-
效果:该项目用于安卓系统的车机大屏控制应用,实现了安卓应用和底层的
CAN报文解析的彻底解耦,并快速解析CAN报文,解决了安卓应用的泛用性问题。 -
原理:核心思想是使用了
java的注解和反射的元编程,使用依赖注入的方式实现。 -
解耦实现:本项目实现了安卓应用和底层的CAN报文解析的彻底解耦,一个相同的安卓应用可快速部署到不同CAN通信协议的车型上,而应用层不需要做修改任何内容,车身CAN协议可以随意变动而不影响应用层
APP,只需要重新绑定DBC即可。 -
具体功能:1.解码CAN报文,用于接收车身CAN报文时,快速解析数组格式的报文至应用层中。2.编码CAN报文,也可以快速由数据模型封装出一帧CAN报文出来。
随着当今汽车技术的发展,智能座舱逐渐成为了汽车的标配。车载大屏比以前更加智能,语音空调、远程大灯、智能按摩椅等等。而这些功能有相应的程序运行在安卓系统之上,实现对车身的控制。车身的通信方式是CAN通信,在某些车企的解决方案中,这些车身应用会直接处理车身的CAN报文,而不是由底层处理。
上层的安卓应用在拿到车身的数据之后,会进行解析,最后呈现到界面中。
而按照传统的汽车软件架构,通常是面向信号的编程,一个CAN信号变动之后,应用层也会变动,这十分不方便,故也就有了本文所说的**“车身CAN报文快速解析框架|一种汽车SOA架构的实现”**,类似于使用面向服务的构架来构建整个应用。
需要解码的CAN报文的数据格式通常就是8字节的报文数组,asc格式的CAN报文如下,后边的8个字节就是实际数据。
date Thu Oct 28 11:03:39 AM 2021
base hex timestamps absolute
787.275800 1 18f0090bx Rx d 8 FF FF 7F 8F 7D 87 7E 7D
787.276500 1 8fe6e0bx Rx d 8 00 00 00 00 00 00 00 00
787.281900 1 cfe0113x Rx d 8 06 33 04 7F 05 00 00 00
里边存了车速、空调温度等数据,而解析这些数据,需要确定每个信号起始位、长度、精度、偏移量等信息。
解析的时候,传入接收报文的CANID和数组,你可能会像这样写。(面向信号的编程)
switch (receiveID){
case MsgID1:
resolution1(data);
break;
case MsgID2:
resolution2(data);
break;
}
// 下边依次解析了设定温度,空调工作模式,除霜状态等数据。
// 设定温度起始位0,长度8,精度1,偏移量-40,
private void resolution1(byte[] data){
tempSetValue = (int) resolution(data,0,8,1,-40).intValue(); // 从报文中解析 空调设定温度
workMode = (int) resolution(data,8,2,1,0).intValue(); // 从报文中解析 空调设定模式
defrostStage = (int) resolution(data,10,2,1,0).intValue(); // 从报文中解析 空调除霜状态
collisionWarningSts = (int) resolution(data,12,3,1,0).intValue();
sterilizeSts = (int) resolution(data,15,1,1,0).intValue();
defrostInterval = (int) resolution(data,16,8,30,0).intValue();
defrostMaxTime = (int) resolution(data,32,8,1,0).intValue();
defrostEndTemp = (int) resolution(data,40,8,1,-40).intValue();
evaporationFanTempMode = (int) resolution(data,49,1,1,0).intValue();
}
public int resolution(){
// ... 该函数省略。用于根据每个信号起始位、长度、精度、偏移量等信息,进行解析工作。
} 上边依次解析了设定温度,空调工作模式,除霜状态等数据。 设定温度起始位0,长度8,精度1,偏移量-40,所以调用了函数 tempSetValue = (int) resolution(data,0,8,1,-40).intValue();来解析数组中的数据,其他的数据类似。
Note
如果不理解我说的起始位、信号长度、精度和偏移量,还有CAN通信协议,你先别着急。等会看第二章节。
这样写,确实可以这样写,但是不够优雅,起始位、信号长度、精度和偏移量只要一个有改变,整个代码都需要改变。如果你的代码想要在另外一个车型上应用,那么解析的协议也会有所变更,那么重复代码会非常的多,甚至几百个信号。如果你有地方写错了之后,排查起来也会非常困难,你会不知道到底哪里的解析数据写错了,因为这样的代码太多了。
Important
这样编程的耦合度太高了,太不优雅了,所以本项目的一大核心要素就是降低耦合度。将安卓应用的逻辑和底层CAN协议的解析彻底地解耦。
由于本文的阅读对象分为汽车行业的,以及计算机行业的各位同事,所以我会尽量把每一部分都讲得详细一点,如果你会的,你可以直接跳过这一部分。
CAN总线是一种用于汽车网络的通信方式。这里附了一些参考链接,可以简单看一下。
一文读懂CAN总线协议 (超详细配34张高清图)_can总线协议详解-CSDN博客
CAN总线的两根信号线通常采用的是双绞线,通过两根信号线的电压差CANH-CANL(CAN高和CAN低)来表示总线电平,传输差分信号,最终到MCU端解析成为字节流数据。CAN通信协议,实际上就类似于TCP/IP协议,你可以简单简单这么理解,只不过少了很多层,只有最基本的物理层和数据链路层,还有应用层和网络层。应用层比如ISO-15765规定了汽车应用层数据,可以看下边的参考,只不过实际很多都是汽车厂家自己定义的。
小猫爪:嵌入式小知识14 - ISO15765(UDS on CAN)详解-CSDN博客
一帧CAN报文通常含有64bit的数据,也就是8个Byte的数组,还有一个报文ID用于表示这帧报文。如下图所示。
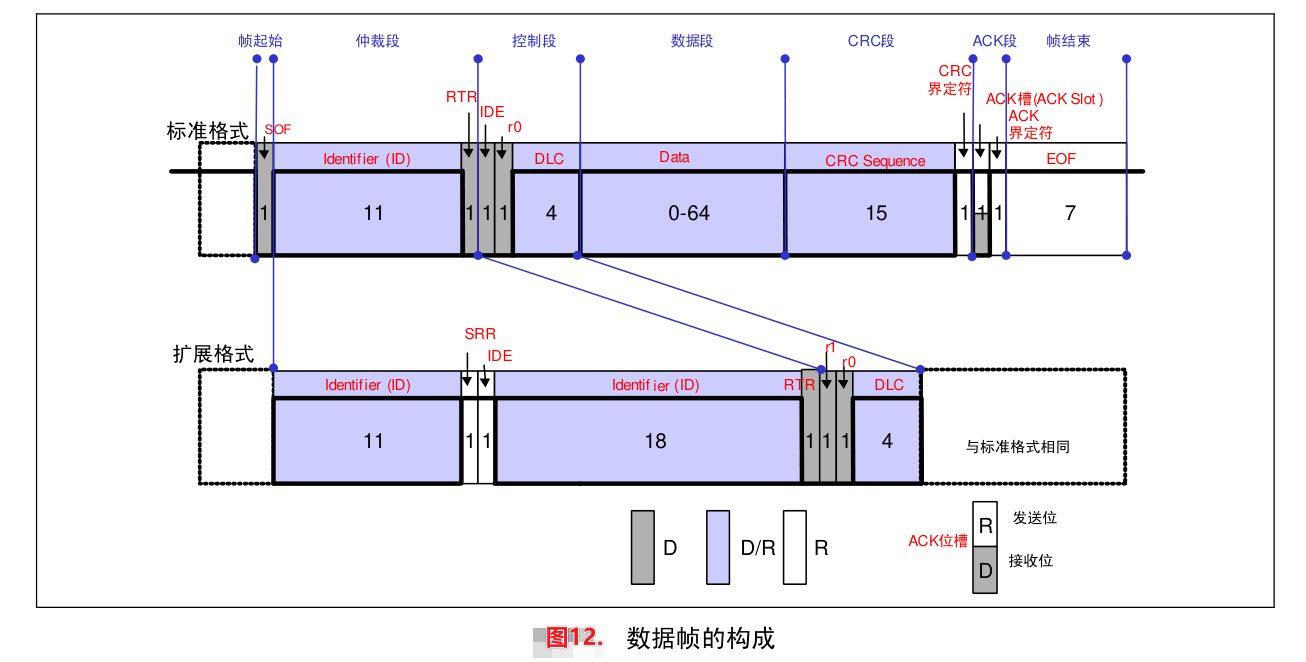
我们这里只关心仲裁段的ID和数据段的64bit数据即可。ID用于标记这是哪一个信号。而64bit的数据中则包含了车身的各种数据,例如车速、电机转速、空调温度等,并且他们在这64bit中占据的长度不一致,并且位置也不一致,他们一起组合在一起,构成一帧报文。如下图所示,每一行表示一个Byte,总共8个Byte,64位数据。
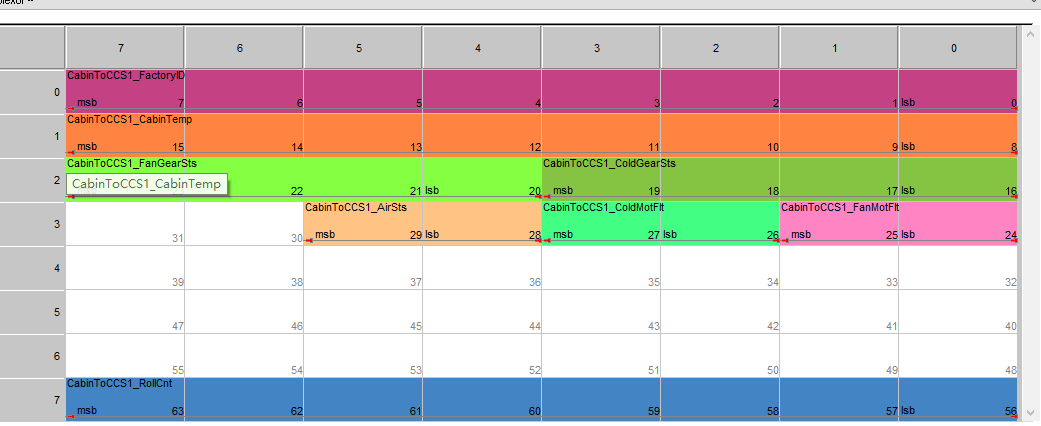
例如,上图中的8bit到 15bit表示的就是Temp,也就是空调温度。16bit到 19bit表示的就是 ColdGearSts,也就是空调的制冷状态。26到 27表示压缩机故障状态。而在我们的安卓车机大屏的应用中,通常就需要解析这些数据(通常是字节流的形式),解析成数据模型的字段,然后显示到屏幕中。
如上图所示,横轴和纵轴都是8个,8*8共64个bit,不同的颜色标记了不同的车身数据,而应用层所需要做的事就是从这64比特的矩阵中取出数据,并解析。例如上图中而描述这些数据在哪一个位置占据多少长度的文件,就叫DBC文件,全称DataBaseCan,顾名思义,就是描述CAN报文的数据库文件,以.dbc结尾。另外,除了数据的储存位置和长度,DBC文件还存了精度和偏移量,以及最大值最小值等多种信息。使用文本格式打开后,长下边这样。
BU_: CCS AC
BO_ 2560107544 CCSToAC1: 8 CCS
SG_ CCSToAC1_FactoryID : 0|8@1+ (1,0) [0|255] "" AC
SG_ CCSToAC1_AirSw : 8|2@1+ (1,0) [0|3] "" AC
SG_ CCSToCabin1_ColdGearReq : 10|4@1+ (1,0) [0|15] "" AC
SG_ CCSToAC1_FanGearReq : 14|4@1+ (1,0) [0|15] "" AC
SG_ heart : 56|8@1+ (1,0) [0|255] "" AC
BO_ 2560104484 ACToCCS1: 8 AC
SG_ CabinToCCS1_FactoryID : 0|8@1+ (1,0) [0|255] "" CCS
SG_ CabinToCCS1_CabinTemp : 8|8@1+ (1,-50) [-50|205] "" CCS
SG_ CabinToCCS1_ColdGearSts : 16|4@1+ (1,0) [0|15] "" CCS
SG_ CabinToCCS1_FanGearSts : 20|4@1+ (1,0) [0|15] "℃" CCS
SG_ CabinToCCS1_FanMotFlt : 24|2@1+ (1,0) [0|3] "" CCS
SG_ CabinToCCS1_ColdMotFlt : 26|2@1+ (1,0) [0|3] "" CCS
SG_ CabinToCCS1_AirSts : 28|2@1+ (1,0) [0|3] "" CCS
SG_ CabinToCCS1_RollCnt : 56|8@1+ (1,0) [0|255] "" CCS
BO_ 2561387265 message1: 8 Vector__XXX
SG_ msg1_sig1 : 0|8@1+ (1,0) [0|255] "" Vector__XXX
SG_ msg1_sig2 : 8|8@1+ (1,0) [0|255] "" Vector__XXX
SG_ msg1_sig3 : 16|8@1+ (1,0) [0|255] "" Vector__XXX
SG_ msg1_sig4 : 24|8@1+ (1,0) [0|255] "" Vector__XXX
SG_ msg1_sig5 : 32|8@1+ (0.2,-20) [-20|31] "" Vector__XXX
SG_ msg1_sig6 : 40|8@1+ (0.5,-50) [-50|77.5] "" Vector__XXX
SG_ msg1_sig7 : 48|8@1+ (0.1,-100.5) [-100.5|-75] "" Vector__XXX
SG_ msg1_sig8 : 56|8@1+ (0.1,100) [100|125.5] "" Vector__XXX
上边这个就是DBC文件了,BO_表示一个消息,你也可以称之为报文,或 Message;SG_表示这个消息中的一个信号,或 signal;一个消息包含若干个信号,共同组成这 64 bit 数据。
BO_ 2560107544 CCSToAC1: 8 CCS
-
2560107544是十进制格式的报文ID编码; -
CCSToAC1是报文名称; -
8指报文长度是8个Byte; -
CCS指节点名称,通常指这个消息是由哪个设备发出来的,也就是节点。2560107544是十进制格式的报文ID编码,需要转换成16进制后,才是我们通常用到的ID的编码,这里等于0x9898_2418。报文通常又分为两种,扩展帧和标准帧,扩展帧范围0到0X0x1FFF_FFFF,标准帧范围0到0x7FF。通常我们将报文ID大于0X7FF的一律当成扩展帧。而0x98982418还要减一个0X8000_0000才得到最终的ID=0X1898_2418,所以这帧报文也就是扩展帧。
OK,我们来看下边一行,下边一行就是信号。
SG_ CCSToAC1_FactoryID : 0|8@1+ (1,0) [0|255] "" AC
CabinToCCS1_FactoryID指信号名称;0|8指这个信号从矩阵中的0开始存,记8位,同理24|2指信号从数组下标的24开始记,记2位,最高位63,没有64。@不用管,是一个标记符号。1+,其中1指英特尔格式,如果是0就是指摩托罗拉格式。英特尔格式,也就是小端排序,数据的低位存放在硬件储存空间中的低位,高位存放在高位。而摩托罗拉格式反过来,也就是大端排序,数据的低位,需要存放在储存空间的高位,反之同理。1+,其中的+值无符号格式,也就是unsigin,而如果是-就表示有符号格式,有符号就是允许存在负数。但是通常在汽车行业中都是采用无符号格式,使用精度和偏移量来表示负数。
SG_ CabinToCCS1_CabinTemp : 8|8@1+ (1,-50) [-50|205] "" CCS
(1,-50)就表示一组精度和偏移量。我们在CAN总线中传输的是16进制的未处理值(也称原始值),需要处理过后得到物理值才拿到应用层使用。其中计算公式是
物理值 = 原始值 * factor(精度) + offset (偏移量)
比如这个时候的(1,-50),假如我们拿到了未处理的十进制的车速70,那么实际车速就是 70*1-50=20。ok,我们看下一条。
[-50|205],也就指最小值和最大值,通常会根据精度和偏移量以及信号长度计算得来,比如刚才这个信号,长度8,那么未处理值的范围也就是0到2^(8)-1,也就是0到255,对最小值和最大值分别进行精度偏移量的计算(0乘1减50得-50,以及255乘1减50得205),得到范围-50到205。你可以不按这个范围来定义,如果是自定义范围,那么也必须在这个范围内,不可以超出范围。- 双引号内部的指单位,后边
CCS的指信号的接收节点,很容易理解。
我们分析完了DBC的文件结构,按照我编程的思维,通常会把过程中事务抽象成一个个的对象。例如,这里就有一个DBC对象,它持有若干个Message对象的引用,然后是Message又同样持有了若干个Signal的引用。于是,我们的数据结构就有了。见下方代码。
首先是DBC类,用于描述整个DBC文件;然后是消息类,一个DBC类包含若干个Message消息;紧接着是Signal信号,一个Message消息包含若干个Signal信号。
/**
* 单个dbc对象
*/
public class CanDbc {
/** 节点列表 Set集合不重复*/
Set<String> canNodeSet = new HashSet<>();
/** 消息列表 。键记录消息ID值,值记录消息的对象 LinkedHashMap ,记录的是 newMsgIDCode,注意,因为DBC文件上下文有严格的依赖关系,故必须维护里边的插入顺序*/
Map<Integer, CanMessage> intMsgMap = new LinkedHashMap<>(); // 一个`DBC`类包含若干个`Message`消息
} 如代码所示,Map<Integer, CanMessage> intMsgMap = new LinkedHashMap<>();DBC类使用一个LinkedHashMap来存储多个消息,键记录报文ID。然后是Message消息类
/**
* 用于描述消息 Message
*/
public class CanMessage { //编程第一步,定义数据结构
/** 报文名称 ,非空*/
protected final String msgName ;
@Deprecated
protected MsgType msgType = MsgType.Normal;
/** 报文标识符 */
protected final int msg_ID ;
/** 报文标识符的DBC编码。<br>标准帧就等于报文标识符。<br>扩展帧等于报文标识符 + 0x8000_0000L */
protected final long msgIDCode;
/** 信号类型默认为 扩展帧 Extended 。<br> 可选值为 Standard 和 Extended 。<br>标准帧 Standard 范围 0x0~0x7FF ; <br>扩展帧 Extended 范围 0x0~0x1FFF_FFFF 。*/
protected final CANMsgIdType msgIdType ;
/** 报文发送类型 默认为周期型 . 暂时不打算更新对周期型的识别*/
protected MsgSendType msgSendType = MsgSendType.Cycle;
/** 报文周期时间 毫秒 。 预留,暂时不打算识别*/
protected int msgCycleTime ;
/** 报文长度 单位: byte*/
private final int msgLength ; //MsgLength(Byte)
/** 报文注释*/
protected String msgComment = "" ;
protected final String nodeName ;
/** 发送节点 , 当前报文的节点名称, 节点名称默认为 Vector__XXX*/
protected Set<String> msgSendNodeList = new HashSet<>();
/** 信号列表 ; 键指信号的名称, 值指的是信号 */
protected Map<String, CanSignal> signalMap = new ConcurrentHashMap<>(); // 一个`Message`消息包含若干个`Signal`信号
public int getMsg_ID() {
return msg_ID;
}
public Map <String, CanSignal> getSignalMap() {
return signalMap;
}
@Override
public String toString() {
return " {消息名称:"+msgName+"}";
