diff --git a/doc/source/ray-overview/examples/index.rst b/doc/source/ray-overview/examples/index.rst
index b3c1bc5fb77d..f7014cb85172 100644
--- a/doc/source/ray-overview/examples/index.rst
+++ b/doc/source/ray-overview/examples/index.rst
@@ -15,3 +15,4 @@ Examples
./object-detection/README.ipynb
./e2e-rag/README.ipynb
./mcp-ray-serve/README.ipynb
+ ./rl-skyrl/README.ipynb
diff --git a/doc/source/ray-overview/examples/rl-skyrl/README.ipynb b/doc/source/ray-overview/examples/rl-skyrl/README.ipynb
new file mode 100644
index 000000000000..c00595bb0b9b
--- /dev/null
+++ b/doc/source/ray-overview/examples/rl-skyrl/README.ipynb
@@ -0,0 +1,137 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "# Reinforcement Learning for LLMs with SkyRL\n",
+ "\n",
+ "**⏱️ Time to complete**: ~40 mins, including the time to train the models\n",
+ "\n",
+ "\n",
+ "This template walks through running [GRPO](https://arxiv.org/pdf/2402.03300) on Anyscale using the [SkyRL](https://github.com/NovaSky-AI/SkyRL) framework. \n",
+ "SkyRL is a modular full-stack RL library for LLMs developed at the Berkeley Sky Computing Lab in collaboration with Anyscale, providing a flexible framework \n",
+ "for training LLMs on tool-use tasks and multi-turn agentic workflows using popular RL algorithms (PPO, GRPO, DAPO). SkyRL uses [Ray](https://github.com/ray-project/ray) extensively for managing training and generation workers, and for orchestration of the RL training loop, allowing it to easily scale to multiple GPUs and nodes within a Ray cluster.\n",
+ "\n",
+ "This template will first show a basic example of training a model to solve math word problems from the GSM8K dataset using GRPO. Next, the template will\n",
+ "show how you can create your own new environment to train on your specific task using the SkyRL-Gym.\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Setup\n",
+ "SkyRL uses the [uv + Ray integration](https://www.anyscale.com/blog/uv-ray-pain-free-python-dependencies-in-clusters) for dependency management, ensuring a consistent set of dependencies get shipped to all Ray workers. This template uses the `novaskyai/skyrl-train-ray-2.48.0-py3.12-cu12.8` docker image to ensure all necessary system depedencies are installed. The exact Dockerfile can be found at [SkyRL/docker/Dockerfile](https://github.com/NovaSky-AI/SkyRL/blob/skyrl_train-v0.2.0/docker/Dockerfile).\n",
+ "\n",
+ "First, clone SkyRL and cd to `skyrl-train/`.\n",
+ "\n",
+ "```bash\n",
+ "git clone --branch skyrl_train-v0.2.0 https://github.com/NovaSky-AI/SkyRL.git\n",
+ "cd SkyRL/skyrl-train/\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## GRPO for solving math problems (GSM8K)\n",
+ "### Dataset preparation\n",
+ "To download and prepare the GSM8K dataset from HuggingFace, run the following command:\n",
+ "\n",
+ "```bash\n",
+ "uv run --isolated examples/gsm8k/gsm8k_dataset.py --output_dir /mnt/cluster_storage/data/gsm8k\n",
+ "```\n",
+ "\n",
+ "This script converts the Huggingface GSM8K dataset to two Parquet files with the [schema required by SkyRL](https://skyrl.readthedocs.io/en/latest/datasets/dataset-preparation.html).\n",
+ "- `train.parquet` - Training data.\n",
+ "- `validation.parquet` - Validation data.\n",
+ "\n",
+ "### Launching your training run\n",
+ "\n",
+ "Now you're ready to launch a training run! If you choose to use the W&B logger (`trainer.logger=\"wandb\"`), first set the `WANDB_API_KEY` environment variable in the [Dependencies tab](https://docs.anyscale.com/development#environment-variables). Otherwise, you can set `trainer.logger=\"console\"` to print training logs to console. \n",
+ "\n",
+ "\n",
+ "```bash\n",
+ "SKYRL_RAY_PG_TIMEOUT_IN_S=90 bash examples/gsm8k/run_gsm8k.sh \\\n",
