The target users for the Data API are Javascript developers who interact with the service through a driver or Object Document Mapper (ODM) library such as Mongoose.
- Preamble
- High-level concepts
- Conventions
- Request and Response Messages
- Keyspace
- Collections
- Documents
- Commands
- Command Considerations
- Clauses
The nature of a Data API lends itself to complex, structured queries that may express compound or multiple operations in a single request. Such as selecting one or more documents and projecting a selection of fields from each, or selecting one or more documents and updating them server side. We consider that most requests are generated via the ODM (for example via mquery which makes it easy for the developer to create complex queries at code time, or at run time in response to the actions taken by a user (such as which fields were updated, or which fields the user wants to see). The implementation of the Data API should therefor be optimized for expressing complex and compound machine generated queries, rather than developers making direct queries via the wire protocol API.
The API should be implemented using HTTP 1 or 2 using JSON as the accepted and returned content type, however adherence to a design pattern such REST is not recommended. This is because of the above expected use through an ODM, and due to the complexity that can be expressed in the Data API. The specification includes compound operations, such as find and update, to be implemented in the server which do not have a clear mapping to the REST verbs.
Additionally consideration should be given to implementing that API such that the body of a request can be machine generated and includes all possible information needed to process the request. With the exception of any out of band information such as authentication and possibly the collection name. This approach makes it easier to integrate the DATA API service with other data services though the use of templates or code to generate a request.
The DATA API consists of the following high level concepts that are composed to create a request:
- Keyspace: Keyspace of Cassandra
- Collection: A logical container of documents that have some meaning to the developer using the API. Often an ODM may map a single developer defined class or type to a collection.
- Document: A document is a hierarchical JSON document with a single reserved
_idfield. All documents in a collection may have different fields and structure. - Command: Commands are performed on Collections of Documents. Commands may return zero or more documents from the collection, update or insert zero or more documents, or both.
- Clause: Clauses are included in operations to control or extend the behavior of an operation. Clauses may be required or optional for an operation, when optional a default behavior is expected.
These concepts are grouped together to form a Request sent by client software for the API to process, the API responds with a response document whose format depends on the command being executed. Each request includes:
- The name of a collection of documents to execute against, a single request may only execute against a single collection.
- A command to execute.
- The required and optional clauses.
- Any out of band metadata such as authentication or tracing information. The nature of such out of band metadata is outside of the scope of this document.
TODO: Do we need to have multiple commands in a single request?
To aid in specifying the DATA API, we will use the following conventions in this document:
- Language rules will be given in a BNF-like notation:
<start> ::= TERMINAL <non-terminal1> <non-terminal1>
- Nonterminal symbols will have
<angle brackets>. - As additional shortcut notations to BNF, we'll use traditional
regular expression's symbols (
?,+and*) to signify that a given symbol is optional and/or can be repeated. We'll also allow parentheses to group symbols and the[<characters>]notation to represent any one of<characters>. - The grammar is provided for documentation purposes and leave some minor details out.
- Sample code will be provided in a code block:
SELECT sample_usage FROM cql;
- References to keywords or API examples text will be shown in a
fixed-width font.
Samples of requests, operations, and clauses will be presented and encoded as a JSON document. This is illustrative of a suggested encoding as described in the Preamble.
The format of Request and Response messages is included in this document so that the format invoking a command, and the structure of its response, can be understood.
Request messages contain only a single command. Batch operations such as bulk loading are implementing using commands that support the inclusion of multiple documents in the command. The request message is a single JSON document (a JSON Object) that represents the command to run.
Syntax:
<request-message> ::= <command-name> <command>
<command-name> and <command> are defined later in this document.
Sample:
{"find" : {
"filter" : {"name": "aaron"},
"projection" : {"name": 1, "age" : 1}
}
}Top-level names in the request message other than a command name are ignored, except where specified in this document.
A single JSON format is used for all response messages, though different elements may be present depending on the command.
Syntax:
<response-message> ::= (errors (<error>)+)?,
(status (<command-status>)+)?,
(data `<response-data>` )?,
<error> ::= message <ascii-string>,
errorCode <ascii-string>,
(<error-field>)*
<error-field> ::= <error-field-name>
<error-field-value>
<error-field-name> ::= <json-string>
<error-field-value> ::= <json-value>
<command-status> ::= <command-status-name>
<command-status-value>
<command-status-name> ::= <json-string>
<command-status-value> ::= `<json-value>
<response-data> ::= <single-response-data> | <multi-response-data>
<single-response-data> ::= document <document>
<multi-response-data> ::= documents (<document>)*,
(nextPageState <page-state>)?
<page-state> ::= <ascii-string>
The contents of the <response-message> depend on the command, in
general though:
- A successful command to read documents must have
<response-data>and may have<command-status>or<error>. - A successful command to insert or update data that does not return
documents must have one or more
<command-status>. - A successful command to insert or update data that returns documents
must have one or more
<command-status>and must have<response-data>. - An unsuccessful command must have one or more
<error>'s and may have other items.
Error information or additional status, such as the _ids of inserted
documents, is included by some commands.
Error responses include one or more <error> under the error name.
Error info must include a message intended for humans, a errorCode
intended for machines to process, and may include other information.
<command-status> information generally describes the side effects of
commands, such as the number of updated documents or the _ids of
inserted documents.
<response-data> contains zero or more documents returned from the
command, if present <page-state> indicates further results are
available. See command details for information on how to use the page
state.
find Sample:
{
"data" : {
"documents" : [
{"username" : "aaron"}
]
}
} insertMany Sample:
{
"status" : {
"insertedIds" : ["doc1", "doc2", "doc3"]
}
} insertOne with error Sample:
{
"errors" : [
{"message": "_id cannot be Null", "errorCode" : "ID_NULL"}
]
} TODO: define the keyspace, its properties, etc. Do we define how to create one?
Keyspace names must follow the regular expression pattern below:
Syntax:
<keyspace-name> ::= ["a-zA-Z"]["a-zA-Z0-9_"]*
The maximum length of a keyspace name is 48 characters.
TODO: define the collection, its properties etc. Do we define how to create one?
Collection names must follow the regular expression pattern below:
Syntax:
<collection-name> ::= ["a-zA-Z"]["a-zA-Z0-9_"]*
The maximum length of a collection name is 48 characters.
TODO: Describe how do we define a document and then refer to the parts of a JSON document, e.g. key or path etc.?
