
Your definitive guide to architecting scalable, reliable, and performant distributed systems. This is where theory meets reality.
You write code. You solve problems. But do you understand the architecture that makes your code succeed or fail at scale?
For too long, "System Design" has been treated as a gatekept topic for senior architects or a final-round interview hurdle. This is a myth. Whether you're a student, a junior developer, or a mid-level engineer, the principles of system design are the most critical, career-differentiating skills you can learn right now.
Most systems don't fail because of scale. They fail because humans struggle to build, change, or even understand them. The system is only as good as the team's ability to work with it.
This repository is not another dry, academic textbook. It's a comprehensive, practical guide forged from real-world notes and battle-tested patterns. We'll transform complex concepts into digestible, actionable insights using clear explanations, powerful analogies, and visual diagrams, Can Take it as your Introduction and Big Overview that get you all you need before diving into each.
Why this guide is different:
- For Everyone: We start from the absolute basics (what's inside a computer?) and build up to advanced, resilient architectures.
- Practical First: We focus on the "why" and "how," not just the "what." You'll learn to solve real-world problems like handling a viral traffic spike or preventing cascading failures.
- Career-Focused: Understanding these concepts is the fastest way to level up, contribute to high-impact projects, and ace your interviews. We even cover salary trends and career paths.
This is your playbook. Let's start building.
This guide is based on a collection of valuable resources, including:
- Courses:
- Books:
I highly recommend getting a broad overview from this repository before diving deep into these courses or books. Some concepts may seem unfamiliar at first, but a quick skim will provide a valuable high-level understanding that will become clearer as you explore each section.
For those who prefer a deep-dive audio format, I've created a comprehensive, detailed +100-minute podcast that covers every concept in this repository from A to Z, helping to enhance your understanding. To help you master and remember this information, I've also created a Quick Reference Guide and KeyNotes for the course, specifically designed for a spaced repetition strategy.
- 🎧 English Podcast (+100 min): Listen here (Recommended for detailed information)
- 🎙️ Arabic Podcast (30 min): Listen here
- 📄 Spaced Repetition PDF: Get it here
- 📄 The Visual Playbook: System Design Distilled: Get it here
To further enhance the presentation, you can use this cover image for the PDF version, which links to the guide:

- Part 1: The Bedrock - Why You Can't Skip the Fundamentals
- Part 2: The Blueprint - Core Principles of Modern Systems
- Part 3: The Communication Lines - Networking & APIs
- Part 4: The Great Debate - Monolith vs. Microservices
- Part 5: Building for Scale - The Architect's Toolkit
- Part 6: The Nervous System - Advanced Architectural Patterns
- Part 7: The Vault - Databases Deep Dive
- Part 8: The Real World - Solving Common Design Problems
- Part 9: The Payoff - Career, Roles & Salaries
- Glossary of Key Terms
- Author
Before you can design a skyscraper, you must understand the brick. Before you architect a global distributed system, you must understand the single computer. Every massive system is built from these fundamental blocks. Ignoring them is like trying to cook without knowing your ingredients.
Think of a single computer as a professional kitchen. Each component has a specialized role, and their interaction determines the kitchen's efficiency.
- CPU (The Chef): The brain. It's the Chief Processing Unit that fetches, decodes, and executes instructions. Your high-level code (Python, Java, C, etc.) is translated by a compiler into machine code that the CPU understands and runs.
- Motherboard (The Kitchen Layout): The central nervous system. It connects everything—CPU, RAM, and Disk—providing the pathways for data to flow between them.
A computer uses a hierarchy of storage to keep the data the CPU needs as close as possible. The closer it is, the faster the access, but the more expensive and smaller the storage.
graph TD
A[CPU] --> B{L1/L2/L3 Cache};
B --> C[RAM];
C --> D[Disk - SSD/HDD];
subgraph "Fastest & Smallest"
B
end
subgraph "Slower & Larger"
C
end
subgraph "Slowest & Largest"
D
end
-
Disk Storage (HDD & SSD) - The Pantry: This is the computer's permanent, non-volatile memory. It holds the operating system, your applications, and files, even when the power is off. Think of it as the pantry where you store all your ingredients for the long term. Mnemonic: "Disk is for 'Don't forget.'"
- HDD (Hard Disk Drive): Slower, mechanical, cheaper. (80-160 MB/s)
- SSD (Solid-State Drive): Much faster, no moving parts, more expensive. (500-3,500 MB/s)
-
RAM (Random Access Memory) - The Countertop: This is the primary active workspace. It's volatile memory, meaning it requires power to hold data. It stores application data, variables, and anything currently in use. It's your kitchen countertop—where you place ingredients you're actively working with. Mnemonic: "RAM is for 'Right-now Active Memory.'" (Often >5,000 MB/s)
-
CPU Cache (L1, L2, L3) - The Personal Cutting Board: Extremely fast, small memory located directly on or near the CPU. It stores the most frequently used data to optimize performance. The CPU checks here first before going to RAM. This is the small cutting board right next to the chef for ingredients used constantly. Mnemonic: "Cache is for 'Constantly Accessed Stuff Here.'" (Access in nanoseconds)
A real-world application is far more than code on a single machine. It's a dynamic, interconnected ecosystem. A single user click can trigger a cascade of events across dozens of services.
- CI/CD Pipeline: An automated process (using tools like Jenkins or GitHub Actions) that takes code from a developer's repository, runs tests, and deploys it to production servers without manual intervention. Mnemonic: "CI/CD = 'Code Is Constantly Delivered.'"
- Traffic Management: Load Balancers and Reverse Proxies sit in front of your servers, distributing user requests to prevent overload and improve reliability.
- Externalized Data: Production apps almost never store primary data on the same server that runs the application code. Data lives on dedicated external storage servers or databases.
- Observability (Logging, Monitoring, Alerting): You can't fix what you can't see.
- Logging: Recording micro-interactions. A single photo upload can generate thousands of log entries.
- Monitoring: Watching application health and performance in real-time.
- Alerting: Automatically notifying teams (e.g., via Slack) when something goes wrong.
Ready for a shock? A single user action on a major website, like posting a photo, can generate hundreds or even thousands of log entries across different services before it's fully processed. That's the scale we're dealing with.
Now that you understand the basic building blocks, let's explore the fundamental laws that govern how we assemble them into robust systems.