+ " data.train_data=\"['/mnt/cluster_storage/data/gsm8k/train.parquet']\" \\\n",
+ " data.val_data=\"['/mnt/cluster_storage/data/gsm8k/validation.parquet']\" \\\n",
+ " trainer.ckpt_path=\"/mnt/cluster_storage/ckpts/gsm8k_1.5B_ckpt\" \\\n",
+ " trainer.micro_forward_batch_size_per_gpu=16 \\\n",
+ " trainer.micro_train_batch_size_per_gpu=16 \\\n",
+ " trainer.epochs=1 \\\n",
+ " trainer.logger=\"console\"\n",
+ "```\n",
+ "\n",
+ "If using W&B, you should see logs like the ones shown below, with detailed metric tracking and timing breakdowns for each stage of the RL pipeline.\n",
+ " \n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Creating a new environment or task\n",
+ "\n",
+ "Now that you've run a basic example to teach an LLM to solve math word problems, you might want to start training on your own custom task! Check out the SkyRL docs for [creating a new environment or task](https://skyrl.readthedocs.io/en/latest/tutorials/new_env.html) for a full walkthrough of the simple steps to implement a custom multi-turn environment using the SkyRL-Gym interface. The commands needed to run the multi-turn example in the linked tutorial on Anyscale are shown below.\n",
+ "\n",
+ "### Preparing your data\n",
+ "\n",
+ "```bash\n",
+ "uv run --isolated examples/multiply/multiply_dataset.py \\\n",
+ " --output_dir /mnt/cluster_storage/data/multiply \\\n",
+ " --num_digits 4 \\\n",
+ " --train_size 10000 \\\n",
+ " --test_size 200\n",
+ "```\n",
+ "\n",
+ "### Training your model\n",
+ "```bash\n",
+ "SKYRL_RAY_PG_TIMEOUT_IN_S=90 bash examples/multiply/run_multiply.sh \\\n",
+ " data.train_data=\"['/mnt/cluster_storage/data/multiply/train.parquet']\" \\\n",
+ " data.val_data=\"['/mnt/cluster_storage/data/multiply/validation.parquet']\" \\\n",
+ " trainer.ckpt_path=\"/mnt/cluster_storage/ckpts/multiply_1.5B_ckpt\" \\\n",
+ " trainer.micro_forward_batch_size_per_gpu=16 \\\n",
+ " trainer.micro_train_batch_size_per_gpu=16 \\\n",
+ " trainer.epochs=1 \\\n",
+ " trainer.logger=\"console\"\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Next steps\n",
+ "\n",
+ "After completing this template, you can:\n",
+ "- Explore more advanced algorithms, like [PPO](https://github.com/NovaSky-AI/SkyRL/tree/main/skyrl-train/examples/ppo) or [DAPO](https://skyrl.readthedocs.io/en/latest/algorithms/dapo.html)\n",
+ "- Explore more advanced tasks like [SWE-Bench](https://skyrl.readthedocs.io/en/latest/examples/mini_swe_agent.html), or [agentic search (Search-R1)](https://skyrl.readthedocs.io/en/latest/examples/search.html).\n",
+ "- Optimize your training pipeline using [Async Training](https://skyrl.readthedocs.io/en/latest/tutorials/async.html)\n",
+ "- Deploy your trained LLM using [Ray Serve LLM on Anyscale](https://console.anyscale.com/template-preview/deployment-serve-llm?utm_source=anyscale_docs&utm_medium=docs&utm_campaign=examples_page&utm_content=deployment-serve-llm?utm_source=anyscale&utm_medium=docs&utm_campaign=examples_page&utm_content=deployment-serve-llm)."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.12.11"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/doc/source/ray-overview/examples/rl-skyrl/README.md b/doc/source/ray-overview/examples/rl-skyrl/README.md
new file mode 100644
index 000000000000..28a9560181ce
--- /dev/null
+++ b/doc/source/ray-overview/examples/rl-skyrl/README.md
@@ -0,0 +1,88 @@
+# Reinforcement Learning for LLMs with SkyRL
+
+**⏱️ Time to complete**: ~40 minutes, including the time to train the models
+
+
+This template walks through running [Group Relative Policy Optimization](https://arxiv.org/pdf/2402.03300) on Anyscale using the [SkyRL](https://github.com/NovaSky-AI/SkyRL) framework.
