Energy, Waste & Urban Intelligence Platform
Spark Hack NYC 2026 | Environmental Impact Track | NVIDIA GB10
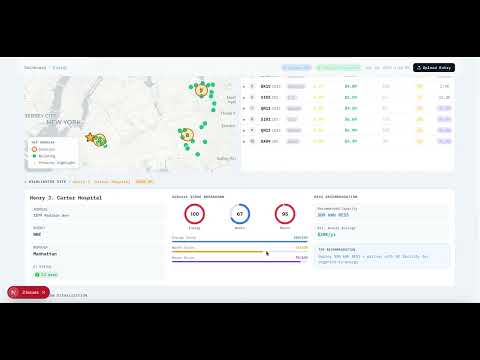
A decision-support platform that merges NYC's energy and waste data into one unified intelligence layer. Built to run entirely on-device using NVIDIA RAPIDS, NIMs, and cuOpt on the Acer Veriton GN100.
# Run the full pipeline
python smart-city-management/build_silver_layer.py
python smart-city-management/build_bridge_layer.py
python smart-city-management/build_spatial_layer.py
python smart-city-management/build_gold_layer.py
python smart-city-management/add_missing_outputs.pysmart-city-management/
├── build_silver_layer.py # Raw → Silver (12 Parquet datasets)
├── build_bridge_layer.py # Create property_to_bbl bridge
├── build_spatial_layer.py # cuSpatial feature joins
├── build_gold_layer.py # → Gold (3 tables + handoffs)
├── add_missing_outputs.py # depots + site_profiles
├── README.md
├── design doc/ # Technical design docs
├── frontend/ # Dashboard UI
├── AI/ # LLM ranker
└── data/
├── raw/ # 12 raw CSVs from NYC Open Data
├── silver/ # Cleaned Parquet (partitioned)
├── gold/ # Unified tables + handoffs
│ ├── route_inputs/ # cuOpt inputs
│ ├── dispatch/ # BESS dispatch
│ └── nim/ # NIM site batches
└── dictionaries/ # Data documentation
| Status | ID | Dataset | Rows | Source |
|---|---|---|---|---|
| ✅ | E1 | Energy Cost Savings Program | 2,363 | NYC Open Data |
| ✅ | E3 | Electric Consumption & Cost | 553,666 | NYC Open Data |
| ✅ | E4 | NYC EV Fleet Station Network | 1,638 | NYC Open Data |
| ✅ | E5 | Municipal Solar Readiness (LL24) | 4,270 | NYC Open Data |
| ✅ | E7 | LL84 Monthly Energy Data | ~2.2M | NYC Open Data |
| ✅ | E10 | LL84 Annual Benchmarking | 103,259 | NYC Open Data |
| Status | ID | Dataset | Rows | Source |
|---|---|---|---|---|
| ✅ | W1 | DSNY Monthly Tonnage | 24,883 | NYC Open Data |
| ✅ | W2 | 311 Service Requests (DSNY) | 1,556,494 | NYC Open Data |
| ✅ | W3 | Litter Basket Inventory | 20,413 | NYC Open Data |
| ✅ | W7 | Food Scrap Drop-Off Locations | 591 | NYC Open Data |
| ✅ | W8 | Disposal Facility Locations | 39 | NYC Open Data |
| ✅ | W12 | Waste Characterization | 2,112 | NYC Open Data |
| File | Description | Partitioned |
|---|---|---|
E3_electric_consumption.parquet |
NYCHA electric usage | No |
E4_ev_fleet_stations.parquet |
EV charging locations | No |
E5_solar_readiness.parquet |
Solar-ready buildings | No |
E5_solar_readiness_enriched.parquet |
+ cuSpatial features | No |
E7_ll84_monthly.parquet |
Monthly energy | ✅ calendar_year |
E10_ll84_benchmarking.parquet |
Annual benchmarking | No |
property_to_bbl.parquet |
Bridge table (48,310 unique) | No |
W1_dsny_monthly_tonnage.parquet |
District tonnage | No |
W2_311_dsny.parquet |
311 complaints | ✅ created_year |
W7_food_scrap_dropoffs.parquet |
Compost sites | No |
W8_disposal_facilities.parquet |
Transfer facilities | No |
| File | Description |
|---|---|
unified_sites.parquet |
Gold Table 1: E5 + E10 + spatial features |
district_waste.parquet |
Gold Table 2: W1 aggregated by district |
time_series.parquet |
Gold Table 3: E7 monthly energy |
route_inputs/depots.parquet |
