我也维护了一个学习深度学习框架(PyTorch和OneFlow)的仓库 https://github.com/BBuf/how-to-learn-deep-learning-framework 以及一个如何学习深度学习编译器(TVM/MLIR/LLVM)的学习仓库 https://github.com/BBuf/tvm_mlir_learn , 有需要的小伙伴可以点一点star
本工程记录如何基于 cuda 优化一些常见的算法。请注意,下面的介绍都分别对应了子目录的代码实现,所以想复现性能的话请查看对应子目录下面的 README 。
- 课程的 Slides 和 脚本:https://github.com/cuda-mode/lectures
- 课程地址:https://www.youtube.com/@CUDAMODE
- 我的课程笔记:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
一直想系统看一下某个课程系统和科学的学习下 CUDA ,感觉 CUDA-MODE 这个课程能满足我的需求。这个课程是几个 PyTorch 的 Core Dev 搞的,比较系统和专业。不过由于这个课程是 Youtube 上的英语课程,所以要学习和理解这个课程还是需要花不少时间的,我这里记录一下学习这个课程的每一课的笔记,希望可以通过这个笔记帮助对这个课程以及 CUDA 感兴趣的读者更快吸收这个课程的知识。这个课程相比于以前的纯教程更加关注的是我们可以利用 CUDA 做什么事情,而不是让读者陷入到 CUDA 专业术语的细节中,那会非常痛苦。伟大无需多言,感兴趣请阅读本文件夹下的各个课程的学习笔记。
记录如何手动编译 PyTorch 源码,学习 PyTorch 的一些 cuda 实现。
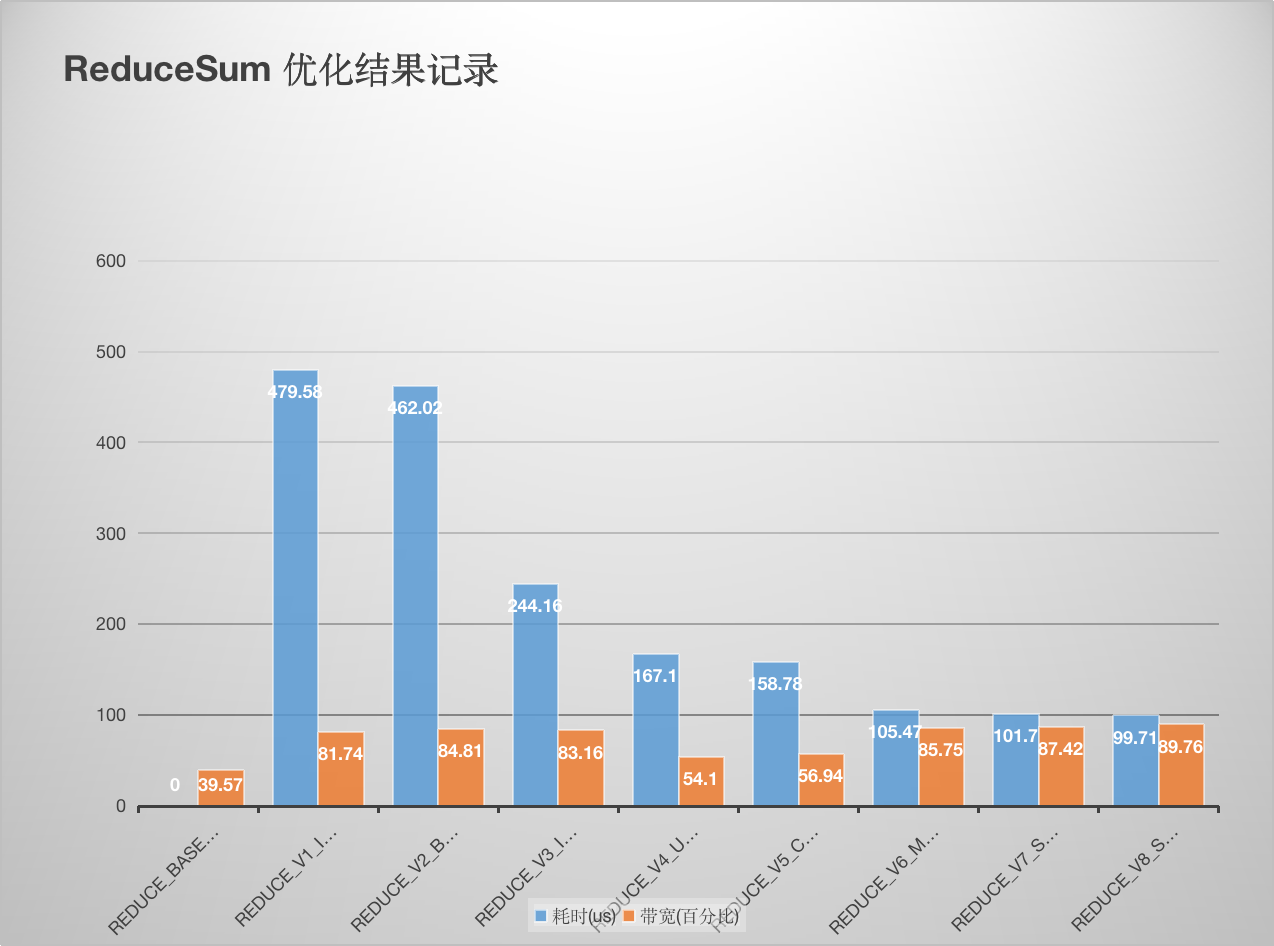
这里记录学习 NIVDIA 的reduce优化官方博客 做的笔记。完整实验代码见这里 , 原理讲解请看:【BBuf的CUDA笔记】三,reduce优化入门学习笔记 。后续又添加了 PyTorch BlockReduce 模板以及在这个模板的基础上额外加了一个数据 Pack ,又获得了一些带宽的提升。详细数据如下:
性能和带宽的测试情况如下 (A100 PCIE 40G):
将 oneflow 的 elementwise 模板抽出来方便大家使用,这个 elementwise 模板实现了高效的性能和带宽利用率,并且用法非常灵活。完整实验代码见这里 ,原理讲解请看:【BBuf 的CUDA笔记】一,解析OneFlow Element-Wise 算子实现 。这里以逐点乘为例,性能和带宽的测试情况如下 (A100 PCIE 40G):
| 优化手段 | 数据类型 | 耗时(us) | 带宽利用率 |
|---|---|---|---|
| naive elementwise | float | 298.46us | 85.88% |
| oneflow elementwise | float | 284us | 89.42% |
| naive elementwise | half | 237.28us | 52.55% |
| oneflow elementwise | half | 140.74us | 87.31% |
可以看到无论是性能还是带宽,使用 oneflow 的 elementwise 模板相比于原始实现都有较大提升。
实现的脚本是针对half数据类型做向量的内积,用到了atomicAdd,保证数据的长度以及gridsize和blocksize都是完全一致的。一共实现了3个脚本:
- https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/FastAtomicAdd/atomic_add_half.cu 纯half类型的atomicAdd。
- https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/FastAtomicAdd/atomic_add_half_pack2.cu half+pack,最终使用的是half2类型的atomicAdd。
- https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/FastAtomicAdd/fast_atomic_add_half.cu 快速原子加,虽然没有显示的pack,但本质上也是通过对单个half补0使用上了half2的原子加。
性能和带宽的测试情况如下 (A100 PCIE 40G):
| 原子加方式 | 性能(us) |
|---|---|
| 纯half类型 | 422.36ms |
| pack half2类型 | 137.02ms |
| fastAtomicAdd | 137.01ms |
可以看到使用pack half的方式和直接使用half的fastAtomicAdd方式得到的性能结果一致,均比原始的half的原子加快3-4倍。
upsample_nearest_2d.cu 展示了 oneflow 对 upsample_nearest2d 的前后向的优化 kernel 的用法,性能和带宽的测试情况如下 (A100 PCIE 40G):
| 框架 | 数据类型 | Op类型 | 带宽利用率 | 耗时 |
|---|---|---|---|---|
| PyTorch | Float32 | UpsampleNearest2D forward | 28.30% | 111.42us |
| PyTorch | Float32 | UpsampleNearest2D backward | 60.16% | 65.12us |
| OneFlow | Float32 | UpsampleNearest2D forward | 52.18% | 61.44us |
| OneFlow | Float32 | UpsampleNearest2D backward | 77.66% | 50.56us |
| PyTorch | Float16 | UpsampleNearest2D forward | 16.99% | 100.38us |
| PyTorch | Float16 | UpsampleNearest2D backward | 31.56% | 57.38us |
| OneFlow | Float16 | UpsampleNearest2D forward | 43.26% | 35.36us |
| OneFlow | Float16 | UpsampleNearest2D backward | 44.82% | 40.26us |
可以看到基于 oneflow upsample_nearest2d 的前后向的优化 kernel 可以获得更好的带宽利用率和性能。注意这里的 profile 使用的是 oneflow 脚本,而不是 upsample_nearest_2d.cu ,详情请看 UpsampleNearest2D/README.md 。
在 PyTorch 中对 index_add 做了极致的优化,我这里将 PyTorch 的 index_add 实现 进行了剥离,方便大家应用于其它框架。具体请看 indexing 文件夹的 README 。其中还有和 oneflow 的 index_add 实现的各个 case 的性能比较结果。整体来说 PyTorch 在 index Tensor元素很小,但Tensor很大的情况下有较大的性能提升,其它情况和 OneFlow 基本持平。详情请看 indexing/README.md 。
OneFlow 深度学习框架中基于 cuda 做的优化工作,动态更新中。
总结 FastTransformer 相关的 cuda 优化技巧。README_BERT.md 总结了 BERT 相关的优化技巧。
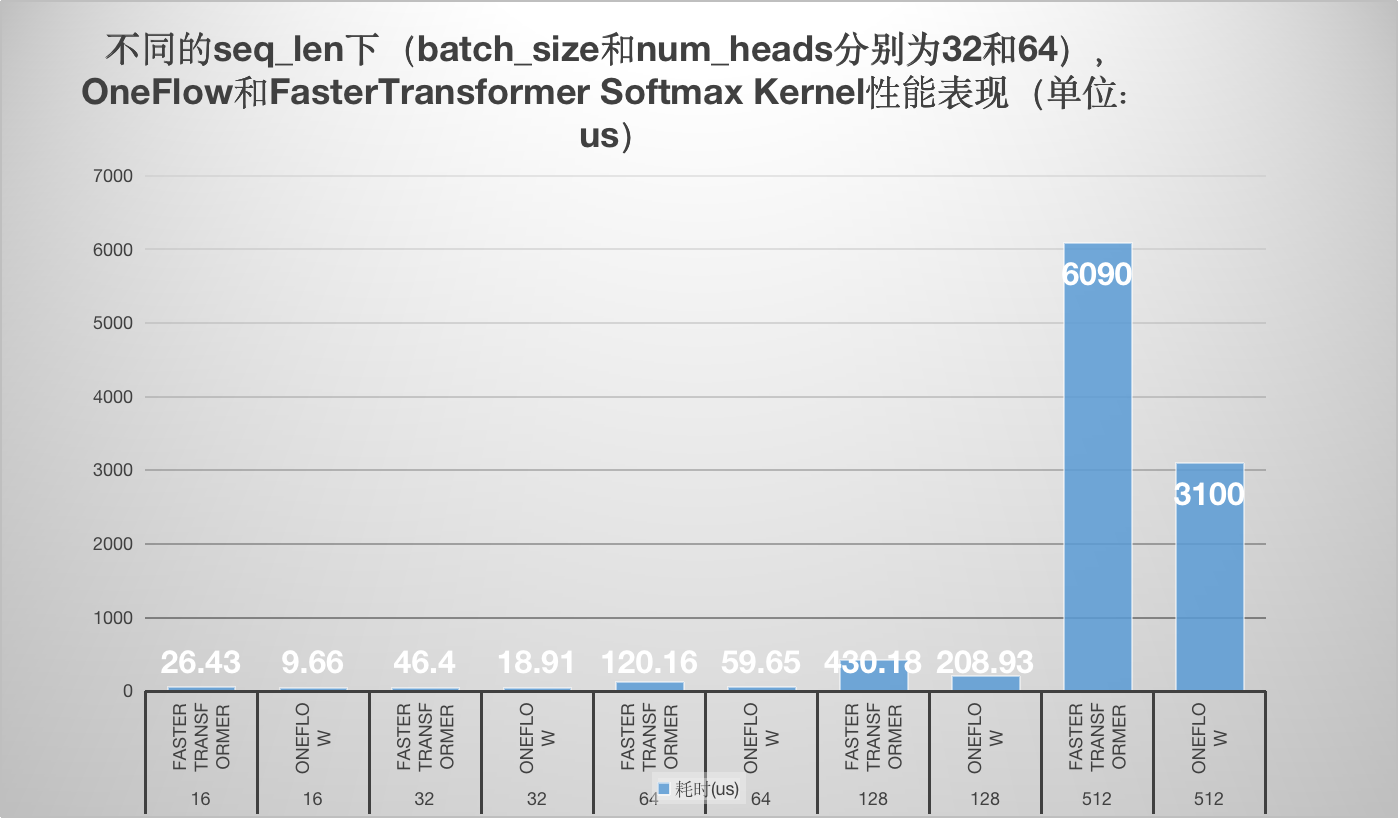
学习了oneflow的softmax kernel实现以及Faster Transformer softmax kernel的实现,并以个人的角度分别解析了原理和代码实现,最后对性能做一个对比方便大家直观的感受到oneflow softmax kernel相比于FasterTransformer的优越性。
学习一些 linear attention 的 cuda 优化技巧。
收集了和大语言模型原理,训练,推理,数据标注的相关文章。
前研的大模型训练相关 AI-Infra 论文收集以及阅读笔记。
Triton 学习过程中的代码记录和学习笔记。
Meagtron-LM 学习笔记。