} //toString()
} 如代码所示,protected Map<String, CanSignal> signalMap = new ConcurrentHashMap<>(); 消息类中使用一个ConcurrentHashMap来储存信号,键是信号名称。
/**
* 用于描述单个信号
*/
public class CanSignal {
protected static final String Vector__XXX = "Vector__XXX";
/** 信号名称*/
protected final String signalName;
/** 分组类型。 默认不启用多路复用 。分为默认分组(不分组)、分组标志位、组号,三个类型*/
protected final GroupType groupType ;
/** 多路复用实际值 M m2 ,组号。 <br>
* 1、空白 表示默认分组,或者说不分组。 默认不分组。<br>
* 2、大写的M 表示这个信号是分组标志位。 一个报文中只可以存在一个分组标志位。<br>
* 3、小写的m加一个数字,表示组号。有组号,则该消息中必须存在分组标志位。*/
protected String strGroupValue = "";
/** 组号。用于多路复用时,区分不同分组。 */
protected final int groupNumber ;
/** 信号注释 */
protected String signalComment = "";
/** 排列格式 ,Intel 或者 Motorola 。排列方式默认为英特尔模式 Intel */
protected final CANByteOrder byteOrder ; // 定义排列格式,并默认为英特尔格式
/** 起始位 bit ; <br> 注意,当数据排列格式为motorola时,无论是MSB还是LSB,存入其中的起始位只能是 MSB 的位置。 */
protected final int startBit;
/** 信号长度 BitLength(Bit) 会用于最大值最小值的计算。*/
protected final int bitLength;
/** CAN数据类型,无符号和有符号,默认无符号; */
protected final CANDataType dataType ;
/** 精度(精度不可以为0,否则无意义) ; 物理值 = 原始值 * factor + offset */
protected final double factor ;
/** 偏移量 (通常为负数) ; 物理值 = 原始值 * factor + offset */
protected final double offset ;
/** 物理最小值*/
protected final double signalMinValuePhys ;
/** 物理最大值*/
protected final double signalMaxValuePhys ;
/** 物理初始值 double rawValue = (sig.getInitialValuePhys()-sig.getOffset()) / sig.getFactor(); */
protected double iniValuePhys = 0;
/** 总线初始值 */
protected double iniValueHex = 0;
/** 当前信号的值 */
public volatile double currentValue = 0;
/** 值是否无效 ,true表示有效,*/
protected volatile boolean valid = true;
/** 单位*/
protected final String unit ;
/** 接收节点列表 默认值 Vector__XXX*/
final Set<String> sigReceiveNodeSet ;
/** 用于标记该信号属于哪个数据模型 */
Object model;
/** 用于标记属于哪个字段 */
Field field;
} 然后就是信号,总体上除了每个对象单独记录自己的东西之外,还用了一个map来持有下一级的数据,形成树形结构,同时使用了final字段来保存固定的数据,防止数据意外修改,值得注意的是下边这两个字段。
/** 用于标记该信号属于哪个数据模型 */
Object model;
/** 用于标记属于哪个字段 */
Field field; 这两个数据等会第六章再讲,会用于绑定车身数据模型,而field字段正是通过反射获取的字段,将其和DBC文件绑定到一起。
创建完整个DBC之后,数据结构用思维导图表示就如下:
%% graph定义了这是流程图,方向从左到右
graph LR
%% 然后别急着画图,我们把每个节点定义成变量。(写代码是一门艺术,一定要写的逻辑清楚,我用o表示根节点,后面按层级的规律给它编码)
dbc(DBC)
msg1(msg1)
msg2(msg2)
msg3(msg3)
msg4(msg4)
sig1_1(sig1_1)
sig1_2(sig1_2)
sig1_3(sig1_3)
sig1_4(sig1_4)
sig2_1(sig2_1)
sig2_2(sig2_2)
sig2_3(sig2_3)
sig2_4(sig2_4)
sig3_1(sig3_1)
sig3_2(sig3_2)
sig3_3(sig3_3)
sig3_4(sig3_4)
field(field)
%% 定义变量后再开始连接节点。
dbc---msg1
dbc---msg2
dbc---msg3
dbc---msg4
msg1---sig1_1
msg1---sig1_2
msg1---sig1_3
msg1---sig1_4
msg2---sig2_1
msg2---sig2_2
msg2---sig2_3
msg2---sig2_4
msg3---sig3_1
msg3---sig3_2
msg3---sig3_3
msg3---sig3_4
sig1_1---field
OK,既然DBC协议的数据是一行一行在存的,那么我用文件流一行一行读取就行了,循环读取每一行,最大程度节约内存。点这里回顾DBC文件内容。
这里的解析的正则表达式如下:
"^(?<title>BU_:|BO_|SG_|BO_TX_BU_|CM_|BA_DEF_|BA_DEF_DEF_|BA_|VAL_)\\s+"首先去掉每一行开头和结尾的空格,然后用这样一串正则表达式去匹配开头,根据匹配结果,再去调用不同的解析函数
switch (lineStart){
case "BU_:":
dbc.addCanNodeSet(parseBU(line)); // 解析节点
break;
case "BO_":
CanMessage msg = parseBO(line); // 解析消息
if (msg != null){
messagesMap.putIfAbsent(msg.getMsg_ID(), msg); //消息集合添加一条消息
}
break;
case "SG_":
CanSignal sig = parseSG(line); // 解析当前信号 .可能抛出异常
CanMessage presentMsg = dbc.getMessageAtIndex(messagesMap.size()-1); // 获取前一个消息(已经添加到了map中)
if (sig != null && presentMsg != null) {
//添加信号到对应的消息,添加信号前,需要校验是否重复。
Map<String, CanSignal> signalMap = presentMsg.getSignalMap();
String sigName = sig.getSignalName();
signalMap.putIfAbsent(sigName, sig);
} // sig != null
break;
default:
break;
} //switch (lineStart)其中,解析消息的具体代码如下,解析信号的就不贴了,大同小异,都是用了正则表达式。点这里可以查看下边的调用位置。
/**
* 解析消息
* @param line 传入单行字符串,例如 : BO_ 2560107544 CCS7: 8 GW ; BO_ 2147483921 MotorMessage: 8 Vector__XXX
* @return 返回一个CAN消息 CanMessage
*/
public static CanMessage parseBO(String line){
line = line.trim();
if ( ! line.startsWith("BO_")){
return null;
}
