Spark Streaming从Kafka中消费Flink CDC数据,多库多表实时同步到Redshift.当前支持
- Glue Streaming Job
- EMR Serverless Streaming Job
- EMR on EC2 (NEW)
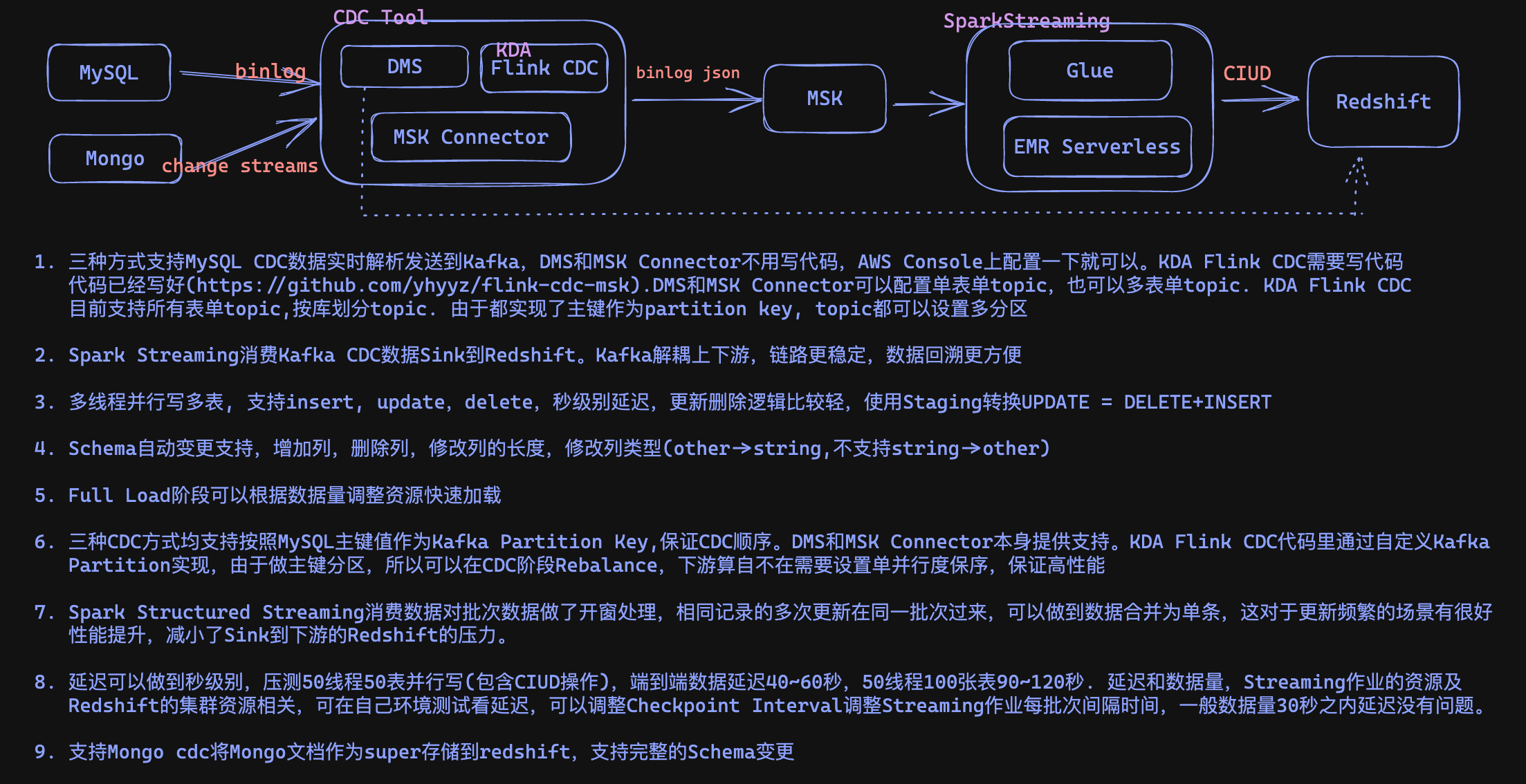
MySQL Flink CDC到Kafka有三种方式:
* Flink CDC(KDA 部署): https://github.com/yhyyz/flink-cdc-msk
* MSK Connector Debezium 托管服务,无需代码,AWS中国区暂时没有托管的MSK Connector
* DMS 托管服务,不需要写代码1. 多线程并行写多表, 支持insert, update,delete,秒级别延迟
2. Schema自动变更支持,增加列,删除列,修改列的长度,修改列类型(other->string,不支持string->other)
3. 从MSK(Kafka)接CDC,链路更稳定,上下游解耦,方便做数据回溯
4. Full Load阶段可以根据数据量调整资源快速加载
5. 支持忽略DDL模式,用户自己控制建表和Schema变更
6. 支持json字符串列存储为Redshift Super类型
7. 支持Mongo, 且支持以super方式存储到Redshift,将doc存储为super, 支持schema变更-
20240702 加入Flink CDC TPCC EMR EC2 文档
-
20240619 修复对于相同mysql表名称,创建spark kafka_source临时表视图(修复的whl: https://dxs9dnjebzm6y.cloudfront.net/tmp/cdc_util_202406190314-1.1-py3-none-any.whl)
-
20240126 对于emr on ec2部署加入batch timeout参数,限定一个batch如果在指定时间未执行完成,抛出异常,加入
-
20231010 支持保留cdc的delete数据,即源端表delete数据,redshift表保留删除记录,只需要在需要的表上配置skip_delete=true即可
sync_table_list = [\ {"db": "test_db", "table": "product", "primary_key": "pid","skip_delete":"true"}\ ]
-
20230913 配置正则匹配表时,对配置的正则取hash作为临时表,避免正则里有的特殊字符spark创建临时表失败
-
20230906 支持Canal CDC格式。添加spark3.3支持的availableNow配置
-
20230829 更新操作的redshift staging表, 使用truncate table代替drop table, 避免实时同步几百张张表时,频繁的在Redshift创建删除临时表。
-
20230808 支持spark3.3 glue-4.0,spark4.0相比glue3.0有进一步的性能提升,同时glue-4.0内置了spark-redshift-connector并且对开源redshift-connector做了优化,glue4.0优化
# 如果使用Glue 4.0注意--extra-jars的配置 # --extra-jars中不需要配置emr-spark-redshift-1.2-SNAPSHOT-07030146.jar,内置已经包含。只需要spark3.3-sql-kafka-offset-committer-1.0.jar支持spark3.3 # spark3.3-sql-kafka-offset-committer-1.0.jar下载链接 https://dxs9dnjebzm6y.cloudfront.net/tmp/spark3.3-sql-kafka-offset-committer-1.0.jar --extra-jars s3://panchao-data/tmp/spark3.3-sql-kafka-offset-committer-1.0.jar -
20230807 执行Redshift SQL列名使用引号("col_1"),避免mysql中的列在Redshift中为关键字时执行错误
-
20230730 python redshift jdbc在每个streaming batch结束时关闭jdbc链接,释放文件句柄资源。
-
20230727 当禁用DDL时,源端增加列,Redshift添加列后,CDC数据中还没有收到增加列的数据时,由于staging表列和target表列不一致,造成的写入异常,当前已修复。
-
20230711 增加maxerror参数,当遇到异常记录(比如json super中的某个值超过65535)造成写入redshift失败时,允许跳过的记录数。maxerror参数在job properties配置文件中,默认值为100,最大值可以为100000。错误的记录可以 redshift系统表STL_LOAD_ERRORS查看详细信息。如果想要遇到copy错误立即终止程序设置maxerror为0。
-
20230703 当禁用DDL时,如果新增的列没有默认值,CDC发送到Kafka中的JSON为空时,可能动态创建的staging表会和源表类型不一致,因为无法识别json null在源表字段是哪种类型, 这里通过
case when trim({col_name}) ~ '^[0-9]+$' then trim({col_name}) else null end::smallint as {col_name}方式做了转换,注意这里当前只是对smallint类型做了转换。其它类型也可以 相同逻辑,但目前还没有加入到代码中。 这种情况仅会出现在加字段后发到Kafka的数据是null且这一批数据该字段都是null的情况下,如果这批json数据中该字段有null还有其它有值的行,spark会merge判断schema,会以 有值的json行该列类型作为这一批数据该字段的类型。 -
