_lyric`, `use_erg_diffusion`, if these parameters are enabled, the temperature will be multiply to the attention to make a weaker, for example with `use_erg_lyric`, lyric condition and make better diversity.\n",
+ "\n",
+ "Some other options which can be specified: `guidance_scale`, `guidance_scale_text`, `guidance_scale_lyric`, `guidance_interval` - guidance interval for the generation, `min_guidance_scale`, `guidance_interval_decay` - guidance interval decay for the generation, guidance scale will decay from guidance_scale to min_guidance_scale in the interval, `omega_scale` - Granularity scale for the generation. Higher values can reduce artifacts, `oss_steps` - optimal Steps for the generation, `audio2audio_enable` - enable Audio-to-Audio generation using a reference audio, `ref_audio_input` - reference audio for audio2audio task, `ref_audio_strength`.\n",
+ "\n",
+ "More information about parameters can be found in [ACE Step repo](https://github.com/ace-step/ACE-Step)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "359fabcb",
+ "metadata": {
+ "test_replace": {
+ " \"audio_duration\": 15.0,\n": " \"audio_duration\": 5.0,\n",
+ " \"infer_step\": 25,\n": " \"infer_step\": 10,\n",
+ " \"lyrics\": \"[verse]\\nWoke up to the sunrise glow\\nTook my heart and hit the road[inst]\",\n": " \"lyrics\": \"[verse]\\nWoke up \\n[inst]\",\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "inputs = {\n",
+ " \"prompt\": \"country rock, folk rock, southern rock, bluegrass, country pop\",\n",
+ " \"lyrics\": \"[verse]\\nWoke up to the sunrise glow\\nTook my heart and hit the road[inst]\",\n",
+ " \"audio_duration\": 15.0,\n",
+ " \"infer_step\": 25,\n",
+ " \"use_erg_tag\": False,\n",
+ " \"use_erg_lyric\": True,\n",
+ " \"use_erg_diffusion\": True,\n",
+ " \"save_path\": Path(\"outputs\").absolute().as_posix(),\n",
+ " \"task\": \"text2music\",\n",
+ "}\n",
+ "\n",
+ "if not Path(inputs[\"save_path\"]).exists():\n",
+ " os.mkdir(inputs[\"save_path\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "f559c85c",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\u001b[32m2025-08-18 21:08:31.631\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36m__call__\u001b[0m:\u001b[36m1488\u001b[0m - \u001b[1mModel loaded in 0.00 seconds.\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:08:31.682\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mtext2music_diffusion_process\u001b[0m:\u001b[36m847\u001b[0m - \u001b[1mcfg_type: apg, guidance_scale: 15.0, omega_scale: 10.0\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:08:31.684\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mtext2music_diffusion_process\u001b[0m:\u001b[36m1072\u001b[0m - \u001b[1mstart_idx: 6, end_idx: 18, num_inference_steps: 25\u001b[0m\n",
+ "100%|███████████████████████████████████████████| 25/25 [00:33<00:00, 1.35s/it]\n",
+ " 0%| | 0/1 [00:00\n",
+ "
\n",
+ "\n",
+ "#### Table of contents:\n",
+ "\n",
+ "- [Prerequisites](#Prerequisites)\n",
+ "- [Music generation with ACE Step Pipeline via PyTorch](#Music-generation-with-ACE-Step-Pipeline-via-PyTorch)\n",
+ " - [Download checkpoints and load PyTorch models](#Download-checkpoints-and-load-PyTorch-models)\n",
+ " - [Configure parameters and generate audio](#Configure-parameters-and-generate-audio)\n",
+ " - [Update audio](#Update-audio)\n",
+ "- [Music Generation with ACE Step via OpenVINO](#Music-Generation-with-ACE-Step-via-OpenVINO)\n",
+ " - [Convert model to OpenVINO](#Convert-model-to-OpenVINO)\n",
+ " - [Select inference device](#Select-inference-device)\n",
+ " - [Create pipeline, read and compile models](#Create-pipeline,-read-and-compile-models)\n",
+ " - [Generate audio](#Generate-audio)\n",
+ " - [Update audio](#Update-audio)\n",
+ "- [ACE Step with LoRA](#ACE-Step-with-LoRA)\n",
+ " - [Load LoRA and apply for Transformer models for ACE Step pipeline](#Load-LoRA-and-apply-for-Transformer-models-for-ACE-Step-pipeline)\n",
+ " - [Convert models with LoRA and load to OpenVINO pipeline](#Convert-models-with-LoRA-and-load-to-OpenVINO-pipeline)\n",
+ " - [Run Inference with LoRA](#Run-Inference-with-LoRA)\n",
+ " - [Deactivate LoRA](#Deactivate-LoRA)\n",
+ "- [Interactive demo](#Interactive-demo)\n",
+ "\n"
+ ]
+ },
+ {
+ "attachments": {},
+ "cell_type": "markdown",
+ "id": "915b561b-3a13-4deb-8a61-9bab9abb6faa",
+ "metadata": {},
+ "source": [
+ "## Prerequisites\n",
+ "[back to top ⬆️](#Table-of-contents:)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "16f5d8e3-87e7-4396-97c1-147b6b82d0f8",
