diff --git a/docs/Events.md b/docs/Events.md
new file mode 100644
index 00000000..e369171b
--- /dev/null
+++ b/docs/Events.md
@@ -0,0 +1,12 @@
+---
+title: Events
+---
+**Conferences 2025**
+
+[CRYPTO](https://crypto.iacr.org/2025/) (August 17-21)
+
+Participants: Chen-Da Liu-Zhang, Elizabeth Crites, and Alistair Stewart
+
+[ACNS](https://acns2025.fordaysec.de/) (June 23-26)
+
+Participants: Jeff Burdges, Elizabeth Crites, Alistair Stewart, and Sergey Vasilyev
\ No newline at end of file
diff --git a/docs/Polkadot/Polkadot-Crypto.png b/docs/Polkadot/Polkadot-Crypto.png
new file mode 100644
index 00000000..3cce4204
Binary files /dev/null and b/docs/Polkadot/Polkadot-Crypto.png differ
diff --git a/docs/Polkadot/economics/1-validator-selection.md b/docs/Polkadot/economics/1-validator-selection.md
deleted file mode 100644
index c63a442a..00000000
--- a/docs/Polkadot/economics/1-validator-selection.md
+++ /dev/null
@@ -1,243 +0,0 @@
----
-title: Validator selection
----
-
-**Authors**: [Jonas Gehrlein](/team_members/Jonas.md)
-
-**Last updated**: 07.12.2020
-
-## Introduction
-
-The validator elections are essential for the security of the network, where nominators have the important task to evaluate and select the most trustworthy and competent validators. However, in reality this task is quite challenging and comes with significant effort. The vast amount of data on validators (which is constantly increasing) requires a substantial technical expertise and engagement. Currently, the process is too cumbersome and many nominators are either not staking or avoiding spending too much time to go through the large amount of data. Therefore, we need to provide tools, which both aid nominators in the selection process, while still ensuring that the outcome is beneficial for the network.
-
-The following write-up provides an overview of several potential steps, which benefit the nominators while maintaining their freedom of choice. As a first step, it is helpful to illustrate why recommendations should be based on user's preferences and cannot be universal for all individuals.
-
-### Problem
-It is not desirable to provide an exogenous recommendation of a set of validators, because user's preferences (especially risk-preferences) are quite different. Therefore, a comparison between metrics on different scales (e.g., self-stake in DOTs vs. performance in %) is not exogenously not possible. In addition, the shape of the marginal utility functions even within one dimension is unclear and based on individual's preferences. It is outside our competence to decide on various trade-offs of the selection process on behalf of nominators. To illustrate this issue, consider the following simple example:
-
-| | Commission | Self-Stake | Identity | Era-Points |
-| -------- | -------- | -------- | -------- | -------- |
-| Validator 1 | 4% | 26 DOTs | Yes | Average |
-| Validator 2 | 7% | 280 DOTs | No | Average - 1%|
-| Validator 3 | 1% | 1 DOT | No | Average + 5% |
-
-All validators in the table have different profiles, where none is dominated. Validator 3 potentially yield high profits but does not have much self-stake (skin-in-the-game) and is without registered identity. Validator 1 charges a higher fee for their service but might leverage a reputable identity. Validator 2 requires substantial fees but has the most self-stake. One could easily think of different preferences of users, who would prefer any one of those validators. While probably every user could make a choice from that selection, the problem gets increasingly difficult for a set of 200-1000 validators.
-
-
-### Code of conduct for recommendations
-As mentioned before, we cannot and do not want to give an exogenous recommendation to the users. We prefer methods, which values this insight and generates a recommendation based on their stated preferences. While valuing the preferences of the users, we still can *nudge* their decisions in a direction beneficial for the network (e.g., to promote decentralization). Nevertheless, the recommendation should be as objective as possible and should not discriminate against any specific validator.
-
-### Organization
-Validator selection is divided into several chapters. In the sections "Underlying dataset" (Link), we illustrate which data might be useful and how additional metrics can be generated. Afterwards, we can apply a simple concept from economics to significantly reduce the size of potentially intresting validators. Afterwards, This is the first step to give users a way to choose at hand. Then, we discuss some ideas to further curate the set of validators to promote goals of the network. As a last section the UTAStar method illustrates a sophisticated approach to estimate the individual marginal preference functions of the user and make a more precise recommendation.
-
-
-# Underlying Data
-This section explains which data can be gathered about validators in Polkadot and Kusama and are relevant for a selection process. Those metrics indicated with a * are used in the final data-set, the other variables are used to generate additional metrics. Currently, we focus on quantitative on-chain data as those are verifiable and easy to process. This purely quantitative approach should be regarded as complementary to a selection process based on qualitative data, where nominators are e.g., voting for validators based on their identity or influence / engagement in the community.
-
-## Retrievable data
-| Name | Historical | On-Chain | Description |
-|- |- |- |- |
-| Public Address* | No | Yes | The public identifier of the validator. |
-| Identity* | No | Yes | Is there a verified on-chain identity? |
-| Self-stake* | No | Yes | The amount of tokens used to self-elect. Can be seen as skin-in-the-game. |
-| Other-Stake | No | Yes | The amount of allocated stake (potentially) by other nominators. |
-| Total-Stake | No | Yes | The sum of self-stake and other-stake. |
-| Commission | Maybe | Yes | The amount of commission in % which is taken by the validator for their service. |
-| Era-Points | Yes | Yes | The amount of points gathered per era. |
-| Number of Nominators* | No | Yes | The amount of nominators allocated to a validator. |
-
-**Era-Points**: The era-points are awarded to a validator for performing beneficial action for the network. Currently this is mainly driven by block production. In general, the distribution of era-points should be uniformly distributed in the long run. However, this can vary if validators operates on a superior setup (stronger machine, more robust internet connection). In addition, there is significant statistical noise from randomness in the short-term, which can create deviations from the uniform distribution.
-
-
-
-## Generated metrics
-Some of the retrieved on-chain data might be not very useful for nominators or can serve some additional metrics, which help in the selection process.
-
-| Name | Historical | On-Chain | Description |
-|- |- |- |- |
-| Average Adjusted Era-Points | Yes | Yes | The average adjusted era-points from previous eras. |
-| Performance | Yes | Yes | The performance of a validator determined by era-points and commission. |
-| Relative Performance* | Yes | Yes | The performance normalized to the set of validators. |
-| Outperforming MLE | Yes | Yes | An indicator how often a validator has outperformed the average era-points. Should be 0.5 for an average validator. |
-| Average Performer* | - | Yes | A statistical test of the outperforming MLE against the uniform distribution. Indicates if a validator statistically over- or underperforms. |
-| Active Eras* | Yes | Yes | The number of active eras. |
-| Relative total stake* | No | Yes | The total stake normalized to the set of validators. |
-| Operator Size* | No | Yes | The number of validators which share a similar on-chain identity. |
-
-**Average Adjusted Era-Points**
-To get a more robust estimate of the era-points, additional data from previous eras should be gathered. Since the total era-points are distributed among all active validators, and the set of active validators might change, it could bias the results. To counter that, we can adjust the era-points of each era by the active set size of that era. As this is the only biasing factor on the theoretical per-capita era-points, we can thereby make the historic data comparable.
-
-It is unclear how many previous eras should be used as having a too long history might bias the results towards the average while too short of a history diminishes the robustness of the metric. One idea could be to use the average of $active-eras$.
-
-**Performance**: The performance of a validator from the point of view of a nominator is determined by the amount of era-points gathered by that validator, the nominator's share of the total stake and the commission a validator is charging. In addition, the performance level is linear in the bond of the nominator and is thereby independent from that. We can combine those metrics into one:
-
-$$
-performance = \frac{averageEraPoints \times (1 - commission)}{totalStake}
-$$
-
-The **relative performance** is then simply defined by:
-$$
-\frac{performance - min(performance)}{max(performance) - min(performance)}
-$$
-This gives a more understandable measure as the performance is normalized between 0 and 1. Additionally, it is robust to potential changes within the network (e.g. with a larger number of validators the era-points are reduced per era) and prevents false anchoring effects.
-
-**Outperforming MLE**: By gathering the historic era-points per validator during past eras, we can calculate how often a validator outperformed the average. As era-points should be distributed uniformly, a validator should outperform the average 50% of times. However, as mentioned before, in reality additional factors as hardware-setup and internet connection can influence this. This helps nominators to select the best performing validators while creating incentives for validators to optimize their setup.
-
-**Significance MLE**: As the expected value of the outperforming MLE is 0.5 and the distribution should be uniformly, we can calculate whether a validator significantly over- or underperforms by:
-$$
-z = \frac{outperformingMLE - 0.5}{\sqrt{\frac{0.5 \times (1-0.5)}{numberActive}}}
-$$
-
-If $z > 1.645$ we can say that the respective validator outperforms significantly (10% significance level), while $z < -1.645$ indicates significant underperformance.
-
-**Operator Size**: Based on the identity of a validator, we can estimate how many validators are run by the same entity. It is both in the interest of users and the network that there are not too many operators and that those operators are not too large. Selecting validators of larger operators might increase the risk of superlinear slashing, because it is reasonable to assume that those operators follow similar security practices. A failure of one validator might mean a failure of several of those validators which increases the punishment superlinearly. A counter-argument to this might be that larger operators are much more sophisticated with their setup and processes. Therefore, this objective measure should be left to the user to judge.
-
-# Filtering Phase
-
-## Dominance-Filtering
-After constructing the dataset as elaborated in the section "underlying data", we can start reducing the set of validators to reduce the amount of information a nominator has to process. One concept is to remove dominated validators. As we do not make qualitative judgements e.g., which "identity" is better or worse than another, we can remove validators who are inferior to another, since there is no rational reason to nominate them. A validator is dominated by another validator if all her properties are equal and at least one property is worse. Consider the following example:
-
-## Example:
-| Number | Public Address | Identity | Self-stake | Nominators | Relative Performance | Outperformer | Active Eras | Operator Size |
-|- |- |- |- |- |- |- |- |- |
-| 1 | 1N6xclmDjjA | 0 | 10 | 10 | 0 | 0 | 3 | 0 |
-| 2 | 1ohS7itG5Np | 0 | 200 | 40 | 0.7 | 0 | 4 | 2 |
-| 3 | 1xgFnMhdOui | 1 | 100 | 89 | 0.3 | 0 | 16 | 3 |
-| 4 | 1vO7JLtSm4F | 1 | 5000 | 89 | 1 | 1 | 29 | 3 |
-
-Validator 1 is dominated by Validator 2, which means that it is worse in every dimension (note, as mentioned above a user might prefer larger operators in which case this would not be true). Validator 3 is dominated by Validator 3 and therefore can be removed from the set. By this process the set can be reduced to two validators. In practice, this shows to be quite powerful to vastly reduce the set size.
-
-## Further curation
-Here we have the opportunity to do additional cleanup to the remaining set. As mentioned in the code of conduct, those should be optional but we can suggest default values for users.
-* Include at least 1 inactive validator. (we might suggest some inactive nodes based on some other processes.)
-* Reduce risk of super-linear slashing (i.e., remove validators from operators).
-* Remove validators who run on the same machine (some analysis of IP addresses possible?).
-
-# Manual selection
-After the set has been reduced by removing dominated validators and giving some filter option the user can easily select preferred validators manually. In this step, the selection is purely based on personal preferences and for example a nominator might order the validators by their relative performance and select those who also satisfy some requirements on a minimum self-stake.
-
-
-# UTAStar
-This method takes the filtered table from section LINK as input and therefore can be seen as a natural extension to the method before.
-## Overview
-UTA (UTilité Additive) belongs to the methods of preference disaggregation ([Jacquet-Lagrèze & Siskos, 1982](https://www.sciencedirect.com/science/article/abs/pii/0377221782901552)). UTAStar is an improvement on the original algorithm. The general idea is that the marginal utility functions of a decision makers (DM) on each dimension of an alternative (i.e. criterion) can be deduced from a-priori ranked lists of alternatives. It uses linear programming to search for utility functions which satisfy the initial ranking of the DM while giving other properties (such as the maximum utility is normalized to 1).
-
-### Some notation:
-**This writeup relies strongly on [Siskos et al., 2005](https://www.researchgate.net/publication/226057347_UTA_methods)**
-* $u_i$: marginal utility function of criteria i.
-* $g_1,g_2,...g_n$: Criteria.
-* $g_i(x)$: Evaluation of alternative x on the $i^{th}$ crterion.
-* $\textbf{g}(x)$: Vector of performances of alternative $x$ on $n$ criteria.
-* $x_1, x_2, ..., x_m \in X_L:$ Learning set which contain alternatives presented to the DM to give a ranking on. Note, that the index on the alternative is dropped.
-
-
-### Model
-The UTAStar method infers an unweighted additive utility function:
-
-$$
-u(\textbf{g}) = \sum_{i=1}^{n} u_i(g_i)
-$$
-
-where $\textbf{g}$ is a vector of performances. with the following constraints:
-
-$$
-\sum_{i=1}^{n} u_i(g^\star) = 1 \; \text{and} \; u_i(g_{i\star}) = 0 \; \forall i = 1,2,...,n
-$$
-
-where $u_i, i=1,2...,n$ are non decreasing valued functions which are normalized between 0 and 1 (also called utility functions).
-
-Thereby the value of each alternative $x \in X_L$:
-$$
-u'[\textbf{g}(x)]=\sum_{i=1}^{n}u_i[g_i(x)])+ \sigma^{+}(x) + \sigma^{-}(x) \forall x \in X_L
-$$
-where $\sigma^{+}(x)$ and $\sigma^{-}(x)$ are the under- and overestimation error. is a potential error relative to $u'[\textbf{g}(x)]$
-
-The corresponding utility functions are defined in a piecewise linear form to be estimated by linear interpolation. For each criterion, the interval $[g_{i\star}, g_i^\star]$ is cut into $(\alpha_i - 1)$ intervals and the endpoints $g_i^j$ are given by:
-
-$$
-g_i^j = g_{i\star} + \frac{j - 1}{\alpha_i - 1} (g_i^\star - g_{i\star}) \forall j = 1,2,...\alpha_i
-$$
-
-The marginal utility function of x is approximated by linear interpolation and thus for $g_i(x) \in [g_i^j - g_i^{j+1}]$
-
-$$
-u_i[g_i(x)]= u_i(g_i^j) + \frac{g_i(x)-g_i^j}{g_i^{j+1}-g_i^j}[u_i(g_i^{j+1}) - u_i(g_i^j)]
-$$
-
-The learning set $X_L$ is rearranged such that $x_1$ (best) is the head and $x_m$ is the tail (worst). This ranking is given by the user.
-
-$$
-\Delta(x_k, x_{k+1}) = u'[\textbf{g}(x_k)] - u'(\textbf{g}(x_{k+1}))
-$$
-
-then we can be sure that the following holds:
-
-$$
-\Delta(x_k, a_{k+1}) \geq \delta \; \textrm{iff} \; x_k > x_{k+1}
-$$
-
-and
-
-$$
-\Delta(x_k, x_{k+1}) = \delta \; \textrm{iff} \; x_k \backsim x_{k+1}
-$$
-
-where $\delta$ is a small and positive number which is an exogenous parameter set as the minimum discrepancy between the utilities of two consecutive options.
-In order to ensure monotonicity we further transform the utility differences between two consecutive interval endpoints:
-
-$$
-w_{ij} = u_i(g_i^{j+1}) - u_i(g_i^j) \geq 0 \forall i=1,...n \; and \; j = 1,... \alpha_i -1
-$$
-
-### Algorithm
-**Step 1**: Express the global value of the alternatives in the learning set $u[g(x_k)], k=1,2,...m$ in terms of marginal values $u_i(g_i)$ and then transform to $w_{ij}$ according to the above mentioned formula and by means of
-
-$$
-u_i(g_i^1) = 0 \; \forall i = 1,2...n
-$$
-
-and
-
-$$
-u_i(g_i^j) = \sum^{j-1}_{i=1}w_{ij} \; \forall i = 1,2..N \; and \; j=2,3,...\alpha_i - 1
-$$
-
-**Step 2**: Introduce two error functions $\sigma^{+}$ and $\sigma^{-}$ on $X_L$ by writing each pair of consecutive alternatives as:
-
-$$
-\Delta(x_k,x_k+1) = u[\textbf{g}(x_k)] - \sigma^{+}(x_k) + \sigma^{-}(x_k) - u[\textbf{g}(x_{k+1})] + \sigma^{+}(x_{k+1}) - \sigma^{-}(x_{k+1})
-$$
-
-**Step 3**: Solve the linear problem:
-
-$$
-[min] z = \sum_{k=1}^{m}[\sigma^{+}(x_k) + \sigma^{-}(x_k)] \\
-\text{subject to} \\
-\Delta(x_k, a_{k+1}) \geq \delta \; \textrm{iff} \; x_k > x_{k+1} \\
-\Delta(x_k, x_{k+1}) = \delta \; \textrm{iff} \; x_k \backsim x_{k+1} \; \forall k \\
-\sum_{i=1}^n \sum_{j=1}^{\alpha_i - 1}w_{ij} = 1 \\
-w_{ij} \geq 0, \sigma^{+}(x_k)\geq 0, \sigma^{-}(x_k)\geq 0 \forall i,j,k
-$$
-
-**Step 4**: Robustness analysis to find find suitable solutions for the above LP.
-
-**Step 5**: Apply utility functions to the full set of validators and return the 16 best scoring ones.
-
-**Step 6**: Make some ad hoc adjustments to the final set (based on input of the user). For example:
-* include favorites
-* at most one validator per operator
-* at least X inactive validators
-* etc.
-
-
-### Remaining Challenges
-There remain a few challenges when we want to apply the theory to our validator selection problem.
-
-1. One challenge is how to construct the learning set. The algorithm needs sufficient information to generate the marginal utility functions.
- - Find methods to guarantee performance dispersion of the different criteria.
- - Use machine learning approaches to iteratively provide smaller learning sets which gradually improve the information gathered.
- - Potentially use simulations to simulate a wide number of learning sets and all potential rankings on them to measure which learning set improves the information the most.
-2. UTAStar assumes piece-wise linear monotone marginal utility functions. Other, methods improve on that but might be more difficult to implement.
-
-
-
diff --git a/docs/Polkadot/economics/2-parachain-theory.md b/docs/Polkadot/economics/2-parachain-theory.md
deleted file mode 100644
index f9fa8c23..00000000
--- a/docs/Polkadot/economics/2-parachain-theory.md
+++ /dev/null
@@ -1,16 +0,0 @@
----
-title: Theoretical Analysis of Parachain Auctions
----
-
-**Authors**: Samuel Häfner and [Alistair Stewart](team_members/alistair.md)
-
-**Last updated**: April 17, 2021
-
-As explained [here](/Polkadot/overview/3-parachain-allocation.md) and [here](https://wiki.polkadot.network/docs/en/learn-auction) Polkadot uses a candle auction format to allocate parachain slots. A candle auction is a dynamic auction with the distinguishing feature that the ending time is random. In this project, we analyze the effects of such a random-closing rule on equilibrium play when some bidders have front-running opportunities.
-
-Front-running opportunities emerge on blockchains because upcoming transaction become known among the network participants before they are included in new blocks. For blockchain implementations of auctions, this means that some bidders can see and potentially react to other bidders' bids before they come into effect; i.e., are recorded on the chain and are thus taken into account by the auction mechanism. In first-price auctions, this gives tech-savvy bidders the possibility to outbid other bidders as they please. In second-price auctions, the auctioneer could raise the payment of the winning bidder at no cost by registering his own (pseudonymous) bidder.
-
-Whereas cryptographic solutions to these problems exist, they are either very computing intensive or require multiple actions by the bidders. In the presence of smart contracts, they do not work at all, because the actions of smart contracts are perfectly anticipatable. As an alternative that works without encrypting bids, this project analyzes a dynamic single-unit first-price auction with a random ending time. Time is discrete and in every round two bidders move sequentially in a fixed order. We show that a random-closing rule both revenue-dominates a hard-closing rule and makes participation for the bidder being front-run more attractive. In particular, under a uniform ending time distribution both the utility of the disadvantaged bidder and total revenues approach that of a second-price auction as the number of rounds grows large. Furthermore, the good is allocated efficiently.
-
-Reference:
-Samuel Häfner and Alistair Stewart (2021): Blockchains, Front-Running, and Candle Auctions. Working Paper. [SSRN](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3846363)
diff --git a/docs/Polkadot/economics/3-parachain-experiment.md b/docs/Polkadot/economics/3-parachain-experiment.md
deleted file mode 100644
index 022f11ca..00000000
--- a/docs/Polkadot/economics/3-parachain-experiment.md
+++ /dev/null
@@ -1,157 +0,0 @@
----
-title: Experimental Investigation of Parachain Auctions
----
-
-**Authors**: [Jonas Gehrlein](/team_members/Jonas.md), Samuel Häfner
-
-**Last updated**: 16.08.2021
-
-## Overview
-The goal of this project is to experimentally test the combinatorial candle auction as it is used in the Polkadot and Kusama protocol. In particular, we want to compare its outcome with those of more traditional, dynamic combinatorial auction formats employed today.
-
-What sets the candle auction apart from other dynamic auctions is that it has a random ending time. Such a closing-rule is important for auctions run on blockchains, because it mitigates several practical problems that other, more common auction formats suffer from (cf. Häfner & Stewart, 2021, for an analysis of the sinlge-unit case).
-
-The combinatorial candle auction has never been studied theoretically and empirically. Therefore, this project fills a gap in the literature. We hypothesize that the candle format is at par with, or even outperforms, dynamic combinatorial auctions that use specfic activity rules. Activity rules specify the feasible bids and close the auction when no more bids are entered in the system. Thus, they put pressure on the bidders to bid seriously early on. We expect a similar effect from the random ending time. In particular, we expect that the pressure to act induces - akin to activity rules - more efficient outcomes than in an auction with a simple hard-closing rule (i.e., a fixed ending time).
-
-We will conduct an experimental investigation with a design that mimics the basic mechanism of the Polkadot parachain auction. In particular, we conduct the experiment in a context where bidders can freely communicate and share their non-binding strategies before the auction. The implementation is off-chain and follows standard experimental economics procedures. Insights from the experiment can be used to gain an understanding of the bidding behavior and to compare efficiency across formats.
-
-
-## Dynamic Combinatorial Auctions
-
-In this section, we first discuss how combinatorial auctions are currently used. Second, we describe the combinatorial candle auction as it used on Polkadot, explain why we use this format, and what we expect about its performance vis-a-vis more standard combinatorial auction formats.
-
-### Currently used Combinatorial Auctions
-Historically, combinatorial auctions have emerged as successors of multi-unit auctions. Combinatorial auctions solve the so-called exposure problem from which multi-unit auctions suffer in the presence of complementarities (Porter and Smith, 2006; Cramton, 2013). In a multi-unit auction, the bidders compete for every unit separately. As a consequence, bidders aiming (and bidding) for a certain combination of items might suddenly find themselves in a situation of obtaining only a subset thereof, which has substantially lower value to them than the whole package. Combinatorial auctions allow bidders to place bids on packages directly and thus avoid this problem. That is, if you bid on a package then you either get the whole package, or nothing.
-
-Today, combinatorial auctions are employed in many contexts. The most well known applications of combinatorial auctions are radio spectrum auctions (Porter and Smith, 2006; Cramton, 2013). Other applications include electricity (Meeus et al., 2009), bus routes, and industrial procurement (cf. Cramton et al., 2006, for an overview).
-
-Many combinatorial auctions are dynamic. There are two distinct formats:
-
-1. *Ascending format*: As long as the auction is open, bidders can submit increasing bids for the different packages (experimentally studied Bichler et al. 2017).
-2. *Clock format*: The auctioneer raises the prices on the individual items or packages and in every round, the bidders have to submit their demand for the different packages. In some formats, bidders can submit last bids in one additional round of simultaneous bidding once the clock phase is over (initially suggested by Ausubel et al. 2006; further discussed in Cramton, 2013).
-
-For example, in the case of US radio spectrum auctions, simple, ascending multi-unit auctions were used first. Then, in 2006 and 2008 among others, the FCC allowed bidding on pre-defined packages of licences in an ascending format (Porter and Smith, 2006; Cramton, 2013). The switch to clock auctions occurred later on (Levin and Skrzypacz, 2016).
-
-An important design feature of any dynamic combinatorial auction is its so-called activity rule. The primary role of the activity rules is to encourage serious bidding from the start and to prevent sniping or jump-bidding.
-
-During the auction phase, the activity rule determines what kind of bids are feasible for any given bidder. In the case of the ascending bid format, the rule usually defines a minimum and a maximum increment that a new bid on a given item or package can have over an older bid (Scheffel et al., 2012). In the clock auction, the activity rule may prevent bidders from jumping onto a given package that they have ignored in earlier rounds; i.e., bidders may reduce demand but not increase it (Levin and Skrzypacz, 2016). In both the ascending auction and the clock auction, the rule sometimes also restricts bidders to bid on packages that are weakly smaller than the ones previously bid on (Cramton, 2013).
-
-Second, the activity rule determines when the auctions end based on all previously entered bids. In the ascending auction, the activity rule closes the auction when no new bids are entered in a round (Scheffel et al., 2012). In the clock auction, the prices on the individual packages are (simultaneously) raised until there is no excess demand for a package and the auction concludes when there is no excess demand for any of the packages (Bichler et al., 2013).
-
-
-
-### The Combinatorial Candle Auction
-In the combinatorial candle auction employed in Polkadot, bidders can submit bids in a pre-defined time window. Bids have to be increasinge but they are otherwise not restricted by an activitiy rule. After the window closes, the ending time is retroactively determined in a random fashion.
-
-Candle auctions are believed to have originated in medieval Europe and they derive their name from the particular way they were conducted. The auctioneer lights a candle in sight of all the bidders and accepts bids until the candle goes out. The highest bidder at the time the candle goes out is declared the winner (cf., e.g., Hobson, 1971). Earliest accounts of this kind of auction date back to 14th century France where they were used to sell chattels and leases. In England, furs were sold in candle auction up to the 18th century (cf. Füllbrunn and Sadrieh, 2012, for more details and references).
-
-Candle auctions have become rare today. A possible reason is that generic randomness is technically hard to achieve and that the commitment to a random device hard to verify. Recent cryptographic advances allow to circumvent these problems and put the candle auction back on the scene. For example, For example, Google held a patent on a dynamic auction with a random ending time that expired in 2020 (Patent No. US6665649B1).
-
-The main reason why the Polkadot protocol employs a candle mechnism is that it mitigates some of the problems associated with front-running in auctions. Front-running is a major problem of blockchain implementations of auctions. Because block production only happens at discrete intervals but all upcoming transactions are stored in the chain's mempool, tech-savvy bidders can in principle inspect and react to upcoming bids. The general worry is that this reduces the overall incentives to bid, thus reducing revenue and possibly efficiency. As argued in Häfner & Stewart (2021) cryptographic solutions to the problem -- though they exist -- are not feasible for the automated setting of Polkadot, primarily because we expect smart contracts among bidders.
-
-
-To the best of our knowledge, Füllbrunn and Sadrieh (2012) is the only experimental paper to also study a candle format. Other than in our planned experiment, they consider a single-unit auction with a second-price payment rule. In the second price auction, it is a weakly dominant strategy to bid the true value whenever there is a positive probability that the current round will be the terminal round. The experimental evidence largely confirms such a prediction. Other than in the first-price auction, where equilibrium bidding depends on the termination probabilities, expected revenue is independent of the termination probabilities.
-
-## Experimental Design
-
-We want to look at an ascending combinatorial auction with discrete rounds $t$ in which bids can be placed. There will be three bidders in every auction. After every round, all new bids are revealed. A round lasts for $6$ seconds.
-
-The set of items is $X = \{1,2\}$ giving us three packages $\{\{1\},\{2\},\{1,2\}\}$ on which bidders can submit bids. A bid $b=(p,x)$ consists of a price $p$ and any package $x \subseteq X$. Prices have to be increasing and must lie in a finite (fine) grid. The winning bids are selected to maximize total payment. The payment rule is pay-as-bid; i.e., winning bids have to be paid.
-
-### The Three Ending Formats
-We want to compare three ending formats: a candle format, a hard-closing rule, and an activity rule.
-
-| | Communication |
-|----------------|------------------|
-| Candle Auction | CA |
-| Hard-Close | HC |
-| Activity Rule | AR |
-
-
-**Candle Format** In the candle auction, bidders can freely submit increasing bids during the auction phase, and the auction is terminated at random. In the specification that we consider, the ending time is determined retroactively; i.e, bids on packages are accepted in a predefined number of rounds, $\bar T$, after which the auctioneer announces the ending time $T \in \{1,...,\bar T\}$. The ending time $T$ is random, the probability that the auction ends in round $t$ is publicly known and given by $q_t \in (0,1)$, where $\sum_{t=1}^{\bar T}q_t=1$.
-
-**Hard-Close Rule** In the hard-close auction, bidders can also freely submit increasing bids yet the auction ends at a fixed end time, $\bar T$.
-
-**Activity Rule** In the activity rule format, the ending time is determined by the activity rule. Specifically, bids have to be increasing and if no new bid is entered for $\tau$ rounds, then the auction concludes. For the experiment, we propose $\tau=5$ (corresponding to $30$ seconds).
-
-### Communication
-Communication is ubiquitous in the blockchain setting. The different bidders are teams that work on similar technical problems, share communication channels, post on social media, etc.
-
-Consequently, we will allow our experimental subjects to communicate in a chat before each auction and discuss non-binding strategies. Specifically, the bidders will have both an open chat as well as closed bilateral chat channels available. The chats will be open prior to the auction start and close thereafter.
-
-### Valuations
-In every auction, three bidders will be active. Bidders can have one of two roles that are commonly known when entering the auction: (1) global bidder, (2) local bidder. There will be one global bidder and two local bidders in every auction.
-
-The global bidder has a positive valuation only for the grand package, $\{1,2\}$. The local bidders hold valuations for the individual packages that add up in case they win the grand package. Specifically, we will assume
-
-
-
-In words, the global bidder draws a valuation $v$ for the package $\{1,2\}$ and always holds a valuation of zero for the packages $\{1\}$ and $\{2\}$. On the other hand, local bidder $i = 1,2$ draws a valuation $v_i$ for $\{1\}$, implying that she values item $\{2\}$ at $80-v_i$ and package $\{1,2\}$ at $80$.
-
-Under this value model it is efficient for the global bidder to obtain the grand package whenever $v \geq \max \{80-v_1+v_2,80-v_2+v_1\}$ and for the two local bidders to each receive one of the items otherwise. In order to win against the global bidder, though, the local bidders must coordinate their bids accordingly.
-
-
-### Hypotheses
-We will be interested in the following outcome variables:
-
-* Efficiency: In what fraction of the auctions does the resulting allocation correspond to the first-best allocation?
-* Revenue: Equals to the total bids paid. This also allows us to compute average shading ratios.
-* Bidding dynamic: How fast do bids increase? Do we see sniping?
-
-In general, the random ending time puts pressure to submit serious bids early on in the auction. We expect this to have two effects vis-a-vis a hard-closing rule (under which the auction ends at a fixed end date) that are similar to what activity and feedback rules should achieve. That is, we conjecture that a candle format can replace these rules to some extent.
-
-* Hypothesis I: Early bids in the candle auction are higher than under the activity rule; and they are higher under the activity rule than they are under the hard-close rule.
-* Hypothesis II: The candle format and the hard-close rule fare better than the hard-close rule in terms of revenue and efficiency.
-* Hyptothesis III: The candle format and the hard-close rule fare similarly in terms of revenue and efficiency. Perhaps: Efficiency is slightly worse in the candle auction while revenue is slightly better.
-
-### Procedure
-
-#### Stage 1: Instructions
-At the beginning of the experiment, participants are randomly allocated to one of the three different auction formats and receive information about specific rules of the game. To ensure that subjects understand the game, we will also ask a few comprehension question.
-
-#### Stage 2: The Auctions
-Before each auction, all bidders learn their type and their private valuations for the individual packages. Each market consists of one global and two local bidders. Their roles remain fixed throughout the experiment but new values are drawn each new auction. To better compare the results across the treatments, we can fix the random draws (i.e., the seed) for each auction across treatments. Every subject participates at n=X auctions while we make sure that we re-shuffle subjects into markets to match a (near-) perfect stranger design. Then, the communication phase starts where all participants of an auction can discuss openly in a chat-format for 45 seconds. After this, the auction starts and subjects are free to submit bids.
-
-The trading page features two tables:
-
-1. (Table 1) Current winning bids: This shows all current bids per package.
-
-2. (Table 2) Winning Allocation: This shows how the packages are currently allocated to bidders based on the current winning bids.
-
-Especially table 2 is considered to significant help with this complex auction design.
-
-#### Stage 3: Feedback and Payoff
-After the end of the auction (depending on the treatment), participants receive feedback about the final winning bids and allocation of packages. In addition, subjects in the candle auction format are informed about the realization of $T$ and the respective snapshot of winning bids to that time. Profits are calculated and shown to the subjects. Afterwards, the next auction (if there are any) is started and new valuations are drawn for each subject.
-
-
-### Outcome variables
-* Success of coordination (given the realized values, were the local bidders able to form a coalition?)
-* Efficiency (Did the packages go to those with the highest valuation? Did they coordinate on the right allocation)
-* Bidding dynamic (how quickly converges the auction)
-* Revenue
-
-### Implementation
-The experiment will be implemented with [oTree](https://www.sciencedirect.com/science/article/pii/S2214635016000101), which is a software to conduct online experiments and provide the necessary infrastructure to create sessions, distribute links to users and maintain a database of behavioral data. It combines python in the back-end with a flexible front-end implementation of HTML/CSS and Django.
-
-## Literature
-Ausubel, L. M., Cramton, P., & Milgrom, P. (2006). The clock-proxy auction: A practical combinatorial auction design. Combinatorial Auctions, 120-140.
-
-Bichler, M., Hao, Z., & Adomavicius, G. (2017). Coalition-based pricing in ascending combinatorial auctions. Information Systems Research, 28(1), 159-179.
-
-Cramton, P. (2013). Spectrum auction design. Review of Industrial Organization, 42(2), 161-190.
-
-Cramton, P., Shoham, Y., & Steinberg, R. (2006). Introduction to combinatorial auctions. Combinatorial auctions, 1-14.
-
-Füllbrunn, S. and A. Sadrieh (2012): \Sudden Termination Auctions|An Experimental Study," Journal of Economics & Management Strategy, 21, 519-540.
-
-Häfner, S., & Stewart, A. (2021). Blockchains, Front-Running, and Candle Auctions. Working Paper, [SSRN](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3846363).
-
-Hobson, A. (1971): A Sale by Candle in 1608," The Library, 5, 215-233.
-
-Levin, J., & Skrzypacz, A. (2016). Properties of the combinatorial clock auction. American Economic Review, 106(9), 2528-51.
-
-Meeus, Leonardo, Karolien Verhaegen, and Ronnie Belmans. “Block order restrictions in combinatorial electric energy auctions.” European Journal of Operational Research 196, No. 3 (2009): 1202-1206.
-
-Porter, David, and Vernon Smith. “FCC license auction design: A 12-year experiment.” Journal of Law, Economics & Policy 3 (2006): 63.
-
-Scheffel, T., Ziegler, G., & Bichler, M. (2012). On the impact of package selection in combinatorial auctions: an experimental study in the context of spectrum auction design. Experimental Economics, 15(4), 667-692.
diff --git a/docs/Polkadot/economics/4-gamification.md b/docs/Polkadot/economics/4-gamification.md
deleted file mode 100644
index c06bb857..00000000
--- a/docs/Polkadot/economics/4-gamification.md
+++ /dev/null
@@ -1,107 +0,0 @@
----
-title: Non-monetary incentives for collective members
----
-
-**Authors**: [Jonas Gehrlein](/team_members/Jonas.md)
-
-**Last updated**: 13.04.2023
-
-## Overview
-
-Behavioral economics has proven that non-monetary incentives are viable motivators and resemble an alternative to incentives created by money (see, e.g., [Frey & Gallus, 2015](https://www.bsfrey.ch/articles/C_600_2016.pdf)). This is especially true for environments where behavior is mainly driven by intrinsic motivation. In those situations, monetary incentives can even crowd-out the intrinsic behavior leading to less motivation ([Gneezy & Rustichini, 2000](https://academic.oup.com/qje/article-abstract/115/3/791/1828156)). The current advances in technologies surrounding Non-fungible Tokens (NFTs) can be utilized as an additional incentive layer for governance participation and the engagement of collective members. NFTs as tool can be perfectly combined with insights from the academic literature about the concept of "gamification" to foster engagement and reward good behavior.
-
-This can help improve on a few issues that are inherent to governance, especially low participation.
-
-### Problem statement
-
-Governance is one of the most important aspects of the future of decentralized systems such as DAOs and other collectives. They rely on active participation of the token holders to achieve an efficient decision making. However, turnout-rates of tend to be quite low, which opens up the danger of exploits by a very motivated minority. There are many points to prevent this from happening, for example usability and user experience improvements to the governance process.
-
-This write-up focuses on providing non-monetary incentives as motivator to engage more actively in a collective. It can be applied to layer0 governance or smaller collectives (DAOs).
-
-
-### Goals
-
-The goals is to design a mechanism which automatically applies certain tools from gamification (e.g., badges, achievements, levels) to collective members to...
-
-* ... promote the engagement and liveness of members.
-* ... use established techniques from the literature to improve on the whole governance process.
-* ... make it easier for users to evaluate and compare members.
-
-Improving on all those domains would further strengthen the position of the network in the blockchain ecosystem.
-
-## Literature
-
-Gamification received increasing attention in the recent years and was even called the "most notable technological developments for human
-engagement" ([Majuri et al., 2018](https://trepo.tuni.fi/bitstream/handle/10024/104598/gamification_of_education_2018.pdf)). It is used to enhance learning outcomes (e.g., [Denny, 2013](https://dl.acm.org/doi/abs/10.1145/2470654.2470763?casa_token=XsWtSZeFt-QAAAAA:MPWbtFfjzQZgWzyTI9hWROarJb1gJDWqDHNG4Fyozzvz3QIK-kMuMxfSwE26y9lKYUuZnV7aDZI)), model online communities (e.g., [Bista, 2012a](https://ieeexplore.ieee.org/abstract/document/6450959)) and improve sustainable behavior (e.g., [Berengueres et al., 2013](https://ieeexplore.ieee.org/abstract/document/6483512?casa_token=tmdUK7mtSSEAAAAA:ZxJnvYNAcuRaMHbwNqTJnahpbxal9xc9kHd6mY4lIahFhWn2Gmy32VDowMLVREQjwVIMhd9wcvY)). Gamification can be used as "means of supporting user engagement and enhancing positive patterns in service use, such as increasing user activity, social interaction, or quality and productivity of actions" ([Hamari, Koivisto & Sarsa, 2014](https://ieeexplore.ieee.org/abstract/document/6758978?casa_token=F2o_LQE-CNgAAAAA:vA_xBEe0ltKmMPRmTfkyW78LThHP9hLKK06oj1gKpOeDfoCTG7l_p-KSVlcdhNpaErLjzrm8p90)). While there is no agreed-upon definition, it can be best described as "a process of enhancing a service with affordances for gameful experiences in order to support user's [sic] overall value creation” ([Huotari & Hamari, 2012, p. 19](https://dl.acm.org/doi/abs/10.1145/2393132.2393137?casa_token=MU2yq2P4TOoAAAAA:Xuy9ZEzo2O7H-WCbqMheezkrodpab2DlFWkLjVt3jYExuP--vsjEROt4BKt5ZEbVou9rVnQSQBs)). That means, applying this concept does change the underlying service into a game but rather enriches it with motivational affordances popular in gaming (points, levels, badges, leaderboards) ([Deterding, 2012](https://dl.acm.org/doi/fullHtml/10.1145/2212877.2212883?casa_token=B9RD9ZPneIMAAAAA:34lrdGKwOUZyZu8fLobERuPLIBzNQxxwlgWLJnonn5Ws8Ya65aO_pdifhlHiSBwjDb0mWyFD0aM), [Hamari, Koivisto & Sarsa, 2014](https://ieeexplore.ieee.org/abstract/document/6758978?casa_token=F2o_LQE-CNgAAAAA:vA_xBEe0ltKmMPRmTfkyW78LThHP9hLKK06oj1gKpOeDfoCTG7l_p-KSVlcdhNpaErLjzrm8p90)).
-Zichermann & Linder (2010) argue that that intrinsic motivation is unreliable and variable. Thereby, gamification can craft extrinsic motivators to internalize the intrinsically motivated behavior. It is crucial that this is done with non-economic incentives, because monetary incentives could lead to the crowding-out of intrinsic motivation ([Gneezy & Rustichini, 2000](https://academic.oup.com/qje/article-abstract/115/3/791/1828156)). A field where gamification has not yet been (explicitly) applied systematically is voting behavior (i.e., governance participation). One notable exception is a large-scale experiment with 61 million users of facebook, where researchers found that an *I voted* indication on their status page, could have been responsible for about 340'000 additional voters in the 2010 election ([Bond et al., 2012](https://www.nature.com/articles/nature11421) and [this article](https://www.nature.com/news/facebook-experiment-boosts-us-voter-turnout-1.11401)). The main driver here is considered to be peer-pressure elicited on facebook friends. While the researchers did not explicitly link this intervention with gamification, it could be perceived as such and might also work to incentivize participation of a small group. A similar application is the famous *I voted* badge in US elections, which has proven to be successful ([see](https://www.usvotefoundation.org/voter-reward-badge)). Voters like to show off badge and motivate others to go as well (some shops even offer perks for customers having that badge).
-
- A review on 91 scientific studies reveals that gamification provides overall positive effects in 71% of cases, 25% of cases no effect and only in 3% of studies were negative results reported ([Majuri et al., 2018](https://trepo.tuni.fi/bitstream/handle/10024/104598/gamification_of_education_2018.pdf)). such as increased engagement and enjoyment, while awcknowledging that the effectiveness is context-dependent. Despite the overwhelming majority of positive results, some studies indicate negative effects of gamification and suggest that there are some caveats. One source of negative effects are higher perceived competition of the interaction with peers, which could demotivate some users ([Hakulinen et al., 2013](https://ieeexplore.ieee.org/abstract/document/6542238)). Another reason for critique is the lack of clear theoretical foundation and the resulting diverse approach to the questions.
-
-The design process of the gamification elements can be further influenced by insights from related social science research. Namely how to counter some psychological biases affecting decision making in small committees as well as leveraging additionally motivational factors generated by *loss-aversion* and the resulting *endowment effect*.
-
-Literature has shown, that small decision making groups tend to suffer from *group think*. This bias describes the situation, where the outcome from the decision process is far from optimal, because the individuals of the group do not speak their opinions freely ([Janis, 1971](http://agcommtheory.pbworks.com/f/GroupThink.pdf)) or are influenced in a way that they act against their best knowledge (consciously or unconsciously). This issue arises especially in groups comprised of members with different power and status. Major disasters have been accounted to *group think*, such as the *Bay of Pigs Invasion* and the *Space Shuttle Challenger disaster* ([Janis, 1991](https://williamwolff.org/wp-content/uploads/2016/01/griffin-groupthink-challenger.pdf)). In later analyses it was found that there were plenty of evidence available, which had been willingful neglected by committee members. This problem is also related to the pressure to behave conform with authority figures, as illustrated by famous psychological experiments (e.g., [Milgram, 1963](https://www.demenzemedicinagenerale.net/pdf/MilgramOriginalWork.pdf), [Asch, 1961](https://psycnet.apa.org/record/1952-00803-001)). It is crucial to keep that in mind, to mitigate that problem by dividing the final decision between important stake-holders. However, knowing about this issue, we can implement mechanisms to further improve the outcome of the decision making. A study by [MacDougall & Baum (1997)](https://journals.sagepub.com/doi/abs/10.1177/104973239700700407) has shown that explicitly announcing a "devil's advocate" can improve the outcome by challenging the consensus frequently.
-
-Studies in behavioral economics further show that individual decision making is influenced by *loss-aversion*. This results from a non-linear utility function with different shapes in the gain and loss domain of a subjective evaluation of an outcome relative to some reference point. Specifically, the absolute dis-utility of a loss is higher than the gain in utility of a corresponding gain ([Kahneman & Tversky, 1992](https://link.springer.com/article/10.1007/BF00122574)). A resulting effect of that is the *endowment effect* ([Kahneman, Knetsch & Thaler, 1990](https://www.journals.uchicago.edu/doi/abs/10.1086/261737)), which describes the situation where a good is valued much more only because of the fact of possessing it. A practical implication for design of incentive systems is that users are exerting higher effort to keep something once there is the option to lose it again.
-
-
-In conclusion, a carefully designing gamified experience can improve the overall governance process and result in more active discussions, and hopefully better decisions.
-
-
-## Awarding mechanism (WIP)
-In general, the most commonly used gamification elements are ([Hamari, Koivisto & Sarsa, 2014](https://ieeexplore.ieee.org/abstract/document/6758978?casa_token=F2o_LQE-CNgAAAAA:vA_xBEe0ltKmMPRmTfkyW78LThHP9hLKK06oj1gKpOeDfoCTG7l_p-KSVlcdhNpaErLjzrm8p90)):
-
-* Points
-* Badges (Trophies)
-* Achievements
-* Levels
-
-A very complex task is to design an automatic mechanism to award members NFTs based on their on-chain (and potentially off-chain) behavior. On the one hand, focusing only on easily measurable outcome levels of participation (e.g., speed of voting, pure quantity of propositions) can easily backfire and are prone to be abused. In addition, it is hard to deduce the quality of a vote by those quantitative measurements. To mitigate this, it is important to observe the whole process and the later outcome of the election.
-
-On the other hand, only incentivizing positive election outcomes could make members too conservative, only proposing winners, neglecting provocative but potentially beneficial proposals. The best strategy is to come up with a mix of different NFTs where the positive weights of the individual NFTs are less severe and therefore leave enough space for all behavior.
-
-In addition, the proposed NFTs should also incorporate important insights from social science research (as mentioned above e.g., to incorporate preventive measures against *Groupthink* or design some NFTs to leverage *Loss-Aversion*).
-
-### Achievements (static)
-
-Achievements are absolute steps to be reached and cannot be lost, once obtained. Potential triggers could be:
-
-* Become a collective member of a certain age
-
-
-### Badges (perishable)
-Generally, Badges are perishable and resemble an achievement relative to something. This means, once the relative status is lost, so is the badge. This is a very interesting concept as it incorporates the motivating factor of the *endowment-effect* (see literature section), where individuals exert higher motivation to hold on to the badge.
-
-Those are good to include states of the situation such as:
-
-* Be the most backed member (if there is some hierarchy in the system)
-* Be the oldest member
-* The devil's advocate (frequently vote against the majority of other members)
-
-### Levels (ranks)
-Gaining certain badges could also mean we can implement some level system which could essentially sum up all the badges and achievements into one quantifiable metric.
-
-### Actions
-The following list, composed by Raul Romanutti, illustrates several frequent actions members can perform and build a good basis of outcome variables to be entwined in an awarding mechanism. This is highly context-specific but might give some examples and are suited to treasury spendings and other proposals.
-
-* Vote on a treasury proposal motion
-* Vote on a runtime upgrade motion
-* Vote on referendum
-* Submit an external motion proposal
-* Submit a preimage for a proposal
-* Close a motion after majority is reached
-* Vote on a treasury proposal motion (proposed by community members)
-* Endorse a tip proposal (proposed by community members)
-* Open a tip to a community member
-* Open a bounty proposal
-* Vote on a bounty proposal
-* Vote on a Bounty curator nomination
-* Open a motion to unassign a bounty curator
-* Become the curator of an active bounty
-* Propose an external motion for a specific chain to use a common-good chain slot
-* Vote on an external motion for a specific chain to use a common-good chain slot
-
-## NFT Gallery
-A prerequisite for NFTs to develop their motivating effect, it is necessary to visually display them and make them viewable in NFT galleries. This requires the support of wallets and explorers. Due to the popularity of NFTs, many of projects are currently working on those solutions and it is expected that solutions will further improve.
-
-As an additional benefit, governance focused applications could orderly display the members, their achievements / badges and levels, which can make it also much more easy and enjoyable for outsiders of the decision-making process to compare and engage with the collective members. This could substantially improve the engagement of members, and results are more precise in representing the opinion of all stakeholders. This, in turn, would further increase the incentives exerted by the NFTs on the members.
-
diff --git a/docs/Polkadot/economics/5-utilitytokendesign.md b/docs/Polkadot/economics/5-utilitytokendesign.md
deleted file mode 100644
index c8ac55ab..00000000
--- a/docs/Polkadot/economics/5-utilitytokendesign.md
+++ /dev/null
@@ -1,19 +0,0 @@
----
-title: Utility Token Design
----
-
-**Authors**: Samuel Häfner
-
-**Last updated**: October 13, 2021
-
-**Paper Link:** [[SSRN]](http://ssrn.com/abstract=3954773)
-
-In this project, I analyze some general design principles of utility tokens that are native to a proof-of-stake blockchain. Utility tokens are cryptographic tokens whose main economic use is to access and consume the respective token issuer’s services.
-
-The services offered by the Polkadot network consist of parachain slots, which come with shared security and means to communicate with other parachains. To obtain one of the slots, the users --- i.e., the teams building on Polkadot --- need to put forth DOTs in recurrent slot auctions.
-
-For the analysis, I set up a dynamic general equilibrium model of utility tokens that serve as a means to consume services on a two-sided market platform.
-
-On the one side of the platform, there are users that derive utility from consuming the services provided by the platform. On the other side, there are validators that provide the required security and receive tokens in return. Validators need to repeatedly sell some of their tokens to cover their costs; users need to repeatedly buy tokens to consume the services. A token market balances token supply and token demand.
-
-The main results of the analysis are the following: First, I find that utility token markets are generally efficient because they result in the socially optimal provision of services. Second, I uncover a tension between the dynamics of utility tokens' value, the evolution of the provided services, and the payment details on the users’ side.
diff --git a/docs/Polkadot/economics/Economics.png b/docs/Polkadot/economics/Economics.png
new file mode 100644
index 00000000..b338e819
Binary files /dev/null and b/docs/Polkadot/economics/Economics.png differ
diff --git a/docs/Polkadot/economics/academic-research/Combinatorial-candle-auction.png b/docs/Polkadot/economics/academic-research/Combinatorial-candle-auction.png
new file mode 100644
index 00000000..729b2af5
Binary files /dev/null and b/docs/Polkadot/economics/academic-research/Combinatorial-candle-auction.png differ
diff --git a/docs/Polkadot/economics/academic-research/Experimental-investigations.png b/docs/Polkadot/economics/academic-research/Experimental-investigations.png
new file mode 100644
index 00000000..e96236c2
Binary files /dev/null and b/docs/Polkadot/economics/academic-research/Experimental-investigations.png differ
diff --git a/docs/Polkadot/economics/academic-research/collective-members.png b/docs/Polkadot/economics/academic-research/collective-members.png
new file mode 100644
index 00000000..4383e64f
Binary files /dev/null and b/docs/Polkadot/economics/academic-research/collective-members.png differ
diff --git a/docs/Polkadot/economics/academic-research/gamification.md b/docs/Polkadot/economics/academic-research/gamification.md
new file mode 100644
index 00000000..65b48338
--- /dev/null
+++ b/docs/Polkadot/economics/academic-research/gamification.md
@@ -0,0 +1,118 @@
+---
+title: Non-monetary incentives for collective members
+---
+
+| Status | Date | Link |
+|----------------|------------|----------------------------------------------------------------------|
+| Stale | 06.10.2025 | -- |
+
+
+
+Behavioral economics has demonstrated that non-monetary incentives can be powerful motivators, offering a viable alternative to financial rewards (see, e.g., [Frey & Gallus, 2015](https://www.bsfrey.ch/articles/C_600_2016.pdf)). This is especially true in environments where intrinsic motivation drives behavior. In such contexts, monetary incentives may even crowd out intrinsic motivation, ultimately reducing engagement ([Gneezy & Rustichini, 2000](https://academic.oup.com/qje/article-abstract/115/3/791/1828156)).
+
+Recent advances in technologies surrounding Non-fungible Tokens (NFTs) present a promising new layer of incentives for governance participation and collective engagement. NFTs, as a tool, can be effectively combined with insights from academic literature on gamification to encourage participation and reward good behavior. This can help address several inherent challenges in governance, particularly low participation.
+
+### Problem statement
+
+Governance is one of the most critical aspects for the future of decentralized systems, such as DAOs and other collectives. These systems rely on active paritcipation from token holders to enable efficient decision-making. However, turnout rates tend to be quite low, which creates the risk of governance exploits by a highly motivated minority. Several factors can help mitigate the risk, for example enhancing usability and user experience within the governance process.
+
+This entry explores non-monetary incentives as a means to encourage more active engagement within a collective. The approach can be applied to layer0 governance as well as smaller collectives, such as DAOs.
+
+
+### Goals
+
+The goal is to design a mechanism that automatically applies selected gamification tools such as badges, achievements, and levels to collective members in order to:
+
+* Promote the engagement and liveness of members.
+* Leverage established techniques from the literature to improve the overall governance process.
+* Enable users to evaluate and compare members more efficiently.
+
+Advancing in these areas would further strengthen the network's position within the blockchain ecosystem.
+
+## Literature
+
+In recent years, gamification has received growing attention, so much that it has been called the "most notable technological developments for human
+engagement" ([Majuri et al., 2018](https://trepo.tuni.fi/bitstream/handle/10024/104598/gamification_of_education_2018.pdf)). Gammification is used to enhance learning outcomes (e.g., [Denny, 2013](https://dl.acm.org/doi/abs/10.1145/2470654.2470763?casa_token=XsWtSZeFt-QAAAAA:MPWbtFfjzQZgWzyTI9hWROarJb1gJDWqDHNG4Fyozzvz3QIK-kMuMxfSwE26y9lKYUuZnV7aDZI)), model online communities (e.g., [Bista, 2012a](https://ieeexplore.ieee.org/abstract/document/6450959)), and promote sustainable behavior (e.g., [Berengueres et al., 2013](https://ieeexplore.ieee.org/abstract/document/6483512?casa_token=tmdUK7mtSSEAAAAA:ZxJnvYNAcuRaMHbwNqTJnahpbxal9xc9kHd6mY4lIahFhWn2Gmy32VDowMLVREQjwVIMhd9wcvY)). Gamification can serve as a "means of supporting user engagement and enhancing positive patterns in service use, such as increasing user activity, social interaction, or quality and productivity of actions" ([Hamari, Koivisto & Sarsa, 2014](https://ieeexplore.ieee.org/abstract/document/6758978?casa_token=F2o_LQE-CNgAAAAA:vA_xBEe0ltKmMPRmTfkyW78LThHP9hLKK06oj1gKpOeDfoCTG7l_p-KSVlcdhNpaErLjzrm8p90)).
+
+While a universally accepted definition is still lacking, gammification is best described as "a process of enhancing a service with affordances for gameful experiences in order to support user's [sic] overall value creation” ([Huotari & Hamari, 2012, p. 19](https://dl.acm.org/doi/abs/10.1145/2393132.2393137?casa_token=MU2yq2P4TOoAAAAA:Xuy9ZEzo2O7H-WCbqMheezkrodpab2DlFWkLjVt3jYExuP--vsjEROt4BKt5ZEbVou9rVnQSQBs)). In other words, applying gammification does not turn a service into a game, it rather enriches it with motivational elements popular in gaming, such as points, levels, badges, and leaderboards ([Deterding, 2012](https://dl.acm.org/doi/fullHtml/10.1145/2212877.2212883?casa_token=B9RD9ZPneIMAAAAA:34lrdGKwOUZyZu8fLobERuPLIBzNQxxwlgWLJnonn5Ws8Ya65aO_pdifhlHiSBwjDb0mWyFD0aM), [Hamari, Koivisto & Sarsa, 2014](https://ieeexplore.ieee.org/abstract/document/6758978?casa_token=F2o_LQE-CNgAAAAA:vA_xBEe0ltKmMPRmTfkyW78LThHP9hLKK06oj1gKpOeDfoCTG7l_p-KSVlcdhNpaErLjzrm8p90)).
+Zichermann & Linder (2010) argue that intrinsic motivation is unreliable and variable. Therefore, gamification can be used to design extrinsic motivators that support the internalization of intrinsically motivated behavior. It is crucial to rely on non-economic incentives, as monetary rewards may crowd out intrinsic motivation ([Gneezy & Rustichini, 2000](https://academic.oup.com/qje/article-abstract/115/3/791/1828156)).
+
+One field where gamification has not yet been systematically applied is voting behavior, particularly governance participation. A notable exception is a large-scale experiment involving 61 million Facebook users, where researchers found that an *I voted* indication on users' status pages may have led to approximately 340,000 additional voters in the 2010 U.S. election ([Bond et al., 2012](https://www.nature.com/articles/nature11421) and [this article](https://www.nature.com/news/facebook-experiment-boosts-us-voter-turnout-1.11401)). The main driver was considered to be peer pressure among Facebook friends. While researchers did not explicitly link this intervention to gamification, it can be interpreted as such, and may have incentivize participation among a small group.
+
+A similar example is the well-known *I voted* badge used in U.S. elections, which has proven quite [successful](https://www.usvotefoundation.org/voter-reward-badge). Voters enjoy displaying the badge and often motivate others to vote as well. Some businesses even offer perks to customers who show the badge.
+
+ A review of 91 scientific studies on gamificaton in education revealed that 71% reported mainly positive effects, such as increased engagement and enjoyment, while 25% showed no significant effect, and only 3% reported negative outcomes ([Majuri et al., 2018](https://trepo.tuni.fi/bitstream/handle/10024/104598/gamification_of_education_2018.pdf)). While acknowledging the effectiveness is context-dependent, and despite the overwhelming majority of positive results, some studies do not report negative effects, highlighting important caveats. One source of negative impact is the heightened perception of competition among peers, which can demotivate certain users ([Hakulinen et al., 2013](https://ieeexplore.ieee.org/abstract/document/6542238)). Another common critique is the lack of a clear theoretical foundation, leading to diverse and inconsistent approaches across studies.
+
+The design process behind gamification elements can be further informed by research from the social sciences, particularly in countering psychological biases that affect decision-making in small committees, and in leveraging additional motivational factors such as *loss aversion* and the resulting *endowment effect*.
+
+Literature has shown that small decision-making groups often suffer from *groupthink*, a bias in which the outcome of the decision process is far from optimal, as individuals do not freely express their opinions ([Janis, 1971](http://agcommtheory.pbworks.com/f/GroupThink.pdf)) or are influenced to act against their better judgement, whether consciously or unconsciously. This issue is particularly pronounced in groups comprised of members with differing levels of power and status. Major disasters have been attributed to *groupthink*, including the *Bay of Pigs Invasion* and the *Space Shuttle Challenger disaster* ([Janis, 1991](https://williamwolff.org/wp-content/uploads/2016/01/griffin-groupthink-challenger.pdf)).
+
+Subsequent analyses revealed that committe members often willfully ignored substantial evidence. This problem is closely linked to the pressure to conform to authority figures, as demonstrated by well-known psychological experiments such as those conducted by [Milgram, 1963](https://www.demenzemedicinagenerale.net/pdf/MilgramOriginalWork.pdf) and [Asch, 1961](https://psycnet.apa.org/record/1952-00803-001).
+
+It is crucial to remain aware of these dynamics and mitigate them by distributing final decision-making power among key stake-holders. With this awareness, mechanisms can be implemented to further improve decision outcomes. For example, a study by [MacDougall & Baum (1997)](https://journals.sagepub.com/doi/abs/10.1177/104973239700700407) demonstrated that explicitly appointing a "devil's advocate" can enhance results by regularly challenging group consensus.
+
+Studies in behavioral economics show that individual decision-making is influenced by *loss aversion*. This phenomenon arises from a non-linear utility function, where the subjective evaluation of outcomes differs between gains and lossess relative to a reference point. Specifically, the disutility of a loss is greater than the utility gained from an equivalent gain ([Kahneman & Tversky, 1992](https://link.springer.com/article/10.1007/BF00122574)). One consequence of this is the *endowment effect* ([Kahneman, Knetsch & Thaler, 1990](https://www.journals.uchicago.edu/doi/abs/10.1086/261737)), which describes the tendency to value an item simply because one possesses it. A practical implication for incentive system design is that users tend to exert greater effort to retain something when there is a possibility of losing it.
+
+
+In conclusion, carefully designing a gamified experience can enhance the overall governance process, leading to more active discussions, and, ideally, better decisions.