+SkyRL is a modular full-stack RL library for LLMs developed at the Berkeley Sky Computing Lab in collaboration with Anyscale, providing a flexible framework
+for training LLMs on tool-use tasks and multi-turn agent workflows using popular RL algorithms such as PPO, Group Relative Policy Optimization, and Direct Alignment from Preference Optimization. SkyRL uses [Ray](https://github.com/ray-project/ray) extensively for managing training and generation workers, and for orchestration of the RL training loop, allowing it to easily scale to multiple GPUs and nodes within a Ray cluster.
+
+This template first shows a basic example of training a model to solve math word problems from the GSM8K dataset using Group Relative Policy Optimization. Next, the template
+shows how you can create your own new environment to train on your specific task using the SkyRL-Gym.
+
+
+## Setup
+SkyRL uses the [uv + Ray integration](https://www.anyscale.com/blog/uv-ray-pain-free-python-dependencies-in-clusters) for dependency management, ensuring a consistent set of dependencies get shipped to all Ray workers. This template uses the `novaskyai/skyrl-train-ray-2.48.0-py3.12-cu12.8` docker image with all necessary system dependencies installed. You can find the exact Dockerfile at [SkyRL/docker/Dockerfile](https://github.com/NovaSky-AI/SkyRL/blob/skyrl_train-v0.2.0/docker/Dockerfile).
+
+First, clone SkyRL and cd to `skyrl-train/`.
+
+```bash
+git clone --branch skyrl_train-v0.2.0 https://github.com/NovaSky-AI/SkyRL.git
+cd SkyRL/skyrl-train/
+```
+
+## Group Relative Policy Optimization for solving math problems on GSM8K
+### Dataset preparation
+To download and prepare the GSM8K dataset from Hugging Face, run the following command:
+
+```bash
+uv run --isolated examples/gsm8k/gsm8k_dataset.py --output_dir /mnt/cluster_storage/data/gsm8k
+```
+
+This script converts the Hugging Face GSM8K dataset to two Parquet files with the [schema required by SkyRL](https://skyrl.readthedocs.io/en/latest/datasets/dataset-preparation.html):
+- `train.parquet` - Training data
+- `validation.parquet` - Validation data
+
+### Launching your training run
+
+Now you're ready to launch a training run. If you choose to use the W&B logger with `trainer.logger="wandb"`, first set the `WANDB_API_KEY` environment variable in the [Dependencies tab](https://docs.anyscale.com/development#environment-variables). Otherwise, you can set `trainer.logger="console"` to print training logs to console.
+
+
+```bash
+SKYRL_RAY_PG_TIMEOUT_IN_S=90 bash examples/gsm8k/run_gsm8k.sh \
+ data.train_data="['/mnt/cluster_storage/data/gsm8k/train.parquet']" \
+ data.val_data="['/mnt/cluster_storage/data/gsm8k/validation.parquet']" \
+ trainer.ckpt_path="/mnt/cluster_storage/ckpts/gsm8k_1.5B_ckpt" \
+ trainer.micro_forward_batch_size_per_gpu=16 \
+ trainer.micro_train_batch_size_per_gpu=16 \
+ trainer.epochs=1 \
+ trainer.logger="console"
+```
+
+If using W&B, you should see logs like the ones shown below, with detailed metric tracking and timing breakdowns for each stage of the RL pipeline.
+
\n"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Creating a new environment or task\n",
+ "\n",
+ "Now that you've run a basic example to teach an LLM to solve math word problems, you might want to start training on your own custom task! Check out the SkyRL docs for [creating a new environment or task](https://skyrl.readthedocs.io/en/latest/tutorials/new_env.html) for a full walkthrough of the simple steps to implement a custom multi-turn environment using the SkyRL-Gym interface. The commands needed to run the multi-turn example in the linked tutorial on Anyscale are shown below.\n",
+ "\n",
+ "### Preparing your data\n",
+ "\n",
+ "```bash\n",
+ "uv run --isolated examples/multiply/multiply_dataset.py \\\n",
+ " --output_dir /mnt/cluster_storage/data/multiply \\\n",
+ " --num_digits 4 \\\n",
+ " --train_size 10000 \\\n",
+ " --test_size 200\n",
+ "```\n",
+ "\n",
+ "### Training your model\n",
+ "```bash\n",
+ "SKYRL_RAY_PG_TIMEOUT_IN_S=90 bash examples/multiply/run_multiply.sh \\\n",
+ " data.train_data=\"['/mnt/cluster_storage/data/multiply/train.parquet']\" \\\n",
+ " data.val_data=\"['/mnt/cluster_storage/data/multiply/validation.parquet']\" \\\n",
+ " trainer.ckpt_path=\"/mnt/cluster_storage/ckpts/multiply_1.5B_ckpt\" \\\n",
+ " trainer.micro_forward_batch_size_per_gpu=16 \\\n",
+ " trainer.micro_train_batch_size_per_gpu=16 \\\n",
+ " trainer.epochs=1 \\\n",
+ " trainer.logger=\"console\"\n",
+ "```"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {},
+ "source": [
+ "## Next steps\n",
+ "\n",
+ "After completing this template, you can:\n",
+ "- Explore more advanced algorithms, like [PPO](https://github.com/NovaSky-AI/SkyRL/tree/main/skyrl-train/examples/ppo) or [DAPO](https://skyrl.readthedocs.io/en/latest/algorithms/dapo.html)\n",
+ "- Explore more advanced tasks like [SWE-Bench](https://skyrl.readthedocs.io/en/latest/examples/mini_swe_agent.html), or [agentic search (Search-R1)](https://skyrl.readthedocs.io/en/latest/examples/search.html).\n",
+ "- Optimize your training pipeline using [Async Training](https://skyrl.readthedocs.io/en/latest/tutorials/async.html)\n",
+ "- Deploy your trained LLM using [Ray Serve LLM on Anyscale](https://console.anyscale.com/template-preview/deployment-serve-llm?utm_source=anyscale_docs&utm_medium=docs&utm_campaign=examples_page&utm_content=deployment-serve-llm?utm_source=anyscale&utm_medium=docs&utm_campaign=examples_page&utm_content=deployment-serve-llm)."
+ ]
+ }
+ ],
+ "metadata": {
+ "kernelspec": {
+ "display_name": "base",
+ "language": "python",
+ "name": "python3"
+ },
+ "language_info": {
+ "codemirror_mode": {
+ "name": "ipython",
+ "version": 3
+ },
+ "file_extension": ".py",
+ "mimetype": "text/x-python",
+ "name": "python",
+ "nbconvert_exporter": "python",
+ "pygments_lexer": "ipython3",
+ "version": "3.12.11"
+ }
+ },
+ "nbformat": 4,
+ "nbformat_minor": 2
+}
diff --git a/doc/source/ray-overview/examples/rl-skyrl/README.md b/doc/source/ray-overview/examples/rl-skyrl/README.md
new file mode 100644
index 000000000000..28a9560181ce
--- /dev/null
+++ b/doc/source/ray-overview/examples/rl-skyrl/README.md
@@ -0,0 +1,88 @@
+# Reinforcement Learning for LLMs with SkyRL
+
+**⏱️ Time to complete**: ~40 minutes, including the time to train the models
+
+
+This template walks through running [Group Relative Policy Optimization](https://arxiv.org/pdf/2402.03300) on Anyscale using the [SkyRL](https://github.com/NovaSky-AI/SkyRL) framework.
+SkyRL is a modular full-stack RL library for LLMs developed at the Berkeley Sky Computing Lab in collaboration with Anyscale, providing a flexible framework
+for training LLMs on tool-use tasks and multi-turn agent workflows using popular RL algorithms such as PPO, Group Relative Policy Optimization, and Direct Alignment from Preference Optimization. SkyRL uses [Ray](https://github.com/ray-project/ray) extensively for managing training and generation workers, and for orchestration of the RL training loop, allowing it to easily scale to multiple GPUs and nodes within a Ray cluster.