Architecting a system is a game of trade-offs. You can't have everything. These core principles are the rules of the game—they define your constraints and guide every decision you make.
Every good system strives for these four goals:
- Scalability: Can the system grow to handle more users, data, and traffic without falling over?
- Reliability: Does the system work correctly and consistently, even when parts of it fail?
- Maintainability: Can future developers understand, modify, and improve the system without breaking it?
- Performance: Is the system fast and responsive for its users?
First presented by Eric Brewer in 2000 and later proven by Seth Gilbert and Nancy Lynch of MIT, the CAP Theorem is the most important rule in distributed systems. It states that a distributed system can only simultaneously guarantee two of the following three properties:
- (C)onsistency: Every read receives the most recent write or an error. All nodes in the system have the same data at the same time.
- (A)vailability: Every request receives a (non-error) response, without the guarantee that it contains the most recent write. The system is always operational.
- (P)artition Tolerance: The system continues to operate despite network partitions (i.e., messages being dropped or delayed between nodes).
In the real world, network partitions are a fact of life. You must design for them. Therefore, the real trade-off is always between Consistency and Availability (C vs. A).
graph TD
subgraph CAP Theorem
C((Consistency)) --- A((Availability))
A --- P((Partition Tolerance))
P --- C
end
subgraph "During a Network Partition"
direction LR
CP[Choose C over A] -->|Result| Unavailable
AP[Choose A over C] -->|Result| Potentially_Stale_Data
end
style CP fill:#f9f,stroke:#333,stroke-width:2px
style AP fill:#ccf,stroke:#333,stroke-width:2px
- CP (Consistency over Availability): Choose this when data accuracy is non-negotiable. A banking system would rather be temporarily unavailable than show you an incorrect balance.
- AP (Availability over Consistency): Choose this when being online is more important than perfect consistency. A social media feed would rather show you slightly stale content than an error page.
Availability is measured in "nines" and is often defined in contracts called SLAs (Service Level Agreements). Internally, teams aim for SLOs (Service Level Objectives).
- 99.9% Availability ("Three Nines"): ~8.76 hours of downtime per year.
- 99.99% Availability ("Four Nines"): ~52.6 minutes of downtime per year.
- 99.999% Availability ("Five Nines"): ~5.26 minutes of downtime per year.
Reliability is achieved through Fault Tolerance and Redundancy. A common pattern is N+1 Redundancy: if you need 'N' servers to handle your load, you run 'N+1' so you always have a spare ready to take over.
These two metrics are often in tension:
- Latency: The time it takes to handle a single request (the delay). Measured in milliseconds (ms). Lower is better.
- Throughput: How many requests a system can handle in a period. Measured in Requests Per Second (RPS) or Queries Per Second (QPS). Higher is better.
The Trade-off: Imagine a ferry. To maximize throughput, you wait until the ferry is completely full before it departs. But this increases the latency for the first person who boarded. Sending the ferry with only one person minimizes latency but kills throughput.
System design is about finding the right balance; it is a game of trade-offs, no more, no less.
With these principles in mind, we can now dive into how different parts of a system actually communicate. Next up: the fundamental protocols and interfaces that power the internet.
Systems are networks of talking components. Understanding the languages they speak (protocols) and the rules of their conversations (APIs) is essential.
- IP Address: A unique numerical identifier for a device on a network (e.g.,
192.168.1.1). IPv4 is the old 32-bit standard, while the newer IPv6 standard provides a virtually inexhaustible number of addresses. - DNS (Domain Name System): The internet's address book. It translates human-friendly domain names (like
google.com) into machine-readable IP addresses. The entire system is anchored by just 13 logical root name servers. - TCP vs. UDP: The two main transport protocols.
- TCP (Transmission Control Protocol): The reliable courier. It guarantees that all data packets are delivered completely and in order. It uses a "three-way handshake" (SYN, SYN-ACK, ACK) to establish a connection. Perfect for web browsing, email, and file transfers where data integrity is critical.
- UDP (User Datagram Protocol): The postcard service. It's faster but less reliable. It sends packets without guaranteeing delivery or order. Ideal for time-sensitive applications like video streaming or online gaming, where losing a single frame is better than lagging. Mnemonic: "UDP = 'Unreliable Data Packets.'"
sequenceDiagram
participant Client
participant Server
Client->>Server: SYN (May I connect?)
Server-->>Client: SYN-ACK (Yes, you may connect.)
Client->>Server: ACK (Okay, connecting now.)
Note right of Server: Connection Established!
An API (Application Programming Interface) is the menu that one part of a system offers to another. It defines how they can interact. Most APIs expose CRUD (Create, Read, Update, Delete) operations on resources.
- REST (Representational State Transfer): The classic à la carte menu. An architectural style (not a protocol) that uses standard HTTP methods (
GET,POST,PUT,DELETE) and URLs to expose resources. It's stateless and widely used, but can lead to over-fetching (getting too much data) or under-fetching (needing multiple requests). Mnemonic: "REST = REally Simple Transactions." - GraphQL (Graph Query Language): The build-your-own-meal. Developed by Facebook, GraphQL allows clients to request exactly the data they need in a single query, solving the over/under-fetching problem. It's strongly typed and typically uses a single
/graphqlPOST endpoint. - gRPC (Google Remote Procedure Call): The pneumatic tube to the robotic chef. A high-performance framework from Google built on HTTP/2. It uses Protocol Buffers for efficient data serialization, making it ideal for high-speed communication between microservices.
- Versioning: Introduce changes without breaking existing clients by versioning your API (e.g.,
/api/v2/products). - Rate Limiting: Protect your service from abuse (accidental or malicious) by limiting how many requests a user can make in a given time. A common method is the "token bucket" algorithm.
- Idempotency: Ensure that making the same request multiple times produces the same result as making it once. Critical for reliability. (We'll dive deeper into this later).
Now that we know how services talk, how do we manage all that conversation at scale? Next, we'll explore the architectural patterns that separate small projects from massive, global applications.