Triton 中国举办的 Meetup 的slides汇总。点卡这个文件夹也可以找到对应的Meetup的视频回放。
对 CUDA PTX ISA 文档的一个翻译和学习。
对 PyTorch 团队发布的 cuda 技术的一些学习笔记。
cutlass 相关的学习笔记。
cuda 相关的 paper 的阅读。
点击展开/收起 BBuf 的 CUDA 学习笔记列表
- 【BBuf的CUDA笔记】一,解析OneFlow Element-Wise 算子实现
- 【BBuf的CUDA笔记】二,解析 OneFlow BatchNorm 相关算子实现
- 【BBuf的CUDA笔记】三,reduce优化入门学习笔记
- 【BBuf的CUDA笔记】四,介绍三个高效实用的CUDA算法实现(OneFlow ElementWise模板,FastAtomicAdd模板,OneFlow UpsampleNearest2d模板)
- 【BBuf的CUDA笔记】五,解读 PyTorch index_add 操作涉及的优化技术
- 【BBuf的CUDA笔记】六,总结 FasterTransformer Encoder(BERT) 的cuda相关优化技巧
- 【BBuf的CUDA笔记】七,总结 FasterTransformer Decoder(GPT) 的cuda相关优化技巧
- 【BBuf的CUDA笔记】八,对比学习OneFlow 和 FasterTransformer 的 Softmax Cuda实现
- 【BBuf的CUDA笔记】九,使用newbing(chatgpt)解析oneflow softmax相关的fuse优化
- CodeGeeX百亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
- 【BBuf的cuda学习笔记十】Megatron-LM的gradient_accumulation_fusion优化
- 【BBuf的CUDA笔记】十,Linear Attention的cuda kernel实现解析
- 【BBuf的CUDA笔记】十一,Linear Attention的cuda kernel实现补档
- 【BBuf的CUDA笔记】十二,LayerNorm/RMSNorm的重计算实现
- 【BBuf的CUDA笔记】十三,OpenAI Triton 入门笔记一
- 【BBuf的CUDA笔记】十四,OpenAI Triton入门笔记二
- 【BBuf的CUDA笔记】十五,OpenAI Triton入门笔记三 FusedAttention
- AI Infra论文阅读之通过打表得到训练大模型的最佳并行配置
- AI Infra论文阅读之将流水线并行气泡几乎降到零(附基于Meagtron-LM的ZB-H1开源代码实现解读)
- AI Infra论文阅读之LIGHTSEQ(LLM长文本训练的Infra工作)
- AI Infra论文阅读之《在LLM训练中减少激活值内存》
- 系统调优助手,PyTorch Profiler TensorBoard 插件教程
- 在GPU上加速RWKV6模型的Linear Attention计算
- flash-linear-attention的fused_recurrent_rwkv6 Triton实现精读
- flash-linear-attention中的Chunkwise并行算法的理解
- 硬件高效的线性注意力机制Gated Linear Attention论文阅读
- GQA,MLA之外的另一种KV Cache压缩方式:动态内存压缩(DMC)
- vAttention:用于在没有Paged Attention的情况下Serving LLM
- 大模型KV Cache节省神器MLA学习笔记(包含推理时的矩阵吸收分析)
- CUDA-MODE 课程笔记 第一课: 如何在 PyTorch 中 profile CUDA kernels
- CUDA-MODE 第一课课后实战(上)
- CUDA-MODE 第一课课后实战(下)
- CUDA-MODE 课程笔记 第二课: PMPP 书的第1-3章速通
- CUDA-MODE 课程笔记 第四课: PMPP 书的第4-5章笔记
- CUDA-MODE课程笔记 第6课: 如何优化PyTorch中的优化器
- CUTLASS 2.x & CUTLASS 3.x Intro 学习笔记
- CUDA-MODE课程笔记 第7课: Quantization Cuda vs Triton
- TRT-LLM中的Quantization GEMM(Ampere Mixed GEMM)CUTLASS 2.x 课程学习笔记
- CUDA-MODE课程笔记 第8课: CUDA性能检查清单
- TensorRT-LLM 中的 Hopper Mixed GEMM 的 CUTLASS 3.x 实现讲解
- 通过微基准测试和指令级分析(Instruction-level Analysis)揭秘英伟达Ampere架构
- CUDA-MODE课程笔记 第9课: 归约(也对应PMPP的第10章)
- 【翻译】Accelerating Llama3 FP8 Inference with Triton Kernels
- 【PyTorch 奇淫技巧】Python Custom Operators翻译
- 【翻译】教程:在PyTorch中为CUDA库绑定Python接口
- 【翻译】教程:CUTLASS中的矩阵转置 (使用CuTe把矩阵转置优化到GPU内存带宽上下限)
- CUDA-MODE课程笔记 第11课: Sparsity
- 【PyTorch 奇淫技巧】Async Checkpoint Save
- CUDA-MODE课程笔记 第12课,Flash Attention
- 【翻译】在 GPU 上如何加速 GPTQ Triton 反量化kernel
- 基于o1-preview解读 Optimized GPTQ INT4 Dequantization Triton Kernel
- 【翻译】深入探讨 Hopper TMA 单元在 FP8 GEMM 运算中的应用
- 【翻译】CUTLASS 教程:掌握 NVIDIA® 张量内存加速器 (TMA)
- 【PyTorch 奇技淫巧】介绍 depyf:轻松掌握 torch.compile
- CUDA-MODE 课程笔记 第13课:Ring Attention
- 【翻译】torch.compile 的详细示例解析教程
- 【翻译】【PyTorch 奇技淫巧】FlexAttetion 基于Triton打造灵活度拉满的Attention
- Flex Attention API 应用 Notebook 代码速览
- 【翻译】CUDA-Free Inference for LLMs
- CUDA-MODE 课程笔记 第14课,Triton 实践指南
- 【翻译】使用PyTorch FSDP最大化训练吞吐量
- 【翻译】使用PyTorch FSDP和Torch.compile最大化训练吞吐量
- 【ml-engineering 翻译系列】大模型推理
- 【ml-engineering 翻译系列】AI系统中的网络概述
- 【ml-engineering 翻译系列】AI系统中的网络 debug
- 【ml-engineering 翻译系列】AI系统中的网络 benchmark
- 【翻译】在FSDP2中开启Float8 All-Gather
- 【ml-engineering 翻译系列】训练之模型并行
- 梳理下Flash Attention的dispatch逻辑
- 【ml-engineering 翻译系列】计算加速器之cpu
- CUDA-MODE课程笔记 Lecture 16 通过CUDA C++核心库把llm.c移植为llm.cpp
- GPU 矩阵乘实际可达最大FLOPS测量工具
- CUDA-MODE 课程笔记 第28课 用在生产环境中的LinkedIn Liger kernel
- RMSNorm的精度陷阱:记一次LLM推理精度调查
- 如何正确理解NVIDIA GPU利用率的概念
- CUDA-MODE 课程笔记 第29课 Triton内部机制
- GTX 4090 的 cuda graph 诡异
- 【ml-engineering 翻译系列】计算加速器之gpu
- CUDA-MODE课程笔记 第17课 GPU集合通信(NCCL)
- Triton Kernel 编译阶段
- 使用torchtune把LLaMa-3.1 8B蒸馏为1B
- [分布式训练与TorchTitan] PyTorch中的Async Tensor Parallelism介绍
- PyTorch 博客 CUTLASS Ping-Pong GEMM Kernel 简介
