Part of FaaS and Curious: Performance Implications of ServerlessFunctions on Edge Computing Platforms, 11 2021, pp. 428–438.
Edge goes hand in hand with event driven architecture since most edge workloads (especially IoT ones) are event driven. In this repo we'll scratch the surface of the serverless architecture on edge nodes. More specifically, this repo contains all the code needed to explore the fundamentals of a Serverless architecture on Edge Devices. To complete this project the following tools were used :
- Raspberry Pi 4 (Using Raspbian OS)
- Lean Openwhisk (Serverless infrastructure)
Almost everyone knows what a Raspberry Pi is. This mini computer is one the first examples that comes to mind when we think about edge nodes.(Even though their computational power has rised to pc standards). In this project we used a Raspberry Pi 4 ,64-bit architecture, 4GB ram equipped with raspbian OS.These hardware specification to run a similar project are not necessary. This raspberry might even be an overkill for the overall project. Even a more performance-constrained device could probably manage all the tasks we are about to do.
Most of the people who have grasped the idea of serverless have probably heard about OpenWhisk. OpenWhisk is an open source Serverless platform that executes functions in response to events (event driven). These events could be HTTP request or they can be more complex triggers coming from Feeds(like a slack message).
The following pictures depict the components of Openwhisk:
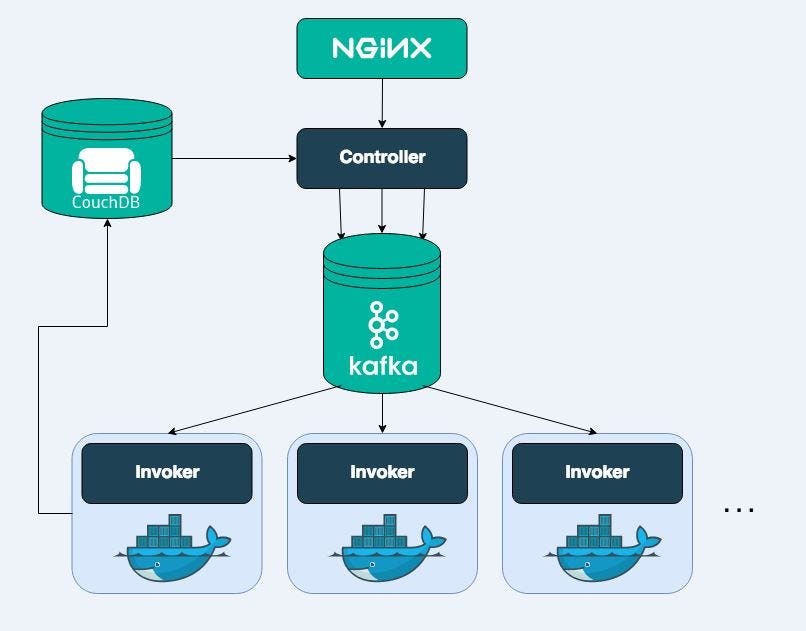
- Lean Openwhisk is a significantly downsized Apache Openwhisk which retains the core functionality profile and core components of Openwhisk