+
+
+## Awarding mechanism (WIP)
+As [Hamari, Koivisto & Sarsa, 2014](https://ieeexplore.ieee.org/abstract/document/6758978?casa_token=F2o_LQE-CNgAAAAA:vA_xBEe0ltKmMPRmTfkyW78LThHP9hLKK06oj1gKpOeDfoCTG7l_p-KSVlcdhNpaErLjzrm8p90) have pointed out, the most commonly used gamification elements generally include:
+
+* Points
+* Badges (or trophies)
+* Achievements
+* Levels
+
+Designing an automatic mechanism to award members NFTs based on their on-chain (and potentially off-chain) behavior is highly complex. On one hand, focusing solely on easily measurable outcomes, such as voting speed or the sheer number of propositions, can backfire and is prone to abuse. Moreover, assessing the quality of a vote through quantitative metrics alone is challenging. To address this, it is essential to observe the entire process and the eventual outcome of the election.
+
+On the other hand, incentivizing only positive election outcomes could lead members to become overly conservative, proposing only safe, likely-to-win ideas while neglecting provocative but potentially beneficial proposals. The best strategy, therefore, is to design a mix of different NFTs, where the positive weighting of each individual NFTs is less pronounced, allowing room for a broader range of behaviors.
+
+In addition, the proposed NFTs should incorporate important key insights from social science research, as mentioned above. For example, some NFTs could include preventive measures against *groupthink*, while others could be designed to leverage *loss aversion*.
+
+### Achievements (static)
+
+Achievements are absolute milestones that, once reached, cannot be lost. Potential triggers include:
+
+* Becoming a collective member of a certain age
+
+
+### Badges (perishable)
+Badges are generally perishable and resemble an achievement relative to a specific status or condition. In other words, once the relative status is lost, the badge is forfeited. This dynamic introduces an intriguing motivational factor known as the *endowment effect*.
+
+Badges are well-suited to reflect situational states such as:
+
+* Being the most backed member (if a hierarchy exists within the system)
+* Being the oldest member
+* Acting as the devil's advocate (frequently voting against the majority)
+
+### Levels (ranks)
+Earning certain badges opens the possibility of implementing a level system that could essentially sum up all badges and achievements into one quantifiable metric.
+
+### Actions
+The following list, compiled by Raul Romanutti, highlights several common actions that members can perform, offering a solid basis of outcome variables to be integrated into an awarding mechanism. While highly context-specific, the list may serve as a useful reference for treasury expenditures and other proposals.
+
+* Vote on a treasury proposal motion
+* Vote on a runtime upgrade motion
+* Vote on a referendum
+* Submit an external motion proposal
+* Submit a preimage for a proposal
+* Close a motion after majority is reached
+* Vote on a treasury proposal motion (submitted by community members)
+* Endorse a tip proposal (submitted by community members)
+* Open a tip for a community member
+* Open a bounty proposal
+* Vote on a bounty proposal
+* Vote on a bounty curator nomination
+* Propose a motion to unassign a bounty curator
+* Serve as the curator of an active bounty
+* Propose an external motion for a specific chain to use a common-good chain slot
+* Vote on an external motion for a specific chain to use a common-good chain slot
+
+## NFT Gallery
+For NFTs to develop a motivating effect, they must be visually displayed and accessible through NFT galleries. Support from wallets and blockchain explorers is essential to achieve this. Given the popularity of NFTs, many projects are actively developing such solutions, from which further improvements are expected.
+
+As an additional benefit, governance-focused applications could present members, their achievements, badges, and levels in an organized an appealing way. This would make it easier and more enjoyable for outsiders, those not direcly involved in the decision-making process, to compare and engage with collective members. A possible outcome would be a substantial improvement in member engagement, leading to a more accurate representation of all stakeholders' opinions. In turn, this could further enhance the incentives that NFTs offer to members.
+
+**For inquieries or questions please contact**: [Jonas Gehrlein](/team_members/Jonas.md)
diff --git a/docs/Polkadot/economics/academic-research/index.md b/docs/Polkadot/economics/academic-research/index.md
new file mode 100644
index 00000000..ec57b4c0
--- /dev/null
+++ b/docs/Polkadot/economics/academic-research/index.md
@@ -0,0 +1,7 @@
+---
+title: Academic Research
+---
+
+import DocCardList from '@theme/DocCardList';
+
+
diff --git a/docs/Polkadot/economics/academic-research/npos.md b/docs/Polkadot/economics/academic-research/npos.md
new file mode 100644
index 00000000..698b9162
--- /dev/null
+++ b/docs/Polkadot/economics/academic-research/npos.md
@@ -0,0 +1,10 @@
+---
+title: Approval-Based Committee Voting in Practice
+---
+
+| Status | Date | Link |
+|----------------|------------|----------------------------------------------------------------------|
+| Published as Proceeding of AAAI Conference on AI | 06.10.2025 | [AAAI](https://ojs.aaai.org/index.php/AAAI/article/view/28807) / [ARXIV](https://arxiv.org/abs/2312.11408) |
+
+
+We provide the first large-scale data collection of real-world approval-based committee elections. These elections have been conducted on the Polkadot blockchain as part of their Nominated Proof-of-Stake mechanism and contain around one thousand candidates and tens of thousands of (weighted) voters each. We conduct an in-depth study of application-relevant questions, including a quantitative and qualitative analysis of the outcomes returned by different voting rules. Besides considering proportionality measures that are standard in the multiwinner voting literature, we pay particular attention to less-studied measures of overrepresentation, as these are closely related to the security of the Polkadot network. We also analyze how different design decisions such as the committee size affect the examined measures.
\ No newline at end of file
diff --git a/docs/Polkadot/economics/academic-research/parachain-auctions.png b/docs/Polkadot/economics/academic-research/parachain-auctions.png
new file mode 100644
index 00000000..7b93a071
Binary files /dev/null and b/docs/Polkadot/economics/academic-research/parachain-auctions.png differ
diff --git a/docs/Polkadot/economics/academic-research/parachain-experiment.md b/docs/Polkadot/economics/academic-research/parachain-experiment.md
new file mode 100644
index 00000000..6f59162a
--- /dev/null
+++ b/docs/Polkadot/economics/academic-research/parachain-experiment.md
@@ -0,0 +1,165 @@
+---
+title: Experimental Investigation of Parachain Auctions
+---
+
+| Status | Date | Link |
+|----------------|------------|----------------------------------------------------------------------|
+| Under Review | 06.10.2025 | [SSRN Paper](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5109856) |
+
+
+
+This entry focuses on experimentally examining the combinatorial candle auction as implemented in the Polkadot and Kusama protocol. Specifically, it compares its outcome with those of more traditional dynamic combinatorial auction formats currently in use.
+
+What distinguishes the candle auction apart from other dynamic auctions formats is its randomly determined ending time. This closing rule enables auctions to operate on blockchains by mitigating several practical issues that more common formats often encounter (cf. Häfner & Stewart, 2021, for an analysis of the single-unit case).
+
+Since the combinatorial candle auction has not yet been studied, either theoretically or empirically, this analysis aims to fill that gap in the literature. The central hypothesis suggests that the candle format performs on par with, or even surpasses, the performance of dynamic combinatorial auctions that rely on specfic activity rules. These rules restrict feasible bids and close the auction when no further bids are submitted, thereby exerting early and serious pressure on bidders. The random ending time is expected to create a similar effect. In particular, this pressure to act may lead to more efficient outcomes, comparable to those generated by activity rules, when contrasted with auctions that use a simple hard-closing rule, such as fixed ending time.
+
+The design of the experimental investigation mirrors the core mechanism of the Polkadot parachain auction. The experiment takes place in a setting where bidders can freely communicate and share non-binding strategies before the auction. It is conducted off-chain and follows standard experimental economics procedures. Insights from the experiment can enhance understanding of bidding behavior and enable comparisons of efficiency across auction formats.
+
+
+## Dynamic combinatorial auctions
+
+The first point of discussion is the current use of combinatorial auctions. Second, it is important to present the combinatorial candle auction as implemented on Polkadot, highlighting the appeal of this format, and discussing its expected performance relative to more conventional combinatorial auction models.
+
+### Currently used combinatorial auctions
+Combinatorial auctions have emerged as successors to multi-unit auctions, primarily due to their ability to solve the so-called exposure problem that arises in the presence of complementarities (Porter and Smith, 2006; Cramton, 2013). In multi-unit auctions, bidders compete for each unit individually. As a consequence, bidders seeking specific combinations of items may end up acquiring only a subset, which may hold significanlty less value than the complete bundle. Combinatorial auctions resolve this issue by allowing bids on item packages directly. In other words, a bidder either wins the entire package or nothing at all.
+
+Today, combinatorial auctions are applied in a wide range of contexts. Among the most well-known examples are radio spectrum auctions (Porter and Smith, 2006; Cramton, 2013). Additional applications include electricity markets (Meeus et al., 2009), bus routes allocations, and industrial procurement (cf. Cramton et al., 2006, for an overview).
+
+Many combinatorial auctions are dynamic, typically employing one of two distinct formats:
+
+1. *Ascending format*: While the auction remains open, bidders can submit progressively higher bids for the different packages (see Bichler et al., 2017 for an experimental study).
+2. *Clock format*: The auctioneer incrementally raises the prices of individual items or packages, and in each round, bidders must submit their demand for the different packages. In some versions, bidders are allowed to place final bids in an additional round of simultaneous bidding after the clock phase concludes (originally proposed by Ausubel et al., 2006; further discussed in Cramton, 2013).
+
+U.S. radio spectrum auctions employed simple ascending multi-unit auctions for the first time. In 2006 and 2008, among other instances, the FCC introduced package bidding on predefined licenses using an ascending format (Porter and Smith, 2006; Cramton, 2013). The transition to clock auctions occurred later (Levin and Skrzypacz, 2016).
+
+An important design feature of any dynamic combinatorial auction is the activity rule. Its primary role is to encourage serious bidding from the outset and to prevent sniping or jump bidding.
+
+During the auction phase, the activity rule determines which bids are feasible for each bidder. In the ascending bid format, the rule tipically specifies a minimum and a maximum increment that a new bid must have on a given item or package relative to a previous bid (Scheffel et al., 2012). In clock auctions, the activity rule may prevent bidders from switching to packages they ignored in earlier rounds; that is, bidders may reduce demand but not increase it (Levin and Skrzypacz, 2016). In both ascending and clock auctions, the rule may also restrict bidders to packages that are weakly smaller than those previously bid on (Cramton, 2013).
+
+The activity rule also determines when the auction ends based on all previously submitted bids. In an ascending auction, the auction closes once no new bids are placed in a given round (Scheffel et al., 2012). In an clock auction, prices for individual packages are raised simultaneously until there is no excess demand for any package, which is when the auction concludes (Bichler et al., 2013).
+
+
+
+### The Combinatorial candle auction
+In the combinatorial candle auction employed in Polkadot, bidders can submit bids within a predefined time window. Bids must increase, without further restrictions imposed by an activitiy rule. After the window closes, the actual ending time is retroactively determined at random.
+
+Originated in medieval Europe, the name "candle auctions" derive from the way they were conducted. The auctioneer would light a candle in view of all the bidders and accept bids until the flame extinguished. The highest bidder at the moment the candle went out was declared the winner (cf., e.g., Hobson, 1971). The earliest accounts of this kind of auction date back to 14th-century France, where they were used to sell chattels and leases. In England, furs were sold via candle auctions up to the 18th century (cf. Füllbrunn and Sadrieh, 2012, for more details and references).
+
+Candle auctions have become rare. Possible reasons include the technical difficulty of generating generic randomness and the challenge of verifying commitment to a random device. Recent advances in cryptography help circumvent these issues and have brought candle auctions back into consideration. For example, Google held a patent for a dynamic auction with a random ending time, which expired in 2020 (Patent No. US6665649B1).
+
+Front-running is a significant challenge in blockchain-based auction implementations. To mitigate this issue, the Polkadot protocol employs a candle auction mechanism. Since block production occurs at discrete intervals and all pending transactions are stored in the chain's mempool, tech-savvy bidders can, in principle, inspect and react to upcoming bids. This raises concerns that such behavior may reduce overall incentives to bid, thereby lowering both revenue and potential efficiency. As Häfner & Stewart (2021) argue, while cryptographic solutions to front-running do exist, they are not feasible within Polkadot's automated setting, primarily because smart contracts among bidders are expected.
+
+
+As far as existing literature indicates, Füllbrunn and Sadrieh (2012) is the only experimental study to examine a candle auction format. Unlike the planned experiment, their study focuses on a single-unit auction with a second-price payment rule. In a second-price auction, bidding one's true value is a weakly dominant strategy whenever there is a positive probability that the current round will be the terminal round. The experimental evidence largely supports this prediction. In contrast to first-price auctions, where equilibrium bidding depends on termination probabilities, expected revenue in second-price auctions is independent of those probabilities.
+
+## Experimental design
+
+The aim is to examine an ascending combinatorial auction with discrete rounds $t$, during which bids can be placed. Each auction involves three bidders. After every round, which lasts $6$ seconds, all newly submitted bids are revealed.
+
+The set of items is $X = \{1,2\}$, resulting in three possible packages $\{\{1\},\{2\},\{1,2\}\}$. Bidders may submit bids, where a bid $b=(p,x)$ consists of a price $p$ and a package $x \subseteq X$. Prices must increase and lie on a finite (fine) grid. Winning bids are selected to maximize total payment. The payment rule is pay-as-bid; that is, winning bidders must pay the amount they bid.
+
+### The three ending formats
+
+As mentioned in the introduction, one main objective is to compare three auction-ending formats: the candle format, the hard-closing rule, and the activity rule.
+
+| Auction Format | Abbreviation |
+|------------------|--------------|
+| Candle Auction | CA |
+| Hard-Close | HC |
+| Activity Rule | AR |
+
+
+**Candle Format.** In a candle auction, bidders can freely submit increasing bids during the auction phase, and the auction terminates at a random time. In this specification, the ending time is determined retroactively: bids on packages are accepted for a predefined number of rounds, denoted by $\bar T$, after which the auctioneer announces the actual ending time $T \in \{1,...,\bar T\}$. The ending time $T$ is random, and the probability that the auction ends in round $t$ is publicly known and given by $q_t \in (0,1)$, where $\sum_{t=1}^{\bar T}q_t=1$.
+
+**Hard-Close Rule.** In a hard-close auction, bidders can freely submit increasing bids, yet the auction ends at a fixed time, denoted by $\bar T$.
+
+**Activity Rule.** In an activity rule format, bidder activity determines the ending time. Specifically, bids must increase, and if no new bid is submitted for $\tau$ consecutive rounds, the auction concludes. In this experiment, $\tau$ is set to 5, corresponding to $30$ seconds.
+
+### Communication
+Communication is ubiquitous in blockchain environments. Different bidders often operate as teams working on similar technical problems, sharing communication channels, posting on social media, and more.
+
+Consequently, experimental subjects are allowed to communicate via chat before each auction to discuss non-binding strategies. Specifically, both an open group chat and closed bilateral chats are available. These channels are accessible prior to the auction and close once it begins.
+
+### Valuations
+In each auction, three bidders participate. Bidders are assigned one of two roles, global bidder or local bidder, which are known prior to the start of the auction. Each auction features one global bidder and two local bidders.
+
+The global bidder has a positive valuation only for the grand package, denoted as $\{1,2\}$. Local bidders, on the other hand, hold valuations for individual packages, which are added up if they win the grand package. Specifically, it is assumed that
+
+
+
+
+
+
+
+This means that the global bidder draws a valuation $v$ for the package $\{1,2\}$, while always holding a zero valuation for the individual packages $\{1\}$ and $\{2\}$. In contrast, each local bidder $i = 1,2$ draws a valuation $v_i$ for item $\{1\}$, which implies a valuation of $80-v_i$ for item $\{2\}$, and a total valuation of $80$ for the combined package $\{1,2\}$.
+
+Under this valuation model, the global bidder can efficiently obtain the grand package whenever $v \geq \max \{80-v_1+v_2,80-v_2+v_1\}$, while the two local bidders receive one item each otherwise. To successfully outbid the global bidder, local bidders must coordinate their bids strategically.
+
+
+### Hypotheses
+The following outcome variables are of main interest:
+
+* Efficiency: What fraction of the auctions result in an allocation that corresponds to the first-best outcome?
+* Revenue: Total amount of bids paid. This also allows for the computation of average shading ratios.
+* Bidding dynamic: How quickly do bids increase? Does sniping occur?
+
+The random ending time generally encourages participants to submit serious bids earlier in the auction. This mechanism is expected to produce two beneficial effects, compared to a hard-closing rule where the auction ends at a fixed time, that resemble the intended impact of activity and feedback rules. The underlying conjecture is that the candle auction format may replace these rules to some extent.
+
+* Hypothesis I: Early bids in the candle auction are higher than under the activity rule, and bids under the activity rule are already higher than under the hard-close rule.
+* Hypothesis II: The candle format and the activity rule outperform the hard-close rule in terms of revenue and efficiency.
+* Hyptothesis III: The candle format and the hard-close rule perform similarly in terms of revenue and efficiency. Efficiency may be slightly lower in the candle auction, while revenue may be slightly higher.
+
+### Procedure
+
+#### Stage 1: Instructions
+As the experiment begins, participants are randomly assigned to one of the three auction formats and receive information about the specific rules of the game. They must then answer a few comprehension questions to confirm their understanding of how the game unfolds.
+
+#### Stage 2: The Auctions
+Before each auction, all bidders learn their type and their private valuations for individual packages. Each market consists of one global bidder and two local bidders, with roles remaining fixed throughout the experiment. New valuations are drawn at the start of each auction. These random draws are held constant across treatments (i.e., by fixing the seed) to better compare the results. Every participant takes part in n=X auctions. Subjects are re-shuffled into new market groups between auctions to approximate a (near-) perfect stranger design. Following this, a communication phase begins during which all participants in a given auction openly discuss strategies via chat for 45 seconds. The auction then starts, and participants are free to submit bids.
+
+The trading page features two tables:
+
+1. Table 1 displays the current winning bids, listing all active bids for each package.
+
+2. Table 2 shows the winning allocation, indicating how packages are currently assigned to bidders based on the prevailing winning bids.
+
+Table 2 is particularly useful for assessing this complex auction design.
+
+#### Stage 3: Feedback and Payoff
+Once the auction concludes, timing depending on the treatment, participants receive feedback on the final winning bids and allocation of packages. In addition, participants in the candle auction format are informed of the realization of $T$ and the corresponding snapshot of winning bids at that moment. Profits are then calculated and displayed to participants. If another auction follows, new valuations are drawn for each subject before it begins.
+
+
+### Outcome variables
+* Success of coordination: Given the realized values, were the local bidders able to form a coalition?
+* Efficiency: Did the packages go to those with the highest valuations? Did bidders coordinate on the optimal allocation?
+* Bidding dynamic: How quickly did the auction converge?
+* Revenue: What was the total reveneu generated?
+
+### Implementation
+The experiment will be implemented using [oTree](https://www.sciencedirect.com/science/article/pii/S2214635016000101), a platform for conducting online experiments. oTree provides the necessary infrastructure to create sessions, distribute links to participants, and maintain a database of behavioral data. It combines Python on the backend with a flexible frontend built using HTML/CSS and Django.
+
+## Literature
+Ausubel, L. M., Cramton, P., & Milgrom, P. (2006). The clock-proxy auction: A practical combinatorial auction design. Combinatorial Auctions, 120-140.
+
+Bichler, M., Hao, Z., & Adomavicius, G. (2017). Coalition-based pricing in ascending combinatorial auctions. Information Systems Research, 28(1), 159-179.
+
+Cramton, P. (2013). Spectrum auction design. Review of Industrial Organization, 42(2), 161-190.
+
+Cramton, P., Shoham, Y., & Steinberg, R. (2006). Introduction to combinatorial auctions. Combinatorial auctions, 1-14.
+
+Füllbrunn, S. and A. Sadrieh (2012): \Sudden Termination Auctions|An Experimental Study," Journal of Economics & Management Strategy, 21, 519-540.
+
+Häfner, S., & Stewart, A. (2021). Blockchains, Front-Running, and Candle Auctions. Working Paper, [SSRN](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3846363).
+
+Hobson, A. (1971): A Sale by Candle in 1608," The Library, 5, 215-233.
+
+Levin, J., & Skrzypacz, A. (2016). Properties of the combinatorial clock auction. American Economic Review, 106(9), 2528-51.
+
+Meeus, Leonardo, Karolien Verhaegen, and Ronnie Belmans. “Block order restrictions in combinatorial electric energy auctions.” European Journal of Operational Research 196, No. 3 (2009): 1202-1206.
+
+Porter, David, and Vernon Smith. “FCC license auction design: A 12-year experiment.” Journal of Law, Economics & Policy 3 (2006): 63.
+
+Scheffel, T., Ziegler, G., & Bichler, M. (2012). On the impact of package selection in combinatorial auctions: an experimental study in the context of spectrum auction design. Experimental Economics, 15(4), 667-692.
+
+**For inquieries or questions please contact** [Jonas Gehrlein](/team_members/Jonas.md)
diff --git a/docs/Polkadot/economics/academic-research/parachain-theory.md b/docs/Polkadot/economics/academic-research/parachain-theory.md
new file mode 100644
index 00000000..ef5aa59e
--- /dev/null
+++ b/docs/Polkadot/economics/academic-research/parachain-theory.md
@@ -0,0 +1,22 @@
+---
+title: Theoretical Analysis of Parachain Auctions
+---
+
+| Status | Date | Link |
+|----------------|------------|----------------------------------------------------------------------|
+| Under Review | 06.10.2025 | [SSRN Paper](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3846363) |
+
+
+
+Polkadot uses a [candle auction format](https://wiki.polkadot.network/docs/en/learn-auction) to allocate parachain slots. A candle auction is a dynamic auction mechanism characterized by a randomly ending time. Such a random-closing rule affects equilibrium behavior, particularly in scenarios where bidders have front-running opportunities.
+
+Front-running opportunities can arise on blockchains when upcoming transactions become visible to network participants before they are included in new blocks. In the context of blockchain auction implementations, this allows certain bidders to observe and potentially respond to others' bids before those bids take effect, such as when they are recorded on-chain and incorporated into the auction mechanism. In first-price auctions, this enables tech-savvy bidders to outbid competitors at will. In second-price auctions, an auctioneer could increase the payment of the winning bidder at no cost by registering their own (pseudonymous) bidder.
+
+While cryptographic solutions to these problems exist, they are either computationally intensive or require multiple actions by the bidders. In the presence of smart contracts, such approaches fail altogether, as smart contract actions are fully predictable.
+
+An alternative to encrypted bidding is the use of a dynamic, single-unit first-price auction with a random ending time. Time is modeled discretely, and in each round, two bidders move sequentially in a fixed order. A random-closing rule not only revenue-dominates a hard-closing rule but also makes participation more attractive for bidders subject to front-running. In particular, under a uniform ending time distribution, both the utility of the disadvantaged bidder and the total revenue converge toward those of a second-price auction as the number of rounds increases. Furthermore, the good is allocated efficiently.
+
+Reference:
+Samuel Häfner and Alistair Stewart (2021): Blockchains, Front-Running, and Candle Auctions. Working Paper. [SSRN](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3846363)
+
+**For inquiries or questions please contact:** [Alistair Stewart](team_members/alistair.md)
diff --git a/docs/Polkadot/economics/academic-research/utility-token.png b/docs/Polkadot/economics/academic-research/utility-token.png
new file mode 100644
index 00000000..912e1125
Binary files /dev/null and b/docs/Polkadot/economics/academic-research/utility-token.png differ
diff --git a/docs/Polkadot/economics/academic-research/utilitytokendesign.md b/docs/Polkadot/economics/academic-research/utilitytokendesign.md
new file mode 100644
index 00000000..a41d7d59
--- /dev/null
+++ b/docs/Polkadot/economics/academic-research/utilitytokendesign.md
@@ -0,0 +1,24 @@
+---
+title: Utility Token Design
+---
+
+| Status | Date | Link |
+|----------------|------------|----------------------------------------------------------------------|
+| Under Review | 06.10.2025 | [SSRN Paper](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3954773) |
+
+
+
+
+Utility tokens are cryptographic tokens primarily used to access and consume services offered by the token issuer. One of the objectives of this [project](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3954773) was to analyze general design principles of utility tokens native to proof-of-stake blockchains.
+
+The Polkadot network provides services through parachain slots, which offer shared security and interoperability with other parachains. To secure a slot, users (namely the teams building on Polkadot) must stake DOT tokens in recurring slot auctions.
+
+The analysis required a dynamic general equilibrium model of utility tokens, which served as a medium for consuming services on a two-sided market platform.
+
+On the one side of the platform, users derive utility from consuming the services it provides. On the other side, validators supply the necessary security and are compensated with tokens. Validators must regularly sell a portion of their tokens to cover operational costs, while users must continually purchase tokens to access services. A token market facilitates the balance between token supply and demand.
+
+The main results of the analysis are as follows: First, utility token markets are generally efficient, as they lead to the socially optimal provision of services. Second, a key tension has been identified between the dynamics of utility token value, specifically between the evolution of the services provided and the payment mechanisms on the users’ side.
+
+**For inquieries or questions please contact**: [Jonas Gehrlein](/team_members/Jonas.md)
+
+
diff --git a/docs/Polkadot/economics/academic-research/validator-selection.jpeg b/docs/Polkadot/economics/academic-research/validator-selection.jpeg
new file mode 100644
index 00000000..d673dd0d
Binary files /dev/null and b/docs/Polkadot/economics/academic-research/validator-selection.jpeg differ
diff --git a/docs/Polkadot/economics/academic-research/validator-selection.md b/docs/Polkadot/economics/academic-research/validator-selection.md
new file mode 100644
index 00000000..776655cb
--- /dev/null
+++ b/docs/Polkadot/economics/academic-research/validator-selection.md
@@ -0,0 +1,245 @@
+---
+title: Validator Selection
+---
+
+| Status | Date | Link |
+|----------------|------------|----------------------------------------------------------------------|
+| Published in Peer-Reviewed Journal | 06.10.2025 | [Omega](https://www.sciencedirect.com/science/article/abs/pii/S0305048323000336) / [SSRN](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4253515) |
+
+
+
+Validator elections play a critical role in securing the network, placing nominators in charge of selecting the most trustworthy and competent validators. This responsibility is both complex and demanding. The vast amount of validator data, constantly growing, requires significant technical expertise and sustained engagement. As a result, the process can become overly cumbersome, leading many nominators to either avoid staking altogether or refrain from investing the time needed to evaluate the data thoroughly. In this context, effective tools are essential, not only to support nominators in making informed selections, but also to help ensure the network's long-term health and resilience.
+
+This entry outlines several potential steps to support nominators while preserving their freedom of choice. As a starting point, it is important to highlight why recommendations should consider individual user preferences rather than attempting to make them universal.
+
+**Problem.** Providing an exogenous recommendation for a set of validators is not advisable, as user preferences, particularly risk preferences, vary significantly. Comparing metrics accross different scales, such as self-stake in DOT versus performance in percentage, is not feasible in an exogenous framework. Moreover, even when considering a single dimension, the shape of marginal utility functions remains unclear and is inherently tied to individual preferences. Determining the trade-offs involved in the selection process on behalf of nominators lies beyond the scope of this note. Yet, to illustrate this issue, consider the following simple example:
+
+
+| | Commission | Self-Stake | Identity | Era-Points |
+| -------- | -------- | -------- | -------- | -------- |
+| Validator 1 | 4% | 26 DOT | Yes | Average |
+| Validator 2 | 7% | 280 DOT | No | Average - 1%|
+| Validator 3 | 1% | 1 DOT | No | Average + 5% |
+
+
+The table above presents validators with diverse profiles, none of which clearly dominate. Validator 3 may offer high potential profits but lacks significant self-stake (skin in the game) and does not have a registered identity. Validator 1 charges a higher service fee, yet may benefit from a reputable identity. Validator 2 has the highest self-stake, but also demands substantial fees. Clearly, user preferences can vary, some may favor one validator over another depending on their priorities. While most users could reasonably make a choice from this small set, the complexity increases when faced with a selection of 200 to 1,000 validators.
+
+
+**Code of conduct for recommendations.** As previously mentioned, the goal is not to provide exogenous recommendations to users, but rather to offer strategies that respect their insight and generate suggestions aligned with their stated preferences. While valuing individual preferences, recommendations may nudge decisions toward outcomes beneficial for the network, such as promoting decentralization. These recommendations should remain as objective as possible and must not discriminate against any specific validator.
+
+**Organization.** This entry is divided into several sections. "Underlying data" presents potentially useful data and explains how to derive additional metrics. "Filtering phase" demonstrates how a simple concept from economics can significantly reduce the number of potentially interesting validators, providing users with a more manageable set of choices. The third section explores ideas to further curate the validator set in support of the network's goals. Lastly, the "UTAStar" section outlines a sophisticated approach for estimating each user's individual marginal preference functions, enabling more precise recommendations.
+
+
+# 1. Underlying data
+Collectible data from Polkadot and Kusama validators is extremely relevant to the selection process. Metrics marked with an asterisk (*) are included in the final data set, while other variables are used to derive additional metrics. The primary focus is on quantitative on-chain data, as it is verifiable and straightforward to process. This purely quantitative approach intends to complement a selection process that incorporates qualitative factors, such as a validator’s identity, reputation, or community engagement, which often influence how nominators cast their votes.
+
+## Retrievable data
+| Name | Historical | On-Chain | Description |
+|- |- |- |- |
+| Public address* | No | Yes | The public identifier of the validator. |
+| Identity* | No | Yes | Is there a verified on-chain identity? |
+| Self stake* | No | Yes | Tokens used for self-election represent a form of "skin in the game". |
+| Other stake | No | Yes | The amount of stake (potentially) allocated by other nominators. |
+| Total stake | No | Yes | The combined total of self stake and other stake. |
+| Commission | Maybe | Yes | Percentage of commission charged by the validator for providing their service. |
+| Era points | Yes | Yes | The number of points accumulated per era. |
+| Number of nominators* | No | Yes | The number of nominators assigned to a validator. |
+
+**Era Points** are awarded to validators for performing beneficial actions that support the network, primarily driven by block production. Over time, these points should be uniformly distributed, although distribution may vary if validators operate on superior setups, like more powerful hardware or more reliable internet connections. In addition, randomness may introduce significant statistical noise in the short term, leading to deviations from a uniform distribution.
+
+
+## Generated metrics
+Some of the retrieved on-chain data might not be particularly useful for nominators, but it can still provide additional metrics that help in the selection process.
+
+| Name | Historical | On-Chain | Description |
+|- |- |- |- |
+| Average adjusted era-points | Yes | Yes | The average adjusted era points from previous eras. |
+| Performance | Yes | Yes | Validator performance is determined by era points and commission. |
+| Relative performance* | Yes | Yes | This represents performance normalized across the set of validators. |
+| Outperforming MLE | Yes | Yes | An indicator of how frequently a validator has outperformed the average era points. A typical validator should score around 0.5. |
+| Average performer* | - | Yes | A statistical test of the MLE for outperformance against a uniform distribution. It indicates whether a validator statistically overperforms or underperforms. |
+| Active eras* | Yes | Yes | The number of active eras. |
+| Relative total stake* | No | Yes | Total stake normalized across the validator set. |
+| Operator size* | No | Yes | The number of validators that share a similar on-chain identity. |
+
+**Average adjusted era points.**
+To obtain a more robust estimate of the era points, additional data from previous eras should be collected. Since the total era points are distributed among all active validators, and the validator set may vary over time, this could introduce bias into the results. To correct for this, era points from each era can be adjusted based on the active set size during that period. As this is the sole factor influencing theoretical per-capita era points, such normalization enables meaningful comparison across historical data.
+
+The optimal number of previous eras to include remains uncertain. Using too long a history may bias results toward the average, while too short a history can weaken the metric’s robustness. One possible approach is to use the average number of $active-eras$.
+
+**Performance.** From a nominator's perspective, validator performance is determined by three main factors: the number of era points earned, the nominator's share of the total stake, and the commission charged by the validator. Since performance scales linearly with the nominator's bond, it can be considered independent of the bond amount. These metrics can be combined into a single performance indicator:
+
+$$
+performance = \frac{averageEraPoints \times (1 - commission)}{totalStake}
+$$
+
+The **relative performance** is then defined as follows:
+$$
+\frac{performance - min(performance)}{max(performance) - min(performance)}
+$$
+These calculations offer a more intuitive measure, as the performance is normalized between 0 and 1. The measure remains robust against potential changes within the network. For instance, when the number of validators increases, the era points per validator tend to decrease. The metric also avoids false anchoring effects.
+
+**Outperforming MLE.** By collecting historical era points per validator accross previous eras, one can determine how frequently a validator outperforms the average. Assuming a uniform distribution of era points, a validator is expected to outperform the average approximately 50% of the time. In practice, other factors like hardware-setup and internet connectivity, can influence this performance metric. These insights not only help nominators identify top-performing validators but also encourage validators to optimize their setup.
+
+**Significance MLE.** Given that the expected value of the outperforming MLE is 0.5 under a presumably uniform distribution, a statistical test may help assess whether a validator significantly overperforms or underperforms relative to this benchmark:
+$$
+z = \frac{outperformingMLE - 0.5}{\sqrt{\frac{0.5 \times (1-0.5)}{numberActive}}}
+$$
+
+If $z > 1.645$, the corresponding validator significantly outperforms at the 10% significance level, while $z < -1.645$ indicates significant underperformance.
+
+**Operator size.** Based on the identity of a validator, it is possible to estimate how many validators are operated by the same entity. For both users and the network, a reduced number of moderately sized operators is often more convenient. Selecting validators from larger operators may increase the risk of superlinear slashing, as these entities likely follow similar security practices. The failure of one validator could therefore imply the failure of several others, increasing superlinearly the likelihood of punishment. On the other hand, larger operators may have more sophisticated setups and processes, which could mitigate such risks. This metric should ultimately be considered an objective measure, leaving the final judgment to the user.
+
+# 2. Filtering phase
+
+## Dominance-filtering
+After shaping the dataset elaborated in the section "Underlying data," it is time to begin reducing the set of validators to ease the information load for nominators. One approach is to eliminate dominated validators. Since qualitative judgements remain out of the picture, such as determining whether one "identity" is better or worse than another, it is reasonable to remove validators that are objectively inferior, as there is no rational basis for nominating them. A validator is said to dominate another when all properties are equal and at least one is strictly better. Consider the following example:
+
+## Example:
+| Number | Public Address | Identity | Self-stake | Nominators | Relative Performance | Outperformer | Active Eras | Operator Size |
+|- |- |- |- |- |- |- |- |- |
+| 1 | 1N6xclmDjjA | 0 | 10 | 10 | 0 | 0 | 3 | 0 |
+| 2 | 1ohS7itG5Np | 0 | 200 | 40 | 0.7 | 0 | 4 | 2 |
+| 3 | 1xgFnMhdOui | 1 | 100 | 89 | 0.3 | 0 | 16 | 3 |
+| 4 | 1vO7JLtSm4F | 1 | 5000 | 89 | 1 | 1 | 29 | 3 |
+
+Validator 2 dominates Validator 1, meaning the latter is strictly worse in every dimension[^1]. Validator 3 also dominates Validator 1, so it can be removed from the set. Through this process, the validator set can be reduced to two. In practice, this method proves to be a powerful tool for significantly shrinking the set size.
+
+## Further curation
+Additional cleanup can still be performed on the remaining set. As stated in the code of conduct, this step is optional, yet here are some suggested default actions for users:
+* Include at least one inactive validator. A suggestion would be inactive nodes based on separate processes.
+* Reduce the risk of super-linear slashing, for instance by removing multiple validators run by the same operator.
+* Remove validators running on the same machine (perhaps some analysis of IP addresses).
+
+# 3. Manual selection
+After reducing the set by removing dominated validators and applying some filtering options, the user can easily select preferred validators manually. In this step, the selection is purely based on personal preferences. For example, a nominator might order the validators by their relative performance, and select those who also meet certain minimum self-stake requirements.
+
+# 4. UTAStar
+As input, this method uses the filtered table from Section LINK and can be considered a natural extension of the previous method.
+### Overview
+ UTilité Additive (UTA) is a preference disaggregation method introduced by [Jacquet-Lagrèze & Siskos (1982)](https://www.sciencedirect.com/science/article/abs/pii/0377221782901552). UTAStar is an enhanced version of the original algorithm. The core idea is that the marginal utility functions of a decision maker (DM), defined over each dimension of a given criterion, can be inferred from a previous ranked list of alternatives. The method employs linear programming to indentify utility functions that respect the DM's initial ranking while incorporating additional properties, such as normalizing the maximum utility to 1.
+
+### Some notation [^2]
+
+* $u_i$: Marginal utility function of criterion i.
+* $g_1,g_2,...g_n$: Criteria.
+* $g_i(x)$: Evaluation of alternative x on the $i^{th}$ criterion.
+* $\textbf{g}(x)$: Performance vector of alternative $x$ across $n$ criteria.
+* $x_1, x_2, ..., x_m \in X_L:$ Learning set containing alternatives presented to the decision maker (DM) for ranking. Note that the index on the alternative is dropped.
+
+
+### Model
+The UTAStar method infers an additive utility function with equal weighting across criteria:
+
+$$
+u(\textbf{g}) = \sum_{i=1}^{n} u_i(g_i)
+$$
+
+where $\textbf{g}$ is a performance vector, subject to the following constraints:
+
+$$
+\sum_{i=1}^{n} u_i(g^\star) = 1 \; \text{and} \; u_i(g_{i\star}) = 0 \; \forall i = 1,2,...,n
+$$
+
+Each $u_i, i=1,2...,n$ is a non-decreasing function normalized between 0 and 1, also referred to as a utility function.
+
+The estimated utility of each alternative $x \in X_L$ is given by:
+$$
+u'[\textbf{g}(x)]=\sum_{i=1}^{n}u_i[g_i(x)])+ \sigma^{+}(x) + \sigma^{-}(x) \forall x \in X_L
+$$
+where $\sigma^{+}(x)$ and $\sigma^{-}(x)$ represent the underestimation and overestimation errors, each reflecting potential deviation in the estimation of $u'[\textbf{g}(x)]$
+
+The utility functions are approximated in piecewise linear form using linear interpolation. For each criterion, the interval $[g_{i\star}, g_i^\star]$ is divided into $(\alpha_i - 1)$ subintervals, and the endpoints $g_i^j$ are defined as:
+
+$$
+g_i^j = g_{i\star} + \frac{j - 1}{\alpha_i - 1} (g_i^\star - g_{i\star}) \forall j = 1,2,...\alpha_i
+$$
+
+The marginal utility function of x is approximated by linear interpolation. Thus, for $g_i(x) \in [g_i^j - g_i^{j+1}]$, the result is:
+
+$$
+u_i[g_i(x)]= u_i(g_i^j) + \frac{g_i(x)-g_i^j}{g_i^{j+1}-g_i^j}[u_i(g_i^{j+1}) - u_i(g_i^j)]
+$$
+
+The learning set $X_L$ is rearranged such that $x_1$ (the best alternative) is placed at the head and $x_m$ is the tail. The user provides this ranking. The utility difference between two consecutive alternatives is defined as:
+
+$$
+\Delta(x_k, x_{k+1}) = u'[\textbf{g}(x_k)] - u'(\textbf{g}(x_{k+1}))
+$$
+
+then the following holds:
+
+$$
+\Delta(x_k, a_{k+1}) \geq \delta \; \textrm{iff} \; x_k > x_{k+1}
+$$
+
+and
+
+$$
+\Delta(x_k, x_{k+1}) = \delta \; \textrm{iff} \; x_k \backsim x_{k+1}
+$$
+
+Here, $\delta$ is a small, positive, exogenous parameter representing the minimum acceptable discrepancy between the utilities of two consecutive options.
+Reinforcing monotonicity involves further transforming the utility differences between two consecutive interval endpoints:
+
+$$
+w_{ij} = u_i(g_i^{j+1}) - u_i(g_i^j) \geq 0 \forall i=1,...n \; and \; j = 1,... \alpha_i -1
+$$
+
+### Algorithm
+**Step 1.** Express the global utility of the alternatives in the learning set $u[g(x_k)], k=1,2,...m$, in terms of marginal utility functions $u_i(g_i)$. Transform these into coefficients $w_{ij}$ according to the formula provided, using the following constraints:
+
+$$
+u_i(g_i^1) = 0 \; \forall i = 1,2...n
+$$
+
+and
+
+$$
+u_i(g_i^j) = \sum^{j-1}_{i=1}w_{ij} \; \forall i = 1,2..N \; and \; j=2,3,...\alpha_i - 1
+$$
+
+**Step 2.** Introduce two error functions, $\sigma^{+}$ and $\sigma^{-}$, on the learning set $X_L$. Represent each pair of consecutive alternatives as:
+
+$$
+\Delta(x_k,x_k+1) = u[\textbf{g}(x_k)] - \sigma^{+}(x_k) + \sigma^{-}(x_k) - u[\textbf{g}(x_{k+1})] + \sigma^{+}(x_{k+1}) - \sigma^{-}(x_{k+1})
+$$
+
+**Step 3.** Solve the following linear optimization problem:
+
+$$
+[min] z = \sum_{k=1}^{m}[\sigma^{+}(x_k) + \sigma^{-}(x_k)] \\
+\text{subject to} \\
+\Delta(x_k, a_{k+1}) \geq \delta \; \textrm{iff} \; x_k > x_{k+1} \\
+\Delta(x_k, x_{k+1}) = \delta \; \textrm{iff} \; x_k \backsim x_{k+1} \; \forall k \\
+\sum_{i=1}^n \sum_{j=1}^{\alpha_i - 1}w_{ij} = 1 \\
+w_{ij} \geq 0, \sigma^{+}(x_k)\geq 0, \sigma^{-}(x_k)\geq 0 \forall i,j,k
+$$
+
+**Step 4.** Perform a robustness analysis to identify suitable solutions for the linear program (LP) described above.
+
+**Step 5.** Apply the derived utility functions to the full set of validators and select the 16 highest-scoring ones.
+
+**Step 6.** Introduce ad hoc adjustments to the final set based on user-defined preferences. For example:
+* Include user-designated favorites
+* Ensure no more than one validator per operator
+* Require at least X inactive validators
+* Additional custom constraints as needed
+
+
+### Remaining Challenges
+Several challenges remain in applying the theoretical framework to the validator selection problem:
+
+1. **Constructing the learning set.** The algorithm requires sufficient information to generate the marginal utility functions. Key subchallenges include:
+ - Developing methods that ensure performance dispersion across criteria.
+ - Applying machine learning techniques to iteratively construct smaller learning sets to gradually improve the collected information.
+ - Using simulations to generate a wide number of learning sets and corresponding rankings, enabling evaluation of which configurations most effectively improve utility estimation.
+2. **Limitations of UTAStar.** UTAStar assumes piecewise linear and monotonic marginal utility functions. While alternative methods offer improvements in this regard, they may introduce additional implementation complexity.
+
+
+[^1] As mentioned above, a user might prefer larger operators in which case the statement would not be true.
+
+[^2] This write-up relies heavily on [Siskos et al., 2005](https://www.researchgate.net/publication/226057347_UTA_methods).
+
+**For inquieries or questions, please contact** [Jonas Gehrlein](/team_members/Jonas.md)
+
diff --git a/docs/Polkadot/economics/applied-research/index.md b/docs/Polkadot/economics/applied-research/index.md
new file mode 100644
index 00000000..ce7f855d
--- /dev/null
+++ b/docs/Polkadot/economics/applied-research/index.md
@@ -0,0 +1,7 @@
+---
+title: Applied Research
+---
+
+import DocCardList from '@theme/DocCardList';
+
+
diff --git a/docs/Polkadot/economics/applied-research/rfc10.md b/docs/Polkadot/economics/applied-research/rfc10.md
new file mode 100644
index 00000000..f0a266ce
--- /dev/null
+++ b/docs/Polkadot/economics/applied-research/rfc10.md
@@ -0,0 +1,33 @@
+# RFC-0010: Burn Coretime Revenue (accepted)
+
+| | |
+| --------------- | ------------------------------------------------------------------------------------------- |
+| **Start Date** | 19.07.2023 |
+| **Description** | Revenue from Coretime sales should be burned |
+| **Authors** | Jonas Gehrlein |
+
+## Summary
+
+The Polkadot UC will generate revenue from the sale of available Coretime. The question then arises: how should we handle these revenues? Broadly, there are two reasonable paths – burning the revenue and thereby removing it from total issuance or divert it to the Treasury. This Request for Comment (RFC) presents arguments favoring burning as the preferred mechanism for handling revenues from Coretime sales.
+
+## Motivation
+
+How to handle the revenue accrued from Coretime sales is an important economic question that influences the value of DOT and should be properly discussed before deciding for either of the options. Now is the best time to start this discussion.
+
+## Stakeholders
+
+Polkadot DOT token holders.
+
+## Explanation
+
+This RFC discusses potential benefits of burning the revenue accrued from Coretime sales instead of diverting them to Treasury. Here are the following arguments for it.
+
+It's in the interest of the Polkadot community to have a consistent and predictable Treasury income, because volatility in the inflow can be damaging, especially in situations when it is insufficient. As such, this RFC operates under the presumption of a steady and sustainable Treasury income flow, which is crucial for the Polkadot community's stability. The assurance of a predictable Treasury income, as outlined in a prior discussion [here](https://forum.polkadot.network/t/adjusting-the-current-inflation-model-to-sustain-treasury-inflow/3301), or through other equally effective measures, serves as a baseline assumption for this argument.
+
+Consequently, we need not concern ourselves with this particular issue here. This naturally begs the question - why should we introduce additional volatility to the Treasury by aligning it with the variable Coretime sales? It's worth noting that Coretime revenues often exhibit an inverse relationship with periods when Treasury spending should ideally be ramped up. During periods of low Coretime utilization (indicated by lower revenue), Treasury should spend more on projects and endeavours to increase the demand for Coretime. This pattern underscores that Coretime sales, by their very nature, are an inconsistent and unpredictable source of funding for the Treasury. Given the importance of maintaining a steady and predictable inflow, it's unnecessary to rely on another volatile mechanism. Some might argue that we could have both: a steady inflow (from inflation) and some added bonus from Coretime sales, but burning the revenue would offer further benefits as described below.
+
+- **Balancing Inflation:** While DOT as a utility token inherently profits from a (reasonable) net inflation, it also benefits from a deflationary force that functions as a counterbalance to the overall inflation. Right now, the only mechanism on Polkadot that burns fees is the one for underutilized DOT in the Treasury. Finding other, more direct target for burns makes sense and the Coretime market is a good option.
+
+- **Clear incentives:** By burning the revenue accrued on Coretime sales, prices paid by buyers are clearly costs. This removes distortion from the market that might arise when the paid tokens occur on some other places within the network. In that case, some actors might have secondary motives of influencing the price of Coretime sales, because they benefit down the line. For example, actors that actively participate in the Coretime sales are likely to also benefit from a higher Treasury balance, because they might frequently request funds for their projects. While those effects might appear far-fetched, they could accumulate. Burning the revenues makes sure that the prices paid are clearly costs to the actors themselves.
+
+- **Collective Value Accrual:** Following the previous argument, burning the revenue also generates some externality, because it reduces the overall issuance of DOT and thereby increases the value of each remaining token. In contrast to the aforementioned argument, this benefits all token holders collectively and equally. Therefore, I'd consider this as the preferrable option, because burns lets all token holders participate at Polkadot's success as Coretime usage increases.
\ No newline at end of file
diff --git a/docs/Polkadot/economics/applied-research/rfc104.md b/docs/Polkadot/economics/applied-research/rfc104.md
new file mode 100644
index 00000000..fcb4a10e
--- /dev/null
+++ b/docs/Polkadot/economics/applied-research/rfc104.md
@@ -0,0 +1,111 @@
+# RFC-0104: Stale Nominations and Declining Reward Curve (stale)
+
+| | |
+| --------------- | ------------------------------------------------------------------------------------------- |
+| **Start Date** | 28 October 2024 |
+| **Description** | Introduce a decaying reward curve for stale nominations in staking. |
+| **Authors** | Shawn Tabrizi & Jonas Gehrlein |
+
+## Summary
+
+This is a proposal to define stale nominations in the Polkadot's staking system and introduce a mechanism to gradually reduce the rewards that these nominations would receive. Upon implementation, this nudges all nominators to become more active and either update or renew their selected validators at least once per period to prevent losing rewards. In response to that, it gives incentives to validators to behave in the best interest of the network and stay competitive. The decaying factor and duration of the period before nominations would be considered stale is long enough to not overburden nominators and compact enough to provide an incentive to regularly engage and revisit their selection.
+
+Apart from the technical specification of how to achieve this goal, we discuss why active nominators are important for the security of the network. Further, we present ample empirical evidence to substantiate the claim that the current lack of direct incentives results in stale nominators.
+
+Importantly, our proposal should neither be misinterpreted as a negative judgment on the current active set nor as a campaign to force out long-standing validators/nominators. Instead, we want to address the systemic issue of stale nominators that, with the growing age of the network, might at some point become a security risk. In that sense, our proposal aims to prevent a detoriation of our validator set before it is too late.
+
+## Motivation
+
+### Background
+
+Polkadot employs the Nominated Proof-of-Stake (NPoS) mechanism that allows to accumulate resources both from validators and nominators to construct the active set. This increases the inclusivity for validators, because they do not necessarily need huge resources themselves but have the opportunity to convince nominators to entrust them with the important task of validating the Polkadot network.
+
+In the absence of enforcing a strict (and significant) lower limit on self-stake of validators, determining trustworthiness and competency is borderline impossible for an automated protocol. To cope with that challenge, we employ nominators as active agents that are able to navigate the fabrics of the social layer and are tasked to scout for, engage with and finally select suitable validators. The aggregated choices of these nominators are used by the election algorithm to determine a robust active set of validators. For this effort and the included risk, nominators are rewarded generously through staking rewards.
+
+### Why nominators must be active
+
+In this setup, the economic security of validators can be approximated by their self-stake, their future rewards (earned through commission), and the reputational costs incurred from causing a slash on their nominators. Although potentially significant in value, the latter factor is hardly measurable and difficult to quantify. Arguably, however, and irrespective of the exact value, it is diminishing the more time has passed of the last interaction between a nominator and their validator(s). This is because validators that were reputable in the past, might not be in the future and a growing distance between the two entities reduces their attachment to each other. In other words, the contribution of nominators to the security of the network is directly linked to how active they are in the process of engaging and scouting viable validators. Therefore, we not only require but also expect nominators to actively engage in the selection of validators to maximize their contribution to Polkadot's economic security.
+
+### Empirical evidence
+
+In the following, we present empirical evidence to illustrate that, in the light of the mechanisms described above, nominator behavior can be improved upon. We include data from the first days of Polkadot up until the End of October 2024 (the full report can be found [here](https://jonasw3f.github.io/nominators_behavior_hosted/)), giving a comprehensive picture of current and historical behavior.
+
+In our analysis, a key results is that the currently active nominators, on average, changed their selection of validators around 546 days ago. Additionally, the vast majority only makes a selection of validators once (when they become a nominator) and never again. This "set and forget" attitude directly translates into the backing of validators. To obtain a meaningful metric, we define the Weighted Backing Age (WBA) per validator. This metric calculates the age of their backing (from nominators) and weighs it with the size of their stake. This is superior to just taking the average, because we the activity of a nominator might be directly linked to their stake size (for more information, see the full report). Conducting this analysis reveals that the overall staleness of nominators translates into high values of WBA. While there are some validators activated by recent nominations, the average value remains rather high with 226 days (with numerous values above 1000 days). Observing the density function of the individual WBAs, we can conclude that 40% of the total stake is older than *at least* 180 days (6 months).
+
+### Implications of stale nominations
+
+The fact that a large share of nominators simply “set and forget” their selections can inadvertently introduce risks into the network. When early-nominated incumbents hold their positions as validators for extended periods, they effectively gain tenure. This dynamic could lead to complacency among established validators, with quality and performance potentially declining over time. Furthermore, this lack of turnover discourages competition, creating barriers for new validators who may offer better performance but struggle to attract nominations, as the network environment disproportionately favors seniority over merit.
+
+One might argue that nominators are naturally motivated to stay informed by the potential risk of slashing, ensuring they actively monitor and update their selections. And it is indeed possible that a selection made years ago is still optimal for a nominator today. However, we would counter these arguments by noting that nominators, as human individuals, are prone to biases that can lead to irrational behavior. To adequately protect themselves, nominators are required to secure themselves against highly unlikely but potentially detrimental events. Yet, the rarity of slashing incidents (which are even more rarely applied) makes it difficult for nominators to perceive a meaningful risk. Psychological phenomena like availability bias could cause decision-makers to underestimate both the probability and potential impact of such events, leaving them less prepared than they should be.
+
+After all, slashing is meant as deterrend and not a frequently applied mechanism. As protocol designers, we must remain vigilant and continuously optimize the network's security, even in the absence of major issues. After all, if we notice a problem, it may already be too late.
+
+
+## Conclusion and TL;DR
+The NPoS system requires nominators to regularly engage and update their selections to meaningfully contribute to economic security. Additionally, they are compensated for their effort and the risk of potential slashes. However, these risks may be underestimated, leading many nominators to set their nominations once and never revisit them.
+
+As the network matures, this behavior could have serious security implications. Our proposal aims to introduce a gentle incentive for nominators to stay actively engaged in the staking system. A positive side effect is that having more engaged nominators encourages validators to consistently perform at their best across all key dimensions.
+
+
+## Stakeholders
+
+Primary stakeholders are:
+
+- Nominators
+- Validators
+
+## Explanation
+
+Detail-heavy explanation of the RFC, suitable for explanation to an implementer of the changeset. This should address corner cases in detail and provide justification behind decisions, and provide rationale for how the design meets the solution requirements.
+
+TODO Shawn
+
+## Drawbacks
+
+The proposed mechanism does come with some potential drawbacks:
+
+### Risk of Alienating Nominators
+- **Problem**: Some nominators, particularly those who don’t engage regularly, may feel alienated, especially if they experience reduced rewards due to lack of involvement, potentially without realizing there was an update.
+- **Response**: Nominators who fail to stay engaged are not fully performing the role that the network rewards them for. We plan to mitigate this by launching informational campaigns to ensure that nominators are aware of any updates and changes. Moreover, any adjustments in rewards would only take effect after six months from implementation, as we won’t apply these changes retroactively.
+
+### Potential for Bot Automation
+- **Problem**: There is a possibility that some nominators might use bots to automate the process, simply reconfirming their selections without actual engagement.
+- **Response**: In the worst-case scenario, automated reconfirmation would maintain the current state, with no improvement but also no additional detriment. Furthermore, running bots is not a feasible option for all nominators, as it requires effort that may exceed the effort of simply updating selections periodically. Recent advances have also made it easier for nominators to make informed choices, reducing the likelihood of relying on bots for this task.
+
+## Testing, Security, and Privacy
+
+Describe the the impact of the proposal on these three high-importance areas - how implementations can be tested for adherence, effects that the proposal has on security and privacy per-se, as well as any possible implementation pitfalls which should be clearly avoided.
+
+## Performance, Ergonomics, and Compatibility
+
+Describe the impact of the proposal on the exposed functionality of Polkadot.
+
+### Performance
+
+Is this an optimization or a necessary pessimization? What steps have been taken to minimize additional overhead?
+
+### Ergonomics
+
+If the proposal alters exposed interfaces to developers or end-users, which types of usage patterns have been optimized for?
+
+### Compatibility
+
+Does this proposal break compatibility with existing interfaces, older versions of implementations? Summarize necessary migrations or upgrade strategies, if any.
+
+## Prior Art and References
+
+- Report: https://jonasw3f.github.io/nominators_behavior_hosted/
+- Github issue discussions:
+
+## Unresolved Questions
+
+Provide specific questions to discuss and address before the RFC is voted on by the Fellowship. This should include, for example, alternatives to aspects of the proposed design where the appropriate trade-off to make is unclear.
+
+## Future Directions and Related Material
+
+Describe future work which could be enabled by this RFC, if it were accepted, as well as related RFCs. This is a place to brain-dump and explore possibilities, which themselves may become their own RFCs.
+
+
+Open Questions:
+- Can we introduce it on the last selection of a nominator or would it be t0 once we activate the mechanism? The latter might cause issues that we see a drop in backing at the same time.
+- How would self-stake be treated? Can it become stale? It shouldn't.
\ No newline at end of file
diff --git a/docs/Polkadot/economics/applied-research/rfc146.md b/docs/Polkadot/economics/applied-research/rfc146.md
new file mode 100644
index 00000000..4927ac3a
--- /dev/null
+++ b/docs/Polkadot/economics/applied-research/rfc146.md
@@ -0,0 +1,47 @@
+# RFC-0146: Deflationary Transaction Fee Model for the Relay Chain and its System Parachains (accepted)
+
+| | |
+| --------------- | ------------------------------------------------------------------------------------------- |
+| **Start Date** | 20th May 2025 |
+| **Description** | This RFC proposes burning 80% of transaction fees on the Relay Chain and all its system parachains, adding to the existing deflationary capacity. |
+| **Authors** | Jonas Gehrlein |
+
+## Summary
+
+This RFC proposes **burning 80% of transaction fees** accrued on Polkadot’s **Relay Chain** and, more significantly, on all its **system parachains**. The remaining 20% would continue to incentivize Validators (on the Relay Chain) and Collators (on system parachains) for including transactions. The 80:20 split is motivated by preserving the incentives for Validators, which are crucial for the security of the network, while establishing a consistent fee policy across the Relay Chain and all system parachains.
+
+* On the **Relay Chain**, the change simply redirects the share that currently goes to the Treasury toward burning. Given the move toward a [minimal Relay](https://polkadot-fellows.github.io/RFCs/approved/0032-minimal-relay.html) ratified by RFC0032, a change to the fee policy will likely be symbolic for the future, but contributes to overall coherence.
+
+* On **system parachains**, the Collator share would be reduced from 100% to 20%, with 80% burned. Since the rewards of Collators do not significantly contribute to the shared security model, this adjustment should not negatively affect the network's integrity.
+
+This proposal extends the system's **deflationary direction** and is enabling direct value capture for DOT holders of an overall increased activity on the network.
+
+## Motivation
+
+Historically, transaction fees on both the Relay Chain and the system parachains (with a few exceptions) have been relatively low. This is by design—Polkadot is built to scale and offer low-cost transactions. While this principle remains unchanged, growing network activity could still result in a meaningful accumulation of fees over time.
+
+Implementing this RFC ensures that potentially increasing activity manifesting in more fees is captured for all token holders. It further aligns the way that the network is handling fees (such as from transactions or for coretime usage) is handled. The arguments in support of this are close to those outlined in [RFC0010](https://polkadot-fellows.github.io/RFCs/approved/0010-burn-coretime-revenue.html). Specifically, burning transaction fees has the following benefits:
+
+### Compensation for Coretime Usage
+
+System parachains do not participate in open-market bidding for coretime. Instead, they are granted a special status through governance, allowing them to consume network resources without explicitly paying for them. Burning transaction fees serves as a simple and effective way to compensate for the revenue that would otherwise have been generated on the open market.
+
+### Value Accrual and Deflationary Pressure
+
+By burning the transaction fees, the system effectively reduces the token supply and thereby increase the scarcity of the native token. This deflationary pressure can increase the token's long-term value and ensures that the value captured is translated equally to all existing token holders.
+
+
+This proposal requires only minimal code changes, making it inexpensive to implement, yet it introduces a consistent policy for handling transaction fees across the network. Crucially, it positions Polkadot for a future where fee burning could serve as a counterweight to an otherwise inflationary token model, ensuring that value generated by network usage is returned to all DOT holders.
+
+## Stakeholders
+
+* **All DOT Token Holders**: Benefit from reduced supply and direct value capture as network usage increases.
+
+* **System Parachain Collators**: This proposal effectively reduces the income currently earned by system parachain Collators. However, the impact on the status-quo is negligible, as fees earned by Collators have been minimal (around $1,300 monthly across all system parachains with data between November 2024 and April 2025). The vast majority of their compensation comes from Treasury reimbursements handled through bounties. As such, we do not expect this change to have any meaningful effect on Collator incentives or behavior.
+
+* **Validators**: Remain unaffected, as their rewards stay unchanged.
+
+
+## Sidenote: Fee Assets
+
+Some system parachains may accept other assets deemed **sufficient** for transaction fees. This has no implication for this proposal as the **asset conversion pallet** ensures that DOT is ultimately used to pay for the fees, which can be burned.
\ No newline at end of file
diff --git a/docs/Polkadot/economics/applied-research/rfc17.md b/docs/Polkadot/economics/applied-research/rfc17.md
new file mode 100644
index 00000000..4ff9d5f3
--- /dev/null
+++ b/docs/Polkadot/economics/applied-research/rfc17.md
@@ -0,0 +1,184 @@
+# RFC-0017: Coretime Market Redesign (accepted)
+
+| | |
+| --------------- | ------------------------------------------------------------------------------------------- |
+| **Original Proposition Date** | 05.08.2023 |
+| **Revision Date** | 04.06.2025 |
+| **Description** | This RFC redesigns Polkadot's coretime market to ensure that coretime is efficiently priced through a clearing-price Dutch auction. It also introduces a mechanism that guarantees current coretime holders the right to renew their cores outside the market—albeit at the market price with an additional charge. This design aligns renewal and market prices, preserving long-term access for current coretime owners while ensuring that market dynamics exert sufficient pressure on all purchasers, resulting in an efficient allocation.
+| **Authors** | Jonas Gehrlein |
+
+## Summary
+
+This document proposes a restructuring of the bulk markets in Polkadot's coretime allocation system to improve efficiency and fairness. The proposal suggests splitting the `BULK_PERIOD` into three consecutive phases: `MARKET_PERIOD`, `RENEWAL_PERIOD`, and `SETTLEMENT_PERIOD`. This structure enables market-driven price discovery through a clearing-price Dutch auction, followed by renewal offers during the `RENEWAL_PERIOD`.
+
+With all coretime consumers paying a unified price, we propose removing all liquidity restrictions on cores purchased either during the initial market phase or renewed during the renewal phase. This allows a meaningful `SETTLEMENT_PERIOD`, during which final agreements and deals between coretime consumers can be orchestrated on the social layer—complementing the agility this system seeks to establish.
+
+In the new design, we obtain a uniform price, the `clearing_price`, which anchors new entrants and current tenants. To complement market-based price discovery, the design includes a dynamic reserve price adjustment mechanism based on actual core consumption. Together, these two components ensure robust price discovery while mitigating price collapse in cases of slight underutilization or collusive behavior.
+
+## Motivation
+
+After exposing the initial system introduced in [RFC-1](https://github.com/polkadot-fellows/RFCs/blob/6f29561a4747bbfd95307ce75cd949dfff359e39/text/0001-agile-coretime.md) to real-world conditions, several weaknesses have become apparent. These lie especially in the fact that cores captured at very low prices are removed from the open market and can effectively be retained indefinitely, as renewal costs are minimal. The key issue here is the absence of price anchoring, which results in two divergent price paths: one for the initial purchase on the open market, and another fully deterministic one via the renewal bump mechanism.
+
+This proposal addresses these issues by anchoring all prices to a value derived from the market, while still preserving necessary privileges for current coretime consumers. The goal is to produce robust results across varying demand conditions (low, high, or volatile).
+
+In particular, this proposal introduces the following key changes:
+
+* **Reverses the order** of the market and renewal phases: all cores are first offered on the open market, and only then are renewal options made available.
+* **Introduces a dynamic `reserve_price`**, which is the minimum price coretime can be sold for in a period. This price adjusts based on consumption and does not rely on market participation.
+* **Makes unproductive core captures sufficiently expensive**, as all cores are exposed to the market price.
+
+The premise of this proposal is to offer a straightforward design that discovers the price of coretime within a period as a `clearing_price`. Long-term coretime holders still retain the privilege to keep their cores **if** they can pay the price discovered by the market (with some premium for that privilege). The proposed model aims to strike a balance between leveraging market forces for allocation while operating within defined bounds. In particular, prices are capped *within* a `BULK_PERIOD`, which gives some certainty about prices to existing teams. It must be noted, however, that under high demand, prices could increase exponentially *between* multiple market cycles. This is a necessary feature to ensure proper price discovery and efficient coretime allocation.
+
+Ultimately, the framework proposed here seeks to adhere to all requirements originally stated in RFC-1.
+
+## Stakeholders
+
+Primary stakeholder sets are:
+
+- Protocol researchers, developers, and the Polkadot Fellowship.
+- Polkadot Parachain teams both present and future, and their users.
+- Polkadot DOT token holders.
+
+## Explanation
+
+### Overview
+
+The `BULK_PERIOD` has been restructured into two primary segments: the `MARKET_PERIOD` and the `RENEWAL_PERIOD`, along with an auxiliary`SETTLEMENT_PERIOD`. The latter does not require any active participation from the coretime system chain except to simply execute transfers of ownership between market participants. A significant departure from the current design lies in the timing of renewals, which now occur after the market phase. This adjustment aims to harmonize renewal prices with their market counterparts, ensuring a more consistent and equitable pricing model.
+
+### Market Period (14 days)
+
+During the market period, core sales are conducted through a well-established **clearing-price Dutch auction** that features a `reserve_price`. Since the auction format is a descending clock, the starting price is initialized at the `opening_price`. The price then descends linearly over the duration of the `MARKET_PERIOD` toward the `reserve_price`, which serves as the minimum price for coretime within that period.
+
+Each bidder is expected to submit both their desired price and the quantity (i.e., number of cores) they wish to purchase. To secure these acquisitions, bidders must deposit an amount equivalent to their bid multiplied by the chosen quantity, in DOT. Bidders are always allowed to post a bid at or below the current descending price, but never above it.
+
+The market reaches resolution once all quantities have been sold or the `reserve_price` is reached. In the former case, the `clearing_price` is set equal to the price that sold the last unit. If cores remain unsold, the `clearing_price` is set to the `reserve_price`. This mechanism yields a uniform price that all buyers pay. Among other benefits discussed in the Appendix, this promotes truthful bidding—meaning the optimal strategy is simply to submit one's true valuation of coretime.
+
+The `opening_price` is determined by: `opening_price = max(MIN_OPENING_PRICE, PRICE_MULTIPLIER * reserve_price)`. We recommend `opening_price = max(150, 3 * reserve_price)`.
+
+### Renewal Period (7 days)
+
+The renewal period guarantees current tenants the privilege to renew their core(s), even if they did not win in the auction (i.e., did not submit a bid at or above the `clearing_price`) or did not participate at all.
+
+All current tenants who obtained less cores from the market than they have the right to renew, have 7 days to decide whether they want to renew their core(s). Once this information is known, the system has everything it needs to conclusively allocate all cores and assign ownership. In cases where the combined number of renewals and auction winners exceeds the number of available cores, renewals are first served and then remaining cores are allocated from highest to lowest bidder until all are assigned (more information in the details on mechanics section). This means that under larger demand than supply (and some renewal decisions), some bidders may not receive the coretime they expected from the auction.
+
+While this mechanism is necessary to ensure that current coretime users are not suddenly left without an allocation, potentially disrupting their operations, it may distort price discovery in the open market. Specifically, it could mean that a winning bidder is displaced by a renewal decision.
+
+Since bidding is straightforward and can be regarded static (it requires only one transaction) and can therefore be trivially automated, we view renewals as a safety net and want to encourage all coretime users to participate in the auction. To that end, we introduce a financial incentive to bid by increasing the renewal price to `clearing_price * PENALTY` (e.g., 30%). This penalty must be high enough to create a sufficient incentive for teams to prefer bidding over passively renewing.
+
+**Note:** Importantly, the `PENALTY` only applies when the number of unique bidders in the auction plus current tenants with renewal rights exceeds the number of available cores. If total demand is lower than the number of offered cores, the `PENALTY` is set to 0%, and renewers pay only the `clearing_price`. This reflects the fact that we would not expect the `clearing_price` to exceed the `reserve_price` even with all coretime consumers participating in the auction. To avoid managing reimbursements, the 30% `PENALTY` is automatically applied to all renewers as soon as the combined count of unique bidders and potential renewers surpasses the number of available cores.
+
+### Reserve Price Adjustment
+
+After each `RENEWAL_PERIOD`, once all renewal decisions have been collected and cores are fully allocated, the `reserve_price` is updated to capture the demand in the next period. The goal is to ensure that prices adjust smoothly in response to demand fluctuations—rising when demand exceeds targets and falling when it is lower—while avoiding excessive volatility from small deviations.
+
+We define the following parameters:
+
+* `reserve_price_t`: Reserve price in the current period
+* `reserve_price_{t+1}`: Reserve price for the next period (final value after adjustments)
+* `consumption_rate_t`: Fraction of cores sold (including renewals) out of the total available in the current period
+* `TARGET_CONSUMPTION_RATE`: Target ratio of sold-to-available cores (we propose 90%)
+* `K`: Sensitivity parameter controlling how aggressively the price responds to deviations (we propose values between 2 and 3)
+* `P_MIN`: Minimum reserve price floor (we propose 1 DOT to prevent runaway downward spirals and computational issues)
+* `MIN_INCREMENT`: Minimum absolute increment applied when the market is fully saturated (i.e., 100% consumption; proposed value: 100 DOT)
+
+We update the price according to the following rule:
+
+```
+price_candidate_t = reserve_price_t * exp(K * (consumption_rate_t - TARGET_CONSUMPTION_RATE))
+```
+
+We then ensure that the price does not fall below `P_MIN`:
+
+```
+price_candidate_t = max(price_candidate_t, P_MIN)
+```
+
+If `consumption_rate_t == 100%`, we apply an additional adjustment:
+
+```
+if (price_candidate_t - reserve_price_t < MIN_INCREMENT) {
+ reserve_price_{t+1} = reserve_price_t + MIN_INCREMENT
+} else {
+ reserve_price_{t+1} = price_candidate_t
+}
+```
+
+In other words, we adjust the `reserve_price` using the exponential scaling rule, except in the special case where consumption is at 100% but the resulting price increase would be less than `MIN_INCREMENT`. In that case, we instead apply the fixed minimum increment. This exception ensures that the system can recover more quickly from prolonged periods of low prices.
+
+We argue that in a situation with persistently low prices and a sudden surge in real demand (i.e., full core consumption), such a jump is both warranted and economically justified.
+
+### Settlement Period / Secondary Market (7 days)
+
+The remaining 7 days of a sales cycle serve as a settlement period, during which participants have ample time to trade coretime on secondary markets before the onset of the next `BULK_PERIOD`. This proposal makes no assumptions about the structure of these markets, as they are entirely operated on the social layer and managed directly by buyers and sellers. In this context, maintaining restrictions on the resale of renewed cores in the secondary market appears unjustified—especially given that prices are uniform and market-driven. In fact, such constraints could be harmful in cases where the primary market does not fully achieve efficiency.
+
+We therefore propose lifting all restrictions on the resale or slicing of cores in the secondary market.
+
+## Additional Considerations
+
+### New Track: Coretime Admin
+
+To enable rapid response, we propose that the parameters of the model be directly accessible by governance. These include:
+
+* `P_MIN`
+* `K`
+* `PRICE_MULTIPLIER`
+* `MIN_INCREMENT`
+* `TARGET_CONSUMPTION_RATE`
+* `PENALTY`
+* `MIN_OPENING_PRICE`
+
+This setup should allow us to adjust the parameters in a timely manner, within the duration of a `BULK_PERIOD`, so that changes can take effect before the next period begins.
+
+### Transition to the new Model
+
+Upon acceptance of this RFC, we should make sure to transition as smoothly as possible to the new design.
+
+* All teams that own cores in the current system should be endowed with the same number of cores in the new system, with the ability to renew them starting from the first period.
+* The initial `reserve_price` should be chosen sensibly to avoid distortions in the early phases.
+* A sufficient number of cores should be made available on the market to ensure enough liquidity to allow price discovery functions properly.
+
+### Details on Some Mechanics
+
+* The price descends linearly from a `opening_price` to the `reserve_price` over the duration of the `MARKET_PERIOD`. Importantly, each discrete price level should be held for a sufficiently long interval (e.g., 6–12 hours).
+* A potential issue arises when we experience demand spikes after prolonged periods of low demand (which result in low reserve prices). In such cases, the price range between `reserve_price` and the upper bound (i.e., `opening_price`) may be lower than the willingness to pay from many bidders. If this affects most participants, demand will concentrate at the upper bound of the Dutch auction, making front-running a profitable strategy—either by excessively tipping bidding transactions or through explicit collusion with block producers.
+ To mitigate this, we propose preventing the market from closing at the `opening_price` prematurely. Even if demand exceeds available cores at this level, we continue collecting all orders. Then, we randomize winners instead of using a first-come-first-served approach. Additionally, we may break up bulk orders and treat them as separate bids. This still gives a higher chance to bidders willing to buy larger quantities, but avoids all-or-nothing outcomes. These steps diminish the benefit of tipping or collusion, since bid timing no longer affects allocation. While we expect such scenarios to be the exception, it's important to note that this will not negatively impact current tenants, who always retain the safety net of renewal. After a few periods of maximum bids at maximum capacity, the range should span wide enough to capture demand within its bounds.
+* One implication of granting the renewal privilege after the `MARKET_PERIOD` is that some bidders, despite bidding above the `clearing_price`, may not receive coretime. We believe this is justified, because the harm of displacing an existing project is bigger than preventing a new project from getting in (if there is no cores available) for a bit. Additionally, this inefficiency is compensated for by the causing entities paying the `PENALTY`. We need, however, additional rules to resolve the allocation issues. These are:
+ 1. Bidders who already hold renewable cores cannot be displaced by the renewal decision of another party.
+ 2. Among those who *can* be displaced, we begin with the lowest submitted bids.
+* If a current tenant wins cores on the market, they forfeit the right to renew those specific cores. For example, if an entity currently holds three cores and wins two in the market, it may only opt to renew one. The only way to increase the number of cores at the end of a `BULK_PERIOD` is to acquire them entirely through the market.
+* Bids **below** the current descending price should always be allowed. In other words, teams shouldn't have to wait idly for the price to drop to their target.
+* Bids below the current descending price can be **raised**, but only up to the current clock price.
+* Bids **above** the current descending price are **not allowed**. This is a key difference from a simple *kth*-price auction and helps prevent sniping.
+* All cores that remain unallocated after the `RENEWAL_PERIOD` are transferred to the On-Demand Market.
+
+### Implications
+
+* The introduction of a single price (`clearing_price`) provides a consistent anchor for all available coretime. This serves as a safeguard against price divergence, preventing scenarios where entities acquire cores at significantly below-market rates and keep them for minimal costs.
+* With the introduction of the `PENALTY`, it is always financially preferable for teams to participate in the auction. By bidding their true valuation, they maximize their chance of winning a core at the lowest possible price without incurring the penalty.
+* In this design, it is virtually impossible to "accidentally" lose cores, since renewals occur after the market phase and are guaranteed for current tenants.
+* Prices within a `BULK_PERIOD` are bounded upward by the `opening_price`. That means, the maximum a renewer could ever pay within a round is `opening_price * PENALTY`. This provides teams with ample time to prepare and secure the necessary funds in anticipation of potential price increases. By incorporating reserve price adjustment into their planning, teams can anticipate worst-case future price increases.
+
+## Appendix
+
+### Further Discussion Points
+
+- **Reintroduction of Candle Auctions**: Polkadot gathered vast experience with candle auctions where more than 200 auctions has been conducted throughout more than two years. [Our study](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=5109856) analyzing the results in much detail reveals that the mechanism itself is both efficient and (nearly) extracting optimal revenue. This provides confidence to use it to allocate the winners instead of a descending clock auction. Notably, this change solely affects the bidding process and winner determination. Core components, such as the k-th price, reserve price, and maximum price, remain unaffected.
+
+### Insights: Clearing Price Dutch Auctions
+Having all bidders pay the market clearing price offers some benefits and disadvantages.
+
+- Advantages:
+ - **Fairness**: All bidders pay the same price.
+ - **Active participation**: Because bidders are protected from overbidding (winner's curse), they are more likely to engage and reveal their true valuations.
+ - **Simplicity**: A single price is easier to work with for pricing renewals later.
+ - **Truthfulness**: There is no need to try to game the market by waiting with bidding. Bidders can just bid their valuations.
+ - **No sniping**: As prices are descending, a player cannot wait until the end to place a high bid. They are only allowed to place the decreasing bid at the time of bidding.
+- Disadvantages:
+ - **(Potentially) Lower Revenue**: While the theory predicts revenue-equivalence between a uniform price and pay-as-bid type of auction, slightly lower revenue for the former type is observed empirically. Arguably, revenue maximization (i.e., squeezing out the maximum willingness to pay from bidders) is not the priority for Polkadot. Instead, it is interested in efficient allocation and the other benefits illustrated above.
+ - **(Technical) Complexity**: Instead of making a final purchase within the auction, the bid is only a deposit. Some refunds might happen after the auction is finished. This might pose additional challenges from the technical side (e.g., storage requirements).
+
+### Prior Art and References
+
+This RFC builds extensively on the available ideas put forward in [RFC-1](https://github.com/polkadot-fellows/RFCs/blob/6f29561a4747bbfd95307ce75cd949dfff359e39/text/0001-agile-coretime.md).
+
+Additionally, I want to express a special thanks to [Samuel Haefner](https://samuelhaefner.github.io/), [Shahar Dobzinski](https://sites.google.com/site/dobzin/), and Alistair Stewart for fruitful discussions and helping me structure my thoughts.
\ No newline at end of file
diff --git a/docs/Polkadot/economics/applied-research/rfc97.md b/docs/Polkadot/economics/applied-research/rfc97.md
new file mode 100644
index 00000000..7df1d94e
--- /dev/null
+++ b/docs/Polkadot/economics/applied-research/rfc97.md
@@ -0,0 +1,168 @@
+# RFC-0097: Unbonding Queue (accepted)
+
+| | |
+| --------------- | ------------------------------------------------------------------------------------------- |
+| **Date** | 19.06.2024 |
+| **Description** | This RFC proposes a safe mechanism to scale the unbonding time from staking on the Relay Chain proportionally to the overall unbonding stake. This approach significantly reduces the expected duration for unbonding, while ensuring that a substantial portion of the stake is always available to slash of validators behaving maliciously within a 28-day window. |
+| **Authors** | Jonas Gehrlein & Alistair Stewart |
+
+## Summary
+
+This RFC proposes a flexible unbonding mechanism for tokens that are locked from [staking](https://wiki.polkadot.network/docs/learn-staking) on the Relay Chain (DOT/KSM), aiming to enhance user convenience without compromising system security.
+
+Locking tokens for staking ensures that Polkadot is able to slash tokens backing misbehaving validators. With changing the locking period, we still need to make sure that Polkadot can slash enough tokens to deter misbehaviour. This means that not all tokens can be unbonded immediately, however we can still allow some tokens to be unbonded quickly.
+
+The new mechanism leads to a signficantly reduced unbonding time on average, by queuing up new unbonding requests and scaling their unbonding duration relative to the size of the queue. New requests are executed with a minimum of 2 days, when the queue is comparatively empty, to the conventional 28 days, if the sum of requests (in terms of stake) exceed some threshold. In scenarios between these two bounds, the unbonding duration scales proportionately. The new mechanism will never be worse than the current fixed 28 days.
+
+In this document we also present an empirical analysis by retrospectively fitting the proposed mechanism to the historic unbonding timeline and show that the average unbonding duration would drastically reduce, while still being sensitive to large unbonding events. Additionally, we discuss implications for UI, UX, and conviction voting.
+
+Note: Our proposition solely focuses on the locks imposed from staking. Other locks, such as governance, remain unchanged. Also, this mechanism should not be confused with the already existing feature of [FastUnstake](https://wiki.polkadot.network/docs/learn-staking#fast-unstake), which lets users unstake tokens immediately that have not received rewards for 28 days or longer.
+
+As an initial step to gauge its effectiveness and stability, it is recommended to implement and test this model on Kusama before considering its integration into Polkadot, with appropriate adjustments to the parameters. In the following, however, we limit our discussion to Polkadot.
+
+## Motivation
+
+Polkadot has one of the longest unbonding periods among all Proof-of-Stake protocols, because security is the most important goal. Staking on Polkadot is still attractive compared to other protocols because of its above-average staking APY. However the long unbonding period harms usability and deters potential participants that want to contribute to the security of the network.
+
+The current length of the unbonding period imposes significant costs for any entity that even wants to perform basic tasks such as a reorganization / consolidation of their stashes, or updating their private key infrastructure. It also limits participation of users that have a large preference for liquidity.
+
+The combination of long unbonding periods and high returns has lead to the proliferation of [liquid staking](https://www.bitcoinsuisse.com/learn/what-is-liquid-staking), where parachains or centralised exchanges offer users their staked tokens before the 28 days unbonding period is over either in original DOT/KSM form or derivative tokens. Liquid staking is harmless if few tokens are involved but it could result in many validators being selected by a few entities if a large fraction of DOTs were involved. This may lead to centralization (see [here](https://dexola.medium.com/is-ethereum-about-to-get-crushed-by-liquid-staking-30652df9ec46) for more discussion on threats of liquid staking) and an opportunity for attacks.
+
+The new mechanism greatly increases the competitiveness of Polkadot, while maintaining sufficient security.
+
+
+## Stakeholders
+
+- Every DOT/KSM token holder
+
+## Explanation
+
+Before diving into the details of how to implement the unbonding queue, we give readers context about why Polkadot has a 28-day unbonding period in the first place. The reason for it is to prevent long-range attacks (LRA) that becomes theoretically possible if more than 1/3 of validators collude. In essence, a LRA describes the inability of users, who disconnect from the consensus at time t0 and reconnects later, to realize that validators which were legitimate at a certain time, say t0 but dropped out in the meantime, are not to be trusted anymore. That means, for example, a user syncing the state could be fooled by trusting validators that fell outside the active set of validators after t0, and are building a competitive and malicious chain (fork).
+
+LRAs of longer than 28 days are mitigated by the use of trusted checkpoints, which are assumed to be no more than 28 days old. A new node that syncs Polkadot will start at the checkpoint and look for proofs of finality of later blocks, signed by 2/3 of the validators. In an LRA fork, some of the validator sets may be different but only if 2/3 of some validator set in the last 28 days signed something incorrect.
+
+If we detect an LRA of no more than 28 days with the current unbonding period, then we should be able to detect misbehaviour from over 1/3 of validators whose nominators are still bonded. The stake backing these validators is considerable fraction of the total stake (empirically it is 0.287 or so). If we allowed more than this stake to unbond, without checking who it was backing, then the LRA attack might be free of cost for an attacker. The proposed mechansim allows up to half this stake to unbond within 28 days. This halves the amount of tokens that can be slashed, but this is still very high in absolute terms. For example, at the time of writing (19.06.2024) this would translate to around 120 millions DOTs.
+
+Attacks other than an LRA, such as backing incorrect parachain blocks, should be detected and slashed within 2 days. This is why the mechanism has a minimum unbonding period.
+
+In practice an LRA does not affect clients who follow consensus more frequently than every 2 days, such as running nodes or bridges. However any time a node syncs Polkadot if an attacker is able to connect to it first, it could be misled.
+
+In short, in the light of the huge benefits obtained, we are fine by only keeping a fraction of the total stake of validators slashable against LRAs at any given time.
+
+## Mechanism
+
+When a user ([nominator](https://wiki.polkadot.network/docs/learn-nominator) or validator) decides to unbond their tokens, they don't become instantly available. Instead, they enter an *unbonding queue*. The following specification illustrates how the queue works, given a user wants to unbond some portion of their stake denoted as `new_unbonding_stake`. We also store a variable, `max_unstake` that tracks how much stake we allow to unbond potentially earlier than 28 eras (28 days on Polkadot and 7 days on Kusama).
+
+To calculate `max_unstake`, we record for each era how much stake was used to back the lowest-backed 1/3 of validators. We store this information for the last 28 eras and let `min_lowest_third_stake` be the minimum of this over the last 28 eras.
+`max_unstake` is determined by `MIN_SLASHABLE_SHARE` x `min_lowest_third_stake`. In addition, we can use `UPPER_BOUND` and `LOWER_BOUND` as variables to scale the unbonding duration of the queue.
+
+At any time we store `back_of_unbonding_queue_block_number` which expresses the block number when all the existing unbonders have unbonded.
+
+Let's assume a user wants to unbond some of their stake, i.e., `new_unbonding_stake`, and issues the request at some arbitrary block number denoted as `current_block`. Then:
+
+```
+unbonding_time_delta = new_unbonding_stake / max_unstake * UPPER_BOUND
+```
+
+This number needs to be added to the `back_of_unbonding_queue_block_number` under the conditions that it does not undercut `current_block + LOWER_BOUND` or exceed `current_block + UPPER_BOUND`.
+
+```
+back_of_unbonding_queue_block_number = max(current_block_number, back_of_unbonding_queue_block_number) + unbonding_time_delta
+```
+
+This determines at which block the user has their tokens unbonded, making sure that it is in the limit of `LOWER_BOUND` and `UPPER_BOUND`.
+
+```
+unbonding_block_number = min(UPPER_BOUND, max(back_of_unbonding_queue_block_number - current_block_number, LOWER_BOUND)) + current_block_number
+```
+
+Ultimately, the user's token are unbonded at `unbonding_block_number`.
+
+### Proposed Parameters
+There are a few constants to be exogenously set. They are up for discussion, but we make the following recommendation:
+- `MIN_SLASHABLE_SHARE`: `1/2` - This is the share of stake backing the lowest 1/3 of validators that is slashable at any point in time. It offers a trade-off between security and unbonding time. Half is a sensible choice. Here, we have sufficient stake to slash while allowing for a short average unbonding time.
+- `LOWER_BOUND`: 28800 blocks (or 2 eras): This value resembles a minimum unbonding time for any stake of 2 days.
+- `UPPER_BOUND`: 403200 blocks (or 28 eras): This value resembles the maximum time a user faces in their unbonding time. It equals to the current unbonding time and should be familiar to users.
+
+### Rebonding
+
+Users that chose to unbond might want to cancel their request and rebond. There is no security loss in doing this, but with the scheme above, it could imply that a large unbond increases the unbonding time for everyone else later in the queue. When the large stake is rebonded, however, the participants later in the queue move forward and can unbond more quickly than originally estimated. It would require an additional extrinsic by the user though.
+
+Thus, we should store the `unbonding_time_delta` with the unbonding account. If it rebonds when it is still unbonding, then this value should be subtracted from `back_of_unbonding_queue_block_number`. So unbonding and rebonding leaves this number unaffected. Note that we must store `unbonding_time_delta`, because in later eras `max_unstake` might have changed and we cannot recompute it.
+
+
+### Empirical Analysis
+We can use the proposed unbonding queue calculation, with the recommended parameters, and simulate the queue over the course of Polkadot's unbonding history. Instead of doing the analysis on a per-block basis, we calculate it on a daily basis. To simulate the unbonding queue, we require the ratio between the daily total stake of the lowest third backed validators and the daily total stake (which determines the `max_unstake`) and the sum of daily and newly unbonded tokens. Due to the [NPoS algorithm](https://wiki.polkadot.network/docs/learn-phragmen), the first number has only small variations and we used a constant as approximation (0.287) determined by sampling a bunch of empirical eras. At this point, we want to thank Parity's Data team for allowing us to leverage their data infrastructure in these analyses.
+
+The following graph plots said statistics.
+
+
+
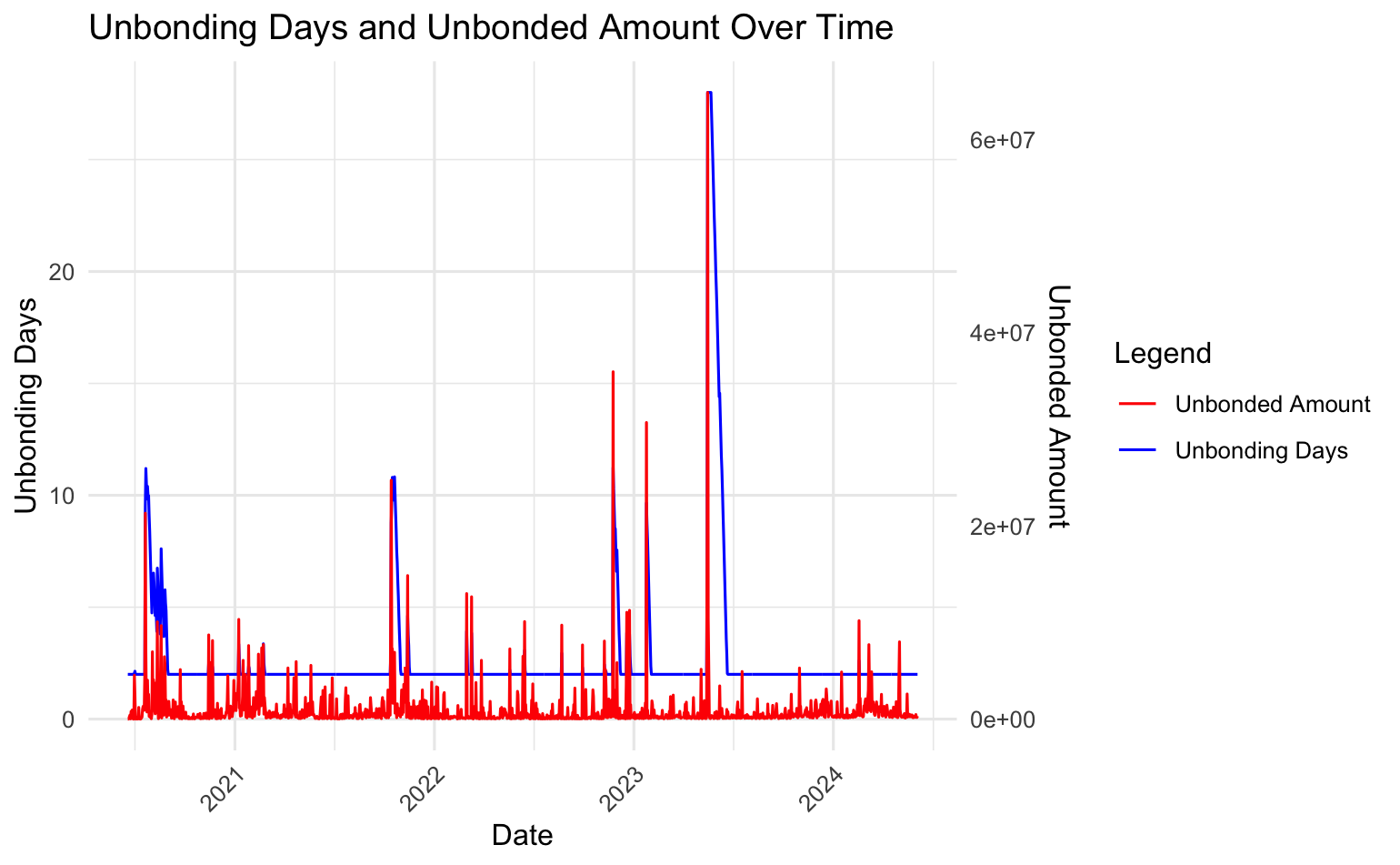
+
-Next we show that, in expectation, the progress in objective value perceived in each round is proportional to the difference between the current and optimal values.
+The next step is to show that, in expectation, the progress in objective value achieved during each round is proportional to the difference between the current value and the optimal one.
-__Lemma 2:__ For each round $i\in\{1,\cdots,r\}$ that starts with vector $w^{i-1}$ and ends with vector $w^i$, the expected objective value of $w^i$ is such that
+__Lemma 2:__ For each round $i\in\{1,\cdots,r\}$, with initial vector $w^{i-1}$ and final vector $w^i$, the expected value of the objective function satisfies
$$val(w^{i-1}) - \mathbb{E}[val(w^{i})] \geq \frac{1}{k^2|N|} [val(w^{i-1}) - val(w^*)].$$
-_Proof:_ We fix a round $i$, and for notational convenience we drop the superscripts $i$ and $i-1$ within the scope of this proof. In particular, we let $w$ be the initial vector, and let $w'^n$ be the final vector in the case that nominator $n$ is picked in the round. Clearly, the expected progress in objective value equals the average progress $\frac{1}{|N|}\sum_{n\in N} [val(w) - val(w'^n)]$. To lower bound the latter, it is sufficient to exhibit a different family of weight vectors $\{w^n\}_{n\in N}$ such that $val(w'^n)\leq val(w^n)$ for each $n$, and then bound the average progress when moving from $w$ to a member of that family.
+_Proof:_ Fix a round $i$, and for notational convenience, drop the superscripts $i$ and $i-1$ throughout this proof. Let $w$ denote the initial weight vector, and let $w'^n$ be the resulting vector when nominator $n$ is selected in that round. The expected improvement in the objective value is given by the average progress $\frac{1}{|N|}\sum_{n\in N} [val(w) - val(w'^n)]$. To establish a lower bound on this quantity, it suffices to define an alternative family of vectors $\{w^n\}_{n\in N}$ such that $val(w'^n)\leq val(w^n)$ for each $n$. It is then possible to analyze the average improvement obtained by transitioning from $w$ to a corresponding vector in this family.
-Define the vector $f:=w-w^*\in\mathbb{R}^E$. The following is a necessary technical observation whose proof we delay temporarily.
+To proceed, define the vector $f:=w-w^*\in\mathbb{R}^E$. The following technical observation is essential, though its proof will be deferred.
__Lemma 3:__ $\|f\|^2 \leq k^2 \|Bf\|^2.$
-Consider the decomposition of vector $f$ as $f=\sum_{n\in N} f^n$, where $f^n$ is the restriction of $f$ over the edges incident to nominator $n$, and define the family of weight vectors $\{w^n:= w-\frac{1}{k^2} f^n\}_{n\in N}$. We have $val(w'^n) \leq val(w^n)$ for all $n\in N$ as desired, because by construction (step 2.b. of the algorithm), $w'^n$ is precisely the vector of minimum objective value among all maximally affordable vectors that differ from $w$ only at the edges incident to $n$. Hence, it only remains to bound the average progress in objective value with respect to the new family.
+Consider the decomposition of vector $f$ as $f=\sum_{n\in N} f^n$, where each $f^n$ denotes the restriction of $f$ to the edges incident to nominator $n$. Define the family of weight vectors $\{w^n:= w-\frac{1}{k^2} f^n\}_{n\in N}$. Then $val(w'^n) \leq val(w^n)$ holds for all $n\in N$, as desired. This follows from the construction in step 2.b of the algorithm: $w'^n$ is the tight, maximally affordable vector minimizing the objective among all vectors differing from $w$ only on edges incident to $n$. All that remains is to bound the average progress in objective value with respect to the newly defined family.
-For a fixed $n\in N$, we have
+For a fixed $n\in N$,
$$\begin{align}
val(w) - val(w^n) &= \|Bw\|^2 - \|B(w-\frac{1}{k^2} f^n)\|^2 \\
@@ -114,14 +123,14 @@ $$
-_Proof of Lemma 3:_ We interpret $f$ as a flow over the network $(N\cup A, E)$. As both $w$ and $w^*$ are tight, there is flow preservation over all nominators. Let $A_s, A_t\subseteq A$ be respectively the sets of sources and sinks, i.e. the sets of validators with net excess and net demand. By the flow decomposition theorem, there exists a decomposition $f=\sum_{v\in A_s} f^v$ into single-source subflows, where $f^v$ has $v$ as its single source. We can assume that this decomposition generates no cycles by adjusting the choice of the optimal solution $w^*=w-f$.
+_Proof of Lemma 3:_ The vector $f$ can be interpreted as a flow over the network $(N\cup A, E)$. Since both $w$ and $w^*$ are tight, flow preservation holds at all nominators. Let $A_s, A_t\subseteq A$ denote the sets of sources and sinks, respectively. That is, the subsets of validators with net excess and net demand. By the flow decomposition theorem, the flow *f* can be expressed as the sum of single-source subflows $f=\sum_{v\in A_s} f^v$, where each $f^v$ originates from a single source validator. This decomposition generates no cycles by suitably adjusting the choice of the optimal solution $w^*=w-f$.
-Consider one of these subflows $f^v$. Its edge support looks like a directed acyclic graph (DAG) with single root $v$. We arrange the edges on this DAG by levels, where the level of an edge is the length of the longest path from $v$ containing this edge. These levels start at 1 for the edges incident to $v$, up to at most $2k$ because any simple path alternates between a nominator and a validator and there are only $k$ validators. We now split $f^v$ by levels, $f^v=\sum_{i\leq 2k} f^{v,i}$, where $f^{v,i}$ is the restriction of $f^v$ over the edges at level $i$. Since the excess in node $v$ is $supp_w(v)-supp_{w^*}(v)=(Bf)_v$ and no other node in the DAG has any excess, the sum of edge weights along each level $i$ is $\|f^{v,i}\|_1 \leq (Bf)_v$. Therefore,
+The edge support of each subflow $f^v$ resembles a directed acyclic graph (DAG) rooted at the single source node $v$. Edges on this DAG are organized by levels, where the level of an edge is defined by the length of the longest path from $v$ that includes this edge. These levels begin at 1 for edges incident to $v$, and go up to at most $2k$, since any simple path alternates between nominators and validators, with only $k$ validators. The next step is to decompose $f^v$ by levels as $f^v=\sum_{i\leq 2k} f^{v,i}$, where each $f^{v,i}$ is the restriction of $f^v$ over edges at level $i$. Because node $v$ is the only source of excess, quantified by $supp_w(v)-supp_{w^*}(v)=(Bf)_v$, and all other nodes in the DAG preserve flow, the total weight along any level $i$ is $\|f^{v,i}\|_1 \leq (Bf)_v$. It follows that:
$$\|f^v\|_2^2 = \sum_{i\leq 2k}\|f^{v,i}\|_2^2
\leq \sum_{i\leq 2k} \|f^{v,i}\|_1^2
\leq 2k\cdot (Bf)^2_v.$$
-Putting things together, we get
+Putting things together, the result is:
\begin{align}
\|f\|^2_2 &= \|\sum_{v\in A_s} f^v\|_2^2 \\
@@ -132,42 +141,43 @@ Putting things together, we get
where the first inequality is an application of a Cauchy-Schwarz inequality.
-In a similar manner, working with sinks instead of sources, we can obtain the bound $\|f\|^2 \leq 2k|A_t| \cdot \|Bf\|^2$. Summing up these two bounds and dividing by two, we get
+Similarly, by considering sinks instead of sources, the resulting bound is $\|f\|^2 \leq 2k|A_t| \cdot \|Bf\|^2$. Summing this with the previous bound and dividing by two, yields
$$\|f\|^2 \leq k(|A_s|+|A_t|) \cdot \|Bf\|^2 \leq k^2 \|Bf\|^2,$$
-which proves the claim.
+which establishes the claim.
$$
\tag{$\blacksquare$}
$$
-For each round $i\leq r$, consider the random variable $\Delta^i:= val(w^i) - val(w^*)$, which represents how far from optimal the current solution is in terms of objective value. We now use Lemma 2 to show that $\Delta^i$ decays exponentially fast in expectation.
+For each round $i\leq r$, let the random variable $\Delta^i:= val(w^i) - val(w^*)$ denote the deviation of the current solution from optimality in terms of objective value. Referring back to Lemma 2, one can demonstrate that $\Delta^i$ decreases exponentially in expectation.
-__Lemma 4:__ For any $0
-Recall now that we want the value of the output solution $val(w^r)$ to be within a factor of $(1+\varepsilon)$ from $val(w^*)$ with probability at least $(1-\delta)$. The next lemma completes the analysis of the algorithm and the proof of the main theorem.
+Since the value of the final output $val(w^r)$ must lie within a factor of $(1+\varepsilon)$ of the optimal value $val(w^*)$ with probability at least $(1-\delta)$, the next lemma completes the algorithm's analysis and establishes the main theorem.
__Lemma 5:__ If $r=\lceil |N|k^2\ln(k/\epsilon \delta) \rceil$, then $\mathbb{P}[val(w^r) > (1+\varepsilon)val(w^*)]\leq \delta$.
-_Proof:_ By Lemma 4 and the choice of value $r$, it follows that
+_Proof:_ By Lemma 4 and the choice of $r$, it follows that
$$\mathbb{E}[\Delta^r]\leq \epsilon\cdot \delta\cdot val(w^*).$$
-As the variable $\Delta^r$ is non-negative, we can use Markov's inequality:
+Since $\Delta^r$ is non-negative, we apply Markov's inequality:
-$$\delta \geq \mathbb{P}[\Delta^r > \frac{\mathbb{E}[\Delta^r]}{\delta}]
-\geq \mathbb{P}[\Delta^r > \epsilon\cdot val(w^*)]
+$$\delta \geq \mathbb{P}[\Delta^r > \frac{\mathbb{E}[\Delta^r]}{\delta}]\geq \mathbb{P}[\Delta^r > \epsilon\cdot val(w^*)]
= \mathbb{P}[val(w^r) > (1+\epsilon)\cdot val(w^*)],$$
-which is the claim.
+and thus the claim is proved.
$$
\tag{$\blacksquare$}
$$
+
+**For inquieries or questions, please contact** [Alistair Stewart](/team_members/alistair.md)
\ No newline at end of file
diff --git a/docs/Polkadot/protocols/NPoS/Committee-election-rule.png b/docs/Polkadot/protocols/NPoS/Committee-election-rule.png
new file mode 100644
index 00000000..1e5f5a1f
Binary files /dev/null and b/docs/Polkadot/protocols/NPoS/Committee-election-rule.png differ
diff --git a/docs/Polkadot/protocols/NPoS/Computed-balanced-solution.jpeg b/docs/Polkadot/protocols/NPoS/Computed-balanced-solution.jpeg
new file mode 100644
index 00000000..d69cfd6e
Binary files /dev/null and b/docs/Polkadot/protocols/NPoS/Computed-balanced-solution.jpeg differ
diff --git a/docs/Polkadot/protocols/NPoS/NPoS_Cover1.png b/docs/Polkadot/protocols/NPoS/NPoS_Cover1.png
new file mode 100644
index 00000000..2f9a56f5
Binary files /dev/null and b/docs/Polkadot/protocols/NPoS/NPoS_Cover1.png differ
diff --git a/docs/Polkadot/protocols/NPoS/Nominated-proof-of-stake.png b/docs/Polkadot/protocols/NPoS/Nominated-proof-of-stake.png
new file mode 100644
index 00000000..bab21ee5
Binary files /dev/null and b/docs/Polkadot/protocols/NPoS/Nominated-proof-of-stake.png differ
diff --git a/docs/Polkadot/protocols/NPoS/index.md b/docs/Polkadot/protocols/NPoS/index.md
index a4965262..ee7e6657 100644
--- a/docs/Polkadot/protocols/NPoS/index.md
+++ b/docs/Polkadot/protocols/NPoS/index.md
@@ -2,18 +2,20 @@
title: Nominated Proof-of-Stake
---
-**Authors**: [Alfonso Cevallos](/team_members/alfonso.md)
+
-Many blockchain projects launched in recent years substitute the highly inefficient Proof-of-Work (PoW) component of Nakamoto’s consensus protocol with Proof-of-Stake (PoS), in which validators participate in block production with a frequency proportional to their token holdings, as opposed to their computational power. While a pure PoS system allows any token holder to participate directly, most projects propose some level of centralized operation, whereby the number of validators with full participation rights is limited. Arguments for this limited validator set design choice are that:
+In recent years, many blockchain projects have replaced the highly inefficient Proof-of-Work (PoW) component of Nakamoto’s consensus protocol with Proof-of-Stake (PoS). In PoS systems, validators participate in block production at a frequency proportional to their token holdings, rather than their computational power. Although a pure PoS model allows any token holder to participate directly, most projects adopt some degree of centralization by limiting the number of validators with full participation rights. The rationale for this limited validator set design is based on the following considerations:
-- The increase in operational costs and communication complexity eventually outmatches the increase in decentralization benefits as the number of validators grows.
-- While many token holders may want to contribute in maintaining the system, the number of candidates with the required knowledge and equipment to ensure a high quality of service is limited.
-- It is typically observed in networks (both PoW- and PoS-based) with a large number of validators that the latter tend to form pools anyway, in order to decrease the variance of their revenue and profit from economies of scale.
+- As the number of validators increases, operational costs and communication complexity eventually outweigh the benefits of decentralization.
+- While many token holders may wish to contribute to system maintenance, the number of candidates with the necessary knowledge and equipment to ensure high-quality service remains limited.
+- In both PoW- and PoS-based networks, when the number of validators becomes large, participants in the latter tend to form pools to reduce revenue variance and benefit from economies of scale.
-Therefore, rather than let pools be formed off-chain, it is more convenient for the system to formalize and facilitate pool formation on-chain, and allow users to vote with their stake to elect validators that represent them and act on their behalf. Networks following this approach include Polkadot, Cardano, EOS, Tezos, and Cosmos, among many others. While similar in spirit, the approaches in these networks vary in terms of design choices such as the incentive structure, the number of validators elected, and the election rule used to select them.
+Rather than allowing pools to form off-chain, it is more effective to formalize and facilitate their formation on-chain, enabling users to vote with their stake to elect validators who represent them and act on their behalf. Networks that follow this model include Polkadot, Cardano, EOS, Tezos, and Cosmos, among others. While united in principle, these networks differ in design choices such as incentive structures, validator set sizes, and election mechanisms.
-Polkadot introduces a variant of PoS called Nominated Proof-of-Stake, with design choices based on first principles and having security, fair representation and satisfaction of users, and efficiency as driving goals. In NPoS, users are free to become validator candidates, or become nominators. Nominators approve of candidates that they trust and back them with their tokens, and once per era a committee of validators is elected according to the current nominators' preferences. In Polkadot, the number k of validators elected is in the order of hundreds, and may be thousands in the future as the number of parachains increases.
+Polkadot introduces a Nominated Proof-of-Stake (NPoS) system. Its design choices are rooted in first principles, with security, fair representation, user satisfaction, and efficiency as guiding goals. In NPoS, users may either become validator candidates or act as nominators. Nominators select trusted candidates and support them by backing their stake. Once per era, a validator committee is elected based on the preferences of the current set of nominators. The number of elected validators k, is currently in the hundreds and may scale into the thousands as the number of parachains grows.
-Both validators and nominators lock their tokens as collateral and receive staking rewards on a pro-rata basis, but may also be slashed and lose their collateral in case a backed validator shows negligent or adversarial behavior. Nominators thus participate indirectly in the consensus protocol with an economic incentive to pay close attention to the evolving set of candidates and make sure that only the most capable and trustworthy among them get elected.
+Validators and nominators lock their tokens as collateral and receive staking rewards on a pro-rata basis. They may be slashed and lose their collateral if a supported validator engages in negligent or adversarial behavior. Nominators participate indirectly in the consensus protocol and have an economic incentive to closely monitor the evolving candidate set, helping ensure that only the most capable and trustworthy validators are elected.
-Visit our [overview page](1.%20Overview.md) for a first introduction to NPoS, and our [research paper](2.%20Paper.md) for an in-depth analysis. We also encourage the reader to visit the [token economics research section](Polkadot/overview/2-token-economics.md) for further information about staking rewards, [the section on slashing](Polkadot/security/slashing/amounts.md), and our [Wiki pages](https://wiki.polkadot.network/docs/en/learn-staking) for more hands-on information about the staking process. We also remark that, unlike other projects, Polkadot keeps validator selection completely independent from [governance](https://wiki.polkadot.network/docs/en/learn-governance), and in particular the user's right to participate in governance is never delegated.
\ No newline at end of file
+In the [overview page](1.%20Overview.md) you can learn about NPoS, and for an in-depth analysis you can read the [research paper](2.%20Paper.md). For more details on staking rewards, check out the [token economics research section](Polkadot/overview/2-token-economics.md), and learn about slashing in [this section](Polkadot/security/slashing/amounts.md). For a broader understanding of the staking process, explore [Wiki pages](https://wiki.polkadot.network/docs/en/learn-staking).
+
+Unlike other projects, Polkadot maintains complete independence between validator selection and [governance](https://wiki.polkadot.network/docs/en/learn-governance). In particular, users' rights to participate in governance are never delegated.
diff --git a/docs/Polkadot/protocols/Polkadot-protocols.png b/docs/Polkadot/protocols/Polkadot-protocols.png
new file mode 100644
index 00000000..f8e44b49
Binary files /dev/null and b/docs/Polkadot/protocols/Polkadot-protocols.png differ
diff --git a/docs/Polkadot/protocols/Sassafras/SLEP.jpeg b/docs/Polkadot/protocols/Sassafras/SLEP.jpeg
new file mode 100644
index 00000000..58ef399b
Binary files /dev/null and b/docs/Polkadot/protocols/Sassafras/SLEP.jpeg differ
diff --git a/docs/Polkadot/protocols/Sassafras/SLEP.png b/docs/Polkadot/protocols/Sassafras/SLEP.png
new file mode 100644
index 00000000..9dd23cb5
Binary files /dev/null and b/docs/Polkadot/protocols/Sassafras/SLEP.png differ
diff --git a/docs/Polkadot/protocols/Sassafras/Sassafras-part-3.md b/docs/Polkadot/protocols/Sassafras/Sassafras-part-3.md
index e6cbb696..36e53ab3 100644
--- a/docs/Polkadot/protocols/Sassafras/Sassafras-part-3.md
+++ b/docs/Polkadot/protocols/Sassafras/Sassafras-part-3.md
@@ -1,16 +1,16 @@
# Sassafras Part 3: Compare and Convince
-Authors: Elizabeth Crites, Handan Kılınç Alper, Alistair Stewart, and Fatemeh Shirazi
This is the third in a series of three blog posts that describe the new consensus protocol Sassafras, which is planned to be integrated into Polkadot, replacing the current [BABE](https://wiki.polkadot.network/docs/learn-consensus#block-production-babe)+[Aura](https://openethereum.github.io/Aura.html) consensus mechanism.
-Here is an overview of the three blog posts:
+:::note Overview of the three blog posts:
**[Part 1 - A Novel Single Secret Leader Election Protocol](sassafras-part-1):** The aim of this blog post is to give an introduction that is understandable to any reader with a slight knowledge of blockchains. It explains why Sassafras is useful and gives a high-level overview of how it works.
**[Part 2 - Deep Dive](sassafras-part-2):** The aim of this blog post is to dive into the details of the Sassafras protocol, focusing on technical aspects and security.
**Part 3 - Compare and Convince:** The aim of this blog post is to offer a comparison to similar protocols and convince the reader of Sassafras's value.
+:::
## If you have not read Part 1 and Part 2
Here is a a summary:
@@ -93,7 +93,6 @@ In particular, we conducted a comprehensive comparison of various protocols base
While the setup phase is expected to be rare in PoS blockchain protocols, shuffle-based solutions (with the exception of WHISK) impose impractical levels of message overhead. For election messages on the blockchain, Shuffle-2 and Shuffle-3 are highly inefficient. In stark contrast, Sassafras introduces a mere 7.64 MB overhead on the blockchain.
-
| Protocol || Setup | Election |
| -------- |--------| -------- | -------- |
|Shuffle-1|Off-Chain
On-Chain
|-
$8790.15$ MB|-
$123.7$ MB|
@@ -123,7 +122,6 @@ In terms of both communication and computational overhead, Sassafras outperforms
Table 3: Computational overhead of SSLE protocols on a blockchain. $N$ is the total number of participants.
-
## Key Takeaways
This concludes the three-part blog post series on Sassafras. Here are some key takeaways:
@@ -131,6 +129,10 @@ This concludes the three-part blog post series on Sassafras. Here are some key
* **Single leader election:** Sassafras elects a single block producer for each slot, ensuring faster consensus compared to protocols that rely on probabilistic leader election, which may not guarantee a unique leader or a leader at all times.
* **Maintaining the secrecy of a block producer:** Sassafras ensures the secrecy of block producers to mitigate against denial-of-service (DoS) attacks.
* **Lightweight:** Sassafras features exceptionally low communication and computational complexity and scales better than existing solutions.
+
+
+**For inquieries or questions, please contact:** [Elizabeth Crites](team_members/elizabeth.md)
+
diff --git a/docs/Polkadot/protocols/Sassafras/index.md b/docs/Polkadot/protocols/Sassafras/index.md
index 514cbfe5..a269c1ed 100644
--- a/docs/Polkadot/protocols/Sassafras/index.md
+++ b/docs/Polkadot/protocols/Sassafras/index.md
@@ -4,6 +4,8 @@ title: Understanding Sassafras
import DocCardList from '@theme/DocCardList';
-A Blog Series:
+This blog series covers the most important aspects of the secret leader election protocol.
+
+
\ No newline at end of file
diff --git a/docs/Polkadot/protocols/Sassafras/sassafras-part-1.md b/docs/Polkadot/protocols/Sassafras/sassafras-part-1.md
index c05bfacf..437023bd 100644
--- a/docs/Polkadot/protocols/Sassafras/sassafras-part-1.md
+++ b/docs/Polkadot/protocols/Sassafras/sassafras-part-1.md
@@ -1,6 +1,5 @@
# Sassafras Part 1: A Novel Single Secret Leader Election Protocol
-Authors: Armando Caracheo, Elizabeth Crites, and Fatemeh Shirazi
Polkadot is set to replace the [BABE](https://wiki.polkadot.network/docs/learn-consensus#block-production-babe)+[Aura](https://openethereum.github.io/Aura.html) consensus protocol with a new one: *Sassafras*. While Sassafras will be used to generate blocks on Polkadot's relay chain, it is also suitable for use in other proof-of-stake (PoS) blockchains. So, what key advantages does this new protocol bring to the blockchain ecosystem?
@@ -67,5 +66,6 @@ Our next blog post [Sassafras Part 2 - Deep Dive](sassafras-part-2), will explai
So stay tuned, brave reader. There's much more to discover in our upcoming Sassafras series, which is packed with valuable insights!
+**For inquieries or questions, please contact:** [Elizabeth Crites](/team_members/elizabeth.md)
[def]: Sassafras-diagram.png
diff --git a/docs/Polkadot/protocols/Sassafras/sassafras-part-2.md b/docs/Polkadot/protocols/Sassafras/sassafras-part-2.md
index b6796e8d..90475c3a 100644
--- a/docs/Polkadot/protocols/Sassafras/sassafras-part-2.md
+++ b/docs/Polkadot/protocols/Sassafras/sassafras-part-2.md
@@ -1,19 +1,17 @@
# Sassafras Part 2: Deep Dive
-Authors: Elizabeth Crites and Fatemeh Shirazi
-
This is the second in a series of three blog posts that describe the new consensus protocol Sassafras, which is planned to be integrated into Polkadot, replacing the current [BABE](https://wiki.polkadot.network/docs/learn-consensus#block-production-babe)+[Aura](https://openethereum.github.io/Aura.html) consensus mechanism.
-Here is an overview of the three blog posts:
+
+:::note Overview of the three blog posts:
**[Part 1 - A Novel Single Secret Leader Election Protocol](sassafras-part-1):** The aim of this blog post is to give an introduction that is understandable to any reader with a slight knowledge of blockchains. It explains why Sassafras is useful and gives a high-level overview of how it works.
**Part 2 - Deep Dive:** The aim of this blog post is to dive into the details of the Sassafras protocol, focusing on technical aspects and security.
**[Part 3 - Compare and Convince](Sassafras-part-3):**
-The aim of this blog post is to offer a comparison to similar protocols and convince the reader of Sassafras's value.
-
-Let's now take a deep dive into the Sassafras protocol, starting with some background on leader election protocols.
+:::
+The aim of this blog post is to offer a comparison to similar protocols and convince the reader of Sassafras's value. Let's now take a deep dive into the Sassafras protocol, starting with some background on leader election protocols.
## Sassafras: Efficient Batch Single Leader Election
@@ -115,6 +113,8 @@ which makes the tickets sent to different receivers indistinguishable,
We now move to [Part 3](Sassafras-part-3), which gives a detailed efficiency analysis and comparison with other approaches to leader election.
+**For inquieries and questions, please contact:** [Elizabeth Crites](/team_members/elizabeth.md)
+
[^1]: We show how to chose the parameter $n_t$ in [the paper](https://eprint.iacr.org/2023/002). For example, $n_t$ should be at least 6 for $2^{13}$ elections, under the assumption that the fraction $\alpha$ of corrupt parties is less than $\approx 0.3$ with $2^{14} = 16384$ total parties. (This is the number of validators running the leader election protocol proposed for Ethereum; see [Part 3](Sassafras-part-3).)
[^2]: Formally, the communication between sender and receiver occurs via a secure diffusion functionality $\mathcal{F}_{\mathsf{com}}^s$, which hides the message and the receiver. Here, we describe Sassafras with a simple and efficient instantiation of $\mathcal{F}_{\mathsf{com}}^s$ using symmetric encryption. By "multicasting the ciphertext to all parties," we mean one-to-many communication via a standard diffusion functionality $\mathcal{F}_{\mathsf{com}}$. Details are given in [the paper](https://eprint.iacr.org/2023/002).
diff --git a/docs/Polkadot/protocols/block-production/BABE.png b/docs/Polkadot/protocols/block-production/BABE.png
new file mode 100644
index 00000000..77dc7189
Binary files /dev/null and b/docs/Polkadot/protocols/block-production/BABE.png differ
diff --git a/docs/Polkadot/protocols/block-production/Babe.md b/docs/Polkadot/protocols/block-production/Babe.md
index fef3b2b4..09da6cf0 100644
--- a/docs/Polkadot/protocols/block-production/Babe.md
+++ b/docs/Polkadot/protocols/block-production/Babe.md
@@ -2,152 +2,129 @@
title: BABE
---
-**Authors**: [Handan Kilinc Alper](/team_members/handan.md)
+
-## 1. Overview
+Polkadot produces relay chain blocks using the **B**lind **A**ssignment for **B**lockchain **E**xtension protocol (BABE), which assigns block production slots based on a randomness cycle similar to that used in Ouroboros Praos.[^2] The process unfolds as follows: All block producers possess a verifiable random function (VRF) key, which is registered alongside their locked stake. These VRFs generate secret randomness, determining when each producer is eligible to create a block. The process carries an inherent risk that producers may attempt to manipulate the outcome by grinding through multiple VRF keys. To mitigate this, the VRF inputs must incorporate public randomness created only after the VRF key is established.
-In Polkadot, we produce relay chain blocks using our
- **B**lind **A**ssignment for **B**lockchain **E**xtension protocol,
- abbreviated BABE.
-BABE assigns block production slots
- using roughly the randomness cycle from Ouroboros Praos [2].
+As a result, the system operates in epochs, during which fresh public on-chain randomness is created by hashing together all the VRF outputs revealed through block production within that epoch This establishes a cycle that alternates between private, verifiable randomness and collaborative public randomness.
-In brief, all block producers have a verifiable random function (VRF)
-key, which they register with the locked stake. These VRFs produce secret
-randomness, which determines when they produce blocks. A priori, there
-is a risk that block producers could grind through VRF keys to bias
-results, so VRF inputs must include public randomness created only
-after the VRF key. We therefore have epochs in which we create fresh
-public on-chain randomness by hashing together all the VRF outputs
-revealed in block creation during the epoch. In this way, we cycle
-between private but verifiable randomness and collaborative public
-randomness.
-
-
-The main differences of BABE from Ouroboros Praos [2] are the best chain selection mechanism and slot synchronization assumption i.e.:
-
-1. BABE's best chain selection is based on GRANDPA and longest chain.
-2. Block producers in BABE do not have access to a central authority (e.g., Network Time Protocol (NTP)) to count slots instead, they construct their own clock to follow the slots.
+BABE differs from Ouroboros Praos [^2] in two main aspects: 1) its best chain selection mechanism, which integrates GRANDPA with the longest-chain rule, and 2) its slot synchronization assumptions. In the latter case, BABE block producers do not depend on a central authority, such as Network Time Protocol (NTP), to count slots. Instead, they build and maintain local clocks to track slot progression.
---
+
+## 1. Epochs, slots, and keys
-## 2. BABE
-
-In BABE, we have sequential non-overlapping epochs $(e_1, e_2,\ldots)$, each of which consists of a number of sequential block production slots ($e_i = \{sl^i_{1}, sl^i_{2},\ldots,sl^i_{t}\}$) up to some bound $t$. At the beginning of an epoch, we randomly assign each block production slot to a "slot leader", often one party or no party, but sometimes more than one party. These assignments are initially secrets known only to the assigned slot leader themselves, but eventually they publicly claim their slots when they produce a new block in one.
+BABE consists of sequential, non-overlapping epochs $(e_1, e_2,\ldots)$, each with a set of consecutive block production slots ($e_i = \{sl^i_{1}, sl^i_{2},\ldots,sl^i_{t}\}$) up to a bound $t$. At the start of each epoch, block production slots are randomly assigned to "slot leaders," sometimes to one party, no party, or multiple parties. The assignments are initially private, known only to the designated slot leader. This changes once they publicly claim their slots by producing a new block.
-Each party $P_j$ has as *session key* containing at least two types of secret/public key pair:
+Each party $P_j$ possesses a *session key* that includes at least two types of secret/public key pairs:
-* a verifiable random function (VRF) key $(\skvrf_{j}, \pkvrf_{j})$, and
-* a signing key for blocks $(\sksgn_j,\pksgn_j)$.
+* A verifiable random function (VRF) key pair $(\skvrf_{j}, \pkvrf_{j})$
+* A signing key pair for blocks $(\sksgn_j,\pksgn_j)$
-We favor VRF keys being relatively long-lived because new VRF keys cannot be used until well after creation and submission to the chain. Yet, parties should update their associated signing keys from time to time to provide forward security against attackers who might exploit from creating slashable equivocations. There are more details about the session key available [here](Polkadot/security/keys/3-session.md).
+VRF keys are preferred because they are relatively long-lived; new VRF keys cannot be used until well after they've been created and submitted to the chain. Yet, parties should periodically update their associated signing keys to maintain forward security, protecting against attackers who might exploit outdated keys to create slashable equivocations. For more details on session keys see [here](Polkadot/security/keys/3-session.md).
-Each party $P_j$ keeps a local set of blockchains $\mathbb{C}_j =\{C_1, C_2,..., C_l\}$. All these chains have some common blocks, at least the genesis block, up until some height.
+Each party $P_j$ maintains a local set of blockchains $\mathbb{C}_j =\{C_1, C_2,..., C_l\}$. These chains share a common prefix of blocks, at minimum the genesis block, up to a certain height.
-We assume that each party has a local buffer that contains a set of transactions to be added to blocks. All transactions in a block are validated with a transaction validation function before entering this buffer.
+Each party also maintains a local buffer containing a set of transactions to be added to blocks. Before entering this buffer, all transactions are validated using a transaction validation function.
-
-In BABE, we would like to achieve that each validator has the same chance to be selected as a block producer on a slot. Therefore, we define the probability that a validator is selected on a slot as
+The aim is to ensure that each validator has an equal opportunity to be selected as a block producer for any given slot. The probability of selection for each validator is:
$$
p = \phi_c(\theta) = 1-(1-c)^{\frac{1}{n}}
$$
-where $0 \leq c \leq 1$ is a constant parameter and $n$ is the number of validators.
+where $0 \leq c \leq 1$ is a constant parameter and $n$ denotes the number of validators.
-In order to achieve the equality of validators in BABE, we define a threshold parameter as in [2] for the slot assignment:
+To ensure equitable slot assignment among validators in BABE, it is necessary to define a threshold parameter. To guide the slot selection process, the approach described in [^2] is useful. The result then is:
$$
-\tau = 2^{\ell_{vrf}}\phi_c(\theta)
+\tau = 2^{\ell_{vrf}}\phi_c(\theta),
$$
where $\ell_{vrf}$ is the length of the VRF's first output (randomness value).
-BABE consists of three phases:
+## 2. Phases
-#### 1st: Genesis Phase
+BABE consists of three phases:
-In this phase, we manually produce the unique genesis block.
+#### 1st: Genesis phase
-The genesis block contain a random number $r_1$ for use during the first two epochs for slot leader assignments. Session public keys of initial validators are ($\pkvrf_{1}, \pkvrf_{2},..., \pkvrf_{n}$), $(\pksgn_{1}, \pksgn_{2},..., \pksgn_{n}$).
+The unique genesis block, manually produced in this phase, contains a random number $r_1$ used during the first two epochs for slot leader assignments. Session public keys of initial validators are ($\pkvrf_{1}, \pkvrf_{2},..., \pkvrf_{n}$), $(\pksgn_{1}, \pksgn_{2},..., \pksgn_{n}$).
-#### 2nd: Normal Phase
+#### 2nd: Normal phase
-We assume that each validator divided their timeline in slots after receiving the genesis block. They determine the current slot number according to their timeline as explained in [Section 4](./Babe.md#-4.-clock-adjustment--relative-time-algorithm-). Similarly, when a new validator joins to BABE after the genesis block, this validator divides his timeline into slots.
+By the time the second phase begins, each validator must have divided their timeline into slots after receiving the genesis block. Validators determine the current slot number according to their local timeline, as explained in [Section 4](./Babe.md#-4.-clock-adjustment--relative-time-algorithm-). If validators join BABE after the genesis block, they should also divide their timelines into slots.
-In normal operation, each slot leader should produce and publish a block. All other nodes attempt to update their chain by extending with new valid blocks they observe.
+During normal operation, the designated slot leader should produce and publish a block. All other nodes update their chains based on the new valid blocks they observe.
-We suppose each validator $V_j$ has a set of chains $\mathbb{C}_j$ in the current slot $sl_k$ in the epoch $e_m$ and has a best chain $C$ selected in $sl_{k-1}$ by our selection scheme in Section 3, and the length of $C$ is $\ell\text{-}1$.
+Each validator $V_j$ maintains a set of chains $\mathbb{C}_j$ for the current slot $sl_k$ in epoch $e_m$, and a best chain $C$ selected during slot $sl_{k-1}$ according to the selection scheme described in Section 3. The length of $C$ is $\ell\text{-}1$.
-Each validator $V_j$ produces a block if he is the slot leader of $sl_k$. If the first output ($d$) of the following VRF computation is less than the threshold $\tau$ then he is the slot leader.
+A validator $V_j$ may produce a block if selected as the slot leader for $sl_k$. If the first output $d$ of the following VRF computation is less than the threshold $\tau$, the validator becomes the slot leader.
$$
\vrf_{\skvrf_{j}}(r_m||sl_{k}) \rightarrow (d, \pi)
$$
-If $P_j$ is the slot leader, $P_j$ generates a block to be added on $C$ in slot $sl_k$. The block $B_\ell$ should at least contain the slot number $sl_{k}$, the hash of the previous block $H_{\ell\text{-}1}$, the VRF output $d, \pi$, transactions $tx$, and the signature $\sigma = \sgn_{\sksgn_j}(sl_{k}||H_{\ell\text{-}1}||d||\pi||tx))$. $P_i$ updates $C$ with the new block and sends $B_\ell$.
-
-In any case (being a slot leader or not being a slot leader), when $V_j$ receives a block $B = (sl, H, d', \pi', tx', \sigma')$ produced by a validator $V_t$, it validates the block with $\mathsf{Validate}(B)$. $\mathsf{Validate}(B)$ must at least check the followings in order to validate the block:
+If $P_j$ is the slot leader, it generates a block to be added to chain $C$ during slot $sl_k$. The block $B_\ell$ must contain at minimum: the slot number $sl_{k}$, the hash of the previous block $H_{\ell\text{-}1}$, the VRF output $d, \pi$, the transactions $tx$, and the signature $\sigma = \sgn_{\sksgn_j}(sl_{k}||H_{\ell\text{-}1}||d||\pi||tx))$. Validator $P_i$ then updates $C$ with the new block and relays $B_\ell$.
-* if $\mathsf{Verify}_{\pksgn_t}(\sigma')\rightarrow \mathsf{valid}$ (signature verification),
+Regardless of whether $V_j$ is a slot leader, upon receiving a block $B = (sl, H, d', \pi', tx', \sigma')$ produced by validator $V_t$, it excecutes $\mathsf{Validate}(B)$. To validate the block, the function $\mathsf{Validate}(B)$ must, at minimum, check the following criteria:
-* if the validator is the slot leader: $\mathsf{Verify}_{\pkvrf_t}(\pi', r_m||sl) \rightarrow \mathsf{valid}$ and $d' < \tau$ (verification with the VRF's verification algorithm).
+* $\mathsf{Verify}_{\pksgn_t}(\sigma')\rightarrow \mathsf{valid}$ – signature verification
-* if there exists a chain $C'$ with the header $H$,
+* If the validator is the slot leader: $\mathsf{Verify}_{\pkvrf_t}(\pi', r_m||sl) \rightarrow \mathsf{valid}$ and $d' < \tau$ – verification using the VRF's algorithm
-* if the transactions in $B$ are valid.
+* There exists a chain $C'$ with header $H$,
-If the validation process goes well, $V_j$ adds $B$ to $C'$. Otherwise, it ignores the block.
+* The transactions in $B$ are valid.
+If all checks pass, $V_j$ adds $B$ to $C'$; otherwise, it discards the block. At the end of the slot, $P_j$ selects the best chain according to the chain selection rule outlined in Section 3.
-At the end of the slot, $P_j$ decides the best chain with the chain selection rule we give in Section 3.
+#### 3rd: Epoch update
-#### 3rd: Epoch Update
+Before starting a new epoch $e_m$, validators must obtain the new epoch randomness and the updated active validator set. A new epoch begins every $R$ slots, starting from the first slot.
-Starting from first slot, in every $R$ slots, the new epoch starts.
-Before starting a new epoch $e_m$, validators should obtain the new epoch randomness and active validators set for the new epoch.
+To ensure participation in epoch $e_m$, the validator set must be included in the relay chain by the end of the last block of epoch $e_{m-3}$. This timing enables validators to actively engage in block production for epoch $e_{m}$. Newly added validators may join block production no earlier that two epochs later after being included in the relay chain.
-The validator set for the epoch $e_m$ has to be included to the relay chain until the end of the last block of the epoch $e_{m-3}$ so that they are able to actively participate the block production in epoch $e_{m}$. So, a new validator can actively join the block production at earliest two epochs later after included to relay chain.
-
-A fresh randomness for the epoch $e_m$ is computed as in Ouroboros Praos [2]: Concatenate all the VRF outputs of blocks in epoch $e_{m-2}$ (let us assume the concatenation is $\rho$). Then the randomness in epoch $e_{m}$:
+Fresh randomness for epoch $e_m$ is computed using the Ouroboros Praos [^2] method: Specifically, all VRF outputs from blocks produced in epoch $e_{m-2}$ (denoted as $\rho$) are concatenated. The randomness for epoch $e_{m}$ is then derived as follows:
$$
r_{m} = H(r_{m-2}||m||\rho)
$$
-The reason of including a validator after two epochs later is to make sure that the VRF keys of the new validators added to the chain before the randomness of the epoch that they are going to be active is revealed.
+Including a validator two epochs later ensures that the VRF keys of newly added validators, submitted to the chain prior to the randomness generation of their active epoch, are properly revealed.
---
-## 3. Best Chain Selection
+## 3. Best chain selection
-Given a chain set $\mathbb{C}_j$ and the parties current local chain $C_{loc}$, the best chain algorithm eliminates all chains which do not include the finalized block $B$ by GRANDPA. Let's denote the remaining chains by the set $\mathbb{C}'_j$. If we do not have a finalized block by GRANDPA, then we use the probabilistic finality in the best chain selection algorithm (the probabilistically finalized block is the block which is $k$ block before than the last block of $C_{loc}$).
+Given a chain set $\mathbb{C}_j$, and the party's current local chain $C_{loc}$, the best chain selection algorithm eliminates all chains that do not contain the finalized block $B$ determined by GRANDPA. The remaining chains form a subset denoted by $\mathbb{C}'_j$. If GRANDPA finalty is not required for a block, the algorithm resorts to probabilistic finality. In this case, the probabillistically finalized block is defined as the block that is $k$ blocks prior to the latest block in $C_{loc}$.
-We do not use the chain selection rule as in Ouroboros Genesis [3] because this rule is useful for parties who become online after a period of time and do not have any information related to current valid chain (for parties always online the Genesis rule and Praos is indistinguishable with a negligible probability). Thanks to Grandpa finality, the new comers have a reference point to build their chain so we do not need the Genesis rule.
+In this case, the chain selection rule does not follow Ouroboros Genesis [^3], as that rule is intended for parties that come online after a period of inactivity and lack information about the current valid chain. For parties that remain continously online, the Genesis rule and Praos are indistinguishable with negligible probability. Thanks to Grandpa finality, newcomers have a reliable reference point to build their chain, making the Genesis rule unnecessary.
---
-## 4. Clock Adjustment (Relative Time Algorithm)
-
-It is important for parties to know the current slot for the security and completeness of BABE. For this, validators can use their computer clocks which is adjusted by the Network Time Protocol. However, in this case, we need to trust servers of NTP. If an attack happens to one of these servers than we cannot claim anymore that BABE is secure. Therefore, we show how a validator realizes the notion of slots without using NTP. Here, we assume we have a partial synchronous network meaning that any message sent by a validator arrives at most $\D$-slots later. $\D$ is an unknown parameter.
+## 4. Clock adjustment (Relative Time Algorithm)
-
-Each party has a local clock and this clock is not updated by any external source such as NTP or GPS. When a validator receives the genesis block, it stores the arrival time as $t_0$ as a reference point of the beginning of the first slot. We are aware that the beginning of the first slot is not the same for everyone. We assume that the maximum difference of start time of the first slot between validators is at most $\delta$. Then each party divides their timeline in slots and update periodically its local clock with the following algorithm.
+ For the security and completeness of BABE, parties must be aware of the current slot. Typically, validators rely on system clocks sinchronized via by the Network Time Protocol (NTP). This introduces a trust assumption, and if an NTP server is compromised, BABE's security can no longer be upheld. To mitigate such a risk, validators can determine slot timing without relying on NTP.
+
+ Let's assume a partially synchronous network scenario, where any message sent by a validator is delivered within at most $\D$-slots, an unknown parameter. Since each party relies on a local clock not sinchronized by any external source such as NTP or GPS, a validator should store the arrival time of the genesis block as $t_0$, which serves as a reference point marking the start of the first slot. This starting point varies accross validators. Assuming the maximum deviation in the first slot's start time between validators is at most $\delta$, each party should divide its timeline into slots and periodically synchronize its local clock using the following algorithm.
**Median Algorithm:**
-The median algorithm is run by all validators in the end of sync-epochs (we note that epoch and sync-epoch are not related). The first sync-epoch ($\varepsilon = 1$) starts just after the genesis block is released. The other sync-epochs ($\varepsilon > 1$) start when the slot number of the last (probabilistically) finalized block is $\bar{sl}_{\varepsilon}$ which is the smallest slot number such that $\bar{sl}_{\varepsilon} - \bar{sl}_{\varepsilon-1} \geq s_{cq}$ where $\bar{sl}_{\varepsilon-1}$ is the slot number of the last (probabilistically) finalized block in the sync-epoch $\varepsilon-1$. Here, $s_{cq}$ is the parameter of the chain quality (CQ) property. If the previous epoch is the first epoch then $sl_{e-1} = 0$. We define the last (probabilistically) finalized block as follows: Retrieve the best blockchain according to the best chain selection rule, prune the last $k$ blocks of the best chain, then the last (probabilistically) finalized block will be the last block of the pruned best chain. Here, $k$ is defined according to the common prefix property.
+The median algorithm is executed by all validators at the end of sync-epochs [^4]. The first sync-epoch ($\varepsilon = 1$) begins once the genesis block is released. Subsequent sync-epochs ($\varepsilon > 1$) begin when the slot number of the last (probabilistically) finalized block is $\bar{sl}_{\varepsilon}$, defined as the smallest slot number such that $\bar{sl}_{\varepsilon} - \bar{sl}_{\varepsilon-1} \geq s_{cq}$. Here, $\bar{sl}_{\varepsilon-1}$ is the slot number of the last finalized block from sync-epoch $\varepsilon-1$, and $s_{cq}$ is the chain quality (CQ) parameter. If the previous epoch is the first epoch then $sl_{e-1} = 0$.
+
+To identify the last (probabilistically) finalized block: Retrieve the best blockchain according to the chain selection rule, prune the final $k$ blocks from this chain, and define the last finalized block as the last block of the pruned best chain, where $k$ is set according to the common prefix property.
-The details of the protocol is the following: Each validator stores the arrival time $t_i$ of valid blocks constantly according to its local clock. In the end of a sync-epoch, each validator retrieves the arrival times of valid and finalized blocks which has a slot number $sl'_x$ where
+The protocol details are as follows: Each validator records the arrival time $t_i$ of valid blocks using its local clock. At the end of a sync-epoch, each validator retrieves the arrival times of valid and finalized blocks with slot number $sl'_x$ where
* $\bar{sl}_{\varepsilon-1} < sl_x \leq \bar{sl}_{\varepsilon}$ if $\varepsilon > 1$.
* $\bar{sl}_{\varepsilon-1} \leq sl_x \leq \bar{sl}_{\varepsilon}$ if $\varepsilon = 1$.
-Let's assume that there are $n$ such blocks that belong to the current sync-epoch and let us denote the stored arrival times of blocks in the current sync-epoch by $t_1,t_2,...,t_n$ whose slot numbers are $sl'_1,sl'_2,...,sl'_n$, respectively. A validator selects a slot number $sl > sl_e$ and runs the median algorithm which works as follows:
+Assuming that no such $n$ blocks belong to the current sync-epoch, and denoting the stored arrival times of blocks in this sync-epoch as $t_1,t_2,...,t_n$, with corresponding slot numbers $sl'_1,sl'_2,...,sl'_n$, validators should select a slot number $sl > sl_e$ and execute the median algorithm as follows:
```
@@ -158,72 +135,72 @@ lst = sort (lst)
return median(lst)
```
-In the end, the validator adjusts its clock by mapping $sl$ to the output of the median algorithm.
+Ultimately, each validator adjusts its local clock by mapping slot $sl$ to the output of the median algorithm.
-The following image with chains explains the algorithm with an example in the first epoch where $s_{cq} = 9$ and $k=1$:
+The image below illustrates the algorithm using a chain-based example in the first epoch, where $s_{cq} = 9$ and $k=1$:
-**Lemma 1:** (The difference between outputs of median algorithms of validators) Asuming that $\delta\_max$ is the maximum network delay, the maximum difference between start time is at most $\delta\_max$.
+**Lemma 1** or the difference between outputs of validators' median algorithms. Asuming $\delta\_max$ is the maximum network delay, the maximum difference between start time is at most $\delta\_max$.
-**Proof Sketch:** Since all validators run the median algorithm with the arrival time of the same blocks, the difference between the output of the median algorithm of each validator differs at most $\delta\_max$.
+**Proof Sketch.** Since all validators run the median algorithm using the arrival times of the same blocks, the difference between the output of each validator's median algorithm is bounded by at most $\delta\_max$.
-**Lemma 2:** (Adjustment Value) Assuming that the maximum total drift on clocks between sync-epochs is at most $\Sigma$ and $2\delta\_max + |\Sigma| \leq \theta$, the maximum difference between the new start time of a slot $sl$ and the old start time of $sl$ is at most $\theta$.
+**Lemma 2** or Adjustment Value. Assuming the maximum total drift between sync-epochs is at most $\Sigma$ and that $2\delta\_max + |\Sigma| \leq \theta$, the maximum difference between the new start time of a slot $sl$ and the old start time of $sl$ is at most $\theta$.
-This lemma says that the block production may stop at most $\theta$ at the beginning of the new synch-epoch.
+In simple terms, this lemma states that the block production may be delayed by at most $\theta$ at the beginning of the new sync epoch.
-**Proof Sketch:** With the chain quality property, we can guarantee that more than half of arrival times of the blocks used in the median algorithm sent on time. Therefore, the output of all validators' median algorithm is the one which is sent on time. The details of the proof is in Theorem 1 our paper [Consensus on Clocks](https://eprint.iacr.org/2019/1348).
+**Proof Sketch.** The chain quality property ensures that more than half of arrival times for blocks used in the median algorithm are timely. As a result, the output of each validator's median algorithm corresponds to a block delivered on time. A formal proof is provided in Theorem 1 of our paper [Consensus on Clocks](https://eprint.iacr.org/2019/1348).
-Having $\theta$ small enough is important not to slow down the block production mechanism a while after a sync-epoch. For example, (a very extreme example) we do not want to end up with a new clock that says that we are in the year 2001 even if we are in 2019. In this case, honest validators may wait 18 years to execute an action that is supposed to be done in 2019.
+Keeping $\theta$ small is crucial to prevent delays in block production after a sync-epoch. For example (albeit an extreme one), it is not desirable that a validator's adjusted clock indicates the year 2001 when it's actually 2019. In such a case, honest validators might have to wait 18 years before executing an action that was originally scheduled for 2019.
-### Temporarily Clock Adjustment
+### Temporarily clock adjustment
-For validators who were offline at some point during one synch-epoch, they can adjust their clock temporarily (till the next synch epoch) with the following algorithm.
+The following algorithm permits validators who were offline during part of a sync epoch to temporarily adjust their local clocks, valid until the next synch-epoch.
-**1. Case:** If $V$ was online at some point of a synch-epoch and when he becomes online if his clock works well, he should continue to collect the arrival time of valid blocks and produce his block according to his clock as usual. A block is considered as valid in this case if it is not equivocated, if the block is sent by the right validator and if its slot number belong to the current synch epoch. In the end of the synch-epoch, if he has collected $n$ arrival time of valid blocks he runs the median algorithm with these blocks.
-If it has less than $n$ blocks it should wait till collecting $n$ arrival time of valid blocks. We note that he does not run the median algorithm not only with the arrival time of the finalized blocks.
+**Case 1:** If validator $V$ was offline at any point of a synch-epoch, and upon returning online its clock is functioning correclty, it should resume collecting the arrival times of valid blocks and produce blocks according to its local clock as usual. A block is considered valid in this case if it is not equivocated, is sent by the right validator, and its slot number falls within the current sync epoch.
-**2. Case:** If $V$ was online at some point of a synch-epoch and when he becomes online if his clock does not work anymore, he should continue to collect the arrival time of valid blocks. He can adjust his clock according to e.g., the arrival time of the last finalized block in GRANDPA to continue to produce block. He can use this clock till collecting $n$ valid blocks. After collecting $n$ valid blocks he should readjust his clock according to the output of the median algorithm with these $n$ valid blocks.
+At the end of the sync epoch, if $V$ has collected $n$ valid block arrival times, it should run the median algorithm using these blocks. In case it has fewer than $n$ blocks, it must wait until the required $n$ arrival times have been gathered. The validator does not run the median algorithm solely with the arrival times of finalized blocks.
-With the temporary clock adjustment, we can guarantee that the difference between this new clock and an honest parties clock is at most $2\delta_{max} + |\Sigma|$.
+**Case 2:** If $V$ was offline at any point during a sync epoch and, upon reconnecting, its clock is no longer functioning properly, it should continue collecting the arrival times of valid blocks. The validator may temporarily adjust its clock using, for example, the arrival time of the last finalized block in GRANDPA, and resume block production accordingly. This temporary clock can be used until $n$ valid blocks have been collected. Once this condition is met, the validator should re-adjust its clock based on the output of the median algorithm applied to these blocks.
-**We note that during one sync-epoch the ratio of such offline validators should not be more than 0.05 otherwise it can affect the security of the relative time algorithm.**
+With the temporary clock adjustment, it is possible to ensure that the difference between the time recorded by the adjusted clock and that of an honest party's clock is bounded by at most $2\delta_{max} + |\Sigma|$.
+
+**Note: During one sync epoch the ratio of such offline validators should not be more than 0.05, otherwise it can affect the security of the relative time algorithm.**
---
-## 5. Security Analysis
+## 5. Security analysis
-(If you are interested in parameter selection and practical results based on the security analysis, you can directly go to the next section)
-BABE is the same as Ouroboros Praos except for the chain selection rule and clock adjustment. Therefore, the security analysis is similar to Ouroboros Praos with few changes.
+BABE functions similarly to Ouroboros Praos, with the exception of the chain selection rule and clock synchronization mechanism. From a security analysis perspective, BABE closely resembles Ouroboros Praos, albeit with a few notable differences. If you are more interested in parameter selection and practical outcomes resulting from the security analysis, feel free to skip this section and proceed directly to the next.
### Definitions
-We give the definitions of security properties before jumping to proofs.
+Before diving into the proofs, let’s establish some key definitions.
-**Definition 1 (Chain Growth (CG)) [1,2]:** Chain growth with parameters $\tau \in (0,1]$ and $s \in \mathbb{N}$ ensures that if the best chain owned by an honest party at the onset of some slot $sl_u$ is $C_u$, and the best chain owned by an honest party at the onset of slot $sl_v \geq sl_u+s$ is $C_v$, then the difference between the length of $C_v$ and $C_u$ is greater or equal than/to $\tau s$.
+**Definition 1 or Chain Growth (CG) [1,2].** Chain growth with parameters $\tau \in (0,1]$ and $s \in \mathbb{N}$ guarantees that if the best chain held by an honest party at the beginning of slot $sl_u$ is $C_u$, and the best chain at the beginning of slot $sl_v \geq sl_u+s$ is $C_v$, then the length of $C_v$ is at least $\tau s$ greater than the length of $C_u$.
-The honest chain growth (HCG) property is a weaker version of CG which is the same definition with the restriction that $sl_v$ and $sl_u$ are assigned to honest validators. The parameters of HCG are $\tau_{hcg}$ and $s_{hcg}$ instead of $\tau$ and $s$ in the CG definition.
+The honest chain growth (HCG) property is a relaxed version of the Chain Growth (CG) property, defined identically except for the added constraint that both $sl_v$ and $sl_u$ are assigned to honest validators. The parameters for HCG are $\tau_{hcg}$ and $s_{hcg}$, in place of $\tau$ and $s$ used in the CG definition.
-**Definition 2 (Existential Chain Quality (ECQ)) [1,2]:** Consider a chain $C$ possessed by an honest party at the onset of a slot $sl$. Let $sl_1$ and $sl_2$ be two previous slots for which $sl_1 + s_{ecq} \leq sl_2 \leq sl$. Then $C[sl_1 : sl_2]$ contains at least one block generated by an honest party.
+**Definition 2 or Existential Chain Quality (ECQ) [1,2].** Consider a chain $C$ held by an honest party at the beginning of slot $sl$. Let $sl_1$ and $sl_2$ be two earlier slots such that $sl_1 + s_{ecq} \leq sl_2 \leq sl$. Then, the segment $C[sl_1 : sl_2]$ contains at least one block produced by an honest party.
-**Definition 2 (Chain Density (CD)):** The CD property with parameters $s_{cd} \in \mathbb{N}$ ensures that any portion $B[s_u:s_v]$ of a final blockchain $B$ spanning between rounds $s_u$ and $s_v = s_u + s_{cd}$ contains more honest blocks.
+**Definition 2 or Chain Density (CD).** The CD property, with parameter $s_{cd} \in \mathbb{N}$, ensures that any segment $B[s_u:s_v]$ of the final blockchain $B$, spanning rounds $s_u$ to $s_v = s_u + s_{cd}$, contains a majority of blocks produced by honest parties.
-**Definition 3 (Common Prefix)** Common prefix with parameters $k \in \mathbb{N}$ ensures that any chains $C_1, C_2$ possessed by two honest parties at the onset of the slots $sl_1 < sl_2$ are such satisfies $C_1^{\ulcorner k} \leq C_2$ where $C_1^{\ulcorner k}$ denotes the chain obtained by removing the last $k$ blocks from $C_1$, and $\leq$ denotes the prefix relation.
+**Definition 3 or Common Prefix.** The Common Prefix property, with parameter $k \in \mathbb{N}$, ensures that for any chains $C_1, C_2$ held by two honest parties at the beginning of slots $sl_1$ and $sl_2$ respectively, where $sl_1 < sl_2$, it holds that $C_1^{\ulcorner k} \leq C_2$. Here, $C_1^{\ulcorner k}$ denotes the chain obtained by removing the last $k$ blocks from $C_1$, and $\leq$ represents the prefix relation.
-With using these properties, we show that BABE has persistence and liveness properties. **Persistence** ensures that, if a transaction is seen in a block deep enough in the chain, it will stay there and **liveness** ensures that if a transaction is given as input to all honest players, it will eventually be inserted in a block, deep enough in the chain, of an honest player.
+The use of these properties demonstrates BABE's persistence and liveness properties. **Persistence** ensures that if a transaction appears in a block sufficiently deep in the chain, it will remain there permanently. **Liveness** guaranteess that if a transaction is provided as input to all honest parties, it will eventually be included in a block, deep enough in the chain, by an honest party.
-### Security Proof of BABE
-We analyze BABE with the NTP protocol and with the Median algorithm.
+### Security proof of BABE
+The next step is to analyze BABE with the NTP protocol and with the Median algorithm.
-We first prove that BABE (both versions) satisfies chain growth, existential chain quality and common prefix properties in one epoch. We also show the chain density property for the BABE with median. Then, we prove that BABE is secure by showing that BABE satisfies persistence and liveness in multiple epochs.
+First, prove that both versions of BABE satisfy the chain growth, existential chain quality, and common prefix properties within a single epoch, as well as to establish the chain density property specifically for BABE with median. Then, demonstrate BABE's overall security by showing that it satisfies persistence and liveness across multiple epochs.
-In Polkadot, all validators have equal stake (the same chance to be selected as slot leader), so the relative stake is $\alpha_i = 1/n$ for each validator where $n$ is the total number of validators. We assume that the ratio of honest validators is $\alpha$ and the ratio of validators sending on time is $\alpha_{timely}$.
+In Polkadot, all validators have an equal chance of being selected as slot leaders due to equal stake allocation. As a result, each validator's relative stake is given by $\alpha_i = 1/n$, where $n$ is the total number of validators. Assume that the proportion of honest validators is $\alpha$, and the proportion of validators sending on time is denoted by $\alpha_{timely}$.
-We use notation $p_h$ (resp. $p_m$) to show the probability of an honest validator (resp. a malicious validator) is selected. Similarly, we use $p_H$ (resp. $p_M$) to show the probability of *only* honest validators (resp. malicious validators) are selected. $p_{\bot}$ is the probability of having an empty slot (no validator selected).
+Using the notation $p_h$ (resp. $p_m$), express the probability of selecting an honest (respectively malicious) validator. Similarly, $p_H$ (respectively $p_M$) denotes the probability of selecting *only* honest (respectively malicious) validators. $p_{\bot}$ represents the probability of an empty slot, where no validator is selected.
$$
p_\bot=\mathsf{Pr}[sl = \bot] = \prod_{i\in \mathcal{P}}1-\phi(\alpha_i) = \prod_{i \in \mathcal{P}} (1-c)^{\alpha_i} = 1-c
@@ -245,24 +222,30 @@ $$
p_m = c - p_H
$$
-The probability of having timely validator is
+The probability of selecting a timely validator is
$$
p_H\_\mathsf{timely} = \prod_{i \in \mathcal{P_m}} 1- \phi(1/n) \sum_{i \in \mathcal{P}_h} \binom{\alpha_{timely} n}{i}\phi(1/n)^i (1- \phi(1/n))^{\alpha_{timely} n - i}
$$
-and probability of having non-timely validator is $p_m\_\mathsf{timely} = c - p_H\_\mathsf{timely}$.
+Meanwhile, the probability of selecting a non-timely validator is given by $p_m\_\mathsf{timely} = c - p_H\_\mathsf{timely}$.
+
+
+Validators in BABE who use NTP are perfectly synchronized (i.e., there is no difference between the time shown on their clocks), whereas validators using the median algorithm may experience a clock discrepancy of up to $\delta\_max + |2\Sigma|$.
+An honest validator in BABE with the NTP can build upon an honest block generated in slot $sl$ if the block reaches all validators before the next **non-empty** slot $sl_{\mathsf{next}}$. Such slots are referred to as good slots. In other words, a slot $sl$ is considered good if it is assigned exclusively to an honest validator and the following $\D = \lfloor \frac{\delta\_max}{T}\rfloor$ slots are empty.
+For validators in BABE that rely on the median algorithm, the process diverges due to clock offsets among validators. If a slot is assigned to an honest validator whose clock runs earliest, then in order to build on top of all blocks from prior honest slots, that validator must see those blocks before generating their own. This requirement is met only if the preceding $\lfloor \frac{\delta\_max + |2 \Sigma|}{T}\rfloor$ slots are empty.
-The validators in BABE with NTP are perfectly synchronized (i.e., the difference between their clocks is 0). On the other hand, the validators in BABE with the median algorithm have their clocks differ at most $\delta\_max + |2\Sigma|$.
-In BABE with the NTP, any honest validator builds on top of an honest block generated in slot $sl$ for sure if the block arrives all validators before starting the next **non-empty** slot $sl_{\mathsf{next}}$. We call these slots good slots. In BABE with NTP, a slot $sl$ is good if it is assigned to only honest validators and the next $\D = \lfloor \frac{\delta\_max}{T}\rfloor$ slots are empty. However, it is different in BABE with the median algorithm because of the clock difference between validators. If a slot is assigned to an honest validator that has the earliest clock, in order to make her to build on top of blocks of all previous honest slots for sure, we should make sure that this validator sees all blocks of the previous slots before generating her block. We can guarantee this if previous $\lfloor \frac{\delta\_max + |2 \Sigma|}{T}\rfloor$ slots are empty. Also, if a slot is assigned to an honest validator that has the latest clock, we should make sure that the next honest block producers see the block of the latest validator before generating her block. We can guarantee this if the next $\lfloor \frac{2\delta\_max + |2 \Sigma|}{T}\rfloor$ slots are empty. We use $\D_m = \lfloor \frac{2\delta\_max + |2 \Sigma|}{T}\rfloor + \lfloor \frac{\delta\_max + |2 \Sigma|}{T}\rfloor$ in our analysis below.
+Conversly, if a slot is assigned to an honest validator whose clock runs latest, it is crucial that subsequent honest block producers see this validator's block before producing their own. This can be ensured if the next $\lfloor \frac{2\delta\_max + |2 \Sigma|}{T}\rfloor$ slots are empty.
+To accomodate both scenarios in the analysis, a parameter such as $\D_m = \lfloor \frac{2\delta\_max + |2 \Sigma|}{T}\rfloor + \lfloor \frac{\delta\_max + |2 \Sigma|}{T}\rfloor$ is required.
-**Theorem 1:** BABE with NTP satisfies HCG property with parameters $\tau_{hcg} = p_hp_\bot^\D(1-\omega)$ where $0 < \omega < 1$ and $s_{hcg} > 0$ in $s_{hcg}$ slots with probability $1-\exp(-\frac{ p_h s_{hcg} \omega^2}{2})$.
-**Proof:** We need to count the honest and good slots (i.e., the slot assigned to at least one honest validator and the next $\D$ slots are empty) (Def. Appendix E.5. in [Genesis](https://eprint.iacr.org/2018/378.pdf)) to show the HCG property. The best chain grows one block in honest slots. If honest slots out of $s_{hcg}$ slot are less than $s_{hcg}\tau_{hcg}$, the HCG property is violated. The probability of having an honest and good slot is $p_hp_\bot^\D$.
+**Theorem 1.** BABE with NTP satisfies the HCG property with parameters $\tau_{hcg} = p_hp_\bot^\D(1-\omega)$, where $0 < \omega < 1$ and $s_{hcg} > 0$. The property holds over $s_{hcg}$ slots with probability $1-\exp(-\frac{ p_h s_{hcg} \omega^2}{2})$.
-We find below the probability of less than $\tau_{hcg} s_{hcg}$ slots are honest slots. From Chernoff bound we know that
+**Proof.** To demonstrate the HCG property, it is necesssary to count the *honest* and *good* slots (slots assigned to at least one honest validator, followed by $\D$ empty slots) (see Definition E.5. in [Genesis](https://eprint.iacr.org/2018/378.pdf)). The best chain grows one block during each honest slot. If the number of honest slots within $s_{hcg}$ total slots is less than $s_{hcg}\tau_{hcg}$, the HCG property no longer holds. The probability of encountering an honest and good slot is given by $p_hp_\bot^\D$.
+
+The probability that fewer than $\tau_{hcg} s_{hcg}$ slots are honest is given below, using the Chernoff bound:
$$
\Pr[\sum honest \leq (1-\omega) p_h p_\bot s_{hcg}] \leq \exp(-\frac{p_hp_\bot^\D s_{hcg} \omega^2}{2})
@@ -274,14 +257,14 @@ $$
-BABE with median satisfies HCG property with parameters $\tau_{hcg} = p_hp_\bot^{D_m}(1-\omega)$ where $0 < \omega < 1$ and $s_{hcg} > 0$ in $s_{hcg}$ slots with probability $1-\exp(-\frac{ p_hp_\bot^{\D_m} s_{hcg} \omega^2}{2})$.
+BABE with median algorithm satisfies the HCG property with parameters $\tau_{hcg} = p_hp_\bot^{D_m}(1-\omega)$, where $0 < \omega < 1$ and $s_{hcg} > 0$. The probability holds over $s_{hcg}$ slots with probability $1-\exp(-\frac{ p_hp_\bot^{\D_m} s_{hcg} \omega^2}{2})$.
-**Theorem 2 (Chain Densisty)** Chain desisty property is satisfied with $s_{cd}$ in BABE with probability $1 - \exp(-\frac{p_H\_\mathsf{timely}p_\bot^{\D_m} s_{cd} \omega_H^2}{2}) - \exp(-\frac{\gamma^2s_{cd}p_m\_\mathsf{timely}}{2+\gamma}) - \exp(-\ell)$ where $\omega_H \in (0,1)$ and $\gamma > 0$.
+**Theorem 2 or Chain Density.** The Chain Density (CD) property is satisfied over $s_{cd}$ slots in BABE with probability $1 - \exp(-\frac{p_H\_\mathsf{timely}p_\bot^{\D_m} s_{cd} \omega_H^2}{2}) - \exp(-\frac{\gamma^2s_{cd}p_m\_\mathsf{timely}}{2+\gamma}) - \exp(-\ell)$, where $\omega_H \in (0,1)$ and $\gamma > 0$.
-**Proof:** We first find the minimum difference between the number of honest slots and the number of malicious slots in $s_{cd}$ slots belonging one synch-epoch. For this, we need to find the minimum number of honest slots $H$ and a maximum number of honest slots $m$.
+**Proof.** Determine the minimum difference between the number of honest slots and the number of malicious slots within $s_{cd}$ slots of a single sync epoch. To achieve this, identify the minimum number of honest slots, denoted by $H$, and the maximum number of malicious slots, denoted by $m$.
-We can show with the Chernoff bound that for all $\omega \in (0,1)$
+Using the Chernoff bound, the probability of deviation can be bounded for all $\omega \in (0,1)$:
$$
\Pr[H < (1-\omega_H) p_H\_\mathsf{timely} p_\bot^{\D_m} s_{cd}] \leq \exp(-\frac{p_H\_\mathsf{timely}p_\bot^{\D_m} s_{cd} \omega^2}{2})
@@ -295,7 +278,11 @@ $$
So, $dif = h-m \geq s_{cd}((1-\omega)p_H\_\mathsf{timely}p_\bot^{\D_m} - (1+\gamma) p_m\_\mathsf{timely})$. Let's denote $dif = m + \ell$ where $\ell \geq dif - (1+\gamma) p_m\_\mathsf{timely} s_{cd}$
-Assume that the last block of the previous sync-epoch is $B$. So, we only consider the chains that are constructed on top of $B$. Consider a chain $C$ which has finalized blocks spanned in subslots $sl_u$ and $sl_v = sl_u + s_{cd}$. The longest subchain produced between $sl_u$ and $sl_v$ is $h \geq 2m + \ell$ because of the honest chain growth among the chains constructed on top $B$. The longest subchain with more malicious blocks than the honest blocks is possible with $m$ malicious blocks and $m$ honest blocks. However, this chain can never beat the longest subchain produced at the end of $sl_u$ except with probability $\frac{1}{2^\ell}$. This means that there is not any subchain that has more malicious block and can be finalized except with a negligible probability. Therefore, all finalized chains in a synch epoch has more honest slots.
+Assuming the last block of the previous sync epoch is denoted by $B$, the chains under consideration are those constructed on top of $B$. Let $C$ be a chain with finalized blocks spanning subslots $sl_u$ to $sl_v$, where $sl_v = sl_u + s_{cd}$. The longest subchain produced between $sl_u$ and $sl_v$ satisfies $h \geq 2m + \ell$, due to the honest chain growth among chains built on top of $B$.
+
+A subchain containing more malicious blocks than honest blocks is achievable with $m$ malicious and $m$ honest blocks. However, such a chain cannot surpass the longest honest subchain, except with probability at most $\frac{1}{2^\ell}$. In other words, a subchain dominated by malicious blocks that can be finalized is possible only with negligible probability.
+
+Therefore, all finalized chains within a sync epoch contain a majority of honest slots.
$$
\tag{$\blacksquare$}
@@ -303,11 +290,11 @@ $$
-We note that we need the chain densisty property only for the BABE with the median algorithm.
+The chain densisty property is required only for BABE with the median algorithm.
-**Theorem 3 (Existential Chain Quality):** Let $\D \in \mathbb{N}$ and let $\frac{p_h\\p_\bot^\D}{c} > \frac{1}{2}$. Then, the probability of an adversary $\A$ violates the ECQ property with parameters $k_{cq}$ with probability at most $e^{-\Omega(k_{cq})}$ in BABE with NTP.
+**Theorem 3 or Existential Chain Quality.** If $\D \in \mathbb{N}$ and $\frac{p_h\\p_\bot^\D}{c} > \frac{1}{2}$, then the probability that an adversary $\A$ violates the ECQ property with parameter $k_{cq}$ is at most $e^{-\Omega(k_{cq})}$ in BABE with NTP.
-**Proof (sketch):** If $k$ proportion of a chain does not include any honest blocks, it means that the malicious slots are more than the good and honest slots between the slots that spans these $k$ blocks. Since the probability of having good and honest slots is greater than $\frac{1}{2}$, having more bad slots falls exponentially with $k_{cq}$. Therefore, the ECQ property is broken in $R$ slots at most with the probability $e^{-\Omega(k_{cq})}$.
+**Proof (sketch).** If a proportion $k$ of a chain contains no honest blocks, this implies that the number of malicious slots exceeds the number of good and honest slots within the slot range spanning those $k$ blocks. Given that the probability of a slot being good and honest is greater than $\frac{1}{2}$, the likelihood of encountering more bad slots than good ones diminishes exponentially with $k_{cq}$. As a result, the ECQ property may be violated in at most $R$ slots, with probability bounded by $e^{-\Omega(k_{cq})}$.
$$
\tag{$\blacksquare$}
@@ -315,30 +302,32 @@ $$
-Let $\D_m \in \mathbb{N}$ and let $\frac{p_Hp_\bot^{\D_m}}{c} > \frac{1}{2}$. Then, the probability of an adversary $\A$ violates the ECQ property with parameters $k_{cq}$ with probability at most $e^{-\Omega(k_{cq})}$ in BABE with median.
+In BABE with the median algorithm, if $\D_m \in \mathbb{N}$ and $\frac{p_Hp_\bot^{\D_m}}{c} > \frac{1}{2}$, then the probability that an adversary $\A$ violates the ECQ property with parameter $k_{cq}$ is at most $e^{-\Omega(k_{cq})}$.
-**Theorem 4 (Common Prefix):** Let $k,\D \in \mathbb{N}$ and let $\frac{p_H p_\bot^\D}{c} > \frac{1}{2}$, the adversary violates the common prefix property with parammeter $k$ in $R$ slots with probability at most $\exp(− \Omega(k))$ in BABE with NTP.
-We should have the condition $\frac{p_Hp_\bot^{\D_m}}{c} > \frac{1}{2}$ for BABE with median.
+**Theorem 4 or Common Prefix.** If $k,\D \in \mathbb{N}$ and $\frac{p_H p_\bot^\D}{c} > \frac{1}{2}$, then an adversary can violate the Common Prefix property with parameter $k$ over $R$ slots with probability at most $\exp(− \Omega(k))$ in BABE with NTP.
+For BABE with the median algorithm, the condition $\frac{p_Hp_\bot^{\D_m}}{c} > \frac{1}{2}$ must be considered instead.
#### Overall Results:
-According to Lemma 10 in [Genesis](https://eprint.iacr.org/2018/378.pdf) **chain growth** is satisfied with
+According to Lemma 10 in [Genesis](https://eprint.iacr.org/2018/378.pdf), the **Chain Growth** property is satisfied with
$$
s_{cg} = 2 s_{ecq} + s_{hcg} \text{ and } \tau = \tau_{hcg} \frac{s_{hcg}}{2 s_{ecq} + s_{hcg}}
$$
-and **chain quality** is satisfied with
+and the **Chain Quality** property is satisfied with
$$
s_{cq} = 2 s_{ecq} + s_{hcq} \text{ and } \mu = \tau_{hcq}\frac{s_{hcq}}{2s_{ecq}+s_{hcq}}
$$
-**Theorem 5 (Persistence and Liveness BABE with NTP):** Assuming that $\frac{p_H p_\bot^\D}{c} > \frac{1}{2}$ and given that $k_{cq}$ is the ECQ parameter, $k > 2k_{cq}$ is the CP parameter, $s_{hcg} = k/\tau_{hcg}$, $s_{ecq} = k_{cq}/\tau$, the epoch length is $R = 2s_{ecq} + s_{hcg}$ BABE with NTP is persistent and live.
+**Theorem 5 or Persistence and Liveness of BABE with NTP.** Assuming $\frac{p_H p_\bot^\D}{c} > \frac{1}{2}$ and given that $k_{cq}$ is the ECQ parameter, $k > 2k_{cq}$ is the Common Prefix parameter, $s_{hcg} = k/\tau_{hcg}$ and $s_{ecq} = k_{cq}/\tau$, then the epoch length is $R = 2s_{ecq} + s_{hcg}$, and BABE with NTP is persistent and liveness.
-**Proof (Sketch):** The overall result says that $\tau = \tau_{hcg}\frac{s_{hcg}}{2s_{ecq}+s_{hcg}} = \frac{k}{s_{hcg}}\frac{s_{hcg}}{2s_{ecq}+s_{hcg}} = \frac{k}{R}$. The best chain at the end of an epoch grows at least $k$ blocks in one epoch thanks to the chain growth.
+**Proof (Sketch).** The overall result shows that $\tau = \tau_{hcg}\frac{s_{hcg}}{2s_{ecq}+s_{hcg}} = \frac{k}{s_{hcg}}\frac{s_{hcg}}{2s_{ecq}+s_{hcg}} = \frac{k}{R}$. So by the chain growth property, the best chain increases by at least $k$ blocks over the course of a single epoch.
- Since $k > 2k_{cq}$, the last $k_{cq}$ block of includes at least one honest block. Therefore, the randomness includes one honest randomness and the adversary can have at most $s_{ecq}$ slots to change the randomness. This grinding effect can be upper-bounded by $s_{ecq}(1-\alpha)nq$ where $q$ is the hashing power [2]. The randomness generated by an epoch is finalized at latest one epoch later thanks to the common prefix property. Similary, the session key update which is going to be used in three epochs later is finalized one epoch later before a randomness of the epoch where the new key are going to be used starts to leak.
+ Since $k > 2k_{cq}$, the last $k_{cq}$ blocks must contain at least one honest block, while the associated randomness must include at least one honest input. This implies that the adversary has at most $s_{ecq}$ slots to attempt to manipulate the randomness. Such a grinding effect can be upper-bounded by $s_{ecq}(1-\alpha)nq$, where $q$ is the adversary's hashing power [^2].
+
+By the Common Prefix property, the randomness generated during an epoch must be finalized no later than one epoch afterward. Similary, the session key update, used three epochs later, must be finalized one epoch earlier, before the randomness of the epoch in which the new key will be used begins to leak.
Therefore, BABE with NTP is persistent and live.
$$
@@ -347,156 +336,170 @@ $$
-**Theorem 6 (Persistence and Liveness BABE with the Median Algorithm):** Assuming that $\frac{p_H p_\bot^{\D_m}}{c} > \frac{1}{2}$ and $\tau_{hcg}-\tau_{hcg}\mu_{hcq} > p_m (1+\gamma)$ where $\tau_{hcg} = p_h p_\bot^{\D_m} (1-\omega)$, $s_{cd}$, the clock difference is between honest valdators is at most $\D_m$, BABE with median is persistent and live given that given that $k_{cq}$ is the ECQ parameter, $k > 2k_{cq}$ is the CP parameter, $s_{hcg} = k/\tau_{hcg}$, $s_{ecq} = k_{cq}/\tau$.
+**Theorem 6 or Persistence and Liveness of BABE with the Median Algorithm.** Assuming that $\frac{p_H p_\bot^{\D_m}}{c} > \frac{1}{2}$ and $\tau_{hcg}-\tau_{hcg}\mu_{hcq} > p_m (1+\gamma)$, where $\tau_{hcg} = p_h p_\bot^{\D_m} (1-\omega)$, $s_{cd}$, and since the clock difference between honest valdators is at most $\D_m$, then BABE with the median algorithm satisfies persistence and liveness given that:
+
+* $k_{cq}$ is the ECQ parameter
+
+* $k > 2k_{cq}$ is the CP parameter
+
+* $s_{hcg} = k/\tau_{hcg}$
+
+* $s_{ecq} = k_{cq}/\tau$
-**These results are valid assuming that the signature scheme with account key is EUF-CMA (Existentially Unforgible Chosen Message Attack) secure, the signature scheme with the session key is forward secure, and VRF realizing is realizing the functionality defined in [2].**
+**These results hold under the following assumptions: the signature scheme using the account key is EUF-CMA (Existentially Unforgeability under Chosen Message Attack) secure, the signature scheme based on the session key is forward-secure, and the VRF correctly realizes the functionality as defined in [^2].**
---
-## 6. Practical Results
+## 6. Practical results
-In this section, we find parameters of two versions of BABE to achieve the security in BABE.
+This section specifies the parameters necessary to achieve security in both variants of the BABE protocol.
-We fix the lifetime of the protocol as $\mathcal{L}=3 \text{ years} = 94670777$ seconds. We denote the slot time by $T$ (e.g., $T = 6$ seconds).
-The lifetime of the protocol in terms of slots is $L = \frac{\mathcal{L}}{T}$. The maximum network delay is $\D$.
+The protocol lifetime is fixed as $\mathcal{L}=3 \text{ years} = 94670777$ seconds. Let $T$ denote the slot duration (e.g., $T = 6$ seconds). The total number of slots over the lifetime is $L = \frac{\mathcal{L}}{T}$. Finally, the maximum network delay is $\D$.
### BABE with the NTP
-* Define $\delta\_max$ and $T$. Let $\D = 0$ if $\delta_{\max} < T$. Otherwise, let $\D = \lceil \frac{\delta\_max - T}{T}\rceil$
-* Decide the parameter $c$ such that the condition $\frac{p_Hp_\bot^{\D}}{c} > \frac{1}{2}$ is satisfied. If there is not any such $c$, then consider to increase $\alpha$ (honest validator assumption) or decrease $\D$ (more optimistic network assumption).
-* Set up a security bound $p_{attack}$ to define the probability of an adversary to break BABE in e.g., 3 years. Of course, very low $p$ is better for the security of BABE but on the other hand it may cause to have very long epochs and long probabilistic finalization. Therefore, I believe that setting $p_{attack}=0.005$ is reasonable enough in terms of security and performance.
-* Set $\omega \geq 0.5$ (e.g., 0.5) and find $s_{ecq}$ and $s_{hcq}$ to set the epoch length $R = 2 s_{ecq} + s_{hcg}$ such that $p_{attack} \leq p$. For this we need an initial value $k_{cp}$ and find $s_{ecq}, s_{hcg}$ and $\tau$ that satisfies the three equations below:
+* Define $\delta\_max$ and $T$. Let $\D = 0$ if $\delta_{\max} < T$; otherwise, let $\D = \lceil \frac{\delta\_max - T}{T}\rceil$
+* Choose the parameter $c$ such that $\frac{p_Hp_\bot^{\D}}{c} > \frac{1}{2}$. If no such $c$ exists, consider increasing the honest validator assumption $\alpha$, or adopting a more optimistic network assumption by decreasing $\D$.
+* Define a security bound $p_{attack}$ to represent the probability that an adversary can break BABE over a fixed duration (e.g., 3 years). A lower value of $p$ improves security, but may lead to longer epochs and extended probabilistic finalization. A value of $p_{attack}=0.005$ represents a reasonable compromise between security and performance.
+* Set $\omega \geq 0.5$ (e.g., 0.5), and compute $s_{ecq}$ and $s_{hcq}$ to define the epoch length $R = 2 s_{ecq} + s_{hcg}$ such that the condition $p_{attack} \leq p$ holds. To do this, select an initial value $k_{cp}$ and determine $s_{ecq}, s_{hcg}$ and $\tau$ such that they satisfy the following three equations:
-From Theorem 6, we want that the best chain grows at least $k$ blocks. Therefore, we need
+From Theorem 6, the goal is for the best chain to grow by at least $k$ blocks. To ensure this, the following condition must hold:
$$
(2s_{ecq} + s_{hcg})\tau = k\text{ }\text{ }\text{ }\text{ }\text{ }\text{ (1)}
$$
-We need $s_{ecq}$ slots to guarantee $k_{cq}$ blocks growth for the ECQ property. So, we need:
+To guarantee $k_{cq}$ blocks for the ECQ property, it is required that:
$$
\tau s_{ecq} = k_{cq} \text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ }\text{ (2)}
$$
-Lastly, we need the following as given in the Overall Result:
+Finally, the Overall Result gives:
$$
\tau = \tau_{hcg} \frac{s_{hcg}}{2 s_{ecq} + s_{hcg}}\text{ }\text{ }\text{ }\text{ }\text{ (3)}
$$
-Iterate $k_{cp}$ to find $s_{hcg}, s_{ecq}, \tau$ that satisfy above conditions until $p_{attack} \leq p$:
+Iterate over $k_{cp}$ to find values for $s_{hcg}, s_{ecq}, \tau$ that satisfy the above conditions until $p_{attack} \leq p$:
-1. Let $k = 4 k_{cp}$ (The CQ property parameter) We note that $4 k_{cp}$ is the optimal value that minimizes $R = 2 s_{ecq} + s_{hcg}$.
-1. $t_{hcg} = p_h p_\bot^\D (1-\omega)$ (to satisfy the condition in Theorem 1)
-1. $s_{hcg} = k / t_{hcg}$ (from Equation (1) and (3))
-1. $\tau = \frac{k - 2k_{cq}}{s_{hcg}}$ (from Equation (1) and (2))
-1. $s_{ecq} = k_{cq}/\tau$
-1. $p = \lceil \frac{L}{T}\rceil\frac{2^{20}(1-\alpha)n}{R}(p_{ecq} + p_{cp} + p_{cg})$
+1. Set the parameter for the Chain Quality (CQ) property at $k = 4 k_{cp}$. $4 k_{cp}$, which is the optimal value to minimize the epoch length $R = 2 s_{ecq} + s_{hcg}$.
+1. Compute $t_{hcg} = p_h p_\bot^\D (1-\omega)$ to satisfy the condition in Theorem 1
+1. Calculate $s_{hcg} = k / t_{hcg}$ based on Equations (1) and (3)
+1. Determine $\tau = \frac{k - 2k_{cq}}{s_{hcg}}$ by using Equations (1) and (2)
+1. Compute $s_{ecq} = k_{cq}/\tau$
+1. Calculate the security parameter: $p = \lceil \frac{L}{T}\rceil\frac{2^{20}(1-\alpha)n}{R}(p_{ecq} + p_{cp} + p_{cg})$
-After finding $k_{cq}$ such that $p \leq p_{attack}$, let the epoch length $R = 2s_{ecq}+s_{hcg}$.
+Once a value for $k_{cq}$ such that $p \leq p_{attack}$ is found, set the epoch length $R = 2s_{ecq}+s_{hcg}$.
-The parameters below are computed with the code in https://github.com/w3f/research/blob/master/experiments/parameters/babe_NTP.py. In this code, we choose the parameter $c$ not only according to security conditions but also according to having in expectation twice more single leader than multiple leaders.
+:::note Parameters
+The parameters below are computed using the code available at the [GitHub entry](https://github.com/w3f/research/blob/master/experiments/parameters/babe_NTP.py). The parameter $c$ is chosen not only to satisfy security conditions, but also to ensure that, in expectation, the number of single-leader slots is at least twice the number of multi-leader slots.
-################### PARAMETERS OF BABE WITH NTP $\D = 0$ ###################
-c = 0.52, slot time T = 6
+c = 0.52, slot time T = 6 seconds
-It is secure in 3 years with a probability 0.99523431732
+Secure over a 3-year horizon with probability 0.99523431732
-It is resistant to (6 - block generation time) second network delay
+Resistant to network delays of up to 6 - block generation time seconds
-~~~~~~~~~~~~~~ Common Prefix Property ~~~~~~~~~~~~~~
k = 140
-It means: Prune the last 140 blocks of the best chain. All the remaining ones are probabilistically finalized
+This means that the last 140 blocks of the best chain are pruned. All preceding blocks are considered probabilistically finalized.
-~~~~~~~~~~~~~~ Epoch Length ~~~~~~~~~~~~~~
-Epoch length should be at least 1440 slots,2.4 hours
-
+Epoch length should be at least 1440 slots (2.4 hours).
-If we want more network resistance, $e.g.,\D = 1$, the parameters should be selected as follows:
+If greater network resistance is desired ($e.g.,\D = 1$), the parameters should be selected as follows:
-################### PARAMETERS OF BABE WITH NTP $\D = 1$ ###################
-c = 0.22, slot time T = 6
+c = 0.22, slot time T = 6 seconds
-It is secure in 3 years with probability 0.996701592969
+Secure over a 3-year period with probability 0.996701592969
-It is resistant to (12 - block generation time) second network delay
+Resistant to network delays of up to 12 - block generation time seconds.
-~~~~~~~~~~~~~~ Common Prefix Property ~~~~~~~~~~~~~~
k = 172
-It means: Prun the last 172 blocks of the best chain. All the remaining ones are probabilistically finalized
+This means that the last 172 blocks of the best chain are pruned. All preceding blocks are considered probabilistically finalized.
-~~~~~~~~~~~~~~ Epoch Length ~~~~~~~~~~~~~~
-Epoch length should be at least 4480 slots, 7.46666666667 hours
+Epoch length should be at least 4480 slots (approximately 7.46666666667 hours)
+:::
+### BABE with the median algorithm
-### BABE with the Median Algorithm
-
-* Define $\alpha_{timely} = 0.85$, $\ell = 20$, $\omega_H = 0.3$ and $\gamma = 0.5$ in Theorem 2.
+* Define the following parameters for Theorem 2: $\alpha_{timely} = 0.85$, $\ell = 20$, $\omega_H = 0.3$ and $\gamma = 0.5$.
* Define $\delta\_max$ and $T$. Let $\D_m = \lfloor \frac{2\delta\_max + |2 \Sigma|}{T}\rfloor + \lfloor \frac{\delta\_max + |2 \Sigma|}{T}\rfloor$
-* Decide the parameter $c$ such that the condition $\frac{p_Hp_\bot^{\D}}{c} > \frac{1}{2}$ and $\frac{p_H\_\mathsf{timely} (1- \omega_H)}{p_m\_\mathsf{timely} (1+\gamma)} > 2$
-is satisfied. If there is not any such $c$, then consider increasing $\alpha$ (honest validator assumption) or $\alpha_{timely}$ or decreasing $\D$ (more optimistic network assumption).
-
-* Do the rest as in BABE with NTP.
-
-Finding synch-epoch length
+* Choose the parameter $c$ such that both of the following conditions hold: $\frac{p_Hp_\bot^{\D}}{c} > \frac{1}{2}$ and $\frac{p_H\_\mathsf{timely} (1- \omega_H)}{p_m\_\mathsf{timely} (1+\gamma)} > 2$. If no such $c$ exists, consider increasing $\alpha$ (honest validator assumption), increasing $\alpha_{timely}$, or decreasing $\D$ (adopting a more optimistic network assumption).
-1. Set $s_{cd}$ with respect to Theorem 2.
+* Proceed with the remaining steps as in BABE with NTP.
+Next, determine the sync-epoch length and set $s_{cd}$ according to Theorem 2.
-The parameters below are computed with the code in https://github.com/w3f/research/blob/master/experiments/parameters/babe_median.py
+:::note Parameters
+The parameters below are computed using the script available at this [GitHub entry](https://github.com/w3f/research/blob/master/experiments/parameters/babe_median.py)
-############## PARAMETERS OF BABE WITH THE MEDIAN ALGORITHM ##############
-c = 0.38, slot time T = 6
+c = 0.38, slot time T = 6 seconds
-It is secure in 3 years with probability 0.99656794973
+Security over 3 years with probability 0.99656794973
-It is resistant to 2.79659722222 second network delay and 0.198402777778 seconds drift in one sync-epoch
+Resistant to network delay of 2.79659722222 seconds and clock drift of 0.198402777778 seconds per sync epoch
-~~~~~~~~~~~~~~ Common Prefix Property ~~~~~~~~~~~~~~
-k = 140
-It means: Prune the last 140 blocks of the best chain. All the remaining ones are probabilistically finalized
+k = 140
+
+This means that the last 140 blocks of the best chain are pruned, while all remaining blocks are probabilistically finalized
-~~~~~~~~~~~~~~ Epoch Length ~~~~~~~~~~~~~~
-Sync-Epoch length should be at least 2857 slots, 4.76166666667 hours
+Sync-epoch length: at least 2857 slots (~4.7617 hours)
-Epoch length should be at least 2000 slots,3.33333333333 hours
+Epoch length: at least 2000 slots (~3.3333 hours)
-~~~~~~~~~~~~~~ Offline validators' parameters for clock adjustment ~~~~~~~~~~~~~~
-$n = 200$ for temporarily clock adjustment.
+$n = 200$ for temporary clock adjustment.
+
+Offline validators should collect.
+:::
+
+**Some Notes on clock drifts:**
-Offline validators should collect
+Computer clocks are inherently imprecise because the frequency that drives time progression is never exactly accurate. For instance, a frequency error of about 0.001% can cause a clock to drift by nearly one second per day.
-**Some Notes about clock drifts:**
-http://www.ntp.org/ntpfaq/NTP-s-sw-clocks-quality.htm#AEN1220
-All computer clocks are not very accurate because the frequency that makes time increase is never exactly right. For example the error about 0.001% make a clock be off by almost one second per day.
-Computer clocks drift because the frequency of clocks varies over time, mostly influenced by environmental changes such as temperature, air pressure or magnetic fields, etc. Below, you can see the experiment in a non-air conditioned environment on linux computer clocks. 12 PPM correspond to one second per day roughly. I seems that in every 10000 second the change on the clocks are around 1 PPM (i.e., every 3 hours the clocks drifts 0.08 seconds.). We can roughly say that the clock drifts around 1 second per day. If we have sync epoch around 12 hours it means that we have 0.5 second drift and
+Clock drift occurs because the oscillation frequency varies over time, primarily due to environmental factors such as temperature, air pressure, and magnetic fields. Experiments conducted on Linux systems in non-air conditioned environments show that a drift of 12 PPM (parts per million) corresponds to roughly one second per day.
+
+Observation suggets that over every 10,000 seconds, the clock frequency changes by 1 PPM, resulting in a drift of approximately 0.08 seconds every three hours. Thus, a rough estimate of one second of drift per day is reasonable. If the sync epoch spans 12 hours, this implies a clock drift of approximately 0.5 seconds over that period. For further details, refer to the [NTP Clock Quality FAQ](http://www.ntp.org/ntpfaq/NTP-s-sw-clocks-quality.htm#AEN1220)
+
+
[](http://www.ntp.org/ntpfaq/NTP-s-sw-clocks-quality.htm#AEN1220)
-**Figure. Frequency Correction within a Week**
+Frequency Correction within a Week
+
-## References
+**For inquieries or questions, please contact** [Bhargav Nagajara Bhatt](/team_members/JBhargav.md)
[1] Kiayias, Aggelos, et al. "Ouroboros: A provably secure proof-of-stake blockchain protocol." Annual International Cryptology Conference. Springer, Cham, 2017.
-[2] David, Bernardo, et al. "Ouroboros praos: An adaptively-secure, semi-synchronous proof-of-stake blockchain." Annual International Conference on the Theory and Applications of Cryptographic Techniques. Springer, Cham, 2018.
+[^2] David, Bernardo, et al. "Ouroboros praos: An adaptively-secure, semi-synchronous proof-of-stake blockchain." Annual International Conference on the Theory and Applications of Cryptographic Techniques. Springer, Cham, 2018.
+
+[^3] Badertscher, Christian, et al. "Ouroboros genesis: Composable proof-of-stake blockchains with dynamic availability." Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2018.
-[3] Badertscher, Christian, et al. "Ouroboros genesis: Composable proof-of-stake blockchains with dynamic availability." Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2018.
+[^4] An epoch and a sync-epoch are distinct concepts
-[4] Aggelos Kiayias and Giorgos Panagiotakos. Speed-security tradeoffs in blockchain protocols. Cryptology ePrint Archive, Report 2015/1019, 2015. http://eprint.iacr.org/2015/1019
+[5] Aggelos Kiayias and Giorgos Panagiotakos. Speed-security tradeoffs in blockchain protocols. Cryptology ePrint Archive, Report 2015/1019, 2015. http://eprint.iacr.org/2015/1019
diff --git a/docs/Polkadot/protocols/block-production/Block-production2.png b/docs/Polkadot/protocols/block-production/Block-production2.png
new file mode 100644
index 00000000..b980e39e
Binary files /dev/null and b/docs/Polkadot/protocols/block-production/Block-production2.png differ
diff --git a/docs/Polkadot/protocols/block-production/SASSAFRAS.md b/docs/Polkadot/protocols/block-production/SASSAFRAS.md
index 46553234..00362786 100644
--- a/docs/Polkadot/protocols/block-production/SASSAFRAS.md
+++ b/docs/Polkadot/protocols/block-production/SASSAFRAS.md
@@ -1,153 +1,184 @@
---
-title: SASSAFRAS
+title: Sassafras
---
-**Authors**: [Jeff Burdges](/team_members/jeff.md), Fatemeh Shirazi, [Alistair Stewart](/team_members/alistair.md), [Sergey Vasilyev](/team_members/Sergey.md)
+
-BADASS BABE is a constant-time block production protocol. It intends to ensure that there is exactly one block produced with constant-time intervals rather than multiple or none. It extends on BABE to address this shortcoming of BABE. While [Jeff's Write-up](https://github.com/w3f/research/tree/master/docs/papers/habe) describes the whole design space of constant-time block production, here we describe a practical instantiation of the protocol using zk-SNARKs to construct a ring-VRF.
+BADASS BABE is a constant-time block production protocol designed to ensure that exactly one block is produced at constant-time intervals, thereby avoiding multiple block production and empty slots. It builds upon BABE to address this limitation in the original protocol. While [Jeff's write-up](https://github.com/w3f/research/tree/master/docs/papers/habe) explores the full design space of constant-time block production, the focus here is on a practical instantiation using zk-SNARKs to construct a ring-VRF.
## Layman overview
-We want to run a lottery to distribute the block production slots in an epoch, to fix the order validators produce blocks by the beginning of an epoch. Each validator signs the same on-chain randomness (VRF input) and publishes this signature (VRF output=[value, proof]). This value is their lottery ticket, that can be validated against their public key. The problem with this approach is that the lottery-winners are publicly known in advance and risk becoming targets of attacks. We aim to keep the block production order anonymous. The assignment of the validators to the slots should be fixed for the whole epoch, but noone besides the assigned validator should know whose a slot is. However, we can't validate the tickets prior the lottery using their public keys as it would deanonymize the validators. If tickets were not validated prior to the lottery then instead we can validate them after the lottery by an honest validator claiming their slots when producing blocks.
+Simply put, the aim of the protocol is twofold: to run a lottery that distributes the block production slots in an epoch, and to fix the order in which validators produce blocks at the start of that epoch. Each validator signs the same on-chain randomness (VRF input) and publishes the resulting signature (VRF output=[value, proof]). This value serves as their lottery ticket, which can be validated against their public key.
-However, the problem is that anyone can submit fake tickets, and though they won't be able to produce a block, slots would be preassigned to them. Effectively, it results in empty slots, which defeats the goal of the protocol. To address this problem, we need a privacy-preserving way of validating a ticket. So an honest validator when submitting their ticket accompanies it with a SNARK of the statement: "Here's my VRF output that has been generated using the given VRF input and my secret key. I'm not telling you my keys, but my public key is among those of the nominated validators", that is validated before the lottery.
+The approach reveals the lottery winners in advance, making them potential targets for attacks. The goal is then to keep the block production order anonymous. While the assignment of the validators to slots should remain fixed throughout the epoch, no one other than the assigned validator should know which slot is assigned to whom.
-Now we have a way of making the ticket itself anonymous, we need a way to anonymously publish it to the chain. All ways of doing this with full anonymity are expensive. Fortunately, one of the simplest schemes is good enough for our purposes: a validator just sends each of their tickets to a random validator who later puts it on-chain as a transaction.
+Validating tickets before the lottery using public keys can compromise anonymity. Instead, tickets can be validated after the lottery, when an honest validator claims their slot by producing a block.
+
+The main issue with this approach is that anyone can submit fake tickets. Although these entities wouldn't be able to produce blocks, slots could still be preassigned to them, resulting in empty slots, which undermines the goal of the protocol. What's needed then is a privacy-preserving method for validating tickets.
+
+Relying on such a method, an honest validator could submit their ticket along with a SNARK, validated before the lottery, proving the statement: "This is my VRF output, generated using the given VRF input and my secret key. I won't reveal my keys, but my public key is among those of the nominated validators."
+
+
+Once the ticket is made anonymous, the next step is to publish it to the chain without revealing its origin. While fully anonymous methods tend to be costly, a simple scheme suffices to achieve the core objectives: each validator can send their ticket to a randomly chosen peer, who then submits it on-chain as a transaction.
## Plan
-In an epoch $e_m$ we use BABE randomness $r_m$ for the epoch as ring VRF inputs to produce a number of outputs and publish them on-chain. After they get finalized we sort them and their order defines the order of block production for the epoch $e_{m+2}$.
+In an epoch $e_m$, BABE randomness $r_m$ is used as the ring VRF input to generate a set of outputs, which are then published on-chain. Once finalized, these outputs are sorted, and their order determines the block production sequence for epoch $e_{m+2}$.
## Parameters
-$V$ - the set of nominated validators
-$s$ - number of slots per epoch, for an hour-long epoch with 6 second slots $s=600$
-$x$ - redundancy factor, for an epoch of $s$ slots we want to have $xs$ tickets in expectation for block production. We set $x=2$.
-$a$ - attempts number of tickets generated per validator in epoch
-$L$ - a bound on a number of tickets that can be gossiped, used for DoS resistance
+* $V$: The set of nominated validators
+* $s$: Number of slots per epoch. For an hour-long epoch with 6-second slots, $s=600$
+* $x$: Redundancy factor. For an epoch with $s$ slots, the aim is to generate $xs$ tickets in expectation for block production. In this analysis, we set $x=2$.
+* $a$: Number of ticket-generation attempts per validator in an epoch
+* $L$: A bound on the number of tickets that can be gossiped, used for DoS resistance
## Keys
-In addition to their regular keys, we introduce for each validator a keypair on a SNARK-friendly curve [Jubjub](https://z.cash/technology/jubjub/). We must ensure that the keys are generated before the randomness for an epoch they are used in is determined.
+In addition to their regular keys, each validator must posssess a keypair on a SNARK-friendly curve such as [Jubjub](https://z.cash/technology/jubjub/). It is essential to generate these keys before the randomness for the epoch is derived or finalized.
+
+Given a security parameter $\lambda$ and randomness $r$, generate a key pair using the RVRF key generation function
+$$
+\texttt{KeyGen}_{RVRF}:\lambda,r\mapsto sk, pk
+$$
-Given the security parameter $\lambda$ and some randomness $r$ generate a key pair $\texttt{KeyGen}_{RVRF}:\lambda,r\mapsto sk, pk$
+To optimize the process, an aggregate public key $apk$, referred to as a commitment in Jeff's write-up, is introduced for the full set of validators. This key is essentially a Merkle root derived from the list of individual public keys.
-As an optimization we introduce an aggregate public key $apk$ (called a commitment in Jeff's writeup) for the whole set of validators, that is basically a Merkle root built upon the list of individual public keys. In conjuction to that we use the copath $ask_v$ to identify a public key in the tree as a private input to a SNARK.
-$\texttt{Aggregate}_{RVRF}: v, \{pk_v\}_{v\in V}\mapsto apk, ask_v$
+$$
+\texttt{Aggregate}_{RVRF}: v, \{pk_v\}_{v\in V}\mapsto apk, ask_v
+$$
+The copath $ask_v$ serves to identify a specific public key within the tree as a private input to a SNARK.
## Phases
-Here we describe the regular operation of the protocol starting from a new set of validators being nominated. Bootstrapping the protocol from the genesis or soft-forking Kusama is not described here.
+Bootstrapping the protocol from genesis or through a soft fork of Kusama is beyond the scope of this description. The regular operation of the protocol thus begins with the nomination of a new set of validators.
### 1) Setup
-Once per era, as a new set of validators $V$ gets nominated or some other parameter changes, we reinitialize the protocol with new values for the threshold $T$ and the aggregated public key $apk$.
+As a new set of validators $V$ is nominated, or another protocol parameter changes, the protocol reinitializes once per era with updated values for the threshold $T$ and the aggregated public key $apk$.
Each validator $v \in V$
-1. Calculates the threshold $T = \frac{xs}{a\mid V\mid}$ that prevents the adversary to predict how many more blocks a block producer is going to produce.
+1. Calculates the threshold $T = \frac{xs}{a\mid V\mid}$. This value prevents adversaries to predicting how many additional blocks a block producer will generate.
2. Computes the aggregated public key and copath of $v$s public key
$$
apk, spk_v = \texttt{Aggregate}_{RVRF}(v, \{pk_v\}_{v\in V})
$$
-3. Obtains the SNARK CRS and checks for subversion if it has changed or $v$ hasn't done it earlier.
+3. Obtains the SNARK CRS and verifies whether the subversion status has changed or if $v$ has not previously performed this step.
-### 2) VRF generation Phase
+### 2) VRF generation phase
-We aim to have at least $s$ VRF outputs (tickets) published on-chain (we can't really guarantee that, but the expected value will be $xS$).
+The objective is to have at least $s$ VRF outputs (tickets) published on-chain. Although this cannot be strictly guaranteed, the expected value is $xS$.
#### Randomness
-At the epoch $e_m$ we use the randomness $r_m$ as provided by [BABE](polkadot/protocols/block-production/Babe), namely
+At the epoch $e_m$, [BABE](polkadot/protocols/block-production/Babe) provides randomness $r_m$, defined as follows:
$$
r_m=H(r_{m-1}, m, \rho)
$$
-We use $r_m$ to create inputs to the ring-VRF, and the corresponding tickets will be consumed in $e_{m+2}$.
+Here, $r_m$ creates inputs to the ring-VRF, with resulting tickets consumed in epoch $e_{m+2}$.
-It's critical that $\rho$ is still the concatenation of regular BABE VRF outputs. It follows that we run regular VRFs and ring VRFs in parallel. This is because ring VRF outputs will be revealed in epoch $e_m$ and hence if we use ring VRF outputs for randomness $r_{m+1}$ would be revealed too early. Thus we use VRFs that are unrevealed until the corresponding blocks are produced.
+It's critical that $\rho$ remains the concatenation of regular BABE VRF outputs. Standard VRFs and ring VRFs are then excecuted regularly and concurrently, with ring-VRF outputs revealed in epoch $e_m$. If VRF outputs are used prematurely for randomness, $r_{m+1}$ would be exposed too early. Thus, only unrevealed VRFs are used until their corresponding blocks have been produced.
-If we have a VDF, then all this would need to be determined an epoch prior i.e.
+In the case of a VDF, randomness would need to be determined one epoch earlier, i.e.,
$$
r_m=VDF(H(r_{m-2}, m, \rho))
$$
-with $\rho$ being the concatenation of BABE VRFs from $e_{m-2}$. The VDF would be run at the start of $e_{m-1}$ so that the output would be on-chain before $e_{m}$ starts.
+where $\rho$ is the concatenation of BABE VRFs from epoch $e_{m-2}$. The VDF would be excecuted at the start of $e_{m-1}$, ensuring that its output is available on-chain before $e_{m}$ begins.
#### VRF production
-Each validator $v \in V$
+Each validator $v \in V$ performs the following steps:
-1. Given the randomness $r_{m}$, computes a bunch of $a$ VRF outputs for the inputs $in_{m,i}=(r_m, i)$, $i = 1,\ldots,a$:
+1. Computes $a$ VRF outputs using the randomness $r_{m}$, for inputs $in_{m,i}=(r_m, i)$, where $i = 1,\ldots,a$:
$$
out_{m,v,i}=\texttt{Compute}_{RVRF}(sk_v, in_{m, i})
$$
-2. Selects the "winning" outputs that are below the threshold $T$: $\texttt{bake}(out_{m,v,i}) < T$
-where $\texttt{bake()}$ is a function that effectively maps VRF outputs to the interval $[0,1]$. We call the set of $i$ corresponding to winning outputs $I_{win}$.
+2. Selects "winning" outputs below the threshold $T$: $\texttt{bake}(out_{m,v,i}) < T$,
+where $\texttt{bake()}$ maps VRF outputs to the interval $[0,1]$. The indices correponding to winning outputs form the set $I_{win}$.
-3. Uses its copath $ask_v$ generate proofs for the selected outputs $i \in I_{win}$,
+3. Generates proofs using its copath $ask_v$ for each winning output $i \in I_{win}$,
$$
\pi_{m,v,i} = \texttt{Prove}_{RVRF}(sk_v, spk_v, in_{m,i} )
$$
-where $\texttt{Prove}_{RVRF}(sk_v, spk_v, in_{m,j} )$ consists of the SNARK and its public inputs $cpk,i$.
+where $\texttt{Prove}_{RVRF}(sk_v, spk_v, in_{m,j} )$ includes the SNARK and associated public inputs $cpk,i$.
-As the result of this phase every validator obtains a number, possibly 0, of winning tickets together with proofs of their validity $(j, out_{m, v,j}, \pi_{m,v,j})$ that need to be published on-chain.
+Once this phase concludes, each validator holds zero or more winning tickets and corresponding validity proofs $(j, out_{m, v,j}, \pi_{m,v,j})$. These must later be published on-chain.
-### 3) Publishing Phase
-We want block producers for at least a large fraction of slots unknown in advance. Thus well-behaved validators should keep their tickets private. To this end validators dont publish their winning VRF outputs themselves immediately, but instead relay them to another randomly selected validator (proxy) who then publishes it.
+### 3) Publishing phase
+The goal is to identify block producers for a large portion of slots unknown in advance. Well-behaved validators should keep their tickets private. To achieve this, validators do not publish their winning VRF outputs immediately; instead, they relay them to another randomly selected validator (a proxy), who is responsible for publishing them on-chain.
-Concretely, $v$ chooses another validator $v'$, based on the output $out_{m,v,i}$ for $i \in I_{win}$. To this end, the validator takes $k=out_{m,v,i} \textrm{mod} |V|$ and sends its winning ticket to the $k$th validator in a fixed ordering. Then the validator signs the message: $(v, l, enc_v'(out_{m,v,i}, \pi_{m,v,i}))$ where $end_{v'}$ refers to encrypted to a public key of $v'$. We number the winning outputs using $l$ ranging from $0$ up to $L-1$ and gossip them. If we have more than $L$ outputs below $T$, we gossip only the lowest $L$. This limitation is so that it is impossible for a validator to spam the network.
+Concretely, validator $v$ selects another validator $v'$ based on the output $out_{m,v,i}$ for $i \in I_{win}$. The validator computes $k=out_{m,v,i} \textrm{mod} |V|$ and sends its winning ticket to the $k$th validator according to a fixed ordering. Then, validator $v$ signs the message: $(v, l, enc_v'(out_{m,v,i}, \pi_{m,v,i}))$ where $end_{v'}$ denotes encryption using the public key of $v'$. Winning outputs are indexed using $l$ ranging from $0$ to $L-1$, and are gossiped through the network. If there are more than $L$ outputs below the threshold $T$, only the lowest $L$ are disseminated. This limitation helps prevent validator from spamming the network.
-Once a valiaotr receives a messages it checks whether it has received a message with the same $v$ and $l$ and if so it discards the new message. Otherwise, the validator forwards (gossips) the message and decrypts it to find out whether the validator is the intended proxy. Validators gossip messages that are intended for them further to be secure against traffic correlation.
+Once a validator receives a message, it checks whether it has already received a message with the same $v$ and $l$; if so, it discards the new message. Otherwise, it decrypts the message to determine whether it is the intended proxy and forwards (gossips) the message. Validators further gossip messages addressed to themselves to mitigate traffic correlation risks.
-Once a validator decrypts a message with their private key they verify that they were the correct proxy, i.e. that $out_{m,v,i} \textrm{mod} |V|$ corresponds to them. If so, then at some fixed block number, they send a transaction including $(out_{m,v,i}, \pi_{m,v,i}))$ for inclusion on-chain. Note that the validator might have been proxy for a number of tickets, in that case, it sends a number of transaction on designated block number.
+When a validator decrypts a message using its private key, it verifies whether it was the correct proxy by checking out that $out_{m,v,i} \textrm{mod} |V|$ corresponds to its index. If confirmed, it then broadcasts a transaction at a designated block number, containing $(out_{m,v,i}, \pi_{m,v,i}))$ for inclusion on-chain. If the validator serves as a proxy for multiple tickets, it submits multiple transactions at the appointed block.
-If a validators $v$ ticket is not included on-chain before some later block number, either because the proxy is misbehaving or because they havent sent the winning ticket to any proxies, then $v$ publishes the transaction $(out_{m,v,i}, \pi_{m,v,i})$ themselves. The reason why a validator would not send a winning ticket to any proxy is that it has more than $L$ winning tickets.
+If validator $v$'s ticket is not included on-chain before a certain block number, either due to proxy misbehavior or because it did not forward the ticket to any proxy, then $v$ submits the transaction $(out_{m,v,i}, \pi_{m,v,i})$ independently. A validator might refrain from selecting a proxy when it holds more than $L$ winning tickets.
### 4) Verification
-A transaction of this sort is valid for inclusion in a block if it can be verified as follows.
-
-To verify the published transactions $(out_{m, v,i}, \pi_{m,v,i})$, we need to verify the SNARK. For this we need
-- the corresponding input $in_{m,i}$, which we can calculate from $i$ and $r_m$,
+A transaction of this type is valid for block inclusion if it can be verified. To check published transactions $(out_{m, v,i}, \pi_{m,v,i})$, the corresponding SNARK proof must hold. This verification requires:
+- the input $in_{m,i}$, which can be computed from $i$ and $r_m$,
- the published output $out_{m,v,i}$
-- the aggregate public key $apk$.
+- the aggregate public key, denoted as $apk$.
-All of these are the public inputs in SNARK verification:
+These values constitute the public inputs to the SNARK verifier:
$$
Verify(\pi_{m,v,i}, apk, out_{m,v,i}, in_{m,i})
$$
### 5) Sorting
-In the epoch $e_{m+2}$ we have the list $\{out_{m,k}\}_{k=1}^{K}$ of $K$ verified VRF outputs generated during the epoch $e_m$ which are finalized on-chain. For each of these outputs, we combine the ouput with the randomness $r'$, with either $r'=r_{m+1}$ if we do not have a VDF or $r'=r_{m+2}$ if we do have a VDF. Then we compute $out'_{m,k}=H(out_{m,k} || r')$.
+Epoch $e_{m+2}$ contains the list $\{out_{m,k}\}_{k=1}^{K}$ of $K$ verified VRF outputs generated during the epoch $e_m$, which are finalized on-chain. Each output is combined with a source of randomness $r'$, where:
+- $r'=r_{m+1}$ if no VDF is used, or
+- $r'=r_{m+2}$ if a VDF is used.
+
+The resulting hash is computed as: $out'_{m,k}=H(out_{m,k} || r')$
-To determine the block production order for the epoch $e_{m+2}$, each validator sorts the list of $out'_{m,k}$ in ascending order and drops the largest $s-K$ values if any: $out'_{m,1},\ldots, out'_{m,l}$, where $l\leq s$ and $out'_{m,p}\leq out'_{m,q}$ for $1\leq p(2,4,5,3,1)
+**Slot assignment via "Outside-in" sorting.** Ticket values $out'_{m,k}$ are assigned to slots using an outside-in ordering:
-In the unlikely event that $K < s$, there will be some unassigned slots in the middle of the epoch, and for these we use AuRa.
+- The lowest value $out'_{m,1}$ maps the last slot
+- The second lowest $out'_{m,2}$ maps the first slot
+- The third $out'_{m,3}$ maps the penultimate slot
+- The fourth $out'_{m,4}$ maps to the second slot, and so on.
-Concretely, for the algorithm for assiging lots that uses outside-in sorting, we take lists of even and odd numbered elements, reverse the list of odd elements, then concatenate the list of even elements, the list of aura slots and the reversed list of odd elements.
+Example of outside-in ordering: Given the input (1,2,3,4,5), the resulting output is (2,4,5,3,1).
+
+In the unlikely event that $K < s$, some slots will remain unassigned in the middle of the epoch. These gaps are filled using the AuRa protocol.
+
+To assign slots using outside-in sorting, split the list of outputs into even- and odd-numbered elements, reverse the list of odd elements, then concatenate the even elements, followed by the Aura-assigned slots, and finally the reversed odd elements.
### 6) Claiming the slots
-To produce a block in the assigned slot, the validator needs to include the ticket, a VRF output $out_{m,v,i}$, that corresponds to the slot together with a non-anonymous proof that this is the output of their VRF.
+To produce a block in the assigned slot, a validator needs to include a ticket, specifically a VRF output $out_{m,v,i}$, corresponding to the slot, along with a non-anonymous proof that this output is the result of their VRF.
+
+Introducing the following functions facilitates this:
-Thus we introduce
$\texttt{Reveal}_{RVRF}: sk_v, out\mapsto \tau$
-and the corresponding
+
$\texttt{Check}_{RVRF}: \tau, out\mapsto true/false$
-calls that are basically Schnorr knowledge of exponent proofs (PoKE).
-When validating the block nodes verify these proofs.
-The validator must also include a never before seen VRF output, called the BABE VRF above. This may be done with the existing (non-jubjub) key on the same input (r_m || i).
+These are esssentially Schnorr-style proofs of knowledge of exponent (PoKE).
+When validating a block, nodes must verify these proofs. Additionally, the validator must include a previously unseen VRF output-referred to as the BABE VRF above, which can be generated using the existing (non-jubjub) key on the same input (r_m || i).
-## Probabilities and parameters.
+## Probabilities and parameters
-The first parameter we consider is $x$. We need that there is a very small probability of their being less than $s$ winning tickets, even if up to $1/3$ of validators are offline. The probability of a ticket winning is $T=xs/a|V|$.
-Let $n$ be the number of validators who actually participate and so $2|V|/3 \leq n \leq |V|$. These $n$ validators make $a$ attempts each for a total of $an$ attempts.
-Let $X$ be the nimber of winning tickets.
+The first parameter under consideration is $x$. The goal is to ensure a very low probability of having fewer than $s$ winning tickets, even if up to $1/3$ of validators are offline. The probability that any given attempt yields a winning ticket is $T=xs/a|V|$.
+Let $n$ be the number of validators who actually participate such that $2|V|/3 \leq n \leq |V|$. Each of the $n$ validators makes $a$ attempts, resulting in a total of $an$ attempts.
+Let $X$ be the number of winning tickets. Its expected value is
-Then it's expectation has $E[X] = Tan = xsn/|V|$. If we set $x=2$, this is $\geq 4s/3$. In this case, $Var[X] = anT(1-T) \leq anT = xsn/|V| = 2sn/|V| \leq 2s$.
+$$
+E[X] = Tan = xsn/|V|
+$$
+
+Setting $x=2$ yields $\geq 4s/3$. In this case, the variance is
+
+$$
+Var[X] = anT(1-T) \leq anT = xsn/|V| = 2sn/|V| \leq 2s
+$$
Using Bernstein's inequality:
$$
@@ -159,9 +190,11 @@ $$
\end{align*}
$$
-For $s=600$, this gives under $4 * 10^{-13}$, which is certainly small enough. We only need the Aura fallback to deal with censorship. On the other hand, we couldn't make $x$ smaller than $3/2$ and still have tolerance against validators going offline. So $x=2$ is a sensible choice, and we should never need the Aura fallback.
+For $s=600$, this yields a probability below $4 * 10^{-13}$, which is sufficiently small. The Aura fallback mechanism is needed only as a safeguard against censorship. It is not feasible to reduce $x$ below $3/2$ while retaining tolerance for offline validators, making $x=2$ a prudent choice. Under this configuration, the Aura fallback should remain unused.
+
+The next parameter to configure is $a$. A challenge arises in that if a validator $v$ receives $a$ winning tickets during an epoch, an adversary observing this will deduce that no additional blocks will be produced by $v$.
-The next parameter we should set is $a$. The problem here is that if a validator $v$ gets $a$ winning tickets in an epoch, then when the adversary sees these, they now know that there will be no more blocks from $v$.
+**For inquieries or questions, please contact** [Jeffrey Burdges](/team_members/JBurdges.md)
diff --git a/docs/Polkadot/protocols/block-production/Sassafras-Part-1.md b/docs/Polkadot/protocols/block-production/Sassafras-Part-1.md
deleted file mode 100644
index c8957508..00000000
--- a/docs/Polkadot/protocols/block-production/Sassafras-Part-1.md
+++ /dev/null
@@ -1,79 +0,0 @@
----
-title: 'Sassafras Part 1: A Novel Single Secret Leader Election Protocol'
-
----
-
-# Sassafras Part 1: A Novel Single Secret Leader Election Protocol
-
-Authors: Armando Caracheo, Elizabeth Crites, and Fatemeh Shirazi
-
-Polkadot is set to replace the [BABE](https://wiki.polkadot.network/docs/learn-consensus#block-production-babe)+[Aura](https://openethereum.github.io/Aura.html) consensus protocol with a new one: *Sassafras*. Sassafras will be used to generate blocks on Polkadot's relay chain, but can be used in other proof-of-stake (PoS) blockchains as well. So, what key advantages does this new protocol bring to the blockchain ecosystem?
-
-Imagine a bread factory where loaves are produced at random time intervals and multiple conveyor belts may release bread simultaneously, but only one loaf can be packaged at once. Clearly, this is not the most efficient way to process as much bread as possible. In a way, what happens in this factory resembles the current state of block production in Polkadot, as well as in other PoS blockchains.
-
-Classical proof-of-stake protocols for block generation create new blocks at unpredictable intervals, due to having multiple eligible block producers at once, or none at all. [BABE](https://wiki.polkadot.network/docs/learn-consensus#block-production-babe) similarly relies on randomized block generation and therefore inherits these traits.
-
-Just like in the bread factory, where the system could benefit from fixed-time production and a single conveyor belt, allowing loaves to be packaged one after another, an optimized block generation mechanism should rely on constant-time intervals and a single block producer per block. These improvements increase the number of loaves that can be produced, and analogously the number of blocks added to the chain.
-
-Production changes often introduce new challenges, and shifting to constant-time intervals within blockchain systems is no exception. Randomized block generation helps protect block producers from attacks, as adversaries are unable to predict the producer of the next block. For this reason, randomized block production has been considered a viable solution.
-
-But what if a protocol could ensure secrecy of block producers, protecting them from a looming adversary, while realizing non-randomized block generation to improve efficiency? Centered on the concept of *single secret leader election* (SSLE) (see [Part 2](https://hackmd.io/@W3F64sDIRkudVylsBHxi4Q/Bkr59i7ekg)), the Sassafras block producer selection protocol achieves exactly that.
-
-Curious to know how Sassafras works? Then keep reading.
-
-## Randomized block production: the root of multiple producers and empty blocks
-
-On Polkadot, [BABE](https://wiki.polkadot.network/docs/learn-consensus#block-production-babe) selects block producers through a process known as *probabilistic leader election* (PLE), which is common in many modern PoS blockchains. Since leader selection is based on a randomized algorithm, the following outcomes may occur: multiple block producers may be eligible to add a block to the chain, or no block producer may be eligible when the block is expected.
-
-Both outcomes have a negative impact on throughput (data processed per unit time), which is crucial to the scalability of blockchain consensus protocols. The absence of eligible block producers results in random time intervals between blocks. This can lead to a decrease in the overall throughput (i.e., fewer blocks in the final chain) and longer time intervals that lower the average block production rate.
-
-One way to mitigate low throughput is to simply reduce the time between produced blocks. Such a reduction, however, introduces the likelihood of certain risks. For instance, block producers who generate new blocks without first seeing the previous one may create forks.
-
-## Consistent timing from the core
-
-Constant-time block generation helps eliminate these potential risks and can be achieved by assigning a single block producer whenever a new block is expected. For example, in a fixed block producer rotation using a round-robin style, each validator takes turns and generates a block in a predefined order. [Aura](https://openethereum.github.io/Aura.html) is a good example of this block production mechanism.
-
-Unfortunately, this simple approach using a non-randomized algorithm for leader selection leaves the door open to attacks. If block producers are designated non-randomly and at fixed time intervals, the chain becomes vulnerable to forking and denial-of-service attacks.
-
-One way to counter these vulnerabilities is to implement an SSLE protocol. In the literature, there are several proposed SSLE protocols for block producer elections (see [Part 3](https://hackmd.io/I8VSv8c6Rfizi9JWmzX25w)). SSLE boasts many desirable features, which make it an attractive option for integration into PoS blockchains. However, existing protocols have various drawbacks, particularly in terms of efficiency. Indeed, none have been deployed to date.
-
-## Sassafras’s innovative approach
-
-Sassafras is a consensus protocol designed to randomly select the next block producer. Its main aim is to efficiently select a unique block producer and release blocks at constant time intervals. To achieve definite finality of blocks, the protocol may be combined with another protocol, such as [Grandpa](https://docs.polkadot.com/polkadot-protocol/architecture/polkadot-chain/pos-consensus/#).
-
-Sassafras operates as an SSLE protocol rather than a PLE protocol. Its novelty lies in using a [ring verifiable random function (VRF)](https://eprint.iacr.org/2023/002) to select a single block producer per block, while maintaining sufficient block producer secrecy within a “ring” of all participants. This design reduces on-chain communication and computation, enhances block production as well as leader selection efficiency, and conceals the identities of a sufficient number of honest block producers (enough to stay secure) until the moment they create blocks.
-
-We are now ready to describe the Sassafras protocol.
-
-## An overview of how Sassafras works, step-by-step
-
-At a high level, Sassafras works as follows. First, every validator generates a ticket, which they publish on-chain in a private manner. These tickets are sorted into a list. The first validator in that list reveals their identity and produces the next block. Tickets are kept private until the moment blocks are produced to protect validators from attacks.
-
-In terms of timing, during an epoch of the blockchain, blocks are generated according to the election results of the previous epoch, and new leaders are elected for the next epoch.
-
-The figure below illustrates the protocol in more detail.
-
-
-
-**Phase A)** Each validator generates a ticket $(y_i, \sigma_i)$ consisting of the ring VRF outputs, and encrypts it using the encryption key of a randomly chosen validator. This validator, called a repeater, acts as an identity guard. Each validator then sends their ciphertext to all validators. Both the ticket and its repeater remain hidden.
-
-**Phase B)** Each repeater receives all tickets and decrypts those for which it holds the decryption key. Repeaters then publish the tickets they have received on-chain.
-
-**Phase C)** All tickets are sorted and recorded on-chain.
-
-**Phase D)** When validator identities leak in Phase B, adversarial repeaters can decrypt their tickets (orange dots) and launch attacks (orange dots with a cross). The figure illustrates the worst-case scenario, in which all validators with leaked identities have been attacked. Even in this situation, the first honest validator on the sorted list (one who has not been attacked) is able to submit proof that they hold the winning ticket and become the next block producer.
-
-**Phase E)** The selected validator then generates the next block.
-
-With these five phases in place, and since all block producers for an epoch are determined in the previous epoch, blocks can be generated seamlessly in constant time (e.g., every 6 seconds on Polkadot). Moreover, Sassafras achieves the highest efficiency among SSLE protocols while maintaining sufficient anonymity to ensure the security of a blockchain that deploys it.
-
-
-Striking this balance is what makes Sassafras an ideal candidate for real-world deployment. In fact, a specification of Sassafras, called Safrole, has already been integrated into the architecture of the upcoming [JAM protocol](https://graypaper.com/).
-
-## Eager to learn more about Sassafras?
-
-So far, we have presented a concise introduction to Sassafras, accessible to readers with a basic understanding of blockchains. We have also outlined the motivation behind the protocol and provided a clear overview of how it works. But this is only the beginning. The Web3 Foundation team has prepared two additional blog posts that explore Sassafras in greater detail.
-
-Our next blog post, [Part 2 - Deep Dive](https://hackmd.io/@W3F64sDIRkudVylsBHxi4Q/Bkr59i7ekg), will explain the concept of an SSLE protocol and delve into the technical details of Sassafras. The final chapter, [Part 3 - Compare and Convince](https://hackmd.io/I8VSv8c6Rfizi9JWmzX25w), will demonstrate how Sassafras achieves unparalleled efficiency in block production and provide readers with a comparison of similar protocols, highlighting its value. The upcoming blog posts aim to describe how Sassafras offers a practical solution for achieving better throughput while maintaining security.
-
-So stay tuned, brave reader. There's much more to discover in our upcoming Sassafras series, which is packed with valuable insights!
diff --git a/docs/Polkadot/protocols/block-production/Sassafras.png b/docs/Polkadot/protocols/block-production/Sassafras.png
new file mode 100644
index 00000000..3e8f6f94
Binary files /dev/null and b/docs/Polkadot/protocols/block-production/Sassafras.png differ
diff --git a/docs/Polkadot/protocols/block-production/index.md b/docs/Polkadot/protocols/block-production/index.md
index 046b1718..69a7d7ea 100644
--- a/docs/Polkadot/protocols/block-production/index.md
+++ b/docs/Polkadot/protocols/block-production/index.md
@@ -4,10 +4,19 @@ title: Block production
import DocCardList from '@theme/DocCardList';
-The relay chain in Polkadot is built with the underlying proof-of-stake (POS) block production mechanism by validators. The currently deployed mechanism is a hybrid of BABE and Aura. We plan to replace BABE+Aura with Sassafras in the future.
-**BABE:** A PoS protocol provides a way to elect validators to produce a block in the corresponding time slot. BABE's election is based on verifiable random function (VRF) of validators invented by David et al. for [Ouroboros Praos](https://eprint.iacr.org/2017/573.pdf) i.e., if a VRF output of a validator is less than a pre-defined threshold, then the validator is legitimate to produce a block. So, one validator or more than one validator or no validator can be elected. This election mechanism is completely private. In other words, no one can guess who is elected until the elected validator publishes a block. The privacy property is very critical for the blockchain security because it is indispensable for achieving security against an adaptive adversary who can corrupt any validator at any time. The drawback of this election mechanism is that no validator will be elected in a significant amount of time. So, validators waste these times by doing nothing which causes slightly worse (and uneven) throughput. Therefore, we fill the empty slots with blocks generated by validators who are deterministically selected by [Aura](https://eprint.iacr.org/2018/1079.pdf). Aura's election mechanism is not private so it is not secure against an adaptive adversary. For example, the adversary can prepare a DDOS attack on the elected validator by Aura to prevent him to publish his block because the adversary knows who is elected beforehand. Therefore, filling the empty slots with Aura blocks is not a solution in the adaptive adversarial model to prevent empty slots. Nevertheless we note that BABE+Aura is secure (safe and live) in the adaptive adversarial model - the security reduces to the BABE's security. It just does not prevent theoretically to have empty slots that we need to have a better throughput in the adaptive adversarial model.
+The Polkadot relay chain, built by validators through a Proof-of-Stake (PoS) block production mechanism, operates with a hybrid system that combines BABE and Aura. The plan is to eventually replace this with Sassafras.
-**Sassafras:** We construct Sassafras to obtain both security and non-empty slot property in the relay chain in the adaptive adversarial model. The election mechanism is based on the new primitive 'ring-VRF' that we define. Ring-VRF has the same properties as VRF e.g. randomness, verifiability of the output but also has verifiability property without knowing the public key of the validator who generated the output. In short, all validators generate a good amount of ring VRF outputs. Then, these outputs are sorted after verification by all validators to determine the order of the validators in the block production. Since a ring-VRF output does not reveal the identity of the validators for the verification, the privacy is preserved. Another good property of Sassafras is that there is only **one** validator is selected for a specified time interval. This property is useful to have fewer forks which is better for the parachain performance.
+
+
+**BABE:** A Proof-of-Stake (PoS) protocol provides a mechanism for electing validators to produce blocks in designated time slots. BABE's election is based on a verifiable random function (VRF), originally introduced by David et al. in [Ouroboros Praos](https://eprint.iacr.org/2017/573.pdf). Specifically, a validator is elligible to produce a block if its VRF output falls below a pre-defined threshold. As a result, a round may yield one, multiple, or no elected validators. This election mechanism is completely private. Until an elected validator publishes a block, no one can know who was selected. Such privacy property is crucial for blockchain security, as it provides resilience against adaptive adversaries capable of corrupting validators at any time.
+
+One limitation of BABE's approach is that blocks may not be produced for extended periods if no validator meets the threshold. These empty slots degrade throughput and create uneven performance. To mitigate this, empty slots are filled using blocks generated by validators deterministically selected by [Aura](https://eprint.iacr.org/2018/1079.pdf). This ensures that the chain continues producing blocks during otherwise idle slots, though it comes with a tradeoff.
+
+Aura's selection process is not private, making it vulnerable to adaptive adversaries. For instance, knowing in advance which validator will be chosen allows an attacker to launch targeted denial-of-service (DDoS) attacks to block publication. Relying solely on Aura is unsuitable under adaptive adversarial conditions. Nevertheless, the BABE+Aura hybrid protocol remains secure and live under such model, since overall security relies on BABE. The only drawback is that empty slots are not prevented in theory, meaning throughput improvements are limited in the adaptive adversarial setting.
+
+**Sassafras:** Sassafras aims to achieve both security and non-empty slot property on the relay chain under an adaptive adversarial model. Its election mechanism is built on a novel primitive called 'ring-VRF.' Like standard VRFs, ring-VRF provides randomness and output verifiability, but it also allows verification without requiring knowledge of the public key of the validator who generated the output.
+
+In essence, all validators generate a sufficient number of ring VRF outputs. These outputs are then verified and sorted to determine the validator order for block production. Because ring-VRF outputs do not disclose the validator's identity during verification, the mechanism preserves privacy. Sassafras limits block production to a **single** validator per time interval. This approach reduces the likelihood of forks, thereby improving parachain performance.
diff --git a/docs/Polkadot/protocols/finality.md b/docs/Polkadot/protocols/finality.md
index eecb7c2f..ade6a332 100644
--- a/docs/Polkadot/protocols/finality.md
+++ b/docs/Polkadot/protocols/finality.md
@@ -4,20 +4,11 @@ title: Finality
import useBaseUrl from '@docusaurus/useBaseUrl';
-Owner: [Alistair Stewart](/team_members/alistair.md)
+
-GRANDPA is the finality (consensus) algorithm for Polkadot. Here we first
-present a high-level overview, as an "extended abstract". Details are presented
-in the full paper directly below that.
+GRANDPA is the finality (consensus) algorithm used in Polkadot. To get started, you can read our "extended abstract," which provides a high-level overview. If you're eager to dive deeper into the technical details, feel free to skip ahead to the full paper just below. And as a bonus, there is a more polished and slightly shorter version of the full paper available on [arxiv](https://arxiv.org/abs/2007.01560).
-We also have an [alternative version](https://arxiv.org/abs/2007.01560) of the
-full paper available on arxiv, which is more polished and a bit shorter.
-
-What is implemented in the Polkadot software and deployed in practise, we refer
-to as "Polite GRANDPA" which includes optimisations required for efficient
-real-world performance in practise. These are not covered in the papers below
-for brevity, but we go into [the details](#polite-grandpa) later here on this
-page. The high-level concepts and design principles remain the same as GRANDPA.
+"Polite GRANDPA" is the implementation of GRANDPA used in the Polkadot software and deployed in practice. It includes optimizations tailored for efficient real-world performance in practice, which are not covered in the papers below for the sake of brevity, You can find the [details](#polite-grandpa) later on this page. The high-level concepts and design principles remain consistent with GRANDPA.
## GRANDPA Abstract paper
@@ -27,4 +18,7 @@ page. The high-level concepts and design principles remain the same as GRANDPA.
## Polite GRANDPA
+**Looking for answers to your questions, feel free to contact:** [Alistair Stewart](/team_members/alistair.md)
+
+
diff --git a/docs/Polkadot/protocols/index.md b/docs/Polkadot/protocols/index.md
index 96d7864c..fc04b9d0 100644
--- a/docs/Polkadot/protocols/index.md
+++ b/docs/Polkadot/protocols/index.md
@@ -4,6 +4,8 @@ title: Protocols
import DocCardList from '@theme/DocCardList';
-This chapter goes into full detail about each of the subprotocols that make up Polkadot. It focuses largely on end-to-end mechanics and the properties relevant at this layer; for point-to-point mechanics see `networking`.
+This section provides a detailed description of some of the subprotocols that comprise Polkadot. The focus is largely on end-to-end mechanics and the properties relevant at this layer; for point-to-point mechanics, see `networking`.
+
+
diff --git a/docs/Polkadot/protocols/secure-and-efficient-bridges.png b/docs/Polkadot/protocols/secure-and-efficient-bridges.png
new file mode 100644
index 00000000..ff83fb7b
Binary files /dev/null and b/docs/Polkadot/protocols/secure-and-efficient-bridges.png differ
diff --git a/docs/Polkadot/protocols/secure-andefficient-bridges.jpeg b/docs/Polkadot/protocols/secure-andefficient-bridges.jpeg
new file mode 100644
index 00000000..4014731e
Binary files /dev/null and b/docs/Polkadot/protocols/secure-andefficient-bridges.jpeg differ
diff --git a/docs/Polkadot/security/Security.png b/docs/Polkadot/security/Security.png
new file mode 100644
index 00000000..dc84b502
Binary files /dev/null and b/docs/Polkadot/security/Security.png differ
diff --git a/docs/Polkadot/security/index.md b/docs/Polkadot/security/index.md
index d44f3df1..70d4be91 100644
--- a/docs/Polkadot/security/index.md
+++ b/docs/Polkadot/security/index.md
@@ -4,6 +4,7 @@ title: Security
import DocCardList from '@theme/DocCardList';
-This chapter talks about general security concerns, that cut across many (if not all) `subprotocols ` of Polkadot.
+
+This section addresses general security concerns that span many, if not all, Polkadot `subprotocols `.
diff --git a/docs/Polkadot/security/keys/1-accounts-more.md b/docs/Polkadot/security/keys/1-accounts-more.md
index 77603265..99c7c31d 100644
--- a/docs/Polkadot/security/keys/1-accounts-more.md
+++ b/docs/Polkadot/security/keys/1-accounts-more.md
@@ -2,64 +2,69 @@
title: Account signatures and keys in Polkadot
---
-We believe Polkadot accounts should primarily use Schnorr signatures with both public keys and the `R` point in the signature encoded using the [Ristretto](https://ristretto.group) point compression for the Ed25519 curve. We should collaborate with the [dalek ecosystem](https://github.com/dalek-cryptography) for which Ristretto was developed, but provide a simpler signature crate, for which [schnorr-dalek](https://github.com/w3f/schnorr-dalek) provides a first step.
+
+Polkadot accounts should primarily use Schnorr signatures, with both the public key and the `R` point in the signature encoded using the [Ristretto](https://ristretto.group) point compression for the Ed25519 curve. It is recommended to collaborate with the [dalek ecosystem](https://github.com/dalek-cryptography), for which Ristretto was developed, while providing a simpler signature crate. The [Schnorr-dalek](https://github.com/w3f/schnorr-dalek) library offers a first step in that direction.
## Schnorr signatures
-We prefer Schnorr signatures because they satisfy the [Bitcoin Schnorr wishlist](https://github.com/bitcoin/bips/blob/master/bip-0340.mediawiki) and work fine with extremely secure curves, like the Ed25519 curve or secp256k1.
+Despite Schnorr signatures satisfying the [Bitcoin Schnorr wishlist](https://github.com/bitcoin/bips/blob/master/bip-0340.mediawiki) and performing well on highly secure curves such as Ed25519 and secp256k1, this wishlist arguably overstates the capabilities of Schnorr-based multi-signatures. In practice, these schemes typically require three round trips, which, while suitable for industrial applications, introduce additional complexity and latency.
-We observe the Bitcoin Schnorr wishlist oversells the promise of schnorr multi-signatures because they actually require three round trips, which works for industrial usage, but complicates. Another scheme call mBCJ from pages 21 and 22 of https://eprint.iacr.org/2018/417.pdf provides a two round trip multi-signature, but we require a delinearized variant of mBCJ for accounts https://github.com/w3f/schnorrkel/issues/15 and mBCJ is not actually a Schnorr signatures.
+An alternative scheme, call mBCJ, described on pages 21-22 of this [paper](https://eprint.iacr.org/2018/417.pdf), offers a two-round multi-signature protocol. That said, a delinearized variant of mBCJ is required for account-based systems, as discussed in this [GitHub issue](https://github.com/w3f/schnorrkel/issues/15). It is also important to note that mBCJ is not a true Schnorr signature scheme, as it uses a different verification model and structural assumptions.
-You could do fancier tricks, including like aggregation, with a pairing based curve like BLS12-381 and the BLS signature scheme. These curves are slower for single verifications, and worse accounts should last decades while pairing friendly curves should be expected become less secure as number theory advances.
+More advanced techniques, such as signature aggregation using a pairing-based curve like BLS12-381 and the BLS signature scheme, are also possible. These curves tend to be slower for single verifications. Moreover, account systems are expected to remain secure for decades, while pairing-friendly curves may become less secure over time as number theory advances.
-There is one sacrifice we make by choosing Schnorr signatures over ECDSA signatures for account keys: Both require 64 bytes, but only [ECDSA signatures communicate their public key](https://crypto.stackexchange.com/questions/18105/how-does-recovering-the-public-key-from-an-ecdsa-signature-work). There are obsolete Schnorr variants that [support recovering the public key from a signature](https://crypto.stackexchange.com/questions/60825/schnorr-pubkey-recovery), but
-they break important functionality like [hierarchical deterministic key derivation](https://www.deadalnix.me/2017/02/17/schnorr-signatures-for-not-so-dummies/). In consequence, Schnorr signatures often take an extra 32 bytes for the public key.
+Choosing Schnorr signatures over ECDSA for account keys involves a trade-off: Both signature types are 64 bytes in size, but only [ECDSA signatures allow public key recovery](https://crypto.stackexchange.com/questions/18105/how-does-recovering-the-public-key-from-an-ecdsa-signature-work). While there are obsolete Schnorr variants that [support public key recovery](https://crypto.stackexchange.com/questions/60825/schnorr-pubkey-recovery), they compromise important features such as [hierarchical deterministic (HD) key derivation](https://www.deadalnix.me/2017/02/17/schnorr-signatures-for-not-so-dummies/). In consequence, Schnorr signatures often require an additional 32 bytes to transmit the public key.
-In exchange, we gain a slightly faster signature scheme with far simpler batch verification than [ECDSA batch verification](http://cse.iitkgp.ac.in/~abhij/publications/ECDSA-SP-ACNS2014.pdf) and more natural threshold and multi-signatures, as well as tricks used by payment channels. I also foresee the presence of this public key data may improve locality in block verification, possibly openning up larger optimisations.
+In return, the signature scheme becomes slightly faster and enables much simpler batch verification compared to [ECDSA](http://cse.iitkgp.ac.in/~abhij/publications/ECDSA-SP-ACNS2014.pdf). It also supports more natural implementation of threshold signatures, multi-signatures, and techniques used in payment channels. Additionaly, the inclusion of public key data may improve locality during block verification, potentially unlocking optimization opportunities.
-Yet most importantly, we can protect Schnorr signatures using both the derandomization tricks of EdDSA along with a random number generator, which gives us stronger side-channel protections than conventional ECDSA schemes provide. If we ever do want to support ECDSA as well, then we would first explore improvements in side-channel protections like [rfc6979](https://tools.ietf.org/html/rfc6979), along with concerns like batch verification, etc.
+Most importantly, by combining the derandomization techniques of ECDSA with a secure random number generator, Schnorr signatures offer enhanced protection. This results in stronger side-channel resistance compared to conventional ECDSA schemes. To improve ECDSA in this regard, the first step would be to explore side-channel mitigation strategies such as [rfc6979](https://tools.ietf.org/html/rfc6979), along with considerations like batch verification and other optimizations.
## Curves
-There are two normal curve choices for accounts on a blockchain system, either secp256k1 or the Ed25519 curve, so we confine our discussion to them. If you wanted slightly more speed, you might choose FourQ, but it sounds excessive for blockchains, implementations are rare, and it appears covered by older but not quite expired patents. Also, you might choose Zcash's JubJub if you wanted fast signature verification in zkSNARKs, but that's not on our roadmap for Polkadot, and Jubjub also lacks many implementations.
+secp256k1 and Ed25519 are two elliptic curves commonly used for account keys in blockchain systems. For slightly more speed, FourQ is a viable alternative, though it may be excessive for blockchain use, as implementations are rare and it appears to be covered by older, though not fully expired, patents. Additionally, for fast signature verification in zkSNARKs a relevant choice is Zcash's JubJub. However, JubJub is not part of Polkadot's roadmap and also lacks widespread implementation support.
### How much secp256k1 support?
-We need some minimal support for secp256k1 keys because token sale accounts are tied to secp256k1 keys on Ethereum, so some "account" type must necessarily use secp256k1 keys. At the same time, we should not encourage using the same private keys on Ethereum and Polkadot. We might pressure users into switching key types in numerous ways, like secp256k1 accounts need not support balance increases, or might not support anything but replacing themselves with an ed25519 key. There are conceivable reasons for fuller secp256k1 support though, like wanting ethereum smart contracts to verify some signatures on Polkadot. We might support secp256k1 accounts with limited functionality, but consider expanding that functionality if such use cases arise.
+secp256k1 keys require minimal support, primarily because token sale accounts on Ethereum are tied to secp256k1 keys. As a result, some "account" type must necessarily support secp256k1. Using the same private keys across Ethereum and Polkadot is discouraged. And since secp256k1 accounts may not support balance increases or may only allow replacement with an ed25519 key, employing multiple key types is adivisable.
+
+That said, there are valid reasons to consider broader support for secp256k1. For example, enabling Ethereum smart contracts to verify signatures originated from Polkadot. While secp256k1 accounts can be supported with limited functionality, it may be worth expanding that functionality if such cross-chain use cases become relevant.
### Is secp256k1 risky?
-There are two theoretical reasons for preferring an twisted Edwards curve over secp256k1: First, secp256k1 has a [small CM field discriminant](https://safecurves.cr.yp.to/disc.html), which might yield better attacks in the distant future. Second, secp256k1 has fairly rigid paramater choices but [not the absolute best](https://safecurves.cr.yp.to/rigid.html). I do not believe either to be serious cause for concern. Among more practical curve weaknesses, secp256k1 does have [twist security](https://safecurves.cr.yp.to/twist.html) which eliminates many attack classes.
+Two theoretical arguments support the preference for a twisted Edwards curve over secp256k1: First, secp256k1 has a [small CM field discriminant](https://safecurves.cr.yp.to/disc.html), which could potentially enable more effective attacks in the distant future. Second, secp256k1 uses fairly rigid paramater choices that are [not optimal](https://safecurves.cr.yp.to/rigid.html). Neither of these concerns is currently regarded as critical.
+
+From a more practical standpoint, secp256k1 does offer [twist security](https://safecurves.cr.yp.to/twist.html), which helps eliminate several classes of attacks and strengthens its overall resilience.
-I foresee only one substancial reason for avoiding secp256k1: All short Weierstrass curves like secp256k1 have [incomplete addition formulas](https://safecurves.cr.yp.to/complete.html), meaning certain curve points cannot be added to other curve points. As a result, addition code must check for failures, but these checks make writing constant time code harder. We could examine any secp256k1 library we use in Polkadot to ensure it both does these checks and has constant-time code. We cannot however ensure that all implementations used by third party wallet software does so.
+The most substantial reason to avoid secp256k1 is that all short Weierstrass curves, including secp256k1, have [incomplete addition formulas](https://safecurves.cr.yp.to/complete.html). This means certain curve points cannot be added to others without special handling. As a result, the addition code must include checks for failures, which complicates writing constant-time implementations.
-I believe incomplete addition formulas looks relatively harmless when used for simple Schnorr signatures, although forgery attacks might exist. I'd worry more however if we began using secp256k1 for less well explored protocols, like multi-signaturtes and key derivation. We ware about such use cases however, especially those listed in the [Bitcoin Schnorr wishlist](https://github.com/bitcoin/bips/blob/master/bip-0340.mediawiki).
+Reviewing any secp256k1 library used in Polkadot is essential to ensure it performs these checks and maintains constant-time execution. Still, it is not possible to ensure that every third-party wallet software does the same.
+
+Incomplete addition formulas are relatively harmless when used for basic Schnorr signatures, though forgery attacks may sill be possible. A greater concern arises when secp256k1 is used in less well-explored protocols, such as multi-signatures and key derivation. Awareness of such use cases exists, especially those outlined in the [Bitcoin Schnorr wishlist](https://github.com/bitcoin/bips/blob/master/bip-0340.mediawiki).
### Is Ed25519 risky? Aka use Ristretto
-Any elliptic curve used in cryptography has order h*l where l is a big prime, normally close to a power of two, and h is some very small number called the cofactor. Almost all protocol implementations are complicated by these cofactors, so implementing complex protocols is safer on curves with cofactor h=1 like secp256k1.
+Any elliptic curve used in cryptography has an order of h*l, where h is a small number known as the cofactor, and l is a large prime, typically close to a power of two. Cofactors complicate almost all protocol implementations, which is why implementing complex protocols is generally safer on curves with a cofactor of h=1, such as secp256k1.
-The Ed25519 curve has cofactor 8 but a simple convention called "clamping" that makes two particularly common protocols secure. We must restrict or drop "clamping" for more complex protocols, like multi-signaturtes and key derivation, or anything else in the [Bitcoin Schnorr wishlist](https://github.com/bitcoin/bips/blob/master/bip-0340.mediawiki).
+The cofactor of the Ed25519 curve is 8, but a simple convention known as "clamping" helps secure two particularly common protocols. For more complex protocols, such as multi-signatures, key derivation, or other advanced constructions listed in the [Bitcoin Schnorr wishlist](https://github.com/bitcoin/bips/blob/master/bip-0340.mediawiki), "clamping" must be restricted or avoided altogether.
-If we simple dropped "clamping" then we'd make implementing protocols harder, but luckily the [Ristretto](https://ristretto.group) encoding for the Ed25519 curve ensures we avoid any curve points with 2-torsion. I thus recommend:
- - our secret key continue being Ed25519 "expanded" secret keys, while
- - our on-chain encoding, aka "point compression" becomes Ristretto for both public keys and the `R` component of Schnorr signatures.
+Simply dropping "clamping" makes protocol implemention more difficult. Fortunately, the [Ristretto](https://ristretto.group) encoding for the Ed25519 curve ensures that no curve points with 2-torsion are used, effectively eliminating cofactor-related issues. Reecommendations are as follows:
+ - The secret key remains an Ed25519 "expanded" secret key.
+ - The on-chain encoding, aka known as "point compression", should use Ristretto for both public keys and the `R` component of Schnorr signatures.
-In principle, we could use the usual Ed25519 "mini" secret keys for simple use cases, but not when doing key derivation. We could thus easily verify standrad Ed25519 signatures with Ristretto encoded public keys. We should ideally use Ristretto throughout instead of the standard Ed25519 point compression.
+In principle, simple use cases can rely on standard Ed25519 "mini" secret keys, except when requiring key derivation. Ristretto-encoded public keys can still verify standard Ed25519 signatures with ease. Ideally, Ristretto should be used throughout in place of the standard Ed25519 point compression, as it eliminates cofactor-related issues and enables safer protocol design.
-In fact, we can import standard Ed25519 compressed points like I do [here](https://github.com/w3f/schnorr-dalek/blob/master/src/ristretto.rs#L877) but this requires the scalar exponentiation done in the [`is_torsion_free` method](https://doc.dalek.rs/curve25519_dalek/edwards/struct.EdwardsPoint.html#method.is_torsion_free), which runs slower than normal signature verification. We might ideally do this only for key migration between PoCs.
+It is indeed possible to import standard Ed25519 compressed points, as this [example](https://github.com/w3f/schnorr-dalek/blob/master/src/ristretto.rs#L877) shows. This requires scalar exponentiation via the [`is_torsion_free` method](https://doc.dalek.rs/curve25519_dalek/edwards/struct.EdwardsPoint.html#method.is_torsion_free), which is significantly slower than standard signature verification. Ideally, this process should be reserved for key migration between PoCs implementations.