- PyTorch博客 《使用 Triton 加速 2D 动态块量化 Float8 GEMM 简介》
- 使用NCU和Cursor Claude-sonnet-3.5写出高效cuda算子的正确姿势
- Fused AllGather_MatMul Triton工程实现
- MoE之年的总结和MoE 推理优化的一些认识
- SGLang DP MLA 特性解读
- Windsurf(可平替 Cursor) 的使用体验和技巧
- SGLang MLA 实现解析
- 详解vLLM和SGLang awq dequantize kernel的魔法
- SGLang 支持Flash Attention V3 Backend
- 分享一个DeepSeek V3和R1中 Shared Experts和普通Experts融合的一个小技巧
- CUDA优化 让向量求和变得非常快
- DeepSeek-V3 + SGLang: 推理优化 (v0.4.3.post2+sgl-kernel:0.0.3.post6)
- 图解DeepSeek V3 biased_grouped_topk cuda融合算子fused_moe_gate kernel
- 一起聊聊Nvidia Hopper 新特性之TMA
- 一起聊聊Nvidia Hopper新特性之WGMMA
- 一起聊聊Nvidia Hopper新特性之Pipeline
- 一起聊聊Nvidia Hopper新特性之计算切分
- 【博客翻译】CUDA中的索引
- 图解Vllm V1系列1:整体流程
- 在 SGLang 中实现 Flash Attention 后端 - 基础和 KV 缓存
- 图解Vllm V1系列2:Executor-Workers架构
- 【博客翻译】让前缀和变得更快
- SGLang Team:在 96 个 H100 GPU 上部署具有 PD 分解和大规模专家并行性的 DeepSeek
- 图解Vllm V1系列3:KV Cache初始化
- 【CUDA 优化】让RMSNorm变得更快
- 在SGLang中使用reasoning模型
- SGLang 源码学习笔记:Cache、Req与Scheduler
- 单机H200最快DeepSeek V3和R1推理系统优化秘籍
- 通过查看GPU Assembly分析CUDA程序
- sglang 源码学习笔记(二)- backend & forward 过程
- Sglang 源码学习笔记(三)- 分布式和并行(以deepseek 为例)(WIP)
- 【CUDA 博客】TMA简介 & 让矩阵转置在Hopper GPUs上变得更快
点击展开/收起 CUDA优质博客列表
- Writing my own communications library - a worklog of creating Penny part 1
- CuteDSL-1: Introduction
- Enable Tensor Core Programming in Python with CUTLASS 4.0
- 一文读懂nvidia-smi topo的输出
- 如果你是一个C++面试官,你会问哪些问题?
- 推理部署工程师面试题库
- [C++特性]对std::move和std::forward的理解
- 论文阅读:Mimalloc Free List Sharding in Action
- 在 C++ 中,RAII 有哪些妙用?
- AI/HPC面试问题整理
- Roofline Model与深度学习模型的性能分析
- FlashAttention核心逻辑以及V1 V2差异总结
- flash attention 1和flash attention 2算法的python和triton实现
- Flash Attention 推公式
- 图解大模型计算加速系列:FlashAttention V1,从硬件到计算逻辑
- flash attention完全解析和CUDA零基础实现
- FlashAttention图解(如何加速Attention)
- FlashAttention:加速计算,节省显存, IO感知的精确注意力
- FlashAttention 反向传播运算推导
- 比标准Attention提速5-9倍,大模型都在用的FlashAttention v2来了
- FlashAttention 的速度优化原理是怎样的?
- FlashAttention 的速度优化原理是怎样的?
- FlashAttention2详解(性能比FlashAttention提升200%)
- FlashAttenion-V3: Flash Decoding详解
- 速通PageAttention2
- PageAttention代码走读
- 大模型推理加速之FlashDecoding++:野生Flash抵达战场
- 学习Flash Attention和Flash Decoding的一些思考与疑惑
- 大模型推理加速之Flash Decoding:更小子任务提升并行度
- FlashAttention与Multi Query Attention
- 动手Attention优化1:Flash Attention 2优化点解析
- Flash Attention推理性能探究
- 记录Flash Attention2-对1在GPU并行性和计算量上的一些小优化
- [LLM] FlashAttention 加速attention计算[理论证明|代码解读]
- FlashAttention核心逻辑以及V1 V2差异总结
- 【手撕LLM-FlashAttention】从softmax说起,保姆级超长文!!
- 动手Attention优化2:图解基于PTX的Tensor Core矩阵分块乘法实现
- flash attention 的几个要点
- GPU内存(显存)的理解与基本使用
- 图文并茂,超详细解读nms cuda拓展源码
- 大模型的好伙伴,浅析推理加速引擎FasterTransformer
- LLM Inference CookBook(持续更新)
- NVIDIA的custom allreduce
- [论文速读] FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- CUDA随笔之Stream的使用
- 简单读读FasterTransformer
- cutlass FusedMultiheadAttention代码解读
- 简单谈谈CUDA Reduce
- GridReduce - CUDA Reduce 部分结果归约
- CUTLASS: Fast Linear Algebra in CUDA C++
- cutlass源码导读(1)——API与设计理念
- cutlass源码导读(2)——Gemm的计算流程
- CUDA GroupNorm NHWC优化
- 传统 CUDA GEMM 不完全指北
- 怎么评估内存带宽的指标,并进行优化?
- TensorRT Diffusion模型优化点
- NVIDIA GPU性能优化基础
- 一文理解 PyTorch 中的 SyncBatchNorm
- 如何开发机器学习系统:高性能GPU矩阵乘法
- CUDA SGEMM矩阵乘法优化笔记——从入门到cublas
- Dropout算子的bitmask优化
- 面向 Tensor Core 的算子自动生成
- PICASSO论文学习
- CUDA翻译:How to Access Global Memory Efficiently in CUDA C/C++ Kernels
- CUDA Pro Tips翻译:Write Flexible Kernels with Grid-Stride Loops
- [施工中] CUDA GEMM 理论性能分析与 kernel 优化
- CUDA Ampere Tensor Core HGEMM 矩阵乘法优化笔记 —— Up To 131 TFLOPS!
- Nvidia Tensor Core-CUDA HGEMM优化进阶
- CUDA C++ Best Practices Guide Release 12.1笔记(一)
- CUDA 矩阵乘法终极优化指南
- 如何用CUDA写有CuBLAS 90%性能的GEMM Kernel
- 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?
- 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?
- 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?
