Clarification on Nested spire #5894
Comments
|
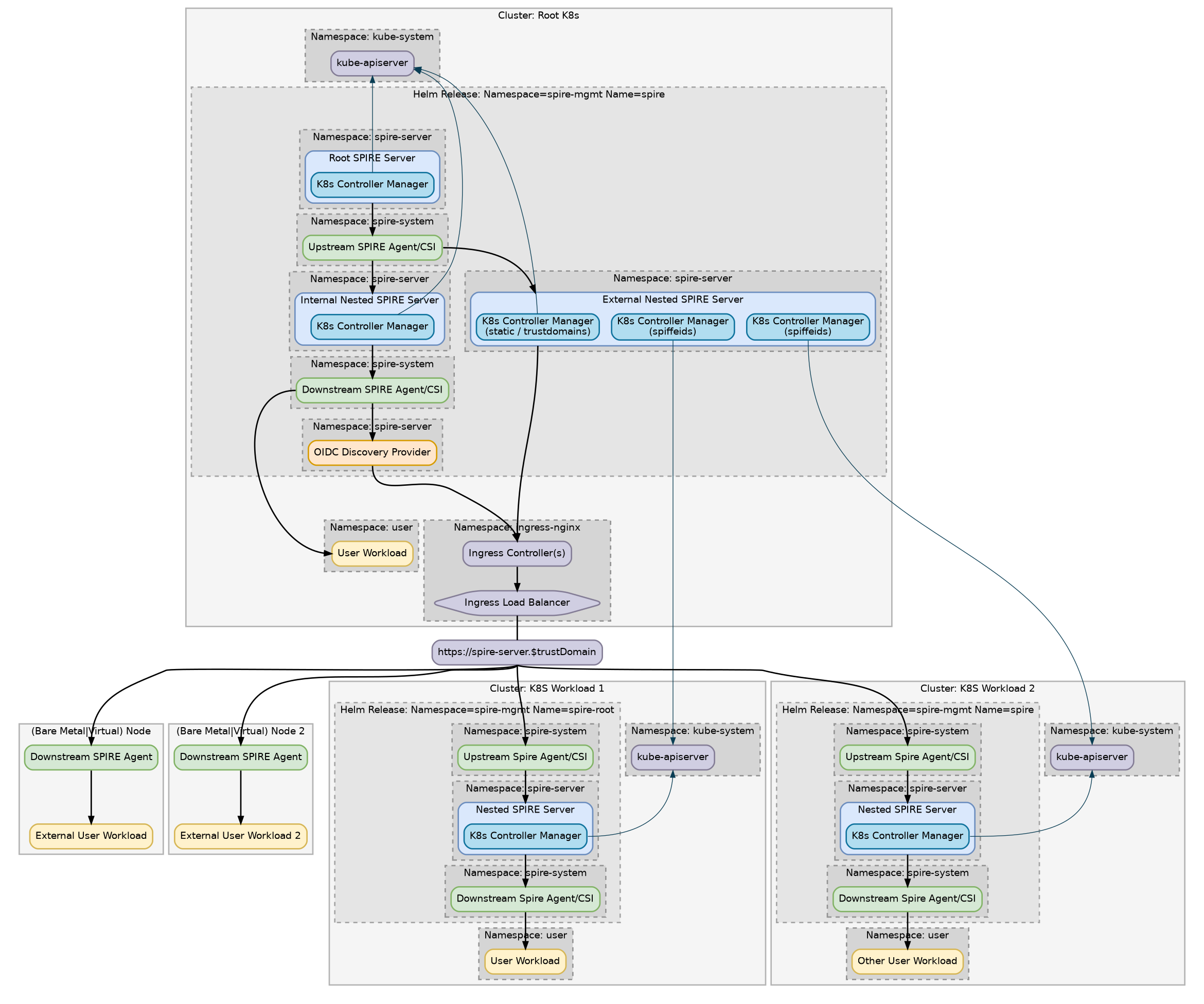
There is some work in progress documentation for the spire-nested chart here: https://deploy-preview-293--spiffe.netlify.app/docs/latest/spire-helm-charts-hardened-advanced/nested-spire/ See https://deploy-preview-293--spiffe.netlify.app/img/spire-helm-charts-hardened/multicluster-alternate3.png for a diagram that may answer your question about agents. |
|
@kfox1111 - Thanks for the info. However, I am struggling to deploy the root and child spire in AWS EKS. |
|
you need to actually set your trust domain to your domain, not just example.com. |
|
@kfox1111 - Thanks a lot for your help.