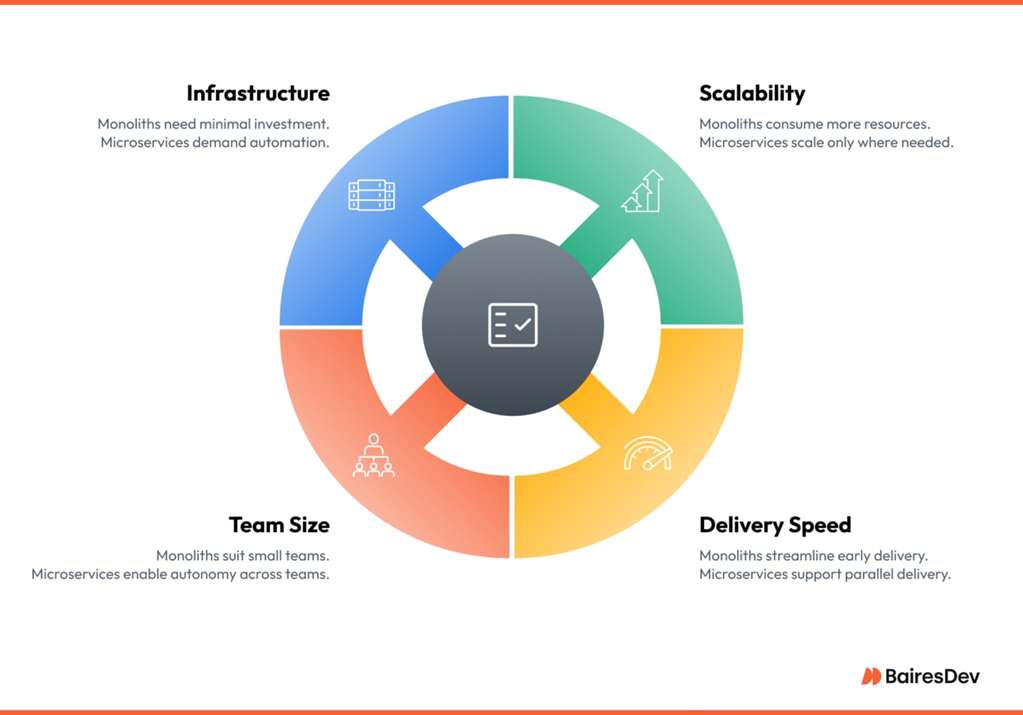
One of the most fundamental architectural decisions you'll face is how to structure your application. For years, the debate has been framed as a binary choice: the traditional, all-in-one Monolith versus the modern, distributed Microservices. As of 2025, the conversation has become more nuanced, but understanding the trade-offs is more critical than ever.
A monolith is an application built as a single, unified unit. The UI, business logic, and data access layer are all combined into one large codebase and deployed as a single artifact.
Analogy: The Traditional Restaurant. Everything—the dining area (frontend), the kitchen (backend), and the manager's office (database layer)—is in one building, operating from a single, massive playbook.
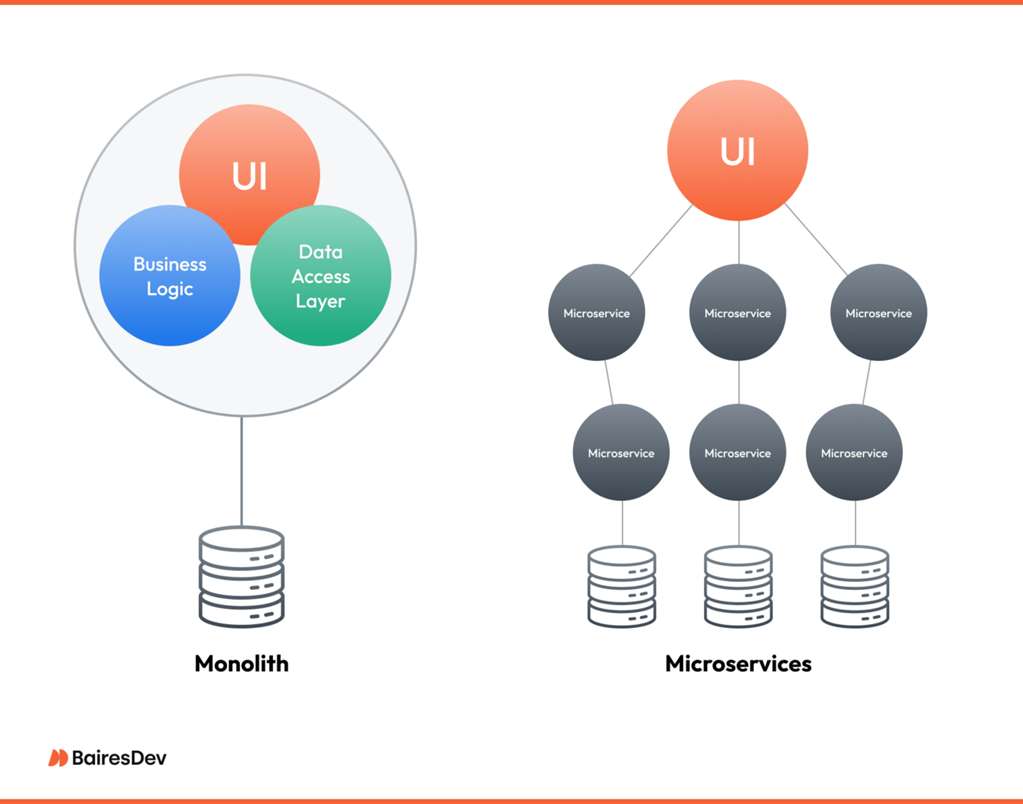
- Simplicity at the Start: Easier to develop, test, and deploy initially. Inter-component communication is just a fast, in-process function call.
- Small Teams: Ideal for small teams and early-stage products or MVPs where rapid iteration is key and coordination overhead is low.
- Slow & Risky Deployments: A small change requires the entire application to be re-tested and re-deployed. A bug in one minor feature can bring down the whole system.
- Difficult to Scale: If one part of the application (e.g., payment processing) is under heavy load, you must scale the entire application by deploying another full copy. This is inefficient and costly.
- Technology Lock-in: You're stuck with the technology stack you started with. The codebase can become a "big ball of mud" that's terrifying to change.
A microservice architecture breaks a large application into a collection of smaller, independent services. Each service is its own mini-application, focused on a single business capability, and can be developed, deployed, and scaled independently.
Analogy: The Food Truck Fleet. Instead of one giant restaurant, your business is a fleet of specialized food trucks (User Truck, Payment Truck, Product Truck). They work together but are completely independent.