Pattern msgPattern = Pattern.compile("BO_\\s*(?<longIdCode>\\d+)\\s*(?<msgName>\\b[a-zA-Z_]\\w*)\\s*:\\s*(?<length>\\d)\\s*(?<node>\\b[a-zA-Z_]\\w*)");
Matcher msgMatch = msgPattern.matcher(line);
CanMessage msg ;
if (msgMatch.find()){
String strIdCode = msgMatch.group("longIdCode");// 需要转换格式
String msgName = msgMatch.group("msgName");
String strLength = msgMatch.group("length"); // 需要转换格式
String strNode = msgMatch.group("node");
//System.out.println("strIdCode = "+strIdCode+" , msgName = "+msgName+" , strLength = "+strLength+" , strNode = "+strNode);
long longIdCode = Long.parseLong(strIdCode,10); // 10进制
CANMsgIdType msgIdType = recognizeMsgID(longIdCode); //根据id识别扩展帧和标准帧
int msgId;
if (msgIdType == CANMsgIdType.Extended) { // id需要转换
msgId = CanMessage.transIdCodeToID(longIdCode);
}
else {
msgId = Math.toIntExact(longIdCode); // 标准帧直接添加 id = longIdCode
}
int msgLength = Integer.parseInt(strLength);
if (strNode == null){
strNode = "Vector__XXX";
}
msg = new CanMessage(msgName,msgId,longIdCode,msgIdType,msgLength,strNode);
}
else {
System.out.println("消息解析失败");
return null;
}
//System.out.println(" msg = "+msg.getMsgBaseInfo());
return msg;
} // parseBO在车载安卓app的开发当中,通常都会有一个或者多个数据模型类,用于描述车上的数据,子线程刷新该类的数据,而主线程则读取数据模型中的数据到界面中,通常是这样一个架构。
数据模型类的代码通常如下。
属性的名称可以不和dbc中的信号名称一致,名称定义取决于你。但,注解中标注的信号名称需要和DBC文件中定义的一致。也就是本篇文章第二章节所写的内容。(单击即可跳转)
// 使用注解将DBC与我们的数据模型绑定到了一起
@DbcBinding({
@DbcBinding.Dbc(dbcTag = Demo1.TEST_DBC, dbcPath = Demo1.DBC_PATH),
@DbcBinding.Dbc(dbcTag = "testDbc2",dbcPath = "E:\\storge\\very\\code\\IntelliJ_IDEA_Project\\QuickCanResolver\\src\\main\\resources\\DBC\\Example2.dbc")
})
public class CarDataModel implements CanCopyable<CarDataModel> , Cloneable {
@CanBinding(signalTag = "CabinToCCS1_FactoryID")
int CabinToCCS1_FactoryID ;
// 属性的名称可以不和dbc中的信号名称一致,名称定义取决于你。但,注解中标注的信号名称需要和DBC文件中定义的一致。
/** 空调温度 */
@CanBinding(signalTag = "CabinToCCS1_CabinTemp")
int airTemperature;
/** 空调制冷级别 */
@CanBinding(signalTag = "CabinToCCS1_ColdGearSts")
int coldGear;
/** 鼓风机档位 */
@CanBinding(signalTag = "CabinToCCS1_FanGearSts")
int fanGear;
/** 鼓风机故障状态 */
@CanBinding(signalTag = "CabinToCCS1_FanMotFlt")
int fanMotFault;
/** 冷机故障状态 */
@CanBinding(signalTag = "CabinToCCS1_ColdMotFlt")
int coldMotFault;
/** 空调运行状态 */
@CanBinding(signalTag = "CabinToCCS1_AirSts")
int airState;
/** rollingCounter,滚动计数,用于校验信号是否正确。 */
@CanBinding(signalTag = "CabinToCCS1_RollCnt")
int rollingCounter;
// 这里是第二个DBC中的数据,框架实现了可以多个模型对应多个DBC的复杂映射关系。
@CanBinding(signalTag = "msg9_sig1")
int msg9_sig1;
@CanBinding(signalTag = "msg9_sig2")
int msg9_sig2;
@CanBinding(signalTag = "msg9_sig3")
int msg9_sig3;
@CanBinding(signalTag = "msg9_sig4")
int msg9_sig4;
@CanBinding(signalTag = "msg9_sig5")
int msg9_sig5;
@CanBinding(signalTag = "msg9_sig6")
int msg9_sig6;
@CanBinding(signalTag = "msg9_sig7")
int msg9_sig7;
@CanBinding(signalTag = "msg9_sig8")
int msg9_sig8;
@Override
public CarDataModel copyNew() {
// TODO 需要你自己实现 CanCopyable<T> 接口,并需要自己实现 拷贝方法,并返回自身 。下边的代码只是一个示例,你也可以采用其他拷贝方式。
return clone();
}
@Override
public CarDataModel clone() {
try {
return (CarDataModel) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException("克隆失败", e);
}
}
}例如上边就依次表示了厂家代号、空调温度、空调制冷状态、鼓风机状态、鼓风机故障、压缩机故障、空调状态。到了实际应用中,可以是车身的任何数据,这里仅仅是举例。
现在简单解释一下上边的代码。@DbcBinding注解绑定了两个DBC文件到数据模型 CarDataModel上,而模型类又实现了两个克隆接口 implements CanCopyable<CarDataModel> , Cloneable ,克隆接口会在第九章中讲,而字段上边使用注解 @CanBinding将DBC中的信号和数据模型中的字段进行了一对一的绑定。这样就完成了DBC与我们数据模型的绑定,实际使用的时候,框架会解析这些绑定好的值,实现自动解析数据
使用的时候,只需要像下边这样就可以了。
// 1 获取一个管理器
CanObjectMapManager manager = CanObjectMapManager.getInstance() ;
// 2 通过管理器,实例化当前的模型,内部完成绑定操作
CarDataModel oldModel = manager.bind(CarDataModel.class) ;然后就可以进行报文的收发操作了,就像下边这样,只需要传入报文id和字节数组格式的报文,就可以实现自动更新数据。
// 使用时,只需要一行代码即可更新数据到绑定的 model 中
manager.receive_B(canId,data); 这几个类的定义和分析看下边的章节。
这一章节会简单介绍一下元编程,之前提到了本文的受众会有汽车行业的,也会有计算机行业的同事,主要是给汽车行业的同事讲懂这一块。如果你懂这一块,可以粗略看一下。
Note
我们先来思考一个问题,什么是元数据?