Does this spire helm create a role in child which needs to be used in root? We are getting an error in child cluster as the spire pods are not coming up hope this is dues to the trust or authentication issue between the root and child. The below is the error which i am getting. Default container name "spire-agent" not found in pod spire-agent-upstream-nvbrs Thanks in advance. |

{kind=link}
|
the kubeconfigs are used to upload the root trust bundle to the child clusters. Without it, the child clusters wont be able to bootstrap, and thats why they are not coming up. As for how to do the auth, we've only ever tested the chart with kubaedm generated user certs. It should be possible to use other auth plugins that kubectl supports, but are untested with exactly how to do that. |
|
@kfox1111 - Thanks for your help.
level=error msg="Fatal run error" error="one or more notifiers returned an error: rpc error: code = Internal desc = notifier(k8sbundle): unable to update: unable to get list: Get "https://xxx.xxx.xxx.xxx.amazonaws.com/api/v1/namespaces/spire-system/configmaps/spire-bundle-upstream\": read tcp xx.xx.xx.xx:39122->xx.xx.xx.xx:443: read: connection reset by peer - error from a previous attempt: read tcp xx.xx.xx.xx:39112->xx.xx.xx.xx:443: read: connection reset by peer" Thanks in advance. |
|
#2 there looks correct. the kubeconfig must be base64 encoded to prevent mangling of special characters. For number 3, it looks like a firewall of some sort may be blocking access from one cluster to the other? |
|
@kfox1111 - Thank you. It was a firewall issue and this is fixed. In root server all pods are running. Now in the child cluster, pods are not starting k -n spire-server logs spire-internal-server-0 k -n spire-system logs spire-agent-upstream-m5m6q Do you have any clues. Thanks in advance. |
|
the upstream agent establishes trust with the root cluster. the root cluster uploads a trust bundle to the child cluster. the agent is saying its not finding a trust bundle. so the external spire-server in the root cluster is not functioning properly yet. may check the logs for it. |
|
@kfox1111 - Thanks for your inputs. k -n spire-mgmt logs spire-external-server-0 | grep -i error Default container name "spire-server" not found in pod spire-external-server-0 Thanks in advance. |
|
Definitely something wrong with the external spire server. Did you change any of its config? |
|
@kfox1111 - There is no changes made in config. I have only created the value.yaml and root value yaml file, similarly for the value file and child value file as mentioned in the doc. Additionally noticed this issue: spiffe/helm-charts-hardened#528
In the child cluster, the below is the status. k -n spire-system get pods
Default container name "spire-server" not found in pod spire-internal-server-0
Default container name "spire-agent" not found in pod spire-agent-upstream-t9kx5 Thanks in advance. |
|
Hi, |
|
@vinod-ps The latest error seems to be because the agent can't connect to spire-server: Is that IP:PORT combination reachable from where the agent is running? It might be easier/faster to get help for this issue on Slack, if you can join it, since it's mostly about debugging a deployment. |
|
@sorindumitru - Yes, IP:PORT is reachable from the nested agent to the root as both clusters are in the same vpc & Subnet. |
|
The logs show that the agent isn't able to talk to the upstream spire-server. I'd look into why that is happening. Generally for your 3 cluster example (root, A, B). You'd need to have:
I think this questions is probably better suited for the helm chart repo, since it seems like you are using the helm chart. If that is the case, we can move it there. The maintainers there would be better suited to help you with the helm chart. |
|
We run this configuration regularly in the helm chart gate tests: https://github.com/spiffe/helm-charts-hardened/tree/main/examples/nested-full I'd go back and either:
|
|
Also, double check the kubeconfig works with a stock kubectl without any other software installed, or make sure you install any plugin / component into a set of custom images needed for the auth plugin you have in mind |
Hi All,
I am trying to deploy nested spire for testing.
I have Cluster01, 02 and 03.
The cluster 01 needs to be the Root and the other two should be nested.
Could you help me to understand the below.
Thanks in advance.
The text was updated successfully, but these errors were encountered: