This is the code base for our paper titled "Segregation dynamics with reinforcement learning and agent based modeling". In our paper, we combined agent based modeling (ABM) with reinforcement learning. As a use case, we investigated how segregation dynamics change as the agents' affinity to integrate changes.
Life is complex and simulations are helpful in exploring spacee of possibilities a policy might cause. To design better policies, we invite social scientists, policy makers and engineers to play with our code and enrich our know-how on how things work under complex settings.
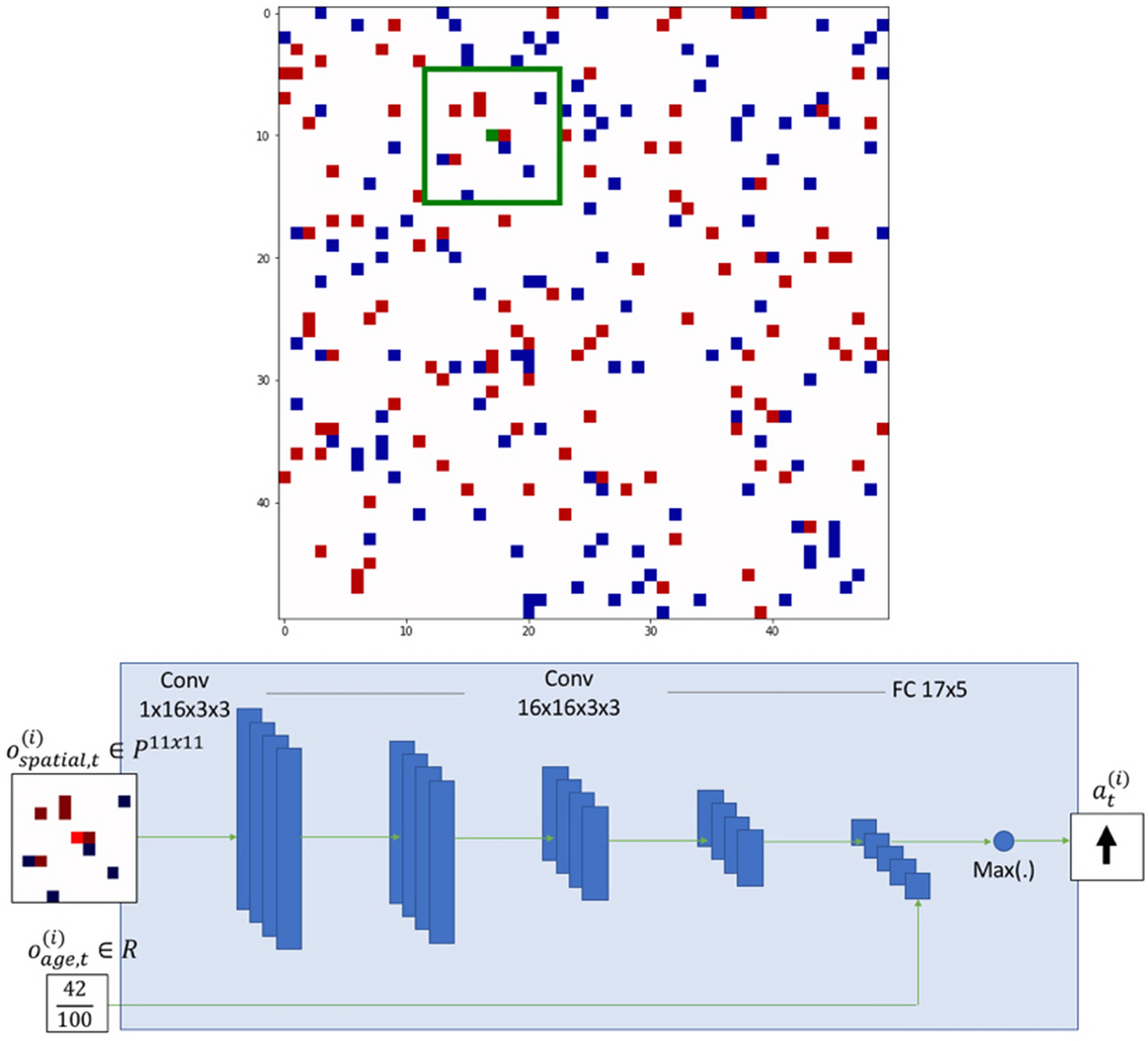
In our code we have three main classes: Mind, Agent and Environment.
