Load DNN from Binary #143
Load DNN from Binary #143
Conversation
| * Layers: A parameter pack of layer types (e.g. DenseLayer<23,32>, DenseLayer<32,1>, etc.) | ||
| */ | ||
| template <class... Layers> | ||
| class Dnn { |
There was a problem hiding this comment.
perhaps keep everything in lst namespace for now
| DenseLayer<23, 32> layer1; | ||
| DenseLayer<32, 32> layer2; | ||
| DenseLayer<32, 1> layer3; |
There was a problem hiding this comment.
don't we have named constants for these 23 and 32?
... also, why DevData ? This doesn't look like a device-specific type
RecoTracker/LSTCore/src/LSTESData.cc
Outdated
| auto model = Dnn<DenseLayer<23, 32>, DenseLayer<32, 32>, DenseLayer<32, 1>>( | ||
| "/mnt/data1/gsn27/cmssw-fresh/CMSSW_14_2_0_pre4/src/RecoTracker/LSTCore/standalone/analysis/DNN/" | ||
| "network_weights.bin"); | ||
|
|
||
| // Copy the loaded model into a host DnnWeightsDevData struct | ||
| lst::DnnWeightsDevData hostDnn; | ||
| { | ||
| auto const& layers = model.getLayers(); | ||
| hostDnn.layer1 = std::get<0>(layers); | ||
| hostDnn.layer2 = std::get<1>(layers); | ||
| hostDnn.layer3 = std::get<2>(layers); | ||
| } |
There was a problem hiding this comment.
I'm curious if there is a way to define the parameter pack and index relationship in DnnWeightsDevData to simplify this code
|
Just committed the first working version, although it's much slower on GPU. |
| ALPAKA_FN_ACC ALPAKA_FN_INLINE void linear_layer( | ||
| const float (&input)[IN_FEATURES], | ||
| float (&output)[OUT_FEATURES], | ||
| const std::array<std::array<float, OUT_FEATURES>, IN_FEATURES>& weights, |
There was a problem hiding this comment.
Line 31 here, changing the weight arrays to these 2d std array's, is what causes most of the timing increase on GPU.
Without changing this line (but keeping all other changes, including the bias change).

After changing this line (and passing in the 2d std arrays from the dnnPtr below).

|
There was a problem while building and running in standalone mode. The logs can be found here. |