Fields names in the JSON document have additional restrictions not imposed on the "member names" by the JSON Specification. These restrictions are to ensure compatibility with the underlying storage system.
Fields names must adhere to the ASCII character set (though may be
encoded using UTF-8) and follow the regular expression below. The field
name _id is the only field name that can be used that does not match
the rules for user defined field names.
Syntax:
<field-name> ::= <id-field-name> |
<user-field-name>
<id-field-name> = _id
<user-field-name> ::= ["a-zA-Z0-9_-"]+
The _id field is a "reserved name" and is always interpreted as the
document identity field. See TODO DOC ID LINK for restrictions on
its use.
TODO consider adding support for allowing "." and/or "$" in the field names, not needed for the initial demo release.
Sample:
{
"_id" : "my_doc",
"a_field" : "the value",
"sub_doc" : {
"inner_field" : 1
},
"__v" : 1
}Array indexes are used in query paths to identify elements in a array.
They are zero based, and must not include leading zeros, i.e. 1 is
a legal array index and 0001 is not. Leading zeros are not legal
numbers in the JSON Specification and should
only be used as a property of an object. Not that the first element in
the array is indexed using a single zero 0.
Syntax:
<array-index> ::= ^0$|^[1-9][0-9]*$
Sample:
// Second element of the `tags` array is equal to "foo"
{"find" : {
"filter" : {"tags.2": "foo"}
}
}
// Filter on the first element of the tags array
{"find" : {
"filter" : {"tags.0": "foo"}
}
} Document paths are used to identify fields in a JSON document in multiple contexts, such as a filter for a query or specifying fields to update.
<document-path> in this specification use JSON Path-like syntax.
Clauses specify where they support the use of <document-path> to filter, update, sort, or project documents.
Syntax:
<document-path> ::= <dotted-notation-path>
Dotted Notation Paths support specifying top level fields, fields in embedded documents (nested fields), array elements, and nested structures in arrays.
In general the dotted notation is one or more <field-name> or
<array-index> concatenated with a period character . and no
additional whitespace.
Syntax:
<dotted-notation-path> ::= <field-name>(.<field-name> | <array-index>)*
Sample:
// _id is equal to 1
{"find" : {
"filter" : {"_id": 1}
}
}
// suburb field in the address sub document is equal to "banana"
{"find" : {
"filter" : {"address.suburb": "banana"}
}
}
// Second element of the `tags` array is equal to "foo"
{"find" : {
"filter" : {"tags.2": "foo"}
}
} JSON documents must adhere to the following limits. Attempting to insert or modify a document beyond these limits will result in the command failing.
Note that all limits are configurable using run-time properties. See the Document limits configuration for further info.
The maximum size of a single document is 1 megabyte. The size is determined by the JSON serialization of the document.
The maximum nesting depth for a single document is 8 levels deep. Each nested document or array adds another level.
The maximum length of a field name is 100 characters. The maximum total Document path length for individual fields (see [Document Paths] section) is 250 characters.
The maximum number of fields allowed in a single JSON object is 64.
The maximum number of fields allowed in a single JSON document is 1000. This includes intermediate fields as well as leaf fields so that document like:
{
"root": {
"branch": {
"leaf": 42
}
}
}has 3 fields: root, root.branch, and root.branch.leaf, for purposes of this limit.
The maximum size of field values are:
| JSON Type | Maximum Value |
|---|---|
string |
Maximum length of 8,000 bytes (UTF-8 encoded) |
number |
Maximum length of 50 number characters |
The maximum length of an array is 1,000 elements.
Given the query {"foo" : "bar"}, this matches:
-
fooas a string with valuebar -
foois an array that contains at least one item that is the string"bar". The length of the array is not important.
Given the query {"foo" : ["bar"]}, this:
-
Matches
fooas an array that is exactly["bar"] -
Does not support sub-arrays. Thus, it does not match
foo == [ ["bar"], "baz"]
NOTE: this query is not a reflexive operation. I.e., if the Right Hand Side (RHS) operand is a string (or other value), we will match against a field of that type or field with an array item of that type. However, if the RHS operand is an array, we only match against fields that are arrays.
For subdocs, the query has to be an exact match. Given the following:
{"foo" : {"col1" : "bar1", "col2" : "bar2"}}It must match a field foo which has document value {"col1" : "bar1", "col2" : "bar2"}.
Commands are included in a request and are executed against a single collection.
Each command specifies one or more Clauses that control how it operates, and may include set of options to further modify behavior.
The following commands are supported for collections:
countDocumentscreateCollectiondeleteManydeleteOneestimatedDocumentCountfindfindCollectionsfindOnefindOneAndReplacefindOneAndUpdateinsertManyinsertOneupdateManyupdateOne
Each command always results in a single response, unless there is an unexpected exception. See Request and Response Messages. Also refer to the DATA API HTTP Specification.
Commands are defined using the BNF-like syntax, with samples presented using a JSON encoding of the language. The use of JSON in these samples does not preclude other encodings of the API in the future.
Sample:
// Select all documents in a collection, return complete documents
{"find" : {} }
// Select where name == "aaron" and return selected fields
{"find" : {
"filter" : {"name": "aaron"},
"projection" : {"name": 1, "age" : 1}
}
} Returns the count of documents that match the query for a collection or view.
Sample:
{
"countDocuments": {
"filter": {
"location": "London",
"race.competitors": {
"$eq": 100
}
}
}
}The countDocuments command does not support any options.
Count the number of the documents in the purchase collection where the field order_date is greater than $date in JSON format. In this example, Epoch 1672531200000 represents 1/1/2023 00:00:00 UTC.
{
"countDocuments": {
"filter": {
"order_date": {
"$date": 1672531200000
}
}
}
}Fail Fast, a storage failure causes the command to stop processing.
See Multi-Document Failure Considerations.
| Response Elements | Description |
|---|---|
data |
Not present |
status |
Present with fields: count: <zero-or-positive-integer> |
errors |
Present if errors occur. |
If an error occurs the command will not return status.
Returns an estimated count of the number of documents in the collection. No guarantee is made on the accuracy of the count. No filtering is supported.
Sample:
{
"estimatedDocumentCount": {}
}The estimatedDocumentCount command does not support any options.
| Response Elements | Description |
|---|---|
data |
Not present |
status |
Present with fields: count: <zero-or-positive-integer> |
errors |
Present if errors occur. |
If an error occurs the command will not return status.
Creates a new collection in the current keyspace.
