Tensorflow trained neural network to determine whether movie reviews are positive or negative.
Skills: Tensorflow, Python

The data we use was imported from Tensorflows's website for this tutorial. They are real reviews from IMDb's webste. 25000 polar movie reviews are for testing data, 25000 are for training data. There is also unlabeled data for use as well.
For both the data that the model was trained on and our individual review, there requires preprocessing on the .txt files inro a readable format for the model. To start, I standardized the length of each review to 250 words to keep it consistent. When training the model, I set the vocabulary size to 88000 meaning it only recognizes the 88000 most common words that appear in the training data and any uncommon word that might only come up once or twice is marked as unknown so it doesn't throw the model off. .The words and integers are placed in a dictionary called word_index, but I added 3 of my own keys first:
word_index["<PAD>"]= 0is an integer to fill extra space in the review to meet a certain length requirementword_index["<START>"]=1is an integer put at the start of every review to indicate that it is the startword_index["<UNK>"]=2is an integer used for unknown words (words not within the dictionary)word_index["<UNUSED>"]=3is used for unknown words
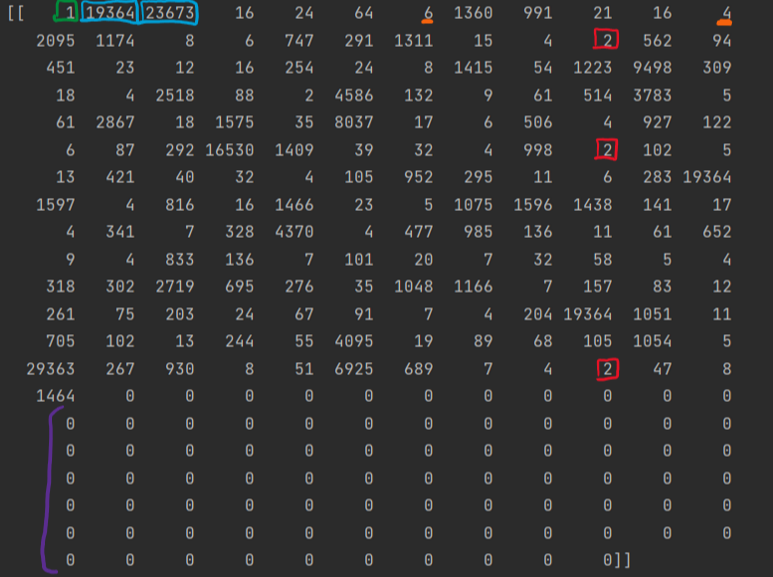
Greenshows how 1 is used at the start of any encoded textBlueshows the use of "Avengers" and "Endgame" and how they are uncommon in the vocablary so their integer is largeOrangeshows the use of 4="the" and 6="a" which are very common words, hence low integers ( 0-3 are custom so 4/the is actually the most used word)Redshows the singalling of an unknow word which is "MCU" in our review. Thus, it was so uncommon in training its not in the dictionaryPurpleshows that the rest of the review is padded to meet the 250 word structure

- The input is a sequence of encoded words from the review. Then we pass it to the embedding layer
- The embedding layer are the words represented as vectors and helps us group similair words together to help extract meaning from the reviews
- The next layer takes these vectors and averages them out; shrinking their data down
- The dense layer has 16 neurons, it looks for patterns of words and tries to classify them into either positive or negative reviews. It does this by modifying weights and biases on each connection
- The output layer gives a value between 0 and 1. The cloer to 1 the more positive the review is. An accuracy is also included
The model is a 3 layered sequential network created with keras
model.add(keras.layers.Embedding(88000, 16))is the embedding layer that creates 88000 word vectors with 16 dimensions.
- For reference, similair words will have a smaller angle between them in the vector space while unrelated words will have a greater angle
model.add(keras.layers.GlobalAveragePooling1D()) essentially flattens our 16 dimensions into a lower dimensions
model.add(keras.layers.Dense(16, activation="relu")) is the dense layer and used rectified linear unit as the activation function
model.add(keras.layers.Dense(1, activation="sigmoid")) is our output layer and uses a sigmoid function because our output must be between 0 and 1
model.compile(optimizer= "adam", loss= "binary_crossentropy",metrics= ["accuracy"]) compiles the model. binary_crossentropy was chosen because there are 2 options for the output neuron (0 or 1)
x_val= train_data[:10000]
x_train= train_data[10000:]
y_val= train_labels[:10000]
y_train= train_labels[10000:]
Here I am splitting up the data into validation data and training data. Validation data checks how well the model performs on new data.
fitModel= model.fit(x_train, y_train, epochs= 40, batch_size=512, validation_data= (x_val, y_val), verbose=1) This trains the model. 512 reviews are read in at once and this proess is repeated 40 times (epochs).
Training the model with 40 epochs took about 45 seconds with my personal computer specs, but this can be avoided in the future by saving the model
model.save("model.h5")