- 使用FasterTransformer实现LLM分布式推理
- 细粒度GPU知识点详细总结
- https://siboehm.com/articles/22/CUDA-MMM
- 【CUDA编程】OneFlow Softmax算子源码解读之BlockSoftmax
- 【CUDA编程】OneFlow Softmax 算子源码解读之WarpSoftmax
- 【CUDA编程】OneFlow Element-Wise 算子源码解读
- 【CUDA编程】Faster Transformer v1.0 源码详解
- 【CUDA编程】Faster Transformer v2.0 源码详解
- FasterTransformer Decoding 源码分析(七)-FFNLayer MoE(上篇)
- FasterTransformer Decoding 源码分析(八)-FFNLayer MoE(下篇)
- 从roofline模型看CPU矩阵乘法优化
- 性能优化的终极手段之 Profile-Guided Optimization (PGO)
- 有没有大模型推理加速引擎FasterTransformer入门级教程?
- 深入浅出GPU优化系列:gemv优化
- NVIDIA Hopper架构TensorCore分析(4)
- GPU host+device的编译流程
- Tensor Core 优化半精度矩阵乘揭秘
- 无痛CUDA实践:μ-CUDA 自动计算图生成
- CUDA(三):通用矩阵乘法:从入门到熟练
- 自己写的CUDA矩阵乘法能优化到多快?
- 高效CUDA Scan算法浅析
- 一次 CUDA Graph 调试经历
- CUDA中的radix sort算法
- NVIDIA Tensor Core微架构解析
- cutlass cute 101
- 在GPU避免分支的方法
- Pytorch-CUDA从入门到放弃(二)
- 腾讯机智团队分享--AllReduce算法的前世今生
- cute 之 Layout
- cute Layout 的代数和几何解释
- cute 之 GEMM流水线
- Using CUDA Warp-Level Primitives
- CUDA Pro Tip: Increase Performance with Vectorized Memory Access
- cute 之 简单GEMM实现
- cute 之 MMA抽象
- cute 之 Tensor
- cute Swizzle细谈
- 基于 CUTE 的 GEMM 优化【2】—— 高效 GEMM 实现,超越 Cublas 20%
- CUDA单精度矩阵乘法(sgemm)优化笔记
- HPC(高性能计算第一篇) :一文彻底搞懂并发编程与内存屏障(第一篇)
- GPU CUDA 编程的基本原理是什么? 怎么入门?
- 如何入门 OpenAI Triton 编程?
- CUDA(二):GPU的内存体系及其优化指南
- nvitop: 史上最强GPU性能实时监测工具
- 使用Triton在模型中构建自定义算子
- CUDA笔记 内存合并访问
- GPGPU架构,编译器和运行时
- GPGPU的memory 体系理解
- nvlink那些事……
- 对NVidia Hopper GH100 的一些理解
- 黑科技:用cutlass进行低成本、高性能卷积算子定制开发
- 乱谈Triton Ampere WMMA (施工中)
- 可能是讲的最清楚的WeightonlyGEMM博客
- GPU 底层机制分析:kernel launch 开销
- GPU内存(显存)的理解与基本使用
- 超越AITemplate,打平TensorRT,SD全系列模型加速框架stable-fast隆重登场
- [手把手带你入门CUTLASS系列] 0x00 cutlass基本认知---为什么要用cutlass
- [手把手带你入门CUTLASS系列] 0x02 cutlass 源码分析(一) --- block swizzle 和 tile iterator (附tvm等价code)
- [手把手带你入门CUTLASS系列] 0x03 cutlass 源码分析(二) --- bank conflict free 的shared memory layout (附tvm等价pass)
- [深入分析CUTLASS系列] 0x04 cutlass 源码分析(三) --- 多级流水线(software pipeline)
- [深入分析CUTLASS系列] 0x03 cutlass 源码分析(二) --- bank conflict free 的shared memory layout (附tvm等价pass)
- GPU 内存概念浅析
- NV_GPU tensor core 算力/带宽/编程模型分析
- Nsight Compute - Scheduler Statistics
- NVidia GPU指令集架构-前言
- 搞懂 CUDA Shared Memory 上的 bank conflicts 和向量化指令(LDS.128 / float4)的访存特点
- 窥探Trition的lower(二)
- 窥探Trition的lower(三)
- ops(2):SoftMax 算子的 CUDA 实现与优化
- cuda学习日记(6) nsight system / nsight compute
- ops(3):Cross Entropy 的 CUDA 实现
- cuda的ldmatrix指令的详细解释
- 揭秘 Tensor Core 底层:如何让AI计算速度飞跃
- NCCL(NVIDIA Collective Communication Library)的来龙去脉
- ldmatrix与swizzle(笔记)
- GPU上GEMM的边界问题以及优化
- NV Tensor Core and Memory Accelerator 理论分析
- CUTLASS CuTe GEMM细节分析(一)——ldmatrix的选择
- Triton到PTX(1):Elementwise
- 由矩阵乘法边界处理引起的CUDA wmma fragment与原始矩阵元素对应关系探究
- NVIDIA Hopper架构TensorCore分析(4)
- NVidia GPU指令集架构-Load和Cache
- NVidia GPU指令集架构-寄存器
- Async Copy 及 Memory Barrier 指令的功能与实现
- tensorcore中ldmatrix指令的优势是什么?
- 使用cutlass cute复现flash attention
- 1. Cuda矩阵乘法GeMM性能优化
- 一步步优化 GEMM by Tensorcore
- CUTLASS 3.x 异构编程随感
- Triton到PTX(1):Elementwise
- Triton到SASS(2):Reduction
- cuda的ldmatrix指令的详细解释
- 基于 CuTe 理解 swizzle, LDSM, MMA
- 一文读懂nsight system与cuda kernel的时间线分析与可视化
- TileLang: 80行Python kernel代码实现FlashMLA 95%的性能
- 简单CUDA Assembly介绍
- Deep Gemm 代码浅析
- 如何看懂deepseek ai开源的FlashMLA中的核心cu代码?
- 浅析GEMM优化multistage数怎么算
- DeepSeek: FlashMLA代码解析
- triton(openai)如何实现splitk和streamk?
- FlashMLA性能简测
- DeepSeek-V3/R1 的 Hosting 成本预估
- 实用 Swizzle 教程(一)
- 实用 Swizzle 教程(二)
- CUDA编程入门之Cooperative Groups(1)
- Flash Attention 3 深度解析
- flashattention中为什么Br的分块要取min,Bc除以4我理解是M要装下QKVO,Br呢?
- FlashAttention笔记
- 由GQA性能数据异常引发的对MHA,GQA,MQA 在GPU上的感性分析
- 动手Attention优化3:理解Bank Conflict及Cutlass Swizzle
- 如何理解GPU Kernel Grid/Block与SM占用率的关系?什么是Tail Effect?
- Triton入门笔记(二):flash attention的Triton/CUDA对比(前向传播部分)
- 基于 CuTe 理解 swizzle, LDSM, MMA
- NCCL通信C++示例(四): AlltoAll_Split实现与分析
- 如何用 Triton实现一个更高效的topk_gating kernel?——算子合并技术
- 关于Nsight Compute中Compute Workload Analysis反映的Tensor Pipe Utilization的理解
- MARLIN: Mixed-Precision Auto-Regressive Parallel Inference on Large Language Models论文解读
- Shader中的条件分支能否节省shader的性能?
- LLM Decode GQA & GEMV算子性能分析(一)
- LLM Decode GQA & GEMV算子性能分析(二)
- cute gemm 优化
- [Triton] Triton-Linalg
- cutlass swizzle机制解析(一)
- vLLM源码之PageAttention
- CUTLASS CUTE MMA
- 了解FlashAttentionV3的优化需要先了解Hopper的主要技术(Hopper White Paper概述)
- 从Hopper架构到HGEMM
- 基于CUTLASS CuTe分析cp.async的Prefetch行为
- 为什么加pad可以解bank conflict?
- cute swizzle
- CUTLASS CuTe GEMM细节分析(三)——Swizzle<B, M, S>模板参数的取值
- OpenAI Triton: Why layout is important
- Triton到SASS(5.5):TMA/Multicast/Warp Specialize踩坑记
- Tile-lang 简介
- CUTLASS:基于CUTE的矩阵乘法优化
- Marlin W4A16&W4A8代码走读
- CUTLASS 3: CuTe Layout Algebra
点击展开/收起 大模型Infra优质博客列表
- Megatron-LM 分布式执行调研
- BLOOM 训练背后的技术
- 聊聊 PyTorch2.0 中新的Distributed API
- 聊聊 PyTorch 中新的Distributed API (二)
- 【LLM】从零开始训练大模型
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
- 人手一个ChatGPT!微软DeepSpeed Chat震撼发布,一键RLHF训练千亿级大模型
- 大型语言模型(LLM)训练指南🚀
- “StackLLaMA”: 用 RLHF 训练 LLaMA 的手把手教程
- 图解大模型训练之:流水线并行(Pipeline Parallelism),以Gpipe为例
- 图解大模型训练之:数据并行上篇(DP, DDP与ZeRO)
- 图解大模型训练之:数据并行下篇( DeepSpeed ZeRO,零冗余优化)
- 图解大模型训练之:张量模型并行(TP),Megatron-LM
- Megatron-LM 中的 pipeline 并行
- 图解大模型系列之:Megatron源码解读1,分布式环境初始化
- 图解大模型训练之:Megatron源码解读2,模型并行
- 聊聊序列并行Sequence parallelism
- 深入理解 Megatron-LM(1)基础知识
- 深入理解 Megatron-LM(2)原理介绍
- 深入理解 Megatron-LM(3)代码结构
- 深入理解 Megatron-LM(4)并行设置
- 深入理解 Megatron-LM(5)张量并行
- 聊聊字节 AML 万卡工作 MegaScale: Scaling Large Language Model Training
- 深度学习里,模型并行中怎么将模型拆分?