Sample
{
"createCollection": {
"name": "some_collection",
"options" : {
"vector" : {
"dimension" : 5,
"metric" : "cosine"
}
}
}
}The createCollection command supports the following options.
| Request Elements | Description |
|---|---|
vector |
Used to define a vector-enabled collection. |
vector.dimension |
The size or dimension of the vector. |
vector.metric |
One of: dot_product, euclidean, or cosine. |
Metrics details follow.
When the createCollection vector metric is set to dot_product, the term refers to a fundamental operation in vector algebra.
The dot product gives a scalar (single number) result. It has important geometric implications: if the dot product is zero, the two vectors are orthogonal (perpendicular) to each other. When normalized vectors are used, the dot product represents the cosine of the angle between the two vectors. Given two vectors:

In an n-dimensional space, their dot product is calculated as:
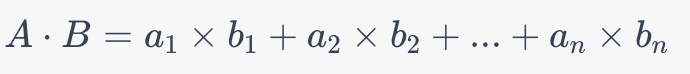
In the context of a vector-enabled Astra DB database, the dot product can be used for similarity searches. Here’s why:
- In high-dimensional vector spaces, such as those produced by embedding algorithms or neural networks, similar items are represented by vectors that are close to each other.
- The cosine similarity between two vectors is a measure of their directional similarity, regardless of their magnitude. If you compute the dot product of two normalized vectors, you get the cosine similarity.
Thus, by computing the dot product between a query vector and the vectors in the Astra DB database, you can efficiently find items in the database that are directionally similar to the query. With dot_product metric set in the DATA API createCollection command, Astra DB can use the dot product as a measure of similarity between vectors.
When the createCollection vector metric is set to euclidean, the term refers to the Euclidean distance, which is the most common way of measuring the "ordinary" straight-line distance between two points in Euclidean space.
Given two points P and Q in an n-dimensional space with the following coordinates:

The Euclidean distance between these two points is defined by the following formula:
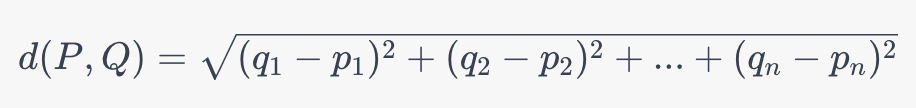
Here’s the formula that calculates how the Euclidean distance (the result of the formula above) is then used to determine the Euclidean similarity value:
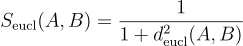
For a 2-dimensional space (like a flat plane), it’s the direct straight-line distance between two points. For a 3-dimensional space (like the space we live in), it’s the direct straight-line distance between two points in that space. The formula generalizes this concept to any number of dimensions.
In the context of a vector-enabled Astra DB database:
-
Vectors as Points: Each vector in the database can be thought of as a point in some high-dimensional space.
-
Distance Between Vectors: When you want to find how "close" two vectors are, you can use various metrics. The Euclidean distance is one of the most intuitive and commonly used metrics. If two vectors have a small Euclidean distance between them, they are close in the vector space; if they have a large Euclidean distance, they are far apart.
-
Querying and Operations: When you set the vector metric to
euclideanin the DATA APIcreateCollectioncommand, Astra DB can use the Euclidean distance as the metric for any operations that require comparing vectors. For instance, if you’re performing a nearest neighbor search, the Astra DB database will return vectors that have the smallest Euclidean distance to the query vector.
When the createCollection vector metric is set to cosine, it refers to the cosine similarity measure, which is a metric used to determine how similar two vectors are. Cosine similarity is commonly used in high-dimensional spaces and is widely used in applications like text analysis, recommendation systems, and more.
Given two vectors A and B, the cosine similarity is computed as the dot product of the vectors divided by the product of their magnitudes (or lengths). The formula for cosine similarity sim(A,B) is:
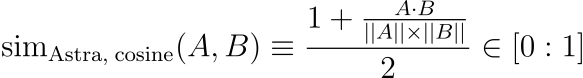
Where:
- A⋅B is the dot product of vectors A and B.
- ∥A∥ is the magnitude (or length) of vector A.
- ∥B∥ is the magnitude (or length) of vector B.
When returned by Astra DB, the result will always be normalized as between 0 and 1:
- A value of 0 indicates that the vectors are diametrically opposed.
- A value of 0.5 suggests the vectors are orthogonal (or perpendicular) and have no match.
- A value of 1 indicates that the vectors are identical in direction.
Fail Fast, a storage failure causes the command to stop processing.
See Multi-Document Failure Considerations.
| Response Elements | Description |
|---|---|
data |
Not present. |
status |
Not preset. |
errors |
Present if errors occur. |
Status example:
{
"status": {
"ok": 1
}
}If an error occurs the command will not return status.
The deleteMany command does not support any options.
Fail Silently, a storage failure does not stop the command from processing.
See Multi-Document Failure Considerations.
The maximum amount of documents that can be deleted in a single operation is 20. This limit is configurable using the Operations configuration properties.
| Response Elements | Description |
|---|---|
data |
Not present |
status |
Present with fields: deletedCount: <zero-or-positive-integer>, moreData with value true if there are more documents that match the delete filter, but were not deleted since the limit of documents to delete in the single operation was hit. |
errors |
Present if errors occur. |
If an error occurs the command will still return status as some documents may have been deleted.
Syntax:
<delete-one-command> ::= delete-one <delete-one-command-payload>
<delete-one-command-payload> ::= <filter-clause>?
<sort-clause>?
The deleteOne command does not support any options.
Fail Fast, a storage failure causes the command to stop processing.
See Multi-Document Failure Considerations.
| Response Elements | Description |
|---|---|
data |
Not present |
status |
Present with fields: deletedCount: <zero-or-one-integer> |
errors |
Present if errors occur. |
If an error occurs the command will not return status.
find selects zero or more documents from a collection that match a
selection filter, and returns either the complete documents or a partial
projection of each document.
Syntax:
<find-command> ::= find <find-command-payload>
<find-command-response> ::= <paginated-document-response>
<find-command-payload> ::= <filter-clause>?
<projection-clause>?
<sort-clause>?
<find-command-options>?
