
🏚 Scrape real estate listings - businesses are using web scraping to gather listed properties
🔎 Scrape products/product reviews from retailer or manufacturer websites to show in your site, provide specs/price comparison
📰 Scrape news websites to apply custom analysis and curation (manual or automatic), provide better-targeted news to your audience
💌 Gathering email addresses for lead generation
As a simple example — we’ll learn to scrape the front page of Hacker News to fetch the Titles and URLs of links. You can aggregate data and perform custom analysis, store it in Airtable, Google sheets, or share it with your team inside Slack. The possibilities are infinite!
Please remember to respect the policies around web crawlers of any sites you scrape.
- Installation
- How It Works
- How to Query Using CSS Selectors
- Test your Web Scraper
- Making Changes
- Versioning Your API
- Support
- Acknowledgements
Select Open in Autocode Button:
You will be prompted to sign in or create a free account. If you have a Standard Library account click Already Registered and sign in using your Standard Library credentials.
Once you sign in, give your project a name and click Start API Project from Github.

Navigate through the Functions folder to _main_.js file.

Next, select the gray Edit Payload button on the upper-right side of the screen to set parameters: url and queries.
Copy and Paste the following test parameters in the Edit Payload screen:
{
"url": "https://news.ycombinator.com/",
"queries": [
[
".storylink",
"text"
]
]
}Click Save Payload:

Select the green "Run" button to test run your code.

Within seconds you should have a list of link titles from the front page of Hacker News.
The web scraper makes a simple GET request to a URL, and runs a series of queries on the resulting page and returns it to you. It uses cheerio DOM (Document Object Model) processor, enabling us to use CSS-selectors to grab data from the page. CSS selectors are patterns used to select the element(s) you want to organize.
Web pages are written in markup languages such as HTML An HTML element is one component of an HTML document or web page. Elements define the way information is displayed to the human eye on the browser- information such as images, multimedia, text, style sheets, scripts etc.
For this example, we used the ".class" selector (class = ".storylink" ) to fetch the titles of all hyperlinks from all elements in the front page of Hacker News.
If you are wondering how to find the names of the elements that make up a website - allow me to show you! Fire up Google Chrome and type in our Hacker News URL address https://news.ycombinator.com/. Then right-click on the title of any article and select "inspect." This will open the Web Console on Google Chrome. Or you can use command key (⌘) + option key (⌥ ) + J key.

The web-developer console will open to the right of your screen. Notice that when you selected the title of a link a section on the console is also highlighted. The highlighted element has "class" defined as "storylink." And now you know how we queried for title of a link!

You're now an expert at finding the names of elements on any site! 😉
You are ready to deploy your web scraper live!
Select Deploy API in the bottom-left of the file manager.

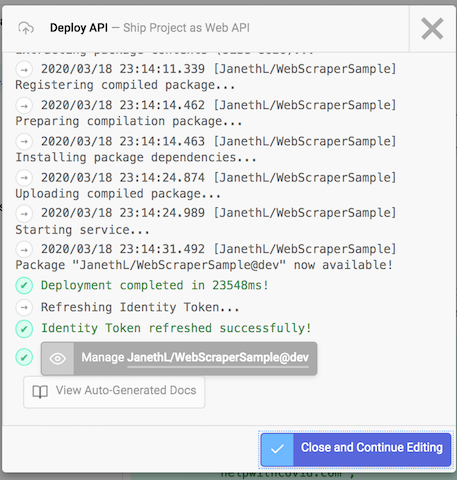
🚀 Congrats! Your website scraper is Live!
If you want to query different metadata on Hacker News, hover your cursor over it. Below you can see that I found the .class selector = "sitestr" to query a link's URL by hovering my mouse over that element on Hacker News.