|
/run all |
There was a problem hiding this comment.
Keeping this here until we find a better location for it.
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
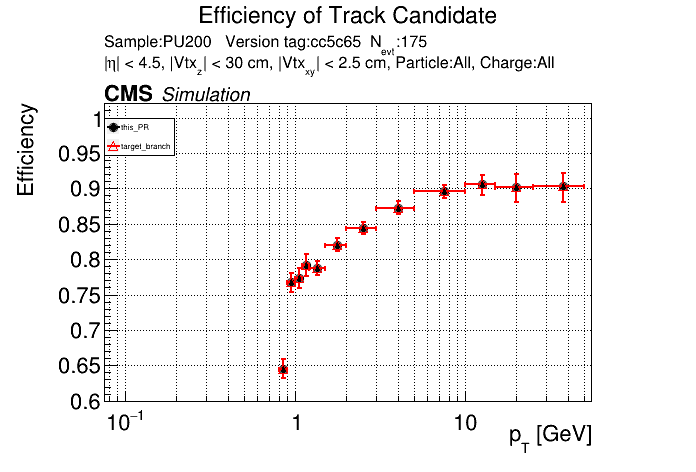
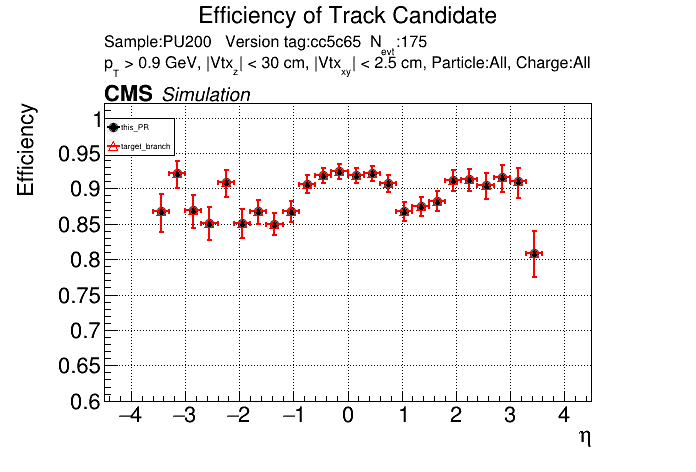
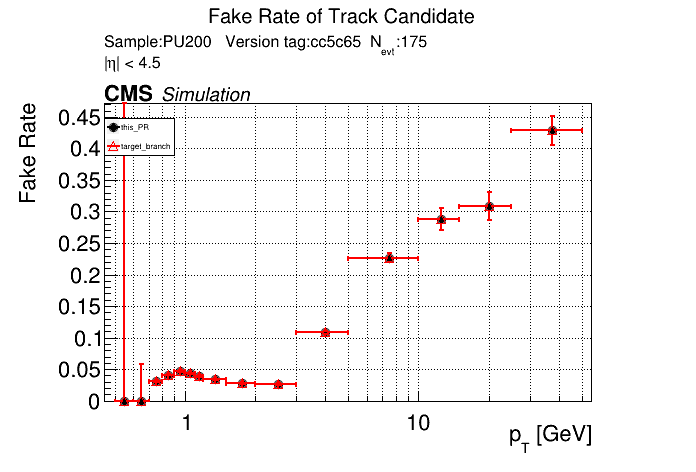
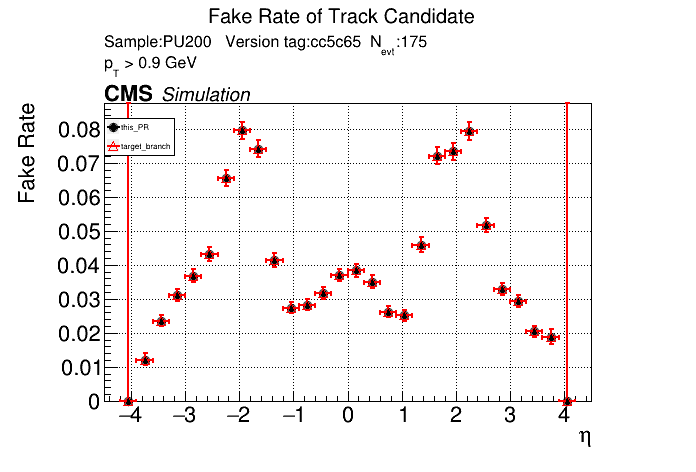
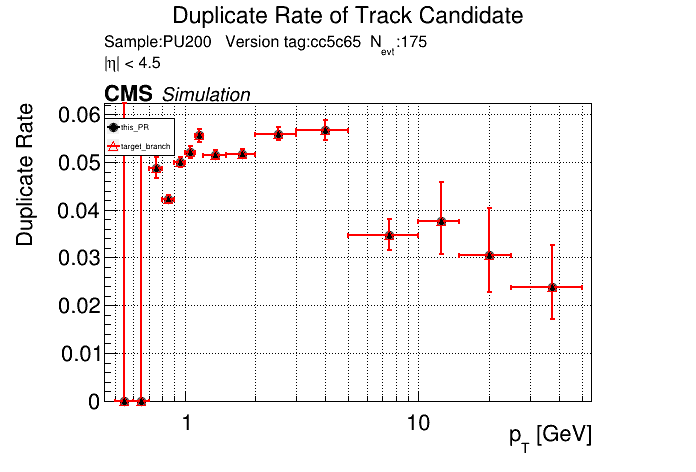
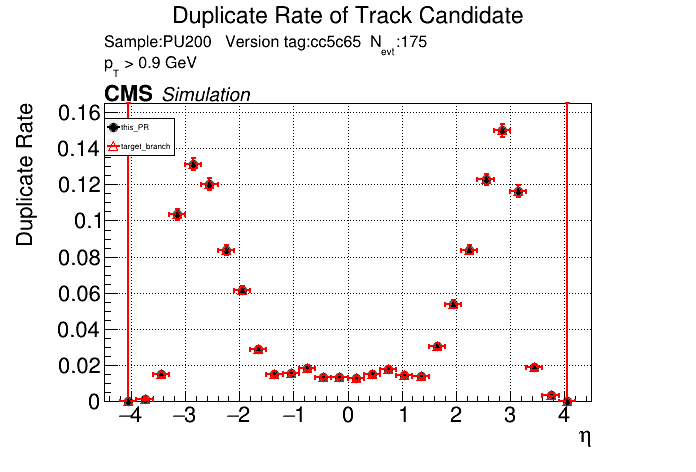
|
There was a problem while building and running with CMSSW. The logs can be found here. |
|
@slava77 It seems like the real issue with the weights is that we get a significant speedup from placing the current weights in constant memory. If I replace the existing weights' constant classifier with just __device__ the timing is exactly the same as what's shown above, 3.8 ms for T5 building for single stream. I will have to declare the weight arrays in constant memory and then copy them into those constant arrays at the start of the run. edit: I'm not sure if it's constant memory or just the const keyword. If I replace ALPAKA_STATIC_ACC_MEM_GLOBAL const with just ALPAKA_STATIC_ACC_MEM_CONSTANT the timing gets substantially worse (~2.4 ms single stream for T5 building). If I replace ALPAKA_STATIC_ACC_MEM_GLOBAL const with __device__ const the timing doesn't change (still fast) but if I remove the const and just have __device__ the timing becomes very slow. I should have to state __constant__ for CUDA to place an array in constant memory, right? Just the keyword const shouldn't do that? So the const keyword must be applying some great optimizations... |
|
Unless I'm misunderstanding something, I don't think this PR can proceed... if optimizations from the const keyword used for the DNN weights are responsible for the fast inference time, then the weights must be stored at compile-time and not loaded at the start of the run. Also, since CUDA doesn't allow for half-precision const arrays, it's currently impossible to see any benefit from both the const keyword and half-precision. It may be the case that the benefits from lower precision outweigh benefits from the const keyword, but that would probably take some effort to figure out. |