<find-command-options> ::= (<find-option-name> <find-option-value>,)*
Sample:
// Select all documents in a collection, return complete documents
{"find" : {} }
// Select where name == "aaron" and return selected fields
{"find" : {
"filter" : {"name": "aaron"},
"projection" : {"name": 1, "age": 1}
}
} TODO: add how cursor state fits into the processing
find commands are processed using the following order of operation:
<filter-clause>is applied to the collection to select candidate set of documents, if no<filter-clause>is supplied all documents in the collection are candidate documents.<sort-clause>is applied to the candidate documents to order them, if no<sort-clause>is supplied the documents sort order is undefined.- The
limitoption from<find-command-options>is applied to reduce the number of candidate documents to no more thanlimit, if nolimitis supplied all candidate documents are included. <projection-clause>is applied to each candidate document to create the result set documents to be included in the<find-command-response>, if no<projection-clause>is specified the complete candidate documents are included in the response.
<find-command-options> is a map of key-value pairs that modify the
behavior of the command. All options are optional, with default behavior
applied when not provided.
| Option | Type | Description |
|---|---|---|
limit |
Positive Integer | Limits the number of documents to be returned by the command. If unspecified, or 0, there is no limit on number of documents returned. Note that results may still be broken into pages. |
pageState |
ASCII String | The page state of the previous page, when supplied the find command will return the next page from the result set. If unspecified, null, or an empty string the first page is returned. |
skip |
Positive Integer | Skips the specified number of documents, in sort order, before returning any documents. |
Fail Fast, a storage failure causes the command to stop processing.
See Multi-Document Failure Considerations.
If <sort-clause> is present, the maximum amount of documents that could be sorted using the in-memory sorting is 10,000. This limit is configurable using the Operations configuration properties.
| Response Elements | Description |
|---|---|
data |
Present with fields : documents and nextPageState. nextPageState may be null if no further data is available. |
status |
Not preset. |
errors |
Present if errors occur. |
If an error occurs the command will not return data.
findCollections returns all collections from a given keyspace.
There is no payload. The keyspace is given as {{base_url}}{{json_port}}/v1/{keyspace}.
Syntax:
<findCollections-command> ::= findCollections
<findCollections-command-response> ::= status.collections: ["col1", "col2"]
None.
| Response Elements | Description |
|---|---|
status |
Status has collections field with array of the available collection names. |
errors |
If the provided keyspace does not exist, return KEYSPACE_DOES_NOT_EXIST. |
findOneAndReplace replaces the first document in the collection that matches the filter. Optionally use a sort-clause to determine which document is modified.
Syntax:
<find-one-and-replace-command> ::= findOneAndReplace <find-one-and-replace-command-payload>
<find-one-and-replace-command-payload> ::= <filter-clause>?
<sort-clause>?
<replacement>?
<find-one-and-replace-command-options>?
<find-one-and-replace-command-option> ::= (<find-one-and-replace-option-name> <find-one-and-replace-option-value>,)*
Sample:
// Replaces a single document based on the specified filter and sort. Returns a document in response.
{ "findOneAndReplace" :
{ "filter" : {<filter-clause>},
"sort" : {<sort-clause>},
"replacement" : {<document-to-replace>},
"options" :
{"returnDocument" : "before/after"},
{"upsert" : "true/false"}
}
}findOneAndReplace commands are processed using the following order of operation:
<filter-clause>is applied to the collection to select one or more candidate document(s). Example:"filter": {"location": "London"}.<sort-clause>can be applied to the candidate document to determine its order. Example:"sort" : ["race.start_date"]. If no<sort-clause>is supplied, the document maintains its current order.<document-to-replace>specifies the replacement action. Example:"replacement": { "location": "New York", "count": 3 }.
The document cannot specify an _id value that differs from the replaced document.
<find-one-and-replace-command-option> is a map of key-value pairs that modify the behavior of the command.
If returnDocument is before, return the existing document. if returnDocument is after, return the replaced document.
| Option | Type | Description |
|---|---|---|
returnDocument |
String | Specifies which document to perform the projection on. If "before" the projection is performed on the document before the update is applied. If "after" the document projection is from the document after replacement. Defaults to "before". |
upsert |
Boolean | When true if no documents match the filter clause the command will create a new empty document and apply the update clause to the empty document. If the _id field is included in the filter the new document will use this _id, otherwise a random value will be used see Upsert Considerations for details. When false the command will only update a document if one matches the filter. Defaults to false. |
Fail Fast, a storage failure causes the command to stop processing.
If the replacement document _id field is different from the document read from the database, the DATA API throws an error.
NOTE: you can omit _id in the replacement document. If _id is in the replacement, it should be exactly equal to the _id in the database. But if _id was omitted,
findOneAndReplace will use the existing document's _id.
If <sort-clause> is present, the maximum amount of documents that could be sorted using the in-memory sorting is 10,000. This limit is configurable using the Operations configuration properties.
| Response Elements | Description |
|---|---|
data |
Present with fields : document only, see findOneAndReplace Command Options for controlling the projection. |
status |
Present with fields: upsertedId: <id of document upserted>, if a document was upserted. |
errors |
Present if errors occur. |
If an error occurs the command will not return data or status.
findOneAndUpdate selects one document from a collection using a match
filter that is updated by the server using an atomic transaction, either
all the changes described in the <update-document-clause> are stored
or none of them are (further details of the transaction requirements
below). It then returns a projection of either the document before or
after the update has been applied.
Syntax:
<find-one-and-update-command> ::= findOneAndUpdate <find-one-and-update-command-payload>
<find-one-and-update-command-response> ::= <single-document-response>
<find-one-and-update-command-payload> ::= <filter-clause>?
<update-document-clause>?
<sort-clause>?
<projection-clause> ?
<find-one-and-update-command-options>?
<find-one-and-update-command-options> ::= (<find-option-name> <find-option-value>,)*
Sample:
// Update the first document (by natural order) to increase the points field by 5
{"findOneAndUpdate" :
"filter": {} ,
"update": { $inc: { "points" : 5 } }
}
// Increase the age for the document with id 123, and return the name and age
{"findOneAndUpdate" : {
"filter" : {"_id": "123"},
"update": { $inc: { "age" : 5 } },
"projection" : {"name": 1, :"age" : 1}
}
} <find-one-and-update-command-options> is a map of key-value pairs that
modify the behavior of the command. All options are optional, with
default behavior applied when not provided.
| Option | Type | Description |
|---|---|---|
returnDocument |
String Enum | Specifies which document to perform the projection on. If "before" the projection is performed on the document before the update is applied, if "after" the document projection is from the document after the update. Defaults to "before". |
upsert |
Boolean | When true if no documents match the filter clause the command will create a new empty document and apply the update clause to the empty document. If the _id field is included in the filter the new document will use this _id, otherwise a random value will be used see Upsert Considerations for details. When false the command will only update a document if one matches the filter. Defaults to false. |
Fail Fast, a storage failure causes the command to stop processing.