- Independent Scalability: Scale only the services that need it, leading to efficient resource use.
- Fault Isolation: A failure in one service doesn't bring down the entire application (if designed correctly).
- Technology Flexibility: Use the best language and tools for each specific job (e.g., Python for ML, Java for transactions).
- Team Autonomy: Small, autonomous teams can own and ship their services independently, increasing velocity. Atlassian notes their teams are "a lot happier" with this model.
- Distributed Complexity: You're now managing a complex distributed system. You have to worry about network latency, fault tolerance, and service discovery.
- Difficult Troubleshooting: A single request might travel through 5-10 services. Tracing a problem requires sophisticated observability tools (logs, metrics, traces).
- Data Consistency: Maintaining data consistency across different services and databases is a major challenge.
The 2025 consensus is moving away from binary thinking. The new question is: "Can this part of the system change independently, and with a low blast radius?". This has led to the rise of the Modular Monolith.
A modular monolith is an application that is built as a single deployable unit, but is internally structured into well-defined, independent, and extractable modules. It offers the operational simplicity of a monolith with the clean boundaries of microservices.
Think of microservices as an end-goal rather than a starting point. A modular monolithic architecture in the early stages... would pave the way for microservices with a well-defined bounded context later.
Here's a comparison of the three architectures:
| Feature | Monolith | Modular Monolith | Microservices |
|---|---|---|---|
| Architecture | A single, large codebase and deployment unit. | A single codebase with logical module boundaries. | A collection of small, independent services. |
| Development | Simpler for small applications. | Improved maintainability and organization. | Each service can be developed independently. |
| Scalability | Scaled as a whole. | Better component scalability. | Highly scalable; individual services scale. |
| Reliability | Single point of failure. | Improved, but still a single deployment unit. | High fault isolation. |
| Maintenance | Can become complex and slow to develop. | High maintainability with clear boundaries. | Easier to maintain and update individual services. |
| Use Cases | Smaller applications with stable needs. | A great starting point for most projects. | Large-scale, complex, and changing applications. |
Key Trade-offs:
- Complexity: Microservices add operational complexity and require more infrastructure.
- Deployment: Microservices have multiple deployment units, while monoliths have one.
- Transition: A modular monolith can be a clear path to microservices.
You might also hear about Service-Oriented Architecture (SOA). Think of it as the predecessor to microservices. While both use "services," their philosophy differs.
| Feature | SOA (Service-Oriented Architecture) | Microservices |
|---|---|---|
| Scope | Services are often large, representing a full business capability (e.g., "Manage All Finances"). Focus on enterprise-wide reusability. | Services are small, specializing in a single task (e.g., "Process Payment"). Focus on decoupling. |
| Communication | Often relies on a central, "smart" pipeline called an Enterprise Service Bus (ESB) for routing and transformation. | Uses "dumb" pipes like lightweight APIs (REST, gRPC). The smarts are in the endpoints (the services themselves). |
| Data Storage | Services often share a single, large database, leading to dependencies. | Each service owns its own data and database, ensuring true independence. |
In essence, microservices are a more refined, decoupled, and cloud-native evolution of SOA principles.
Choosing an architecture is a massive commitment. Now, let's look at the tools you'll use to make any architecture performant and scalable, starting with the most powerful optimization strategy: caching.
Regardless of your architecture, you need tools to handle the load. Caching, proxies, and load balancing are the workhorses of any scalable system, responsible for speed, security, and reliability.
Caching is the single most effective strategy for making a system feel fast. The core idea is to store copies of frequently accessed data in a temporary, high-speed storage layer to reduce latency and offload work from your servers and databases.
There are only two hard things in Computer Science: cache invalidation and naming things. — Phil Karlton
This famous quote highlights how difficult it is to correctly decide when to delete old data from a cache. Caching is a multi-layered strategy:
graph TD
User[User's Browser] -->|Request| Layer1[Browser Cache]
Layer1 -- Cache Miss --> Layer2[CDN]
Layer2 -- Cache Miss --> Layer3[Load Balancer]
Layer3 --> Layer4[Server-Side Cache e.g., Redis]
Layer4 -- Cache Miss --> Layer5[Application Server]
Layer5 --> Layer6[Database]
subgraph "Closest to User"
Layer1
end
subgraph "Global Network"
Layer2
end
subgraph "Your Infrastructure"
Layer3 & Layer4 & Layer5 & Layer6
end
- Browser Cache: The user's own browser stores static assets (CSS, JS, images) on their local machine. Controlled by the
Cache-ControlHTTP header. - CDN (Content Delivery Network): A geographically distributed network of servers that caches static content closer to your users. When a user in Japan requests an image, it's served from a CDN server in Tokyo, not your origin server in Virginia. This dramatically reduces latency. Over 75% of all internet traffic is served from CDNs.
- Server-Side Cache (e.g., Redis, Memcached): An in-memory key-value store that sits between your application and your database. It stores the results of expensive database queries or frequently accessed data, preventing the database from being the bottleneck. Redis stands for REmote DIctionary Server.
A proxy server is an intermediary that sits between clients and servers. The word 'proxy' comes from the Latin procuratia, meaning 'to take care of on behalf of another.'
- Forward Proxy: Sits in front of clients. It makes requests on behalf of the client, hiding the client's IP address. Use cases: corporate firewalls, accessing geo-restricted content.
- Reverse Proxy: Sits in front of servers. It receives all incoming requests from the internet and forwards them to the appropriate backend server. This hides the server's identity and internal architecture. This is the foundation for load balancing.
A Load Balancer is a specialized reverse proxy that distributes incoming traffic across multiple backend servers. This is the key to horizontal scaling and high availability.
Why it's critical:
- Scalability: When traffic increases, you can simply add more backend servers to the pool. The load balancer will start sending traffic to them.
- Reliability: The load balancer performs continuous health checks on the servers. If a server fails a health check, the load balancer immediately stops sending traffic to it, ensuring users don't see errors.
Common Load Balancing Algorithms:
- Round Robin: Sends requests to servers in a simple, rotating order. Best for servers with similar capacity.
- Least Connections: Sends the next request to the server with the fewest active connections. Better for uneven loads.
- IP Hashing: Assigns a user to a specific server based on their IP address. This creates "sticky sessions," which can be useful but is often considered an anti-pattern in modern stateless design.