-Ristretto is far simpler than the Ed25519 curve itself, so Ristretto can be added to Ed25519 implementations, but the [curve25519-dalek](https://github.com/dalek-cryptography/curve25519-dalek) crate already provides a highly optimised rust implementation.
+Ristretto is conceptually simpler than the Ed25519 curve itself, making it easy to integrate into existing Ed25519 implementations. The [curve25519-dalek](https://github.com/dalek-cryptography/curve25519-dalek) crate already offers a highly optimized pure-rust implementation of both Ristretto and Curve25519 group operations.
### Zero-knowledge proofs in the dalek ecosystem
-In fact, the [dalek ecosystem](https://github.com/dalek-cryptography) has an remarkably well designed infrastructure for zero-knowledge proofs without pairings. See:
- https://medium.com/interstellar/bulletproofs-pre-release-fcb1feb36d4b
- https://medium.com/interstellar/programmable-constraint-systems-for-bulletproofs-365b9feb92f7
-
-All these crates use Ristretto points so using Ristretto for account public keys ourselves gives us the most advanced tools for building protocols not based on pairings, meaning that use our account keys. In principle, these tools might be abstracted for twisted Edwards curves like FourQ and Zcash's Jubjub, but yu might loose some batching operations in abstracting them for short Weierstrass curves like secp256k1.
+The [dalek ecosystem](https://github.com/dalek-cryptography) offers a remarkably well-designed infrastructure for zero-knowledge proofs without relying on pairings. For deeper insights, see these two foundational articles on bulletproofs and programmable constraint systems:
+ [Bulletproofs Pre-release](https://medium.com/interstellar/bulletproofs-pre-release-fcb1feb36d4b) and [Programmable Constrait Systems for Bulletproofs](https://medium.com/interstellar/programmable-constraint-systems-for-bulletproofs-365b9feb92f7)
+All these crates use Ristretto points, so adopting Ristretto for account public keys provides access to advanced tools for building protocols that avoid pairings and operate directly on account keys. In principle, these tools could be abstracted to support other twisted Edwards curves, such as FourQ and Zcash's Jubjub. Abstracting them for short Weierstrass curves, like secp256k1, may result in the loss of certain batching optimizations, though.
+**For further inquieries or questions please contact**: [Jeffrey Burdges](/team_members/jeff.md)
diff --git a/docs/Polkadot/security/keys/1-accounts.md b/docs/Polkadot/security/keys/1-accounts.md
index 31f38e62..d7000583 100644
--- a/docs/Polkadot/security/keys/1-accounts.md
+++ b/docs/Polkadot/security/keys/1-accounts.md
@@ -2,50 +2,55 @@
title: Account signatures and keys
---
-## Ristretto
+
-We believe Polkadot accounts should primarily use Schnorr signatures with both public keys and the `R` point in the signature encoded using the [Ristretto](https://ristretto.group) point compression for the Ed25519 curve. We should collaborate with the [dalek ecosystem](https://github.com/dalek-cryptography) for which Ristretto was developed, but provide a simpler signature crate, for which [schnorr-dalek](https://github.com/w3f/schnorr-dalek) provides a first step.
+## Ristretto
-I'll write a another comment giving more details behind this choice, but the high level summary goes:
+Polkadot accounts should primarily use Schnorr signatures, with both the public key and the `R` point in the signature encoded using the [Ristretto](https://ristretto.group) point compression for the Ed25519 curve. It is recommended to collaborate with the [dalek ecosystem](https://github.com/dalek-cryptography), for which Ristretto was developed, while providing a simpler signature crate. The [Schnorr-dalek](https://github.com/w3f/schnorr-dalek) library offers a first step in that direction.
+Account keys must support the diverse functionality expected of account systems like Ethereum and Bitcoin. To that end, Polkadot keys use Schnorr signatures, which enable fast batch verification and hierarchical deterministic key derivation, as outlined in [BIP32](https://github.com/bitcoin/bips/blob/master/bip-0032.mediawiki#Child_key_derivation_CKD_functions). Features from the [Bitcoin Schnorr wishlist](https://github.com/bitcoin/bips/blob/master/bip-0340.mediawiki) further highlight the advantages of Schnorr signatures, including:
-Account keys must support the diverse functionality desired of account keys on other systems like Ethereum and Bitcoin. As such, our account keys shall use Schnorr signatures because these support fast batch verification and hierarchical deterministic key derivation ala [BIP32](https://github.com/bitcoin/bips/blob/master/bip-0032.mediawiki#Child_key_derivation_CKD_functions). All features from the [Bitcoin Schnorr wishlist](https://github.com/bitcoin/bips/blob/master/bip-0340.mediawiki) provides a case for Schnorr signatures matter too, like
+ - Interactive threshold and multi-signatures
+ - Adaptor signatures, and potentionally blind signatures, for swaps and payment channels.
- - interactive threshold and multi-signatures, as well as
- - adaptor, and perhaps even blind, signatures for swaps and payment channels.
+Since account keys are expected to remain valid for decades, conservative curve choices are essential. In particular, pairing-based cryptography and BLS signatures should be avoided for account-level operations. This comes at the cost of true aggregation when verifying blocks, and reduces support for highly interactive threshold and multi-signature schemes.[^1]
-We make conservative curve choices here because account keys must live for decades. In particular, we avoid pairing-based cryptography and BLS signatures for accounts, at the cost of true aggregation of the signatures in a block when verifying blocks, and less interactive threshold and multi-signaturtes. [1].
+In the past, choosing between more secure elliptic curves involved a subtle trade-off:
-In the past, there was a tricky choice between the more secure curves:
+ - Misimplementation resistance is stronger with Edwards curves, such as Ed25519
+ - Misuse resistance is stronger with curves that have a cofactor of 1, such as secp256k1
- - miss-implementation resistance is stronger with Edwards curves, including the Ed25519 curve, but
- - miss-use resistance in stronger when curves have cofactor 1, like secp256k1.
+Historically, misuse resistance was a major selling point for Ed25519, which is itself a Schnorr variant. This resistance applies only to the basic properties of the signature scheme. Advanced signature functionalities, beyond batch verification, tend to break precisely because of Ed25519's misuse resistance.
-In fact, miss-use resistance was historically a major selling point for Ed25519, which itself is a Schnorr variant, but this miss-use resistance extends only so far as the rudimentary signature scheme properties it provided. Yet, any advanced signature scheme functions, beyond batch verification, break precisely due to Ed25519's miss-use resistance. In fact, there are tricks for doing at least hierarchical deterministic key derivation on Ed25519, as implemented in [hd-ed25519](https://github.com/w3f/hd-ed25519), but almost all previous efforts [produced insecure results](https://forum.web3.foundation/t/key-recovery-attack-on-bip32-ed25519/44).
+There are tricks for implementing hierarchical deterministic key derivation (HDKD) on Ed25519, such as those used in [hd-ed25519](https://github.com/w3f/hd-ed25519). Yet, most prior attempts [resulted in insecure designs](https://forum.web3.foundation/t/key-recovery-attack-on-bip32-ed25519/44).
-We observe that secp256k1 provides a good curve choice from among the curves of cofactor 1, which simplify make implementing fancier protocols. We do worry that such curves appear at least slightly weaker than Edwards curves. We worry much more than such curves tend to be harder to implement well, due to having incomplete addition formulas, and thus require more review (see [safecurves.cr.yp.to](https://safecurves.cr.yp.to)). We could select only solid implementations for Polkadot itself, but we cannot control the implementations selected elsewhere in our ecosystem, especially by wallet software.
+secp256k1 is a strong candidate among cofactor-1 curves, which simplify the implementation of advanced cryptographic protocols. Concerns remain, as such curves appear at least slightly weaker than Edwards curves and are generally more difficult to implement securely due to their incomplete addition formulas, which require more rigorous review (see [safecurves.cr.yp.to](https://safecurves.cr.yp.to)). While it is possible to ensure solid implementations within Polkadot itself, controlling the choices elsewhere in the ecosystem, particularly by wallet software, is far more challenging.
-In short, we want an Edwards curve but without the cofactor, which do not exist, except..
+In short, the ideal would be an Edwards curve without a cofactor, though such a curve does not exist. A practical alternative is an Edwards curve with cofactor 4, combined with [Mike Hamburg's Decaf point compression](https://www.shiftleft.org/papers/decaf/), which enables serialising and deserialising points on the subgroup of order $l$, offering a robust solution.
-In Edwards curve of with cofactor 4, [Mike Hamburg's Decaf point compression](https://www.shiftleft.org/papers/decaf/) only permits serialising and deserialising points on the subgroup of order $l$, which provides a perfect solution. [Ristretto](https://ristretto.group) pushes this point compression to cofactor 8, making it applicable to the Ed25519 curve. Implementations exist in both [Rust](https://doc.dalek.rs/curve25519_dalek/ristretto/index.html) and [C](https://github.com/Ristretto/libristretto255). If required in another language, the compression and decompression functions are reasonable to implement using an existing field implementation, and fairly easy to audit.
+[Ristretto](https://ristretto.group) extends this compression technique to cofactor 8, making it compatible with the Ed25519 curve. Implementations are available in both [Rust](https://doc.dalek.rs/curve25519_dalek/ristretto/index.html) and [C](https://github.com/Ristretto/libristretto255). If needed in another language, the compression and decompression functions can be implemented using an existing field arithmetic library, and are relatively easy to audit.
-In the author's words, "Rather than bit-twiddling, point mangling, or otherwise kludged-in ad-hoc fixes, Ristretto is a thin layer that provides protocol implementors with the correct abstraction: a prime-order group."
+In plain words, "Rather than relying on bit-twiddling, point mangling, or other kludged ad-hoc fixes, Ristretto offers a thin layer abstraction that provides protocol implementors with a clean, prime-order group."
## Additional signature types
-We could support multiple signature schemes for accounts, preferably with each account supporting only one single signature scheme, and possessing only one public key. There are at least three or four additional signature types worth considering:
+It is possible to support multiple signature schemes for accounts, ideally with each account using only a single signature scheme and possessing just one public key. In fact, there are at least three or four additional signature types worth considering.
-We could support Ed25519 itself so as to improve support for HSMs, etc. It's security is no different from Ristretto Schnorr signatures for normal use cases. We've provided a secure HDKD solution, but users might encounter problems from existing tools that provide HDKD solutions.
+By supporting Ed25519, compatibility with HSMs and similar hardware may be improved. It's security is equivalent to Ristretto-based Schnorr signatures for typical use cases. Although a secure HDKD solution exists, users may encounter issues with existing tools that implement HDKD in less secure ways.
-At least initially, we have allocated dots to secp256k1 keys compatible with ECDSA signatures on Ethereum. We could use Schnorr / EdDSA signatures with these same keys instead. We could however restrict these keys to doing only outgoing transfers, with the hope that they disappear completely without the first six months. We might alternatively keep secp256k1 key support long term in the hopes that either the secp vs secq duality proves useful, or that parties with legacy infrastructure like exchanges benefit.
+secp256k1 keys were initially used to allocate DOT, as they are compatible with ECDSA signatures on Ethereum. These same keys can alternatively be used with Schnorr or EdDSA signatures and restricted to outgoing transfers only, with the expectation that they will be phased out within the first six months. Alternatively, long term support for secp256k1 keys may be retained, either to leverage the secp vs secq duality or to accommodate legacy infrastructure, such as exchanges.
-We might develop a delinearized variant of the proof-of-possesion based mBCJ signatures from pages 21 and 22 of https://eprint.iacr.org/2018/417.pdf which provide two-round trip multi-signatures. All current Schnorr multi-signature schemes require three round trips. See https://github.com/w3f/schnorrkel/issues/15 I'd expect such a delinearized variant of mBCJ to use Ristretto keys too, but the signature scheme differs.
+One possibility is to develop a delinearized variant of the proof-of-possesion-based mBCJ signatures described on pages 21 and 22 of [this paper](https://eprint.iacr.org/2018/417.pdf), which enables two-round trip multi-signatures. In contrast, all current Schnorr multi-signature schemes require three round trips (see [this issue](https://github.com/w3f/schnorrkel/issues/15)). Such a delinearized variant of mBCJ would likely use Ristretto keys as well, though it would involve a different signature scheme.
-We could support BLS12-381 signatures to provide true signature aggregation. We could even integrate these with how session keys appear on-chain, but we've currently no argument for doing this.
+Supporting BLS12-381 signatures enables true aggregation. These could also be integrated with how session keys appear on-chain, though no compelling argument currently justifies doing so.
---
-[1] Aggregation can dramatically reduce signed message size when applying numerous signatures, but if performance is the only goal then batch verification techniques similar results, and exist for mny signature schemes, including Schnorr. There are clear advantages to reducing interactiveness in threshold and multi-signaturtes, but parachains can always provide these on Polkadot. Importantly, there are numerous weaknesses in all known curves that support pairings, but the single most damning weakness is the pairing $e : G_1 \times G_2 \to G_T$ itself. In essence, we use elliptic curves in the first palce because they insulate us somewhat from mathematicians ever advancing understanding of number theory. Yet, any known pairing maps into a group $G_T$ that re-exposes us, so attacks based on index-calculus, etc. improve more quickly. As a real world example, there were weaknesses found in BN curve of the sort used by ZCash during development, so after launch they needed to develop and migrate to a [new curve](https://z.cash/blog/new-snark-curve/). We expect this to happen again for roughly the same reasons that RSA key sizes increase slowly over time.
+[^1] Aggregation can significantly reduce signed message size when applying numerous signatures. If performance is the sole objective, batch verification techniques offer similar benefits and are available for many signature schemes, including Schnorr. Reducing interactivity in threshold and multi-signaturtes presents clear advantages, though parachains on Polkadot can always provide these features.
+
+Importantly, all known pairing-friendly elliptic curves suffer from various weaknesses, and the most fundamental issue lies in pairing itself: $e : G_1 \times G_2 \to G_T$. Elliptic curves are used precisely because they offer some insulation from advances in number theory. Yet, any known pairing maps into a target group $G_T$, which reintroduces vulnerabilities and enables faster attacks based on index calculus and related techniques.
+A real world example is the BN curve used during ZCash development, which was later found to have weaknesses. After launch, the team had to design and migrate to a [new curve](https://z.cash/blog/new-snark-curve/) to restore security margins. Similar transitions are expected in the future, for much the same reason that RSA key sizes gradually increase over time.
+**For further inquieries or questions please contact**: [Jeffrey Burdges](/team_members/jeff.md)
diff --git a/docs/Polkadot/security/keys/2-staking.md b/docs/Polkadot/security/keys/2-staking.md
index 94864551..58154532 100644
--- a/docs/Polkadot/security/keys/2-staking.md
+++ b/docs/Polkadot/security/keys/2-staking.md
@@ -1,46 +1,50 @@
---
title: Nomination
---
+
-In some sense, all public keys derive their authority from some combination of ceremonies and certificates, with certificate root keys deriving their authority entirely from ceremonies. As an example, trust-on-first-use schemes might be considered a pair of cerimonies, the key being associated to an identity first, and the threat of other comparing keys fingerprints.
+In a sense, all public keys derive their authority from some combination of ceremonies and certificates, with certificate root keys relying entirely on ceremonies for their authority. For example, trust-on-first-use schemes can be viewed as a pair of ceremonies: first, the key is associated with an identity, and second, its fingerprint is compared against others to detect potential threats.
-We apply this perspective to a consensus algorithm for a proof-of-stake blockchains like polkadot by regarding the chain itself as one large ceremony and treating the staked/bonded account as the root of trust. We then have certificates issued by these staked account keys that authenticate both the session keys used by Polkadot validators and block producers, as well as the long-term transport layer authentication keys required by TLS or Noise (see concerns about libp2p's secio).
+This perspective can be applied to consensus algorithms in proof-of-stake blockchains, like Polkadot, by viewing the chain itself as a large, ongoing ceremony and treating the staked or bonded account as the root of trust. Certificates issued by these staked account keys authenticate both the session keys used by Polkadot validators and block producers, as well as the long-term transport layer authentication keys required by protocols like TLS or Noise (see concerns about libp2p's secio).
## Stash account keys
-In polkadot, these staked or bonded account keys are called "stash account keys" to help disambiguate them from other key roles discussed below. We currently describe `unbond`, `withdraw_unbonded`, and `bond_extra` transactions in [2]. There are several ways to implement these, or related operations, but if accounts are not too constrained in size then one extremely flexible approach goes:
+In Polkadot, these staked or bonded account keys are referred to as "stash account keys" to distinguish them from other key roles discussed below. The transactions `unbond`, `withdraw_unbonded`, and `bond_extra` are examples described in this [GitHub entry](https://github.com/paritytech/substrate/blob/1a2ec9eec1fe9b3cc2677bac629fd7e9b0f6cf8e/srml/staking/Staking.md).[^2] There are several ways to implement these or related operations, but if account size is not overly constrained, a highly flexible approach can be considered.
-These stash accounts has an unstaked balance $u \ge 0$ and a list of pending unstaking dates and balances $T = { (t,v) }$ with $v>0$, one of which lack any unstaking date, meaning $t = \infty$. An unstaking operation splits $(\infty,v) \in T$ into $(\infty,v - v')$ and $(t,v')$. Any payment out of a staked account completes any pending unstaking operations by moving their value into the unstaked balance $u$. In other words, at block height $h$, a payment of value $v'$ with fees $f$ out of a stash account is valid if
+Each stash account maintains an unstaked balance $u \ge 0$ and a list of pending unstaking dates and balances $T = { (t,v) }$ with $v>0$, where one entry lacks a specific unstaking date, i.e., $t = \infty$. An unstaking operation splits $(\infty,v) \in T$ into $(\infty,v - v')$ and $(t,v')$. Any payment from a staked account completes pending unstaking operations by transferring their value into the unstaked balance $u$. In other words, at block height $h$, a payment of value $v'$ with fees $f$ from a stash account is valid if:
- $T_1 = \{ (t,v) \in T_0 : t > h \}$,
- $u_1 := u_0 + \sum \{ (t,v) \in T_0 : t \le h \} - h - f$ remains positive.
-We might require additional metadata in $T$ so that delayed slashing cannot impact more recently added stake, but this resembles the above discussion.
+Additional metadata in $T$ may be required to ensure that delayed slashing does not affect more recently added stake. This concern closely resembles the discussion above.
## Stake controller account keys
-We must support, or may even require, that these session keys and TLS keys rotate periodically. At the same time, we must support stash account keys being air gapped, which prevents them from signing anything regularly. In consequence, we require another layer, called "stake controller account keys", that lies strictly between, and control the nomination of or delegation from stash account keys to session keys.
+Session keys and TLS keys must rotate periodically. At the same time, stash account keys should remain air-gapped, preventing them from being used for regular signing. In consequence, an additional layer, called "stake controller account keys", is required. These keys act as intermediaries, managing the nomination or delegation from stash account keys to session keys.
-As we require small transactions associated to staking, these "stake controller account keys" are actual account keys with their own separate balance, usually much smaller than the "stash account key" for which they manage nomination/delegation.
+Since staking involves small, frequent transactions, "stake controller account keys" are actual account keys with their own separate balances, typically much smaller than the "stash account key" they represent.
-In future, we might permit the certificate from the stash account key to limit the actions of a controller keys, which improves our stakers' security when certain functions permit less slashing. In particular, we might admit modes for fishermen and block producers that prohibit nominating or running a validator.
+In the future, it may be possible to allow certificates issued by stash account keys to restrict the actions of controller keys. This would enhance staker security, especially when certain functions involve reduced slashing risk. For example, enabling modes for fishermen or block producers could explicitly prohibit nominating or running a validator.
-At the moment however, we only support one such slashing level, so all mode transitions are functions of the controller key itself, as described in [2].
+Currently, however, only one slashing level is supported. As such, all mode transitions are determined by the controller key itself, as described in the already mentioned [GitHub entry](https://github.com/paritytech/substrate/blob/1a2ec9eec1fe9b3cc2677bac629fd7e9b0f6cf8e/srml/staking/Staking.md).[^2]
## Certificate location
-We could either store certificates with account data, or else provide certificates in protocol interactions, but almost surely the certificate delegating from the staked account to the nominator key belongs in the account data.
+Certificates can either be stored with account data or provided during protocol interactions. In most cases, the certificate delegating authority, from the staked account to the nominator key, should be stored within the account data.
-We should take care with the certificates from the controller key to the session key because the session key requires a proof-of-possesion. If we place them into the controller account, then there is a temptation to trust them and not check the proof-of-possesion ourselves. We cannot necessarily trust the chain for proofs-of-possesion because doing so might provides escalation for attackers who succeed in posting any invalid data. If we provide them in interactions then there is a temptation to check the proof-of-possesion repeatedly. We should evaluate either attaching a self-checked flag to the staked account database vs storing session keys in some self-checked account database separate from the account database for which nodes trust the chain.
+Special attention must be given to certificates issued from the controller key to the session key, as the session key requires a proof of possesion. If these certificates are stored in the controller account, there may be a temptation to trust them without verifying the proof of possesion. However, the proof-of-possesion chain cannot be inherently trusted, as doing so could allow attackers to escalate privileges by submitting invalid data. On the other hand, if certificates are provided through interactions, there may be a tendency to verify the proof of possesion repeatedly. This trade-off should be carefully evaluated, either attaching a self-checked flag to the staked account database or by storing session keys in a separate, self-checked account database distinct from the one nodes rely on via the chain.
## Certificate size
-We could save some space by using implicit certificates to issue nominator keys, but we consider our initial implementation in [`schnorr-dalek/src/cert.rs`](https://github.com/w3f/schnorr-dalek/blob/master/src/cert.rs#L181) insufficient, so we'd require another implicit certificate scheme for this. In essence, an accounts nominator key could be defined by an additional 32 bytes attached to the account, along with any associated data. Actually doing this requires understanding (a) what form this associated data should take, and (b) if the space savings are worth the complexity of an implicit certificates scheme, mostly [reviewing the literature](https://github.com/w3f/schnorr-dalek/issues/4). We favor simplicity by avoiding implicit certificates currently.
+It is possible to save space by using implicit certificates to issue nominator keys. Yet, the initial implementation in [`schnorr-dalek/src/cert.rs`](https://github.com/w3f/schnorr-dalek/blob/master/src/cert.rs#L181) proved insufficient, so a different implicit certificate scheme would be required for this purpose.
+
+In essence, an account's nominator key could be defined by appending an additional 32 bytes to the account, along with any associated data. Implementing this approach requires a clear understanding of a) the appropriate structure for the associated data, and b) whether the space savings justify the added complexity of an implicit certificate scheme, primarily through [reviewing the literature](https://github.com/w3f/schnorr-dalek/issues/4). For now, simplicity is favored by avoiding implicit certificates.
## Implementation
-[1] https://github.com/paritytech/substrate/pull/1782#discussion_r260265815
-[2] https://github.com/paritytech/substrate/blob/1a2ec9eec1fe9b3cc2677bac629fd7e9b0f6cf8e/srml/staking/Staking.md aka https://github.com/paritytech/substrate/commit/1a2ec9eec1fe9b3cc2677bac629fd7e9b0f6cf8e
+[^1] https://github.com/paritytech/substrate/pull/1782#discussion_r260265815
+[^2] aka https://github.com/paritytech/substrate/commit/1a2ec9eec1fe9b3cc2677bac629fd7e9b0f6cf8e
+**For further inquieries or questions please contact**: [Jeffrey Burdges](/team_members/jeff.md)
diff --git a/docs/Polkadot/security/keys/3-session.md b/docs/Polkadot/security/keys/3-session.md
index 873b0991..512911e4 100644
--- a/docs/Polkadot/security/keys/3-session.md
+++ b/docs/Polkadot/security/keys/3-session.md
@@ -1,33 +1,37 @@
---
title: Session keys
---
+
-A session public key should consist of three or four public keys types:
+A session public key should consist of three or four types of public keys:
- - Ristretto Schnorr public key (32 bytes public keys, 64 byte signatures, 96 byte VRFs)
+ - Ristretto Schnorr public key (32-byte public keys, 64-byte signatures, 96-byte VRFs)
- We issue these from the nominator keys acting as validator operators. We might use an implicit certificate but doing so either restricts us to one validator operator, or else increases code complexity and forces a primary validator operator. Implicit certificates also make session key records impossible to authenticate without the nominator account, but this sounds desirable.
+ These are issued from the nominator keys acting as validator operators. Using an implicit certificate either restricts the setup to a single validator operator or increases code complexity by requiring a designated primary operator. Implicit certificates also make session key records impossible to authenticate without access to the nominator account, though this may be a desirable property.
- We know signers can easily batch numerous VRF outputs into a single proof with these, ala CloudFlare's Privacy Pass. If we employ these VRFs for block production then signers could periodically publish a "sync digest" that consolidated thousands of their past block production VRFs into a single check, which improves syncing speed. There is also an avenue to batch verify these VRFs by multiply signers, but it requires enlarging the VRF output and proofs from from 96 to 128 bytes.
+ Signers can efficiently batch numerous VRF outputs into a single proof using these keys, similar to CloudFlare's Privacy Pass. If these VRFs are employed for block production, signers could periodically publish a "sync digest" to consolidate thousands of past block production VRFs into a single verification, significantly improving syncing speed. Additionally, there is a pathway to batch-verify these VRFs across multiple signers, which would require enlarging the VRF output and proof size from 96 to 128 bytes.
- - Small curve of BLS12-381 (48 byte public keys, 96 byte signatures)
+ - Small curve of BLS12-381 (48-byte public keys, 96-byte signatures)
- Aggregated signatures verify can faster when using this key if the signer set for a particular message is large but irregularly composed, as in GRANDPA. Actual signatures are slower than the opposite orientation, and non-constant time extension field arithmetic makes them even slower, or more risky. Aggregating signatures on the same message like this incurs malleability risks too. We also envision using this scheme in some fishermen schemes.
+ Aggregated signatures can be verified more efficiently with this key if the signer set for a particular message is large but irregularly composed, as in GRANDPA. Individual signature generation is slower compared to the the reverse orientation, and the use of non-constant-time extension field arithmetic further increases latency and introduces potential security risks. Aggregating signatures on the same message also introduces malleability risks. This scheme may be applicable in certain fishermen protocols.
- We should consider [slothful reduction](https://eprint.iacr.org/2017/437) as discussed in https://github.com/zkcrypto/pairing/issues/98 for these eventually, but initially key splitting should provide solid protection against timing attacks, but with even slower signature speed.
+ [Slothful reduction](https://eprint.iacr.org/2017/437), as discussed in [this GitHub issue](https://github.com/zkcrypto/pairing/issues/98), may eventually be considered for these keys. For now, key splitting offers solid protection against timing attacks, but with even slower signature speed.
- - Big curve of BLS12-381 (96 bytes public keys, 48 byte signatures) (optional)
+ - Big curve of BLS12-381 (96-byte public keys, 48-byte signatures) (optional)
- Aggregated signatures in which we verify many messages by the same signer verify considerably faster when using this key. We might use these for block production VRFs because they aggregating over the same signer sounds useful for syncing. Initially, we envisioned aggregation being useful for some VRF non-winner proofs designs, but our new non-winner proof design mostly avoids this requirement. Right now, we favor the Ristretto Schnorr VRF for block production because individual instances verify faster and it provides rather extreme batching over the same signer already.
+ This key type can verify aggregated signatures, where the same signer authorizes many messages, considerably faster. This makes them a potential fit for block production VRFs, as aggregation over the same signer could aid syncing. Initially, aggregation may be useful for certain VRF non-winner proof designs, but the updated design largerly avoids that dependency. At present, the Ristretto Schnorr VRF appears to be a stronger candidate for block production, offering faster individual verification and highly efficient batching for repeated signers.
- We also expect faster aggregate verification from these when signer sets get repeated frequently, so conceivably these make sense for some settings in which small curve keys initially sound optimal. We envision signature aggregation being "wild" in GRANDPA, so the small curve key still sounds best there.
+ Faster aggregate verification is expected when signer sets are frequently reused, making this scheme suitable for contexts where small-curve keys might initially seem optimal. Signature aggregation is expected to be "wild" in GRANDPA, making the small-curve key a better fit in that setting.
- Authentication key for the transport layer.
- We might ideally include node identity form libp2p, but secio handles authentication poorly ([see the secio discussion](https://forum.web3.foundation/t/transport-layer-authentication-libp2ps-secio/69)).
+ Including node identity from libp2p is ideal, although secio handles authentication poorly ([see the secio discussion](https://forum.web3.foundation/t/transport-layer-authentication-libp2ps-secio/69)).
-A session public key record has a prefix consisting of the above three keys, along with a certificate from the validator operator on the Ristretto Schnorr public key and some previous block hash and height. We follow this prefix with a first signature block consisting two BLS signatures on the prefix, one by each the BLS keys. We close the session public key record with a second signature block consisting of a Ristretto Schnorr signature on both the prefix and first signature block. In this way, we may rotate our BLS12-381 keys without rotating our Ristretto Schnorr public key, possibly buying us some forward security.
+A session public key record begins with a prefix consisting of the three keys mentioned above, along with a certificate from the validator operator on the Ristretto Schnorr public key, and a recent block hash and height. This prefix is followed by a first signature block containing two BLS signatures on the prefix, one from each BLS key. The record is finalized with a second signature block containing a Ristretto Schnorr signature over both, the prefix and the first signature block. This structure allows the BLS12-381 keys to be rotated independently of the Ristretto Schnorr public key, possibly enhancing forward security.
-We include the recent block hash in the certificate, so that if the chain were trusted for proofs-of-possession then attackers cannot place rogue keys that attack honestly created session keys created after their fork. We recommend against trusting the chain for proofs-of-possession however because including some recent block hash like this only helps against longer range attacks.
+The recent block hash is included in the certificate to prevent attacks from inserting rogue keys that could compromise session keys after a fork, assuming the chain is trusted for proofs-of-possession. It is generally advisable not to trust the chain for such proofs, as including a recent block hash only mitigates long-range attacks.
-We still lack any wonderful aggregation strategy for block production VRFs, so they may default to Ristretto Schnorr VRFs. In this case, the Ristretto Schnorr session key component living longer also help minimize attacks on our random beacon.
+Currently, there is no aggregation strategy for block production VRFs, so Ristretto Schnorr VRFs may remain the default. In this case, the longer-lived Ristretto Schnorr session key component may help reduce attacks on the random beacon.
+
+
+**For further inquieries or questions please contact**: [Jeffrey Burdges](/team_members/jeff.md)
\ No newline at end of file
diff --git a/docs/Polkadot/security/keys/Nomination.png b/docs/Polkadot/security/keys/Nomination.png
new file mode 100644
index 00000000..2541c41a
Binary files /dev/null and b/docs/Polkadot/security/keys/Nomination.png differ
diff --git a/docs/Polkadot/security/keys/Session-keys.png b/docs/Polkadot/security/keys/Session-keys.png
new file mode 100644
index 00000000..aa015634
Binary files /dev/null and b/docs/Polkadot/security/keys/Session-keys.png differ
diff --git a/docs/Polkadot/security/keys/account-signatures-and-keys.png b/docs/Polkadot/security/keys/account-signatures-and-keys.png
new file mode 100644
index 00000000..897b1443
Binary files /dev/null and b/docs/Polkadot/security/keys/account-signatures-and-keys.png differ
diff --git a/docs/Polkadot/security/keys/account-signatures.png b/docs/Polkadot/security/keys/account-signatures.png
new file mode 100644
index 00000000..c0608143
Binary files /dev/null and b/docs/Polkadot/security/keys/account-signatures.png differ
diff --git a/docs/Polkadot/security/keys/creation.md b/docs/Polkadot/security/keys/creation.md
index 696fbbcd..6b262b23 100644
--- a/docs/Polkadot/security/keys/creation.md
+++ b/docs/Polkadot/security/keys/creation.md
@@ -2,18 +2,20 @@
title: Account key creation ideas for Polkadot
---
-https://forum.web3.foundation/t/account-key-creation-ideas-for-polkadot/68
+
-We found a trick for using Ed25519 "mini" private keys in [schnorr-dalek](https://github.com/w3f/schnorr-dalek/blob/master/src/keys.rs), meaning users' "mini" private key consists of 32 bytes of unstructured entropy.
+There's a trick for using Ed25519 "mini" private keys in [Schnorr-Dalek](https://github.com/w3f/schnorr-dalek/blob/master/src/keys.rs), where a user's "mini" private key consists of 32 bytes of unstructured entropy.
-There are no serious problems with [BIP39](https://github.com/bitcoin/bips/blob/master/bip-0039.mediawiki) so we suggest a similar strategy for deriving secret keys in Polkadot. We could however modernize BIP39 in a couple small but straightforward ways:
+Since [BIP39](https://github.com/bitcoin/bips/blob/master/bip-0039.mediawiki) doesn't present any serious issue, one suggestion is to adopt a similar strategy for deriving secret keys in Polkadot. Alternatively, BIP39 could be modernized in a few small but straightforward ways:
- - *Argon2id should replace PBKDF2.* Adam Langely sugests [using time=2 and 64mb of memopry](https://github.com/golang/crypto/commit/d9133f5469342136e669e85192a26056b587f503) for interactive scenarios like this. In principle, one might question if this scenario should truly be considered interactive, but conversely one could imagine running this on relatively constrained devices. We might also improve the [argone2rs](https://github.com/bryant/argon2rs/issues) crate too, especially to [ensure we use at least v1.3 since v1.2.1 got weaker](https://crypto.stackexchange.com/a/40000).
- - *Rejection sampling to support larger wordlists.* We could employ rejection sampling from the initial entropy stream to avoid tying ourselves to the list size being a power of two, as BIP39 seemingly requires. We can provide roughly the existing error correction from BIP32, even working in a ring of this order.
- - *Actually provide a larger wordlist.* We're discussing enough entropy that users might benefit form using diceware-like word lists with 12.9 bits of entropy per word, as opposed to BIP32's 11 bits of entropy per word. It's possible some diceware word lists contained confusable words, but reviews exists at least for English. We might worry that larger wordlists might simply not exist for some languges. It's also easier to quickly curate shorter lists.
+ - *Argon2id should replace PBKDF2.* Adam Langely suggests [using time=2 and 64mb of memory](https://github.com/golang/crypto/commit/d9133f5469342136e669e85192a26056b587f503) for interactive scenarios like this. While one might question whether this scenario is truly interactive, it's reasonable to consider constrained devices as a target. The [argone2rs](https://github.com/bryant/argon2rs/issues) crate could also be improved, especially to [ensure the use of at least v1.3, since v1.2.1 was found to be weaker](https://crypto.stackexchange.com/a/40000).
+ - *Rejection sampling to support larger wordlists.* One possibility is to apply rejection sampling to the initial entropy stream, avoiding the constraint that the wordlist size must be a power of two, as BIP39 seemingly requires. It's feasible to retain roughly the same level of error correction as BIP32, even when working in a ring of this order.
+ - *Actually provide a larger wordlist.* There's been discussion around increasing entropy per word. Users might benefit from diceware-style wordlists, which offer 12.9 bits of entropy per word compared to BIP32's 11 bits. While some diceware lists may contain confusable words, reviewed versions are available (at least for English). Larger wordlists may not be available for some languages, and shorter lists are easier to curate quickly.
-There are also more speculative directions for possible improvements:
+More speculative directions for improvement includes:
- - *Improve error correction.* Right now BIP39 has only a basic checksum for error correction. We could design schemes that corrected errors by choosing the words using Reed-Solomon, meaning non-systematic word list creation with code words, except naively this limits our word list sizes to finite field sizes, meaning prime powers. We would instead likely run Reed-Solomon separately on each prime power divisor of the word list's order. We should however evaluate alternatives like other [generalisations of Reed-Solomon codes to rings](https://hal.inria.fr/hal-00670004/file/article.pdf), or even working in a field of slightly larger order and reject choices that fall outside the wordlist.
- - *Support multiple Argon2id configurations.* We might conceivably support multiple argon2id configurations, if small device constraints become a serious concern. We could select among a few argon2id configuration options using yet another output from the Reed-Solomon code. We'd simply use rejection sampling to choose the user's desired configuration.
+ - *Enhanced error correction.* BIP39 currently uses only a basic checksum. One idea is to design schemes that correct errors by selecting words via Reed-Solomon. This would involve non-systematic wordlist creation using codewords. Naively, this limits wordlist sizes to finite field sizes (i,e., prime powers), but a workaround could be to run Reed-Solomon separately on each prime power divisor of the wordlist's order. Alternatives such as [generalizations of Reed-Solomon codes to rings](https://hal.inria.fr/hal-00670004/file/article.pdf) could also be explored, or even using a field of slightly larger order and rejecting choices that fall outside the wordlist.
+ - *Support multiple Argon2id configurations.* If small device constraints become a serious concern, it may be useful to support multiple Argon2id configurations. The idea would be to select among a few predefined configurations using an additional output from the Reed-Solomon code. The user's desired configuration could then be chosen via rejection sampling.
+
+**For further inquieries or questions please contact**: [Jeffrey Burdges](/team_members/jeff.md)
diff --git a/docs/Polkadot/security/keys/ideas-for-account-key-creation.jpeg b/docs/Polkadot/security/keys/ideas-for-account-key-creation.jpeg
new file mode 100644
index 00000000..62a899dc
Binary files /dev/null and b/docs/Polkadot/security/keys/ideas-for-account-key-creation.jpeg differ
diff --git a/docs/Polkadot/security/keys/ideas-for-account-key-creation.png b/docs/Polkadot/security/keys/ideas-for-account-key-creation.png
new file mode 100644
index 00000000..cddddbbb
Binary files /dev/null and b/docs/Polkadot/security/keys/ideas-for-account-key-creation.png differ
diff --git a/docs/Polkadot/security/keys/index.md b/docs/Polkadot/security/keys/index.md
index 4709115c..cb2ab797 100644
--- a/docs/Polkadot/security/keys/index.md
+++ b/docs/Polkadot/security/keys/index.md
@@ -2,60 +2,66 @@
title: Polkadot's keys
---
-**Authors**: [Jeff Burdges](/team_members/jeff.md)
+
-In polkadot, we necessarily distinguish among different permissions and functionalities with different keys and key types, respectively. We roughly categories these into account keys with which users interact and session keys that nodes manage without operator intervention beyond the certification process.
+In Polkadot, different keys and key types grant access to essential permissions and functionalities. Roughly, categories are: account keys, which users interact with directly, and session keys, which nodes manage without operator intervention beyond the certification process.
## Account keys
-Account keys have an associated balance of which portions can be _locked_ to play roles in staking, resource rental, and governance, including waiting out some unlocking period. We allow several locks of varying durations, both because these roles impose different restrictions, and for multiple unlocking periods running concurrently.
+Account keys have an associated balance, portions of which can be _locked_ to participate in staking, resource rental, and governance. These locks may include a waiting period before funds are fully unlocked. The system supports multiple locks with varying durations to accommodate the different restrictions of each role and to enable concurrent unlocking periods.
-We encourage active participation in all these roles, but they all require occasional signatures from accounts. At the same time, account keys have better physical security when kept in inconvenient locations, like safety deposit boxes, which makes signing arduous. We avoid this friction for users as follows.
+Active participation in these roles is encouraged, though they all occasionally require signatures from account holders. At the same time, account keys benefit from stronger physical security when stored in inconvenient locations, like safety deposit boxes, making signing arduous. This friction for users can be mitigated as follows.
-Accounts declare themselves to be _stash accounts_ when locking funds for staking. All stash accounts register a certificate on-chain that delegates all validator operation and nomination powers to some _controller account_, and also designates some _proxy key_ for governance votes. In this state, the controller and proxy accounts can sign for the stash account in staking and governance functions, respectively, but not transfer fund.
+Accounts become _stash accounts_ when locking funds for staking. Each stash account registers an on-chain certificate that delegates all validator operations and nomination powers to a designated _controller account_, and also assigns a _proxy key_ for governance voting. In this state, the controller and proxy accounts can sign on behalf of the stash account for staking and governance functions, respectively, but cannot transfer funds.
-As a result, the stash account's locked funds can benefit from maximum physical security, while still actively participating via signatures from their controller or proxy account keys. At anytime the stash account can replace its controller or proxy account keys, such as if operational security mistakes might've compromised either.
+The locked funds in the stash account benefit from enhanced physical security, while still actively participating (via signatures) through their controller or proxy account keys. At any time, the stash account can replace its controller or proxy keys, for instance, if operational security mistakes may have compromised either.
-At present, we suport both ed25519 and schnorrkel/sr25519 for account keys. These are both Schnorr-like signatures implemented using the Ed25519 curve, so both offer extremely similar security. We recommend ed25519 keys for users who require HSM support or other external key management solution, while schnorrkel/sr25519 provides more blockchain-friendly functionality like HDKD and multi-signatures.
+At present, account keys are supported by both Ed25519 and schnorrkel/Sr25519. These are Schnorr-like signatures implemented using the Ed25519 curve that offer very similar levels of security. For users who require HSM support or other external key management solution, Ed25519 keys are a suitable choice. Meanwhile, schnorrkel/Sr25519 provides more blockchain-friendly features like HDKD and multi-signature capabilities.
-In particular, schnorrkel/sr25519 uses the [Ristretto](https://doc.dalek.rs/curve25519_dalek/ristretto/index.html) implementation of section 7 of Mike Hamburg's [Decaf](https://eprint.iacr.org/2015/673.pdf) paper, which provide the 2-torsion free points of the Ed25519 curve as a prime order group. Avoiding the cofactor like this means Ristretto makes implementing more complex protocols significantly safer. We employ Blake2b for most conventional hashing in polkadot, but schnorrkel/sr25519 itself uses the [merlin](https://doc.dalek.rs/merlin/index.html) limited implementation of Mike Hamberg's [STROBE](http://strobe.sourceforge.io/), which is based on Keccak-f(1600) and provides a hashing interface well suited to signatures and NIZKs. See https://github.com/w3f/schnorrkel/blob/master/annoucement.md for more detailed design notes.
+In particular, schnorrkel/Sr25519 uses the [Ristretto](https://doc.dalek.rs/curve25519_dalek/ristretto/index.html) implementation described in section 7 of Mike Hamburg's [Decaf](https://eprint.iacr.org/2015/673.pdf) paper. Ristretto provides the 2-torsion free points of the Ed25519 curve as a prime-order group. By avoiding the cofactor, Ristretto makes the implementation of more complex cryptographic protocols significantly safer.
+
+Blake2b is used for most conventional hashing operations in Polkadot, but schnorrkel/sr25519 itself relies on the [merlin](https://doc.dalek.rs/merlin/index.html) limited implementation of Mike Hamberg's [STROBE](http://strobe.sourceforge.io/), which is based on Keccak-f(1600) and offers a hashing interface well suited for signatures and non-interactive zero knowledge (NIZKs).
+
+For more detailed design notes, see the [announcement on GitHub](https://github.com/w3f/schnorrkel/blob/master/annoucement.md).
## Session keys
-Session keys each fill roughly one particular role in consensus or security. All session keys gain their authority from a session certificate that is signed by some controller key and that delegates appropriate stake.
+All session keys gain their authority from a session certificate, which is signed by a controller key who delegates the appropriate stake. Roughly, each session key fills a particular role either in consensus or security.
-At any time, the controller key can pause or revoke this session certificate and/or issue replacement with new session keys. All new session keys can be registered in advance, and some must be, so validators can cleanly transition to new hardware by issuing session certificates that only become valid after some future session. We suggest using pause for emergency maintenance and using revocation if a session key might be compromised.
+The controller key can pause or revoke this session certificate and/or issue a replacement with new session keys at any time. New session keys can be registered in advance, and some must be, so validators can smoothly transition to new hardware by issuing session certificates that become valid in a future session. It is recommended to use "pause" for emergency maintenance and "revocation" in case a session key may have been compromised.
-We suggest session keys remain tied to one physical machine, so validator operators issue the session certificate using the RPC protocol, not handle the session secret keys themselves. In particular, we caution against duplicating session secret keys across machines because such "high availability" designs invariably gets validator operators slashed. Anytime new validator hardware must be started quickly the operator should first start the new node, and then certify the new session keys it creates using the RPC protocol.
+As a suggestion, session keys should remain tied to a single physical machine. Validator operators should issue the session certificate using the RPC protocol, without handling the session secret keys. In particular, duplicating session secret keys across machines is strongly discouraged, as such "high availability" designs almost always result in validator slashing. Whenever new validator hardware needs to be started quickly, the operator should first launch the new node and then certify the newly generated session keys using the RPC protocol.
-We impose no prior restrictions on the cryptography employed by specific substrate modules or associated session keys types.
+No prior restrictions are imposed on the cryptographic algorithms used by specific substrate modules or the associated session keys types.
-In BABE, validators use schnorrkel/sr25519 keys both for a verifiable random function (VRF) based on on [NSEC5](https://eprint.iacr.org/2017/099.pdf), as well as for regular Schnorr signatures.
+In BABE, validators use Schnorrkel/sr25519 keys both for a verifiable random function (VRF) based on [NSEC5](https://eprint.iacr.org/2017/099.pdf), as well as for standard Schnorr signatures.
-A VRF is the public-key analog of a pseudo-random function (PRF), aka cryptographic hash function with a distinguished key, such as many MACs. We award block productions slots when the block producer scores a low enough VRF output $\mathtt{VRF}(r_e || \mathtt{slot_number} )$, so anyone with the VRF public keys can verify that blocks were produced in the correct slot, but only the block producers know their slots in advance via their VRF secret key.
+A VRF is a public-key analog of a pseudo-random function (PRF), that is, a cryptographic hash function with a distinguished key, as seen in many MAC constructions. Block production slots are awarded when a block producer generates a sufficiently low VRF output, denoted as $\mathtt{VRF}(r_e || \mathtt{slot_number} )$. This allows anyone with the corresponding VRF public keys to verify that blocks were produced in the correct slot, while only block producers, using their VRF secret keys, can determine their slots in advance.
-As in [Ouroboros Praos](https://eprint.iacr.org/2017/573.pdf), we provide a source of randomness $r_e$ for the VRF inputs by hashing together all VRF outputs form the previous session, which requires that BABE keys be registered at least one full session before being used.
+As in [Ouroboros Praos](https://eprint.iacr.org/2017/573.pdf), a source of randomness $r_e$ for the VRF inputs is provided by hashing together all VRF outputs from the previous session. This approach requires the registration of BABE keys at least one full session before they are used.
-We reduce VRF output malleability by hashing the signer's public key along side the input, which dramatically improves security when used with HDKD. We also hash the VRF input and output together when providing output used elsewhere, which improves compossibility in security proofs. See the 2Hash-DH construction from Theorem 2 on page 32 in appendix C of ["Ouroboros Praos: An adaptively-secure, semi-synchronous proof-of-stake blockchain"](https://eprint.iacr.org/2017/573.pdf).
+Hashing the signer's public key alongside the input helps reduce VRF output malleability, significantly improving security when used with HDKD. Additionally, hashing the VRF input and output together when producing output for use elsewhere, improves compossibility in security proofs. For reference, see the 2Hash-DH construction in Theorem 2 on page 32, Appendix C of ["Ouroboros Praos: An adaptively-secure, semi-synchronous proof-of-stake blockchain"](https://eprint.iacr.org/2017/573.pdf).
-In GRANDPA, validators shall vote using BLS signatures, which supports convenient signature aggregation and select ZCash's BLS12-381 curve for performance. There is a risk that BLS12-381 might drops significantly below 128 bits of security, due to number field sieve advancements. If and when this happens, we expect upgrading GRANDPA to another curve to be straightforward. See also https://mailarchive.ietf.org/arch/msg/cfrg/eAn3_8XpcG4R2VFhDtE_pomPo2Q
+In GRANDPA, validators vote using BLS signatures, which support efficient signature aggregation and utilize ZCash's BLS12-381 curve for performance. However, there is a risk that BLS12-381 could fall significantly below 128-bit security due to potential advancements in the number field sieve algorithm. If and when this occurs, upgrading GRANDPA to another curve is expected to be straightforward. For further discussion, see this [CFRG mailing list thread](https://mailarchive.ietf.org/arch/msg/cfrg/eAn3_8XpcG4R2VFhDtE_pomPo2Q)
-We treat libp2p's transport keys roughly like session keys too, but they include the transport keys for sentry nodes, not just for the validator itself. As such, the operator interacts slightly more with these.
+Libp2p transport keys are treated similarly to session keys, but they also encompass the transport keys for sentry nodes, not just for the validator. As a result, operators interact with them more frequently.
## old
-In this post, we shall first give a high level view of the various signing keys planned for use in Polkadot. We then turn the discussion towards the certificate chain that stretches between staked account keys and the session keys used for our proof-of-stake design. In other words, we aim to lay out the important questions on the "glue" between keys rolls here, but first this requires introducing the full spectrum of key rolls.
+First, a high-level view of the signing keys planned for use in Polkadot would be helpful. The discussion can then shift toward the certificate chain that links staked account keys to the session keys used for the proof-of-stake design. In other words, the goal is to lay out the key questions surrounding the "glue" between keys roles, but this first requires introducing the full spectrum of those roles.
+
+There are roughly four cryptographic layers in Polkadot:
-We have roughly four cryptographic layers in Polkadot:
+ - [*Account keys*](1-accounts.md) are owned by users and tied to a single DOT-denominated account on Polkadot. Accounts may be staked/bonded, unstaked/unbonded, or in the process of unstaking/unbonding. However, only an unstaked/unbonded account key can transfer DOT between accounts ([more](1-accounts-more.md)).
+ - [*Nomination*](2-staking.md) establishes a certificate chain between staked (or bonded) account keys and the session keys used by nodes for block production and validation. Since nominator keys cannot transfer DOT, they serve to insulate account keys that may remain air-gapped from the nodes actively operating on the internet.
+ - [*Session keys*](3-session.md) consist of multiple keys grouped together to provide the various signing functions required by validators. These include several types of VRF keys.
+ - [*Transport layer static keys*](https://forum.web3.foundation/t/transport-layer-authentication-libp2ps-secio/69) are used by libp2p to authenticate connections between nodes. These should either be certified by the session key or potentially incorporated directly into the session key.
- - [*Account keys*](1-accounts.md) are owned by users and tied to one actual dot denominated account on Polkadot. Accounts could be staked/bonded, unstaked/unbonded, or unstaking/unbonding, but only an unstaked/unbonded account key can transfer dots from one account to another. ([more](1-accounts-more.md))
- - [*Nomination*](2-staking.md) provide a certificate chain between staked/bonded account keys and the session keys used by nodes in block production or validating. As nominator keys cannot transfer dots, they insulate account keys, which may remain air gapped, from nodes actually running on the internet.
- - [*Session keys*](3-session.md) are actually several keys kept together that provide the various signing functions required by validators, including a couple types of verifiable random function (VRF) keys.
- - [*Transport layer static keys*](https://forum.web3.foundation/t/transport-layer-authentication-libp2ps-secio/69) are used by libp2p to authenticate connections between nodes. We shall either certify these with the session key or perhaps include them directly in the session key.
+**For further inquieries or questions please contact**: [Jeffrey Burdges](/team_members/jeff.md)
diff --git a/docs/Polkadot/security/keys/polkadot-keys.png b/docs/Polkadot/security/keys/polkadot-keys.png
new file mode 100644
index 00000000..6d0604ca
Binary files /dev/null and b/docs/Polkadot/security/keys/polkadot-keys.png differ
diff --git a/docs/Polkadot/security/slashing/Slashing-mechanisms.jpeg b/docs/Polkadot/security/slashing/Slashing-mechanisms.jpeg
new file mode 100644
index 00000000..17a20a2c
Binary files /dev/null and b/docs/Polkadot/security/slashing/Slashing-mechanisms.jpeg differ
diff --git a/docs/Polkadot/security/slashing/Slashing-with-NPoS.png b/docs/Polkadot/security/slashing/Slashing-with-NPoS.png
new file mode 100644
index 00000000..b1f60e1c
Binary files /dev/null and b/docs/Polkadot/security/slashing/Slashing-with-NPoS.png differ
diff --git a/docs/Polkadot/security/slashing/Slashing.png b/docs/Polkadot/security/slashing/Slashing.png
new file mode 100644
index 00000000..1b748a34
Binary files /dev/null and b/docs/Polkadot/security/slashing/Slashing.png differ
diff --git a/docs/Polkadot/security/slashing/amounts.md b/docs/Polkadot/security/slashing/amounts.md
index 797416a3..cb94b27b 100644
--- a/docs/Polkadot/security/slashing/amounts.md
+++ b/docs/Polkadot/security/slashing/amounts.md
@@ -2,91 +2,98 @@
title: Slashing mechanisms
---
-**Authors**: [Alfonso Cevallos](/team_members/alfonso.md)
+
## General principles
-**Security threat levels.** The yearly interest rate of a validator pool is between 10% and 20%. So, slashing 1% of their stake is already a strong punishment (worth many weeks of work). With this in mind, we define the following security threat levels and corresponding punishments. Besides the security risk, here we also consider factors like likelihood of the misconduct happening in good faith, level of coordination/correlation among validators, and computational costs for the system.
+To define appropriate slashing amounts, it is important to understand the annual earnings of validators. Validator pool interest rates typically range between 10% and 20%. Therefore, slashing just 1% of a validator's stake already represents a significant penalty, roughly equivalent to several weeks of earnings.
-* Level 1. Misconducts that are likely to happen eventually to most validators, such as isolated cases of unresponsiveness. We slash up to 0.1% of the stake in the validator slot, or exercise non-slashing punishments only like kicking out the validator.
+**Security threat levels.** With this in mind, it is necessary to define security threat levels and corresponding punishments. In addition to assessing the severity of the security risk, it is also important to consider factors such as the likelihood of the misconduct occurring in good faith, the degree of coordination or correlation among validators, and the computational costs imposed on the system.
-* Level 2. Misconducts that can occur in good faith, but show bad practices. Examples are concurrent cases of unresponsiveness, and isolated cases of equivocation. We want culprits to seriously re-consider their practices, and we slash up to 1%.
+* Level 1: Misconduct likely to eventually occur among most validators, for example isolated cases of unresponsiveness. The penalty involves slashing up to 0.1% of the stake in the validator slot, or applying non-slashing punishments such as removing the validator from the set.
-* Level 3. Misconducts that are unlikely to happen in good faith or by accident, but do not lead to serious security risks or resource use. They show i) a concerning level of coordination/correlation among validators, ii) that the software of the validator node has been modified, iii) that a validator account has been hacked, or iv) that there is a bug in the software (if this last case is confirmed we would reimburse any slashings). Examples are concurrent cases of equivocation, or isolated cases of unjustified voting in Grandpa. We want culprits to lose a considerable amount of power, meaning both stake and reputation, and we want the punishment to work as a deterrent. We slash up to 10%.
+* Level 2: Misconduct that may occur in good faith but reflects poor practices. Examples include concurrent cases of unresponsiveness and isolated instances of equivocation. The goal is to promt culprits to seriously reconsider their behavior, so the slashing amount can be up to 1%.
-* Level 4. Misconducts that a) pose a serious security risk to the system, b) show large levels of collusion among validators, and/or c) force the system to spend a large amount of resources to deal with them. We want the punishment to work as the worst possible deterrent, so we slash up to 100%.
+* Level 3: Misconduct unlikely to happen in good faith or by accident, yet not serious enough to pose security risks or consume significant system resources. Such cases may indicate i) a concerning level of coordination or correlation among validators, ii) modification of the validator node software, iii) a compromised validator account, or iv) a bug in the software (if confirmed, any slashing is reimbursed). Examples include concurrent cases of equivocation, or isolated instances of unjustified voting in Grandpa. In such cases, validators should lose a substantial amount of both stake and reputation, with punishments designed as a deterrent. The slashing amount can be up to 10%.
-**Details on how we slash validators and nominators.** When a validator is found guilty of a misconduct, we slash the corresponding validator slot (validator plus nominators) a fixed percentage of their stake (and NOT a fixed amount of DOTs). This means that validator slots with more stake will be slashed more DOTs. We do this to encourage nominators to gradually shift their support to less popular validators.
+* Level 4: Misconduct that: a) poses a serious security risk to the system, b) involves significant collusion among validators, and/or c) requires the system to expend considerable resources to address. Punishments at this level should serve as the strongest possible deterrent, with slashing amounts of up to 100%.
-*(Q. Should we slash the validator more than his nominators? How much more? We should be careful not to bankrupt him for misconducts of levels 1 and 2).*
+**Details on slashing validators and nominators.** When a validator is found guilty of misconduct, the corresponding validator slot (which includes the validator and their nominators) is slashed by a fixed percentage of their stake, not a fixed amount of DOT. This means that validator slots with larger stakes will incur greater losses in DOT. The goal is to incentivize nominators to gradually shift their support to less popular validators.
-**Kicking out.** *Context: There is an NPoS election of candidates at the beginning of each era. Under normal circumstances, current validators are automatically considered as candidates in the next election (unless they state otherwise), and we keep the nominators' lists of trusted candidates unmodified (unless nominators state otherwise). On the other hand, unelected candidates need to re-confirm their candidacy in each era, to make sure they are online.*
+:::note Question
+Should the validator be slashed more heavily than their nominators? If so, by how much? Care must be taken to avoid bankrupting validators for Level 1 and Level 2 misconducts.*
+:::
-When a validator is found guilty of a misconduct:
+**Kicking out.** *Context: At the beginning of each era, an NPoS election is held to select validator candidates. Under normal circumstances, current validators are automatically considered candidates for the next election (unless they opt out), and nominators' lists of trusted candidates remain unchanged unless explicitly modified. In contrast, unelected candidates must reconfirm their candidacy in each era to ensure they are online and active.*
-a) We remove them from the list of candidates in the next NPoS validator election (for all misconducts).
+When a validator is found guilty of misconduct:
-b) We immediately mark them as inactive in the current era (for misconducts of levels 2 and up).
+a) They are removed from the list of candidates in the next NPoS validator election. This applies to all levels of misconduct.
-c) We remove them from all the nominators' lists of trusted candidates (for misconduct of levels 3 and up).
+b) They are marked as inactive for the current era. This applies to level 2 misconduct and beyond.
-The reasons to do this are the following:
+c) They are removed from all nominators' lists of trusted candidates. This applies to level 3 misconduct and above.
-* As a punishment to the validator, as he won't be able to perform payable actions, and won't get paid while he is kicked out.
+Rationale for these actions:
-* As a safeguard to protect the system and the validator himself. If a validator node has committed a misconduct, chances are that it will do it again soon. To err on the side of security, we assume that the validator node remains unreliable until the validator gives confirmation that the necessary checks are in place and he's ready to continue operating. Furthermore, if the validator has been heavily slashed, he may decide to stop being a validator immediately, and we shouldn't assume otherwise.
+* **Punishment for the validator.** The validator loses the ability to perform payable actions and will not receive rewards while excluded.
-* As a safeguard for nominators. If a validator is heavily slashed, we should ensure that his backing nominators are aware of this. We should wait for them to give consent that they still want to back him in the future, and not assume it.
+* **System and validator protection.** If a validator node has committed misconduct, there is a high likelihood it may do so again. To err on the side of caution, it's prudent to assume the node remains unreliable until the validator confirms that all necessary checks have been completed and they are ready to resume operations. Additionaly, if the validator has been heavily slashed, they may choose to exit the role immediately; no further assumptions should be made about their continued participation.
-To avoid operational issues, when a validator is kicked out we modify schemes as little as possible. The duration of the current epoch is not shortened, and for the remainder of the epoch this validator is still assigned to parachains as before, etc. In other words, kicking someone out just means marking him as inactive; we act as if that validator was non-responsive and we ignore his messages.
+* **Protection for nominators.** In cases of heavy slashing, nominators should be aware. Their continued support should not be assumed; instead, explicit consent should be obtained before allowing them to back the validator again.
-If a large number of validators are kicked out, or simply unresponsive, we can optionally end the era early, after the completion of an epoch, so that we can elect new validators. Or, we just wait for the end of the era; during this time finality may stop but Babe should continue going, and Grandpa will catch up at the beginning of the next era.
+To minimize disruption, validator removal should involve minimal changes to existing schemes. The duration of the current epoch remains unchanged, and the validator continues to be assigned to parachains for the rest of the epoch. In practice, being "kicked out" simply means that the validator is marked as inactive, treated as non-responsive, and their messages would be ignored.
-**Database of validators.** We need to keep a database of the current validators and previous validators. In this database, we register
+If a large number of validators are kicked out, or become unresponsive, the era may end early, after the completion of an epoch, to allow for the election of new validators. Alternatively, the system may wait until the end of the era. During this time, Finality may pause, while BABE continues producing blocks. Grandpa can catch up at the beginning of the next era.