- Transformers DeepSpeed官方文档
- DeepSeek-V3 MTP 工程实现思考
- DeepSeek V3/R1 推理效率分析(1):关于DeepSeek V3/R1 Decoding吞吐极限的一些不负责任估计
- DeepSeek V3/R1 推理效率分析(2): DeepSeek 满血版逆向工程分析
- DeepSeek V3/R1 推理效率分析(3):Decode 配置泛化讨论
- 如何估算不同规格的芯片 EP 部署 Deepseek 的单卡吞吐 V1.0
- 深度解析FlashMLA: 一文读懂大模型加速新利器
- Flash MLA 笔记
- MoE Inference On AnyScale
- 大模型分布式通信技术博客汇总
- sglang 源码学习笔记(一)- Cache、Req与Scheduler
- DualPipe 深入浅出:没有分布式训练基础也能看懂的 DualPipe 全方位讲解
- DeepSeek MLA引发的一些记忆碎片
- DeepSeek MLA的序列并行和张量并行
- SGLang: Triton算子extend_attention/Prefix优化
- DeepSeek-V3 (671B) 模型参数量分解计算
- DeepSeek关键技术再总结
- PP->VPP->ZeroBubblePP->deepseekv3 dualPipe,对PP bubble的极致压缩
- 双流并行(DualPipe) 没有双流会更好
- deepseek 训练 profile data 基础分析
- Deepseek FlashMLA解析
- 理解DeepGEMM源码和实现逻辑
- DeepEP Dispatch/Combine 图示
- MoE并行负载均衡:EPLB的深度解析与可视化
- 给 Megatron 的长文本训练抓了一个 Bug
- 对DualPipe的一些想法
- SGLang: Triton算子prefill_attention
- [CUDA基础]📚CUDA-Learn-Notes: v3.0 大升级-面试刷题不迷路
- [大模型推理系统] SGlang的异步调度:Overlap CPU和GPU流水
- 计算DeepSeekV3训练的MFU
- 如何评价 DeepSeek 的 DeepSeek-V3 模型?
- SGLang _fwd_kernel_stage2 计算公式推导
- SGLang代码快速上手(with openRLHF)
- DiT并行推理引擎-xDiT的设计哲学
- 记一次对 SGLang weight update latency 的优化
- vllm代码快速上手
- 由Ring-Attention性能问题引发的计算通信overlap分析
- TensorRT-LLM的allreduce插件
- DeepSeek-V2 MLA KV Cache 真的省了吗?
- PyTorch FSDP 设计解读
- 大模型推理-5-大模型推理优化之缓存及调度
- 【22token/s|又提升20%】榨干ktransformers的每一滴性能
- 从零开始设计SGLang的KV Cache
- LLM(33):MoE 的算法理论与 EP 的工程化问题
- Megatron中的MoE TokenDispatcher机制
- KTransformers v0.2.4: 多并发支持(上万行代码的诚意更新),Xeon6+MRDIMM 加持下单机单卡环境下四并发超过 40 tokens/s
- 从零开始的verl框架解析
- [AI Infra] VeRL 框架入门&代码带读
- 【AI Infra】【RLHF框架】一、VeRL中基于Ray的执行流程源码解析
- 【AI Infra】【RLHF框架】二、VeRL中colocate实现源码解析
- 【AI Infra】【RLHF框架】三、VeRL中的Rollout实现源码解析
- SGLang-veRL Server:从 Engine 到 Server,我们需要更灵活的 RLHF rollout 接口
- vLLM V1 源码阅读
- veRL框架初探
点击展开/收起 大模型和AIGC的演进
- github仓库
- rwkv论文原理解读
- RWKV的微调教学,以及RWKV World:支持世界所有语言的生成+对话+任务+代码
- RWKV:用RNN达到Transformer性能,且支持并行模式和长程记忆,既快又省显存,已在14B参数规模检验
- 谈谈 RWKV 系列的 prompt 设计,模型选择,解码参数设置
- RWKV进展:一键生成论文,纯CPU高速INT4,纯CUDA脱离pytorch,ctx8192不耗显存不变慢
- 开源1.5/3/7B中文小说模型:显存3G就能跑7B模型,几行代码即可调用
- 发布几个RWKV的Chat模型(包括英文和中文)7B/14B欢迎大家玩
- 实例:手写 CUDA 算子,让 Pytorch 提速 20 倍(某特殊算子)
- BlinkDL/RWKV-World-7B gradio demo
- ChatRWKV(有可用猫娘模型!)微调/部署/使用/训练资源合集
- pengbo的专栏
- RWKV 模型解析
- [线性RNN系列] Mamba: S4史诗级升级
- 状态空间模型: RWKV & Mamba
- Transformer,SSM,Linear Attention的联系与理解
- mixture-of-experts-with-expert-choice
- MoE训练论文解读之Megablocks:打破动态路由限制
- MoE训练论文解读之Tutel: 动态切换并行策略实现动态路由
- ACM SIGCOMM 2023有哪些亮点?
- LLM终身学习的可能性——Mixture of Experts
- MoE 入门介绍 核心工作回顾 模型篇
- 大语言模型结构之:浅谈MOE结构
- 训不动Mixtral,要不试试LLaMA-MoE?
- Mixtral-8x7B MoE大模型微调实践,超越Llama2-65B
- Mixtral-8x7B 模型挖坑
- Mixture of Experts(MoE)学习笔记
- 群魔乱舞:MoE大模型详解
- Mixtral 8x7B论文终于来了:架构细节、参数量首次曝光
- MoE(Mixture-of-Experts)大模型架构的优势是什么?为什么?
- 图解大模型训练系列之:DeepSpeed-Megatron MoE并行训练(原理篇
- 图解大模型训练系列之:DeepSpeed-Megatron MoE并行训练(源码解读篇)
- LLM 学习笔记-Deepspeed-MoE 论文
- 图解Mixtral 8 * 7b推理优化原理与源码实现
- 压缩下一个 token 通向超过人类的智能
- LLM 入门笔记-Tokenizer
- 【Transformer 基础系列】手推显存占用
- 《A Survey of Large Language Models》笔记
- 分析transformer模型的参数量、计算量、中间激活、KV cache
- Transformer模型的基础演算
- Transformer 估算 101
- 通向AGI之路:大型语言模型(LLM)技术精要
- Transformer学习笔记二:Self-Attention(自注意力机制)
- Transformer学习笔记三:为什么Transformer要用LayerNorm/Batch Normalization & Layer Normalization (批量&层标准化)
- Transformer学习笔记五:Subword Tokenization(子词分词器)
- ChatGPT技术解析系列之:GPT1、GPT2与GPT3
- ChatGPT技术解析系列之:训练框架InstructGPT
- ChatGPT技术解析系列之:赋予GPT写代码能力的Codex
- 大模型推理性能优化之KV Cache解读
- 拆解追溯 ChatGPT各项能力的起源
- ChatGPT 的突现能力,我们是否真的面临范式转变?
- 复杂推理:大型语言模型的"北极星"能力
- 深入理解NLP Subword算法:BPE、WordPiece、ULM
- ChatGPT 背后的“功臣”——RLHF 技术详解
- 深入浅出,解析ChatGPT背后的工作原理
- 这是Meta版ChatGPT雏形?开源、一块GPU就能跑,1/10参数量打败GPT-3
- LLaMA模型惨遭泄漏,Meta版ChatGPT被迫「开源」!GitHub斩获8k星,评测大量出炉
- LeCun狂赞:600刀GPT-3.5平替! 斯坦福70亿参数「羊驼」爆火,LLaMA杀疯了
- LeCun转赞:在苹果M1/M2芯片上跑LLaMA!130亿参数模型仅需4GB内存
- Stanford Alpaca (羊驼):ChatGPT 学术版开源实现
- Alpaca-Lora (羊驼-Lora): 轻量级 ChatGPT 的开源实现(对标 Standford Alpaca)
- Alpaca-cpp(羊驼-cpp): 可以本地运行的 Alpaca 大语言模型
- NLP(九):LLaMA, Alpaca, ColossalChat 系列模型研究
- 全球最大ChatGPT开源平替来了!支持35种语言,写代码、讲笑话全拿捏
- 国产ChatGPT又开源了!效果大幅升级,在手机上也可以跑
- 世界首款真开源类ChatGPT大模型Dolly 2.0,可随意修改商用
- 用ChatGPT训练羊驼:「白泽」开源,轻松构建专属模型,可在线试玩
- 3090单卡5小时,每个人都能训练专属ChatGPT,港科大开源LMFlow
- 300美元复刻ChatGPT九成功力,GPT-4亲自监考,130亿参数开源模型「小羊驼」来了
- 学术专用版ChatGPT火了,一键完成论文润色、代码解释、报告生成
- 笔记本就能运行的ChatGPT平替来了,附完整版技术报告
- 训练个中文版ChatGPT没那么难:不用A100,开源Alpaca-LoRA+RTX 4090就能搞定
- 弥补斯坦福70亿参数「羊驼」短板,精通中文的大模型来了,已开源
- 还在为玩不了ChatGPT苦恼?这十几个开源平替也能体验智能对话
- 斯坦福70亿参数开源模型媲美GPT-3.5,100美元即可复现
- 真·ChatGPT平替:无需显卡,MacBook、树莓派就能运行LLaMA
- ChatGPT开源替代来了!参数量200亿,在4300万条指令上微调而成
- B站UP主硬核自制智能音箱:有ChatGPT加持,才是真・智能
- 熔岩羊驼LLaVA来了:像GPT-4一样可以看图聊天,无需邀请码,在线可玩
- 3天近一万Star,无差体验GPT-4识图能力,MiniGPT-4看图聊天、还能草图建网站
- ChatGPT 中文调教指南。各种场景使用指南。学习怎么让它听你的话
- ChatGPT提示工程师|AI大神吴恩达教你写提示词
- [分析] 浅谈ChatGPT的Tokenizer
- OPT-175B是如何炼成的
- Meta复刻GPT-3“背刺”OpenAI,完整模型权重及训练代码全公开
- Limitations of LLaMA
- Hugging News #0506: StarCoder, DeepFloyd/IF 好多新的重量级模型
- StarCoder: 最先进的代码大模型
- VideoChat🦜: 基于视频指令数据微调的聊天机器人
- MiniGPT-4 本地部署 RTX 3090
- 更擅长推理的LLaMA大模型,支持中文!