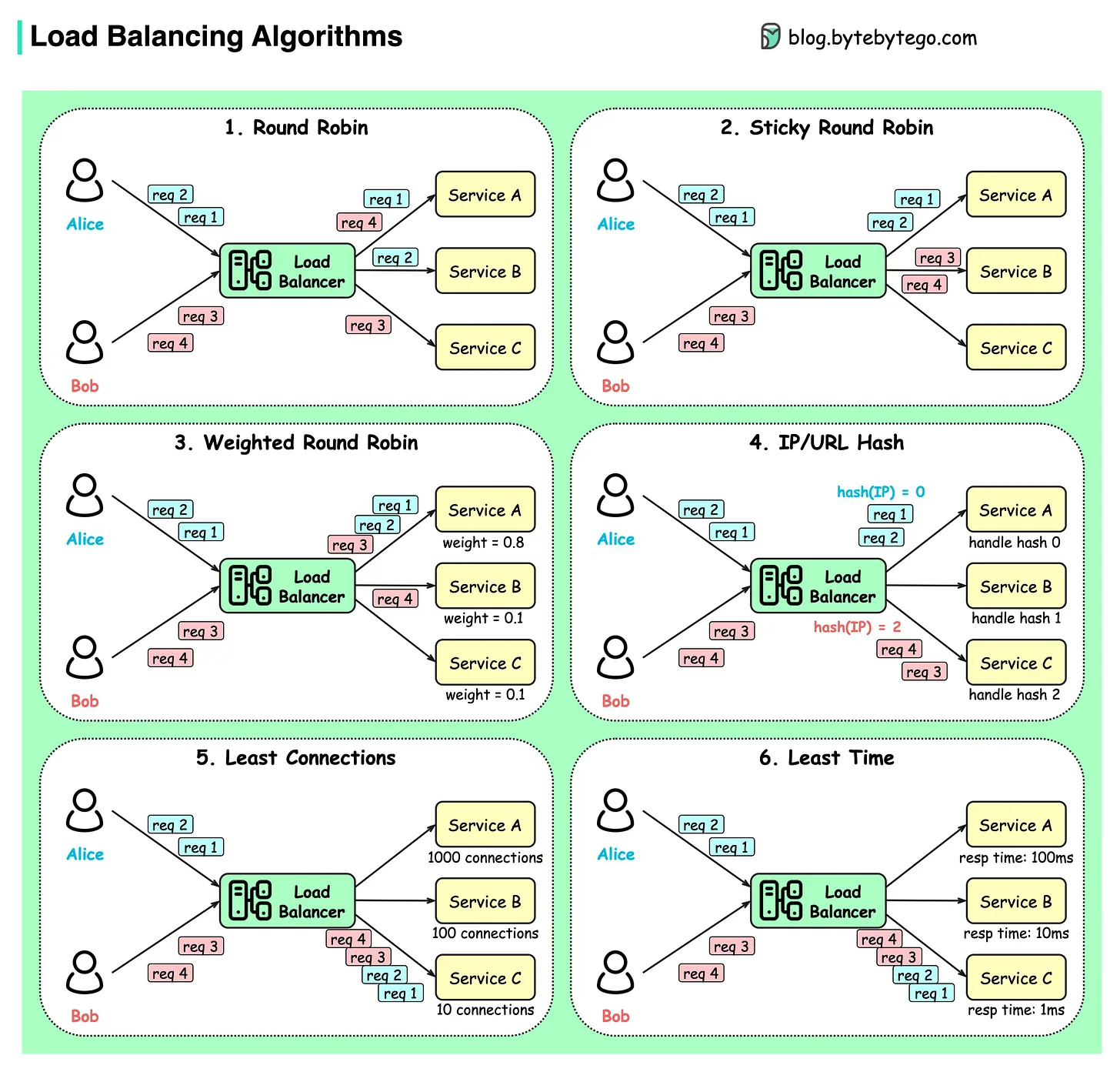
With traffic flowing smoothly, we can now look at the more sophisticated patterns that enable complex, asynchronous communication and make our systems truly resilient. Welcome to the nervous system of modern architecture.
Beyond simple request-response, modern systems need to perform complex, long-running tasks, handle failures gracefully, and manage data distribution intelligently. These advanced patterns form the nervous system that makes it all possible.
A Message Queue is an intermediary component that enables asynchronous communication. A "producer" service writes a message (a task) to the queue, and a "consumer" service processes it later at its own pace. This concept has been around since the 1980s but is fundamental to modern microservices.
Analogy: The Restaurant Order System. A waiter (producer) places an order ticket on the spindle (queue). The chefs (consumers) pick up tickets and cook the food when they are ready. The waiter doesn't have to stand and wait for the food to be cooked.
graph TD
Producer[Producer Service e.g., Orders API] -- "Writes Message (Order #123)" --> MQ((Message Queue));
MQ -- "Reads Message" --> Consumer[Consumer Service e.g., Kitchen];
Producer -->|Immediately Responds to Client| Client(User);
Consumer -->|Processes at its own pace| DB[(Database)];
subgraph "Popular Tools"
direction LR
Tool1[RabbitMQ]
Tool2[Apache Kafka]
Tool3[Amazon SQS]
end
Key Benefits:
- Decoupling: The producer and consumer don't need to know about each other. They only need to know about the queue.
- Asynchronicity: The frontend can respond to the user instantly ("Your order is placed!") while the heavy work (payment processing, inventory update) happens in the background.
- Load Leveling: During a traffic spike, messages can pile up in the queue, preventing the backend services from being overwhelmed. The consumers can process the backlog steadily once the spike subsides.
When you distribute data or requests across a cluster of servers (e.g., in a cache or a sharded database), what happens when you add or remove a server? With a simple hash (like key % num_servers), nearly all your keys will remap, causing a catastrophic cache miss event or massive data reshuffling.
Consistent Hashing solves this. It maps servers and keys onto a circular "hash ring." When a server is added or removed, only a small, localized fraction of keys needs to be remapped, typically to an adjacent server on the ring. This makes cluster changes calm and manageable.