+
+This template first shows a basic example of training a model to solve math word problems from the GSM8K dataset using Group Relative Policy Optimization. Next, the template
+shows how you can create your own new environment to train on your specific task using the SkyRL-Gym.
+
+
+## Setup
+SkyRL uses the [uv + Ray integration](https://www.anyscale.com/blog/uv-ray-pain-free-python-dependencies-in-clusters) for dependency management, ensuring a consistent set of dependencies get shipped to all Ray workers. This template uses the `novaskyai/skyrl-train-ray-2.48.0-py3.12-cu12.8` docker image with all necessary system dependencies installed. You can find the exact Dockerfile at [SkyRL/docker/Dockerfile](https://github.com/NovaSky-AI/SkyRL/blob/skyrl_train-v0.2.0/docker/Dockerfile).
+
+First, clone SkyRL and cd to `skyrl-train/`.
+
+```bash
+git clone --branch skyrl_train-v0.2.0 https://github.com/NovaSky-AI/SkyRL.git
+cd SkyRL/skyrl-train/
+```
+
+## Group Relative Policy Optimization for solving math problems on GSM8K
+### Dataset preparation
+To download and prepare the GSM8K dataset from Hugging Face, run the following command:
+
+```bash
+uv run --isolated examples/gsm8k/gsm8k_dataset.py --output_dir /mnt/cluster_storage/data/gsm8k
+```
+
+This script converts the Hugging Face GSM8K dataset to two Parquet files with the [schema required by SkyRL](https://skyrl.readthedocs.io/en/latest/datasets/dataset-preparation.html):
+- `train.parquet` - Training data
+- `validation.parquet` - Validation data
