Using object oriented programming, this repository implements a tree based learning algorithm and provides support for ensemble learning.
Decision tree learning uses a widely known tree data structure to construct a machine learning model for supervised tasks (supervised tasks are those with predefined labels). For example, here is a tree model for predicting animal species:
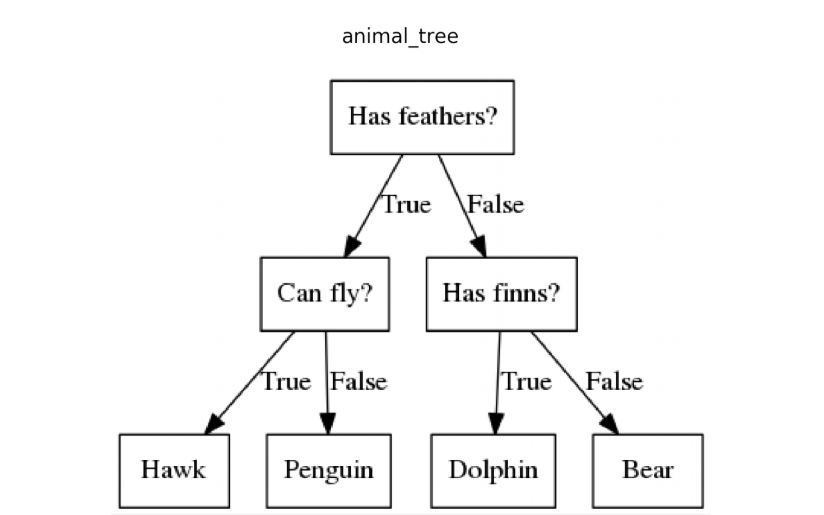
{kind=link}
More formally a decision tree contains:
- Internal nodes that contain a boolean question
- A "true" child node if the parent node's boolean question evaluates to true
- A "false" child node if the parent node's boolean question evaluates to false
- Terminal node, contains the final label to predict, i.e. a string signifying classname for classification problems and numerical value for regression problems.
Furthermore ensemble methods, which are machine learning methods that builds multiple models using samples from the full dataset, and then making predictions by taking the mean or mode of what each of individual model predicts (sort of like democraticly voting). Specifically I implement bagged decision trees, and random forests in Python.
- Python (this project was "built from scratch").
- Pandas and numpy for data preprocessing and storing.
- Test_case_1: using data about credit card holders to predict if they will default.
- Test_case_2: using data about a specific vehicle to predict its type (van, regular, bus, etc.).
Before starting the algorithm, one much pick the following hyperparameters:
- nmin: the minimum number of training examples an internal node can have before it must become a terminal node.
- alpha: after the tree is built, this parameter controls the amount of tree pruning/shrinkage (removal of subtrees and converting internal nodes to terminal nodes) we do. This is because in machine learning we often prefer simpler, smaller models.
- impurity function: a function for telling how "impure" or "mixed" a node is. For example in regression tasks the impurity is the variance of the labels, or in classification tasks the impurity could be the entropy of the labels within that node.
- ntree: how many tree models to make (only for ensemble models).
- number of features to consider: This limits the number of possible boolean questions a node can have, only needed if the random forests implementation is chosen. More specifically a node can only pick "number of features to consider" random columns in the input, and the boolean question can only use information from those columns.
Another thing to note is that every node contains the following information: inputs (drop all the training data down the decision tree, store the features of instances that use this node in there path), labels (drop all the training data down the decision tree, store the label of every instance of data that uses this node in there path), impurity (calculated from the labels).
- Initialize a root node with class "unexplored" and all the data.
- Pick any "unexplored" node.
- "Build" the node, which is basically calculate the node impurity and then
- If the number of instances of data is less then nmin, convert the "unexplored" node to a "terminal" node with prediction as the most mean or mode of the labels of that node (mode if classification, mean if regression).
- Else convert the node to a "nonterminal" node, by making a greedy decision: pick the boolean question that would minimize the impurity of the two children. Make 2 new "unexplored nodes", a true child node and false child node. Apply the boolean function to every input label pair, and send them to the true or false node accordingly. Note that the boolean function must be picked subject to the constraints of the "number of features to consider".
- While there is an unexplored node, do step 3 on it.
- Prune the tree: the algorithm is complicated, but in a nut shell if the decrease in impurity of a subtree (impurity of root subtract sum of impurity of terminal nodes) is not large enough, remove the subtree.
- Take a bootstrap sample (for example if there were N instances in the whole dataset, a bootstrap would be to take N samples with replacement). Build an tree (steps 1-5) on each bootstrap sample. Do this ntree times.
- Make predictions on a test instance by averaging (for regression tasks) or taking the mode(for classification tasks) the predictions of the ntree models.
- Test_case_1.py: Script to build a tree model for predicting if a given credit card holder will default.
- Test_case_2.py: Script to build a tree and ensemble model to predict if vehicle type (van, regular, bus, etc.).
- Tree.py: Contains tree class, which is the only class the user must interact with to make a single tree model. To create a tree model the user simply has to initialize a tree object (the root node is automatically initialized), make the complete tree (internal and terminal nodes) by calling the make method, and prune the tree. It also contains a method "draw" to visualize the tree.
- BuildNode.py: Implements BuildNode function which takes a unexplored node and returns a terminal or nonterminal node. The build method of the tree works by passing an unexplored node to the BuildNode function, and reassigning to the unexplored node to the node returned by the BuildNode function (nodes are explored in the order given breadth first search).
- Node.py: Implements the node class, terminal node class, and nonterminal node class. The terminal node class and nonterminal node class inherit from the node class. Things to note:
-
- Terminal nodes are futher split into subclasses "ClassificationTerminal" and "RegressionTerminal" depending on if the task is classification or regression.
-
- Whenever a nonterminal node is initialized two more unexplored child nodes are initialized, the true node and the false node.
- Decision.py: Contains classes for making "boolean questions".The both numerical and categorical questions inherit from the "Decision" class.
- SelectFeature.py: Constructs all possible "boolean questions" using Decision.py, calculates what the impurity of the children that would results from that question, and returns the boolean question that minimizes impurity of the children.
- Ensemble.py: Contains ensemble class, which is the only class the user must interact with to make a ensemble model. So if all you want is an ensembled model, the user does not need to use the Tree.py.