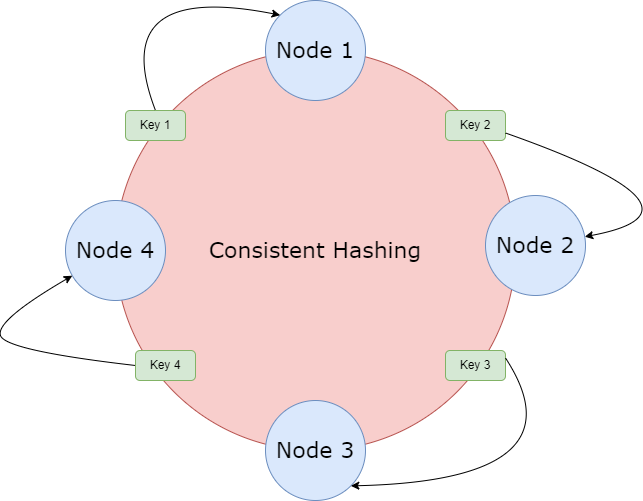
Use Cases: NoSQL databases like DynamoDB and Cassandra, CDNs, and load balancers.
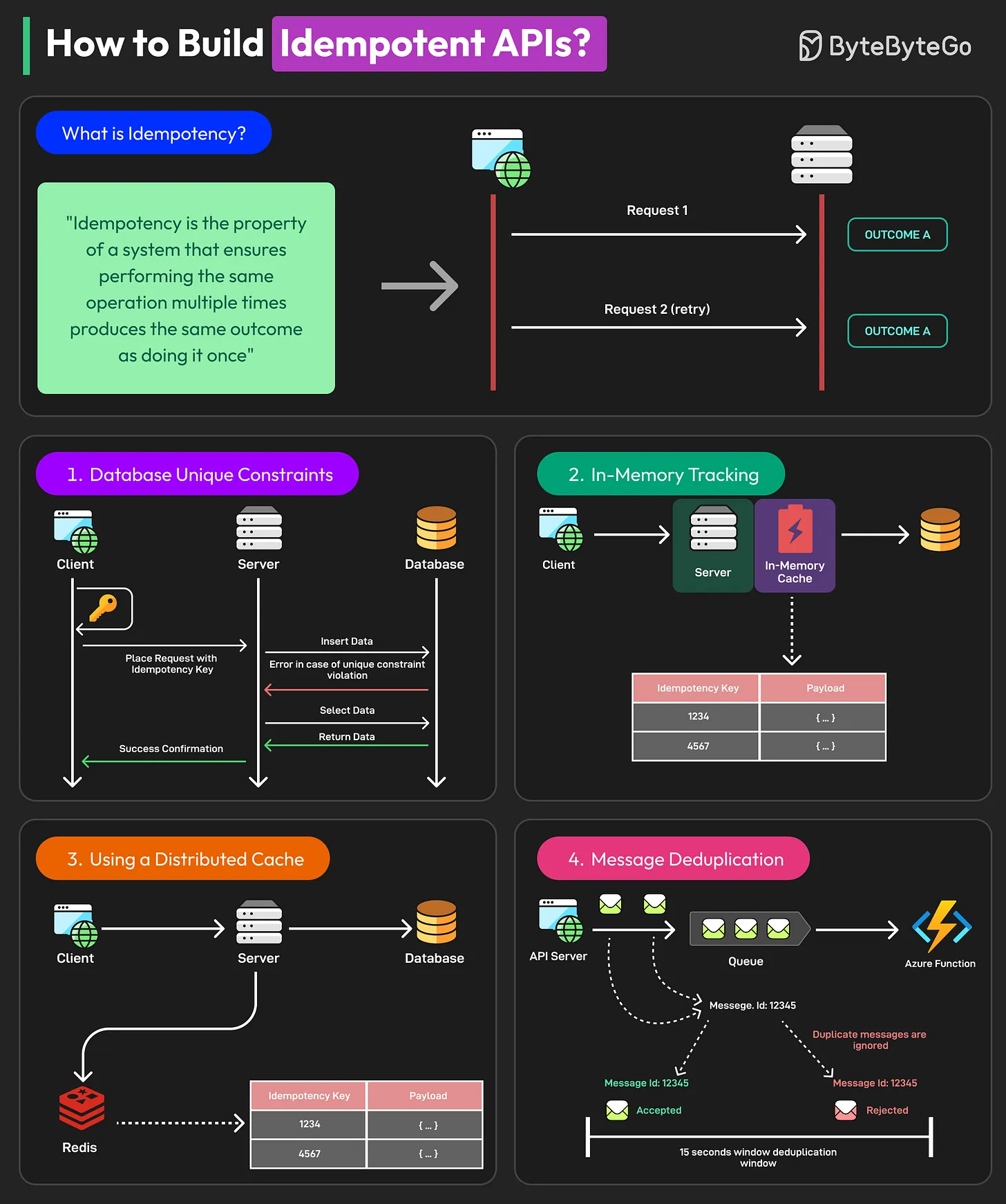
An operation is idempotent if performing it multiple times has the same effect as performing it once. Pressing an elevator button that's already lit does nothing new. This is a critical concept for building reliable systems in unreliable networks where requests can be duplicated.
- Idempotent HTTP Methods:
GET,PUT,DELETE. - Non-Idempotent Method:
POST. SendingPOST /orderstwice could create two orders.
Real-World Implementation: Payment APIs like Stripe rely heavily on this. When creating a charge, you can include a unique
Idempotency-Keyin the request header. If the network fails and your client retries the request with the same key, Stripe's server recognizes it and guarantees it won't charge the card a second time.
In a distributed system, failure is not an "if," but a "when." A failure in one small, non-critical service can cause a "cascading failure" that brings down your entire application. These patterns are your defense.
stateDiagram-v2
[*] --> Healthy: System Normal
Healthy --> Tripped: Failure Threshold Reached
Tripped --> HalfOpen: Timeout Period Elapsed
HalfOpen --> Healthy: Test Request Succeeds
HalfOpen --> Tripped: Test Request Fails
note right of Healthy
Requests are allowed through.
end note
note left of Tripped
Circuit is "open".
Requests are blocked immediately.
Allows failing service to recover.
end note
note right of HalfOpen
Allow a single test request through.
If it succeeds, close the circuit.
If it fails, start the timeout again.
end note
- Timeouts: Never wait forever. Set a limit on how long one service will wait for a response from another. An infinite default timeout is a common cause of cascading failures.