+
+### Launching your training run
+
+Now you're ready to launch a training run. If you choose to use the W&B logger with `trainer.logger="wandb"`, first set the `WANDB_API_KEY` environment variable in the [Dependencies tab](https://docs.anyscale.com/development#environment-variables). Otherwise, you can set `trainer.logger="console"` to print training logs to console.
+
+
+```bash
+SKYRL_RAY_PG_TIMEOUT_IN_S=90 bash examples/gsm8k/run_gsm8k.sh \
+ data.train_data="['/mnt/cluster_storage/data/gsm8k/train.parquet']" \
+ data.val_data="['/mnt/cluster_storage/data/gsm8k/validation.parquet']" \
+ trainer.ckpt_path="/mnt/cluster_storage/ckpts/gsm8k_1.5B_ckpt" \
+ trainer.micro_forward_batch_size_per_gpu=16 \
+ trainer.micro_train_batch_size_per_gpu=16 \
+ trainer.epochs=1 \
+ trainer.logger="console"
+```
+
+If using W&B, you should see logs like the ones shown below, with detailed metric tracking and timing breakdowns for each stage of the RL pipeline.
+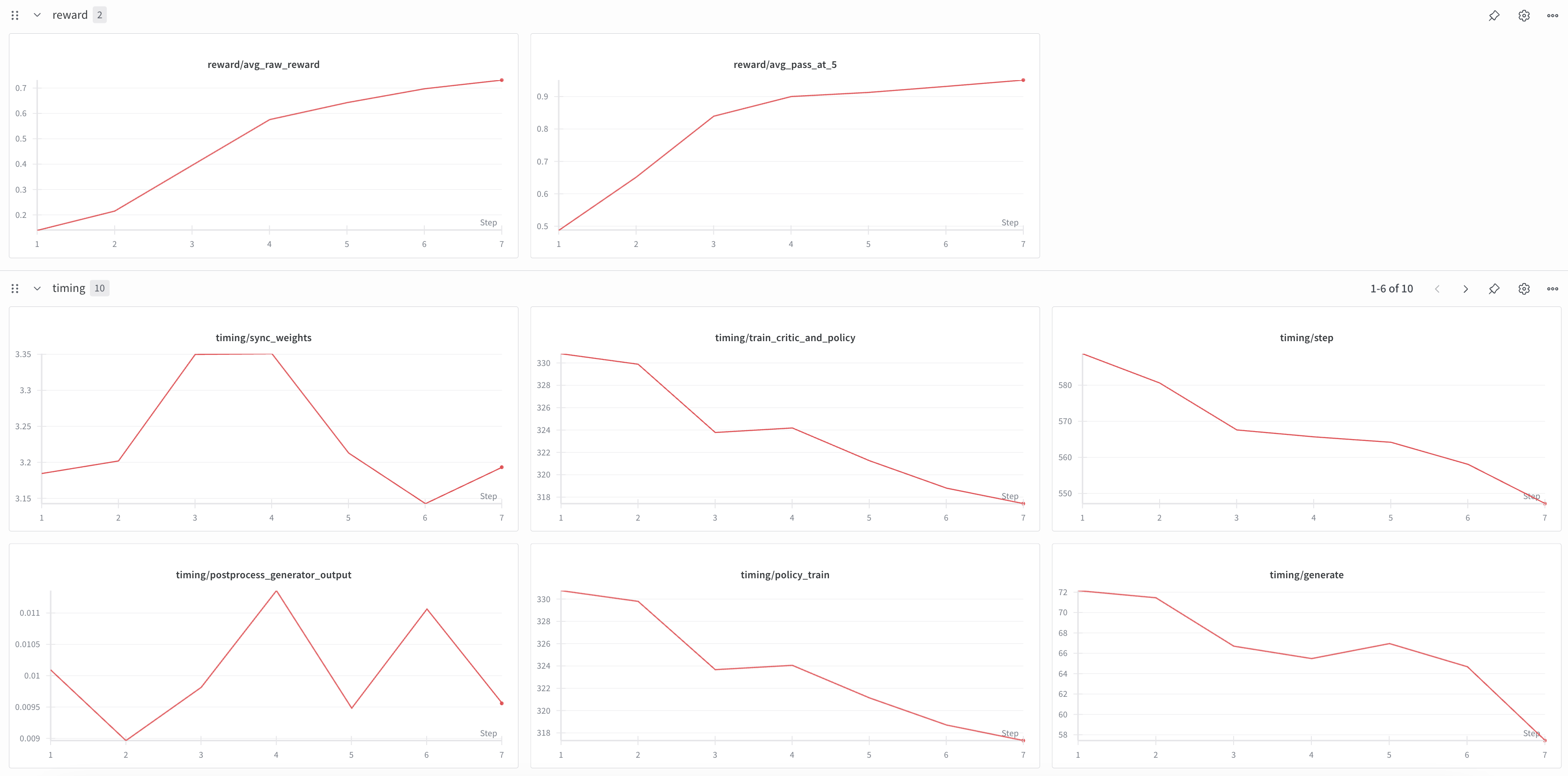 +
+
+## Creating a new environment or task
+
+Now that you've run a basic example to teach an LLM to solve math word problems, you might want to start training on your own custom task. Check out the SkyRL docs for [creating a new environment or task](https://skyrl.readthedocs.io/en/latest/tutorials/new_env.html) for a full walk-through of the simple steps to implement a custom multi-turn environment using the SkyRL-Gym interface. The following commands run the multi-turn example in the linked tutorial on Anyscale.