cuOpt depot locations (39) |
route_inputs/demand_nodes.parquet |
cuOpt demand nodes (59 districts) |
nim/site_batches.jsonl |
NIM scoring batch (20 sites) |
dispatch/site_profiles.parquet |
BESS dispatch profiles (4,268 sites) |
E5.bbl ← E10.bbl (via property_to_bbl)
E7.property_id → E10.property_id → E10.bbl → E5.bbl
From E5 building points:
- EV ports within 500m
- EV ports within 1km
- Compost sites within 1km
- Nearest transfer facility distance
Map both Problem/Problem Detail and Complaint Type/Descriptor into one canonical category column.
| Layer | Tool | Purpose |
|---|---|---|
| Data Processing | RAPIDS cuDF + cuSpatial | GPU-accelerated data processing |
| Route Optimization | RAPIDS cuOpt | Waste collection vehicle routing |
| LLM Inference | NVIDIA NIMs (Llama 3.1 8B) | Local site scoring |
| Simulation | Custom Python (GPU-vectorized) | BESS dispatch |
| Dashboard | Streamlit + Folium | Interactive maps, charts |
import cuopt
# Load demand nodes and depots
demand_nodes = pd.read_parquet("data/gold/route_inputs/demand_nodes.parquet")
depots = pd.read_parquet("data/gold/route_inputs/depots.parquet")
# Solve route
# (See: https://docs.nvidia.com/cuopt/user-guide/latest/introduction.html)# Run NIM container
docker run -d --gpus=1 --name nimLlama \
-v ./smart-city-management/data/gold/nim:/app/nim \
nvcr.io/nim/nvidia/llama-3.1-nim:8b-instruct-q4
# Score sites
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d @nim/site_batches.jsonl# Load site profiles and time series
profiles = pd.read_parquet("data/gold/dispatch/site_profiles.parquet")
time_series = pd.read_parquet("data/gold/time_series.parquet")
# Run dispatch simulation
# (See: design doc/BESS_simulation.md)The mini workstation already has the Qwen 3 80B model activated and available for local inference. For future local LLM scoring of sites, we can leverage this model directly:
# Using the local Qwen 3 80B endpoint (already running on the workstation)
curl -X POST http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3-80b",
"messages": [{"role": "user", "content": "Score this site for solar potential..."}]
}'The Qwen 3 80B provides significantly more capacity than Llama 3.1 8B NIM for nuanced site scoring, natural language reasoning about building characteristics, and batch processing of site evaluations.
Built for Spark Hack NYC 2026 — Environmental Impact Track.
NVIDIA GB10: 128 GB unified memory, 1 PFLOP FP4 on Acer Veriton GN100
Both datasets were preprocessed and reorganized into four unified classification categories:
- Organics
- Electronic
- Plastic
- Others
Images from both sources were partitioned into folder-based class directories to maintain consistent labeling and balanced training structure.
- Model Name: NVIDIA Nemotron Nano 12B v2 VL FP8
- Model ID:
nvidia/NVIDIA-Nemotron-Nano-12B-v2-VL-FP8
This project uses LoRA (Low-Rank Adaptation) for parameter-efficient fine-tuning, enabling adaptation of the multimodal vision-language model with lower memory and compute overhead.
The objective is to fine-tune the model for garbage image classification across mixed-source datasets, improving recognition accuracy for real-world waste sorting applications.