20230703 spark写s3的临时存储支持以json格式,可以在properties中配置tempformat = JSON, 但相比CSV作为临时存储,JSON作为存储,copy性能会有损失, 同时写的文件会比较大,因为每条数据都带着json key. 但JSON得优势是当禁用DDL时,能够在源端列和Redshift列不一致时,依然能成功copy。需要注意的是JSON作为临时存储时,不支持将json字符串列转换为redshift super存储。默认格式是CSV, 建议值是CSV, 非特定情况,不使用JSON. CSV是比较高效的方式。
-
20230614 支持配置指定timestamp类型列和date列
# 通过dateformat 'auto' timeformat 'auto'做了自动转换,所以下方配置方式只需在该文档中(https://docs.aws.amazon.com/redshift/latest/dg/automatic-recognition.html),不支持的自动转换格式是配置,其它情况无需配置。大部分场景是不用配置的
# timestamp_columns 指定timestamp列,多个列逗号分隔。 如果需要指定格式 col1:col2|yyyy-MM-dd HH:mm:ss, 默认的格式是yyyy-MM-dd\'T\'HH:mm:ss\'Z\', flink cdc和dms cdc解析到json的string默认值。
# create_date 指定date列,多个列逗号分隔。如果需要指定格式 col1:col2|yyyy-MM-dd,默认格式是flink CDC解析date格式,是1970-01-01年到当前的天数。
sync_table_list = [\
{"db": "test_db", "table": "product","target_table":"product_super","primary_key": "id","ignore_ddl":"true","super_columns":"other_fields","timestamp_columns":"create_time","date_columns":"create_date"}\
]
- 20230524 支持Mongo cdc,cdc格式为flink cdc change streams发送到kafka的数据。将整个doc存储为super
1. 使用[mongo_cdc_redshift.py](glue%2Fmongo_cdc_redshift.py)作为执行脚本,config下的[mongo-job-4x.properties](config%2Fmongo-job-4x.properties)作为参考配置即可.
2. 对于mongo当前支持以flink cdc发送的使用MongoDB’s official Kafka Connector的数据格式,暂时不支持msk debezium的格式.因为mongo的Connector有两个选择可以参看说明(https://ververica.github.io/flink-cdc-connectors/release-2.1/content/connectors/mongodb-cdc.html#change-streams) cdc程序部署 https://github.com/yhyyz/flink-cdc-msk
3. 将mongo的doc存储为super,当前redshift super最大1MB, 16MB是preview. 支持schema变更,因为是以整个doc_id和doc super来更新文档的,所以任何的schema改变都可以支持
4. 为表自动添加doc_id,ts_date, ts_ms列。 doc_id是文档_id。ts_date,ts_ms是flink cdc程序执行获取到文档的日期和时间
- 20230511 支持将json字符串列存储为super字段
# 如果mysql中字段内容为json字符串,可以将其存储为Redshift的super方便解析,同时super长度可以支持最大1MB的,16MB(预览版),super_columns添加需要存储为super的列名字即可
sync_table_list = [\
{"db": "test_db", "table": "product", "primary_key": "pid","super_columns":"info,pdesc"}\
]- 20230425 支持delete数据单独写到一张表,表名自动以_delete结尾, 支持只同步delete数据,不同步原表数据,表名字自动以_delete结尾,配置例子如下
# save_delete设置为true,表示同步原表同时,将delete数据单独写一张表
# only_save_delete设置为true,表示只同步delete数据,不同步原表数据
sync_table_list = [\
{"db": "test_db", "table": "product", "primary_key": "pid","ignore_ddl":"true","save_delete":"true"},\ # 忽略ddl变更,表需要用户自己创建,创建表名如果不配置,请用源端的表名字创建redshift表
{"db": "test_db", "table": "user", "primary_key": "id","only_save_delete":"true"}\
]- 20230422 添加忽略Schema变更的支持,可以在配置中设置ignore_ddl=true, 如果设置之后,不会帮用户自动创建表,需要用户自己预先创建表,同样不会自动添加删除列,源端变更需要用户自己处理。
# 例如在job properties中配置如下
sync_table_list = [\
{"db": "test_db", "table": "product", "primary_key": "pid","ignore_ddl":"true"},\ # 忽略ddl变更,表需要用户自己创建,创建表名如果不配置,请用源端的表名字创建redshift表
