Add Support for Linux Trad Files #44
Draft
Conversation
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
…a bool. Games like SteelDivision 2 uses this unknown compression method.
This is to help debugging other string format.
…tead of a bool." This reverts commit bec006c.
Sign up for free
to join this conversation on GitHub.
Already have an account?
Sign in to comment
1 participant
Add this suggestion to a batch that can be applied as a single commit.
This suggestion is invalid because no changes were made to the code.
Suggestions cannot be applied while the pull request is closed.
Suggestions cannot be applied while viewing a subset of changes.
Only one suggestion per line can be applied in a batch.
Add this suggestion to a batch that can be applied as a single commit.
Applying suggestions on deleted lines is not supported.
You must change the existing code in this line in order to create a valid suggestion.
Outdated suggestions cannot be applied.
This suggestion has been applied or marked resolved.
Suggestions cannot be applied from pending reviews.
Suggestions cannot be applied on multi-line comments.
Suggestions cannot be applied while the pull request is queued to merge.
Suggestion cannot be applied right now. Please check back later.
This PR add a way to read Linux traduction files that are encoded as UTF32 instead of Unicode Widestring like on Windows. This should fix #21 .
The way this is done for now is check for the filename on the construction of
EdataManagerand assign a most likely OSPlatform for the file. When aTradFileViewModelis built, it will read the OSPlatform value and send the string stype to theTradManager.In addition, some files were split into a separate project and with a crossplatform target of net5.0 instead of net5.0-windows, allowing a test suite that can also be run under Linux.
Leaving in draft so I can get comment, while I still work on the UI and additional tests.
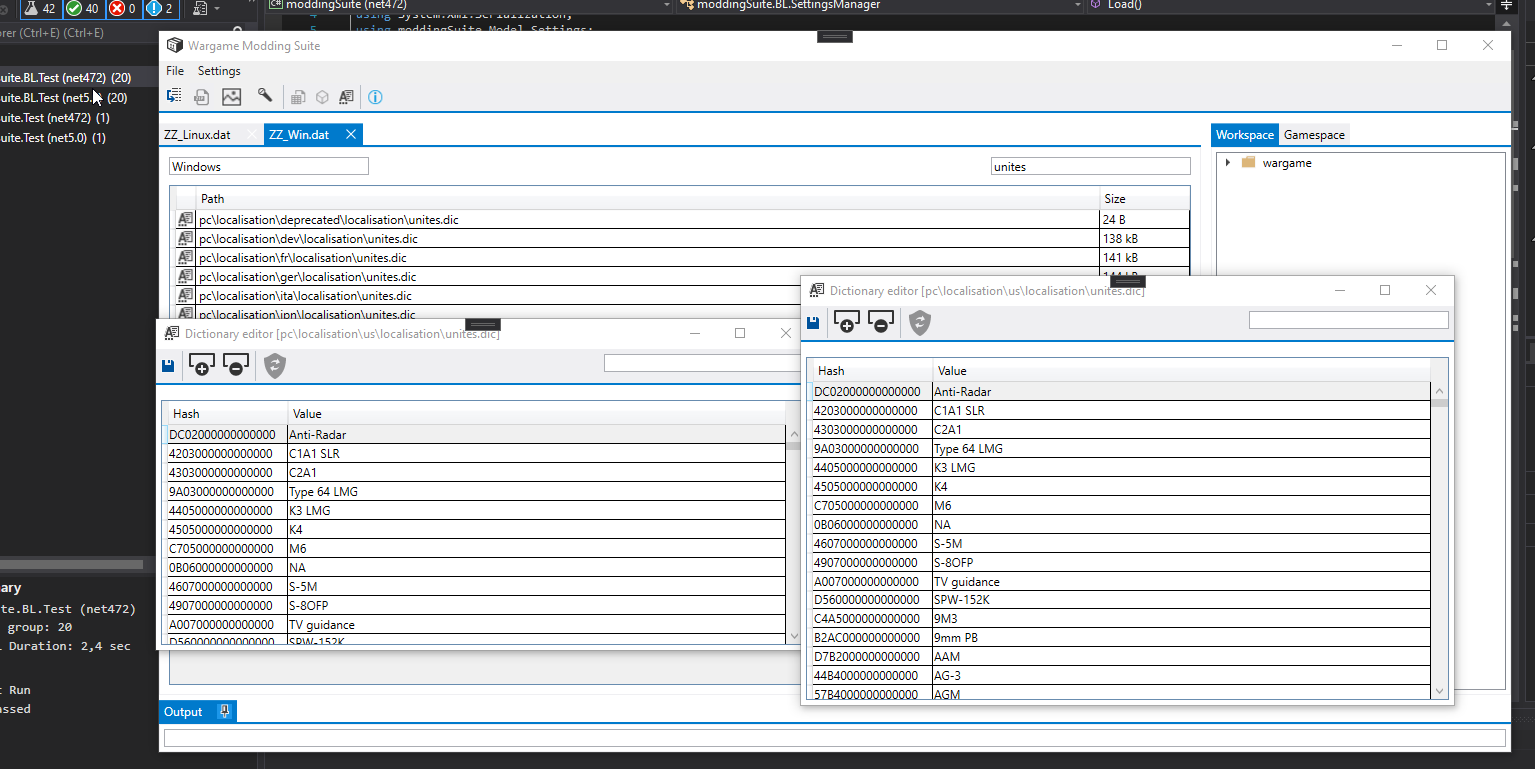
Linux and Windows dictionary, side-by-side:
For now, I show a textbox with the OSPlatform, either Linux, Windows or Generic. I plan to switch to an icon. Do you guys have any better idea to present this? Should I simply hide this?