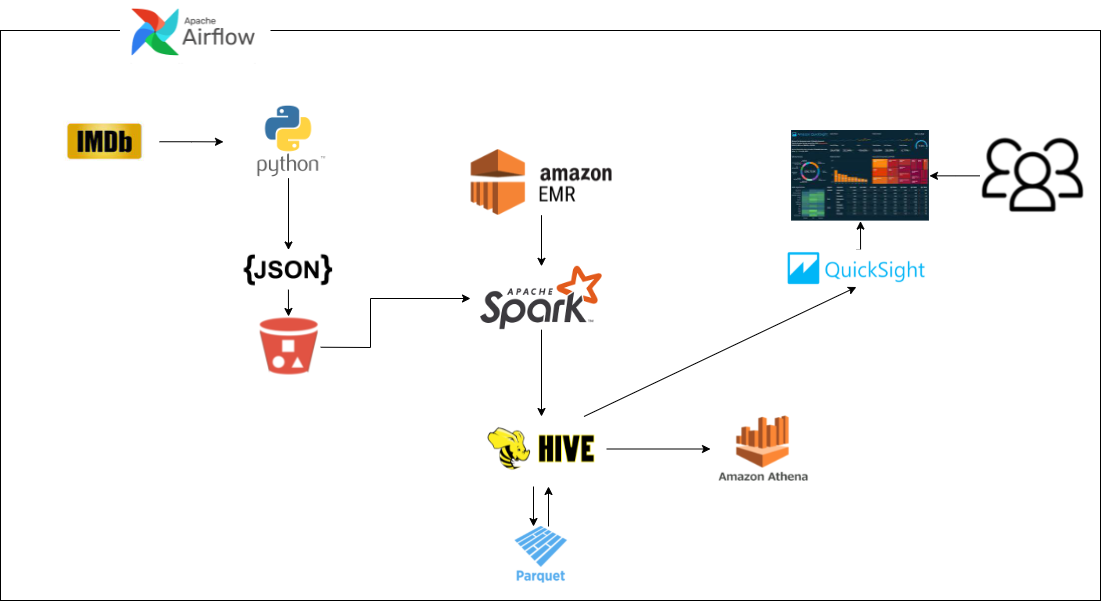
- PySpark
- Hive
- requests
- boto3
- Beautiful Soup
- IMDbPY
- EMR
- S3
- Athena
- QuickSight
- Apache Airflow
Movie_Analysis
├─ .github
│ └─ ISSUE_TEMPLATE
│ ├─ story.md
│ └─ task.md
├─ .gitignore
├─ app
│ ├─ code
│ │ ├─ create_bucket.py
│ │ ├─ data_cleaning.py
│ │ ├─ data_quality_check.py
│ │ ├─ get_movie_data.py
│ │ ├─ schema_creation.py
│ │ └─ __init__.py
│ ├─ conf
│ │ ├─ config.yml
│ │ └─ __init__.py
│ ├─ data
│ ├─ parquet
│ ├─ run.py
│ ├─ utils
│ │ ├─ helper.py
│ │ └─ s3_helper.py
│ └─ __init__.py
├─ dags
│ └─ movie_data_dag.py
├─ images
│ ├─ movie_data_dag.PNG
│ └─ movie_ER.jpg
├─ LICENSE
├─ main.py
├─ README.md
└─ run.sh
- config.yml - configuration file
- main.py - main file to run all the modules
- get_movie_data.py - extracts recent movie data from using IMDbPY
- data_cleaning.py - preprocesses the data using PySpark
- schema_creation.py - creates schema for tables in AWS Athena
- data_quality_check.py - performs the following checks:-
- row count check
- null values check
- table exists check
- helper.py - general purpose helper functions
- s3_helper.py - AWS S3 helper functions
- movie_data_dag.py - DAG which runs on every Friday to extract recently released movies data
MIT