Now that you have the .class selector for the links of url, test your live web scraper. Find and select your project from your dashboard at https://build.stdlib.com/. Enter your project manager by selecting dev.
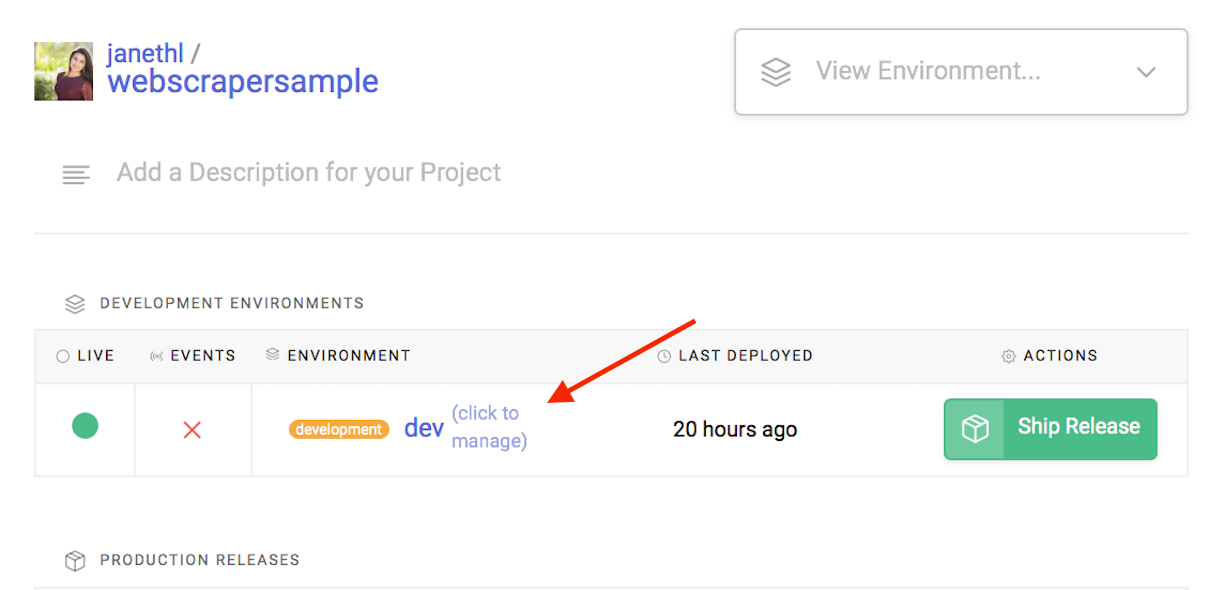
Select the Docs link for your Web Scraper.