- 点击鼠标,让ChatGPT更懂视觉任务!
- [分析] ROPE的不同实现:llama&palm
- 羊驼系列大模型和ChatGPT差多少?详细测评后,我沉默了
- 【开源骆驼】更好的翻译prompt,中英文token比例,比alpaca更强的中文数据集WizardLM
- ImageBind: 表征大一统?也许还有一段距离
- 训练开销骤减,10%成本定制专属类GPT-4多模态大模型
- 国内首个可复现的RLHF基准,北大团队开源 PKU-Beaver
- 北大紧跟步伐开源PKU-Beaver (河狸)——不仅支持RLHF训练, 还开源RLHF训练数据
- 大模型迎来「开源季」,盘点过去一个月那些开源的LLM和数据集
- 超越GPT-4!华人团队爆火InstructBLIP抢跑看图聊天,开源项目横扫多项SOTA
- 基于 ChatGLM-6B 搭建个人专属知识库
- 大模型-LLM分布式训练框架总结
- 没有RLHF,一样媲美GPT-4、Bard,Meta发布650亿参数语言模型LIMA
- 在Transformer时代重塑RNN,RWKV将非Transformer架构扩展到数百亿参数
- 马腾宇团队新出大模型预训练优化器,比Adam快2倍,成本减半
- 跑分达ChatGPT的99%,人类难以分辨!开源「原驼」爆火,iPhone都能微调大模型了
- 大模型词表扩充必备工具SentencePiece
- RWKV – transformer 与 RNN 的强强联合
- Falcon 登陆 Hugging Face 生态
- 详解大模型RLHF过程(配代码解读)
- 详解Transformer-XL
- 教科书级数据is all you need:1.3B小模型逆袭大模型的秘密
- 清华第二代60亿参数ChatGLM2开源!中文榜居首,碾压GPT-4,推理提速42%
- NLP(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能
- AGI最前沿:GPT-4之后大模型学术进展速览
- LLM学习记录(一)--关于大模型的一些知识
- UC伯克利LLM排行榜首次重磅更新!GPT-4稳居榜首,全新330亿参数「小羊驼」位列开源第一
- 【Falcon Paper】我们是靠洗数据洗败 LLaMA 的!
- [中文开源震撼首发]33B QLoRA大语言模型Anima真的太强大了!QLoRA技术可能是AI转折点!
- 详解大模型RLHF过程(配代码解读)
- 羊驼家族大模型集体进化!32k上下文追平GPT-4,成本忽略不计
- 大模型LLM知识整理
- Relative position embedding
- ICLR 2023 Spotlight | ViT-Adapter:针对原始ViT结构设计密集预测任务适配器
- DevChat:将 GPT-4 无缝融入 VS Code,极致提升你的编程体验
- OpenAI早就不卷大模型,开始卷AI Agents了?这是一篇来自OpenAI应用研究主管关于Agent的万字长文
- 为什么说大模型训练很难?
- LLM学习记录(五)--超简单的RoPE理解方式
- langchain源码剖析-模块整体介绍【1】
- 如何为GPT/LLM模型添加额外知识?
- LLaMA Plus版来了,谷歌推出LongLLaMA,不仅让你的大模型更集中注意力,还能处理超长上线文
- Transformer升级之路:10、RoPE是一种β进制编码
- 大模型的幻觉问题调研: LLM Hallucination Survey
- [Transformer 101系列] 初探LLM基座模型
- LLaMA2 RLHF 技术细节
- 万字长文谈多模态预训练(UNITER、ViLBERT、CLIP、ALBEF、BLIP、METER)
- 大模型中的分词器tokenizer:BPE、WordPiece、Unigram LM、SentencePiece
- 【LLM系列】开源模型和闭源模型之争--写在LLaMA2 开源之后
- 0718 - LLaMA2讨论 - Memo
- 0723 - LLaMA 2 第二次讨论 - Memo
- Bert/Transformer 被忽视的细节(或许可以用来做面试题)
- 大模型面试八股
- 降龙十八掌:这套优化transformer内存占用的组合技值得收藏
- 十分钟读懂旋转编码(RoPE)
- [LLM] multi query attention加速推理解码
- 大模型(LLM) + 上下文检索增强
- 语言模型的训练时间:从估算到 FLOPs 推导
- 大模型基础|位置编码|RoPE|ALiBi
- RoPE外推的缩放法则 —— 尝试外推RoPE至1M上下文
- NTK-ALiBi:通过插值实现大模型ALiBi位置编码的长文本外推
- miniGPT-4的同期工作: 微软LLaVa模型论文笔记
- Function Call: Chat 应用的插件基石与交互技术的变革黎明
- 关于 Llama 2 的一切资源,我们都帮你整理好了
- 大模型升级与设计之道:ChatGLM、LLAMA、Baichuan及LLM结构解析
- 如何评价超越Llama的Falcon模型?
- From LLaMA2 to GPT4
- 大杀器,多模态大模型MiniGPT-4入坑指南
- 视觉Transformer如何优雅地避开位置编码?
- 动动嘴就可以创建专属的AI智能体小队,LinkSoul.AI、北大、港科大等发布AutoAgents技术
- MiniGPT-4模型原理及复现
- 手把手教学!部署MiniGPT4模型
- LLM投机采样(Speculative Sampling)为何能加速模型推理
- LangChain之Memory
- LLM/阿里:通义千问Qwen-VL与Qwen-VL-Chat多模态大模型【对标VisualGLM】
- 不用4个H100!340亿参数Code Llama在Mac可跑,每秒20个token,代码生成最拿手|Karpathy转赞
- 超长上下文 LLM 推理简要分析
- LongMem: 大模型的长期记忆
- 【LLM】Meta LLaMA 2中RLHF技术细节
- LLM大模型训练Trick系列(一)之拒绝采样
- 想让大模型在prompt中学习更多示例,这种方法能让你输入更多字符
- 主流大语言模型从预训练到微调的技术原理
- AI Agents大爆发:OpenAI的下一步
- 小写一下llama2,破除迷信
- LLM评估指标困惑度的理解
- Anima新模型发布,100K窗口长度,突破极限,真的巨巨巨强大!长才是王道!
- Mixture-of-Experts (MoE) 经典论文一览
- [LLM] 从实践到理论,Byte Pair Encoding(BPE) 深度调研
- 理解NLP最重要的编码方式 — Byte Pair Encoding (BPE),这一篇就够了
- NLP三大Subword模型详解:BPE、WordPiece、ULM
- 再读VIT,还有多少细节是你不知道的
- Transformer位置编码(基础)
- Llama 2 中使用 RLHF 的一些细节:margin r、reject sampling 和 PPO
- 创造性vs确定性:大语言模型(LLM)中的温度(Temperature)和Top_P怎么调?
- 如何混合大模型SFT阶段的各能力项数据?
- 【llm大语言模型】一文看懂llama2(原理,模型,训练)
- 如何更好地继续预训练(Continue PreTraining)
- [[大模型推理]WINT8/4🔥通俗易懂讲解-快速反量化算法](https://zhuanlan.zhihu.com/p/657072856)
- Llama 2详解
- 垂直领域大模型的思考
- 解读 Effective Long Context Scaling of Foundation Models(强烈推荐)
- 解析大模型中的Scaling Law
- NLP(廿三):LLM 中的长文本问题
- 十分钟读懂Beam Search 1:基础
- 颠覆Transformer霸权!CMU普林斯顿推Mamba新架构,解决致命bug推理速度暴增5倍
- 矩阵模拟!Transformer大模型3D可视化,GPT-3、Nano-GPT每一层清晰可见
- 旋转式位置编码 (RoPE) 知识总结
- 大模型生成去重技术总结
- 如何优雅地编码文本中的位置信息?三种positional encoding方法简述
- adam在大模型预训练中的不稳定性分析及解决办法
- 饮鸩止渴?LLM训练要不要过采样/训多个epoch
- 多个大语言微调模型并行推断的潜力
- 剖析GPT推断中的批处理效应
- RoPE旋转位置编码深度解析:理论推导、代码实现、长度外推
- 再论大模型位置编码及其外推性(万字长文)
- RoPE外推优化——支持192K上下文长度
- 想研究大模型Alignment,你只需要看懂这几篇paper
- MiniCPM:揭示端侧大语言模型的无限潜力
- GPT-4内幕大泄露!1.8万亿巨量参数,13万亿token训练,斥资6300万美元
- 一览大模型长文本能力
- LLM(廿六):从信息论的角度解释 scaling law
- Mamba技术背景详解:从RNN到Mamba一文搞定!