- Retries with Exponential Backoff: When a request fails, don't retry immediately. Wait, then retry. If it fails again, wait for a longer period before the next retry (e.g., 1s, 2s, 4s, 8s). This prevents a "thundering herd" of retries from overwhelming a struggling service.
- Circuit Breaker: Named after the electrical component, this pattern monitors for failures. After a certain number of failures, the circuit "trips" and all further calls to the failing service are blocked for a set period. This gives the downstream service time to recover.
- Graceful Degradation: Design your application so that if a non-critical component fails (e.g., the recommendations service), the core functionality (e.g., showing the product page) still works. The user gets a slightly degraded experience, not a crash.
Chaos Engineering: Netflix famously created a tool called "Chaos Monkey" that deliberately and randomly shuts down their own production servers to force their engineers to build a truly resilient, fault-tolerant system.
These patterns are the difference between a fragile system and an anti-fragile one. Next, we'll look at the foundation where all your critical data lives: the database.
The database is the heart of your system. It's where your most valuable asset—data—lives. Choosing the right database and scaling it effectively is one of the most critical decisions in system design.
The database world is broadly split into two paradigms: relational (SQL) and non-relational (NoSQL).
SQL databases store data in structured tables with predefined schemas (like a spreadsheet). They use SQL (Structured Query Language) and are known for their reliability and data integrity.
- Core Strength: ACID Guarantees. First formalized in the 1980s for banking systems, ACID is a set of properties that guarantee transactions are processed reliably.
- Atomicity: All operations in a transaction succeed, or none do.
- Consistency: The database is always in a valid state.
- Isolation: Concurrent transactions don't interfere with each other.
- Durability: Once a transaction is committed, it's permanent.
- Best For: Systems requiring high data integrity, like e-commerce order systems, financial applications, and banking.
- Examples: PostgreSQL, MySQL, SQL Server.
NoSQL databases are designed for scale, flexibility, and speed, often relaxing strict ACID guarantees. They are ideal for unstructured or semi-structured data. The term is now often interpreted as "Not Only SQL."
- Core Strength: Horizontal scalability and schema flexibility.
- Types:
- Key-Value Stores (e.g., Redis): Simple, fast data storage.
- Document Databases (e.g., MongoDB): Store data in flexible, JSON-like documents.
- Columnar Databases (e.g., Cassandra): Optimized for fast reads over large datasets.
- Graph Databases (e.g., Neo4j): For data with complex relationships, like social networks.

{kind=link}
- Best For: Big data applications, social media feeds, IoT sensor data, and real-time systems.
You can't just put a load balancer in front of a database. Scaling a database requires more sophisticated techniques.
- Vertical Scaling (Scale-Up): Make the database server more powerful (more CPU, RAM, faster disk). It's simple but has hard physical and cost limits.
- Horizontal Scaling (Scale-Out): Add more machines. This is the modern approach for massive scale, achieved through two primary techniques:
Replication involves creating multiple copies of your database. In a common Master-Slave setup, the Master database handles all writes, and these changes are copied to one or more read-only Slave (or Replica) databases. Read requests can then be distributed across the replicas.
Benefits: Increases read throughput and provides fault tolerance (if the master fails, a replica can be promoted to become the new master).
Challenge: The delay for a write on the master to be copied to a replica is called "replication lag." Managing this is a major challenge in large-scale systems.
Sharding (or horizontal partitioning) involves splitting your data across multiple database servers. Each server holds a subset (a "shard") of the data. For example, you could shard users by the first letter of their username or by their geographic region.
Benefits: Dramatically increases write throughput, as writes are distributed across multiple machines. It's the key to handling truly massive datasets.
graph TD
subgraph Replication
direction LR
Master[Master DB <br> Handles Writes ] -- "Replicates Data" --> Replica1[Replica 1<br/> Handles Reads]
Master -- "Replicates Data" --> Replica2[Replica 2<br/> Handles Reads]
App[Application] -- "Writes" --> Master
App -- "Reads" --> Replica1
App -- "Reads" --> Replica2
end
subgraph Sharding
direction LR
App2[Application] -- "Writes/Reads for Users A-M" --> Shard1[Shard 1<br/> Users A-M]
App2 -- "Writes/Reads for Users N-Z" --> Shard2[Shard 2<br/> Users N-Z]
end
Now that we've covered the core components and patterns, let's put it all together to solve some of the most common and challenging problems you'll face in the wild.
Theory is great, but the real test is applying it. Here are common scenarios you will encounter and the architectural stacks used to solve them.
- Problem: Your service is featured on the news and traffic explodes from 1,000 users/hour to 1,000,000. Your single server crashes.
- Solution Stack:
- Load Balancer: Distribute requests across multiple servers.
- Auto-Scaling Group: Automatically add more application servers when CPU or latency metrics are high, and remove them when traffic subsides.
- CDN & Caching: A CDN offloads static assets (images, CSS), while a server-side cache (Redis) reduces database load for dynamic content.
- Database Read Replicas: Scale the database's read capacity to handle the influx of new users browsing content.
- Problem: Your application is hosted in the US, and users in Australia are complaining about slow load times.
- Solution Stack:
- CDN: The first and easiest step. Caches static assets in edge locations around the world, including Australia.
- Multi-Region Architecture: Deploy your application servers in multiple geographic regions (e.g., US-East, EU-West, AP-Southeast).
- GeoDNS Routing: Use a DNS service that detects a user's location and routes them to the nearest application server region.
- Problem: Two users try to book the last available seat on a flight at the exact same time. Without proper controls, you might sell the seat twice.
- Solution Stack:
- Database Transactions (ACID): Wrap the "check availability" and "book seat" operations in a single, atomic transaction. This ensures that once one user's transaction starts, the other must wait.
- Locking:
- Pessimistic Locking: The first transaction places an exclusive lock on the "seat" record, preventing anyone else from even reading it until the transaction is complete. Good for high-contention resources.
- Optimistic Locking: Assumes conflicts are rare. Both transactions proceed, but before committing, they check if the data has changed (e.g., via a version number). If it has, the second transaction fails and must retry.
- Problem: A user uploads a photo. Your application server saves it to its local disk to be processed later. The server crashes before processing, and the photo is lost forever.
- Solution Stack:
- Stateless Application Servers: A core principle. Servers should never store unique, permanent data on their local disk. This makes them interchangeable and disposable.