元数据就是你的局部变量名、类名、字段名、方法名、局部变量的类型等信息。
对比一些低级编程语言,例如C和 C++,这些编程语言,更节约内存,更多的用于嵌入式编程。而为了节约内存,这些语言类比我们的高级语言(例如java和python)做了什么事呢?也就是在编译的时候,抹去了元数据,在编码阶段,我们看得到变量名称,而编译之后,在计算机眼里,这些变量实际上只剩下了一个个地址。计算机只知道要把这个地址的值和另外一个地址的值相加,这个地址的值要和那个地址的值做逻辑运算,至于这个地址的变量名称是什么?计算机不知道。这就是元数据。编译时抹去元数据的好处就是,可以节约运行内存,这对于嵌入式设备非常重要,这也就是为什么,C和C++常用于嵌入式设备。
Note
好了,明白了元数据,我们再来解释一下元编程。
对于高级语言,比如java,java在编译时,程序实际上也是只知道地址不知道变量名的,同样也是抹去了变量名。但是,却在方法区里边单独存储了类元信息,这些信息实际上就是保存了一个类的数据结构,会在类实例化的时候被调用,也会在被反射调用的时候被读取。而程序在堆和栈中运行的时候,实际上也是一个个的地址而已。这样讲就很明白了吧,总结一下,java在运行代码时,很多时候,和C++类似,变量也只是一个个地址,不同的地方是java会在额外的地方存储这些元数据,以供必要的时候调用这些元数据。
而元编程就是在运行时读取这些元数据,并执行一些操作,很容易理解。
你可能会问,我为什么会需要读取元数据呢?因为读取元数据会让编程更加灵活,比如本篇的例子。
反射和注解就是最常用的元编程的技术,他们通常会在一起使用。
反射就是程序可以动态的,绕过一些程序限制,使用元数据进行编程的一种技术。而注解,你可以理解为它就是注释;只不过普通的注释是给人看的,而注解是给程序看的一种特殊的注释。与其说是注释,不如说是给程序的提示,这样就很好理解了。
例如,如果你需要让程序知道,这段代码是覆写了父类的方法,就需要加@Override注解,编译器会检查覆写的返回值和参数等是否正确。如果没有加注解,那么如果参数不正确,则不会覆盖父类方法,而是会当成一个新方法,程序将不会得到正确调用。
好,明白了注解和反射,我们再来看看上边的@DbcBinding和@CanBinding注解是如何定义的。
@Target(ElementType.TYPE) // 作用于类上
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface DbcBinding {
Dbc[] value();
// 注解中只可以注解编译时常量,不可注解运行时常量,这一点和 switch 的用法一致,只能是编译时常量。
// 故如果想要更复杂的数据,只能是嵌套注解或者枚举或者基本数据类型的数组。
/**
* 单个dbc文件。<br>
* dbcTag : String = dbc标签名 <br>
* dbcPath : String = dbc文件路径 <br>
*/
@interface Dbc{
/**
* dbc标签名
*/
String dbcTag() ;
/**
* dbc文件路径
* */
String dbcPath() ;
}
}
@Target(ElementType.FIELD) // 作用于字段上
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface CanBinding {
int Default = -1 ;
/**
* CAN报文的ID,如0x18ABAB01 。存在默认值,可不填写。(填写了之后可提高程序效率,这取决于你)
* @return CAN报文的ID,如0x18ABAB01
*/
int messageId() default Default ;
/**
* CAN信号在dbc文件中的名称,需要保持一致。
*/
String signalTag() ;
}总结:
DbcBinding使用了嵌套注解,使能够标注更复杂的数据。内部定义了Dbc注解,里边定义了dbc标签名和dbc文件路径,就是提示程序需要识别这些信息。
然后是CanBinding注解,里边定义了CAN报文的ID和信号名称,标注这个字段的数据来源是哪一个信号,车速吗,还是温度。
在第五章的数据模型中使用这些注解后,就相当于告知了程序,你接下来需要特别注意这个变量,你需要按照注解的内容来进行解析。
这一部分,我会介绍如何将注解绑定到框架中。
使用步骤如下,每个操作都只需要一行代码,十分的简单优雅。
// 1 获取一个管理器
CanObjectMapManager manager = CanObjectMapManager.getInstance();
// 2 通过管理器,实例化当前的模型,内部完成绑定操作
CarDataModel model = manager.bind(CarDataModel.class);
// 3 使用时,只需要一行代码即可更新数据到绑定的 model 中
manager.receive_B(canId,data);首先,使用单例模式获取了一个管理器的实例。代码如下
public class CanObjectMapManager {
protected Map<String, CanDbc> dbcMap;
protected Map<String, CanIOHandler> canIOMap;
protected static volatile CanObjectMapManager manager;
/**
* 使用单例模式获取一个 “CAN对象映射管理器”
* @return “CAN对象映射管理器”
*/
public static CanObjectMapManager getInstance() {
if (manager == null){
synchronized (CanObjectMapManager.class){
if (manager == null){
return manager = new CanObjectMapManager();
}
}
}
return manager;
}
private CanObjectMapManager() {
dbcMap = new ConcurrentHashMap<>();
canIOMap = new ConcurrentHashMap<>();
}
}/**框架最主要方法 : 绑定 dbc <br>
* 使用注解,直接绑定dbc和数据模型,省略手动调用的步骤。<br>
* 已经封装好所有步骤,供外部直接调用。
* @param clazz 数据模型Class
*/
public <T> T bind(Class<T> clazz) {
// 获取类上的注解
if (! clazz.isAnnotationPresent(DbcBinding.class)) {
return null; // 没有则直接返回null
}
// 拿到注解
DbcBinding dbcBinding = clazz.getAnnotation(DbcBinding.class);
// 现在可以一次性给一个数据模型绑定多个DBC
DbcBinding.Dbc[] rawDbcArray = dbcBinding.value();
// 循环,遍历多个DBC文件,绑定DBC
for (DbcBinding.Dbc rawDbc : rawDbcArray) {
String dbcTag = rawDbc.dbcTag();
String dbcFilePath = rawDbc.dbcPath();
// 增加校验,避免反复创建dbc。
if (dbcMap.containsKey(dbcTag)) {
continue;
}
// 生成 dbc ,并添加到map中。即初始化一个Dbc文件
addDbcToMap(dbcTag,dbcFilePath);
System.out.println("DBC绑定成功,dbcTag = " + dbcTag + ", dbcFilePath = " + dbcFilePath);
} // 循环,遍历多个DBC文件
T instance = creatInstance(clazz);
// 给 dbc 中的 CanSignal 绑定字段 ,以及模型
bindModelAndField(clazz,instance);
return instance; // 返回实例化之后的数据模型
}
public static <T> T creatInstance(Class<T> clazz) {
try {
// 获取无参构造函数
Constructor<T> constructor = clazz.getDeclaredConstructor();
// 允许访问私有构造函数
constructor.setAccessible(true);
// 创建实例并返回
return constructor.newInstance();
} catch (NoSuchMethodException | InstantiationException | IllegalAccessException | InvocationTargetException e) {
throw new RuntimeException("反射实例化数据模型时出错"+e.getMessage(), e);
}
} 首先会循环解析数据模型类上边定义的多个DBC文件,框架允许你定义给一个数据模型绑定多个DBC文件,非常自由。
拿到文件地址之后,就会交给之前的代码进行解析,解析成一个DBC对象。点这里查看上边定义的解析代码。然后调用 addDbcToMap(dbcTag,dbcFilePath);将dbc引用起来,由管理器进行管理。
再由方法 bindModelAndField(clazz,instance);将字段和模型绑定到刚才绑定好的dbc中。
最后用反射T instance = creatInstance(clazz);,实例化绑定好的类,再返回给调用者,由调用者进行使用。
具体的绑定代码如下。
public void bindModelAndField(Class<?> dataModelClass, Object model){
// 循环,查找所有字段
for (Field field : dataModelClass.getDeclaredFields()) {
// 设置setAccessible为true,绕过访问控制检查
field.setAccessible(true);
// 不含有 CanBinding 注解,则忽略,执行下一次循环。
if (! field.isAnnotationPresent(CanBinding.class)) { // 查找注解
continue;
}
// 故以下代码都默认字段包含了 CanBinding 注解。
CanSignal signal = findSignalByBind(field);
// 这里的意思就是在包含 CanBinding 注解的情况下,找到了相关信号。
if (signal == null){
// 这里抛出异常的意思就是,在包含 CanBinding 注解的情况下,绑定的信息有误,字段绑定的信号在dbc中没有找到,DBC实际上不含这个信号。
throw new RuntimeException("字段: '"+field.getName()+
"' 绑定信息有误; 实际上未在DBC中未找到你想要绑定的信号{" + field.getAnnotation(CanBinding.class).signalTag() + "} 。");
}
// 绑定字段
signal.setField(field);
// 绑定模型
signal.setDataModel(model);
} //查找所有字段
} 这一段代码也很简单,使用了反射来解析字段上的 CanBinding注解,看标记的信号名称是否在DBC中出现,如果出现了就绑定到一起,也就是让Signal持有当前字段。前边我们提到了,signal会持有绑定的字段,实现一对一的绑定,部分代码如下。