+ "metadata": {
+ "tags": []
+ },
+ "outputs": [],
+ "source": [
+ "import requests\n",
+ "import platform\n",
+ "from pathlib import Path\n",
+ "\n",
+ "if not Path(\"ov_ace_helper.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/ace-step-music-generation/ov_ace_helper.py\")\n",
+ " open(\"ov_ace_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"gradio_helper.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/notebooks/ace-step-music-generation/gradio_helper.py\")\n",
+ " open(\"gradio_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"notebook_utils.py\").exists():\n",
+ " r = requests.get(url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/notebook_utils.py\")\n",
+ " open(\"notebook_utils.py\", \"w\").write(r.text)\n",
+ "\n",
+ "if not Path(\"pip_helper.py\").exists():\n",
+ " r = requests.get(\n",
+ " url=\"https://raw.githubusercontent.com/openvinotoolkit/openvino_notebooks/latest/utils/pip_helper.py\",\n",
+ " )\n",
+ " open(\"pip_helper.py\", \"w\").write(r.text)\n",
+ "\n",
+ "from pip_helper import pip_install\n",
+ "\n",
+ "pip_install(\"gradio>=4.19\")\n",
+ "if platform.system() == \"Darwin\":\n",
+ " pip_install(\"numpy<2.0\")\n",
+ "\n",
+ "pip_install(\n",
+ " \"git+https://github.com/ace-step/ACE-Step.git@6ae0852b1388de6dc0cca26b31a86d711f723cb3\", \"--extra-index-url\", \"https://download.pytorch.org/whl/cpu\"\n",
+ ")\n",
+ "\n",
+ "pip_install(\"openvino>=2025.1.0\", \"openvino-tokenizers>=2025.1.0\", \"nncf>=2.16.0\")\n",
+ "\n",
+ "# Read more about telemetry collection at https://github.com/openvinotoolkit/openvino_notebooks?tab=readme-ov-file#-telemetry\n",
+ "from notebook_utils import collect_telemetry\n",
+ "\n",
+ "collect_telemetry(\"ace-step-music-generation.ipynb\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "358dd910",
+ "metadata": {},
+ "source": [
+ "## Music generation with ACE Step Pipeline via PyTorch\n",
+ "[back to top ⬆️](#Table-of-contents:)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "cc3880f0",
+ "metadata": {},
+ "source": [
+ "### Download checkpoints and load PyTorch models\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "The architecture of ACE Step consists of following components.\n",
+ "\n",
+ "Linear Diffusion Transformer.\n",
+ "\n",
+ "Core Diffusion Model is a Linear Diffusion Transformer (DiT). DiT architecture adapts the Transformer to serve as the backbone for diffusion models, primarily replacing U-Net structures common in image generation. DiTs treat latent representations (e.g., image patches or segments of audio features) as sequences of tokens. These tokens, along with embeddings for the diffusion timestep and any conditioning information, are processed by a series of Transformer blocks. ACE-Step adapt the Linear DiT structure from Sana with several modifications. This significantly reduces model size and memory consumption; And added 1D Convolutional FeedForward Layers (FFN).\n",
+ "\n",
+ "Conditioning Encoders.\n",
+ "\n",
+ "To guide the generation process, the Linear DiT is conditioned on embeddings from the following encoders:\n",
+ "- Text Encoder: It is a mT5-base model, which generate 768-dimensional embeddings from textual prompts.\n",
+ "- Lyric Encoder: The lyric encoder architecture and hyperparameters are adopted from SongGen.\n",
+ "- Speaker Encoder: The speaker encoder processes a 10 - second unaccompanied vocal segment, which is separated by demucs, into a 512 - dimensional embedding. For full songs with vocals, embeddings from multiple such segments are averaged. A zero vector is used as the speaker embedding for instrumental tracks. The encoder, pre-trained on a large and diverse singing voice corpus, draws architectural inspiration from\n",
+ "PLR-OSNet, originally designed for face recognition. The model was tuned to prevents the model from over-relying on timbre information for stylistic interpretation, thereby enabling reasonable timbre generation even without explicit speaker input.\n",
+ "\n",
+ "Deep Compression AutoEncoders.\n",
+ "\n",