+
+### Preparing your data
+
+```bash
+uv run --isolated examples/multiply/multiply_dataset.py \
+ --output_dir /mnt/cluster_storage/data/multiply \
+ --num_digits 4 \
+ --train_size 10000 \
+ --test_size 200
+```
+
+### Training your model
+```bash
+SKYRL_RAY_PG_TIMEOUT_IN_S=90 bash examples/multiply/run_multiply.sh \
+ data.train_data="['/mnt/cluster_storage/data/multiply/train.parquet']" \
+ data.val_data="['/mnt/cluster_storage/data/multiply/validation.parquet']" \
+ trainer.ckpt_path="/mnt/cluster_storage/ckpts/multiply_1.5B_ckpt" \
+ trainer.micro_forward_batch_size_per_gpu=16 \
+ trainer.micro_train_batch_size_per_gpu=16 \
+ trainer.epochs=1 \
+ trainer.logger="console"
+```
+
+## Next steps
+
+After completing this template, you can:
+- Explore more advanced algorithms, such as [PPO](https://github.com/NovaSky-AI/SkyRL/tree/main/skyrl-train/examples/ppo) or [Direct Alignment from Preference Optimization](https://skyrl.readthedocs.io/en/latest/algorithms/dapo.html)
+- Explore more advanced tasks such as the [Software Engineering Benchmark](https://skyrl.readthedocs.io/en/latest/examples/mini_swe_agent.html) or [agent search with Search-R1](https://skyrl.readthedocs.io/en/latest/examples/search.html)
+- Optimize your training pipeline using [async training](https://skyrl.readthedocs.io/en/latest/tutorials/async.html)
+- Deploy your trained LLM using [Ray Serve LLM on Anyscale](https://console.anyscale.com/template-preview/deployment-serve-llm?utm_source=anyscale_docs&utm_medium=docs&utm_campaign=examples_page&utm_content=deployment-serve-llm?utm_source=anyscale&utm_medium=docs&utm_campaign=examples_page&utm_content=deployment-serve-llm)
diff --git a/doc/source/ray-overview/examples/rl-skyrl/assets/gsm8k_wandb.png b/doc/source/ray-overview/examples/rl-skyrl/assets/gsm8k_wandb.png
new file mode 100644
index 000000000000..3df9c59ae058
Binary files /dev/null and b/doc/source/ray-overview/examples/rl-skyrl/assets/gsm8k_wandb.png differ
+
+
+## Creating a new environment or task
+
+Now that you've run a basic example to teach an LLM to solve math word problems, you might want to start training on your own custom task. Check out the SkyRL docs for [creating a new environment or task](https://skyrl.readthedocs.io/en/latest/tutorials/new_env.html) for a full walk-through of the simple steps to implement a custom multi-turn environment using the SkyRL-Gym interface. The following commands run the multi-turn example in the linked tutorial on Anyscale.
+
+### Preparing your data
+
+```bash
+uv run --isolated examples/multiply/multiply_dataset.py \
+ --output_dir /mnt/cluster_storage/data/multiply \
+ --num_digits 4 \
+ --train_size 10000 \
+ --test_size 200
+```
+
+### Training your model
+```bash
+SKYRL_RAY_PG_TIMEOUT_IN_S=90 bash examples/multiply/run_multiply.sh \
+ data.train_data="['/mnt/cluster_storage/data/multiply/train.parquet']" \
+ data.val_data="['/mnt/cluster_storage/data/multiply/validation.parquet']" \
+ trainer.ckpt_path="/mnt/cluster_storage/ckpts/multiply_1.5B_ckpt" \
+ trainer.micro_forward_batch_size_per_gpu=16 \
+ trainer.micro_train_batch_size_per_gpu=16 \
+ trainer.epochs=1 \
+ trainer.logger="console"
+```
+
+## Next steps
+
+After completing this template, you can:
+- Explore more advanced algorithms, such as [PPO](https://github.com/NovaSky-AI/SkyRL/tree/main/skyrl-train/examples/ppo) or [Direct Alignment from Preference Optimization](https://skyrl.readthedocs.io/en/latest/algorithms/dapo.html)
+- Explore more advanced tasks such as the [Software Engineering Benchmark](https://skyrl.readthedocs.io/en/latest/examples/mini_swe_agent.html) or [agent search with Search-R1](https://skyrl.readthedocs.io/en/latest/examples/search.html)
+- Optimize your training pipeline using [async training](https://skyrl.readthedocs.io/en/latest/tutorials/async.html)
+- Deploy your trained LLM using [Ray Serve LLM on Anyscale](https://console.anyscale.com/template-preview/deployment-serve-llm?utm_source=anyscale_docs&utm_medium=docs&utm_campaign=examples_page&utm_content=deployment-serve-llm?utm_source=anyscale&utm_medium=docs&utm_campaign=examples_page&utm_content=deployment-serve-llm)
diff --git a/doc/source/ray-overview/examples/rl-skyrl/assets/gsm8k_wandb.png b/doc/source/ray-overview/examples/rl-skyrl/assets/gsm8k_wandb.png
new file mode 100644
index 000000000000..3df9c59ae058
Binary files /dev/null and b/doc/source/ray-overview/examples/rl-skyrl/assets/gsm8k_wandb.png differ