/**
* 用于描述单个信号
*/
public class CanSignal {
/** 信号名称*/
protected final String signalName;
//....省略部分代码
/** 用于标记该信号属于哪个数据模型 */
Object model;
/** 用于标记属于哪个字段 */
Field field;
}Important
总结:可以看到,整个绑定逻辑,实际上就是下边两步
首先,根据DBC文件,将DBC文件解析成一个DBC对象,里边保存了信号的解析规则。
其次,程序依次解析类和字段的注解,到刚才解析好的DBC文件中查找注解的信号,有对应的信号就进行绑定。
实际上就是由DBC这个类同时持有了解析的规则,和同时持有了绑定的字段。
start=>start: 开始
inputDbc=>inputoutput: 输入DBC文件
inputModel=>inputoutput: 输入绑定了注解的数据模型
end=>end: 结束
parseDbc=>operation: 解析DBC文件
ParseModel=>operation: 解析模型上的注解
getDbc=>operation: 得到DBC类
bindFieldToDbc=>operation: 绑定字段到DBC类中
start->inputDbc->parseDbc->getDbc->inputModel
inputModel->ParseModel->bindFieldToDbc->end
到这里,就完成了框架的初始化工作。
然后,就需要定义报文的收发了。
具体代码如下 receive_B,此处的方法没有对操作加锁,点击这里可以查看下边的加锁的代码。
/**
* 将接收到的CAN报文,解析后存入绑定好的数据模型中。<br>
* 8 --> 64 --> signal --> field
* @param canId 报文id
* @param data8 8位数组的CAN报文,Byte数组格式。
*/
public void receive_B(int canId, byte[] data8) {
// 拿到id之后,需要到DBC文件中查询对应的对象。然后修改这个对象
CanMessage msg = msgMap.get(canId);
if (msg == null){
return;
}
byte[] data64 = MyByte.from8BytesTo64Bits(data8,MyByte.DataType.Intel); // 8 -->64
// 64 --> signal ;循环,逐个将 64bits数组中的数据按位取出,并解析到信号的字段中。
for (CanSignal signal : msg.getSignalMap().values()) {
// 解析值
double phyValue = bits64ToValue(data64, signal, signal.getStartBit(), signal.getBitLength(), signal.getFactor(), signal.getOffset());
// 刷新值
signal.writeValue(phyValue) ;
}
}
private double bits64ToValue(byte[] data64, CanSignal signal, int startBit , int bitLength , double factor , double offset ) {
//System.out.println("待计算值,startBit = " + startBit +" ; bitLength = "+bitLength+" ; factor = " + factor + " ; offset = " + offset) ;
int rawValue ; //总线值,未处理值
double phyValue; //实际值
MyByte.DataType inputType = transOrder(signal.getByteOrder());
rawValue = MyByte.bitsToInt(Arrays.copyOfRange(data64,startBit,startBit + bitLength),inputType) ; // MyByte.DataType.Intel
phyValue = (rawValue * factor) + offset ;
// ... 省略部分
return phyValue;
} // bits64ToValue() 接收报文的时候,会传入接收的CAN报文ID和8字节的报文数组。
首先,将8字节的报文数组转换成64位的数组。
其次,依次按照解析规则,依次从这64位数组中按位取出数据,将一个一个的bit组合成int类型数据。
最后,再写入解析好的数据到绑定的字段中。
8字节转64bits的代码如下,实际上就是一个位运算,很简单,使用位运算依次取出最后一位放数组上,每次取完之后,数据右移一位,然后再重复取值。
public static byte[] from8BytesTo64Bits(byte[] bytes, DataType type) {
byte[] bits = new byte[64];
for(int i=0;i<8;i++){
System.arraycopy(byteTo8Bits(bytes[i],type),0,bits,i*8,8);
}
return bits;
}
public static byte[] byteTo8Bits(byte mByte, DataType type) {
byte[] array = new byte[8];
switch (type){
case Intel: default:
for(int i = 0;i<8;i++){
array[i] = (byte)(mByte & 0b0000_0001); //bytes&0b00000001 //取最后一位放0
mByte = (byte) (mByte >> 1); //右移
}
break;
case Motorola:
for (int i = 7; i >= 0; i--) { //摩托罗拉格式 例如 32 = 0010 0000 0123 4567
array[i] = (byte)(mByte & 0b0000_0001); //bytes&0b00000001 //取最后一位放最高位7 0123 4567
mByte = (byte) (mByte >> 1); //右移,继续取最后一位放6,依次类推
}
break;
}
return array;
} 将bit数组组合成一个int类型的字段的部分代码如下,实际上也是位运算,原理类似。
/**
* 输入任意长度的 bits数组,长度小于等于32,转换成一个int型数据
* @param bits 任意长度的 bits数组
* @param type 要转换的类型 "motorola":大端模式,数据高位存放数组低位 ; "intel" :低位存放至低位
* @return 一个int型数据
*/
public static int bitsToInt(byte[] bits,DataType type) {
int re = 0;
int len = bits.length;
switch (type){
case Intel: default:
for(int i = len-1; i>=0;i--){ //数据高位存放到高位;把数据低位存放到低位
re = re << 1;
re = re | (bits[i] & 0x0000_0001); // len-1 存放到最高位
}
break;
case Motorola:
for(int i =0;i<len;i++){
re = re << 1;
re = re | (bits[i] & 0x0000_0001); //把 bits[0]存放到 数据的最高位
}
break;
}
return re;
} 以上就是解析报文的部分逻辑,而发送报文的逻辑则相反,代码实现逻辑类似,就不在这里说明了,具体逻辑可以到我的github中查看全部源代码。
Note
你可能会问,你这个如果出现多线程同时调用怎么办,多线程同时修改同一个数据模型,可能会出现数据不一致的情况,出现数据覆盖和丢失的问题。
是个好问题。在我们编程中确实应该注意多线程的问题,特别是在安卓的环境下,搞不好就会出现各种闪烁,卡顿等。
好,我们可以给操作加上一个锁就行了,当然不是给整个类加锁,那样范围太大了;也不是给某一个字段和信号加锁,那样范围太小了,加锁解锁的次数会变多。由于我们车身报文的最小单位起始是一组64bit的CAN报文,故我们给一组CAN报文加锁即可。而一组CAN报文由ID唯一标识,所以我们可以用CANID作为锁的标识来加锁,不同CANID使用不同的锁,所以当接收到不同CANID的报文时,依然可以异步进行操作,而相同CANDI则需要等待。好主意,然后动手改造了以下代码。syncReceive_B()
/**
* 在写入字段的时候,加锁写入。
* @param canId 报文id
* @param data8 8位数组的CAN报文
*/
public void syncReceive_B(int canId, byte[] data8) {
// 拿到id之后,需要到DBC文件中查询对应的对象。然后修改这个对象
CanMessage msg = msgMap.get(canId);
if (msg == null) {
return;
}
byte[] data64 = MyByte.from8BytesTo64Bits(data8,MyByte.DataType.Intel); // 8 --> 64
// 64 --> signal ;循环,逐个将 64bits数组中的数据按位取出,并解析到信号的字段中。
ReentrantLock lock = getLock(canId); // 获取锁
lock.lock(); // 加锁
// 加锁执行字段的写入操作
try {
for (CanSignal signal : msg.getSignalMap().values()) {
double phyValue = bits64ToValue(data64, signal, signal.getStartBit(), signal.getBitLength(), signal.getFactor(), signal.getOffset());
signal.writeValue(phyValue) ;
}
} finally {
lock.unlock(); // 解锁
}
}
/**
* 获取一个锁,该锁锁住了单个报文的操作,不同报文则是不同的锁。
*/
public ReentrantLock getLock(int canId) {
ReentrantLock lock = msgWriteLockMap.get(canId);
if (lock == null) {
lock = new ReentrantLock();
msgWriteLockMap.put(canId,lock);
}
return lock;
} 相比于之前的receive_B()方法,这里对写入操作加上了锁,保证了线程安全。
过了几天,同事用了之后反馈,不对不对,使用新方法进行多线程操作报文之后,当有大量报文时,运行时间反而更长了。
我摸摸脑袋瓜,一拍大腿,对喔,每次处理的数据实际上只有64bit,一次任务下来,可能1毫秒都不到就处理完成了,线程会反复切换,增加了线程切换上下文的开销,实际运行效率还不如单线程。但是这样异步处理数据还是会有问题,每次都会加锁,频繁加锁解锁和等待,增加程序的性能消耗。
Important
那怎么样才能解决异步处理数据的问题呢?