See Multi-Document Failure Considerations.
If <sort-clause> is present, the maximum amount of documents that could be sorted using the in-memory sorting is 10,000. This limit is configurable using the Operations configuration properties.
| Response Elements | Description |
|---|---|
data |
Present with fields : document only, see findOneAndUpdate Command Options for controlling the projection. |
status |
Present with fields: upsertedId: <json-value> only if a document was upserted. |
errors |
Present if errors occur. |
If upsert option was set to true, and no documents matched a filter a new document is created. The _id of the document is included in the status field upsertedId, otherwise no status is returned.
If an error occurs the command will not return data or status.
The findOne command does not support any options.
Fail Fast, a storage failure causes the command to stop processing.
See Multi-Document Failure Considerations.
If <sort-clause> is present, the maximum amount of documents that could be sorted using the in-memory sorting is 10,000. This limit is configurable using the Operations configuration properties.
| Response Element | Description |
|---|---|
data |
Present with fields : document only |
status |
Not present. |
errors |
Present if errors occur. |
If an error occurs the command will not return data.
<insert-many-command-options> is a map of key-value pairs that modify the behavior of the command. All options are optional, with default behavior applied when not provided.
| Option | Type | Description |
|---|---|---|
ordered |
Boolean | When true the server will insert the documents in sequential order, ensuring each document is successfully inserted before starting the next. Additionally the command will "fail fast", failing the first document that fails to insert. When false the server is free to re-order the inserts for performance including running multiple inserts in parallel, in this mode more than one document may fail to be inserted (using the "fail silently" mode). See Multi-Document Failure Considerations for details. Defaults to true. |
Depends on the ordered option. When true the command uses Fail Fast to stop processing at the first fault, when false the command uses Fail Silently and attempts to insert all documents.
See insertMany Command Options for ordered.
See Multi-Document Failure Considerations.
The maximum amount of documents that can be inserted in a single operation is 20. This limit is configurable using the Operations configuration properties.
| Response Element | Description |
|---|---|
data |
Not present. |
status |
Present with field: insertedIds and array of doc _id 's that were inserted. |
errors |
Present if errors occur. |
If an error occurs the command will still return status as some documents may have been inserted.
The insertOne command does not support any options.
Fail Fast, a storage failure causes the command to stop processing.
See Multi-Document Failure Considerations.
| Response Element | Description |
|---|---|
data |
Not present. |
status |
Present with field: insertedId with the single document _id that was inserted. |
errors |
Present if errors occur. |
If an error occurs the command will not return status.
<update-many-command-options> is a map of key-value pairs that modify
the behavior of the command. All options are optional, with default
behavior applied when not provided.
| Option | Type | Description |
|---|---|---|
upsert |
Boolean | When true if no documents match the filter clause the command will create a new empty document and apply the update clause to the empty document. If the _id field is included in the filter the new document will use this _id, otherwise a random value will be used see Upsert Considerations for details. When false the command will only update a document if one matches the filter. Defaults to false. |
Fail Silently, a storage failure does not stop the command from processing.
See Multi-Document Failure Considerations.
The maximum amount of documents that can be updated in a single operation is 20. This limit is configurable using the Operations configuration properties.
| Response Element | Description |
|---|---|
data |
Not present. |
status |
Present with fields: matchedCount count of documents that matched the filter, modifiedCount count of document updated (may be less than match count), upsertedId if a document was upserted (when matchCount is zero) not present otherwise, moreData with value true if there are more documents that match the update filter, but were not updated since the limit of documents to update in the single operation was hit. |
errors |
Present if errors occur. |
If an error occurs the command will still return status as some documents may have been inserted.
<update-one-command> ::= deleteOne <update-one-command-payload>
<update-one-command-payload> ::= <filter-clause>?
<update-clause>?
<sort-clause>?
<update-one-command-options>?
<update-one-command-options> ::= <update-one-command-options>?
<update-one-command-options> is a map of key-value pairs that modify the behavior of the command. All options are optional, with default behavior applied when not provided.
| Response Element | Type | Description |
|---|---|---|
upsert |
Boolean | When true, if no documents match the filter clause, the command will create a new empty document and apply the update clause to the empty document. If the _id field is included in the filter, the new document will use this _id, otherwise a random value will be used. See Upsert Considerations for details. When false the command will only update a document if one matches the filter. Defaults to false. |
Fail Fast, a storage failure causes the command to stop processing.
See Multi-Document Failure Considerations.
| Response Element | Description |
|---|---|
data |
Not present. |
status |
Present with fields: matchedCount count of documents that matched the filter (no more than 1), modifiedCount count of document updated (may be less than match count, no more than 1), upsertedId if a document was upserted (when matchCount is zero) otherwise not present. |
errors |
Present if errors occur. |
If an error occurs the command will still return status as some
documents may have been inserted.
Additional considerations that apply to multiple commands.
Multiple concurrent requests that use upsert may result in multiple
documents created when the intention was to only create one. This is
because the default behavior of upsert is to create a new document with
a random, server assigned, _id and then apply the updates to that
document.
If the filter clause of the command includes the _id field when
performing an upsert the new document will use the supplied _id. This
will ensure a single document is created, as the _id is unique.
Overlapping commands may read the new document and update it.
Fields included in the filter clause in addition to the _id are
ignored.
Commands that modify multiple documents in a single operation, such as
updateMany or insertMany, do not perform all of the modification in
a single transaction. Instead each document is updated individually and
concurrently with other modifications and reads. As a consequence there
are two failure modes for multi document updates, and each command
specifies if it supports one, or both.
The two failure modes are "Fail Fast" and "Fail Silently". Where the main different is Fail Fast commands normally return results about individual documents, and Fail Silent commands normally return a summary or count of affected document.
There are two category of storage failures under consideration:
- Availability Faults: These occur when the underlying storage platform is unable to successfully complete an operation due node failures. These errors may be transient and the DATA API may retry operations, if operations still fail after retrying the operation will be considered to have failed.
- Concurrency Faults: These occur when the a document is under very high concurrent modification which make it impossible for the DATA API to complete an optimistic "compare-and-set" update. Modification operations read documents from the storage platform and update or delete it only if it has not changed since being read. If the document has changed, the filter that selected the document is tested again on that document, and the modification is re-tried. Under high contention it is possible for one request to "starve" and be unable to complete.