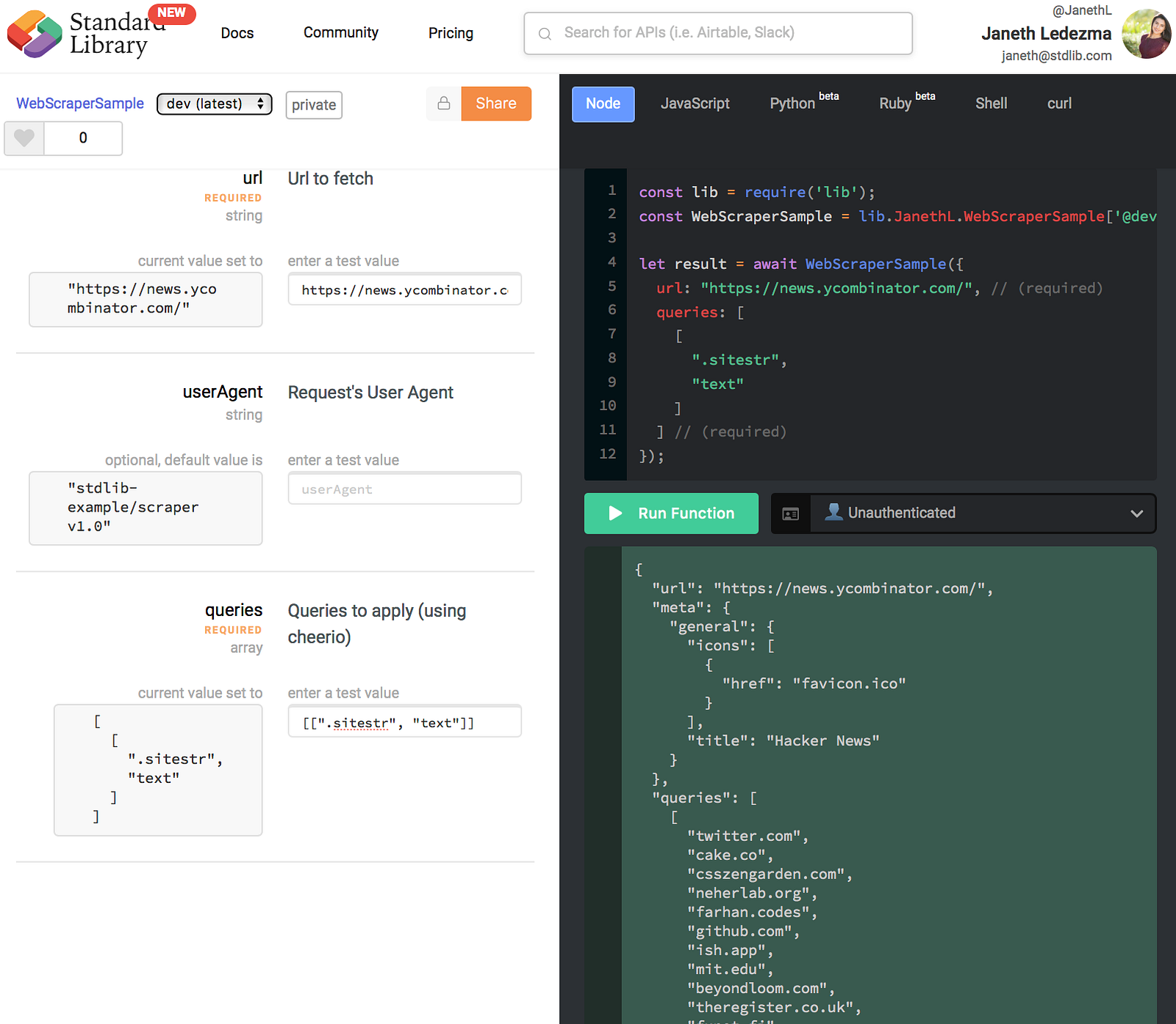
Input the url for Hacker News: https://news.ycombinator.com/
Input queries: [[".sitestr", "text"]]
And select Run Function.
You should see a list of link urls returned as shown in this screenshot:
There are two ways to modify your application. The first is via our in-browser editor, Autocode. The second is via the Standard Library CLI.
Simply visit Autocode.com and select your project.
You can easily make updates and changes this way, and deploy directly from your browser.
You can install the CLI tools from stdlib/lib to test, makes changes, and deploy.
To retrieve your package via lib get...
lib get <username>/<project-name>@dev# Deploy to dev environment
lib up devStandard Library has easy dev / prod environment management, if you'd like to ship to production,
visit build.stdlib.com/projects,
find your project and select it.
From the environment management screen, simply click Ship Release.
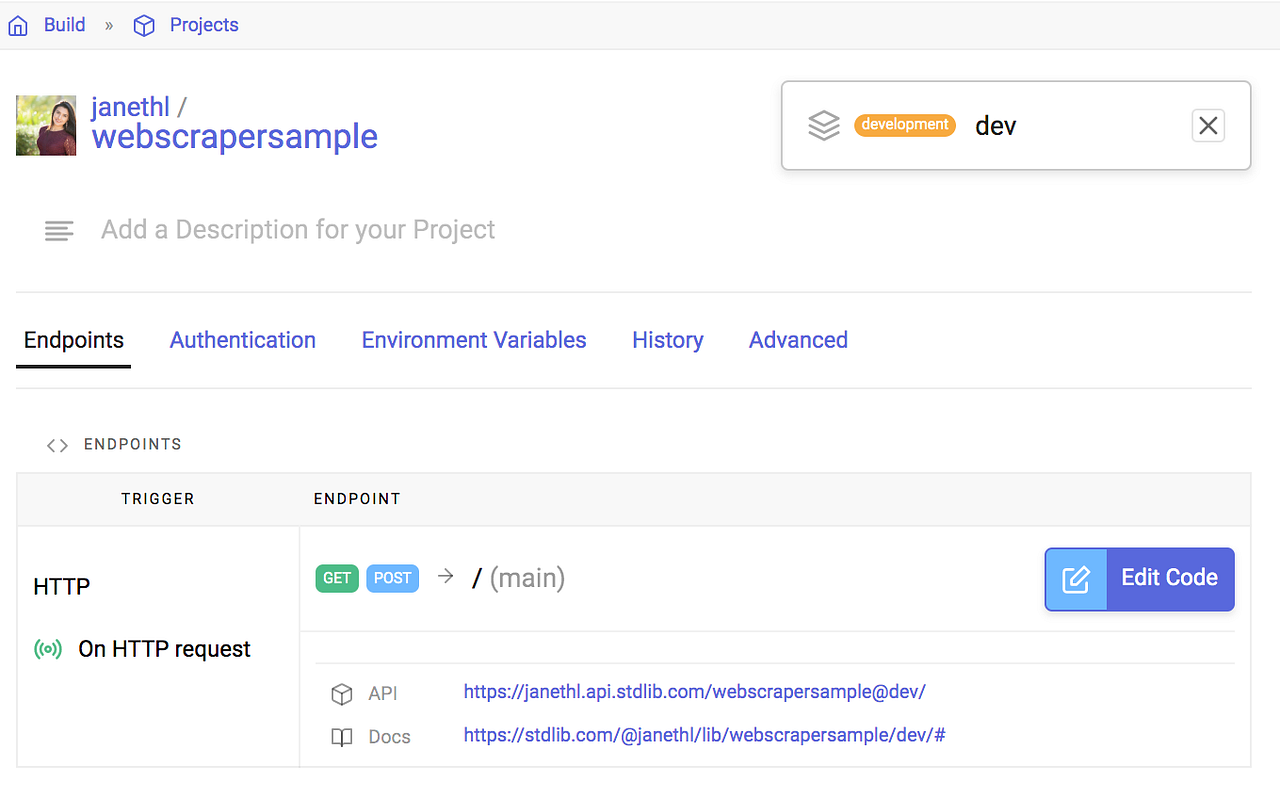
Link any necessary resources, specify the version of the release and click Create Release to proceed.
That's all you need to do!
Via Slack: libdev.slack.com
You can request an invitation by clicking Community > Slack in the top bar
on https://stdlib.com.
Via Twitter: @SandardLibrary
Via E-mail: [email protected]
Thanks to the Standard Library team and community for all the support!
Keep up to date with platform changes on our Blog.
Happy hacking!