{"db": "test_db", "table": "product", "primary_key": "pid","ignore_ddl":"true","target_table":"t_product"},\ # 忽略ddl变更,表需要用户自己创建,target_table配置自己在Redshift创建的表名称
{"db": "test_db", "table": "user", "primary_key": "id"}\ # 自动创建表,自动schema变更
]- 20230415 支持MSK Connector Debezium CDC 数据格式,截止目前,支持Flink CDC(Debezium),MSK Connector, DMS三种CDC数据格式,Flink CDC和MSK Connector都是Debezium格式
- 20230414 修复指定Redshift非public之外的schema时,执行SQL时没有set search_path造成的异常
- 下载依赖
# 下载依赖的JAR, 上传到S3
https://dxs9dnjebzm6y.cloudfront.net/tmp/emr-spark-redshift-1.2-SNAPSHOT-07030146.jar
wget https://dxs9dnjebzm6y.cloudfront.net/tmp/spark-sql-kafka-offset-committer-1.0.jar
# cdc_util build成whl,方便再在多个环境中使用,直接执行如下命令build 或者下载build好的
python3 setup.py bdist_wheel
# 编译好的
https://dxs9dnjebzm6y.cloudfront.net/tmp/cdc_util_202310201517-1.1-py3-none-any.whl
# 作业运行需要的配置文件放到了在项目的config下,可以参考job-4x.properties,将文件上传到S3,后边配置Glue作业用
- Glue job配置
--extra-jars s3://panchao-data/jars/emr-spark-redshift-1.2-SNAPSHOT-07030146.jar,s3://panchao-data/tmp/spark-sql-kafka-offset-committer-1.0.jar
--additional-python-modules redshift_connector,jproperties,s3://panchao-data/tmp/cdc_util_202310201517-1.1-py3-none-any.whl
--aws_region us-east-1
# 注意这个参数 --conf 直接写后边内容,spark.executor.cores 调成了8,表示一个worker可以同时运行的task是8
# --conf spark.sql.shuffle.partitions=1 --conf spark.default.parallelism=1 设置为1,这是为了降低并行度,保证当多个线程同时写多张表时,都尽可能有资源执行,设置为1时,最终生产的数据文件也是1个,如果数据量很大,生产的一个文件可能会比较大,比如500MB,这样redshift copy花费的时间就会长一些,如果想要加速,就把这两个值调大一些,比如4,这样就会生产4个125M的文件,Redshift并行copy就会快一些,但Glue作业的资源对应就要设置多一些,可以观察执行速度评估
--conf spark.sql.streaming.streamingQueryListeners=net.heartsavior.spark.KafkaOffsetCommitterListener --conf spark.executor.cores=8 --conf spark.sql.shuffle.partitions=1 --conf spark.default.parallelism=1 --conf spark.speculation=false
--config_s3_path s3://panchao-data/kafka-cdc-redshift/job-4x.properties
--enable-spark-ui false
# Glue 选择3.x,作业类型选择Spark Streaming作业,worker个数根据同步表的数量和大小选择,Number of retries 在Streaming作业下可以设置大些,比如100。 失败自动重启,且会从checkpoint自动重启。 - python lib venv
# python lib
python3 -m venv cdc_venv
source cdc_venv/bin/activate
pip3 install --upgrade pip
pip3 install redshift_connector jproperties
# cdc_util是封装好的Spark CDC Redshift 的包,源代码在cdc_util中
wget https://dxs9dnjebzm6y.cloudfront.net/tmp/cdc_util_202310201517-1.1-py3-none-any.whl
pip3 install cdc_util_202310201517-1.1-py3-none-any.whl
pip3 install venv-pack
venv-pack -f -o cdc_venv.tar.gz
# 上传到S3
aws s3 cp cdc_venv.tar.gz s3://panchao-data/cdc/- submit job
# https://dxs9dnjebzm6y.cloudfront.net/tmp/spark-sql-kafka-offsert-commiter-1.0.jar
# https://dxs9dnjebzm6y.cloudfront.net/tmp/emr-spark-redshift-1.2-SNAPSHOT-07030146.jar
app_id=00f8frvjd84ve709