+ "For efficient latent space modeling, ACE-Step uses Deep Compression AutoEncoder (DCAE). A DCAE is an encoder to map high-dimensional input (e.g., mel-spectrograms) to a much lower-dimensional latent representation, and a decoder to reconstruct the original input from this latent code. The \"deep compression\" aspect implies a focus on achieving a highly compact latent space while minimizing reconstruction error. For audio, this means capturing salient acoustic features essential for perception and quality within a small number of latent variables. This not only reduces the computational burden for subsequent generative models operating in this latent space but also encourages the generative model to focus on higher-level structural and semantic aspects rather than low-level waveform details. The specific architecture of DCAE (e.g., convolutional layers, quantization if used) is optimized for this trade-off. For converting the generated mel-spectrograms back to waveform (vocoding), ACE-Step utilizes a pre-trained universal music vocoder from Fish Audio."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "8b542df6",
+ "metadata": {},
+ "outputs": [],
+ "source": [
+ "from acestep.pipeline_ace_step import ACEStepPipeline\n",
+ "\n",
+ "checkpoint_dir = \"\"\n",
+ "pipeline = ACEStepPipeline(checkpoint_dir=checkpoint_dir, dtype=\"float32\", cpu_offload=False)\n",
+ "pipeline.load_checkpoint(checkpoint_dir)"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "id": "e23dd34c",
+ "metadata": {},
+ "source": [
+ "### Configure parameters and generate audio\n",
+ "[back to top ⬆️](#Table-of-contents:)\n",
+ "\n",
+ "We will specify some parameters: `prompt`, `lyrics`, `infer_step` `save_path`, `audio_duration` in second, `task` and parameters related to the Entropy Rectifying Guidance `use_erg_tag`, `use_erg_lyric`, `use_erg_diffusion`, if these parameters are enabled, the temperature will be multiply to the attention to make a weaker, for example with `use_erg_lyric`, lyric condition and make better diversity.\n",
+ "\n",
+ "Some other options which can be specified: `guidance_scale`, `guidance_scale_text`, `guidance_scale_lyric`, `guidance_interval` - guidance interval for the generation, `min_guidance_scale`, `guidance_interval_decay` - guidance interval decay for the generation, guidance scale will decay from guidance_scale to min_guidance_scale in the interval, `omega_scale` - Granularity scale for the generation. Higher values can reduce artifacts, `oss_steps` - optimal Steps for the generation, `audio2audio_enable` - enable Audio-to-Audio generation using a reference audio, `ref_audio_input` - reference audio for audio2audio task, `ref_audio_strength`.\n",
+ "\n",
+ "More information about parameters can be found in [ACE Step repo](https://github.com/ace-step/ACE-Step)."
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "id": "359fabcb",
+ "metadata": {
+ "test_replace": {
+ " \"audio_duration\": 15.0,\n": " \"audio_duration\": 5.0,\n",
+ " \"infer_step\": 25,\n": " \"infer_step\": 10,\n",
+ " \"lyrics\": \"[verse]\\nWoke up to the sunrise glow\\nTook my heart and hit the road[inst]\",\n": " \"lyrics\": \"[verse]\\nWoke up \\n[inst]\",\n"
+ }
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "\n",
+ "inputs = {\n",
+ " \"prompt\": \"country rock, folk rock, southern rock, bluegrass, country pop\",\n",
+ " \"lyrics\": \"[verse]\\nWoke up to the sunrise glow\\nTook my heart and hit the road[inst]\",\n",
+ " \"audio_duration\": 15.0,\n",
+ " \"infer_step\": 25,\n",
+ " \"use_erg_tag\": False,\n",
+ " \"use_erg_lyric\": True,\n",
+ " \"use_erg_diffusion\": True,\n",
+ " \"save_path\": Path(\"outputs\").absolute().as_posix(),\n",
+ " \"task\": \"text2music\",\n",
+ "}\n",
+ "\n",
+ "if not Path(inputs[\"save_path\"]).exists():\n",
+ " os.mkdir(inputs[\"save_path\"])"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": 4,
+ "id": "f559c85c",
+ "metadata": {},
+ "outputs": [
+ {
+ "name": "stderr",
+ "output_type": "stream",
+ "text": [
+ "\u001b[32m2025-08-18 21:08:31.631\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36m__call__\u001b[0m:\u001b[36m1488\u001b[0m - \u001b[1mModel loaded in 0.00 seconds.\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:08:31.682\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mtext2music_diffusion_process\u001b[0m:\u001b[36m847\u001b[0m - \u001b[1mcfg_type: apg, guidance_scale: 15.0, omega_scale: 10.0\u001b[0m\n",
+ "\u001b[32m2025-08-18 21:08:31.684\u001b[0m | \u001b[1mINFO \u001b[0m | \u001b[36macestep.pipeline_ace_step\u001b[0m:\u001b[36mtext2music_diffusion_process\u001b[0m:\u001b[36m1072\u001b[0m - \u001b[1mstart_idx: 6, end_idx: 18, num_inference_steps: 25\u001b[0m\n",
+ "100%|███████████████████████████████████████████| 25/25 [00:33<00:00, 1.35s/it]\n",
+ " 0%| | 0/1 [00:00\n",
+ "