In the context of Multi Document Failures we consider a failure (after a configured number of retries) from either of these categories as a failure to complete a command.
The server should use the following retry policy:
- Availability Faults: a single retry, for a total of two (2) attempts.
- Concurrency Faults: two retries, for a total of three (3) attempts.
Note Neither of these faults will leave a document in an inconsistent state, that would cause "eventually consistent" reads. Document retain internal consistency as they are stored on a single row which is always atomically updated. And they maintain cluster wide consistency through the user of cluster wide "compare-and-set" operations.
Under the "fail fast" mode, each operation on the database is performed sequentially, ensuring the previous operation has succeeded before starting the next. In this mode a single failure causes the command to stop processing and return information on the work that has completed together with an error.
For example, consider an ordered insertMany
command that is inserting three documents. This command will use "fail
fast", the second document will be inserted once the first is
successful. If inserting the second document fails the command will
return both the _id of the first document and an error describing the
failure inserting the second. No attempt will be made to insert the
third document.
Under the "fail silently" mode the command will attempt to perform all operations on the database, which may include successfully processing some operations after others have failed. In this mode a single failure does not cause the command to stop processing, instead it makes a best effort to complete and returns information on the work that was completed and potentially what was not.
Fail silently also allows the server to re-order the database operations to achieve best performance, which may include running multiple operations in parallel.
Commands that use Fail Silently may return an error(s) and status information about what was successfully completed. See Response Messages for the structure of responses, and Commands for individual command responses. Multiple errors may be returned; the server should rationalize the errors by category. For example, it should not return 10 errors that each say "DB service timeout". Instead, the server should return a single error that covers the 10 documents to which this error condition occurred.
For example, consider an unordered insertMany command that is inserting three documents. This command will use "fail silently", and may run all database operations at once in parallel. If inserting the second document fails, the first and third may success. In this case command will return the _id of the first and third documents and an error describing the failure inserting the second.
Similarly a deleteMany command always uses "fail silently", and will attempt to delete many candidate documents in parallel. If an Availability or Concurrency fault occurs the command will retry the operation some configured number of times before marking that document operation as failed. At completion the command will return a count of deleted documents and an error describing any failures.
The filter clause is used to select zero or more documents from collection, how the documents are operated on depends on the command the clause is used with.
Sample:
// Identity filter that returns all documents
{}
// Equality match for a single field\
{"name" : "aaron"}
{"name" : {"eq" : "aaron"}}
// Combination of literal and operator expressions
{"name" : "aaron", "age" : {"$gt" : 40}}Syntax:
`<filter-clause>` ::= `<filter-expression>` *
`<filter-expression>` ::= `<filter-comparison-expression>` | `<filter-logical-expression>`
(, `<filter-comparison-expression>` |
`<filter-logical-expression>` )*
`<filter-comparison-expression>` ::=
`<filter-comparison-path>` ( `<literal>` |
`<filter-operator-expression>` )
`<filter-comparison-path>` :== `<document-path>`
`<filter-operator-expression>` ::= `<filter-operation>` (,
`<filter-operation>` )*
`<filter-operation>` ::= `<filter-comparison-operation>` |
`<filter-logical-unary-operation>` |
`<filter-element-operation>` |
`<filter-array-operation>`
`<filter-comparison-operation>` ::=
`<filter-comparison-value-operation>` |
`<filter-comparison-array-operation>`
`<filter-comparison-value-operation>` ::=
`<filter-comparison-value-operator>` ,
`<filter-comparison-value-operand>`
`<filter-comparison-value-operator>` ::= $eq, $gt, $gte, $lt, $lte, $ne
`<filter-comparison-value-operand>` ::= `<literal>`
`<filter-comparison-array-operation>` ::=
`<filter-comparison-array-operator>` ,
`<filter-comparison-array-operand>`
`<filter-comparison-array-operator>` ::= $in, $nin\
`<filter-comparison-array-operand>` ::= `<literal-list>`
`<filter-logical-unary-operation>` ::=
`<filter-logical-unary-operator-not>`
`<filter-logical-unary-operator-not>` ::= $not
`<filter-operator-expression>`
`<filter-element-operation>` ::=
`<filter-element-operation-exists>`
`<filter-element-operation-exists>` ::= $exists
`<filter-element-operation-exists-operand>`
`<filter-element-operation-exists-operand>` ::= true | false
`<filter-array-operation>` ::=
`<filter-array-operation-all>` |
`<filter-array-operation-elemMatch>` |
`<filter-array-operation-size>`
`<filter-array-operation-all>` ::= $all `<literal-list>`
`<filter-array-operation-elemMatch>` ::= $elemMatch
`<filter-comparison-operation>` (,
`<filter-comparison-operation>` )*
`<filter-array-operation-size>` ::= $size
`<positive-integer>`
`<filter-logical-expression>` ::=
`<filter-logical-compound-operator>`
`<filter-logical-compound-operand>`
`<filter-logical-compound-operator>` ::= $and, $or, $nor
`<filter-logical-compound-operand>` ::=
[`<filter-expression>` (, `<filter-expression>` )]*
BEGIN TODO =
#
# filter-element-operation - type
# \<filter-evaluation-operators\> ::= $mod
# END TODO ===
Also:
BEGIN Excluded =
$expr, $jsonSchema, $regex, $text, $where, all geo things
# END Excluded ===
A <filter-expression> may either apply to a node in the document
identified by a path (<filter-comparison-expression>), or be a logical
expression that evaluates the result of sub expressions
(<filter-logical-expression>).
A (<filter-comparison-expression>) identifies a context node in
the document using a <document-path>. The context node, including the
value, name, type, document path, and any other meta data, may then
tested by the expression. If the expression specifies a <literal> then
the value of the node is tested using an $eq operation. Otherwise the
expression will specify one <filter-operator-expression> which defines
one or more <filter-operation>'s which must all evaluate to True for
the <filter-operator-expression> to evaluate to True.
Sample:
// Comparison expression using a literal value
{"name" : "aaron"}
// Comparison expression using a single operator expression, equivalent to the previous example
{"name" : {"eq" : "aaron"}}
// Comparison expression using a single and a multiple operator expression
{"name" : {"eq" : "aaron"}, "age" : {"$gt" : 40, "$lt" : 50}}
// Comparison expression testing metadata about the context node
{"name" : {"$exists" : false}}The <document-path> may fail to select a context node, either for all
documents in the collection or only some. Whenever this happens a
"Missing" context node is evaluated by the <filter-operation>'s as the
operations may handle a missing context node differently. For example
$eq and $ne have opposite behavior, see the operation descriptions
below for details.