这个时候,我们的救星来了,LiveData加 ViewModel,LiveData默认会在主线程中修改数据;而在子线程中,LiveData会调用 postValue来将数据的修改请求发送到主线程中进行排队,这样就避免了异步操作数据的同步问题。
但是,LiveData会把数据进行一个封装,不可以直接由反射调用,就像下边这样
// 示例数据类
class User {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
// Getter 方法...
}
// ViewModel 类
public class MyViewModel extends AndroidViewModel {
// MutableLiveData 用于内部修改,对外暴露不可变的 LiveData
private MutableLiveData<User> userLiveData;
private MutableLiveData<String> messageLiveData = new MutableLiveData<>();
public MyViewModel(@NonNull Application application) {
super(application);
// 初始化操作
init();
}
private void init() {
userLiveData = new MutableLiveData<>();
// 模拟数据加载
loadUserData();
}
// 对外暴露不可变的 LiveData
public LiveData<User> getUser() {
return userLiveData;
}
public LiveData<String> getMessage() {
return messageLiveData;
}
// 模拟异步数据加载
private void loadUserData() {
new Thread(() -> {
try {
// 模拟网络请求延迟
Thread.sleep(2000);
// 后台线程使用 postValue
User user = new User("John Doe", 30);
userLiveData.postValue(user);
messageLiveData.postValue("Data loaded successfully");
} catch (InterruptedException e) {
messageLiveData.postValue("Error loading data");
}
}).start();
}
// 更新数据的公共方法
public void updateUserName(String newName) {
User current = userLiveData.getValue();
if (current != null) {
User updatedUser = new User(newName, current.getAge());
userLiveData.setValue(updatedUser); // 主线程使用 setValue
}
}
} 好,现在我们来做一下 LiveData加 ViewModel的适配。
虽然适配是很麻烦的,但是只要思路清晰,还是没有问题的。使用 LiveData封装之后,无法直接使用反射赋值了,但是也可以强行使用反射来进行赋值。所以我们就有了两种方法来解决 LiveData的适配问题。
Note
方法一:还是使用反射直接调用 postValue
类似的伪代码如下:
postValueMethod = getMethod("postValue");
postValueMethod.invoke(mutableLiveData, value); 好吧,非常暴力,但是我并不推荐这样写,因为这不优雅。LiveData已经是别人封装好的东西了,这样写会破坏代码的封装性。
Note
方法二:拷贝一个新对象给 LiveData
这种方法就优雅多了,相当于是跟着 LiveData的用法,进行了扩展。
Note
首先定义一个拷贝接口。
/**
* 自定义的 copy 接口,用于拷贝数据模型,请返回拷贝之后的数据模型。
*/
public interface CanCopyable<T> {
/**
* 自定义的 copy 接口,用于拷贝数据模型,请返回拷贝之后的数据模型。
* @return 返回拷贝之后的数据模型
*/
T copyNew();
}Note
实现拷贝接口
然后,在我们的数据模型上使用这个接口。你可能已经注意到了,我们第五章数据模型一节,已经使用了拷贝接口
我把代码单独粘贴下来,如下。接口方法返回一个拷贝好的新对象回来。
public class CarDataModel implements CanCopyable<CarDataModel> , Cloneable {
@Override
public CarDataModel copyNew() {
// TODO 需要你自己实现 CanCopyable<T> 接口,并需要自己实现 拷贝方法,并返回自身 。下边的代码只是一个示例,你也可以采用其他拷贝方式。
return clone();
}
@Override
public CarDataModel clone() {
try {
return (CarDataModel) super.clone();
} catch (CloneNotSupportedException e) {
throw new RuntimeException("克隆失败", e);
}
}
}Note
然后在代码中使用拷贝接口
public <T extends CanCopyable<T>> T createNewModel(int canId, byte[] data8, T oldDataModel) {
// 根据 canId 确定要写入哪一个 DBC
String dbcTag = findDbcTagByCanId(canId);
// 根据 DbcTag 获取处理者
CanIOHandler canIOHandler = getCanIo(dbcTag);
// 更新数据到 模型中
canIOHandler.updateObj_B(canId,data8,oldDataModel);
// 直接使用拷贝接口,拷贝一个新的对象。
return oldDataModel.copyNew();
} 实际上就相当于更新数据之后,我再把旧的数据拷贝了一个出来。
LiveData拿到数据之后,再使用 postValue或者 setValue刷新数据,发现是新对象,也就是对象的地址发生了改变,自然也就会通知观察者了。
至此,LiveData的适配也就完成了。
使用注解加反射的元编程。使用的时候,只需要用几个注解标注数据的来源,更换车型的时候,如果大的数据类型没有变动,只是变动了数据的解析规则,我们只需要改最上边那一行就行了;如果新车型更改了信号名称,改动的地方也很少,如果名称写错了,程序也会自动报错。总之就是在实际应用过程中,改动的地方会非常少,且固定,并且改动了之后,并不会影响外边的逻辑(该是哪个变量,还是哪个变量)。实现了车身安卓应用和CAN通信协议的解耦。
来做一个代码的对比。
这里是以前的写法:
switch (receiveID){
case MsgID1:
resolution1(data);
break;
case MsgID2:
resolution2(data);
break;
}
// 下边依次解析了设定温度,空调工作模式,除霜状态等数据。
// 设定温度起始位0,长度8,精度1,偏移量-40,
private void resolution1(byte[] data){
tempSetValue = (int) resolution(data,0,8,1,-40).intValue(); // 从报文中解析 空调设定温度
workMode = (int) resolution(data,8,2,1,0).intValue(); // 从报文中解析 空调设定模式
defrostStage = (int) resolution(data,10,2,1,0).intValue(); // 从报文中解析 空调除霜状态
collisionWarningSts = (int) resolution(data,12,3,1,0).intValue();
sterilizeSts = (int) resolution(data,15,1,1,0).intValue();
defrostInterval = (int) resolution(data,16,8,30,0).intValue();
defrostMaxTime = (int) resolution(data,32,8,1,0).intValue();
defrostEndTemp = (int) resolution(data,40,8,1,-40).intValue();
evaporationFanTempMode = (int) resolution(data,49,1,1,0).intValue();
}
public int resolution(){
// ... 该函数省略。用于根据每个信号起始位、长度、精度、偏移量等信息,进行解析工作。
}这里是更新之后的写法,通过标注
DBC名称和信号名称,快速绑定CAN协议层。
// 框架使用注解解耦了CAN数据层和应用层
@DbcBinding({
@DbcBinding.Dbc(dbcTag = Demo1.TEST_DBC, dbcPath = Demo1.DBC_PATH)
})
public class CarDataModel implements CanCopyable<CarDataModel> , Cloneable {
@CanBinding(signalTag = "CabinToCCS1_FactoryID") // 标注信号名
int FactoryID ;// 应用层的 FactoryID 变量只需要关注 信号名称为“CabinToCCS1_FactoryID”的信号即可,不需要关注信号内部的任何变化,实现了解耦。
@CanBinding(signalTag = "CabinToCCS1_CabinTemp") // 标注信号名
int airTemperature ;
// ... 省略了其他信号
}做一个对比
应用层的 airTemperature 变量只需要关注信号名称为“CabinToCCS1_CabinTemp”的信号即可,自己实现空调温度的显示逻辑,不需要关注信号内部的任何变化,不需要关注数据的来源,应用层就只关心应用层。然后呢,倘若我们这个信号发生了变化,例如我们这个信号在DBC中的定义如下
// 旧的DBC文件
SG_ CabinToCCS1_CabinTemp : 8|8@1+ (1,-50) [-50|205] "" CCS 原来的解析如下,我们需要把8,8,1,-50作为参数手动传入函数解析,一旦变动,改起来非常麻烦,并且出现问题也不容易找到。
// 原来的 java 解析代码