role_arn=
script_path=s3://panchao-data/serverless-script/cdc_redshift.py
config_path=s3://panchao-data/kafka-cdc-redshift/job.properties
aws emr-serverless start-job-run \
--region us-east-1 \
--name cdc_redshift \
--application-id 00f8nmbb3mgik909 \
--execution-role-arn arn:aws:iam::946277762357:role/admin-role-panchao \
--execution-timeout-minutes 0 \
--job-driver '{
"sparkSubmit": {
"entryPoint": "s3://panchao-data/serverless-script/cdc_redshift.py",
"entryPointArguments": ["us-east-1","s3://panchao-data/kafka-cdc-redshift/job.properties"],
"sparkSubmitParameters": "--conf spark.speculation=false --conf spark.sql.streaming.streamingQueryListeners=net.heartsavior.spark.KafkaOffsetCommitterListener --conf spark.executor.cores=8 --conf spark.executor.memory=16g --conf spark.driver.cores=8 --conf spark.driver.memory=16g --conf spark.executor.instances=10 --conf spark.sql.shuffle.partitions=2 --conf spark.default.parallelism=2 --conf spark.dynamicAllocation.enabled=false --conf spark.emr-serverless.driver.disk=150G --conf spark.emr-serverless.executor.disk=150G --conf spark.jars=s3://panchao-data/tmp/spark-sql-kafka-offsert-commiter-1.0.jar,s3://panchao-data/emr-serverless-cdc/jars/spark320/*.jar,/usr/share/aws/redshift/jdbc/RedshiftJDBC.jar,/usr/share/aws/redshift/spark-redshift/lib/spark-avro.jar,/usr/share/aws/redshift/spark-redshift/lib/minimal-json.jar --conf spark.archives=s3://panchao-data/cdc/cdc_venv.tar.gz#environment --conf spark.emr-serverless.driverEnv.PYSPARK_DRIVER_PYTHON=./environment/bin/python --conf spark.emr-serverless.driverEnv.PYSPARK_PYTHON=./environment/bin/python --conf spark.executorEnv.PYSPARK_PYTHON=./environment/bin/python --conf spark.hadoop.hive.metastore.client.factory.class=com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory"
}
}' \
--configuration-overrides '{
"monitoringConfiguration": {
"s3MonitoringConfiguration": {
"logUri": "s3://panchao-data/emr-serverless/logs"
}
}
}'- python lib venv
- emr 6.7.0
# python lib
export s3_location=s3://panchao-data/tmp
deactivate
rm -rf ./cdc_venv
rm -rf ./cdc_util_*.whl
rm -rf ./cdc_venv.tar.gz
python3 -m venv cdc_venv
source cdc_venv/bin/activate
pip3 install --upgrade pip
pip3 install redshift_connector jproperties
# cdc_util是封装好的Spark CDC Redshift的包,源代码在cdc_util中
wget https://dxs9dnjebzm6y.cloudfront.net/tmp/cdc_util_202310201517-1.1-py3-none-any.whl
pip3 install cdc_util_202310201517-1.1-py3-none-any.whl
pip3 install venv-pack
venv-pack -f -o cdc_venv.tar.gz
# 上传到S3
aws s3 cp cdc_venv.tar.gz ${s3_location}/- depedency jars
# kafka lib
export s3_location=s3://panchao-data/tmp