A <filter-operation> is an operation on the context node identified by
the expression. The node provides the Left Hand Side (LHS) operand of
the operation, while the definition provides the operator and Right Hand
Side (RHS) operand (if required). All <filter-operation> must
evaluate to either True or False.
The other form of <filter-expression> is a
<filter-logical-expression> which applies a logical operation to a
list of sub <filter-expression>'s. As such this type of expression
does not specify a context node for operations to be evaluated.
Sample:
// Logical expression using a literal value and single operator expressions
{ "$and" : [{"name" : "aaron"}, {"age" : {"$gt" : 40}}]}
// Note, there is an implicit $and operator for all top level expressions, so this is equivalent
{ "name" : "aaron"}, {"age" : {"$gt" : 40}} }
// Logical expression using multiple operator expressions
{ "$or" : [{"name" : {"eq" : "aaron"}}, {"age" : {"$gt" : 40}}]}The filter clause is made up of zero or more expressions that evaluate
to True or False.
The <filter-clause> is evaluated using the following order of
operations:
- If the filter clause has zero expressions then all documents in the collection are selected.
- If the filter clause has a single
<filter-expression>then all documents in the collection where the expression evaluates toTrueare selected. - If the filter clause has more than one top level
<filter-expression>then all documents in the collection where all expressions evaluate toTrueare selected.
A literal comparison operation performs the $eq operation on the
context node using the supplied literal value. See
$eq for the definition.
$eq applies a type sensitive equals operation to the value context
node and the <literal> operand.
Note: This version of the specification only defines equality for atomic values such as string or a number. It does not support equality between arrays or sub documents.
$eq$ evaluates to True when all of the following conditions are
True:
- The context node exists.
- The type of the context node value matches the type of the operand, i.e. string can be compared to string, or number to number. However a number cannot be compared to a string.
- The value of the node is equal to the
<literal>operand. String comparisons use string binary comparison i.e. it is sensitive to case and other modifiers.
TODO: node must exist
TODO: node must exist
TODO: node must exist
TODO: node must exist
$ne applies a type sensitive not-equals operation to the value of the
context node and the <literal> operand.
Note: This version of the specification only defines equality for atomic values such as string or a number. It does not support equality between arrays or sub documents.
$ne$ evaluates to True when either of the following conditions
are True:
- The context node does not exist.
- The type of the context node value is different to the type of the operand.
- The value of the node is not-equal to the
<literal>operand. String comparisons use string binary comparison i.e. it is sensitive to case and other modifiers.
$in applies to context node values that are either atomic or an array,
in either case the RHS operand is a list of literals. The operation
tests if the value of the context node is present in the RHS operand.
When the value of the context node is atomic, $in evaluates to True
when all of the following conditions are True:
- The context node exists
$eqevaluates toTruefor any pair of the node value and a value from the RHS operand list.
When the value of the context node is an array, $in evaluates to
True when all of the following conditions are True:
- The context node exists
$eqevaluates toTruefor any pair of a value from the node array or value in the RHS operand.
$nin applies to context node values that are either atomic or an
array, in either case the RHS operand is a list of literals. The
operation tests if the value of the context node is not present in the
RHS operand.
When the value of the context node is atomic, $nin evaluates to True
when either of the following conditions are True:
- The context node does not exist.
$eqevaluates toFalsefor all pairs of the node value and a value from the RHS operand list.
When the value of the context node is an array, $nin evaluates to
True when either of the following conditions are True:
- The context node does not exist
$eqevaluates toFalsefor all pairs of a value from the node array and a value in the RHS operand.
$not applies a logical Not to a <filter-operator-expression>,
which is evaluated against the context node identified by the
<filter-comparison-path> of the comparison express. While $not is
logical operation it behaves differently to $and, $or, and $nor as
they apply logical operations to the results of 1 or more sub
<filter-expression> while $not applies to a single
<filter-operator-expression>.
Sample:
// Applying $not to an $eq operation
{"name" : {"$not" : {"eq" : "aaron"}}}Note that the behavior of $not when the context node does not exist
means that it can change the behavior of operations and should not
always be considered a logical opposite.
$not$ evaluates to True when either of the following conditions
are True:
- The context node does not exist.
- The result of evaluating the RHS
<filter-operator-expression>isFalse.
The performance of applying $not to a multi-clause
<filter-operator-expression> will often be slower than constructing a
<filter-operator-expression> that uses operations that directly
express the test. This is because the <filter-operation>'s in the
<filter-operator-expression> are joined with a logical AND, meaning
only one operation has to fail for the whole expression to fail allowing
the expression to fail before testing all operations. In contrast
applying NOT to the output of the <filter-operator-expression> means
that all operations must be tested (and evaluate to TRUE) for document
to be excluded.
$exists applies to the metadata of the context node, to test if it
exists. The RHS operand is a boolean value that controls the return
value of the operation.
Sample:
// Select documents that have a name
{"name" : {"$exists" : true}}
// Select documents that do not have a name
{"name" : {"$exists" : false}}$exists evaluates to True when all of the following conditions are True:
- The context node exits.
- The value of the RHS operand is
true.
The $all operation allows users to check for documents that have an array field with all of the given values. Example:
{"locations" : { $all : ["New York", "Texas"]}}If provided to a find(), return all the documents where the locations field contains the two values – “New York” and “Texas”. It does not matter how many more values the locations field contains. The operation will match if the specified values are present. Similarly, if even one the value is missing, the document will not be matched. So the $all operation is useful while retrieving data.
TODO:
The $size operation allows users to match any array with the number of elements specified by the argument. Example:
db.collection.find( { field: { $size: 2 } } );That expression returns, e.g.: { field: [ red, green ] } and { field: [ apple, lime ] }, but not { field: fruit } or { field: [ orange, lemon, grapefruit ] }.
If the given field is not an array, there's no match. $size should ignore non-arrays.
A Projection clause is applied to zero or more input documents to project all of part of each document into an output document. Each input document maps to a single output document, although each output document may have a different document layout. For example, when an input document is missing a projected field, it will not appear in the output document.