- [大模型 08] 水多加面面多加水——参数量和数据的缩放定律
- GPT-4o解耦之旅
- CLA:降低Transformer模型内存需求的新方法
- 为什么需要RLHF?SFT不够吗?
- 从Nemotron-4 看 Reward Model 发展趋势
- Cosmopedia: 如何为预训练构建大规模合成数据集
- 一个不是很长的综述:AI-Agent,Language Agent(语言代理,智能体)下一代语言大模型的发展
- NLP(廿二):LLM 时代的 multi-agent 系统
- 关于 Agent 开发的一些思考
- AI Agent万字长文总结
- 多模态大模型 CLIP, BLIP, BLIP2, LLaVA, miniGPT4, InstructBLIP 系列解读
- 多模态大模型超详细解读 (目录)
- 我们与 GPT-4V 的距离
- LLaVA(二)LLaVA-1.5 论文解读
- Megatron-LM 分布式执行调研
- BLOOM 训练背后的技术
- 聊聊 PyTorch2.0 中新的Distributed API
- 聊聊 PyTorch 中新的Distributed API (二)
- 【LLM】从零开始训练大模型
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
- 人手一个ChatGPT!微软DeepSpeed Chat震撼发布,一键RLHF训练千亿级大模型
- 大型语言模型(LLM)训练指南🚀
- “StackLLaMA”: 用 RLHF 训练 LLaMA 的手把手教程
- 图解大模型训练之:流水线并行(Pipeline Parallelism),以Gpipe为例
- 图解大模型训练之:数据并行上篇(DP, DDP与ZeRO)
- 图解大模型训练之:数据并行下篇( DeepSpeed ZeRO,零冗余优化)
- 图解大模型训练之:张量模型并行(TP),Megatron-LM
- Megatron-LM 中的 pipeline 并行
- 图解大模型系列之:Megatron源码解读1,分布式环境初始化
- 图解大模型训练之:Megatron源码解读2,模型并行
- 聊聊序列并行Sequence parallelism
- Megatron-LM 近期的改动
- 深入理解 Megatron-LM(1)基础知识
- 深入理解 Megatron-LM(2)原理介绍
- 深入理解 Megatron-LM(3)代码结构
- 深入理解 Megatron-LM(4)并行设置
- 深入理解 Megatron-LM(5)张量并行
- 聊聊字节 AML 万卡工作 MegaScale: Scaling Large Language Model Training
- 深度学习里,模型并行中怎么将模型拆分?
- Transformers DeepSpeed官方文档
- 当红炸子鸡 LoRA,是当代微调 LLMs 的正确姿势?
- GLM、LLAMA用Accelerate+deepspeed做RLHF时可能遇到的问题
- GPT fine-tune实战: 训练我自己的 ChatGPT🚀🚀🚀
- DeepSpeed之ZeRO系列:将显存优化进行到底
- 大模型也内卷,Vicuna训练及推理指南,效果碾压斯坦福羊驼
- 一键式 RLHF 训练 DeepSpeed Chat(一):理论篇
- 使用DeepSpeed/P-Tuning v2对ChatGLM-6B进行微调
- 从0到1基于ChatGLM-6B使用LoRA进行参数高效微调
- 足够惊艳,使用Alpaca-Lora基于LLaMA(7B)二十分钟完成微调,效果比肩斯坦福羊驼
- 基于LLaMA-7B/Bloomz-7B1-mt复现开源中文对话大模型BELLE及GPTQ量化
- 从0到1复现斯坦福羊驼(Stanford Alpaca 7B)
- 如何使用 Megatron-LM 训练语言模型
- [源码解析] 模型并行分布式训练Megatron (1) --- 论文&基础
- [源码解析] 模型并行分布式训练Megatron (2) --- 整体架构
- [源码解析] 模型并行分布式训练 Megatron (3) ---模型并行实现
- [源码解析] 模型并行分布式训练 Megatron (4) --- 如何设置各种并行
- [源码解析] 模型并行分布式训练Megatron (5) --Pipedream Flush
- 模型并行训练:Megatron-LM pipeline并行源码解读
- Pytorch Distributed Data Parallal
- 【分布式训练技术分享五】聊聊 Zero Bubble Pipeline Parallelism
- 大模型参数高效微调技术原理综述(七)-最佳实践、总结
- 【万字长文】LLaMA, ChatGLM, BLOOM的参数高效微调实践
- CPT:兼顾理解和生成的中文预训练模型
- 大模型流水线并行(Pipeline)实战
- QLoRA:4-bit级别的量化+LoRA方法,用3090在DB-GPT上打造基于33B LLM的个人知识库
- 大模型高效微调综述上:Adapter Tuning、AdaMix、PET、Prefix-Tuning、Prompt Tuning、P-tuning、P-tuning v2
- 大模型高效微调综述下: DiffPruning、BitFit、LoRa、AdaLoRA、MAM Adapters、UniPELT
- RLHF实践中的框架使用与一些坑 (TRL, LMFlow)
- QLoRA: 4bit量化+LoRA训练=瞬间起飞
- baichuan-7B 模型使用/训练/Lora/测评
- LLM - finetuning - 踩坑经验之谈
- 使用 RLHF 训练 LLaMA 的实践指南:StackLLaMA
- 预训练模型时代:告别finetune, 拥抱adapter
- ChatGLM2微调保姆级教程~
- LLM训练指南:Token及模型参数准备
- 单样本微调给ChatGLM2注入知识~
- 想要微调清华chatglm6b模型,数据集给多少条比较合适?
- 如何看待chatglm2?真实效果怎么样?
- 百川13B-chat开箱及LORA进行PT/SFT微调
- 打造 LLM 界的 Web UI:24GB 显卡训练百亿大模型
- 大模型训练 Pipeline Parallel 流水并行性能分析
- 【LLM系列】中文LLaMA2的一些工作
- LLaMA2中文微调
- 图解大模型微调系列之:大模型低秩适配器LoRA(原理篇)
- 大模型参数高效微调技术实战(二)-Prompt Tuning
- [调研]Megatron-LM 的分布式执行
- 深入理解 Megatron-LM(5)模型并行
- GPT-3模型为何难以复现?这也许是分布式AI框架的最优设计
- 北大硕士RLHF实践,基于DeepSpeed-Chat成功训练上自己的模型
- Megatron-LM 第三篇Paper总结——Sequence Parallelism & Selective Checkpointing
- 【llm大语言模型】code llama详解与应用
- DeepSpeed-Chat更新: Llama/Llama-2系统支持,效率提升和训练稳定性改进
- RLHF实践
- LLM - finetuning - 踩坑经验之谈
- 从头训练一个迷你中文版Llama2--一个小项目踏上LLM之旅
- 用 Decision Transformer/Offline RL 做 LLM Alignment
- 代码生成模型评价指标 pass@k 的计算
- BaiChuan2技术报告细节分享&个人想法
- 大模型参数高效微调技术实战(六)-IA3
- 图解大模型微调系列之:AdaLoRA,能做“财务”预算的低秩适配器
- 【2023Q4】再谈Long-Context LLM
- 【大语言模型】LongLoRA:大语言模型长文本的高效微调方法
- RLHF 训练中,如何挑选最好的 checkpoint?