+**Validators database.** This off-chain database tracks both current and past validators and should include:
-* if a validator is active or inactive (kicked out),
-* the misconducts that each validator has been found guilty of,
-* any rewards for reporting a misconduct,
-* the (weighted) nominators supporting each validator (to know who to slash/reward),
-* the number of payable actions of each validator so far in the current era,
-* whether that validator is the target of an ongoing challenge (for unjustified votes in Grandpa), etc.
+* Whether a validator is active or inactive (i.e., kicked out)
+* The misconduct each validator has been found guilty of
+* Any rewards issued for reporting a misconduct
+* The (weighted) nominators supporting each validator, to determine who should be slashed or rewarded
+* The number of payable actions performed by each validator in the current era
+* Whether a validator is the target of an ongoing challenge (e.g., for unjustified votes in Grandpa)
+* And other relevant metadata
-This database should be off-chain and should *resist chain reversions*. Moreover, we should be able to see who the validators were, up to 8 weeks in the past, so that we can slash the culprits of a misconduct that is detected late (this is the same period that we freeze the nominators and validators' stake). We will also use this database to ensure that a validator is not slashed twice for the same misconduct.
+ This database must be off-chain and designed to *resist chain reversions*. It should retain visibility into validator history for up to eight weeks, enabling slashing of validators for misconduct detected after the fact. This retention period aligns with the freeze duration for nominators' and validators' stakes. Additionally, the database must ensure that a validator is not slashed more than once for the same misconduct.
-Finally, we can also use this database to run an extra protocol where, if a validator has had a cumulative slashing of more than 1% for whatever reason, then we remove him from all the nominators' lists (example: if a validator is unresponsive in one era, we won't remove him from the nominators' lists, but if he is unresponsive in several eras, then we should remove him, as a safeguard to nominators.)
+Finally, the database should support an auxiliary protocol: if a validator accumulates more than 1% slashing, regardless of the reason, they should be removed from all the nominators' lists. For example, a validator who is unresponsive in a single era may not be removed, but repeated unresponsiveness over several eras should trigger removals as a safeguard for nominators.
-*(Q. How to maintain such database? How to keep it memory efficient?)*
+:::note Question
+How can such a database be efficiently maintained while keeping memory usage low?
+:::
+**Detection mechanisms.** To slash a validator, an objective on-chain "attestation of misconduct" is required. This must be short, *valid on all forks*, and remain valid even in the event of a *chain reversion*. Two attestations for the same misconduct cannot be valid simultaneously, preventing double punishment for a single offense. The previously mentioned database plays a key role in supporting this logic.
+There are two types of detection mechanisms:
-**Detection mechanisms.** In order to slash somebody, we want to have an on-chain "attestation of misconduct" that is objective, short, and *valid on all forks*. Moreover it should remain valid in case of *chain reversion*. We also need to ensure that two attestations for the same misconduct cannot both be valid simultaneously, so that we don't punish twice for the same crime. We take care of this by using the above mentioned database.
+* **Proof of misconduct.** This is the straighforward case, where a concise proof of misconduct can be submitted on-chain as a transaction. Its validity can be quickly verified by the block producer, making both the generation and verification of the proof efficient. A typical example is equivocation in Grandpa, where the proof consists of two signed votes by the same validator in the same round.
-We identify two types of detection mechanisms.
+* **Voting certificate.** When no direct proof is available, a collecting voting mechanism is used. Validators vote off-chain, and a certificate of the final decision (containing the signed votes) is issued and submitted on-chain as the attestation of misconduct. This procedure is resource-intensive, hence it is reserved for level 4 misconduct and avoided whenever possible.
-* **Proof of misconduct.** The easy case is when there is a short proof of misconduct, which can be inserted on-chain as a transaction, and whose validity can be quickly verified by the block producer (hence both producing and verifying the proof can be done efficiently). An example is equivocation in Grandpa, where a proof consists of two signed votes by the same validator in the same round.
+**Reporters and their rewards.** In general, rewards are available for actors who execute the protocols necessary to detect misconduct. These rewards are capped at 10% of the total amount slashed, with the rest allocated to the treasury. Should the council choose to reimburse a slashing event, sufficient DOT is typically available in the treasury, and only a small portion may need to be minted to cover the reward payout. Depending on the detection mechanism and the security level, three reward scenarios are considered:
-* **Voting certificate.** When there is no proof of misconduct, we resort to a mechanism where all validators vote. At the end, we can issue a certificate of the voting decision, with the signed votes, and this can be used as an attestation of misconduct. All the mechanism occurs off-chain, with only the final certificate added on-chain. This procedure is resource expensive, so we avoid it whenever possible and use it only for level 4 misconducts.
+* **Levels 1 and 2.** A reward of approximately 10% of the slashed amount is granted to the first party who submits a valid transaction with proof of misconduct. The reward is intentionally modest, just enough to discourage a "no-snitch code of honor" among validators.
-**Reporters and their rewards.** In general we give a reward to the actor(s) who run the protocols necessary to detect the culprits. We usually limit rewards to 10% of the total amount slashed, with the remainder going to treasury. So, if the council ever decides to reimburse a slashing event, most of the DOTS are readily available in treasury, and we only need to mint new DOTS to make up for the part that went to rewards. We consider three cases, depending on the detection mechanism and the security level.
+* **Levels 3 and 4 (with proof of misconduct).** The same procedure applies, but only *validators* are allowed to submit reports. The reward must be shared among all nominators in the corresponding validator slot to prevent wealth concentration. Multiple culprits and reporters may be involved in a single case (e.g., rejecting a set of Grandpa votes). Regardless, total rewards must not exceed 10% of the total slashed amount, nor exceed 100% of the slashed validators' self-stake. This cap prevents an attack scenario where a validator intentionally fails to benefit at the expense of their nominators. For example, if an entity runs Validator A with 1% self-stake and Validator B with 100%, it might be tempted to have B report A if the potential reward exceeds A's self-stake. Additionally, each validator reporter may receive a reward no greater than 20% of their own stake, roughly equivalent to their annual interest rate, ensuring the incentive remains meaningful but not excessive.
-* For levels 1 and 2, we reward around 10% of the slashed amount to whoever first submits a transaction with the proof of misconduct. The reward is expected to be pretty low, just large enough to disincentivize a "no-snitch code of honor" among validators.
+* **Level 4 misconduct requiring voting.** In this case **fishermen**, staked actors who anonymously monitor the system, play a critical role. At some point, a fisherman may submit a **report** as a transaction, detailing suspected misconduct, but without providing direct proof. Along with the report the fisherman bonds a portion of their stake, referred to as the "bait". This report initiates an **inspection phase**, during which a subset of validators conduct an investigation. Depending on the outcome, this may escalate into a full **voting phase** involving all validators. If the vote confirms the fisherman's report, the fisherman is rewarded with a substantial amount of DOT. If the report is rejected, the fisherman forfeits their bait. This penalty discourages spam reports, which would otherwise waste system resources. At the same time, the reward must be high enough to justify the risk and the ongoing cost of running system checks. Multiple fishermen may report the same misconduct. In such cases, the seriousness of the threat is gauged by the total amount of bait bonded. The higher the total bait, the more resources are allocated during the inspection phase. Rewards are distributed among all fishermen who submited reports before the voting phase begins. Therefore, if a single fisherman detects misconducts, it is in their interest to quickly rally other fishermen or validators to join the inspection. Fishermen rewards are capped at:
+ * no more than 10% of all the total slashed amount
+ * no more than 100% of the slashed validators' self-stake
+ * no more than 10 times the fisherman's own bait.
-* For misconducts of levels 3 and 4 that admit a proof of misconduct, we do as above, except that we only allow for *validators* to submit reports, and we require that the reward be shared among all nominators in the corresponding validator slot. We do this to dilute the reward and not let a single actor claim it, to avoid compounding wealth to a few. There may be several culprits and several reporters involved in the same mechanism (e.g. for rejecting set of votes in Grandpa); in any case, the total rewards are no more than 10% of the total slashings, and also no more than 100% of the slashed validators' self-stake. This last bound is to discourage an attack where a validator fails on purpose to have a personal gain at the expense of his nominators (e.g. if the same organization runs a validator A with 1% of self-stake and a validator B with 100% of sef-stake, it may be tempted to make B report A, if the reward is higher than A's self-stake). Finally, each validator reporter gets a reward no more than 20% of her own stake (an amount equal to her yearly interest rate), as this should be a large enough incentive.
-
-* For level 4 misconducts that require voting, we need **fishermen**. A fisherman is any staked actor which is running checks on the system anonymously, and at some point posts a **report** as a transaction, with some details of a suspected misconduct, but without proof. In this transaction, it also bonds some stake -- the "bait". The report starts an **inspection phase** which engages some of the validators, and which may or may not lead to a full blown **voting phase** by all validators. If there is a vote and the voting decision confirms the fisherman report, the latter gets rewarded a large amount of DOTs. Otherwise, the fisherman loses all of its bait. This last possibility discourages spamming by fisherman reports, which would lead to a lot of wasted resources. On the other hand, the reward should be large enough so that it is worth the inherent risk and the cost of constantly running checks on the system. There can be several fishermen reporting the same misconduct, and we weigh the seriousness of the threat by the total amount of bait. The higher this value, the more resources are assigned in the inspection phase. The reward is shared by all the fishermen that provided reports early on, before the start of the voting phase; thus, if a single fisherman detects a misconduct, it is in its interest to convince other fishermen or validators to join in asap to inspect it. We pay fishermen: no more than 10% of all the slashings, and no more than 100% of the slashed validators' self-stake; and we pay each fisherman no more than 10 times its own bait.
-
-## Network Protocol
+## Network protocol
### Unresponsiveness
-We propose two different methods to detect unresponsiveness.
+Two types of detection mechanisms are in place for identifying unresponsiveness.
-**Method 1.** Validators have an "I'm online" heartbeat, which is a signed message submitted on-chain every session. If a validator takes too long to send this message, we can mark them as inactive.
+**Method 1.** Validators submit an "I'm online" heartbeat, a signed message posted on-chain every session. If a validator takes too long to submit this message, they are marked as inactive.
-The advantage of this method is that we can detect unresponsive validators very quickly, and act upon this information, for instance by ending the current era early. A disadvantage is that it only detects validators that are accidentally off-line, and not those who are purposely unresponsive as part of an attack on the system.
+The advantage of this method is that it enables rapid detection of unresponsive validators, allowing the system to act quickly, for example by ending the current era early. A disadvantage is that it only identifies validators who are accidentally offline, not those who are deliberately unresponsive as part of a coodinated attack.
-**Method 2.** Recall that we keep counters of all the payable actions performed by each validator (blocks produced in Babe, uncle references, validity statements), and we use these counters to compute the payouts at the end of each era. In particular, validators should be able to sign validity statements of parachain blocks consistently. Thus, we can use this counter as a measure of responsiveness. Let $c_v$ be the number of validity statements signed by validator $v$ during an era. Our proposal is to consider $v$ unresponsive if
+**Method 2.** The system tracks counters for all payable actions performed by each validator (e.g., blocks produced in BABE, uncle references, validity statements, etc.). These counters are used to calculate payouts at the end of each era. In particular, validators are expected to consistently sign validity statements for each parachain block. This counter serves as a measure of responsiveness. Let $c_v$ be the number of validity statements signed by validator $v$ during an era. A validator $v$ is considered unresponsive if:
$$
c_v < \frac{1}{4}\cdot \max_{v'} c_{v'}
@@ -96,120 +103,142 @@ where the maximum is taken over all validators in the same era.
**Lemma.** *No validator will be wrongfully considered unresponsive in a billion years.*
-*Proof.* (We critically assume in this proof that validators are shuffled among parachains often enough so that, in every era, any two validators have the opportunity to validate a similar amount of parachain blocks, even if some parachains have a higher block production rate than others. If this assumption is incorrect, the threshold of $1/4$ can be lowered and the analysis can be adjusted accordingly.)
+:::note Assumption
+Validators are shuffled among parachains frequently enough that, in every era, any two validators have the opportunity to validate a similar number of parachain blocks, even if some parachains produce blocks at a higher rate than others. If this assumption does not hold, the threshold of $1/4$ can be lowered, and the analysis adjusted accordingly.
+:::
-Fix an era, and let $n$ be the total number of parachain blocks that a validator can *potentially* validate. Being conservative, we have $n\geq 1000$ (3 blocks per minute, 60 min per hour, 6 hours per era). Now fix a responsive validator $v$, and let $p$ be the probability that $v$ successfully issues a validity statement for any of these blocks. The value of $p$ will depend on many factors, but it should be the case that $p\geq 1/2$ if $v$ is responsive. Therefore, the number $c_v$ of validity statements produced by $v$ follows a binomial distribution with expected value $p\cdot n \geq 500$.
+**Proof.** Fix an era, and let $n$ be the total number of parachain blocks that a validator can *potentially* validate. Conservatively, take $n\geq 1000$, based on 3 blocks per minute, 60 minutes per hour, and 6 hours per era. Consider a responsive validator $v$, and let $p$ be the probability that $v$ successfully issues a validity statement for any given block. Although $p$ depends on many factors, assume $p\geq 1/2$ for a responsive validator. Then the number $c_v$ of validity statements produced by $v$ follows a binomial distribution with expected value $p\cdot n \geq 500$.
-The crux of the argument is that this distribution is highly concentrated around its expectation. Notice that the maximum number of validity statements over all validators in this era is at most $n$. Hence, $v$ would be wrongfully considered unresponsive only if it produces $c_v < n/4\leq p\cdot n/2$ validity statements. Using Chernoff's inequality to bound the tail of the binomial distribution, we get that the probability of this occurence is at most
+This distribution is tightly concentrated around its expectation. The maximum number of validity statements across all validators in the era is at most $n$. Hence, validator $v$ would be wrongfully considered unresponsive only if it produces fewer than $c_v < n/4\leq p\cdot n/2$ validity statements. Applying Chernoff's inequality to bound the tail of the binomial distribution yields:
$$
e^{-\frac{(p\cdot n - c_v)^2}{2p\cdot n}} \leq e^{- \frac{(p\cdot n/2)^2}{2p\cdot n}} = e^{-\frac{p\cdot n}{8}}\leq e^{-\frac{500}{8}}\approx 7\cdot 10^{-28}
$$
-This probability is negligible.
+This probability is negligible, confirming the claim.
$$
\tag{$\blacksquare$}
$$
-We use the following slashing mechanism, which has no reporters. If at the end of an era we find that $k$ out of $n$ validators are unresponsive, then we slash a fraction
+The following slashing mechanism operates without reporters. If, at the end of an era, $k$ out of $n$ validators are unresponsive, then a fraction
$$
0.05\cdot \min\{\frac{3(k-1)}{n}, 1\}
$$
-from each one of them. Notice that this fraction is zero for isolated cases, less than one third of a percent for two concurrent cases (assuming $n\geq 50$), growing to 5% for the critical case when around 1/3 of all validators are unresponsive (we don't want to punish too harshly for concurrent unresponsiveness, as it could potentially happen in good faith. The parameter of 5% can be adjusted). We consider it a misconduct of level 2 if the slashing fraction is at most 1%, and of level 3 otherwise. However, we do not immediately remove unresponsive validators from the current era, as removing a validator is equivalent to marking it as unresponsive (so the cure would not be better than the disease), and because it is algorithmically simpler to just check at the end of each era.
+is slashed from each of them. This fraction is zero in isolated cases, less than one-third of a percent for two concurrent cases (assuming $n\geq 50$), and increases to 5% in the critical scenario where approximately one-third of all validators are unresponsive. The intention is to avoid overly harsh penalties for concurrent unresponsiveness, which may occur in good faith. The 5% parameter can be adjusted as needed. Misconduct is classified as Level 2 if the slashing fraction is at most 1%, and as Level 3 otherwise. However, unresponsive validators are not removed immediately during the current era. Removing a validator is equivalent to marking them as unresponsive, which would not improve the situation. Additionally, it is algorithmically simpler to perform these checks at the end of each era.
## Grandpa
### Unjustified vote
-Relative to a block $B$ that was finalized in Grandpa round $r_B$, an unjustified vote is either a pre-vote or a pre-commit signed by a validator $v$ in some round $r_v>r_B$, for a chain that does not contain $B$. Simply put, it means voting for a chain that is incompatible with the current chain of finalized blocks.
+Relative to a block $B$ finalized in Grandpa round $r_B$, an unjustified vote is defined as either a prevote or a precommit signed by a validator $v$ in some round $r_v>r_B$, for a chain that does not include $B$. Simply put, it refers to voting for a chain that is incompatible with the current chain of finalized blocks.
+
+According to the Grandpa paper, this behavior can only occur under two conditions: either the validator $v$ is not following the standard protocol (classified as level 3 misconduct), or $v$ has observed a *rejecting set of votes* (defined further below) for block $B$ in a prior round. The detection mechanism thus operates as follows. It begins when another validator $v'$ submits a transaction $T$. This transaction includes a reference to block $B$, proof that $B$ is finalized, and the unjustified vote (or a collection of votes, in case of concurrence) associated with $B$.
-It follows from Grandpa paper that this can only occur if either the validator $v$ is not following the standard protocol (level 3 misconduct), or $v$ observed a *rejecting set of votes* (defined further below) for $B$ in a prior round. The detection mechanism thus works as follows. It starts when another validator $v'$ submits a transaction $T$ containing a reference to block $B$ with a proof that it is finalized, and the unjustified vote (or collection or votes in case of concurrence) relative to $B$. This transaction raises a public time-bound challenge. If the challenge goes unanswered for some time (to be defined), we slash 10% from the signer(s) of the unjustified vote(s), and reward $v'$ 10% of the slashings (as the signer(s) should be in capacity to answer the challenge if they are honest). Otherwise, any validator $v''$ can answer the challenge by, in turn, starting a detection mechanism for a *rejecting set of votes* (defined below). In that case, we finalize the current mechanism without penalizing anybody, and we keep a register of all the validators that have raised or answered challenges so far (i.e. $v'$ and $v''$), as they will all be rewarded when the culprits are eventually found.
+This transaction initiates a public, time-bound challenge. If the challenge goes unanswered within a specified time frame, 10% of the stake from the signer(s) of the unjustified vote(s) is slashed, and validator $v'$ is rewarded with 10% of the slashed amount, on the assumption that honest signers should be capable of responding to the challenge. Alternatively, any validator $v''$ may respond to the challenge by initiating a detection mechanism for a *rejecting set of votes* (defined below). In this case, the current mechanism is finalized without penalizing anyone, and a record is kept of all validators who have raised or answered challenges (i.e., $v'$ and $v''$). These validators will be rewarded once the actual culprits are identified.
-As mentioned before, we slash 10% if a single validator is guilty of an unjustified vote. We will say more about slashing concurrent cases of unjustified votes by several validators further below. We ignore any further unjustified votes by the same validator in the same era (we will ignore all messages from that validator in the remainder of the era anyway).
+As previously mentioned, a 10% slash is applied if a single validator is found guilty of an unjustified vote. Additionaly, below you can find details about slashing in cases of concurrent unjustified votes by multiple validators. Any further unjustified votes by the same validator in the same era are ignored, and all subsequent messages from that validator during the rest of the era are disregarded.
-### Rejecting set of votes
+### Rejecting a set of votes
-*Context: Recall from the Grandpa paper that a set $S$ of votes has supermajority for a block $B$ if there are $>2/3$ validators who vote in $S$ for chains that contain $B$. Similarly, we say that it is impossible for set $S$ to have supermajority for block $B$ if there are $>2/3$ validators who vote in $S$ for chains that don't contain $B$. It follows that a set $S$ has both of these properties simultaneously only when there are $>1/3$ validators that equivocate in $S$. Recall also that if block $B$ is finalized in a round $r_B$, then (assuming honest behaviors) there must be a set $V_B$ of pre-votes and a set $C_B$ of pre-commits on that round, so that both sets have supermajority for $B$. Finally, a validator $v$ considers block $B$ as finalized iff $v$ can see such a set $C_B$ of pre-commits, even if it does not yet see sufficiently many pre-votes.*
+:::note Context
+According to the Grandpa paper, a set $S$ of votes has supermajority for a block $B$ if more than $2/3$ of validators in $S$ vote for chains that contain $B$. Similarly, it is impossible for set $S$ to have supermajority for $B$ if more than $2/3$ of validators vote for chains that don't contain $B$. Therefore, a set $S$ can exhibit both properties simultaneously only if more than $1/3$ of validators equivocate within $S$.
+
+If block $B$ is finalized in a round $r_B$, and assuming honest behavior, there must exist a set $V_B$ of prevotes and a set $C_B$ of precommits in that round, both forming a supermajority for $B$. A validator $v$ considers block $B$ finalized if it can observe such a set $C_B$ of precommits, even if it has not yet seen a sufficient number of prevotes.
+:::
-Relative to a block $B$ finalized in round $r_B$, a rejecting set of votes is a set $S$ of votes of the same type (either pre-votes or pre-commits) and on the same round $r_S\geq r_B$, for which it is impossible to have a supermajority for $B$.
+Relative to a block $B$ finalized in round $r_B$, a rejecting set of votes is defined as a set $S$ of votes of the same type (either prevotes or precommits), cast in the same round $r_S\geq r_B$, for which it is impossible to achieve a supermajority for $B$.
-Such a set implies the collusion of $>1/3$ of validators, and is one of the most dangerous attacks on the system as it can lead to finalizing blocks in different chains (see Section 4.1 in Grandpa paper). We consider it of level 4 and slash 100% from all culprits.
+Such a set implies collusion among more than $1/3$ of validators and represents one of the most dangerous attacks on the system, as it can lead to the finalization of blocks on conflicting chains (see Section 4.1 of the Grandpa paper). This is classified as a Level 4 misconduct, with a 100% slash applied to all culprits.
-The detection mechanism is somewhat involved. It starts when a validator $v$ submits a transaction $T$ containing a) the rejecting set of votes $S$ in round $r_S$, b) a reference to block $B$ together with a set $C_B$ of pre-commit votes in round $r_B$ having supermajority for $B$ (proving that $B$ was finalized), and c) a reference to a previous challenge, if the current transaction is an answer to it. We now explain how to process this transaction, depending on the value of $(r_S-r_B)$ and the type of votes in $S$.
+The detection mechanism begins when a validator $v$ submits a transaction $T$ containing: a) the rejecting set of votes $S$ from round $r_S$, b) a reference to block $B$, along with a set $C_B$ of precommit votes from round $r_B$ demonstrating supermajority for $B$ (proving its finalization), and c) a reference to a previous challenge, if the current transaction is a response to one.
-If $r_S=r_B$ and $S$ is a set of pre-commits, then $S\cup C_B$ is a set of pre-commits which simultaneously has supermajority for $B$, and for which it is impossible to have supermajority for $B$; hence there must be $>1/3$ validators that equivocate in $S\cup C_B$, and transaction $T$ has enough information to identify them quickly. We slash 100% from all equivocators.
+The next step is to explain how this transaction should be processed, depending on the value of $(r_S-r_B)$ and the type of votes contained in $S$. If $r_S=r_B$ and $S$ is a set of precommits, then $S\cup C_B$ forms a set of precommits that has supermajority for block $B$, yet for which it is impossible to have supermajority for $B$. This contradiction implies that more than $1/3$ of validators must have equivocated within $S\cup C_B$, and transaction $T$ contains sufficient information to identify them efficiently. All equivocators will be slashed 100%. If $r_S=r_B$ and $S$ is a set of prevotes, transaction $T$ initiates a time-bound challenge that any validator may respond to. A valid answer consists of a new transaction $T'$ containing: a) a set $V_B$ of prevotes from round $r_B$ with supermajority for $B$, and b) a reference to $T$.
-If $r_S=r_B$ and $S$ is a set of pre-votes, transaction $T$ raises a time-bound challenge which can be answered by any validator, and where a valid answer consists of a new transaction $T'$ containing a) a set $V_B$ of pre-votes in round $r_B$ which has supermajority for $B$, and b) a reference to $T$. If a validator $v'$ provides such answer, then $S\cup V_B$ is a set of pre-votes which simultaneously has supermajority for $B$, and for which it is impossible to have supermajority for $B$. As before, there must be $>1/3$ validators that equivocate in this set, and we slash all of them 100%. If nobody answers the challenge within a specified period of time, we slash 100% from all the validators that voted in set $C_B$, because each one of them should be in capacity to answer the challenge immediately (and be rewarded if they are the first to do so) if they are honest.
+If a validator $v'$ submits such a response, then the combined set $S\cup V_B$ simultaneously satisfies two contradictory conditions: it has a supermajority for $B$, and it is impossible to have a supermajority for $B$. This implies that more than $1/3$ of validators must have equivocated within the set, and all such validators are slashed 100%.
-Finally, if $r_s>r_B$, transaction $T$ raises a time-bound challenge which can be answered by any validator, and where a valid answer consists of a new transaction $T'$ containing a) set $C_B$ and a reference to block $B$, b) a set $S'$ of votes of the same type (either pre-votes or pre-commits) and on the same round $r_{S'}$ for some $r_B\leq r_{S'}r_B$, transaction $T$ raises a time-bound challenge that any validator may answer. A valid response consists of a new transaction $T'$ containing: a) the set $C_B$ and a reference to block $B$, b) a set $S'$ of votes of the same type (either prevotes or precommits), cast in the same round $r_{S'}$ for some $r_B\leq r_{S'}n/3$ (where $n$ is the number of validators), and the other is not, we take the plurality vote as official. If it is decided that the blob is invalid, we slash all validators that stated otherwise and we reward all fishermen; if it is decided that the blob is valid, we slash fishermen and all validators that stated otherwise.
+If both the number of validity statements and the number of invalidity statements exceed $n/3$, there is unfortunately no way to determine who the culprits are. In such a case, which by the way should never occur, no one is slashed, any prior slashing is reimbursed, and the blob is considered invalid to err on the side of caution.
-If it happens that both the number of statements of validity and the number of statements of invalidity are $>n/3$, we unfortunately don't know who the culprits are (this should never happen). In this case we slash no-one (and reimburse any slashing done), and consider the blob as invalid to err on the safe side.
+**For further questions and inquiries please contact**: [Jeffrey Burdges](/team_members/jeff.md)
diff --git a/docs/Polkadot/security/slashing/index.md b/docs/Polkadot/security/slashing/index.md
new file mode 100644
index 00000000..249962f2
--- /dev/null
+++ b/docs/Polkadot/security/slashing/index.md
@@ -0,0 +1,11 @@
+---
+title: Slashing
+---
+
+import DocCardList from '@theme/DocCardList';
+
+This section intends to explain slashing, with a focus on its mechanics and its application across eras under NPoS.
+
+
+
+
diff --git a/docs/Polkadot/security/slashing/npos.md b/docs/Polkadot/security/slashing/npos.md
index ea2727b9..9be359cd 100644
--- a/docs/Polkadot/security/slashing/npos.md
+++ b/docs/Polkadot/security/slashing/npos.md
@@ -1,149 +1,192 @@
---
title: Slashing across eras with NPoS
---
+
-**Authors**: [Jeffrey Burdges](/team_members/jeff.md)
-
-**Other authors**: Robert Habermeier, [Alfonso Cevallos](/team_members/alfonso.md)
-
-We need our slashing algorithm to be fair and effective. We discuss how this means slashing must respect nominators' exposure, be anti-Sibel, and be monotonic.
+The slashing algorithm must be both fair and effective. To achieve this, slashing should respect nominators' exposure, be resistant to Sybil attacks, and maintain monotonicity.
## Reduced rewards
## Slashing within one era
-In any era $e$, there is a fixed amount of stake aka base exposure $x_{\eta,\nu,e}$ assigned by any nominator $\eta$ to any validator $\nu$. We demand that slashing never exceeds nominators' exposure because doing so creates an incentive to break up stash keys. We avoid encouraging such Sibel-ish behavior in Polkadot because doing so makes Polkadot less fair and harms our information about nominator behavior.
+In any era $e$, a fixed amount of stake, also referred to as base exposure, denoted by $x_{\eta,\nu,e}$, is assigned by a nominator $\eta$ to a validator $\nu$. Slashing should never exceed a nominators' exposure, as doing so incentivizes fragmentation of stash keys. Encouraging such Sybil-like behavior within Polkadot undermines fairness and distorts insights into nominator behavior.
-We immediately remove any validator $\nu$ whenever they gets slashed, which prevents repeated slashing after that block height. There is however an inconsistency in that $\nu$ might commit multiple violations before the chain acknowledges the slash and kicks $\nu$. We fear this introduces significant randomness into our slashing penalties, which increases governance workload and makes the slashing less fair. We also worry that $\nu$ might equivocate retroactively, perhaps to extort their own nominators. As a counter measure, if era $e$ sees validator $\nu$ slashed for several distinct proportions $p_i$, then we define $p_{\nu,e} := \max_i p_i$ and slash their nominator $\eta$ only $p_{\nu,e} x_{\eta,\nu,e}$.
+The first step is to remove any validator $\nu$ immediately upon being slashed, which prevents repeated slashing beyond that block height. However, an inconsistency arises when $\nu$ commits multiple violations before the chain acknowledges the slash and removes them. This can introduce significant randomness into slashing penalties, increasing the governance workload and reducing slashing fairness. Additionaly, $\nu$ might equivocate retroactively, potentially to extort their own nominators. As a countermeasure, if validator $\nu$ is slashed in era $e$ for several distinct proportions $p_i$, then $p_{\nu,e} := \max_i p_i$ can ensure that nominator $\eta$ is only slashed by $p_{\nu,e} x_{\eta,\nu,e}$.
-As an aside, we could write $p_{\eta,\nu,e}$ throughout if we wanted to slash different nominators differently, like by slashing the validator themselves more, i.e. $p_{\nu,\nu,e} > p_{\eta,\nu,e}$ for $\nu \ne \eta$. We abandoned this idea because validators could always be their own nominators.
+As an aside, one could define $p_{\eta,\nu,e}$ throughout to allow different slashing rates across nominators. For example, slashing the validator more heavily, i.e., $p_{\nu,\nu,e} > p_{\eta,\nu,e}$ for $\nu \ne \eta$. This approach, however, is problematic as validators can always nominate themselves.
-We actually have only minimal concerns about multiple miss-behaviours from the same validator $\nu$ in one era, but if we discover some in future then the slashing lock could combine them before producing these $p_i$. In other words, $p_{\nu,e} \ge \max_i p_i$ with equality by default, but a strict inequality remains possible for some $p_i$ combinations. We expect this would complicate cross era logic, but such issues should be addressed by considering the specific miss-behaviour.
+Although there are minimal concerns about multiple misbehaviors by the same validator $\nu$ within a single era, in such cases, the slashing mechanism could combine them before computing the individual slashing proportions $p_i$. In other words, $p_{\nu,e} \ge \max_i p_i$ with equality by default. Yet, strict inequality may occur for certain combinations of $p_i$. This could complicate cross-era logic, although such issues can be addressed by considering the specific nature of each misbehavior.
-In essence, this $p_{\nu,e} := \max_i p_i$ definition provides default mechanism for combining slashes within one era that is simple, fair, and commutative, but alternative logic remains possible so long as we slash the same regardless of the order in which offenses are detected. We emphasise that future slashing logic might take numerous factors into consideration, so doing $\max_i p_i$ here retains the most flexibility for future slashing logic.
+In essence, the definition $p_{\nu,e} := \max_i p_i$ provides a default mechanism that is simple, fair, and commutative for combining slashes within a single era. Alternative logic remains possible, as long as the resulting slash is independent of the order in which offenses are detected. Future slashing logic may incorporate additional factors, so using $\max_i p_i$ here retains flexibility for future enhancements.
-We do however worry about miss-behaviours from different validators $\nu \ne \nu'$ both because nomination must restrict Sibels and also because correlated slashing need not necessarily involve the same validators. We therefore let $N_{\eta,e}$ denote the validators nominated by $\eta$ in era $e$ and slash $\sum_{\nu \in N_e} p_{\nu,e} x_{\eta,\nu,e}$ from $\eta$ when multiple validators $\nu \in N_{\eta,e}$ get slashed.
+Misbehaviors from different validators $\nu \ne \nu'$ present a separate concern. This is both because nomination must be resistant to Sybil attacks and because correlated slashing events may involve multiple validators. Therefore, if $N_{\eta,e}$ denotes the set of validators nominated by $\eta$ in era $e$, then the total slash applied to $\eta$ when multiple validators $\nu \in N_{\eta,e}$ are slashed is:
+
+$$
+\sum_{\nu \in N_e} p_{\nu,e} x_{\eta,\nu,e}
+$$
## Slashing in past eras
-As hinted above, we cannot assume that all events that warrant slashing a particular stash account get detected early or occur within the same era. If $e$ and $e'$ are distinct eras then we expect $x_{\eta,\nu_j,e} \ne x_{\eta,\nu_j,e'}$ so the above arguments fail. Indeed, we cannot even sum slashes applied to different validators because doing so could quickly exceeds nominators exposure $x_{\eta,\nu,e}$.
+As hinted above, it would be misleading to assume that all events warranting the slashing of a particular stash account are detected early or occur within the same era. If $e$ and $e'$ are distinct eras, then $x_{\eta,\nu_j,e} \ne x_{\eta,\nu_j,e'}$, and thus the previous arguments no longer hold. In fact, summing slashes applied to different validators could quickly exceed the nominators exposure $x_{\eta,\nu,e}$.
-We might assume $\min \{ x_{\eta,\nu_j,e}, x_{\eta,\nu_j,e'} \}$ to be the "same" stake, but this does not obviously buy us much. We therefore suggest slashing $\eta$ the amount
+One might assume that $\min \{ x_{\eta,\nu_j,e}, x_{\eta,\nu_j,e'} \}$ represents the "same" stake across eras, but this assumption offers limited practical benefit. The suggestion, therefore, is to slash $\eta$ the amount
$$
\max_e \sum_{\nu \in N_e} p_{\nu,e} x_{\eta,\nu,e}
$$
-where again $N_e$ is the validators nominated by $\eta$ in era $e$
+where $N_e$ denotes the set of validators nominated by $\eta$ in era $e$
-In particular, there is still an extortion attack in which someone runs many poorly staked validators, receives nominations, and then threatens their nominators with being slashed. We cannot prevent such attacks entirely, but this outer $\max_e$ reduces the damage over formula that add slashing from different eras.
+An extortion attack remains plausible: an adversary could run many poorly staked validators, attract nominations, and then threaten nominators with slashing. While such attacks cannot be entirely prevented, the outer $\max_e$ helps mitigate the impact of compounded slashing across different eras.
## Slashing spans
-We thus far kept our slashing relatively simple and fixed some fairness issues with the outer maximum $\max_e \cdots$, but created another problem: If $\nu$ gets slashed once, then $\nu$ could thereafter commit similar offenses with impunity, which is neither fair nor effective. As noted above, we accept this within a single era because validators get removed when they get slashed, but across eras nominators can support multiple validators. We therefore need another mechanism that removes this impunity to minimize any further risks to the network going forwards.
+Hitherto, slashing has been kept relatively simple, addressing some fairness concerns through the outer maximum $\max_e \cdots$. This simplicity introduces another issue: If $\nu$ is slashed once, they may subsequently commit similar offenses without further consequences, an outcome neither fair nor effective. As previously noted, this can occur within a single era due to validator removal upon slashing. Yet, nominators may continue to support multiple validators across eras. To eliminate this impunity and reduce ongoing risk to the network, an additional mechanism is required.
-We propose to limit the eras spanned by this outer maximum to an explicit spans $\bar{e}$ that end after an eras $e \in \bar{e}$ in which any slashing events for that span $\bar{e}$ gets detected. In concrete terms, we partition the eras of some nominator $\eta$ into _slashing spans_ which are maximal contiguous sequence of eras $\bar{e} = \left[ e_1, \ldots, e_n \right]$ such that $e_n$ is the least era in which $\eta$ gets slashed for actions in one of the $e_i \in \bar{e}$.
+The problem may be resolved by limiting the eras spanned by the outer maximum to explicit ranges $\bar{e}$. Termination occurs following an era $e \in \bar{e}$ in which any slashing events for that span $\bar{e}$ are detected. Concretely, the eras associated with a nominator $\eta$ are divided into _slashing spans_, maximal contiguous sequence of eras $\bar{e} = \left[ e_1, \ldots, e_n \right]$ such that $e_n$ is the earliest era in which $\eta$ is slashed for actions commited in one of the $e_i \in \bar{e}$.
-We shall sum offences across slashing spans. In other words, if we $\bar{e}$ range over the slashing spans for $\eta$ then we have slashed $\eta$ in total
+Offences are then summed across slashing spans. In other words, if $\bar{e}$ ranges over the slashing spans for $\eta$, then the total amount slashed from $\eta$ is:
$$
\sum_{\bar{e} \in \bar{E}} \max_{e \in \bar{e}} \sum_{\nu \in N_e} p_{\nu,e} x_{\eta,\nu,e} \tag{\dag}
$$
-In particular, if $\eta$ gets slashed in epoch 1 with the detection occurring in epoch 2, then resumes nomination in epoch 3, and only then gets slashed again for actions in epoch 1 and 2, then these later slashes are counted as part of the same slashing span as $\eta$'s first slash from epoch 1, but any slash in epoch 3 count afresh in a new span that gets added.
+In particular, if $\eta$ is slashed in epoch 1 with the detection occurring in epoch 2, nomination resumes in epoch 3, and only then is $\eta$ slashed again for actions commited in epoch 1 and 2. These later slashes are counted as part of the same slashing span, originating from $\eta$'s initial slash in epoch 1. Any slash occurring in epoch 3 is treated as a new event and initiates a fresh slashing span.
+
+Slashing Span Lemma. Any slashing span-like construction must terminate whenever slash is detected.
-Slashing Span Lemma. Any slashing span-like construction must end whenever we detect some slash.
+Proof. Let $x'$ be the validators' minimum self-exposure, and let $y$ be the total stake required to become a validator. Suppose a nominator $\eta_1$ nominates validators $\nu_e$ for $e=1\ldots$, using their account with stake $y-x'$. In epoch $e-1$, each $\nu_i$ stakes enough to become a validator in epoch $e$, with $\nu_1$ staking only $x'$ and $\nu_i$ for $i>1$ slightly more.
-Proof. Let $x'$ be the validators' minimum self exposure and let $y$ be the stake to become a validator. Some nominator $\eta_1$ nominates validators $\nu_e$ for $e=1\ldots$ with her account of $y-x'$ stake. In epoch $e-1$, $\nu_i$ stakes enough to become a validator in epoch $e$, so $\nu_1$ stakes only $x'$ and $\nu_i$ for $i>1$ stakes somewhat more. In epoch $i$, $\nu_i$ commits a violation. If we did not end $\eta_1$'s slashing span $\bar{e}$ then then $max_{e \in \bar{e}}$ rule would prevent these slashes from actually slashing $\eta_1$ further. In this way, a planned series of violations causing slashes across epochs only actually slashes $x' / y$ of the desired slash value.
+Now, suppose $\nu_i$ commits a violation in epoch $i$. If the system does not end $\eta_1$'s slashing span $\bar{e}$, then the rule $max_{e \in \bar{e}}$ would prevent subsequent slashing events from further penalizing $\eta_1$. As a result, a planned series of violations across epochs would only slash a fraction $x' / y$ of the intended penalty, undermining the effectiveness of the slashing mechanism.
$$
\tag{$\blacksquare$}
$$
-There are many design choices that restrain this lemma somewhat, but they make our slashing fragile, which harms our analysis and compossibility.
+Many design choices constrain this lemma to some extent, but they also make slashing fragile, complicating analysis and reducing composability.
## Actions
-We now detail several additional actions taken whenever some validator $\nu$ causes the slashing of some nominator $\eta$. Among other concerns, these help mitigate reenlistment mistakes that nominators would occasionally make.
+Several additional mechanisms are triggered whenever a validator $\nu$ causes the slashing of a nominator $\eta$. Among other considerations, these mechanisms help mitigate reenlistment mistakes that nominators may occasionally make.
-We first post a slashing transaction to the chain, which drops the offending validator $\nu$ from the active validator list by invalidating their controller key, or maybe just their session keys. In consequence, all nodes ignore $\nu$ for the remainder of the era. It invalidates any future blocks that do not ignore $\nu$ too. We also remove all nomination approval votes by any nominator for $\nu$, even those who currently allocate $\nu$ zero stake.
+The first step then is to post a slashing transaction to the chain, which removes the offending validator $\nu$ from the active validator set by invalidating either their controller key or, maybe potentionally, just their session keys. As a result, all nodes ignore $\nu$ for the rest of the era. Any future blocks that fail to ignore $\nu$ are considered invalid. All nomination approval votes by any nominator for $\nu$ are also removed, including those currently allocating $\nu$ zero stake.
-We handle the nominator $\eta$ less speedily though. We merely update the slashing accounting below when the offense occurred in some past slashing span for $\eta$, meaning we need not end their current slashing span. We go further assuming the usual case that the offense occurred in $\eta$'s currently running slashing span though: We terminate $\eta$'s current slashing span at the end of the current era, which should then start a new slashing span for $\eta$.
+Nominator $\eta$ is handled with less urgency. The slashing accounting is updated only when the offense occurred in a past slashing span for $\eta$, meaning it is not necessary to terminate their current span. In the more typical case, where the offense occurrs during $\eta$'s currently active slashing span, that span is terminated at the end of the current era, and a new slashing span begins for $\eta$.
-We also mark $\eta$ _suppressed_ which partially _suppresses_ all of $\eta$'s nomination approval votes for future eras. We do not suppress or remove $\eta$'s current nominations for the current era or reduce the stake currently backing other validators. In principle, we could suppresses $\eta$'s nomination approval votes somewhat whenever $\eta$ gets slashed in previous slashing spans, but doing so appears unnecessary because suppression really comes only as part of ending a slashing span.
+Nominator $\eta$ is then _suppressed_, which partially suppresses all of $\eta$'s nomination approval votes for future eras. $\eta$'s current nominations for the ongoing era are not suppressed or removed, and the stake currently backing other validators remains unaffected. In principle, it is possible to suppress $\eta$'s nomination approval votes whenever they are slashed in a previous slashing span. This seems to be unnecessary, as suppression is primarily tied to the termination of a slashing span.
-Also, we permit $\eta$ to update their nomination approval votes for future eras during the current or future era, but doing so removes them from the aka suppressed state. We also notify $\eta$ that $\nu$ cause them to be slashed and suppressed.
+Additionally, $\eta$ can update their nomination approval votes for future eras during the current or any subsequent era. Doing so removes them from the suppressed state. $\eta$ also receives a notification indicating that validator $\nu$ caused them to be slashed and suppressed.
-These state alterations reduce the risks of unintentional reenlistment of any nominator, while also balancing risks to the network. In particular, these measures provide justification for treating any future nominations by $\eta$ separately from any that happen in the current era or before.
+These state changes help reduce the risk of unintentional reenlistment by nominators, while also balancing systemic risks to the network. In particular, they provide justification for treating any future nominations by $\eta$ separately from those made in the current or previous eras.
## Accounting
-We cannot slash for anything beyond the unbonding period and must expire slashing records when they go past the unbonding period. We address this easily thanks to slashing spans: We track the maximum slash $s_{\eta}$ within each slashing span, which we update anytime a slash raises the slashing span's maximum slash. We shall use $s_{\eta}$ again below in rewards computations.
+Slashing is not permitted for any events occurring beyond the unbonding period, and slashing records must expire once this period has elapsed. Slashing spans help address this requirement by tracking the maximum slash $s_{\eta}$ within each span. This value can be updated whenever a new slash increases the span's maximum. The $s_{\eta}$ is referenced again below in reward computations.
+
+As an aside, consider an alternative accounting strategy. By recording all slashing events along with a value $s_{\eta,\nu,e}$, it is possible to represent the amount actually slashed at time $e$. If $e'>e$, then the initial slash is recorded as
-As an aside, there was another accounting strategy here: Record all slash events along with some value $s_{\eta,\nu,e}$ recording the amount actually slashed at that time. If $e'$ is later than $e$ then we record the initial slash $s_{\eta,\nu,e} := p_{\nu,e} x_{\eta,\nu_j,e}$ at $e$ and record a lesser slash $s_{\eta,\nu,e'} := p_{\nu,e'} x_{\eta,\nu_j,e'} - p_{\nu,e} x_{\eta,\nu_j,e}$ at the later $e'$. These $s_{\eta,\nu,e}$ values permit slashes to expire without unfairly increasing other slashes. We believe this extra complexity and storage, does not improve network security, and strengthens extortion attacks on nominators.
+$$
+s_{\eta,\nu,e} := p_{\nu,e} x_{\eta,\nu_j,e}
+$$
+
+at time $e$. A subsequent lesser slash is then recorded as
+
+$$
+s_{\eta,\nu,e'} := p_{\nu,e'} x_{\eta,\nu_j,e'} - p_{\nu,e} x_{\eta,\nu_j,e}
+$$
+
+at time $e'$. These $s_{\eta,\nu,e}$ values allow slashes to expire without unfairly increasing future slashes. The added complexity and storage overhead does not enhance network security and may exacerbate extortion attacks against nominators.
## Monotonicity
-We ask that slashing be monotonic increasing for all parties so that validators cannot reduce any nominator's slash by additional miss-behavior. In other words, the amount any nominator gets slashed can only increase with more slashings events, even ones involving the same validator but not the same nominator.
+Slashing must be monotonically increasing for all parties, ensuring that validators cannot reduce a nominator's penalty through additional misbehavior. In other words, the amount any nominator is slashed can only increase with more slashing events, even those involving the same validator but different nominators.
-We think fairness imposes this condition because otherwise validators can reduce the slash of their favoured nominators, normally by making other nominators be slashed more. We know trusted computing environments (TEE) avoid this issue, but we do not currently foresee requiring that all validators use them.
+Fairness demands this condition; otherwise, validators could manipulate slashing to benefit favored nominators, typically by increasing the penalties applied to others. Trusted Execution Environments (TEE) can help prevent such manipulation, but not all validators are expected to use them.
-We have achieved monotonicity with ($\dag$) because summation and maximums are monotonically increasing over the positive real numbers, assuming any logic that adjusts the $p_{\nu,e}$ also adheres to monotonicity.
+Monotonicity can be achieved with ($\dag$), since both summation and maximum operations are monotonically increasing over the positive real numbers, assuming that any logic to adjust $p_{\nu,e}$ also preserves monotonicity.
-There are no meaningful limits on the diversity of nominators who nominated a particular validator within the unbonding period. As a direct consequence of monotonicity, almost every nominators can be slashed simultaneously, even if only one validator gets slashed. In particular, there are "rage quit attacks" in which one widely trusted validator adds past equivocations that cover many nominators. We therefore cannot bound the total stake destroyed by a combined slashing event much below the slash applied to the total stake of the network.
+There are no meaningful limits on the diversity of nominators who may nominate a particular validator during the unbonding period. As a direct consequence of monotonicity, nearly all nominators can be slashed simultaneously, even if only one validator is penalized. This opens the door to "rage quit attacks", where a widely trusted validator retroactively introduces equivocations that implicate many nominators. As a result, the total stake destroyed by a combined slashing event, though far below the total stake of the network, cannot be reliably bounded.
-In particular, we cannot prevent validators from retroactively validating invalid blocks, which causes a 100% slash. We could reduce these high slashes from old offenses if truly uncorrelated, but if correlated then only governance could interveen by searching historical logs for the invalid block hash.
+Moreover, validators can retroactively validate invalid blocks, which results in a 100% slash. While it may be possible to reduce the severity of slashes for older offenses if they are truly uncorrelated, in case of correlation, only governance can intervene by searching historical logs to identify the invalid block hash.
## Suppressed nominators in Phragmen
-Above, we defined a slashing span $\bar{e}$ for a nominator $\eta$ to end after the era $e$ during which a slashing event during $\bar{e}$ gets detected and acknowledged by the chain. We asked above that all $\eta$'s nomination approval votes, for any validator, should be _suppressed_ after the era $e$ that ends a slashing span $\bar{e}$, but never defined suppressed.
+The slashing span $\bar{e}$ for a nominator $\eta$ is defined to end in the era $e$ during which a slashing event within $\bar{e}$ is detected and acknowledged by the chain. Under this definition all of $\eta$'s nomination approval votes, for any validator, should be _suppressed_ after the era $e$ that concludes a slashing span $\bar{e}$. The notion of suppression itself has not been formally defined, though.
+
+Let $\xi$ be the _suppression factor_, a recently introduced network parameter. Let $s_{\eta,\bar{e}}$ denote the amount slashed from nominator $\eta$ during slashing span $\bar{e}$, and let $E$ represent the set of slashing spans $\eta$ within the unbonding period during which $\eta$ has not updated their nominations. When $\eta$ is marked as suppressed, a portion of their stake in Phragmen, specifically $\xi \sum_{\bar{e} \in E} s_{\eta,\bar{e}}$ of $\eta$'s, is ignored.
-We introduce a network paramater $\xi$ called the _suppression factor_. We let $s_{\eta,\bar{e}}$ denote the value slashed from nominator $\eta$ in slashing span $\bar{e}$. We also let $E$ denote the slashing spans of $\eta$ within the unbonding period for which $\eta$ has not updated their nominations. We now ignore $\xi \sum_{\bar{e} \in E} s_{\eta,\bar{e}}$ of $\eta$'s stake in Phragmen when $\eta$ is marked as suppressed.
+If suppression has no effect ($\xi = 0$), then at the next epoch, $\eta$ enters a new slashing span by the Slashing Span Lemma, risking additive slashing. This is problematic for several reasons:
-If suppression does nothing ($\xi = 0$), then at the next epoch $\eta$ enters a fresh slashing span by the Slashing Span Lemma, and risks additive slashing. We consider this problematic for several reasons: First, we consider $\eta$'s judgement flawed, so they should reevaluate their votes' risks, both for themselves and the network's good. Second, $\eta$ could easily be slashed several times if reports are prompt, but only once if reports are delayed, which incentivizes delaying reports. Also, slashes could be caused by intermittent bugs.
+* First, $\eta$'s judgement is flawed, and they should reassess the risks associated with their vote, for both their own sake and the network's integrity.
+* Second, $\eta$ could be slashed multiple times if reports are prompt, but only once if reports are delayed, creating a perverse incentive to delay reporting.
+* Additionally, intermittent bugs could trigger slashes.
-If suppression removes all $\eta$'s nominations ($\xi = \infty$), then $\eta$ remains completely safe, but widespread slashing could remove massive amounts of stake from the system if many nominators get slashed nearly simultaneously, perhaps only by some small amount. If these fail to renominate quickly, then much of the total stake invested by nominators becomes suppressed, not unlike the "rage quit attacks" enabled by monotonicity. We consider this problematic because an adversary might suddenly control more than one third of the stake.
+If suppression removes all $\eta$'s nominations ($\xi = \infty$), then $\eta$ remains completely safe. However, widespread slashing could eliminate large amounts of stake from the system if many nominators are slashed nearly simultaneously, even by small amounts. If these nominators fail to renominate quickly, a significant portion of the total stake becomes suppressed, unlike the "rage quit attacks" enabled by monotonicity. This poses a risk, as an adversary could suddenly control more than one-third of the stake.
-We think $\xi = 1$ or $2$ sounds reasonable. We suspect $\xi > 2$ meshes poorly with our 2/3rds honest assumption elsewhere. At some point $\xi < 0.5$ creates similar issues to $\xi = 0$, but no intuitive arguments present themselves.
+A suppression factor of $\xi = 1$ or $2$ sounds reasonable, as values of $\xi > 2$ may conflict with the protocol's assumption of two-thirds honest participation. Conversely, when $\xi < 0.5$, issues similar to those at $\xi = 0$ arise, though no intuitive arguments currently support this threshold.
-We have intentionally kept the above computation $\xi \sum_{\bar{e} \in E} s_{\eta,\bar{e}}$ extremely simple so that $\xi$ can dynamically be changed by governance to reintroduce suppressed stake in an emergency. We code could change $\xi$ automatically but doing so appears pointless.
+The computation $\xi \sum_{\bar{e} \in E} s_{\eta,\bar{e}}$ is intentionally simple, allowing $\xi$ to be dynamically adjusted by governance to reintroduce suppressed stake in the event of an emergency. While the code could theoretically modify $\xi$ automatically, this appears unnecessary and offers little practical benefit.
-TODO: Import any discussion from Alfonso's text
## Rewards for slashable offense reports
-Interestingly, we find that monotonicity also constrains our rewards for offense reports that result in slashing: If a validator $\nu$ gets slashed, then they could freely equivocate more and report upon themselves to earn back some of the slashed value. It follows that slashes should always slash the validator's self stake more than the reward for the slash.
+Interestingly, monotonicity also places constraints on the reward structure for offense reports that lead to slashing. For example, if a validator $\nu$ is slashed, they could freely equivocate again and report themselves in an attempt to recover some of the slashed value. To prevent this exploit, slashing must always penalize the validator's self-stake by an amount greater than any reward granted for the report.
### Rewards based on slashing nominators
-We quickly give an inefficient straw-man that describes issuing rewards based upon slashing nominators.
+An inefficient straw-man proposal describes issuing rewards based upon slashing nominators.
-We define $f_\infty$ to be the maximum proportion of a slash that ever gets paid out, presumably $f_\infty < 0.1$. We also define $f_1 \le {1\over2}$ to be the proportion of $f_\infty$ paid out initially on the first offence detection. So a fresh slash of value $s$ results in a payout of $f_\infty f_1 s$. Set $f_0 := {1-f_1 \over f_1} f_\infty$ so that $f_\infty = {f_1 \over 1-f_1} f_0$.
+Let $f_\infty$ be the maximum proportion of a slash that can ever be paid out, presumably with $f_\infty < 0.1$. Let $f_1 \le {1\over2}$ represent the proportion of $f_\infty$ paid out initially upon first offence detection. A fresh slash of value $s$ then results in a payout of $f_\infty f_1 s$. Define $f_0 := {1-f_1 \over f_1} f_\infty$ so that $f_\infty = {f_1 \over 1-f_1} f_0$.
-We consider a slash of value $s := p_{\nu,e} x_{\eta,\nu,e}$ being applied to the nominator $\eta$. We let $s_{\eta,i}$ and $s_{\eta,i+1}$ denote $\eta$'s actual slash in slashing span $\bar{e}$ given by $\max_{e \in \bar{e}} \sum_{\nu \in N_e} p_{\nu,e} x_{\eta,\nu,e}$ before and after applying the new slash, respectively, so when $\eta$'s slash increases by $s_{\eta,i+1} - s_{\eta,i}$.
+Consider a slash of value $s := p_{\nu,e} x_{\eta,\nu,e}$ applied to the nominator $\eta$. Let $s_{\eta,i}$ and $s_{\eta,i+1}$ denote $\eta$'s actual slash in slashing span $\bar{e}$, given by
-We track the value $s_{\eta,i}$ in $\eta$'s slashing span record, but we also track another value $t_{\eta,i} < s_{\eta,i}$ that represents the total amount paid out so far. If $s_{\eta,i+1} > s_{\eta,i}$ then we pay out $r := f_1 (f_0 s_{\eta,i+1} - t_{\eta,i})$ and increase $t_{\eta,i}$ by this amount. If $s_{\eta,i+1} = s_{\eta,i}$ then we pay out $r := f_1 \max(f_0 s - t_{\eta,i},0)$. In either case, we store $t_{\eta,i+1} := t_{\eta,i} + r$.
+$$
+\max_{e \in \bar{e}} \sum_{\nu \in N_e} p_{\nu,e} x_{\eta,\nu,e}
+$$
+
+before and after applying the new slash, respectively. Thus, $\eta$'s slash increases by $s_{\eta,i+1} - s_{\eta,i}$.
+
+Track the value $s_{\eta,i}$ in $\eta$'s slashing span record, along with another value $t_{\eta,i} < s_{\eta,i}$ representing the total amount paid out so far. If $s_{\eta,i+1} > s_{\eta,i}$, then the pay out is
+
+$$
+r := f_1 (f_0 s_{\eta,i+1} - t_{\eta,i}),
+$$
+
+increasing $t_{\eta,i}$ by this amount. If $s_{\eta,i+1} = s_{\eta,i}$, then the payout is $r := f_1 \max(f_0 s - t_{\eta,i},0)$.
+
+In either case, the updated value stored is $t_{\eta,i+1} := t_{\eta,i} + r$.
-In this way, our validator $\nu$ cannot reclaim more than $f_{\infty} f_1 s$ from a slash of value $s$, even by repeatedly equivocations, so $f_{\infty} f_1$ should remain below the required self stake. Any slash of size $s_{\eta,i}$ always results in some payout, but slashes less than $t_{\eta,i}$ never pay out.
+In this way, validator $\nu$ cannot reclaim more than $f_{\infty} f_1 s$ from a slash of value $s$, even through repeated equivocations. For this reason, the product $f_{\infty} f_1$ should remain below the required self-stake. Any slash of size $s_{\eta,i}$ always results in some payout, yet slashes smaller than $t_{\eta,i}$ never trigger a payout.
### Rewards based on slashing only validators
-We dislike that the above reward scheme requires both considering all impacted $\eta$ when doing payouts, and imposing the bound that $f_{\infty} f_1$ remain below the self stake remains tricky.
+Since the above reward scheme requires both accounting for all impacted nominators $\eta$ during payouts and enforcing the constraint that $f_{\infty} f_1$ remains below the valitor's self-stake, the proposal is to compute rewards only for validators who are directly slashed. This approach requires that validators are always slashed whenever their nominators are slashed, meaning a validator cannot be slashed 100% unless all of their nominators are also slashed 100%.
-We therefore propose to compute rewards only for validators being slashed instead. We shall require that validators always get slashed whenever their nominators get slashed, which means validators cannot be slashed 100% without their nominators all also being slashed 100%.
+Let $x'$ denote the minimum self-exposure (i.e., stake) that validator operators must provide, such that $x_{\nu,\nu,e} \ge x'$. As a simplifying assumption, $f_\infty$ should be kept small enough to ensure that rewards are always covered by validators' self-exposure, i.e.,
-We have some minimum exposure aka stake $x'$ that validator operators must provide themselves, meaning $x_{\nu,\nu,e} \ge x'$. As a simplifying assumption, we ask that $f_\infty$ be kept small enough that rewards can always be covered by the validators' exposure, meaning $x' \ge f_{\infty} \sum_\eta x_{\eta,\nu,e}$. We do not explore any cases where this fails here, but doing so requires a subtle definition of some $x' > x_{\nu,\nu,e}$ such that rewards still cannot create inflation.
+$$
+x' \ge f_{\infty} \sum_\eta x_{\eta,\nu,e}
+$$
+
+Cases where this condition fails are not explored further here. Addressing such scenarios would require a more nuanced definition of $x' > x_{\nu,\nu,e}$ to ensure that reward payouts do not introduce inflationary pressure.
+
+Define $f' > f_0$ such that $f' x' = {1-f_1 \over f_1} f_{\infty} x_{\min}$ where $x_{\min} = \sum_\eta x_{\eta,\nu,e}$ represents the required minimum total stake for any validator. In the revised scheme, replace $f_{\infty}$ with $f'$, and apply payouts to slashes against the validator operator's minimum exposure $x'$. This means replacing the slash value $p_{\nu,e} x_{\eta,\nu,e}$ with $\max_{e \in \bar{e}} p_{\nu,e} x'$.
+
+A slash of value $s := p_{\nu,e} x_{\nu,\nu,e}$ is applied to validator $\nu$. The _minimum validator adjusted slash_ value $s' := p_{\nu,e} x'$ represents the fraction of this slash applied to the minimum validator stake $x'$. The _total minimum validator-adjusted slash_, given by $\max_{e \in \bar{e}} p_{\nu,e} x'$, serves as an analog to total regular slashes, but considers only the validator's own exposure.
-We now define $f' > f_0$ such that $f' x' = {1-f_1 \over f_1} f_{\infty} x_{\min}$ where $x_{\min} = \sum_\eta x_{\eta,\nu,e}$ is our required minimum total stake for any validator. In the above scheme, we shall replace $f_{\infty}$ by $f'$ and only apply the payouts to slashes against validator operators minimum exposure $x'$, meaning replace the slash value $p_{\nu,e} x_{\eta,\nu,e}$ by $\max_{e \in \bar{e}} p_{\nu,e} x'$.
+The next step is to let $s^\prime_{\nu,i}$ and $s^\prime_{\nu,i+1}$ denote validator $\nu$'s total validator-adjusted slash within their slashing span $\bar{e}$, before and after applying the new slash, respectively. When the total validator-adjusted slash increases, the change is given by
+
+$$
+s^\prime_{\nu,i+1} - s^\prime_{\nu,i} = \max(s^\prime - s^\prime_{\nu,i},0).