Syntax:
`<projection-clause>` ::= `<projection-expression>` *
`<projection-expression>` ::=
`<projection-field-expression>` |
`<projection-array-expression>`
`<projection-field-expression>` ::=
`<projection-field-path>` `<projection-field-inclusion>`
`<projection-field-path>` ::= `<document-path>`
`<projection-field-inclusion>` ::= 0 | 1 | true | false
`<projection-array-expression>` ::=
`<projection-field-path>` `<projection-array-projection>`
`<projection-array-projection>` ::=
`<projection-array-elem-match-projection>` |
`<projection-array-slice-projection>` |
`<projection-array-limit-projection>`
`<projection-array-elem-match-projection>` ::= $elemMatch
`<filter-comparison-operation>` (,
`<filter-comparison-operation>` )*
`<projection-array-slice-projection>` ::= $slice
`<slice-number>` | `<slice-to-skip>`
`<slice-to-return>`
`<slice-number>` ::= `<integer>`
`<slice-to-skip>` ::= `<integer>`
`<slice-to-return>` ::= `<positive-integer>`
@TODO: this is $ in projection, not sure if mquery supports this
`<projection-array-limit-projection>` ::= $
Each <projection-clause> is contains zero or more <projection-expression>'s which are all applied to each input document
in an order decided by the server. The output of all <projection-expression>'s evaluated for a single input document create
a single output document.
The <projection-clause> is evaluated using the following order of operations:
- If the projection clause is missing or empty the entire input document is selected for the output document.
- Each
<projection-expression>is evaluated against the input document in an undefined order. The output is mapped to a field with the same path as the<projection-field-path>for the expression. - Unless excluded via a
<projection-field-expression>the<_id>field is included in the output document.
<projection-field-expression> is the simplest form of expression. It identifies a field using a <document-path> and includes or specifically excludes it from the output. Note that for any <projection-clause> other than the identity clause any fields not listed are excluded from the output document. The <projection-field-expression> includes a field using 1 or true and excludes it using 0 or false. See Projection Clause Order of Operations for special treatment of the _id field.
Sample:
// Identity projection, selects the entire document
{}
// Select top level and lower level fields
{ "name" : 1, "address.country" : true}
// Select top level and lower level fields and exclude the _id
{ "name" : 1, "address.country" : true, "_id": 0}When the <document-path> does not exist in the input document:
The output document will not include a field with that key.
When the <document-path> does exist in the input document:
- If
<projection-field-inclusion>is1ortruethe key and its entire value (including a sub-document if present) will be included in the output document. - If
<projection-field-inclusion>is0orfalsethe output document will not include a field with that key
TODO: confirm this is supported by mquery, not in the docs - should be supported, cannot see where
<projection-array-slice-projection> is used to select a 1 or more
elements from a source document array for the output document based on
their position in the array. The element and any sub document are all
selected. The slice expression has three forms based on the parameters
passed.
Regardless of the supplied parameters
<projection-array-slice-projection> has the following behavior:
- If the input document does not contain the node specified by the
<projection-field-path>the field is not selected for the output document. - If the input node does exist, and is not an array the field is not selected for the output document.
If only <slice-number> is supplied and the value is a positive integer
then:
- If the size of the array is less than or equal to the
<slice-number>the entire array is selected for the output document. - If the size of the array is greater than the
<slice-number>then the first<slice-number>elements of the array are selected for the output in array order.
If only <slice-number> is supplied and the value is a negative integer
then:
- If the size of the array is less than or equal to the
absolute(<slice-number>)the entire array is selected for the output document. - If the size of the array is greater than the
<slice-number>then the last<slice-number>elements of the array are selected for the output in array order.
If only <slice-number> is supplied and the value is a zero then:
- The field is selected for the output document as a zero length array.
If both <slice-to-skip> and <slice-to-return> are supplied then:
- If
<slice-to-skip>is a positive integer and greater than or equal to the size of the input array an empty array is returned. - If
<slice-to-skip>is a positive integer and less than the size of the input array it is the number of elements to skip before selecting elements. For a 0 based array a value of 1 indicates elements should be selected starting at the second element at index 1. - If
<slice-to-skip>is a negative integer and its absolute value is greater than or equal to the size of the input array the starting position is the start of the array. - If
<slice-to-skip>is a negative integer and its absolute value is less than the size of the input array, it is the number of elements to skip backwards from the end of the array. For a 0 based array a value of --1 indicates elements should be selected starting with the last element. <slice-to-return>indicates the number of elements to return after skipping<slice-to-skip>.
Sample:
// With the input array ["foo", "bar", "baz"]
// Select first 2 elements ["foo", "bar"]
{"$slice" : 2}
// Select last 2 elements ["bar", "baz"]
{"$slice" : -2}
// Select one element starting at second ["bar"]
{"$slice" : [1,1]}
// Select the last element, same as -1 ["baz"]
{"$slice" : [-1,1]}TODO: not sure if supported by mquery, this is the $ - should be supported, cannot see where.
A sort clause is applied to a set of documents to order them. Examples of this include ordering a large result set that will returned as pages, or sorting a candidate set of documents to determine which document will be returned when only a single document is required.
Syntax:
`<sort-clause>` ::= `<sort-expression>` *
`<sort-expression>` ::= `<sort-field-path>` `<sort-field-order>`
`<sort-field-path>` ::= `<document-path>`
`<sort-field-order>` ::= `<sort-ascending>` | `<sort-descending>`
`<sort-ascending>` ::= `1`
`<sort-descending>` ::= `-1`
Each <sort-clause> contains a json document <sort-expression>'s
which are used to sort set of documents. The order of
<sort-expression>'s is important and should be preserved as the
request is transmitted and processed.
Each <sort-expression> identifies a field in the document to sort by.
<sort-field-path> is a Document Path that identifies
the field to sort by.
<sort-field-order> can have value 1 for ascending and -1 for descending order.
Sample:
// Sort by one field ascending
["name"]
// Sort by one field descending, and a second ascending
["-age", "name"]
The <sort-clause> is evaluated using the following order of operations:
- If the sort clause is missing or contains zero
<sort-expression>'s the order of candidate documents is unchanged, and is assumed to be the natural order applied by the underlying database. - If the
<sort-clause>contains a single<sort-expression>the candidate documents are ordered by that field using the Sort Order. If two or more documents have equivalent value for a field, the order of the documents will be natural order. - If the
<sort-clause>contains two or more<sort-expression>'s the first expression is used to sort the documents, and the second is used to sort all documents that have the same value for the first expression. A third<sort-expression>is used to sort documents with a duplicate value for the second expression, and so on.
TODO: type coercion, missing fields.
TODO BNF for update commands, need to use <document-path>.