aws s3 rm --recursive ${s3_location}/jars/
mkdir jars
wget -P ./jars https://repo1.maven.org/maven2/org/apache/spark/spark-sql-kafka-0-10_2.12/3.2.1/spark-sql-kafka-0-10_2.12-3.2.1.jar
wget -P ./jars https://repo1.maven.org/maven2/org/apache/kafka/kafka-clients/2.8.2/kafka-clients-2.8.2.jar
wget -P ./jars https://repo1.maven.org/maven2/org/apache/spark/spark-token-provider-kafka-0-10_2.12/3.2.1/spark-token-provider-kafka-0-10_2.12-3.2.1.jar
wget -P ./jars https://repo1.maven.org/maven2/org/apache/commons/commons-pool2/2.11.1/commons-pool2-2.11.1.jar
aws s3 sync ./jars ${s3_location}/jars/
# job lib
rm -rf emr-spark-redshift-1.2-*.jar
rm -rf spark-sql-kafka-offset-committer-*.jar
wget https://dxs9dnjebzm6y.cloudfront.net/tmp/emr-spark-redshift-1.2-SNAPSHOT-07030146.jar
wget https://dxs9dnjebzm6y.cloudfront.net/tmp/spark-sql-kafka-offset-committer-1.0.jar
aws s3 cp emr-spark-redshift-1.2-SNAPSHOT-07030146.jar ${s3_location}/
aws s3 cp spark-sql-kafka-offset-committer-1.0.jar ${s3_location}/
- submit job
export s3_location=s3://panchao-data/tmp
# cluster mode
# 代码中的emr_ec2中cdc_redshift.py和conf的djob-ec2.properties
rm -rf cdc_redshift*.py
rm -rf job-ec2*.properties
wget https://raw.githubusercontent.com/yhyyz/kafka-cdc-redshift/main/emr_ec2/cdc_redshift.py
wget https://raw.githubusercontent.com/yhyyz/kafka-cdc-redshift/main/config/job-ec2.properties
aws s3 cp cdc_redshift.py ${s3_location}/
aws s3 cp job-ec2.properties ${s3_location}/
spark-submit --master yarn --deploy-mode cluster \
--num-executors 5 \
--conf "spark.yarn.dist.archives=${s3_location}/cdc_venv.tar.gz#cdc_venv" \
--conf "spark.pyspark.python=./cdc_venv/bin/python" \
--conf spark.speculation=false \
--conf spark.sql.streaming.streamingQueryListeners=net.heartsavior.spark.KafkaOffsetCommitterListener \
--conf spark.executor.cores=4 \
--conf spark.executor.memory=8g \
--conf spark.driver.cores=4 \
--conf spark.driver.memory=8g \
--conf spark.sql.shuffle.partitions=2 \
--conf spark.default.parallelism=2 \
--conf spark.dynamicAllocation.enabled=false \
--conf spark.jars=${s3_location}/emr-spark-redshift-1.2-SNAPSHOT-07030146.jar,${s3_location}/spark-sql-kafka-offset-committer-1.0.jar,${s3_location}/jars/*.jar,/usr/share/aws/redshift/jdbc/RedshiftJDBC.jar,/usr/share/aws/redshift/spark-redshift/lib/spark-avro.jar,/usr/share/aws/redshift/spark-redshift/lib/minimal-json.jar \
${s3_location}/cdc_redshift.py us-east-1 ${s3_location}/job-ec2.properties
# client mode
export s3_location=s3://panchao-data/tmp
spark-submit --master yarn --deploy-mode client \
--num-executors 5 \
--conf "spark.yarn.dist.archives=${s3_location}/cdc_venv.tar.gz#cdc_venv" \