- Lean Openwhisk is built on the core source code of Openwhisk and it's an official branch of the Apache Openwhisk project on github
To minimize the overhead of Openwhisk and downsize it enough to run on edge nodes the components of Openwhisk needed to change a bit. The Lean Openwhisk components are shown below:
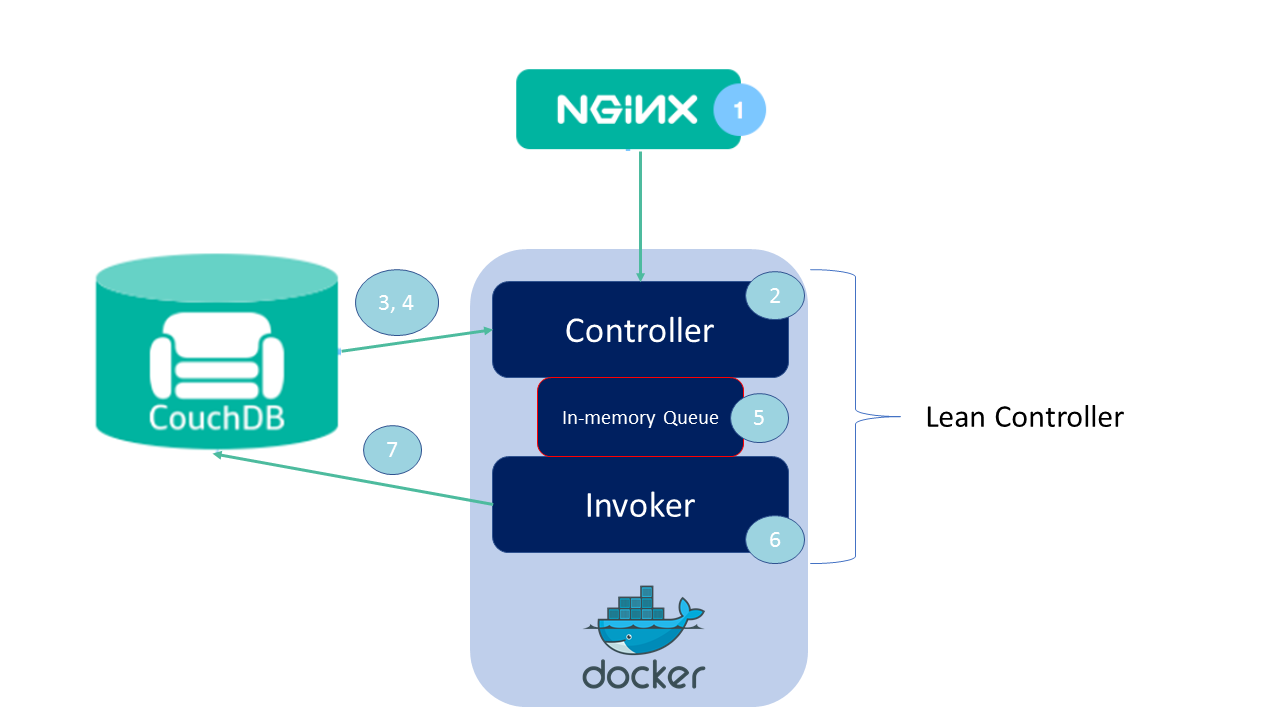
The core differences are:
- Lean Loadbalancer is implemented
- Controller and Invoker are compiled together (Lean Load Balancer calls the Invoker's method for an action queued in the in-memory queue)
- Removal of Kafka (biggest impact in reducing size) which is now mimiced by an in-memory-queue.
Now that we got all the theoretic fundamentals out of the way, let's move to what this project is.
We wanted to setup Lean OpenWhisk on our Raspberry Pi and then play with/test it. Before setting up Lean Openwhisk there are some prerequisites that should be installed.
- pip 19.1 ( I had some trouble installing OpenWhisk using a later version)
- ansible 2.7.9 (Strongly recommended to have 2.7.9 since 2.8+ will require changes in parts of the source code)
- Docker (I freshly installed to be 100% sure) using the following commands
sudo curl -sSL https://get.docker.com | shsudo usermod -aG docker piexec su -l $USERdocker ps(To make sure docker works)sudo pip install docker-py(Python lib fro Docker Engine API)
Assuming that we installed all the recommended versions of the needed tools as described above ,we now move to the Lean OpenWhisk part. You can either download the code provided by the creators of lean openwhisk and perform some minor tweaks to get it to work with a Raspberry Pi 4 or you can clone this repository and use the provided code above.