|
@GNiendorf |
|
Sounds good, I'll prepare some commits like you suggested. Here is a table version of the different results. 
|
do I understand correctly that the first 4 lines refer to the code in the baseline/master, when changing the array qualifiers in RecoTracker/LSTCore/src/alpaka/NeuralNetworkWeights.h |

|
@slava77 it's the first one, changing the keywords in NeuralNetworkWeights.h for the baseline/master. Not the function arguments. |
I'm curious if a similar pattern is visible on an older GPU, like V100 (on phi3). |

|
https://forums.developer.nvidia.com/t/performance-benefit-of-const-keyword-on-dnn-inference/319454 From looking at the SASS, I see that when the const keyword is used the NN weights are embedded directly into the FFMA instructions and this seems to be what is causing the speedup. Also linked a very closely related (but slightly outdated) stackoverflow discussion below. |
Work in progress, the timing on GPU becomes much slower with these changes (see below). Timing on CPU is largely unchanged.
To summarize, it seems like the const keyword for the DNN weights applies optimizations that significantly improve inference time. More than even keeping the weights in constant memory. Which is unfortunate because there's no way to use half-precision with const arrays in CUDA at the moment since they have to be defined at compile-time. So unless half-precision improves the inference time by some large factor, it makes sense to keep the weights in const arrays instead of loading them at the start of the run.
From looking at the SASS, I see that when the const keyword is used the NN weights are embedded directly into the FFMA instructions and this seems to be what is causing the speedup.
https://forums.developer.nvidia.com/t/performance-benefit-of-const-keyword-on-dnn-inference/319454