+$$
-We consider a slash of value $s := p_{\nu,e} x_{\nu,\nu,e}$ being applied to the validator $\nu$. We define the _minimum validator adjusted slash_ value $s' := p_{\nu,e} x'$ to be the fraction of this slash applied to the minimum validator stake $x'$. We have a _total minimum validator adjusted slash_ given by $\max_{e \in \bar{e}} p_{\nu,e} x'$, which provides an analog of total regular slashes but only considering the validator themselves.
+Now, track the value $s^\prime_{\nu,i}$ in validator $\nu$'s slashing span record, along with another value $t_{\nu,i} < s^\prime_{\nu,i}$, which represents the total payout issued so far. If $s^\prime_{\nu,i+1} > s^\prime_{\nu,i}$, then the payout is $r := f_1 (f' s^\prime_{\nu,i+1} - t_{\nu,i})$ and $t_{\eta,i}$ increases by this amount. If $s^\prime_{\nu,i+1} = s^\prime_{\nu,i}$, then the payout is $r := f_1 \max(f' s' - t_{\nu,i},0)$. In both cases, the updated value $t_{\nu,i+1} := t_{\nu,i} + r$ is stored.
-We next let $s^\prime_{\nu,i}$ and $s^\prime_{\nu,i+1}$ denote $\nu$'s total validator adjusted slash in their slashing span $\bar{e}$ before and after applying the new slash, respectively, so when $\nu$'s total validator adjusted slash increases by $s^\prime_{\nu,i+1} - s^\prime_{\nu,i} = \max(s^\prime - s^\prime_{\nu,i},0)$.
+In this way, validator $\nu$ cannot reclaim more than $f' f_1 s$ from a slash of value $s$, even through repeated equivocations. Any slash of size $s_{\nu,i}$ always results in some payout, but slashes smaller than $t_{\nu,i}$ do not trigger additional rewards.
-We track the value $s^\prime_{\nu,i}$ in the validator $\nu$'s slashing span record, but we also track another value $t_{\nu,i} < s^\prime_{\nu,i}$ that represents the total amount paid out so far. If $s^\prime_{\nu,i+1} > s^\prime_{\nu,i}$ then we pay out $r := f_1 (f' s^\prime_{\nu,i+1} - t_{\nu,i})$ and increase $t_{\eta,i}$ by this amount. If $s^\prime_{\nu,i+1} = s^\prime_{\nu,i}$ then we pay out $r := f_1 \max(f' s' - t_{\nu,i},0)$. In either case, we store $t_{\nu,i+1} := t_{\nu,i} + r$.
+Both schemes yield similar payouts initially, but the second scheme, where rewards are based only on validator slashes, results in smaller payouts when cross-era slashing logic is applied. For instance, if validator $\nu$ receives similar slashes across multiple epochs, the $r_1$ factor reduces the total reward under the validator-only scheme. Still, if $\nu$ has disjoint nominators in each epoch, the impact of the $r_1$ factor is minimal.
-In this way, our validator $\nu$ cannot reclaim more than $f' f_1 s$ from a slash of value $s$, even by repeatedly equivocations. Any slash of size $s_{\nu,i}$ always results in some payout, but slashes less than $t_{\nu,i}$ never pay out.
-In both scheme, we have similar payouts initially, but our second scheme with payouts based only on the validator slashes results in smaller reward payouts when cross era slashing logic kicks in. As an example, if a validator $\nu$ gets similar slashes for different epochs, then the $r_1$ factor would reduce the entire reward if payouts are based only on the validator slashes, but if $\nu$ has disjoin nominators in every epoch then the $r_1$ factor makes only a minimal appearance.
+**For further questions and inquieries, please contact**: [Jeffrey Burdges](/team_members/jeff.md)
diff --git a/docs/Polkadot/token-economics/index.md b/docs/Polkadot/token-economics/index.md
new file mode 100644
index 00000000..27e90dba
--- /dev/null
+++ b/docs/Polkadot/token-economics/index.md
@@ -0,0 +1,14 @@
+---
+title: Token Economics
+---
+
+import DocCardList from '@theme/DocCardList';
+
+
+
+
+
+The recent information on the token economics of Polkadot can be found in the [Polkadot Wiki](https://wiki.polkadot.com/learn/learn-dot/)
+
+
+
diff --git a/docs/Polkadot/token-economics/polkadot-token.png b/docs/Polkadot/token-economics/polkadot-token.png
new file mode 100644
index 00000000..e0385118
Binary files /dev/null and b/docs/Polkadot/token-economics/polkadot-token.png differ
diff --git a/docs/Web3-foundation-research.png b/docs/Web3-foundation-research.png
new file mode 100644
index 00000000..06b87999
Binary files /dev/null and b/docs/Web3-foundation-research.png differ
diff --git a/docs/research.md b/docs/research.md
index 376d001a..cdfd064f 100644
--- a/docs/research.md
+++ b/docs/research.md
@@ -4,17 +4,14 @@ title: Research at Web3 Foundation
-Web3 Foundation Research is being done in an in-house [research team](team_members), mostly located in Zug (Switzerland), as well as in collaboration with industrial projects and academic research groups.
+
-Our research focuses on a number of areas that are relevant to decentralised systems:
-- (Proveable) Security, Cryptography, and Privacy
-- Decentralised Algorithms: Consensus and Optimization
-- Cryptoeconomics and Game Theory
-- Networking
-- Behavioral Economics and Useability
+Web3 Foundation's research focuses on several areas relevant to decentralized systems, including: (1) networking, (2) cryptoeconomics and game theory, (3) provable security, cryptography, and privacy, (4) behavioral economics and usability, and (5) decentralized algorithms for consensus and optimization.
-We analyze existing protocols, come up with new ones and specify them. We work closely with development teams to make sure our work is practical and useful in context of Web3 technologies.
+The [research team](team_members) collaborates closely with development groups to ensure its work is practical and impactful for Web3 technologies. One of its key priorities is to analyze existing protocols, design new ones, and provide formal specifications.
+
+The core research team is based in Zug, Switzerland, with research efforts carried out in collaboration with both industrial initiatives and academic institutions.
Talk to us on Element at #w3f:matrix.org.
diff --git a/docs/team_members/Alistair.jpg b/docs/team_members/Alistair.jpg
new file mode 100644
index 00000000..1712fe0d
Binary files /dev/null and b/docs/team_members/Alistair.jpg differ
diff --git a/docs/team_members/Andrew.md b/docs/team_members/Andrew.md
index 9aec1e9d..d51868e2 100644
--- a/docs/team_members/Andrew.md
+++ b/docs/team_members/Andrew.md
@@ -1,13 +1,14 @@
# Andrew Burger
- +
andrew@web3.foundation
-Andrew joined Web3 Foundation in August 2023 as a Researcher who assists in implementation of schemes and protocols in the Polkadot-SDK Substrate framework.He gives lectures and works as an educator for the Polkadot Blockchain Academy. Andrews current work has been focused on the implementation and prototyping of the XCMP protocol as well as the latest Threshold Cryptography features of Polkadot. His biggest areas of interest in research are Blockchain Bridging protocols, Threshold Cryptography, Elliptic Curves, and Consensus protocols.
+Andrew joined Web3 Foundation as a researcher in August 2023 and has since supported the implementation of schemes and protocols within the Polkadot-SDK Substrate framework. His current work focuses on the development and prototyping of the XCMP protocol, along with the latest threshold cryptography features in Polkadot. Andrew also lectures and serves as an educator at the Polkadot Blockchain Academy.
-**Short Biography**:
-Before joining W3F Andrew has worked on W3F grants project Tuxedo as one of the two core designers of the substrate based UTXO framework. As well he attended as a student at the first Polkadot Blockchain Academy at Corpus Christi University of Cambridge. Since he has been a lecturer and content creator at the Academy since. He enjoys time with Family, Friends, Squash and Traveling. Favorite programming language Rust. Least favorite language C++
+**Research Areas.** His main research interests include blockchain bridging protocols, threshold cryptography, elliptic curves, and consensus mechanisms.
+
+**Short Bio.** Before joining W3F, Andrew worked on the W3F Grants project Tuxedo as one of the two core designers of its Substrate-based UTXO framework. He was also a student at the first Polkadot Blockchain Academy, held at Corpus Christi College, University of Cambridge. Since then, he has served as a lecturer and content creator at the Academy. Outside of work, Andrew enjoys spending time with family and friends, playing squash, and traveling. His favorite programming language is Rust; his least favorite is C++.
**Related Works**
@@ -17,3 +18,5 @@ Before joining W3F Andrew has worked on W3F grants project Tuxedo as one of the
* [Lecture UTXO vs Accounts UBA](https://www.youtube.com/watch?v=cI75Je1Nvk8)
* [UTXO Tuxedo Framework](https://github.com/Off-Narrative-Labs/Tuxedo)
* [PBA content](https://github.com/Polkadot-Blockchain-Academy/pba-content)
+
+
diff --git a/docs/team_members/Andrew.png b/docs/team_members/Andrew.png
new file mode 100644
index 00000000..fe434068
Binary files /dev/null and b/docs/team_members/Andrew.png differ
diff --git a/docs/team_members/Bhargav.md b/docs/team_members/Bhargav.md
index 2418358f..756afcc4 100644
--- a/docs/team_members/Bhargav.md
+++ b/docs/team_members/Bhargav.md
@@ -2,12 +2,12 @@
import useBaseUrl from '@docusaurus/useBaseUrl';
-
+
andrew@web3.foundation
-Andrew joined Web3 Foundation in August 2023 as a Researcher who assists in implementation of schemes and protocols in the Polkadot-SDK Substrate framework.He gives lectures and works as an educator for the Polkadot Blockchain Academy. Andrews current work has been focused on the implementation and prototyping of the XCMP protocol as well as the latest Threshold Cryptography features of Polkadot. His biggest areas of interest in research are Blockchain Bridging protocols, Threshold Cryptography, Elliptic Curves, and Consensus protocols.
+Andrew joined Web3 Foundation as a researcher in August 2023 and has since supported the implementation of schemes and protocols within the Polkadot-SDK Substrate framework. His current work focuses on the development and prototyping of the XCMP protocol, along with the latest threshold cryptography features in Polkadot. Andrew also lectures and serves as an educator at the Polkadot Blockchain Academy.
-**Short Biography**:
-Before joining W3F Andrew has worked on W3F grants project Tuxedo as one of the two core designers of the substrate based UTXO framework. As well he attended as a student at the first Polkadot Blockchain Academy at Corpus Christi University of Cambridge. Since he has been a lecturer and content creator at the Academy since. He enjoys time with Family, Friends, Squash and Traveling. Favorite programming language Rust. Least favorite language C++
+**Research Areas.** His main research interests include blockchain bridging protocols, threshold cryptography, elliptic curves, and consensus mechanisms.
+
+**Short Bio.** Before joining W3F, Andrew worked on the W3F Grants project Tuxedo as one of the two core designers of its Substrate-based UTXO framework. He was also a student at the first Polkadot Blockchain Academy, held at Corpus Christi College, University of Cambridge. Since then, he has served as a lecturer and content creator at the Academy. Outside of work, Andrew enjoys spending time with family and friends, playing squash, and traveling. His favorite programming language is Rust; his least favorite is C++.
**Related Works**
@@ -17,3 +18,5 @@ Before joining W3F Andrew has worked on W3F grants project Tuxedo as one of the
* [Lecture UTXO vs Accounts UBA](https://www.youtube.com/watch?v=cI75Je1Nvk8)
* [UTXO Tuxedo Framework](https://github.com/Off-Narrative-Labs/Tuxedo)
* [PBA content](https://github.com/Polkadot-Blockchain-Academy/pba-content)
+
+
diff --git a/docs/team_members/Andrew.png b/docs/team_members/Andrew.png
new file mode 100644
index 00000000..fe434068
Binary files /dev/null and b/docs/team_members/Andrew.png differ
diff --git a/docs/team_members/Bhargav.md b/docs/team_members/Bhargav.md
index 2418358f..756afcc4 100644
--- a/docs/team_members/Bhargav.md
+++ b/docs/team_members/Bhargav.md
@@ -2,12 +2,12 @@
import useBaseUrl from '@docusaurus/useBaseUrl';
-}/) +
bhargav@web3.foundation
-**Bio:** I am researcher focussing on security at the Web3 Foundation. I am also the maintainer of the Polkadot Protocol [Specifications](https://spec.polkadot.network/). I have an research background in Formal Verification and previously worked at ETH Zurich, USI Lugano, Microsoft Research, working on topics like Model Checking, Runtime Verification and Static Analysis. At W3F, i have worked on security analysis of Cross-chain Bridges and Light-Clients, and also on tooling for security and reliability of the Polkadot SDK.
+Bhargav is a researcher at the Web3 Foundation specializing in security. He has contributed to security analysis of cross-chain bridges and light clients, as well as to tooling that strengthens the security and reliability of the Polkadot SDK. He also maintains the Polkadot Protocol [Specifications](https://spec.polkadot.network/).
**Research Areas**
@@ -15,6 +15,8 @@ bhargav@web3.foundation
* Formal Verification and Static Analysis
* Security Tooling
+**Short Bio.** Bhargav has a research background in formal verification, with previous experience at ETH Zurich, USI Lugano, and Microsoft Research, where he worked on topics such as model checking, runtime verification, and static analysis.
+
**Links to selected paper and talks**
* [New Paper](https://eprint.iacr.org/2025/057.pdf):Trustless Bridges via Random Sampling Light Clients
@@ -22,4 +24,5 @@ bhargav@web3.foundation
* Bhargav Nagaraja Bhatt. "Experience Report: Formally Verifying Critical Blockchain Network Component", ETAPS Industry Day, 2024, Luxembourg.
* [Automated repair of resource leaks in Android applications](https://www.sciencedirect.com/science/article/pii/S0164121222001273?via%3Dihub), Journal of Systems and Software, 2022.
* [Almost event-rate independent monitoring](https://link.springer.com/article/10.1007/s10703-018-00328-3), Formal Methods and System Design, 2022.
-* [Formal Methods for Rust](https://polkadot-blockchain-academy.github.io/pba-content/berkeley-2023/syllabus/0-Miscellaneous/1-Formal-Methods/1-intro_formal_methods_slides.html#/), PBA 2023 Berkeley
\ No newline at end of file
+* [Formal Methods for Rust](https://polkadot-blockchain-academy.github.io/pba-content/berkeley-2023/syllabus/0-Miscellaneous/1-Formal-Methods/1-intro_formal_methods_slides.html#/), PBA 2023 Berkeley
+
\ No newline at end of file
diff --git a/docs/team_members/Bhargav.png b/docs/team_members/Bhargav.png
new file mode 100644
index 00000000..2d0cd64b
Binary files /dev/null and b/docs/team_members/Bhargav.png differ
diff --git a/docs/team_members/Chen-Da.png b/docs/team_members/Chen-Da.png
new file mode 100644
index 00000000..522fd429
Binary files /dev/null and b/docs/team_members/Chen-Da.png differ
diff --git a/docs/team_members/Elizabeth.png b/docs/team_members/Elizabeth.png
new file mode 100644
index 00000000..d17851bf
Binary files /dev/null and b/docs/team_members/Elizabeth.png differ
diff --git a/docs/team_members/Jeffrey.png b/docs/team_members/Jeffrey.png
new file mode 100644
index 00000000..129c21e6
Binary files /dev/null and b/docs/team_members/Jeffrey.png differ
diff --git a/docs/team_members/Jonas.md b/docs/team_members/Jonas.md
index 9d730b21..e63aee17 100644
--- a/docs/team_members/Jonas.md
+++ b/docs/team_members/Jonas.md
@@ -1,14 +1,17 @@
# Jonas Gehrlein
-
+
bhargav@web3.foundation
-**Bio:** I am researcher focussing on security at the Web3 Foundation. I am also the maintainer of the Polkadot Protocol [Specifications](https://spec.polkadot.network/). I have an research background in Formal Verification and previously worked at ETH Zurich, USI Lugano, Microsoft Research, working on topics like Model Checking, Runtime Verification and Static Analysis. At W3F, i have worked on security analysis of Cross-chain Bridges and Light-Clients, and also on tooling for security and reliability of the Polkadot SDK.
+Bhargav is a researcher at the Web3 Foundation specializing in security. He has contributed to security analysis of cross-chain bridges and light clients, as well as to tooling that strengthens the security and reliability of the Polkadot SDK. He also maintains the Polkadot Protocol [Specifications](https://spec.polkadot.network/).
**Research Areas**
@@ -15,6 +15,8 @@ bhargav@web3.foundation
* Formal Verification and Static Analysis
* Security Tooling
+**Short Bio.** Bhargav has a research background in formal verification, with previous experience at ETH Zurich, USI Lugano, and Microsoft Research, where he worked on topics such as model checking, runtime verification, and static analysis.
+
**Links to selected paper and talks**
* [New Paper](https://eprint.iacr.org/2025/057.pdf):Trustless Bridges via Random Sampling Light Clients
@@ -22,4 +24,5 @@ bhargav@web3.foundation
* Bhargav Nagaraja Bhatt. "Experience Report: Formally Verifying Critical Blockchain Network Component", ETAPS Industry Day, 2024, Luxembourg.
* [Automated repair of resource leaks in Android applications](https://www.sciencedirect.com/science/article/pii/S0164121222001273?via%3Dihub), Journal of Systems and Software, 2022.
* [Almost event-rate independent monitoring](https://link.springer.com/article/10.1007/s10703-018-00328-3), Formal Methods and System Design, 2022.
-* [Formal Methods for Rust](https://polkadot-blockchain-academy.github.io/pba-content/berkeley-2023/syllabus/0-Miscellaneous/1-Formal-Methods/1-intro_formal_methods_slides.html#/), PBA 2023 Berkeley
\ No newline at end of file
+* [Formal Methods for Rust](https://polkadot-blockchain-academy.github.io/pba-content/berkeley-2023/syllabus/0-Miscellaneous/1-Formal-Methods/1-intro_formal_methods_slides.html#/), PBA 2023 Berkeley
+
\ No newline at end of file
diff --git a/docs/team_members/Bhargav.png b/docs/team_members/Bhargav.png
new file mode 100644
index 00000000..2d0cd64b
Binary files /dev/null and b/docs/team_members/Bhargav.png differ
diff --git a/docs/team_members/Chen-Da.png b/docs/team_members/Chen-Da.png
new file mode 100644
index 00000000..522fd429
Binary files /dev/null and b/docs/team_members/Chen-Da.png differ
diff --git a/docs/team_members/Elizabeth.png b/docs/team_members/Elizabeth.png
new file mode 100644
index 00000000..d17851bf
Binary files /dev/null and b/docs/team_members/Elizabeth.png differ
diff --git a/docs/team_members/Jeffrey.png b/docs/team_members/Jeffrey.png
new file mode 100644
index 00000000..129c21e6
Binary files /dev/null and b/docs/team_members/Jeffrey.png differ
diff --git a/docs/team_members/Jonas.md b/docs/team_members/Jonas.md
index 9d730b21..e63aee17 100644
--- a/docs/team_members/Jonas.md
+++ b/docs/team_members/Jonas.md
@@ -1,14 +1,17 @@
# Jonas Gehrlein
- +
+
jonas@web3.foundation
PGP Fingerprint: 16C2 2CBD 92E4 E7A1 7D79 D0D0 1F79 CDDC 0A5F FC5B
-Jonas has joined the team of the Web3 Foundation at the beginning of July 2020 as a research scientist, where he focuses on economic questions regarding the Polkadot and Kusama ecosystem. In particular, he analyzes and optimizes the interplay between human behavior and the protocol. By doing so, he applied insights from Psychology and Behavioral Economics. For his studies, he uses empirical and experimental data.
+Jonas joined the Web3 Foundation as a research scientist in July 2020. His work focuses on economic questions related to the Polkadot and Kusama ecosystem.
+
+**Research Areas.** In particular, Jonas analyzes and optimizes the interplay between human behavior and protocol dynamics, applying insights from psychology and behavioral economics. His research incorporate both empirical and experimental data.
-**Short Biography**: Before joining W3F, Jonas earned his Ph.D. in Behavioral and Experimental Economics from the University of Bern, where he investigated human behavior in markets and organizations. Before that, he obtained an MSc degree in Quantitative Economics at the University of Konstanz.
+**Short Bio.** Before joining W3F, Jonas earned a Ph.D. in Behavioral and Experimental Economics from the University of Bern, where he investigated human behavior in markets and organizations. He also holds an MSc in Quantitative Economics from the University of Konstanz.
**Polkadot-related Publications**
@@ -32,3 +35,4 @@ Jonas has joined the team of the Web3 Foundation at the beginning of July 2020 a
* von Bieberstein, Frauke and Crede, Ann-Kathrin and Dietrich, Jan and Gehrlein, Jonas and Neumann, Oliver and Stürmer, Matthias, Otree: Implementing Websockets to Allow for Real-Time Interactions – a Continuous Double Auction Market as First Application (April 29, 2019). Available at SSRN: https://ssrn.com/abstract=3631680. (Working Paper)
+
\ No newline at end of file
diff --git a/docs/team_members/Jonas.png b/docs/team_members/Jonas.png
new file mode 100644
index 00000000..f4ca6dd7
Binary files /dev/null and b/docs/team_members/Jonas.png differ
diff --git a/docs/team_members/ResearchTeam.jpg b/docs/team_members/ResearchTeam.jpg
new file mode 100644
index 00000000..4ab01ec5
Binary files /dev/null and b/docs/team_members/ResearchTeam.jpg differ
diff --git a/docs/team_members/Sergey.md b/docs/team_members/Sergey.md
index 27ebf2ce..ca8b946b 100644
--- a/docs/team_members/Sergey.md
+++ b/docs/team_members/Sergey.md
@@ -2,8 +2,10 @@
sergey@web3.foundation
-Sergey is research engineer at Web3 Foundation working on implementations of cryptographic primitives such as zero-knowledge-proof. He has previously done consulting work.
+Sergey is a research engineer at the Web3 Foundation. He works on implementing cryptographic primitives, such as zero-knowledge proofs.
-Currently his work focuses on investigating constant-time block production using ring-VRFs and the design for succinct parachains using ZK-rollups.
+**Research Areas.** His current work focuses on investigating constant-time block production using ring-VRFs and designing succinct parachains with ZK-rollups.
+
+**Short Bio**. Sergey has prior experience in consulting.
diff --git a/docs/team_members/Syed.png b/docs/team_members/Syed.png
new file mode 100644
index 00000000..8cfa1064
Binary files /dev/null and b/docs/team_members/Syed.png differ
diff --git a/docs/team_members/Web3-Foundation-research-team.jpg b/docs/team_members/Web3-Foundation-research-team.jpg
new file mode 100644
index 00000000..bd689deb
Binary files /dev/null and b/docs/team_members/Web3-Foundation-research-team.jpg differ
diff --git a/docs/team_members/alistair.md b/docs/team_members/alistair.md
index 2a0f7633..f4f08c88 100644
--- a/docs/team_members/alistair.md
+++ b/docs/team_members/alistair.md
@@ -2,11 +2,11 @@
title: Alistair Stewart
---
-
+
+
jonas@web3.foundation
PGP Fingerprint: 16C2 2CBD 92E4 E7A1 7D79 D0D0 1F79 CDDC 0A5F FC5B
-Jonas has joined the team of the Web3 Foundation at the beginning of July 2020 as a research scientist, where he focuses on economic questions regarding the Polkadot and Kusama ecosystem. In particular, he analyzes and optimizes the interplay between human behavior and the protocol. By doing so, he applied insights from Psychology and Behavioral Economics. For his studies, he uses empirical and experimental data.
+Jonas joined the Web3 Foundation as a research scientist in July 2020. His work focuses on economic questions related to the Polkadot and Kusama ecosystem.
+
+**Research Areas.** In particular, Jonas analyzes and optimizes the interplay between human behavior and protocol dynamics, applying insights from psychology and behavioral economics. His research incorporate both empirical and experimental data.
-**Short Biography**: Before joining W3F, Jonas earned his Ph.D. in Behavioral and Experimental Economics from the University of Bern, where he investigated human behavior in markets and organizations. Before that, he obtained an MSc degree in Quantitative Economics at the University of Konstanz.
+**Short Bio.** Before joining W3F, Jonas earned a Ph.D. in Behavioral and Experimental Economics from the University of Bern, where he investigated human behavior in markets and organizations. He also holds an MSc in Quantitative Economics from the University of Konstanz.
**Polkadot-related Publications**
@@ -32,3 +35,4 @@ Jonas has joined the team of the Web3 Foundation at the beginning of July 2020 a
* von Bieberstein, Frauke and Crede, Ann-Kathrin and Dietrich, Jan and Gehrlein, Jonas and Neumann, Oliver and Stürmer, Matthias, Otree: Implementing Websockets to Allow for Real-Time Interactions – a Continuous Double Auction Market as First Application (April 29, 2019). Available at SSRN: https://ssrn.com/abstract=3631680. (Working Paper)
+
\ No newline at end of file
diff --git a/docs/team_members/Jonas.png b/docs/team_members/Jonas.png
new file mode 100644
index 00000000..f4ca6dd7
Binary files /dev/null and b/docs/team_members/Jonas.png differ
diff --git a/docs/team_members/ResearchTeam.jpg b/docs/team_members/ResearchTeam.jpg
new file mode 100644
index 00000000..4ab01ec5
Binary files /dev/null and b/docs/team_members/ResearchTeam.jpg differ
diff --git a/docs/team_members/Sergey.md b/docs/team_members/Sergey.md
index 27ebf2ce..ca8b946b 100644
--- a/docs/team_members/Sergey.md
+++ b/docs/team_members/Sergey.md
@@ -2,8 +2,10 @@
sergey@web3.foundation
-Sergey is research engineer at Web3 Foundation working on implementations of cryptographic primitives such as zero-knowledge-proof. He has previously done consulting work.
+Sergey is a research engineer at the Web3 Foundation. He works on implementing cryptographic primitives, such as zero-knowledge proofs.
-Currently his work focuses on investigating constant-time block production using ring-VRFs and the design for succinct parachains using ZK-rollups.
+**Research Areas.** His current work focuses on investigating constant-time block production using ring-VRFs and designing succinct parachains with ZK-rollups.
+
+**Short Bio**. Sergey has prior experience in consulting.
diff --git a/docs/team_members/Syed.png b/docs/team_members/Syed.png
new file mode 100644
index 00000000..8cfa1064
Binary files /dev/null and b/docs/team_members/Syed.png differ
diff --git a/docs/team_members/Web3-Foundation-research-team.jpg b/docs/team_members/Web3-Foundation-research-team.jpg
new file mode 100644
index 00000000..bd689deb
Binary files /dev/null and b/docs/team_members/Web3-Foundation-research-team.jpg differ
diff --git a/docs/team_members/alistair.md b/docs/team_members/alistair.md
index 2a0f7633..f4f08c88 100644
--- a/docs/team_members/alistair.md
+++ b/docs/team_members/alistair.md
@@ -2,11 +2,11 @@
title: Alistair Stewart
---
- +
alistair@web3.foundation
-Alistair is lead researcher at Web3 Foundation mainly working on protocol design. Alistair is the architect behind GRANDPA, Polkadot’s novel finality gadget. Moreover, he has worked on the validator selection scheme NPoS and designed Polkadot’s availability and validity scheme.
+Alistair is lead researcher at Web3 Foundation mainly working on protocol design. He is the architect behind GRANDPA, Polkadot’s novel finality gadget. Moreover, he has worked on the validator selection scheme NPoS and designed Polkadot’s availability and validity scheme.
**Research Areas**
@@ -14,7 +14,7 @@ Alistair is lead researcher at Web3 Foundation mainly working on protocol design
* Learning theory
* Stochatsic models
-**Short Bio**. Alistair has been a postdoc in theoretical Computer Science at University of Southern California working with Professor Ilias Diakonikolas, where he worked in learning theory with breakthrough results in high-dimensional robust statistics. Prior to that, in 2015 he obtained a PhD in Informatics from the University of Edinburgh on infinite-state stochastic models. Alistair holds a masters degree in Informatics from the University of Edinburgh and an undergraduate degree from Oxford University.
+**Short Bio.** Alistair has been a postdoc in theoretical Computer Science at University of Southern California working with Professor Ilias Diakonikolas, where he worked in learning theory with breakthrough results in high-dimensional robust statistics. Prior to that, in 2015 he obtained a PhD in Informatics from the University of Edinburgh on infinite-state stochastic models. Alistair holds a masters degree in Informatics from the University of Edinburgh and an undergraduate degree from Oxford University.
**Selected Publication**
@@ -23,3 +23,5 @@ Alistair is lead researcher at Web3 Foundation mainly working on protocol design
* I. Diakonikolas, D. Kane, A. Stewart. "The Fourier Transform of Poisson Multinomial Distributions and its Algorithmic Applications", the 48th Annual ACM Symposium on Theory of Computing (STOC 2016).
* K. Etessami, A. Stewart, M. Yannakakis. "Polynomial-time Algorithms for Multi-type Branching Processes and Stochastic Context-Free Grammars", ACM Symposium on Theory of Computing (STOC'12).
+
+
diff --git a/docs/team_members/chenda.md b/docs/team_members/chenda.md
index fb3d2505..3ac25aa7 100644
--- a/docs/team_members/chenda.md
+++ b/docs/team_members/chenda.md
@@ -1,10 +1,14 @@
# Chen-Da Liu-Zhang
+
+
chenda@web3.foundation
-Chen-Da has joined the Web3 Foundation team in July 2023 as a research scientist. His area of expertise encompasses both Cryptography and Distributed Systems, with a broad focus on the theory and practice of multi-party computation, consensus, peer-to-peer network, data availability, provable composable security and many others. His research has led to more than 25 publications at top international venues.
+Chen-Da joined the Web3 Foundation as a research scientist in July 2023. His areas of expertise span both cryptography and distributed systems, with a broad focus on theory and practice.
+
+**Research Areas.** Chen-Da's research areas include multi-party computation, consensus mechanisms, peer-to-peer networking, data availability, provable composable security, and more. His research has resulted in over 25 publications at top international venues.
-**Short Bio.** Prior to joining W3F, Chen-Da spent two years as a Post Doctoral Fellow in the Computer Science Department at Carnegie Mellon University (Pennsylvania) and in the Cryptography and Information Security (CIS) Laboratory at NTT Research (California). Chen-Da completed his Ph.D. in the Cryptography and Information Security group at ETH Zurich. Before that, he obtained a master's degree in computer science from ETH Zurich, and two bachelor degrees in computer science and mathematics from Universidad Autónoma Madrid.
+**Short Bio.** Prior to joining W3F, Chen-Da spent two years as a postdoctoral fellow in the Computer Science Department at Carnegie Mellon University (Pennsylvania) and at the Cryptography and Information Security (CIS) Laboratory at NTT Research (California). He completed his Ph.D. in the Cryptography and Information Security group at ETH Zurich, where he had previously earned a master’s degree in computer science. He also holds bachelor’s degrees in computer science and mathematics from Universidad Autónoma de Madrid.
**Selected Publications**
diff --git a/docs/team_members/elizabeth.md b/docs/team_members/elizabeth.md
index f8793167..e162a847 100644
--- a/docs/team_members/elizabeth.md
+++ b/docs/team_members/elizabeth.md
@@ -5,18 +5,15 @@ title: Elizabeth Crites
# Elizabeth C. Crites
-
+
alistair@web3.foundation
-Alistair is lead researcher at Web3 Foundation mainly working on protocol design. Alistair is the architect behind GRANDPA, Polkadot’s novel finality gadget. Moreover, he has worked on the validator selection scheme NPoS and designed Polkadot’s availability and validity scheme.
+Alistair is lead researcher at Web3 Foundation mainly working on protocol design. He is the architect behind GRANDPA, Polkadot’s novel finality gadget. Moreover, he has worked on the validator selection scheme NPoS and designed Polkadot’s availability and validity scheme.
**Research Areas**
@@ -14,7 +14,7 @@ Alistair is lead researcher at Web3 Foundation mainly working on protocol design
* Learning theory
* Stochatsic models
-**Short Bio**. Alistair has been a postdoc in theoretical Computer Science at University of Southern California working with Professor Ilias Diakonikolas, where he worked in learning theory with breakthrough results in high-dimensional robust statistics. Prior to that, in 2015 he obtained a PhD in Informatics from the University of Edinburgh on infinite-state stochastic models. Alistair holds a masters degree in Informatics from the University of Edinburgh and an undergraduate degree from Oxford University.
+**Short Bio.** Alistair has been a postdoc in theoretical Computer Science at University of Southern California working with Professor Ilias Diakonikolas, where he worked in learning theory with breakthrough results in high-dimensional robust statistics. Prior to that, in 2015 he obtained a PhD in Informatics from the University of Edinburgh on infinite-state stochastic models. Alistair holds a masters degree in Informatics from the University of Edinburgh and an undergraduate degree from Oxford University.
**Selected Publication**
@@ -23,3 +23,5 @@ Alistair is lead researcher at Web3 Foundation mainly working on protocol design
* I. Diakonikolas, D. Kane, A. Stewart. "The Fourier Transform of Poisson Multinomial Distributions and its Algorithmic Applications", the 48th Annual ACM Symposium on Theory of Computing (STOC 2016).
* K. Etessami, A. Stewart, M. Yannakakis. "Polynomial-time Algorithms for Multi-type Branching Processes and Stochastic Context-Free Grammars", ACM Symposium on Theory of Computing (STOC'12).
+
+
diff --git a/docs/team_members/chenda.md b/docs/team_members/chenda.md
index fb3d2505..3ac25aa7 100644
--- a/docs/team_members/chenda.md
+++ b/docs/team_members/chenda.md
@@ -1,10 +1,14 @@
# Chen-Da Liu-Zhang
+
+
chenda@web3.foundation
-Chen-Da has joined the Web3 Foundation team in July 2023 as a research scientist. His area of expertise encompasses both Cryptography and Distributed Systems, with a broad focus on the theory and practice of multi-party computation, consensus, peer-to-peer network, data availability, provable composable security and many others. His research has led to more than 25 publications at top international venues.
+Chen-Da joined the Web3 Foundation as a research scientist in July 2023. His areas of expertise span both cryptography and distributed systems, with a broad focus on theory and practice.
+
+**Research Areas.** Chen-Da's research areas include multi-party computation, consensus mechanisms, peer-to-peer networking, data availability, provable composable security, and more. His research has resulted in over 25 publications at top international venues.
-**Short Bio.** Prior to joining W3F, Chen-Da spent two years as a Post Doctoral Fellow in the Computer Science Department at Carnegie Mellon University (Pennsylvania) and in the Cryptography and Information Security (CIS) Laboratory at NTT Research (California). Chen-Da completed his Ph.D. in the Cryptography and Information Security group at ETH Zurich. Before that, he obtained a master's degree in computer science from ETH Zurich, and two bachelor degrees in computer science and mathematics from Universidad Autónoma Madrid.
+**Short Bio.** Prior to joining W3F, Chen-Da spent two years as a postdoctoral fellow in the Computer Science Department at Carnegie Mellon University (Pennsylvania) and at the Cryptography and Information Security (CIS) Laboratory at NTT Research (California). He completed his Ph.D. in the Cryptography and Information Security group at ETH Zurich, where he had previously earned a master’s degree in computer science. He also holds bachelor’s degrees in computer science and mathematics from Universidad Autónoma de Madrid.
**Selected Publications**
diff --git a/docs/team_members/elizabeth.md b/docs/team_members/elizabeth.md
index f8793167..e162a847 100644
--- a/docs/team_members/elizabeth.md
+++ b/docs/team_members/elizabeth.md
@@ -5,18 +5,15 @@ title: Elizabeth Crites
# Elizabeth C. Crites
- +
elizabeth@web3.foundation
-I am a Research Scientist in Cryptography at Web3 Foundation. Currently, my main area of research is threshold cryptography. My contributions in this area include the development of novel multi-signature and threshold signature schemes, such as Sparkle (CRYPTO’23, Best Early Career Paper Award), Snowblind (CRYPTO’23), FROST2 (CRYPTO’22), TSPS (ASIACRYPT'23), and SpeedyMuSig (an optimized version of MuSig2). Multi-party signatures are used in blockchains in myriad ways. They are also the subject of an upcoming call from the U.S. National Institute of Standards and Technology (NIST). I am a team member submitting FROST.
+Elizabeth is a research scientist in cryptography at Web3 Foundation. She works on protocol design and provable security for core cryptographic primitives in Polkadot. Currently, her work focuses on verifiable random functions (VRFs) with advanced functionalities, which are implemented in leader election protocols and in the distributed generation of public randomness.
-<<<<<<< HEAD
-=======
-I work on protocol design and provable security for core cryptographic primitives in Polkadot. Currently, my work focuses on verifiable random functions (VRFs) with advanced functionalities, which are implemented in leader election protocols and in the distributed generation of public randomness.
+**Research Areas.** Currently, her main area of research is threshold cryptography. Her contributions in this area include the development of novel multi-signature and threshold signature schemes, such as Sparkle (CRYPTO’23, Best Early Career Paper Award), Snowblind (CRYPTO’23), FROST2 (CRYPTO’22), TSPS (ASIACRYPT'23), and SpeedyMuSig (an optimized version of MuSig2). Multi-party signatures are used in blockchains in myriad ways. They are also the subject of an upcoming call from the U.S. National Institute of Standards and Technology (NIST). I am a team member submitting FROST.
->>>>>>> 8ccd6f0b05c514faa2c700fb50a5d1cac078ac2f
-**Short Bio.** I hold a PhD in Mathematics from Brown University, a master's degree in Applied Mathematics from Columbia University and a bachelor's degree in Honours Mathematics from The University of Western Ontario.
+**Short Bio.** Elizabeth holds a PhD in Mathematics from Brown University, a master's degree in Applied Mathematics from Columbia University, and a bachelor's degree in Honours Mathematics from the University of Western Ontario.
**Selected Publications**
@@ -28,3 +25,4 @@ I work on protocol design and provable security for core cryptographic primitive
* **Better than Advertised Security for Non-Interactive Threshold Signatures**. Mihir Bellare, Elizabeth Crites, Chelsea Komlo, Mary Maller, Stefano Tessaro, and Chenzhi Zhu. CRYPTO 2022. *Security analysis for the FROST and BLS threshold signature schemes.* https://crypto.iacr.org/2022/papers/538806_1_En_18_Chapter_OnlinePDF.pdf
+
\ No newline at end of file
diff --git a/docs/team_members/index.md b/docs/team_members/index.md
index 9e6827a2..daa06756 100644
--- a/docs/team_members/index.md
+++ b/docs/team_members/index.md
@@ -2,8 +2,14 @@
title: Team Members
---
-import DocCardList from '@theme/DocCardList';
+
-The core Web3 Foundation research team working on various areas relevant to decentralised systems.
+| [](https://research.web3.foundation/team_members/Jonas) | [](https://research.web3.foundation/team_members/Andrew) | [](https://research.web3.foundation/team_members/Elizabeth) |
+|----------------------------------------|----------------------------------------|------------------------------------------|
+| [](https://research.web3.foundation/team_members/jeff) | [](https://research.web3.foundation/team_members/alistair) | [](https://research.web3.foundation/team_members/Sergey) |
+| [](https://research.web3.foundation/team_members/Syed) | [](https://research.web3.foundation/team_members/Chenda) | [](https://research.web3.foundation/team_members/Bhargav) |
-
+
+
+
+
diff --git a/docs/team_members/jeff.md b/docs/team_members/jeff.md
index 69e52c57..45290e3e 100644
--- a/docs/team_members/jeff.md
+++ b/docs/team_members/jeff.md
@@ -2,15 +2,16 @@
import useBaseUrl from '@docusaurus/useBaseUrl';
-
+
elizabeth@web3.foundation
-I am a Research Scientist in Cryptography at Web3 Foundation. Currently, my main area of research is threshold cryptography. My contributions in this area include the development of novel multi-signature and threshold signature schemes, such as Sparkle (CRYPTO’23, Best Early Career Paper Award), Snowblind (CRYPTO’23), FROST2 (CRYPTO’22), TSPS (ASIACRYPT'23), and SpeedyMuSig (an optimized version of MuSig2). Multi-party signatures are used in blockchains in myriad ways. They are also the subject of an upcoming call from the U.S. National Institute of Standards and Technology (NIST). I am a team member submitting FROST.
+Elizabeth is a research scientist in cryptography at Web3 Foundation. She works on protocol design and provable security for core cryptographic primitives in Polkadot. Currently, her work focuses on verifiable random functions (VRFs) with advanced functionalities, which are implemented in leader election protocols and in the distributed generation of public randomness.
-<<<<<<< HEAD
-=======
-I work on protocol design and provable security for core cryptographic primitives in Polkadot. Currently, my work focuses on verifiable random functions (VRFs) with advanced functionalities, which are implemented in leader election protocols and in the distributed generation of public randomness.
+**Research Areas.** Currently, her main area of research is threshold cryptography. Her contributions in this area include the development of novel multi-signature and threshold signature schemes, such as Sparkle (CRYPTO’23, Best Early Career Paper Award), Snowblind (CRYPTO’23), FROST2 (CRYPTO’22), TSPS (ASIACRYPT'23), and SpeedyMuSig (an optimized version of MuSig2). Multi-party signatures are used in blockchains in myriad ways. They are also the subject of an upcoming call from the U.S. National Institute of Standards and Technology (NIST). I am a team member submitting FROST.
->>>>>>> 8ccd6f0b05c514faa2c700fb50a5d1cac078ac2f
-**Short Bio.** I hold a PhD in Mathematics from Brown University, a master's degree in Applied Mathematics from Columbia University and a bachelor's degree in Honours Mathematics from The University of Western Ontario.
+**Short Bio.** Elizabeth holds a PhD in Mathematics from Brown University, a master's degree in Applied Mathematics from Columbia University, and a bachelor's degree in Honours Mathematics from the University of Western Ontario.
**Selected Publications**
@@ -28,3 +25,4 @@ I work on protocol design and provable security for core cryptographic primitive
* **Better than Advertised Security for Non-Interactive Threshold Signatures**. Mihir Bellare, Elizabeth Crites, Chelsea Komlo, Mary Maller, Stefano Tessaro, and Chenzhi Zhu. CRYPTO 2022. *Security analysis for the FROST and BLS threshold signature schemes.* https://crypto.iacr.org/2022/papers/538806_1_En_18_Chapter_OnlinePDF.pdf
+
\ No newline at end of file
diff --git a/docs/team_members/index.md b/docs/team_members/index.md
index 9e6827a2..daa06756 100644
--- a/docs/team_members/index.md
+++ b/docs/team_members/index.md
@@ -2,8 +2,14 @@
title: Team Members
---
-import DocCardList from '@theme/DocCardList';
+
-The core Web3 Foundation research team working on various areas relevant to decentralised systems.
+| [](https://research.web3.foundation/team_members/Jonas) | [](https://research.web3.foundation/team_members/Andrew) | [](https://research.web3.foundation/team_members/Elizabeth) |
+|----------------------------------------|----------------------------------------|------------------------------------------|
+| [](https://research.web3.foundation/team_members/jeff) | [](https://research.web3.foundation/team_members/alistair) | [](https://research.web3.foundation/team_members/Sergey) |
+| [](https://research.web3.foundation/team_members/Syed) | [](https://research.web3.foundation/team_members/Chenda) | [](https://research.web3.foundation/team_members/Bhargav) |
-
+
+
+
+
diff --git a/docs/team_members/jeff.md b/docs/team_members/jeff.md
index 69e52c57..45290e3e 100644
--- a/docs/team_members/jeff.md
+++ b/docs/team_members/jeff.md
@@ -2,15 +2,16 @@
import useBaseUrl from '@docusaurus/useBaseUrl';
-}/) +
jeff@web3.foundation
-Jeff Burdges is an applied cryptography researcher working with Web3 foundation, where he works on cryptography for decentralized and/or privacy preserving protocols.
+Jeff Burdges is an applied cryptography researcher at the Web3 Foundation, where he focuses on cryptographic solutions for decentralized and privacy-preserving protocols.
-Jeff's work often involves collaborative randomness, specialized signature schemes like verifiable random functions (VRFs) or anonymous credentials, and increasingly both zero-knowledge proofs and incentives or mechanism design using VRFs. He is also researching a peer-to-peer private messaging service that will use mix networks.
+**Research Areas.** Jeff's work includes collaborative randomness, specialized signature schemes such as verifiable random functions (VRFs) or anonymous credentials, as well as increasing exploration into zero-knowledge proofs and incentive or mechanism design using VRFs. He also researches peer-to-peer private messaging systems that utilize mix networks.
-Jeff has ocasionally finds vulnerabilities, most recently the BIP32-Ed25519 proposal, but previously in blind signature deployments, and mix network designs, including broad limitations on the post-quantum kety exchanges suitable for mix networks.
+Jeff occasionally discovers vulnerabilities, most recently in the BIP32-Ed25519 proposal, and previously in blind signature deployments and mix network designs, including broad limitations in post-quantum key exchanges suitable for mix networks.
-**Short Bio**. Jeff previously worked on [Taler](https://taler.net/en/) and [GNUNet](https://gnunet.org/en/) as a postdoc for Christian Grothoff at Inria, Rennes, where he worked on anonymity protocols primarily mix networks, blind signatures, security proofs, distributed authentication, forward-secure ratchets, and pairing-based protocols. Jeff holds a PhD degree in Mathematics from Rutgers University in New Jersey.
+**Short Bio.** Jeff previously worked on [Taler](https://taler.net/en/) and [GNUNet](https://gnunet.org/en/) as a postdoctoral researcher under Christian Grothoff at Inria in Rennes, France. His contributions focused on anonymity protocols, including mix networks, blind signatures, security proofs, distributed authentication, forward-secure ratchets, and pairing-based protocols. Jeff holds a Ph.D. in Mathematics from Rutgers University in New Jersey.
+
\ No newline at end of file
diff --git a/docs/team_members/syed.md b/docs/team_members/syed.md
index b5ca27c9..4f27f511 100644
--- a/docs/team_members/syed.md
+++ b/docs/team_members/syed.md
@@ -1,7 +1,11 @@
-# Syed Hosseini
+# Seyed Hosseini
+
+
syed@web3.foundation
-Seyed is a Web3 Foundation researcher writing the Polkadot Runtime Environment (PRE) specification. He is also researching some of PRE’s primitives to see if they can be improved or simplified and helping with the implementation of various Algebraic and cryptographic primitives.
+Seyed is a researcher at the Web3 Foundation, where he works on the specification of the Polkadot Runtime Environment (PRE).
+
+**Research Areas.** Seyed investigates ways to improve or simplify the primitives of the Polkadot Runtime Environment (PRE) and contributes to the implementation of various algebraic and cryptographic components.
-**Short Bio**. As a mathematician studying for his PhD, Seyed focused on curve based cryptography, specifically geometric structures that offer richer mathematical properties than elliptic curves. He has studied and designed provably secure messaging protocols. He has been involved in the development of various network protocols, ML-based attack mitigation and analysis and distributed and cooperative network solutions.
+**Short Bio**. As a mathematician pursuing his Ph.D., Seyed focused on curve-based cryptography, particularly geometric structures that offer richer mathematical properties than elliptic curves. He studied and designed provably secure messaging protocols and contributed to the development of various machine learning–based attack mitigation and analysis techniques, network protocols, and distributed and cooperative network solutions.
\ No newline at end of file
diff --git a/docusaurus.config.js b/docusaurus.config.js
index e1ac1af6..4325a3c4 100644
--- a/docusaurus.config.js
+++ b/docusaurus.config.js
@@ -80,7 +80,7 @@ const config = {
items: [
{
type: 'doc',
- docId: 'Polkadot/overview/index',
+ docId: 'Polkadot/index',
position: 'right',
label: 'Polkadot',
},
diff --git a/sidebars.js b/sidebars.js
index 5e2f6666..94f2288c 100644
--- a/sidebars.js
+++ b/sidebars.js
@@ -1,22 +1,13 @@
/**
* Creating a sidebar enables you to:
- - create an ordered group of docs
- - render a sidebar for each doc of that group
- - provide next/previous navigation
-
- The sidebars can be generated from the filesystem, or explicitly defined here.
-
- Create as many sidebars as you want.
+ * - create an ordered group of docs
+ * - render a sidebar for each doc of that group
*/
// @ts-check
/** @type {import('@docusaurus/plugin-content-docs').SidebarsConfig} */
const sidebars = {
- // By default, Docusaurus generates a sidebar from the docs folder structure
- // sidebar: [{type: 'autogenerated', dirName: '.'}],
-
- // But you can create a sidebar manually
sidebar: [
{
type: 'doc',
@@ -25,14 +16,44 @@ const sidebars = {
{
type: 'category',
label: 'Polkadot',
+ link: { type: 'doc', id: 'Polkadot/index' },
collapsed: false,
items: [
{
type: 'category',
- label: 'Overview',
- link: {type:'doc', id:'Polkadot/overview/index'},
+ label: 'Economics',
+ link: { type: 'doc', id: 'Polkadot/economics/index' },
items: [
- 'Polkadot/overview/token-economics',
+ {
+ type: 'category',
+ label: 'Token Economics',
+ link: { type: 'doc', id: 'Polkadot/token-economics/index' },
+ items: [
+ ],
+ },
+ {
+ type: 'category',
+ label: 'Academic Research',
+ items: [
+ 'Polkadot/economics/academic-research/validator-selection',
+ 'Polkadot/economics/academic-research/npos',
+ 'Polkadot/economics/academic-research/parachain-experiment',
+ 'Polkadot/economics/academic-research/parachain-theory',
+ 'Polkadot/economics/academic-research/utilitytokendesign',
+ 'Polkadot/economics/academic-research/gamification',
+ ],
+ },
+ {
+ type: 'category',
+ label: 'Applied Research',
+ items: [
+ 'Polkadot/economics/applied-research/rfc17',
+ 'Polkadot/economics/applied-research/rfc97',
+ 'Polkadot/economics/applied-research/rfc146',
+ 'Polkadot/economics/applied-research/rfc10',
+ 'Polkadot/economics/applied-research/rfc104',
+ ],
+ },
],
},
{
@@ -57,11 +78,9 @@ const sidebars = {
items: [
'Polkadot/protocols/block-production/Babe',
'Polkadot/protocols/block-production/SASSAFRAS',
- ],
- },
- {
+ {
type: 'category',
- label: 'Sassafras',
+ label: 'Understanding Sassafras',
description: 'Understanding Sassafras',
link: {type:'doc', id:'Polkadot/protocols/Sassafras/index'},
items: [
@@ -70,22 +89,13 @@ const sidebars = {
'Polkadot/protocols/Sassafras/Sassafras-part-3',
],
},
+ ],
+ },
+
'Polkadot/protocols/finality',
'Polkadot/protocols/LightClientsBridges',
],
},
- {
- type: 'category',
- label: 'Economics',
- link: {type:'doc', id:'Polkadot/economics/index'},
- items: [
- 'Polkadot/economics/validator-selection',
- 'Polkadot/economics/parachain-theory',
- 'Polkadot/economics/parachain-experiment',
- 'Polkadot/economics/gamification',
- 'Polkadot/economics/utilitytokendesign',
- ],
- },
{
type: 'category',
label: 'Security',
@@ -106,6 +116,7 @@ const sidebars = {
{
type: 'category',
label: 'Slashing',
+ link: {type:'doc', id:'Polkadot/security/slashing/index'},
items: [
'Polkadot/security/slashing/amounts',
'Polkadot/security/slashing/npos',
@@ -119,23 +130,17 @@ const sidebars = {
type: 'category',
label: 'Team Members',
link: {type:'doc', id:'team_members/index'},
- items: [
- 'team_members/alistair',
- 'team_members/Andrew',
- 'team_members/elizabeth',
- 'team_members/jeff',
- 'team_members/Jonas',
- 'team_members/Sergey',
- 'team_members/syed',
- 'team_members/chenda',
- 'team_members/Bhargav'
- ],
+ items: [],
},
{
type: 'doc',
id: 'Publications',
},
+ {
+ type: 'doc',
+ id: 'Events',
+ },
],
};
-module.exports = sidebars;
+module.exports = sidebars;
\ No newline at end of file
+
jeff@web3.foundation
-Jeff Burdges is an applied cryptography researcher working with Web3 foundation, where he works on cryptography for decentralized and/or privacy preserving protocols.
+Jeff Burdges is an applied cryptography researcher at the Web3 Foundation, where he focuses on cryptographic solutions for decentralized and privacy-preserving protocols.
-Jeff's work often involves collaborative randomness, specialized signature schemes like verifiable random functions (VRFs) or anonymous credentials, and increasingly both zero-knowledge proofs and incentives or mechanism design using VRFs. He is also researching a peer-to-peer private messaging service that will use mix networks.
+**Research Areas.** Jeff's work includes collaborative randomness, specialized signature schemes such as verifiable random functions (VRFs) or anonymous credentials, as well as increasing exploration into zero-knowledge proofs and incentive or mechanism design using VRFs. He also researches peer-to-peer private messaging systems that utilize mix networks.
-Jeff has ocasionally finds vulnerabilities, most recently the BIP32-Ed25519 proposal, but previously in blind signature deployments, and mix network designs, including broad limitations on the post-quantum kety exchanges suitable for mix networks.
+Jeff occasionally discovers vulnerabilities, most recently in the BIP32-Ed25519 proposal, and previously in blind signature deployments and mix network designs, including broad limitations in post-quantum key exchanges suitable for mix networks.
-**Short Bio**. Jeff previously worked on [Taler](https://taler.net/en/) and [GNUNet](https://gnunet.org/en/) as a postdoc for Christian Grothoff at Inria, Rennes, where he worked on anonymity protocols primarily mix networks, blind signatures, security proofs, distributed authentication, forward-secure ratchets, and pairing-based protocols. Jeff holds a PhD degree in Mathematics from Rutgers University in New Jersey.
+**Short Bio.** Jeff previously worked on [Taler](https://taler.net/en/) and [GNUNet](https://gnunet.org/en/) as a postdoctoral researcher under Christian Grothoff at Inria in Rennes, France. His contributions focused on anonymity protocols, including mix networks, blind signatures, security proofs, distributed authentication, forward-secure ratchets, and pairing-based protocols. Jeff holds a Ph.D. in Mathematics from Rutgers University in New Jersey.
+
\ No newline at end of file
diff --git a/docs/team_members/syed.md b/docs/team_members/syed.md
index b5ca27c9..4f27f511 100644
--- a/docs/team_members/syed.md
+++ b/docs/team_members/syed.md
@@ -1,7 +1,11 @@
-# Syed Hosseini
+# Seyed Hosseini
+
+
syed@web3.foundation
-Seyed is a Web3 Foundation researcher writing the Polkadot Runtime Environment (PRE) specification. He is also researching some of PRE’s primitives to see if they can be improved or simplified and helping with the implementation of various Algebraic and cryptographic primitives.
+Seyed is a researcher at the Web3 Foundation, where he works on the specification of the Polkadot Runtime Environment (PRE).
+
+**Research Areas.** Seyed investigates ways to improve or simplify the primitives of the Polkadot Runtime Environment (PRE) and contributes to the implementation of various algebraic and cryptographic components.
-**Short Bio**. As a mathematician studying for his PhD, Seyed focused on curve based cryptography, specifically geometric structures that offer richer mathematical properties than elliptic curves. He has studied and designed provably secure messaging protocols. He has been involved in the development of various network protocols, ML-based attack mitigation and analysis and distributed and cooperative network solutions.
+**Short Bio**. As a mathematician pursuing his Ph.D., Seyed focused on curve-based cryptography, particularly geometric structures that offer richer mathematical properties than elliptic curves. He studied and designed provably secure messaging protocols and contributed to the development of various machine learning–based attack mitigation and analysis techniques, network protocols, and distributed and cooperative network solutions.
\ No newline at end of file
diff --git a/docusaurus.config.js b/docusaurus.config.js
index e1ac1af6..4325a3c4 100644
--- a/docusaurus.config.js
+++ b/docusaurus.config.js
@@ -80,7 +80,7 @@ const config = {
items: [
{
type: 'doc',
- docId: 'Polkadot/overview/index',
+ docId: 'Polkadot/index',
position: 'right',
label: 'Polkadot',
},
diff --git a/sidebars.js b/sidebars.js
index 5e2f6666..94f2288c 100644
--- a/sidebars.js
+++ b/sidebars.js
@@ -1,22 +1,13 @@
/**
* Creating a sidebar enables you to:
- - create an ordered group of docs
- - render a sidebar for each doc of that group
- - provide next/previous navigation
-
- The sidebars can be generated from the filesystem, or explicitly defined here.
-
- Create as many sidebars as you want.
+ * - create an ordered group of docs
+ * - render a sidebar for each doc of that group
*/
// @ts-check
/** @type {import('@docusaurus/plugin-content-docs').SidebarsConfig} */
const sidebars = {
- // By default, Docusaurus generates a sidebar from the docs folder structure
- // sidebar: [{type: 'autogenerated', dirName: '.'}],
-
- // But you can create a sidebar manually
sidebar: [
{
type: 'doc',
@@ -25,14 +16,44 @@ const sidebars = {
{
type: 'category',
label: 'Polkadot',
+ link: { type: 'doc', id: 'Polkadot/index' },
collapsed: false,
items: [
{
type: 'category',
- label: 'Overview',
- link: {type:'doc', id:'Polkadot/overview/index'},
+ label: 'Economics',
+ link: { type: 'doc', id: 'Polkadot/economics/index' },
items: [
- 'Polkadot/overview/token-economics',
+ {
+ type: 'category',
+ label: 'Token Economics',
+ link: { type: 'doc', id: 'Polkadot/token-economics/index' },
+ items: [
+ ],
+ },
+ {
+ type: 'category',
+ label: 'Academic Research',
+ items: [
+ 'Polkadot/economics/academic-research/validator-selection',
+ 'Polkadot/economics/academic-research/npos',
+ 'Polkadot/economics/academic-research/parachain-experiment',
+ 'Polkadot/economics/academic-research/parachain-theory',
+ 'Polkadot/economics/academic-research/utilitytokendesign',
+ 'Polkadot/economics/academic-research/gamification',
+ ],
+ },
+ {
+ type: 'category',
+ label: 'Applied Research',
+ items: [
+ 'Polkadot/economics/applied-research/rfc17',
+ 'Polkadot/economics/applied-research/rfc97',
+ 'Polkadot/economics/applied-research/rfc146',
+ 'Polkadot/economics/applied-research/rfc10',
+ 'Polkadot/economics/applied-research/rfc104',
+ ],
+ },
],
},
{
@@ -57,11 +78,9 @@ const sidebars = {
items: [
'Polkadot/protocols/block-production/Babe',
'Polkadot/protocols/block-production/SASSAFRAS',
- ],
- },
- {
+ {
type: 'category',
- label: 'Sassafras',
+ label: 'Understanding Sassafras',
description: 'Understanding Sassafras',
link: {type:'doc', id:'Polkadot/protocols/Sassafras/index'},
items: [
@@ -70,22 +89,13 @@ const sidebars = {
'Polkadot/protocols/Sassafras/Sassafras-part-3',
],
},
+ ],
+ },
+
'Polkadot/protocols/finality',
'Polkadot/protocols/LightClientsBridges',
],
},
- {
- type: 'category',
- label: 'Economics',
- link: {type:'doc', id:'Polkadot/economics/index'},
- items: [
- 'Polkadot/economics/validator-selection',
- 'Polkadot/economics/parachain-theory',
- 'Polkadot/economics/parachain-experiment',
- 'Polkadot/economics/gamification',
- 'Polkadot/economics/utilitytokendesign',
- ],
- },
{
type: 'category',
label: 'Security',
@@ -106,6 +116,7 @@ const sidebars = {
{
type: 'category',
label: 'Slashing',
+ link: {type:'doc', id:'Polkadot/security/slashing/index'},
items: [
'Polkadot/security/slashing/amounts',
'Polkadot/security/slashing/npos',
@@ -119,23 +130,17 @@ const sidebars = {
type: 'category',
label: 'Team Members',
link: {type:'doc', id:'team_members/index'},
- items: [
- 'team_members/alistair',
- 'team_members/Andrew',
- 'team_members/elizabeth',
- 'team_members/jeff',
- 'team_members/Jonas',
- 'team_members/Sergey',
- 'team_members/syed',
- 'team_members/chenda',
- 'team_members/Bhargav'
- ],
+ items: [],
},
{
type: 'doc',
id: 'Publications',
},
+ {
+ type: 'doc',
+ id: 'Events',
+ },
],
};
-module.exports = sidebars;
+module.exports = sidebars;
\ No newline at end of file