- deepspeed入门教程
- S-LORA:单卡服务两千个LLM模型,vLLM团队指出行业大模型新范式
- 大模型微调技巧 | 高质量指令数据筛选方法-MoDS
- 2023年神秘而难以理解的大模型强化学习技术:RLHF PPO,DPO,以及InstructGPT,DeepSpeed-Chat, LLama2,Baichuan2的RLHF
- 影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)
- Transformer的浮点数计算
- ChatGLM3保姆级P-Tuning v2微调教程
- 使用 PyTorch 完全分片数据并行技术加速大模型训练
- 显存优化之加速通信算子内存释放
- Transformer第四章:vllm之PagedAttention代码分析(2)
- 探索大模型SFT过程中的不稳定的原因
- 【手撕RLHF-Rejection Sampling】如何优雅的从SFT过渡到PPO
- 数据并行Deep-dive: 从DP 到 Fully Sharded Data Parallel (FSDP)完全分片数据并行
- ChatGLM2-6B多轮对话训练方式
- 显存优化之重计算在长文场景的思考
- 一文读懂分布式训练启动方式
- DeepSpeed ZeRO理论与VLM大模型训练实践
- LLM中的RLHF——ppo、dpo算法实践(基于qwen、chatglm3)
- 使用Firefly在单卡V100上对Qwen1.5进行SFT和DPO,大幅超越Qwen1.5和Gemma
- DeepSpeed-Ulysses (SequenceParallel)
- NLP(九十六)使用LLaMA-Factory实现function calling
- 不那么显然的 RLHF
- 分布式训练与DeepSpeed浅谈
- 序列并行做大模型训练,你需要知道的六件事
- 我爱DeepSpeed-Ulysses:重新审视大模型序列并行技术
- 由Ring-Attention性能问题引发的计算通信overlap分析
- 为Token-level流水并行找PMF:从TeraPipe,Seq1F1B,HPipe到PipeFusion
- SFT Packing详解
- 聊聊大模型推理服务中的优化问题
- 聊聊大模型推理中的分离式推理
- 大幅优化推理过程,字节高性能Transformer推理库获IPDPS 2023最佳论文奖
- CodeGeeX百亿参数大模型的调优笔记:比FasterTransformer更快的解决方案
- 优化故事: BLOOM 模型推理
- 大型语言模型的推理演算
- 简单读读WeightOnly
- [大模型技术祛魅]关于FlexGen的一点理解
- LLM Inference CookBook(持续更新)
- 优化故事: BLOOM 模型推理
- GPTQ-for-LLaMa 量化分析和优化
- Web-LLM:机器学习编译纯浏览器运行大模型
- 陈天奇等人新作引爆AI界:手机原生跑大模型,算力不是问题了
- NLP(十一):大语言模型的模型量化(INT8)技术
- 大(语言)模型推理原理及加速
- AI算力碎片化:矩阵乘法的启示
- 大大大模型部署方案抛砖引玉
- BELLE(LLaMA-7B/Bloomz-7B1-mt)大模型使用GPTQ量化后推理性能测试
- 大模型的好伙伴,浅析推理加速引擎FasterTransformer
- 模型推理服务化框架Triton保姆式教程(一):快速入门
- 模型推理服务化框架Triton保姆式教程(二):架构解析
- 模型推理服务化框架Triton保姆式教程(三):开发实践
- 【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
- 使用bitsandbytes、4 位量化和 QLoRA 使 LLM 更易于访问
- NLP(十七):从 FlashAttention 到 PagedAttention, 如何进一步优化 Attention 性能
- 【LLM 加速技巧】Muti Query Attention 和 Attention with Linear Bias(附源码)
- 如何优化transformer的attention?
- Huggingface Accelerate文档:超大模型推理方法
- vLLM框架top down概览
- LLaMa 量化部署
- 为什么现在大家都在用 MQA 和 GQA?
- 小记:主流推理框架在Llama 2 的上性能比较
- vllm vs TGI 部署 llama v2 7B 踩坑笔记
- TGI + exllama - llama 量化部署方案
- BELLE(LLaMA-7B/Bloomz-7B1-mt)大模型使用GPTQ量化后推理性能测试
- QLoRA、GPTQ:模型量化概述
- LLM推理性能优化探索
- CNN量化 vs. LLM量化
- LLM大语言模型之Generate/Inference(生成/推理)中参数与解码策略原理及其代码实现
- NLP(十八):LLM 的推理优化技术纵览
- LLM推理部署(一):LLM七种推理服务框架总结
- LLM系列笔记:LLM Inference量化分析与加速
- 在大模型推理方面,有哪些研究热点?
- LLM推理加速-Medusa
- PagedAttention--大模型推理服务框架vLLM要点简析 (中)
- [LLM]KV cache详解 图示,显存,计算量分析,代码
- LLM推理优化技术综述:KVCache、PageAttention、FlashAttention、MQA、GQA
- 大规模 Transformer 模型 8 比特矩阵乘简介 - 基于 Hugging Face Transformers、Accelerate 以及 bitsandbytes
- 使用bitsandbytes、4 位量化和 QLoRA 使 LLM 更易于访问
- ByteTransformer源码解析
- LLM推理加速的文艺复兴:Noam Shazeer和Blockwise Parallel Decoding
- LLM大模型之不同精度下显存占用与相互转换实践
- CUDA PagedAttention kernel源码解析--大模型推理服务框架vLLM要点简析(下)
- [vllm]kernels分析
- LLM大模型之精度问题(FP16,FP32,BF16)详解与实践
- PAI BladeLLM推理引擎: 超长上下文、更高性能
- 大语言模型推理性能优化综述
- 大模型推理优化--Prefill阶段seq_q切分
- LLM大语言模型之Generate/Inference(生成/推理)中参数与解码策略原理及其代码实现
- NLP(二十):漫谈 KV Cache 优化方法,深度理解 StreamingLLM
- 【小白学习笔记】FP8 量化基础 - 英伟达
- 大语言模型量化相关技术
- LLM Decoding Attention-KV Cache Int8量化
- 大模型推理-TensorRT-LLM初探(一)运行llama,以及triton tensorrt llm backend
- llama.cpp源码解析--CUDA流程版本
- 多个大语言微调模型并行推断的潜力
- DeepSpeed-FastGen:通过 MII 和 DeepSpeed-Inference 实现 LLM 高吞吐量文本生成
- 关于大模型推理的量化算法总结
- Triton部署TensorRT-LLM
- Nvidia CUDA Core-LLM Decoding Attention推理优化
- 【模型推理】谈谈为什么卷积加速更喜欢 NHWC Layout
- ChatGLM3 的工具调用(FunctionCalling)实现原理
- DeepSpeed Inference中的kernel优化
- 【手撕LLM-投机解码】大模型迈向"并行"解码时代
- 一行代码加速28倍大模型推理速度
- Continuous Batching:一种提升 LLM 部署吞吐量的利器
- 大语言模型推理加速技术:计算加速篇
- 不到1000行代码,PyTorch团队让Llama 7B提速10倍
- 笔记:DeepSpeed inference 代码理解
- 大模型推理核心技术之Continuous Batching和我的WXG往事
- 论文笔记:DejaVu、LLM in Flash、PowerInfer
- TensorRT-LLM 如何加速推理之 -- Batching
- [ICML'23] DejaVu:LLM中的动态剪枝
- 笔记:Llama.cpp 代码浅析(一):并行机制与KVCache
- LLM推理百倍加速之稀疏篇
- vLLM-prefix浅析(System Prompt,大模型推理加速)
- Text Generation Inference源码解读(一):架构设计与业务逻辑
- Text Generation Inference源码解读(二):模型加载与推理
- Weight Only Quantization 的性能优化
- LLM推理加速(三):AWQ量化
- OmniQuant-目前最优的LLM PTQ量化算法
- W4A16模型量化大法 AWQ
- 大模型推理框架 vLLM 源码解析(二):Block 模块分配和管理
- FP8量化解读--8bit下最优方案?(一)
- LLM PTQ量化经典研究解析
- GPTQ & SmoothQuant & AWQ 代码解析
- 深入理解AWQ量化技术
- FP8 量化-原理、实现与误差分析
- 从continuous batching到vLLM中的batching
- 都2023年了,我不允许你还不懂DDPM!
- Kandinsky-3:最大的开源文生图模型
- 视频生成迎来SD时代:Stable Video Diffusion开源了!
- 一文带你看懂DDPM和DDIM(含原理简易推导,pytorch代码)
- AIGC优质模型导读:数据为王DALL-E 3
- SDXL Turbo来了:一步生成高质量图像
- 十分钟读懂Diffusion:图解Diffusion扩散模型
- Stable Diffusion生图越来越快,TensorRT扩展实现SD秒速生图
- stable diffusion中Lora的原理和实践
- 深入浅出完整解析Stable Diffusion XL(SDXL)核心基础知识
- 大模型推理加速-Decoding Attention优化
- 新一代文生图模型Stable Cascade来了
- 基于扩散的生成模型架构理论综述
- 深入浅出完整解析Stable Diffusion(SD)核心基础知识
- DALL-E 3技术报告阅读笔记
- Scalable Diffusion Models with Transformers(DiTs)论文阅读 -- 文生视频Sora模型基础结构DiT
- 一文读懂DDIM凭什么可以加速DDPM的采样效率
- Stable Diffusion 中的自注意力替换技术与 Diffusers 实现
- 从continuous batching到vLLM中的batching
- 图解大模型计算加速系列:分离式推理架构1,从DistServe谈起
- [LLM性能优化]聊聊长文本推理性能优化方向
- Datawhale AI视频生成学习
- OpenAI Sora背后的技术架构
- 从零实现CLIP模型
- CLIP 模型解读
- Sora 技术解读(附带 DiT 模型详解)
- OpenAI 的视频生成大模型Sora的核心技术详解(一):Diffusion模型原理和代码详解
- DiT详解
- Diffusion Transformer Family:关于Sora和Stable Diffusion 3你需要知道的一切
- 聊聊 DiT 和 GenTron
- OpenAI 视频模型 Sora 科研贡献速览
- 技术神秘化的去魅:Sora关键技术逆向工程图解
- Stable Video 3D震撼登场:单图生成无死角3D视频、模型权重开放
- PipeFusion:如何用PCIe互联GPU 低成本并行推理扩散模型
- Agent is all you need | AI智能体前沿进展总结
- Qwen 7B大模型ReAct Prompt详解以及LLM 智能体Agent实战
- 开源大语言模型作为 LangChain 智能体
- 详谈大模型训练中的数据收集、处理与模型影响:A Survey of Large Language Models工作中的数据总结
- 过去三个月,LLaMA系模型发展如何?指令微调的核心问题又是什么?
- cc_cleaner │ 一种丝滑高效且易扩展的数据清洗流程
- BigCode 背后的大规模数据去重
- LLM数据为王: Textbooks Are All You Need