--conf "spark.pyspark.python=./cdc_venv/bin/python" \
--conf "spark.pyspark.driver.python=./cdc_venv/bin/python" \
--conf spark.speculation=false \
--conf spark.sql.streaming.streamingQueryListeners=net.heartsavior.spark.KafkaOffsetCommitterListener \
--conf spark.executor.cores=4 \
--conf spark.executor.memory=8g \
--conf spark.driver.cores=4 \
--conf spark.driver.memory=8g \
--conf spark.sql.shuffle.partitions=2 \
--conf spark.default.parallelism=2 \
--conf spark.dynamicAllocation.enabled=false \
--conf spark.jars=${s3_location}/emr-spark-redshift-1.2-SNAPSHOT-07030146.jar,${s3_location}/spark-sql-kafka-offset-committer-1.0.jar,${s3_location}/jars/commons-pool2-2.11.1.jar,${s3_location}/jars/kafka-clients-2.8.2.jar,${s3_location}/jars/spark-sql-kafka-0-10_2.12-3.2.1.jar,${s3_location}/jars/spark-token-provider-kafka-0-10_2.12-3.2.1.jar,/usr/share/aws/redshift/jdbc/RedshiftJDBC.jar,/usr/share/aws/redshift/spark-redshift/lib/spark-avro.jar,/usr/share/aws/redshift/spark-redshift/lib/minimal-json.jar \
${s3_location}/cdc_redshift.py us-east-1 ${s3_location}/job-ec2.properties
# 可以使用cloudwatch对任务做常规的监控报警
* KDA Metric:
uptime 报警值 < 1000
fullRestarts 报警值 > 5
* MSK Metric:
Topic级别的ConsumerGroup的SumOffsetLag 报警值,这个根据数据领,先观察作业几个小时,设置一个大于比常规值*2值就可以
* Glue Metric:
glue.driver.jvm.heap.used 报警值: < 1000 (这个单位是字节,当glue作业失败,这个值是missing data)
# 以上所有指标在配置cloudwatch报警时,都在高级配置里配置treat missing data as bad
# 配置以上报警在cloudwatch发送到SNS, 之后可以按照这个blog发送到钉钉或者企业微信 https://aws.amazon.com/cn/blogs/china/enterprise-wechat-and-dingtalk-receiving-amazon-cloudwatch-alarms/- 在job properties中有disable_msg配置默认
disable_msg=true表示关闭详细日志输出,调试过程可以打开详细日志数出设置disable_msg=false即可。之后在spark driver 日志中搜索my_log即可看到有程序打印出详细日志信息,便于排查错误。需要注意是的生产中一定要将其设置为disable_msg=true,因为打印详细日志是非常耗费时间的,详细日志执行的是spark 的df.show()的action动作,所以非常耗时,因此切记生产将其设置为disable_msg=true
// flink debezium cdc 和 mak connector debezium cdc,两者格式一样
{
"before": {
"id": 19770,
"k": 4996,
"c": "36318400304-63111352071-68840643492-77717971110-29599028240-56080607483-01147782222-68426958377-82107614964-35141906795",
"pad": "85969145563-90374725884-50995688213-61744612362-32329632183"
},
"after": {
"id": 19770,
"k": 4997,
"c": "36318400304-63111352071-68840643492-77717971110-29599028240-56080607483-01147782222-68426958377-82107614964-35141906795",
"pad": "85969145563-90374725884-50995688213-61744612362-32329632183"
},
"source": {
"version": "1.6.4.Final",
"connector": "mysql",
"name": "mysql_binlog_source",
"ts_ms": 1681561501000,
"snapshot": "false",
"db": "cdc_db_02",
"sequence": null,
"table": "sbtest19",
"server_id": 57330068,
"gtid": null,
"file": "mysql-bin-changelog.050156",