- Creators Repo :
git clone --single-branch --branch rpi-lean https://github.com/kpavel/incubator-openwhisk.git - My tweaked Code is under /Lean-Openwhisk/ (Disclaimer: The tweaks needed are 3-4 and can easily be performed ,I would suggest cloning the creators Repo and troubleshoot yourself to get a better understanding of the installation process)
Move to openwhisk folder and set some needed enviroment variables
cd incubator-openwhisk
export OPENWHISK_HOME=/home/pi/incubator-openwhisk
export OPENWHISK_TMP_DIR=$OPENWHISK_HOME/tmpConfigure the metadata database
$ cd ~/incubator-openwhisk/ansible
$ cat << EOF > db_local.ini
[db_creds]
db_provider=CouchDB
db_username=whisk_admin
db_password=some_passw0rd
db_protocol=http
db_host=172.17.0.1
db_port=5984
[controller]
db_username=whisk_local_controller0
db_password=some_controller_passw0rd
[invoker]
db_username=whisk_local_invoker0
db_password=some_invoker_passw0rd
EOFPull the docker image of Node.js especially made for actionsLean-Openwhisk actions for Pi,and the Lean-Controller Image
sudo docker pull kpavel/nodejs6action:rpi
sudo docker pull kpavel/controller:rpiThis is the most crucial step ,the ansible-playbook installation commands
$ansible-playbook setup.yml
$ansible-playbook couchdb.yml
$ansible-playbook initdb.yml
$ansible-playbook wipe.yml
$ansible-playbook openwhisk.yml -e lean=true -e invoker_user_memory=1024m -e docker_image_prefix=kpavel -e docker_image_tag=rpi
$ansible-playbook postdeploy.ymlIf nothing crashed or failed ,you can now probably see some docker containers up and running. You need to have these containers up and running

We now need to intall the wsk client
$ sudo wget -qO- https://github.com/apache/incubator-openwhisk-cli/releases/download/0.10.0-incubating/OpenWhisk_CLI-0.10.0-incubating-linux-arm.tgz | tar xvz -C $OPENWHISK_HOME/bin wsk
$export PATH=$PATH:$OPENWHISK_HOME/binBefore using it the final step of the wsk client installation is updating .wskprops file
cat ~/.wskprops
AUTH=23bc46b1-71f6-4ed5-8c54-816aa4f8c502:123zO3xZCLrMN6v2BKK1dXYFpXlPkccOFqm12CdAsMgRU4VrNZ9lyGVCGuMDGIwP
APIHOST=172.17.0.1
NAMESPACE=guestIn case this file doesn't exist,Create it yourself
We have now successfuly set up Lean Openwhisk. We can now create some actions and invoke them.However, doing that wouldn't be so fun ,so what we wanted to do with Lean Openwhisk was test it and see how efficient or inefficient it is.Is it worth using Lean Openwhisk on edge? What level of concurrency can we achieve in these performance-constrained machines? How bad are the cold-start times ,and what is the upper limit of payload a RPi can handle? Results and metrics are provided in this section
We used the tests constructed by the creators of Lean-Openwhisk to cross-check their findings and see if the same performance is achieved by our own setup. We used this repository lean-performance-evaluation for the following Experiments.
How changing back-end concurrency (how many simultaneous actions Lean OpenWhisk can execute) affects latency and throughput using a small payload


Takeaways: Average Latency increases when we increase the backend concurrency while throughput seems to decrease slightly. Increasing concurrency above 4-5 (max 6) is probably not a smart idea since it doesn't help with increasing performance. All these results are with a really small payload. Results may differ in case we use bigger payloads. That's what we wanted to discover in our next experimenent
Keeping concurrency range from 1 to 5 ,we wanted to observe how different payloads affect latency and throughput.


Takeaways: Payloads affect latency (as expected) due to the fact that the device we run these experimenets on is resource constrained.Throughput is acceptable only if we use small payloads (approx. 1K-50K) and the same applies to latency since as we can easily observe it skyrockets with high payloads. Payloads above 100KB have a pretty high latency. Possible solution which needs further investigation is using sequential action invokes so that high payload functions are converted into many smaller ones.
To examine how efficient existing serverless platforms transfer data between functions ,we use a testcase provided by ServerlessBench slightly changed so that it can run on Lean Openwhisk. We evaluate a Node.js serverless application which transfers images with different sizes. Our intent is to find if there is a payload-high that causes an unacceptable deteriorated performance.

Takeaway: It's fairly obvious that increasing data transfer payload above 200K is discouraged. What is really optimistic is that payloads up to 100K do not increase latency significantly which gives a lot of room for improvement in optimizing the way functions are scheduled (sequence of functions) in order to achieve maximum performance