- Durable Object Storage (e.g., Amazon S3): Upload files directly to a highly durable, replicated storage service. S3 is designed for 99.999999999% (11 nines) of durability.
- Pre-signed URLs: A secure way to allow a client (like a web browser) to upload a file directly to object storage, bypassing your application server entirely for the heavy data transfer.
Solving these problems is the day-to-day reality of a systems engineer. But the field is constantly evolving. Let's look at the trends shaping the future of system design.
Why learn all this? Because it directly translates to career growth, impact, and compensation. Understanding system design is the bridge from being a coder to being an architect of solutions. It's how you move from implementing features to leading technical strategy.
While "Software Engineer" is a broad title, understanding systems opens doors to specialized and senior roles. It is an essential skill in the AI era, which often lacks the broader architectural context but excels at remembering syntax:
- Software Engineer: Spends most of their day coding, but with system design knowledge, they make better implementation choices, understand the "why" behind their tasks, and can contribute to architectural discussions.
- Systems Engineer: Focuses more on the overall management of engineering projects, infrastructure, and ensuring all systems are running correctly. They deal with the physical aspects, stakeholder analysis, and configuration management, and typically do less day-to-day coding than a software engineer.
- System Design Specialist / Solutions Architect: A role focused on high-level design. They bridge the gap between business requirements and technical solutions, designing complex systems and ensuring all components work together seamlessly. This role often commands a higher salary due to its strategic importance.
- Staff/Principal Engineer: An advanced individual contributor track for software engineers. These are the top technical leaders who solve the hardest architectural problems, set technical direction, and mentor other engineers.
Expertise in system design is highly valued and compensated. As of 2025, the demand for professionals who can design robust, scalable systems continues to drive competitive salaries.
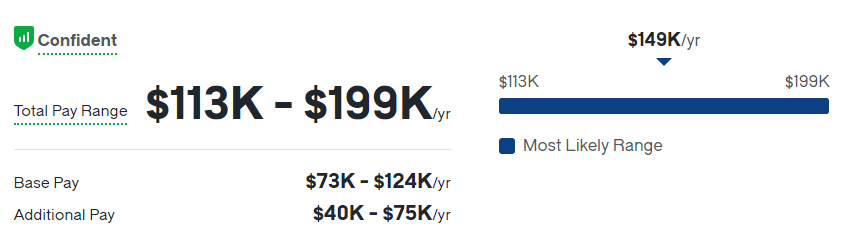
According to a report from Data Engineer Academy, the total pay for a Systems Design Specialist in the United States ranges from $113,000 to $199,000 per year, with a median of approximately $149,000. This includes a base salary and significant additional compensation (bonuses, profit sharing).
For Software Engineers, the career path shows significant growth as skills develop. Data from Levels.fyi for a major tech company like LinkedIn illustrates this progression:
| Level | Title | Median Total Compensation (US) |
|---|---|---|
| IC2 | Software Engineer | $238,000 |
| IC3 | Senior Software Engineer | $301,000 |
| IC4 | Staff Software Engineer | $478,000 |
Note: Data as of Sep 1, 2025. Compensation includes base, stock, and bonus.
The leap from Senior to Staff Engineer often hinges on the ability to demonstrate strong system design and architectural leadership. This is not just about knowing patterns; it's about making the right trade-offs, influencing teams, and owning the technical vision for complex projects.
A quick reference for the essential vocabulary of system design.
ACID : A set of properties (Atomicity, Consistency, Isolation, Durability) guaranteeing reliable database transactions.
API (Application Programming Interface) : A set of rules and definitions allowing software applications to communicate.
Availability : The measure of a system's operational uptime, often expressed in "nines" (e.g., 99.9%).
Cache : A temporary, high-speed storage layer that stores copies of frequently accessed data to reduce access time.
CAP Theorem : A theorem stating that a distributed system can only achieve two of Consistency, Availability, and Partition Tolerance at the same time.
CDN (Content Delivery Network) : A geographically distributed network of servers that caches static content closer to users to reduce latency.
CI/CD : Continuous Integration/Continuous Deployment. An automated process for integrating, testing, and deploying code.
Circuit Breaker : A resilience pattern that prevents an application from repeatedly calling a failing service.
Consistency : The property that all nodes in a distributed system have the same, most up-to-date data at the same time.
Database Replication : The process of creating and maintaining multiple copies of a database for high availability and read scalability.
Database Sharding : A horizontal scaling technique that partitions a large database into smaller pieces (shards) across multiple servers.
DNS (Domain Name System) : The internet's "phonebook" that translates human-friendly domain names into IP addresses.
Fault Tolerance : The ability of a system to continue operating even when some components fail.
Horizontal Scaling (Scale-Out) : Adding more servers (machines) to a system to handle increased load.
Idempotency : The property of an operation where executing it multiple times has the same effect as executing it once.
Latency : The delay or time it takes for a single request to get a response.
Load Balancer : A server that distributes incoming network traffic across multiple backend servers.
Message Queue : An intermediary component enabling asynchronous communication between different parts of a system.
Microservices : An architectural style where an application is structured as a collection of loosely coupled, independently deployable services.
Monolith : An application built as a single, unified unit where all components are combined into one large codebase.
NoSQL : A class of databases that are schema-less, highly scalable, and often relax ACID properties.
Observability : The ability to understand the internal state of a system by examining its external outputs (logs, metrics, traces).
Partition Tolerance : The ability of a system to continue functioning even when communication between its servers fails.
Proxy Server : An intermediary server that handles requests on behalf of other clients (Forward Proxy) or servers (Reverse Proxy).
REST (Representational State Transfer) : An architectural style for designing APIs, typically stateless and using standard HTTP methods.
Scalability : The ability of a system to handle a growing amount of work or users.
SQL (Relational) Databases : Databases that store data in structured tables and enforce a predefined schema, guaranteeing ACID properties.
Stateless : A design principle where the server does not store any information about past client interactions; each request is treated as new and independent.
Throughput : The amount of data or number of requests a system can handle over a certain period of time.
Vertical Scaling (Scale-Up) : Increasing the resources (CPU, RAM, disk) of a single server to handle increased load.
Youssef Mazini
This guide/overview now you can take the resources i give you above for deep diving was compiled and structured to be a living document for the engineering community. If you find it useful, please ⭐ this repository to show your support!