"pos": 5865,
"row": 0,
"thread": null,
"query": null
},
"op": "u",
"ts_ms": 1681561501093,
"transaction": null
}
// time json
{
"before": {
"id": 19,
"name": "c11",
"info": "stest",
"pdesc": "stest",
"other_fields": "{\"is_hfss\": false, \"action_v2\": [], \"buy_reach\": null, \"frequency\": null, \"deep_cpabid\": 0, \"rf_buy_type\": null, \"brand_safety\": null, \"device_price\": null, \"external_type\": \"APP_ANDROID\", \"buy_impression\": null, \"rf_predict_cpr\": null, \"statistic_type\": null, \"video_download\": \"PREVENT_DOWNLOAD\", \"ios14_quota_type\": \"UNOCCUPIED\", \"is_new_structure\": false, \"is_share_disable\": false, \"scheduled_budget\": 0, \"conversion_window\": null, \"frequency_schedule\": null, \"automated_targeting\": \"OFF\", \"brand_safety_partner\": null, \"rf_predict_frequency\": null, \"daily_retention_ratio\": null, \"exclude_custom_actions\": [], \"include_custom_actions\": [], \"split_test_adgroup_ids\": [], \"enable_inventory_filter\": false}",
"create_time": "2023-06-14T14:15:45Z",
"create_date": 19522
},
"after": {
"id": 19,
"name": "c12",
"info": "stest",
"pdesc": "stest",
"other_fields": "{\"is_hfss\": false, \"action_v2\": [], \"buy_reach\": null, \"frequency\": null, \"deep_cpabid\": 0, \"rf_buy_type\": null, \"brand_safety\": null, \"device_price\": null, \"external_type\": \"APP_ANDROID\", \"buy_impression\": null, \"rf_predict_cpr\": null, \"statistic_type\": null, \"video_download\": \"PREVENT_DOWNLOAD\", \"ios14_quota_type\": \"UNOCCUPIED\", \"is_new_structure\": false, \"is_share_disable\": false, \"scheduled_budget\": 0, \"conversion_window\": null, \"frequency_schedule\": null, \"automated_targeting\": \"OFF\", \"brand_safety_partner\": null, \"rf_predict_frequency\": null, \"daily_retention_ratio\": null, \"exclude_custom_actions\": [], \"include_custom_actions\": [], \"split_test_adgroup_ids\": [], \"enable_inventory_filter\": false}",
"create_time": "2023-06-14T14:15:51Z",
"create_date": 19522
},
"source": {
"version": "1.6.4.Final",
"connector": "mysql",
"name": "mysql_binlog_source",
"ts_ms": 1686752151000,
"snapshot": "false",
"db": "test_db",
"sequence": null,
"table": "product",
"server_id": 57330068,
"gtid": null,
"file": "mysql-bin-changelog.085201",
"pos": 2184,
"row": 0,
"thread": null,
"query": null
},
"op": "u",
"ts_ms": 1686752151386,
"transaction": null
}
// dms data
{
"data": {
"pid": 2,
"pname": "prodcut-002",
"pprice": 110,
"create_time": "2023-02-13T22:16:38Z",
"modify_time": "2023-04-15T08:38:10Z",
"pdesc": "bbbbbbbbbbba"
},
"metadata": {
"timestamp": "2023-04-15T12:38:13.780065Z",
"record-type": "data",
"operation": "update",