airTemperature = (int) resolution(data,8,8,1,-50).intValue(); // 从报文中解析 空调设定温度 好了,现在这个信号在DBC中的文件定义改成了这样。
// 新的DBC文件
SG_ CabinToCCS1_CabinTemp : 0|16@1+ (1,-100) [-100|205] "" CCS 我们的代码不需要做任何变动,因为已经使用了@CanBinding注解,绑定了空调设定温度airTemperature这个变量,如下所示。
@CanBinding(signalTag = "CabinToCCS1_CabinTemp") // 标注信号名
int airTemperature ;如果是改了信号的来源,信号名称不变,也只需要该最上边那一行即可,如下。
@DbcBinding({
@DbcBinding.Dbc(dbcTag = Demo1.TEST_DBC, dbcPath = Demo1.DBC_PATH) ,
// 这里改动为了新的DBC文件地址。
@DbcBinding.Dbc(dbcTag = Demo1.TEST_DBC_2, dbcPath = Demo1.DBC_PATH_2) ,
// 你甚至可以同时绑定多个DBC来源,只要内部的信号名称不重复(或者重复信号的定义一致)。
@DbcBinding.Dbc(dbcTag = Demo1.TEST_DBC_3, dbcPath = Demo1.DBC_PATH_3) ,
})
public class CarDataModel implements CanCopyable<CarDataModel> , Cloneable {
@CanBinding(signalTag = "CabinToCCS1_CabinTemp") // 标注信号名
int airTemperature ;
// ... 省略了其他信号
} 使用的时候也很方便,只需要像下边这样三行代码即可。
// 1 获取一个管理器
CanObjectMapManager manager = CanObjectMapManager.getInstance();
// 2 通过管理器,实例化当前的模型,内部完成绑定操作
CarDataModel model = manager.bind(CarDataModel.class);
// 3 使用时,只需要一行代码即可更新数据(解码CAN报文)到绑定的 model 中
manager.receive_B(canId,data); 如果有异步编程需求,也适配了LiveData,只需要一行 createNewModel()即可生成新的对象给 LiveData使用。
完整的测试数据如下:
测试用DBC如下:
BO_ 2561387265 message1: 8 Vector__XXX
SG_ msg1_sig1 : 0|8@1+ (1,0) [0|255] "" Vector__XXX
SG_ msg1_sig2 : 8|8@1+ (1,0) [0|255] "" Vector__XXX
SG_ msg1_sig3 : 16|8@1+ (1,0) [0|255] "" Vector__XXX
SG_ msg1_sig4 : 24|8@1+ (1,0) [0|255] "" Vector__XXX
SG_ msg1_sig5 : 32|8@1+ (0.2,-20) [-20|31] "" Vector__XXX
SG_ msg1_sig6 : 40|8@1+ (0.5,-50) [-50|77.5] "" Vector__XXX
SG_ msg1_sig7 : 48|8@1+ (0.1,-100.5) [-100.5|-75] "" Vector__XXX
SG_ msg1_sig8 : 56|8@1+ (0.1,100) [100|125.5] "" Vector__XXX 测试代码如下:
static final int msg1_Id = 0x18AB_AB01 ; // 模拟报文ID
static byte[] data8_ = new byte[]{30, 29, 28, 20, (byte) 211, 121, (byte) 200, 100}; // 模拟 初始化数据
static byte[] data8_2 = new byte[]{7, 8, 9, 10, (byte) 211, 121, (byte) 200, 100}; // 模拟新数据
/**
* 测试生成新的模型
*/
@Test
public void test2() {
System.out.println("test2");
int num = 10;
// 1 获取一个管理器
CanObjectMapManager manager = CanObjectMapManager.getInstance() ;
// 2 通过管理器,实例化当前的模型,内部完成绑定操作
CarDataModel oldModel = manager.bind(CarDataModel.class) ;
// 初始化数据,也可以不初始化 data8_ = new byte[]{30, 29, 28, 20, (byte) 211, 121, (byte) 200, 100};
manager.receive_B(msg1_Id,data8_);
System.out.println("oldModel Value = " + oldModel.getMsg1Value()); //打印值
/* 初始化数据打印如下
* oldModel Value =
* Msg1 = {msg1_sig1 :30,
* msg1_sig2 :29,
* msg1_sig3 = 28,
* msg1_sig4 = 20 ,
* msg1_sig5: 22.200000000000003,
* msg1_sig6 :10.5,
* msg1_sig7 = -80.5,
* msg1_sig8 = 110.0}
*/
System.out.println("oldModel = " + oldModel + "\n");
// 打印 原始对象的 hash 码 Demo.CarDataModel@6ec8211c
long startTime = System.currentTimeMillis();
for (int i = 0 ; i < num ; i++) {
// 用新数据和旧的模型生成一个新的模型 data8_2 = new byte[]{7, 8, 9, 10, (byte) 211, 121, (byte) 200, 100};
CarDataModel newModel = manager.createNewModel(msg1_Id,data8_2,oldModel);
System.out.println("newModel Value = "+ newModel.getMsg1Value());
/* 更新数据打印如下
* newModel Value =
* Msg1 = {msg1_sig1 :7,
* msg1_sig2 :8,
* msg1_sig3 = 9,
* msg1_sig4 = 10 ,
* msg1_sig5: 22.200000000000003,
* msg1_sig6 :10.5,
* msg1_sig7 = -80.5,
* msg1_sig8 = 110.0}
*/
//System.out.println("newModel = " + newModel);
// 打印 新对象 的 hash 码 Demo.CarDataModel@7276c8cd
// 可见, Demo.CarDataModel@6ec8211c 和 Demo.CarDataModel@7276c8cd ;对象的hash码发生了变化,数据得到了更新
}
long endTime = System.currentTimeMillis();
long timeCost = endTime - startTime;
System.out.println("采用单线程处理报文,并且不加锁,测试生成新对象,运行次数 = " + num + " ,程序运行时间: " + timeCost + " 毫秒");
} 如果你要适配新的异步编程框架的话,欢迎你克隆我的代码拿去改进,它实现了 Cloneable接口,地址在这里车身Can报文快速解析框架。如果你有新的想法,有什么改进意见,欢迎到我的 github上发起 PR和 issue。
最后谈一点自己的想法。自己学习编程以来,独立完成的大项目其实并不多,感觉自己都还是菜鸟,经过这次项目,确实对编程的理解更加深切了。其实实现这样一个框架并不难,涉及的其实都是java的一些很基础知识,位运算、集合框架、注解、反射、泛型、多线程(其实并不涉及)、对设计模式的理解、对数据结构的理解、抽象思维的能力,如何将复杂问题抽象成一个个对象等等。以前不知道学习数据结构有什么用,算时间复杂度,空间复杂度有什么用。冒泡排序、快速排序、平衡二叉树,大学学这些,只是为了应付考试,死记硬背,根本没理解数据结构的意义。到了工作中,从写的代码一坨屎,到逐渐可以看了。实际运用的时候,才知道学的东西的意义,你写的程序内存占用 100M,别人写的程序占用 10M,为什么别人占用的内存比你少?你的程序跑10分钟,别人跑1分钟,为什么别人比你快。从前觉得看源码没意义,到如今在 github上沉迷分析别人的源码。
本项目最初的灵感就是在学习了安卓的jetpack之后,又用了一下 retrofit,对 Room和 Retrofit使用注解进行编程的方式很感兴趣,后来有看了一些别人分析 Retrofit源码的博客,才逐渐形成了本项目,Retrofit其实也是使用了注解和反射的元编程,包括著名的 Junit框架也是使用了这样的技术,现在才明白了看源码的意义,从源码中进行学习和模仿,学习别人的技术,同时提升自己的代码阅读能力。
同学们,编程这条路,任重而道远啊,学无止境,绝不是这么简单的。
QuickCanResolver :车身CAN报文快速解析框架|一种汽车SOA架构的实现|汽车SOA架构设计与软件平台框架|BY 阿城同学
- 改用编译期注解解析:现有代码中,最耗时的部分就是
DBC文件的解析,实际运行时,需要放到安卓的自定义Application里去做一下初始化,这是一个耗时点。如果不采用反射,而是采用编译是注解解析(对应到代码中就是把注解作用域由“运行时”改为“编译时”),性能消耗会低很多,还会减少应用的启动时间(DBC解析本来就应该编译期检查,而不是运行时检查)。并且如果DBC绑定有误,可以在编译时就检查出来,而不用在运行时才发现DBC绑定有误。 - 改用编译期代码生成:现有代码中,解码
CAN报文和编码CAN报文时,实际上还是动态的执行一些反射赋值的操作,和一些hashmap的查表工作,这也是一个性能的消耗点。如果我可以提前生成编码和解码的代码,动态生成一个java类来替我操作(类似于butterKnifie动态生成绑定类),那么对比反射赋值,性能消耗又会得到降低。 - 其他框架的适配?
-
C++语言的框架开发,有些车辆的智能驾驶功能的代码(不仅限于车身控制),使用的是C++或C语言开发,未来我可能会开发这些语言的框架版本(我是说可能)。