-
Mind is the class that maintains the decision function of an agent kind. We used deep Q networks as decision functions, a deep reinforcement learning based approach. Feel free to try other functions such as DDPG, MCTS, Bayesian approaches etc.
-
Agent is the class to represent an agent in the agent based model. Environment and Agent classes communicate among each other to run a simulation.
-
Environment is the class where a grid world is maintained. Administrative tasks such as moving an agent from a grid to another grid, or removing an agent from the simulation are implemented in this class.
Consequently, while running a simulation, environment initiates a grid world with a number of agents. Then each agent communicates with its respective mind to select an action. After an agent selects an action, the environment makes the necessary changes in the grid world.
Our classes encapsulate all the machinery if you want to run a simulations where smart agents interact in a grid world. All you need to do is declaring how the simulation should function under numerous circumstances. Those circumstances are on how the environment should continue when an agent chooses to:
- move to an unoccupied grid
on_free, - move over an opponent
on_opponent, - move over an ally
on_same, - move over an obstacle
on_obstacle, - stay still
on_still
Each of these functions take one or two agents as input and returns a scalar reward.
For example, in schelling_example.py we have implemented the model we have used in our paper.
In our model, when an agent chooses to move to an unoccupied grid, we want to move the agent there and reward it for
being alive and being segregated (please check the paper on segregation reward). So the code equivalent is as following:
def on_free(self, agent):
self.move(agent) # a built in moving function of the environment. The environment moves the agent to a location based on the agent's decision.
return REWARDThen, we want our agent to eliminate the opponent by moving onto that agent and get a reward for it.
def on_opponent(self, agent, opponent):
self.kill(opponent, killer=agent)
return REWARD
def kill(self, victim, killer=False):
i, j = victim.get_loc() # get victim's location
state = self.get_agent_state(victim)
self.map[i, j] = 0 # clear the location
del self.loc_to_agent[(i, j)] # remove the agent's location index
victim.die(state, -self.death_penalty) # kill the agent, die is a built-in method of the Agent class
if killer:
killer.eat(REWARD) # inject reward
self.move(killer) # move the killer to victim's location
return REWARDWhen the agent stays still, chooses to go towards an obstacle or towards the same kind, we do not move the agent and penalize it for that action.
def on_still(self, agent):
return REWARD # penalty
def on_obstacle(self, agent):
return REWARD
def on_same(self, agent, other):
return REWARDNote that the environment automatically detects when to fire respective actions. You just need to tell the system what happens during those actions.
Overall, steps to create your own simulation is as following:
- Create your simulation as a subclass of Environment
class MySimulation(Environment):
def __init__(self, some_arguments):
super(MySimulation, self).__init__(some_arguments) # initialize the parent class- Declare action definitions
class MySimulation(Environment):
def __init__(self, some_arguments):
super(MySimulation, self).__init__(some_arguments) # initialize the parent class
def on_free(self, agent):
pass
def on_opponent(self, agent, opponent):
pass
def on_still(self, agent):
pass
def on_obstacle(self, agent):
pass
def on_same(self, agent, other_agent):
pass- Run the simulation using the
playfunction. - Analyze the simulation using the simulation save crystal.npy.gz. The crystal is a four dimensional tensor of the simulation where the
dimensions are as following: (ITERATION_INDEX, HORIZONTAL_LOCATION, VERTICAL_LOCATION, CHANNEL). CHANNEL = {0: agent type, 1: agent age, 2: agent id}. For example the slice
slice = crystal[0, 5, 5, :]gives the type, age and id of the agent at location (5,5) in the first iteration. If the location is not occupied by an agent, then the slice is a zero vector.
The following shell command runs a Schelling simulation named "my_experiment" with the parameters:
- Agent Range: 5
- Interdependence Reward: 75
- Max Age: 100
- alpha, beta, gamma: 1
python schelling_example.py my_experiment 5 75 100 1 1 1
Details of the parameters are in our paper.
We are very pleased if our study and code is helpful in your work. Please cite our work as:
@article{Sert2020,
doi = {10.1038/s41598-020-68447-8},
url = {https://doi.org/10.1038/s41598-020-68447-8},
year = {2020},
month = jul,
publisher = {Springer Science and Business Media {LLC}},
volume = {10},
number = {1},
author = {Egemen Sert and Yaneer Bar-Yam and Alfredo J. Morales},
title = {Segregation dynamics with reinforcement learning and agent based modeling},
journal = {Scientific Reports}
}