"partition-key-type": "primary-key",
"partition-key-value": "test_db.product.2",
"schema-name": "test_db",
"table-name": "product",
"transaction-id": 215426970434175
}
}# replace
{
"_id": "{\"_id\": {\"_id\": 1.0}}",
"operationType": "replace",
"fullDocument": "{\"_id\": 1.0, \"price\": 3.243, \"name\": \"p1\", \"desc\": {\"dname\": \"desc\"}}",
"source": {
"ts_ms": 1684918116000,
"snapshot": "false"
},
"ts_ms": 1684918116915,
"ns": {
"db": "test_db",
"coll": "product"
},
"to": null,
"documentKey": "{\"_id\": 1.0}",
"updateDescription": null,
"clusterTime": "{\"$timestamp\": {\"t\": 1684918116, \"i\": 1}}",
"txnNumber": null,
"lsid": null
}
# insert
{
"_id": "{\"_id\": {\"_id\": 1.0}}",
"operationType": "insert",
"fullDocument": "{\"_id\": 1.0, \"price\": 2.243, \"name\": \"p1\", \"desc\": {\"dname\": \"desc\"}}",
"source": {
"ts_ms": 1684918589000,
"snapshot": "false"
},
"ts_ms": 1684918589037,
"ns": {
"db": "test_db",
"coll": "product"
},
"to": null,
"documentKey": "{\"_id\": 1.0}",
"updateDescription": null,
"clusterTime": "{\"$timestamp\": {\"t\": 1684918589, \"i\": 1}}",
"txnNumber": null,
"lsid": null
}
# update
{
"_id": "{\"_id\": {\"_id\": 1.0}}",
"operationType": "update",
"fullDocument": "{\"_id\": 1.0, \"price\": 2.243, \"name\": \"p2\", \"desc\": {\"dname\": \"desc\"}}",
"source": {
"ts_ms": 1684920703000,
"snapshot": "false"
},
"ts_ms": 1684920703411,
"ns": {
"db": "test_db",
"coll": "product"
},
"to": null,
"documentKey": "{\"_id\": 1.0}",
"updateDescription": {
"updatedFields": "{\"name\": \"p2\"}",
"removedFields": []
},
"clusterTime": "{\"$timestamp\": {\"t\": 1684920703, \"i\": 1}}",
"txnNumber": null,
"lsid": null
}
# delete
{
"_id": "{\"_id\": {\"_id\": 1.0}}",
"operationType": "delete",
"fullDocument": null,
"source": {
"ts_ms": 1684918449000,
"snapshot": "false"
},
"ts_ms": 1684918450355,
"ns": {
"db": "test_db",
"coll": "product"
},
"to": null,
"documentKey": "{\"_id\": 1.0}",
"updateDescription": null,
"clusterTime": "{\"$timestamp\": {\"t\": 1684918449, \"i\": 4}}",
"txnNumber": null,
"lsid": null
}
# doc_id multiple column
{
"_id": "{\"_id\": {\"_id\": {\"user\": \"u1\", \"id\": 1.0}}}",
"operationType": "insert",
"fullDocument": "{\"_id\": {\"user\": \"u1\", \"id\": 1.0}, \"price\": 3.243, \"name\": \"p1\", \"desc\": {\"dname\": \"desc\"}}",
"source": {
"ts_ms": 1684921366000,
"snapshot": "false"
},
"ts_ms": 1684921366342,
"ns": {
"db": "test_db",
"coll": "product"
},
"to": null,
"documentKey": "{\"_id\": {\"user\": \"u1\", \"id\": 1.0}}",
"updateDescription": null,
"clusterTime": "{\"$timestamp\": {\"t\": 1684921366, \"i\": 1}}",
"txnNumber": null,
"lsid": null
}